1. NVIDIA GPUDirect Storage 基准测试和配置指南#
本基准测试和配置指南旨在帮助您通过使用示例应用程序评估和测试 GDS 功能和性能。
2. 简介#
NVIDIA® GPUDirect® Storage (GDS) 是 GPUDirect 系列的最新成员。GDS 为 GPU 内存和存储之间的直接内存访问 (DMA) 传输启用直接数据路径,从而避免了通过 CPU 的反弹缓冲区。这种直接路径提高了系统带宽,并降低了 CPU 的延迟和利用率负载。
本指南的目的是帮助用户通过使用示例应用程序评估和测试 GDS 功能和性能。这些应用程序可以在您设置和安装 GDS 之后以及在您运行已修改为利用 GDS 的自定义应用程序之前运行。
有关 GDS 的更多信息,请参阅以下指南
要了解有关 GDS 的更多信息,请参阅以下帖子
3. 关于本指南#
配置和基准测试是紧密耦合的活动。基准测试提供了根据当前系统配置确定潜在性能以及配置更改的影响的能力。有时需要进行配置更改以获得最佳基准测试结果,这可能会转化为生产工作负载性能的提升。
本指南提供了各种系统配置属性(包括硬件和软件)的信息和示例,以及它们如何影响 GPUDirect Storage 的交付性能。涵盖了本地驱动器配置(直接连接存储 - DAS)和网络存储(网络连接存储 - NAS)。本指南还介绍了 GDS 安装时包含的基准测试工具 gdsio,并演示了其用法。
附录 A 概述了基准测试和一般性能,以及基准测试存储系统时的注意事项。
4. GPUDirect Storage 基准测试#
GDS 支持存储和 GPU 内存之间的高吞吐量和低延迟数据传输,这使您能够使用正确的映射对 PCIe 设备的 DMA 引擎进行编程,以将数据移入和移出目标 GPU 的内存。因此,GPU 和网卡或存储设备/控制器之间的路径显然对交付的性能(吞吐量和延迟)有重大影响。在对 GDS 进行基准测试时,需要检查 PCIe 拓扑、PCIe 根联合体、交换机以及 GPU 和网络和存储设备的物理位置,并将其纳入配置详细信息中。
要通过 GDS 基准测试实现最佳性能,需要仔细研究 PCIe 拓扑并确定
哪些 IO 设备和 GPU 位于同一 PCIe 交换机或根联合体上
哪些设备通信路径需要遍历多个 PCIe 端口,并可能跨越 CPU 插槽边界
以下部分中的图表说明了 PCIe 拓扑的示例,显示了跨多个 PCIe 交换机的不同设备。
确定 PCIe 设备邻近性并非易事,因为它需要使用多个 Linux 实用程序将设备名称和编号与用于标识 PCIe 设备的分层编号方案相关联,该方案称为 BDF 表示法 (bus:device.func) 或扩展 BDF 表示法,它在表示法中添加了 PCIe 域标识符,如 domain:bus:device.func。
$ lspci | grep -i nvidia
36:00.0 3D controller: NVIDIA Corporation Device 20b0 (rev a1)
$ lspci -D | grep -i nvidia
0000:36:00.0 3D controller: NVIDIA Corporation Device 20b0 (rev a1)
在第一个示例中,请注意第一个 NVIDIA GPU 的标准 PCIe BDF 表示法,36:00.0。在第二个示例中,添加了 -D 标志以显示 PCIe 域(扩展 BDF),0000:36:00.0。
4.1. 确定 PCIe 设备亲缘性#
本节中的示例是在 NVIDIA DGX-2™ 系统上执行的。下图显示了 DGX-2 系统架构的子集,说明了 PCIe 拓扑
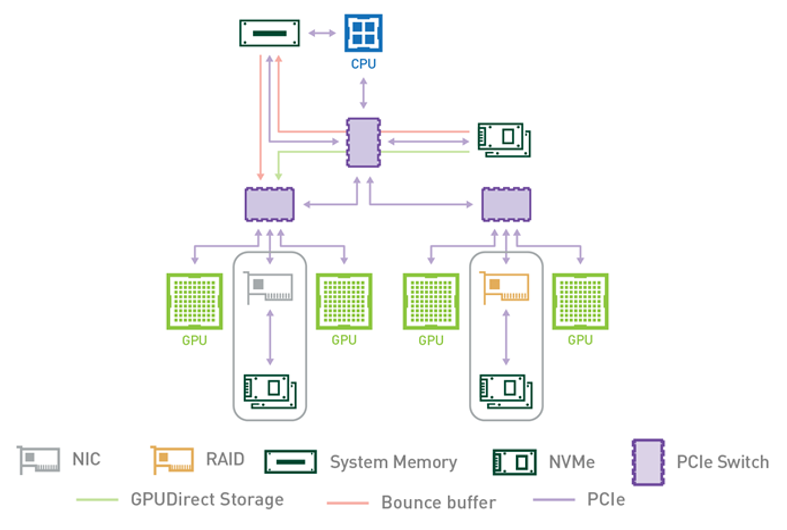
图 1 PCIe 拓扑#
DGX-2 系统有两个 CPU 插槽,每个插槽有两个 PCIe 树。四个 PCIe 树中的每一个(上图仅显示一个)都有两个级别的交换机。最多四个 NVMe 驱动器挂载在第一级交换机上。每个第二级交换机都连接到第一级交换机、可以安装 NIC 或 RAID 卡的 PCIe 插槽以及两个 GPU。
以下示例输出中的命令和方法适用于运行 Linux 的任何系统。目标是将 GPU 和 NVMe 驱动器关联到 PCIe 层级结构中,并确定要用于共享同一上游 PCIe 交换机的 GPU 和 NVMe 驱动器的设备名称。要解决此问题,您必须将 Linux 设备名称与 PCIe BDF 值相关联。对于本地连接的 NVMe 磁盘,以下示例使用 Linux /dev/disk/by-path 目录条目
dgx2> ls -l /dev/disk/by-path
total 0
lrwxrwxrwx 1 root root 9 Nov 19 12:08 pci-0000:00:14.0-usb-0:8.1:1.0-scsi-0:0:0:0 -> ../../sr0
lrwxrwxrwx 1 root root 9 Nov 19 12:08 pci-0000:00:14.0-usb-0:8.2:1.0-scsi-0:0:0:0 -> ../../sda
lrwxrwxrwx 1 root root 13 Nov 19 12:08 pci-0000:01:00.0-nvme-1 -> ../../nvme0n1
lrwxrwxrwx 1 root root 15 Nov 19 12:08 pci-0000:01:00.0-nvme-1-part1 -> ../../nvme0n1p1
lrwxrwxrwx 1 root root 15 Nov 19 12:08 pci-0000:01:00.0-nvme-1-part2 -> ../../nvme0n1p2
lrwxrwxrwx 1 root root 13 Nov 19 12:08 pci-0000:05:00.0-nvme-1 -> ../../nvme1n1
lrwxrwxrwx 1 root root 15 Nov 19 12:08 pci-0000:05:00.0-nvme-1-part1 -> ../../nvme1n1p1
lrwxrwxrwx 1 root root 15 Nov 19 12:08 pci-0000:05:00.0-nvme-1-part2 -> ../../nvme1n1p2
lrwxrwxrwx 1 root root 13 Nov 19 12:08 pci-0000:2e:00.0-nvme-1 -> ../../nvme2n1
lrwxrwxrwx 1 root root 13 Nov 19 12:08 pci-0000:2f:00.0-nvme-1 -> ../../nvme3n1
lrwxrwxrwx 1 root root 13 Nov 19 12:08 pci-0000:51:00.0-nvme-1 -> ../../nvme4n1
lrwxrwxrwx 1 root root 13 Nov 19 12:08 pci-0000:52:00.0-nvme-1 -> ../../nvme5n1
lrwxrwxrwx 1 root root 13 Nov 19 12:08 pci-0000:b1:00.0-nvme-1 -> ../../nvme6n1
lrwxrwxrwx 1 root root 13 Nov 19 12:08 pci-0000:b2:00.0-nvme-1 -> ../../nvme7n1
lrwxrwxrwx 1 root root 13 Nov 19 12:08 pci-0000:da:00.0-nvme-1 -> ../../nvme8n1
lrwxrwxrwx 1 root root 13 Nov 19 12:08 pci-0000:db:00.0-nvme-1 -> ../../nvme9n1
由于当前系统配置已将 nvme0 和 nvme1 设备配置到 RAID0 设备中(此处未显示 /dev/md0),因此重点是剩余的可用 nvme 设备,nvme2 到 nvme9。您可以获得 GPU 的相同 PCIe 到设备信息,该信息使用 nvidia-smi 实用程序并指定要查询的 GPU 属性
dgx2> nvidia-smi --query-gpu=index,name,pci.domain,pci.bus,pci.device,pci.device_id,pci.sub_device_id --format=csv
index, name, pci.domain, pci.bus, pci.device, pci.device_id, pci.sub_device_id
0, Tesla V100-SXM3-32GB, 0x0000, 0x34, 0x00, 0x1DB810DE, 0x12AB10DE
1, Tesla V100-SXM3-32GB, 0x0000, 0x36, 0x00, 0x1DB810DE, 0x12AB10DE
2, Tesla V100-SXM3-32GB, 0x0000, 0x39, 0x00, 0x1DB810DE, 0x12AB10DE
3, Tesla V100-SXM3-32GB, 0x0000, 0x3B, 0x00, 0x1DB810DE, 0x12AB10DE
4, Tesla V100-SXM3-32GB, 0x0000, 0x57, 0x00, 0x1DB810DE, 0x12AB10DE
5, Tesla V100-SXM3-32GB, 0x0000, 0x59, 0x00, 0x1DB810DE, 0x12AB10DE
6, Tesla V100-SXM3-32GB, 0x0000, 0x5C, 0x00, 0x1DB810DE, 0x12AB10DE
7, Tesla V100-SXM3-32GB, 0x0000, 0x5E, 0x00, 0x1DB810DE, 0x12AB10DE
8, Tesla V100-SXM3-32GB, 0x0000, 0xB7, 0x00, 0x1DB810DE, 0x12AB10DE
9, Tesla V100-SXM3-32GB, 0x0000, 0xB9, 0x00, 0x1DB810DE, 0x12AB10DE
10, Tesla V100-SXM3-32GB, 0x0000, 0xBC, 0x00, 0x1DB810DE, 0x12AB10DE
11, Tesla V100-SXM3-32GB, 0x0000, 0xBE, 0x00, 0x1DB810DE, 0x12AB10DE
12, Tesla V100-SXM3-32GB, 0x0000, 0xE0, 0x00, 0x1DB810DE, 0x12AB10DE
13, Tesla V100-SXM3-32GB, 0x0000, 0xE2, 0x00, 0x1DB810DE, 0x12AB10DE
14, Tesla V100-SXM3-32GB, 0x0000, 0xE5, 0x00, 0x1DB810DE, 0x12AB10DE
15, Tesla V100-SXM3-32GB, 0x0000, 0xE7, 0x00, 0x1DB810DE, 0x12AB10DE
使用 Linux lspci 命令将其全部联系起来
dgx2> lspci -tv | egrep -i "nvidia | micron"
-+-[0000:d7]-+-00.0-[d8-e7]----00.0-[d9-e7]--+-00.0-[da]----00.0 Micron Technology Inc 9200 PRO NVMe SSD
| | +-01.0-[db]----00.0 Micron Technology Inc 9200 PRO NVMe SSD
| | +-04.0-[de-e2]----00.0-[df-e2]--+-00.0-[e0]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
| | | \-10.0-[e2]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
| | \-0c.0-[e3-e7]----00.0-[e4-e7]--+-00.0-[e5]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
| | \-10.0-[e7]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
+-[0000:ae]-+-00.0-[af-c7]----00.0-[b0-c7]--+-00.0-[b1]----00.0 Micron Technology Inc 9200 PRO NVMe SSD
| | +-01.0-[b2]----00.0 Micron Technology Inc 9200 PRO NVMe SSD
| | +-04.0-[b5-b9]----00.0-[b6-b9]--+-00.0-[b7]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
| | | \-10.0-[b9]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
| | +-0c.0-[ba-be]----00.0-[bb-be]--+-00.0-[bc]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
| | | \-10.0-[be]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
| | \-10.0-[bf-c7]----00.0-[c0-c7]--+-02.0-[c1]----00.0 NVIDIA Corporation Device 1ac2
| | +-03.0-[c2]----00.0 NVIDIA Corporation Device 1ac2
| | +-04.0-[c3]----00.0 NVIDIA Corporation Device 1ac2
| | +-0a.0-[c5]----00.0 NVIDIA Corporation Device 1ac2
| | +-0b.0-[c6]----00.0 NVIDIA Corporation Device 1ac2
| | \-0c.0-[c7]----00.0 NVIDIA Corporation Device 1ac2
+-[0000:4e]-+-00.0-[4f-67]----00.0-[50-67]--+-00.0-[51]----00.0 Micron Technology Inc 9200 PRO NVMe SSD
| | +-01.0-[52]----00.0 Micron Technology Inc 9200 PRO NVMe SSD
| | +-04.0-[55-59]----00.0-[56-59]--+-00.0-[57]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
| | | \-10.0-[59]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
