重要提示
您正在查看 NeMo 2.0 文档。此版本对 API 和一个新库 NeMo Run 进行了重大更改。我们目前正在将 NeMo 1.0 中的所有功能移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
模型#
本节简要概述了 NeMo 的 ASR 集合中支持的说话人日志模型。
目前 NeMo Speech AI 支持两种类型的说话人日志系统
1. 端到端说话人日志: Sortformer Diarizer Sortformer 是一种基于 Transformer 编码器的端到端说话人日志模型,可直接从输入音频片段生成预测的说话人标签。
2. 级联(流水线式)说话人日志: 带有多尺度说话人日志解码器 (MSDD) 的聚类日志器 NeMo Speech AI 中的说话人日志流水线涉及使用 MarbleNet 模型进行语音活动检测 (VAD)、使用 TitaNet 模型进行说话人嵌入提取,以及使用多尺度说话人日志解码器进行神经日志,所有这些都在本页中进行了解释。
Sortformer Diarizer#
说话人日志旨在弄清楚音频记录中是谁在何时说话。在自动语音识别 (ASR) 领域,这对于处理与多位说话人的对话变得更加重要。多说话人 ASR(也称为说话人归属或多说话者 ASR)使用此过程不仅转录所说的内容,还使用正确的说话人标记转录的每个部分。
