图#
cuDNN 库提供了一种声明式编程模型,用于将计算描述为操作图。这个图 API 在 cuDNN 8.0 中引入,旨在提供更灵活的 API,尤其是在操作融合日益重要的情况下。
用户首先构建一个操作图。在高层次上,用户描述的是张量操作的数据流图,它通常代表用户完整网络图的一个分区,用户希望将其卸载到 GPU 内核(或少量内核集)。给定一个最终确定的图,用户然后选择并配置一个可以执行该图的引擎。有几种方法可以选择和配置引擎,这些方法在易用性、运行时开销和引擎性能方面有所权衡。
关键概念#
如前所述,图 API 中的关键概念是
这些概念将在下面的小节中介绍。稍后我们将通过一个示例将它们联系起来。
操作和操作图#
操作图是张量操作的数据流图。它旨在成为数学规范,并与可以实现它的底层引擎解耦,因为对于给定的图,可能有多个引擎可用。
I/O 张量隐式地连接操作,例如,操作 A 可能产生张量 X,然后张量 X 被操作 B 消耗,这意味着操作 B 依赖于操作 A。
引擎和引擎配置#
对于给定的操作图,有一些引擎是实现该图的候选者。查询候选引擎列表的典型方法是通过启发式查询,如下所述。
引擎具有用于配置引擎的旋钮 (knobs)。
其他运行时概念#
启发式方法#
启发式方法是一种获取引擎配置列表的方式,这些配置旨在按性能从最高到最低排序,以用于给定的操作图。有三种模式
启发式模式 A - 旨在快速且能够处理大多数操作图模式。它返回一个按预期性能排序的引擎配置列表。
启发式模式 B - 旨在比模式 A 更准确,但以更高的 CPU 延迟为代价来返回引擎配置列表。在已知模式 A 可以做得更好的情况下,底层实现可能会回退到模式 A 启发式方法。
回退启发式模式 - 旨在快速并提供功能性回退,但不期望获得最佳性能。
推荐的工作流程是查询模式 A 或模式 B 并检查支持。第一个具有支持的引擎配置预计具有最佳性能。
您可以“自动调优”,即迭代列表并为每个引擎配置计时,并为特定设备上的特定问题选择最佳配置。C++ 和 Python API 都有用于执行此操作的实用函数。
如果所有引擎配置都不受支持,则使用模式回退来查找功能性回退。
专家用户可能还希望根据引擎的属性(例如数值注释、行为注释或可调旋钮)来过滤引擎配置。数值注释告知用户引擎的数值属性,例如它是否在输入时或在输出规约期间进行数据类型向下转换。行为注释可以发出有关底层实现的信号,例如它是否使用运行时编译。可调旋钮允许对引擎的行为和性能进行细粒度控制。
支持的图模式#
cuDNN 图 API 支持一组图模式。这些模式受到大量引擎的支持,每个引擎都有自己的支持面。这些引擎分为四个不同的类别,如下面四个小节所示:预编译的单操作引擎、通用运行时融合引擎、专用运行时融合引擎和专用预编译融合引擎。专用引擎,无论它们使用运行时编译还是预编译,都针对一组重要的用例,因此它们当前支持的模式集相当有限。随着时间的推移,我们希望在实际可行的情况下,通过通用运行时融合引擎支持更多这些用例。
由于这些引擎在它们支持的模式中存在一些重叠,因此给定的模式可能会产生零个、一个或多个引擎。
预编译的单操作引擎#
一类基本的引擎包括预编译的引擎,它们支持仅具有一个操作的操作图;具体来说:ConvolutionFwd、ConvolutionBwdFilter、ConvolutionBwdData 或 ConvolutionBwBias。
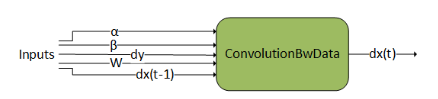
ConvolutionBwdData#
ConvolutionBwdData 计算张量 dy 的卷积数据梯度。此外,它使用缩放因子 ɑ 和 ꞵ 将此结果与先前的输出混合。此图操作类似于 cudnnConvolutionBackwardData()。
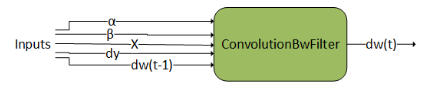
ConvolutionBwdFilter#
ConvolutionBwdFilter 计算张量 dy 的卷积滤波器梯度。此外,它使用缩放因子 ɑ 和 ꞵ 将此结果与先前的输出混合。此图操作类似于 cudnnConvolutionBackwardFilter()。
ConvolutionFwd#
ConvolutionFwd 计算 X 与滤波器数据 W 的卷积。此外,它使用缩放因子 ɑ 和 ꞵ 将此结果与先前的输出混合。此图操作类似于 cudnnConvolutionForward()。

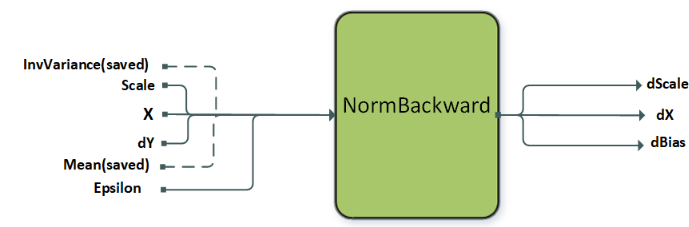
NormalizationBackward#
NormalizationBackward 计算梯度 dX 以及缩放和偏置梯度 dScale 和 dBias。此操作支持多种模式,这些模式由属性 CUDNN_ATTR_OPERATION_NORM_BWD_MODE 设置。目前,层归一化 (layer norm)、批归一化 (batch norm) 和 RMS 归一化都支持在 GRAPH_JIT_ONLY 和 FULL 库配置中(请参阅 DReluForkDBn)。实例归一化 (instance norm) 仅在 FULL 库配置中受支持。在正向训练 (forward training) 过程中保存的均值和方差作为输入传递给 NormBackward 操作。
节点和其他属性 |
实例归一化反向传播 (Instance Normalization Backward) |
层归一化反向传播 (Layer Normalization Backward) |
RMS 归一化反向传播 (RMS Normalization Backward) |
|---|---|---|---|
|
|
|
|
|
[N, C, (D), H, W], 输入, I 类型 (type) |
[N, C, (D), H, W], 输入, I 类型 (type) |
[N, C, (D), H, W], 输入, I 类型 (type) |
|
[N,C,(1),1,1], 输入, 计算类型 (compute type) |
[N,1,(1),1,1], 输入, 计算类型 |
N/A |
|
[N,C,(1),1,1], 输入, 计算类型 (compute type) |
[N,1,(1),1,1], 输入, 计算类型 |
[N,1,(1),1,1], 输入, 计算类型 |
|
[1,C,(1),1,1], 输入权重, W 类型 |
[1,C,(D),H,W], 输入权重, W 类型 |
[1,C,(D),H,W], 输入权重, W 类型 |
|
[N, C, (D), H, W], 输入, O 类型 |
[N, C, (D), H, W], 输入, O 类型 |
[N, C, (D), H, W], 输入, O 类型 |
|
[N, C, (D), H, W], 输出, I 类型 |
[N, C, (D), H, W], 输出, I 类型 |
[N, C, (D), H, W], 输出, I 类型 |
|
[1,C,(1),1,1], 输出, W 类型 |
[1,C,(D),H,W], 输出, W 类型 |
[1,C,(D),H,W], 输出, W 类型 |
|
[1,C,(1),1,1], 输出, W 类型 |
[1,C,(D),H,W], 输出, W 类型 |
可选 (Optional) |
|
|
|
|
支持的布局 (Supported layout) |
NC(D)HW, N(D)HWC |
NC(D)HW, N(D)HWC |
NC(D)HW, N(D)HWC |
支持的 I 和 O 类型 (Supported I and O types) |
FP16, FP32, BF16 |
FP16, FP32, BF16 |
FP16, FP32, BF16 |
支持的计算类型 (Supported compute type) |
FP32 |
FP32 |
FP32 |
支持的 W 类型 (Supported W types) |
FP32 |
FP16, FP32, BF16 |
FP16, FP32, BF16 |
I/O 类型的对齐要求 (Alignment requirements for I/O type) |
8 字节对齐 (8 bytes aligned) |
16 字节对齐 (16 bytes aligned) |
16 字节对齐 (16 bytes aligned) |
对于每个操作,所有适用的张量必须具有相同的布局。不支持混合 I/O 类型或混合计算类型。
层归一化和 RMS 归一化也受专用运行时编译引擎的支持,CUDNN_ATTR_ENGINE_GLOBAL_INDEX = 3 用于归一化反向传播操作。对于这些性能更高的引擎,适用 sizeof(Itype) >= sizeof(Otype) 限制。
NormalizationForward#
