Visual Language Models (VLM) 与 Jetson Platform Services#
概述#
VLMs 是支持图像、视频和文本的多模态模型,它结合了大型语言模型和视觉 Transformer。基于这种能力,它们能够支持文本提示来查询视频和图像,从而实现与视频聊天以及定义基于自然语言的警报等功能。
VLM AI 服务支持通过 Jetson Platform Services 快速部署 VLM,以用于视频洞察应用。VLM 服务公开 REST API 端点,用于配置视频流输入、设置警报以及用自然语言询问有关输入视频流的问题。
API 端点 |
描述 |
|---|---|
/api/v1/live-stream |
管理 AI 服务可以访问的直播流。 |
/api/v1/chat/completion |
使用 OpenAI 风格的聊天补全功能与 VLM 聊天。支持在提示中引用已添加的流。 |
/api/v1/alerts |
设置警报提示,VLM 将在输入直播流上持续评估。可用于在警报状态为真时触发通知。 |
此外,VLM 的输出可以作为 RTSP 流查看,警报状态由 jetson-monitoring 服务存储,并通过 websocket 发送以与其他服务集成。
此 AI 服务以预构建的 Docker 容器形式提供,可以使用 Docker Compose 启动。它通过 JSON 配置文件进行配置,并与基础服务(如 Jetson-monitoring 和 jetson-ingress)集成。我们在参考工作流程资源中提供了示例 compose 和配置文件,以便于轻松部署。
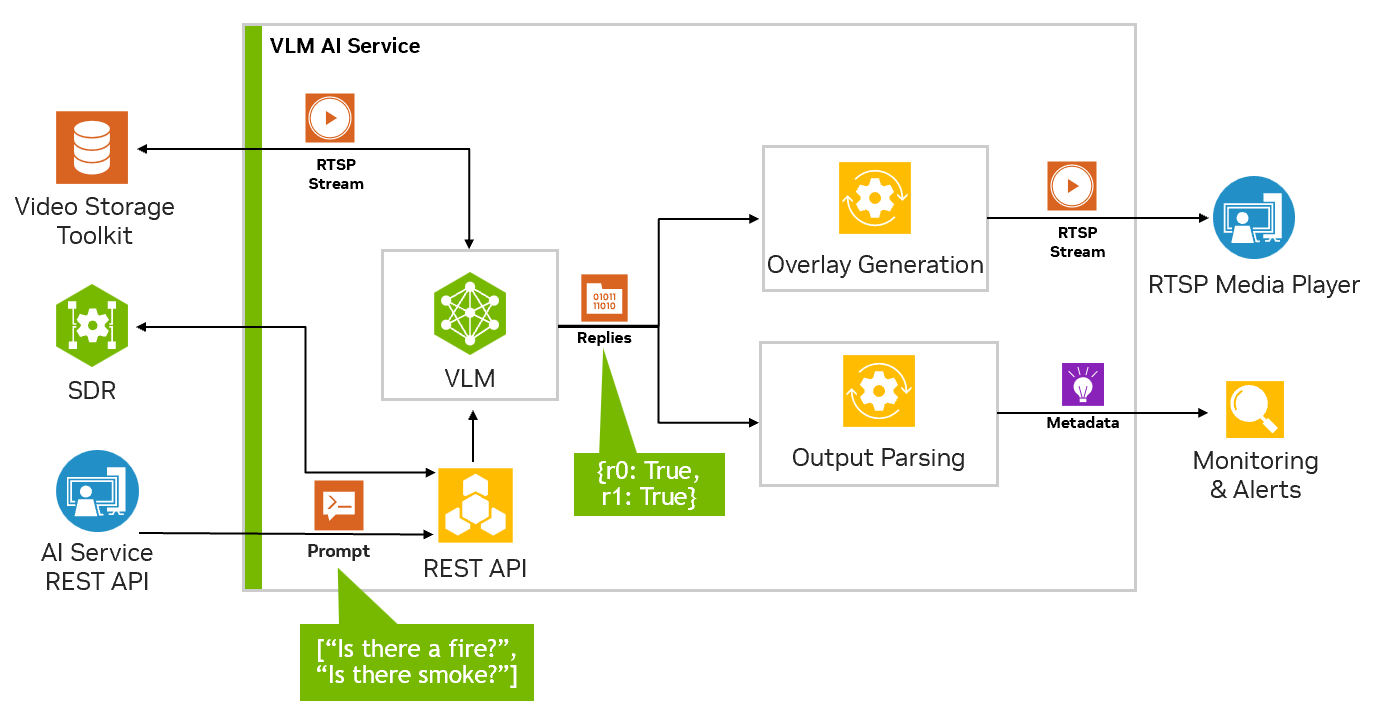
下表总结了 VLM 服务如何与其他 Jetson Platform Services 交互。
服务 |
必需 |
备注 |
|---|---|---|
jetson-ingress |
✓ |
需要通过 API 网关端口 (30080) 访问 VLM REST API |
jetson-storage |
✓ |
除了外部存储设备外,还需要此服务。否则,Jetson 很可能耗尽存储空间。 |
jetson-monitoring |
✓ |
需要在 Prometheus 仪表板中跟踪警报和 VLM 指标 |
jetson-firewall |
⭘ |
建议在实际部署中使用,以限制对 API 网关端口以外端口的访问。 |
jetson-vst |
⭘ |
建议管理可用作 AI 服务输入的 RTSP 流 |
jetson-sys-monitoring |
⭘ |
建议启用以监控系统状态,但不是必需的 |
jetson-gpu-monitoring |
⭘ |
建议启用以监控 GPU 状态,但不是必需的 |
jetson-networking |
✗ |
仅当将 VST 和 IP 摄像头与 VLM 服务一起使用时才需要 |
jetson-redis |
✗ |
仅当将 VST 和 SDR 与 VLM 服务一起使用时才需要。 |
入门指南#
