Databricks 部署指南#
Databricks 开发了一个基于 Web 的平台,用于使用 Spark,该平台提供自动化的集群管理和 IPython 风格的笔记本。NVIDIA RAPIDS Accelerator for Apache Spark 在 Databricks 上可用,允许用户使用 GPU 加速数据处理和机器学习工作负载。此集成完全由 Databricks 支持,并使用户能够以优化的性能和效率运行其 Spark 工作负载。
步骤概述#
本指南提供了关于开始在 Databricks 集群上使用 RAPIDS Accelerator 的分步说明。
RAPIDS Accelerator Java 存档 (JAR) 文件用于集成必要的依赖项和类,这些依赖项和类启用 Apache Spark 工作负载的 GPU 加速。集群创建完成后,将提交 GPU 加速的 Spark 作业/应用程序。
先决条件#
在 Databricks 上开始使用 RAPIDS Accelerator for Apache Spark 之前,请确保您具备以下先决条件
具有 NGC 目录访问权限的 NGC 帐户
连接性#
检查与 Databricks 的连接性的一个简单方法是列出工作区。
databricks workspace ls
上传 Jar 和初始化脚本#
为了加快集群创建速度,请将 jar 文件上传到 Databricks 文件系统 (DBFS) 目录,并为集群创建初始化脚本。
从命令行,导航到与从 NGC 下载的 jar 文件相同的目录。将 JAR_NAME 替换为您的 jar 的名称。运行以下命令以上传 jar 并创建一个初始化脚本,该脚本将 jar 从 DBFS 移动到集群中的每个节点
1export JAR_NAME=rapids-4-spark_2.12-23.02.0.jar
2
3# Create directory for jars.
4dbfs mkdirs dbfs:/FileStore/jars
5
6# Copy local jar into DBFS for reuse:
7dbfs cp ./$JAR_NAME dbfs:/FileStore/jars
8
9# Create init script:
10echo "sudo cp /dbfs/FileStore/jars/${JAR_NAME} /databricks/jars/" > init.sh
11
12# Upload init.sh:
13dbfs cp ./init.sh dbfs:/databricks/init_scripts/init.sh --overwrite
使用 Databricks Clusters API 创建集群#
通过命令行界面,用户可以绕过对 GUI 的一些限制,例如在 GPU 加速集群上使用仅 CPU 的驱动程序节点以节省额外成本。CLI 中公开了 GUI 中可能尚不可用的其他功能。
以下是使用仅 CPU 的驱动程序节点在 AWS Databricks 上创建基本 GPU 加速集群的集群创建脚本
1databricks clusters create --json '{
2"cluster_name": "my-cluster",
3"spark_version": "10.4.x-gpu-ml-scala2.12",
4"driver_node_type_id": "m5d.4xlarge",
5"node_type_id": "g4dn.4xlarge",
6"num_workers": "2",
7"spark_conf": {
8 "spark.plugins": "com.nvidia.spark.SQLPlugin",
9 "spark.task.resource.gpu.amount": "0.1",
10 "spark.rapids.memory.pinnedPool.size": "2G",
11 "spark.rapids.sql.concurrentGpuTasks": "2",
