cudnn_cnn 库#
数据类型参考#
这些是 cudnn_cnn 库中的数据类型参考。
结构体类型#
这些是 cudnn_cnn 库中的结构体类型。
cudnnConvolutionBwdDataAlgoPerf_t#
此枚举类型已弃用,目前仅由已弃用的 API 使用。考虑使用已弃用 API 的替代品,这些 API 使用此枚举类型。
cudnnConvolutionBwdDataAlgoPerf_t 是一个结构体,包含 cudnnFindConvolutionBackwardDataAlgorithm() 返回的性能结果或 cudnnGetConvolutionBackwardDataAlgorithm_v7() 返回的启发式结果。
数据成员
cudnnConvolutionBwdDataAlgo_t algo运行该算法以获得相关的性能指标。
cudnnStatus_t status如果在 cudnnConvolutionBackwardData() 的工作区分配或计时期间发生任何错误,此状态将表示该错误。否则,此状态将是 cudnnConvolutionBackwardData() 的返回状态。
如果在工作区分配期间发生任何错误或提供的工作区不足,则为
CUDNN_STATUS_ALLOC_FAILED。如果在计时计算或工作区释放期间发生任何错误,则为
CUDNN_STATUS_INTERNAL_ERROR。否则,这将是 cudnnConvolutionBackwardData() 的返回状态。
float timecudnnConvolutionBackwardData() 的执行时间(以毫秒为单位)。
size_t memory工作区大小(以字节为单位)。
cudnnDeterminism_t determinism算法的确定性。
cudnnMathType_t mathType提供给算法的数学类型。
int reserved[3]为未来属性保留的空间。
cudnnConvolutionBwdFilterAlgoPerf_t#
此枚举类型已弃用,目前仅由已弃用的 API 使用。考虑使用已弃用 API 的替代品,这些 API 使用此枚举类型。
cudnnConvolutionBwdFilterAlgoPerf_t 是一个结构体,包含 cudnnFindConvolutionBackwardFilterAlgorithm() 返回的性能结果或 cudnnGetConvolutionBackwardFilterAlgorithm_v7() 返回的启发式结果。
数据成员
cudnnConvolutionBwdFilterAlgo_t algo运行该算法以获得相关的性能指标。
cudnnStatus_t status如果在 cudnnConvolutionBackwardFilter() 的工作区分配或计时期间发生任何错误,此状态将表示该错误。否则,此状态将是 cudnnConvolutionBackwardFilter() 的返回状态。
如果在工作区分配期间发生任何错误或提供的工作区不足,则为
CUDNN_STATUS_ALLOC_FAILED。如果在计时计算或工作区释放期间发生任何错误,则为
CUDNN_STATUS_INTERNAL_ERROR。否则,这将是 cudnnConvolutionBackwardFilter() 的返回状态。
float timecudnnConvolutionBackwardFilter() 的执行时间(以毫秒为单位)。
size_t memory工作区大小(以字节为单位)。
cudnnDeterminism_t determinism算法的确定性。
cudnnMathType_t mathType提供给算法的数学类型。
int reserved[3]为未来属性保留的空间。
cudnnConvolutionFwdAlgoPerf_t#
此枚举类型已弃用,目前仅由已弃用的 API 使用。考虑使用已弃用 API 的替代品,这些 API 使用此枚举类型。
cudnnConvolutionFwdAlgoPerf_t 是一个结构体,包含 cudnnFindConvolutionForwardAlgorithm() 返回的性能结果或 cudnnGetConvolutionForwardAlgorithm_v7() 返回的启发式结果。
数据成员
cudnnConvolutionFwdAlgo_t algo运行该算法以获得相关的性能指标。
cudnnStatus_t status如果在 cudnnConvolutionForward() 的工作区分配或计时期间发生任何错误,此状态将表示该错误。否则,此状态将是 cudnnConvolutionForward() 的返回状态。
如果在工作区分配期间发生任何错误或提供的工作区不足,则为
CUDNN_STATUS_ALLOC_FAILED。如果在计时计算或工作区释放期间发生任何错误,则为
CUDNN_STATUS_INTERNAL_ERROR。否则,这将是 cudnnConvolutionForward() 的返回状态。
float timecudnnConvolutionForward() 的执行时间(以毫秒为单位)。
size_t memory工作区大小(以字节为单位)。
cudnnDeterminism_t determinism算法的确定性。
cudnnMathType_t mathType提供给算法的数学类型。
int reserved[3]为未来属性保留的空间。
指向不透明结构体类型的指针#
这些是 cudnn_cnn 库中指向不透明结构体类型的指针。
cudnnConvolutionDescriptor_t#
此枚举类型已弃用,目前仅由已弃用的 API 使用。考虑使用已弃用 API 的替代品,这些 API 使用此枚举类型。
cudnnConvolutionDescriptor_t 是一个指向不透明结构的指针,该结构保存卷积操作的描述。cudnnCreateConvolutionDescriptor() 用于创建一个实例,cudnnSetConvolutionNdDescriptor() 或 cudnnSetConvolution2dDescriptor() 必须用于初始化此实例。
cudnnFusedOpsConstParamPack_t#
此枚举类型已弃用,目前仅由已弃用的 API 使用。考虑使用已弃用 API 的替代品,这些 API 使用此枚举类型。
cudnnFusedOpsConstParamPack_t 是一个指向不透明结构的指针,该结构保存 cudnnFusedOps 常量参数的描述。使用函数 cudnnCreateFusedOpsConstParamPack() 创建此结构的一个实例,并使用函数 cudnnDestroyFusedOpsConstParamPack() 销毁先前创建的描述符。
cudnnFusedOpsPlan_t#
此枚举类型已弃用,目前仅由已弃用的 API 使用。考虑使用已弃用 API 的替代品,这些 API 使用此枚举类型。
cudnnFusedOpsPlan_t 是一个指向不透明结构的指针,该结构保存 cudnnFusedOpsPlan 的描述。此描述符包含计划信息,包括问题类型和大小、应运行的内核以及内部工作区分区。使用函数 cudnnCreateFusedOpsPlan() 创建此结构的一个实例,并使用函数 cudnnDestroyFusedOpsPlan() 销毁先前创建的描述符。
cudnnFusedOpsVariantParamPack_t#
此枚举类型已弃用,目前仅由已弃用的 API 使用。考虑使用已弃用 API 的替代品,这些 API 使用此枚举类型。
cudnnFusedOpsVariantParamPack_t 是一个指向不透明结构的指针,该结构保存 cudnnFusedOps 变体参数的描述。使用函数 cudnnCreateFusedOpsVariantParamPack() 创建此结构的一个实例,并使用函数 cudnnDestroyFusedOpsVariantParamPack() 销毁先前创建的描述符。
枚举类型#
这些是 cudnn_cnn 库中的枚举类型。
cudnnFusedOps_t#
此枚举类型已弃用,目前仅由已弃用的 API 使用。考虑使用已弃用 API 的替代品,这些 API 使用此枚举类型。
cudnnFusedOps_t 类型是一个枚举类型,用于选择要在融合操作中执行的特定计算序列。
成员和描述
CUDNN_FUSED_SCALE_BIAS_ACTIVATION_CONV_BNSTATS = 0在每个通道的基础上,它按以下顺序执行这些操作:
scale、add bias、activation、convolution,并生成batchNorm统计信息。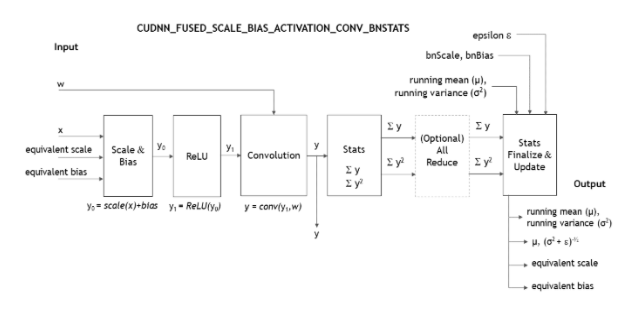
CUDNN_FUSED_SCALE_BIAS_ACTIVATION_WGRAD = 1在每个通道的基础上,它按以下顺序执行这些操作:
scale、add bias、activation、卷积反向权重,并生成batchNorm统计信息。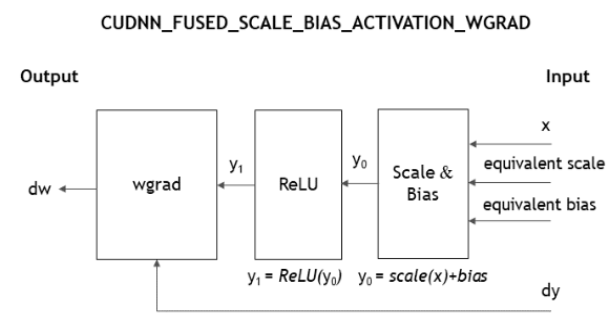
CUDNN_FUSED_BN_FINALIZE_STATISTICS_TRAINING = 2从
ySum、ySqSum、学习到的scale和bias计算等效的scale和bias。 可选地,更新运行统计信息并生成保存的统计信息。CUDNN_FUSED_BN_FINALIZE_STATISTICS_INFERENCE = 3从学习到的运行统计信息和学习到的
scale和bias计算等效的scale和bias。CUDNN_FUSED_CONV_SCALE_BIAS_ADD_ACTIVATION = 4在每个通道的基础上,按以下顺序执行这些操作:
convolution、scale、add bias、与另一个张量逐元素相加,以及activation。CUDNN_FUSED_SCALE_BIAS_ADD_ACTIVATION_GEN_BITMASK = 5在每个通道的基础上,按以下顺序执行这些操作:对一个张量执行
scale和bias,对第二个张量执行scale和bias,将这两个张量逐元素相加,并在结果张量上执行activation并生成激活位掩码。CUDNN_FUSED_DACTIVATION_FORK_DBATCHNORM = 6在每个通道的基础上,按以下顺序执行这些操作:反向激活,分支(意味着,为残差分支写出梯度),以及反向批归一化。
cudnnFusedOpsConstParamLabel_t#
此枚举类型已弃用,目前仅由已弃用的 API 使用。考虑使用已弃用 API 的替代品,这些 API 使用此枚举类型。
cudnnFusedOpsConstParamLabel_t 是一个枚举类型,用于选择 cudnnFusedOps 描述符的类型。 有关更多信息,请参阅 cudnnSetFusedOpsConstParamPackAttribute()。
typedef enum { CUDNN_PARAM_XDESC = 0, CUDNN_PARAM_XDATA_PLACEHOLDER = 1, CUDNN_PARAM_BN_MODE = 2, CUDNN_PARAM_BN_EQSCALEBIAS_DESC = 3, CUDNN_PARAM_BN_EQSCALE_PLACEHOLDER = 4, CUDNN_PARAM_BN_EQBIAS_PLACEHOLDER = 5, CUDNN_PARAM_ACTIVATION_DESC = 6, CUDNN_PARAM_CONV_DESC = 7, CUDNN_PARAM_WDESC = 8, CUDNN_PARAM_WDATA_PLACEHOLDER = 9, CUDNN_PARAM_DWDESC = 10, CUDNN_PARAM_DWDATA_PLACEHOLDER = 11, CUDNN_PARAM_YDESC = 12, CUDNN_PARAM_YDATA_PLACEHOLDER = 13, CUDNN_PARAM_DYDESC = 14, CUDNN_PARAM_DYDATA_PLACEHOLDER = 15, CUDNN_PARAM_YSTATS_DESC = 16, CUDNN_PARAM_YSUM_PLACEHOLDER = 17, CUDNN_PARAM_YSQSUM_PLACEHOLDER = 18, CUDNN_PARAM_BN_SCALEBIAS_MEANVAR_DESC = 19, CUDNN_PARAM_BN_SCALE_PLACEHOLDER = 20, CUDNN_PARAM_BN_BIAS_PLACEHOLDER = 21, CUDNN_PARAM_BN_SAVED_MEAN_PLACEHOLDER = 22, CUDNN_PARAM_BN_SAVED_INVSTD_PLACEHOLDER = 23, CUDNN_PARAM_BN_RUNNING_MEAN_PLACEHOLDER = 24, CUDNN_PARAM_BN_RUNNING_VAR_PLACEHOLDER = 25, CUDNN_PARAM_ZDESC = 26, CUDNN_PARAM_ZDATA_PLACEHOLDER = 27, CUDNN_PARAM_BN_Z_EQSCALEBIAS_DESC = 28, CUDNN_PARAM_BN_Z_EQSCALE_PLACEHOLDER = 29, CUDNN_PARAM_BN_Z_EQBIAS_PLACEHOLDER = 30, CUDNN_PARAM_ACTIVATION_BITMASK_DESC = 31, CUDNN_PARAM_ACTIVATION_BITMASK_PLACEHOLDER = 32, CUDNN_PARAM_DXDESC = 33, CUDNN_PARAM_DXDATA_PLACEHOLDER = 34, CUDNN_PARAM_DZDESC = 35, CUDNN_PARAM_DZDATA_PLACEHOLDER = 36, CUDNN_PARAM_BN_DSCALE_PLACEHOLDER = 37, CUDNN_PARAM_BN_DBIAS_PLACEHOLDER = 38, } cudnnFusedOpsConstParamLabel_t;
使用的缩写形式 |
代表 |
|---|---|
Setter |
|
Getter |
|
|
|
属性键列中的 |
代表枚举器名称中的 |
属性键 |
在 Setter 中传递的预期描述符类型 |
描述 |
创建后的默认值 |
|---|---|---|---|
|
在 setter 中, |
张量描述符,描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 scale、bias 和统计信息的操作模式。 从 cuDNN 7.6.0 开始,仅支持 |
|
|
在 setter 中, |
张量描述符,描述 batchNorm 等效 scale 和 bias 张量的大小、布局和数据类型。 形状必须与 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述激活操作。 从 7.6.0 开始,仅支持 |
|
|
在 setter 中, |
描述卷积操作。 |
|
|
在 setter 中, |
Filter 描述符,描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
张量描述符,描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
张量描述符,描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
注意
如果
ConstParamPack中的相应指针占位符设置为CUDNN_PTR_NULL,则VariantParamPack中的设备指针也需要为NULL。如果
ConstParamPack中的相应指针占位符设置为CUDNN_PTR_ELEM_ALIGNED或CUDNN_PTR_16B_ALIGNED,则VariantParamPack中的设备指针可能不为NULL,并且需要分别至少元素对齐或 16 字节对齐。
从 cuDNN 7.6.0 开始,如果满足表中的以下条件,则将触发完全融合的快速路径。 否则,将触发较慢的部分融合路径。
参数 |
条件 |
|---|---|
设备计算能力 |
需要是 |
|
|
|
|
|
|
|
|
|
|
属性键 |
在 Setter 中传递的预期描述符类型 |
描述 |
创建后的默认值 |
|---|---|---|---|
|
在 setter 中, |
张量描述符,描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 scale、bias 和统计信息的操作模式。 从 cuDNN 7.6.0 开始,仅支持 |
|
|
在 setter 中, |
张量描述符,描述 batchNorm 等效 scale 和 bias 张量的大小、布局和数据类型。 形状必须与 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述激活操作。 从 7.6.0 开始,仅支持 |