NormalizationForward 从输入 X 计算归一化输出 Y。此操作用于推理和训练阶段。阶段由属性 CUDNN_ATTR_OPERATION_NORM_FWD_PHASE 区分。
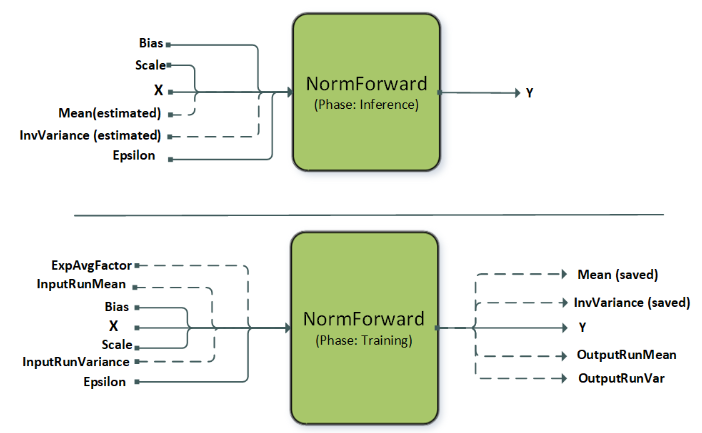
此操作支持不同的归一化模式,这些模式由属性 CUDNN_ATTR_OPERATION_NORM_FWD_MODE 设置。虚线表示可选输入,这些输入通常用于此操作的批归一化模式。目前,层归一化、批归一化和 RMS 归一化都支持在 GRAPH_JIT_ONLY 和 FULL 库配置中,使用运行时编译的内核(请参阅 BnAddRelu)。实例归一化仅在 FULL 库配置中受支持。
节点和其他属性 |
实例归一化正向传播 (Instance Normalization Forward) |
层归一化正向传播 (Layer Normalization Forward) |
RMS 归一化正向传播 (RMS Normalization Forward) |
|---|---|---|---|
|
|
|
|
|
[N, C, (D), H, W], 输入, I 类型 (type) |
[N, C, (D), H, W], 输入, I 类型 (type) |
[N, C, (D), H, W], 输入, I 类型 (type) |
|
[N,C,(1),1,1], 输出, 计算类型, 仅适用于 |
[N,1,(1),1,1], 输出, 计算类型, 仅适用于 |
N/A |
|
[N,C,(1),1,1], 输出, 计算类型, 仅适用于 |
[N,1,(1),1,1], 输出, 计算类型, 仅适用于 |
[N,1,(1),1,1], 输出, 计算类型, 仅适用于 |
|
[1,C,(1),1,1], 输入权重, W 类型 |
[1,C,(D),H,W], 输入权重, W 类型 |
[1,C,(D),H,W], 输入权重, W 类型 |
|
[1,C,(1),1,1], 输入权重, W 类型 |
[1,C,(D),H,W], 输入权重, W 类型 |
可选 (默认无偏置) (Optional (no bias by default)) |
|
[N, C, (D), H, W], 输出, O 类型 |
[N, C, (D), H, W], 输出, O 类型 |
[N, C, (D), H, W], 输出, O 类型 |
|
[1,1,1,1], 输入, 常量 (constant) |
[1,1,1,1], 输入, 常量 (constant) |
[1,1,1,1], 输入, 常量 (constant) |
|
|
|
|
支持的 |
|
|
|
支持的布局 (Supported layout) |
NC(D)HW, N(D)HWC |
NC(D)HW, N(D)HWC |
NC(D)HW, N(D)HWC |
支持的 I 和 O 类型 (Supported I and O types) |
FP16, FP32, BF16 |
FP16, FP32, BF16 |
FP16, FP32, BF16 |
支持的计算类型 (Supported compute type) |
FP32 |
FP32 |
FP32 |
支持的权重类型,W 类型 (Supported weight types, W type) |
FP32 |
FP16, FP32, BF16 |
FP16, FP32, BF16 |
I/O 类型的对齐要求 (Alignment requirements for I/O type) |
8 字节对齐 (8 bytes aligned) |
16 字节对齐 (16 bytes aligned) |
16 字节对齐 (16 bytes aligned) |
对于每个操作,所有适用的张量必须具有相同的布局。
层归一化和 RMS 归一化也受专用运行时编译引擎的支持,CUDNN_ATTR_ENGINE_GLOBAL_INDEX = 3,fmode 设置为 CUDNN_NORM_FWD_TRAINING;CUDNN_ATTR_ENGINE_GLOBAL_INDEX = 4,fmode 设置为 CUDNN_NORM_FWD_INFERENCE。对于这些性能更高的引擎,适用 sizeof(Itype) >= sizeof(Otype) 限制。对于非运行时编译的引擎,W 类型为计算类型。
通用运行时融合引擎#
上一节中记录的引擎支持单操作模式。当然,为了使融合有趣,图需要支持多个操作。理想情况下,我们希望支持的模式足够灵活,以涵盖各种用例。为了实现这种通用性,cuDNN 具有运行时融合引擎,这些引擎在运行时根据图模式生成内核(或多个内核)。本节概述了这些运行时融合引擎(即具有 CUDNN_BEHAVIOR_NOTE_RUNTIME_COMPILATION 行为注释的引擎)支持的模式。
我们可以将支持面视为覆盖以下通用模式
Matmul融合:\(g_{2}\left( C=Matmul\left( A=g_{1A} \left( inputs \right), B=g_{1B} \right(inputs)), inputs \right)\)ConvolutionFwd融合:\(g_{2}\left( Y=ConvolutionFwd\left( X=g_{1} \left( inputs \right), W\right), inputs \right)\)ConvolutionBwdFilter融合:\(g_{2}\left( dw=ConvolutionBwdFiler\left( dy, X=g_{1} \right(inputs)), inputs \right)\)ConvolutionBwdData融合:\(g_{2}\left( dx=ConvolutionBwdData\left( dy=g_{1} \left( inputs \right), W \right), inputs \right)\)Pointwise融合:\(g_{2}\left( inputs \right)\)

注意
g 1 (包括 g 1A 和 g 1B) 表示应用于
matmul和convolution操作的输入的融合操作。g 2 表示应用于
matmul和convolution操作的输出的融合操作。g 2 可以有多个输出。
g 1 中的融合模式将称为主循环融合,g 2 中的融合模式将称为尾声融合。
进入 g 2 的箭头可以进入 g 2 的任何节点,并且不一定需要馈送到根节点。
操作的缩写符号用于图表中以及整个文本中,以用于可视化目的。
支持面#
通用运行时融合引擎包括三个独立的的支持面,索引为 90、80 和 70。满足至少一个支持面要求的 cuDNN 图将能够由通用运行时融合引擎执行。下表列出了每个支持面中功能的摘要。为了获得最佳性能,我们建议尽可能以最高索引的支持面为目标,并在需要时回退到较低索引的支持面。
功能 (Feature) |
支持面 90 |
支持面 80 |
支持面 70 |
|---|---|---|---|
计算能力 (Compute Capability) |
>= 9.0 |
>= 8.0 |
>= 7.0 |
|
支持 |
支持 |
支持 |
|
支持 |
支持 |
支持 |
|
支持 |
不支持 |
支持 |
|
部分支持 |
不支持 |
支持 |
|
不支持 |
不支持 |
支持 |
FP8 |
支持 |
支持计算能力 >= 8.9 |
不支持 |
g 1 (主循环) 融合 |
支持 |
支持 |
部分支持 |
g 2 (尾声) 融合 |
支持 |
支持 |
支持 |
混合输入精度 Matmul/Convolution (Mixed Input Precision Matmul/Convolution) |
支持 |
支持 |
不支持 |
分组卷积 (Grouped Convolution) |
支持 |
支持 |
不支持 |
每个支持面的详细支持功能在以下小节中列出。
支持面 90#
计算能力 (Compute Capability)
支持计算能力为 9.0 的 NVIDIA GPU。
通用限制 (Generic Limitations)
不支持带步幅的
ConvolutionBwdData融合。不支持
Pointwise和Reduction融合。
高级 Matmul/Convolution 变体 (Advanced Matmul/Convolution Variations)
支持混合输入精度
Matmul、ConvolutionFwd和ConvolutionBwdData融合。支持分组
ConvolutionFwd、ConvolutionBwdFilter和ConvolutionBwdData融合。
I/O 和中间数据类型 (I/O and Intermediate Data Type)
输入张量数据类型可以是
