Amazon EMR 部署用户指南#
Amazon EMR(之前称为 Amazon Elastic MapReduce)是一个托管集群平台,简化了在 AWS 上运行大数据框架(例如 Apache Hadoop 和 Apache Spark)以处理和分析海量数据的过程。适用于 Apache Spark 的 NVIDIA RAPIDS Accelerator 在 EMR 上可用,允许用户使用 GPU 加速数据处理和机器学习工作负载。此集成完全由 AWS 支持,使用户能够以优化的性能和效率运行其 Spark 工作负载。
步骤概述#
本指南提供了关于开始在 AWS EMR 集群上使用 RAPIDS Accelerator 的分步说明。我们从基于 Ubuntu 的操作系统开始,运行 AWS CLI 以连接 EMR 集群和 s3 存储桶并与之交互。创建集群后,我们可以通过 Spark Submit 提交 GPU 加速的 Spark 作业/应用程序。还提供了关于将 EMR Studio 与 GPU 加速实例结合使用的说明。
先决条件#
在开始在 AWS EMR 上使用适用于 Apache Spark 的 RAPIDS Accelerator 之前,请确保您已具备以下先决条件
可以访问 AWS 的 Ubuntu 操作系统
具有 NGC Catalog 访问权限的 NGC 帐户
已安装并配置了 AWS Cloud Tools 以及 AWS 密钥对
下表列出了将 NVIDIA RAPIDS Accelerator 与 EMR 结合使用的受支持组件。
EMR |
Spark |
RAPIDS Accelerator jar |
cuDF jar |
xgboost4j-spark jar |
|---|---|---|---|---|
6.10 |
3.3.1 |
rapids-4-spark_2.12-22.12.0-amzn-0.jar |
与 rapids-4-spark 捆绑 |
xgboost4j-spark_3.0-1.4.2-0.3.0.jar |
连接性#
验证对 EMR 的访问权限的一种简单方法是通过以下命令列出 EMR 集群
aws emr list-clusters
创建和启动带有 GPU 节点的 AWS EMR#
以下步骤基于 AWS EMR 文档 使用 NVIDIA RAPIDS Accelerator for Spark。本文档提供了帮助用户入门的基本配置。
my-configurations.json 在您的集群上安装 spark-rapids 插件,配置 YARN 以使用 GPU,配置 Spark 以使用 RAPIDS,并配置 YARN 容量调度器。创建一个名为 my-configurations.json 的本地文件,其中包含以下默认配置
1[
2 {
3 "Classification":"spark",
4 "Properties":{
5 "enableSparkRapids":"true"
6 }
7 },
8 {
9 "Classification":"yarn-site",
10 "Properties":{
11 "yarn.nodemanager.resource-plugins":"yarn.io/gpu",
12 "yarn.resource-types":"yarn.io/gpu",
13 "yarn.nodemanager.resource-plugins.gpu.allowed-gpu-devices":"auto",
14 "yarn.nodemanager.resource-plugins.gpu.path-to-discovery-executables":"/usr/bin",
15 "yarn.nodemanager.linux-container-executor.cgroups.mount":"true",
16 "yarn.nodemanager.linux-container-executor.cgroups.mount-path":"/sys/fs/cgroup",
17 "yarn.nodemanager.linux-container-executor.cgroups.hierarchy":"yarn",
18 "yarn.nodemanager.container-executor.class":"org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor"
19 }
