cudnn_adv 库#
数据类型参考#
以下是 cudnn_adv 库中的数据类型参考。
指向不透明结构类型的指针#
以下是 cudnn_adv 库中指向不透明结构类型的指针。
cudnnAttnDescriptor_t#
此枚举类型已弃用,目前仅供已弃用的 API 使用。请考虑使用已弃用 API 的替代方法,这些 API 使用此枚举类型。
cudnnAttnDescriptor_t 是指向不透明结构的指针,该结构保存多头注意力层的参数,例如
权重和偏置张量形状(线性投影之前和之后的向量长度)
可以提前设置且在调用函数以评估前向响应和梯度时不会更改的参数(注意力头的数量、softmax 平滑和锐化系数)
计算临时缓冲区大小所需的其他设置。
使用 cudnnCreateAttnDescriptor() 函数创建注意力描述符对象的实例,使用 cudnnDestroyAttnDescriptor() 删除先前创建的描述符。使用 cudnnSetAttnDescriptor() 函数配置描述符。
cudnnRNNDataDescriptor_t#
cudnnRNNDataDescriptor_t 是指向不透明结构的指针,该结构保存 RNN 数据集的描述。函数 cudnnCreateRNNDataDescriptor() 用于创建一个实例,并且必须使用 cudnnSetRNNDataDescriptor() 初始化此实例。
cudnnRNNDescriptor_t#
cudnnRNNDescriptor_t 是指向不透明结构的指针,该结构保存 RNN 操作的描述。cudnnCreateRNNDescriptor() 用于创建一个实例。
cudnnSeqDataDescriptor_t#
此枚举类型已弃用,目前仅供已弃用的 API 使用。请考虑使用已弃用 API 的替代方法,这些 API 使用此枚举类型。
cudnnSeqDataDescriptor_t 是指向不透明结构的指针,该结构保存序列数据容器或缓冲区的参数。序列数据容器用于存储由 VECT 维度定义的固定大小向量。向量排列在另外三个维度中:TIME、BATCH 和 BEAM。
TIME 维度用于将向量捆绑到向量序列中。实际序列可以短于 TIME 维度,因此,需要有关每个序列长度以及应如何保存未使用的(填充)向量的额外信息。
假定序列数据容器已完全打包。当向量以地址升序遍历时,TIME、BATCH 和 BEAM 维度可以采用任何顺序。六种数据布局(TIME、BATCH 和 BEAM 的排列)是可能的。
cudnnSeqDataDescriptor_t 对象包含以下参数
向量使用的数据类型
TIME、BATCH、BEAM和VECT维度数据布局
沿
TIME维度的每个序列的长度要复制到输出填充向量的可选值
使用 cudnnCreateSeqDataDescriptor() 函数创建一个序列数据描述符对象的实例,使用 cudnnDestroySeqDataDescriptor() 删除先前创建的描述符。使用 cudnnSetSeqDataDescriptor() 函数配置描述符。
此描述符由多头注意力 API 函数使用。
枚举类型#
以下是 cudnn_adv 库中的枚举类型。
cudnnDirectionMode_t#
cudnnDirectionMode_t 是一种枚举类型,用于指定循环模式。
值
CUDNN_UNIDIRECTIONAL网络从第一个输入到最后一个输入进行循环迭代。
CUDNN_BIDIRECTIONAL网络的每一层都从第一个输入到最后一个输入进行循环迭代,并单独地从最后一个输入到第一个输入进行循环迭代。两者的输出在每次迭代时连接起来,从而给出该层的输出。
cudnnForwardMode_t#
cudnnForwardMode_t 是一种枚举类型,用于在 RNN API 中指定推理或训练模式。此参数允许 cuDNN 库更精确地调整工作区缓冲区的大小,该缓冲区的大小在推理和训练方案中可能不同。
值
CUDNN_FWD_MODE_INFERENCE选择推理模式。
CUDNN_FWD_MODE_TRAINING选择训练模式。
cudnnLossNormalizationMode_t#
cudnnLossNormalizationMode_t 是一种枚举类型,用于控制损失函数的输入归一化模式。此类型可以与 cudnnSetCTCLossDescriptorEx() 一起使用。
值
CUDNN_LOSS_NORMALIZATION_NONEcudnnCTCLoss() 函数的输入概率应为归一化概率,输出
gradients是损失相对于未归一化概率的梯度。CUDNN_LOSS_NORMALIZATION_SOFTMAXcudnnCTCLoss() 函数的输入概率应为来自上一层的未归一化激活,输出
gradients是损失相对于激活的梯度。在内部,概率通过 softmax 归一化计算。
cudnnMultiHeadAttnWeightKind_t#
cudnnMultiHeadAttnWeightKind_t 是一种枚举类型,用于指定 cudnnGetMultiHeadAttnWeights() 函数中的权重或偏置组。
值
CUDNN_MH_ATTN_Q_WEIGHTS选择
queries的输入投影权重。CUDNN_MH_ATTN_K_WEIGHTS选择
keys的输入投影权重。CUDNN_MH_ATTN_V_WEIGHTS选择
values的输入投影权重。CUDNN_MH_ATTN_O_WEIGHTS选择输出投影权重。
CUDNN_MH_ATTN_Q_BIASES选择
queries的输入投影偏置。CUDNN_MH_ATTN_K_BIASES选择
keys的输入投影偏置。CUDNN_MH_ATTN_V_BIASES选择
values的输入投影偏置。CUDNN_MH_ATTN_O_BIASES选择输出投影偏置。
cudnnRNNAlgo_t#
cudnnRNNAlgo_t 是一种枚举类型,用于指定算法。
值
CUDNN_RNN_ALGO_STANDARD此算法使用 cuBLASLt 执行所有矩阵乘法,并使用专用内核执行特定于单元的操作,例如应用非线性或添加偏置。这是最通用的 RNN 算法。它支持 RNN 层之间的伪随机 dropout 掩码、未打包数据布局中的可变长度序列、LSTM 模型中的循环投影以及 RNN 偏置的多种选择:无偏置、单偏置或双偏置。该算法逐层遍历 RNN 单元,或以对角线模式遍历多个层,其中一定数量的时间步长分组到一个“计算块”中。在可能的情况下,GEMM 在并行 CUDA 流中执行。预计此算法将在各种 RNN 配置中提供强大的性能。它也受到包括最旧 GPU 在内的广泛架构的支持。
CUDNN_RNN_ALGO_PERSIST_STATIC此算法中的输入 GEMM 由 cuBLASLt 执行。循环 GEMM(通常带有融合的逐元素单元操作)由持久内核处理,这些内核要求网格的所有线程块在 GPU 上并发运行并进行通信。所有循环权重都以协作方式存储在流多处理器 (SM) 寄存器中,并且可以选择存储在共享内存中。RNN 单元逐层遍历。具有更多 SM 数量的 GPU 可以使用此算法处理更长的隐藏状态向量。当输入张量的第一个维度较小时(意味着小批量),预计此方法会很快。
CUDNN_RNN_ALGO_PERSIST_STATIC在计算能力 >= 6.0 的设备上受支持。CUDNN_RNN_ALGO_PERSIST_DYNAMIC网络的循环部分使用持久内核方法执行。对于小型 RNN 模型,预计此方法会表现良好。
CUDNN_RNN_ALGO_PERSIST_DYNAMIC内核在运行时编译,并针对 RNN 模型和活动 GPU 的特定参数进行优化。使用CUDNN_RNN_ALGO_PERSIST_DYNAMIC时,隐藏向量的最大大小限制可能高于CUDNN_RNN_ALGO_PERSIST_STATIC的相应限制。此算法不使用 NVIDIA Tensor Core。CUDNN_RNN_ALGO_PERSIST_DYNAMIC在计算能力 >= 6.0 的设备上受支持。CUDNN_RNN_ALGO_PERSIST_STATIC_SMALL_H尽管名称如此,但此算法不依赖于持久 GPU 内核(所有线程块同时处于活动状态),但在其他方面,它的运行方式与
CUDNN_RNN_ALGO_PERSIST_STATIC类似。所有时间步长的输入 GEMM 由 cuBLASLt 执行,融合了逐元素操作的循环 GEMM 由“常规” CUDA 线程块处理。一个线程块协作加载一个层的所有循环权重(方阵)和少量输入数据向量,以计算相同数量的输出元素,而无需与其他线程块同步。该算法受可用寄存器资源的限制,因此隐藏向量大小不能太大,例如,在前向传递中,LSTM/GRU 单元最多 192 个元素,RELU/TANH 单元最多 384 个元素。对于大批量大小,此算法可能非常快,并且可以随着可用 SM 数量的增加而很好地扩展。
cudnnRNNBiasMode_t#
cudnnRNNBiasMode_t 是一种枚举类型,用于指定 RNN 函数的偏置向量的数量。有关基于偏置模式的每种单元类型的公式,请参阅 cudnnRNNMode_t 枚举类型的描述。
值
CUDNN_RNN_NO_BIAS应用不使用偏置的 RNN 单元公式。
CUDNN_RNN_SINGLE_INP_BIAS应用在输入 GEMM 中使用一个输入偏置向量的 RNN 单元公式。
CUDNN_RNN_DOUBLE_BIAS应用使用两个偏置向量的 RNN 单元公式。
CUDNN_RNN_SINGLE_REC_BIAS应用在循环 GEMM 中使用一个循环偏置向量的 RNN 单元公式。
cudnnRNNClipMode_t#
cudnnRNNClipMode_t 是一种枚举类型,用于选择 LSTM 单元裁剪模式。
值
CUDNN_RNN_CLIP_NONE禁用 LSTM 单元裁剪。
CUDNN_RNN_CLIP_MINMAX启用 LSTM 单元裁剪。
cudnnRNNDataLayout_t#
cudnnRNNDataLayout_t 是一种枚举类型,用于选择 RNN 数据布局。它在 API 调用 cudnnGetRNNDataDescriptor() 和 cudnnSetRNNDataDescriptor() 中使用。
值
CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_UNPACKED数据布局已填充,外步长从一个时间步长到下一个时间步长。
CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_PACKED序列长度已排序并打包,如基本 RNN API 中所示。
CUDNN_RNN_DATA_LAYOUT_BATCH_MAJOR_UNPACKED数据布局已填充,外步长从一个批次到下一个批次。
cudnnRNNInputMode_t#
cudnnRNNInputMode_t 是一种枚举类型,用于指定第一层的行为。
值
CUDNN_LINEAR_INPUT在第一个循环层的输入处执行有偏置的矩阵乘法。
CUDNN_SKIP_INPUT在第一个循环层的输入处不执行任何操作。如果使用
CUDNN_SKIP_INPUT,则输入张量的引导维度必须等于网络的隐藏状态大小。
cudnnRNNMode_t#
cudnnRNNMode_t 是一种枚举类型,用于指定网络类型。
值
CUDNN_RNN_RELU具有 ReLU 激活函数的单门循环神经网络。
在前向传递中,给定矩阵
W、R和偏置向量,以及ReLU(x) = max(x, 0),可以根据循环输入 h t-1 和上一层输入 x t 计算给定迭代的输出 h t。如果