随着 ASR 技术的不断进步,说话人日志正日益成为 ASR 工作流程本身的一部分。一些系统现在在解码期间同时处理说话人标记和转录。这意味着您不仅可以获得准确的文本,还可以深入了解谁说了什么,使其对于对话分析更有用。
然而,尽管取得了重大进展,但将说话人日志和 ASR 集成到一个统一、无缝的系统中仍然是一项相当大的挑战。一个主要障碍在于需要大量高质量、带注释的音频数据,其中包含多位说话人。获取此类数据比收集单声道说话人数据集要复杂得多。对于低资源语言和医疗保健等领域,这一挑战尤为突出,在这些领域,严格的隐私法规进一步限制了数据的可用性。
最重要的是,许多实际用例需要这些模型来处理非常长的音频文件,有时一次对话长达数小时。对此类冗长数据进行训练更加复杂,因为很难找到或注释它们。这在需求和可用资源之间造成了巨大的差距,使得多说话人 ASR 成为语音技术领域最难啃的骨头之一。
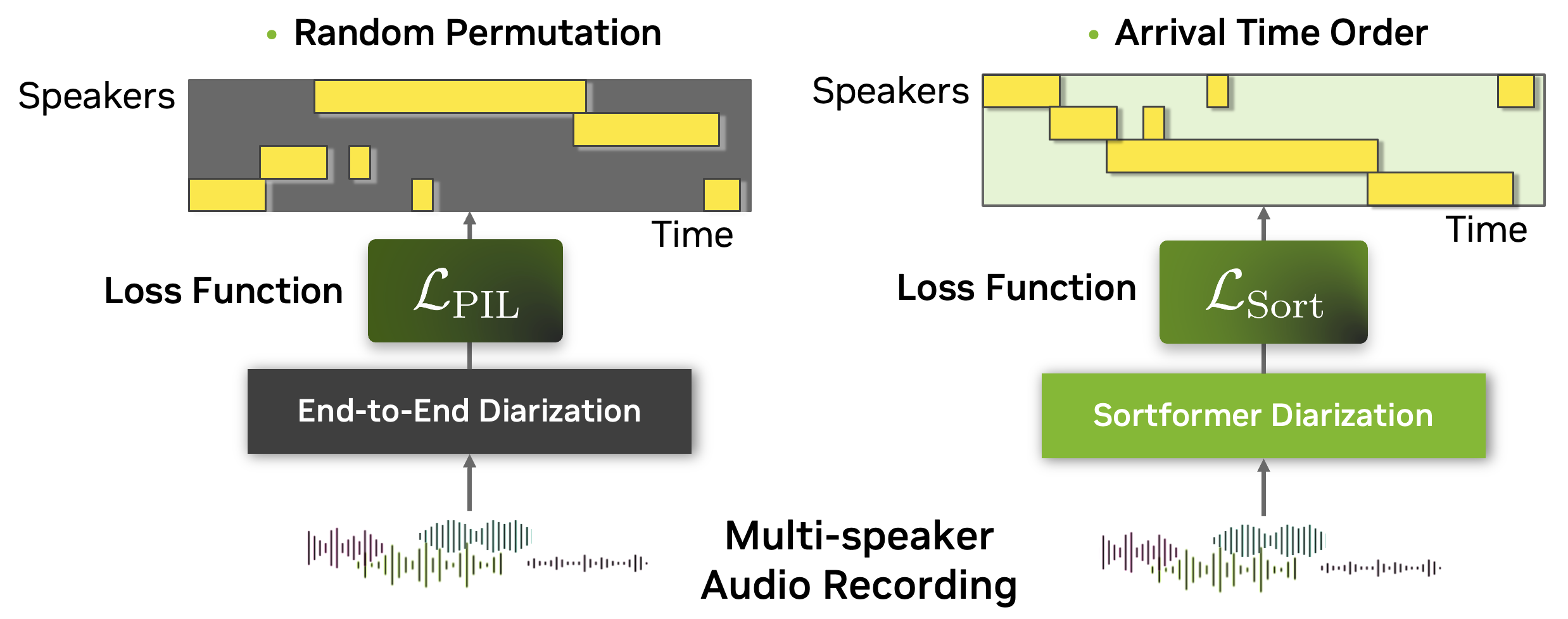
为了解决多说话人自动语音识别 (ASR) 的复杂性,我们引入了 Sortformer,这是一种新方法,结合了排序损失和将时间戳与文本标记对齐的技术。当应用于可批处理和可微分的计算图时,传统的排列不变损失 (PIL) 等方法面临挑战,特别是因为基于标记的目标难以将说话人特定属性融入到基于 PIL 的损失函数中。
