DIGITS 用户指南
深度学习 GPU 训练系统™ (DIGITS) 让工程师和数据科学家掌握了深度学习的力量。
DIGITS 不是框架。DIGITS 是 NVCaffe™ 和 TensorFlow™ 的封装器;它为这些框架提供了图形化的 Web 界面,而不是直接在命令行上处理它们。
DIGITS 可用于快速训练高度精确的深度神经网络 (DNN),以用于图像分类、分割、对象检测任务等。DIGITS 简化了常见的深度学习任务,例如管理数据、在多 GPU 系统上设计和训练神经网络、使用高级可视化实时监控性能,以及从结果浏览器中选择性能最佳的模型进行部署。DIGITS 是完全交互式的,因此数据科学家可以专注于设计和训练网络,而不是编程和调试。
1.1. DIGITS 应用程序的内容
NVIDIA® GPU Cloud™ (NGC) 注册中心和 NVIDIA® DGX™ 容器注册中心提供的容器镜像 nvcr.io 已预先构建并安装到 /usr/local/python/ 目录中。
DIGITS 还包括 TensorFlow 深度学习框架。
在从 NGC 注册中心拉取容器之前,您必须安装 Docker 和 nvidia-docker。对于 DGX 用户,这在准备使用 NVIDIA 容器入门指南中进行了解释。
对于 DGX 以外的用户,请根据您的平台按照 NVIDIA® GPU Cloud™ (NGC) 注册中心nvidia-docker 安装文档进行操作。
您还必须拥有访问权限并登录到 NGC 注册中心,如NGC 入门指南中所述。您可以在四个存储库中找到 NGC docker 容器。
-
nvcr.io/nvidia - 深度学习框架容器存储在
nvcr.io/nvidia存储库中。 -
nvcr.io/hpc - HPC 容器存储在
nvcr.io/hpc存储库中。 -
nvcr.io/nvidia-hpcvis - HPC 可视化容器存储在
nvcr.io/nvidia-hpcvis存储库中。 -
nvcr.io/partner - 合作伙伴容器存储在
nvcr.io/partner存储库中。目前,合作伙伴容器专注于深度学习或机器学习,但这并不意味着它们仅限于这些类型的容器。
关于此任务
3.1. 运行 DIGITS
关于此任务
- 运行 DIGITS
- 从开发者专区运行 DIGITS
- Docker®。有关更多信息,请参阅 GitHub 上的 DIGITS。
在您的系统上,在运行应用程序之前,请使用 docker pull 命令确保安装了最新的镜像。拉取完成后,您可以运行应用程序。这是因为 nvidia-docker 确保使用与主机匹配的驱动程序并为容器配置驱动程序。如果没有 nvidia-docker,您在尝试运行容器时很可能会收到错误。
步骤
- 为您需要的容器的适用版本发出命令。以下命令假定您要拉取最新的容器。
docker pull nvcr.io/nvidia/digits:21.04-tensorflow
- 打开命令提示符并粘贴拉取命令。容器镜像的拉取开始。确保拉取成功完成,然后再继续下一步。
- 运行应用程序。启动应用程序的典型命令是
docker run --gpus all -it --rm –v local_dir:container_dir nvcr.io/nvidia/digits:<xx.xx>-<framework>
-it表示交互式--rm表示在完成后删除应用程序–v表示挂载目录local_dir是您要从容器内部访问的主机系统中的目录或文件(绝对路径)。例如,以下路径中的local_dir是/home/jsmith/data/mnist。-v /home/jsmith/data/mnist:/data/mnist
如果您在容器内部,例如
ls /data/mnist,您将看到与从容器外部发出ls /home/jsmith/data/mnist命令时相同的文件。container_dir是您在容器内部时的目标目录。例如,/data/mnist是示例中的目标目录-v /home/jsmith/data/mnist:/data/mnist
<xx.xx>是容器版本。例如,21.01。<framework>是您要拉取的框架。例如,tensorflow。
- 要将服务器作为守护程序运行并将容器中的端口 5000 公开到主机上的端口 8888
docker run --gpus all --name digits -d -p 8888:5000 nvcr.io/nvidia/digits:<xx.xx>-<framework>
注意注意:DIGITS 6.0 默认使用端口 5000。
- 要挂载一个包含您的数据的本地目录(只读)和另一个用于写入 DIGITS 作业的目录
docker run --gpus all --name digits -d -p 8888:5000 -v /home/username/data:/data -v /home/username/digits- jobs:/workspace/jobs nvcr.io/nvidia/digits:<xx.xx>-<framework>
注意注意:为了在 ranks 之间共享数据,NVIDIA® Collective Communications Library ™ (NCCL) 可能需要共享系统内存用于 IPC 和固定(页锁定)系统内存资源。可能需要相应地增加操作系统对这些资源的限制。有关详细信息,请参阅您的系统文档。特别是,Docker 容器默认限制共享和固定内存资源。在容器内部使用 NCCL 时,建议您通过发出以下命令来增加这些资源
--shm-size=1g --ulimit memlock=-1
在命令行中到
docker run --gpus all
- 有关自定义 DIGITS 应用程序的信息,请参阅容器内的
/workspace/README.md。有关 DIGITS 的更多信息,请参阅:- DIGITS 网站
- DIGITS 项目
- nvidia-docker 文档
注意
注意:Dockerhub 镜像和此镜像之间可能存在细微差异。
从开发者专区运行 DIGITS
关于此任务
有关下载、运行和使用 DIGITS 的更多信息,请参阅:NVIDIA DIGITS:交互式深度学习 GPU 训练系统。
3.3. 使用来自 S3 端点的数据创建数据集
关于此任务
DIGITS 可以在存储在 S3 端点上的数据上进行训练。这对于数据已存储在不同节点,并且您不想手动将数据迁移到运行 DIGITS 的节点的情况非常有用。
步骤
- 将数据加载到 S3 中。例如,我们将使用以下数据集
