同时使用 iGPU 和 dGPU#
您的 NVIDIA IGX Orin™ 开发套件 具有 NVIDIA Ampere 集成 GPU (iGPU) 和用于附加独立 GPU (dGPU) 的 PCIe 插槽。通常,您可以在 iGPU 模式或 dGPU 模式下配置您的开发套件。有关详细信息,请参阅 GPU 配置。
本文档介绍了高级配置,使您能够同时使用集成 GPU (iGPU) 和独立 GPU (dGPU)(同时模式)。在同时模式下,您可以使用 Docker 容器在 iGPU 上运行应用程序。
您可以利用同时模式将计算强度较低的工作负载从 dGPU 卸载到 iGPU,从而为计算强度更高的工作负载保留 dGPU。下表显示了同时模式下每个 GPU 支持的功能。
dGPU |
iGPU |
|
|---|---|---|
计算 |
是 |
是 |
图形(无头) |
是 |
是 |
显示 |
是 |
否 |
RDMA |
是 |
否 |
视频 |
是 |
未测试 |
先决条件#
IGX Orin 开发套件支持以下软件版本的同步模式
dGPU 模式下的 IGX SW 1.0 GA (L4T r36.3)
dGPU 模式下的 IGX SW 1.0 DP (L4T r36.1)
Docker 容器#
在同时模式下,您可以使用 Docker 容器在 iGPU 上运行应用程序。对于初始测试以及本文档中的示例,您可以使用简单的容器,例如 ubuntu:22.04。
对于您的生产工作,请使用具有 GPU 特定计算堆栈和加速功能的 iGPU 特定容器。 有关 IGX iGPU 特定容器的列表,请参阅 容器。
配置同时模式#
启用访问#
要启用对 iGPU 和 dGPU 的同时访问,请执行以下操作。
运行以下命令,只需运行一次。
1sudo /opt/nvidia/l4t-igpu-container-on-dgpu-host-config/l4t-igpu-container-on-dgpu-host-config.sh configure
警告
在 IGX SW 1.0 DP (L4T r36.1) 上,iGPU 的此配置中缺少 libnvdla_compiler.so,当您尝试在 iGPU 上使用 TensorRT 时,可能会导致以下错误
1libnvinfer.so: undefined reference to `nvdla::...`
作为一种解决方法,请运行以下命令
1lib="/usr/lib/aarch64-linux-gnu/tegra/libnvdla_compiler.so" sudo cp $lib "/nvidia/igpu_on_dgpu/root/$lib" 2sudo /opt/nvidia/l4t-igpu-container-on-dgpu-host-config/l4t-igpu-container-on-dgpu-host-config.sh generate_cdi
(可选)运行以下命令以显示其他有用命令的列表。
1l4t-igpu-container-on-dgpu-host-config.sh --help
(可选)如果您不再想使用同时模式,要恢复,请运行以下命令。
1sudo /opt/nvidia/l4t-igpu-container-on-dgpu-host-config/l4t-igpu-container-on-dgpu-host-config.sh clean
标准 iGPU 访问#
在您在上节中运行一次性配置后,任何裸机应用程序默认使用 dGPU。要使用 iGPU,请在 docker 容器中运行应用程序并使用以下标志
--runtime=nvidia— 这确保使用 nvidia 容器运行时。-e NVIDIA_VISIBLE_DEVICES=nvidia.com/igpu=0— 这会在容器中公开 iGPU 驱动程序库。
提示
如果您的 Docker 版本等于或晚于 25.0,并且 NVIDIA Container Toolkit 等于或晚于 1.14.5,您可以选择加入 docker 的原生容器设备接口 (CDI) 支持。 在这种情况下,您可以在 docker 容器中运行应用程序并使用以下标志
--device=nvidia.com/igpu=0
要选择加入 Docker 的原生 CDI 支持,请运行以下代码。
1sudo nvidia-ctk runtime configure --runtime=docker --cdi.enable
2sudo systemctl restart docker
高级 iGPU 访问#
您可以尝试通过在运行应用程序之前设置库路径,在 iGPU 上运行裸机应用程序。 要设置您的库路径,请运行以下命令。
1LD_LIBRARY_PATH=/nvidia/igpu_on_dgpu/root/usr/lib/aarch64-linux-gnu/tegra <executable>
警告
设置库路径可能会导致意外行为。 如果发生意外行为,请改用标准 iGPU 访问方法。
验证 iGPU 和 dGPU 访问#
要验证 iGPU 和 dGPU 是否都可访问,请执行以下操作:
运行以下命令,该命令默认在 dGPU 上运行。
1nvidia-smi --query-gpu=name --format=csv,noheader
您应该看到类似于以下的输出,其中显示了 dGPU。