为了解决这个问题,我们提出了一种到达时间排序 (ATS) 方法。在这种方法中,来自 ASR 输出的说话人标记和来自日志输出的说话人时间戳按其到达时间排序,以解决排列问题。这种方法允许使用基于标记的交叉熵损失来训练或微调多说话人 ASR 系统,从而无需使用基于时间戳或帧级别的 PIL 目标。
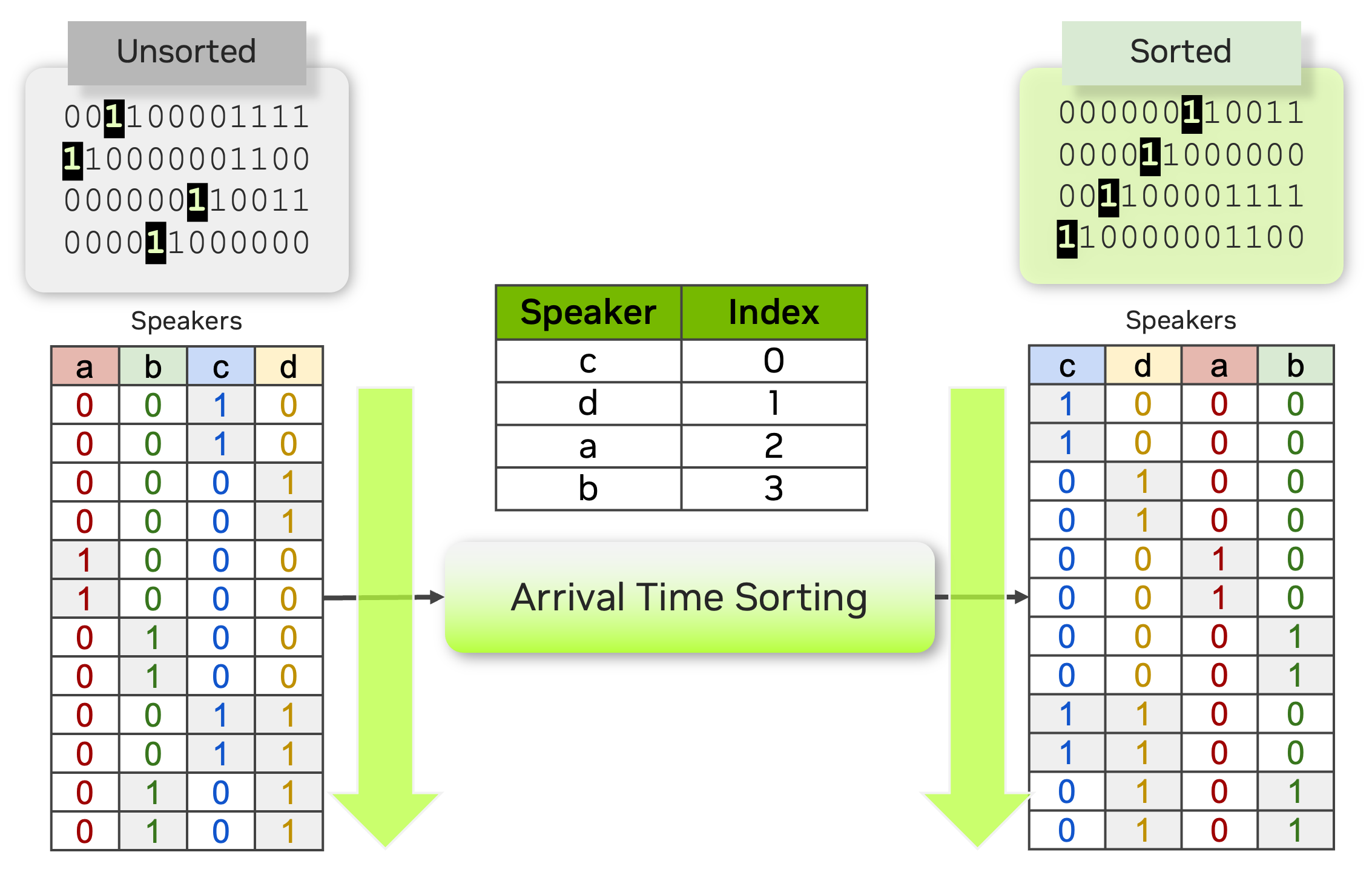
基于 ATS 的多说话人 ASR 系统由端到端神经日志模型 Sortformer 提供支持,该模型以到达时间顺序 (ATO) 生成说话人标签时间戳。为了训练神经日志器生成排序输出,我们引入了排序损失,这是一种创建梯度的方法,使 Transformer 模型能够学习 ATS 机制。

此外,如上图所示,我们的日志系统直接与 ASR 编码器集成。通过将说话人监督数据作为说话人内核嵌入到 ASR 编码器状态中,系统无缝地结合了说话人和转录信息。这种统一的方法提高了性能并简化了整体架构。
因此,我们的端到端多说话人 ASR 系统可以使用标记目标进行完全或部分训练,从而允许 ASR 和说话人日志模块都使用这些目标进行训练或微调。此外,在使用 Sortformer 时,在多说话人 ASR 训练阶段,不需要专门的损失计算函数,因为可以使用标准单说话人 ASR 模型的框架。这些兼容性大大简化并加速了多说话人 ASR 系统的训练和微调过程。
除了所有这些优势之外,Sortformer 还可以用作独立的端到端说话人日志模型。通过专门在高精度模拟数据上训练具有准确时间戳的 Sortformer 日志模型,您可以通过将 Sortformer 模型作为计算图中的说话人监督模型集成,来提高多说话人 ASR 系统的性能。
