重要提示
您正在查看 NeMo 2.0 文档。此版本对 API 和新库 NeMo Run 进行了重大更改。我们目前正在将 NeMo 1.0 中的所有功能移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
Megatron Core 定制#
Megatron Core (Mcore) 提供了一系列功能,其中最值得注意的是用户能够在史诗般的规模上训练 Transformer 模型。用户可以通过使用 megatron.core.models.gpt.GPTModel (Mcore GPTModel) 初始化模型来启用解码器/GPT 变体,然后将预训练/加载权重到模型中。Mcore GPTModel 采用典型的 GPT 结构,从嵌入层、位置编码开始,然后是一系列 Transformer 层,最后是输出层。
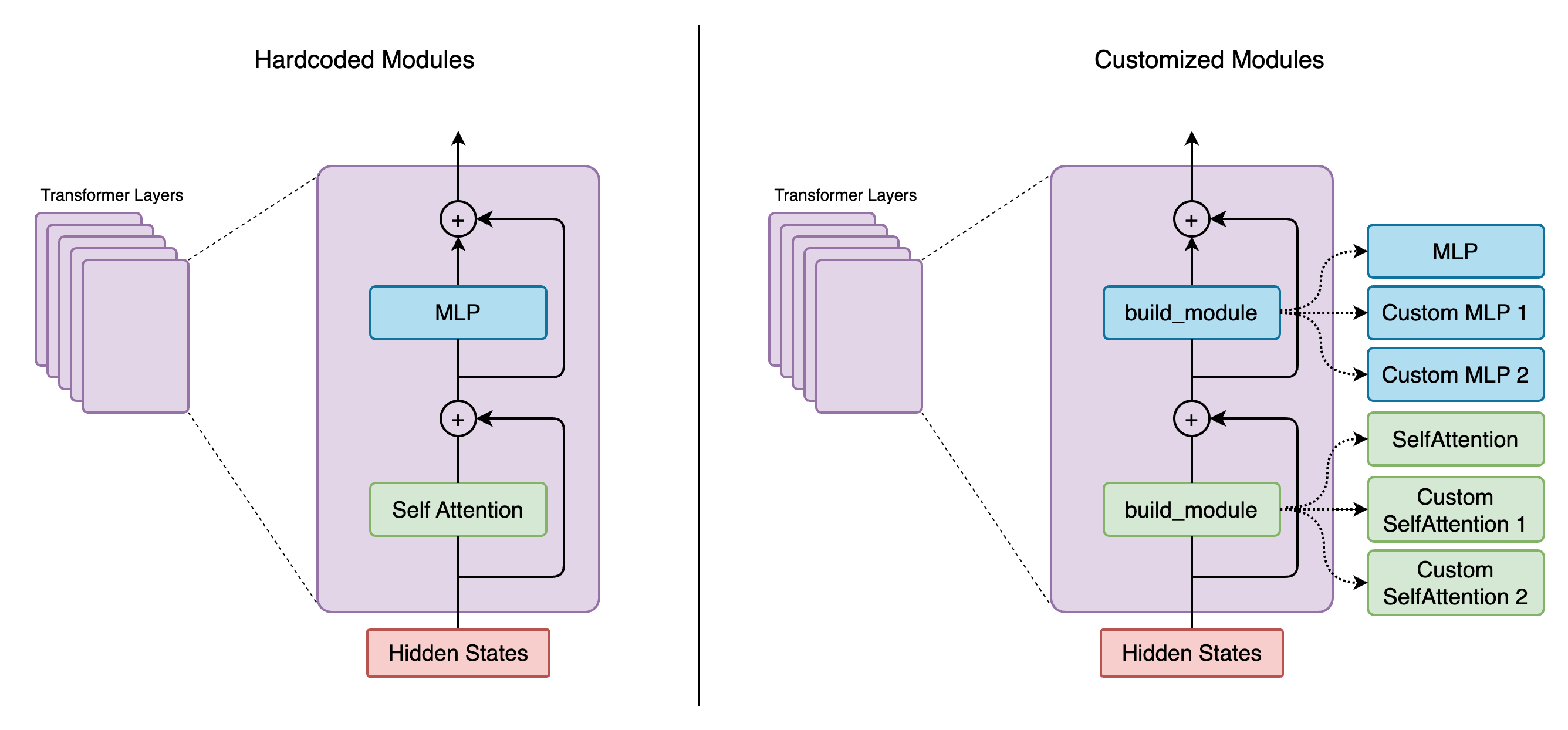
在快速发展的大型语言模型 (LLM) 世界中,试验每个 Transformer 层中 Transformer 块的各种配置变得越来越重要。其中一些配置涉及使用不同的模块类。虽然可以使用 Mcore 中的 “if else” 语句来实现这一点,但这会使 Mcore 的可读性和长期可维护性降低。Mcore spec 旨在通过允许用户在每层中指定 Transformer 块的定制,而无需修改 mcore 中的代码来解决这一挑战。我们将在本博客的第一部分深入探讨 mcore spec 的详细信息。然后,我们将以 Falcon 为例,演示 mcore spec 的实用性。
什么是 Mcore Spec#
Mcore spec 系统需要一个“规范”来定义 mcore GPTModel 模块(例如层、自注意力、MLP 等)及其子模块的初始化。这允许用户通过提供自己的规范来自定义这些组件。
这是一个来自 mcore spec 原始合并请求的 diff 代码片段。我们可以看到 mcore GPTModel 初始化所需的额外参数 (megatron/core/models/gpt/gpt_model.py)
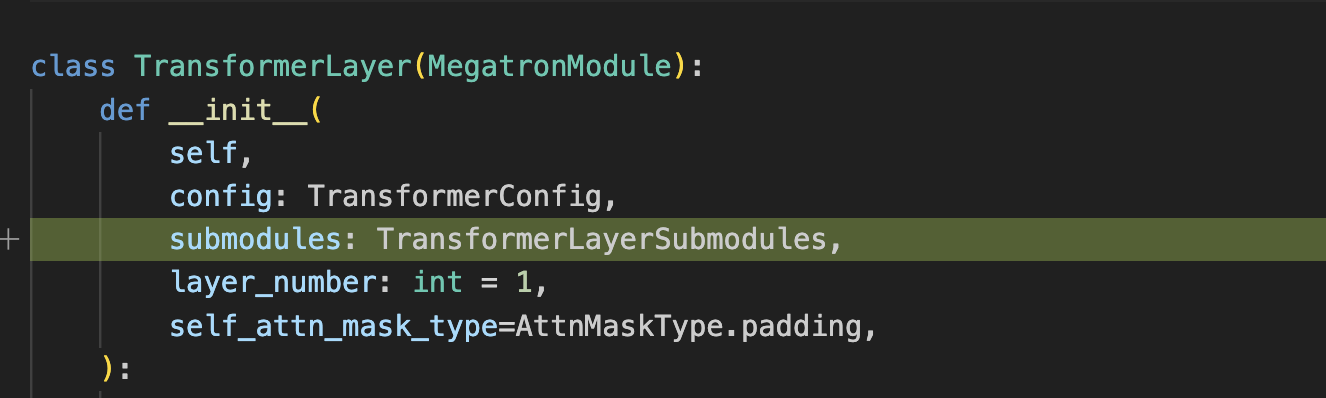
其中所需的 transformer_layer_spec (用于 mcore GPTModel 层) 看起来像
gpt_layer_with_transformer_engine_spec = ModuleSpec(
module=TransformerLayer,
submodules=TransformerLayerSubmodules(
self_attention=ModuleSpec(
module=SelfAttention,
params={"attn_mask_type": AttnMaskType.causal},
submodules=SelfAttentionSubmodules(
linear_qkv=TELayerNormColumnParallelLinear,