rnnDesc中的cudnnRNNBiasMode_t biasMode为CUDNN_RNN_DOUBLE_BIAS(默认模式),则以下带有偏置 b W 和 b R 的公式适用h t = ReLU(W i x t + R i h t-1 + b Wi + b Ri)
如果
rnnDesc中的cudnnRNNBiasMode_t biasMode为CUDNN_RNN_SINGLE_INP_BIAS或CUDNN_RNN_SINGLE_REC_BIAS,则以下带有偏置b的公式适用h t = ReLU(W i x t + R i h t-1 + b i)
如果
rnnDesc中的cudnnRNNBiasMode_t biasMode为CUDNN_RNN_NO_BIAS,则以下公式适用h t = ReLU(W i x t + R i h t-1)
CUDNN_RNN_TANH具有
tanh激活函数的单门循环神经网络。在前向传递中,给定矩阵
W、R和偏置向量,以及tanh是双曲正切函数,可以根据循环输入 h t-1 和上一层输入 x t 计算给定迭代的输出 h t。如果
rnnDesc中的cudnnRNNBiasMode_t biasMode为CUDNN_RNN_DOUBLE_BIAS(默认模式),则以下带有偏置 b W 和 b R 的公式适用h t = tanh(W i x t + R i h t-1 + b Wi + b Ri)
如果
rnnDesc中的cudnnRNNBiasMode_t biasMode为CUDNN_RNN_SINGLE_INP_BIAS或CUDNN_RNN_SINGLE_REC_BIAS,则以下带有偏置b的公式适用h t = tanh(W i x t + R i h t-1 + b i)
如果
rnnDesc中的cudnnRNNBiasMode_t biasMode为CUDNN_RNN_NO_BIAS,则以下公式适用h t = tanh(W i x t + R i h t-1)
CUDNN_LSTM不带窥孔连接的四门 LSTM(长短期记忆)网络。
在前向传递中,给定矩阵
W、R和偏置向量,可以根据循环输入 h t-1、单元输入 c t-1 和上一层输入 x t 计算给定迭代的输出 h t 和单元输出 c t。此外,以下各项适用σ 是 sigmoid 运算符,使得:σ(x) = 1 / (1 + e -x),
◦ 表示逐点乘法,
tanh是双曲正切函数,并且i t、f t、o t、c’ t 分别表示输入门、遗忘门、输出门和新门。
如果
rnnDesc中的cudnnRNNBiasMode_t biasMode为CUDNN_RNN_DOUBLE_BIAS(默认模式),则以下带有偏置 b W 和 b R 的公式适用i t = σ(W i x t + R i h t-1 + b Wi + b Ri)
f t = σ(W f x t + R f h t-1 + b Wf + b Rf)
o t = σ(W o x t + R o h t-1 + b Wo + b Ro)
c’ t = tanh(W c x t + R c h t-1 + b Wc + b Rc)
c t = f t ◦ c t-1 + i t ◦ c’ t
h t = o t ◦ tanh(c t)
如果
rnnDesc中的cudnnRNNBiasMode_t biasMode为CUDNN_RNN_SINGLE_INP_BIAS或CUDNN_RNN_SINGLE_REC_BIAS,则以下带有偏置b的公式适用i t = σ(W i x t + R i h t-1 + b i)
f t = σ(W f x t + R f h t-1 + b f)
o t = σ(W o x t + R o h t-1 + b o)
c’ t = tanh(W c x t + R c h t-1 + b c)
c t = f t ◦ c t-1 + i t ◦ c’ t
h t = o t ◦ tanh(c t)
如果
rnnDesc中的cudnnRNNBiasMode_t biasMode为CUDNN_RNN_NO_BIAS,则以下公式适用i t = σ(W i x t + R i h t-1)
f t = σ(W f x t + R f h t-1)
o t = σ(W o x t + R o h t-1)
c’ t = tanh(W c x t + R c h t-1)
c t = f t ◦ c t-1 + i t ◦ c’ t
h t = o t ◦ tanh(c t)
CUDNN_GRU由门控循环单元 (GRU) 组成的三门网络。
在前向传递中,给定矩阵
W、R和偏置向量,可以根据循环输入 h t-1 和上一层输入 x t 计算给定迭代的输出 h t。此外,以下各项适用σ 是 sigmoid 运算符,使得:σ(x) = 1 / (1 + e -x),
◦ 表示逐点乘法,
tanh是双曲正切函数,并且i t、r t、h’ t 分别表示输入门、重置门和新门。
如果
rnnDesc中的cudnnRNNBiasMode_t biasMode为CUDNN_RNN_DOUBLE_BIAS(默认模式),则以下带有偏置 b W 和 b R 的公式适用i t = σ(W i x t + R i h t-1 + b Wi + b Ru)
r t = σ(W r x t + R r h t-1 + b Wr + b Rr)
h’ t = tanh(W h x t + r t ◦ (R h h t-1 + b Rh) + b Wh)
h t = (1 - i t) ◦ h’ t + i t ◦ h t-1
如果
rnnDesc中的cudnnRNNBiasMode_t biasMode为CUDNN_RNN_SINGLE_INP_BIAS,则以下带有偏置b的公式适用i t = σ(W i x t + R i h t-1 + b i)
r t = σ(W r x t + R r h t-1 + b r)
h’ t = tanh(W h x t + r t ◦ (R h h t-1) + b Wh)
h t = (1 - i t) ◦ h’ t + i t ◦ h t-1
如果
rnnDesc中的cudnnRNNBiasMode_t biasMode为CUDNN_RNN_SINGLE_REC_BIAS,则以下带有偏置b的公式适用i t = σ(W i x t + R i h t-1 + b i)
r t = σ(W r x t + R r h t-1 + b r)
h’ t = tanh(W h x t + r t ◦ (R h h t-1 + b Rh))
h t = (1 - i t) ◦ h’ t + i t ◦ h t-1
如果
rnnDesc中的cudnnRNNBiasMode_t biasMode为CUDNN_RNN_NO_BIAS,则以下公式适用i t = σ(W i x t + R i h t-1)
r t = σ(W r x t + R r h t-1)
h’ t = tanh(W h x t + rt ◦ (R h h t-1))
h t = (1 - i t) ◦ h’ t + i t ◦ h t-1
cudnnSeqDataAxis_t#
cudnnSeqDataAxis_t 是一种枚举类型,它在传递给 cudnnSetSeqDataDescriptor() 函数以配置 cudnnSeqDataDescriptor_t 类型的序列数据描述符的 dimA[] 参数中索引活动维度。
cudnnSeqDataAxis_t 常量也用于 cudnnSetSeqDataDescriptor() 调用的 axis[] 参数中,以定义内存中序列数据缓冲区的布局。有关如何使用 cudnnSeqDataAxis_t 枚举类型的详细说明,请参阅 cudnnSetSeqDataDescriptor()。
CUDNN_SEQDATA_DIM_COUNT 宏定义了 cudnnSeqDataAxis_t 枚举类型中常量的数量。此值当前设置为 4。
值
CUDNN_SEQDATA_TIME_DIM标识
TIME(序列长度)维度,或在数据布局中指定TIME。CUDNN_SEQDATA_BATCH_DIM标识
BATCH维度,或在数据布局中指定BATCH。CUDNN_SEQDATA_BEAM_DIM标识
BEAM维度,或在数据布局中指定BEAM。CUDNN_SEQDATA_VECT_DIM标识
VECT(向量)维度或指定数据布局中的VECT。
cudnnWgradMode_t#
cudnnWgradMode_t 是一种枚举类型,用于选择如何更新保存损失函数梯度的缓冲区(相对于可训练参数计算)。目前,此类型仅供 cudnnMultiHeadAttnBackwardWeights() 和 cudnnRNNBackwardWeights_v8() 函数使用。
值
CUDNN_WGRAD_MODE_ADD对应于新一批输入的权重梯度分量被添加到先前评估的权重梯度中。在使用此模式之前,应将保存权重梯度的缓冲区初始化为零。或者,首次调用 API 以输出到未初始化的缓冲区时,应使用
CUDNN_WGRAD_MODE_SET选项。CUDNN_WGRAD_MODE_SET对应于新一批输入的权重梯度分量会覆盖输出缓冲区中先前存储的权重梯度。
API 函数#
这些是 cudnn_adv 库的 API 函数。
cudnnAdvVersionCheck()#
跨库版本检查器。每个子库都有一个版本检查器,用于检查其自身的版本是否与其依赖项的版本匹配。
返回值
CUDNN_STATUS_SUCCESS版本检查通过。
CUDNN_STATUS_SUBLIBRARY_VERSION_MISMATCH版本不一致。
cudnnBuildRNNDynamic()#
当选择 CUDNN_RNN_ALGO_PERSIST_DYNAMIC 算法时,此函数使用 CUDA 运行时编译库 (NVRTC) 编译 RNN 持久代码。该代码针对当前 GPU 和特定超参数 (miniBatch) 量身定制。此调用预计在运行时方面开销很大,应不频繁调用。请注意,CUDNN_RNN_ALGO_PERSIST_DYNAMIC 算法不支持批次内的可变长度序列。
cudnnStatus_t cudnnBuildRNNDynamic( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, int32_t miniBatch);
参数
handle输入。指向先前创建的 cuDNN 上下文的句柄。
rnnDesc输入。先前初始化的 RNN 描述符。
miniBatch输入。批次中序列的确切数量。
返回值
CUDNN_STATUS_SUCCESS代码已成功构建和链接。
CUDNN_STATUS_MAPPING_ERRORGPU/CUDA 资源(例如纹理对象、共享内存或零复制内存)在所需大小下不可用,或者用户资源与 cuDNN 内部资源之间存在不匹配。例如,当调用
cudnnSetStream()时,可能会发生资源不匹配。当调用cudnnCreate()时,用户提供的 CUDA 流与 cuDNN 句柄中实例化的内部 CUDA 事件之间可能存在不匹配。当此错误状态与纹理维度、共享内存大小或零复制内存可用性相关时,可能无法纠正。如果
cudnnSetStream()返回CUDNN_STATUS_MAPPING_ERROR,则通常可以纠正,但这表示 cuDNN 句柄是在一个 GPU 上创建的,而传递给此函数的用户流与另一个 GPU 相关联。CUDNN_STATUS_ALLOC_FAILED无法分配资源。
CUDNN_STATUS_RUNTIME_PREREQUISITE_MISSING找不到必备的运行时库。
CUDNN_STATUS_NOT_SUPPORTED当前超参数无效。
cudnnCreateAttnDescriptor()#
此函数已在 cuDNN 9.0 中弃用。
此函数通过为其分配主机内存并初始化所有描述符字段来创建一个不透明的注意力描述符对象实例。当无法分配注意力描述符对象时,该函数将 NULL 写入 attnDesc。
