1. NVIDIA Magnum IO GPUDirect Storage 概述指南#
NVIDIA® Magnum IO GPUDirect® Storage 概述指南提供了 GDS 的高级概述。
2. 简介#
GDS 实现了 GPU 内存和存储之间直接内存访问 (DMA) 传输的直接数据路径,从而避免了通过 CPU 的反弹缓冲区。使用此直接路径可以缓解系统带宽瓶颈,并减少 CPU 的延迟和利用率负载。
本指南提供了 GPUDirect Storage (GDS) 的高级概述,帮助您为 GDS 启用文件系统的指导,以及关于文件系统特性及其与 GDS 关系的见解。本指南还概述了关于 GDS 的功能、注意事项和软件架构。此高级别介绍为 cuFile API 参考指南 中更深入的技术信息奠定了基础,该指南适用于需要修改内核的 GDS 用户。
2.2. 开发人员的优势#
GDS 为应用程序开发人员提供以下优势
在 GPU 内存和存储之间启用直接路径。
可以缓解带宽瓶颈,减少延迟,并减少数据传输时 CPU 的负载。
减少性能影响,并降低 CPU 处理存储数据传输的依赖性。
在完全迁移到 GPU 的计算管线上,性能倍增器位于计算优势之上,从而使 GPU 而不是 CPU 成为移动在存储和 GPU 之间的数据的首次和最后一次接触点。
支持与其他基于操作系统的文件访问的互操作性,这使得可以使用传统文件 IO 将数据传输到设备和从设备传输数据,然后中间件或使用 cuFile API 的应用程序程序可以访问这些数据。
cuFile API 及其实现提供了以下优势
一系列 API,为 CUDA® 应用程序提供对本地或分布式文件和块存储的最佳性能访问。
当与 GPU 之间进行传输时,相对于现有标准 Linux 文件 IO,性能更高,CPU 负载更低。
通过消除对内存分配和数据移动的仔细专家管理的需求,更易于使用。
相对于现有隐式文件-GPU 数据移动方法,API 序列更简单,后者需要更复杂的内存和数据移动管理,无论是在 CPU 和 GPU 上还是在两者之间。
在各种存储类型之间具有通用性,这些存储类型跨越各种本地和分布式文件系统、块接口和命名空间系统,包括标准 Linux 和第三方解决方案。
用于执行独立于 GPU 应用程序内存类型的文件 I/O 的主要 API。
能够将内存定位于已使用 cudaMalloc 或 cuMemAlloc 或 cuMemCreate/cuMemMap 分配给 GPU,或 cudaHostAlloc 或 cudaMallocHost 分配给 CPU 的内存。GDS 对等模式不支持可迁移内存,即可使用
cudaMallocManaged分配的内存或系统分配的内存(malloc、堆栈等),在支持 UVM 的系统(如 Grace-Hopper)上。GDS 将使用兼容路径(使用内部 GPU/CPU 反弹缓冲区)支持对这些内存分配的 IO。
cuFile API 的 Stream 子集提供了以下优势
异步卸载操作相对于 CUDA 流进行排序。
IO 后计算:GPU 内核在数据传输到 IO 之前生成数据。
IO 后计算:在数据传输完成后,GPU 内核可以继续进行。
跨流的可用并发。
使用不同的 CUDA 流允许并发执行的可能性以及并发使用多个 DMA 引擎的可能性。
2.3. 预期用途#
cuFile 功能可以通过以下方式使用
当存储和 GPU 内存之间的 IO 成为性能瓶颈时,cuFile 实现可以提高吞吐量。
这种情况发生在计算管线已从 CPU 迁移到 GPU 的情况下,以便在与存储进行传输之前或之后,第一个和最后一个接触数据的代理在 GPU 上执行。
cuFile API 目前是显式的,并且在存储和完全适合可用 GPU 物理内存的缓冲区之间进行读取或写入。
cuFile API 适用于粗粒度流式传输,而不是细粒度随机访问。
对于细粒度访问,可以摊销用于进行内核转换和通过操作系统的底层软件开销。
3. 功能概述#
本节提供 GDS 的功能概述。它涵盖了基本用法、通用性、性能考虑因素和解决方案的范围。本文档适用于从 CPU 发出的 cuFile API。
3.1. 显式和直接#
GDS 是一种以性能为中心的解决方案,因此端到端传输的性能是延迟开销和最大可实现带宽的函数。
以下是 GDS 中使用的一些术语
- 显式编程请求
立即调用存储和 GPU 内存之间传输的显式编程请求是主动的。
- 隐式请求
对存储的隐式请求,该请求是由内存引用引起的,该内存引用导致页面错误从 GPU 返回到 CPU,并可能从 CPU 返回到存储,是被动的。
注意
被动活动往往会产生更多开销。由于 GDS 是显式和主动的,因此 GDS 通过其显式 cuFile API 最大化了性能。
当避免额外的副本并且采用最高带宽路径时,延迟更低。没有 GDS,则必须通过 CPU 中的反弹缓冲区进行额外复制,这会引入延迟并降低有效带宽。
注意
GDS 的延迟改进在小传输中最明显。
使用 GDS,虽然有例外,但零拷贝方法是可能的。此外,当不再需要通过 CPU 进行复制时,即使数据路径必须通过 CPU 根端口,数据路径也不包括 CPU 内存,因为 PCIe 拓扑。在某些系统上,与通过 CPU 的数据路径相比,本地或远程存储的直接路径(通过 PCIe 交换机或充当 PCIe 交换机的 NIC)提供的峰值带宽至少是其两倍。使用 cuFile API 访问 GDS 技术可以实现显式和直接传输,从而提供更低的延迟和更高的带宽。
对于 GPU 内存和存储之间的直接数据传输,必须以 O_DIRECT 模式打开文件。如果文件未以此模式打开,则内容可能会在 CPU 系统内存中缓冲,这与直接传输不兼容。有关更多详细信息,请参阅 GPUDirect Storage O_DIRECT 要求指南。
注意
从 CUDA Toolkit 12.2(GDS 版本 1.7.x)开始,即使对于以非 O_DIRECT 模式打开的文件,cuFile 库也采用 GDS 驱动的 O_DIRECT 路径,用于在 GPU 内存和存储之间传输页对齐缓冲区以及对齐大小和偏移量。
显式复制与使用 mmap
以下代码示例比较了显式复制与使用 mmap 并根据需要产生隐式页面错误的代码序列。
此代码示例使用显式复制
int fd = open(file_name,...)