| | +-0c.0-[5a-5e]----00.0-[5b-5e]--+-00.0-[5c]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
| | | \-10.0-[5e]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
| | \-10.0-[5f-67]----00.0-[60-67]--+-02.0-[61]----00.0 NVIDIA Corporation Device 1ac2
| | +-03.0-[62]----00.0 NVIDIA Corporation Device 1ac2
| | +-04.0-[63]----00.0 NVIDIA Corporation Device 1ac2
| | +-0a.0-[65]----00.0 NVIDIA Corporation Device 1ac2
| | +-0b.0-[66]----00.0 NVIDIA Corporation Device 1ac2
| | \-0c.0-[67]----00.0 NVIDIA Corporation Device 1ac2
+-[0000:2b]-+-00.0-[2c-3b]----00.0-[2d-3b]--+-00.0-[2e]----00.0 Micron Technology Inc 9200 PRO NVMe SSD
| | +-01.0-[2f]----00.0 Micron Technology Inc 9200 PRO NVMe SSD
| | +-04.0-[32-36]----00.0-[33-36]--+-00.0-[34]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
| | | \-10.0-[36]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
| | \-0c.0-[37-3b]----00.0-[38-3b]--+-00.0-[39]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
| | \-10.0-[3b]----00.0 NVIDIA Corporation GV100GL [Tesla V100 SXM3 32GB]
在上面的示例中,我们显式搜索了来自给定供应商的 SSD。要确定系统上 NVMe SSD 设备的制造商,只需运行 lsblk -o NAME,MODEL。或者,使用 nvme 作为要与 nvidia 匹配的字符串。
这里有几点需要注意。首先,NVMe SSD 设备在每个 PCIe 上游交换机上成对分组,如显示的扩展 BDF 格式(最左列)所示,显示域零和总线 ID 0xd7 (0000:d7)、0xae、0x4e 和 0x2b。此外,还显示了两个不同的 NVIDIA 设备 ID(最右列)- 0x1db8 和 0x1ac2。0x1db8 设备是 Tesla V100 SXM3 32GB GPU,0x1ac2 设备是 NVSwitch。我们在此处关注的是 GPU 设备,拓扑结构表明,NVMe SSD 对和四个可能的 V100 GPU 之间将存在最佳性能路径。根据此信息,我们可以创建一个由同一 PCIe 交换机上的两个 NVMe SSD 组成的 RAID0 设备,并确定哪些 GPU 位于同一 PCIe 上游交换机上。
从 lspci 输出的顶部开始,请注意 PCIe 总线 0xda 和 0xdb 处的两个 NVMe 驱动器。disk-by-path 数据表明这些是 nvme8 和 nvme9 设备。同一段 0xe0、0xe2、0xe5 和 0xe7 上的四个 GPU 分别是 GPU 12、13、14 和 15,这由 nvidia-smi 输出确定。下表显示了所有已安装 GPU 和相应 NVMe SSD 对的 PCIe GPU 到 NVMe 的亲缘性。
参见 |
参见 |
||
|---|---|---|---|
GPU 编号 |
GPU PCIe |
NVMe 编号 |
NVMe PCIe |
0, 1, 2, 3 |
0x34, 0x36, 0x39, 0x3b |
nvme2, nvme3 |
0x2e, 0x2f |
4, 5, 6, 7 |
0x57, 0x59, 0x5c, 0x5e |
nvme4, nvme5 |
0x51, 0x52 |
8, 9, 10, 11 |
0xb7, 0xb9, 0xbc, 0xbe |
nvme6, nvme7 |
0xb1, 0xb2 |
12, 13, 14, 15 |
0xe0, 0xe2, 0xe5, 0xe7 |
nvme8, nvme9 |
0xda, 0xdb |
有了这些信息,我们可以配置目标工作负载以获得最佳吞吐量和延迟,从而利用 PCIe 拓扑以及 GPU 和 NVMe SSD 的设备邻近性。这将在接下来的几个部分中演示。请注意,不能保证每个 NVIDIA DGX-2 的实际 PCIe BDF 值都相同。这是因为 PCIe 拓扑的枚举基于特定的配置详细信息,并在启动时确定。
相同的逻辑适用于网络连接的存储 (NAS)。就 GPU 和存储之间的数据流而言,网络接口 (NIC) 成为“存储控制器”。幸运的是,对于 GPU 和 NIC,确定 PCIe 拓扑是一项容易得多的任务,因为 nvidia-smi 实用程序包含用于生成此信息的选项。具体而言,nvidia-smi topo -mp 生成一个简单的拓扑图,该图以矩阵形式显示已安装 GPU 和网络接口交叉处的连接。
为了便于阅读,来自 DGX-2 系统的以下示例输出显示了前八列和前四个 Mellanox 设备行,而不是执行 nvidia-smi topo -mp 时生成的整个表。
dgx2> nvidia-smi topo -mp
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7
GPU0 X PIX PXB PXB NODE NODE NODE NODE
GPU1 PIX X PXB PXB NODE NODE NODE NODE
GPU2 PXB PXB X PIX NODE NODE NODE NODE
GPU3 PXB PXB PIX X NODE NODE NODE NODE
GPU4 NODE NODE NODE NODE X PIX PXB PXB
GPU5 NODE NODE NODE NODE PIX X PXB PXB
GPU6 NODE NODE NODE NODE PXB PXB X PIX
GPU7 NODE NODE NODE NODE PXB PXB PIX X
GPU8 SYS SYS SYS SYS SYS SYS SYS SYS
GPU9 SYS SYS SYS SYS SYS SYS SYS SYS
GPU10 SYS SYS SYS SYS SYS SYS SYS SYS
GPU11 SYS SYS SYS SYS SYS SYS SYS SYS
GPU12 SYS SYS SYS SYS SYS SYS SYS SYS
GPU13 SYS SYS SYS SYS SYS SYS SYS SYS
GPU14 SYS SYS SYS SYS SYS SYS SYS SYS
GPU15 SYS SYS SYS SYS SYS SYS SYS SYS
mlx5_0 PIX PIX PXB PXB NODE NODE NODE NODE
mlx5_1 PXB PXB PIX PIX NODE NODE NODE NODE
mlx5_2 NODE NODE NODE NODE PIX PIX PXB PXB
mlx5_3 NODE NODE NODE NODE PXB PXB PIX PIX
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (for example, QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
GPU 和 NIC 之间的最佳路径将是一个 PCIe 交换机路径,指定为 PIX。最不理想的路径指定为 SYS,这表明数据路径需要遍历 CPU 到 CPU 的互连(NUMA 节点)。
如果您在配置和测试 GDS 性能时使用此数据,则理想的设置示例是,从 mlx5_0 到/从 GPU 0 和 1 的数据流,从 mlx5_1 到/从 GPU 1 和 2 的数据流,依此类推。
在 nvidia-smi 不可用且无法安装的系统上,仍然可以完成确定理想设置的任务。使用诸如 lscpi 或 hwloc 的 lstopo 之类的工具可以使管理员能够识别 GPU 与 NVMe 和 NIC 的最佳配对。以下是来自不同 DGX-2 机器的 lstopo 的示例输出
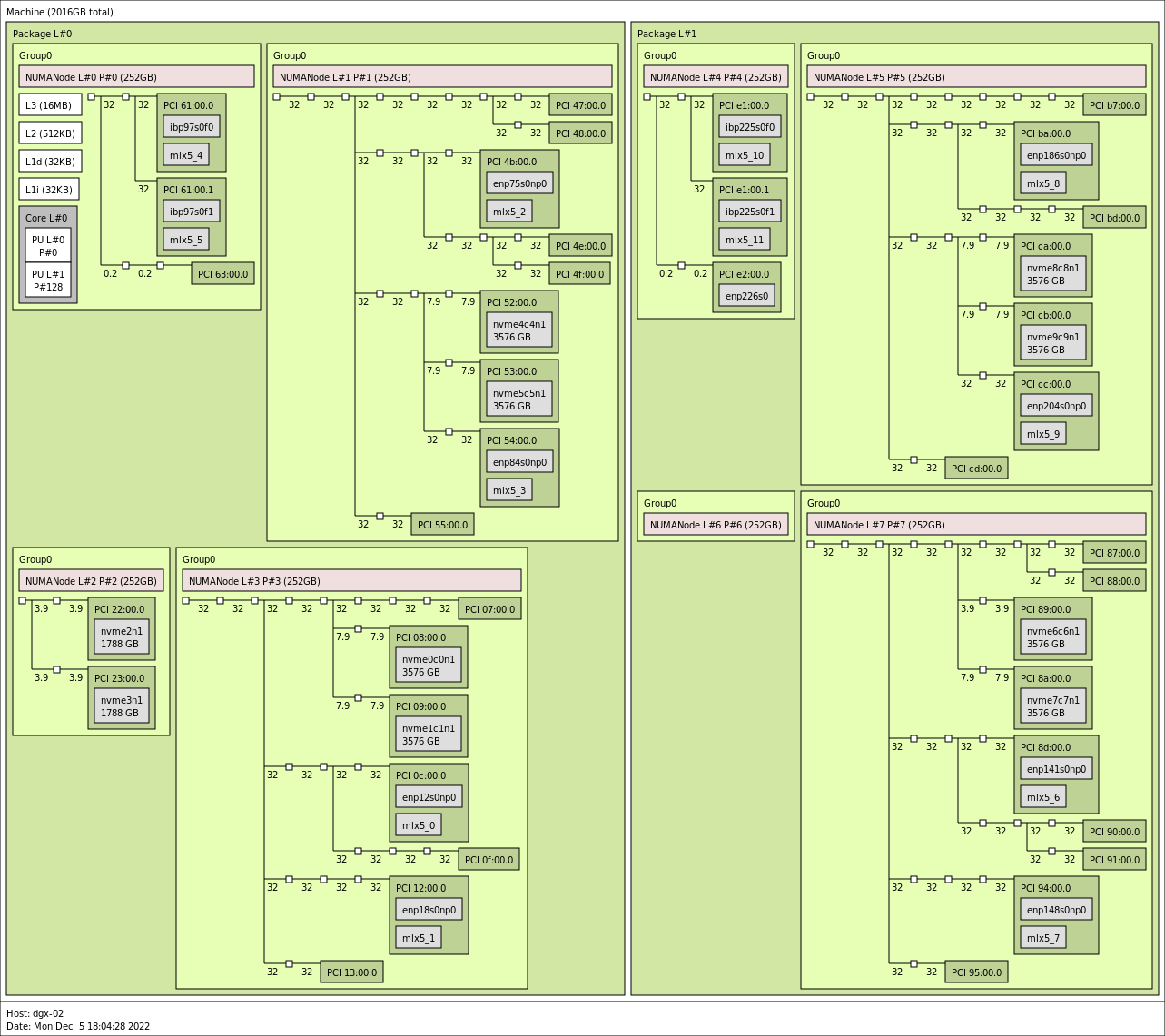
图 2 dgx2> lstopo –of png#
以左下象限中与 NUMANode L#3 关联的分组为例,可以看出,由 PCI 07:00.0 标识的 GPU 最好与 NVMe nvme0c0n1 (PCI 08:00.0) 和 nvme1c1nc (PCI 09:00.0) 关联。由 PCI 0f:00.0 标识的 GPU 也可以与这些相同的 NVMe 关联,nvidia-smi 会将其关系归类为 PXB,但如图所示,与 07 GPU 相比,这将涉及跨越更多数量的 PCIe 桥接器。还应注意,由于两个 GPU 都必须通过一个公共交换机向下通信到 NVMe,因此两个 GPU 与 NVMe 的并发通信可能会降低性能。关于 NIC 亲缘性,将 mlx5_0 与 GPU 0f:00.0 和 mlx5_1 与 GPU 07:00.0 结合使用可能更有意义,以避免跨共享桥接器的并发通信。
对于无法呈现图形输出的机器,lstopo 的 xml 输出也可以用于识别相同的功能。以下是此类输出的片段,通过运行 lstopo --of xml 获得,用于刚刚检查的 NUMANode L#3 分组。为了便于阅读和简洁起见,删除了各种行,但拓扑结构未更改。
<object type="Bridge" gp_index="867" bridge_type="1-1" depth="2" bridge_pci="0000:[02-13]" pci_busid="0000:01:00.0" pci_type="0604 [1000:c010] [1000:a096] b0" pci_link_speed="31.507692">
<info name="PCIVendor" value="Broadcom / LSI"/>
<object type="Bridge" gp_index="843" bridge_type="1-1" depth="3" bridge_pci="0000:[03-09]" pci_busid="0000:02:00.0" pci_type="0604 [1000:c010] [1000:a096] b0" pci_link_speed="31.507692">
<info name="PCIVendor" value="Broadcom / LSI"/>
<object type="Bridge" gp_index="822" bridge_type="1-1" depth="4" bridge_pci="0000:[04-09]" pci_busid="0000:03:00.0" pci_type="0604 [1000:c010] [1000:a096] b0" pci_link_speed="31.507692">
<info name="PCIVendor" value="Broadcom / LSI"/>
<object type="Bridge" gp_index="951" bridge_type="1-1" depth="5" bridge_pci="0000:[05-07]" pci_busid="0000:04:00.0" pci_type="0604 [1000:c010] [1000:a096] b0" pci_link_speed="31.507692">
<info name="PCIVendor" value="Broadcom / LSI"/>
<object type="Bridge" gp_index="924" bridge_type="1-1" depth="6" bridge_pci="0000:[06-07]" pci_busid="0000:05:00.0" pci_type="0604 [1000:c010] [10de:13b8] b0" pci_link_speed="31.507692">
<info name="PCIVendor" value="Broadcom / LSI"/>
<object type="Bridge" gp_index="903" bridge_type="1-1" depth="7" bridge_pci="0000:[07-07]" pci_busid="0000:06:00.0" pci_type="0604 [1000:c010] [10de:13b8] b0" pci_link_speed="31.507692">
<info name="PCIVendor" value="Broadcom / LSI"/>
<object type="PCIDev" gp_index="878" pci_busid="0000:07:00.0" pci_type="0302 [10de:20b2] [10de:1463] a1" pci_link_speed="31.507692">
<info name="PCIVendor" value="NVIDIA Corporation"/>
<object type="OSDev" gp_index="1017" name="opencl0d0" subtype="OpenCL" osdev_type="5">
<info name="GPUModel" value="NVIDIA A100-SXM4-80GB"/>
...
<object type="Bridge" gp_index="900" bridge_type="1-1" depth="5" bridge_pci="0000:[08-08]" pci_busid="0000:04:10.0" pci_type="0604 [1000:c010] [1000:a096] b0" pci_link_speed="7.876923">
<info name="PCIVendor" value="Broadcom / LSI"/>
<object type="PCIDev" gp_index="852" pci_busid="0000:08:00.0" pci_type="0108 [144d:a824] [144d:a801] 00" pci_link_speed="7.876923">
<info name="PCIVendor" value="Samsung Electronics Co Ltd"/>
<object type="OSDev" gp_index="984" name="nvme0c0n1" subtype="Disk" osdev_type="0">
...