{FLOAT, INT32, HALF, BFLOAT16, INT8, FP8_E4M3, FP8_E5M2}中的任何一种。Matmul、ConvolutionFwd、ConvolutionBwdFilter和ConvolutionBwdData操作的输入张量数据类型可以是{FLOAT, HALF, BFLOAT16, INT8, FP8_E4M3, FP8_E5M2}中的任何一种。输出张量数据类型可以是
{INT64, FLOAT, INT32, HALF, BFLOAT16, INT8, UINT8, FP8_E4M3, FP8_E5M2}中的任何一种。CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR操作的输出数据类型只能是FLOAT。中间虚拟张量数据类型可以是
{FLOAT, INT32, HALF, BFLOAT16, INT8, FP8_E4M3, FP8_E5M2}中的任何一种,代码生成器会遵守此中间存储类型。通常,建议使用FP32。
计算数据类型 (Compute Data Type)
对于
CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR操作,计算数据类型可以是FP32或INT32。对于
CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR操作,计算数据类型只能是FP32。Matmul、ConvolutionFwd、ConvolutionBwdFilter和ConvolutionBwdData操作的计算数据类型的支持面取决于操作的输入数据类型。组合支持面在下表中列出。
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
主循环融合:g :sub:`1`
g 1 是有向无环图 (DAG),可以包含零个或任意数量的
CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR操作。所有输入张量都必须具有 128 位的对齐。对于分组
ConvolutionFwd、ConvolutionBwdFilter和ConvolutionBwdData融合,对齐要求是按组进行的。所有中间张量都必须是虚拟的。
维度和布局的支持面在下表中列出。此表不适用于 g 2 中的张量。
模式 (Pattern) |
维度 (Dimension) |
布局 (Layout) |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
尾声融合:g :sub:`2`
g 2 是有向无环图 (DAG),可以包含零个或任意数量的
CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR操作,以及零个或一个CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR操作。CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR操作只能是 g 2 的出口节点。所有输入和输出张量都必须具有 8 位的对齐。对于分组
ConvolutionFwd、ConvolutionBwdFilter和ConvolutionBwdData融合,对齐要求是按组进行的。在
CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR操作中,正在广播的张量不能作为第一个输入放置。维度和布局的支持面在下表中列出。此表不适用于 g 1 中的张量。
模式 (Pattern) |
维度 (Dimension) |
布局 (Layout) |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
不支持 |
不支持 |
支持 Surface 80#
计算能力 (Compute Capability)
支持计算能力为 8.0、8.6、8.7、8.9 和 9.0 的 NVIDIA GPU。
通用限制 (Generic Limitations)
不支持
ConvolutionBwdFilter融合。不支持
ConvolutionBwdData融合。不支持
Pointwise和Reduction融合。
高级 Matmul/Convolution 变体 (Advanced Matmul/Convolution Variations)
支持混合输入精度
Matmul和ConvolutionFwd融合。支持分组的
ConvolutionFwd融合。
I/O 和中间数据类型 (I/O and Intermediate Data Type)
输入张量数据类型可以是
{FLOAT, INT32, HALF, BFLOAT16, INT8, FP8_E4M3, FP8_E5M2}中的任何一种。Matmul和ConvolutionFwd操作的输入张量数据类型可以是{FLOAT, HALF, BFLOAT16, INT8, FP8_E4M3, FP8_E5M2}中的任何一种。FP8_E4M3和FP8_E5M2输入张量数据类型仅在计算能力为 8.9 时可用于Matmul和ConvolutionFwd操作。输出张量数据类型可以是
{INT64, FLOAT, INT32, HALF, BFLOAT16, INT8, UINT8, FP8_E4M3, FP8_E5M2}中的任何一种。CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR操作的输出数据类型只能是FLOAT。中间虚拟张量数据类型可以是
{FLOAT, INT32, HALF, BFLOAT16, INT8, FP8_E4M3, FP8_E5M2}中的任何一种,代码生成器会遵守此中间存储类型。通常,建议使用FP32。FP8_E4M3和FP8_E5M2输入、输出和中间张量数据类型仅在计算能力为 8.9 和 9.0 时可用。
计算数据类型 (Compute Data Type)
对于
CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR操作,计算数据类型可以是FP32或INT32。对于
CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR操作,计算数据类型只能是FP32。Matmul、ConvolutionFwd、ConvolutionBwdFilter和ConvolutionBwdData操作的计算数据类型的支持面取决于操作的输入数据类型。组合支持面在下表中列出。
|
|
注意 |
|---|---|---|
|
|
|
|
|
仅在计算能力为 8.9 时可用 |
|
|
|
|
|
|
|
|
主循环融合:g :sub:`1`
g 1 是一个有向无环图 (DAG),可以由零个或任意数量的
CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR操作组成。所有输入张量必须具有 32 位的对齐。对于 g 1 中没有操作的 ConvolutionFwd 融合,输入张量可以具有 8 位的对齐。对于分组的
ConvolutionFwd融合,对齐要求是按组进行的。所有中间张量都必须是虚拟的。
维度和布局的支持面在下表中列出。此表不适用于 g 2 中的张量。
模式 (Pattern) |
维度 (Dimension) |
布局 (Layout) |
|---|---|---|
|
|
|
|
|
|
|
不支持 |
不支持 |
|
不支持 |
不支持 |
尾声融合:g :sub:`2`
g 2 是有向无环图 (DAG),可以包含零个或任意数量的
CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR操作,以及零个或一个CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR操作。CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR操作只能是 g 2 的出口节点。所有输入和输出张量必须具有 8 位的对齐。对于分组的
ConvolutionFwd融合,对齐要求是按组进行的。在
CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR操作中,正在广播的张量不能作为第一个输入放置。维度和布局的支持面在下表中列出。此表不适用于 g 1 中的张量。
模式 (Pattern) |
维度 (Dimension) |
布局 (Layout) |
|---|---|---|
|
|
|
|
|
|
|
不支持 |
不支持 |
|
不支持 |