在本教程中,我们将引导您完成使用玩具数据集训练 Sortformer 日志模型的过程。在开始之前,我们将介绍排序损失计算和混合损失技术的概念。
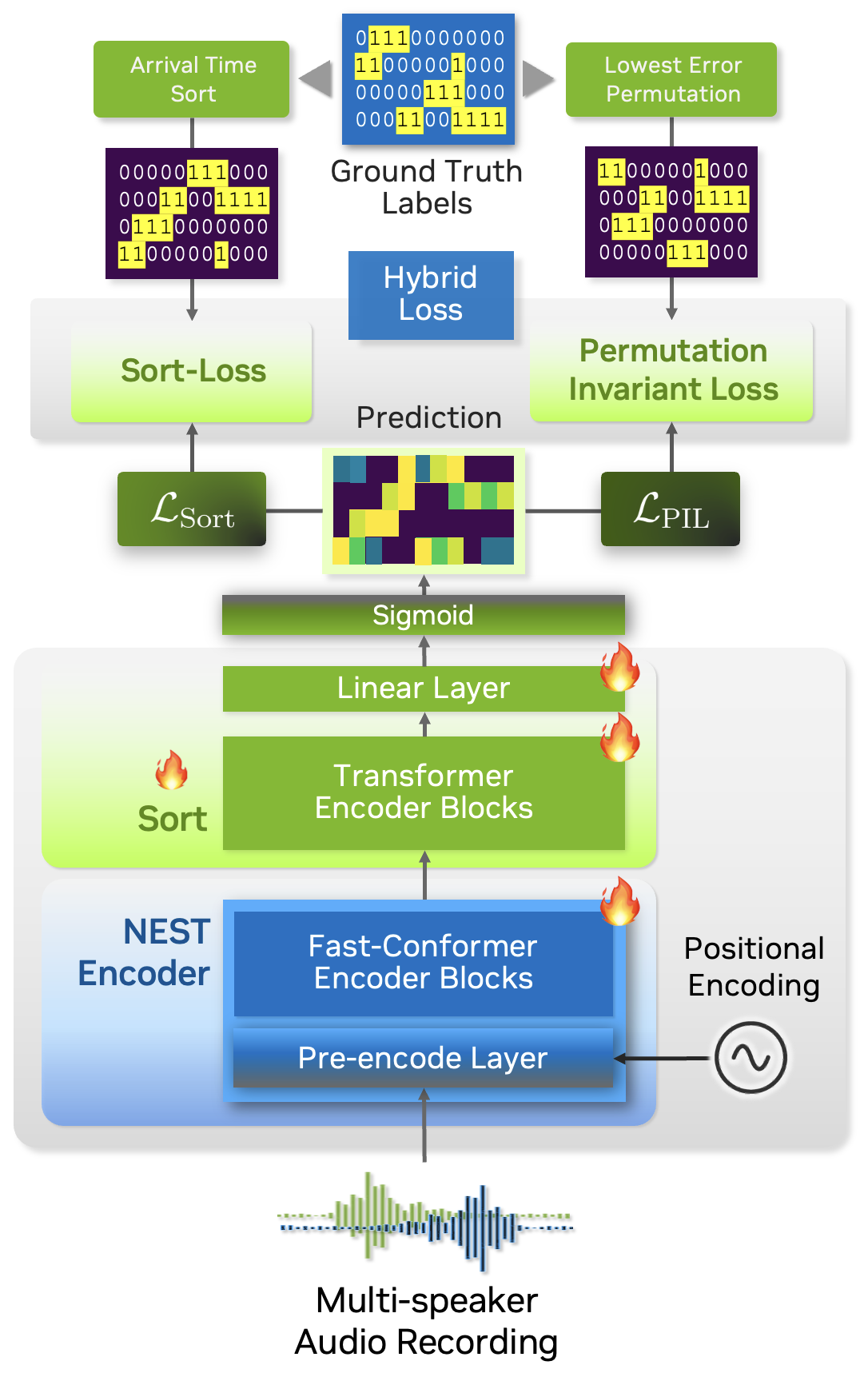
排序损失旨在将预测输出与真实标签进行比较,真实标签通常按到达时间顺序或其他相关指标排序。与之前的端到端日志系统(例如 EEND-SA、EEND-EDA)相比,Sortformer 引入的关键区别在于类别存在 $mathbf{hat{Y}}$ 的组织方式。
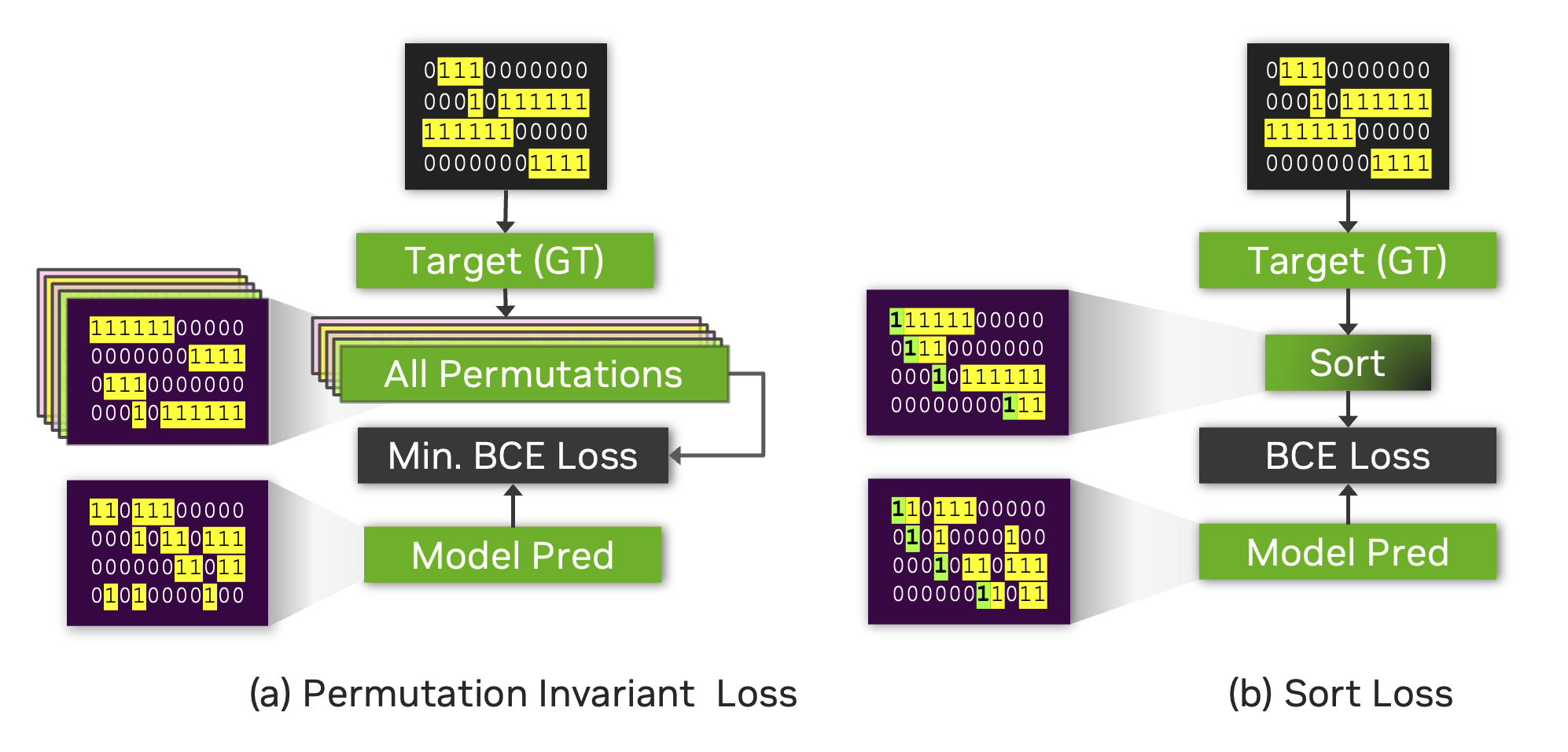
下图说明了排序损失与排列不变损失 (PIL) 或无排列损失之间的区别。
PIL 的计算方法是找到目标的排列,该排列可以最大限度地减少预测和目标之间的损失值。
排序损失只是比较预测和目标的说话人活动输出的到达时间排序版本。请注意,有时相同的真实标签会导致 Sort Loss 和 PIL 的目标矩阵不同。
例如,下图显示了两个相同的源目标矩阵(顶部的两个矩阵),但 Sort Loss 和 PIL 的结果目标矩阵是不同的。
多尺度说话人日志解码器#
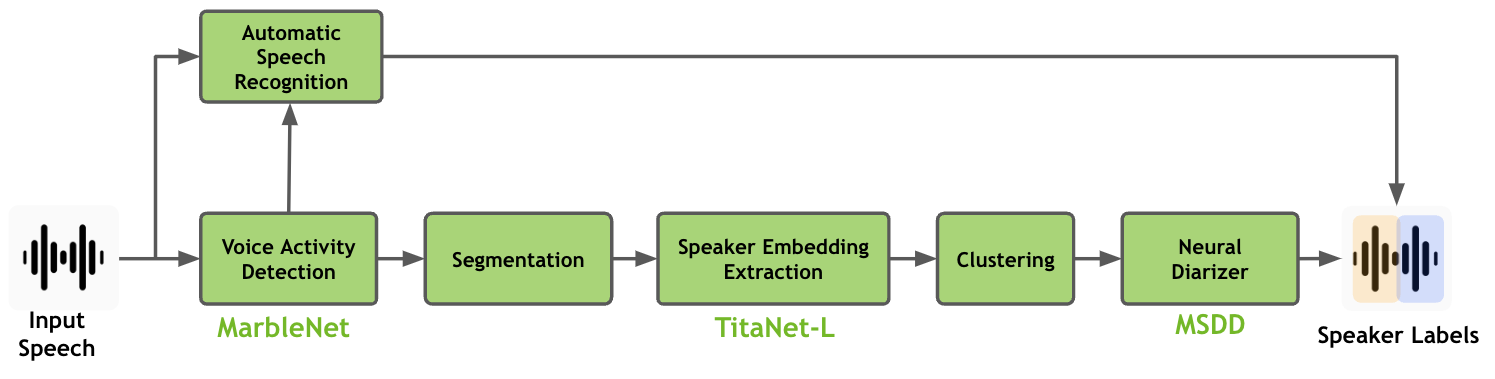
