故障排除#
本节列出了针对各种模块和场景的故障排除解决方案和技巧。
设置#
首次部署耗时过长#
容器在首次安装期间从 NGC 下载,因此首次部署的时间可能会受到下载容器的网络带宽的影响。
部署后容器未运行#
运行 df 命令并验证使用情况,检查根文件系统是否已满。
nvidia@tegra-ubuntu:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mmcblk3p1 54G 54G 0 100% /
检查根文件系统内容,以确定可能删除的文件,例如使用 du 命令。
如果系统未连接外部存储来支持数据分区,则尤其可能发生这种情况。
Grafana 中 DeepStream FPS 不正确或未更新#
确保监控和 DeepStream 都已启动。之后,确保 DeepStream 日志文件已正确更新。这可以使用 tail -f /data/logging-volume/deepstream.log 完成。Grafana 解析此日志以获取当前流 FPS 值。
如果 DeepStream 日志不是每约 5 秒更新一次,请确保日志卷未满。如果已满,请删除(或移动)DeepStream 日志,然后重启 DeepStream 和指标监控容器。如果日志卷未满且此日志未更新,请尝试仅重启 DeepStream 容器,因为 DeepStream 可能最终进入了错误状态。
DeepStream FPS 下降#
使用动态流添加机制,可能会出现轻微的 FPS 下降(例如:从 30 降至 29),尤其是在流数量较大时。
确保您的输入流在质量和 FPS 方面是健康的。例如,VLC 视频播放器可以显示流指标,包括丢帧、损坏帧和比特率。可以通过导航:工具 > 媒体信息 > 统计信息 查看。
使用 sudo tegrastats 验证利用率指标,以验证您的系统是否过载。请参阅文档中 快速入门指南 部分下 AI-NVR 工作流程的受支持流数量,其中还描述了性能调优的注意事项和技巧。
同样,请确保您为系统运行适当的配置。例如,如果您在 Orin NX8 上部署 Orin AGX 配置,则可能会发生性能下降。
确保以设置指南中提到的最大时钟和功率设置运行。请参阅 快速入门指南 中的 更新性能设置 说明
- 在极少数情况下,当摄像头 FPS 下降时,该摄像头的 DeepStream FPS 会变为 0 且无法恢复。此外,已观察到从那时起 DeepStream 的 FPS 日志将停止打印,从而导致 DeepStream FPS 的监控统计信息被错误地报告为 0。删除导致问题的流并重启 DeepStream 以从此问题中恢复。
DeepStream 容器无法在 docker compose down 时退出#
有时,当尝试使用 docker compose down 命令删除时,DeepStream 容器会挂起。在这种情况下,您可能会看到类似于以下的错误
Error response from daemon: cannot stop container: 40997391f8fe65b604cf64166da7e0fe9992c99620c5872ed16e478f1b15e020: tried to kill container, but did not receive an exit event
在这种情况下,首先找到 DeepStream 容器进程的 PID。
ps auxw | grep $(sudo docker container ls | grep deepstream | awk '{print $1}') | awk '{print $2}'
将该命令的输出用作以下命令的输入。
sudo kill -9 <PID given by previous command>
此后您可能还需要重启系统。
DeepStream 容器持续崩溃/重启#