|
|
在 setter 中, |
描述卷积操作。 |
|
|
在 setter 中, |
Filter 描述符,描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
张量描述符,描述 |
|
|
在 setter 中, |
描述 |
|
注意
如果
ConstParamPack中的相应指针占位符设置为CUDNN_PTR_NULL,则VariantParamPack中的设备指针也需要为NULL。如果
ConstParamPack中的相应指针占位符设置为CUDNN_PTR_ELEM_ALIGNED或CUDNN_PTR_16B_ALIGNED,则VariantParamPack中的设备指针可能不为NULL,并且需要分别至少元素对齐或 16 字节对齐。
从 cuDNN 7.6.0 开始,如果满足表中的以下条件,则将触发完全融合的快速路径。 否则,将触发较慢的部分融合路径。
参数 |
条件 |
|---|---|
设备计算能力 |
需要是 |
|
|
|
|
|
|
|
|
属性键 |
在 Setter 中传递的预期描述符类型 |
描述 |
创建后的默认值 |
|---|---|---|---|
|
在 setter 中, |
描述 scale、bias 和统计信息的操作模式。 从 cuDNN 7.6.0 开始,仅支持 |
|
|
在 setter 中, |
张量描述符,描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
一个通用的张量描述符,描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
属性键 |
在 Setter 中传递的预期描述符类型 |
描述 |
创建后的默认值 |
|---|---|---|---|
|
在 setter 中, |
描述缩放、偏差和统计信息的操作模式。截至 cuDNN 7.6.0,仅支持 |
|
|
在 setter 中, |
一个通用的张量描述符,描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
以下操作执行计算,其中 \(*\) 表示卷积运算符:\(y=\alpha_{1}\left( w*x \right)+\alpha_{2}z+b\)
属性键 |
在 Setter 中传递的预期描述符类型 |
描述 |
创建后的默认值 |
|---|---|---|---|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述卷积操作。 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 \(\alpha_{1}\) 缩放和偏差张量的大小、布局和数据类型的张量描述符。张量应具有形状 (1,K,1,1),其中 K 是输出特征的数量。 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 \(\alpha_{2}\) 张量的大小、布局和数据类型的张量描述符。如果设置为 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述激活操作。 从 7.6.0 开始,仅支持 |
|
|
在 setter 中, |
描述 |
|
|
在 setter 中, |
描述 |
|
cudnnFusedOpsPointerPlaceHolder_t#
此枚举类型已弃用,目前仅由已弃用的 API 使用。考虑使用已弃用 API 的替代品,这些 API 使用此枚举类型。
cudnnFusedOpsPointerPlaceHolder_t 是一种枚举类型,用于选择 cudnnFusedOps 描述符指针的对齐类型。
成员和描述
CUDNN_PTR_NULL = 0指示
variantPack中张量的指针将为NULL。CUDNN_PTR_ELEM_ALIGNED = 1指示
variantPack中张量的指针将不为NULL,并将具有元素对齐。CUDNN_PTR_16B_ALIGNED = 2指示
variantPack中张量的指针将不为NULL,并将具有 16 字节对齐。
cudnnFusedOpsVariantParamLabel_t#
此枚举类型已弃用,目前仅由已弃用的 API 使用。考虑使用已弃用 API 的替代品,这些 API 使用此枚举类型。
cudnnFusedOpsVariantParamLabel_t 是一种枚举类型,用于设置缓冲区指针。这些缓冲区指针可以在每次迭代中更改。
typedef enum { CUDNN_PTR_XDATA = 0, CUDNN_PTR_BN_EQSCALE = 1, CUDNN_PTR_BN_EQBIAS = 2, CUDNN_PTR_WDATA = 3, CUDNN_PTR_DWDATA = 4, CUDNN_PTR_YDATA = 5, CUDNN_PTR_DYDATA = 6, CUDNN_PTR_YSUM = 7, CUDNN_PTR_YSQSUM = 8, CUDNN_PTR_WORKSPACE = 9, CUDNN_PTR_BN_SCALE = 10, CUDNN_PTR_BN_BIAS = 11, CUDNN_PTR_BN_SAVED_MEAN = 12, CUDNN_PTR_BN_SAVED_INVSTD = 13, CUDNN_PTR_BN_RUNNING_MEAN = 14, CUDNN_PTR_BN_RUNNING_VAR = 15, CUDNN_PTR_ZDATA = 16, CUDNN_PTR_BN_Z_EQSCALE = 17, CUDNN_PTR_BN_Z_EQBIAS = 18, CUDNN_PTR_ACTIVATION_BITMASK = 19, CUDNN_PTR_DXDATA = 20, CUDNN_PTR_DZDATA = 21, CUDNN_PTR_BN_DSCALE = 22, CUDNN_PTR_BN_DBIAS = 23, CUDNN_SCALAR_SIZE_T_WORKSPACE_SIZE_IN_BYTES = 100, CUDNN_SCALAR_INT64_T_BN_ACCUMULATION_COUNT = 101, CUDNN_SCALAR_DOUBLE_BN_EXP_AVG_FACTOR = 102, CUDNN_SCALAR_DOUBLE_BN_EPSILON = 103, } cudnnFusedOpsVariantParamLabel_t;
使用的缩写形式 |
代表 |
|---|---|
Setter |
|
Getter |
|
属性键列中的 |
代表枚举器名称中的 |
属性键 |
在 Setter 中传递的预期描述符类型 |
I/O 类型 |
描述 |
默认值 |
|---|---|---|---|---|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上用户分配的工作空间的指针。如果请求的工作空间大小为 |
|
|
|
输入 |
指向主机内存中 |
|
注意
如果
ConstParamPack中的相应指针占位符设置为CUDNN_PTR_NULL,则VariantParamPack中的设备指针也需要为NULL。如果
ConstParamPack中的相应指针占位符设置为CUDNN_PTR_ELEM_ALIGNED或CUDNN_PTR_16B_ALIGNED,则VariantParamPack中的设备指针可能不为NULL,并且需要分别至少元素对齐或 16 字节对齐。
属性键 |
在 Setter 中传递的预期描述符类型 |
I/O 类型 |
描述 |
默认值 |
|---|---|---|---|---|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输出 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上用户分配的工作空间的指针。如果请求的工作空间大小为 |
|
|
|
输入 |
指向主机内存中 |
|
注意
如果
ConstParamPack中的相应指针占位符设置为CUDNN_PTR_NULL,则VariantParamPack中的设备指针也需要为NULL。如果
ConstParamPack中的相应指针占位符设置为CUDNN_PTR_ELEM_ALIGNED或CUDNN_PTR_16B_ALIGNED,则VariantParamPack中的设备指针可能不为NULL,并且需要分别至少元素对齐或 16 字节对齐。
属性键 |
在 Setter 中传递的预期描述符类型 |
I/O 类型 |
描述 |
默认值 |
|---|---|---|---|---|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输出 |
指向设备上 |
|
|
|
输出 |
指向设备上 |
|
|
|
输入/输出 |
指向设备上 |
|
|
|
输入/输出 |
指向设备上 |
|
|
|
输出 |
指向设备上 |
|
|
|
输出 |
指向设备上 |
|
|
|
输入 |
指向主机内存中 |
|
|
|
输入 |
指向主机内存中 double 标量值的指针。用于移动平均计算的因子。请参阅 |
|
|
|
输入 |
指向主机内存中 double 标量值的指针。批归一化公式中使用的调节常数。其值应等于或大于 |
|
|
|
输入 |
指向设备上用户分配的工作空间的指针。如果请求的工作空间大小为 |
|
|
|
输入 |
指向主机内存中 |
|
注意
如果
ConstParamPack中的相应指针占位符设置为CUDNN_PTR_NULL,则VariantParamPack中的设备指针也需要为NULL。如果
ConstParamPack中的相应指针占位符设置为CUDNN_PTR_ELEM_ALIGNED或CUDNN_PTR_16B_ALIGNED,则VariantParamPack中的设备指针可能不为NULL,并且需要分别至少元素对齐或 16 字节对齐。
属性键 |
在 Setter 中传递的预期描述符类型 |
I/O 类型 |
描述 |
默认值 |
|---|---|---|---|---|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输入/输出 |
指向设备上 |
|
|
|
输入/输出 |
指向设备上 |
|
|
|
输出 |
指向设备上 |
|
|
|
输出 |
指向设备上 |
|
|
|
输入 |
指向主机内存中 double 标量值的指针。批归一化公式中使用的调节常数。其值应等于或大于 |
|
|
|
输入 |
指向设备上用户分配的工作空间的指针。如果请求的工作空间大小为 |
|
|
|
输入 |
指向主机内存中 |
|
注意
如果
ConstParamPack中的相应指针占位符设置为CUDNN_PTR_NULL,则VariantParamPack中的设备指针也需要为NULL。如果
ConstParamPack中的相应指针占位符设置为CUDNN_PTR_ELEM_ALIGNED或CUDNN_PTR_16B_ALIGNED,则VariantParamPack中的设备指针可能不为NULL,并且需要分别至少元素对齐或 16 字节对齐。
属性键 |
在 Setter 中传递的预期描述符类型 |
I/O 类型 |
描述 |
默认值 |
|---|---|---|---|---|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输入 |
指向设备上 |
|
|
|
输出 |
指向设备上 |
|
|
|
输入 |
指向设备上用户分配的工作空间的指针。如果请求的工作空间大小为 |
|
|
|
输入 |
指向主机内存中 |
|
注意
如果
ConstParamPack中的相应指针占位符设置为CUDNN_PTR_NULL,则VariantParamPack中的设备指针也需要为NULL。如果
ConstParamPack中的相应指针占位符设置为CUDNN_PTR_ELEM_ALIGNED或CUDNN_PTR_16B_ALIGNED,则VariantParamPack中的设备指针可能不为NULL,并且需要分别至少元素对齐或 16 字节对齐。
API 函数#
以下是 cudnn_cnn 库中的 API 函数。
cudnnCnnVersionCheck()#
跨库版本检查器。每个子库都有一个版本检查器,用于检查其自身的版本是否与其依赖项的版本匹配。
返回
CUDNN_STATUS_SUCCESS版本检查通过。
CUDNN_STATUS_SUBLIBRARY_VERSION_MISMATCH版本不一致。
cudnnConvolutionBackwardBias()#
此函数在 cuDNN 9.0 中已弃用。
此函数计算关于偏差的卷积函数梯度,偏差是属于输入张量所有图像的同一特征图的每个元素的总和。因此,生成的元素数量等于输入张量的特征图数量。
cudnnStatus_t cudnnConvolutionBackwardBias( cudnnHandle_t handle, const void *alpha, const cudnnTensorDescriptor_t dyDesc, const void *dy, const void *beta, const cudnnTensorDescriptor_t dbDesc, void *db)
参数
handle输入。指向先前创建的 cuDNN 上下文的句柄。有关更多信息,请参阅 cudnnHandle_t。
alpha,beta输入。指向缩放因子(在主机内存中)的指针,用于将计算结果与输出层中的先前值混合,如下所示
dstValue = alpha[0]*result + beta[0]*priorDstValue
有关更多信息,请参阅 缩放参数。
dyDesc输入。指向先前初始化的输入张量描述符的句柄。有关更多信息,请参阅 cudnnTensorDescriptor_t。
dy输入。指向与张量描述符
dyDesc关联的 GPU 内存的数据指针。dbDesc输入。指向先前初始化的输出张量描述符的句柄。
db输出。指向与输出张量描述符
dbDesc关联的 GPU 内存的数据指针。
返回
CUDNN_STATUS_SUCCESS操作已成功启动。
CUDNN_STATUS_NOT_SUPPORTED该函数不支持提供的配置。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
输出张量的参数
n、height或width之一不是1。输入张量和输出张量的特征图数量不同。
两个张量描述符的
dataType不同。
cudnnConvolutionBackwardData()#
此函数在 cuDNN 9.0 中已弃用。
此函数计算张量 dy 的卷积数据梯度,其中 y 是 cudnnConvolutionForward() 中前向卷积的输出。它使用指定的 algo,并将结果返回到输出张量 dx 中。缩放因子 alpha 和 beta 可用于缩放计算结果或与当前的 dx 累积。
cudnnStatus_t cudnnConvolutionBackwardData( cudnnHandle_t handle, const void *alpha, const cudnnFilterDescriptor_t wDesc, const void *w, const cudnnTensorDescriptor_t dyDesc, const void *dy, const cudnnConvolutionDescriptor_t convDesc, cudnnConvolutionBwdDataAlgo_t algo, void *workSpace, size_t workSpaceSizeInBytes, const void *beta, const cudnnTensorDescriptor_t dxDesc, void *dx)
参数
handle输入。指向先前创建的 cuDNN 上下文的句柄。有关更多信息,请参阅 cudnnHandle_t。
alpha,beta输入。指向缩放因子(在主机内存中)的指针,用于将计算结果与输出层中的先前值混合,如下所示
dstValue = alpha[0]*result + beta[0]*priorDstValue
有关更多信息,请参阅 缩放参数。
wDesc输入。指向先前初始化的滤波器描述符的句柄。有关更多信息,请参阅 cudnnFilterDescriptor_t。
w输入。指向与滤波器描述符
wDesc关联的 GPU 内存的数据指针。dyDesc输入。指向先前初始化的输入微分张量描述符的句柄。有关更多信息,请参阅 cudnnTensorDescriptor_t。
dy输入。指向与输入微分张量描述符
dyDesc关联的 GPU 内存的数据指针。convDesc输入。先前初始化的卷积描述符。有关更多信息,请参阅 cudnnConvolutionDescriptor_t。
algo输入。枚举器,用于指定应使用哪种后向数据卷积算法来计算结果。有关更多信息,请参阅 cudnnConvolutionBwdDataAlgo_t。