在开始使用此示例之前,请仔细阅读先决条件部分。
先决条件#
首先,按照快速入门指南设置您的 Jetson Platform Services 系统。建议同时按照 Hello World 示例熟悉 Jetson Platform Services。在继续之前,使用 docker compose down 命令关闭之前启动的任何 JPS 示例,如 AI-NVR。
VLM AI 服务在 RTSP 流上运行。RTSP 流可以来自任何源,例如 IP 摄像头、视频存储工具包 (VST) 或 NVStreamer。获取 RTSP 流进行测试的最快方法是使用 NVStreamer,它可以将视频文件作为 RTSP 流提供。要了解如何使用 NVStreamer 创建 RTSP 流,请参阅Jetson Orin 上的 NVStreamer页面。
运行 VLM 容器将需要大约 50GB 的存储空间。容器将占用 20GB,默认模型 (VILA1.5 13b) 将使用 32.3 GB。强烈建议在运行此示例之前使用 Jetson Storage 服务。Jetson Storage 服务将设置连接的外部存储设备,并将容器存储和 /data 位置重新映射到外部存储。您的 Jetson 设备上的默认存储空间可能没有足够的空间来运行此示例的默认配置。查看存储页面以获取更多详细信息。
要获取 Docker Compose 和配置文件,请从 NGC 或 SDK Manager 下载 Jetson Platform Services 资源包。下载后,找到 vlm-2.0.0.tar.gz 文件并将其放在您的主目录中。以下命令将假定 tar 文件从您的主目录开始。
cd ~/
tar -xvf vlm-2.0.0.tar.gz
cd ~/vlm/example_1
VLM AI 服务将使用 jetson-ingress 和 jetson-monitoring 服务。需要配置这两个服务以与 VLM AI 服务集成。将提供的默认配置复制到相应的服务配置目录。
sudo cp config/vlm-nginx.conf /opt/nvidia/jetson/services/ingress/config
sudo cp config/prometheus.yml /opt/nvidia/jetson/services/monitoring/config/prometheus.yml
sudo cp config/rules.yml /opt/nvidia/jetson/services/monitoring/config/rules.yml
然后启动基础服务。
sudo systemctl start jetson-ingress
sudo systemctl start jetson-monitoring
sudo systemctl start jetson-sys-monitoring
sudo systemctl start jetson-gpu-monitoring
注意
如果之前启动过任何基础服务,请使用“restart”命令而不是“start”。
现在部署 VLM AI 服务!