不支持 |
|
不支持 |
不支持 |
支持 Surface 70#
计算能力支持面
支持计算能力为 7.0、7.2、7.5、8.0、8.6、8.7、8.9 和 9.0 的 NVIDIA GPU。
I/O 和中间数据类型 (I/O and Intermediate Data Type)
输入张量数据类型可以是
{FLOAT, INT32, HALF, BFLOAT16, INT8, FP8_E4M3, FP8_E5M2}中的任何一种。Matmul、ConvolutionFwd、ConvolutionBwdFilter和ConvolutionBwdData操作的输入张量数据类型可以是{FLOAT, HALF, BFLOAT16, INT8}中的任何一种。输出张量数据类型可以是
{INT64, FLOAT, INT32, HALF, BFLOAT16, INT8, UINT8, FP8_E4M3, FP8_E5M2, BOOLEAN}中的任何一种。CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR操作的输出数据类型只能是FLOAT。中间虚拟张量数据类型可以是
{FLOAT, INT32, HALF, BFLOAT16, INT8, FP8_E4M3, FP8_E5M2, BOOLEAN}中的任何一种,代码生成器会遵守此中间存储类型。通常,建议使用FP32。FP8_E4M3和FP8_E5M2数据类型仅允许在纯Pointwise和Reduction融合中使用。
计算数据类型 (Compute Data Type)
对于
CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR操作,计算数据类型可以是FP32或BOOLEAN。对于
CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR操作,计算数据类型只能是FP32。Matmul、ConvolutionFwd、ConvolutionBwdFilter和ConvolutionBwdData操作的计算数据类型的支持面取决于操作的输入数据类型。组合支持面在下表中列出。
|
|
注意 |
|---|---|---|
|
|
不适用于 |
|
|
仅在计算能力为 8.9 时可用 |
|
|
|
|
|
|
|
|
主循环融合:g :sub:`1`
g 1 是一个有向无环图 (DAG),可以由零个或任意数量的以下操作组成
CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTORCUDNN_BACKEND_OPERATION_CONCAT_DESCRIPTORCUDNN_BACKEND_OPERATION_SIGNAL_DESCRIPTOR
CUDNN_BACKEND_OPERATION_CONCAT_DESCRIPTOR或CUDNN_BACKEND_OPERATION_SIGNAL_DESCRIPTOR操作(如果存在)应在任何Pointwise操作之前。对于计算能力 < 8.0,不支持 g 1。
所有输入张量必须具有 32 位的对齐。
所有中间张量都必须是虚拟的。
在
CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR操作中,正在广播的张量不能作为第一个输入放置。维度和布局的支持面在下表中列出。此表**不**适用于 g:sub:2 中的张量。
模式 (Pattern) |
维度 (Dimension) |
布局 (Layout) |
|---|---|---|
|
|
|
|
|
所有张量必须采用完全打包的 NHWC 布局。 |
|
|
所有张量必须采用完全打包的 NHWC 布局。 |
|
|
所有张量必须采用完全打包的 NHWC 布局。 |
尾声融合:g :sub:`2`
g 2 是一个有向无环图 (DAG),可以由零个或任意数量的以下操作组成
CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTORCUDNN_BACKEND_OPERATION_RESAMPLE_FWD_DESCRIPTORCUDNN_BACKEND_OPERATION_RESAMPLE_BWD_DESCRIPTORCUDNN_BACKEND_OPERATION_GEN_STATS_DESCRIPTORCUDNN_BACKEND_OPERATION_SIGNAL_DESCRIPTOR
以及零个或一个 CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR 操作。
CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR操作只能是 g 2 的出口节点。CUDNN_BACKEND_OPERATION_SIGNAL_DESCRIPTOR操作(如果存在)必须是 g 2 中的最终节点。因此,CUDNN_BACKEND_OPERATION_SIGNAL_DESCRIPTOR操作不能与CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR操作结合使用。CUDNN_BACKEND_OPERATION_RESAMPLE_FWD_DESCRIPTOR或CUDNN_BACKEND_OPERATION_RESAMPLE_BWD_DESCRIPTOR操作的输入张量不应由此图中的另一个操作产生,而应来自全局内存。这两个操作不能用于Matmul、ConvolutionBwdFilter和ConvolutionBwdData融合,并且仅在计算能力 >= 7.5 时受支持。所有输入和输出张量必须具有 32 位的对齐,但
CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR操作的输出可以具有 8 位的对齐。在
CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR操作中,正在广播的张量不能作为第一个输入放置。维度和布局的支持面在下表中列出。此表**不**适用于 g:sub:1 中的张量。
模式 (Pattern) |
维度 (Dimension) |
布局 (Layout) |
|---|---|---|
|
|
|
|
|
所有张量必须采用完全打包的 NHWC 布局。 |
|
|
所有张量必须采用完全打包的 NHWC 布局。 |
|
|
所有张量必须采用完全打包的 NHWC 布局。 |
|
|
|
运行时融合引擎的操作特定约束#
运行时融合引擎支持的通用模式中的每个操作都受到一些关于其参数面的特定约束。以下小节记录了这些约束。
请注意,这些约束是 (1) 后端描述符类型 中提到的任何约束,以及 (2) 支持面 部分提到的关于有向无环图 (DAG) 中其他操作的限制的补充。
Matmul#
此操作表示矩阵-矩阵乘法:A * B = C。有关接口的完整详细信息,请参阅 CUDNN_BACKEND_OPERATION_MATMUL_DESCRIPTOR 部分。
卷积#
有三个操作节点表示不同类型的卷积,即
ConvolutionFwd
此操作表示前向卷积,即计算图像张量与滤波器张量卷积的响应张量。有关接口的完整详细信息以及一般约束,请参阅 CUDNN_BACKEND_OPERATION_CONVOLUTION_FORWARD_DESCRIPTOR 部分。
ConvolutionBwdFilter
此操作表示卷积反向滤波器,即从响应张量和图像张量计算滤波器梯度。有关接口的完整详细信息以及一般约束,请参阅 CUDNN_BACKEND_OPERATION_CONVOLUTION_BACKWARD_FILTER_DESCRIPTOR 部分。
ConvolutionBwdData
此操作表示卷积反向数据,即从响应张量和滤波器张量计算输入数据梯度。有关接口的完整详细信息以及一般约束,请参阅 CUDNN_BACKEND_OPERATION_CONVOLUTION_BACKWARD_DATA_DESCRIPTOR 部分。
输入张量属性名称 |
输出张量属性名称 |
|
|---|---|---|
|
|
|
|
|
|
|
|
|
自 NVIDIA Ada Lovelace 架构以来的 FP8 数据类型有两种变体:CUDNN_DATA_FP8_E4M3 和 CUDNN_DATA_FP8_E5M2 作为 I/O 数据类型。将它们用作操作的输入将导致使用 FP8 Tensor Cores。FP8 Tensor Cores 内部累加的精度由计算类型控制,计算类型可能具有两个可能的值之一:CUDNN_DATA_FLOAT 和 CUDNN_DATA_FAST_FLOAT_FOR_FP8。
