重要提示
您正在查看 NeMo 2.0 文档。此版本为 API 和新库 NeMo Run 引入了重大更改。我们目前正在将 NeMo 1.0 的所有功能移植到 2.0。有关先前版本或 2.0 中尚未提供的功能的文档,请参阅 NeMo 24.07 文档。
数据集#
说话人日志聚类训练的数据准备(对于端到端日志聚类)#
说话人日志聚类训练和推理都需要相同类型的清单文件。此清单文件可以使用 <NeMo_git_root>/scripts/speaker_tasks/pathfiles_to_diarize_manifest.py 中的脚本创建。以下示例展示了如何通过提供路径列表文件来运行 pathfiles_to_diarize_manifest.py。
python NeMo/scripts/speaker_tasks/pathfiles_to_diarize_manifest.py \
--add_duration \
--paths2audio_files='/path/to/audio_file_path_list.txt' \
--paths2rttm_files='/path/to/rttm_file_list.txt' \
--manifest_filepath='/path/to/manifest_filepath/train_manifest.json
所有三个参数都是必需的。请注意,我们需要通过仅更改文件名扩展名来保持每个字段(键)唯一文件名的统一性。例如,如果有一个名为 abcd01.wav 的音频文件,则 rttm 文件应命名为 abcd01.rttm,转录文件应命名为 abcd01.txt。
示例音频文件路径列表
audio_file_path_list.txt
/path/to/abcd01.wav
/path/to/abcd02.wav
要训练日志聚类模型,需要提供富文本转录时间标记 (RTTM) 文件作为 ground truth 标签文件。以下是 RTTM 文件中的一行示例
SPEAKER TS3012d.Mix-Headset 1 32.679 0.671 <NA> <NA> MTD046ID <NA> <NA>
为您在 audio_file_path_list.txt 中的音频文件创建 RTTM 文件列表。
示例 RTTM 文件路径列表
rttm_file_path_list.txt
/path/to/abcd01.rttm
/path/to/abcd02.rttm
注意
我们期望所有提供的文件(例如音频、rttm、文本)都具有相同的基本名称,并且名称应该是唯一的 (uniq-id)。
作为输出文件,train_manifest.json 将为每个音频文件包含以下行
{"audio_filepath": "/path/to/abcd01.wav", "offset": 0, "duration": 90, "label": "infer", "text": "-", "num_speakers": 2, "rttm_filepath": "/path/to/rttm/abcd01.rttm"}
对于端到端说话人日志聚类训练,本节中描述的清单文件满足输入清单文件的要求。对于级联说话人日志聚类训练(TS-VAD 样式),应进一步处理清单文件以生成会话式清单文件。
MSDD(TS-VAD 样式模型)训练的清单 JSON 文件#
本节介绍如何格式化用于级联日志聚类训练的数据集(例如,TS-VAD、MSDD 等)。要训练或微调说话人日志聚类系统,您可以单独训练/微调说话人嵌入提取器模型,也可以同时训练/微调说话人嵌入提取器和神经日志聚类器。
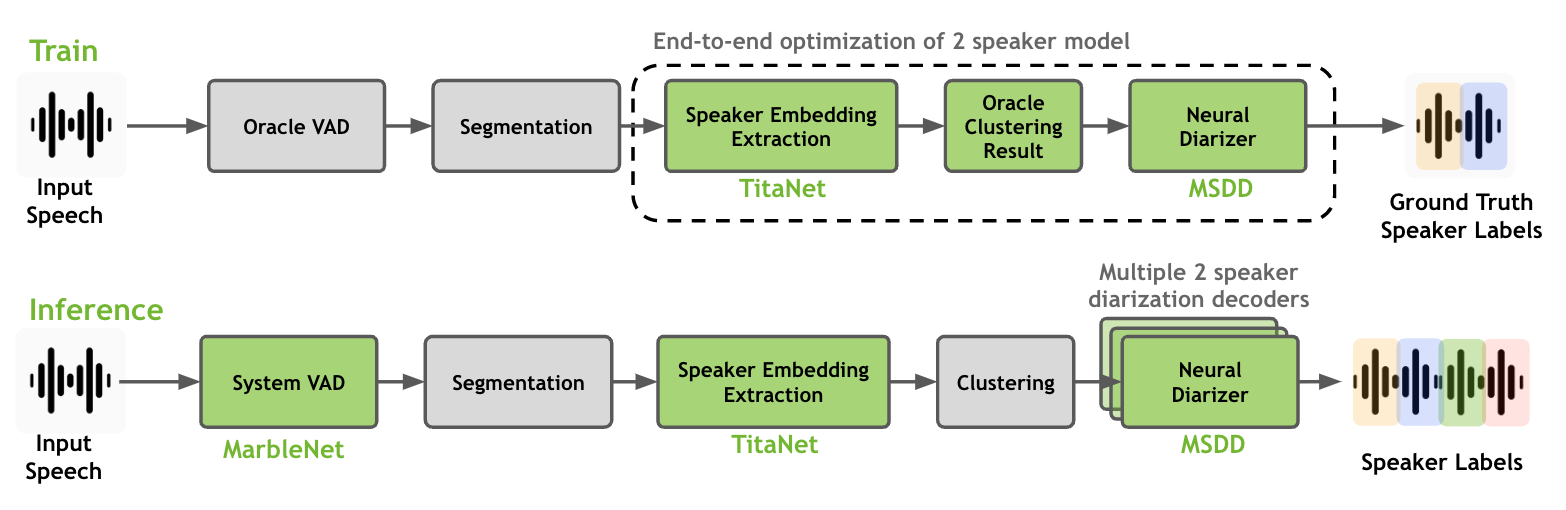
如上图所示,完整的说话人日志聚类过程包括说话人嵌入提取器、聚类算法和神经日志聚类器。请注意,只有说话人嵌入提取器和神经日志聚类器是可训练模型,它们可以在日志聚类数据集上一起训练/微调。我们建议使用在大量单说话人数据集上训练的说话人嵌入提取器模型,并将其用于训练神经日志聚类器模型。
对于训练 MSDD,我们需要一个额外的步骤,即将会话清单截断为更短的块。生成会话式清单文件后,我们需要将每个会话式清单文件分解为拆分清单文件,其中包含拆分样本的开始时间和持续时间,以适应内存容量。更重要的是,由于 MSDD 仅使用成对(双说话人)模型和数据样本,如果说话人超过两个,我们需要拆分 RTTM 文件。
请注意,在生成训练样本的清单文件时,应指定 MSDD 模型基本尺度的窗口长度和位移长度。更重要的是,step_count 决定了拆分数据样本中包含多少步(即基本尺度段)。如果 step_count 太长,您可能无法在一个批次中加载单个样本。
python NeMo/scripts/speaker_tasks/create_msdd_train_dataset.py \
--input_manifest_path='path/to/train_manifest.json' \
--output_manifest_path='path/to/train_manifest.50step.json' \
--pairwise_rttm_output_folder='path/to/rttm_output_folder' \
