核心概念#
本节介绍 cuDNN 后端 API 的核心概念。
cuDNN 句柄#
cuDNN 库公开了一个主机 API,但假设对于使用 GPU 的操作,必要的数据可以直接从设备访问。
使用 cuDNN 的应用程序必须通过调用 cudnnCreate() 初始化库上下文的句柄。此句柄显式传递给每个后续的、在 GPU 数据上运行的库函数。一旦应用程序完成使用 cuDNN,它可以使用 cudnnDestroy() 释放与库句柄关联的资源。当使用多个主机线程、GPU 和 CUDA 流时,这种方法允许用户显式控制库的功能。
例如,应用程序可以使用 cudaSetDevice(在创建 cuDNN 句柄之前)将不同的设备与不同的主机线程关联,并在每个主机线程中,创建一个唯一的 cuDNN 句柄,将后续的库调用定向到与其关联的设备。在这种情况下,使用不同句柄进行的 cuDNN 库调用将自动在不同的设备上运行。
与特定 cuDNN 上下文关联的设备被假定在相应的 cudnnCreate() 和 cudnnDestroy() 调用之间保持不变。为了使 cuDNN 库在同一主机线程中使用不同的设备,应用程序必须通过调用 cudaSetDevice 设置要使用的新设备,然后创建另一个 cuDNN 上下文,该上下文将通过调用 cudnnCreate() 与新设备关联。
Tensor Core 操作#
cuDNN v7 库引入了在支持的 GPU SM 版本上使用 Tensor Core 硬件加速计算密集型例程的功能。Tensor Core 操作从 NVIDIA Volta GPU 开始支持。
Tensor Core 操作加速矩阵数学运算;cuDNN 使用 Tensor Core 操作,将结果累加到 FP16、FP32 和 INT32 值中。通过 cudnnMathType_t 枚举器将数学模式设置为 CUDNN_TENSOR_OP_MATH 表示库将使用 Tensor Core 操作。此枚举器指定启用 Tensor Core 的可用选项,应在每个例程的基础上应用。
默认数学模式是 CUDNN_DEFAULT_MATH,这表示库将避免使用 Tensor Core 操作。由于 CUDNN_TENSOR_OP_MATH 模式使用 Tensor Core,因此由于浮点运算的不同排序,这两种模式可能会产生略微不同的数值结果。
例如,使用 Tensor Core 操作乘以两个矩阵的结果非常接近,但并不总是与使用一系列标量浮点运算获得的结果相同。因此,cuDNN 库要求用户显式选择启用 Tensor Core 操作,然后才能使用。
然而,对常用深度学习模型进行训练的实验表明,使用 Tensor Core 操作和标量浮点路径之间的差异可以忽略不计,通过最终网络精度和收敛的迭代次数来衡量。因此,cuDNN 库将这两种操作模式视为功能上无法区分,并允许标量路径作为在不适合使用 Tensor Core 操作的情况下合法的后备方案。
使用 Tensor Core 操作的内核可用于
卷积
RNN
多头注意力机制
有关更多信息,请参阅 NVIDIA 混合精度训练。
对于深度学习编译器,以下是关键指南
通过避免任何大填充和大滤波器的组合,确保卷积操作适用于 Tensor Core。
将输入和滤波器转换为 NHWC,预先填充通道和批量大小,使其成为 8 的倍数。
确保所有用户提供的张量、工作区和保留空间都对齐到 128 位边界。请注意,1024 位对齐可能会提供更好的性能。
关于 Tensor Core 精度的注意事项#
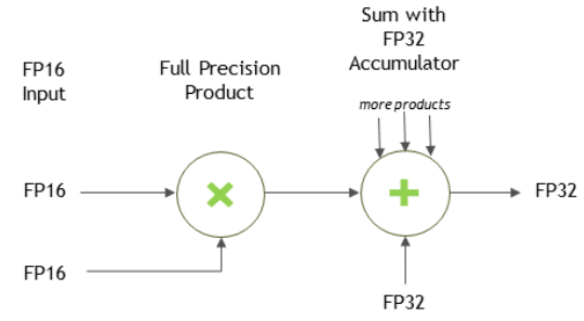
对于 FP16 数据,Tensor Core 对 FP16 输入进行操作,以 FP16 输出,并且可以累积在 FP16 或 FP32 中。FP16 乘法产生全精度结果,该结果在 FP32 操作中与给定点积中的其他乘积累积,对于维度为 m x n x k 的矩阵。
对于 FP32 累积,使用 FP16 输出,累加器的输出被下转换为 FP16。通常,累积类型具有大于或等于输出类型的精度。