CUDNN_DATA_FAST_FLOAT_FOR_FP8 更快,并且对于推理或训练的前向传播来说已足够精确。然而,对于 FP8 训练的反向传播计算(即,计算权重和激活梯度),我们建议选择更精确的 CUDNN_DATA_FLOAT 计算类型,以保持可能对某些模型必要的更高精度。
操作 |
推荐的 I/O 类型 |
推荐的计算类型 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Pointwise#
表示实现方程 Y = op (alpha1 * X) 或 Y = op (alpha1 * X, alpha2 * B) 的逐点运算。有关更多信息和一般约束,请参阅 CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR 和 CUDNN_BACKEND_POINTWISE_DESCRIPTOR 部分。
下表列出了 Pointwise 操作的约束,除了上面列出的一般约束以及 支持面 部分中列出的与其他操作相关的任何约束。请注意,这些附加约束仅在运行时融合引擎中使用这些操作时适用。
属性 |
要求 |
|---|---|
用于 |
对于所有运算符,支持所有数据类型。 |
|
|
|
|
|
|
属性 |
要求 |
|---|---|
用于 |
|
|
|
|
|
|
|
GenStats#
表示生成每通道统计信息的操作。有关更多信息和一般约束,请参阅 CUDNN_BACKEND_OPERATION_GEN_STATS_DESCRIPTOR 部分。
下表列出了 GenStats 操作的约束,除了上面列出的一般约束以及 支持面 部分中列出的与其他操作相关的任何约束。请注意,这些附加约束仅在运行时融合引擎中使用 GenStats 操作时适用。
属性 |
要求 |
|---|---|
用于 |
|
用于 |
对于 2D 卷积,两者都应为 [1, C, 1, 1] 形状;对于 3D 卷积,两者都应为 [1, C, 1, 1, 1] 形状。 |
用于 |
|
|
|
用于 |
NHWC 完全打包 |
Reduction#
此操作表示在一个或多个维度中缩减张量的值。有关更多信息和一般约束,请参阅 CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR 部分。
下表列出了 Reduction 前向操作的约束,除了上面列出的一般约束以及 支持面 部分中列出的与其他操作相关的任何约束。请注意,这些附加约束仅在运行时融合引擎中使用 Reduction 操作时适用。
属性 |
要求 |
|---|---|
用于 |
|
|
|
用于 |
NHWC/NDHWC/BMN 完全打包 |
|
|
ResampleFwd#
此操作表示将图像的空间维度重采样到所需的值。重采样支持向上采样和向下采样两个方向。向下采样表示池化的标准操作,常用于卷积神经网络。有关更多信息和一般约束,请参阅 CUDNN_BACKEND_OPERATION_RESAMPLE_FWD_DESCRIPTOR 部分。
以下是 ResampleFwd 操作的约束,除了上面列出的一般约束以及 支持面 部分中列出的与其他操作相关的任何约束。请注意,这些附加约束仅在运行时融合引擎中使用 ResampleFwd 操作时适用。
我们允许在四种重采样模式中进行选择。所有模式都具有以下通用支持规范
支持的布局:NHWC 或 NDHWC,NCHW 或 NCDHW
支持的空间维度:2 或 3
支持的输入维度:4 或 5
不支持打包的布尔数据类型。
如果指定,索引张量维度应等于响应张量维度。
当张量格式为 NCHW/NCDHW 时,以下附加限制适用
不支持向上采样。
不支持
Int64_t索引。仅支持使用预填充后端 API 的对称填充。
还有一些特定于模式的限制。下表列出了特定参数允许的值。对于未列出的参数,我们允许任何在数学上正确的值。
支持以下向下采样模式
CUDNN_RESAMPLE_AVGPOOL_INCLUDE_PADDING
CUDNN_RESAMPLE_AVGPOOL_EXCLUDE_PADDING
CUDNN_RESAMPLE_MAXPOOL
属性 |
平均池化 |
最大池化 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
对于向上采样模式,对于任何参数组合,都不支持 CUDNN_RESAMPLE_NEAREST。CUDNN_RESAMPLE_BILINEAR 具有以下支持规范。
属性 |
双线性 |
|---|---|
输入维度 |
等于 |
|
|
|
|
|
|
|
|
用于 |
|
|
|
|
|
|
|
|
|
用于训练的重采样索引张量转储#
对于最大池化重采样模式,可以提供索引张量用作反向传播的掩码。
索引张量中的值是
重采样窗口中输入张量最大值的从零开始的行优先位置。
如果存在多个具有最大值的输入像素,则选择从左到右、从上到下扫描中的第一个索引。
索引元素选择示例
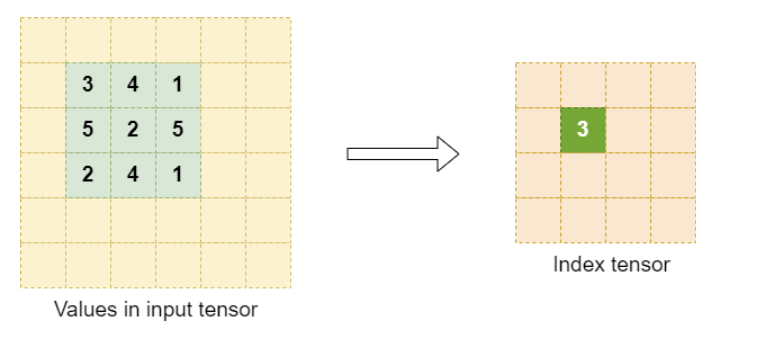
为索引张量选择合适的元素大小。作为参考,任何元素大小,只要能容纳最大的从零开始的窗口位置即可。
ResampleBwd#
此操作表示将输出响应的空间维度反向重采样到所需的值。重采样支持向上采样和向下采样两个方向。反向向下采样表示反向池化的标准操作,常用于卷积神经网络。有关更多信息和一般约束,请参阅 CUDNN_BACKEND_OPERATION_RESAMPLE_BWD_DESCRIPTOR 部分。
以下是 Resample 反向操作的约束,除了上面列出的一般约束以及 支持面 部分中列出的与其他操作相关的任何约束。请注意,这些附加约束仅在运行时融合引擎中使用 Resample 反向操作时适用。
我们允许在四种重采样模式中进行选择。所有模式都具有以下通用支持规范
支持的布局:NHWC 或 NDHWC,NCHW 或 NCDHW
支持的空间维度:2 或 3
支持的输入维度:4 或 5
对于布局 NHWC 或 NDHWC
索引张量应仅为最大池化模式提供,并且应符合 用于训练的重采样索引张量转储 部分中描述的格式。
索引张量维度应等于输入梯度张量维度。
对于布局 NCHW 或 NCDHW
当使用最大池化模式时,需要 X、Y 和 DY。
不支持
Int64_t索引。
还有一些特定于模式的限制。下表列出了特定参数允许的值。对于未列出的参数,我们允许任何在数学上正确的值。
支持以下反向向下采样模式
CUDNN_RESAMPLE_AVGPOOL_INCLUDE_PADDING
CUDNN_RESAMPLE_AVGPOOL_EXCLUDE_PADDING
CUDNN_RESAMPLE_MAXPOOL
属性 |
平均池化 |
最大池化 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
目前不支持反向向上采样模式。
支持的模式示例#
以下部分按复杂性递增的顺序提供支持模式的示例。我们采用与整体模式相同的颜色方案,以帮助识别 g 1 (蓝色) 和 g 2 (紫色) 的结构。
为了便于说明,我们缩写了使用的操作。要完整映射到实际的后端描述符,请参阅 与后端描述符的映射。
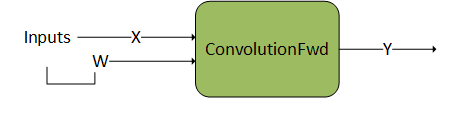
单操作#
以下示例说明了一个卷积操作,其前后没有任何操作。这意味着,g 1 和 g 2 是空图。
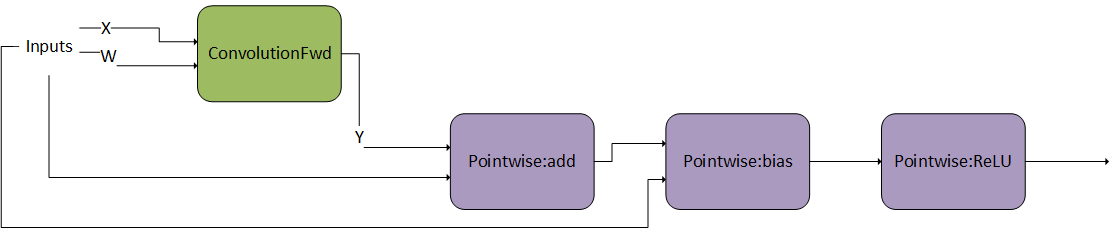
卷积后的 Pointwise 操作 1#
在此示例中,g 2 由卷积后的一系列两个 Pointwise 操作组成。

卷积后的 Pointwise 操作 2#
与上一个示例类似,g 2 由一系列多个 Pointwise 操作组成。
矩阵乘法前的 Pointwise 操作#
Pointwise 操作也可以先于卷积或矩阵乘法,也就是说,g 1 由 Pointwise 操作组成。

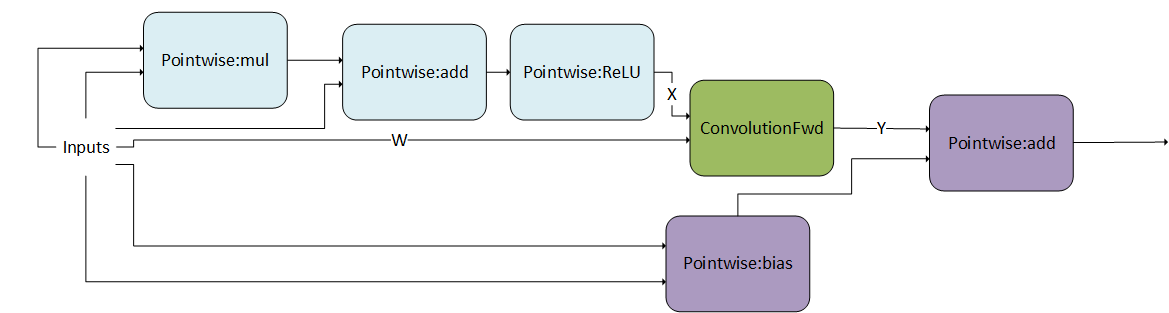
DAG 中间的卷积生产者节点#
以下模式显示 g 1 为 DAG,由馈入卷积的 Pointwise 操作组成。此外,g 2 是由两个 Pointwise 操作组成的 DAG。请注意,卷积在 g 2 的中间而不是 g 2 的第一个节点被消耗。这是一个有效的模式。
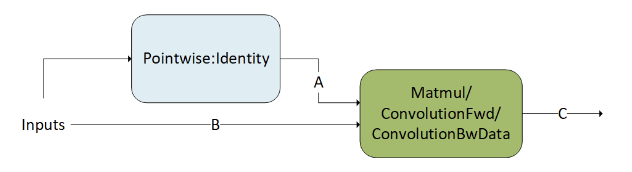
混合输入精度 Matmul 和卷积#
matmul 和卷积的混合输入精度实现为主循环融合的特殊情况。输入可能具有不同的数据类型,并将通过 Pointwise:Identity 操作转换为所需的用作 matmul 或 convolution 操作输入的的数据类型。以下模式显示 g 1 为 DAG,由 Pointwise:Identity 操作组成,该操作将张量 A 的输入数据类型转换为 matmul 操作。这是一个有效的模式。