void *sysmem_buf, *gpumem_buf;
sysmem_buf = malloc(buf_size);
cudaMalloc(gpumem_buf, buf_size);
pread(fd, sysmem_buf, buf_size);
cudaMemcpy(sysmem_buf,
gpumem_buf, buf_size, H2D);
doit<<<gpumem_buf, ...>>>
// no faults;
此代码示例使用 mmap
int fd = open(file_name, O_DIRECT,...)
void *mgd_mem_buf;
cudaMallocManaged(mgd_mem_buf, buf_size);
mmap(mgd_mem_buf, buf_size, ..., fd, ...)
doit<<<mgd_mem_buf, ...>>>
// fault on references to mgdmem_buf
在第一个示例中,pread 用于将数据从存储移动到 CPU 反弹缓冲区 sysmem_buf,cudaMemcpy 用于将该数据移动到 GPU。在第二个示例中,mmap 使托管内存由文件支持。从 GPU 对托管内存的引用(GPU 内存中不存在)将导致错误返回到 CPU,然后返回到存储,从而导致隐式传输。
GDS 实现了靠近存储的代理(NIC 或 NVMe 驱动器)和 GPU 内存之间的 DMA。传统的 POSIX 读取和写入 API 仅适用于驻留在 CPU 系统内存中的缓冲区的地址。相比之下,cuFile API 在驻留在 GPU 内存中的缓冲区的地址上运行。因此它们看起来非常相似,但有一些差异,如图 2 所示。
比较 POSIX API 和 cuFile API
以下代码示例比较了 POSIX API 和 cuFile API。POSIX pread 和 pwrite 需要 CPU 系统内存中的缓冲区和一个额外的副本,但 cuFile 读取和写入仅需要文件句柄注册。
此代码示例使用 POSIX API
int fd = open(...)
void *sysmem_buf, *gpumem_buf;
sysmem_buf = malloc(buf_size);
cudaMalloc(gpumem_buf, buf_size);
pread(fd, sysmem_buf, buf_size);
cudaMemcpy(sysmem_buf,
gpumem_buf, buf_size, H2D);
cuStreamSynchronize(0);
doit<<<gpumem_buf, ...>>>
此代码示例使用 cuFile API
int fd = open(file_name, O_DIRECT,...)
CUFileHandle_t *fh;
CUFileDescr_t desc;
desc.type=CU_FILE_HANDLE_TYPE_OPAQUE_FD;
desc.handle.fd = fd;
cuFileHandleRegister(&fh, &desc);
void *gpumem_buf;
cudaMalloc(gpumem_buf, buf_size);
cuFileRead(&fh, gpumem_buf, buf_size, ...);
doit<<<gpumem_buf, ...>>>
基本的 cuFile 功能是
存储和 GPU 内存之间的显式数据传输,非常类似于 POSIX
pread和pwrite。在 CUDA 流中执行 IO,使其相对于同一流中的其他命令既是异步的又是排序的。
GDS 提供的直接数据路径依赖于启用了 GDS 的文件系统驱动程序的可用性。这些驱动程序在 CPU 上运行,并实现设置直接数据路径的控制路径。
3.2. 性能优化#
在存在将数据在存储和 GPU 内存之间显式且直接移动的可行路径之后,还有其他机会可以提高性能。
3.2.1. 实施性能增强#
GDS 提供了一个用户界面,该界面抽象了实现细节。通过该实现中的性能优化,在权衡取舍方面,随着时间的推移会得到增强,并针对每个平台和拓扑进行调整。
下图向您展示了其中一些性能优化的列表
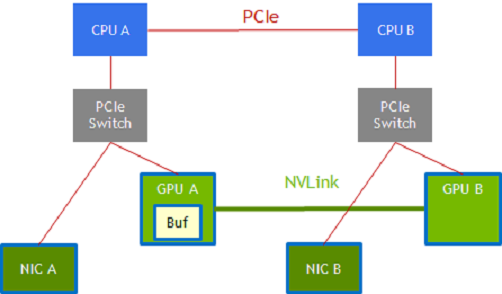
图 1 性能优化#
路径选择
端点之间可能存在多个可用路径。例如,在 NVIDIA DGX-2 系统中,分别连接到 CPU 插槽 CPU A 和 CPU B 的 GPU A 和 GPU B 可以通过两条路径连接。
GPU A –> CPU A PCIe 根端口 –> 通过 CPU 互连 的 CPU A 到 CPU B –> 沿另一条 PCIe 路径到 GPU B 的 CPU B。
使用 NVLink 的 GPU A –> GPU B。
类似地,通过使用中间交换机,通过 PCIe 连接到 CPU A 和 GPU A 的 NIC 可以选择到 GPU B 的数据路径
NIC –> CPU A PCIe 根端口,通过 CPU 互连的 CPU A –> CPU B,以及沿另一条 PCIe 路径 的 CPU B –> GPU B。
NIC –> GPU A 中的暂存缓冲区和 NVLink –> GPU B。
中间缓冲区中的暂存
批量数据传输通过 DMA 复制引擎执行。并非通过系统的所有路径都可以通过单阶段传输实现,有时传输会分解为多个阶段,并在途中设置暂存缓冲区。
在图形中的 NIC-GPU A-GPU B 示例中,需要 GPU A 中的暂存缓冲区,并且 GPU A 或 GPU B 中的 DMA 引擎用于在 GPU A 的内存和 GPU B 的内存之间传输数据。