<object type="Bridge" gp_index="866" bridge_type="1-1" depth="5" bridge_pci="0000:[09-09]" pci_busid="0000:04:14.0" pci_type="0604 [1000:c010] [1000:a096] b0" pci_link_speed="7.876923">
<info name="PCIVendor" value="Broadcom / LSI"/>
<object type="PCIDev" gp_index="831" pci_busid="0000:09:00.0" pci_type="0108 [144d:a824] [144d:a801] 00" pci_link_speed="7.876923">
<info name="PCIVendor" value="Samsung Electronics Co Ltd"/>
<object type="OSDev" gp_index="983" name="nvme1c1n1" subtype="Disk" osdev_type="0">
...
<object type="Bridge" gp_index="966" bridge_type="1-1" depth="3" bridge_pci="0000:[0a-0f]" pci_busid="0000:02:04.0" pci_type="0604 [1000:c010] [1000:a096] b0" pci_link_speed="31.507692">
<info name="PCIVendor" value="Broadcom / LSI"/>
<object type="Bridge" gp_index="870" bridge_type="1-1" depth="4" bridge_pci="0000:[0b-0f]" pci_busid="0000:0a:00.0" pci_type="0604 [1000:c010] [1000:a096] b0" pci_link_speed="31.507692">
<info name="PCIVendor" value="Broadcom / LSI"/>
<object type="Bridge" gp_index="848" bridge_type="1-1" depth="5" bridge_pci="0000:[0c-0c]" pci_busid="0000:0b:00.0" pci_type="0604 [1000:c010] [1000:a096] b0" pci_link_speed="31.507692">
<info name="PCIVendor" value="Broadcom / LSI"/>
<object type="PCIDev" gp_index="824" pci_busid="0000:0c:00.0" pci_type="0207 [15b3:101b] [15b3:0007] 00" pci_link_speed="31.507692">
<info name="PCIVendor" value="Mellanox Technologies"/>
<info name="PCIDevice" value="MT28908 Family [ConnectX-6]"/>
<object type="OSDev" gp_index="995" name="ibp12s0" osdev_type="2">
</object>
<object type="OSDev" gp_index="1011" name="mlx5_0" osdev_type="3">
...
<object type="Bridge" gp_index="948" bridge_type="1-1" depth="5" bridge_pci="0000:[0d-0f]" pci_busid="0000:0b:10.0" pci_type="0604 [1000:c010] [1000:a096] b0" pci_link_speed="31.507692">
<info name="PCIVendor" value="Broadcom / LSI"/>
<object type="Bridge" gp_index="954" bridge_type="1-1" depth="6" bridge_pci="0000:[0e-0f]" pci_busid="0000:0d:00.0" pci_type="0604 [1000:c010] [10de:13b8] b0" pci_link_speed="31.507692">
<info name="PCIVendor" value="Broadcom / LSI"/>
<object type="Bridge" gp_index="926" bridge_type="1-1" depth="7" bridge_pci="0000:[0f-0f]" pci_busid="0000:0e:00.0" pci_type="0604 [1000:c010] [10de:13b8] b0" pci_link_speed="31.507692">
<info name="PCIVendor" value="Broadcom / LSI"/>
<object type="PCIDev" gp_index="907" pci_busid="0000:0f:00.0" pci_type="0302 [10de:20b2] [10de:1463] a1" pci_link_speed="31.507692">
<info name="PCIVendor" value="NVIDIA Corporation"/>
<object type="OSDev" gp_index="1018" name="opencl0d1" subtype="OpenCL" osdev_type="5">
<info name="GPUModel" value="NVIDIA A100-SXM4-80GB"/>
...
检查 XML 将得出关于 GPU 和 NVMe/NIC 亲缘性的相同结论,再次以与 pci_busid=0000:07:00.0 关联的 GPU 为例,我们看到它与深度为 3 的 NVMe nvme0c0n1 和 nvme1c1n1 共享一个上游桥接器 (gp_index="822")。与 pci_busid=0000:0f:00.0 关联的 GPU 也与这些 NVMe 共享一个上游桥接器,但在更上游的深度为 2 (gp_index="867"),这与先前检查的图形输出中的描述相符。
4.2. GPUDirect Storage 配置参数#
有各种参数和设置会影响交付的性能。除了特定于存储/文件系统的参数外,/etc/cufile.json 中还定义了系统设置和特定于 GDS 的参数。
4.2.1. 系统参数#
在系统方面,应检查以下各项
PCIe 访问控制服务 (ACS)
PCIe ACS 是对等事务的安全功能。每个事务都会经过检查,以确定是否允许源设备和目标设备之间的对等通信。每个此类事务都必须通过根联合体路由,这会引起延迟并影响可持续吞吐量。当禁用 PCIe ACS 时,可获得最佳 GDS 性能。
IOMMU
PCIe 输入/输出内存管理单元 (IOMMU) 是一种处理 IO 设备的地址转换的工具,需要通过 PCIe 根联合体路由。在大多数系统上,建议禁用 IOMMU,因为它可能导致 GDS IO 操作失败或性能不佳。对于基于 Grace Hopper 的系统,无需禁用 IOMMU。
4.2.2. GPUDirect Storage 参数#
本节介绍 GDS 使用的 JSON 配置参数。
安装 GDS 时,将安装具有默认值的 /etc/cufile.json 参数文件。该实现允许通用 GDS 设置以及特定于文件系统或存储合作伙伴的参数。
注意
对于尚未设置 GDS 支持的系统或挂载点,请考虑使用 compat_mode。
参数 |
默认值 |
描述 |
|---|---|---|
|
CWD |
GDS 日志文件的位置。 |
|
ERROR |
日志记录的详细程度。 |
|
false |
布尔值,如果设置为 true,则生成 NVTX 跟踪以进行性能分析。 |
|
0 |
启用 cuFile IO 统计信息。级别 0 表示没有 cuFile 统计信息。 |
|
128 |
允许的最大批处理大小。 |
|
16384 |
cuFile 用于每个 IO 请求的最大 IO 块大小(4K 对齐)(以 KB 为单位)。 |
|
131072 |
用于为整个 GPU 保留反弹缓冲区的最大设备内存大小(4K 对齐)(以 KB 为单位)。 |
|
33554432 |
每个 GPU 可以固定的最大内存大小(以 KB 为单位),包括内部反弹缓冲区的内存。 |
|
false |
布尔值,指示 cuFile 库是使用轮询还是同步等待存储完成 IO。轮询可能对小型 IO 事务有用。请参阅下面的轮询模式。 |
|
4 |
库将轮询的最大 IO 请求大小(4K 对齐),小于或等于此大小(以 KB 为单位)。 |
|
false |
如果为 true,则可以使用此选项强制所有 IO 使用兼容模式。或者,管理员可以卸载 |
|
false |
如果为 true,则启用兼容模式,该模式允许 cuFile 发出 POSIX 读取/写入。要切换到启用 GDS 的 I/O,请将其设置为 |
|
false |
如果为 true,则启用 GDS 以优先使用 p2pdma 而不是传统的 nvidia-fs 路径(如果内核支持)。否则,将使用通过 nvidia-fs 的传统路径。请参阅下面的 P2P 模式。 |
|
[] |
为可用于 RDMA 的所有接口提供相关客户端 IPv4 地址的列表。 |
|
RoundRobin |
指定 RDMA 内存注册的负载平衡策略。默认情况下,此值设置为 RoundRobin。以下是可以用于此属性的有效值:
|
|
false |
布尔参数,仅适用于基于网络的文件系统。对于 GPU 和 NIC 不共享公共 PCIe 根端口的平台,可以启用此参数。 |
|
|
仅当启用 |
|
128 |
每个批处理的最大 IO 操作数。 |
|
true |
为基于 RDMA 的存储启用 GDS 写入支持。 |
|
default |
启用相对于计算流的 io 优先级 有效选项为“default”、“low”、“med”、“high” 在 |
|
false |
设置为 |
|
4KB |
仅适用于 EXAScaler 文件系统。这适用于读取和写入。对于等于或低于阈值的读取/写入 (4K 对齐) 的 IO 阈值,cuFile 将使用 POSIX 读取/写入。据观察,对于较小的 IO 大小(如 4KB/8KB),将此阈值设置为 4KB/8KB 会产生更好的性能。 |
|
[] |
为单个 lustre 挂载可使用的所有接口提供相关客户端 IPv4 地址的列表。cuFile 动态路由功能使用此属性来推断首选 RDMA 设备。 |
|
[] |
指定 IPv4 挂载地址与 Lustre 挂载点的字典。cuFile 动态路由功能使用此属性。有关示例用法,请参阅默认 |
|
[] |
为单个 NFS 挂载可使用的所有接口提供 IPv4 地址的列表。cuFile 动态路由功能使用此属性来推断首选 RDMA 设备。 |
|
[] |
指定 IPv4 挂载地址与 Lustre 挂载点的字典。cuFile 动态路由功能使用此属性。有关示例用法,请参阅默认 |
|
false |
如果设置为 true,则 cuFileWrite 将使用 RDMA 写入,而不是回退到 posix 写入以进行 WekaFs 挂载。 |
|
[] |
为单个 WekaFS 挂载可使用的所有接口提供相关客户端 IPv4 地址的列表。cuFile 动态路由功能也使用此属性来推断首选 rdma 设备。 |
|
[] |
指定 IPv4 挂载地址与 WekaFS 挂载点的字典。cuFile 动态路由功能使用此属性。有关示例用法,请参阅默认 |
|
[] |
禁用节点上受支持的存储驱动程序的管理设置。 |
|
[] |
禁用节点上特定受支持的块设备的管理设置。 不适用于 DFS。 |
|
[] |
禁用节点上受支持的启用 GDS 的文件系统中特定挂载点的管理设置。 |
|
[] |
禁用节点上特定受支持的 GDS 就绪文件系统的管理设置。 |
|
false |
将此设置为 true 将跳过兼容模式下的拓扑检测。这将减少在具有多个 PCI 设备的系统上兼容模式下看到的较高启动延迟。 |
|
128 |
这指定了 cuFile 库的内部线程池子系统可以容纳的最大待处理工作项数。 |
|
4 |
这指定了可以处理由与系统上单个 GPU 对应的工作队列生成的工作项的线程池线程数。 |
|
true |
将此设置为 true 将允许通过排队到 cuFile 库提供的线程池子系统来并行处理工作项 |
|
8192 |
此选项指定应用程序提交的 I/O 工作项将被拆分的 KB 大小,以便在排队到线程池子系统时使用,前提是有足够的并行缓冲区可用。 |
|
4 |
此数字指定了可用的最大并行缓冲区数,当排队到线程池子系统时,原始 I/O 工作项缓冲区可以拆分为这些缓冲区。 |
注意
可以通过使用设置为指向备用 cufile.json 文件的 CUFILE_ENV_PATH_JSON 环境变量来设置特定于工作负载/应用程序的参数,例如,CUFILE_ENV_PATH_JSON=/home/gds_user/my_cufile.json。
您可以在 cufile.json 配置文件中设置两种模式类型
轮询模式
cuFile API 集包括将驱动程序置于轮询模式的接口。有关更多信息,请参阅 cuFile API 参考指南中的
cuFileDriverSetPollMode()。当设置轮询模式时,发出的读取或写入操作小于或等于properties:poll_mode_max_size_kb(默认为 4KB)将导致库轮询 IO 完成情况,而不是阻止(睡眠)。对于小型 IO 大小工作负载,启用轮询模式可能会减少延迟。兼容模式
在某些情况下,GDS 可能不可用或不受支持,例如,当未安装 GDS 软件、目标文件系统不受 GDS 支持、无法在目标文件上启用
O_DIRECT等。当您启用兼容模式,并且 GDS 对于 IO 目标不起作用时,使用 cuFile API 的代码将回退到标准 POSIX 读取/写入路径。要了解有关兼容模式的更多信息,请参阅 cuFile 兼容模式。
在较新的 Linux 内核中,已添加对设备之间对等 DMA 的支持,而无需使用自定义内核模块。从 CUDA 12.8 开始,GDS 支持这种新的 P2P 操作模式,并且在某些配置下不再需要 nvidia-fs。有关系统要求以及如何启用此模式的更多信息,请参阅 GDS 故障排除指南。
从基准测试和性能的角度来看,默认设置在各种 IO 负载和用例中都运行良好。我们建议您对 max_direct_io_size_kb、max_device_cache_size_kb 和 max_device_pinned_mem_size_kb 使用默认值,除非存储提供商有特定建议,或者分析和测试表明在您更改一个或多个默认值后性能更好。
cufile.json 文件被设计为可扩展的,因此可以设置适用于所有受支持文件系统的通用参数 (fs:generic),或者特定于文件系统的参数 (fs:lustre)。 fs:generic:posix_unaligned_writes 参数允许在遇到未对齐写入时使用 POSIX 写入路径。未对齐写入通常不是最优的,因为它们可能需要读取-修改-写入操作。
如果目标工作负载生成未对齐写入,您可能希望将 posix_unaligned_writes 设置为 true,因为处理未对齐写入的 POSIX 路径可能更高效,具体取决于目标文件系统和底层存储。此外,在这种情况下,POSIX 路径会将数据写入页缓存(系统内存)。
当 IO 大小小于或等于 posix_gds_min_kb 时,fs:lustre:posix_gds_min_kb 设置会调用 POSIX 读取/写入路径,而不是 cuFile 路径。 在使用 Lustre 时,对于较小的 IO 大小,POSIX 路径可能具有更好的(更低的)延迟。
GDS 参数是影响交付存储 IO 性能的几个因素之一。建议从默认设置开始,仅根据存储供应商的建议或在目标工作负载的测试和测量期间获得的经验数据进行更改。
这是 JSON 模式
# /etc/cufile.json
{
"logging": {
// log directory, if not enabled will create log file
// under current working directory
//"dir": "/home/<xxxx>",
// ERROR|WARN|INFO|DEBUG|TRACE (in decreasing order of priority)
"level": "ERROR"
},
"profile": {
// nvtx profiling on/off
"nvtx": false,
// cufile stats level(0-3)
"cufile_stats": 0
},
"execution" : {
// max number of workitems in the queue;
"max_io_queue_depth": 128,
// max number of host threads per gpu to spawn for parallel IO
"max_io_threads" : 4,