cudnnStatus_t cudnnCreateAttnDescriptor(cudnnAttnDescriptor_t *attnDesc);
使用 cudnnSetAttnDescriptor() 函数配置注意力描述符,并使用 cudnnDestroyAttnDescriptor() 函数销毁它并释放已分配的内存。
参数
attnDesc输出。应写入新创建的注意力描述符地址的指针。
返回值
CUDNN_STATUS_SUCCESS描述符对象已成功创建。
CUDNN_STATUS_BAD_PARAM遇到无效的输入参数 (
attnDesc=NULL)。CUDNN_STATUS_ALLOC_FAILED内存分配失败。
cudnnCreateCTCLossDescriptor()#
此函数创建一个 CTC 损失函数描述符。
cudnnStatus_t cudnnCreateCTCLossDescriptor( cudnnCTCLossDescriptor_t* ctcLossDesc)
参数
ctcLossDesc输出。要设置的 CTC 损失描述符。有关更多信息,请参阅 cudnnCTCLossDescriptor_t。
返回值
CUDNN_STATUS_SUCCESS函数成功返回。
CUDNN_STATUS_BAD_PARAM传递给函数的 CTC 损失描述符无效。
CUDNN_STATUS_ALLOC_FAILED此 CTC 损失描述符的内存分配失败。
cudnnCreateRNNDataDescriptor()#
此函数通过分配保存其不透明结构所需的内存来创建 RNN 数据描述符对象。
cudnnStatus_t cudnnCreateRNNDataDescriptor( cudnnRNNDataDescriptor_t *RNNDataDesc)
参数
RNNDataDesc输出。指向应写入新创建的 RNN 数据描述符地址的位置的指针。
返回值
CUDNN_STATUS_SUCCESSRNN 数据描述符对象已成功创建。
CUDNN_STATUS_BAD_PARAMRNNDataDesc参数为NULL。CUDNN_STATUS_ALLOC_FAILED无法分配资源。
cudnnCreateRNNDescriptor()#
此函数通过分配保存其不透明结构所需的内存来创建通用 RNN 描述符对象。
cudnnStatus_t cudnnCreateRNNDescriptor( cudnnRNNDescriptor_t *rnnDesc)
参数
rnnDesc输出。指向应写入新创建的 RNN 描述符地址的位置的指针。
返回值
CUDNN_STATUS_SUCCESS对象已成功创建。
CUDNN_STATUS_BAD_PARAMrnnDesc参数为NULL。CUDNN_STATUS_ALLOC_FAILED无法分配资源。
cudnnCreateSeqDataDescriptor()#
此函数已在 cuDNN 9.0 中弃用。
此函数通过为其分配主机内存并初始化所有描述符字段来创建一个不透明的序列数据描述符对象实例。当无法分配序列数据描述符对象时,该函数将 NULL 写入 seqDataDesc。
cudnnStatus_t cudnnCreateSeqDataDescriptor(cudnnSeqDataDescriptor_t *seqDataDesc)
使用 cudnnSetSeqDataDescriptor() 函数配置序列数据描述符,并使用 cudnnDestroySeqDataDescriptor() 函数销毁它并释放已分配的内存。
参数
seqDataDesc输出。指向应写入新创建的序列数据描述符地址的位置的指针。
返回值
CUDNN_STATUS_SUCCESS描述符对象已成功创建。
CUDNN_STATUS_BAD_PARAM遇到无效的输入参数 (
seqDataDesc=NULL)。CUDNN_STATUS_ALLOC_FAILED内存分配失败。
cudnnCTCLoss()#
此函数返回 CTC 成本和梯度,给定概率和标签。
cudnnStatus_t cudnnCTCLoss( cudnnHandle_t handle, const cudnnTensorDescriptor_t probsDesc, const void *probs, const int hostLabels[], const int hostLabelLengths[], const int hostInputLengths[], void *costs, const cudnnTensorDescriptor_t gradientsDesc, const void *gradients, cudnnCTCLossAlgo_t algo, const cudnnCTCLossDescriptor_t ctcLossDesc, void *workspace, size_t *workSpaceSizeInBytes)
此函数可能具有不一致的接口,具体取决于选择的 cudnnLossNormalizationMode_t(绑定到具有 cudnnSetCTCLossDescriptorEx() 的 cudnnCTCLossDescriptor_t)。对于 CUDNN_LOSS_NORMALIZATION_NONE,此函数具有不一致的接口,例如,probs 输入是 softmax 归一化的概率,但梯度输出是相对于未归一化的激活。但是,对于 CUDNN_LOSS_NORMALIZATION_SOFTMAX,该函数具有一致的接口;所有值都由 softmax 归一化。
参数
handle输入。指向先前创建的 cuDNN 上下文的句柄。有关更多信息,请参阅 cudnnHandle_t。
probsDesc输入。指向先前初始化的概率张量描述符的句柄。有关更多信息,请参阅 cudnnTensorDescriptor_t。
probs输入。指向先前初始化的概率张量的指针。这些输入概率由 softmax 归一化。
hostLabels输入。指向先前初始化的标签列表的指针,位于 CPU 内存中。
hostLabelLengths输入。指向 CPU 内存中先前初始化的长度列表的指针,用于遍历上述标签列表。
hostInputLengths输入。指向 CPU 内存中先前初始化的每个批次中时序步长长度列表的指针。
costs输出。指向计算出的 CTC 成本的指针。
gradientsDesc输入。指向先前初始化的梯度张量描述符的句柄。
gradients输出。指向计算出的 CTC 梯度的指针。这些计算出的梯度输出是相对于未归一化的激活。
algo输入。枚举器,指定选择的 CTC 损失算法。有关更多信息,请参阅 cudnnCTCLossAlgo_t。
ctcLossDesc输入。指向先前初始化的 CTC 损失描述符的句柄。有关更多信息,请参阅 cudnnCTCLossDescriptor_t。
workspace输入。指向 GPU 内存工作区的指针,该工作区是执行指定算法所必需的。
sizeInBytes输入。作为工作区所需的 GPU 内存量,以便能够使用指定的
algo执行 CTC 损失计算。
返回值
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
probsDesc的维度与gradientsDesc的维度不匹配。inputLengths与probsDesc的第一个维度不一致。workSpaceSizeInBytes不足。labelLengths大于255。
CUDNN_STATUS_NOT_SUPPORTED选择了除
FLOAT之外的计算或数据类型,或者选择了未知的算法类型。CUDNN_STATUS_EXECUTION_FAILED函数无法在 GPU 上启动。
cudnnCTCLoss_v8()#
此函数返回 CTC 成本和梯度,给定概率和标签。版本 8 中更新了许多 CTC API 函数,带有 _v8 后缀,以支持 CUDA 图。标签和输入数据现在在 GPU 内存中传递。
cudnnStatus_t cudnnCTCLoss_v8( cudnnHandle_t handle, cudnnCTCLossAlgo_t algo, const cudnnCTCLossDescriptor_t ctcLossDesc, const cudnnTensorDescriptor_t probsDesc, const void *probs, const int labels[], const int labelLengths[], const int inputLengths[], void *costs, const cudnnTensorDescriptor_t gradientsDesc, const void *gradients, size_t *workSpaceSizeInBytes, void *workspace)
此函数可能具有不一致的接口,具体取决于选择的 cudnnLossNormalizationMode_t(绑定到具有 cudnnSetCTCLossDescriptorEx() 的 cudnnCTCLossDescriptor_t)。对于 CUDNN_LOSS_NORMALIZATION_NONE,此函数具有不一致的接口,例如,probs 输入是 softmax 归一化的概率,但梯度输出是相对于未归一化的激活。但是,对于 CUDNN_LOSS_NORMALIZATION_SOFTMAX,该函数具有一致的接口;所有值都由 softmax 归一化。
参数
handle输入。指向先前创建的 cuDNN 上下文的句柄。有关更多信息,请参阅 cudnnHandle_t。
algo输入。枚举器,指定选择的 CTC 损失算法。有关更多信息,请参阅 cudnnCTCLossAlgo_t。
ctcLossDesc输入。指向先前初始化的 CTC 损失描述符的句柄。有关更多信息,请参阅 cudnnCTCLossDescriptor_t。
probsDesc输入。指向先前初始化的概率张量描述符的句柄。有关更多信息,请参阅 cudnnTensorDescriptor_t。
probs输入。指向先前初始化的概率张量的指针。这些输入概率由 softmax 归一化。
labels输入。指向先前初始化的标签列表的指针,位于 GPU 内存中。
labelLengths输入。指向 GPU 内存中先前初始化的长度列表的指针,用于遍历上述标签列表。
inputLengths输入。指向 GPU 内存中先前初始化的每个批次中时序步长长度列表的指针。
costs输出。指向计算出的 CTC 成本的指针。
gradientsDesc输入。指向先前初始化的梯度张量描述符的句柄。
gradients输出。指向计算出的 CTC 梯度的指针。这些计算出的梯度输出是相对于未归一化的激活。
workspace输入。指向 GPU 内存工作区的指针,该工作区是执行指定算法所必需的。
sizeInBytes输入。作为工作区所需的 GPU 内存量,以便能够使用指定的 algo 执行 CTC 损失计算。
返回值
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
probsDesc的维度与gradientsDesc的维度不匹配。workSpaceSizeInBytes不足。
CUDNN_STATUS_NOT_SUPPORTED选择了除
FLOAT之外的计算或数据类型,或者选择了未知的算法类型。CUDNN_STATUS_EXECUTION_FAILED函数无法在 GPU 上启动。
cudnnDestroyAttnDescriptor()#
此函数已在 cuDNN 9.0 中弃用。