数据可能仅通过 PCIe 沿 CPU 传输,也可能通过 NVLink 在 GPU 之间直接传输。虽然 DMA 引擎可以跨越 PCIe 端点,但涉及 NVLink 的路径可能涉及通过缓冲区 (GPU A) 进行暂存。
动态路由
路径和暂存。上图中的两条路径在左半部分和右半部分的端点之间可用,红色 PCIe 路径或绿色 NVLink 路径。
3.2.2. 跨线程的并发#
注意
所有 API 都是线程安全的。
使用 GDS 是一种性能优化。在应用程序在功能上能够通过将指向 GPU 缓冲区的指针向下传递到应用程序层,从而直接在存储和 GPU 缓冲区之间移动数据之后,性能是下一个关注点。系统级别的 IO 性能来自多个链路和多个设备上的并发传输。每个 4 x 4 NVMe PCIe 设备的并发传输对于从一个 x16 PCIe 链路获得完整带宽是必要的。由于存在到每个 GPU 和每个 NIC 的 PCIe 链路,因此需要许多并发传输来使系统饱和。GDS 不会提高并发性,因此此级别的性能调整由应用程序管理。
3.2.3. 异步性#
CPU 和一个或多个 GPU 之间的另一种并发形式可以通过应用程序线程中的异步性来实现。
在此过程中,工作被提交以供 CPU 延迟执行,并且 CPU 可以继续向 GPU 提交更多工作或完成 CPU 上的工作。此过程在 CUDA 中添加了对异步 IO 的支持,这可以使包含 IO 的相互依赖的工作图能够提交以供延迟执行。
3.2.4. 批处理#
每次从应用程序提交到 cuFile 实现时,都会涉及固定的开销。对于同时提交许多 IO 事务的使用模型,批处理通过摊销批处理中事务的固定开销来减少开销,从而提高性能。
批处理 API 本质上是异步的。有关更多信息,请参阅 cuFile API 参考指南。
3.2.5. 在 cuFile 中使用 CUDA 流#
提供一种机制,用于按照 CUDA 流语义执行 I/O 的异步提交和异步执行。
数据大小、缓冲区和文件中的偏移量可能会在有效范围内动态更改,具体取决于先前 CUDA 内核或函数的执行。
3.3. 兼容性和通用性#
虽然 GDS 的目的是避免在 CPU 系统内存中使用反弹缓冲区,但即使在次优情况下,回退到此方法的能力也允许普遍使用 cuFile API。兼容模式适用于不支持的配置,该模式将 IO 操作映射到回退路径。
对于以下一个或多个条件为真的系统,此路径通过 CPU 系统内存进行暂存
通过使用用户版本的
cufile.json文件进行显式配置控制。有关更多信息,请参阅 cuFile API 参考指南。
缺少
nvidia-fs.ko内核驱动程序,例如,因为它未安装在主机上,其中运行着使用 cuFile 的容器。nvidia-fs.ko内核驱动程序对于 CUDA 版本 12.8 及更高版本中 cuFile 的 NVMe(本地或带有 NVIDIA DOCA SNAP)挂载不是必需的。所选文件挂载上缺少相关的启用 GDS 的文件系统,例如,因为使用的几个系统挂载之一不支持 GDS。
文件系统特定的条件,例如,当
O_DIRECT无法应用时。正在对文件系统进行低级别分析的供应商、中间件开发人员和用户应查看 GPUDirect Storage O_DIRECT 要求指南 以获取更多信息。
有关更多信息,请参阅 cuFile API 参考指南 中的 cuFileHandleRegister。当未使用 GDS 时,在兼容模式下在存储和 GPU 内存之间传输的基于 GPU 的应用程序的性能通常至少与或优于当前基于 CPU 的 API。CPU 路径的测试仅限于基于 POSIX 的 API 以及不包括 GDS 的合格平台和文件系统。
即使可以使用 GDS 进行传输,也并非始终可以进行直接传输。以下是 cuFile API 无缝处理的一些案例示例
缓冲区未对齐,例如以下情况
文件的偏移量未与 cufile 块大小对齐。
GPU 内存缓冲区地址未与 cufile 块大小对齐。
IO 请求大小不是 cufile 块大小的倍数。
请求的 IO 大小太小,文件系统无法支持 RDMA。
传输大小超过 GPU BAR1 光圈的大小。
GPU 内存缓冲区和存储之间的最佳传输路径涉及中间暂存缓冲区,例如,使用 NVLink。
兼容模式和需要额外步骤的案例的无缝处理扩展了 GDS 的通用性,并使其更易于使用。
3.4. 监控#
本节提供有关可用于跟踪 GDS 中的功能和性能问题的监控工具的信息。
GDS 支持以下监控工具,用于跟踪功能和性能问题
Ftrace可以使用
Ftrace跟踪 GDS 功能的导出符号。您还可以使用libcufile.so库中的静态跟踪点,但nvidia-fs.ko尚不支持跟踪点。有关更多信息,请参阅 GPUDirect Storage 故障排除指南。日志记录错误条件和调试输出可以在日志文件中生成。此信息对于影响许多 API 但只需要报告一次的情况,或者影响没有返回值来报告错误的 API 的情况非常有用。
cufile.json文件用于选择至少报告级别,例如ERROR、WARN、INFO、DEBUG和TRACE。性能分析GDS 可以配置为收集各种统计信息。
这些工具以及第三方工具支持的限制在 GPUDirect Storage 故障排除指南 中进行了更详细的描述。
3.5. GDS 中解决方案的范围#
GDS 添加了新 API,其功能是当今操作系统不支持的,包括直接传输到 GPU 缓冲区、异步性和批处理。这些 API 提供了性能提升,具有平台调整和拓扑调整的路径和暂存选择,这增加了持久价值。
