前提条件
创建您的 NGC 个人密钥
您需要创建一个 NGC 个人密钥才能将 UCS Tools 与 NGC 一起使用。请勿将 NGC 个人密钥与 NGC API 密钥混淆。NGC 个人密钥以 “nvapi-” 开头,允许您设置作用域。请按照以下步骤获取具有必要作用域的 NGC 个人密钥
登录 NGC
点击右上角的个人资料,然后选择 “设置”
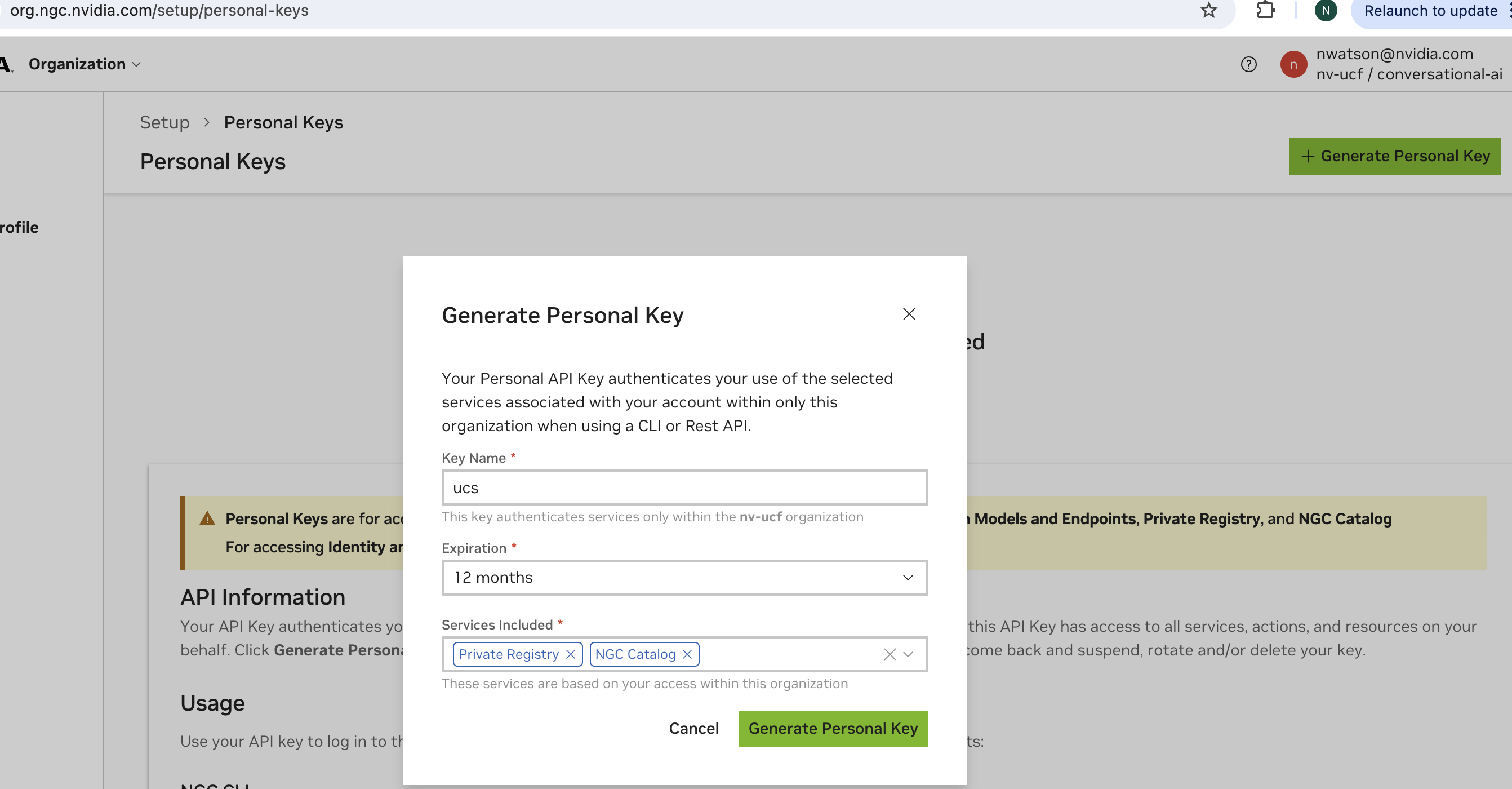
点击 “生成个人密钥”
您将看到一个对话框,您可以在其中创建密钥。添加以下作用域
私有仓库
NGC 目录
它应该看起来类似于下面显示的图像
一旦您拥有了具有必要作用域的 NGC 个人密钥,下一步是在 UCS Tools 中通过运行以下命令设置此密钥。
ucf_ms_builder_cli registry repo set-api-key -a $NGC_PERSONAL_KEY
部署系统
这些说明需要在您的系统上安装 Ubuntu Server LTS 22.04。
开发者系统的 MicroK8s
本文档中的说明已在以下环境中测试通过:
Ubuntu: 22.04
安装 MicroK8s
使用 MicroK8s 安装并等待 Kubernetes 启动
$ sudo snap install microk8s --classic
$ microk8s status --wait-ready
$ microk8s start
启用插件
安装以下 MicroK8s 插件
$ microk8s enable dashboard dns gpu helm3 ingress registry storage
开发者系统的 NVIDIA 云原生堆栈
请参考以下链接以阅读更多关于云原生堆栈的信息:https://github.com/NVIDIA/cloud-native-stack。
安装 Ubuntu 操作系统
Ubuntu Server 可以从 http://cdimage.ubuntu.com/releases/22.04/release/ 下载。
有关安装 Ubuntu Server 的更多信息,请参阅 Ubuntu Server 安装指南。
安装 CUDA 驱动程序
一旦 NVIDIA 驱动程序安装完成,请重启系统并运行以下命令以验证 NVIDIA 驱动程序已加载
nvidia-smi预期输出
+---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.104.05 Driver Version: 535.104.05 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 NVIDIA GeForce RTX 4090 On | 00000000:65:00.0 Off | Off | | 0% 30C P8 5W / 450W | 133MiB / 24564MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | 0 N/A N/A 1119 G /usr/lib/xorg/Xorg 107MiB | | 0 N/A N/A 1239 G /usr/bin/gnome-shell 13MiB | +---------------------------------------------------------------------------------------+
安装 Docker CE
设置仓库并更新 apt 包索引
$ sudo apt-get update
安装软件包以允许 apt 通过 HTTPS 使用仓库
$ sudo apt-get install -y \ apt-transport-https \ ca-certificates \ curl \ gnupg-agent \ software-properties-common
添加 Docker 的官方 GPG 密钥
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
通过搜索指纹的最后 8 个字符,验证您现在是否拥有指纹为 9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88 的密钥
$ sudo apt-key fingerprint 0EBFCD88 pub rsa4096 2017-02-22 [SCEA] 9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88 uid [ unknown] Docker Release (CE deb) <docker@docker.com> sub rsa4096 2017-02-22 [S]
使用以下命令设置稳定仓库
$ sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable"
安装 Docker Engine - Community 更新 apt 包索引
$ sudo apt-get update
安装 Docker Engine
$ sudo apt-get install -y docker-ce docker-ce-cli containerd.io
通过运行 hello-world 镜像来验证 Docker Engine - Community 是否正确安装
$ sudo docker run hello-world
有关如何安装 Docker 的更多信息,请访问 https://docs.dockerd.com.cn/install/linux/docker-ce/ubuntu/。
安装 NVIDIA 容器工具包
设置软件包仓库
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \ && curl -fsSL https://nvda.org.cn/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvda.org.cn/libnvidia-container/$distribution/libnvidia-container.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
更新软件包索引
sudo apt update
安装 NVIDIA 容器工具包
sudo apt-get install -y nvidia-docker2
更新 Docker 默认运行时。
编辑 docker 守护程序配置以添加以下行并保存文件
"default-runtime" : "nvidia"示例
$ sudo nano /etc/docker/daemon.json { "runtimes": { "nvidia": { "path": "nvidia-container-runtime", "runtimeArgs": [] } }, "default-runtime" : "nvidia" }
现在执行以下命令以重启 docker 守护程序
sudo systemctl daemon-reload && sudo systemctl restart docker
验证 docker 默认运行时。
执行以下命令以验证 docker 默认运行时为 NVIDIA
$ sudo docker info | grep -i runtime输出
Runtimes: nvidia runc Default Runtime: nvidia
安装 Containerd
设置仓库并更新 apt 包索引
sudo apt-get update
安装软件包以允许 apt 通过 HTTPS 使用仓库
sudo apt-get install -y apt-transport-https gnupg-agent libseccomp2 autotools-dev debhelper software-properties-common
配置 Containerd 的前提条件
cat <<EOF | sudo tee /etc/modules-load.d/containerd.conf overlay br_netfilter EOFsudo modprobe overlay sudo modprobe br_netfilter
