DIGITS 容器用户指南
摘要
本指南详细概述了如何使用 DIGITS 容器。DIGITS 是一个训练平台,可以与 NVIDIA TensorFlow 深度学习框架一起使用。使用此框架,DIGITS 将在您的数据集上训练您的深度学习模型。
深度学习 GPU 训练系统™ (DIGITS) 将深度学习的力量赋予工程师和数据科学家。
DIGITS 不是一个框架。DIGITS 是 TensorFlow™ 的一个封装器;它为这些框架提供了一个图形化 Web 界面,而不是直接在命令行上与它们交互。
DIGITS 可用于快速训练高度准确的深度神经网络 (DNN),用于图像分类、语义分割、目标检测任务等。DIGITS 简化了常见的深度学习任务,例如管理数据、在多 GPU 系统上设计和训练神经网络、使用高级可视化实时监控性能,以及从结果浏览器中选择性能最佳的模型进行部署。DIGITS 是完全交互式的,因此数据科学家可以专注于设计和训练网络,而不是编程和调试。
DIGITS 可以使用存储在 S3 端点上的数据进行训练。这对于数据存储在不同节点,并且您不想手动将数据迁移到运行 DIGITS 的节点的情况非常有用。
- 将数据加载到 S3 中。例如,我们将使用以下数据集:
python -m digits.download_data mnist ~/mnist有一个名为
upload_s3_data.py的 python 脚本,它被提供并可用于将这些文件上传到配置的 S3 端点。此脚本及其随附的配置文件upload_config.cfg位于digits/digits/tools目录中。[S3 Config] endpoint = http://your-s3-endpoint.com:80 accesskey = 0123456789abcde secretkey = PrIclctP80KrMi6+UPO9ZYNrkg6ByFeFRR6484qL bucket = digits prefix = mnist
endpoint- 指定 S3 数据将存储在的端点的 URL。accesskey- 用于验证您对端点访问权限的访问密钥。secretkey- 用于验证您对端点访问权限的私钥。bucket- 应该存储此数据的存储桶的名称。如果它不存在,脚本将创建它。prefix- 将添加到所有键名称的前缀。这将在稍后创建数据集期间使用。
- 配置文件配置完成后,使用以下命令运行它:
python upload_s3_data.py ~/mnist注意注意:完成上传过程所需的时间取决于您的网络速度和 S3 端点的计算资源。
上传完成后,数据集中的所有键都将上传到 S3 中,并带有适当的前缀结构,以便稍后在数据集创建期间使用。例如,在上述配置中,文件将位于存储桶
digits中,并以mnist/train/<0-9>为前缀。 - 在 DIGITS 中创建数据集。
- 在主屏幕上,单击图像 > 分类。
- 单击使用 S3 选项卡以指定您希望从 S3 端点访问数据。注意
注意:训练图像 URL 和存储桶名称字段可以分别从上传配置文件字段 endpoint 和 bucket 中填充。训练图像路径由上传期间指定的前缀加上
train/组成。对于我们的示例,它将是mnist/train/。访问密钥和私钥是将用于从 S3 端点访问数据的凭据。与任何其他数据集类似,包括数据库后端、图像编码、组名称和数据集名称在内的属性可以在屏幕底部指定。当数据集配置为您想要的方式后,单击创建。
- 如果作业处理正确,则您已成功从存储在 S3 端点中的数据创建了数据集。您将看到类似于以下图像的图像:
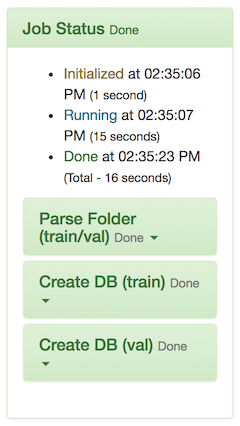
您现在可以继续使用此数据集来训练您的模型。

这是一个编写 DIGITS 插件的教程。本节将引导您完成添加自己的插件的过程。DIGITS 支持从有限数量的数据源摄取数据(支持的图像文件格式列表)。
DIGITS 数据插件启用了一种机制,您可以通过该机制扩展 DIGITS 以从自定义源摄取数据。
同样,DIGITS 提供了多种模型输出可视化类型,例如图像分类、目标检测或图像分割。DIGITS 可视化插件使可视化非标准模型的输出成为可能。
3.1. 从 DICOM 文件读取数据
在本示例中,我们将为图像分割实现一个数据插件,该插件从 DICOM 文件读取图像,并从文本文件读取其 ground-truth。此插件已在 医学影像示例 中介绍过。此插件被称为 Sunnybrook 插件,来自相应数据集的名称。完整代码可在此处获得 这里。DIGITS 可以在以下情况下使用数据插件:
- 创建新数据集时,为了创建数据库
- 执行推理时,为了将数据馈送到模型
注意
我们需要理解的大多数概念来创建数据插件也适用于编写可视化插件。
安装插件后,DIGITS 开始在主页上显示相应的菜单。例如:

可选地,如果您的数据模块已指示它也可以在推理期间摄取数据,您将在模型页面上看到可视化选项菜单。
3.1.1. 数据插件文件树

3.1.1.1. setup.py
setup.py 文件指定如何安装插件。此处主要的关注部分是来自 setuptools 包的 setup 命令的调用
setup(
name="digits_sunnybrook_data_plugin",
version="0.0.1",
author="Greg Heinrich",
description=("A data ingestion plugin for the Sunnybrook cardiac dataset"),
long_description=read('README'),
license="Apache",
packages=find_packages(),
entry_points={
DIGITS_PLUGIN_GROUP: [
'class=digitsDataPluginSunnybrook:DataIngestion',
]},
include_package_data=True,
install_requires=['pydicom'],
)