cuFile API 下的实现克服了当前操作系统中的限制。其中一些限制是暂时的,可能会在未来版本的操作系统中消除。虽然这些解决方案目前不可用,并且可能需要时间才能采用,但今天仍需要其他启用 GDS 的解决方案。以下是当前 GDS 中可用的解决方案
分布式文件系统的第三方供应商解决方案。
通过开源、上游 Linux 的长期支持,未来的 GDS 实现将无缝使用。
通过使用修改后的存储驱动程序实现的本地文件系统支持。
总体 cuFile 架构涉及组件的组合,其中一些来自 NVIDIA,一些来自第三方。
以下是 NVIDIA 原创内容列表
用户级 cuFile 库
libcufile.so,它在闭源代码中实现以下内容cuFile 驱动程序 API
cuFileDriver{Open, Close}cuFileDriver{GetProperties, Set*}
cuFile 同步 IO API
cuFileHandle{Register, Deregister}cuFileBuf(Register, Deregister}cuFile{Read, Write}
cuFile API 的 Stream 子集
cuFile{Read, Write}Async, cuFileStreamRegister, cuFileStreamDeregister
cuFileBatch API
cuFileBatchIO{SetUp, Submit, GetStatus, Cancel, Destroy}调用标准 Linux 中的 VFS 组件,无论文件系统是用于所有基于内核的文件系统和原始设备文件的标准 Linux。
nvidia-fs.ko,内核级驱动程序实现来自修改后的 Linux 内核模块或来自专有文件系统的回调,这些回调启用到 GPU 内存的直接 DMA。
根据 GPLv2 获得许可。
同样,任何调用 nvidia-fs API 的第三方内核组件都应期望受 GPLv2 约束。
CUDA 12.8 起,NVMe(本地驱动器或 DOCA SNAP)不需要
第三方内容
替换 Linux 文件系统和块系统等部分的专有代码堆栈。
3.6. 动态路由#
GDS 动态路由是一项功能,用于为 cuFileReads 和 cuFileWrites 选择进出基于网络的文件系统(如 DDN-EXAScaler、VAST-NFS 和 WekaFS)上的文件的最佳路径。对于 GPU 与存储 NIC 不共享同一根端口的硬件平台,与 PCIe 交换机下的 p2p 流量相比,对等事务 (p2p) 可能具有更高的延迟且效率低下。
借助此功能,cuFile 库会根据平台配置,尝试有效地路由进出 GPU 的 I/O,而无需支付跨根端口 p2p 流量的代价。例如,如果存储 NIC 与另一个允许的 GPU(例如 GPU1)共享一个公共 PCIe 根端口,并且目标 GPU(例如 GPU0)跨 CPU 根复合体,则 cuFile 库可以使用 GPU1 上的反弹缓冲区来执行到 GPU1 的 p2p 事务,并将数据复制到目标 GPU0。GPU 之间 NVLINK 的存在可以进一步加速后续设备到设备 (GPU1->GPU0) 的 I/O 传输,方法是使用 NVLINK 而不是 PCIe。
对于每个挂载/卷,cuFile 库预先计算出最佳 GPU,这些 GPU 与可用的存储 NIC 具有最小的 PCI 距离,以路由 I/O。在读取和写入期间,cuFile 检查目标 GPU 是否共享一个公共 PCIe 交换机,并且是否不需要流量跨 CPU 根复合体。如果路径已经是最佳路径,则动态路由不适用,否则 cuFile 库会选择候选 GPU 作为中间反弹缓冲区,并执行设备到设备复制到目标 GPU 缓冲区。
注意
可能会有多个候选 GPU 用于暂存中间缓冲区,并且可能与所有存储 NIC 的距离不等,在这种情况下,cuFile 依赖于底层文件系统驱动程序来选择最佳存储 NIC 以用于候选 GPU,基于 nvidia-fs 回调接口,以根据 GPU 缓冲区选择最佳 NIC。
3.6.1. 动态路由的 cuFile 配置#
"properties.rdma_dynamic_routing" 启用/禁用分布式文件系统(Lustre、WekaFS、NFS)的动态路由功能。默认情况下,此功能处于关闭状态。
在 I/O 传输到 GPU 将导致跨 RootPort PCie 传输的平台上,启用此功能可能有助于提高整体 BW,前提是存在一个或多个 GPU,其 Root Port 与存储 NIC 的 Root Port 通用。如果启用此功能,请在特定于文件系统的部分(用于 mount_table)或属性部分中的 rdma_dev_addr_list 属性中提供挂载使用的 IP 地址。
"rdma_dynamic_routing": false
properties.rdma_dynamic_routing order 表示路由规则。如果路由策略适用,则根据指定路由策略的顺序选择路由策略。默认情况下,路由顺序如下所示。如果第一个策略不适用,则回退到下一个策略,依此类推。
policy GPU_MEM_NVLINKS:使用具有 NVLink 的 GPU 内存以在 GPU 之间传输数据
policy GPU_MEM:使用具有 PCIe 的 GPU 内存以在 GPU 之间传输数据
policy SYS_MEM:使用具有 PCIe 的系统内存以将数据传输到 GPU
policy P2P:使用 P2P PCIe 以在 NIC 和 GPU 之间进行传输
"rdma_dynamic_routing_order": [ "GPU_MEM_NVLINKS", "GPU_MEM", "SYS_MEM", "P2P" ]
下表总结了动态路由可以应用的用例,并描述了每个路由策略。
用例 |