设置必需的 sysctl 参数;这些参数在重启后仍然保留
cat <<EOF | sudo tee /etc/sysctl.d/99-kubernetes-cri.conf net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 net.bridge.bridge-nf-call-ip6tables = 1 EOF
无需重启应用 sysctl 参数
sudo sysctl --system
下载 Containerd tarball
wget https://github.com/containerd/containerd/releases/download/v1.6.6/cri-containerd-cni-1.6.6-linux-amd64.tar.gz sudo tar --no-overwrite-dir -C / -xzf cri-containerd-cni-1.6.6-linux-amd64.tar.gz rm -rf cri-containerd-cni-1.6.6-linux-amd64.tar.gz
安装 Containerd
sudo mkdir -p /etc/containerd wget https://raw.githubusercontent.com/NVIDIA/cloud-native-stack/master/playbooks/config.toml sudo mv config.toml /etc/containerd/ && sudo sed -i 's/SystemdCgroup \= false/SystemdCgroup \= true/g' /etc/containerd/config.tomlsudo systemctl enable containerd && sudo systemctl restart containerd
有关安装 Containerd 的更多信息,请参考使用发布 Tarball 安装 Containerd。
安装 Kubernetes
在开始安装之前,请确保 Containerd 已启动并启用
sudo systemctl start containerd && sudo systemctl enable containerd
执行以下命令以添加 apt 密钥
sudo apt-get update && sudo apt-get install -y apt-transport-https curl curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add - sudo mkdir -p /etc/apt/sources.list.d/
创建 kubernetes.list
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF
现在执行以下命令以安装 kubelet、kubeadm 和 kubectl
sudo apt-get update sudo apt-get install -y -q kubelet=1.27.0-00 kubectl=1.24.1-00 kubeadm=1.27.0-00 sudo apt-mark hold kubelet kubeadm kubectl
使用 Containerd 创建 kubelet 默认配置
cat <<EOF | sudo tee /etc/default/kubelet KUBELET_EXTRA_ARGS=--cgroup-driver=systemd --container-runtime=remote --runtime-request-timeout=15m --container-runtime-endpoint="unix:/run/containerd/containerd.sock" EOF
重新加载系统守护程序
sudo systemctl daemon-reload
禁用交换分区
sudo swapoff -a
sudo nano /etc/fstab
注意
在所有以 /swap 开头的行之前添加 #。# 是注释,结果应如下所示
UUID=e879fda9-4306-4b5b-8512-bba726093f1d / ext4 defaults 0 0
UUID=DCD4-535C /boot/efi vfat defaults 0 0
#/swap.img none swap sw 0 0
初始化 Kubernetes
以下步骤说明如何初始化 Kubernetes 集群以作为控制平面节点运行
执行以下命令
sudo kubeadm init --pod-network-cidr=192.168.0.0/16 --cri-socket=/run/containerd/containerd.sock --kubernetes-version="v1.27.0"输出
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.ac.cn/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join <your-host-IP>:6443 --token 489oi5.sm34l9uh7dk4z6cm \ --discovery-token-ca-cert-hash sha256:17165b6c4a4b95d73a3a2a83749a957a10161ae34d2dfd02cd730597579b4b34
按照输出中的说明,执行如下所示的命令
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
通过以下命令,您将 pod 网络插件安装到控制平面节点。我们在此处使用 calico 作为 pod 网络插件
kubectl apply -f https://docs.projectcalico.org/v3.21/manifests/calico.yaml
更新 Calico Daemonset
kubectl set env daemonset/calico-node -n kube-system IP_AUTODETECTION_METHOD=interface=ens\*,eth\*,enc\*,enp\*
执行以下命令以确保所有 Pod 都已启动并正在运行
kubectl get pods --all-namespaces
输出
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-65b8787765-bjc8h 1/1 Running 0 2m8s kube-system calico-node-c2tmk 1/1 Running 0 2m8s kube-system coredns-5c98db65d4-d4kgh 1/1 Running 0 9m8s kube-system coredns-5c98db65d4-h6x8m 1/1 Running 0 9m8s kube-system etcd-#yourhost 1/1 Running 0 8m25s kube-system kube-apiserver-#yourhost 1/1 Running 0 8m7s kube-system kube-controller-manager-#yourhost 1/1 Running 0 8m3s kube-system kube-proxy-6sh42 1/1 Running 0 9m7s kube-system kube-scheduler-#yourhost 1/1 Running 0 8m26s
get nodes 命令显示控制平面节点已启动并准备就绪
kubectl get nodes输出
NAME STATUS ROLES AGE VERSION #yourhost Ready control-plane,master 10m v1.27.0
由于我们使用的是单节点 Kubernetes 集群,因此默认情况下集群不会在控制平面节点上调度 Pod。要在控制平面节点上调度 Pod,我们必须通过执行以下命令来删除污点
kubectl taint nodes --all node-role.kubernetes.io/master-
有关更多信息,请参考 kubeadm 安装指南。