workSpace输入。指向 GPU 内存的数据指针,该内存指向执行指定算法所需的工作空间。如果特定算法不需要工作空间,则该指针可以为
NIL。workSpaceSizeInBytes输入。指定提供的
workSpace的大小(以字节为单位)。dxDesc输入。指向先前初始化的输出张量描述符的句柄。
dx输入/输出。指向与输出张量描述符
dxDesc关联的 GPU 内存的数据指针,该描述符携带结果。
支持的配置
此函数支持 wDesc、dyDesc、convDesc 和 dxDesc 的以下数据类型组合。
数据类型配置 |
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
支持的算法
指定单独的算法可能会导致性能、支持和计算确定性方面的变化。请参阅以下算法选项列表及其各自支持的参数和确定性行为。
下表显示了支持的 2D 和 3D 卷积列表。首先描述 2D 卷积,然后是 3D 卷积。
为简洁起见,下表中使用后跟 > 的简写版本
CUDNN_CONVOLUTION_BWD_DATA_ALGO_0>_ALGO_0
CUDNN_CONVOLUTION_BWD_DATA_ALGO_1>_ALGO_1
CUDNN_CONVOLUTION_BWD_DATA_ALGO_FFT>_FFT
CUDNN_CONVOLUTION_BWD_DATA_ALGO_FFT_TILING>_FFT_TILING
CUDNN_CONVOLUTION_BWD_DATA_ALGO_WINOGRAD>_WINOGRAD
CUDNN_CONVOLUTION_BWD_DATA_ALGO_WINOGRAD_NONFUSED>_WINOGRAD_NONFUSED
CUDNN_TENSOR_NCHW>_NCHW
CUDNN_TENSOR_NHWC>_NHWC
CUDNN_TENSOR_NCHW_VECT_C>_NCHW_VECT_C
算法名称 |
确定性 |
为 |
为 |
支持的数据类型配置 |
重要提示 |
|---|---|---|---|---|---|
|
NHWC HWC 打包 |
NHWC HWC 打包 |
|
算法名称 |
确定性 |
为 |
为 |
支持的数据类型配置 |
重要提示 |
|---|---|---|---|---|---|
|
否 |
NCHW CHW 打包 |
除 |
|
膨胀:所有维度 |
|
是 |
NCHW CHW 打包 |
除 |
|
膨胀:所有维度 |
|
是 |
NCHW CHW 打包 |
NCHW HW 打包 |
|
膨胀:所有维度 |
|
是 |
NCHW CHW 打包 |
NCHW HW 打包 |
当任务可以通过 1D FFT 处理时,也支持 |
空洞率:所有维度均为 |
|
是 |
NCHW CHW 打包 |
除 |
|
空洞率:所有维度均为 |
|
是 |
NCHW CHW 打包 |
除 |
|
空洞率:所有维度均为 |
算法名称 (3D 卷积) |
确定性 |
为 |
为 |
支持的数据类型配置 |
重要提示 |
|---|---|---|---|---|---|
|
是 |
NCDHW CDHW-packed |
除 |
|
膨胀:所有维度 |
|
是 |
NCDHW CDHW-packed |
NCDHW CDHW-packed |
|
空洞率:所有维度均为 |
|
是 |
NCDHW CDHW-packed |
NCDHW DHW-packed |
|
空洞率:所有维度均为 |
算法名称 (3D 卷积) |
确定性 |
为 |
为 |
支持的数据类型配置 |
重要提示 |
|---|---|---|---|---|---|
|
是 |
NDHWC DHWC-packed |
NDHWC DHWC-packed |
|
膨胀:所有维度 |
返回
CUDNN_STATUS_SUCCESS操作已成功启动。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
以下至少有一个为
NULL: handle,dyDesc,wDesc,convDesc,dxDesc,dy,w,dx,alpha, 和betawDesc和dyDesc的维度数量不匹配wDesc和dxDesc的维度数量不匹配wDesc的维度数量少于三个wDesc,dxDesc和dyDesc的数据类型不匹配wDesc和dxDesc的每个图像(或分组卷积情况下的组)的输入特征图数量不匹配dyDesc空间大小与 cudnnGetConvolutionNdForwardOutputDim() 确定的预期大小不匹配
CUDNN_STATUS_NOT_SUPPORTED满足以下至少一个条件
dyDesc或dxDesc具有负张量步幅dyDesc,wDesc或dxDesc的维度数量不是4或5所选算法不支持提供的参数;请参阅上表,其中详尽列出了支持每种算法的参数。
dyDesc或wDesc指示的输出通道计数不是组计数的倍数(如果在convDesc中设置了组计数)
CUDNN_STATUS_MAPPING_ERROR在与滤波器数据或输入微分张量数据关联的纹理对象创建的纹理绑定期间发生错误。
CUDNN_STATUS_EXECUTION_FAILED该函数无法在 GPU 上启动。
cudnnConvolutionBackwardFilter()#
此函数在 cuDNN 9.0 中已弃用。
此函数计算张量 dy 的卷积权重(滤波器)梯度,其中 y 是 cudnnConvolutionForward() 中正向卷积的输出。它使用指定的 algo,并在输出张量 dw 中返回结果。比例因子 alpha 和 beta 可用于缩放计算结果或与当前的 dw 累积。
cudnnStatus_t cudnnConvolutionBackwardFilter( cudnnHandle_t handle, const void *alpha, const cudnnTensorDescriptor_t xDesc, const void *x, const cudnnTensorDescriptor_t dyDesc, const void *dy, const cudnnConvolutionDescriptor_t convDesc, cudnnConvolutionBwdFilterAlgo_t algo, void *workSpace, size_t workSpaceSizeInBytes, const void *beta, const cudnnFilterDescriptor_t dwDesc, void *dw)
参数
handle输入。指向先前创建的 cuDNN 上下文的句柄。有关更多信息,请参阅 cudnnHandle_t。
alpha,beta输入。指向缩放因子(在主机内存中)的指针,用于将计算结果与输出层中的先前值混合,如下所示
dstValue = alpha[0]*result + beta[0]*priorDstValue
有关更多信息,请参阅 缩放参数。
xDesc输入。先前初始化的张量描述符的句柄。有关更多信息,请参阅 cudnnTensorDescriptor_t。
x输入。与张量描述符
xDesc关联的 GPU 内存的数据指针。dyDesc输入。先前初始化的输入微分张量描述符的句柄。
dy输入。与反向传播梯度张量描述符
dyDesc关联的 GPU 内存的数据指针。convDesc输入。先前初始化的卷积描述符。有关更多信息,请参阅 cudnnConvolutionDescriptor_t。
algo输入。枚举器,指定应使用哪种卷积算法来计算结果。有关更多信息,请参阅 cudnnConvolutionBwdFilterAlgo_t。
workSpace输入。指向 GPU 内存的数据指针,该内存指向执行指定算法所需的工作空间。如果特定算法不需要工作空间,则该指针可以为
NIL。workSpaceSizeInBytes输入。指定提供的
workSpace的大小(以字节为单位)。dwDesc输入。先前初始化的滤波器梯度描述符的句柄。有关更多信息,请参阅 cudnnFilterDescriptor_t。
dw输入/输出。与滤波器梯度描述符
dwDesc关联的 GPU 内存的数据指针,该描述符携带结果。
支持的配置
此函数支持 xDesc、dyDesc、convDesc 和 dwDesc 的以下数据类型组合。
数据类型配置 |
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
支持的算法
指定单独的算法可能会导致性能、支持和计算确定性发生变化。请参阅下表,其中详尽列出了算法选项及其各自支持的参数和确定性行为。
下表显示了支持的 2D 和 3D 卷积列表。首先描述 2D 卷积,然后是 3D 卷积。
对于以下术语,下表中使用括号中所示的简短版本,以保持简洁
为简洁起见,下表中使用后跟 > 的简写版本
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_0>_ALGO_0
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_1>_ALGO_1
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_3>_ALGO_3
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_FFT>_FFT
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_FFT_TILING>_FFT_TILING
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_WINOGRAD_NONFUSED>_WINOGRAD_NONFUSED
CUDNN_TENSOR_NCHW>_NCHW
CUDNN_TENSOR_NHWC>_NHWC
CUDNN_TENSOR_NCHW_VECT_C>_NCHW_VECT_C
算法名称 |
确定性 |
|
为 |
支持的数据类型配置 |
重要提示 |
|---|---|---|---|---|---|
|
除 |
NHWC HWC 打包 |
|
算法名称 |
确定性 |
|
为 |
支持的数据类型配置 |
重要提示 |
|---|---|---|---|---|---|
|
否 |
除 |
NCHW CHW 打包 |
|
膨胀:所有维度 |
|
是 |
除 |
NCHW CHW 打包 |
|
膨胀:所有维度 |
|
是 |
NCHW CHW 打包 |
NCHW CHW 打包 |
|
空洞率:所有维度均为 |
|
否 |
除 |
NCHW CHW 打包 |
|
空洞率:所有维度均为 |
|
是 |
除 |
NCHW CHW 打包 |
|
空洞率:所有维度均为 |
|
是 |
NCHW CHW 打包 |
NCHW CHW 打包 |
|
空洞率:所有维度均为 |
算法名称 (3D 卷积) |
确定性 |
|
为 |
支持的数据类型配置 |
重要提示 |
|---|---|---|---|---|---|
|
否 |
除 |
NCDHW CDHW-packed NCDHW W-packed NDHWC |
|
膨胀:所有维度 |
|
否 |
除 |
NCDHW CDHW-packed NCDHW W-packed NDHWC |
|
膨胀:所有维度 |
|
否 |
NCDHW fully-packed |
NCDHW fully-packed |
|
膨胀:所有维度 |
算法名称 (3D 卷积) |
确定性 |
|
为 |
支持的数据类型配置 |
重要提示 |
|---|---|---|---|---|---|
|
是 |
NDHWC HWC-packed |
NDHWC HWC-packed |
|
膨胀:所有维度 |
返回
CUDNN_STATUS_SUCCESS操作已成功启动。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
以下至少有一个为
NULL:handle,xDesc,dyDesc,convDesc,dwDesc,xData,dyData,dwData,alpha, 或betaxDesc和dyDesc的维度数量不匹配xDesc和dwDesc的维度数量不匹配xDesc的维度数量少于三个xDesc,dyDesc和dwDesc的数据类型不匹配xDesc和dwDesc的每个图像(或分组卷积情况下的组)的输入特征图数量不匹配yDesc或dwDesc指示的输出通道计数不是组计数的倍数(如果在 convDesc 中设置了组计数)
CUDNN_STATUS_NOT_SUPPORTED满足以下至少一个条件
xDesc或dyDesc具有负张量步幅xDesc,dyDesc`,` or ``dwDesc的维度数量不是4或5所选
algo不支持提供的参数;有关每种algo的参数支持的详尽列表,请参见上文
CUDNN_STATUS_MAPPING_ERROR在与滤波器数据关联的纹理对象创建期间发生错误。
CUDNN_STATUS_EXECUTION_FAILED该函数无法在 GPU 上启动。
cudnnConvolutionBiasActivationForward()#
此函数在 cuDNN 9.0 中已弃用。
此函数将偏置和激活应用于 cudnnConvolutionForward() 的卷积或互相关,并在 y 中返回结果。完整计算遵循公式 y = act (alpha1 * conv(x) + alpha2 * z + bias)。
cudnnStatus_t cudnnConvolutionBiasActivationForward( cudnnHandle_t handle, const void *alpha1, const cudnnTensorDescriptor_t xDesc, const void *x, const cudnnFilterDescriptor_t wDesc, const void *w, const cudnnConvolutionDescriptor_t convDesc, cudnnConvolutionFwdAlgo_t algo, void *workSpace, size_t workSpaceSizeInBytes, const void *alpha2, const cudnnTensorDescriptor_t zDesc, const void *z, const cudnnTensorDescriptor_t biasDesc, const void *bias, const cudnnActivationDescriptor_t activationDesc, const cudnnTensorDescriptor_t yDesc, void *y)
例程 cudnnGetConvolution2dForwardOutputDim() 或 cudnnGetConvolutionNdForwardOutputDim() 可用于确定输出张量描述符 yDesc 相对于 xDesc、convDesc 和 wDesc 的正确维度。
只有 CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM 算法在 CUDNN_ACTIVATION_IDENTITY 中启用。换句话说,在输入 activationDesc 的 cudnnActivationDescriptor_t 结构中,如果 cudnnActivationMode_t 字段的模式设置为枚举值 CUDNN_ACTIVATION_IDENTITY,则此函数 cudnnConvolutionBiasActivationForward() 的输入 cudnnConvolutionFwdAlgo_t 必须设置为枚举值 CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM。有关更多信息,请参阅 cudnnSetActivationDescriptor()。
设备指针 z 和 y 可能指向相同的缓冲区,但是,x 不能与 z 或 y 指向相同的缓冲区。
参数
handle输入。指向先前创建的 cuDNN 上下文的句柄。有关更多信息,请参阅 cudnnHandle_t。
alpha1,alpha2输入。指向比例因子(在主机内存中)的指针,用于将卷积的计算结果与
z和偏置混合,如下所示y = act (alpha1 * conv(x) + alpha2 * z + bias)
有关更多信息,请参阅 缩放参数。
xDesc输入。先前初始化的张量描述符的句柄。有关更多信息,请参阅 cudnnTensorDescriptor_t。
x输入。与张量描述符
xDesc关联的 GPU 内存的数据指针。wDesc输入。指向先前初始化的滤波器描述符的句柄。有关更多信息,请参阅 cudnnFilterDescriptor_t。
w输入。指向与滤波器描述符
wDesc关联的 GPU 内存的数据指针。convDesc输入。先前初始化的卷积描述符。有关更多信息,请参阅 cudnnConvolutionDescriptor_t。