说话人日志系统需要生成非常准确的时间戳,因为在对话环境中,说话人轮次可能非常短。人类对话通常涉及非常短的后通道词,例如“是”、“嗯哼”或“哦”,这些词对于机器转录和识别说话人来说非常具有挑战性。因此,在根据说话人身份分割音频记录时,说话人日志需要在相对较短的片段上做出细粒度的决策,范围从十分之几秒到几秒。在如此短的音频片段上做出准确、细粒度的决策具有挑战性,因为不太可能从非常短的音频片段中捕获可靠的说话人特征。我们将讨论如何通过引入一种称为多尺度方法和多尺度日志解码器的新技术来处理多尺度输入,从而解决此问题。
就说话人特征的质量而言,提取长音频片段是可取的。但是,音频片段的长度也限制了粒度,这导致说话人标签决策的单位长度较粗。因此,说话人日志系统面临着时间分辨率和说话人表示的保真度之间的权衡,如下图所示的曲线所示。在说话人日志流水线中的说话人特征提取过程中,为了获得高质量的说话人表示向量,不可避免地会牺牲时间分辨率,方法是采用较长的语音片段。用通俗易懂的语言来说,如果我们试图非常准确地了解声音特征,那么我们需要查看更长的时间跨度。但是,与此同时,如果我们查看更长的时间跨度,我们必须对相当长的时间跨度做出决定,这会导致粗略的决策(时间分辨率较低)。如果我们考虑到即使是人类听众也无法准确判断谁在说话(如果只给出半秒的录音),那么这很容易理解。