此函数销毁注意力描述符对象并释放其内存。attnDesc 参数可以为 NULL。使用 NULL 参数调用 cudnnDestroyAttnDescriptor() 是空操作 (NOP)。
cudnnStatus_t cudnnDestroyAttnDescriptor(cudnnAttnDescriptor_t attnDesc);
cudnnDestroyAttnDescriptor() 函数无法检测 attnDesc 参数是否持有有效地址。如果传递无效指针(不是由 cudnnCreateAttnDescriptor() 函数返回的指针)或在有效地址的双重删除场景中,将发生未定义的行为。
参数
attnDesc输入。指向要销毁的注意力描述符对象的指针。
返回值
CUDNN_STATUS_SUCCESS描述符已成功销毁。
cudnnDestroyCTCLossDescriptor()#
此函数销毁 CTC 损失函数描述符对象。
cudnnStatus_t cudnnDestroyCTCLossDescriptor( cudnnCTCLossDescriptor_t ctcLossDesc)
参数
ctcLossDesc输入。要销毁的 CTC 损失函数描述符。
返回值
CUDNN_STATUS_SUCCESS函数成功返回。
cudnnDestroyRNNDataDescriptor()#
此函数销毁先前创建的 RNN 数据描述符对象。使用 NULL 参数调用 cudnnDestroyRNNDataDescriptor() 是空操作 (NOP)。
cudnnStatus_t cudnnDestroyRNNDataDescriptor( cudnnRNNDataDescriptor_t RNNDataDesc)
cudnnDestroyRNNDataDescriptor() 函数无法检测 RNNDataDesc 参数是否持有有效地址。如果传递无效指针(不是由 cudnnCreateRNNDataDescriptor() 函数返回的指针)或在有效地址的双重删除场景中,将发生未定义的行为。
参数
RNNDataDesc输入。指向要销毁的 RNN 数据描述符对象的指针。
返回值
CUDNN_STATUS_SUCCESSRNN 数据描述符对象已成功销毁。
cudnnDestroyRNNDescriptor()#
此函数销毁先前创建的 RNN 描述符对象。使用 NULL 参数调用 cudnnDestroyRNNDescriptor() 是空操作 (NOP)。
cudnnStatus_t cudnnDestroyRNNDescriptor( cudnnRNNDescriptor_t rnnDesc)
cudnnDestroyRNNDescriptor() 函数无法检测 rnnDesc 参数是否持有有效地址。如果传递无效指针(不是由 cudnnCreateRNNDescriptor() 函数返回的指针)或在有效地址的双重删除场景中,将发生未定义的行为。
参数
rnnDesc输入。指向要销毁的 RNN 描述符对象的指针。
返回值
CUDNN_STATUS_SUCCESS对象已成功销毁。
cudnnDestroySeqDataDescriptor()#
此函数已在 cuDNN 9.0 中弃用。
此函数销毁序列数据描述符对象并释放其内存。seqDataDesc 参数可以为 NULL。使用 NULL 参数调用 cudnnDestroySeqDataDescriptor() 是空操作 (NOP)。
cudnnStatus_t cudnnDestroySeqDataDescriptor(cudnnSeqDataDescriptor_t seqDataDesc);
cudnnDestroySeqDataDescriptor() 函数无法检测 seqDataDesc 参数是否持有有效地址。如果传递无效指针(不是由 cudnnCreateSeqDataDescriptor() 函数返回的指针)或在有效地址的双重删除场景中,将发生未定义的行为。
参数
seqDataDesc输入。指向要销毁的序列数据描述符对象的指针。
返回值
CUDNN_STATUS_SUCCESS描述符已成功销毁。
cudnnGetAttnDescriptor()#
此函数已在 cuDNN 9.0 中弃用。
此函数从先前创建的注意力描述符中检索设置。当不需要检索的值时,用户可以将 NULL 分配给除 attnDesc 之外的任何指针。
cudnnStatus_t cudnnGetAttnDescriptor( cudnnAttnDescriptor_t attnDesc, unsigned *attnMode, int *nHeads, double *smScaler, cudnnDataType_t *dataType, cudnnDataType_t *computePrec, cudnnMathType_t *mathType, cudnnDropoutDescriptor_t *attnDropoutDesc, cudnnDropoutDescriptor_t *postDropoutDesc, int *qSize, int *kSize, int *vSize, int *qProjSize, int *kProjSize, int *vProjSize, int *oProjSize, int *qoMaxSeqLength, int *kvMaxSeqLength, int *maxBatchSize, int *maxBeamSize);
参数
attnDesc输入。注意力描述符。
attnMode输出。用于存储二进制注意力标志的指针。
nHeads输出。用于存储注意力头数的指针。
smScaler输出。用于存储 softmax 平滑/锐化系数的指针。
dataType输出。注意力权重、序列数据输入和输出的数据类型。
computePrec输出。用于存储计算精度的指针。
mathType输出。NVIDIA Tensor Core 设置。
attnDropoutDesc输出。应用于 softmax 输出的 dropout 操作的描述符。
postDropoutDesc输出。应用于多头注意力输出的 dropout 操作的描述符。
qSize、kSize、vSize输出。Q、K 和 V 嵌入向量长度。
qProjSize、kProjSize、vProjSize输出。输入投影后的 Q、K 和 V 嵌入向量长度。
oProjSize输出。用于存储投影后输出向量长度的指针。
qoMaxSeqLength输出。与 Q、O、dQ、dO 输入和输出相关的序列数据描述符中预期的最大序列长度。
kvMaxSeqLength输出。与 K、V、dK、dV 输入和输出相关的序列数据描述符中预期的最大序列长度。
maxBatchSize输出。cudnnSeqDataDescriptor_t 容器中预期的最大批次大小。
maxBeamSize输出。cudnnSeqDataDescriptor_t 容器中预期的最大束大小。
返回值
CUDNN_STATUS_SUCCESS请求的注意力描述符字段已成功检索。
CUDNN_STATUS_BAD_PARAM找到无效的输入参数。
cudnnGetCTCLossDescriptor()#
此函数已在 cuDNN 9.0 中弃用;请改用 cudnnGetCTCLossDescriptor_v9()。
此函数返回传递的 CTC 损失函数描述符的配置。
cudnnStatus_t cudnnGetCTCLossDescriptor( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t* compType)
参数
ctcLossDesc输入。传递的 CTC 损失函数描述符,从中检索配置。
compType输出。与此 CTC 损失函数描述符关联的计算类型。
返回值
CUDNN_STATUS_SUCCESS函数成功返回。
CUDNN_STATUS_BAD_PARAM传递的输入
ctcLossDesc描述符无效。
cudnnGetCTCLossDescriptor_v8()#
此函数已在 cuDNN 9.0 中弃用;请改用 cudnnGetCTCLossDescriptor_v9()。
此函数返回传递的 CTC 损失函数描述符的配置。
cudnnStatus_t cudnnGetCTCLossDescriptor_v8( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t *compType, cudnnLossNormalizationMode_t *normMode, cudnnNanPropagation_t *gradMode, int *maxLabelLength)
参数
ctcLossDesc输入。传递的 CTC 损失函数描述符,从中检索配置。
compType输出。与此 CTC 损失函数描述符关联的计算类型。
normMode输出。此 CTC 损失函数描述符的输入归一化类型。有关更多信息,请参阅 cudnnLossNormalizationMode_t。
gradMode输出。此 CTC 损失函数描述符的 NaN 传播类型。
maxLabelLength输出。此 CTC 损失函数描述符的最大标签长度。
返回值
CUDNN_STATUS_SUCCESS函数成功返回。
CUDNN_STATUS_BAD_PARAM传递的输入
ctcLossDesc描述符无效。
cudnnGetCTCLossDescriptor_v9()#
此函数返回传递的 CTC 损失函数描述符的配置。
cudnnStatus_t cudnnGetCTCLossDescriptor_v8( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t *compType, cudnnLossNormalizationMode_t *normMode, cudnnCTCGradMode_t *ctcGradMode, int *maxLabelLength)
参数
ctcLossDesc输入。传递的 CTC 损失函数描述符,从中检索配置。
compType输出。与此 CTC 损失函数描述符关联的计算类型。
normMode输出。此 CTC 损失函数描述符的输入归一化类型。有关更多信息,请参阅 cudnnLossNormalizationMode_t。
ctcGradMode输出。用于处理此 CTC 损失函数描述符的 OOB 样本的梯度模式。有关更多信息,请参阅 cudnnSetCTCLossDescriptor_v9()。
maxLabelLength输出。此 CTC 损失函数描述符的最大标签长度。
返回值
CUDNN_STATUS_SUCCESS函数成功返回。
CUDNN_STATUS_BAD_PARAM传递的输入
ctcLossDesc描述符无效。
cudnnGetCTCLossDescriptorEx()#
此函数已在 cuDNN 9.0 中弃用;请改用 cudnnGetCTCLossDescriptor_v9()。
此函数返回传递的 CTC 损失函数描述符的配置。
cudnnStatus_t cudnnGetCTCLossDescriptorEx( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t *compType, cudnnLossNormalizationMode_t *normMode, cudnnNanPropagation_t *gradMode)
参数
ctcLossDesc输入。传递的 CTC 损失函数描述符,从中检索配置。
compType输出。与此 CTC 损失函数描述符关联的计算类型。
normMode输出。此 CTC 损失函数描述符的输入归一化类型。有关更多信息,请参阅 cudnnLossNormalizationMode_t。
