AI 从业者#
在数据中心使用 AI 时,IT 管理员通常会创建 VM,这些 VM 将由 AI 从业者(用于模型训练和创建)或 DevOps 工程师(用于模型部署)访问。 有关更多信息,请参阅 用户角色 部分。 如果您的 IT 管理员想了解有关如何创建 VM 模板的详细信息,请参阅本指南的 IT 管理员 部分。
一旦 IT 管理员成功创建了 VM,AI 从业者就可以快速利用该 VM,因为软件堆栈已预先安装,并且 Jupyter notebook 服务器正在运行。
以下步骤概述如下,将在 AI 训练 VM 内部执行
训练 BERT 问答 (QA) 模型。
将模型导出为 Triton 推理服务器格式。
可选 - 将模型转换为 TensorRT。
训练 BERT QA 模型#
在您的 Web 浏览器上打开一个选项卡,输入以下 URL 以打开 Jupyter 服务器实例。 VM IP 地址将由 IT 管理员提供给 AI 从业者。
例如: http://<VM_IP>:8888
由于 VM 基于包含 NVIDIA NGC 的 BERT 容器的模板,因此 VM 中还提供了一个示例 Jupyter Notebook,可以快速利用它来执行 BERT QA 模型训练。 在此 Notebook 中,AI 从业者将使用预训练的模型,并在小得多的数据集上对其进行微调,以获得客户特定用例所需的准确性。
打开并运行 bert fine-tuning Jupyter Notebook,它位于您的 jupyter notebook 容器的 notebooks 文件夹中的
$HOME/notebooks目录中,以在 SQuAD 数据集上微调 BERT 模型。在 Jupyer Notebook 上打开终端,并使用以下命令下载 squad 数据集
python3 /workspace/bert/data/bertPrep.py --action download --dataset squad
注意
Linux bash 命令可以在 Jupyter Notebook 内部运行,方法是在 Jupyter Notebook 单元格内的命令前添加井号 (!)。 这在上面链接的 notebook 中显示,用于下载预训练的 BERT 模型以进行微调。
将模型导出为 Triton 推理服务器格式#
现在,我们将训练好的模型导出为 Triton 使用的格式。 Triton 推理服务器可以部署使用 TensorFlow、Pytorch、ONNX 和 TensorRT 训练的模型。 在本指南中,我们将首先保存 TensorFlow 模型,然后在接下来的步骤中,我们将模型转换为 TensorRT 以获得最佳性能。
注意
如果您已经拥有 Triton 格式的训练好的模型,则可以跳过此步骤。
对于 TensorFlow 保存的模型,Triton 要求将模型导出到以下格式的目录中
1<model-repository-path>/
2 <model-name>/
3 config.pbtxt
4 1/
5 model.savemodel/
6 <save-model files>
有关 ONNX、TensorRT 和 Pytorch 的模型库格式的更多信息,请参阅 Triton 推理服务器 模型库。
以下步骤显示了将 TensorFlow 检查点导出为上面显示的目录格式的过程。 如果您已经从 NVIDIA NGC Catalog 中以上述格式保存了模型,则可以跳过以下部分。
创建 bert_dllog.json 文件。
1mkdir /results 2touch /results/bert_dllog.json
导出 Triton 模型。
python run_squad.py --vocab_file=/workspace/bert/data/download/finetuned_large_model_SQUAD1.1/vocab.txt --bert_config_file=/workspace/bert/data/download/finetuned_large_model_SQUAD1.1/bert_config.json --init_checkpoint=/workspace/bert/data/download/finetuned_large_model_SQUAD1.1/model.ckpt --max_seq_length=384 --doc_stride=128 --predict_batch_size=8 --output_dir=/triton --export_triton=True --amp --use_xla
运行导出 python 脚本后,您应该在 VM 内部拥有以下目录结构
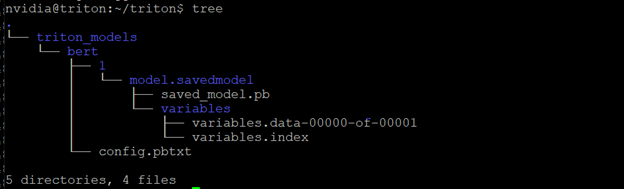
注意
作为 AI 从业者工作流程的一部分,请确保文件位于 VM 的
$HOME/triton目录中。 需要重启服务器 VM 才能加载模型并使更改生效。
企业可能既有 IT 管理员,也有 DevOps 工程师,而另一些企业可能没有,这取决于企业的规模。 对于没有 DevOps 工程师的企业,AI 从业者可能需要继续执行 DevOps 部分中的步骤,以便将模型部署到 Triton 推理服务器。 在这种情况下,请确保您的 IT 管理员已按照 IT 管理员 中的说明创建了 Triton 推理服务器 VM。
注意
对于大规模生产推理部署,请参阅 附录 – 扩展 Triton 推理服务器。