旧版 API#
Graph API 部分可以被认为是声明式 API,从某种意义上说,您声明一个图,然后构建并运行它。 以前,cuDNN 只有命令式 API,这对于基本用例来说更方便,但事实证明,随着深度学习领域发展到需要更多操作和更复杂的操作融合,这种 API 过于局限。 随着图 API 的支持范围与旧版 API 达到对等,我们正在逐步弃用和删除旧版 API 的部分内容。 然而,仍然存在差距,因此仍然存在旧版 API。
卷积函数#
先决条件#
对于受支持的 GPU,只有当通过将 mathType 设置为 CUDNN_TENSOR_OP_MATH 或 CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION 在适当的卷积描述符上调用 cudnnSetConvolutionMathType() 时,才会为卷积函数触发 Tensor Core 操作。
支持的算法#
当满足先决条件时,以下卷积函数可以作为 Tensor Core 操作运行
支持的卷积函数 |
支持的算法 |
|---|---|
|
|
|
|
|
|
数据和滤波器格式#
cuDNN 库可能会使用填充、折叠和 NCHW 到 NHWC 的转换来调用 Tensor Core 操作。 有关更多信息,请参阅 Tensor 变换。
对于 *_ALGO_WINOGRAD_NONFUSED 以外的算法,当满足以下要求时,cuDNN 库将触发 Tensor Core 操作
输入、滤波器和输出描述符(
xDesc、yDesc、wDesc、dxDesc、dyDesc和dwDesc,如果适用)的dataType = CUDNN_DATA_HALF(即 FP16)。 对于 FP32 数据类型,请参阅 FP32 到 FP16 的转换。输入和输出特征图的数量(即通道维度 C)是 8 的倍数。 当通道维度不是 8 的倍数时,请参阅 填充。
滤波器的类型为
CUDNN_TENSOR_NCHW或CUDNN_TENSOR_NHWC。如果使用类型为
CUDNN_TENSOR_NHWC的滤波器,则输入、滤波器和输出数据指针(X、Y、W、dX、dY和dW,如果适用)与 128 位边界对齐。
RNN 函数#
先决条件#
当 cudnnSetRNNDescriptor_v8() 中的 mathType 参数设置为 CUDNN_TENSOR_OP_MATH 或 CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION 时,Tensor Core 操作可用于 RNN 函数 cudnnRNNForward()、cudnnRNNBackwardData_v8() 和 cudnnRNNBackwardWeights_v8()。
支持的算法#
当满足上述先决条件时,以下 RNN 函数可以作为 Tensor Core 操作运行
支持的 RNN 函数 |
支持的算法 |
|---|---|
支持 Tensor Core 操作的所有 RNN 函数 |
|
数据和滤波器格式#
当满足以下要求时,cuDNN 库将触发 Tensor Core 操作
对于
algo = CUDNN_RNN_ALGO_STANDARD
隐藏状态大小、输入大小和批次大小是 8 的倍数。
所有用户提供的张量和 RNN 权重缓冲区都与 128 位边界对齐。
对于 FP16 输入/输出,选择
CUDNN_TENSOR_OP_MATH或CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION。对于 FP32 输入/输出,选择
CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION。对于
algo = CUDNN_RNN_ALGO_PERSIST_STATIC
隐藏状态大小和输入大小是 32 的倍数。
批次大小是 8 的倍数。
如果批次大小超过 96(对于前向训练或推理)或 32(对于后向数据),则批次大小约束可能会更严格,并且可能需要较大的 2 的幂批次大小。
所有用户提供的张量和 RNN 权重缓冲区都与 128 位边界对齐。
对于 FP16 输入/输出,选择
CUDNN_TENSOR_OP_MATH或CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION。对于 FP32 输入/输出,选择
CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION。
有关更多信息,请参阅 RNN 函数的特性。
RNN 函数的特性#
有关每个 RNN 函数支持的特性列表,请参阅下表。
对于以下每个术语,下表中的简短形式版本用括号显示,以保持简洁: CUDNN_RNN_ALGO_STANDARD (_ALGO_STANDARD)、CUDNN_RNN_ALGO_PERSIST_STATIC (_ALGO_PERSIST_STATIC)、CUDNN_RNN_ALGO_PERSIST_DYNAMIC (_ALGO_PERSIST_DYNAMIC)、CUDNN_RNN_ALGO_PERSIST_STATIC_SMALL_H (_ALGO_SMALL_H) 和 CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION (_ALLOW_CONVERSION)。
函数 |
支持的 I/O 布局 |
支持批次中的可变序列长度 |
|---|---|---|
|
序列主轴解包。 批次主轴解包。 序列主轴打包。 |
仅适用于 |
|
序列主轴解包。 批次主轴解包。 序列主轴打包。 |
仅适用于 |
|
序列主轴解包。 批次主轴解包。 序列主轴打包。 |
仅适用于 |
注意
要使用解包布局,请通过 cudnnSetRNNDescriptor_v8() 的 auxFlags 参数设置 CUDNN_RNN_PADDED_IO_ENABLED。