sudo docker compose up -d
要检查所有必要的容器是否已启动,您可以运行以下命令
sudo docker ps
输出应类似于以下图像。

注意
首次启动 VLM 服务时,它将自动下载并量化 VLM。这需要一些时间。如果在 Orin NX16 上部署,则可能需要挂载更多 SWAP,因为模型的量化可能会占用大量内存。有关更多详细信息,请参阅以下部分VLM 模型加载失败。
要验证 VLM 是否已正确启动,您可以检查 VLM 服务的健康状况端点。在 Web 浏览器中,您可以访问页面 http://0.0.0.0:5015/v1/health。如果 VLM 已准备就绪,它将返回 {“detail”:”ready”}。如果您是第一次启动 VLM,则需要一些时间才能完全加载。
与 VLM 服务交互#
现在我们可以通过多种方式与 VLM 服务交互
通过 REST API 控制流输入
您可以首先添加一个 RTSP 流供 VLM 使用,使用以下 curl 命令。这将对 live-stream 端点使用 POST 方法。
目前,VLM 仅支持 1 个流,但将来此 API 将允许支持多流。
将 0.0.0.0 替换为您的 Jetson IP,并将 RTSP 链接替换为您的 RTSP 链接。
curl --location 'http://0.0.0.0:5010/api/v1/live-stream' \
--header 'Content-Type: application/json' \
--data '{
"liveStreamUrl": "rtsp://0.0.0.0:31554/nvstream/root/store/nvstreamer_videos/video.mp4"
}'
注意
除了 curl 命令之外,还可以通过 API 文档页面直接测试 REST API,该页面在 VLM 服务启动时位于 http://0.0.0.0:5010/docs。
此请求将返回唯一的流 ID,该 ID 稍后用于设置警报、询问后续问题和删除流。
{
"id": "a782e200-eb48-4d17-a1b9-5ac0696217f7"
}
您还可以对 live-stream 端点使用 GET 方法来列出已添加的流及其 ID
curl --location 'http://0.0.0.0:5010/api/v1/live-stream'
[
{
"id": "a782e200-eb48-4d17-a1b9-5ac0696217f7",
"liveStreamUrl": "rtsp://0.0.0.0:31554/nvstream/root/store/nvstreamer_videos/video.mp4"
}
]
设置警报
警报是 VLM 将在直播流输入上持续评估的问题。对于每个警报规则集,VLM 将尝试根据直播流的最新帧来判断其为 True 或 False。由 VLM 确定的这些 True 和 False 状态将发送到 websocket 和 jetson 监控服务。
设置警报时,警报规则应措辞为是/否问题。例如“有火吗?”或“有烟吗?”。请求的正文还必须包含“id”字段,该字段对应于添加 RTSP 流时返回的流 ID。
默认情况下,VLM 服务最多支持 10 个警报规则。可以通过调整配置文件来增加此数量。
curl --location 'http://0.0.0.0:5010/api/v1/alerts' \ --header 'Content-Type: application/json' \ --data '{ "alerts": ["is there a fire?", "is there smoke?"], "id": "a782e200-eb48-4d17-a1b9-5ac0696217f7" }'添加警报后,您应该在 RTSP 输出流上看到生成的叠加输出。
查看 RTSP 流输出
添加流后,它将传递到输出 RTSP 流。您可以在 rtsp://0.0.0.0:5011/out 查看此流。添加查询或警报后,我们可以在此输出流上查看 VLM 响应。
在 Prometheus 中查看警报状态
警报的 True/False 状态将发送到基于 Prometheus 的 Jetson Monitoring 服务。您可以在 http://0.0.0.0:5012 查看原始指标,这些指标随后由 Prometheus 抓取并保存为时间序列数据。这可以在 Prometheus 仪表板上查看,地址为 http://0.0.0.0:9090
询问后续问题
除了设置警报外,您还可以使用聊天补全端点向 VLM 询问开放式问题。聊天补全端点类似于 OpenAI 聊天补全 API,并额外支持在提示中引用直播流。
当在提示中引用流时,它将附加直播流的最新帧,并将其传递给 VLM 以用于完成聊天。
要询问有关直播流的后续问题,例如,您可以提交以下 curl 命令
curl --location 'http://0.0.0.0:5010/api/v1/chat/completions' \ --header 'Content-Type: application/json' \ --data '{ "messages": [ { "role": "system", "content": "You are a helpful AI assistant." }, { "role": "user", "content":[ { "type": "stream", "stream": { "stream_id": "a782e200-eb48-4d17-a1b9-5ac0696217f7" } }, { "type":"text", "text": "Can you describe the scene?" } ] } ], "min_tokens": 1, "max_tokens": 128 } '
请注意用户消息如何引用流内容类型,然后使用文本内容类型以及用户的问题进行跟进。当流引用出现在文本内容之前时,VILA 模型效果最佳。
聊天补全端点将返回以下内容
{
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The scene is a beautiful mountain range."