dot_product_attention=TEDotProductAttention,
linear_proj=TERowParallelLinear,
),
),
self_attn_bda=get_bias_dropout_add,
mlp=ModuleSpec(
module=MLP,
submodules=MLPSubmodules(
linear_fc1=TELayerNormColumnParallelLinear, linear_fc2=TERowParallelLinear,
),
),
mlp_bda=get_bias_dropout_add,
),
)
spec 系统引入了一种新的模块初始化方法。以下是自注意力初始化 (megatron/core/transformer/transformer_layer.py) 的前后对比示例

我们没有硬编码 SelfAttention 类,而是使用 build_module 函数在层内部构建我们的 self.self_attention。层的初始化已变为 (megatron/core/transformer/transformer_block.py)
def build_layer(layer_spec, layer_number):
return build_module(layer_spec, config=self.config, layer_number=layer_number,)
而不是硬编码 TransformerLayer 类。
在以下小节中,我们将介绍 mcore spec 系统中的几个要素。
子模块#
在构建模块(例如 Transformer 层、注意力或 MLP)时,我们需要提供一个 python dataclass 来指定要使用的子模块(如果有)。Mcore GPTModel 使用 TransformerLayerSubmodules 作为层子模块的模板。类似地,还有 SelfAttentionSubmodules、CrossAttentionSubmodules、MLPSubmodules 等。
TransformerLayerSubmodules 是一个 python dataclass,列出了您在 Transformer 块中可能需要的所有可定制组件
@dataclass
class TransformerLayerSubmodules:
input_layernorm: Union[ModuleSpec, type] = IdentityOp
self_attention: Union[ModuleSpec, type] = IdentityOp
self_attn_bda: Union[ModuleSpec, type] = IdentityFuncOp
pre_cross_attn_layernorm: Union[ModuleSpec, type] = IdentityOp
cross_attention: Union[ModuleSpec, type] = IdentityOp
cross_attn_bda: Union[ModuleSpec, type] = IdentityFuncOp