GPU_MEM_NVLINKS |
GPU_MEM |
SYS_MEM |
P2P |
|---|---|---|---|---|
NIC 和 GPU 不共享公共父 PCIe 交换机 如果启用,将使用动态路由 |
系统中的 GPU 具有 NVLink 使用具有 NVLink 的 GPU 内存以在 GPU 之间传输数据。此策略仅在以下情况下适用
|
系统中的 GPU 没有 NVLink 使用具有 PCIe 的 GPU 内存以在 GPU 之间传输数据。此策略仅在存在与 NIC 位于同一 PCIe 树中的 GPU 时适用。 |
没有 GPU 与存储 NIC 共享公共根端口 使用固定系统内存和 PCIe 将数据传输到 GPU |
这是没有动态路由的默认模式。 使用 P2P PCIe 以在 NIC 和 GPU 之间进行传输。PCIe 流量将跨 RootPort。 |
NIC 和 GPU 位于同一 PCIe 树中 即使启用,也不会使用动态路由 |
P2P/兼容模式 |
P2P/兼容模式 |
P2P/兼容模式 |
P2P/兼容模式 |
一个示例路由顺序可能是
"rdma_dynamic_routing_order": [ "GPU_MEM_NVLINKS", "SYS_MEM"]
一个用例可能是,如果存在一对 GPU 但没有 NVLink,则路由策略应回退到使用系统内存进行 I/O 传输。
另一个示例路由顺序可能是
"rdma_dynamic_routing_order": [ "SYS_MEM"]
如果指定了这样的顺序,即使存在一对带有 NVLinks 的 GPU,路由策略也将使用系统内存进行 I/O 传输。
3.6.2. cuFile DFS 挂载配置#
用户可以通过 json 属性 rdma_dev_addr_list 向库指定分布式文件系统挂载使用的存储 NIC 列表。库使用此信息来计算可用于路由 IO 的最佳 GPU。设备地址列表可以分层格式指定。
属性名称 |
描述 |
|---|---|
property.rdma_dev_addr_list : {}
|
适用于单个文件系统、单个挂载。 这是全局配置,仅当每个文件系统或每个挂载 IP 地址列表为空时才使用。 |
fs.lustre.rdma_dev_addr_list : {}
|
适用于所有 Lustre 文件系统挂载。 这是每个文件系统的 IP 地址列表。对于属于此文件系统的文件,此列表将覆盖全局 IP 地址列表。请注意,如果设置了此键,则用户不应配置每个 mount_table,这将被视为配置错误。 |
fs.lustre.mount_table : {
/mnt/001 : { rdma_dev_addr_list : []
}
|
适用于多个 Lustre 挂载。 |
/mnt/002 : {
rdma_dev_addr_list : [] }
}
|
这是每个挂载的 IP 地址列表。此列表将覆盖每个文件系统的 IP 地址列表。此设置在地址列表配置中具有最高优先级,并覆盖该挂载的所有上述设置。 |
fs.nfs.rdma_dev_addr_list : {}
|
适用于所有 NFS 挂载。 |
fs.nfs.mount_table : {
/mnt/003 : { rdma_dev_addr_list : [] }
/mnt/004 : { rdma_dev_addr_list : [] }
}
|
适用于 NFS 共享。 |
RDMA 配置示例
{
"lustre": {
// IO threshold for read/write (param should be 4K aligned)) equal to or below which
// cuFile will use posix read/write
"posix_gds_min_kb" : 0,
"rdma_dev_addr_list" : [],
"mount_table" : {
"/lustre/ai200/client1" : {
"rdma_dev_addr_list" : ["172.172.1.40"]
},
"/lustre/ai200/client2" : {
"rdma_dev_addr_list" : ["172.172.2.40"]
}
}
},
"nfs": {
"rdma_dev_addr_list" : [],
"mount_table" : {
"/mnt/nfs/ib0/data/0" : {
"rdma_dev_addr_list" : ["192.168.0.12"]
},
"/mnt/nfs/ib1/data/0" : {
"rdma_dev_addr_list" : ["192.168.1.12"]
},
"/mnt/nfs/ib2/data/0" : {
"rdma_dev_addr_list" : ["192.168.2.12"]
},
"/mnt/nfs/ib3/data/0" : {
"rdma_dev_addr_list" : ["192.168.3.12"]
}
},
"weka": {
// enable/disable RDMA write
"rdma_write_support" : false
},
}
}
限制
该库无法区分使用通过配置指定的同一网络共享文件系统共享的多个挂载点;并将所有此类 IP 地址视为唯一的挂载条目。因此,建议仅为配置中的唯一共享提供配置。
3.6.3. 用于动态路由的 cuFile 配置验证#
一旦为具有所需 IP 地址配置的动态路由启用了 cuFile 配置,用户可以使用 gdscheck 来验证它。
$ ./gdscheck -p
...