--window=0.5 \
--shift=0.25 \
--step_count=50
所有参数都是生成新清单文件所必需的。在 --input_manifest_path 中指定会话式日志聚类清单文件,并在 --output_manifest_path 中指定输出文件名。在为 --pairwise_rttm_output_folder 指定的文件夹中,脚本将从给定的 RTTM 文件创建多个双说话人 RTTM 文件,并创建仅包含指定 RTTM 范围内的两个说话人的清单文件。
例如,如果 abcd01.wav 有三个说话人 (1911,1988,192),则将创建三个 RTTM 文件:abcd01.1911_1988.rttm、abcd01.1911_192.rttm 和 abcd01.1988_192.rttm。随后,段将仅从新生成的双说话人 RTTM 文件生成。
在 MSDD 模型中指定基本尺度的 window 和 shift。在本示例中,我们使用 window=0.5 和 shift=0.25 以及 step_count=50 的默认设置。以下是输出文件 /path/to/train_manifest.50step.json 中的示例行。
示例清单文件
train_manifest.50step.json。
{"audio_filepath": "/path/to/abcd01.wav", "offset": 0.007, "duration": 14.046, "label": "infer", "text": "-", "num_speakers": 2, "rttm_filepath": "simulated_train/abcd01.1919_1988.rttm"}
{"audio_filepath": "/path/to/abcd01.wav", "offset": 13.553, "duration": 16.429, "label": "infer", "text": "-", "num_speakers": 2, "rttm_filepath": "simulated_train/abcd01.1919_1988.rttm"}
{"audio_filepath": "/path/to/abcd02.wav", "offset": 0.246, "duration": 15.732, "label": "infer", "text": "-", "num_speakers": 2, "rttm_filepath": "path/to/rttm_output_folder/abcd02.777_5694.rttm"}
{"audio_filepath": "/path/to/abcd02.wav", "offset": 15.478, "duration": 14.47, "label": "infer", "text": "-", "num_speakers": 2, "rttm_filepath": "path/to/rttm_output_folder/abcd02.777_5694.rttm"}
为训练和验证准备 msdd 训练数据集。训练数据集准备好后,您可以使用以下脚本训练 MSDD 模型
python ./multiscale_diar_decoder.py --config-path='../conf/neural_diarizer' --config-name='msdd_5scl_15_05_50Povl_256x3x32x2.yaml' \
trainer.devices=1 \
trainer.max_epochs=20 \
model.base.diarizer.speaker_embeddings.model_path="titanet_large" \
model.train_ds.manifest_filepath="<train_manifest_path>" \
model.validation_ds.manifest_filepath="<dev_manifest_path>" \
model.train_ds.emb_dir="<train_temp_dir>" \
model.validation_ds.emb_dir="<dev_temp_dir>" \
exp_manager.name='sample_train' \
exp_manager.exp_dir='./msdd_exp' \
在上面的训练会话示例中,我们使用 titanet_large 模型作为预训练的说话人嵌入模型。
日志聚类推理的数据准备:适用于端到端和级联系统#
与日志聚类训练的数据集准备一样,日志聚类推理基于 Hydra 配置,Hydra 配置由 .yaml 文件满足。有关设置说话人日志聚类推理的输入 Hydra 配置文件,请参阅 NeMo 说话人日志聚类配置文件。输入数据应以如下所示的行分隔 JSON 格式提供
{"audio_filepath": "/path/to/abcd.wav", "offset": 0, "duration": null, "label": "infer", "text": "-", "num_speakers": null, "rttm_filepath": "/path/to/rttm/abcd.rttm", "uem_filepath": "/path/to/uem/abcd.uem"}
