1. NVIDIA GPUDirect Storage 设计指南#
本设计指南旨在向 OEM、CSP 和 ODM 展示如何设计服务器以利用 GPUDirect Storage,并帮助应用程序开发人员了解 GPUDirect Storage 如何为应用程序性能带来价值。
2. 简介#
本节简要介绍 NVIDIA® GPUDirect® Storage (GDS)。
GDS 是 GPUDirect 系列的最新成员。类似于 GPUDirect 对等互连 (https://developer.nvidia.com/gpudirect),它在两个图形处理器 (GPU) 的内存之间建立直接内存访问 (DMA) 路径;以及 GPUDirect RDMA,它在网络接口卡 (NIC) 之间建立直接 DMA 路径,GDS 在 GPU 内存和存储之间建立直接 DMA 数据路径,从而避免了通过 CPU 的反弹缓冲区。这种直接路径可以提高系统带宽,同时降低 CPU 和 GPU 的延迟和利用率负载(请参阅图 1)。有些人将超级计算机定义为将计算密集型问题转变为 IO 密集型问题的机器。GDS 有助于缓解 IO 瓶颈,从而创建更平衡的系统。
虽然 GDS 旨在消除 CPU 作为瓶颈,但它依赖于 CPU 来准备通信,以指定应访问的内容。GDS 的较新变体包括异步性,方法是在 CUDA 流或图的上下文中排队存储 IO。这些使开发人员能够利用 GPU 同步硬件在数据加载后启动内核,或在内核完成后存储数据。在 GPUDirect 分类法的术语中,这种形式的 GDS 是 GPUDirect 异步流触发 (GDA-ST) 和图形触发 (GDA-GT)。
GDS 功能通过 cuFile API 公开。libcufile.so 提供用于动态链接的 cuFile API,libcufile_static.a 提供用于静态链接的 cuFile API。支持 GPUDirect Storage 对等传输的内核驱动程序作为内核源包分发,并作为名为 nvidia_fs.ko 的 DKMS 内核模块安装。
这些库和内核源作为 CUDA 工具包的一部分打包,分别为 Ubuntu 和 RedHat 发行版提供 deb 和 RPM 包。nvidia_fs.ko 的内核源也作为 DGX™ BaseOS 6.0 及更高版本发布的一部分分发。
有关 GDS 的更多信息,请参阅以下指南
要了解有关 GDS 的更多信息,请参阅以下帖子
3. GPU 和存储的数据传输问题#
本节提供有关在使用 GDS 和存储进行数据传输时可能遇到的问题的信息。
GPU 内存和存储之间的数据移动是使用在 CPU 上执行的系统软件驱动程序设置和管理的。我们将其称为控制路径。数据移动可以由列出的三个代理中的任何一个管理。
GPU 及其 DMA 引擎。GPU 的 DMA 引擎由 CPU 编程。第三方设备通常不会公开其内存以供另一个 DMA 引擎直接寻址。因此,GPU 的 DMA 引擎只能复制到 CPU 内存和从 CPU 内存复制,这意味着 CPU 内存中存在反弹缓冲区。
CPU 使用加载和存储指令。CPU 通常不能在两个其他设备之间直接复制。因此,它需要使用 CPU 内存中的中间反弹缓冲区。
靠近存储的 DMA 引擎,例如,在 NVMe 驱动器、NIC 或存储控制器(如 RAID 卡)中。GPU PCIe 基地址寄存器 (BAR) 地址可以暴露给其他 DMA 引擎。例如,GPUDirect RDMA 通过 NIC 的驱动程序将这些地址暴露给 NIC 中的 DMA 引擎。Mellanox 和其他公司的 NIC 驱动程序支持此功能。但是,当端点位于文件系统存储中时,操作系统会介入。遗憾的是,当今的操作系统不支持通过文件系统传递 GPU 虚拟地址。
4. GPUDirect Storage 的优势#
本节介绍使用 GDS 的优势。
使用 GDS 功能可以避免 CPU 系统内存中的“反弹缓冲区”,其中反弹缓冲区定义为系统内存中的临时缓冲区,以方便 GPU 和存储等两个设备之间的数据传输。
通过使用 GPUDirect Storage 可以实现以下性能优势