pre_mlp_layernorm: Union[ModuleSpec, type] = IdentityOp
mlp: Union[ModuleSpec, type] = IdentityOp
mlp_bda: Union[ModuleSpec, type] = IdentityFuncOp
所有层子模块都初始化为 IdentityOp 或 IdentityFuncOp,这允许用户保持这些模块不变而不进行修改。Mcore GPTModel 的 TransformerLayer 初始化每个列出的子模块。如果您不需要某些子模块,则可以在层规范中忽略它(这将在下一节中介绍),将其保留为 IdentityOp (或 IdentityFuncOp)。
ModuleSpec#
ModuleSpec 是 spec 系统的基本可配置构建块,它支持嵌套。这非常适合 TransformerLayer,它可能具有多个可配置的子模块(如 Attention、MLP 等)。接下来,我们将展示如何为模块创建 spec。Mcore 提供了 ModuleSpec 类 (megatron/core/transformer/spec_utils.py),如下所示。文档字符串提供了 ModuleSpec 中组件的描述。
@dataclass
class ModuleSpec:
"""This is a Module Specification dataclass.
Specification defines the location of the module (to import dynamically)
or the imported module itself. It also defines the params that need to be
passed to initialize the module.
Args:
module (Union[Tuple, type]): A tuple describing the location of the
module class e.g. `(module.location, ModuleClass)` or the imported
module class itself e.g. `ModuleClass` (which is already imported
using `from module.location import ModuleClass`).
params (dict): A dictionary of params that need to be passed while init.
submodules (type): A dataclass that contains the names of submodules that comprise the module (specified by this `ModuleSpec`) and their corresponding `ModuleSpec`s.
