杂项#
本节包含一组随机的主题和概念。
可重复性(确定性)#
根据设计,来自给定版本的大多数 cuDNN 例程在具有相同架构的 GPU 上执行时,跨运行生成相同的按位结果。但也存在一些例外。例如,以下例程不保证跨运行的可重复性,即使在相同的架构上也是如此,因为它们以引入真正随机的浮点舍入误差的方式使用原子操作
cudnnConvolutionBackwardFilter当使用CUDNN_CONVOLUTION_BWD_FILTER_ALGO_0或CUDNN_CONVOLUTION_BWD_FILTER_ALGO_3时
cudnnConvolutionBackwardData当使用CUDNN_CONVOLUTION_BWD_DATA_ALGO_0时
cudnnPoolingBackward当使用CUDNN_POOLING_MAX时
cudnnSpatialTfSamplerBackward
cudnnCTCLoss和cudnnCTCLoss_v8当使用CUDNN_CTC_LOSS_ALGO_NON_DETERMINSTIC时
在不同的架构之间,没有 cuDNN 例程保证按位可重复性。例如,当比较在 NVIDIA Volta 和 NVIDIA Turing 架构上运行的相同例程时,不保证按位可重复性。
缩放参数#
许多 cuDNN 例程(如 cudnnConvolutionForward())接受主机内存中指向缩放因子 alpha 和 beta 的指针。这些缩放因子用于将计算值与目标张量中的先前值混合,如下所示
dstValue = alpha*computedValue + beta*priorDstValue
在读取后,dstValue 被写入。
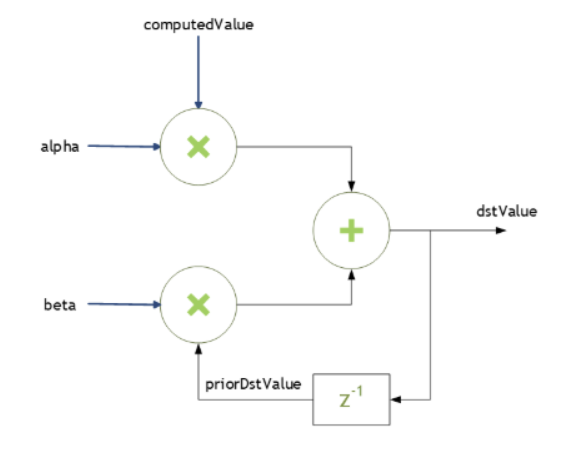
当 beta 为零时,输出不会被读取,并且可能包含未初始化的数据(包括 NaN)。
这些参数使用主机内存指针传递。alpha 和 beta 的存储数据类型是
float用于HALF和FLOAT张量,以及
double用于DOUBLE张量。
为了提高性能,请使用 beta = 0.0。仅当需要将当前输出张量值与输出张量的先前值混合时,才使用非零的 beta 值。
类型转换
当数据输入 x、滤波器输入 w 和输出 y 均为 INT8 数据类型时,函数 cudnnConvolutionBiasActivationForward() 将执行类型转换。累加器是 32 位整数,在溢出时会回绕。

弃用策略#
- cuDNN 对所有 API 和枚举更改使用简化的两步弃用策略,以实现快速创新步伐
- 步骤 1:标记为弃用
当前主要版本将 API 函数或枚举标记为已弃用,而不会更改其行为。
已弃用的枚举值标有
CUDNN_DEPRECATED_ENUM宏。如果只是简单地重命名,则旧名称将映射到新名称,并且旧名称将被标记为
CUDNN_DEPRECATED_ENUM宏。
已弃用的 API 函数标有 CUDNN_DEPRECATED 宏。
- 步骤 2:移除
下一个主要版本将移除已弃用的 API 函数或枚举值,并且其名称永远不会被重用。
此弃用方案允许我们在一个主要版本中淘汰已弃用的 API。在当前主要版本中弃用的功能可以在不进行任何更改的情况下进行编译。向后兼容性在引入另一个主要的 cuDNN 版本时结束。
弃用函数的原型将在 cuDNN 标头中使用 CUDNN_DEPRECATED 宏进行前置处理。当将 -DCUDNN_WARN_DEPRECATED 开关传递给编译器时,代码中任何已弃用的函数调用都会发出编译器警告,例如
warning: 'cudnnStatus_t cudnnRNNSetClip_v8(cudnnRNNDescriptor_t, cudnnRNNClipMode_t, ...)' is deprecated [-Wdeprecated-declarations]
或
warning C4996: 'cudnnRNNSetClip_v8': was declared deprecated
默认情况下,上述警告被禁用,以避免在编译器警告被视为错误的情况下,可能导致软件设置中的构建中断。
同样,对于已弃用的枚举值,当尝试使用已弃用的值时,编译器会发出警告
warning: 'EXAMPLE_VAL' is deprecated: value not allowed [-Wdeprecated-declarations]
或
warning C4996: 'EXAMPLE_VAL': was declared deprecated
特殊情况:API 行为变更
为了帮助简化过渡并避免给开发者带来任何意外,特定 API 函数的两个主要版本之间的行为更改通过在函数后附加 _v 标签以及当前的主要 cuDNN 版本来适应。在下一个主要版本中,已弃用的函数将被移除,并且其名称永远不会被重用。(全新的 API 首次引入时没有 _v 标签)。
以这种方式更新函数的行为会使用 API 的名称来嵌入 API 调用被修改的 cuDNN 版本。因此,API 更改将更容易跟踪和记录。