algo输入。枚举器,指定应使用哪种卷积算法来计算结果。有关更多信息,请参阅 cudnnConvolutionFwdAlgo_t。
workSpace输入。指向 GPU 内存的数据指针,该内存指向执行指定算法所需的工作空间。如果特定算法不需要工作空间,则该指针可以为
NIL。workSpaceSizeInBytes输入。指定提供的
workSpace的大小(以字节为单位)。zDesc输入。先前初始化的张量描述符的句柄。
z输入。与张量描述符 zDesc 关联的 GPU 内存的数据指针。
biasDesc输入。先前初始化的张量描述符的句柄。
bias输入。与张量描述符
biasDesc关联的 GPU 内存的数据指针。activationDesc输入。先前初始化的激活描述符的句柄。有关更多信息,请参阅 cudnnActivationDescriptor_t。
yDesc输入。先前初始化的张量描述符的句柄。
y输入/输出。与张量描述符
yDesc关联的 GPU 内存的数据指针,该描述符携带卷积的结果。
对于卷积步骤,此函数支持 xDesc、wDesc、convDesc 和 yDesc 的特定数据类型组合,如 cudnnConvolutionForward() 的文档中所列。下表指定了 x、y、z、bias、alpha1 和 alpha2 支持的数据类型组合。
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
返回
除了 cudnnConvolutionForward() 文档中列出的错误值之外,此函数返回的可能错误值及其含义如下所示。
CUDNN_STATUS_SUCCESS操作已成功启动。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
以下至少有一个为
NULL: handle,xDesc,wDesc,convDesc,yDesc,zDesc,biasDesc,activationDesc,xData,wData,yData,zData,bias,alpha1, 和alpha2。xDesc、wDesc、yDesc和zDesc的维度数量不等于convDesc+ 2 的数组长度。
CUDNN_STATUS_NOT_SUPPORTED该函数不支持提供的配置。一些不支持的配置示例包括
activationDesc的mode不是CUDNN_ACTIVATION_RELU或CUDNN_ACTIVATION_IDENTITY。activationDesc的reluNanOpt不是CUDNN_NOT_PROPAGATE_NAN。biasDesc的第二个步幅不等于1。biasDesc的第一个维度不等于1。biasDesc的第二个维度和filterDesc的第一个维度不相等。biasDesc的数据类型与上面数据类型表格中列出的yDesc的数据类型不对应。zDesc和destDesc不匹配。
CUDNN_STATUS_EXECUTION_FAILED该函数无法在 GPU 上启动。
cudnnConvolutionForward()#
此函数在 cuDNN 9.0 中已弃用。
此函数使用 w 指定的滤波器对 x 执行卷积或互相关运算,并将结果返回到 y 中。缩放因子 alpha 和 beta 可分别用于缩放输入张量和输出张量。
cudnnStatus_t cudnnConvolutionForward( cudnnHandle_t handle, const void *alpha, const cudnnTensorDescriptor_t xDesc, const void *x, const cudnnFilterDescriptor_t wDesc, const void *w, const cudnnConvolutionDescriptor_t convDesc, cudnnConvolutionFwdAlgo_t algo, void *workSpace, size_t workSpaceSizeInBytes, const void *beta, const cudnnTensorDescriptor_t yDesc, void *y)
例程 cudnnGetConvolution2dForwardOutputDim() 或 cudnnGetConvolutionNdForwardOutputDim() 可用于确定输出张量描述符 yDesc 相对于 xDesc、convDesc 和 wDesc 的正确维度。
参数
handle输入。指向先前创建的 cuDNN 上下文的句柄。有关更多信息,请参阅 cudnnHandle_t。
alpha,beta输入。指向缩放因子(在主机内存中)的指针,用于将计算结果与输出层中的先前值混合,如下所示
dstValue = alpha[0]*result + beta[0]*priorDstValue
有关更多信息,请参阅 缩放参数。
xDesc输入。先前初始化的张量描述符的句柄。有关更多信息,请参阅 cudnnTensorDescriptor_t。
x输入。与张量描述符
xDesc关联的 GPU 内存的数据指针。wDesc输入。指向先前初始化的滤波器描述符的句柄。有关更多信息,请参阅 cudnnFilterDescriptor_t。
w输入。指向与滤波器描述符
wDesc关联的 GPU 内存的数据指针。convDesc输入。先前初始化的卷积描述符。有关更多信息,请参阅 cudnnConvolutionDescriptor_t。
algo输入。枚举器,指定应使用哪种卷积算法来计算结果。有关更多信息,请参阅 cudnnConvolutionFwdAlgo_t。
workSpace输入。指向 GPU 内存的数据指针,该内存指向执行指定算法所需的工作空间。如果特定算法不需要工作空间,则该指针可以为
NIL。workSpaceSizeInBytes输入。指定提供的
workSpace的大小(以字节为单位)。yDesc输入。先前初始化的张量描述符的句柄。
y输入/输出。指向 GPU 内存的数据指针,该内存与携带卷积结果的张量描述符
yDesc相关联。
支持的配置
此函数支持 xDesc、wDesc、convDesc 和 yDesc 的以下数据类型组合。
数据类型配置 |
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
支持的算法
对于此函数,所有算法都执行确定性计算。指定单独的算法可能会导致性能和支持方面的变化。
下表显示了支持的 2D 和 3D 卷积列表。首先描述 2D 卷积,然后是 3D 卷积。
为简洁起见,下表中使用后跟 > 的简写版本
CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_GEMM>_IMPLICIT_GEMM
CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM>_IMPLICIT_PRECOMP_GEMM
CUDNN_CONVOLUTION_FWD_ALGO_GEMM>_GEMM
CUDNN_CONVOLUTION_FWD_ALGO_DIRECT>_DIRECT
CUDNN_CONVOLUTION_FWD_ALGO_FFT>_FFT
CUDNN_CONVOLUTION_FWD_ALGO_FFT_TILING>_FFT_TILING
CUDNN_CONVOLUTION_FWD_ALGO_WINOGRAD>_WINOGRAD
CUDNN_CONVOLUTION_FWD_ALGO_WINOGRAD_NONFUSED>_WINOGRAD_NONFUSED
CUDNN_TENSOR_NCHW>_NCHW
CUDNN_TENSOR_NHWC>_NHWC
CUDNN_TENSOR_NCHW_VECT_C>_NCHW_VECT_C
算法名称 |
|
为 |
支持的数据类型配置 |
重要提示 |
|---|---|---|---|---|
|
除 |
除 |
|
空洞:对于所有维度 |
|
除 |
除 |
|
空洞:对于所有维度 |
|
除 |
除 |
|
空洞:对于所有维度 |
|
NCHW HW 打包 |
NCHW HW 打包 |
|
空洞:对于所有维度 |
|
NCHW HW 打包 |
NCHW HW 打包 |
当任务可以通过 1D FFT 处理时,也支持 |
空洞:对于所有维度 |
|
除 |
除 |
|
空洞:对于所有维度 |
|
除 |
除 |
|
空洞:对于所有维度 |
|
目前,cuDNN 中未实现。 |
目前,cuDNN 中未实现。 |
目前,cuDNN 中未实现。 |
目前,cuDNN 中未实现。 |
算法名称 |
|
为 |
支持的数据类型配置 |
重要提示 |
|---|---|---|---|---|
|
除 |
除 |
|
空洞率:所有维度均为 |
|
除 |
除 |
|
空洞:对于所有维度 |
算法名称 |
|
为 |
支持的数据类型配置 |
重要提示 |
|---|---|---|---|---|
|
NHWC 完全打包 |
NHWC 完全打包 |
|
空洞:对于所有维度为 |
|
NHWC HWC 打包 |
NHWC HWC 打包 NCHW CHW 打包 |
|
|
算法名称 |
|
为 |
支持的数据类型配置 |
重要提示 |
|---|---|---|---|---|
|
除 |
除 |
|
空洞:对于所有维度 |
|
NCDHW DHW-packed |
NCDHW DHW-packed |
|
空洞:对于所有维度为 |
算法名称 |
|
为 |
支持的数据类型配置 |
重要提示 |
|---|---|---|---|---|
|
NDHWC DHWC-packed |
NDHWC DHWC-packed |
|
空洞:对于所有维度 |
张量可以使用 cudnnTransformTensor() 转换为 CUDNN_TENSOR_NCHW_VECT_C 和从 CUDNN_TENSOR_NCHW_VECT_C 转换。
返回
CUDNN_STATUS_SUCCESS操作已成功启动。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
以下至少一项为
NULL:handle、xDesc、wDesc、convDesc、yDesc、xData、w、yData、alpha和betaxDesc和yDesc的维度数不匹配xDesc和wDesc的维度数不匹配xDesc的维度数量少于三个xDesc的维度数不等于convDesc数组长度 + 2xDesc和wDesc的每张图像(或分组卷积情况下的组)输入特征图数量不匹配yDesc或wDesc指示的输出通道计数不是组计数的倍数(如果在convDesc中设置了组计数)xDesc、wDesc和yDesc的数据类型不匹配对于某些空间维度,
wDesc的空间大小大于输入空间大小(包括零填充大小)
CUDNN_STATUS_NOT_SUPPORTED满足以下至少一个条件
xDesc或yDesc具有负张量步幅xDesc、wDesc或yDesc的维度数不是4或5yDesc空间大小与 cudnnGetConvolutionNdForwardOutputDim() 确定的预期大小不匹配所选算法不支持提供的参数;有关每个算法支持的参数的详尽列表,请参见上文
CUDNN_STATUS_MAPPING_ERROR在与滤波器数据关联的纹理对象创建期间发生错误。
CUDNN_STATUS_EXECUTION_FAILED该函数无法在 GPU 上启动。
cudnnCreateConvolutionDescriptor()#
此函数在 cuDNN 9.0 中已弃用。
此函数通过分配存储其不透明结构所需的内存来创建卷积描述符对象。有关更多信息,请参阅 cudnnConvolutionDescriptor_t。
cudnnStatus_t cudnnCreateConvolutionDescriptor( cudnnConvolutionDescriptor_t *convDesc)
返回
CUDNN_STATUS_SUCCESS对象已成功创建。
CUDNN_STATUS_ALLOC_FAILED资源无法分配。
cudnnCreateFusedOpsConstParamPack()#
此函数在 cuDNN 9.0 中已弃用。
此函数创建一个不透明结构,用于存储各种问题大小信息,例如张量的形状、布局和类型,以及所选 cudnnFusedOps 计算序列的卷积和激活描述符。
cudnnStatus_t cudnnCreateFusedOpsConstParamPack( cudnnFusedOpsConstParamPack_t *constPack, cudnnFusedOps_t ops);
参数
constPack输入。此函数创建的不透明结构。有关更多信息,请参阅 cudnnFusedOpsConstParamPack_t。
ops输入。要在
cudnnFusedOps计算中执行的特定计算序列,如枚举类型 cudnnFusedOps_t 中定义。
返回
CUDNN_STATUS_BAD_PARAM如果
constPack或ops为NULL。CUDNN_STATUS_ALLOC_FAILED资源无法分配。
CUDNN_STATUS_SUCCESS如果描述符已成功创建。
cudnnCreateFusedOpsPlan()#
此函数在 cuDNN 9.0 中已弃用。
此函数为 cudnnFusedOps 计算创建计划描述符。此描述符包含计划信息,包括问题类型和大小、应运行的内核以及内部工作区分区。
cudnnStatus_t cudnnCreateFusedOpsPlan( cudnnFusedOpsPlan_t *plan, cudnnFusedOps_t ops);
参数
plan输入。指向此函数创建的描述符实例的指针。
ops输入。应为其创建此计划描述符的特定融合操作计算序列。有关更多信息,请参阅 cudnnFusedOps_t。
返回
CUDNN_STATUS_BAD_PARAM如果输入
*plan为NULL,或者ops输入不是有效的cudnnFusedOp枚举。CUDNN_STATUS_ALLOC_FAILED资源无法分配。
CUDNN_STATUS_SUCCESS计划描述符已成功创建。
cudnnCreateFusedOpsVariantParamPack()#
此函数在 cuDNN 9.0 中已弃用。
此函数为 cudnnFusedOps 计算创建变体包描述符。
cudnnStatus_t cudnnCreateFusedOpsVariantParamPack( cudnnFusedOpsVariantParamPack_t *varPack, cudnnFusedOps_t ops);
参数
varPack输入。指向此函数创建的描述符的指针。有关更多信息,请参阅 cudnnFusedOpsVariantParamPack_t。
ops输入。应为其创建此描述符的特定融合操作计算序列。
返回
CUDNN_STATUS_SUCCESS描述符已成功销毁。
CUDNN_STATUS_ALLOC_FAILED资源无法分配。
CUDNN_STATUS_BAD_PARAM如果任何输入无效。
cudnnDestroyConvolutionDescriptor()#
此函数在 cuDNN 9.0 中已弃用。
此函数销毁先前创建的卷积描述符对象。
cudnnStatus_t cudnnDestroyConvolutionDescriptor( cudnnConvolutionDescriptor_t convDesc)
返回
CUDNN_STATUS_SUCCESS描述符已成功销毁。
cudnnDestroyFusedOpsConstParamPack()#
此函数在 cuDNN 9.0 中已弃用。
此函数销毁先前创建的 cudnnFusedOpsConstParamPack_t 结构。
cudnnStatus_t cudnnDestroyFusedOpsConstParamPack( cudnnFusedOpsConstParamPack_t constPack);
参数
constPack输入。应销毁的 cudnnFusedOpsConstParamPack_t 结构。
返回
CUDNN_STATUS_SUCCESS描述符已成功销毁。
CUDNN_STATUS_INTERNAL_ERRORops枚举值不受支持或无效。
cudnnDestroyFusedOpsPlan()#
此函数在 cuDNN 9.0 中已弃用。
此函数销毁提供的计划描述符。
cudnnStatus_t cudnnDestroyFusedOpsPlan( cudnnFusedOpsPlan_t plan);
参数
plan输入。应由此函数销毁的描述符。
返回
CUDNN_STATUS_SUCCESS计划描述符为
NULL或描述符已成功销毁。
cudnnDestroyFusedOpsVariantParamPack()#
此函数在 cuDNN 9.0 中已弃用。
此函数销毁先前创建的 cudnnFusedOps 常量参数描述符。
cudnnStatus_t cudnnDestroyFusedOpsVariantParamPack( cudnnFusedOpsVariantParamPack_t varPack);
参数