在传统的日志系统中,音频片段长度范围为 1.5~3.0 秒,因为这些数字在说话人特征的质量和时间分辨率之间取得了很好的折衷。我们将这种类型的分割方法称为单尺度方法。即使采用重叠技术,单尺度分割也将时间分辨率限制为 0.75~1.5 秒,这在时间精度方面留有改进空间。时间分辨率粗略不仅会降低日志的性能,还会降低说话人计数精度,因为无法正确捕获短语音片段。更重要的是,说话人时间戳中如此粗略的时间分辨率使得解码后的 ASR 文本与说话人日志结果之间的匹配更容易出错。

为了解决这个问题,提出了多尺度方法,通过从多个片段长度中提取说话人特征,然后组合来自多个尺度的结果,从而应对这种权衡。多尺度方法通过采用多尺度分割并从每个尺度提取说话人嵌入来实现。上图的左侧显示了如何在多尺度分割方法中执行四个不同的尺度。在片段亲和力计算过程中,来自最长尺度到最短尺度的所有信息都会被组合,但仅针对最短片段范围做出决策。当组合来自每个尺度的特征时,每个尺度的权重在很大程度上影响说话人日志性能。
由于尺度权重在很大程度上决定了说话人日志系统的准确性,因此应将尺度权重设置为具有最大化的说话人日志性能。因此,我们提出了一种新颖的多尺度日志系统,称为多尺度日志解码器 [SD-MODELS1],它可以动态确定每个尺度在每个时间步的重要性。
多尺度日志解码器从多个尺度获取多个说话人嵌入向量,然后估计所需的尺度权重。基于估计的尺度权重,生成说话人标签。因此,如果输入信号被认为在某些尺度上具有更准确的信息,则所提出的系统会更侧重于大尺度。
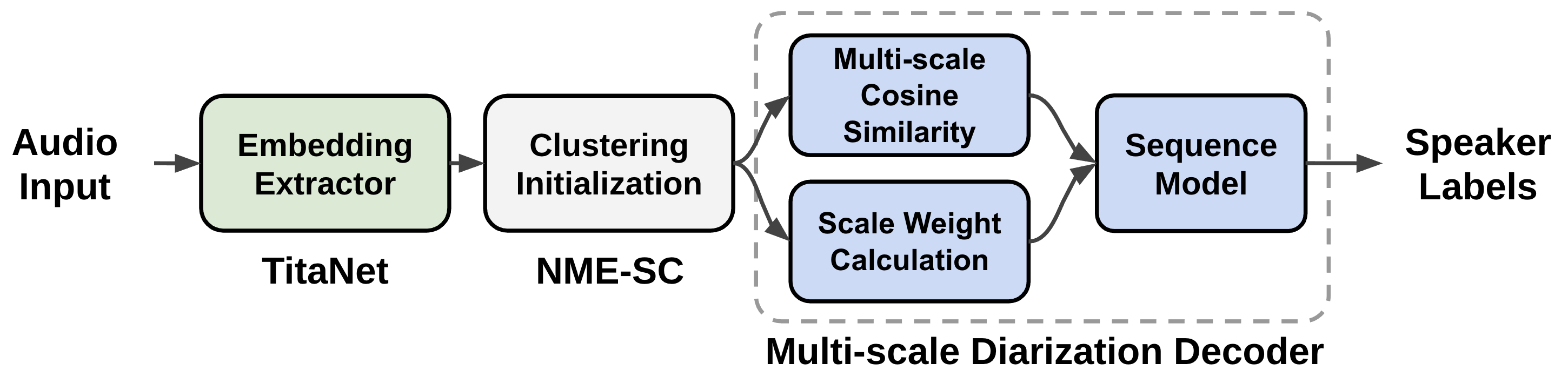