带宽:进出 CPU 的 PCIe 带宽可能低于 GPU 的带宽能力。这种差异可能是由于基于服务器 PCIe 拓扑,连接到 CPU 的 PCIe 路径较少。位于公共 PCIe 交换机下的 GPU、NIC 和存储设备通常在它们之间具有更高的 PCIe 带宽。利用 GPUDirect Storage 应缓解这些 CPU 带宽问题,尤其是在 GPU 和存储设备位于同一 PCIe 交换机下时。如图 1 所示,GDS 启用了一条直接数据路径(绿色),而不是通过 CPU 中的反弹缓冲区的间接路径(红色)。这提高了带宽,降低了延迟,并减少了 CPU 和 GPU 的吞吐量负载。此外,它还使靠近存储的 DMA 引擎能够将数据直接移动到 GPU 内存中。
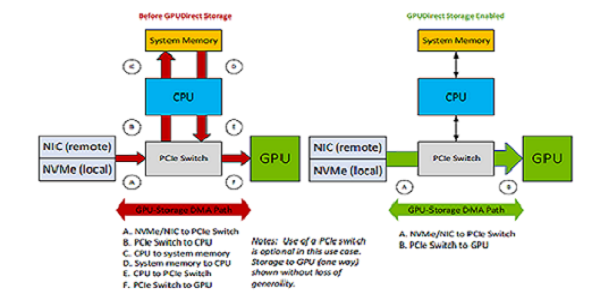
图 1 比较 GPUDirect Storage 路径#
延迟:使用反弹缓冲区会导致两次复制操作
将数据从源复制到反弹缓冲区。
再次从反弹缓冲区复制到目标设备。
直接数据路径只有一次复制,从源到目标。如果 CPU 执行数据移动,则延迟可能会受到 CPU 可用性冲突的影响,这可能会导致抖动。GDS 缓解了这些延迟问题。
CPU 利用率:如果 CPU 用于移动数据,则总体 CPU 利用率会增加,并干扰 CPU 上的其余工作。使用 GDS 可减少 CPU 工作负载,从而使应用程序代码在更短的时间内运行。因此,使用 GDS 可以避免计算和内存带宽瓶颈。GDS 缓解了这两个组件的压力。
一旦数据不再需要遵循通过 CPU 内存的路径,新的可能性就会被打开。
新的 PCIe 路径:考虑具有两级 PCIe 交换机的系统。NVMe 驱动器挂载在第一级交换机上,每个 PCIe 树最多有四个驱动器。每个 PCIe 树中可能有两到四个 NVMe 驱动器,挂载在第一级交换机上。如果使用足够快的驱动器,它们几乎可以饱和通过第一级 PCIe 交换机的 PCIe 带宽。例如,NVIDIA GPUDirect Storage 工程团队在 PCIe Gen 3 机箱上,从 4 个驱动器的 2x2 RAID 0 配置中测量到 13.3 GB/s 的速度。通过 CPU 在控制路径上使用 RAID 0 不会阻碍直接数据路径。在 NVIDIA DGX™-2 中,八个 PCIe 插槽挂载在第二级交换机上,这些插槽可以配置 NIC 或 RAID 卡。在这种 Gen 3 配置中,NIC 的测量速度为 11 GB/s,RAID 卡的测量速度为 14 GB/s。本地存储和远程存储的这两条路径可以同时使用,重要的是,带宽在整个系统中是累加的。
- PCIe ATS:随着 PCIe 地址转换服务 (ATS) 支持添加到设备,它们可能不再需要
使用 CPU 的输入输出内存管理单元 (IOMMU) 进行虚拟化所需的地址转换。由于不需要 CPU 的 IOMMU,因此可以采用直接路径。
- 容量和成本:当数据通过 CPU 内存复制时,必须在 CPU 内存中分配空间。
CPU 内存的容量有限,通常在 1TB 左右,而更高密度的内存最昂贵。本地存储的容量可能在 10TB 左右,远程存储的容量可能在 PB 级。磁盘存储比 CPU 内存便宜得多。对于 GDS 来说,存储在哪里并不重要,重要的是它在节点中、在同一机架中还是在远处。
- 内存分配:CPU 反弹缓冲区必须进行管理:分配和释放。这需要时间和精力。
在某些情况下,缓冲区管理可能会成为影响性能的关键路径。如果没有 CPU 反弹缓冲区,则可以避免此管理成本。当 CPU 上不需要反弹缓冲区时,系统内存将释放用于其他目的。
可迁移内存: 使用
cudaMallocManaged在 CPU 和 GPU 之间来回迁移内存早已成为可能。最近,基于 x86 系统的异构内存管理 (HMM) 以及 Grace-Hopper 世代的 CPU 和 GPU 的集成,使得支持可能位于任何位置的缓冲区目标变得更加重要。从 CUDA 12.2 开始,GDS 支持以任何类型的分配为目标的缓冲区,无论是仅 CPU 还是可在 CPU 和 GPU 之间迁移的缓冲区。异步性:虽然最初的 cuFile API 集不是异步的,但 CUDA 12.2 中增强的 API 添加了 CUDA 流参数,从而实现了异步提交和执行。