确保系统有足够的可用内存来运行 DeepStream。DeepStream 需要 1-2.5GB,具体取决于正在处理的流数量。可以使用 tegrastats 实用程序查看可用内存。没有足够的可用内存可能会导致 DeepStream 崩溃或导致多个流卡在 0fps,尤其是在 PVA 无法分配足够的内存时。
DeepStream 冻结#
有时,使用 RTSP 流时,应用程序在到达 EOS 时会卡住。这是因为 rtpjitterbuffer 组件中存在问题。要解决此问题,请按照说明更新 DeepStream 安装指南 中描述的 rtpmanager 库。
请注意,这些步骤必须在 DeepStream 容器内运行,而不是在 Jetson 设备上本地运行。
有时,使用 RTSP 流时,在大流数量下使用 VIC 进行预处理和缩放会导致管道冻结,这是由于目前正在解决的 VIC 中的已知问题。作为一种解决方法,请配置管道元素以使用 GPU 而不是 VIC。有关如何操作的说明,请参阅 AGX 的 DeepStream 配置 (ds-config-0_agx.yaml)。
WebRTC 流媒体问题#
视频未播放#
确保流媒体客户端(VST webUI 浏览器或移动应用)与设备在同一网络中。否则,需要中继流媒体服务(如 Twilio),并且必须配置 VST 以使用它。
使用移动应用/浏览器进行视频流式传输时看到黑屏#
确保 Jetson 设备和客户端(手机)在同一网络中。否则,必须使用 Twilio 等服务设置视频中继流,如 VST 文档中所述。
视频质量故障排除 - 深入分析#
如果您已遵循一般故障排除指南,但仍然遇到视频质量问题,则本节提供了一种详细的方法来隔离和定位 VST webUI 和移动应用中遇到的流媒体质量问题。
检查从摄像头到 Jetson 设备的传入 RTSP 流质量:#
使用以下选项确保从摄像头输入的 RTSP 流以预期的质量在连接的 Jetson 设备上接收。
VST 指标
通过导航到 Debug >> Stream Stats,通过 VST webUI 访问流媒体指标。
在 FPS 统计信息中,确保摄像头 FPS 指标始终显示大约 30 FPS。
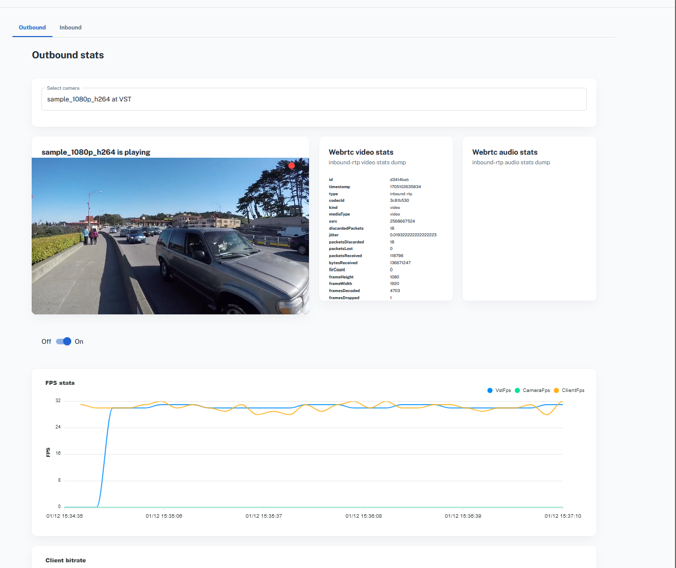
来自 DeepStream 日志的 FPS
使用以下命令查看 DeepStream 日志
` sudo docker logs -f deepstream `确认记录的平均 FPS 接近 30 FPS。
手动流检查
将显示器连接到 Jetson 设备。
在 Jetson 设备上打开终端并执行
gst-launch-1.0 playbin uri=rtsp://<camera_url>
手动检查来自摄像头的输入流,以确保它在 Jetson 设备上以良好的质量播放。
检查客户端应用上的输出流质量:#
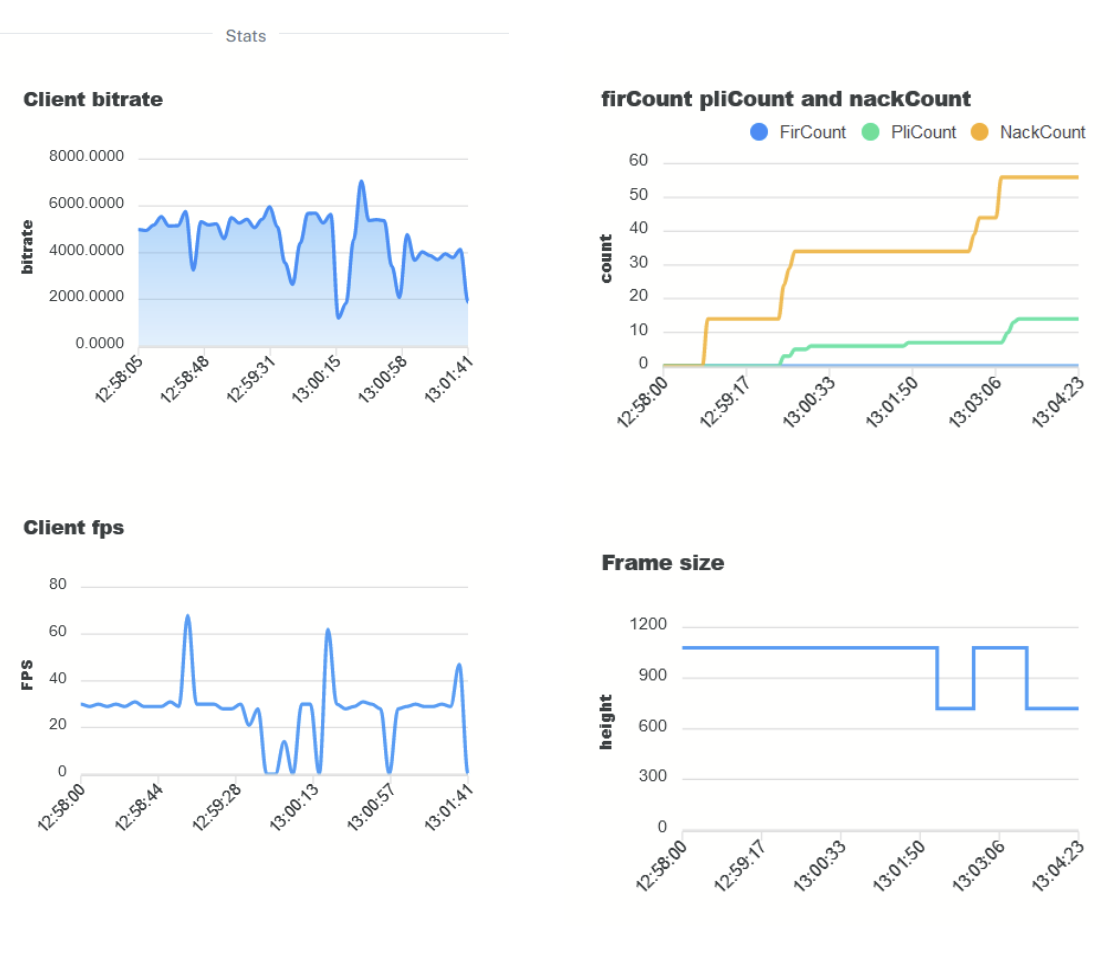
VST 指标
使用 VST webUI 通过导航到 Debug >> Stream Stats 来访问流媒体指标。
此视图显示客户端比特率、丢帧计数和客户端 FPS。
丢帧 (nackCount) 可能表示网络带宽不足,而比特率或客户端 FPS 的波动可能表明 Jetson 系统存在性能问题。
在 NVMe 上记录多个流一段时间后,VST 崩溃#
如果您发现由于 NVMe 驱动器上的写入操作备份,当在连接的 NVMe 驱动器上记录多个流一段时间后,VST 会因内存使用量逐渐增加而崩溃,则可能是因为驱动器的写入操作正在备份。要解决此问题,您可以尝试以下选项之一。
选项 1:编辑 /boot/extlinux/extlinux.conf 并在 APPEND 参数中添加 nvme.use_threaded_interrupts=1,然后重启您的设备。请参阅下面显示的示例文件
TIMEOUT 30
DEFAULT primary