20 },
21 {
22 "Classification":"container-executor",
23 "Properties":{
24
25 },
26 "Configurations":[
27 {
28 "Classification":"gpu",
29 "Properties":{
30 "module.enabled":"true"
31 }
32 },
33 {
34 "Classification":"cgroups",
35 "Properties":{
36 "root":"/sys/fs/cgroup",
37 "yarn-hierarchy":"yarn"
38 }
39 }
40 ]
41 },
42 {
43 "Classification":"spark-defaults",
44 "Properties":{
45 "spark.plugins":"com.nvidia.spark.SQLPlugin",
46 "spark.sql.sources.useV1SourceList":"",
47 "spark.executor.resource.gpu.discoveryScript":"/usr/lib/spark/scripts/gpu/getGpusResources.sh",
48 "spark.executor.extraLibraryPath":"/usr/local/cuda/targets/x86_64-linux/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/cuda/compat/lib:/usr/local/cuda/lib:/usr/local/cuda/lib64:/usr/lib/hadoop/lib/native:/usr/lib/hadoop-lzo/lib/native:/docker/usr/lib/hadoop/lib/native:/docker/usr/lib/hadoop-lzo/lib/native",
49 "spark.executor.resource.gpu.amount":"1",
50 "spark.rapids.sql.concurrentGpuTasks":"2",
51 "spark.sql.files.maxPartitionBytes":"256m",
52 "spark.sql.adaptive.enabled":"true"
53 }
54 },
55 {
56 "Classification":"capacity-scheduler",
57 "Properties":{
58 "yarn.scheduler.capacity.resource-calculator":"org.apache.hadoop.yarn.util.resource.DominantResourceCalculator"
59 }
60 }
61]
自 Spark 3.2.0 起,默认启用自适应查询执行 (AQE),但是,RAPIDS 加速器在 EMR 6.10+ 之前不完全支持 AQE。可以通过 spark.sql.adaptive.enabled 切换此设置。对于较低的 EMR 版本,此设置应设置为 false。更多高级配置详细信息可以在配置文档中找到。
my-bootstrap-action.sh 脚本打开集群上 YARN 的 cgroup 权限,以供 YARN 使用 GPU。在本地创建此文件,内容如下。
1#!/bin/bash
2set -ex
3sudo chmod a+rwx -R /sys/fs/cgroup/cpu,cpuacct
4sudo chmod a+rwx -R /sys/fs/cgroup/devices
将其上传到 S3 存储桶并导出文件路径。在以下命令中,将 <my-bucket> 替换为您的存储桶名称。
export BOOTSTRAP_ACTION_SCRIPT=s3://<my-bucket>/my-bootstrap-action.sh
此文件将用于 启动 EMR 集群
创建密钥对#
在启动集群之前,需要在创建集群时使用密钥对,以便允许 SSH 访问集群。如果您尚未创建密钥对,请按照 https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/create-key-pairs.html 上的说明进行操作。