安装最新版本的 Helm
执行以下命令以下载并 安装最新版本的 Helm
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh
添加额外节点
以下步骤说明如何向 NVIDIA 云原生堆栈添加额外节点
注意
如果您不添加额外节点,请跳过此步骤并继续下一步安装 NVIDIA Network Operator
确保在额外节点上安装 Containerd 和 Kubernetes 软件包。
一旦在额外节点上完成前提条件,请在控制平面节点上执行以下命令,然后在额外节点上执行 join 命令输出,以将额外节点添加到 NVIDIA 云原生堆栈
sudo kubeadm token create --print-join-command输出
示例
sudo kubeadm join 10.110.0.34:6443 --token kg2h7r.e45g9uyrbm1c0w3k --discovery-token-ca-cert-hash sha256:77fd6571644373ea69074dd4af7b077bbf5bd15a3ed720daee98f4b04a8f524e注意
控制平面节点和工作节点不应具有相同的节点名称。
get nodes 命令显示主节点和工作节点已启动并准备就绪
kubectl get nodes输出
NAME STATUS ROLES AGE VERSION #yourhost Ready control-plane,master 10m v1.27.0 #yourhost-worker Ready 10m v1.27.0
安装 GPU Operator
添加 NVIDIA 仓库
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
更新 Helm 仓库
helm repo update
安装 GPU Operator
注意
由于我们预装了 NVIDIA 驱动程序和 NVIDIA 容器工具包,因此在安装 GPU Operator 时需要设置为 false。
helm install --version 23.3.2 --create-namespace --namespace nvidia-gpu-operator --devel nvidia/gpu-operator --set driver.enabled=false,toolkit.enabled=false --wait --generate-name
验证 GPU Operator 的状态
请注意,GPU Operator 的安装可能需要几分钟。安装所需的时间取决于您的互联网速度。
kubectl get pods --all-namespaces | grep -v kube-system NAMESPACE NAME READY STATUS RESTARTS AGE default gpu-operator-1622656274-node-feature-discovery-master-5cddq96gq 1/1 Running 0 2m39s default gpu-operator-1622656274-node-feature-discovery-worker-wr88v 1/1 Running 0 2m39s default gpu-operator-7db468cfdf-mdrdp 1/1 Running 0 2m39s gpu-operator-resources gpu-feature-discovery-g425f 1/1 Running 0 2m20s gpu-operator-resources nvidia-cuda-validator-s6x2p 0/1 Completed 0 48s gpu-operator-resources nvidia-dcgm-exporter-wtxnx 1/1 Running 0 2m20s gpu-operator-resources nvidia-dcgm-jbz94 1/1 Running 0 2m20s gpu-operator-resources nvidia-device-plugin-daemonset-hzzdt 1/1 Running 0 2m20s gpu-operator-resources nvidia-device-plugin-validator-9nkxq 0/1 Completed 0 17s gpu-operator-resources nvidia-operator-validator-cw4j5 1/1 Running 0 2m20s有关更多信息,请参考 NGC 上的 GPU Operator 页面。
对于多个工作节点,执行以下命令以修复 CoreDNS 和节点功能发现。
kubectl delete pods $(kubectl get pods -n kube-system | grep core | awk '{print $1}') -n kube-system; kubectl delete pod $(kubectl get pods -o wide -n gpu-operator-resources | grep node-feature-discovery | grep -v master | awk '{print $1}') -n gpu-operator-resources带有 MIG 的 GPU Operator
注意
带有 MIG 的 GPU Operator 仅支持 A100 和 A30 GPU
多实例 GPU (MIG) 允许基于 NVIDIA Ampere 架构(例如 NVIDIA A100)的 GPU 安全地划分为独立的 GPU 实例,用于 CUDA 应用程序。有关启用 MIG 功能的更多信息,请参考带有 MIG 的 GPU Operator。
验证 GPU Operator
GPU Operator 通过 nvidia-device-plugin-validation pod 和 nvidia-driver-validation pod 进行验证。如果两者都成功完成(请参阅 kubectl get pods --all-namespaces | grep -v kube-system 的输出),则 NVIDIA 云原生堆栈按预期工作。本节提供了两个示例,用于验证 GPU 是否可从 Pod 内部使用以手动验证。
示例 1:nvidia-smi
执行以下命令
cat <<EOF | tee nvidia-smi.yaml apiVersion: v1 kind: Pod metadata: name: nvidia-smi spec: restartPolicy: OnFailure containers: - name: nvidia-smi image: "nvidia/cuda:12.2.0-base-ubuntu22.04" args: ["nvidia-smi"] EOF kubectl apply -f nvidia-smi.yaml kubectl logs nvidia-smi输出
+---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.104.05 Driver Version: 535.104.05 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 NVIDIA GeForce RTX 4090 On | 00000000:65:00.0 Off | Off | | 0% 30C P8 5W / 450W | 133MiB / 24564MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | 0 N/A N/A 1119 G /usr/lib/xorg/Xorg 107MiB | | 0 N/A N/A 1239 G /usr/bin/gnome-shell 13MiB | +---------------------------------------------------------------------------------------+
示例 2:CUDA-Vector-Add
创建 pod YAML 文件