1NVIDIA RTX A6000
在 iGPU 上的容器中运行以下命令。
注意
此示例在 iGPU 上使用
ubuntu:22.04容器。 对于您的生产工作,请使用 iGPU 特定容器。 有关详细信息,请参阅 Docker 容器。1docker run --rm \ 2 --runtime=nvidia \ 3 -e NVIDIA_VISIBLE_DEVICES=nvidia.com/igpu=0 \ 4 ubuntu:22.04 \ 5 nvidia-smi --query-gpu name --format=csv,noheader
您应该看到类似于以下的输出,其中显示了 iGPU。
1Orin (nvgpu)
设备查询示例#
在此示例中,您使用 Device Query CUDA 示例应用程序 来获取有关 iGPU 和 dGPU 的信息。
克隆并构建设备查询示例应用程序。
1git clone --depth 1 --branch v12.2 https://github.com/NVIDIA/cuda-samples.git 2cd cuda-samples/Samples/1_Utilities/deviceQuery 3make
通过运行以下命令获取 dGPU 的设备信息。 它默认在 dGPU 上运行。
1./deviceQuery您应该看到类似于以下的输出。
1./deviceQuery Starting... 2 3 CUDA Device Query (Runtime API) version (CUDART static linking) 4 5Detected 1 CUDA Capable device(s) 6 7Device 0: "NVIDIA RTX 6000 Ada Generation" 8 CUDA Driver Version / Runtime Version 12.2 / 12.2 9 CUDA Capability Major/Minor version number: 8.9 10 Total amount of global memory: 48436 MBytes (50789154816 bytes) 11 (142) Multiprocessors, (128) CUDA Cores/MP: 18176 CUDA Cores 12 GPU Max Clock rate: 2505 MHz (2.50 GHz) 13 ...
使用以下命令获取 iGPU 的设备信息,以在 iGPU 上的容器中运行应用程序。
注意
此示例在 iGPU 上使用
ubuntu:22.04容器。 对于您的生产工作,请使用 iGPU 特定容器。 有关详细信息,请参阅 Docker 容器。1docker run --rm -it --init \ 2 --runtime=nvidia \ 3 -e NVIDIA_VISIBLE_DEVICES=nvidia.com/igpu=0 \ 4 -v ./deviceQuery:/opt/deviceQuery \ 5 ubuntu:22.04 \ 6 /opt/deviceQuery
您应该看到类似于以下的输出。
1/opt/deviceQuery Starting... 2 3 CUDA Device Query (Runtime API) version (CUDART static linking) 4 5Detected 1 CUDA Capable device(s) 6 7Device 0: "Orin" 8 CUDA Driver Version / Runtime Version 12.2 / 12.2 9 CUDA Capability Major/Minor version number: 8.7 10 Total amount of global memory: 54792 MBytes (57453330432 bytes) 11 (016) Multiprocessors, (128) CUDA Cores/MP: 2048 CUDA Cores 12 GPU Max Clock rate: 1185 MHz (1.18 GHz) 13 ...
加速计算示例#
在此示例中,您同时在 iGPU 和 dGPU 上运行 GPU 加速应用程序。 您运行 矩阵乘法 CUDA 示例应用程序,并且您使用大于默认值的矩阵大小,以便应用程序运行更长时间。
克隆并构建矩阵乘法示例应用程序。
1git clone --depth 1 --branch v12.2 https://github.com/NVIDIA/cuda-samples.git 2cd cuda-samples/Samples/0_Introduction/matrixMul 3make
运行矩阵乘法应用程序。 它默认在 dGPU 上运行。
1./matrixMul -wA=6400 -hA=3200 -wB=3200 -hB=6400
您应该看到类似于以下的输出。
1[Matrix Multiply Using CUDA] - Starting... 2GPU Device 0: "Ada" with compute capability 8.9 3 4MatrixA(6400,3200), MatrixB(3200,6400) 5Computing result using CUDA Kernel... 6...