}
}
]
}
请注意,如果在容器运行时重新启动系统,它将自动恢复,但添加的流和警报将不会持久存在。它们需要重新添加。为了使流在重启后持久存在,AI 服务可以与 SDR 结合使用,如零样本检测工作流程页面所示。
关闭
要关闭示例,您可以首先使用 DELETE 方法在 live-stream 端点上删除流。请注意,流 ID 已添加到 URL 路径中。
curl --location --request DELETE 'http://0.0.0.0:5010/api/v1/live-stream/a782e200-eb48-4d17-a1b9-5ac0696217f7'
然后从用于启动示例的 compose.yaml 文件所在的同一文件夹中运行
sudo docker compose down
总而言之,本节介绍了如何启动 VLM AI 服务,然后通过 REST API 与其交互,并在 Prometheus 中查看 RTSP 输出和警报状态。
以下是与 VLM 服务交互时有用的地址摘要。
VLM 服务的访问点
名称 |
本地 URI |
API 网关 URI |
描述 |
|---|---|---|---|
REST API 文档 |
VLM AI 服务 REST API 文档 |
||
REST API |
VLM AI 服务控制 REST API |
||
Web Socket 警报 |
ws://0.0.0.0:5016/api/v1/alerts/ws |
ws://0.0.0.0:30080/ws-vlm/api/v1/alerts/ws |
当 VLM 确定为 True 时,将输出警报的 Web Socket。 |
RTSP 输出 |
VLM 的叠加输出 |
||
Prometheus 警报指标 |
由 Prometheus 抓取的 VLM AI 服务公开的警报指标 |
||
Prometheus 推理指标 |
由 Prometheus 抓取的 VLM 推理指标,例如令牌计数、解码率、解码时间等。 |
||
Prometheus 仪表板 |
用于查看 Prometheus 警报和指标的仪表板。由 jetson-monitoring 服务启动。 |
配置#
所有配置文件都可以在 ~/vlm/example_1/config 目录下找到。可用的配置选项分为两类。
VLM 服务配置
chat_server_config.json
main_config.json
基础服务配置
prometheus.yml
rules.yml
vlm-nginx.conf
AI 服务配置是 JSON 格式的文件,并假定位于 AI 服务的名为 config 的文件夹中。此 config 文件夹必须与用于启动 AI 服务的 compose.yaml 文件位于同一目录中。
在 config 目录中找到的基础服务配置仅供参考,必须复制到 /opt/nvidia/jetson/services 下的相应基础服务配置文件夹中才能生效。在调整配置后,必须使用 systemctl 重新启动相应的服务,更改才能生效。
chat_server_config.json
chat_server_config.json 配置聊天服务器,该服务器使用类似 OpenAI 的 REST API 接口加载和运行 VLM 模型。VLM 模型也可以在此配置文件中进行调整。当您更改模型时,重新启动服务,它将自动下载并量化新模型。
{
"api_server_port": 5015,
"prometheus_port": 5017,
"model": "Efficient-Large-Model/VILA1.5-13b",
"log_level": "INFO",
"print_stats": true
}
键 |
值类型 |
值示例 |
描述 |
备注 |
|---|---|---|---|---|
“api_server_port” |
int |
5015 |
主管道将公开其 REST API 以进行流和模型控制的端口 |
|
“prometheus_port” |
int |
5017 |
用于输出 Prometheus 模型统计信息的端口 |
包括嵌入时间、解码时间、解码率等指标。 |
“model” |
str |
“Efficient-Large-Model/VILA-13b” |
VLM 模型的 Huggingface 路径或本地路径 |
有关支持的模型键,请参见下表。 |
“log_level” |
str |
“INFO” |
基于 Python 的日志级别 |
支持的值:[“DEBUG”, “INFO”, “WARNING”, “ERROR”, “CRITICAL”] |
“print_stats” |