python -m digits.download_data mnist ~/mnist
upload_s3_data.py的 python 脚本,该脚本已提供,可用于将这些文件上传到配置的 S3 端点。此脚本及其随附的配置文件upload_config.cfg位于digits/digits/tools目录中。[S3 Config] endpoint = http://your-s3-endpoint.com:80 accesskey = 0123456789abcde secretkey = PrIclctP80KrMi6+UPO9ZYNrkg6ByFeFRR6484qL bucket = digits prefix = mnist
endpoint- 指定 S3 数据将存储在其中的端点的 URL。accesskey- 将用于验证您对端点访问权限的访问密钥。secretkey- 将用于验证您对端点访问权限的密钥。bucket- 应该存储此数据的存储桶的名称。如果它不存在,脚本将创建它。prefix- 将预先添加到所有键名称的前缀。稍后将在数据集创建期间使用它。
- 文件配置完成后,使用以下命令运行它
python upload_s3_data.py ~/mnist
注意注意:很大程度上取决于您的网络速度和 S3 端点的计算资源,上传过程将花费相当长的时间才能完成。
上传完成后,数据集中的所有键都将上传到 S3 中,并带有适当的前缀结构,以便稍后在数据集创建期间使用。例如,在上述配置中,文件将位于存储桶 digits 中,并以
mnist/train/<0-9>为前缀。 - 在 DIGITS 中创建数据集。
- 在主屏幕上,单击图像 > 分类。
- 单击使用 S3 选项卡以指定您希望从 S3 端点访问数据。注意
注意:训练图像 URL 和存储桶名称字段可以分别从上传配置字段端点和存储桶中填写。训练图像路径由上传期间指定的前缀附加
train/组成。对于我们的示例,它将是mnist/train/。访问密钥和密钥是将用于从 S3 端点访问数据的凭据。与任何其他数据集类似,可以在屏幕底部指定属性,包括数据库后端、图像编码、组名称和数据集名称。当数据集配置为您想要的方式后,单击创建。
- 如果作业处理正确,那么您已成功从存储在 S3 端点中的数据创建了数据集。您将看到类似于以下图像的图像:
图 1. 成功从存储在 S3 端点中的数据创建数据集的确认

您现在可以继续使用此数据集来训练您的模型。

nvidia-docker 存储库 nvcr.io 中的 DIGITS 应用程序附带 DIGITS,但也附带 TensorFlow。您可以在容器发行说明中阅读详细信息 https://docs.nvda.net.cn/deeplearning/dgx/index.html。例如,DIGITS 的 19.01 版本包括 TensorFlow 的 19.01 版本。
DIGITS 是一个训练平台,可以与 TensorFlow 深度学习框架一起使用。使用这些框架中的任何一个,DIGITS 都将在您的数据集上训练您的深度学习模型。
以下各节包含使用 DIGITS 和 TensorFlow 后端的示例。
用于 DIGITS 的 TensorFlow
用于 DIGITS 的 TensorFlow 适用于 DIGITS 6.0 及更高版本。
4.1.1. 示例 1:MNIST
步骤
- 使用 DIGITS 和 TensorFlow 训练模型的第一步是从
nvcr.io注册中心拉取 DIGITS 容器(确保您已登录到适当的注册中心)。$ docker pull nvcr.io/nvidia/digits:17.04
- 拉取应用程序后,您可以启动 DIGITS。由于 DIGITS 是 TensorFlow 的基于 Web 的前端,我们将使用以下命令以非交互方式运行 DIGITS 应用程序。
docker run --gpus all -d --name digits-17.04 -p 8888:5000 --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 nvcr.io/nvidia/digits:17.04
- 第一个选项
-d告诉nvidia-docker以“守护程序”模式运行应用程序。 --name选项命名正在运行的应用程序(稍后我们将需要它)。- 两个
ulimit选项和shmem选项是为了增加 TensorFlow 的内存量,因为它使用共享内存跨 GPU 共享数据。 -p 8888:5000选项将 DIGITS 端口 5000 映射到端口 8888(您将在下面看到如何使用它)。
运行此命令后,您需要找到 DIGITS 节点的 IP 地址。可以通过运行
ifconfig命令找到,如下所示。$ ifconfig docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.99.1 netmask 255.255.255.0 broadcast 0.0.0.0 inet6 fe80::42:5cff:fefb:1c30 prefixlen 64 scopeid 0x20<link> ether 02:42:5c:fb:1c:30 txqueuelen 0 (Ethernet) RX packets 22649 bytes 5171804 (4.9 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 29088 bytes 123439479 (117.7 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 enp1s0f0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.31.229.99 netmask 255.255.255.128 broadcast 10.31.229.127 inet6 fe80::56ab:3aff:fed6:614f prefixlen 64 scopeid 0x20<link> ether 54:ab:3a:d6:61:4f txqueuelen 1000 (Ethernet) RX packets 8116350 bytes 11069954019 (10.3 GiB) RX errors 0 dropped 9 overruns 0 frame 0 TX packets 1504305 bytes 162349141 (154.8 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ...