varPack输入。应销毁的描述符。
返回
CUDNN_STATUS_SUCCESS描述符已成功销毁。
cudnnFindConvolutionBackwardDataAlgorithm()#
此函数在 cuDNN 9.0 中已弃用。
此函数尝试 cudnnConvolutionBackwardData() 的所有可用算法。它将尝试提供的 convDesc mathType 和 CUDNN_DEFAULT_MATH(假设两者不同)。
cudnnStatus_t cudnnFindConvolutionBackwardDataAlgorithm( cudnnHandle_t handle, const cudnnFilterDescriptor_t wDesc, const cudnnTensorDescriptor_t dyDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t dxDesc, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionBwdDataAlgoPerf_t *perfResults)
不具备 CUDNN_TENSOR_OP_MATH 可用性的算法将仅使用 CUDNN_DEFAULT_MATH 进行尝试,并以此方式返回。
内存通过 cudaMalloc() 分配。性能指标在用户分配的 cudnnConvolutionBwdDataAlgoPerf_t 数组中返回。这些指标以排序方式写入,其中第一个元素具有最低的计算时间。可以通过 API cudnnGetConvolutionBackwardDataAlgorithmMaxCount() 查询生成的算法总数。
注意
此函数是主机阻塞的。
建议在分配层数据之前运行此函数;否则可能会因资源使用而无谓地抑制某些算法选项。
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
wDesc输入。先前初始化的滤波器描述符的句柄。
dyDesc输入。先前初始化的输入微分张量描述符的句柄。
convDesc输入。先前初始化的卷积描述符。
dxDesc输入。指向先前初始化的输出张量描述符的句柄。
requestedAlgoCount输入。要存储在
perfResults中的最大元素数。returnedAlgoCount输出。存储在
perfResults中的输出元素数。perfResults输出。用户分配的数组,用于存储按计算时间升序排序的性能指标。
返回
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
handle未正确分配wDesc、dyDesc或dxDesc未正确分配wDesc、dyDesc或dxDesc的维度数少于1returnedCount或perfResults为NILrequestedCount小于1
CUDNN_STATUS_ALLOC_FAILED此函数无法分配内存来存储示例输入、滤波器和输出。
CUDNN_STATUS_INTERNAL_ERROR满足以下至少一个条件
该函数无法分配必要的计时对象
该函数无法释放必要的计时对象
该函数无法释放示例输入、滤波器和输出
cudnnFindConvolutionBackwardDataAlgorithmEx()#
此函数在 cuDNN 9.0 中已弃用。
此函数尝试 cudnnConvolutionBackwardData() 的所有可用算法。它将尝试提供的 convDesc mathType 和 CUDNN_DEFAULT_MATH(假设两者不同)。
cudnnStatus_t cudnnFindConvolutionBackwardDataAlgorithmEx( cudnnHandle_t handle, const cudnnFilterDescriptor_t wDesc, const void *w, const cudnnTensorDescriptor_t dyDesc, const void *dy, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t dxDesc, void *dx, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionBwdDataAlgoPerf_t *perfResults, void *workSpace, size_t workSpaceSizeInBytes)
不具备 CUDNN_TENSOR_OP_MATH 可用性的算法将仅使用 CUDNN_DEFAULT_MATH 进行尝试,并以此方式返回。
内存通过 cudaMalloc() 分配。性能指标在用户分配的 cudnnConvolutionBwdDataAlgoPerf_t 数组中返回。这些指标以排序方式写入,其中第一个元素具有最低的计算时间。可以通过 API cudnnGetConvolutionBackwardDataAlgorithmMaxCount() 查询生成的算法总数。
注意
此函数是主机阻塞的。
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
wDesc输入。先前初始化的滤波器描述符的句柄。
w输入。指向与滤波器描述符
wDesc关联的 GPU 内存的数据指针。dyDesc输入。先前初始化的输入微分张量描述符的句柄。
dy输入。指向与滤波器描述符
dyDesc关联的 GPU 内存的数据指针。convDesc输入。先前初始化的卷积描述符。
dxDesc输入。指向先前初始化的输出张量描述符的句柄。
dx输入/输出。指向与张量描述符
dxDesc关联的 GPU 内存的数据指针。此张量的内容将被任意值覆盖。requestedAlgoCount输入。要存储在
perfResults中的最大元素数。returnedAlgoCount输出。存储在
perfResults中的输出元素数。perfResults输出。用户分配的数组,用于存储按计算时间升序排序的性能指标。
workSpace输入。指向 GPU 内存的数据指针,是一些算法的必要工作区。此工作区的大小将决定算法的可用性。
NIL指针被视为0字节的workSpace。workSpaceSizeInBytes输入。指定提供的
workSpace的大小(以字节为单位)。
返回
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
handle未正确分配wDesc、dyDesc或dxDesc未正确分配wDesc、dyDesc或dxDesc的维度数少于1returnedCount或perfResults为NILrequestedCount小于1
CUDNN_STATUS_INTERNAL_ERROR满足以下至少一个条件
该函数无法分配必要的计时对象
该函数无法释放必要的计时对象
该函数无法释放示例输入、滤波器和输出
cudnnFindConvolutionBackwardFilterAlgorithm()#
此函数在 cuDNN 9.0 中已弃用。
此函数尝试 cudnnConvolutionBackwardFilter() 的所有可用算法。它将尝试提供的 convDesc mathType 和 CUDNN_DEFAULT_MATH(假设两者不同)。
cudnnStatus_t cudnnFindConvolutionBackwardFilterAlgorithm( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const cudnnTensorDescriptor_t dyDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnFilterDescriptor_t dwDesc, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionBwdFilterAlgoPerf_t *perfResults)
不具备 CUDNN_TENSOR_OP_MATH 可用性的算法将仅使用 CUDNN_DEFAULT_MATH 进行尝试,并以此方式返回。
内存通过 cudaMalloc() 分配。性能指标在用户分配的 cudnnConvolutionBwdFilterAlgoPerf_t 数组中返回。这些指标以排序方式写入,其中第一个元素具有最低的计算时间。可以通过 API cudnnGetConvolutionBackwardFilterAlgorithmMaxCount() 查询生成的算法总数。
注意
此函数是主机阻塞的。
建议在分配层数据之前运行此函数;否则可能会因资源使用而无谓地抑制某些算法选项。
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
xDesc输入。先前初始化的输入张量描述符的句柄。
dyDesc输入。先前初始化的输入微分张量描述符的句柄。
convDesc输入。先前初始化的卷积描述符。
dwDesc输入。先前初始化的滤波器描述符的句柄。
requestedAlgoCount输入。要存储在
perfResults中的最大元素数。returnedAlgoCount输出。存储在
perfResults中的输出元素数。perfResults输出。用户分配的数组,用于存储按计算时间升序排序的性能指标。
返回
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
handle未正确分配xDesc、dyDesc或dwDesc未正确分配xDesc、dyDesc或dwDesc的维度数少于1returnedCount或perfResults为NILrequestedCount小于1
CUDNN_STATUS_ALLOC_FAILED 此函数无法分配内存来存储示例输入、滤波器和输出。
CUDNN_STATUS_INTERNAL_ERROR 满足以下至少一个条件
该函数无法分配必要的计时对象。
该函数无法释放必要的计时对象。
该函数无法释放示例输入、滤波器和输出。
cudnnFindConvolutionBackwardFilterAlgorithmEx()#
此函数在 cuDNN 9.0 中已弃用。
此函数尝试 cudnnConvolutionBackwardFilter() 的所有可用算法。它将尝试提供的 convDesc mathType 和 CUDNN_DEFAULT_MATH(假设两者不同)。
cudnnStatus_t cudnnFindConvolutionBackwardFilterAlgorithmEx( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const void *x, const cudnnTensorDescriptor_t dyDesc, const void *dy, const cudnnConvolutionDescriptor_t convDesc, const cudnnFilterDescriptor_t dwDesc, void *dw, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionBwdFilterAlgoPerf_t *perfResults, void *workSpace, size_t workSpaceSizeInBytes)
不具备 CUDNN_TENSOR_OP_MATH 可用性的算法将仅使用 CUDNN_DEFAULT_MATH 进行尝试,并以此方式返回。
内存通过 cudaMalloc() 分配。性能指标在用户分配的 cudnnConvolutionBwdFilterAlgoPerf_t 数组中返回。这些指标以排序方式写入,其中第一个元素具有最低的计算时间。可以通过 API cudnnGetConvolutionBackwardFilterAlgorithmMaxCount() 查询生成的算法总数。
注意
此函数是主机阻塞的。
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
xDesc输入。先前初始化的输入张量描述符的句柄。
x输入。指向与滤波器描述符
xDesc关联的 GPU 内存的数据指针。dyDesc输入。先前初始化的输入微分张量描述符的句柄。
dy输入。先前初始化的输入微分张量描述符的句柄。
convDesc输入。先前初始化的卷积描述符。
dwDesc输入。先前初始化的滤波器描述符的句柄。
dw输入/输出。指向与滤波器描述符
dwDesc关联的 GPU 内存的数据指针。此张量的内容将被任意值覆盖。requestedAlgoCount输入。要存储在
perfResults中的最大元素数。returnedAlgoCount输出。存储在
perfResults中的输出元素数。perfResults输出。用户分配的数组,用于存储按计算时间升序排序的性能指标。
workSpace输入。指向 GPU 内存的数据指针,是一些算法的必要工作区。此工作区的大小将决定算法的可用性。
NIL指针被视为0字节的workSpace。workSpaceSizeInBytes输入。指定提供的
workSpace的大小(以字节为单位)。
返回
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
handle未正确分配xDesc、dyDesc或dwDesc未正确分配xDesc、dyDesc或dwDesc的维度数少于1x、dy或dw为NILreturnedCount或perfResults为NILrequestedCount小于1
CUDNN_STATUS_INTERNAL_ERROR 满足以下至少一个条件
该函数无法分配必要的计时对象。
该函数无法释放必要的计时对象。
该函数无法释放示例输入、滤波器和输出。
cudnnFindConvolutionForwardAlgorithm()#
此函数在 cuDNN 9.0 中已弃用。
此函数尝试 cudnnConvolutionForward() 的所有可用算法。它将尝试提供的 convDesc mathType 和 CUDNN_DEFAULT_MATH(假设两者不同)。
cudnnStatus_t cudnnFindConvolutionForwardAlgorithm( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const cudnnFilterDescriptor_t wDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t yDesc, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionFwdAlgoPerf_t *perfResults)
不具备 CUDNN_TENSOR_OP_MATH 可用性的算法将仅使用 CUDNN_DEFAULT_MATH 进行尝试,并以此方式返回。
内存通过 cudaMalloc() 分配。性能指标在用户分配的 cudnnConvolutionFwdAlgoPerf_t 数组中返回。这些指标以排序方式写入,其中第一个元素具有最低的计算时间。可以通过 API cudnnGetConvolutionForwardAlgorithmMaxCount() 查询结果算法的总数。
注意
此函数是主机阻塞的。
建议在分配层数据之前运行此函数;否则可能会因资源使用而无谓地抑制某些算法选项。
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
xDesc输入。先前初始化的输入张量描述符的句柄。
wDesc输入。先前初始化的滤波器描述符的句柄。
convDesc输入。先前初始化的卷积描述符。
yDesc输入。指向先前初始化的输出张量描述符的句柄。
requestedAlgoCount输入。要存储在
perfResults中的最大元素数。returnedAlgoCount输出。存储在
perfResults中的输出元素数。perfResults输出。用户分配的数组,用于存储按计算时间升序排序的性能指标。
返回
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
handle未正确分配xDesc、dyDesc或dwDesc未正确分配xDesc、dyDesc或dwDesc的维度数少于1returnedCount或perfResults为NILrequestedCount小于1
CUDNN_STATUS_ALLOC_FAILED此函数无法分配内存来存储示例输入、滤波器和输出。
CUDNN_STATUS_INTERNAL_ERROR 满足以下至少一个条件
该函数无法分配必要的计时对象。
该函数无法释放必要的计时对象。
该函数无法释放示例输入、滤波器和输出。
cudnnFindConvolutionForwardAlgorithmEx()#
此函数在 cuDNN 9.0 中已弃用。
此函数尝试 cudnnConvolutionForward() 的所有可用算法。它将尝试提供的 convDesc mathType 和 CUDNN_DEFAULT_MATH(假设两者不同)。