上图显示了多尺度说话人日志系统的数据流。从音频输入中提取多尺度片段,并通过使用说话人嵌入提取器 (TitaNet) 生成多尺度音频输入的相应说话人嵌入向量。随后,提取的多尺度嵌入由聚类算法处理,以向 MSDD 模块提供初始聚类结果。MSDD 模块使用聚类平均说话人嵌入向量将这些向量与输入说话人嵌入序列进行比较。估计每个步骤的尺度权重以衡量每个尺度的重要性。最后,训练序列模型以输出每个说话人的说话人标签概率。

一个名为多尺度日志解码器 (MSDD) 的神经网络模型经过训练,可以通过动态计算每个尺度的权重来利用多尺度方法。MSDD 获取初始聚类结果,并将提取的说话人嵌入与聚类平均说话人表示向量进行比较。
最重要的是,每个时间步每个尺度的权重是通过尺度加权机制确定的,其中尺度权重是从应用于多尺度说话人嵌入输入和聚类平均嵌入的 1-D 卷积神经网络 (CNN) 计算得出的,如上图所述。
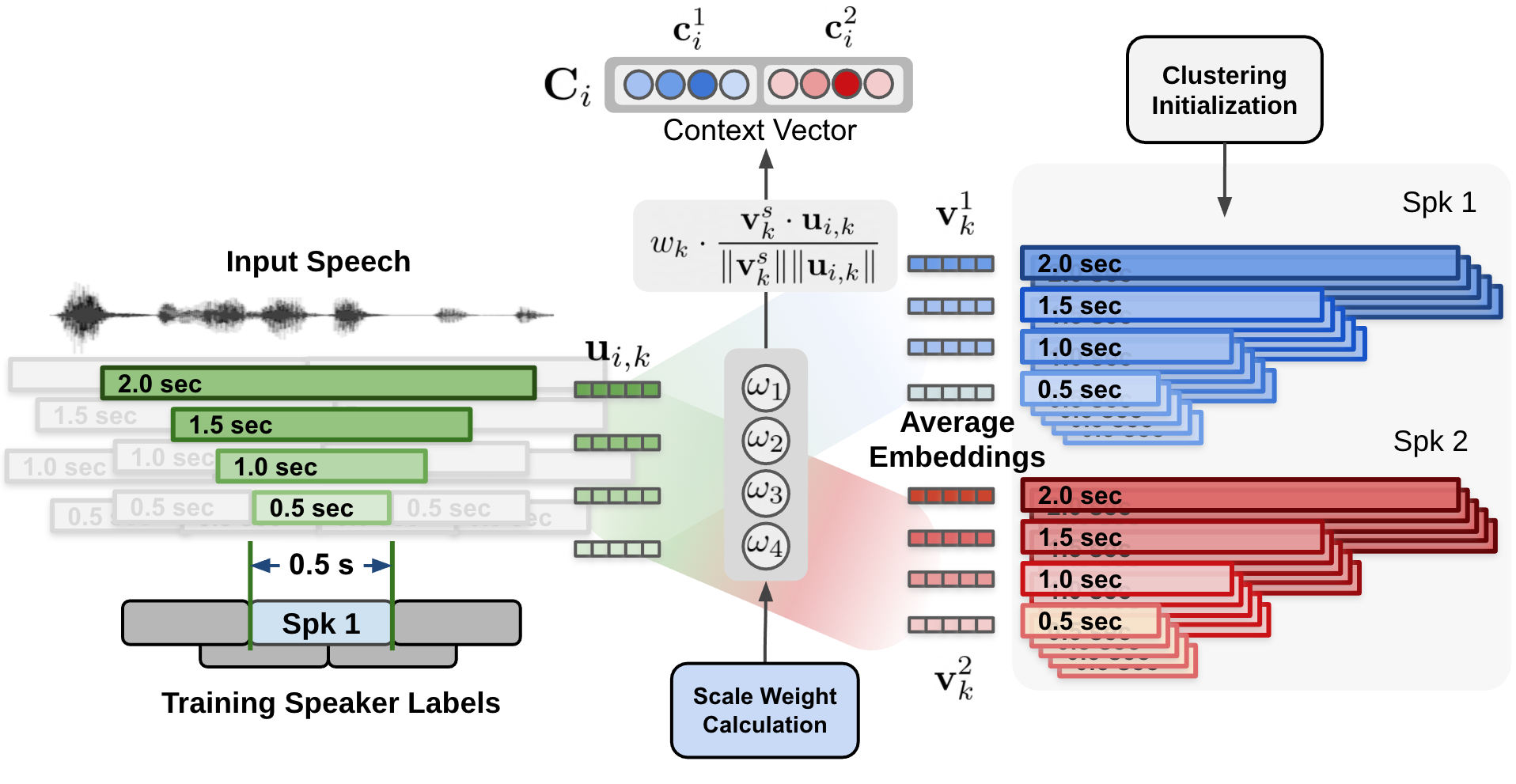
估计的尺度权重应用于为每个说话人和每个尺度计算的余弦相似度值。上图显示了通过将估计的尺度权重应用于在聚类平均说话人嵌入和输入说话人嵌入之间计算的余弦相似度来计算上下文向量的过程。
除了基于 CNN 的加权方案外,NeMo 工具包中的 MSDD 实现还允许使用多种选项来计算尺度权重 model.msdd_module.weighting_scheme