MENU TITLE L4T boot options
LABEL primary
MENU LABEL primary kernel
LINUX /boot/Image
INITRD /boot/initrd
APPEND ${cbootargs} root=PARTUUID=1efddf3c-894d-4b21-a230-82476db0ee5e rw rootwait rootfstype=ext4 mminit_loglevel=4 console=ttyTCU0,115200 console=ttyAMA0,115200 firmware_class.path=/etc/firmware fbcon=map:0 net.ifnames=0 nospectre_bhb video=efifb:off console=tty0 nvme.use_threaded_interrupts=1
选项 2:如果您正在刷写并使用 AGX Orin 开发套件,则可以通过选项 -C 将内核模块参数附加到 flash 命令,如下所示
sudo ./flash.sh -C nvme.use_threaded_interrupts=1 jetson-agx-orin-devkit internal
AI 服务(VLM 和零样本检测)#
VLM 和零样本检测服务在其各自的页面上还有其他故障排除部分。
已知问题#
VST 文档中指定的受支持列表之外的摄像头可能无法检测到。此外,不符合 s-profile 的摄像头可能无法与 VST 配合使用。
由于以下指出的几个已知问题偶尔会发生,DeepStream 容器中可能会发生偶尔的崩溃。
跟踪器错误,消息为 gstnvtracker: All sub-batches are fully allocated. Modify “sub-batches” configuraion to accommodate more number of streams,导致问题管道中的所有流降至 0FPS。使用 sudo docker restart deepstream 重启 DeepStream 容器以恢复。
DeepStream 启动时 PVA 问题导致崩溃,错误为 VPI_ERROR_INVALID_OPERATION: PVA is not available and may be oversubscribed in the system。重启系统以恢复。
由于 add/remove API 超时,新添加到 VST 的流未在 DeepStream 中拾取;这尤其可能在 VST 重启时发生(例如在崩溃后),此时 DeepStream 流被 SDR 删除并重新添加。
添加 RTSP 流时偶尔会看到 VST 崩溃。但是,docker compose 将自动重启容器,系统将恢复运行。
观察到偶尔的 DeepStream 容器崩溃,但 docker compose 将自动重启容器,系统应在无需任何干预的情况下恢复运行。
重启 VST 后,在极少数情况下,流可能在感知管道中显示 0 fps。尝试重启 DeepStream 容器以将流重新添加到感知管道。
在系统重启后,Docker compose 部署可能无法正常运行。这是因为当容器在重启后由 Docker 自动启动时,未强制执行容器的所需启动顺序。
在 VST 中更改流名称不会反映在 DeepStream 中。
WebRTC 流媒体传输期间出现间歇性冻结和失真;请参阅流媒体问题故障排除,以获取诊断原因的提示。
在流数量增加的情况下,移动应用视频流式传输可能会导致视频质量下降,具体取决于手机规格。
AI 服务:添加到 VLM 和零样本检测服务的流和提示不会在重启后持久存在。可以通过与 SDR 结合使用使流在重启后持久存在,如 零样本检测工作流程 页面所示。
VLM 服务:当向 VLM 发送聊天完成请求时,它可能会响应空字符串。调整提示、更改模型或再次发送查询可能会产生更好的响应。