cudnnStatus_t cudnnFindConvolutionForwardAlgorithmEx( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const void *x, const cudnnFilterDescriptor_t wDesc, const void *w, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t yDesc, void *y, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionFwdAlgoPerf_t *perfResults, void *workSpace, size_t workSpaceSizeInBytes)
不具备 CUDNN_TENSOR_OP_MATH 可用性的算法将仅使用 CUDNN_DEFAULT_MATH 进行尝试,并以此方式返回。
内存通过 cudaMalloc() 分配。性能指标在用户分配的 cudnnConvolutionFwdAlgoPerf_t 数组中返回。这些指标以排序方式写入,其中第一个元素具有最低的计算时间。可以通过 API cudnnGetConvolutionForwardAlgorithmMaxCount() 查询结果算法的总数。
注意
此函数是主机阻塞的。
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
xDesc输入。先前初始化的输入张量描述符的句柄。
x输入。与张量描述符
xDesc关联的 GPU 内存的数据指针。wDesc输入。先前初始化的滤波器描述符的句柄。
w输入。指向与滤波器描述符
wDesc关联的 GPU 内存的数据指针。convDesc输入。先前初始化的卷积描述符。
yDesc输入。指向先前初始化的输出张量描述符的句柄。
y输入/输出. 指向与张量描述符
yDesc关联的 GPU 内存的数据指针。此张量的内容将被任意值覆盖。requestedAlgoCount输入。要存储在
perfResults中的最大元素数。returnedAlgoCount输出。存储在
perfResults中的输出元素数。perfResults输出。用户分配的数组,用于存储按计算时间升序排序的性能指标。
workSpace输入。指向 GPU 内存的数据指针,是一些算法的必要工作区。此工作区的大小将决定算法的可用性。
NIL指针被视为0字节的workSpace。workSpaceSizeInBytes输入。指定提供的
workSpace的大小(以字节为单位)。
返回
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
handle未正确分配xDesc、dyDesc或dwDesc未正确分配xDesc、dyDesc或dwDesc的维度数少于1x、w或y为NILreturnedCount或perfResults为NILrequestedCount小于1
CUDNN_STATUS_INTERNAL_ERROR 满足以下至少一个条件
该函数无法分配必要的计时对象。
该函数无法释放必要的计时对象。
该函数无法释放示例输入、滤波器和输出。
cudnnFusedOpsExecute()#
此函数执行 cudnnFusedOps 操作序列。
cudnnStatus_t cudnnFusedOpsExecute( cudnnHandle_t handle, const cudnnFusedOpsPlan_t plan, cudnnFusedOpsVariantParamPack_t varPack);
参数
handle输入. 指向 cuDNN 库上下文的指针。
plan输入. 指向先前创建和初始化的计划描述符的指针。
varPack输入. 指向变体参数包描述符的指针。
返回
CUDNN_STATUS_BAD_PARAM如果计划描述符中 cudnnFusedOps_t 的类型不受支持。
cudnnGetConvolution2dDescriptor()#
此函数在 cuDNN 9.0 中已弃用。
此函数查询先前初始化的 2D 卷积描述符对象。
cudnnStatus_t cudnnGetConvolution2dDescriptor( const cudnnConvolutionDescriptor_t convDesc, int *pad_h, int *pad_w, int *u, int *v, int *dilation_h, int *dilation_w, cudnnConvolutionMode_t *mode, cudnnDataType_t *computeType)
参数
convDesc输入/输出. 先前创建的卷积描述符的句柄。
pad_h输出. 零填充高度:隐式连接到输入图像顶部和底部的零行数。
pad_w输出. 零填充宽度:隐式连接到输入图像左侧和右侧的零列数。
u输出. 垂直滤波器步幅。
v输出. 水平滤波器步幅。
dilation_h输出. 滤波器高度膨胀。
dilation_w输出. 滤波器宽度膨胀。
mode输出. 卷积模式。
computeType输出. 计算精度。
返回
CUDNN_STATUS_SUCCESS操作成功。
CUDNN_STATUS_BAD_PARAM参数
convDesc为NIL。
cudnnGetConvolution2dForwardOutputDim()#
此函数在 cuDNN 9.0 中已弃用。
此函数返回 2D 卷积产生的 4D 张量的维度,给定卷积描述符、输入张量描述符和滤波器描述符。此函数可以帮助设置输出张量,并在启动实际卷积之前分配适当数量的内存。
cudnnStatus_t cudnnGetConvolution2dForwardOutputDim( const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t inputTensorDesc, const cudnnFilterDescriptor_t filterDesc, int *n, int *c, int *h, int *w)
输出图像的每个维度 h 和 w 的计算方式如下
outputDim = 1 + ( inputDim + 2*pad - (((filterDim-1)*dilation)+1) )/convolutionStride;注意
调用 cudnnConvolutionForward() 或 cudnnConvolutionBackwardBias() 时,必须严格遵守此例程提供的维度。卷积例程不支持提供更小或更大的输出张量。
参数
convDesc输入. 先前创建的卷积描述符的句柄。
inputTensorDesc输入。先前初始化的张量描述符的句柄。
filterDesc输入。先前初始化的滤波器描述符的句柄。
n输出. 输出图像的数量。
c输出. 每个输出图像的输出特征图的数量。
h输出. 每个输出特征图的高度。
w输出. 每个输出特征图的宽度。
返回
CUDNN_STATUS_BAD_PARAM一个或多个描述符未正确创建,或者
inputTensorDesc和filterDesc的特征图之间存在不匹配。CUDNN_STATUS_SUCCESS对象设置成功。
cudnnGetConvolutionBackwardDataAlgorithm_v7()#
此函数在 cuDNN 9.0 中已弃用。
此函数作为启发式方法,用于为给定层规范的 cudnnConvolutionBackwardData() 获取最合适的算法。此函数将返回所有算法(包括 CUDNN_TENSOR_OP_MATH 和 CUDNN_DEFAULT_MATH 版本的算法,其中 CUDNN_TENSOR_OP_MATH 可能可用),并按预期(基于内部启发式)相对性能排序,最快的算法是 perfResults 的索引 0。要彻底搜索最快的算法,请使用 cudnnFindConvolutionBackwardDataAlgorithm()。可以通过 returnedAlgoCount 变量查询结果算法的总数。
cudnnStatus_t cudnnGetConvolutionBackwardDataAlgorithm_v7( cudnnHandle_t handle, const cudnnFilterDescriptor_t wDesc, const cudnnTensorDescriptor_t dyDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t dxDesc, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionBwdDataAlgoPerf_t *perfResults)
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
wDesc输入。先前初始化的滤波器描述符的句柄。
dyDesc输入。先前初始化的输入微分张量描述符的句柄。
convDesc输入。先前初始化的卷积描述符。
dxDesc输入。指向先前初始化的输出张量描述符的句柄。
requestedAlgoCount输入。要存储在
perfResults中的最大元素数。returnedAlgoCount输出。存储在
perfResults中的输出元素数。perfResults输出。用户分配的数组,用于存储按计算时间升序排序的性能指标。
返回
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
参数
handle、wDesc、dyDesc、convDesc、dxDesc、perfResults或returnedAlgoCount之一为NULL。输入张量和输出张量的特征图数量不同。
两个张量描述符或滤波器的
dataType不同。requestedAlgoCount小于或等于0。
cudnnGetConvolutionBackwardDataAlgorithmMaxCount()#
此函数在 cuDNN 9.0 中已弃用。
此函数返回可以从 cudnnFindConvolutionBackwardDataAlgorithm() 和 cudnnGetConvolutionForwardAlgorithm_v7() 返回的算法的最大数量。这是所有算法的总和加上当前设备支持的 Tensor Core 操作的所有算法的总和。
cudnnStatus_t cudnnGetConvolutionBackwardDataAlgorithmMaxCount( cudnnHandle_t handle, int *count)
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
count输出. 结果的最大算法数。
返回
CUDNN_STATUS_SUCCESS函数执行成功。
CUDNN_STATUS_BAD_PARAM提供的句柄未正确分配。
cudnnGetConvolutionBackwardDataWorkspaceSize()#
此函数在 cuDNN 9.0 中已弃用。
此函数返回用户需要分配的 GPU 内存工作区大小,以便能够使用指定的算法调用 cudnnConvolutionBackwardData()。分配的工作区将传递给例程 cudnnConvolutionBackwardData()。指定的算法可以是调用 cudnnGetConvolutionBackwardDataAlgorithm_v7() 的结果,也可以由用户任意选择。请注意,并非每个算法都适用于输入张量的每种配置和/或卷积描述符的每种配置。
cudnnStatus_t cudnnGetConvolutionBackwardDataWorkspaceSize( cudnnHandle_t handle, const cudnnFilterDescriptor_t wDesc, const cudnnTensorDescriptor_t dyDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t dxDesc, cudnnConvolutionBwdDataAlgo_t algo, size_t *sizeInBytes)
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
wDesc输入。先前初始化的滤波器描述符的句柄。
dyDesc输入。先前初始化的输入微分张量描述符的句柄。
convDesc输入。先前初始化的卷积描述符。
dxDesc输入。指向先前初始化的输出张量描述符的句柄。
algo输入. 指定所选卷积算法的枚举。
sizeInBytes输出. 执行具有指定
algo的前向卷积所需的工作区 GPU 内存量。
返回
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
输入张量和输出张量的特征图数量不同。
两个张量描述符或滤波器的
dataType不同。
CUDNN_STATUS_NOT_SUPPORTED对于指定的算法,不支持张量描述符、滤波器描述符和卷积描述符的组合。
cudnnGetConvolutionBackwardFilterAlgorithm_v7()#
此函数在 cuDNN 9.0 中已弃用。
此函数作为启发式方法,用于为给定层规范的 cudnnConvolutionBackwardFilter() 获取最合适的算法。此函数将返回所有算法(包括 CUDNN_TENSOR_OP_MATH 和 CUDNN_DEFAULT_MATH 版本的算法,其中 CUDNN_TENSOR_OP_MATH 可能可用),并按预期(基于内部启发式)相对性能排序,最快的算法是 perfResults 的索引 0。要彻底搜索最快的算法,请使用 cudnnFindConvolutionBackwardFilterAlgorithm()。可以通过 returnedAlgoCount 变量查询结果算法的总数。
cudnnStatus_t cudnnGetConvolutionBackwardFilterAlgorithm_v7( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const cudnnTensorDescriptor_t dyDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnFilterDescriptor_t dwDesc, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionBwdFilterAlgoPerf_t *perfResults)
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
xDesc输入。先前初始化的输入张量描述符的句柄。
dyDesc输入。先前初始化的输入微分张量描述符的句柄。
convDesc输入。先前初始化的卷积描述符。
dwDesc输入。先前初始化的滤波器描述符的句柄。
requestedAlgoCount输入。要存储在
perfResults中的最大元素数。returnedAlgoCount输出。存储在
perfResults中的输出元素数。perfResults输出。用户分配的数组,用于存储按计算时间升序排序的性能指标。
返回
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
参数
handle、xDesc、dyDesc、convDesc、dwDesc、perfResults或returnedAlgoCount之一为NULL。输入张量和输出张量的特征图数量不同。
两个张量描述符或滤波器的
dataType不同。requestedAlgoCount小于或等于0。
cudnnGetConvolutionBackwardFilterAlgorithmMaxCount()#
此函数在 cuDNN 9.0 中已弃用。
此函数返回可以从 cudnnFindConvolutionBackwardFilterAlgorithm() 和 cudnnGetConvolutionForwardAlgorithm_v7() 返回的算法的最大数量。这是所有算法的总和加上当前设备支持的 Tensor Core 操作的所有算法的总和。
cudnnStatus_t cudnnGetConvolutionBackwardFilterAlgorithmMaxCount( cudnnHandle_t handle, int *count)
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
count输出. 结果的最大算法计数。
返回
CUDNN_STATUS_SUCCESS函数执行成功。
CUDNN_STATUS_BAD_PARAM提供的句柄未正确分配。
cudnnGetConvolutionBackwardFilterWorkspaceSize()#