bool |
true |
启用/禁用打印 VLM 统计信息的 true/false 值 |
模型 |
配置键 |
所需存储空间 (GB) |
|---|---|---|
“Efficient-Large-Model/VILA-2.7b” |
7.1 |
|
“Efficient-Large-Model/VILA-7b” |
17.3 |
|
“Efficient-Large-Model/VILA-13b” |
31.2 |
|
“Efficient-Large-Model/VILA1.5-3b” |
7.3 |
|
“Efficient-Large-Model/Llama-3-VILA1.5-8B” |
19.9 |
|
“Efficient-Large-Model/VILA1.5-13b” |
32.3 |
|
“liuhaotian/llava-v1.5-7b” |
17.3 |
|
“liuhaotian/llava-v1.5-13b” |
31.2 |
main_config.json
main_config.json 配置流式处理管道,该管道将在 VLM 上评估流输入,并公开 REST API 以配置流输入、警报规则和查询。
{
"api_server_port": 5010,
"prometheus_port": 5012,
"websocket_server_port":5016,
"stream_output": "rtsp://0.0.0.0:5011/out",
"chat_server": "http://0.0.0.0:5015",
"alert_system_prompt": "You are an AI assistant whose job is to evaluate a yes/no question on an image. Your response must be accurate and based on the image and MUST be 'yes' or 'no'. Do not respond with any numbers.",
"max_alerts": 10,
"alert_cooldown": 60,
"log_level": "INFO",
"multi_frame_input": 8,
"multi_frame_input_time": 1000
}
键 |
值类型 |
值示例 |
描述 |
备注 |
|---|---|---|---|---|
“api_server_port” |
int |
5010 |
主管道将公开其 REST API 以进行流和模型控制的端口 |
|
“prometheus_port” |
int |
5012 |
Prometheus 的警报指标端口 |
|
“websocket_server_port” |
int |
5016 |
警报事件的 websocket 将可用的端口 |
|
“stream_output” |
str |
AI 服务生成的 RTSP 流的输出 URI。 |
||
“chat_server” |
str |
主管道访问 VLM 的内部聊天服务器的 URI |
||
“alert_system_prompt” |
str |
“您是一个 AI 助手,您的工作是评估图像上的“是/否”问题。” |
用于评估警报规则的 VLM 系统提示 |
|
“max_alerts” |
str |
10 |
支持的警报数量 |
如果更改,则必须更新 rules.yml |
“alert_cooldown” |
int |
60 |
在 websocket 上发送警报的冷却时间段。 |
例如,如果设置为 60,则在多个帧上为真的警报最多每 60 秒在 websocket 上仅发送 1 个警报事件。 |
“log_level” |
str |
“INFO” |
基于 Python 的日志级别 |
支持的值:[“DEBUG”, “INFO”, “WARNING”, “ERROR”, “CRITICAL”] |
“multi_frame_input” |
int |
8 |
每次 VLM 调用(用于警报和聊天)时,从直播流中使用的帧数。 |
支持的值:[1,8]。帧数越多,VLM 获得的时间上下文就越多,但处理时间会更长。 |
“multi_frame_input_time” |
int |
1000 |
在每次 VLM 调用中,用于采样帧的时间长度 |
值必须大于或等于 0。单位为毫秒。 |