gradMode输出。此 CTC 损失函数描述符的 NaN 传播类型。
返回值
CUDNN_STATUS_SUCCESS函数成功返回。
CUDNN_STATUS_BAD_PARAM传递的输入
ctcLossDesc描述符无效。
cudnnGetCTCLossWorkspaceSize()#
此函数返回用户需要分配的 GPU 内存工作区量,以便能够使用指定的算法调用 cudnnCTCLoss()。分配的工作区随后将传递给例程 cudnnCTCLoss()。
cudnnStatus_t cudnnGetCTCLossWorkspaceSize( cudnnHandle_t handle, const cudnnTensorDescriptor_t probsDesc, const cudnnTensorDescriptor_t gradientsDesc, const int *labels, const int *labelLengths, const int *inputLengths, cudnnCTCLossAlgo_t algo, const cudnnCTCLossDescriptor_t ctcLossDesc, size_t *sizeInBytes)
参数
handle输入。指向先前创建的 cuDNN 上下文的句柄。
probsDesc输入。指向先前初始化的概率张量描述符的句柄。
gradientsDesc输入。指向先前初始化的梯度张量描述符的句柄。
labels输入。指向先前初始化的标签列表的指针。
labelLengths输入。指向先前初始化的长度列表的指针,用于遍历上述标签列表。
inputLengths输入。指向先前初始化的每个批次中时序步长长度列表的指针。
algo输入。枚举器,指定选择的 CTC 损失算法。
ctcLossDesc输入。指向先前初始化的 CTC 损失描述符的句柄。
sizeInBytes输出。作为工作区所需的 GPU 内存量,以便能够使用指定的
algo执行 CTC 损失计算。
返回值
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
probsDesc的维度与gradientsDesc的维度不匹配inputLengths与probsDesc的第一个维度不一致workSpaceSizeInBytes不足labelLengths大于256
CUDNN_STATUS_NOT_SUPPORTED选择了除
FLOAT之外的计算或数据类型,或者选择了未知的算法类型。
cudnnGetCTCLossWorkspaceSize_v8()#
此函数返回用户需要分配的 GPU 内存工作区量,以便能够使用指定的算法调用 cudnnCTCLoss_v8。分配的工作区随后将传递给例程 cudnnCTCLoss_v8()。
cudnnStatus_t cudnnGetCTCLossWorkspaceSize_v8( cudnnHandle_t handle, cudnnCTCLossAlgo_t algo, const cudnnCTCLossDescriptor_t ctcLossDesc, const cudnnTensorDescriptor_t probsDesc, const cudnnTensorDescriptor_t gradientsDesc, size_t *sizeInBytes)
参数
handle输入。指向先前创建的 cuDNN 上下文的句柄。
algo输入。枚举器,指定选择的 CTC 损失算法。
ctcLossDesc输入。指向先前初始化的 CTC 损失描述符的句柄。
probsDesc输入。指向先前初始化的概率张量描述符的句柄。
gradientsDesc输入。指向先前初始化的梯度张量描述符的句柄。
sizeInBytes输出。作为工作区所需的 GPU 内存量,以便能够使用指定的
algo执行 CTC 损失计算。
返回值
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM满足以下至少一个条件
probsDesc的维度与gradientsDesc的维度不匹配
CUDNN_STATUS_NOT_SUPPORTED - 选择了除 FLOAT 之外的计算或数据类型,或者选择了未知的算法类型。- 对于确定性 CTC 损失算法,ctcLossDesc 中的 maxLabelLength 大于或等于 256。- 对于非确定性 CTC 损失算法,ctcLossDesc 中的 maxLabelLength 大于或等于 2048。
cudnnGetMultiHeadAttnBuffers()#
此函数已在 cuDNN 9.0 中弃用。
此函数计算以下函数使用的权重、工作区和保留空间缓冲区大小
cudnnStatus_t cudnnGetMultiHeadAttnBuffers( cudnnHandle_t handle, const cudnnAttnDescriptor_t attnDesc, size_t *weightSizeInBytes, size_t *workSpaceSizeInBytes, size_t *reserveSpaceSizeInBytes);
将 NULL 分配给 reserveSpaceSizeInBytes 参数表示用户不计划调用多头注意力梯度函数:cudnnMultiHeadAttnBackwardData() 和 cudnnMultiHeadAttnBackwardWeights()。这种情况发生在推理模式下。
注意
NULL不能分配给weightSizeInBytes和workSpaceSizeInBytes指针。
用户必须使用 cudaMalloc() 和报告的缓冲区大小在 GPU 内存中分配权重、工作区和保留空间缓冲区大小。缓冲区也可以从较大的已分配内存块中划分出来,但缓冲区地址必须至少为 16B 对齐。
工作区缓冲区用于临时存储。在相应 API 启动的所有 GPU 内核完成后,可以丢弃或修改其内容。保留空间缓冲区用于将中间结果从 cudnnMultiHeadAttnForward() 传输到 cudnnMultiHeadAttnBackwardData(),以及从 cudnnMultiHeadAttnBackwardData() 传输到 cudnnMultiHeadAttnBackwardWeights()。在上述三个多头注意力 API 函数完成之前,无法修改保留空间缓冲区的内容。
所有多头注意力权重和偏差张量都存储在单个权重缓冲区中。为了速度优化,cuDNN API 可能会根据提供的注意力参数更改张量布局及其在权重缓冲区中的相对位置。使用 cudnnGetMultiHeadAttnWeights() 函数获取每个权重或偏差张量的起始地址和形状。
参数
handle输入。当前的 cuDNN 上下文句柄。
attnDesc输入。指向先前初始化的注意力描述符的指针。
weightSizeInBytes输出。存储所有多头注意力可训练参数所需的最小缓冲区大小。
workSpaceSizeInBytes输出。保存前向和梯度多头注意力 API 调用使用的所有临时表面所需的最小缓冲区大小。
reserveSpaceSizeInBytes输出。存储在前向和后向(梯度)多头注意力函数之间交换的所有中间数据所需的最小缓冲区大小。在推理模式下,将此参数设置为
NULL,表示不会调用梯度 API。
返回值
CUDNN_STATUS_SUCCESS请求的缓冲区大小已成功计算。
CUDNN_STATUS_BAD_PARAM找到无效的输入参数。
cudnnGetMultiHeadAttnWeights()#
此函数已在 cuDNN 9.0 中弃用。
此函数获取权重或偏差张量的形状。它还会检索位于 weight 缓冲区中的张量数据的起始地址。使用 wKind 参数选择特定的张量。有关更多信息,请参阅 cudnnMultiHeadAttnWeightKind_t 以获取枚举类型的描述。
cudnnStatus_t cudnnGetMultiHeadAttnWeights( cudnnHandle_t handle, const cudnnAttnDescriptor_t attnDesc, cudnnMultiHeadAttnWeightKind_t wKind, size_t weightSizeInBytes, const void *weights, cudnnTensorDescriptor_t wDesc, void **wAddr);
当在注意力描述符中设置 CUDNN_ATTN_ENABLE_PROJ_BIASES 标志时,输入和输出投影中使用偏差。有关控制投影偏差的标志的描述,请参阅 cudnnSetAttnDescriptor()。
当相应的权重或偏差张量不存在时,该函数将 NULL 写入 wAddr 指向的存储位置,并在 wDesc 张量描述符中返回零。cudnnGetMultiHeadAttnWeights() 函数的返回状态在这种情况下为 CUDNN_STATUS_SUCCESS。
cuDNN multiHeadAttention 示例代码演示了如何访问多头注意力权重。尽管包含权重和偏置的缓冲区应在 GPU 内存中分配,但用户可以将其复制到主机内存,并调用 cudnnGetMultiHeadAttnWeights() 函数以及主机权重地址,以获取主机内存中的张量指针。此方案允许用户直接在 CPU 内存中检查可训练参数。
参数
handle输入。当前的 cuDNN 上下文句柄。
attnDesc输入。先前配置的注意力描述符。
wKind输入。枚举类型,用于指定应检索哪个权重或偏置张量。
weightSizeInBytes输入。存储所有多头注意力权重和偏置的缓冲区大小。
weights输入。指向主机或设备内存中
weight缓冲区的指针。wDesc输出。描述权重或偏置张量形状的描述符。对于权重,
wDesc.dimA[]数组包含三个元素:[nHeads, projected size, original size]。对于偏置,wDesc.dimA[]数组也包含三个元素:[nHeads, projected size, 1]。wDesc.strideA[]数组描述了张量元素在内存中的排列方式。wAddr输出。指向应写入请求张量起始地址的位置的指针。当禁用对应的投影时,写入到
wAddr的地址为NULL。
返回值
CUDNN_STATUS_SUCCESS权重张量描述符和设备内存中的数据地址已成功检索。
CUDNN_STATUS_BAD_PARAM遇到无效或不兼容的输入参数。例如,
wKind没有有效值,或者weightSizeInBytes太小。
cudnnGetRNNDataDescriptor()#
此函数检索先前创建的 RNN 数据描述符对象。
cudnnStatus_t cudnnGetRNNDataDescriptor( cudnnRNNDataDescriptor_t RNNDataDesc, cudnnDataType_t *dataType, cudnnRNNDataLayout_t *layout, int *maxSeqLength, int *batchSize, int *vectorSize, int arrayLengthRequested, int seqLengthArray[], void *paddingFill);
参数
RNNDataDesc输入。先前创建并初始化的 RNN 描述符。
dataType输出。指向主机内存位置的指针,用于存储 RNN 数据张量的数据类型。
layout输出。指向主机内存位置的指针,用于存储 RNN 数据张量的内存布局。
maxSeqLength输出。此 RNN 数据张量中的最大序列长度,包括填充向量。