// enable support for parallel IO
"parallel_io" : true,
// minimum IO threshold before splitting the IO
"min_io_threshold_size_kb" :8192,
// maximum parallelism for a single request
"max_request_parallelism" : 4
},
"properties": {
// max IO size (4K aligned) issued by cuFile to nvidia-fs driver(in KB)
"max_direct_io_size_kb" : 16384,
// device memory size (4K aligned) for reserving bounce buffers
// for the entire GPU (in KB)
"max_device_cache_size_kb" : 131072,
// limit on maximum memory (4K aligned) that can be pinned
// for a given process (in KB)
"max_device_pinned_mem_size_kb" : 33554432,
// true or false (true will enable asynchronous io submission to nvidia-fs driver)
"use_poll_mode" : false,
// maximum IO request size (4K aligned) within or equal
// to which library will poll (in KB)
"poll_mode_max_size_kb": 4,
// allow compat mode, this will enable use of cufile posix read/writes
"allow_compat_mode": false,
// client-side rdma addr list for user-space file-systems
// (e.g ["10.0.1.0", "10.0.2.0"])
"rdma_dev_addr_list": [ ]
},
"fs": {
"generic": {
// for unaligned writes, setting it to true
// will use posix write instead of cuFileWrite
"posix_unaligned_writes" : false
},
"lustre": {
// IO threshold for read/write (4K aligned)) equal to or below
// which cufile will use posix reads (KB)
"posix_gds_min_kb" : 0
}
},
"blacklist": {
// specify list of vendor driver modules to blacklist for nvidia-fs
"drivers": [ ],
// specify list of block devices to prevent IO using libcufile
"devices": [ ],
// specify list of mount points to prevent IO using libcufile
// (e.g. ["/mnt/test"])
"mounts": [ ],
// specify list of file-systems to prevent IO using libcufile
// (e.g ["lustre", "wekafs", "vast"])
"filesystems": [ ]
}
// Application can override custom configuration via
// export CUFILE_ENV_PATH_JSON=<filepath>
// e.g : export CUFILE_ENV_PATH_JSON="/home/<xxx>/cufile.json"
}
4.3. GPUDirect 存储基准测试工具#
Linux 系统有几种存储基准测试工具和实用程序,它们的功能和特性各不相同。 fio 实用程序是更流行和强大的工具之一,用于生成存储 IO 负载,并为根据所需的 IO 负载特性调整 IO 生成提供了极大的灵活性。 对于熟悉 Linux 系统上的 fio 的用户来说,gdsio 的使用将非常直观。
由于 GDS 是一项相对较新的技术,具有支持依赖项和一组特定的库和 API,这些库和 API 不属于标准的 POSIX IO API,因此现有的存储 IO 负载生成实用程序都不包含 GDS 支持。 因此,GDS 的安装包中包含了 gdsio 负载生成器,它提供了几个命令行选项,可以通过传统的 CPU 和 GDS 数据路径生成各种存储 IO 负载特性。
4.3.1. gdsio 实用程序#
gdsio 实用程序类似于许多磁盘/存储 IO 负载生成工具。 它支持一系列命令行参数,用于指定目标文件、文件大小、IO 大小、IO 线程数等等。 此外,gdsio 还内置支持使用传统 IO 路径 (CPU) 以及 GDS 路径 - 存储到/从 GPU 内存。
从 12.2 版本开始,该工具还支持三种新的内存类型 (-m <2, 3, 4>),以使用 cuFile API 来练习主机内存支持选项。 新的内存类型选项仅在某些传输模式下受支持,例如 -x (0, 5, 6, 7)。 此外,还引入了对非 O_DIRECT 文件描述符的支持。 可以通过选项 -O 1 指定。 默认情况下,gdsio 实用程序使用 O_DIRECT 文件描述符,由 -O 0 表示,尽管不需要显式指定。
dgx2> ./gdsio --help
gdsio version :1.1
Usage [using config file]: gdsio rw-sample.gdsio
Usage [using cmd line options]:./gdsio
-f <file name>
-D <directory name>
-d <gpu_index (refer nvidia-smi)>
-n <numa node>
-m <memory type(0 - (cudaMalloc), 1 - (cuMem), 2 - (cudaMallocHost), 3 - (malloc) 4 - (mmap))>
-w <number of threads for a job>
-s <file size(K|M|G)>
-o <start offset(K|M|G)>
-i <io_size(K|M|G)> <min_size:max_size:step_size>
-p <enable nvlinks>
-b <skip bufregister>
-o <start file offset>
-V <verify IO>
-x <xfer_type>
-I <(read) 0|(write)1| (randread) 2| (randwrite) 3>
-T <duration in seconds>
-k <random_seed> (number e.g. 3456) to be used with random read/write>
-U <use unaligned(4K) random offsets>
-R <fill io buffer with random data>
-F <refill io buffer with random data during each write>
-B
xfer_type:
0 - Storage->GPU (GDS)
1 - Storage->CPU
2 - Storage->CPU->GPU
3 - Storage->CPU->GPU_ASYNC
4 - Storage->PAGE_CACHE->CPU->GPU
5 - Storage->GPU_ASYNC_STREAM
6 - Storage->GPU_BATCH
7 - Storage->GPU_BATCH_STREAM
Note:
read test (-I 0) with verify option (-V) should be used with files written (-I 1) with -V option
read test (-I 2) with verify option (-V) should be used with files written (-I 3) with -V option, using same random seed (-k),
same number of threads(-w), offset(-o), and data size(-s)
write test (-I 1/3) with verify option (-V) will perform writes followed by read
这些 gdsio 选项提供了必要的灵活性,可以根据一组特定的需求构建 IO 测试,和/或简单地评估几种不同负载类型的性能。 重要提示,当使用 -D 标志指定目标目录时,gdsio 必须首先执行写入负载 (-I 1 或 -I 3) 以创建文件。 创建的文件数量基于线程数 (-w 标志);每个线程创建一个文件。 这是使用 -f 标志(指定文件路径名)的替代方法。 -D 和 -f 标志不能一起使用。
传输类型 (-x 标志) 在下表中进一步定义
x |
传输类型 |
文件打开 O_DIRECT? |
主机内存分配类型 |
设备内存分配类型 |
副本数 |
|---|---|---|---|---|---|
0 |
XFER_GPU_DIRECT |
是 |
|
|
零拷贝 |
1 |
XFER_CPU_ONLY |
是 |
Posix_mem_align (4k) |
N/A |
零拷贝 |
2 |
XFER_CPU_GPU |
是 |
|
(使用多个 CUDA 流进行 |
一个副本 |
3 |
XFER_CPU_ASYNC_GPU |
是 |
|
(使用 |
一个副本(流式缓冲区) |
4 |
XFER_CPU_CACHED_GPU |
否(使用页缓存) |
|
(使用多个 CUDA 流进行 |
两个副本 |
5 |
XFER_GPU_DIRECT_ASYNC |
是 |
|
|
零拷贝 |
6 |
XFER_GPU_BATCH |
是 |
|
|
零拷贝 |
7 |
XFER_GPU_BATCH_STREAM |
是 |
|
|
零拷贝 |
* 从 GDS 1.7 版本开始,如果通过 cufile.json 启用了轮询模式,则将使用轮询模式。 否则,XFER_GPU_DIRECT_ASYNC 选项将练习基于流的异步 I/O 机制
与 Linux fio 存储负载生成器类似,gdsio 支持使用配置文件,其中包含用于 gdsio 执行的参数值。 这提供了一种替代冗长命令行字符串的方法,并且能够构建一组配置文件,这些文件可以轻松地重复使用,以测试不同的配置和工作负载。 gdsio 配置文件语法支持全局参数以及各个作业参数。 GDS 在 /usr/local/cuda/gds/tools 中安装了一些示例 gdsio 配置文件。 扩展名为 .gdsio 的文件是示例 gdsio 配置文件,同一目录中包含的 README 文件提供了有关 gdsio 的命令行和配置文件语法的更多信息。
通过这些选项和对参数配置文件的支持,运行 gdsio 并使用不同的数据路径往返 GPU/CPU 内存评估性能是一个相对简单的过程。
4.3.2. gds-stats 工具#
gds_stats 工具用于提取每个进程的 GDS IO 统计信息。 它可以与其他通用工具(Linux iostat)和 GPU 特定工具(nvidia-smi、数据中心 GPU 管理器 (DCGM) 命令行工具 dcgmi)结合使用,以全面了解目标系统上的数据流。
要使用 gds_stats,必须将 /etc/cufile.json 中的 profile:cufile_stats 属性必须设置为 1、2 或 3。
注意
默认值 0 禁用统计信息收集。
不同的级别提供越来越多的统计数据。 当 profile:cufile_stats 设置为 3(最高级别)时,gds_stats 实用程序提供 -l(级别)CLI 标志。 即使 GDS 正在收集级别 3 统计信息,也只能显示级别 1 或级别 2 统计信息。
在下面的示例中,gdsio 作业在后台启动,并提取级别 3 gds_stats
dgx2> gdsio -D /nvme23/gds_dir -d 2 -w 8 -s 1G -i 1M -x 0 -I 0 -T 300 &
[1] 850272
dgx2> gds_stats -p 850272 -l 3
cuFile STATS VERSION : 3
GLOBAL STATS:
Total Files: 8
Total Read Errors : 0
Total Read Size (MiB): 78193
Read BandWidth (GiB/s): 6.32129
Avg Read Latency (us): 1044
Total Write Errors : 0
Total Write Size (MiB): 0
Write BandWidth (GiB/s): 0
Avg Write Latency (us): 0
READ-WRITE SIZE HISTOGRAM :
0-4(KiB): 0 0
4-8(KiB): 0 0
8-16(KiB): 0 0
16-32(KiB): 0 0
32-64(KiB): 0 0
64-128(KiB): 0 0
128-256(KiB): 0 0
256-512(KiB): 0 0
512-1024(KiB): 0 0
1024-2048(KiB): 78193 0
2048-4096(KiB): 0 0
4096-8192(KiB): 0 0
8192-16384(KiB): 0 0
16384-32768(KiB): 0 0
32768-65536(KiB): 0 0
65536-...(KiB): 0 0
PER_GPU STATS:
GPU 0 Read: bw=0 util(%)=0 n=0 posix=0 unalign=0 r_sparse=0 r_inline=0 err=0 MiB=0 Write: bw=0 util(%)=0 n=0 posix=0 unalign=0 err=0 MiB=0 BufRegister: n=0 err=0 free=0 MiB=0
GPU 1 Read: bw=0 util(%)=0 n=0 posix=0 unalign=0 r_sparse=0 r_inline=0 err=0 MiB=0 Write: bw=0 util(%)=0 n=0 posix=0 unalign=0 err=0 MiB=0 BufRegister: n=0 err=0 free=0 MiB=0
GPU 2 Read: bw=6.32129 util(%)=797 n=78193 posix=0 unalign=0 r_sparse=0 r_inline=0 err=0 MiB=78193 Write: bw=0 util(%)=0 n=0 posix=0 unalign=0 err=0 MiB=0 BufRegister: n=8 err=0 free=0 MiB=8
GPU 3 Read: bw=0 util(%)=0 n=0 posix=0 unalign=0 r_sparse=0 r_inline=0 err=0 MiB=0 Write: bw=0 util(%)=0 n=0 posix=0 unalign=0 err=0 MiB=0 BufRegister: n=0 err=0 free=0 MiB=0
. . .
GPU 15 Read: bw=0 util(%)=0 n=0 posix=0 unalign=0 r_sparse=0 r_inline=0 err=0 MiB=0 Write: bw=0 util(%)=0 n=0 posix=0 unalign=0 err=0 MiB=0 BufRegister: n=0 err=0 free=0 MiB=0
PER_GPU POOL BUFFER STATS:
PER_GPU POSIX POOL BUFFER STATS:
GPU 0 4(KiB) :0/0 1024(KiB) :0/0 16384(KiB) :0/0
GPU 1 4(KiB) :0/0 1024(KiB) :0/0 16384(KiB) :0/0
GPU 2 4(KiB) :0/0 1024(KiB) :0/0 16384(KiB) :0/0
. . .
GPU 14 4(KiB) :0/0 1024(KiB) :0/0 16384(KiB) :0/0
GPU 15 4(KiB) :0/0 1024(KiB) :0/0 16384(KiB) :0/0
PER_GPU RDMA STATS:
GPU 0000:34:00.0 :
GPU 0000:36:00.0 :
. . .
GPU 0000:39:00.0 :
GPU 0000:e5:00.0 :
GPU 0000:e7:00.0 :
RDMA MRSTATS:
peer name nr_mrs mr_size(MiB)
以下是捕获和显示的 gds_stats 级别
级别 3.