在这种情况下,我们需要以太网 IP 地址,因为它是 DIGITS 的 Web 服务器的地址(本例中为 10.31.229.56)。您的 IP 地址会有所不同。
- 第一个选项
- 我们现在需要将 MNIST 数据集下载到应用程序中。DIGITS 应用程序有一个简单的脚本,用于将数据集下载到应用程序中。作为检查,运行以下命令以确保应用程序正在运行。
$ docker ps -a CONTAINER ID IMAGE ... NAMES c930962b9636 nvcr.io/nvidia/digits:17.04 ... digits-17.04
应用程序正在运行,并且具有我们给它的名称 (
digits-17.04)。接下来,您需要从系统上的另一个终端“shell”进入正在运行的应用程序。
$ docker exec -it digits-17.04 bash root@XXXXXXXXXXXX:/workspace#
我们想将数据放入目录/data/mnist中。应用程序中有一个简单的 Python 脚本可以为我们完成此操作。它也会以正确的格式下载数据。# python -m digits.download_data mnist /data/mnist Downloading url=http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz ... Downloading url=http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz ... Downloading url=http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz ... Downloading url=http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz ... Uncompressing file=train-images-idx3-ubyte.gz ... Uncompressing file=train-labels-idx1-ubyte.gz ... Uncompressing file=t10k-images-idx3-ubyte.gz ... Uncompressing file=t10k-labels-idx1-ubyte.gz ... Reading labels from /data/mnist/train-labels.bin ... Reading images from /data/mnist/train-images.bin ... Reading labels from /data/mnist/test-labels.bin ... Reading images from /data/mnist/test-images.bin ... Dataset directory is created successfully at '/data/mnist' Done after 13.4188599586 seconds.
- 您现在可以打开 Web 浏览器,访问上一步中的 IP 地址。请务必使用端口 8888,因为我们将 DIGITS 端口从 5000 映射到端口 8888。对于此示例,URL 将是以下内容。
10.31.229.56:8888
图 2. DIGITS 主页
- 加载数据集。我们将使用 MNIST 数据集作为示例,因为它随应用程序一起提供。
- 单击数据集选项卡。
- 单击图像下拉菜单,然后选择分类。如果 DIGITS 要求输入用户名,您可以输入任何您想要的内容。“新建图像分类数据集”窗口将显示。填写字段后,您的屏幕应如下所示。
图 3. 新建图像分类数据集
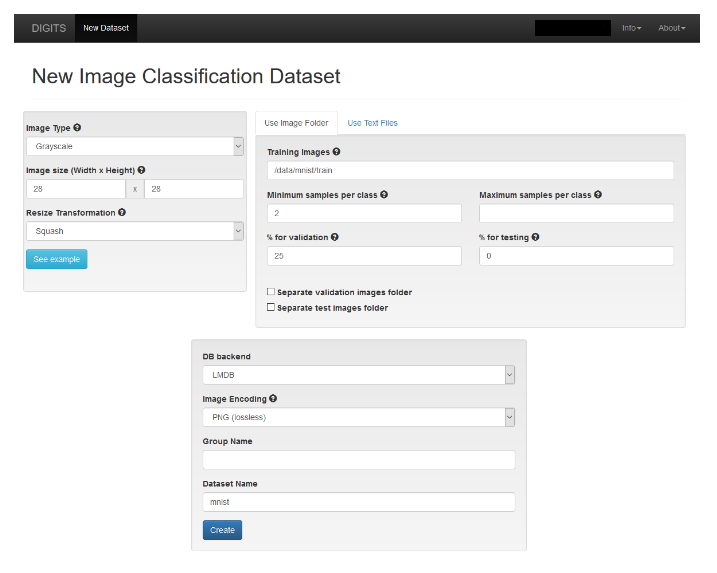
- 为图像类型和图像大小提供值,如上图所示。