专用运行时融合引擎#
专用运行时融合引擎针对并优化流行深度学习模型中常见的专用图模式。这些引擎在支持的融合模式、支持的数据类型和支持的张量布局方面提供了有限的灵活性。从长远来看,这些模式有望变得更加通用。
以下部分重点介绍支持的模式。
BnAddRelu#
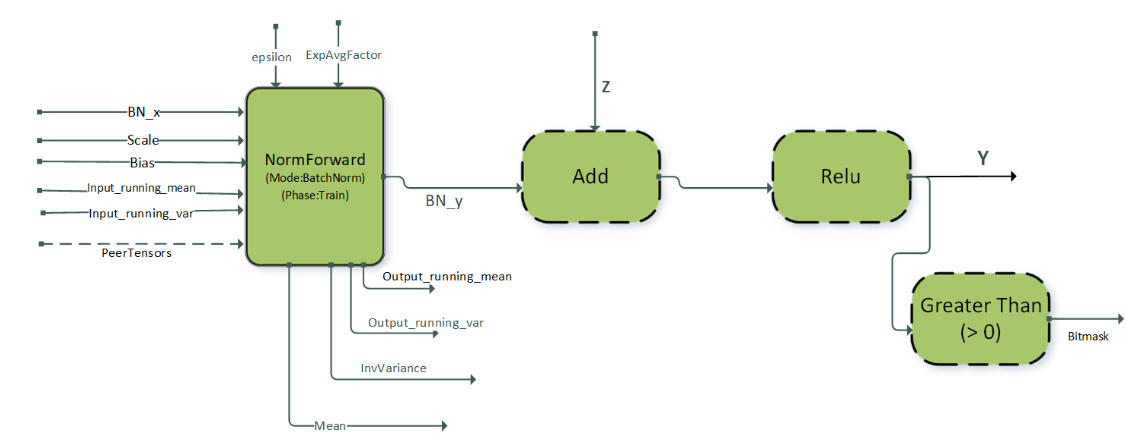
在类似 ResNet 的视觉模型中,批归一化后跟 ReLU 激活是一种常见的模式。使用运行时编译引擎支持的 BNAddRelu 融合模式旨在优化这种重复出现的操作图。它还支持单节点多 GPU 批归一化,以加速多 GPU 系统中的批归一化计算。该模式旨在用于训练阶段的前向传播。带有 add 节点的完整模式 BNAddRelu 用于模型中存在跳跃连接的情况。
该模式在下图中说明,其选项和限制包括
逐点节点:
Add,ReLU, 和GT(大于) 是可选的。所有张量都应采用 NHWC 打包布局格式。
支持 4D 和 5D 张量。
仅支持 ReLU 激活。
norm 前向操作的属性
CUDNN_ATTR_OPERATION_NORM_FWD_MODE必须设置为CUDNN_BATCH_NORM。norm 前向操作的属性
CUDNN_ATTR_OPERATION_NORM_FWD_PHASE必须设置为CUDNN_NORM_FWD_TRAINING。批归一化输入张量:
Scale,Bias,Input_running_mean, 和Input_running_var必须为float数据类型。批归一化输出张量:
output_running_mean,output_running_var,mean, 和InvVariance必须为float数据类型。批归一化输入张量
BN_x、残差输入Z和输出张量Y可以是{FP32, FP16, BF16}数据类型中的任何一种。对于FP16和BF16数据类型,张量的通道计数 C 必须是 8 的倍数,而对于 float 数据类型,通道计数必须是 4 的倍数。这些模式在计算能力 >= 8.0 的设备上受支持。
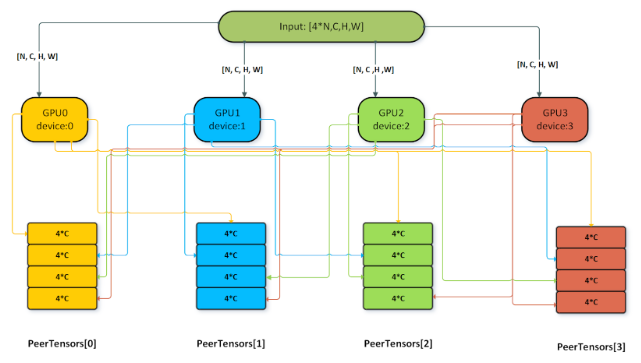
在单节点多 GPU 批归一化的情况下,每个 GPU 基于其输入数据计算本地统计信息,并将本地统计信息写入 peerTensors。每个 peerTensor 驻留在节点上的单独 GPU 上,用于从对等 GPU 读取和写入本地统计信息。之后是全局统计信息计算阶段,其中每个 GPU 聚合来自对等点的统计信息,并计算批归一化输出计算在其本地数据上的全局均值和方差。除了上面列出的选项和限制外,以下附加限制适用于使用多 GPU 批归一化
NormForward操作的属性CUDNN_ATTR_OPERATION_NORM_FWD_PEER_STAT_DESCS必须设置。
peerTensors向量的大小应等于节点中参与批归一化计算的 GPU 数量。
peerTensors向量的最大大小为 32。每个 GPU 应在相同大小的输入数据 [N,C,H,W] 上运行。
peerTensors向量中每个张量的大小应等于num_gpu * 4 * C,其中 C 是BN_x张量的通道计数,num_gpu是节点中参与批归一化计算的 GPU 数量。
peerTensors向量中每个张量的所有元素在变体包中传递该张量之前都应memset为0。
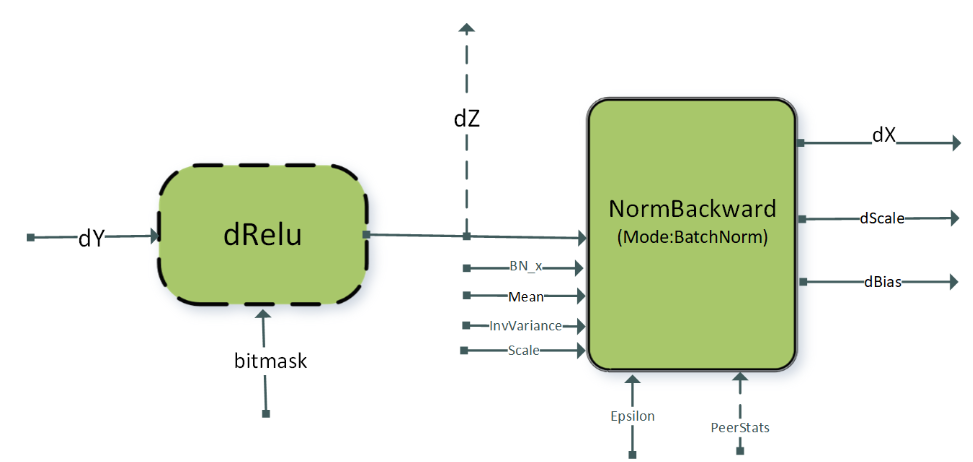
DReluForkDBn#
与 BnAddRelu 模式类似,DReluForkDBn 模式也针对类似 ResNet 的视觉网络。它旨在用于训练期间的反向传播。DReluForkDBn 模式通过运行时编译引擎支持,该引擎通常补充 BnAddRelu 模式。它还支持单节点多 GPU 批归一化,以加速多 GPU 系统中的批归一化反向计算。
该模式在下图中说明,其选项和限制包括
逐点节点
dRelu是可选的。中间张量
dZ可以是虚拟的或非虚拟的。所有张量都应采用 NHWC 打包布局格式。
支持 4D 和 5D 张量。
仅支持
dRelu激活。
dRelu节点需要位掩码张量输入。norm 反向操作的属性
CUDNN_ATTR_OPERATION_NORM_BWD_MODE必须设置为CUDNN_BATCH_NORM。批归一化反向输入张量:
Scale,Mean,InvVariance和输出张量dScale和dBias必须为float数据类型。
dRelu输入张量dY、批归一化反向输入BN_x、偏差梯度dZ和输出张量dX可以是{FP32, FP16, BF16}数据类型中的任何一种。对于FP16和BF16数据类型,张量的通道计数 C 必须是 8 的倍数,而对于float数据类型,通道计数必须是 4 的倍数。这些模式在计算能力 >= 8.0 的设备上受支持。
此模式的单节点多 GPU 版本通常用于跨 GPU 的 dScale 和 dBias 梯度聚合。对于使用多 GPU 版本,必须设置 NormBackward 操作的属性 CUDNN_ATTR_OPERATION_NORM_BWD_PEER_STAT_DESCS。上一节中列出的 peerTensors 向量的其他限制也适用于此模式。
融合注意力 fprop#
Mha-Fprop 融合 \(O=matmul\left( S=g_{4} \left( P=matmul\left( Q, g_{3}\left( K \right) \right), V \right)\right)\) 已添加到运行时融合引擎,以服务于注意力机制中常用的模式。这些模式可用于 BERT、T5 等。
与后面章节中描述的闪速融合注意力模式相比,有两个主要区别
支持的输入大小包含小序列长度 (<= 512)。
操作图可以灵活地在不同类型的掩码、两个矩阵乘法之间的不同操作等之间切换。

g 3 可以是空图或单个比例操作,比例为标量值(模式为 CUDNN_POINTWISE_MUL 的 CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR)。
g 4 可以为空,也可以是 cuDNN 操作的以下 DAG 的组合。这些 DAG 中的每一个都是可选的,如虚线所示。

该组合必须遵守我们呈现它们的顺序。例如,如果您想使用填充掩码和 softmax,则填充掩码必须出现在 softmax 之前。
这些操作通常用于注意力机制。在下图中,我们描述了如何为每个操作创建 DAG。在后续版本中,我们将扩展 g 3 和 g 4 的可能 DAG。
填充掩码
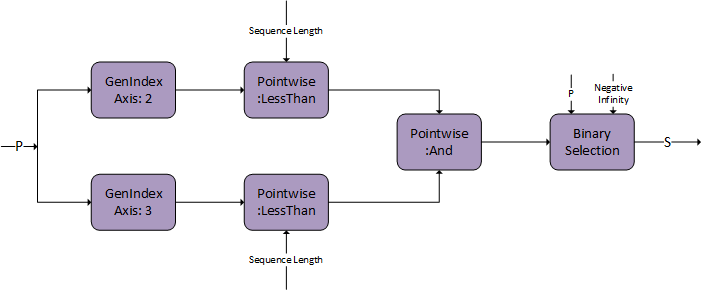
因果掩码

Softmax

Dropout
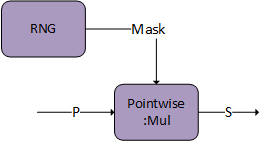
g 4 能够将标记为 S 的中间张量存储到全局内存,该张量可用于融合多头注意力 bprop。DAG:Softmax 和 DAG:Dropout 都具有此功能。将 S 设置为图中最后一个 DAG 的输出。
标记为 S 的张量描述符必须将 CUDNN_ATTR_TENSOR_REORDERING_MODE 设置为 CUDNN_TENSOR_REORDERING_F16x16。这是因为张量以特殊格式存储,并且只能由融合注意力 bprop 消耗。
还有一个额外的选项,即在用户端生成掩码,并将其直接传递给逐元素乘法器。掩码需要是 I/O 数据类型 FP16/BF16,并且 S 将掩码存储在符号位中,以便与 bprop 通信。
限制 |
|
|---|---|
矩阵乘法 (Matmul) |
|
g 3 和 g 4 中的逐元素运算 |
计算类型必须是 |
g 3 和 g 4 中的规约运算 |
I/O 类型和计算类型必须是 |
g 3 和 g 4 中的 RNG 运算 |
|
Mha-fprop 融合的布局要求包括
所有 I/O 张量都必须有 4 个维度,前两个维度表示批次维度。
matmul运算中 rank-4 张量的用法可以从 后端描述符类型 文档中读取。第一个 matmul 的收缩维度(维度
K)必须为 64。第一个 matmul 的非收缩维度(维度
M和N)必须小于或等于 512。在推理模式下,任何序列长度都是有效的。对于训练,仅支持 64 的倍数。
Q、V和O中的最后一个维度(对应于隐藏维度)预计步长为1。对于
K张量,预计倒数第二个维度的步长为1。
S张量预计将CUDNN_ATTR_TENSOR_REORDERING_MODE设置为CUDNN_TENSOR_REORDERING_F16x16。
融合注意力反向传播#
Mha-Bprop 融合在一个内核中的融合模式下执行。