此函数在 cuDNN 9.0 中已弃用。
此函数返回用户需要分配的 GPU 内存工作区大小,以便能够使用指定的算法调用 cudnnConvolutionBackwardFilter()。分配的工作区将传递给例程 cudnnConvolutionBackwardFilter()。指定的算法可以是调用 cudnnGetConvolutionBackwardFilterAlgorithm_v7() 的结果,也可以由用户任意选择。请注意,并非每个算法都适用于输入张量的每种配置和/或卷积描述符的每种配置。
cudnnStatus_t cudnnGetConvolutionBackwardFilterWorkspaceSize( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const cudnnTensorDescriptor_t dyDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnFilterDescriptor_t dwDesc, cudnnConvolutionBwdFilterAlgo_t algo, size_t *sizeInBytes)
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
xDesc输入。先前初始化的输入张量描述符的句柄。
dyDesc输入。先前初始化的输入微分张量描述符的句柄。
convDesc输入。先前初始化的卷积描述符。
dwDesc输入。先前初始化的滤波器描述符的句柄。
algo输入. 指定所选卷积算法的枚举。
sizeInBytes输出. 执行具有指定
algo的前向卷积所需的工作区 GPU 内存量。
返回
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
输入张量和输出张量的特征图数量不同。
两个张量描述符或滤波器的
dataType不同。
CUDNN_STATUS_NOT_SUPPORTED对于指定的算法,不支持张量描述符、滤波器描述符和卷积描述符的组合。
cudnnGetConvolutionForwardAlgorithm_v7()#
此函数在 cuDNN 9.0 中已弃用。
此函数作为启发式方法,用于为给定层规范的 cudnnConvolutionForward() 获取最合适的算法。此函数将返回所有算法(包括 CUDNN_TENSOR_OP_MATH 和 CUDNN_DEFAULT_MATH 版本的算法,其中 CUDNN_TENSOR_OP_MATH 可能可用),并按预期(基于内部启发式)相对性能排序,最快的算法是 perfResults 的索引 0。要彻底搜索最快的算法,请使用 cudnnFindConvolutionForwardAlgorithm()。可以通过 returnedAlgoCount 变量查询结果算法的总数。
cudnnStatus_t cudnnGetConvolutionForwardAlgorithm_v7( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const cudnnFilterDescriptor_t wDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t yDesc, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionFwdAlgoPerf_t *perfResults)
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
xDesc输入。先前初始化的输入张量描述符的句柄。
wDesc输入. 先前初始化的卷积滤波器描述符的句柄。
convDesc输入。先前初始化的卷积描述符。
yDesc输入。指向先前初始化的输出张量描述符的句柄。
requestedAlgoCount输入。要存储在
perfResults中的最大元素数。returnedAlgoCount输出。存储在
perfResults中的输出元素数。perfResults输出。用户分配的数组,用于存储按计算时间升序排序的性能指标。
返回
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
参数
handle、xDesc、wDesc、convDesc、yDesc、perfResults或returnedAlgoCount之一为NULL。yDesc或wDesc的维度与xDesc不同。张量
xDesc、yDesc或wDesc的数据类型不完全相同。xDesc和wDesc中的特征图数量不同。张量
xDesc的维度小于3。requestedAlgoCount小于或等于0。
cudnnGetConvolutionForwardAlgorithmMaxCount()#
此函数在 cuDNN 9.0 中已弃用。
此函数返回可以从 cudnnFindConvolutionForwardAlgorithm() 和 cudnnGetConvolutionForwardAlgorithm_v7() 返回的算法的最大数量。这是所有算法的总和加上当前设备支持的 Tensor Core 操作的所有算法的总和。
cudnnStatus_t cudnnGetConvolutionForwardAlgorithmMaxCount( cudnnHandle_t handle, int *count)
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
count输出. 结果的最大算法数。
返回
CUDNN_STATUS_SUCCESS函数执行成功。
CUDNN_STATUS_BAD_PARAM提供的句柄未正确分配。
cudnnGetConvolutionForwardWorkspaceSize()#
此函数在 cuDNN 9.0 中已弃用。
此函数返回用户需要分配的 GPU 内存工作区大小,以便能够使用指定的算法调用 cudnnConvolutionForward()。分配的工作区将传递给例程 cudnnConvolutionForward()。指定的算法可以是调用 cudnnGetConvolutionForwardAlgorithm_v7() 的结果,也可以由用户任意选择。请注意,并非每个算法都适用于输入张量的每种配置和/或卷积描述符的每种配置。
cudnnStatus_t cudnnGetConvolutionForwardWorkspaceSize( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const cudnnFilterDescriptor_t wDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t yDesc, cudnnConvolutionFwdAlgo_t algo, size_t *sizeInBytes)
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
xDesc输入. 先前初始化的
x张量描述符的句柄。wDesc输入。先前初始化的滤波器描述符的句柄。
convDesc输入。先前初始化的卷积描述符。
yDesc输入. 先前初始化的
y张量描述符的句柄。algo输入. 指定所选卷积算法的枚举。
sizeInBytes输出. 执行具有指定
algo的前向卷积所需的工作区 GPU 内存量。
返回
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
参数
handle、xDesc、wDesc、convDesc或yDesc之一为NULL。张量
yDesc或wDesc的维度与xDesc不同。张量
xDesc、yDesc或wDesc的数据类型不相同。张量
xDesc和wDesc的特征图数量不同。张量
xDesc的维度小于3。
CUDNN_STATUS_NOT_SUPPORTED对于指定的算法,不支持张量描述符、滤波器描述符和卷积描述符的组合。
cudnnGetConvolutionGroupCount()#
此函数在 cuDNN 9.0 中已弃用。
此函数返回给定卷积描述符中指定的组计数。
cudnnStatus_t cudnnGetConvolutionGroupCount( cudnnConvolutionDescriptor_t convDesc, int *groupCount)
返回
CUDNN_STATUS_SUCCESS组计数已成功返回。
CUDNN_STATUS_BAD_PARAM提供了无效的卷积描述符。
cudnnGetConvolutionMathType()#
此函数在 cuDNN 9.0 中已弃用。
此函数返回给定卷积描述符中指定的数学类型。
cudnnStatus_t cudnnGetConvolutionMathType( cudnnConvolutionDescriptor_t convDesc, cudnnMathType_t *mathType)
返回
CUDNN_STATUS_SUCCESS数学类型已成功返回。
CUDNN_STATUS_BAD_PARAM提供了无效的卷积描述符。
cudnnGetConvolutionNdDescriptor()#
此函数在 cuDNN 9.0 中已弃用。
此函数查询先前初始化的卷积描述符对象。
cudnnStatus_t cudnnGetConvolutionNdDescriptor( const cudnnConvolutionDescriptor_t convDesc, int arrayLengthRequested, int *arrayLength, int padA[], int filterStrideA[], int dilationA[], cudnnConvolutionMode_t *mode, cudnnDataType_t *dataType)
参数
convDesc输入/输出. 先前创建的卷积描述符的句柄。
arrayLengthRequested输入. 预期卷积描述符的维度。它也是数组
padA、filterStrideA和dilationA的最小大小,以便能够保存结果arrayLength输出. 卷积描述符的实际维度。
padA输出. 维度至少为
arrayLengthRequested的数组,该数组将填充来自提供的卷积描述符的填充参数。filterStrideA输出. 维度至少为
arrayLengthRequested的数组,该数组将填充来自提供的卷积描述符的滤波器步幅。dilationA输出. 维度至少为
arrayLengthRequested的数组,该数组将填充来自提供的卷积描述符的膨胀参数。mode输出. 提供的描述符的卷积模式。
datatype输出. 提供的描述符的数据类型。
返回
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
描述符
convDesc为NIL。arrayLengthRequest为负数。
CUDNN_STATUS_NOT_SUPPORTEDarrayLengthRequested大于CUDNN_DIM_MAX-2。
cudnnGetConvolutionNdForwardOutputDim()#
此函数在 cuDNN 9.0 中已弃用。
此函数返回 nbDims-2-D 卷积产生的 Nd 张量的维度,给定卷积描述符、输入张量描述符和滤波器描述符。此函数可以帮助设置输出张量,并在启动实际卷积之前分配适当数量的内存。
cudnnStatus_t cudnnGetConvolutionNdForwardOutputDim( const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t inputTensorDesc, const cudnnFilterDescriptor_t filterDesc, int nbDims, int tensorOuputDimA[])
输出张量的 (nbDims-2)-D 图像的每个维度的计算方式如下
outputDim = 1 + ( inputDim + 2*pad - (((filterDim-1)*dilation)+1) )/convolutionStride;
调用 cudnnConvolutionForward() 或 cudnnConvolutionBackwardBias() 时,必须严格遵守此例程提供的维度。卷积例程不支持提供更小或更大的输出张量。
参数
convDesc输入. 先前创建的卷积描述符的句柄。
inputTensorDesc输入。先前初始化的张量描述符的句柄。
filterDesc输入。先前初始化的滤波器描述符的句柄。
nbDims输入. 输出张量的维度
tensorOuputDimA输出. 维度为
nbDims的数组,该数组在此例程退出时包含输出张量的大小
返回
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
参数
convDesc、inputTensorDesc和filterDesc之一为NIL。滤波器描述符
filterDesc的维度与输入张量描述符inputTensorDesc的维度不同。卷积描述符的维度与输入张量描述符
inputTensorDesc-2的维度不同。滤波器描述符
filterDesc的特征图与输入张量描述符inputTensorDesc的特征图不同。膨胀滤波器
filterDesc的大小大于输入张量的填充大小。输出数组的维度
nbDims为负数或大于输入张量描述符inputTensorDesc的维度。
CUDNN_STATUS_SUCCESS例程成功退出。
cudnnGetConvolutionReorderType()#
此函数在 cuDNN 9.0 中已弃用。
此函数从给定的卷积描述符中检索卷积重排序类型。
cudnnStatus_t cudnnGetConvolutionReorderType( cudnnConvolutionDescriptor_t convDesc, cudnnReorderType_t *reorderType);
参数
convDesc输入. 应从中检索重排序类型的卷积描述符。
reorderType输出. 检索到的重排序类型。有关更多信息,请参阅 cudnnReorderType_t。
返回
CUDNN_STATUS_BAD_PARAM此函数的输入之一无效。
CUDNN_STATUS_SUCCESS重排序类型已成功检索。
cudnnGetFoldedConvBackwardDataDescriptors()#
此函数计算后向数据梯度的折叠描述符。它将数据描述符与卷积描述符一起作为输入,并计算折叠数据描述符和折叠变换描述符。这些描述符随后可用于执行实际的折叠变换。
cudnnStatus_t cudnnGetFoldedConvBackwardDataDescriptors(const cudnnHandle_t handle, const cudnnFilterDescriptor_t filterDesc, const cudnnTensorDescriptor_t diffDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t gradDesc, const cudnnTensorFormat_t transformFormat, cudnnFilterDescriptor_t foldedFilterDesc, cudnnTensorDescriptor_t paddedDiffDesc, cudnnConvolutionDescriptor_t foldedConvDesc, cudnnTensorDescriptor_t foldedGradDesc, cudnnTensorTransformDescriptor_t filterFoldTransDesc, cudnnTensorTransformDescriptor_t diffPadTransDesc, cudnnTensorTransformDescriptor_t gradFoldTransDesc, cudnnTensorTransformDescriptor_t gradUnfoldTransDesc) ;
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
filterDesc输入. 折叠前的滤波器描述符。
diffDesc输入. 折叠前的
Diff描述符。convDesc输入. 折叠前的卷积描述符。
gradDesc输入. 折叠前的梯度描述符。
transformFormat输入. 折叠的变换格式。
foldedFilterDesc输出. 折叠的滤波器描述符。
paddedDiffDesc输出. 填充的
Diff描述符。foldedConvDesc输出. 折叠的卷积描述符。
foldedGradDesc输出. 折叠的梯度描述符。
filterFoldTransDesc输出. 滤波器的折叠变换描述符。
diffPadTransDesc输出.