- 在数据集名称字段中为您的数据集命名。您可以将数据集命名为您喜欢的任何名称。在本例中,名称只是“mnist”。
- 单击创建。这告诉 DIGITS 告诉 TensorFlow 加载数据集。加载数据集后,您的屏幕应类似于以下内容。注意
注意:此屏幕截图已被截断,因为网页非常长。
图 4. MNIST 顶层
图 5. MNIST 底层
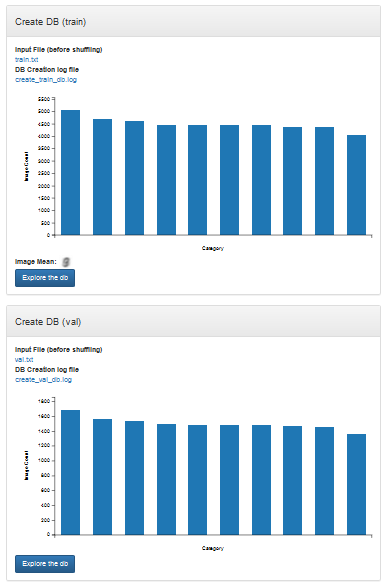
注意注意:有两个部分允许您“浏览”数据库(数据库)。创建 DB(训练)用于训练数据,创建 DB(验证)用于验证数据。在这些显示中的任何一个中,您可以单击浏览 db 以获取训练集。
- 训练模型。我们将使用 Yann Lecun 的 LeNet 模型作为示例,因为它随应用程序一起提供。
- 定义模型。单击左上角的 DIGITS 返回主页。
- 单击模型选项卡。
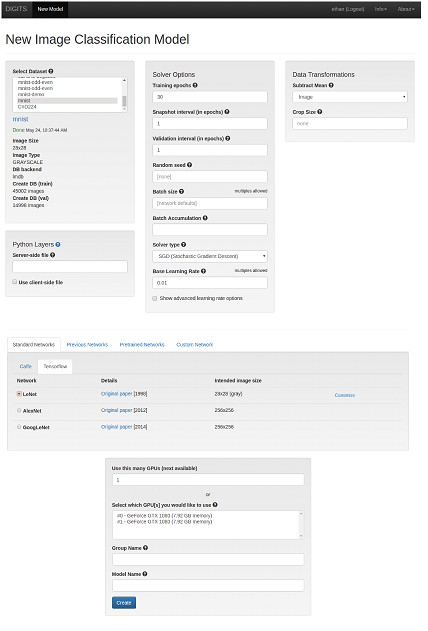
- 单击图像下拉菜单,然后选择分类。“新建图像分类模型”窗口将显示。
- 为选择数据集和训练参数字段提供值。
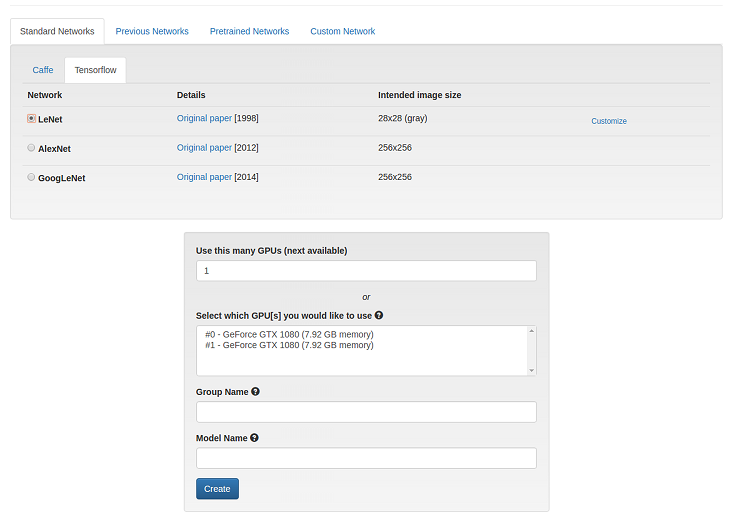
- 在标准网络选项卡中,单击 TensorFlow 并选择 LeNet 单选按钮。注意
注意:如果需要,DIGITS 允许您使用以前的网络、预训练网络和客户网络。
- 单击创建。LeNet 模型的训练开始。注意
注意:此屏幕截图已被截断,因为网页非常长。
图 6. 新建图像分类模型顶层
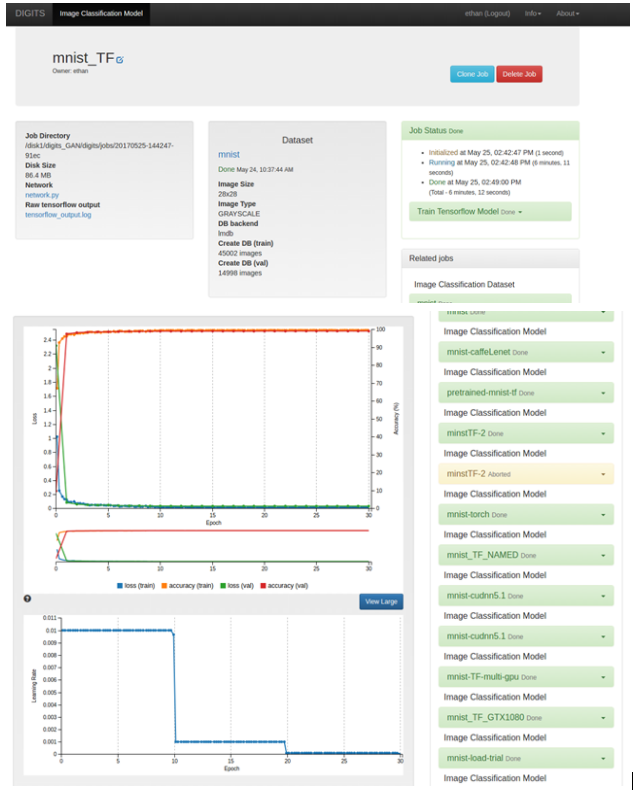
在训练期间,DIGITS 显示训练参数的历史记录,特别是训练数据的损失函数、验证数据集的准确率以及验证数据的损失函数。训练完成后(所有 30 个 epoch 都已训练),您的屏幕应类似于以下内容。
注意注意:此屏幕截图已被截断,因为网页非常长。
图 7. 图像分类模型
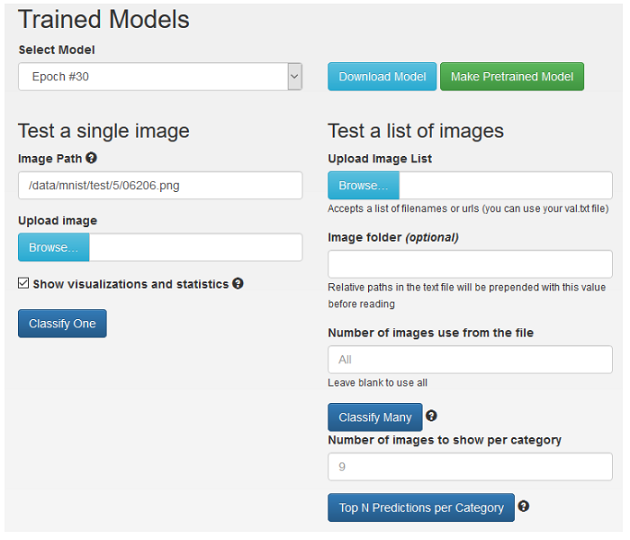
- 可选:您可以通过滚动到网页底部来针对训练后的模型测试一些图像(推理)。为了便于说明,从测试数据集中输入单个图像。您可以随时上传图像。如果您愿意,还可以输入“测试”图像列表。以下屏幕针对名为
/data/mnist/test/5/06206.png的测试图像进行推理。此外,选中统计信息和可视化复选框,以确保您可以查看来自网络的所有详细信息以及网络预测。图 8. 训练后的模型
 注意
注意注意:您可以根据需要从任何 epoch 中选择模型。为此,请单击选择模型下拉箭头并选择不同的 epoch。
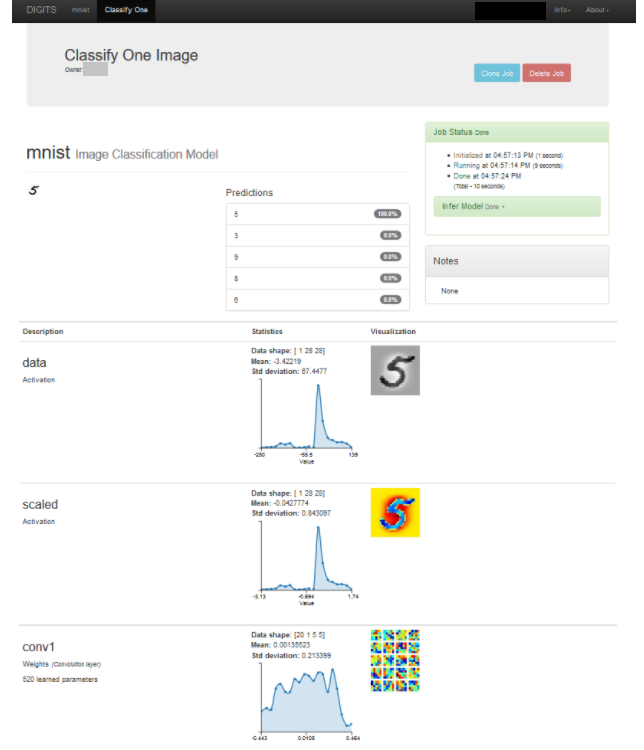
- 单击分类一个。这将打开另一个浏览器选项卡并显示预测。以下屏幕是数字“5”的测试图像的输出。
图 9. 分类一个图像








4.1.2. 示例 2:Siamese 网络
开始之前
- 为了训练 Siamese 数据集,您必须首先拥有 MNIST 数据集。要创建 MNIST 数据集,请参阅示例 1:MNIST。
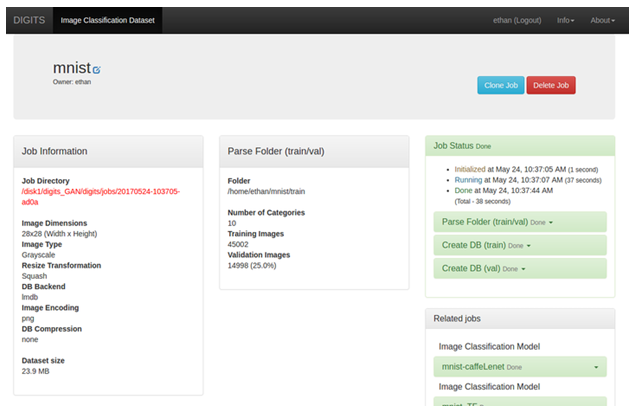
- 记住作业目录路径,因为此任务中需要它。
图 10. 作业目录

步骤
- 运行以下位置提供的 Python 脚本:GitHub:siamese-TF.py。该脚本需要以下参数
Create_db.py <where to save results> <the job directory> -c <how many samples>
<where to save results>是您要保存输出的目录路径。<the job directory>是您在先决条件中记下的目录名称。<how many samples>是您定义样本数量的位置。将此数字设置为100000。
- 创建 Siamese 数据集。
- 单击新建模型 > 图像 > 其他以创建模型。在本例中,我们将使用 TensorFlow 来训练我们的 Siamese 网络。