"""
module: Union[Tuple, type]
params: dict = field(default_factory=lambda: {})
submodules: type = None
记住我们如何创建 mcore GPTModel 层 spec
gpt_layer_with_transformer_engine_spec = ModuleSpec(
module=TransformerLayer,
submodules=TransformerLayerSubmodules(
self_attention=ModuleSpec(
module=SelfAttention,
params={"attn_mask_type": AttnMaskType.causal},
submodules=SelfAttentionSubmodules(
linear_qkv=TELayerNormColumnParallelLinear,
dot_product_attention=TEDotProductAttention,
linear_proj=TERowParallelLinear,
),
),
self_attn_bda=get_bias_dropout_add,
mlp=ModuleSpec(
module=MLP,
submodules=MLPSubmodules(
linear_fc1=TELayerNormColumnParallelLinear, linear_fc2=TERowParallelLinear,
),
),
mlp_bda=get_bias_dropout_add,
),
)
我们在这里做了两件事
分配
module,即 mcore GPTModel 中使用的TransformerLayer类使用所需的子模块初始化
TransformerLayerSubmodules,覆盖IdentityOp/IdentityFuncOps(此处未指定的任何内容将保持为 identity 操作)
请注意,self_attention 模块本身包含子模块,因此我们创建一个 ModuleSpec 来初始化 self_attention,方式与 GPT 层相同。
下一步,构建模块。
构建模块#
megatron/core/transformer/spec_utils.py 中的 build_module 根据给定的配置和 spec 构建模块。如果 ModuleSpec 中的模块是一个可实例化的类(它处理的许多其他情况之一),build_module 尝试使用以下内容创建该类的实例:
所有提供的配置 (
ModuleSpec中的 params, 传递给build_module的 args, kwargs。某些配置包含在TransformerConfig类中)ModuleSpec中的submodules字段(如果存在)作为参数传递给该子模块的类,以便可以用来初始化这些模块。
让我们以层初始化为例。GPTModel 将层 spec 和提供的配置传递给 TransformerBlock,层使用 build_module 构建。Mcore GPTModel 使用上面示例中所示的 gpt_layer_with_transformer_engine_spec。根据 spec,module=TransformerLayer 表示应该使用提供的配置和 TransformerLayerSubmodules 初始化 TransformerLayer 类。在 TransformerLayer.__init__ 内部,层子模块是使用 build_module 构建的。
定制示例#
使用 Mcore Spec,我们可以定制模型初始化和模型前向传播。
让我们以 Falcon 为例,看看如何使用带有 spec 的 mcore GPTModel 创建其层。Falcon Transformer 层和传统的 GPTModel Transformer 层之间存在一些差异。如果没有 mcore spec,则很难实现这些 Falcon 模型变体的定制。
一些 Falcon 变体使用并行注意力,其中注意力和 MLP 是并行的而不是顺序的
一些 Falcon 变体将
input_layernorm的输出并行馈送到 MLP 和自注意力,因此我们不能在 Falcon 层 spec 中使用默认的融合 layernorm + linearTELayerNormColumnParallelLinear类一些 Falcon 变体在 attn 之前有一个
input_layernorm,在 MLP 之前有另一个mlp_layernorm一些 Falcon 变体有一个额外的
post_self_attn_layernorm子模块
定制模型初始化#
这里我们展示了如何使用 spec 在初始化时定制模块
对于 Falcon 示例,我们实例化 TransformerLayerSubmodule dataclass 并手动添加额外的属性 - post_self_attn_layernorm (一种更简洁的替代方法也可以是子类化 TransformerLayerSubmodules dataclass,然后向其中添加另一个属性 - post_self_attn_layernorm)。我们在 Falcon 层中为每个子模块指定我们想要的类/模块。最后,我们将层类指定为我们自己的 FalconTransformerLayer,并传入子模块以创建 ModuleSpec。
def get_falcon_layer_spec() -> ModuleSpec:
falcon_submodules = TransformerLayerSubmodules(
input_layernorm=TENorm,
self_attention=ModuleSpec(
module=SelfAttention,
params={"attn_mask_type": AttnMaskType.causal},
submodules=SelfAttentionSubmodules(
linear_qkv=TEColumnParallelLinear,
core_attention=TEDotProductAttention,
linear_proj=TERowParallelLinear,
),
),
self_attn_bda=get_bias_dropout_add,
pre_mlp_layernorm=TENorm,
mlp=ModuleSpec(
module=MLP, submodules=MLPSubmodules(linear_fc1=TEColumnParallelLinear, linear_fc2=TERowParallelLinear,),
),
mlp_bda=get_bias_dropout_add,
)