安装后,Python 包将导出入口点 (entry_points)。示例代码将 digitsDataPluginSunnybrook 包中的 DataIngestionclass 分配给 DIGITS_PLUGIN_GROUP 入口点组。这将使 DIGITS 能够在启动时发现已安装的插件。
在 install_requires 参数中,我们指定此插件的 Python 包依赖项列表。在本例中,插件需要 pydicom 包。
3.1.1.2. MANIFEST.in
MANIFEST.in 文件指定要包含在插件包中的资源文件。在本示例中,我们递归地包含 digitsDataPluginSunnybrook 文件夹中的所有 .html 文件。如果您正在编写自己的插件,请确保这些文件位于包文件夹内。
recursive-include digitsDataPluginSunnybrook *.html
3.1.1.3. init.py
digitsDataPluginSunnybrook/init.py 文件指示 digitsDataPluginSunnybrook 文件夹是一个 Python 包。在大多数情况下,digitsDataPluginSunnybrook 文件夹可以留空。在我们的例子中,因为我们正在创建 data.py 文件的 DataIngestion 成员的快捷方式,我们可以在 setup.py 文件中将其称为 digitsDataPluginSunnybrook:DataIngestion。
3.1.1.4. data.py
digitsDataPluginSunnybrook/data.py 文件实现了一个 DataIngestion 类,该类实现了 DIGITS 数据扩展数据库 (https://github.com/NVIDIA/DIGITS/blob/digits-5.0/digits/extensions/data/interface.py )。请务必查看接口 API 及其文档字符串。
DataIngestion 类是 DIGITS 和 Sunnybrook 插件之间唯一的接口。熟悉该接口以了解有关此类中需要实现的必需方法的详细信息。最重要的有:
get_dataset_form -这是一个静态方法,返回一个表单(flask.ext.wtf.Form的子类),其中包含创建数据集所需的所有字段。例如,表单可能包含文本字段,以允许用户指定文件名或各种数据集选项。get_dataset_template -这是一个静态方法,它返回一个 Jinja 模板,用于在 DIGITS Web 用户界面中显示表单;此方法还返回一个上下文变量字典,该字典应包含 Jinja 模板中引用的所有变量。例如,Sunnybrook 插件将表单作为上下文提供,因为 Jinja 模板引用此变量以将表单呈现到 Web 用户界面中。get_inference_form -这类似于get_dataset_form,但这用于在推理期间显示数据摄取选项时。注意注意:此方法可能返回
None以指示您的数据插件无法在推理期间运行。在这种情况下,预计 DIGITS 中的常规图像推理选项将适用于您正在训练的模型。get_inference_template -这类似于get_dataset_template,但这用于推理期间。__init__ -这是用于创建类实例的初始化例程。在初始化期间,会提供两个参数。第一个参数名为is_inference_db,指示此实例是否将在推理期间使用。第二个参数是一个字典,其中包含用户在数据集创建期间或在指定推理数据选项时指定的所有表单字段。itemize_entries -此方法解析表单字段以生成数据样本标识符列表。例如,如果您的数据插件需要编码目录中的所有文件,则 itemized entries 可以是所有文件名的列表。encode_entry -此方法是数据插件的核心。它读取与itemize_entries中返回的标识符之一关联的数据,并将数据转换为 3 维 NumPy 数组。此函数还返回一个标签,该标签可以是标量或另一个 3 维 NumPy 数组。注意:在 DICOM 文件中读取图像的过程相对简单f = dicom.read_file(full_path) img = f.pixel_array.astype(np.int)
3.1.1.5. form.py
digitsDataPluginSunnybrook/form.py 文件是我们定义的位置:
- 用于指定数据集的
DatasetForm类 - 可选地,用于指定推理数据的
InferenceForm类
在 Sunnybrook 示例中,这些类的实例在 DataIngestion:get_dataset_form 和 DataIngestion:get_inference_form 中创建和返回。这些类是 flask.ext.wtf.Form 的子类。有关更多信息,请参阅 WTForms 文档 。
3.1.1.6. dataset_template.py
digitsDataPluginSunnybrook/templates/dataset_template.py 文件是一个 Jinja 模板,用于定义您将在 Web 用户界面中看到的内容。有关更多信息,请参阅 Jinja 文档 。
注意:Sunnybrook 模板引用了在 DataIngestion:get_dataset_template 中作为上下文给出的 form 变量。例如
{{ form.image_folder.label }}
3.1.1.7. inference_template.py
digitsDataPluginSunnybrook/templates/inference_template.py 文件是用于显示推理数据选项的 Jinja 模板。
3.1.2. 安装插件
为了安装插件,您需要从包含您的数据插件 setup.py 文件的目录中运行以下命令。
$ pip install
接下来,重新启动 DIGITS 以使更改生效。
您的插件已安装。
3.2. 可视化插件
可视化插件的工作方式与数据插件类似。主要区别在于可视化插件实现了 view 接口。有关使用方法的更多信息,请参阅此文件中的内联文档字符串。