properties.rdma_dynamic_routing : 1
properties.rdma_dynamic_routing_order : GPU_MEM_NVLINKS GPU_MEM SYS_MEM P2P
fs.lustre.mount_table :
/lustre/ai200/client1 dev_id 64768 : 172.172.1.40
/lustre/ai200/client2 dev_id 64769 : 172.172.2.40
fs.weka.rdma_write_support: 0
fs.nfs.mount_table :
/mnt/nfs/ib0/data/0 dev_id 58 : 192.168.0.12
/mnt/nfs/ib1/data/0 dev_id 59 : 192.168.1.12
/mnt/nfs/ib2/data/0 dev_id 60 : 192.168.2.12
/mnt/nfs/ib3/data/0 dev_id 61 : 192.168.3.12
...
4. 软件架构#
GDS 使靠近存储(NVMe 或 NIC)的 DMA 引擎能够将数据直接推(或拉)入(和拉出)GPU 内存。cuFile API 传递一个文件的参数、文件偏移量、要传输的大小以及 GPU 虚拟地址,参数可以读取或写入到该地址。虽然最终的聚合传输是一个连续的虚拟地址范围,但在实现中可能会发生几个较小的传输。文件系统将连续的虚拟地址范围分解为可能成为跨越多个设备的多个传输。一个例子是 RAID-0 和可能具有非连续物理地址范围的多个页面。生成的物理地址范围集称为散列表。
现有的尝试对 DMA 引擎进行编程的操作系统在没有帮助的情况下无法处理 GPU 虚拟地址。启用 GDS 的内核驱动程序使用回调到 GDS 内核模块 nvidia-fs.ko,对于 CUDA 12.8 之前的所有接口以及对于 CUDA 12.8 及更高版本的非 NVMe 挂载。这些回调提供了最终散列表中需要的 GPU 虚拟地址,该散列表用于对 DMA 引擎进行编程。
4.1. 软件组件#
GDS 软件堆栈中存在以下层
应用程序,包括 cufile.h,它从 CPU 发出 cuFile API 调用。
GDS 用户级库,
libcufile.so。Linux 虚拟文件系统,VFS。
Linux 或供应商内核存储驱动程序。
GDS 内核级库,
nvidia-fs.ko(见下文条件)。
4.2. 主要组件#
GDS 软件架构中的主要组件是
(来自 NVIDIA)
libcufile.so,它是用户级 cuFile 库实现 cuFile API,它是面向应用程序的 GDS API。
cuFileRead显示在部署的软件组件中的架构概述图中。有两种替代方案来实现 cuFile API
使用
nvidia-fs.ko内核驱动程序。除了下面在
nvidia-fs.ko下列出的情况外,所有使用 VFS 的文件系统都使用此路径。
cuFile 用户库实现了一种替代实现,它执行以下操作
在其 CPU 系统内存中使用其非页面缓存缓冲。
使用标准 POSIX 调用实现。
不需要使用 NVFS 内核驱动程序。
这是一种兼容模式,不享受 GDS 的好处。
(非来自 NVIDIA)非基于块的或分布式文件系统
这些文件系统可能是标准 Linux 虚拟文件系统 (VFS),例如 NFS 驱动程序或第三方专有系统。
控制路径的选择基于文件系统的挂载方式
<文件路径> –> <挂载点> –> <文件系统选择>
在某些情况下,NVIDIA 为这些或替代实现提供补丁,例如,用于 NVMe 和 NVMe-oF 的内核模块。
(来自 NVIDIA)内核级
nvidia-fs.ko驱动程序处理来自 cuFile 用户库的 IOCTL。
实现 DMA 回调以检查和转换 GPU 虚拟地址到物理地址。这些回调从存储驱动程序调用。
管理启用设备 DMA 的机制和缓冲。
从 CUDA 12.8 开始,GDS 支持使用上游内核 PCI P2PDMA 基础架构的 NVMe 设备的额外对等 DMA,用于 x86_64 平台(本地或带有 SNAP 的远程)。此功能将不再依赖
nvidia-fs.ko或nvme.ko的自定义补丁。此功能依赖于支持 PCI P2PDMA 的操作系统发行版,例如 Ubuntu 发行版上的 linux 内核版本 6.2 及更高版本。此外,必须安装 OpenRM 驱动程序版本 570.x 或更高版本以及特定的注册密钥,以允许 OpenRM 驱动程序启用 PCI P2PDMA 支持。RAID0、NVMe 多路径当前在上游内核中未启用 PCI P2PDMA,并且在没有专门补丁的情况下将无法工作。有关配置详细信息,请参阅 <哪个指南>。可以按如下方式检查操作系统对 P2PDMA 功能的支持
$ cat /proc/kallsyms | grep -i p2pdma_pgmap_ops 0000000000000000 d p2pdma_pgmap_ops
注意
Linux 内核核心是完全未修改的。
4.2.1. GDS 功能的工作流程#
以下图形说明了与 GDS 功能相关的两个工作流程
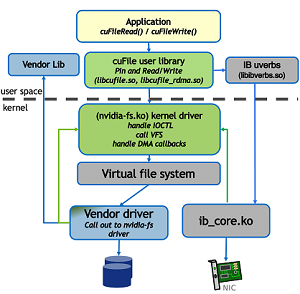
图 2 GDS 功能的工作流程#
4.2.2. 工作流程 1#
使用以下步骤完成工作流程 1。
第一个工作流程与 cuFileRead 和 cuFileWrite 的使用有关。GPU 虚拟地址由代理 CPU 系统内存地址表示。代理 CPU 系统内存地址通过 Linux IO 堆栈传递,并转换为设备特定的 DMA 总线地址。
注意
以下步骤在标准 pread 或 pwrite POSIX 调用中均未使用。
``App`` 到 ``libcufile.so``。
GPU 应用程序或启用 GPU 的框架链接到 cuFile 库