让我们通过一个使用两个连续的主要 cuDNN 版本(版本 8 和 9)的示例来解释此过程。在此示例中,API 函数 foo() 将其行为从 cuDNN v7 更改为 cuDNN v8。
主要版本 8
更新后的 API 作为 foo_v8() 引入。已弃用的 API foo() 保持不变,以保持向后兼容性,直到下一个主要版本。
主要版本 9
已弃用的 API foo() 被永久移除,并且其名称不再重用。foo_v8() 函数取代了已淘汰的调用 foo()。
GPU 和驱动程序要求#
对于最新的操作系统、CUDA、CUDA 驱动程序和 NVIDIA 硬件的兼容软件版本,请参阅 cuDNN 支持矩阵。
卷积的约定和特性#
卷积函数包括
卷积公式#
本节介绍 cuDNN 卷积函数为 cudnnConvolutionForward() 路径实现的各种卷积公式。
下表描述的卷积项适用于以下所有卷积公式。
术语 |
描述 |
|---|---|
|
输入(图像)张量 |
|
权重张量 |
|
输出张量 |
|
当前批次大小 |
|
当前输入通道 |
|
总输入通道数 |
|
输入图像高度 |
|
输入图像宽度 |
|
当前输出通道 |
|
总输出通道数 |
|
当前输出高度位置 |
|
当前输出宽度位置 |
|
组计数 |
|
填充值 |
|
垂直子采样步幅(沿高度方向) |
|
水平子采样步幅(沿宽度方向) |
dil h |
垂直空洞(沿高度方向) |
dil w |
水平空洞(沿宽度方向) |
|
当前滤波器高度 |
|
总滤波器高度 |
|
当前滤波器宽度 |
|
总滤波器宽度 |
C g |
\(\frac{C}{G}\) |
K g |
\(\frac{K}{G}\) |
- 卷积(卷积模式设置为
CUDNN_CROSS_CORRELATION) \(y_{n,k,p,q}=\sum_{c}^{C}\sum_{r}^{R}\sum_{s}^{S} x_{n,c,p+r,q+s}\times W_{k,c,r,s}\)
- 带填充的卷积
\(x_{\lt 0,\lt 0}=0\) \(x_{\gt H,\gt W}=0\) \(y_{n,k,p,q}=\sum_{c}^{C}\sum_{r}^{R}\sum_{s}^{S} x_{n,c,p+r-pad,q+s-pad}\times W_{k,c,r,s}\)
- 带子采样步幅的卷积
\(y_{n,k,p,q}=\sum_{c}^{C}\sum_{r}^{R}\sum_{s}^{S} x_{n,c,\left( p\ast u \right)+r,\left( q\ast v \right)+s}\times W_{k,c,r,s}\)
- 带空洞的卷积
\(y_{n,k,p,q}=\sum_{c}^{C}\sum_{r}^{R}\sum_{s}^{S} x_{n,c,p+\left( r\ast dil_{h} \right),q+\left( s\ast dil_{w} \right)}\times W_{k,c,r,s}\)
- 卷积(卷积模式设置为
CUDNN_CONVOLUTION) \(y_{n,k,p,q}=\sum_{c}^{C}\sum_{r}^{R}\sum_{s}^{S} x_{n,c,p+r,q+s}\times W_{k,c,R-r-1,S-s-1}\)
- 使用分组卷积的卷积
\(C_{g}=\frac{C}{G}\) \(K_{g}=\frac{K}{G}\) \(y_{n,k,p,q}=\sum_{c}^{C_{g}}\sum_{r}^{R}\sum_{s}^{S} x_{n,C_{g}\ast floor\left( k/K_{g} \right)+c,p+r,q+s}\times W_{k,c,r,s}\)
分组卷积#
cuDNN 通过为卷积描述符 convDesc 设置 groupCount > 1,使用 cudnnSetConvolutionGroupCount() 来支持分组卷积。默认情况下,卷积描述符 convDesc 的 groupCount 设置为 1。
基本思想
从概念上讲,在分组卷积中,输入通道和滤波器通道被分成 groupCount 个独立的组,每个组具有减少的通道数。然后,分别在这些输入和滤波器组上执行卷积运算。例如,考虑以下情况:如果输入通道数为 4,滤波器通道数为 12。对于正常的、未分组的卷积,执行的计算操作数为 12*4。
如果 groupCount 设置为 2,则现在有两个输入通道组,每个组有两个输入通道,以及两个滤波器通道组,每个组有六个滤波器通道。因此,每个分组卷积现在将执行 2*6 次计算操作,并且执行两个这样的分组卷积。因此,计算量节省了 2 倍:(12*4)/(2*(2*6))。
cuDNN 分组卷积
当使用 groupCount 进行分组卷积时,您仍然必须定义所有张量描述符,以便它们描述整个卷积的大小,而不是指定每组的大小。