batchSize输出。小批量处理中的序列数量。
vectorSize输出。每个时间步输入或输出张量的向量长度(即,嵌入大小)。
arrayLengthRequested输入。用户为
seqLengthArray请求的元素数量。seqLengthArray输出。指向主机内存位置的指针,用于存储描述每个序列长度(即,时间步数)的整数数组。如果
arrayLengthRequested为0,则允许为NULL指针。paddingFill输出。指向主机内存位置的指针,用于存储用户定义的符号。该符号应解释为与 RNN 数据张量相同的数据类型。
返回值
CUDNN_STATUS_SUCCESS参数已成功获取。
CUDNN_STATUS_BAD_PARAM以下任何一种情况均会发生
RNNDataDesc、dataType、layout、maxSeqLength、batchSize、vectorSize或paddingFill中的任何一个是NULL。当
arrayLengthRequested大于零时,seqLengthArray为NULL。arrayLengthRequested小于零。
cudnnGetRNNDescriptor_v8()#
此函数检索由 cudnnSetRNNDescriptor_v8() 配置的 RNN 网络参数。当不需要检索值时,用户可以将 NULL 分配给除 rnnDesc 之外的任何指针。该函数不检查检索参数的有效性。
cudnnStatus_t cudnnGetRNNDescriptor_v8( cudnnRNNDescriptor_t rnnDesc, cudnnRNNAlgo_t *algo, cudnnRNNMode_t *cellMode, cudnnRNNBiasMode_t *biasMode, cudnnDirectionMode_t *dirMode, cudnnRNNInputMode_t *inputMode, cudnnDataType_t *dataType, cudnnDataType_t *mathPrec, cudnnMathType_t *mathType, int32_t *inputSize, int32_t *hiddenSize, int32_t *projSize, int32_t *numLayers, cudnnDropoutDescriptor_t *dropoutDesc, uint32_t *auxFlags);
参数
rnnDesc输入。先前创建并初始化的 RNN 描述符。
algo输出。指向应存储 RNN 算法类型的位置的指针。
cellMode输出。指向应保存 RNN 单元类型的位置的指针。
biasMode输出。指向应保存 RNN 偏置模式 cudnnRNNBiasMode_t 的位置的指针。
dirMode输出。指向应保存 RNN 单向/双向模式的位置的指针。
inputMode输出。指向应保存第一个 RNN 层的模式的位置的指针。
dataType输出。指向应存储 RNN 权重/偏置数据类型的位置的指针。
mathPrec输出。指向应存储数学精度类型的位置的指针。
mathType输出。指向 Tensor Cores 首选选项的保存位置的指针。
inputSize输出。指向 RNN 输入向量大小存储位置的指针。
hiddenSize输出。指向应存储隐藏状态大小的位置的指针(每个 RNN 层中使用相同的值)。
projSize输出。指向应存储循环投影后 LSTM 单元输出大小的位置的指针。
numLayers输出。指向应存储 RNN 层数的位置的指针。
dropoutDesc输出。指向应存储先前配置的 dropout 描述符句柄的位置的指针。
auxFlags输出。指向其他 RNN 选项(标志)的指针,这些选项不需要传递额外的数值来配置。
返回值
CUDNN_STATUS_SUCCESSRNN 参数已从 RNN 描述符成功检索。
CUDNN_STATUS_BAD_PARAM找到无效的输入参数(
rnnDesc为NULL)。CUDNN_STATUS_NOT_INITIALIZEDcuDNN 库未正确初始化。
cudnnGetRNNTempSpaceSizes()#
此函数基于 rnnDesc 中存储的 RNN 网络几何形状、由 fMode 参数指定的指定用法(推理或训练)以及从 xDesc 检索的当前 RNN 数据维度(maxSeqLength、batchSize)计算工作空间和保留空间缓冲区大小。当 RNN 数据维度更改时,必须再次调用 cudnnGetRNNTempSpaceSizes(),因为 RNN 临时缓冲区大小不是单调的。
cudnnStatus_t cudnnGetRNNTempSpaceSizes( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, cudnnForwardMode_t fMode, cudnnRNNDataDescriptor_t xDesc, size_t *workSpaceSize, size_t *reserveSpaceSize);
当不需要对应的值时,用户可以将 NULL 分配给 workSpaceSize 或 reserveSpaceSize 指针。
参数
handle输入。当前的 cuDNN 上下文句柄。
rnnDesc输入。先前初始化的 RNN 描述符。
fMode输入。指定临时缓冲区是在推理模式还是训练模式下使用。保留空间缓冲区在推理期间不使用。因此,当
fMode参数为CUDNN_FWD_MODE_INFERENCE时,返回的保留空间缓冲区大小将为零。xDesc输入。单个 RNN 数据描述符,用于指定当前 RNN 数据维度:
maxSeqLength和batchSize。workSpaceSize输出。作为工作区缓冲区所需的最小 GPU 内存量(以字节为单位)。工作区缓冲区不用作在 API 之间传递中间结果的缓冲区,而是用作临时读/写缓冲区。
reserveSpaceSize输出。作为保留空间缓冲区所需的最小 GPU 内存量(以字节为单位)。保留空间缓冲区用于将中间结果从 cudnnRNNForward() 传递到 RNN
BackwardData和BackwardWeights例程,这些例程计算关于 RNN 输入或可训练权重和偏置的一阶导数。
返回值
CUDNN_STATUS_SUCCESSRNN 临时缓冲区大小已成功计算。
CUDNN_STATUS_BAD_PARAM检测到无效的输入参数。
CUDNN_STATUS_NOT_SUPPORTED检测到不兼容或不支持的输入参数组合。
cudnnGetRNNWeightParams()#
此函数用于获取循环神经网络模型中每个伪层中每个 RNN 权重矩阵和偏置向量的起始地址和形状。
cudnnStatus_t cudnnGetRNNWeightParams( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, int32_t pseudoLayer, size_t weightSpaceSize, const void *weightSpace, int32_t linLayerID, cudnnTensorDescriptor_t mDesc, void **mAddr, cudnnTensorDescriptor_t bDesc, void **bAddr);
参数
handle输入。先前创建的 cuDNN 库描述符的句柄。
rnnDesc输入。先前初始化的 RNN 描述符。
pseudoLayer输入。要查询的伪层。在单向 RNN 中,伪层与物理层相同(
pseudoLayer=0是 RNN 输入层,pseudoLayer=1是第一个隐藏层)。在双向 RNN 中,伪层的数量是物理层的两倍pseudoLayer=0指的是物理输入层的前向子层pseudoLayer=1指的是物理输入层的后向子层pseudoLayer=2是第一个隐藏层的前向子层,依此类推
weightSpaceSize输入。权重空间缓冲区的地址。从 cuDNN 版本 9.1 开始,此参数可以为
NULL。这允许您检索权重/偏置偏移量,而不是缓冲区内的实际指针。为了获得最佳性能,权重空间缓冲区的推荐对齐方式应为 256 B 或与cudaMalloc()返回的对齐方式相同。weightSpace输入。指向权重空间缓冲区的指针。
linLayerID输入。权重矩阵或偏置向量线性 ID 索引。
如果
rnnDesc中的cellMode设置为CUDNN_RNN_RELU或CUDNN_RNN_TANH值
0引用与来自上一层的输入或 RNN 模型的输入结合使用的权重矩阵或偏置向量。值
1引用与来自先前时间步的隐藏状态或初始隐藏状态结合使用的权重矩阵或偏置向量。
如果
rnnDesc中的cellMode设置为CUDNN_LSTM值
0、1、2和3引用与来自上一层的输入或 RNN 模型的输入结合使用的权重矩阵或偏置向量。值
4、5、6和7引用与来自先前时间步的隐藏状态或初始隐藏状态结合使用的权重矩阵或偏置向量。值 8 对应于投影矩阵(如果启用)(此操作中没有偏置)。
值及其 LSTM 门控
linLayerID 0和4对应于输入门。linLayerID 1和5对应于遗忘门。linLayerID 2和6对应于使用双曲正切的新单元状态计算。linLayerID 3和7对应于输出门。
如果
rnnDesc中的cellMode设置为CUDNN_GRUValues 0、1和2引用与来自上一层的输入或 RNN 模型的输入结合使用的权重矩阵或偏置向量。Values 3、4和5引用与来自先前时间步的隐藏状态或初始隐藏状态结合使用的权重矩阵或偏置向量。
值及其 GRU 门控
linLayerID 0和3对应于重置门。linLayerID 1和4引用更新门。linLayerID 2和5对应于使用双曲正切的新隐藏状态计算。
有关模式和偏置模式的更多信息,请参阅 cudnnRNNMode_t。
mDesc输出。先前创建的张量描述符的句柄。相应权重矩阵的形状在此描述符中以以下格式返回:
dimA[3] = {1, rows, cols}。当权重矩阵不存在时,报告的张量维度数为零。当选择CUDNN_SKIP_INPUT时,或者当禁用该功能时,LSTM 投影矩阵的第一层的输入 GEMM 矩阵会发生这种情况。mAddr输出。指向权重空间缓冲区内权重矩阵起点的指针。当权重矩阵不存在时,写入到
mAddr的返回地址为NULL。从 cuDNN 版本 9.1 开始,mDesc和mAddr参数都可以为NULL。在这种情况下,将不会报告权重矩阵的形状及其地址。通过分配mDesc=NULL和mAddr=NULL,您可以仅检索有关偏置向量的信息。bDesc输出。先前创建的张量描述符的句柄。相应偏置向量的形状在此描述符中以以下格式返回:
dimA[3] = {1, rows, 1}。当偏置向量不存在时,报告的张量维度数为零。bAddr输出。指向权重空间缓冲区内偏置向量起点的指针。当偏置向量不存在时,返回的地址为
NULL。从 cuDNN 版本 9.1 开始,bDesc和bAddr参数都可以为NULL。在这种情况下,将不会报告偏置向量的形状及其地址。通过分配bDesc=NULL和bAddr=NULL,您可以仅检索有关权重矩阵的信息。
返回值
CUDNN_STATUS_SUCCESS查询已成功完成。
CUDNN_STATUS_BAD_PARAM遇到无效的输入参数。例如,
pseudoLayer的值超出范围,或者linLayerID为负数或大于8。CUDNN_STATUS_INVALID_VALUE某些权重/偏置元素超出权重空间缓冲区边界。
CUDNN_STATUS_NOT_INITIALIZEDcuDNN 库未正确初始化。
cudnnGetRNNWeightSpaceSize()#
此函数报告权重空间缓冲区所需的字节大小。权重空间缓冲区保存所有 RNN 权重矩阵和偏置向量。