应用程序或框架调用 cuFile 驱动程序和 IO API,例如
cuFileRead和cuFileWrite。
对齐在此级别处理,并且可能会有一些性能影响,因此缓冲区不需要对齐,例如 4KB 页面或 512KB 存储偏移量和块大小。
``libcufile``。
libcufile根据文件系统、配置和硬件支持来决定使用哪种模式,以在兼容模式和 GDS 之间进行选择,以及是否使用内部 GPU 缓冲区来提高效率。``libcufile.so`` 到 ``nvidia-fs.ko``。
cuFile 库
libcufile.so服务于这些调用,并向nvidia-fs.ko驱动程序发出适当的 IOCTL 调用。该库根据需要与 CUDA 用户模式驱动程序库
libcuda.so交互,以用于 cuFile API 的流子集。
``nvidia-fs.ko`` 到 ``VFS``。
内核驱动程序迭代必要的 IO 操作集,并在
kiocb->common.ki_complete中传入 IO 完成回调,回调函数值为nvfs_io_complete,将在步骤 7 中使用。这些调用是针对 VFS 的,VFS 调用适当的较低层,例如标准 Linux 块系统(ext4/XFS 和 NVMe)或另一个供应商分布式文件系统,例如 EXAScaler。
存储内核驱动程序到 ``nvidia-fs.ko``:回调 API 通过
cuFileDriverOpen初始化注册,如 GDS 外部架构规范中的文件系统互操作性中所述。通过这种设计,驱动程序只需要通过以下子步骤处理 GPU 地址。GPU 内存地址在单独的映射中可用,在 Linux 页面映射之外,因此使用
nvidia-fs.koAPI 完成以下任务检查 DMA 目标地址是否在 GPU 上 (
nvfs_is_gpu_page) 并且需要以不同方式处理。通过使用
nvfs_dma_map_sg*查询 GPU DMA 目标地址列表,这些地址用于代替通过 VFS 传递的 CPU 系统内存地址。
存储内核驱动程序到 DMA/RDMA 引擎:在获得适当的 GPU 内存地址后,可以对(例如,NVMe 驱动程序)或靠近(例如,NIC)存储的底层 DMA 引擎进行编程,以在存储(例如,NVMe 或存储控制器或 NIC)和 GPU 内存之间直接移动数据。DMA 引擎不访问 CPU 系统内存中的特殊代理地址。
DMA/RDMA 引擎到存储内核驱动程序:每个块传输的完成都会信号返回到存储驱动程序层。
每个迭代的完成都通过使用步骤 4 中注册的回调来信号返回到 nvidia-fs.ko 驱动程序。
4.2.3. 工作流程 2#
本节提供有关第二个工作流程的信息,该工作流程与使用 ib_verbs 的用户空间 RDMA 的读取和写入有关。
App 到 ``libcufile.so``:GPU 应用程序或启用 GPU 的框架链接到 cuFile 库并调用 cuFile 驱动程序和 IO API。对齐在此级别处理,尽管可能会有一些性能影响,因此缓冲区不需要对齐,例如 4KB 页面或 512KB 存储偏移量和块大小。
``libcufile_rdma.so``:获取 RDMA 信息(密钥、GID、LID 等)到 libcufile。
``libcufile.so``
到 供应商 库:libcufile 调用适当的供应商库回调函数,以直接在用户空间或通过nvidia-fs内核回调来传达 Rkeys,具体取决于供应商驱动程序实现。
4.3. 与其他 Linux 倡议对齐#
Linux 社区一直在努力添加对等设备之间 DMA 的本机支持,其中可以包括 NIC 和 GPU。随着此支持被上游化,所有用户都需要时间通过发行版采用新的 Linux 版本。与此同时,NVIDIA 与各种第三方供应商合作以启用 GDS。
具体而言,Linux 在 Linux 内核版本 6.2 及更高版本的内核中添加了对 PCI P2PDMA 的支持,在 NVMe 的情况下,允许 ZONE_DEVICE 地址指针传递到 GPU 内存,而不会导致页面错误,nvidia-fs.ko
cuFile API 及其实现是 CUDA 添加文件 IO 支持的机制。cuFile API 涵盖 CPU 和 GPU 存储和内存之间的显式传输。API 还添加了对异步和批处理的支持,这在 POSIX IO 中不可用。在稍后将前面提到的功能添加到 Linux 后,cuFile API 仍将保持相关性。只有底层实现会发生变化,但现有的 cuFile API 不会改变。
NVIDIA 对 cuFile 的初始实现侧重于分布式文件系统和已安装适当驱动程序的系统,以实现存储和 GPU 内存之间的直接传输,而无需在 CPU 中使用反弹缓冲区。为了兼容性和更广泛的适用性,以后的实现可能会支持本地存储和隐式传输的扩展。
5. 部署#
有效使用 GDS 需要很好地了解 GDS 的部署方式、其依赖项以及其限制和约束。
5.1. 部署的软件组件#
以下是有关部署 GDS 所需的软件组件的一些信息。
cuFile API 是 CUDA 驱动程序和运行时 API 的补充,并与 CUDA 工具包一起分发和安装。
应用程序通过包含 cuFile.h 并链接到 libcufile.so 库来访问 cuFile 功能。cuFile API 的流子集,需要 CUDA 流参数,对于运行时和驱动程序 API,参数采用不同的形式。cudaFile 和 cuFile 前缀分别用于这两种情况。从运行时到驱动程序 API 的转换可以在头文件中完成。
除了 libcufile.so 之外,没有使用 cuFile API 所需的链接器依赖项,但存在对 libcuda.so 的运行时动态依赖项。当前不存在对其他 CUDA 工具包库、CUDA 运行时库或显示驱动程序的任何其他组件的链接依赖项。但是,对于在使用添加到 CUDA Runtime 后的 cudaFile* API 的应用程序,应预期最终对 CUDA Runtime 库的运行时依赖项。此步骤与应用程序使用任何其他 cuda* API 一致,并且 CUDA 部署文档(位于 NVIDIA 开发者文档)中介绍了部署中使用 CUDA Runtime 的情况。