函数 cudnnConvolutionForward()、cudnnConvolutionBackwardData() 和 cudnnConvolutionBackwardFilter() 当前支持的所有格式都支持分组卷积。
为 groupCount 为 1 设置的张量步幅也适用于任何组计数。
默认情况下,卷积描述符 convDesc 的 groupCount 设置为 1。有关 cuDNN 分组卷积背后的数学原理,请参阅 卷积公式。
示例
以下示例显示了 NCHW 格式的 2D 卷积的分组卷积的维度和步幅。符号 * 和 / 用于表示乘法和除法。
xDesc 或 dxDesc
维度:
[batch_size, input_channel, x_height, x_width]步幅:
[input_channels*x_height*x_width, x_height*x_width, x_width, 1]
wDesc 或 dwDesc
维度:
[output_channels, input_channels/groupCount, w_height, w_width]格式:
NCHW
convDesc
组计数:
groupCount
yDesc 或 dyDesc
维度:
[batch_size, output_channels, y_height, y_width]步幅:
[output_channels*y_height*y_width, y_height*y_width, y_width, 1]
3D 卷积的最佳实践#
注意
这些指南适用于 NVIDIA cuDNN v7.6.3 及更高版本中的 3D 卷积和反卷积函数。
以下指南用于设置 cuDNN 库参数,以增强 3D 卷积的性能。具体而言,这些指南侧重于滤波器大小、填充和空洞设置等设置。此外,还提供了一个特定于应用的用例,即医学成像,以演示使用这些推荐设置增强 3D 卷积的性能。
具体而言,这些指南适用于以下函数及其关联的数据类型
有关更多信息,请参阅 cuDNN API 参考。
推荐设置#
下表显示了在 cuDNN 中执行 3D 卷积时推荐的设置。
推荐设置 |
|
|---|---|
平台 |
|
卷积(3D 或 2D) |
3D 和 2D |
卷积或反卷积 ( |
|
分组卷积大小 |
|
数据布局格式 (NHWC/NCHW)。NHWC/NCHW 对应于 3D 卷积中的 NDHWC/NCDHW。 |
NDHWC |
I/O 精度(FP16、FP32、INT8 或 FP64) |
|
累加器(计算)精度(FP16、FP32、INT32 或 FP64) |
|
滤波器(内核)大小 |
无限制 |
填充 |
无限制 |
图像大小 |
张量的 2 GB 限制 |
|
|
|
|
卷积模式 |
互相关和卷积 |
步幅 |
无限制 |
空洞 |
无限制 |
数据指针对齐 |
所有数据指针都是 16 字节对齐的。 |
限制#
如果模型的通道数低于 32(越低越差),您的应用程序将可以正常运行,但性能可能会降低。如果网络中存在上述情况,请使用 cuDNNFind* 以获得最佳选项。
环境变量#
cuDNN 的行为可以通过一组环境变量来影响。以下环境变量是 cuDNN 官方支持的
环境变量 |
描述和用法 |
|---|---|
|
|
|
|
|
|
|
故障排除 - 已弃用 |
|
故障排除 - 已弃用 |
|
故障排除 - 已弃用 |
|
|
|
注意
除了上面列出的环境变量外,我们不提供对任何其他以 CUDNN_ 为前缀的环境变量的使用提供支持或保证。
针对 CUDNN_VERSION 进行版本检查#
CUDNN_VERSION 的定义是
CUDNN_MAJOR * 10000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL
从
CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL
因此,任何使用 CUDNN_VERSION 的版本检查都应相应更新。例如,如果用户只想在 cuDNN 大于或等于 9.0.0 时执行代码路径,他们将必须使用宏条件,例如 CUDNN_VERSION >= 90000 而不是 CUDNN_VERSION >= 9000。
cuDNN 符号服务器#
对于在您的应用程序中调试或分析的 cuDNN 库的混淆符号,可以从 Linux 的符号存储库下载。该存储库托管符号文件 (.sym),其中包含模糊的符号名称(不分发调试数据)。
当 cuDNN API 出现问题时,使用符号服务器来符号化其堆栈跟踪可以帮助加快调试过程。
有两种推荐的方法可以将混淆符号用于 GNU 调试器 (GDB) 的每个 cuDNN 库
通过解剥库
通过将
.sym文件作为单独的调试信息文件部署
以下代码说明了在 x86_64 Ubuntu 22.04 上使用混淆符号的推荐方法