多帧选项允许 VLM 基于从输入直播流中采样的多个帧(在设定的时间段内)回答聊天和警报。当需要时间理解时,这很有用。例如,从单个帧无法描述来自交通摄像头的汽车的运动,但如果 VLM 查看在五秒内采样的 8 帧,则它可以描述车辆在该五秒间隔内的移动方式。管道存储由 multi_frame_input 选项配置的缓冲区。此缓冲区从直播流持续更新,并在 multi_frame_input_time 配置中采样。例如,如果 multi_frame_input 设置为 5,而 multi_frame_input_time 设置为 5000,则管道将保持 5 帧的滚动缓冲区,该缓冲区每秒更新一次(5000 毫秒 / 5)。这样,一旦发送警报或聊天的请求,此缓冲区(具有所需帧数)将连同用户提示一起转发到 VLM,以生成响应。VLM 处理更多帧会产生额外的开销,因此如果用例不需要时间理解(例如,像火或烟雾这样的简单检测),则建议将 multi_frame_input 设置为 1。如果需要时间理解,则对于 Orin Nano 和 NX8,建议最多使用 4 帧,否则在生成响应时会出现较长的延迟。对于 NX16 和 AGX,建议使用 8 帧,以最大限度地提高 VLM 的时间理解能力。可以调整此值以权衡 VLM 的性能和时间理解能力。
基础服务配置
prometheus.yml
rules.yml
vlm-nginx.conf
prometheus.yml 和 rules.yml 用于配置 jetson-monitoring 服务,以跟踪 VLM 警报评估。监控中提供了 jetson-monitoring 的文档
vlm-nginx.conf 用于配置 jetson-ingress 服务(API 网关),以将 HTTP 流量路由到 VLM 服务。API 网关 (Ingress)中提供了 jetson-ingress 的文档
VLM 服务集成#
VLM 服务可以与 Jetson Platform Services 的其他部分集成,以构建完整的端到端视频监控工作流程。要了解有关完整工作流程以及 VLM 服务如何与 VST、SDR、云和移动应用集成的更多信息,请转到VLM 工作流程页面。
延伸阅读#
要了解有关 VLM AI 服务的更多信息,请在jetson-platform-services 存储库上查看开源代码。Jetson 上对 VLM 的支持来自 NanoLLM 项目。有关 Jetson 上的基准测试和其他生成式 AI 示例,请访问 Jetson AI Lab。
故障排除#
VLM 模型加载失败#
首次启动 VLM AI 服务时,它将下载容器和 VLM 模型。使用默认配置时,大小约为 50GB。
确保您的 Jetson 具有稳定的互联网连接以完成下载。下载时间将取决于您的网络速度。
下载容器和模型后,它将自动量化和优化 Jetson 的模型。这是一个一次性过程,需要 10-20 分钟,并且对于最大的模型 (13b) 将占用高达 32GB 的内存。
您必须确保 Jetson 的总可用虚拟内存至少为 32GB。(物理内存 + 交换空间)。
例如,NX16 需要额外的 8GB SWAP 才能通过量化阶段(16GB 物理内存 + 8GB 默认交换空间 + 8GB 额外交换空间)。如果您有 /data 驱动器,可以运行以下命令来挂载更多交换空间。
sudo fallocate -l 8G /data/8GB.swap
sudo mkswap /data/8GB.swap
sudo swapon /data/8GB.swap
挂载额外的交换空间后,您可以启动 VLM 服务容器以下载和量化模型。
如果您重新启动 Jetson 并且仍然需要额外的交换空间,则需要再次运行 swapon 命令。
当模型完成量化后,如果您想回收交换空间使用的磁盘空间,可以运行以下命令
sudo swapoff /data/8GB.swap
sudo rm /data/8GB.swap
管理容器#
启动 VLM 服务容器后,如果遇到任何问题,可以通过从与 Docker Compose 文件相同的文件夹中运行以下命令来手动重启它
sudo docker compose down
sudo docker compose up -d
也可以通过运行以下命令将其杀死
sudo docker kill jps_vlm
如果容器有可用更新,请从 NGC 下载最新版本。
系统警告#
在运行带有警报的 VLM 服务时,它将使用大量资源。这可能会导致您的 Jetson 显示诸如“由于过电流而导致系统节流”之类的警告。在最大功率模式下运行时,这是预期的。
建议将 Jetson 风扇设置为最大以获得额外的冷却效果。这可以使用 jetson_clocks 命令完成
sudo jetson_clocks --fan
如果您想进一步降低功耗或热量产生,可以通过使用 nvpmodel 命令控制功率模式来完成。
sudo nvpmodel --help