在图 2 中,NVIDIA DGX A100 系统有两个 CPU 插槽,每个插槽有两个 PCIe 树。四个 PCIe 树中的每一个(上面只显示了一个)都有一级交换机。每个交换机最多可以挂载两个 NVMe 驱动器,以及两个可以配置 DPU、NIC 或 RAID 卡的 PCIe 插槽,以及两个 GPU。
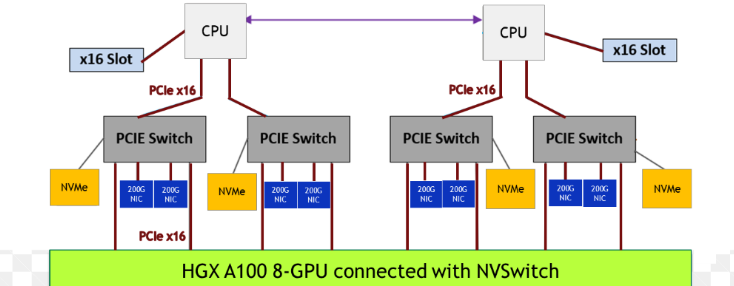
图 2 半个系统的示例拓扑#
5. 应用程序适用性#
本节提供有关 GDS 中应用程序可持续性的信息。
本节提供有关应用程序在哪些条件下适合使用 GDS 加速并享受 GDS 提供的优势的信息,总结如下
数据传输或 IO 传输直接往返于 GPU,而不是通过 CPU。
IO 必须是重要的性能瓶颈。
数据传输或 IO 传输必须是显式的。
缓冲区必须固定在 GPU 内存中。
必须将 CUDA 和 cuFile API 与支持 GPUDirect 的 NVIDIA GPU(仅限 Quadro® 或数据中心 GPU)一起使用。
需要一组通用的 IO API 来处理设备和主机内存,并根据系统拓扑利用最佳路径,并且可以与 CUDA 语义(如 CUDA 上下文、流和图)无缝协作的应用程序。
5.1. 往返于 GPU 的传输#
GPUDirect Storage 支持 GPU 内存和存储之间的直接数据传输。如果应用程序在 GPU 计算之前或之后使用 CPU 来解析或处理数据,则 GPUDirect Storage 没有帮助。要受益,GPU 必须是第一个和/或最后一个接触传输到或从存储传输的数据的代理。
5.2. 了解 IO 瓶颈#
要使 IO 成为瓶颈,它必须位于关键路径上。如果计算时间远大于 IO 时间,则 GPUDirect Storage 几乎没有好处。如果 IO 时间可以与计算完全重叠,例如,使用异步 IO,那么它就不一定是瓶颈。流式传输大量数据并在每个数据元素上执行少量计算的工作负载往往是 IO 密集型的。
5.3. 显式 GDS API#
当前使用 mmap 的任何应用程序都会导致数据隐式而不是显式地移动。这种间接和被动的方法速度较慢,因为数据从存储加载到 CPU 内存,然后再从 CPU 内存加载到 GPU 内存,并且因为故障引入了显著的开销,而显式传输可以避免这些开销。
对于使用显式 API 的应用程序,GPU 内存必须使用 cudaMalloc 分配,以便将其固定,而不是使用可以迁移的 cudaMallocManaged。当应用程序确切知道要传输的数据和位置时,显式 API 的使用是适用的。
GDS 提供的 API 是显式的,类似于 Linux pread 和 pwrite,而不是隐式的并使用内存页错误模型。这可能需要更改一些应用程序代码,例如,从在 GPU 上根据需要直接访问内存之前 mmap 内存的模型切换过来。显式模型提供更高的性能,因为它避免了页错误和复制开销,但也可能导致抖动。
5.4. 用于 DMA 传输的固定内存#
GPU 上的内存必须固定才能启用 DMA 传输。这要求内存使用 cudaMalloc 而不是 cudaMallocManaged 或 malloc 分配。随着更多操作系统的启用,此限制将来可能会放宽。每次数据传输的大小必须适合分配的缓冲区。传输不需要对齐到字节边界以外的任何内容。
5.5. cuFile API#
应用程序和框架开发人员通过整合 cuFile API 来启用 GPUDirect Storage 功能。应用程序可以直接使用 cuFile API,也可以利用 RAPIDS 或 DALI 等框架以及使用 vikio 的 C++ 或 Python 等更高级别的 API。cuFile 提供同步和异步 API。同步 API(如 cuFileRead 和 cuFileWrite)支持类似于 POSIX pread 和 pwrite 以及 O_DIRECT 的读取和写入。cuFile Batch API 提供类似于 linux AIO 的 IO 异步执行。从 CUDA 12.2 版本开始的 cuFile 流 API 支持 CUDA 流中的异步提交和类似于 Linux AIO 的异步执行。此外,还有用于驱动程序初始化、最终化、缓冲区注册等的 cuFile API。基于 cuFile 的 IO 传输是显式和直接的,从而实现最佳性能。