如上所示,包括(从顶部开始)摘要部分、GLOBAL STATS、然后是 READ-WRITE SIZE HISTOGRAM 部分、PER_GPU STATS、PER_GPU POOL BUFFER STATS、PER_GPU POSIX POOL BUFFER STATS、PER_GPU RDMA STATS 和 RDMA MRSTATS。
级别 2
GLOBAL STATS 和 READ-WRITE SIZE HISTOGRAM 部分。
级别 1
GLOBAL STATS。
这些描述为
GLOBAL STATS - 摘要数据,包括读取/写入吞吐量和延迟。
READ-WRITE SIZE HISTOGRAM - 读取和写入 IO 大小的分布。
PER_GPU STATS - 每个 GPU 的各种统计信息,包括读取和写入吞吐量、稀疏 IO、POSIX IO、错误、未对齐 IO 和已注册缓冲区的数据的计数器。
接下来的两个统计信息提供了有关用于 GDS IO 和 POSIX IO 的反弹缓冲区的缓冲区池的信息。 这些池在 128MB 池中使用固定大小的 1MB 缓冲区(请参阅 /etc/cufile.json 参数中的 “max_device_cache_size_kb” : 131072)。 当缓冲区未注册、未对齐的缓冲区或文件偏移量以及存储和 GPU 跨越 NUMA 节点(通常是 CPU 插槽)时,将使用此池。
PER_GPU POOL BUFFER STATS - 使用 GDS 时的反弹缓冲区统计信息。
PER_GPU POSIX POOL BUFFER STATS - 使用兼容模式 (POSIX IO) 时的系统内存反弹缓冲区统计信息。
最后两个统计信息提供了与 GDS 配置了网络附加存储 (NAS) 时的 RDMA 流量相关的数据
PER_GPU RDMA STATS - RDMA 流量。
PER_GPU RDMA MRSTATS - RDMA 内存注册数据。
gds_stats 对于理解 IO 负载的重要方面非常有用。 不仅是性能(带宽和延迟),还有 IO 大小分布,用于理解工作负载的重要属性,而 PER_GPU STATS 可以查看哪些 GPU 正在读取/写入存储的数据。
您可以使用各种方法定期监视 gds_stats 数据,例如定义间隔并提取感兴趣数据的 shell 包装器。 此外,Linux watch 命令可用于定期监视 gds_stats 数据
Every 1.0s: gds_stats -p 951816 | grep 'BandWidth\|Latency'
psg-dgx2-g02: Fri Nov 20 13:16:36 2020
Read BandWidth (GiB/s): 6.38327
Avg Read Latency (us): 1261
Write BandWidth (GiB/s): 0
Avg Write Latency (us): 0
在上面的示例中,gds_stats 是使用 Linux watch 命令启动的
watch -n 1 "gds_stats -p 31470 | grep 'BandWidth\|Latency'"
此命令导致带宽和延迟统计信息每秒在命令提示符窗口中更新。
5. GPUDirect 存储在直接连接存储上的基准测试#
本节介绍在直接连接到服务器的存储上对 GDS 进行基准测试,通常以 PCIe 总线上的 NVMe SSD 设备的形式。 DGX-2 和 DGX A100 上的具体示例可以用作任何服务器配置的指南。 请注意,在以下示例中,包括了各种命令行工具和实用程序的输出。 在某些情况下,为了提高可读性和清晰度,删除了行或列。
5.1. DGX-2 系统上的 GPUDirect 存储性能#
目前,GDS 支持 NVMe 设备作为直接连接存储,其中 NVMe SSD 直接插入 PCIe 总线。 DGX-2 系统配置了多达 16 个此类设备,这些设备通常配置为大型 RAID 元设备。 如上一节所述,用于执行这些示例的 DGX-2 系统经过非常具体的配置,使得同一 PCIe 交换机上的 NVMe SSD 对位于 RAID0 组中,并且 gdsio 命令行有意选择与同一上游 PCIe 交换机共享的 GPU。
一个简单的示例:使用 GDS 路径将数据写入大型文件,并使用大型 IO 大小。
此示例使用配置了 nvme2 和 nvme3 的 RAID0 设备,以及 ext4 文件系统(挂载为 /nvme23,并使用 gds_dir 子目录来保存生成的文件)。
dgx2> gdsio -D /nvme23/gds_dir -d 2 -w 8 -s 500M -i 1M -x 0 -I 0 -T 120
IoType: READ XferType: GPUD Threads: 8 DataSetSize: 818796544/4096000(KiB) IOSize: 1024(KiB) Throughput: 6.524658 GiB/sec, Avg_Latency: 1197.370995 usecs ops: 799606 total_time 119.679102 secs
以下是有关示例中选项的一些其他信息
-D /nvme23/gds_dir,目标目录。-d 2,选择 GPU # 2 作为数据目标/目的地。-w 8,8 个工作线程(8 个 IO 线程)-s 500M,目标文件大小。-i 1M,IO 大小(对于评估吞吐量很重要)。-x 0,IO 数据路径,在本例中为 GDS。有关更多信息,请参阅 gdsio 实用程序 中的表 2。
-I 0,写入 IO 负载(0 表示读取,1 表示写入)-T 120,运行 120 秒。
gdsio 生成的结果显示了预期的性能,因为存储 IO 目标是两个 NVMe SSD 的 RAID 0 配置,其中每个 SSD 配置为大约 3.4GB/秒的大型读取性能。 平均持续吞吐量为 6.5GB/秒,平均延迟为 1.2 毫秒。 我们可以查看 gdsio 执行期间的系统数据,以获取有关数据速率和移动的其他数据点。 这通常对于验证负载生成器报告的结果以及确保数据路径符合预期非常有用。 使用 Linux iostat 实用程序 (iostat -cxzk 1)
avg-cpu: %user %nice %system %iowait %steal %idle
0.03 0.00 0.42 7.87 0.00 91.68
Device r/s rkB/s r_await rareq-sz w/s wkB/s . . . %util
md127 54360.00 6958080.00 0.00 128.00 0.00 0.00 . . . 0.00
nvme2n1 27173.00 3478144.00 1.03 128.00 0.00 0.00 . . . 100.00
nvme3n1 27179.00 3478912.00 0.95 128.00 0.00 0.00 . . . 100.00
还有来自 nvidia-smi dmon 命令的数据
dgx2> nvidia-smi dmon -i 2 -s putcm
# gpu pwr gtemp mtemp sm mem enc dec rxpci txpci mclk pclk fb bar1
# Idx W C C % % % % MB/s MB/s MHz MHz MB MB
2 63 37 37 0 4 0 0 8923 0 958 345 326 15
2 63 37 37 0 4 0 0 8922 0 958 345 326 15
2 63 37 37 0 4 0 0 8930 0 958 345 326 15
2 63 37 37 0 4 0 0 8764 0 958 345 326 15
此数据与 gdsio 报告的结果一致。 iostat 数据显示来自两个 NVMe 驱动器中的每个驱动器的吞吐量略高于 3.4GB/秒,每个设备的延迟接近 1 毫秒。 请注意,每个驱动器持续大约 27k 次写入/秒 (IOPS)。 来自 nvidia-smi 的 dmon 子命令的第二个数据集,请注意 rxpci 列。 回忆一下我们的 gdsio 命令行启动了 GPUDirect 存储读取,因此是从存储到 GPU 的读取。 我们看到选定的 GPU 2 通过 PCIe 接收超过 8GB/秒的数据。 这就是 GPUDirect 存储在起作用 - GPU 通过 PCIe 直接从 NVMe 驱动器读取(PCIe 接收)。
虽然前面的信息对于启用最佳配置很重要,但 GDS 软件将始终尝试维护最佳数据路径,在某些情况下,通过另一个与存储目标具有更好亲和力的 GPU。 通过使用 nvidia-smi 或 dcgmi(DCGM 的命令行组件)监视 PCIe 流量,我们可以观察 GPU 的数据输入和输出速率。
使用之前的示例,在由同一 PCIe 交换机上的两个 NVMe 驱动器组成的同一 RAID0 元设备上运行,但这次指定 GPU 12,并使用 dcgmi 捕获 GPU PCIe 流量,我们将观察到次优性能,因为 GPU 12 与我们的两个 NVMe 驱动器不在同一个下游 PCIe 交换机上。
dgx2> gdsio -D /nvme23/gds_dir -d 12 -w 8 -s 500M -i 1M -x 0 -I 0 -T 120
IoType: READ XferType: GPUD Threads: 8 DataSetSize: 491438080/4096000(KiB) IOSize: 1024(KiB) Throughput: 3.893747 GiB/sec, Avg_Latency: 2003.091575 usecs ops: 479920 total_time 120.365276 secs
请注意,吞吐量从 6.5GB/秒降至 3.9GB/秒,延迟几乎翻了一番,达到 2 毫秒。 PCIe 流量数据讲述了一个有趣的故事
dgx2> dcgmi dmon -e 1009,1010 -d 1000
# Entity PCITX PCIRX
Id
GPU 0 4712070210 5237742827
GPU 1 435418 637272
. . .
GPU 11 476420 739272
GPU 12 528378278 4721644934
GPU 13 481604 741403
GPU 14 474700 736417
GPU 15 382261 611617
请注意,我们观察到 GPU 12 上的 PCIe 流量,以及 GPU 0 上的流量。 这再次是 GDS 在起作用。 cuFile 库将为数据缓冲区(GPU 内存)选择一个与存储在同一 PCIe 交换机上的 GPU。 在本例中,库选择了 GPU 0,因为它是与 NVMe 设备位于同一 PCIe 交换机上的四个 GPU 中的第一个。 然后,数据被移动到目标 GPU (12)。
次优设备选择的最终结果是整体吞吐量降低和延迟增加。 对于 GPU 2,平均吞吐量为 6.5GB/秒,平均延迟为 1 毫秒。 对于 GPU 12,平均吞吐量为 3.9GB/秒,平均延迟为 2 毫秒。 因此,当使用非最优配置时,我们观察到吞吐量降低了 40%,延迟增加了 2 倍。
并非所有工作负载都与吞吐量有关。 较小的 IO 大小和随机 IO 模式是许多生产工作负载的属性,评估 IOPS(每秒 IO 操作数)性能是存储基准测试过程的必要组成部分。
确定可以实现的峰值性能级别的关键组成部分是确保有足够的负载。 具体而言,对于存储基准测试,生成 IO 的进程/线程数对于确定最大性能至关重要。
gdsio 工具提供了指定随机读取或随机写入 (-I 标志) 的功能。 在下面的示例中,我们再次展示了 GPU (0) 和 NVMe 设备的最佳组合,生成了一个小 (4k) 随机读取低负载,线程数 (-w) 逐渐增加。
dgx2> gdsio -D /nvme23/gds_dir -d 0 -w 4 -s 1G -i 4K -x 0 -I 2 -k 0308 -T 120
IoType: RANDREAD XferType: GPUD Threads: 4 DataSetSize: 11736528/4194304(KiB) IOSize: 4(KiB) Throughput: 0.093338 GiB/sec, Avg_Latency: 163.478958 usecs ops: 2934132 total_time 119.917332 secs
dgx2> gdsio -D /nvme23/gds_dir -d 0 -w 8 -s 1G -i 4K -x 0 -I 2 -k 0308 -T 120
IoType: RANDREAD XferType: GPUD Threads: 8 DataSetSize: 23454880/8388608(KiB) IOSize: 4(KiB) Throughput: 0.187890 GiB/sec, Avg_Latency: 162.422553 usecs ops: 5863720 total_time 119.049917 secs
dgx2> gdsio -D /nvme23/gds_dir -d 0 -w 16 -s 1G -i 4K -x 0 -I 2 -k 0308 -T 120
IoType: RANDREAD XferType: GPUD Threads: 16 DataSetSize: 48209436/16777216(KiB) IOSize: 4(KiB) Throughput: 0.385008 GiB/sec, Avg_Latency: 158.918796 usecs ops: 12052359 total_time 119.415992 secs
dgx2> gdsio -D /nvme23/gds_dir -d 0 -w 32 -s 1G -i 4K -x 0 -I 2 -k 0308 -T 120
IoType: RANDREAD XferType: GPUD Threads: 32 DataSetSize: 114100280/33554432(KiB) IOSize: 4(KiB) Throughput: 0.908862 GiB/sec, Avg_Latency: 139.107219 usecs ops: 28525070 total_time 119.726070 secs
dgx2> gdsio -D /nvme23/gds_dir -d 0 -w 64 -s 1G -i 4K -x 0 -I 2 -k 0308 -T 120
IoType: RANDREAD XferType: GPUD Threads: 64 DataSetSize: 231576720/67108864(KiB) IOSize: 4(KiB) Throughput: 1.848647 GiB/sec, Avg_Latency: 134.554997 usecs ops: 57894180 total_time 119.465109 secs
dgx2> gdsio -D /nvme23/gds_dir -d 0 -w 128 -s 1G -i 4K -x 0 -I 2 -k 0308 -T 120
IoType: RANDREAD XferType: GPUD Threads: 128 DataSetSize: 406924776/134217728(KiB) IOSize: 4(KiB) Throughput: 3.243165 GiB/sec, Avg_Latency: 151.508258 usecs ops: 101731194 total_time 119.658960 secs
我们可以通过将 ops 值除以总时间来计算 IOPS。 请注意,在所有情况下,总时间都略高于 119 秒(命令行上指定了 120 秒的运行持续时间)。
线程数 (-w) |
IOPS (ops / total_time) |
|---|---|
4 |
24,468 |
8 |
49,255 |
16 |
100,928 |
32 |
238,245 |
64 |
484,612 |
128 |
850,240 |
有趣的是,观察到每次运行的平均延迟 (Avg_Latency) 实际上随着线程数和 IOPS 的增加而变得更好,在 484,612 IOPS 和 64 个线程运行时,平均延迟为 134.5us。 将线程数增加到 128,我们观察到延迟略有上升至 151.51us,同时维持每秒 850,240 次随机读取。 在表征交付的性能时,跟踪延迟和吞吐量(或在本例中为 IOPS)非常重要。 在本例中,构成 RAID0 设备的 NVMe 驱动器的规范表明每个驱动器的随机读取能力约为 800k IOPS。 因此,即使使用 128 个线程生成负载,延迟也非常好,因为负载完全在驱动器规范范围内,因为 RAID0 设备中的两个驱动器中的每个驱动器都维持了大约 425,000 IOPS。 这是通过 iostat 实用程序观察到的
avg-cpu: %user %nice %system %iowait %steal %idle
16.03 0.00 6.52 76.97 0.00 0.48
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz . . . %util
md127 856792.00 3427172.00 0.00 0.00 0.00 4.00 . . . 0.00
nvme2n1 425054.00 1700216.00 0.00 0.00 0.13 4.00 . . . 100.80
nvme3n1 431769.00 1727080.00 0.00 0.00 0.13 4.00 . . . 100.00
我们观察到显示 RAID0 元设备 md127 的行,每秒总读取次数 (r/s) 反映了两个底层 NVMe 驱动器的总和。
扩展此示例以演示当指定的 GPU 目标不属于同一 PCIe 段时交付的性能
dgx2> gdsio -D /nvme23/gds_dir -d 10 -w 64 -s 1G -i 4K -x 0 -I 2 -k 0308 -T 120
IoType: RANDREAD XferType: GPUD Threads: 64 DataSetSize: 13268776/67108864(KiB) IOSize: 4(KiB) Throughput: 0.105713 GiB/sec, Avg_Latency: 2301.201214 usecs ops: 3317194 total_time 119.702494 secs
在本例中,我们指定 GPU 10 作为数据读取目标。 请注意性能的巨大差异。 在 64 个线程生成随机读取的情况下,延迟从 151.51us 变为 2.3ms,IOPS 从 850k IOPS 降至约 28k IOPS。 这是由于 GDS 使用同一 PCIe 段上的 GPU 作为主读取缓冲区,然后将数据移动到指定 GPU 的开销造成的。 同样,这可以通过监视 GPU PCIe 流量来观察到
dgx2> dcgmi dmon -e 1009,1010 -d 1000
# Entity PCITX PCIRX
Id
GPU 0 108216883 122481373
GPU 1 185690 61385
. . .