$ cat <<EOF | tee cuda-samples.yaml apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add image: "k8s.gcr.io/cuda-vector-add:v0.1" EOF
执行以下命令以创建示例 GPU Pod
$ kubectl apply -f cuda-samples.yaml
确认 cuda-samples Pod 已创建
$ kubectl get pods
如果 get pods 命令显示 Pod 状态为 completed,则 NVIDIA 云原生堆栈按预期工作。
AWS 的 NVIDIA 云原生堆栈
本文档中的说明已在以下环境中测试通过:
EC2 实例配置
实例类型:g4dn.2xlarge
操作系统:带有 64 位 (x86) 的 Ubuntu Server 22.04 LTS 镜像
存储:最小 150 GB
网络
保持端口 22 对 ssh 开放
部署应用程序后可能需要打开其他端口
使用您在实例创建时生成的密钥 SSH 进入实例
ssh -i /path/to/<your_key>.pem ubuntu@<aws_instance_ip>
安装 Containerd
安装软件包以允许 apt 通过 HTTPS 使用仓库
sudo apt-get update sudo apt-get install -y apt-transport-https ca-certificates gnupg-agent libseccomp2 autotools-dev debhelper software-properties-common
配置 Containerd 的前提条件
cat <<EOF | sudo tee /etc/modules-load.d/containerd.conf overlay br_netfilter EOF sudo modprobe overlay sudo modprobe br_netfilter
设置必需的 sysctl 参数;这些参数在重启后仍然保留
cat <<EOF | sudo tee /etc/sysctl.d/99-kubernetes-cri.conf net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 net.bridge.bridge-nf-call-ip6tables = 1 EOF
无需重启应用 sysctl 参数
sudo sysctl --system
下载 Containerd tarball
wget https://github.com/containerd/containerd/releases/download/v1.6.8/cri-containerd-cni-1.6.8-linux-amd64.tar.gz sudo tar --no-overwrite-dir -C / -xzf cri-containerd-cni-1.6.8-linux-amd64.tar.gz rm -rf cri-containerd-cni-1.6.8-linux-amd64.tar.gz
安装 Containerd
sudo mkdir -p /etc/containerd containerd config default | sudo tee /etc/containerd/config.toml sudo systemctl restart containerd有关安装 Containerd 的更多信息,请参考使用发布 Tarball 安装 Containerd。
安装 Kubernetes
在开始安装之前,请确保 Containerd 已启动并启用
sudo systemctl start containerd && sudo systemctl enable containerd
执行以下命令以安装 kubelet kubeadm 和 kubectl
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add - sudo mkdir -p /etc/apt/sources.list.d/
创建 Kubernetes.list
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF
现在执行以下命令
sudo apt-get update sudo apt-get install -y -q kubelet=1.23.12-00 kubectl=1.23.12-00 kubeadm=1.23.12-00 sudo apt-mark hold kubelet kubeadm kubectl
初始化 Kubernetes 集群以作为主节点运行
禁用交换分区
sudo swapoff -a sudo nano /etc/fstab
在所有以 /swap 开头的行之前添加 #。# 是注释,结果应如下所示
UUID=e879fda9-4306-4b5b-8512-bba726093f1d / ext4 defaults 0 0 UUID=DCD4-535C /boot/efi vfat defaults 0 0 #/swap.img none swap sw 0 0执行以下命令
sudo kubeadm init --pod-network-cidr=192.168.0.0/16 --cri-socket=/run/containerd/containerd.sock --kubernetes-version="v1.23.12"输出将显示在执行时将 pod 网络部署到集群的命令以及加入集群的命令。
按照输出中的说明,执行如下所示的命令
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
通过以下命令,您将 pod 网络插件安装到控制平面节点。此处使用 Calico 作为 pod 网络插件
kubectl apply -f https://projectcalico.docs.tigera.io/archive/v3.21/manifests/calico.yaml
您可以执行以下命令以确保所有 Pod 都已启动并正在运行
kubectl get pods --all-namespaces输出
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-65b8787765-bjc8h 1/1 Running 0 2m8s kube-system calico-node-c2tmk 1/1 Running 0 2m8s kube-system coredns-5c98db65d4-d4kgh 1/1 Running 0 9m8s kube-system coredns-5c98db65d4-h6x8m 1/1 Running 0 9m8s kube-system etcd-#hostname 1/1 Running 0 8m25s kube-system kube-apiserver-#hostname 1/1 Running 0 8m7s kube-system kube-controller-manager-#hostname 1/1 Running 0 8m3s kube-system kube-proxy-6sh42 1/1 Running 0 9m7s kube-system kube-scheduler-#hostname 1/1 Running 0 8m26s
get nodes 命令显示控制平面节点已启动并准备就绪
kubectl get nodes Output: NAME STATUS ROLES AGE VERSION #yourhost Ready control-plane 10m v1.23.12
由于我们使用的是单节点 Kubernetes 集群,因此默认情况下集群不会在控制平面节点上调度 Pod。要在控制平面节点上调度 Pod,我们必须通过执行以下命令来删除污点
kubectl taint nodes --all node-role.kubernetes.io/master-有关更多信息,请参阅 kubeadm 安装指南
安装 Helm
执行以下命令以下载 Helm 3.10.0
wget https://get.helm.sh/helm-v3.10.0-linux-amd64.tar.gz