6. 平台性能适用性#
在本文所述的条件下,GPUDirect Storage 的优势可以最大化。
6.1. 来自存储的带宽#
当来自 NIC 或 RAID 卡的带宽与进入 GPU 的 PCIe 带宽相匹配时(直到 IO 需求的限制),从远程存储到 GPU 的带宽最大化。各种示例包括与 Gen 4 PCIe GPU(如 NVIDIA Ampere 架构)匹配的 200 GbE NIC,以及与 Gen 5 PCIe GPU(如 Hopper)匹配的 NDR400 CX8 或 BlueField 3。
对于本地存储,需要更多数量的驱动器才能接近 PCIe 饱和。驱动器的数量是首要重要的。至少需要 4 个 x4 PCIe 驱动器才能饱和 x16 PCIe 链路。系统的 IO 存储带宽与驱动器数量成正比。许多系统(如 NVIDIA DGX-2)最多可以采用 16 个通过 Level-1 PCIe 交换机连接的驱动器。每个驱动器的峰值带宽是次要重要的。NVMe 驱动器往往比 SAS 驱动器提供更高的带宽和更低的延迟。一些文件系统和块系统供应商仅支持 NVMe 驱动器和非 SAS 驱动器。
6.2. 从存储到 GPU 的路径#
PCIe 交换机不是实现某些性能优势所必需的,因为 PCIe 端点之间的直接路径可能通过 CPU,而无需使用反弹缓冲区。
使用 PCIe 交换机可以增加 NIC 或 RAID 卡或本地驱动器与 GPU 之间的峰值带宽。每个 PCIe 树上的一级交换机可以将潜在带宽翻倍。例如
一些 HGX 系统具有 Gen4 CPU,每个树的峰值为 25 GB/s。但 A100 GPU 和 CX6 NIC 支持 50 GB/s。
拥有一个 PCIe 交换机,可以在通过 NIC 和 GPU 到达的远程存储之间建立直接数据路径,可以使用 GDS 维持 50 GB/s 的带宽,而如果不使用 GDS,带宽将降低到 CPU 的 25 GB/s 限制。
存储控制器是 NIC 上远程存储的替代方案。通过绕过 CPU,Gen 4 RAID 卡已被证实可以通过 GDS 提供 26 GiB/s 的速度。
图 3 比较从存储到 GPU 的路径#
6.3. GPU BAR1 大小#
GPU PCIe BAR1 孔径与 CPU 芯片组 DMA 控制器以外的 DMA 引擎相关;它是它们“看到”GPU 内存的方式。GPUDirect Storage 使 DMA 引擎能够将数据从 CPU 以外的设备直接通过 GPU BAR1 孔径移动到 GPU 内存中或从 GPU 内存中移出。传输大小可能超过当前 GPU BAR1 孔径的大小。在这种情况下,GPUDirect Storage 软件会识别到这一点,将大型传输分块以适应,并使用 GPU 内存中的中间缓冲区供 DMA 引擎复制到其中,GPU 从其中复制到目标缓冲区。这是透明处理的,但会增加一些开销。
增加 GPU BAR1 大小,或选择具有更大最大 BAR1 大小的 GPU,可以减少或消除此类复制开销。
只有一部分 GPU 公开 BAR1,包括 NVIDIA RTX 和数据中心 GPU。有关具有适当支持的 GPU 列表,请参阅 GPUDirect Storage 发行说明。
7. 行动号召#
以下列表建议了今天可以做的事情或作为 GPUDirect Storage 实施的一部分可以做的事情。
选择成为未来 GPU 存储平台的一部分。
通过将其完全移植到 GPU 来启用您的应用程序,以便 IO 直接在 GPU 内存和存储之间进行。
使用进行显式传输的接口:直接使用 cuFile API 或通过已启用使用 cuFile API 的框架层使用。
对任何类型的内存分配(包括 CPU 上的内存)使用 cuFile API,以便在整个应用程序中为存储使用一组一致的接口。利用 GPUDirect Storage 最佳实践指南 来选择和应用最佳 API。
选择和使用启用了 GPUDirect Storage 的分布式文件系统或分布式块系统。
8. 声明#