在输入清单文件的每一行中,audio_filepath 项是必需的,而其余项是可选的,可以传递以用于所需的日志聚类设置。我们将此文件称为清单文件。此清单文件可以使用 <NeMo_git_root>/scripts/speaker_tasks/pathfiles_to_diarize_manifest.py 中的脚本创建。以下示例展示了如何通过提供路径列表文件来运行 pathfiles_to_diarize_manifest.py。
python pathfiles_to_diarize_manifest.py --paths2audio_files /path/to/audio_file_path_list.txt \
--paths2txt_files /path/to/transcript_file_path_list.txt \
--paths2rttm_files /path/to/rttm_file_path_list.txt \
--paths2uem_files /path/to/uem_file_path_list.txt \
--paths2ctm_files /path/to/ctm_file_path_list.txt \
--manifest_filepath /path/to/manifest_output/input_manifest.json
--paths2audio_files 和 --manifest_filepath 是必需的参数。请注意,我们需要通过仅更改文件名扩展名来保持每个字段(键)唯一文件名的统一性。例如,如果有一个名为 abcd.wav 的音频文件,则 rttm 文件应命名为 abcd.rttm,转录文件应命名为 abcd.txt。
示例音频文件路径列表
audio_file_path_list.txt
/path/to/abcd01.wav
/path/to/abcd02.wav
示例 RTTM 文件路径列表
rttm_file_path_list.txt
/path/to/abcd01.rttm
/path/to/abcd02.rttm
包含 WAV、RTTM、TXT、CTM 和 UEM 文件的绝对路径的路径列表文件应如上例所示提供。pathsfiles_to_diarize_manifest.py 脚本将使用唯一文件名(例如 abcd)匹配每个文件。最后,应通过 Hydra 配置提供创建的清单文件的绝对路径,如下所示
diarizer.manifest_filepath="path/to/manifest/input_manifest.json"
以下是有关输入清单 JSON 文件中每个字段的描述。
注意
我们期望所有提供的文件(例如音频、rttm、文本)都具有相同的基本名称,并且名称应该是唯一的 (uniq-id)。
audio_filepath(必需)
一个字符串,包含音频文件的绝对路径。
num_speakers(可选)
如果已知说话人数量,请提供整数,如果未知,则分配 null。
rttm_filepath(可选)
要使用已知的 rttm 文件评估日志聚类系统,需要提供富文本转录时间标记 (RTTM) 文件作为 ground truth 标签文件。如果提供了 RTTM 文件,将启动日志聚类评估。以下是 RTTM 文件中的一行示例
SPEAKER TS3012d.Mix-Headset 1 331.573 0.671 <NA> <NA> MTD046ID <NA> <NA>
text(可选)
用于 ASR 推理的日志聚类的 Ground truth 转录。以字符串格式提供给定音频文件的 Ground truth 转录
{"text": "this is an example transcript"}
uem_filepath(可选)
UEM 文件用于指定要在给定音频文件中评估的评分区域。UEM 文件遵循以下约定:
<uniq-id> <channel ID> <start time> <end time>。<channel ID>设置为 1。UEM 文件的示例行
TS3012d.Mix-Headset 1 12.31 108.98
TS3012d.Mix-Headset 1 214.00 857.09
ctm_filepath(可选)
CTM 文件用于评估词级日志聚类结果和词时间戳对齐。CTM 文件遵循以下约定:
<session name> <channel ID> <start time> <duration> <word> <confidence> <type of token> <speaker>。请注意,<speaker>应与 RTTM 中的说话人 ID 完全匹配。由于评估日志聚类结果不需要置信度,我们将<confidence>值分配为NA。如果令牌类型为单词,我们将<type of token>分配为lex。CTM 文件的示例行
TS3012d.Mix-Headset 1 12.879 0.32 okay NA lex MTD046ID
TS3012d.Mix-Headset 1 13.203 0.24 yeah NA lex MTD046ID