有关最新的发行说明,请参阅 DIGITS 发行说明文档网站:(https://docs.nvda.net.cn/deeplearning/digits/digits-release-notes/index.html )。有关 DIGITS 的更多信息,请参阅:
- DIGITS 网站 (https://developer.nvidia.com/digits )
- DIGITS 项目 (https://github.com/NVIDIA/DIGITS/blob/digits-5.0/README.md )
- GitHub 文档 (https://github.com/NVIDIA/nvidia-docker/wiki/DIGITS )
注意:NVIDIA-docker 镜像和此镜像之间可能存在细微差异。
声明
本文档仅供参考,不得视为对产品的特定功能、条件或质量的保证。NVIDIA Corporation (“NVIDIA”) 对本文档中包含的信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对使用此类信息或因使用此类信息而可能导致的侵犯第三方专利或其他权利的后果不承担任何责任。本文档不构成对开发、发布或交付任何材料(如下定义)、代码或功能的承诺。
NVIDIA 保留随时修改、修正、增强、改进本文档以及对其进行任何其他更改的权利,恕不另行通知。
客户在下订单前应获取最新的相关信息,并应核实该等信息是当前的和完整的。
NVIDIA 产品的销售受 NVIDIA 标准销售条款和条件的约束,这些条款和条件在订单确认时提供,除非 NVIDIA 和客户的授权代表签署的个别销售协议另有约定(“销售条款”)。NVIDIA 在此明确反对将任何客户一般条款和条件适用于购买本文档中引用的 NVIDIA 产品。本文档既不直接也不间接地形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命维持设备,也不适用于 NVIDIA 产品的故障或失灵可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对将 NVIDIA 产品包含和/或使用在上述设备或应用中不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不保证或声明基于本文档的产品将适用于任何特定用途。NVIDIA 不一定对每个产品的所有参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适用于客户计划的应用并适合该应用,并为该应用执行必要的测试,以避免应用或产品的默认设置。客户产品设计的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同条件和/或要求。对于可能基于或归因于以下原因的任何默认设置、损坏、成本或问题,NVIDIA 不承担任何责任:(i)以任何违反本文档的方式使用 NVIDIA 产品或(ii)客户产品设计。
本文档未授予 NVIDIA 专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成 NVIDIA 对其的保证或认可。使用此类信息可能需要获得第三方的专利或其他知识产权下的许可,或获得 NVIDIA 的专利或其他知识产权下的许可。
只有在事先获得 NVIDIA 书面批准的情况下,才能复制本文档中的信息,复制时不得进行任何修改,且必须完全遵守所有适用的出口法律和法规,并附带所有相关的条件、限制和声明。
本文档以及所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均“按原样”提供。NVIDIA 对材料不作任何明示、暗示、法定或其他形式的保证,并明确否认所有关于非侵权性、适销性和特定用途适用性的暗示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对因使用本文档而引起的任何损害(包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害),无论是何种原因造成,也无论责任理论如何,承担任何责任,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因遭受任何损害,但 NVIDIA 对本文所述产品的客户的累计总责任应根据产品的销售条款进行限制。
VESA DisplayPort
DisplayPort 和 DisplayPort Compliance Logo、Dual-mode Sources 的 DisplayPort Compliance Logo 以及 Active Cables 的 DisplayPort Compliance Logo 是 Video Electronics Standards Association 在美国和其他国家/地区拥有的商标。
HDMI
HDMI、HDMI 徽标和 High-Definition Multimedia Interface 是 HDMI Licensing LLC 的商标或注册商标。
OpenCL
OpenCL 是 Apple Inc. 的商标,已获得 Khronos Group Inc. 的许可使用。
商标
NVIDIA、NVIDIA 徽标以及 cuBLAS、CUDA、cuDNN、DALI、DIGITS、DGX、DGX-1、DGX-2、DGX Station、DLProf、Jetson、Kepler、Maxwell、NCCL、Nsight Compute、Nsight Systems、NvCaffe、PerfWorks、Pascal、SDK Manager、Tegra、TensorRT、Triton Inference Server、Tesla、TF-TRT 和 Volta 是 NVIDIA Corporation 在美国和其他国家/地区的商标和/或注册商标。其他公司和产品名称可能是与其相关联的各自公司的商标。