tar -zxvf helm-v3.10.0-linux-amd64.tar.gz
sudo mv linux-amd64/helm /usr/local/bin/helm
有关 Helm 的更多信息,请参阅 Helm 3.10.0 发行说明 和 安装 Helm 指南 以获取更多信息。
安装 GPU Operator
添加 NVIDIA helm 仓库
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
更新 helm 仓库
helm repo update
要为带有 Tesla T4 的 AWS G4 实例安装 GPU Operator
helm install --version 23.3.2 --create-namespace --namespace gpu-operator-resources --devel nvidia/gpu-operator --wait --generate-name
验证 GPU Operator 的状态
kubectl get pods --all-namespaces | grep -v kube-system NAMESPACE NAME READY STATUS RESTARTS AGE gpu-operator-resources gpu-operator-1590097431-node-feature-discovery-master-76578jwwt 1/1 Running 0 5m2s gpu-operator-resources gpu-operator-1590097431-node-feature-discovery-worker-pv5nf 1/1 Running 0 5m2s gpu-operator-resources gpu-operator-74c97448d9-n75g8 1/1 Running 1 5m2s gpu-operator-resources gpu-feature-discovery-6986n 1/1 Running 0 5m2s gpu-operator-resources nvidia-container-toolkit-daemonset-pwhfr 1/1 Running 0 4m58s gpu-operator-resources nvidia-cuda-validator-8mgr2 0/1 Completed 0 5m3s gpu-operator-resources nvidia-dcgm-exporter-bdzrz 1/1 Running 0 4m57s gpu-operator-resources nvidia-device-plugin-daemonset-zmjhn 1/1 Running 0 4m57s gpu-operator-resources nvidia-device-plugin-validator-spjv7 0/1 Completed 0 4m57s gpu-operator-resources nvidia-driver-daemonset-7b66v 1/1 Running 0 4m57s gpu-operator-resources nvidia-operator-validator-phndq 1/1 Running 0 4m57s
要使用 nvidia-smi 验证 GPU Operator 安装,请执行以下操作
执行以下命令
cat <<EOF | tee nvidia-smi.yaml apiVersion: v1 kind: Pod metadata: name: nvidia-smi spec: restartPolicy: OnFailure containers: - name: nvidia-smi image: "nvidia/cuda:12.2.0-base-ubuntu22.04" args: ["nvidia-smi"] EOF kubectl apply -f nvidia-smi.yaml kubectl logs nvidia-smi输出
+---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.104.05 Driver Version: 535.104.05 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 NVIDIA GeForce RTX 4090 On | 00000000:65:00.0 Off | Off | | 0% 30C P8 5W / 450W | 133MiB / 24564MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | 0 N/A N/A 1119 G /usr/lib/xorg/Xorg 107MiB | | 0 N/A N/A 1239 G /usr/bin/gnome-shell 13MiB | +---------------------------------------------------------------------------------------+这就结束了 AWS 集群的设置。
AWS 弹性 Kubernetes 服务 (AWS EKS)
启动 Holoscan 就绪 EKS 集群
Holoscan 就绪 EKS 集群将连接到您的 AWS 账户,并使用 terraform 以及 NVIDIA GPU Operator 创建所有需要的资源。默认情况下,它会创建一个 CPU 节点(实例类型 = t2.xlarge,磁盘大小 = 512GB)和 2 个 GPU 节点(实例类型 = p3.2xlarge,磁盘大小 = 512GB)。
请克隆仓库 NVIDIA Terraform Modules / EKS 。
如果您想使用 NVIDIA 云原生附加组件包(有关更多详细信息,请参阅 在 AWS EKS 上安装 NVIDIA 云原生附加组件包(可选) 部分)作为部署系统的一部分,请将您的工作目录更改为 examples/cnpack 目录。否则,请从 nvidia-terraform-modules/eks 文件夹运行以下命令。
按照仓库中的说明启动集群。一旦 terraform apply 完成,您可以执行以下验证步骤。
通过运行以下命令,使用 aws cli 更新您的 kube 配置
aws eks update-kubeconfig --name tf-<cluster-name-in-terraform.tfvars> --region us-west-2
现在您应该可以在 kubectl cli 中看到集群,并且应该看到三个节点(默认:1 个 CPU 节点和 2 个 GPU 节点)。
kubectl get nodes
通过运行以下命令验证 GPU operator。(请注意,集群创建后可能需要约 5 分钟才能使所有 GPU Operator 资源准备就绪)
kubectl get pod -n gpu-operator
名称中带有 -validator 的 Pod 应处于 Completed 状态,所有其他 Pod 应正在运行。
我们还将通过运行以下命令来验证驱动程序是否正常工作,您应该看到 NVIDIA-SMI 输出。
kubectl exec -it -n gpu-operator nvidia-device-plugin-daemonset-<your-pod-number> -- nvidia-smi
现在您的集群已准备好使用。
在 AWS EKS 上安装 NVIDIA 云原生附加组件包(可选)
NVIDIA 云原生服务附加组件包是一系列工具的集合,旨在支持在 Kubernetes 集群上创建和运行云原生服务。
在继续之前,请确保您已启动并有权访问 Holoscan 就绪 EKS 的 CNPack 版本。(有关更多详细信息,请参阅 启动 Holoscan 就绪 EKS 集群 中的步骤 1。)
连接 AWS 托管服务
在您的
nvidia-terraform-modules/eks/examples/cnpack文件夹中,运行terraform output以获取以下信息。
~/nvidia-terraform-modules/eks/examples/cnpack $ terraform output