本文档仅供参考,不应被视为对产品的特定功能、状况或质量的保证。NVIDIA 公司(“NVIDIA”)对本文档所含信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。对于因使用此类信息或因使用此类信息而可能导致的侵犯专利或第三方其他权利的行为,NVIDIA 概不负责。本文档不构成对开发、发布或交付任何材料(定义如下)、代码或功能的承诺。
NVIDIA 保留随时对本文档进行更正、修改、增强、改进和任何其他更改的权利,恕不另行通知。
客户在下订单前应获取最新的相关信息,并应验证此类信息是否为最新且完整。
NVIDIA 产品的销售受订单确认时提供的 NVIDIA 标准销售条款和条件的约束,除非 NVIDIA 和客户的授权代表签署的个别销售协议(“销售条款”)另有约定。NVIDIA 特此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档不直接或间接地构成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命支持设备,也不适用于 NVIDIA 产品的故障或失灵可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在上述设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,包含和/或使用此类产品由客户自行承担风险。
NVIDIA 不保证或声明基于本文档的产品将适用于任何特定用途。NVIDIA 不一定对每个产品的所有参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合且符合客户计划的应用,并为该应用执行必要的测试,以避免应用或产品的缺陷。客户产品设计的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同条件和/或要求。对于因以下原因可能导致或归因于的任何缺陷、损坏、成本或问题,NVIDIA 概不负责:(i)以任何与本文档相悖的方式使用 NVIDIA 产品或(ii)客户产品设计。
本文档未授予任何 NVIDIA 专利权、版权或其他 NVIDIA 知识产权的明示或暗示许可。NVIDIA 发布的关于第三方产品或服务的信息不构成 NVIDIA 授予的使用此类产品或服务的许可,也不构成对此类产品或服务的保证或认可。使用此类信息可能需要获得第三方在其专利或其他知识产权下的许可,或获得 NVIDIA 在其专利或其他知识产权下的许可。
只有在事先获得 NVIDIA 书面批准的情况下,才可以复制本文档中的信息,复制时不得进行修改,并且必须完全遵守所有适用的出口法律和法规,并且必须附带所有相关的条件、限制和声明。
本文档以及所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均“按原样”提供。NVIDIA 对这些材料不作任何明示、暗示、法定或其他形式的保证,并明确否认所有关于不侵权、适销性和特定用途适用性的暗示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对因使用本文档而引起的任何损害(包括但不限于任何直接、间接、特殊、偶然、惩罚性或后果性损害,无论因何种原因造成,也无论责任理论如何)承担责任,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因遭受任何损害,但 NVIDIA 对本文所述产品的客户承担的总体和累积责任应根据产品的销售条款进行限制。
9. OpenCL#
OpenCL 是 Apple Inc. 的商标,已授权 Khronos Group Inc. 使用。
10. 商标#
NVIDIA、NVIDIA 徽标、CUDA、DGX、DGX-1、DGX-2、DGX-A100、Tesla 和 Quadro 是 NVIDIA Corporation 在美国和其他国家/地区的商标和/或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。