- 训练模型。
- 单击自定义网络选项卡,然后选择 TensorFlow。
- 复制并粘贴以下网络定义:GitHub:mnist_siamese_train_test.prototxt
- 确保基本学习率设置为
0.01,保持其他字段的默认设置,然后单击训练。图 13. 新建图像模型
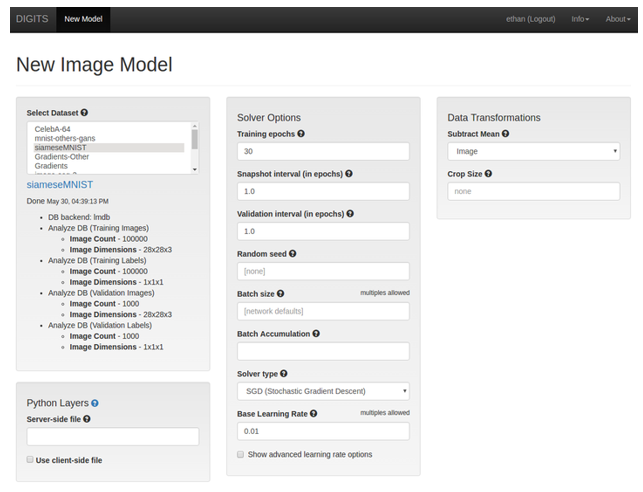
图 14. 自定义模型
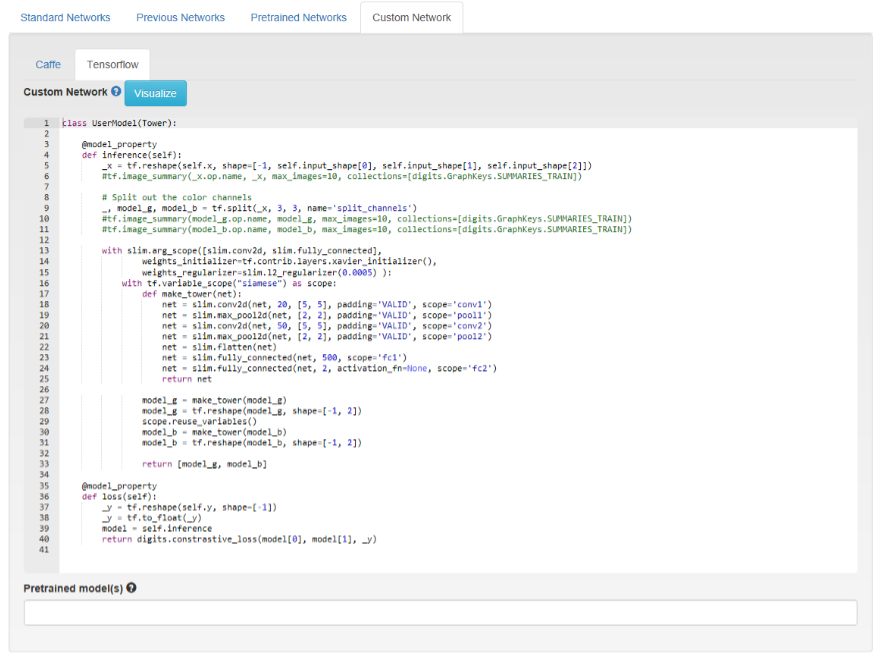
图 15. 在 TensorFlow 上训练
模型训练完成后,图形输出应类似于以下内容
图 16. TensorFlow 图形输出
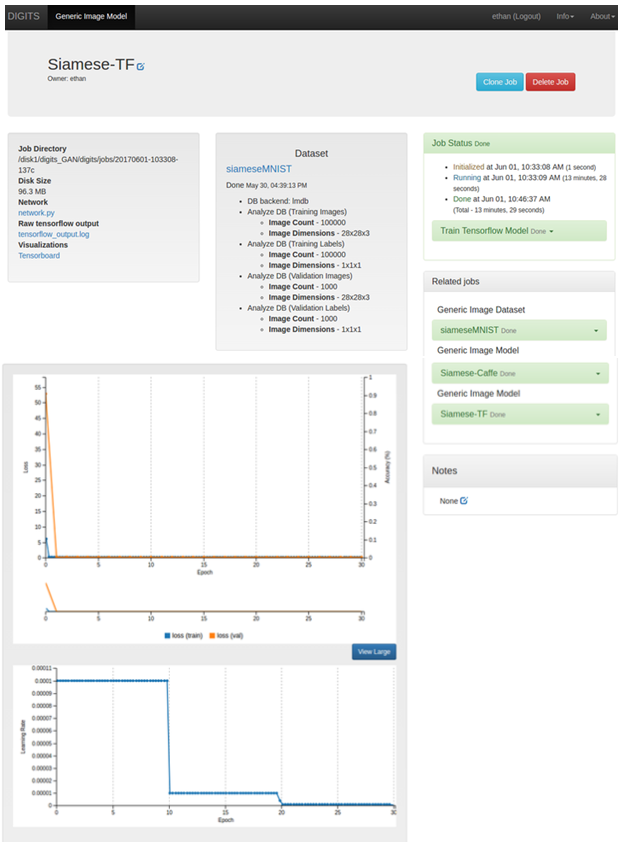
- 通过从您在
<where to save results>路径中指定的同一目录位置上传图像来测试图像。









5.1. 调整模型以适应输入维度和类数
以下网络定义了一个线性网络,该网络将任何 3D 张量作为输入,并为每个类生成一个分类输出
return function(p)
-- model should adjust to any 3D-input
local nClasses = p.nclasses or 1
local nDim = 1
if p.inputShape then p.inputShape:apply(function(x) nDim=nDim*x end) end
local model = nn.Sequential()
model:add(nn.View(-1):setNumInputDims(3)) -- c*h*w -> chw (flattened)
model:add(nn.Linear(nDim, nclasses)) -- chw -> nClasses
model:add(nn.LogSoftMax())
return {
model = model
}
end
5.2. 选择 nn 后端
卷积层受各种后端(例如 nn、cunn、cudnn 等)支持。以下代码段显示了如何根据 nn、cunn、cudnn 在系统中的可用性在它们之间进行选择
if pcall(function() require('cudnn') end) then
backend = cudnn
convLayer = cudnn.SpatialConvolution
else
pcall(function() require('cunn') end)
backend = nn -- works with cunn or nn
convLayer = nn.SpatialConvolutionMM
end
local net = nn.Sequential()
lenet:add(backend.SpatialConvolution(1,20,5,5,1,1,0)) -- 1*28*28 -> 20*24*24
lenet:add(backend.SpatialMaxPooling(2, 2, 2, 2)) -- 20*24*24 -> 20*12*12
lenet:add(backend.SpatialConvolution(20,50,5,5,1,1,0)) -- 20*12*12 -> 50*8*8
lenet:add(backend.SpatialMaxPooling(2,2,2,2)) -- 50*8*8 -> 50*4*4
lenet:add(nn.View(-1):setNumInputDims(3)) -- 50*4*4 -> 800
lenet:add(nn.Linear(800,500)) -- 800 -> 500
lenet:add(backend.ReLU())
lenet:add(nn.Linear(500, 10)) -- 500 -> 10
lenet:add(nn.LogSoftMax())