amp_ingest_role_arn = "arn:aws:iam::0000000000000:role/amp-ingest-role-f1b"
amp_query_endpoint = "https://aps-workspaces.us-west-2.amazonaws.com/workspaces/ws-example/api/v1/query"
amp_remotewrite_endpoint = "https://aps-workspaces.us-west-2.amazonaws.com/workspaces/ws-example/api/v1/remote_write"
aws_pca_arn = "arn:aws:acm-pca:us-west-2:0000000000000:certificate-authority/example-pca-arn-hash"
从 NGC 下载 CNPack。
ngc registry resource download-version "nv-holoscan-cloud-native/cnpack/cnpack:0.16.0"
cd cnpack_v0.16.0
chmod +x nvidia-cnpack-linux-x86_64
./nvidia-cnpack-linux-x86_64 --help
使用以下模板创建 CNPack 配置,并将文件命名为
nvidia-platform.yaml。对于 EKS 集成,我们启用了 fluentbit 用于日志聚合、prometheus 用于指标以及 cert-manager。
apiVersion: v1alpha3
kind: NvidiaPlatform
spec:
# The platform block contains general configuration that is important to all components
platform:
# Required value specifying the Wildcard Domain to configure for ingress.
wildcardDomain: "*.my-cluster.my-domain.com"
# Required value to specify the port to configure for ingress.
externalPort: 443
# Optional infrastructure provider configuration for AWS EKS
eks:
# The region in-which the cluster is installed.
region: us-west-2
# The ingress block configures the ingress controller
ingress:
# Whether this component should be enabled Default is true.
enabled: false
# The postgres block configures the postgres operator
postgres:
# Whether this component should be enabled Default is true.
enabled: false
# The certManager block configures the certificate management system
certManager:
# Whether this component should be enabled Default is true.
enabled: true
# Optional configuration for the AWS Private CA service integration.
#
# Dependencies:
# - EKS Infrastructure provider configuration (spec.platform.eks)
awsPCA:
# Whether this component should be enabled Default is true.
enabled: true
# The ARN required to communicate with the AWS Private CA service.
arn: <aws_pca_arn>
# The common name of the configured Private CA.
commonName: my-cert.my-domain.com
# The domain name of the configured Private CA.
domainName: my-domain.com
# The trustManager block configures the trust bundle management system
#
# Dependencies:
# - cert-manager
trustManager:
# Whether this component should be enabled Default is true.
enabled: false
# The keycloack block configures Keycloak as an OIDC provider
#
# Dependencies:
# - cert-manager
# - postgres
# - ingress
keycloak:
# Whether this component should be enabled Default is true.
enabled: false
# The prometheus block configures the Prometheus metrics service
#
# Dependencies:
# - cert-manager
prometheus:
# Whether this component should be enabled Default is true.
enabled: true
# Optional configuration for connecting Prometheus to an AWS Managed Prometheus instance.
awsRemoteWrite:
# The URL of the AWS managed prometheus service.
url: <amp_remotewrite_endpoint>
# The ARN required to communicate with the AWS Managed Prometheus Service.
arn: <amp_ingest_role_arn>
# The grafana block configures the Grafana dashboard service
#
# Dependencies:
# - prometheus
# - cert-manager
# - ingress
grafana:
# Whether this component should be enabled Default is true.
enabled: true
# Optional value to override the hostname used to expose grafana.
customHostname: my-host.my-cluster.my-domain.com
# The elastic block configures the Elastic Cloud on Kubernetes operator
elastic:
# Whether this component should be enabled Default is true.
enabled: true
# The fluentbit block configures the fluentbit log aggregation service
#
# Dependencies:
# - Infrastructure provider configuration (spec.platform.eks or spec.platform.aks or empty spec.platform for CNS)
fluentbit:
# Whether this component should be enabled Default is true.
enabled: true
使用以下命令在您的集群中创建 CNPack。CNPack 将使用您的 KUBECONFIG 连接到集群并执行其服务的安装。
./nvidia-cnpack-linux-x86_64 create -f nvidia-platform.yaml
通过运行以下两个命令验证 CNPack 安装状态,并确保所有 Pod 都处于运行状态。
kubectl get po -n nvidia-platform
kubectl get po -n nvidia-monitoring
如果您想从集群中删除 cnpack,请运行
./nvidia-cnpack-linux-x86_64 delete
故障排除
如果在任何时候,您的 kubectl 或 terraform 命令显示类似 “couldn’t get current server API group list: the server has asked for the client to provide credentials” 的错误,请刷新您 ~/.aws/credentials 文件中的 AWS 凭证。
删除 Holoscan 就绪 EKS 集群
注意: 请确保在运行 destroy 命令之前,已删除您安装的所有应用程序(helm charts、其他 Kubernetes 资源)。
刷新您的 AWS 凭证。
在您运行
terraform apply的同一目录中,运行terraform destroy,并在提示时输入 “yes”。
Azure Kubernetes 服务 (Microsoft AKS)
启动 Holoscan 就绪 AKS 集群
Holoscan 就绪 AKS 集群将连接到您的 Azure 账户,并使用 terraform 以及 NVIDIA GPU Operator 创建所有需要的资源。默认情况下,它会创建一个 CPU 节点(实例类型 = Standard_D16_v5,磁盘大小 = 100GB)和 2 个 GPU 节点(实例类型 = Standard_NC6s_v3,磁盘大小 = 100GB)。
请克隆仓库 NVIDIA Terraform Modules / AKS。
如果您想使用 NVIDIA 云原生附加组件包(有关更多详细信息,请参阅 在 Azure AKS 上安装 NVIDIA 云原生附加组件包(可选) 部分)作为部署系统的一部分,请将您的工作目录更改为 examples/cnpack 目录。否则,请从 nvidia-terraform-modules/aks 根目录运行以下命令。
按照仓库中的说明启动集群。一旦 terraform apply 完成,您可以执行以下验证步骤。
通过运行以下命令,使用 az cli 更新您的 kube 配置
az aks get-credentials --name ucf-cnpack-cluster --resource-group ucf-cnpack-cluster-rg
现在您应该可以在 kubectl cli 中看到集群,并且应该看到三个节点(1 个 CPU 节点和 2 个 GPU 节点)。(注意:第一次在集群上运行此命令时,可能会要求您登录 Microsoft。)
kubectl get nodes
通过运行以下命令验证 GPU operator。(请注意,集群创建后可能需要约 5 分钟才能使所有 GPU Operator 资源准备就绪)
kubectl get pod -n gpu-operator
名称中带有 -validator 的 Pod 应处于 Completed 状态,所有其他 Pod 应正在运行。
我们还将通过运行以下命令来验证驱动程序是否正常工作,您应该看到 NVIDIA-SMI 输出。
kubectl exec -it -n gpu-operator nvidia-device-plugin-daemonset-<your-pods-number> -- nvidia-smi
现在您的集群已准备好使用。
在 Azure AKS 上安装 NVIDIA 云原生附加组件包(可选)
NVIDIA 云原生服务附加组件包是一系列工具的集合,旨在支持在 Kubernetes 集群上创建和运行云原生服务。
在继续之前,请确保您已启动并有权访问 Holoscan 就绪 AKS 的 CNPack 版本。(有关更多详细信息,请参阅 启动 Holoscan 就绪 AKS 集群 中的步骤 1。)
连接 Azure 托管服务
在您的 nvidia-terraform-modules/aks/examples/cnpack 文件夹中,运行
terraform output以获取以下信息。
~/nvidia-terraform-modules/aks/examples/cnpack $ terraform output
cluster_managed-client-id = "x123xxxxxxx"
fluentbit-secret-name = "fluentbit-secrets"
fluentbit-secret-namespace = "nvidia-platform"
prometheus-query-url = "https://ucf-cnpack-prom-xxxx.westus2.prometheus.monitor.azure.com"
从 NGC 下载 CNPack。
ngc registry resource download-version "nv-holoscan-cloud-native/cnpack/cnpack:0.16.0"
cd cnpack_v0.16.0
chmod +x nvidia-cnpack-linux-x86_64
./nvidia-cnpack-linux-x86_64 --help
使用以下模板创建 CNPack 配置,并将文件命名为
nvidia-platform.yaml。对于 EKS 集成,我们启用了 fluentbit 用于日志聚合、prometheus 用于指标以及 cert-manager。
apiVersion: v1alpha3
kind: NvidiaPlatform
spec:
platform:
wildcardDomain: "*.holoscandev.nvidia.com"
externalPort: 443
aks: {}
certManager:
enabled: true
prometheus:
enabled: true
aksRemoteWrite:
url: "<see note #1>"
clientId: "<cluster_managed-client-id> in your terraform output"
fluentbit:
enabled: true
aks:
secretName: "<fluentbit-secret-name in your terraform output>"
trustManager:
enabled: false
keycloak:
enabled: false
grafana:
customHostname: grafana.holoscandev.com
enabled: false
elastic:
enabled: false
ingress:
enabled: false
postgres:
enabled: false
注意 #1:要获取 AKS Remote Write URL,您需要转到 Azure 门户,搜索 ucf-cnpack-prom(或您在 terraform.tfvars 文件中使用的名称),然后选择同名的 Azure Monitor Workspace 的资源。然后,将 Metrics Ingestion Endpoint 的值复制到 spec.Promtheus.aksRemoteWrite.url。
使用以下命令在您的集群中创建 CNPack。CNPack 将使用您的 KUBECONFIG 连接到集群并执行其服务的安装。
./nvidia-cnpack_Linux_x86_64 create -f nvidia-platform.yaml
通过运行以下两个命令验证 CNPack 安装状态,并确保所有 Pod 都处于运行状态。
kubectl get po -n nvidia-platform
kubectl get po -n nvidia-monitoring
如果您想从集群中删除 cnpack,请运行