# falcon-rw-1b/7b uses post_self_attn_layernorm that is not included in TransformerLayerModules.
falcon_submodules.post_self_attn_layernorm = TENorm
return ModuleSpec(module=FalconTransformerLayer, submodules=falcon_submodules)
定制模型前向传播#
下图显示了传统 Mcore GPTModel 与 Falcon 的前向函数。
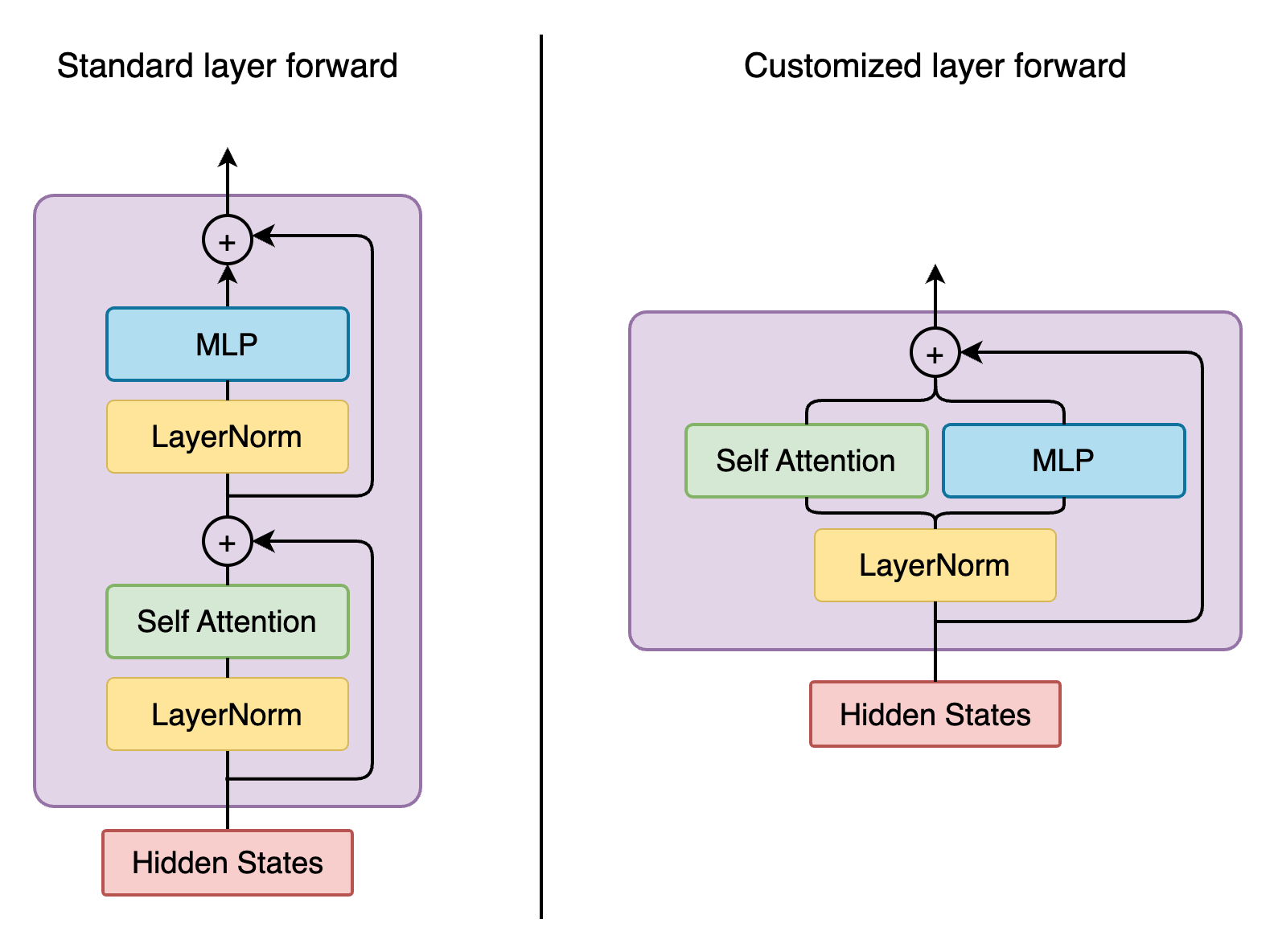
为了实现这一点,我们创建 FalconTransformerLayer,从 mcore TransformerLayer 子类化它并覆盖
__init__:我们可以重用 TransformerLayer 的大部分初始化,但我们需要处理额外post_self_attn_layernorm的创建forward():重新配置计算图
有必要从 mcore TransformerLayer 类子类化您自己的 Transformer 层。
来自 NeMo repo 的完整实现
class FalconTransformerLayer(TransformerLayer):
def __init__(
self,
config: TransformerConfig,
submodules: TransformerLayerSubmodules,
layer_number: int = 1,
self_attn_mask_type=AttnMaskType.padding,
):
super().__init__(config=config, submodules=submodules, layer_number=layer_number)
if hasattr(self.config, 'new_decoder_architecture'):
self.new_decoder_architecture = self.config.new_decoder_architecture
else:
self.new_decoder_architecture = None
if hasattr(self.config, 'parallel_attention'):
self.parallel_attention = self.config.parallel_attention
else:
self.parallel_attention = None
if self.new_decoder_architecture or self.parallel_attention:
self.post_self_attn_layernorm = None
else:
self.post_self_attn_layernorm = build_module(
submodules.post_self_attn_layernorm,
config=self.config,
hidden_size=self.config.hidden_size,
eps=self.config.layernorm_epsilon,
)
if self.new_decoder_architecture:
self.pre_mlp_layernorm = build_module(
submodules.pre_mlp_layernorm,
config=self.config,
hidden_size=self.config.hidden_size,
eps=self.config.layernorm_epsilon,
)
