概述#
在 3.1 版本中添加。
NVIDIA AI Enterprise 包括 RAPIDS 加速器(用于 Apache Spark),它利用 GPU 通过 RAPIDS 库加速处理。
RAPIDS 加速器(用于 Apache Spark)和 NVIDIA GPU 使透明地(无需代码更改)加速 Spark 数据帧工作负载成为可能。该软件通过与 Spark 查询计划器集成的插件,提供 Spark 数据帧作业的透明加速。无法加速的操作将继续在 CPU 上使用 Spark 的内置实现运行。

RAPIDS 加速器以 jar 文件的形式交付,并拦截数据帧和 SQL 操作,以便评估可加速的操作及其在 GPU 上执行的实现。
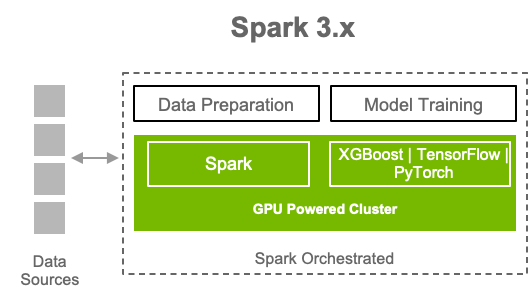
加速的 Spark 堆栈由三个主要组件组成,每个组件都在帮助 Spark 用户加速其 ETL 或 DL 或 ML 应用程序方面发挥作用。
Spark 3.0 核心引擎:Spark 3.0 核心提供两个关键功能,一是 GPU 调度,二是用于 RAPIDS 加速器的列式处理,以便在 GPU 上执行 Spark 操作。该插件支持 SQL 和数据帧操作,以 Spark 组件层中的绿色轮廓突出显示,这通常用于数据处理。
第二个组件是 RAPIDS SW,这是一个旨在普及 GPU 上数据科学的开源库集合
NVIDIA GPU 加速基础设施
NVIDIA AI Enterprise 包括在三个领先的 Spark 平台上运行 RAPIDS 加速器(用于 Apache Spark)的支持
Google Cloud Dataproc
Databricks
Azure
AWS
Amazon EMR
使用 RAPIDS 加速器时的重要优势领域包括
无需代码更改
透明的 GPU 加速,通过一个插件在所有主要的 Apache Spark 平台上工作,包括 Google Cloud Dataproc、Amazon EMR 和 Databricks。
全栈加速
运行现有的 Apache Spark 3.x 作业,速度比同等的纯 CPU 系统快 5 倍。
企业支持
通过 NVIDIA AI Enterprise 提供关键任务支持、错误修复和专业服务。RAPIDS 加速器(用于 Apache Spark)与 NVIDIA AI Enterprise 通过自带许可证 (BYOL) 方式获得许可。有关更多详细信息,请参阅 NVIDIA AI Enterprise 封装、定价和许可指南。
本文档的其余部分将概述为每个领先的 Spark 平台启动并运行 GPU 加速集群的步骤。第一节解释如何访问用于加速集群的 jar 文件。以下各节将包括特定于平台的详细信息,说明如何设置访问 Spark 平台并使用 RAPIDS 加速器 (jar) 运行所需的先决条件,以及启动包含 jar 文件的集群的步骤。
提示
本指南的以下各节提供了针对每个受支持的 Spark 平台实施 RAPIDS 加速器的快速入门说明。