conv_scale_weight:默认设置。使用 1-D CNN 过滤器计算尺度权重。attn_scale_weight:通过在聚类平均嵌入和输入嵌入之间应用注意力机制来计算尺度权重。这可以看作是每个时间步尺度的注意力值。
最后,每个步骤的每个上下文向量都被馈送到一个多层 LSTM 模型,该模型生成每个说话人的说话人存在概率。下图显示了 LSTM 模型和上下文向量输入如何估计说话人标签序列。
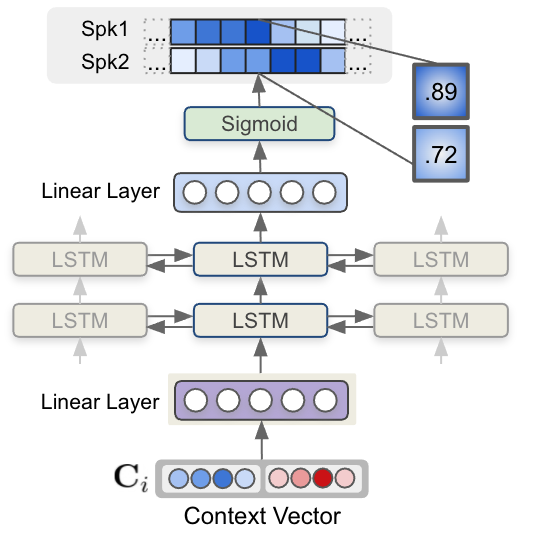
在 NeMo 工具包中,MSDD 实现通过指定 model.msdd_module.context_vector_type 提供了上下文向量的多个选项
cos_sim:如本文档所述,尺度权重应用于聚类平均嵌入向量和输入嵌入向量之间的余弦相似度值。默认为cos_sim。elem_prod:尺度权重直接应用于说话人嵌入向量,然后为聚类平均嵌入向量和输入嵌入向量计算加权说话人嵌入向量。最后,计算聚类平均加权说话人嵌入向量和输入多尺度嵌入向量之间的元素乘积,并将其作为每个步骤的上下文向量馈送到 LSTM。
参考文献#
Tae Jin Park、Nithin Rao Koluguri、Jagadeesh Balam 和 Boris Ginsburg。多尺度说话人日志与动态尺度加权。2022 年。URL:https://arxiv.org/abs/2203.15974,doi:10.48550/ARXIV.2203.15974。