GPU 9 183268 60918
GPU 10 22110153 124205217
. . .
我们观察到 GPU 10(在 gdsio 命令行中指定)和 GPU 0(由 GDS 选择作为主读取缓冲区,因为它靠近 NVMe 设备)上的 PCIe 流量。 使用 gds_stats,我们可以看到 GPU 0 上的缓冲区分配
dgx2> gds_stats -p 1545037 -l 3
cuFile STATS VERSION : 3
GLOBAL STATS:
Total Files: 64
Total Read Errors : 0
Total Read Size (MiB): 4996
Read BandWidth (GiB/s): 0.126041
Avg Read Latency (us): 2036
Total Write Errors : 0
Total Write Size (MiB): 0
Write BandWidth (GiB/s): 0
Avg Write Latency (us): 0
READ-WRITE SIZE HISTOGRAM :
0-4(KiB): 0 0
4-8(KiB): 1279109 0
8-16(KiB): 0 0
. . .
65536-...(KiB): 0 0
PER_GPU STATS:
GPU 0 Read: bw=0 util(%)=0 n=0 posix=0 unalign=0 r_sparse=0 r_inline=0 err=0 MiB=0 Write: bw=0 util(%)=0 n=0 posix=0 unalign=0 err=0 MiB=0 BufRegister: n=0 err=0 free=0 MiB=0
. . .
GPU 9 Read: bw=0 util(%)=0 n=0 posix=0 unalign=0 r_sparse=0 r_inline=0 err=0 MiB=0 Write: bw=0 util(%)=0 n=0 posix=0 unalign=0 err=0 MiB=0 BufRegister: n=0 err=0 free=0 MiB=0
GPU 10 Read: bw=0.124332 util(%)=6387 n=1279109 posix=0 unalign=0 r_sparse=0 r_inline=0 err=0 MiB=4996 Write: bw=0 util(%)=0 n=0 posix=0 unalign=0 err=0 MiB=0 BufRegister: n=64 err=0 free=0 MiB=0
GPU 11 Read: bw=0 util(%)=0 n=0 posix=0 unalign=0 r_sparse=0 r_inline=0 err=0 MiB=0 Write: bw=0 util(%)=0 n=0 posix=0 unalign=0 err=0 MiB=0 BufRegister: n=0 err=0 free=0 MiB=0
. . .
PER_GPU POOL BUFFER STATS:
GPU : 0 pool_size_MiB : 64 usage : 63/64 used_MiB : 63
来自 gds_stats 的输出显示了 GPU 10(在 gdsio 命令行上指定)上的读取活动,以及 GPU 0 上的 POOL BUFFER 活动,其中使用了 64 个 1MB 缓冲区中的 63 个。 回忆一下,GDS 选择 GPU 0 是因为它是在与 NVMe 设备位于同一 PCIe 段上的第一个 GPU。 这说明了 GPU POOL BUFFER 的用途之一(请参阅有关 gds_stats 的部分)。
根据这些结果,需要考虑两个关键点。 首先,对于小的随机 IO 负载,需要大量线程生成负载才能评估峰值性能能力。 其次,对于小的随机 IO 负载,次优配置的性能损失比在面向大型吞吐量的 IO 负载中观察到的要严重得多。
5.2. DGX A100 系统上的 GPUDirect 存储性能#
GDS 也支持 DGX A100 系统,这是世界上首个采用新一代 GPU、NVMe 驱动器和网络接口构建的 5 百万兆次浮点 AI 系统。 有关详细信息,请参阅 DGX A100 产品页面。 在本节中,我们将使用与 DGX-2 示例中使用的相同测试方法来基准测试 DGX A100 系统上的 GDS 性能。
首先,我们映射 GPU 和 NMVe 驱动器亲缘性
检查 NVMe 驱动器名称和 PICe BFD 值
dgxuser@dgxa100:~$ ls -l /dev/disk/by-path/ total 0 lrwxrwxrwx 1 root root 13 Oct 26 10:52 pci-0000:08:00.0-nvme-1 -> ../../nvme0n1 lrwxrwxrwx 1 root root 13 Oct 26 10:52 pci-0000:09:00.0-nvme-1 -> ../../nvme1n1 lrwxrwxrwx 1 root root 13 Oct 26 10:51 pci-0000:22:00.0-nvme-1 -> ../../nvme2n1 lrwxrwxrwx 1 root root 15 Oct 26 10:51 pci-0000:22:00.0-nvme-1-part1 -> ../../nvme2n1p1 lrwxrwxrwx 1 root root 15 Oct 26 10:51 pci-0000:22:00.0-nvme-1-part2 -> ../../nvme2n1p2 lrwxrwxrwx 1 root root 13 Oct 26 10:51 pci-0000:23:00.0-nvme-1 -> ../../nvme3n1 lrwxrwxrwx 1 root root 15 Oct 26 10:51 pci-0000:23:00.0-nvme-1-part1 -> ../../nvme3n1p1 lrwxrwxrwx 1 root root 15 Oct 26 10:51 pci-0000:23:00.0-nvme-1-part2 -> ../../nvme3n1p2 lrwxrwxrwx 1 root root 9 Oct 26 10:51 pci-0000:25:00.3-usb-0:1.1:1.0-scsi-0:0:0:0 -> ../../sr0 lrwxrwxrwx 1 root root 13 Oct 26 10:52 pci-0000:52:00.0-nvme-1 -> ../../nvme4n1 lrwxrwxrwx 1 root root 13 Oct 26 10:52 pci-0000:53:00.0-nvme-1 -> ../../nvme5n1 lrwxrwxrwx 1 root root 13 Oct 26 10:52 pci-0000:89:00.0-nvme-1 -> ../../nvme6n1 lrwxrwxrwx 1 root root 13 Oct 26 10:52 pci-0000:8a:00.0-nvme-1 -> ../../nvme7n1 lrwxrwxrwx 1 root root 13 Oct 26 10:52 pci-0000:c8:00.0-nvme-1 -> ../../nvme8n1 lrwxrwxrwx 1 root root 13 Oct 26 10:52 pci-0000:c9:00.0-nvme-1 -> ../../nvme9n1
检查与 PCIe BFD 相关的 GPU 索引编号
dgxuser@gpu01:~$ nvidia-smi --query-gpu=index,name,pci.domain,pci.bus, --format=csv
index, name, pci.domain, pci.bus
0, A100-SXM4-40GB, 0x0000, 0x07
1, A100-SXM4-40GB, 0x0000, 0x0F
2, A100-SXM4-40GB, 0x0000, 0x47
3, A100-SXM4-40GB, 0x0000, 0x4E
4, A100-SXM4-40GB, 0x0000, 0x87
5, A100-SXM4-40GB, 0x0000, 0x90
6, A100-SXM4-40GB, 0x0000, 0xB7
7, A100-SXM4-40GB, 0x0000, 0xBD
检查 NVMe 驱动器和 GPU PCIe 插槽关系
dgxuser@dgxa100:~$ lspci -tv | egrep -i "nvidia|NVMe" | +-01.1-[b1-cb]----00.0-[b2-cb]--+-00.0-[b3-b7]----00.0-[b4-b7]----00.0-[b5-b7]----00.0-[b6-b7]----00.0-[b7]----00.0 NVIDIA Corporation Device 20b0 | | | \-10.0-[bb-bd]----00.0-[bc-bd]----00.0-[bd]----00.0 NVIDIA Corporation Device 20b0 | | +-08.0-[be-ca]----00.0-[bf-ca]--+-00.0-[c0-c7]----00.0-[c1-c7]--+-00.0-[c2]----00.0 NVIDIA Corporation Device 1af1 | | | | +-01.0-[c3]----00.0 NVIDIA Corporation Device 1af1 | | | | +-02.0-[c4]----00.0 NVIDIA Corporation Device 1af1 | | | | +-03.0-[c5]----00.0 NVIDIA Corporation Device 1af1 | | | | +-04.0-[c6]----00.0 NVIDIA Corporation Device 1af1 | | | | \-05.0-[c7]----00.0 NVIDIA Corporation Device 1af1 | | | +-04.0-[c8]----00.0 Samsung Electronics Co Ltd NVMe SSD Controller PM173X | | | +-08.0-[c9]----00.0 Samsung Electronics Co Ltd NVMe SSD Controller PM173X | +-01.1-[81-95]----00.0-[82-95]--+-00.0-[83-8a]----00.0-[84-8a]--+-00.0-[85-88]----00.0-[86-88]--+-00.0-[87]----00.0 NVIDIA Corporation Device 20b0 | | | +-10.0-[89]----00.0 Samsung Electronics Co Ltd NVMe SSD Controller PM173X | | | \-14.0-[8a]----00.0 Samsung Electronics Co Ltd NVMe SSD Controller PM173X | | | \-10.0-[8e-91]----00.0-[8f-91]--+-00.0-[90]----00.0 NVIDIA Corporation Device 20b0 | +-01.1-[41-55]----00.0-[42-55]--+-00.0-[43-48]----00.0-[44-48]----00.0-[45-48]----00.0-[46-48]--+-00.0-[47]----00.0 NVIDIA Corporation Device 20b0 | | | \-10.0-[4c-4f]----00.0-[4d-4f]--+-00.0-[4e]----00.0 NVIDIA Corporation Device 20b0 | | +-08.0-[50-54]----00.0-[51-54]--+-00.0-[52]----00.0 Samsung Electronics Co Ltd NVMe SSD Controller PM173X | | | +-04.0-[53]----00.0 Samsung Electronics Co Ltd NVMe SSD Controller PM173X | +-03.2-[22]----00.0 Samsung Electronics Co Ltd NVMe SSD Controller SM981/PM981/PM983 | +-03.3-[23]----00.0 Samsung Electronics Co Ltd NVMe SSD Controller SM981/PM981/PM983 +-01.1-[01-13]----00.0-[02-13]--+-00.0-[03-09]----00.0-[04-09]--+-00.0-[05-07]----00.0-[06-07]----00.0-[07]----00.0 NVIDIA Corporation Device 20b0 | | +-10.0-[08]----00.0 Samsung Electronics Co Ltd NVMe SSD Controller PM173X | | \-14.0-[09]----00.0 Samsung Electronics Co Ltd NVMe SSD Controller PM173X | | \-10.0-[0d-0f]----00.0-[0e-0f]----00.0-[0f]----00.0 NVIDIA Corporation Device 20b0 dgxuser@dgxa100:~$
然后映射 NVMe 和 GPU 亲缘性
GPU 编号 |
GPU PCIe 总线 # |
NVMe 编号 |
NVMe PCIe 总线 # |
|---|---|---|---|
0, 1 |
0x07, 0x0F |
nvme0, nvme1 |
0x08, 0x09 |
2, 3 |
0x47, 0x4e |
nvme4, nvme5 |
0x52, 0x53 |
4, 5 |
0x87, 0x90 |
nvme6, nvme7 |
0x89, 0x8a |
6, 7 |
0xb7, 0xb |
nvme8, nvme9 |
0xc8, 0xc9 |
默认情况下,DGX 系统中的所有 NVMe 驱动器都配置为 RAID0 存储阵列 /dev/md1,但它们与不同的 PCIe 交换机连接,如下所示。
6. GPUDirect 存储在网络附加存储上的基准测试#
NAS 配置将网络元素引入存储等式,这当然必须在评估性能时考虑在内。 吞吐量、IOPS 和延迟都取决于网络配置,例如配置的接口数量、接口速度以及后端存储配置。 例如,如果存储后端是 NVMe SSD,则 4 个此类设备进行流式读取将使单个 100GB 网络饱和。 需要检查和调整整个端到端配置,以确保识别并解决任何潜在的硬件瓶颈。
6.1. GPUDirect 存储在 NFS 上的基准测试#
网络文件系统 NFS 是 Sun Microsystems 在 1980 年代初期发明的,并成为最早广泛部署在生产环境中的网络存储解决方案之一。 具有直接连接存储的 NFS 服务器可以通过网络导出该存储,使导出的文件系统可供任意数量的 NFS 客户端使用。 NFS 易于使用和管理,代码库成熟(已经存在数十年),这使其相对稳定。 早期的实现依赖 UDP 或 TCP 作为通过网络使用 NFS 传输数据的协议。 借助远程直接内存访问 (RDMA) 功能,网络开销显着降低,从而实现 NFS 客户端和服务器之间更高的吞吐量和更低的延迟读取/写入操作。
对于为 NFS 配置的 GPUDirect 存储,传输协议是 RDMA,利用客户端和服务器之间的高速、低延迟数据流。 RDMA 操作通过 IB 接口在网络上传输数据,然后通过 DMA 操作将数据从 IB 卡移动到 GPU,绕过 CPU 和系统内存。
如前所述,PCIe 拓扑是确定 NFS 客户端最佳配置的一个因素。 理想情况下,向 NFS 服务器发出读取/写入请求的 NIC 应与发出请求的 GPU 位于同一 PCIe 交换机上。 在 NVIDIA DGX 系统上,nvidia-smi 实用程序有助于确定最佳 NIC/GPU 配对
nfs_client> nvidia-smi topo -mp
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 . . . mlx5_0 mlx5_1 mlx5_2 mlx5_3
GPU0 X PIX PXB PXB NODE NODE NODE NODE . . . PIX PXB NODE NODE
GPU1 PIX X PXB PXB NODE NODE NODE NODE . . . PIX PXB NODE NODE
GPU2 PXB PXB X PIX NODE NODE NODE NODE . . . PXB PIX NODE NODE
GPU3 PXB PXB PIX X NODE NODE NODE NODE . . . PXB PIX NODE NODE
GPU4 NODE NODE NODE NODE X PIX PXB PXB . . . NODE NODE PIX PXB
GPU5 NODE NODE NODE NODE PIX X PXB PXB . . . NODE NODE PIX PXB
GPU6 NODE NODE NODE NODE PXB PXB X PIX . . . NODE NODE PXB PIX
GPU7 NODE NODE NODE NODE PXB PXB PIX X . . . NODE NODE PXB PIX
mlx5_0 PIX PIX PXB PXB NODE NODE NODE NODE . . . X PXB NODE NODE
mlx5_1 PXB PXB PIX PIX NODE NODE NODE NODE . . . PXB X NODE NODE
mlx5_2 NODE NODE NODE NODE PIX PIX PXB PXB . . . NODE NODE X PXB
mlx5_3 NODE NODE NODE NODE PXB PXB PIX PIX . . . NODE NODE PXB X
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (for example, QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