cudnnStatus_t cudnnGetRNNWeightSpaceSize( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, size_t *weightSpaceSize);
参数
handle输入。当前的 cuDNN 上下文句柄。
rnnDesc输入。先前初始化的 RNN 描述符。
weightSpaceSize输出。所有 RNN 可训练参数所需的最小 GPU 内存大小(以字节为单位)。
返回值
CUDNN_STATUS_SUCCESS查询成功。
CUDNN_STATUS_BAD_PARAM遇到无效的输入参数。例如,任何输入参数为
NULL。CUDNN_STATUS_NOT_INITIALIZEDcuDNN 库未正确初始化。
cudnnGetSeqDataDescriptor()#
此函数已在 cuDNN 9.0 中弃用。
此函数从先前创建的序列数据描述符中检索设置。当不需要检索值时,用户可以将 NULL 分配给除 seqDataDesc 之外的任何指针。nbDimsRequested 参数适用于 dimA[] 和 axes[] 数组。当对应的数组 dimA[]、axes[] 或 seqLengthArray[] 为 NULL 时,nbDimsRequested 或 seqLengthSizeRequested 的正值将被忽略。
cudnnStatus_t cudnnGetSeqDataDescriptor( const cudnnSeqDataDescriptor_t seqDataDesc, cudnnDataType_t *dataType, int *nbDims, int nbDimsRequested, int dimA[], cudnnSeqDataAxis_t axes[], size_t *seqLengthArraySize, size_t seqLengthSizeRequested, int seqLengthArray[], void *paddingFill);
cudnnGetSeqDataDescriptor() 函数不报告序列数据缓冲区中的实际步幅。这些步幅在计算任何序列数据元素的偏移量时可能很有用。用户必须根据 cudnnGetSeqDataDescriptor() 函数报告的 axes[] 和 dimA[] 数组预先计算步幅。以下是执行此任务的示例代码
// Array holding sequence data strides. size_t strA[CUDNN_SEQDATA_DIM_COUNT] = {0}; // Compute strides from dimension and order arrays. size_t stride = 1; for (int i = nbDims - 1; i >= 0; i--) { int j = int(axes[i]); if (unsigned(j) < CUDNN_SEQDATA_DIM_COUNT-1 && strA[j] == 0) { strA[j] = stride; stride *= dimA[j]; } else { fprintf(stderr, "ERROR: invalid axes[%d]=%d\n\n", i, j); abort(); } }
现在,strA[] 数组可用于计算任何序列数据元素的索引,例如
// Using four indices (batch, beam, time, vect) with ranges already checked. size_t base = strA[CUDNN_SEQDATA_BATCH_DIM] * batch + strA[CUDNN_SEQDATA_BEAM_DIM] * beam + strA[CUDNN_SEQDATA_TIME_DIM] * time; val = seqDataPtr[base + vect];
以上代码假定所有四个索引(batch、beam、time、vect)都小于 dimA[] 数组中的对应值。示例代码还省略了 strA[CUDNN_SEQDATA_VECT_DIM] 步幅,因为其值始终为 1,这意味着,一个向量的元素占用连续的内存块。
参数
seqDataDesc输入。序列数据描述符。
dataType输出。序列数据缓冲区中使用的数据类型。
nbDims输出。
dimA[]和axes[]数组中活动维度的数量。nbDimsRequested输入。可以从索引零开始写入到
dimA[]和axes[]数组的最大连续元素数。此参数的建议值为CUDNN_SEQDATA_DIM_COUNT。dimA[]输出。保存序列数据维度的整数数组。
axes[]输出。cudnnSeqDataAxis_t 数组,用于定义序列数据在内存中的布局。
seqLengthArraySize输出。
seqLengthArray[]中保存所有序列长度所需的元素数量。seqLengthSizeRequested输入。可以从索引零开始写入到
seqLengthArray[]数组的最大连续元素数。seqLengthArray[]输出。保存序列长度的整数数组。
paddingFill输出。指向
dataType存储位置的指针,其中包含应写入所有填充向量的填充值。当未请求显式初始化输出填充向量时,请使用NULL。
返回值
CUDNN_STATUS_SUCCESS请求的序列数据描述符字段已成功检索。
CUDNN_STATUS_BAD_PARAM找到无效的输入参数。
CUDNN_STATUS_INTERNAL_ERROR遇到不一致的内部状态。
cudnnMultiHeadAttnBackwardData()#
此函数已在 cuDNN 9.0 中弃用。
此函数计算多头注意力模块关于其输入 Q、K、V 的精确一阶导数。如果 y=F(w) 是表示多头注意力层的向量值函数,并且它接受某个向量 \(\chi\epsilon\mathbb{R}^{n}\) 作为输入(所有其他参数和输入保持不变),并输出向量 \(\chi\epsilon\mathbb{R}^{m}\),则 cudnnMultiHeadAttnBackwardData() 计算 \(\left(\partial y_{i}/\partial x_{j}\right)^{T} \delta_{out}\) 的结果,其中 \(\delta_{out}\) 是损失函数关于多头注意力输出的 mx1 梯度。\(\delta_{out}\) 梯度通过深度学习模型的先前层反向传播。\(\partial y_{i}/\partial x_{j}\) 是 F(x) 的 mxn Jacobian 矩阵。输入通过 dout 参数提供,Q、K、V 的梯度结果写入 dqueries、dkeys 和 dvalues 缓冲区。
cudnnMultiHeadAttnBackwardData() 函数不输出残差连接的偏导数,因为此结果等于 \(\delta_{out}\)。如果多头注意力模型启用了直接来自 Q 的残差连接,则需要将 dout 张量添加到 dqueries 以获得后者的正确结果。此操作在 cuDNN multiHeadAttention 示例代码中演示。
cudnnStatus_t cudnnMultiHeadAttnBackwardData( cudnnHandle_t handle, const cudnnAttnDescriptor_t attnDesc, const int loWinIdx[], const int hiWinIdx[], const int devSeqLengthsDQDO[], const int devSeqLengthsDKDV[], const cudnnSeqDataDescriptor_t doDesc, const void *dout, const cudnnSeqDataDescriptor_t dqDesc, void *dqueries, const void *queries, const cudnnSeqDataDescriptor_t dkDesc, void *dkeys, const void *keys, const cudnnSeqDataDescriptor_t dvDesc, void *dvalues, const void *values, size_t weightSizeInBytes, const void *weights, size_t workSpaceSizeInBytes, void *workSpace, size_t reserveSpaceSizeInBytes, void *reserveSpace);
cudnnMultiHeadAttnBackwardData() 函数必须在 cudnnMultiHeadAttnForward() 之后调用。loWinIdx[]、hiWinIdx[]、queries、keys、values、weights 和 reserveSpace 参数应与 cudnnMultiHeadAttnForward() 调用中的参数相同。devSeqLengthsDQDO[] 和 devSeqLengthsDKDV[] 设备数组应包含与前向函数调用中的 devSeqLengthsQO[] 和 devSeqLengthsKV[] 数组相同的起始和结束注意力窗口索引。
注意
cudnnMultiHeadAttnBackwardData()不验证devSeqLengthsDQDO[]和devSeqLengthsDKDV[]中存储的序列长度是否包含与相应序列数据描述符中seqLengthArray[]相同的设置。
参数
handle输入。当前的 cuDNN 上下文句柄。
attnDesc输入。先前初始化的注意力描述符。
loWinIdx[],hiWinIdx[]输入。两个主机整数数组,用于指定每个 Q 时间步的注意力窗口的起始和结束索引。K、V 集合中的起始索引是包含的,结束索引是排除的。
devSeqLengthsDQDO[]输入。设备数组,包含来自
dqDesc或doDesc序列数据描述符的序列长度数组的副本。devSeqLengthsDKDV[]输入。设备数组,包含来自
dkDesc或dvDesc序列数据描述符的序列长度数组的副本。doDesc输入。\(\delta_{out}\) 梯度(损失函数关于多头注意力输出的偏导数向量)的描述符。
dout输入。指向设备内存中 \(\delta_{out}\) 梯度数据的指针。
dqDesc输入。
queries和dqueries序列数据的描述符。dqueries输出。指向损失函数梯度的设备指针,该梯度是关于
queries向量计算的。queries输入。指向设备内存中
queries数据的指针。这与 cudnnMultiHeadAttnForward() 中的输入相同。dkDesc输入。keys 和
dkeys序列数据的描述符。dkeys输出。指向损失函数梯度的设备指针,该梯度是关于
keys向量计算的。keys输入。指向设备内存中
keys数据的指针。这与 cudnnMultiHeadAttnForward() 中的输入相同。dvDesc输入。
values和dvalues序列数据的描述符。dvalues输出。指向损失函数梯度的设备指针,该梯度是关于
values向量计算的。values输入。指向设备内存中
values数据的指针。这与 cudnnMultiHeadAttnForward() 中的输入相同。weightSizeInBytes输入。
weight缓冲区的字节大小,其中存储了所有多头注意力可训练参数。weights输入。设备内存中
weight缓冲区的地址。workSpaceSizeInBytes输入。用于临时 API 存储的工作区缓冲区的字节大小。
