DevOps 工程师#
现在数据科学家已成功将训练好的模型导出为 Triton 可以使用的格式,DevOps 工程师将在 VM 上部署该模型。这位 DevOps 工程师专注于确保 Triton Inference Server 启动并运行,并为最终用户做好准备。
以下步骤在下面列出,将在 VM 内部执行
检查 Triton Inference Server 健康状况。
验证
检查 Triton Inference Server 健康状况#
您现在需要使用以下命令在 VM 上启动 Triton Inference Server。
sh ~/triton-startup.sh
Triton HTTP 和 gRPC 服务应在 Triton Inference Server VM 上运行。要检查服务器的健康状况,请在 VM 内部的不同 SSH 会话中运行 curl 命令。
curl -m 1 -L -s -o /dev/null -w %{http_code} https://:8001/v2/health/ready
它应该输出 200 OK HTTP 代码。
验证#
获取 Triton 客户端库和示例#
为了与 Triton Inference Server 通信,软件层公开了客户端库。gPRC 和 HTTP 库以 Python 包的形式提供,可以使用 pip 安装。
1pip install nvidia-pyindex
2pip install tritonclient[all]
注意
Pip 安装仅在 Linux 上可用。我们正在 HTTP/REST 和 GRPC 客户端库上使用所有安装。
使用 Triton gRPC 客户端运行推理#
您的 Jupyter 笔记本容器具有 Triton 服务器客户端库,因此我们将使用该容器向 Trition Inference Server 容器发送推理请求。
python /workspace/bert/triton/run_squad_triton_client.py --triton_model_name=bert --triton_model_version=1 --vocab_file=/workspace/bert/data/download/finetuned_large_model_SQUAD1.1/vocab.txt --predict_batch_size=1 --max_seq_length=384 --doc_stride=128 --triton_server_url=localhost:8001 --context="A Complex password should atleaset be 20 characters long" --question="How long should a good password generally be?"
注意
该脚本指向在端口 8001(triton gRPC 服务器)上的 localhost 上运行的 Triton 服务器。我们指定上下文,即 BERT 将用来回答问题的段落(在本例中,它是 IT 帮助台关于选择密码的最佳实践的段落。然后您可以向 BERT 模型提出问题,在本例中是:密码中字母的常见替换是什么?”)
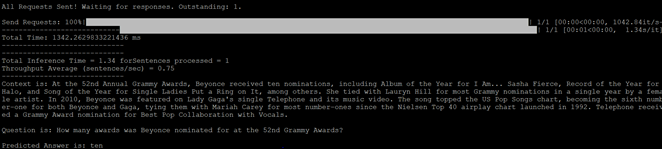
控制台输出显示预测的答案是 @ 代表 a,1 代表 l。