else:
self.pre_mlp_layernorm = None
def forward(
self,
hidden_states,
attention_mask,
context=None,
context_mask=None,
rotary_pos_emb=None,
inference_params=None,
):
residual = hidden_states
mlp_ln_output = None
if self.new_decoder_architecture:
mlp_ln_output = self.pre_mlp_layernorm(hidden_states)
input_layernorm_output = self.input_layernorm(hidden_states)
input_mlp_ln = input_layernorm_output
attention_output_with_bias = self.self_attention(
input_layernorm_output,
attention_mask=attention_mask,
inference_params=inference_params,
rotary_pos_emb=rotary_pos_emb,
)
with self.bias_dropout_add_exec_handler():
hidden_states = self.self_attn_bda(self.training, self.config.bias_dropout_fusion)(
attention_output_with_bias, residual, self.config.hidden_dropout
)
if not self.new_decoder_architecture:
if self.parallel_attention:
layernorm_output = input_mlp_ln
else:
residual = hidden_states
layernorm_output = self.post_self_attn_layernorm(hidden_states)
else:
layernorm_output = mlp_ln_output
mlp_output_with_bias = self.mlp(layernorm_output)
# falcon specific:
if self.new_decoder_architecture or self.parallel_attention:
mlp_output = mlp_output_with_bias[0]
attn_output = attention_output_with_bias[0]
mlp_output_without_bias = mlp_output + attn_output
mlp_output_with_bias = (mlp_output_without_bias, None)
with self.bias_dropout_add_exec_handler():
hidden_states = self.mlp_bda(self.training, self.config.bias_dropout_fusion)(
mlp_output_with_bias, residual, self.config.hidden_dropout
)
output = make_viewless_tensor(inp=hidden_states, requires_grad=hidden_states.requires_grad, keep_graph=True)
return output, context