Triton Inference Server 基准测试#
Triton Inference Server 是在任何平台(无论是 CPU 还是 GPU)上部署深度学习模型的默认方式。与 CPU 相比,在 GPU 上部署 Triton 可以提供更低的推理延迟和更高的并行请求处理能力。在开始介绍结果之前,我们需要了解一些参数,这些参数是基准测试的一部分,可以进行调整以获得模型的最佳性能。
我们定义
动态批处理,即对传入查询进行服务器端批处理,可显著提高延迟和性能。
并发性,即服务器的并发请求数。
延迟,即服务器处理一个查询所需的平均时间。
吞吐量,即服务器每秒处理的平均查询数。
这些参数可以在启动 Triton Inference Server 期间设置。请按照 readme 步骤为您的模型设置这些参数。
Triton BERT Large 基准测试#
下图显示了 Triton Inference Server 在 T4 GPU 上与 CPU 相比的吞吐量和延迟。批处理大小和并发性经过调整,以实现 BERT Large 在推理方面的最佳性能。
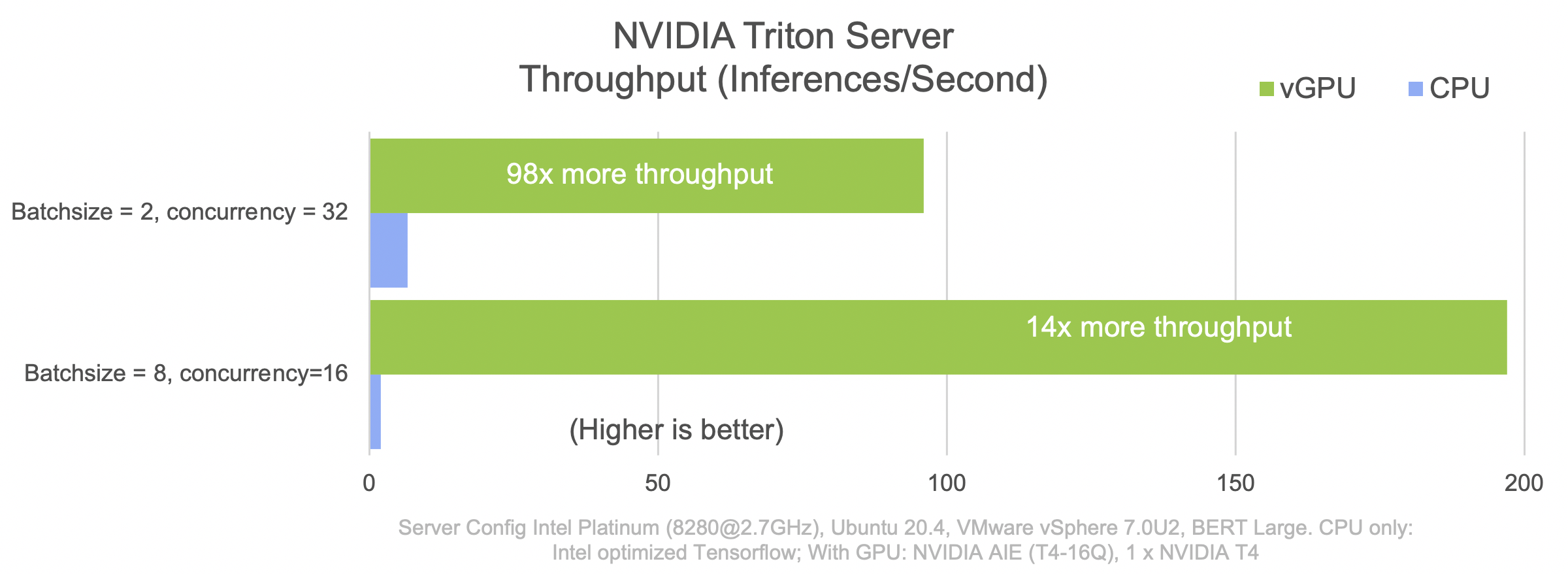

可以使用上述 VM 配置,根据 CPU 和 GPU 在 Google Cloud 实例上每小时推理成本来计算总拥有成本 (TCO)。对于第一种配置(批处理大小为 2,并发性为 32)和第二种配置(批处理大小为 8,并发性为 16),GPU 支持的 VM 具有 37 倍的性价比。