5.3. 监督回归学习
在监督回归学习中,标签可能不是像分类学习中那样的标量。要学习回归模型,可以使用一个数据库用于输入样本,一个数据库用于标签(目前仅支持 1D 行标签向量)来创建通用数据集。必须使用损失内部参数指定适当的损失函数。例如,以下代码段定义了一个使用 MSE 损失的 1x10x10 图像上的简单回归模型
local net = nn.Sequential()
net:add(nn.View(-1):setNumInputDims(3)) -- 1*10*10 -> 100
net:add(nn.Linear(100,2))
return function(params)
return {
model = net,
loss = nn.MSECriterion(),
}
end
5.4. 命令行推理
DIGITS Lua 封装器也可以从命令行使用。例如,要使用模型作业 20160707-093158-9ed6 的 epoch 30 处的快照和数据集 20160117-131355-ba71 对图像 test.png 进行分类
th /home/greg/ws/digits/tools/torch/wrapper.lua test.lua --image=test.png --network=model --networkDirectory=/home/greg/ws/digits/digits/jobs/20160707-093158-9ed6 --snapshot=/home/greg/ws/digits/digits/jobs/20160707-093158-9ed6/snapshot_30_Model.t7 --labels=/home/greg/ws/digits/digits/jobs/20160117-131355-ba71/labels.txt --mean=/home/greg/ws/digits/digits/jobs/20160707-093158-9ed6/mean.jpg --subtractMean=image
2016-07-07 09:43:20 [INFO ] Loading mean tensor from /home/greg/ws/digits/digits/jobs/20160707-093158-9ed6/mean.jpg file
2016-07-07 09:43:20 [INFO ] Loading network definition from /home/greg/ws/digits/digits/jobs/20160707-093158-9ed6/model
Using CuDNN backend
2016-07-07 09:43:20 [INFO ] For image 1, predicted class 1: 5 (4) 0.99877911806107
2016-07-07 09:43:20 [INFO ] For image 1, predicted class 2: 10 (9) 0.0011787103721872
2016-07-07 09:43:20 [INFO ] For image 1, predicted class 3: 8 (7) 3.8778140151408e-05
2016-07-07 09:43:20 [INFO ] For image 1, predicted class 4: 7 (6) 2.3879254058556e-06
2016-07-07 09:43:20 [INFO ] For image 1, predicted class 5: 1 (0) 4.1431232489231e-07
对于分类网络,显示了前 5 个类。对于每个类,标签显示在括号内。例如,预测类 1:5 (4) 0.99877911806107 表示网络预测最有可能的类是 labels.txt 中的第 5 个类,标签为“4”,概率为 99.88%。