除了 libcuda.so 之外,cuFile 还依赖于外部第三方库。
下表提供有关第三方库和 CUDA 库级别的信息
级别 |
API、类型和枚举样式 |
依赖项 |
打包在一起 |
|---|---|---|---|
cuFile 用户库 |
匹配以下 CUDA 驱动程序约定
|
|
与 |
CUDA 运行时 + 工具包 |
|
无 |
|
|
|
|
相对于 NVIDIA 驱动程序单独交付(直到可能合并),但它可能会变为共同安装。 |
注意
GDS 没有对其他库的内部依赖项
cuFile 库和驱动程序不修改 CUDA。
cuFile API 的流子集使用 CUDA 用户驱动程序 (
libcuda.so) 和 CUDA 运行时 (libcudart.so)。这些驱动程序使用的唯一 API 是公共 API。
5.2. 在容器中使用 GPUDirect Storage#
GDS 具有用户级和内核级组件。容器仅包含用户级代码,并依赖于主机上已安装的内核级组件。可以使用 GDS 的头文件和用户级库开发应用程序,并在容器中分发。当未安装或正确配置适当的驱动程序和供应商启用的内核软件时,GDS 的兼容模式使 cuFile API 能够继续保持功能运行,同时最大限度地减少性能影响。
有关在容器中使用 GDS 的示例,请参阅 NVIDIA/MagnumIO。
6. 声明#
本文档仅供参考,不得视为对产品的特定功能、条件或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含的信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对使用此类信息或因使用此类信息而可能导致的侵犯第三方专利或其他权利的后果或使用不承担任何责任。本文档不构成开发、发布或交付任何材料(如下定义)、代码或功能的承诺。
NVIDIA 保留在不另行通知的情况下随时对本文档进行更正、修改、增强、改进和任何其他更改的权利。
客户在下订单前应获取最新的相关信息,并应验证此类信息是否为最新且完整。
NVIDIA 产品根据订单确认时提供的 NVIDIA 标准销售条款和条件进行销售,除非 NVIDIA 和客户的授权代表签署的单独销售协议(“销售条款”)另有约定。NVIDIA 特此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档不直接或间接地形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、飞机、航天或生命支持设备,也不适用于 NVIDIA 产品的故障或故障可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在上述设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,此类包含和/或使用风险由客户自行承担。
NVIDIA 不保证或声明基于本文档的产品将适用于任何特定用途。NVIDIA 不一定对每个产品的所有参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合并符合客户计划的应用,并为应用执行必要的测试,以避免应用或产品的默认设置。客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同条件和/或要求。对于可能基于或归因于以下原因的任何默认设置、损坏、成本或问题,NVIDIA 不承担任何责任:(i) 以任何违反本文档的方式使用 NVIDIA 产品;或 (ii) 客户产品设计。
本文档未授予 NVIDIA 专利权、版权或本文档项下的其他 NVIDIA 知识产权的任何明示或暗示的许可。NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成对其的保证或认可。使用此类信息可能需要从第三方获得第三方专利或其他知识产权项下的许可,或从 NVIDIA 获得 NVIDIA 专利或其他知识产权项下的许可。
仅当事先获得 NVIDIA 书面批准,在不更改且完全符合所有适用的出口法律法规的情况下复制本文档中的信息,并附带所有相关的条件、限制和声明时,才允许复制本文档中的信息。
本文档和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均“按原样”提供。NVIDIA 不对材料作出任何明示、暗示、法定或其他形式的保证,并明确否认所有关于不侵权、适销性和特定用途适用性的暗示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对任何损害承担责任,包括但不限于因使用本文档而引起的任何直接、间接、特殊、偶然、惩罚性或后果性损害,无论其由何种原因引起,也无论其责任理论如何,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因而遭受任何损害,但 NVIDIA 对本文所述产品的客户的累计总责任应根据产品的销售条款中的规定进行限制。
7. OpenCL#
OpenCL 是 Apple Inc. 的商标,经 Khronos Group Inc. 许可使用。
8. 商标#
NVIDIA、NVIDIA 徽标、CUDA、DGX、DGX-1、DGX-2、DGX-A100、Tesla 和 Quadro 是 NVIDIA Corporation 在美国和其他国家/地区的商标和/或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。