\(dV=matmul\left( g_{5}\left( S \right), dO \right)\) \(dS=matmul\left( dO, VT\right)\) \(dQ=matmul\left( g_{6}\left( dS \right), K \right)\) \(dK=matmul\left( Q, g_{7}\left( dS \right)\right)\)
cuDNN 支持用于融合注意力的相应反向传播图。这可以与融合注意力 fprop 图一起使用,以对具有类似于 BERT 和 T5 架构的模型执行训练。这与 flash 融合注意力 bprop 操作图不兼容。

g 5、g 6 和 g 7 只能支持固定的 DAG。我们正在努力推广这些图。

g 6 表示 softmax 和掩码的反向传播,以获得 dP。
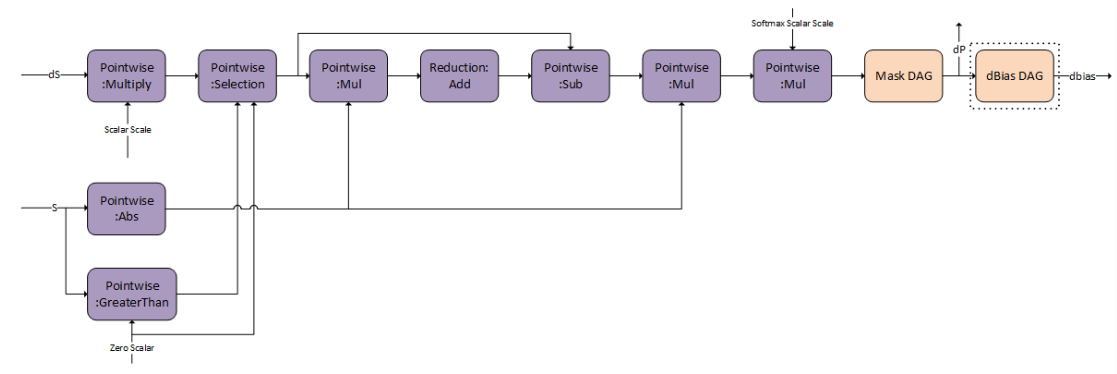
您可以选择 Mask DAG 的选项。您可以选择使用填充/因果掩码、通用掩码作为输入,或者不进行任何掩码。
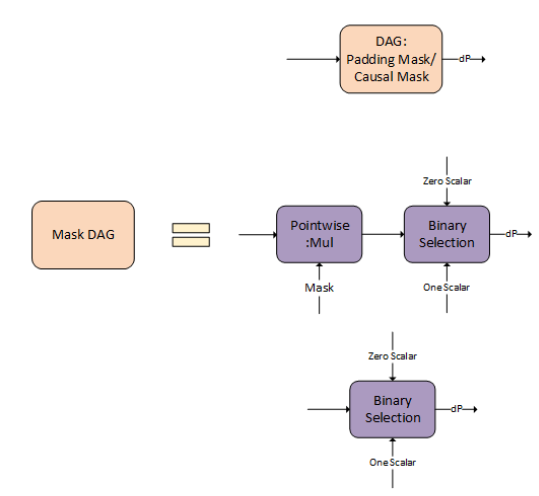
dBias DAG 用于计算相对位置编码的 bprop,它是可选的,您可以选择启用。

g 7 是 g 6 输出 dP 的转置。

限制 |
|
|---|---|
矩阵乘法 (Matmul) |
|
g 5、g 6 和 g 7 中的逐元素运算 |
计算类型必须是 |
g 5、g 6 和 g 7 中的规约运算 |
I/O 类型和计算类型必须是 |
Mha-bprop 融合的布局要求包括
所有 I/O 张量都必须有 4 个维度,前两个维度表示批次维度。
matmul运算中 rank-4 张量的用法可以从 后端描述符类型 文档中读取。第二个 matmul 的收缩维度(维度
K)必须为 64。第一个、第二个和第三个 matmul 的收缩维度(维度
K)必须小于或等于 512 且为 64 的倍数。
Q、K、V、O和dO中的最后一个维度(对应于隐藏维度)预计步长为1。
S和dP张量预计将CUDNN_ATTR_TENSOR_REORDERING_MODE设置为CUDNN_TENSOR_REORDERING_F16x16。
融合 Flash 注意力前向传播#
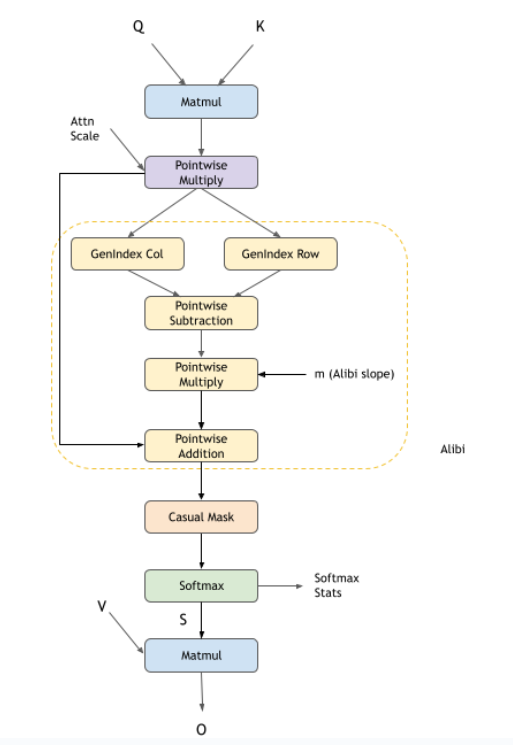
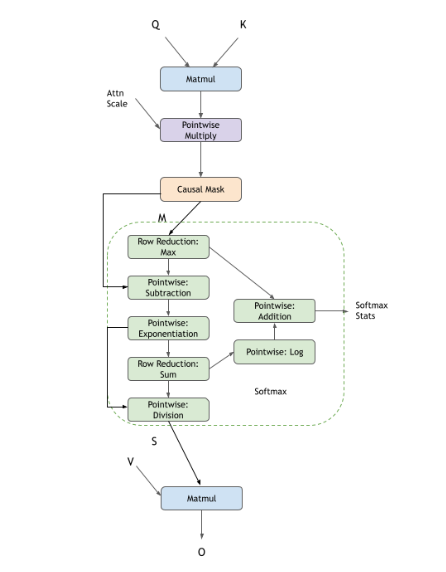
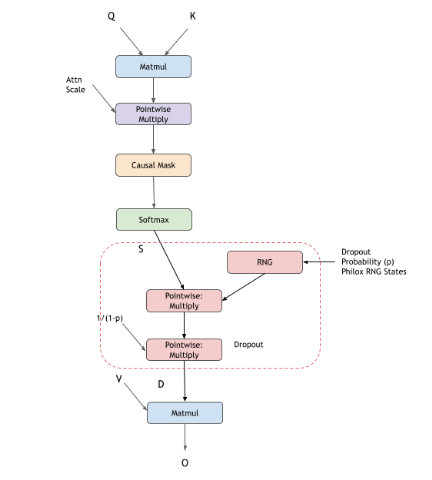
cuDNN 支持 flash 融合注意力,以执行通常在 GPT、BERT 等模型中使用的缩放点积注意力。此引擎支持的通用模式是 BMM-Softmax-BMM,以及您可以选择启用的许多其他可选功能。您可以选择自己创建图,或者使用 cuDNN frontend 中的自定义 sdpa 节点。使用 frontend 节点将使启用不同的选项(如因果掩码、dropout、alibi 掩码等)变得非常容易。
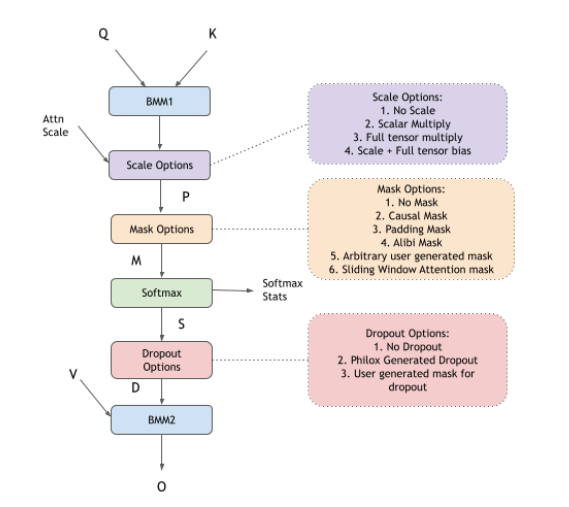
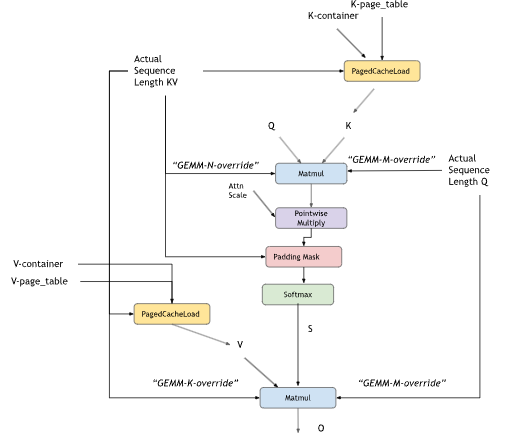
K-cache 和 V-cache 输入可以是非虚拟张量,或者可以选择由分页缓存加载操作组成
预 softmax 可选 DAG 涵盖了用户配置的多种选项
第一个 matmul 后的注意力缩放的逐元素
Multiply节点用于相对位置编码的逐元素
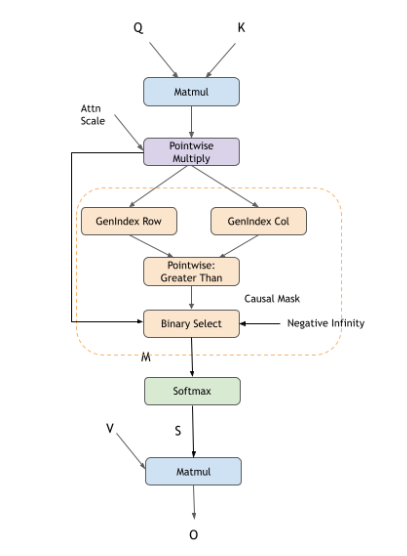
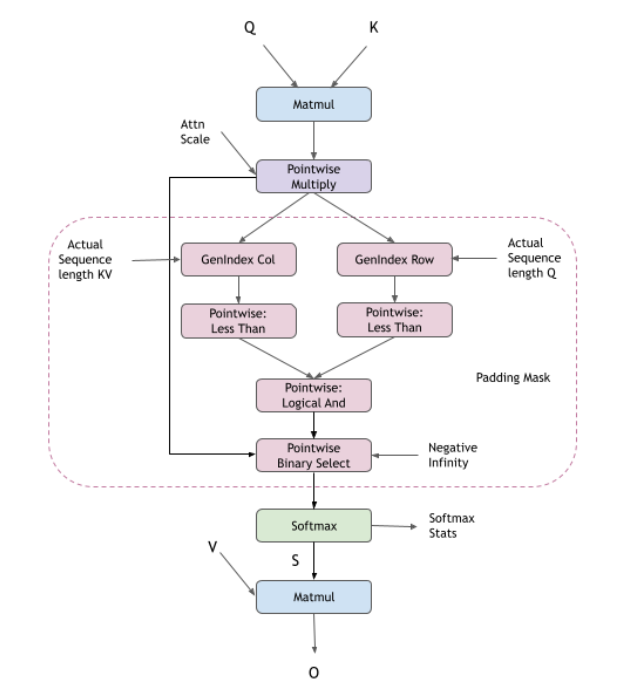
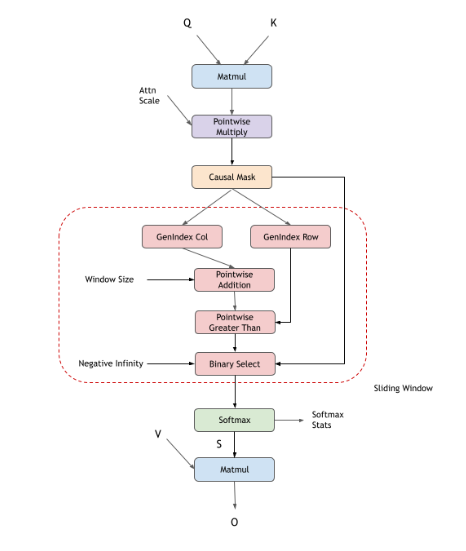
Add节点,以在第一个 matmul 后添加偏置不同的掩码选项,如因果掩码、填充掩码、滑动窗口注意力和 alibi 掩码。用户可以选择多个掩码方案一起使用,也可以不使用掩码。
逐元素
Multiply节点,它接受可以用作用户生成的自定义掩码的完整张量表示激活函数的逐元素节点,如
CUDNN_POINTWISE_TANH_FWD
后 softmax 可选 DAG 涵盖了用户配置的多种选项
带有 RNG 节点的逐元素
Multiply节点,用于表示 dropout带有用户生成的张量(充当 dropout 掩码)的逐元素
Multiply节点
所有这些 DAG 都是可选的。用户可以根据他们 targeting 的 cuDNN API 启用它们。如果使用 cuDNN frontend 中的 sdpa 节点,他们可以将提供的 API 选项设置为 true,例如 use_causal_mask(True),并且在内部,frontend 将自动添加正确的图。直接使用 graph API 时,用户可以将他们想要的操作的相应图添加到 cuDNN 图中。
复合操作,例如:因果掩码、滑动窗口掩码、Softmax 等,可以使用 cuDNN 中的以下操作图表示。
因果掩码
填充掩码
滑动窗口掩码
Alibi 掩码
Softmax
Dropout
分页 KV 缓存
限制 |
|
|---|---|
|
|
分页注意力张量: |
|
Softmax 统计信息 |
|
|
|
|
主机或 GPU 中的 INT32 或 INT64 标量 |
|
注意力缩放可以是 FP16/BF16/FP32。 |
可以通过将 Softmax 统计信息作为虚拟张量传递并将 RNG 节点概率设置为 0.0f 来开启推理模式。此模式支持具有 NVIDIA Ampere 架构及更高版本的 GPU。
cuDNN 还支持 NVIDIA Hopper GPU 上支持的 FP8 数据类型中的融合 Flash 注意力。除了标准的 fprop 图之外,还有额外的反量化比例、量化比例和绝对最大值 (amax) 计算。当前的 FP8 支持是 BF16 支持中支持的功能的子集。我们正在积极扩展对 FP8 内核的支持。
由于 FP8 数据类型的数值精度有限,对于实际用例,您必须先缩放以 FP32 格式计算的值,然后再将其存储为 FP8 格式,并在对 FP8 格式存储的值执行计算之前,先对其进行反缩放。有关更多信息,请参阅 Transformer Engine FP8 primer。
缩放和反缩放
在 FP8 的上下文中,缩放是指将 FP32 张量的每个元素乘以量化因子。
量化因子的计算公式为:(FP8 格式中最大可表示值)/(张量中看到的最大绝对值)。
对于 E4M3 格式,量化因子为 448.f/ tensor_amax(四舍五入到最接近的较低的 2 的幂)。
对于 E5M2 格式,量化因子为 57344.f / tensor_amax(四舍五入到最接近的较低的 2 的幂)。
反量化因子是量化因子的倒数。
缩放背后的含义是在 FP8 值上进行计算和存储 FP8 值时,生成 FP8 格式的完整范围,从而最大限度地减少精度损失。FP32 格式的真实值在存储为 FP8 格式的缩放值之前,先乘以量化因子。FP8 格式的缩放值的计算通过乘以反量化因子进行反缩放,以将其转换回 FP32 格式的真实值。
缩放和反缩放对于 FP8 数据类型的收敛至关重要,因此 cuDNN 仅支持存在缩放和反缩放节点的 FP8 融合注意力的图模式。
在下图中,红色张量表示 FP8 数据类型张量,黑色张量表示 FP32 数据类型。
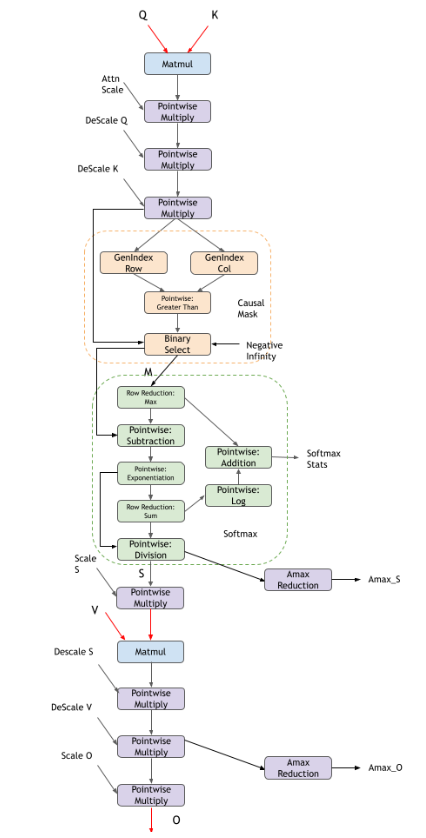
预 softmax 可选 DAG 涵盖了您可以配置的多种选项
第一个 matmul 后的注意力缩放的逐元素
Multiply节点掩码选项包括因果掩码和无掩码
后 softmax 可选 DAG 涵盖了您可以配置的多种选项
目前不支持 dropout
限制 |
|
|---|---|
|
|
Softmax 统计信息 |
|
|
|
|
注意力缩放可以是 FP32。 |
反量化比例( |
|
Amax 值( |
|
我们建议对 cuDNN 融合 flash 注意力内核使用 cuDNN frontend 缩放点积注意力节点。以下 cuDNN frontend 示例可用:- 注意力 Python 示例 - 注意力 C++ 示例
有关 cuDNN frontend 缩放点积注意力的更多信息,请参阅 注意力。
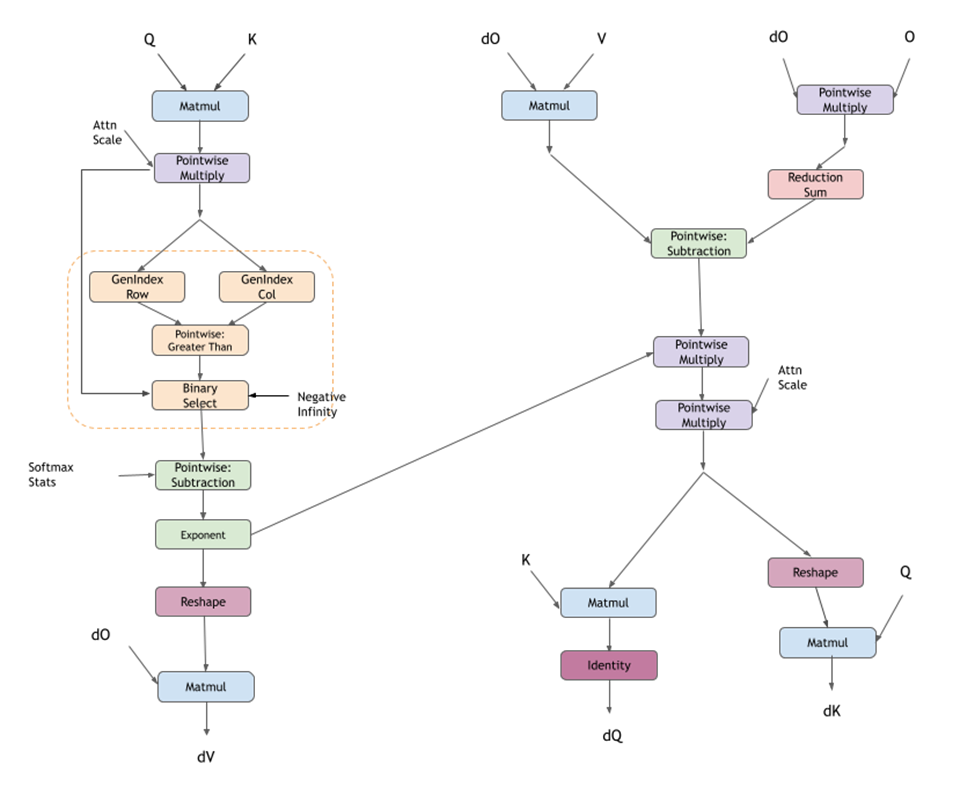
融合 Flash 注意力反向传播#
cuDNN 支持用于融合 flash 注意力的相应反向传播图。这可以与 fprop 图一起使用,以对大型语言模型 (LLM) 执行训练。
fprop 中提到的所有选项也适用于 bprop 图。bprop frontend 节点包含相同的选项,并且可以配置为执行 bprop。选择 graph API 的用户再次需要添加他们想要的操作的图。下面显示的图是 GPT 中带有因果掩码的标准注意力层的图。
注意
NVIDIA Ampere GPU 上尚未添加激活函数的
bprop支持;它仅存在于 NVIDIA Hopper GPU 上。