在下面的 export 语句中使用您的个人密钥对 (*.pem 文件) 更新 KEYNAME。密钥对是安全访问 EMR 集群所必需的
使用 AWS CLI 启动 EMR 集群#
您可以使用 AWS CLI 启动一个集群,其中包含一个主节点 (m5.xlarge) 和两个 g4dn.2xlarge 工作节点
1export KEYNAME=my-key-pair
2export CLUSTER_NAME=spark-rapids-cluster
3export EMR_LABEL=emr-6.10.0
4export MASTER_INSTANCE_TYPE=m4.4xlarge
5export NUM_WORKERS=2
6export WORKER_INSTANCE_TYPE=g4dn.2xlarge
7export CONFIG_JSON_LOCATION=./my-configurations.json
创建 EMR 集群
1aws emr create-cluster \
2--name $CLUSTER_NAME \
3--release-label $EMR_LABEL \
4--applications Name=Hadoop Name=Spark Name=Livy Name=JupyterEnterpriseGateway \
5--service-role EMR_DefaultRole \
6--ec2-attributes KeyName=$KEYNAME,InstanceProfile=EMR_EC2_DefaultRole \
7--instance-groups InstanceGroupType=MASTER,InstanceCount=1,InstanceType=$MASTER_INSTANCE_TYPE \
8InstanceGroupType=CORE,InstanceCount=$NUM_WORKERS,InstanceType=$WORKER_INSTANCE_TYPE \
9--configurations file://$CONFIG_JSON_LOCATION \
10--bootstrap-actions Name='My Spark Rapids Bootstrap action',Path=$BOOTSTRAP_ACTION_SCRIPT
输出示例
1{
2 "ClusterId": "j-GEXQ0J54HTI0",
3 "ClusterArn": "arn:aws:elasticmapreduce:us-west-2:123456789:cluster/j-GEXQ0J54HTI0"
4}
保存 ClusterId 以在后续部分中检查集群状态。
创建具有指定子网的 EMR 集群(可选)#
EMR Studio 提供了一个 Jupyter Notebook 环境,可以连接到 EMR 集群。需要虚拟私有云 (VPC) 来保护连接。这可以通过在 aws emr create-cluster 期间,在 ec2-attributes 选项中包含 SubnetId 参数,在 EMR 集群创建步骤中指定 SubnetId 来强制执行。
--ec2-attributes KeyName=$KEYNAME,InstanceProfile=EMR_EC2_DefaultRole,SubnetId=<gpu_enabled_subnet> \
为了帮助确定要使用哪个 VPC SubnetId (subnet-*),请搜索 VPC 配置页面。从 VPC 页面左侧导航菜单中,选择 “Virtual private cloud” >> “Your VPCs” >> 选择现有 VPC 或创建新的 VPC。对 us-west-2b 或 GPU 可用的其他可用区使用 SubnetId。子网可用区可以从资源映射中确定
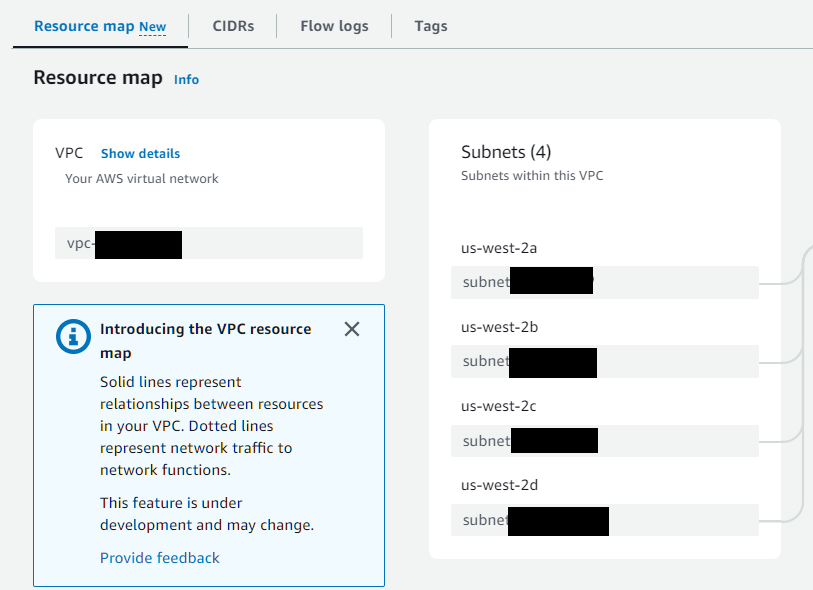
注意
GPU 集群创建时间可能需要 15 分钟以上。
验证#
检查集群状态
$ aws emr describe-cluster --cluster-id <cluster_id>
以下是输出示例
1{
2 "Cluster": {
3 "Id": "j-1I7SZJ8DRXCWY",
4 "Name": "sample-cluster",
5 "Status": {
6 "State": "WAITING",
7 "StateChangeReason": {
8 "Message": "Cluster ready to run steps."