./nvidia-cnpack_Linux_x86_64 delete。
故障排除
如果在任何时候,您的 kubectl 或 terraform 命令显示类似 “couldn’t get current server API group list: the server has asked for the client to provide credentials” 的错误,请再次运行 az login。
如果您从 terraform apply 中看到以下内容
│ Error: chart "gpu-operator" matching vX.Y.Z not found in nvidia index. (try 'helm repo update'): no chart
│ version found for gpu-operator-vX.Y.Z
运行 helm repo update,然后再次运行 terraform apply。
删除 Holoscan 就绪 AKS 集群
注意
确保在运行 destroy 命令之前,已删除您安装的所有应用程序(helm charts、其他 Kubernetes 资源)。
通过运行
az login刷新您的 Azure 登录。在您运行
terraform apply的同一目录中,运行terraform destroy,并在提示时输入 “yes”。
Google Kubernetes 引擎 (GCP GKE)
启动 Holoscan 就绪 GKE 集群
Holoscan 就绪 GKE 集群将连接到您的 GCP 账户,并使用 terraform 以及 NVIDIA GPU Operator 创建所有需要的资源。默认情况下,它会创建一个 CPU 节点(实例类型 = n1-standard-4,磁盘大小 = 512GB)和 2 个 GPU 节点(实例类型 = n1-standard-4,带有 nvidia-tesla-v100,磁盘大小 = 512GB)。
请克隆仓库 NVIDIA Terraform Modules / GKE。
如果您想使用 NVIDIA 云原生附加组件包(有关更多详细信息,请参阅 在 GKE 上安装 NVIDIA 云原生附加组件包(可选) 部分)作为部署系统的一部分,请将您的工作目录更改为 examples/cnpack 目录。否则,请从 nvidia-terraform-modules/gke 根目录运行以下命令。
按照仓库中的说明启动集群。一旦 terraform apply 完成,您可以执行以下验证步骤。
通过运行以下命令,使用 az cli 更新您的 kube 配置
gcloud components install gke-gcloud-auth-plugin
gcloud container clusters get-credentials <CLUSTER_NAME> --region=<REGION>
现在您应该可以在 kubectl cli 中看到集群,并且应该看到三个节点(1 个 CPU 节点和 2 个 GPU 节点)。(注意:第一次在集群上运行此命令时,可能会要求您登录 Microsoft。)
kubectl get nodes
通过运行以下命令验证 GPU operator。(请注意,集群创建后可能需要约 5 分钟才能使所有 GPU Operator 资源准备就绪)
kubectl get pod -n gpu-operator
名称中带有 -validator 的 Pod 应处于 Completed 状态,所有其他 Pod 应正在运行。
我们还将通过运行以下命令来验证驱动程序是否正常工作,您应该看到 NVIDIA-SMI 输出。
kubectl exec -it -n gpu-operator nvidia-device-plugin-daemonset-<your-pods-number> -- nvidia-smi
现在您的集群已准备好使用。
在 GKE 上安装 NVIDIA 云原生附加组件包(可选)
NVIDIA 云原生服务附加组件包是一系列工具的集合,旨在支持在 Kubernetes 集群上创建和运行云原生服务。
在继续之前,请确保您已启动并有权访问 Holoscan 就绪 GKE 的 CNPack 版本。(有关更多详细信息,请参阅 启动 Holoscan 就绪 GKE 集群 中的步骤 1。)
连接 GCP 托管服务
在您的 nvidia-terraform-modules/gke/examples/cnpack 文件夹中,运行
terraform output以获取以下信息。
~/nvidia-terraform-modules/gke/examples/cnpack $ terraform output
gcp_service_account_email_for_prometheus = "tf-gke-prom-svc-acct-xxxxxdxxx.com"
从 NGC 下载 CNPack。
ngc registry resource download-version "nv-holoscan-cloud-native/cnpack/cnpack:0.16.0"
cd cnpack_v0.16.0
chmod +x nvidia-cnpack-linux-x86_64
./nvidia-cnpack-linux-x86_64 --help
使用以下模板创建 CNPack 配置,并将文件命名为
nvidia-platform.yaml。对于 EKS 集成,我们启用了 fluentbit 用于日志聚合、prometheus 用于指标以及 cert-manager。
apiVersion: v1alpha3
kind: NvidiaPlatform
spec:
platform:
wildcardDomain: "*.holoscandev.nvidia.com"
externalPort: 443
gke: {}
certManager:
enabled: true
prometheus:
enabled: true
gkeRemoteWrite:
gcpServiceAccount: "<name-of-your-gcp-service-account> in your terraform output"
fluentbit:
enabled: true
trustManager:
enabled: false
keycloak:
enabled: false
grafana:
customHostname: grafana.holoscandev.com
enabled: false
elastic:
enabled: false
ingress:
enabled: false
postgres:
enabled: false
使用以下命令在您的集群中创建 CNPack。CNPack 将使用您的 KUBECONFIG 连接到集群并执行其服务的安装。
./nvidia-cnpack_Linux_x86_64 create -f nvidia-platform.yaml
通过运行以下两个命令验证 CNPack 安装状态,并确保所有 Pod 都处于运行状态。
kubectl get po -n nvidia-platform
kubectl get po -n nvidia-monitoring
如果您想从集群中删除 cnpack,请运行
./nvidia-cnpack_Linux_x86_64 delete。
故障排除
如果在任何时候,您的 kubectl 或 terraform 命令显示类似 “couldn’t get current server API group list: the server has asked for the client to provide credentials” 的错误,请再次运行 gcloud auth application-default login。
删除 Holoscan 就绪 GKE 集群
注意
确保在运行 destroy 命令之前,已删除您安装的所有应用程序(helm charts、其他 Kubernetes 资源)。
通过运行
gcloud auth application-default login刷新您的 GCP 登录。在您运行
terraform apply的同一目录中,运行terraform state rm kubernetes_namespace_v1.gpu-operator,然后运行terraform destroy,并在提示时输入 “yes”。