对于分组查询注意力 (GQA) 和多查询注意力 (MQA),您可以为 dK 和 dV 配置一个额外的规约节点,该节点将张量从头的完整数量(Q 头)减少到实际的 K 和 V 头。
对于输入和输出张量,fprop 图的限制被继承。对于 bprop 特定张量,限制如下
限制 |
|
|---|---|
|
|
Softmax 和 |
|
|
|
|
|
此模式支持具有 NVIDIA Ampere 架构及更高版本的 GPU。
cuDNN 还支持 NVIDIA Hopper GPU 上支持的本机 FP8 数据类型中的融合 Flash 注意力 bprop。除了标准的 bprop 图之外,还有额外的反量化比例、量化比例和绝对最大值 (amax) 计算。当前的 FP8 Flash 注意力 bprop 支持对应于 FP8 Flash 注意力 fprop 支持。
在下图中,红色张量表示 FP8 数据类型张量,黑色张量表示 FP32 数据类型。
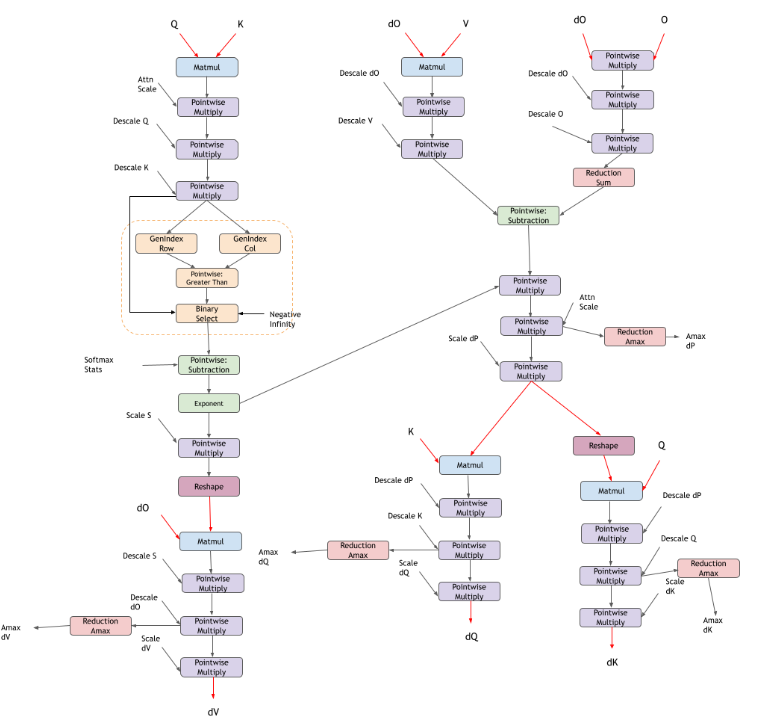
限制 |
|
|---|---|
|
|
|
|
专用预编译引擎#
预编译的专用引擎针对并优化具有不规则支持表面的专用图模式。由于这种 targeting,这些图不需要运行时编译。
在大多数情况下,专用模式只是运行时融合引擎中使用的通用模式的特殊情况,但在某些情况下,专用模式不适合任何通用模式。如果您的图模式与专用模式匹配,您将至少获得一个模式匹配引擎,并且您可能还会获得运行时融合引擎作为另一个选项。
目前,模式匹配引擎支持以下模式。某些节点是可选的。可选节点用虚线轮廓表示。
ConvBNfprop#
ConvBNfprop 模式如下图所示。其限制和选项包括
三个逐元素节点 scale、bias 和 ReLU 是可选的。
X、Z、W、s 1、b 1 都必须是 FP16 数据类型。
Z 需要是形状为 [N, C, H, W],NHWC packed 布局。
W 需要是形状为 [K, C, R, S],KRSC packed 布局。
s 1、b 1 需要是形状为 [1, C, 1, 1],NHWC packed 布局。
仅支持 ReLU 激活。
所有中间张量都需要是虚拟的,除了 Y 需要是非虚拟的。
I/O 指针应为 16 字节对齐。
此模式仅在计算能力 >= 8.0 的设备上受支持(NVIDIA Ada Lovelace 架构 8.9 除外)。
在计算能力 >= 9.0 的设备上,我们仅支持两种模式
完整模式:scale + bias + ReLU + Conv + GenStats,以及
部分模式:Conv + GenStats。

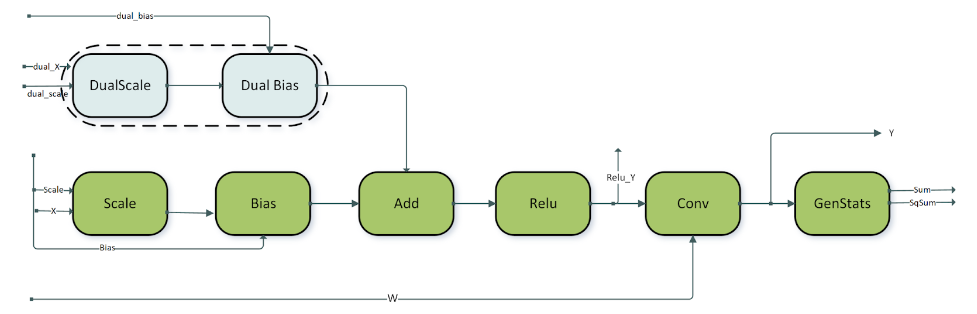
跳跃连接在类似 ResNet 的模型中很常见。为了支持跳跃连接中的融合,我们支持上述模式的变体,即 DBARCS 模式(Dual, Scale, Bias, Add, ReLU, Conv genStats 的缩写)。DBARCS 模式的限制和选项包括
逐元素 dual scale 和 dual bias 节点要么都存在,要么都不存在。这由围绕 dual scale 和 dual bias 节点的虚线框表示。如果两个节点都丢失,则
dual_X张量直接作为输入馈送到 add 节点。逐元素节点 scale、bias、add 和 ReLU 是必需的节点。
目前,仅在 Hopper GPU 上受支持。
对于所有其他数据类型,
ConvBNfprop模式的布局和虚拟性限制也适用于此模式。
dual_X、dual_scale和dual_bias都必须是 FP16 数据类型。
dual_scale和dual_bias必须是形状为 [1,C,1,1],NHWC packed 布局。ReLU 和 Conv 节点的中间输出:
Relu_Y和Y是非虚拟的。所有其他中间输出都是虚拟的。卷积的权重张量 W 需要是形状为 [K,C,1,1]。DBARCS 模式中的卷积仅支持 padding 为 0 的 1x1 滤波器。
ConvBNwgrad#
ConvBNwgrad 模式如下图所示。其限制和选项包括
三个逐元素操作都是可选的,如虚线轮廓所示。
仅支持 ReLU 激活。
X、s 1、b 1 和
dy都必须是 FP16 数据类型。I/O 指针应为 16 字节对齐。
X、s 1、b 1 和
dy都必须具有 NHWC packed 布局。所有中间张量都需要是虚拟的。
此模式仅在计算能力 >= 8.0 的设备上受支持(NVIDIA Ada Lovelace 架构 8.9 除外)。
在计算能力 >= 9.0 的设备上,支持仅限于
完整模式:scale + bias + ReLU +
wgrad。

ConvBiasAct#
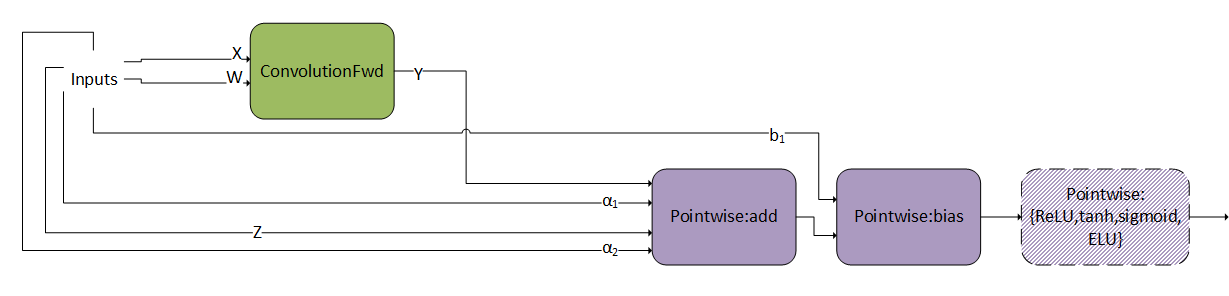
ConvBiasAct 模式如下图所示。其限制和选项包括
\(\alpha_{1}\) 和 \(\alpha_{2}\) 需要是标量。
激活节点是可选的。
偏置张量的大小应为 [1, K, 1, 1]。
不支持内部转换。也就是说,节点之间的虚拟输出需要与节点的计算类型具有相同的数据类型,该数据类型应与卷积节点的 epilog 类型相同。
对支持的数据类型组合有一些限制,可以在 API 参考中找到(请参阅 cudnnConvolutionBiasActivationForward())。
ConvScaleBiasAct#
ConvScaleBiasAct 模式如下图所示。其限制和选项包括
\(\alpha_{1}\)、\(\alpha_{2}\) 和 \(b_{1}\) 应具有相同的数据类型/布局,并且只能是 FP32。
X、W 和 Z 只能是 INT8x4 或 INT8x32。
偏置张量的大小应为 [1, K, 1, 1]。
不支持内部转换。也就是说,节点之间的虚拟输出需要与它们的计算类型相同。
目前,
Pointwise:ReLU是唯一的可选逐元素节点。
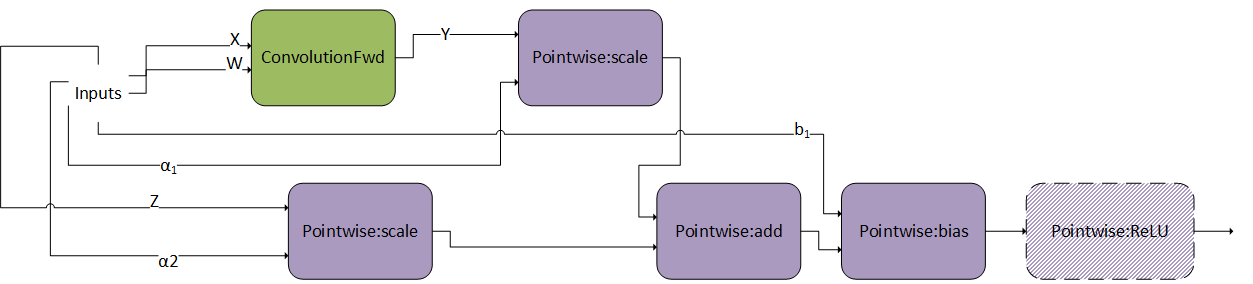
此模式与 ConvBiasAct 非常相似。区别在于,这里的比例 \(\alpha_{1}\) 和 \(\alpha_{2}\) 是张量,而不是标量。如果它们是标量,则此模式变为正常的 ConvBiasAct。
DgradDreluBNBwdWeight#
DgradDreluBNBwdWeight 模式如下图所示。其限制和选项包括
Dgrad 输入
dy和 W 是 FP16 数据类型。批归一化前向传播输入
X_bn是 FP16 数据类型,而其他张量mean_bn、invstd_dev_bn、scale_bn和bias_bn是 FP32。输出:
dScale、dBias、A、B、C 是 FP32 数据类型。所有指针都是 16 字节对齐的。
此模式仅在计算能力 >= 8.0 的设备上受支持(NVIDIA Ada Lovelace 架构 8.9 除外)。
DgradDreluBNBwdWeight 是一个预编译引擎,可以与 dBNApply 模式结合使用,以计算批归一化的反向路径。
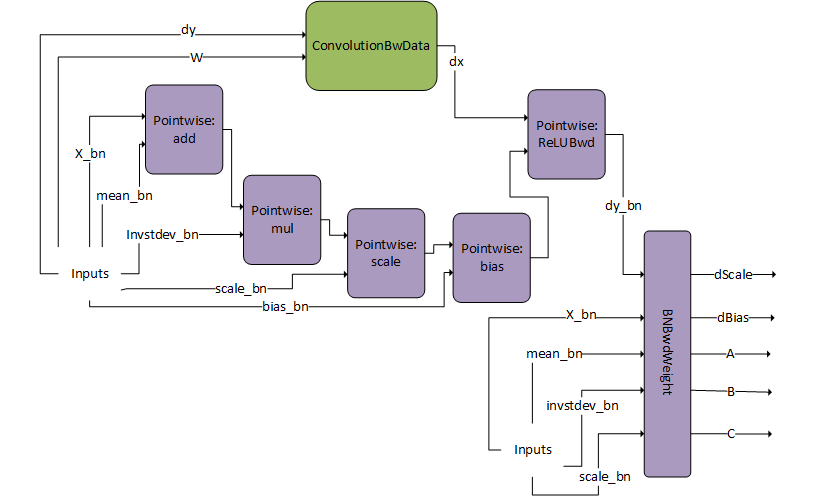
BNBwdWeightX_bnmean_bninvstddev_bnscale_bndy_bnReLUBwd
它产生五个输出:批归一化 scale 和 bias 参数的梯度,dScaledBias
这种模式通常用于批归一化反向传播的计算中。
当计算批归一化的反向传播时,需要 dScaledBiasdX_bnDgradDreluBnBwdWeightdBNApplydXdx_bn = A*dy_bn + B*X_bn +C
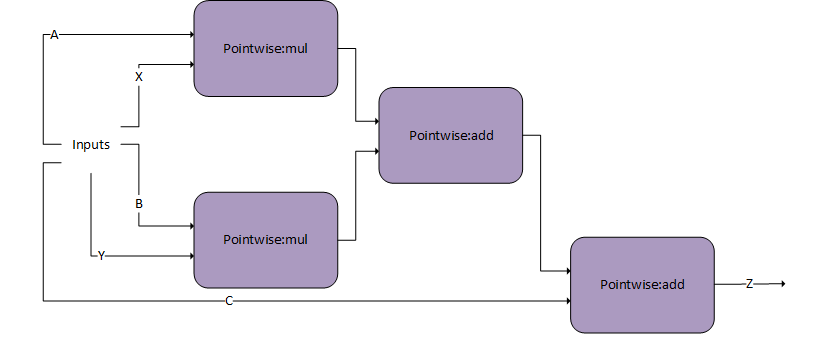
dBNApply
请注意,DgradDreluBNBwdWeightConvBNfpropConvBNfpropY_bnDgradDreluBnBwdWeightX_bnmean_bnalpha2-1
FP8 融合 Flash Attention#
cuDNN 通过预编译引擎支持输入和输出数据类型为 FP8 格式的融合 flash attention,但形状支持有限,最大序列长度允许达 512。我们的一般建议是使用专门的 Fused Flash Attention fprop 和 Fused Flash Attention bprop 运行时融合引擎以获得 FP8 数据类型支持。
使用后端描述符进行映射#
为了便于阅读,本节中使用的操作已缩写。实际后端描述符的映射可以在此表中找到
本节中使用的符号 |
后端描述符 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一种张量核心操作模式,用于加速浮点卷积或矩阵乘法。这可以用于计算类型为 |