对于其他类型的网络,请在命令行上设置 --allPredictions=yes 以显示原始网络输出。例如
th /home/greg/ws/digits/tools/torch/wrapper.lua test.lua --image=test.png --network=model --networkDirectory=/home/greg/ws/digits/digits/jobs/20160707-093158-9ed6 --snapshot=/home/greg/ws/digits/digits/jobs/20160707-093158-9ed6/snapshot_30_Model.t7 --mean=/home/greg/ws/digits/digits/jobs/20160707-093158-9ed6/mean.jpg --subtractMean=image --allPredictions=yes
2016-07-07 09:46:31 [INFO ] Loading mean tensor from /home/greg/ws/digits/digits/jobs/20160707-093158-9ed6/mean.jpg file
2016-07-07 09:46:31 [INFO ] Loading network definition from /home/greg/ws/digits/digits/jobs/20160707-093158-9ed6/model
Using CuDNN backend
2016-07-07 09:46:32 [INFO ] Predictions for image 1: [-14.696645736694,-16.256759643555,-16.247381210327,-20.25181388855,-0.0012216567993164,-18.055643081665,-12.945085525513,-10.157653808594,-15.657314300537,-6.7433342933655]
5.5. 多 GPU 训练
Torch7 中的 cunn 通过 DataParallelTable 模块支持数据并行性。DIGITS 通过 ngpus 外部参数提供可用 GPU 的数量。
假设 net 是一个容器,它封装了网络的定义,则可以使用以下代码段将数据并行性启用到一个名为 model 的容器中
local model
if ngpus>1 then
model = nn.DataParallelTable(1) -- Split along first (batch) dimension
for i = 1, ngpus do
cutorch.setDevice(i)
model:add(net:clone(), i) -- Use the ith GPU
end
cutorch.setDevice(1) -- This is the 'primary' GPU
else
model = net
end
声明
本文档仅供参考,不应视为对产品特定功能、条件或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。对于因使用此类信息或因其使用而可能导致的任何专利或第三方其他权利的侵权行为,NVIDIA 概不负责。本文档不承诺开发、发布或交付任何材料(下文定义)、代码或功能。
NVIDIA 保留随时对此文档进行更正、修改、增强、改进和任何其他更改的权利,恕不另行通知。
客户在下订单之前应获取最新的相关信息,并应验证此类信息是否为最新且完整。