上面的示例是在 DGX-2 系统上生成的。 为了简洁起见,显示了 16 个 GPU 中的 8 个和 8 个 NIC 中的 4 个。 从拓扑图提供的图例中,我们看到最佳路径表示为 PIX(Connection traversing at most a single PCIe bridge)。 因此,对于 GPU 0 和 1,mlx5_0 是最近的 NIC,对于 GPU 2 和 3,它是 mlx5_1,依此类推。 Linux 中的网络设备名称使用前缀 ib,因此我们需要查看哪些接口名称映射到哪些设备名称。 这可以使用 ibdev2netdev 实用程序完成
nfs_client> ibdev2netdev
mlx5_0 port 1 ==> ib0 (Up)
mlx5_1 port 1 ==> ib1 (Up)
mlx5_2 port 1 ==> ib2 (Up)
mlx5_3 port 1 ==> ib3 (Up)
mlx5_4 port 1 ==> ib4 (Down)
mlx5_5 port 1 ==> ib5 (Down)
mlx5_6 port 1 ==> ib6 (Up)
mlx5_7 port 1 ==> ib7 (Up)
mlx5_8 port 1 ==> ib8 (Up)
mlx5_9 port 1 ==> ib9 (Up)
NFS 服务器和客户端之间的网络配置显然会显着影响交付的性能。 详细介绍配置网络、子网、路由表的步骤超出了本文档的范围。 概述介绍了在开始介绍在 NFS 上运行 gdsio 的示例之前的基础知识。
在服务器端,有一个由 8 个本地连接的 NVMe SSD 组成的单个 RAID0 设备。 该设备配置了 ext4 文件系统,并通过两个挂载点进行访问。 服务器上配置了两个 100GB 网络接口用于 NFS 流量,并且每个 NIC 都分配了多个 IP 地址到不同的子网,以平衡来自客户端的网络流量。
在客户端,配置了 8 个 100GB 网络。网络配置(子网、路由表)决定了当客户端发起 NFS 挂载时,客户端的哪个接口将路由到服务器端的两个接口中的哪一个。客户端的挂载路径被有意地命名,以反映客户端和服务器之间的网络路径。具体来说,客户端的挂载点分解如下:
/mnt/nfs/``[客户端网络接口]``/data/``[服务器端网络接口]``
其中,客户端网络接口名称是实际设备(ib9、ib8 等),服务器端是 0 或 1,表示两个服务器网络中的哪一个将处理连接。
nfs_client> mount | grep nfs
192.168.0.10:/mnt/nfs_10/10 on /mnt/nfs/ib9/data/0 type nfs (rw,relatime,vers=3,rsize=1048576,wsize=1048576,namlen=255,hard,proto=rdma,port=20049,timeo=600,retrans=2,sec=sys,mountaddr=192.168.0.10,mountvers=3,mountproto=tcp,local_lock=none,addr=192.168.0.10)
192.168.0.11:/mnt/nfs_11/11 on /mnt/nfs/ib9/data/1 type nfs (rw,relatime,vers=3,rsize=1048576,wsize=1048576,namlen=255,hard,proto=rdma,port=20049,timeo=600,retrans=2,sec=sys,mountaddr=192.168.0.11,mountvers=3,mountproto=tcp,local_lock=none,addr=192.168.0.11)
192.168.1.10:/mnt/nfs_10/10 on /mnt/nfs/ib8/data/0 type nfs (rw,relatime,vers=3,rsize=1048576,wsize=1048576,namlen=255,hard,proto=rdma,port=20049,timeo=600,retrans=2,sec=sys,mountaddr=192.168.1.10,mountvers=3,mountproto=tcp,local_lock=none,addr=192.168.1.10)
192.168.1.11:/mnt/nfs_11/11 on /mnt/nfs/ib8/data/1 type nfs (rw,relatime,vers=3,rsize=1048576,wsize=1048576,namlen=255,hard,proto=rdma,port=20049,timeo=600,retrans=2,sec=sys,mountaddr=192.168.1.11,mountvers=3,mountproto=tcp,local_lock=none,addr=192.168.1.11)
. . .
在客户端的 mount 输出(部分,如上所示)中,/mnt/nfs/ib9/data/0 将通过客户端的 ib9 接口路由到服务器上分配了 192.168.0.10 的接口(在路径字符串中反映为 ‘0’),而 /mnt/nfs/ib9/data/1 也将通过客户端的 ib9 接口路由到服务器上的第二个接口,192.168.0.11(在路径字符串中反映为 ‘1’)。此约定用于所有客户端挂载,因此可以选择 IO 路径名以有效地平衡所有接口上的负载。
从性能/基准测试的角度来看,除了刚才讨论的均衡网络设置外,被测配置的关键方面是服务器上的底层存储配置(8 个 NVMe SSD)以及服务器上网络接口的数量和速度(2 个 100Gb)。就吞吐量而言,在理想条件下,两个 100Gb 网络每个可以维持大约 12GB/秒。存储服务器可以支持大约 (2 x 12GB/秒) 24GB/秒,但请记住,有很多因素会影响实际性能 - 协议开销、网络 MTU 大小、NFS 属性、软件堆栈、负载特性等等。
在第一个示例中,gdsio 用于生成小 IO(4k)的随机写入负载到一个 NFS 挂载点,该挂载点将遍历客户端的 ib0 接口。ib0 接口与 GPU 0 和 1 在同一个 PCIe 段上。
nfs_client> gdsio -D /mnt/nfs/ib0/data/0/gds_dir -d 0 -w 32 -s 500M -i 4K -x 0 -I 3 -T 120
IoType: RANDWRITE XferType: GPUD Threads: 32 DataSetSize: 81017740/16384000(KiB) IOSize: 4(KiB) Throughput: 0.645307 GiB/sec, Avg_Latency: 189.166333 usecs ops: 20254435 total_time 119.732906 secs
nfs_client> gdsio -D /mnt/nfs/ib0/data/0/gds_dir -d 12 -w 32 -s 500M -i 4K -x 0 -I 3 -T 120
IoType: RANDWRITE XferType: GPUD Threads: 32 DataSetSize: 71871140/16384000(KiB) IOSize: 4(KiB) Throughput: 0.572407 GiB/sec, Avg_Latency: 213.322597 usecs ops: 17967785 total_time 119.742801 secs
第一个调用指定 GPU 0,第二个调用指定 GPU 12。请注意操作数和延迟的差异。在最佳 GPU/IB 情况下,我们观察到略高于 169k IOPS,平均延迟为 189.2us。在非最佳情况下(GPU 12 到相同的挂载点),我们看到延迟增加到 213.3 微秒,IOPS 大约为 150k。性能差异不是很大(延迟增加 12%,IOPS 降低 19%),但仍然值得注意。
对于随机读取,最佳情况和次优情况之间的差异更大
nfs_client> gdsio -D /mnt/nfs/ib0/data/0/gds_dir -d 0 -w 32 -s 500M -i 4K -x 0 -I 2 -T 120
IoType: RANDREAD XferType: GPUD Threads: 32 DataSetSize: 111181604/16384000(KiB) IOSize: 4(KiB) Throughput: 0.890333 GiB/sec, Avg_Latency: 137.105980 usecs ops: 27795401 total_time 119.091425 secs
nfs_client> gdsio -D /mnt/nfs/ib0/data/0/gds_dir -d 10 -w 32 -s 500M -i 4K -x 0 -I 2 -T 120
IoType: RANDREAD XferType: GPUD Threads: 32 DataSetSize: 78621148/16384000(KiB) IOSize: 4(KiB) Throughput: 0.629393 GiB/sec, Avg_Latency: 193.975032 usecs ops: 19655287 total_time 119.129013 secs
使用 GPU 0 和 ib0,我们看到大约 234k IOPS,平均延迟为 194us。使用 GPU 10 和 ib0,我们看到大约 165k IOPS,延迟为 194us。
小型随机 IO 完全取决于 IOPS 和延迟。为了确定吞吐量,我们使用更大的文件大小和更大的 IO 大小。
nfs_client> gdsio -D /mnt/nfs/ib0/data/0/gds_dir -d 0 -w 32 -s 1G -i 1M -x 0 -I 1 -T 120
IoType: WRITE XferType: GPUD Threads: 64 DataSetSize: 876086272/67108864(KiB) IOSize: 1024(KiB) Throughput: 6.962237 GiB/sec, Avg_Latency: 8976.802942 usecs ops: 855553 total_time 120.004668 secs
nfs_client> gdsio -D /mnt/nfs/ib0/data/0/gds_dir -d 0 -w 32 -s 1G -i 1M -x 0 -I 0 -T 120
IoType: READ XferType: GPUD Threads: 32 DataSetSize: 1196929024/33554432(KiB) IOSize: 1024(KiB) Throughput: 9.482088 GiB/sec, Avg_Latency: 3295.183817 usecs ops: 1168876 total_time 120.382817 secs
上面生成了一个大型顺序写入,然后是读取。在这两种情况下,都生成了 32 个线程 (-w 32) 执行 1M IO。在写入情况下,我们维持了 6.9GB/秒,在读取情况下维持了 9.5GB/秒的吞吐量。两个调用都使用了 ib0 和 GPU 0。将 GPU 从 0 更改为 8
nfs_client> gdsio -D /mnt/nfs/ib0/data/0/gds_dir -d 8 -w 32 -s 1G -i 1M -x 0 -I 0 -T 120
IoType: READ XferType: GPUD Threads: 32 DataSetSize: 1053419520/33554432(KiB) IOSize: 2048(KiB) Throughput: 8.352013 GiB/sec, Avg_Latency: 7480.408305 usecs ops: 514365 total_time 120.284676 secs
我们再次注意到吞吐量下降(从 9.5GB/秒降至 8.3GB/秒)和延迟增加(从 3.4ms 增加到 7.5ms)。
使用支持的 gdsio 配置文件可以轻松地重用 IO 负载和配置的“工具箱”。此外,在运行多个作业时,gdsio 将聚合结果,从而更容易看到完整的性能图景。
这是一个示例配置文件,用于为 4 个不同的 GPU 生成到多个 NFS 挂载点的 4k 随机读取。请注意全局部分中定义的各种参数,然后在每个作业部分中定义特定于作业的参数(GPU、目标挂载点、线程数)。
[global]
name=nfs_random_read
#0,1,2,3,4,5
xfer_type=0
#IO type, rw=read, rw=write, rw=randread, rw=randwrite
rw=randread
#block size, for variable block size can specify range e.g. bs=1M:4M:1M, (1M : start block size, 4M : end block size, 1M :steps in which size is varied)
bs=4k
#file-size
size=500M
#secs
runtime=120
[job1]
#numa node
numa_node=0
#gpu device index (check nvidia-smi)
gpu_dev_id=0
num_threads=16
directory=/mnt/nfs/ib0/data/0/gds_dir
[job2]
numa_node=0
gpu_dev_id=2
num_threads=16
directory=/mnt/nfs/ib1/data/0/gds_dir
[job3]
numa_node=0
gpu_dev_id=4
num_threads=16
directory=/mnt/nfs/ib2/data/0/gds_dir
[job4]
numa_node=0
gpu_dev_id=6
num_threads=16
directory=/mnt/nfs/ib3/data/0/gds_dir
使用上述配置文件执行 gdsio,只需将文件名作为唯一参数传递即可
nfs_client> gdsio nfs_rr.gdsio
IoType: RANDREAD XferType: GPUD Threads: 64 DataSetSize: 277467756/32768000(KiB) IOSize: 4(KiB) Throughput: 2.213928 GiB/sec, Avg_Latency: 110.279539 usecs ops: 69366939 total_time 119.522363 secs
持续的随机读取速率约为 580k IOPS (69366939 / 119.52)。
对于吞吐量测试,需要更改负载属性,以便 gdsio 发出读取和写入,而不是随机读取和随机写入(请参阅全局部分中的 rw=)。此外,IO 大小(全局部分中的 bs=)必须增加以最大化吞吐量。
使用编辑过的 gdsio 配置文件反映这些更改,我们可以生成一个面向吞吐量的工作负载,其中包含多个 GPU。配置文件如下:
[global]
name=nfs_large_read
xfer_type=0
rw=read
bs=1M
size=1G
runtime=120
do_verify=0
[job1]
numa_node=0
gpu_dev_id=0
num_threads=8
directory=/mnt/nfs/ib0/data/0/gds_dir
[job3]
numa_node=0
gpu_dev_id=2
num_threads=8
directory=/mnt/nfs/ib1/data/1/gds_dir
[job5]
numa_node=0
gpu_dev_id=4
num_threads=8
directory=/mnt/nfs/ib2/data/0/gds_dir
[job7]
numa_node=0
gpu_dev_id=6
num_threads=8
directory=/mnt/nfs/ib3/data/1/gds_dir
[job9]
numa_node=1
gpu_dev_id=8
num_threads=8
directory=/mnt/nfs/ib6/data/0/gds_dir
[job11]
numa_node=1
gpu_dev_id=10
num_threads=8
directory=/mnt/nfs/ib7/data/1/gds_dir
[job13]
numa_node=1
gpu_dev_id=12
num_threads=8
directory=/mnt/nfs/ib8/data/0/gds_dir
[job15]
numa_node=1
gpu_dev_id=14
num_threads=8
directory=/mnt/nfs/ib9/data/1/gds_dir
运行大型读取负载
nfs_client> gdsio nfs_sr.gdsio
IoType: READ XferType: GPUD Threads: 64 DataSetSize: 1608664064/67108864(KiB) IOSize: 1024(KiB) Throughput: 12.763141 GiB/sec, Avg_Latency: 4896.861494 usecs ops: 1570961 total_time 120.200944 secs
我们看到使用配置实现了 12.76GB/秒的持续吞吐量。
所示示例旨在作为起点。NAS 存储环境、NFS 或合作伙伴解决方案的配置可能很复杂,因为一旦在存储 IO 路径中引入网络,就会有很多变量发挥作用。可以更改各种配置选项,包括负载生成方面(gdsio 命令行或配置文件)以及系统设置方面(网络、NFS 等),以便确定目标工作负载的最佳配置。
为了在负载下观察数据速率,有几种选择。当然,在服务器端,应使用 Linux 实用程序(如 iostat)来监控流量并捕获后端存储的统计信息,并在客户端和服务器端都使用 nfsstat 来获取 NFS 特定的统计信息。对于网络上的字节和数据包速率,这取决于实际的网络设备和软件堆栈,以及是否维护任何按接口统计的信息。在我们的配置中,使用了 NVIDIA/Mellanox 网卡
nfs_client> lspci -v | grep -i mellanox
35:00.0 Infiniband controller: Mellanox Technologies MT27800 Family [ConnectX-5]
Subsystem: Mellanox Technologies MT27800 Family [ConnectX-5]
. . .