9 },
10 "Timeline": {
11 "CreationDateTime": "2023-03-17T17:29:10.912000+00:00",
12 "ReadyDateTime": "2023-03-17T17:42:06.963000+00:00"
13 }
14 },
使用以下命令连接到 EMR 集群主节点。修改命令以包含您的 <cluster_id> 和密钥对。
aws emr ssh --cluster-id <cluster_id> --key-pair-file ~/.ssh/my-key-pair.pem
使用 Spark Shell 运行示例连接操作#
在主节点上,通过键入以下内容激活 spark-shell
spark-shell
在 Spark Shell 中运行以下 Scala 代码
1val data = 1 to 10000
2val df1 = sc.parallelize(data).toDF()
3val df2 = sc.parallelize(data).toDF()
4val out = df1.as("df1").join(df2.as("df2"), $"df1.value" === $"df2.value")
5out.count()
6out.explain()
退出 spark-shell 和 SSH 会话,然后再继续下一步。
将 Spark 作业提交到由 GPU 加速的 EMR 集群#
可以像使用 Apache Spark 一样,通过登录到主节点并通过 spark-submit 提交应用程序来启动 EMR 作业。默认情况下,YARN 在客户端模式下运行。 spark-submit 中引用的所有适用文件都应可在主节点上访问。
export SPARK_HOME=/usr/lib/spark
1$SPARK_HOME/bin/spark-submit \
2--class org.apache.spark.examples.SparkPi \
3--master yarn \
4$SPARK_HOME/examples/jars/spark-examples.jar \
51000
控制台输出将如下所示
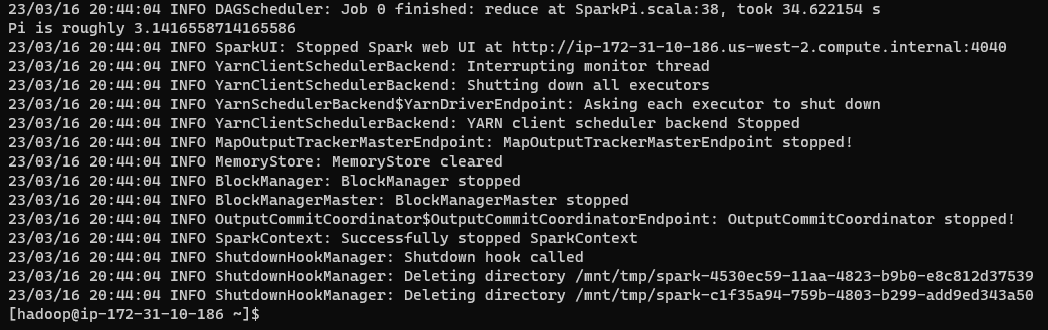
输出的底部部分是退出应用程序的信息。感兴趣的结果是
123/03/16 20:44:04 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 34.622154 s
2Pi is roughly 3.1416558714165586
Spark History Server UI#
Spark 历史服务器 UI 位于端口 18080 上,可以通过端口映射访问。要查看 spark 日志,请通过启用端口 18080 的端口转发 SSH 连接到主节点。
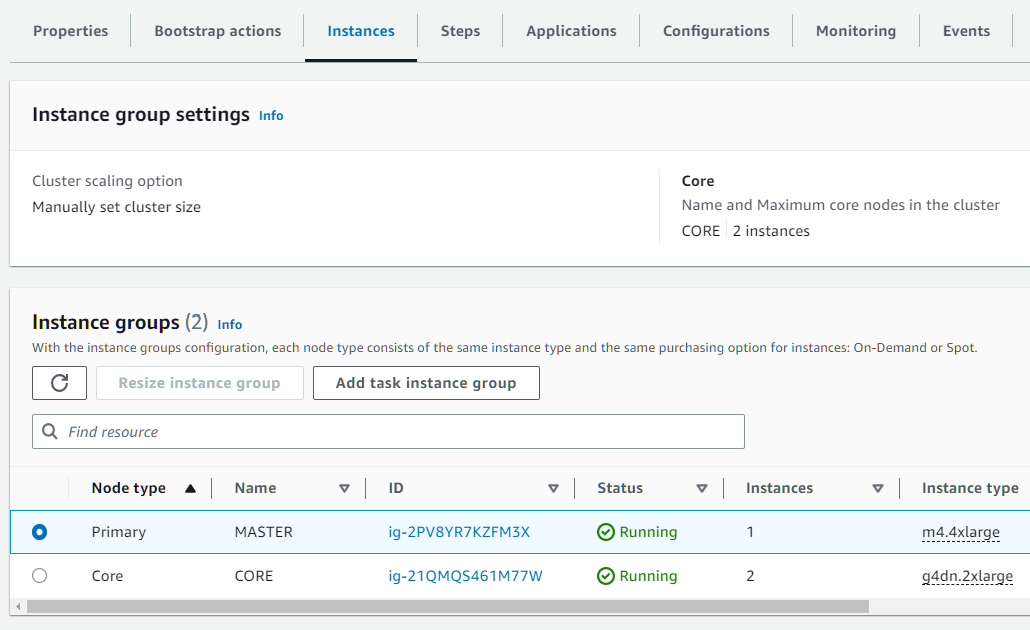
主节点公共 IP 可以通过 AWS Web 控制台 UI 找到。选择您的 EMR 集群,然后单击如下所示的 “Instances” 选项卡。选择与主节点对应的 Instance Group 的 ID 列下以 “ig-” 开头的链接。与主节点对应的 EC2 实例的公有 IP 地址显示在 “Public IP address” 列中(您可能需要向右滚动)。
使用此 IP 地址更新以下命令中的 <master_node_public_ip>
ssh -i ~/.ssh/my-key-pair.pem hadoop@<master_node_public_ip> -L 18080:localhost:18080
然后打开浏览器窗口并导航到:localhost:18080。保持 SSH 会话打开以维护端口转发。可以通过 Web UI 下载 spark 事件日志。
集群清理#
可以通过在 GUI 中搜索 EMR,然后选择您的集群并单击右上角的 “Terminate” 按钮来终止集群。
或者,可以使用以下 CLI 命令终止集群
aws emr terminate-clusters --cluster-id <cluster_id>
如果您启动了 EMR Studio 会话,则可以通过 EMR Studio 网页停止会话。从左侧导航面板中选择 “Workspaces”,单击活动的 Workspace,按右上角的 “Actions” 按钮,然后选择 “Stop”。