# Determine the Build ID of the library $ readelf -n /usr/lib/x86_64-linux-gnu/libcudnn_graph.so # ... Build ID: 457c8f5dea095b0f90af2abddfcb69946df61b76 # Browse to https://cudatoolkit-symbols.nvidia.com/libcudnn_graph.so/457c8f5dea095b0f90af2abddfcb69946df61b76/index.html to determine .sym filename to download $ wget https://cudatoolkit-symbols.nvidia.com/libcudnn_graph.so/457c8f5dea095b0f90af2abddfcb69946df61b76/libcudnn_graph.so.9.0.0.sym # Then with appropriate permissions, either unstrip, $ eu-unstrip /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9.0.0 libcudnn_graph.so.9.0.0.sym -o /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9.0.0 # Or, with appropriate permissions, deploy as a separate debug info file # By splitting the Build ID into two parts, with the first two characters as the directory # And the remaining characters as the filename with the ".debug" extension $ cp libcudnn_graph.so.9.0.0.sym /usr/lib/debug/.build-id/45/7c8f5dea095b0f90af2abddfcb69946df61b76.debug
示例:符号化#
这是一个简化的示例,展示了符号化的用途。一个名为 test_shared 的示例应用程序调用 cuDNN API cudnnDestroy(),这会导致段错误。使用 cuDNN 的默认安装且没有模糊符号,GDB 中的输出可能如下所示
Thread 1 "test_shared" received signal SIGSEGV, Segmentation fault. 0x00007ffff7a4ac01 in ?? () from /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9 (gdb) bt #0 0x00007ffff7a4ac01 in ?? () from /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9 #1 0x00007ffff7a4c919 in cudnnDestroy () from /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9 #2 0x00000000004007b7 in main ()
在以先前描述的方式之一应用模糊符号后,堆栈跟踪将如下所示
Thread 1 "test_shared" received signal SIGSEGV, Segmentation fault. 0x00007ffff7a4ac01 in libcudnn_graph_148ced18265f5231d89551dcbdcf5cf3fe6d77d1 () from /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9 (gdb) bt #0 0x00007ffff7a4ac01 in libcudnn_graph_148ced18265f5231d89551dcbdcf5cf3fe6d77d1 () from /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9 #1 0x00007ffff7a4c919 in cudnnDestroy () from /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9 #2 0x00000000004007b7 in main ()
然后,符号化的调用堆栈可以作为提供给 NVIDIA 进行分析的错误描述的一部分进行记录。
初始化和终止期间的 API 用法#
cuDNN 使用在主机程序启动期间初始化并在主机程序终止期间销毁的全局状态。cuDNN 无法检测此状态是否无效,因此在程序启动或终止期间在 main() 之后隐式或显式地使用任何这些接口可能会导致未定义的行为。CUDA 具有相同的限制。