12 "spark.databricks.optimizer.dynamicFilePruning": "false"
13 },
14"init_scripts": [{
15 "dbfs": {"destination": "dbfs:/databricks/init_scripts/init.sh"}
16 }]
17}'
在 Azure Databricks 中,需要替换实例类型才能使集群有效。提供了一个示例替换
1"driver_node_type_id": "Standard_E16ads_v5",
2"node_type_id": "Standard_NC16as_T4_v3",
cluster_id 作为 CLI 中上述集群创建命令的响应提供。保存此 cluster_id 以供后续步骤使用。也可以通过在 GUI 中选择集群并检查 URL 来查看 cluster_id。
https://<databricks-instance>/#/setting/clusters/<cluster-id>
有关 Databricks Clusters API 的更多信息,请访问 此处。
databricks clusters list
验证#
使用 CLI 界面创建一个作业。在 JSON 中输入您的 cluster_id 作为 existing_cluster_id
1# Download pi example jar:
2wget https://docs.databricks.com/_static/examples/SparkPi-assembly-0.1.jar
3
4# Upload jar to /docs/sparkpi.jar
5dbfs cp ./SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar
6
7# Create job:
8databricks jobs create --json '{
9"name": "pi_computation",
10"max_concurrent_runs": 1,
11"tasks": [
12 {
13 "task_key": "pi_test",
14 "description": "Compute pi",
15 "depends_on": [ ],
16 "existing_cluster_id": "<cluster_id>",
17 "spark_jar_task": {
18 "main_class_name": "org.apache.spark.examples.SparkPi",
19 "parameters": "1000"
20 },
21 "libraries": [{ "jar": "dbfs:/docs/sparkpi.jar"}]
22 }]
23}'
确保集群在线并准备好接受新任务。启动 GPU 加速集群大约需要 10 分钟。可以在 GUI 的“计算”选项卡下查看集群状态。或者在 CLI 中使用:databricks clusters list 查看。
通过进入“工作流”选项卡并查找名为“pi_computation”的作业来运行作业,然后按右上角的“立即运行”按钮。或者,响应中给出的 job_id 可以用于
databricks jobs run-now --job-id <job_id>
通过单击最近完成的运行的“Spark”列下的 日志 链接来检查日志。
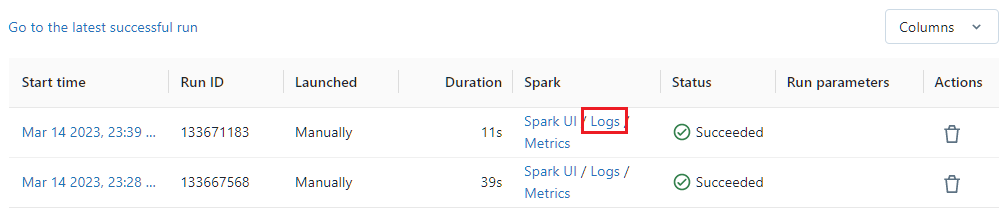
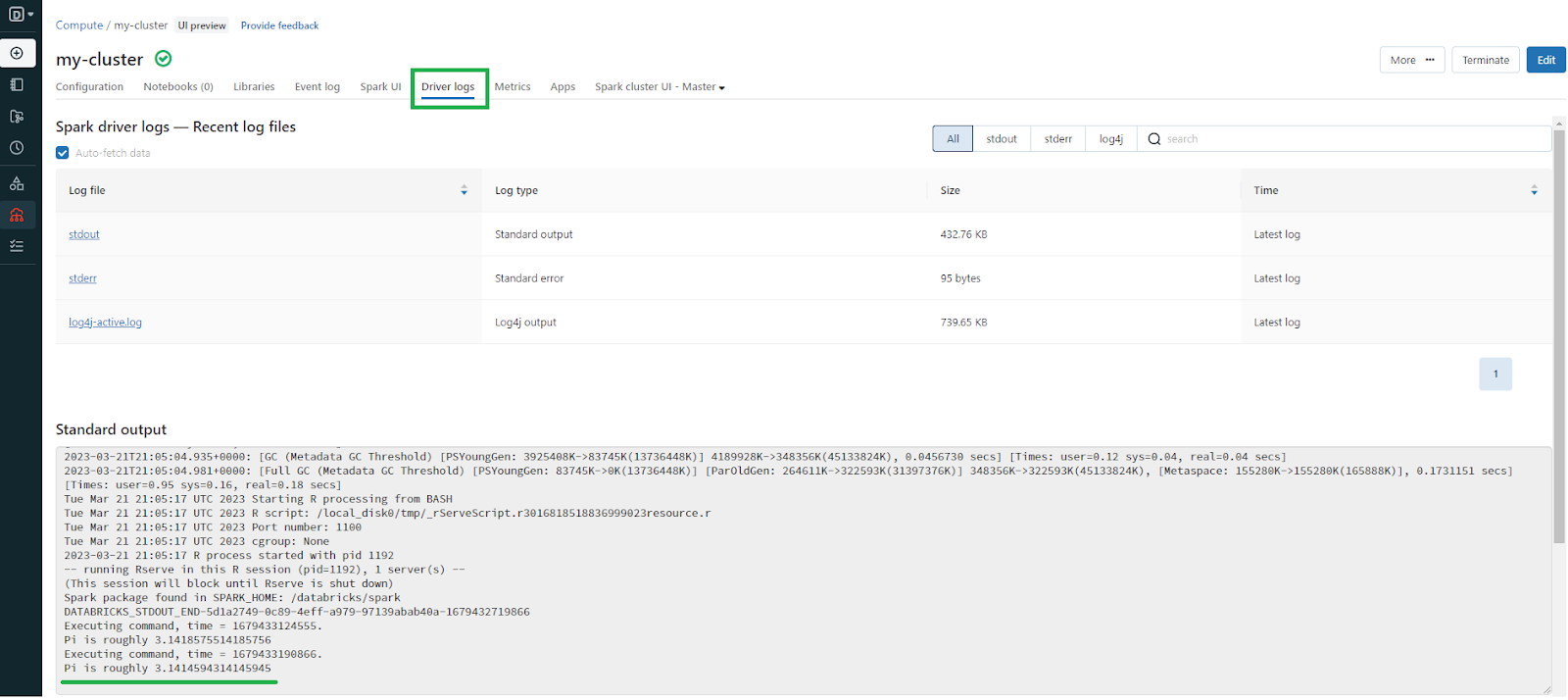
然后查看“标准输出”以查看 π 的估计值。
集群清理#
使用 GUI 通过选择“计算” >> [集群名称] >> “终止”来终止集群。终止的集群可以在未来某个时间使用相同的配置和 cluster_id 完整地重新启动。您也可以通过单击集群名称旁边的三点菜单并选择“删除”来完全删除集群。