在单独的终端中,在 iGPU 上的容器中运行矩阵乘法应用程序。
注意
此示例在 iGPU 上使用
ubuntu:22.04容器。 对于您的生产工作,请使用 iGPU 特定容器。 有关详细信息,请参阅 Docker 容器。1docker run --rm -it --init \ 2--runtime=nvidia \ 3-e NVIDIA_VISIBLE_DEVICES=nvidia.com/igpu=0 \ 4-v ./matrixMul:/opt/matrixMul \ 5ubuntu:22.04 \ 6/opt/matrixMul -wA=6400 -hA=3200 -wB=3200 -hB=6400
您应该看到类似于以下的输出。
1[Matrix Multiply Using CUDA] - Starting... 2GPU Device 0: "Ampere" with compute capability 8.7 3 4MatrixA(6400,3200), MatrixB(3200,6400) 5Computing result using CUDA Kernel... 6...
监控 GPU 利用率#
当您运行此示例时,您可以在单独的终端中监控两个 GPU 的利用率。
要监控 iGPU 利用率,请运行以下命令。
1# Monitor continuously 2watch -n 0.25 'tegrastats --interval 1 | head -n1 | sed -E "s|.*(GR3D_FREQ [0-9]+).*|\1%|"' 3 4# -- OR -- 5 6# One time 7# tegrastats --interval 1 | head -n1 | sed -E "s|.*(GR3D_FREQ [0-9]+).*|\1%|"
要监控 dGPU 利用率,请运行以下命令。
1# Monitor continuously 2watch -n 0.25 'nvidia-smi --query-gpu=utilization.gpu --format=csv' 3 4# -- OR -- 5 6# One time 7# nvidia-smi --query-gpu=utilization.gpu --format=csv
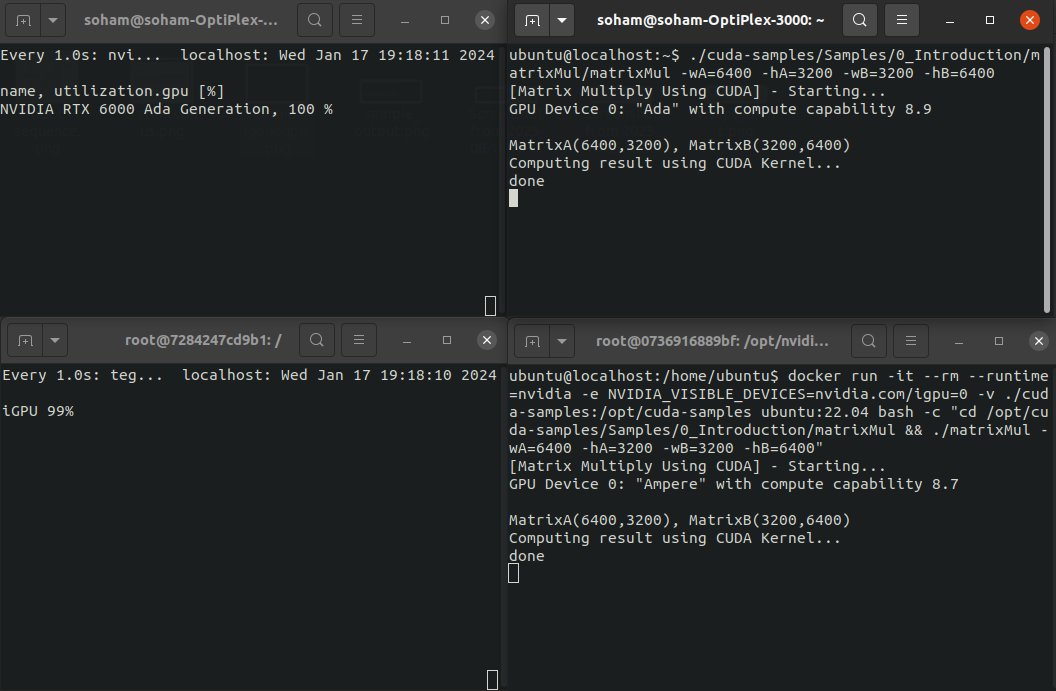
下图显示了 iGPU 和 dGPU 同时被访问和使用。
左上图像 — dGPU 利用率
右上图像 — dGPU matMul
左下图像 — iGPU 利用率
右下图像 — iGPU matMul