在这种环境中,维护了各种计数器,可以对其进行检查,并且通过一个相对简单的脚本,可以监控每秒的数据和数据包速率。这些计数器可以在 /sys/class/infiniband/[INTERFACE]/ports/[PORT NUMBER]/counters 中找到,例如 /sys/class/infiniband/mlx5_19/ports/1/counters。感兴趣的计数器是
port_rcv_data- 接收字节port_xmit_data- 传输字节port_rcv_packets- 接收数据包port_xmit_packets- 传输数据包
请注意,应使用 ibdev2netdev 实用程序来确定与配置的设备名称对应的正确接口名称。当然,假设使用相同的网络硬件和软件,这些相同的计数器在客户端上也将可用。
在客户端,GDS 维护一个包含 GDS 特定有用计数器的统计信息文件
nfs_client> cat /proc/driver/nvidia-fs/stats
GDS Version: 0.9.0.743
NVFS statistics(ver: 2.0)
NVFS Driver(version: 2:3:1)
Active Shadow-Buffer (MiB): 128
Active Process: 1
Reads : n=424436862 ok=424436734 err=0 readMiB=21518771 io_state_err=0
Reads : Bandwidth(MiB/s)=13081 Avg-Latency(usec)=9773
Sparse Reads : n=19783000 io=0 holes=0 pages=0
Writes : n=309770912 ok=309770912 err=0 writeMiB=9748727 io_state_err=0 pg-cache=0 pg-cache-fail=0 pg-cache-eio=0
Writes : Bandwidth(MiB/s)=6958 Avg-Latency(usec)=18386
Mmap : n=3584 ok=3584 err=0 munmap=3456
Bar1-map : n=3584 ok=3584 err=0 free=3456 callbacks=0 active=128
Error : cpu-gpu-pages=0 sg-ext=0 dma-map=0
Ops : Read=128 Write=0
GPU 0000:be:00.0 uuid:87e5c586-88ed-583b-df45-fcee0f1e7917 : Registered_MiB=0 Cache_MiB=0 max_pinned_MiB=8 cross_root_port(%)=0
GPU 0000:e7:00.0 uuid:029faa3b-cb0d-2718-259c-6dc650c636eb : Registered_MiB=0 Cache_MiB=0 max_pinned_MiB=8 cross_root_port(%)=0
. .
GDS 统计信息提供读取和写入操作计数(例如,Reads : n=[read_count] 和 Writes : n=[write_count]),以及 MB/秒为单位的带宽。此外,还维护了应定期监控的错误计数器。
7. 总结#
配置和基准测试存储可能是一项复杂的任务。幸运的是,该行业的技术和工具已经达到成熟状态,降低了复杂性,并缩短了设置、测量和部署满足生产性能要求的配置的时间。
随着 GPUDirect Storage 加入 GPUDirect 系列,我们现在拥有了技术和工具,可以以极高的吞吐量和极低的延迟为数据密集型 GPU 提供数据。这转化为更快地执行计算密集型工作负载,从而利用 NVIDIA GPU 的强大计算能力。
8. 基准测试与性能#
基准测试是运行专门设计的软件以生成数据,从而评估性能的过程。所利用/测量的范围会有所不同。许多基准测试旨在模拟生产工作负载(MLperf、TPC、SPEC 等),利用整个系统,并且需要审核流程才能让供应商公开基准测试结果。一些基准测试的目标是测量特定子系统的性能;CPU、GPU、存储等。此类基准测试有时被称为微基准测试,并且通常是公开可用的软件,旨在生成负载并报告特定于被测组件的性能结果,例如,iperf 用于网络性能,fio 用于磁盘/存储性能。这些特定于子系统的基准测试和工具非常有用,因为它们支持“构建块”方法来评估整体系统能力和性能。它们也是在转向完整系统工作负载之前验证各种计算子系统的良好工具。
8.1. 性能语言#
系统性能通常以特定于应用程序的术语(例如,每秒图像数、每秒事务数、深度学习 (DL) 每个 epoch 的训练时间、推理吞吐量等等)或更通用的术语来描述
- 带宽 - 多少
带宽是理论上可实现的最大数据速率,以字节/秒或有时以比特/秒表示。
- 吞吐量 - 多快
吞吐量可以反映数据速率,例如,网络链路上的 12GB/秒,NVMe SSD 的顺序读取为 3.4GB/秒。我们还以吞吐量来表示一些特定于工作负载的指标,例如,每秒字数、每秒图像数等等。
- IOPS - 多少个
每秒输入/输出操作数,通常用于磁盘 IO(每秒读取操作数、每秒写入操作数)和网络 IO(每秒数据包数、每秒消息数)的上下文中。
- 延迟 - 多长时间
完成操作所需的时间,例如,在 HDD 上执行磁盘读取操作需要 5 毫秒 (ms),写入 SSD 需要 40 微秒 (us),CPU 从系统内存中读取数据需要 70 纳秒 (ns)。
GPU 和 CPU 性能的特定方面也可以用上述一个或多个术语来表示,例如,吞吐量(每秒浮点或整数运算次数)、内存带宽和延迟、互连(UPI/QPI、NVswitch 等)带宽和延迟等等。
监控性能并捕获属于上述一个或多个类别的指标通常使用基本操作系统实用程序完成。有许多可用于 Linux 的工具和实用程序,旨在提供对系统利用率和性能的可观察性。对这些工具的讨论超出了本文档的范围,但我们将根据适用情况参考具体示例。此外,各种基准测试工具都会生成这些详细的指标,例如,作为 GDS 一部分安装的 gdsio 实用程序会生成吞吐量、延迟和 IOPS 的详细数据点。
8.2. 基准测试存储性能#
确定预期存储性能(以及网络性能)的优势在于可以根据被测底层硬件的规格进行数学计算。例如,如果目标存储是直连存储 (DAS),其形式为系统 PCIe 总线上的 NVMe SSD,则设备规格会提供吞吐量、IOPS 和延迟值,并且该信息与已知的 PCIe 带宽(Gen3、Gen4)和为设备配置的 PCIe 通道数(通常为 16 个通道)相结合,可以计算出最大理论性能。这在 深度学习存储性能基础知识 博客文章中进行了进一步讨论。
例如,NVIDIA DGX-2 系统包含用于本地存储的 NVMe SSD。对于配置为 RAID0 卷的此类设备,大型读取和写入的预期性能将是单个设备指定性能的四倍。相同的逻辑适用于 IOPS 更密集的工作负载(小型读取和写入)。在此示例中添加一些数字,大型读取的设备规格指示为 3.5GB/秒,因此 RAID0 卷的大型读取的预期吞吐量为 (4 x 3.5GB/秒) 14GB/秒。由于这些是 PCIe 设备,因此根据 PCIe 拓扑,实现 14GB/秒会逼近 PCI3 Gen3 16 通道的理论极限。这里的关键点在于,必须充分了解配置细节才能建立性能预期。
相同的逻辑和方法适用于网络附加存储 (NAS),例如,四个 NVMe SSD 执行大型读取或写入操作可能会使 100Gb NIC 饱和,因此务必了解整个存储数据路径,以便正确评估实际性能。
基准测试存储时的一个重要考虑因素是文件系统的存在。文件系统有两个组件会影响性能
操作系统的页面缓存
页面缓存以透明方式实现,并在默认情况下用于从文件系统读取和写入数据时,将数据和元数据缓存在系统的主内存中。页面缓存的性能优势可能非常大,因为典型的双 CPU 插槽系统读取/写入系统内存的吞吐量和延迟都远高于存储。
特定于文件系统的设置和可调参数
特定于文件系统的设置/参数可以在创建时 (
mkfs) 和挂载时(以挂载选项的形式)进行设置。某些挂载选项是文件系统独立的(例如,atime、async等),而其他选项则特定于文件系统。对存储技术的任何性能评估都需要绕过页面缓存,以确保测量的是实际存储性能,而不是页面缓存的读取/写入性能。
GDS 当前支持 Linux 上的 ext4 文件系统,并且要求在 GDS IO API 目标读取/写入的文件上使用 O_DIRECT 标志。设置 O_DIRECT 后,您可以绕过系统的页面缓存。
评估存储性能结果的另一个因素是 IO 特性,历史上这些特性被分为
随机 IO(小 IO 大小)
顺序 IO(大 IO 大小)
术语“随机”和“顺序”指的是目标文件在磁盘上的块布局,并且在评估使用硬盘驱动器 (HDD) 的存储时相关。HDD 技术实现了旋转磁盘,其读/写磁头执行寻道操作以定位要读取或写入数据的目标块。由于机电延迟(移动读/写磁头在盘片上移动),此寻道时间会导致 IO 延迟。使用固态硬盘 (SSD) 时,不存在此类机电延迟,因此 SSD 上的顺序 IO 与随机 IO 在寻道时间和延迟方面不是需要考虑的因素。
但是,在设置结果预期时,仍然必须考虑 IO 大小。对于趋于较小(< 500kB)的 IO 负载,相关的性能指标是每秒 IO 操作数 (IOPS) 和延迟,而不是吞吐量,因为 IO 大小较小的负载不一定会最大化可用吞吐量。如果评估最大吞吐量是目标,则在基准测试时应使用更大的 IO 大小。
9. 声明#
本文档仅供参考,不应被视为对产品的特定功能、条件或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含的信息的准确性或完整性不做任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。对于因使用此类信息或因其使用而可能导致侵犯专利或第三方的其他权利而造成的后果或责任,NVIDIA 概不负责。本文档不构成对开发、发布或交付任何材料(如下定义)、代码或功能的承诺。
NVIDIA 保留随时对此文档进行更正、修改、增强、改进和任何其他更改的权利,恕不另行通知。
客户应在下订单前获取最新的相关信息,并应验证此类信息是否为最新且完整。
NVIDIA 产品的销售受订单确认时提供的 NVIDIA 标准销售条款和条件的约束,除非 NVIDIA 和客户的授权代表签署的单独销售协议另有约定(“销售条款”)。NVIDIA 在此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档未直接或间接地形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命支持设备,也不适用于 NVIDIA 产品的故障或失灵可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在此类设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不保证基于本文档的产品将适用于任何特定用途。NVIDIA 不一定对每个产品的所有参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合并满足客户计划的应用,并为该应用执行必要的测试,以避免应用或产品的默认设置。客户产品设计的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的额外或不同的条件和/或要求。NVIDIA 对可能基于或归因于以下原因的任何默认设置、损坏、成本或问题不承担任何责任:(i) 以任何与本文档相悖的方式使用 NVIDIA 产品,或 (ii) 客户产品设计。
本文档未授予 NVIDIA 专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成对其的保证或认可。使用此类信息可能需要获得第三方在其专利或其他知识产权下的许可,或获得 NVIDIA 在其专利或其他 NVIDIA 知识产权下的许可。
只有在事先获得 NVIDIA 书面批准的情况下,才能复制本文档中的信息,并且复制时不得进行更改,必须完全遵守所有适用的出口法律法规,并附带所有相关的条件、限制和声明。
本文档和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均“按原样”提供。NVIDIA 对材料不作任何明示、暗示、法定或其他方面的保证,并明确否认所有关于不侵权、适销性和特定用途适用性的暗示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对任何损害(包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害,无论因何种原因造成,也无论责任理论如何)负责,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因遭受任何损害,但 NVIDIA 对本文所述产品的客户承担的累计总责任应根据产品的销售条款进行限制。
10. OpenCL#
OpenCL 是 Apple Inc. 的商标,已获得 Khronos Group Inc. 的许可使用。
11. 商标#
NVIDIA、NVIDIA 徽标、CUDA、DGX、DGX-1、DGX-2、DGX-A100、Tesla 和 Quadro 是 NVIDIA Corporation 在美国和其他国家/地区的商标和/或注册商标。其他公司和产品名称可能是与其关联的各自公司的商标。