Desc的折叠变换描述符。gradFoldTransDesc输出. 梯度的折叠变换描述符。
gradUnfoldTransDesc输出. 折叠梯度展开变换描述符。
返回
CUDNN_STATUS_SUCCESS折叠描述符计算成功。
CUDNN_STATUS_BAD_PARAM如果任何输入参数为
NULL,或者如果输入张量的维度超过 4。CUDNN_STATUS_EXECUTION_FAILED计算折叠描述符失败。
cudnnGetFusedOpsConstParamPackAttribute()#
此函数检索由 param 指针输入指向的描述符的值。描述符的类型由 paramLabel 输入的枚举值指示。
cudnnStatus_t cudnnGetFusedOpsConstParamPackAttribute( const cudnnFusedOpsConstParamPack_t constPack, cudnnFusedOpsConstParamLabel_t paramLabel, void *param, int *isNULL);
参数
constPack输入. 不透明的 cudnnFusedOpsConstParamPack_t 结构,其中包含各种问题大小信息,例如张量的形状、布局和类型,以及卷积和激活的描述符,用于选定的 cudnnFusedOps_t 计算序列。
paramLabel输入. 此 getter 函数可以检索多种类型的描述符。
param输入指向描述符本身,此输入指示param输入指向的描述符的类型。cudnnFusedOpsConstParamLabel_t 枚举类型允许选择描述符的类型。请参阅下面的param描述。param输入. 指向与应检索的描述符关联的主机内存的数据指针。此描述符的类型取决于
paramLabel的值。对于给定的paramLabel,如果constPack内的关联值设置为NULL或默认NULL,则 cuDNN 会将constPack中的值或不透明结构复制到param指向的主机内存缓冲区。有关更多信息,请参阅 cudnnFusedOpsConstParamLabel_t 中的表。isNULL输入/输出. 用户必须在此字段中传递指向主机内存中整数的指针。如果与给定
paramLabel关联的constPack中的值默认值为NULL或先前由用户设置为NULL,则 cuDNN 会将非零值写入isNULL指向的位置。
返回
CUDNN_STATUS_SUCCESS描述符值已成功检索。
CUDNN_STATUS_BAD_PARAM如果
constPack、param或isNULL任何一个为NULL;或者如果paramLabel无效。
cudnnGetFusedOpsVariantParamPackAttribute()#
此函数检索变量参数包描述符的设置。
cudnnStatus_t cudnnGetFusedOpsVariantParamPackAttribute( const cudnnFusedOpsVariantParamPack_t varPack, cudnnFusedOpsVariantParamLabel_t paramLabel, void *ptr);
参数
varPack输入. 指向
cudnnFusedOps变体参数包 (varPack) 描述符的指针。paramLabel输入. 缓冲区指针参数的类型(在
varPack描述符中)。有关更多信息,请参阅 cudnnFusedOpsConstParamLabel_t。检索到的描述符值根据此类型而变化。ptr输出. 指向主机或设备内存的指针,此函数将在其中写入检索到的值。指针的数据类型以及主机/设备内存位置取决于
paramLabel输入选择。有关更多信息,请参阅 cudnnFusedOpsVariantParamLabel_t。
返回
CUDNN_STATUS_SUCCESS描述符值已成功检索。
CUDNN_STATUS_BAD_PARAM如果
varPack或ptr任何一个为NULL,或者如果paramLabel设置为无效值。
cudnnIm2Col()#
此函数在 cuDNN 9.0 中已弃用。
此函数构造执行 GEMM 卷积前向传递所需的 A 矩阵。
cudnnStatus_t cudnnIm2Col( cudnnHandle_t handle, cudnnTensorDescriptor_t srcDesc, const void *srcData, cudnnFilterDescriptor_t filterDesc, cudnnConvolutionDescriptor_t convDesc, void *colBuffer)
此 A 矩阵的高度为 batch_size*y_height*y_width,宽度为 input_channels*filter_height*filter_width,其中
batch_size是srcDesc的第一个维度
y_height/y_width从 cudnnGetConvolutionNdForwardOutputDim() 计算得出input_channels 是
srcDesc的第二个维度(当采用 NCHW 布局时)
filter_height/filter_width是wDesc的第三个和第四个维度
A 矩阵以 HW 格式完全打包存储在 GPU 内存中。
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
srcDesc输入。先前初始化的张量描述符的句柄。
srcData输入. 指向与输入张量描述符关联的 GPU 内存的数据指针。
filterDesc输入。先前初始化的滤波器描述符的句柄。
convDesc输入. 先前初始化的卷积描述符的句柄。
colBuffer输出. 指向存储输出矩阵的 GPU 内存的数据指针。
返回
CUDNN_STATUS_BAD_PARAMsrcData或colBuffer为NULL。CUDNN_STATUS_NOT_SUPPORTEDsrcDesc、filterDesc、convDesc中的任何一个的dataType为CUDNN_DATA_INT8、CUDNN_DATA_INT8x4、CUDNN_DATA_INT8或CUDNN_DATA_INT8x4,或者convDesc的groupCount大于1。CUDNN_STATUS_EXECUTION_FAILEDCUDA 内核执行失败。
CUDNN_STATUS_SUCCESS输出数据数组已成功生成。
cudnnMakeFusedOpsPlan()#
此函数在 cuDNN 9.0 中已弃用。
此函数确定要执行的最佳内核,以及用户在通过 cudnnFusedOpsExecute() 实际执行融合操作之前应分配的工作区大小。
cudnnStatus_t cudnnMakeFusedOpsPlan( cudnnHandle_t handle, cudnnFusedOpsPlan_t plan, const cudnnFusedOpsConstParamPack_t constPack, size_t *workspaceSizeInBytes);
参数
handle输入. 指向 cuDNN 库上下文的指针。
plan输入. 指向先前创建和初始化的计划描述符的指针。
constPack输入。指向常量参数包描述符的指针。
workspaceSizeInBytes输出。用户应为此计划的执行分配的工作区大小量。
返回
CUDNN_STATUS_BAD_PARAM如果任何输入为
NULL,或者如果constPack描述符中 cudnnFusedOps_t 的类型不受支持。CUDNN_STATUS_SUCCESS函数执行成功。
cudnnReorderFilterAndBias()#
此函数在 cuDNN 9.0 中已弃用。
此函数为数据类型为 CUDNN_DATA_INT8x32 和张量格式为 CUDNN_TENSOR_NCHW_VECT_C 的张量重新排序滤波器和偏置值。它可用于通过将重新排序操作与卷积分离来提高推理时间。
cudnnStatus_t cudnnReorderFilterAndBias( cudnnHandle_t handle, const cudnnFilterDescriptor_t filterDesc, cudnnReorderType_t reorderType, const void *filterData, void *reorderedFilterData, int reorderBias, const void *biasData, void *reorderedBiasData);
数据类型为 CUDNN_DATA_INT8x32(也暗示张量格式为 CUDNN_TENSOR_NCHW_VECT_C)的滤波器和偏置张量需要置换输出通道轴,以便利用 Tensor Core IMMA 指令。当卷积描述符的重新排序类型属性设置为 CUDNN_DEFAULT_REORDER 时,这在每个 cudnnConvolutionForward() 和 cudnnConvolutionBiasActivationForward() 调用中完成。用户可以通过首先使用此调用重新排序滤波器和偏置张量,并使用设置为 CUDNN_NO_REORDER 的重新排序类型调用卷积前向 API,来避免重复的重新排序内核调用。
例如,多层神经网络中的卷积可能需要在每一层重新排序内核,这可能占用总推理时间的很大一部分。使用此函数,可以对滤波器和偏置数据执行一次重新排序。之后是对多层执行卷积操作,从而提高推理时间。
参数
handle输入。先前创建的 cuDNN 上下文的句柄。
filterDesc输入。内核数据集的描述符。
reorderType输入。设置为执行或不执行重新排序。有关更多信息,请参阅 cudnnReorderType_t。
filterData输入。指向设备内存中滤波器(内核)数据位置的指针。
reorderedFilterData输出。指向设备内存中位置的指针,重新排序的滤波器数据将由此函数写入到该位置。此张量具有与
filterData相同的维度。reorderBias输入。如果 > 0,则也重新排序
biasData。如果 <= 0,则不对biasData执行重新排序操作。biasData输入。指向设备内存中偏置数据位置的指针。
reorderedBiasData输出。指向设备内存中位置的指针,重新排序的
biasData将由此函数写入到该位置。此张量具有与biasData相同的维度。
返回
CUDNN_STATUS_SUCCESS重新排序成功。
CUDNN_STATUS_EXECUTION_FAILED滤波器数据或
biasData的重新排序失败。CUDNN_STATUS_BAD_PARAM句柄、滤波器描述符、滤波器数据或重新排序的数据为
NULL。或者,如果请求偏置重新排序 (reorderBias > 0),则biasData或重新排序的biasData为NULL。如果滤波器维度大小不是4,也可能返回此状态。CUDNN_STATUS_NOT_SUPPORTED滤波器描述符数据类型不是
CUDNN_DATA_INT8x32;滤波器描述符张量不是矢量化布局 (CUDNN_TENSOR_NCHW_VECT_C)。
cudnnSetConvolution2dDescriptor()#
此函数在 cuDNN 9.0 中已弃用。
此函数将先前创建的卷积描述符对象初始化为 2D 互相关。此函数假定张量和滤波器描述符对应于前向卷积路径,并检查其设置是否有效。只要它对应于同一层,同一个卷积描述符就可以在后向路径中重复使用。
cudnnStatus_t cudnnSetConvolution2dDescriptor( cudnnConvolutionDescriptor_t convDesc, int pad_h, int pad_w, int u, int v, int dilation_h, int dilation_w, cudnnConvolutionMode_t mode, cudnnDataType_t computeType)
参数
convDesc输入/输出. 先前创建的卷积描述符的句柄。
pad_h输入。零填充高度:隐式连接到输入图像顶部和底部的零行数。
pad_w输入。零填充宽度:隐式连接到输入图像左侧和右侧的零列数。
u输入。垂直滤波器步幅。
v输入。水平滤波器步幅。
dilation_h输入。滤波器高度膨胀。
dilation_w输入。滤波器宽度膨胀。
mode输入。在
CUDNN_CONVOLUTION和CUDNN_CROSS_CORRELATION之间选择。computeType输入。计算精度。
返回
CUDNN_STATUS_SUCCESS对象设置成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
描述符
convDesc为NIL。参数
pad_h、pad_w之一严格为负数。参数
u、v之一为负数或零。参数
dilation_h、dilation_w之一为负数或零。参数模式具有无效的枚举值。
cudnnSetConvolutionGroupCount()#
此函数在 cuDNN 9.0 中已弃用。
此函数允许用户指定要在关联卷积中使用的组数。
cudnnStatus_t cudnnSetConvolutionGroupCount( cudnnConvolutionDescriptor_t convDesc, int groupCount)
返回
CUDNN_STATUS_SUCCESS组计数设置成功。
CUDNN_STATUS_BAD_PARAM提供了无效的卷积描述符。
cudnnSetConvolutionMathType()#
此函数在 cuDNN 9.0 中已弃用。
此函数允许用户指定是否允许在与给定卷积描述符关联的库例程中使用张量运算。
cudnnStatus_t cudnnSetConvolutionMathType( cudnnConvolutionDescriptor_t convDesc, cudnnMathType_t mathType)
返回
CUDNN_STATUS_SUCCESS数学类型设置成功。
CUDNN_STATUS_BAD_PARAM提供了无效的卷积描述符或指定了无效的数学类型。
cudnnSetConvolutionNdDescriptor()#
此函数在 cuDNN 9.0 中已弃用。
此函数将先前创建的通用卷积描述符对象初始化为 Nd 互相关。只要它对应于同一层,同一个卷积描述符就可以在后向路径中重复使用。卷积计算将在指定的 dataType 中完成,这可能与输入/输出张量不同。
cudnnStatus_t cudnnSetConvolutionNdDescriptor( cudnnConvolutionDescriptor_t convDesc, int arrayLength, const int padA[], const int filterStrideA[], const int dilationA[], cudnnConvolutionMode_t mode, cudnnDataType_t dataType)
参数
convDesc输入/输出. 先前创建的卷积描述符的句柄。
arrayLength输入。卷积的维度。
padA输入。维度为
arrayLength的数组,包含每个维度的零填充大小。对于每个维度,填充表示在该维度的每个元素的开头和结尾隐式连接的额外零的数量。filterStrideA输入。维度为
arrayLength的数组,包含每个维度的滤波器步幅。对于每个维度,滤波器步幅表示滑动以到达下一个点的滤波窗口的下一个起点的元素数。dilationA输入。维度为
arrayLength的数组,包含每个维度的膨胀因子。mode输入。在
CUDNN_CONVOLUTION和CUDNN_CROSS_CORRELATION之间选择。datatype输入。选择将在其中完成计算的数据类型。
注意
cudnnSetConvolutionNdDescriptor()中的CUDNN_DATA_HALF不建议使用,因为它已知对训练的任何实际用例都没有用处,并且在未来的 cuDNN 版本中将被阻止。建议在 cudnnSetTensorNdDescriptor() 中对输入张量使用CUDNN_DATA_HALF,并在cudnnSetConvolutionNdDescriptor()中对HALF_CONVOLUTION_BWD_FILTER使用CUDNN_DATA_FLOAT,这在许多知名的深度学习框架中与自动混合精度 (AMP) 训练一起使用。
返回
CUDNN_STATUS_SUCCESS对象设置成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
描述符
convDesc为NIL。arrayLengthRequest为负数。枚举模式具有无效值。
枚举
datatype具有无效值。padA的元素之一严格为负数。strideA的元素之一为负数或零。dilationA的元素之一为负数或零。
CUDNN_STATUS_NOT_SUPPORTED满足以下至少一个条件
arrayLengthRequest大于CUDNN_DIM_MAX。
cudnnSetConvolutionReorderType()#
此函数在 cuDNN 9.0 中已弃用。
此函数为给定的卷积描述符设置卷积重新排序类型。
cudnnStatus_t cudnnSetConvolutionReorderType( cudnnConvolutionDescriptor_t convDesc, cudnnReorderType_t reorderType);
参数
convDesc输入。要为其设置重新排序类型的卷积描述符。
reorderType输入。将重新排序类型设置为此值。有关更多信息,请参阅 cudnnReorderType_t。
返回
CUDNN_STATUS_BAD_PARAM提供的重新排序类型不受支持。
CUDNN_STATUS_SUCCESS重新排序类型设置成功。
cudnnSetFusedOpsConstParamPackAttribute()#
此函数在 cuDNN 9.0 中已弃用。
此函数设置由 param 指针输入指向的描述符。要设置的描述符类型由 paramLabel 输入的枚举值指示。
cudnnStatus_t cudnnSetFusedOpsConstParamPackAttribute( cudnnFusedOpsConstParamPack_t constPack, cudnnFusedOpsConstParamLabel_t paramLabel, const void *param);
参数
constPack输入。不透明的 cudnnFusedOpsConstParamPack_t 结构,其中包含各种问题大小信息,例如张量的形状、布局和类型、卷积和激活的描述符,以及卷积和激活等操作的设置。
paramLabel输入。可以通过此 setter 函数设置多种类型的描述符。
param输入指向描述符本身,此输入指示param输入指向的描述符的类型。cudnnFusedOpsConstParamPack_t 枚举类型允许选择描述符的类型。param输入。与特定描述符关联的主机内存的数据指针。描述符的类型取决于
paramLabel的值。有关更多信息,请参阅 cudnnFusedOpsConstParamPack_t 中的表格。如果此指针设置为
NULL,则 cuDNN 库将记录为 NULL。否则,此指针指向的值(意味着,值或下面的不透明结构)将在cudnnSetFusedOpsConstParamPackAttribute()操作期间复制到constPack中。
返回
CUDNN_STATUS_SUCCESS描述符设置成功。
CUDNN_STATUS_BAD_PARAM如果
constPack为NULL,或者如果paramLabel或constPack的操作设置无效。
cudnnSetFusedOpsVariantParamPackAttribute()#
此函数在 cuDNN 9.0 中已弃用。
此函数设置可变参数包描述符。
cudnnStatus_t cudnnSetFusedOpsVariantParamPackAttribute( cudnnFusedOpsVariantParamPack_t varPack, cudnnFusedOpsVariantParamLabel_t paramLabel, void *ptr);
参数
varPack输入. 指向
cudnnFusedOps变体参数包 (varPack) 描述符的指针。paramLabel输入。此函数设置缓冲区指针参数(在
varPack描述符中)的类型。有关更多信息,请参阅 cudnnFusedOpsConstParamLabel_t。ptr输入。指向主机或设备内存的指针,指向要将描述符参数设置为的值。指针的数据类型以及主机/设备内存位置取决于
paramLabel输入选择。有关更多信息,请参阅 cudnnFusedOpsVariantParamLabel_t。
返回
CUDNN_STATUS_BAD_PARAM如果
varPack为NULL或如果paramLabel设置为不受支持的值。CUDNN_STATUS_SUCCESS描述符设置成功。