NVIDIA 产品的销售受订单确认时提供的 NVIDIA 标准销售条款和条件的约束,除非 NVIDIA 和客户的授权代表签署的个人销售协议(“销售条款”)另有约定。NVIDIA 在此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档未直接或间接地形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命支持设备,也不适用于 NVIDIA 产品的故障或故障可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。对于在上述设备或应用中包含和/或使用 NVIDIA 产品,NVIDIA 不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不保证基于本文档的产品将适用于任何特定用途。NVIDIA 不一定会执行每个产品所有参数的测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合并满足客户计划的应用,并执行应用所需的测试,以避免应用或产品的默认设置。客户产品设计的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同条件和/或要求。对于可能基于或归因于以下原因的任何默认设置、损坏、成本或问题,NVIDIA 不承担任何责任:(i) 以任何与本文档相悖的方式使用 NVIDIA 产品,或 (ii) 客户产品设计。
本文档未授予 NVIDIA 专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成对其的保证或认可。使用此类信息可能需要获得第三方在其专利或其他知识产权下的许可,或获得 NVIDIA 在其专利或其他知识产权下的许可。
只有在事先获得 NVIDIA 书面批准的情况下,且在不更改内容、完全遵守所有适用的出口法律法规并随附所有相关条件、限制和声明的情况下,才允许复制本文档中的信息。
本文档以及所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”,单独称为“材料”)均“按原样”提供。NVIDIA 对这些材料不作任何明示、暗示、法定或其他方面的保证,并且明确否认所有关于非侵权、适销性和特定用途适用性的暗示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对因使用本文档而引起的任何损害(包括但不限于任何直接、间接、特殊、偶然、惩罚性或后果性损害,无论何种原因造成,也无论责任理论如何)承担责任,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因遭受任何损害,NVIDIA 对本文所述产品的累积总责任应根据产品的销售条款进行限制。
VESA DisplayPort
DisplayPort 和 DisplayPort Compliance Logo、用于双模源的 DisplayPort Compliance Logo 以及用于有源电缆的 DisplayPort Compliance Logo 是视频电子标准协会在美国和其他国家/地区拥有的商标。
HDMI
HDMI、HDMI 徽标和 High-Definition Multimedia Interface 是 HDMI Licensing LLC 的商标或注册商标。
OpenCL
OpenCL 是 Apple Inc. 的商标,已获得 Khronos Group Inc. 的许可使用。
商标
NVIDIA、NVIDIA 徽标以及 cuBLAS、CUDA、cuDNN、DALI、DIGITS、DGX、DGX-1、DGX-2、DGX Station、DLProf、Jetson、Kepler、Maxwell、NCCL、Nsight Compute、Nsight Systems、NvCaffe、PerfWorks、Pascal、SDK Manager、Tegra、TensorRT、Triton Inference Server、Tesla、TF-TRT 和 Volta 是 NVIDIA Corporation 在美国和其他国家/地区的商标和/或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。