常用支持
- 模式(单元类型)
CUDNN_RNN_RELU、CUDNN_RNN_TANH、CUDNN_LSTM和CUDNN_GRU。- 算法
_ALGO_STANDARD、_ALGO_PERSIST_STATIC、_ALGO_PERSIST_DYNAMIC、_ALGO_SMALL_H。 请勿在cudnnRNNForward()、cudnnRNNBackwardData_v8()和cudnnRNNBackwardWeights_v8()函数中混合使用不同的算法。- 数学模式
CUDNN_DEFAULT_MATH、CUDNN_TENSOR_OP_MATH(如果在 Volta 之前的架构上运行或算法不支持 Tensor Core,将自动回退)、_ALLOW_CONVERSION(可能会执行向下转换以利用 Tensor Core)。- 方向模式
CUDNN_UNIDIRECTIONAL、CUDNN_BIDIRECTIONAL- RNN 输入模式
CUDNN_LINEAR_INPUT、CUDNN_SKIP_INPUT
特性 |
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
不支持 |
不支持 |
|
LSTM 循环投影 |
支持 |
不支持 |
不支持 |
不支持 |
LSTM 单元剪裁 |
支持 |
支持 |
支持 |
支持 |
批次中的可变序列长度 |
支持 |
不支持 |
不支持 |
不支持 |
Tensor Core |
|
|
|
不支持,将正常执行,忽略 |
其他限制 |
最大问题规模受 GPU 规格限制。 |
|
需要通过 NVRTC 进行实时编译。 |
Tensor 变换#
cuDNN 库中的一些函数将在执行实际函数操作时执行变换,例如折叠、填充和 NCHW 到 NHWC 的转换。
FP32 和 FP16 之间的转换#
cuDNN API 参考允许您指定可以将 FP32 输入数据复制并在内部转换为 FP16 数据,以使用 Tensor Core 操作来潜在地提高性能。 这可以通过为 cudnnMathType_t 选择 CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION 枚举来实现。 在此模式下,FP32 张量在内部向下转换为 FP16,执行 Tensor Op 数学运算,最后向上转换为 FP32 作为输出。
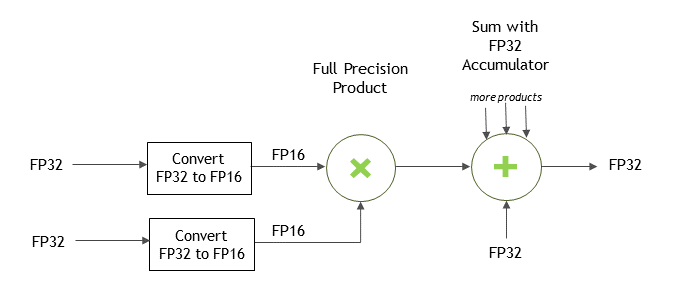
对于卷积
对于卷积,可以通过将 CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION 枚举值传递给 cudnnSetConvolutionMathType() 调用来实现 FP32 到 FP16 的转换。
// Set the math type to allow cuDNN to use Tensor Cores: checkCudnnErr(cudnnSetConvolutionMathType(cudnnConvDesc, CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION));
对于 RNN
对于 RNN,可以通过将 CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION 枚举值分配给 cudnnSetRNNDescriptor_v8() 调用的 mathType 参数,以允许 FP32 输入数据向下转换以在 RNN 中使用,从而实现 FP32 到 FP16 的转换。
填充#
对于打包的 NCHW 数据,当通道维度不是 8 的倍数时,cuDNN 库将根据需要填充张量以启用 Tensor Core 操作。 对于 CUDNN_TENSOR_OP_MATH 和 CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION 两种情况下的打包 NCHW 数据,此填充都是自动的。
折叠#
在折叠操作中,cuDNN 库隐式地执行输入张量的格式化,并将输入张量保存在内部工作区中。 这可以加速对 Tensor Core 的调用。
通过折叠或通道折叠,cuDNN 可以在内部工作区中隐式地格式化输入张量,以加速整体计算。 为用户执行此转换通常允许 cuDNN 使用对卷积步幅有限制的内核来支持带步幅的卷积问题。
NCHW 和 NHWC 之间的转换#
Tensor Core 要求张量采用 NHWC 数据布局。 当用户请求 Tensor Op 数学运算时,将执行 NCHW 和 NHWC 之间的转换。 但是,使用 Tensor Core 的请求只是一个请求,在某些情况下可能不会使用 Tensor Core。 仅当请求并实际使用 Tensor Core 时,cuDNN 库才会在 NCHW 和 NHWC 之间进行转换。
如果您的输入(和输出)为 NCHW,则预期布局会发生变化。
非 Tensor Op 卷积不会执行 NCHW 和 NHWC 之间的转换。
在非常罕见且难以限定的情况下(这是填充和滤波器大小的复杂函数),Tensor Ops 可能未启用。 在这种情况下,用户可以预先填充以启用 Tensor Ops 路径。
混合精度数值精度#
当计算精度和输出精度不同时,数值精度可能会因算法而异。
例如,当计算以 FP32 执行且输出为 FP16 时,CUDNN_CONVOLUTION_BWD_FILTER_ALGO_0 (ALGO_0) 的精度低于 CUDNN_CONVOLUTION_BWD_FILTER_ALGO_1 (ALGO_1)。 这是因为 ALGO_0 不使用额外的工作区,并且被迫以 FP16(即半精度浮点数)累积中间结果,这会降低精度。 另一方面,ALGO_1 使用额外的工作区以 FP32(即全精度浮点数)累积中间值。