workSpace输入/输出。设备内存中工作区缓冲区的地址。
reserveSpaceSizeInBytes输入。用于在前向和后向(梯度)API 调用之间进行数据交换的保留空间缓冲区的字节大小。
reserveSpace输入/输出。设备内存中保留空间缓冲区的地址。
返回值
CUDNN_STATUS_SUCCESS在处理 API 输入参数和启动 GPU 内核时未检测到错误。
CUDNN_STATUS_BAD_PARAM遇到无效或不兼容的输入参数。
CUDNN_STATUS_EXECUTION_FAILED启动 GPU 内核的过程返回错误,或者较早的内核未成功完成。
CUDNN_STATUS_INTERNAL_ERROR遇到不一致的内部状态。
CUDNN_STATUS_NOT_SUPPORTED不支持请求的选项或输入参数组合。
CUDNN_STATUS_ALLOC_FAILED共享内存不足,无法启动 GPU 内核。
cudnnMultiHeadAttnBackwardWeights()#
此函数已在 cuDNN 9.0 中弃用。
此函数计算多头注意力模块关于其可训练参数(投影权重和投影偏差)的精确一阶导数。如果 y=F(w) 是一个向量值函数,表示多头注意力层,并且它接受某个向量 \(\chi\epsilon\mathbb{R}^{n}\) (“扁平化”的权重或偏差)作为输入(所有其他参数和输入固定),并输出向量 \(\chi\epsilon\mathbb{R}^{m}\),那么 cudnnMultiHeadAttnBackwardWeights() 计算 \(\left(\partial y_{i}/\partial w_{j}\right)^{T} \delta_{out}\) 的结果,其中 \(\delta_{out}\) 是损失函数关于多头注意力输出的 mx1 梯度。\(\delta_{out}\) 梯度通过深度学习模型的先前层反向传播。\(\partial y_{i}/\partial w_{j}\) 是 F(w) 的 mxn Jacobian 矩阵。\(\delta_{out}\) 输入通过 dout 参数提供。
cudnnStatus_t cudnnMultiHeadAttnBackwardWeights( cudnnHandle_t handle, const cudnnAttnDescriptor_t attnDesc, cudnnWgradMode_t addGrad, const cudnnSeqDataDescriptor_t qDesc, const void *queries, const cudnnSeqDataDescriptor_t kDesc, const void *keys, const cudnnSeqDataDescriptor_t vDesc, const void *values, const cudnnSeqDataDescriptor_t doDesc, const void *dout, size_t weightSizeInBytes, const void *weights, void *dweights, size_t workSpaceSizeInBytes, void *workSpace, size_t reserveSpaceSizeInBytes, void *reserveSpace);
所有关于权重和偏差的梯度结果都写入 dweights 缓冲区。dweights 缓冲区的大小和组织方式与保存多头注意力权重和偏差的 weights 缓冲区相同。cuDNN multiHeadAttention 示例代码演示了如何访问这些权重。
损失函数关于权重或偏差的梯度通常在多个批次上计算。在这种情况下,应将每个批次计算的部分结果加在一起。addGrad 参数指定是否应将当前批次的梯度添加到先前计算的结果中,或者是否应用新结果覆盖 dweights 缓冲区。
应在 cudnnMultiHeadAttnBackwardData() 之后调用 cudnnMultiHeadAttnBackwardWeights() 函数。queries、keys、values、weights 和 reserveSpace 参数应与 cudnnMultiHeadAttnForward() 和 cudnnMultiHeadAttnBackwardData() 调用中的相同。dout 参数应与 cudnnMultiHeadAttnBackwardData() 中的相同。
参数
handle输入。当前的 cuDNN 上下文句柄。
attnDesc输入。先前初始化的注意力描述符。
addGrad输入。权重梯度输出模式。
qDesc输入。查询序列数据的描述符。
queries输入。指向设备内存中
queries序列数据的指针。kDesc输入。
keys序列数据的描述符。keys输入。指向设备内存中
keys序列数据的指针。vDesc输入。
values序列数据的描述符。values输入。指向设备内存中
values序列数据的指针。doDesc输入。\(\delta_{out}\) 梯度(损失函数关于多头注意力输出的偏导数向量)的描述符。
dout输入。指向设备内存中 \(\delta_{out}\) 梯度向量的指针。
weightSizeInBytes输入。
weights和dweights缓冲区的大小(以字节为单位)。weights输入。设备内存中
weight缓冲区的地址。dweights输出。设备内存中权重梯度缓冲区的地址。
workSpaceSizeInBytes输入。用于临时 API 存储的工作区缓冲区的字节大小。
workSpace输入/输出。设备内存中工作区缓冲区的地址。
reserveSpaceSizeInBytes输入。用于在前向和后向(梯度)API 调用之间进行数据交换的保留空间缓冲区的字节大小。
reserveSpace输入/输出。设备内存中保留空间缓冲区的地址。
返回值
CUDNN_STATUS_SUCCESS在处理 API 输入参数和启动 GPU 内核时未检测到错误。
CUDNN_STATUS_BAD_PARAM遇到无效或不兼容的输入参数。
CUDNN_STATUS_EXECUTION_FAILED启动 GPU 内核的过程返回错误,或者较早的内核未成功完成。
CUDNN_STATUS_INTERNAL_ERROR遇到不一致的内部状态。
CUDNN_STATUS_NOT_SUPPORTED不支持请求的选项或输入参数组合。
cudnnMultiHeadAttnForward()#
此函数已在 cuDNN 9.0 中弃用。
cudnnMultiHeadAttnForward() 函数计算多头注意力层的前向响应。当 reserveSpaceSizeInBytes=0 且 reserveSpace=NULL 时,该函数在推理模式下运行,其中不调用后向(梯度)函数;否则,假定为训练模式。在训练模式下,保留空间用于将中间结果从 cudnnMultiHeadAttnForward() 传递到 cudnnMultiHeadAttnBackwardData(),以及从 cudnnMultiHeadAttnBackwardData() 传递到 cudnnMultiHeadAttnBackwardWeights()。
cudnnStatus_t cudnnMultiHeadAttnForward( cudnnHandle_t handle, const cudnnAttnDescriptor_t attnDesc, int currIdx, const int loWinIdx[], const int hiWinIdx[], const int devSeqLengthsQO[], const int devSeqLengthsKV[], const cudnnSeqDataDescriptor_t qDesc, const void *queries, const void *residuals, const cudnnSeqDataDescriptor_t kDesc, const void *keys, const cudnnSeqDataDescriptor_t vDesc, const void *values, const cudnnSeqDataDescriptor_t oDesc, void *out, size_t weightSizeInBytes, const void *weights, size_t workSpaceSizeInBytes, void *workSpace, size_t reserveSpaceSizeInBytes, void *reserveSpace);
在推理模式下,currIdx 指定要处理的嵌入向量的时间步或序列索引。在此模式下,用户可以为时间步零执行一次迭代 (currIdx=0),然后更新 Q、K、V 向量和注意力窗口,并执行下一步 (currIdx=1)。可以为所有时间步重复迭代过程。
当所有 Q 时间步都可用时(例如,在训练模式下或在自注意力中的编码器侧的推理模式下),用户可以将负值分配给 currIdx,cudnnMultiHeadAttnForward() API 将自动扫描所有 Q 时间步。
loWinIdx[] 和 hiWinIdx[] 主机数组为每个 Q 时间步指定注意力窗口大小。在典型的自注意力情况下,用户必须包括所有先前访问过的嵌入向量,但不包括当前或未来的向量。在这种情况下,用户应设置
currIdx=0: loWinIdx[0]=0; hiWinIdx[0]=0; // initial time-step, no attention window currIdx=1: loWinIdx[1]=0; hiWinIdx[1]=1; // attention window spans one vector currIdx=2: loWinIdx[2]=0; hiWinIdx[2]=2; // attention window spans two vectors (...)
当 currIdx 在 cudnnMultiHeadAttnForward() 中为负数时,loWinIdx[] 和 hiWinIdx[] 数组必须为所有时间步完全初始化。当使用 currIdx=0、currIdx=1、currIdx=2 等调用 cudnnMultiHeadAttnForward() 时,用户可以仅在调用前向响应函数之前更新 loWinIdx[currIdx] 和 hiWinIdx[currIdx] 元素。loWinIdx[] 和 hiWinIdx[] 数组中的所有其他元素将不会被访问。任何自适应注意力窗口方案都可以通过这种方式实现。
当注意力窗口应为最大尺寸时(例如,在交叉注意力中),请使用以下设置
currIdx=0: loWinIdx[0]=0; hiWinIdx[0]=maxSeqLenK; currIdx=1: loWinIdx[1]=0; hiWinIdx[1]=maxSeqLenK; currIdx=2: loWinIdx[2]=0; hiWinIdx[2]=maxSeqLenK; (...)
上面的 maxSeqLenK 值应等于或大于 kDesc 描述符中的 dimA[CUDNN_SEQDATA_TIME_DIM]。一个好的选择是使用 limits.h 中的 maxSeqLenK=INT_MAX。
注意
在 cudnnSetSeqDataDescriptor() 中的
seqLengthArray[]中定义的任何 K 序列的实际长度可以短于maxSeqLenK。有效注意力窗口跨度是根据存储在 K 序列描述符中的seqLengthArray[]以及保存在loWinIdx[]和hiWinIdx[]数组中的索引计算得出的。
devSeqLengthsQO[] 和 devSeqLengthsKV[] 是指向设备(而非主机)数组的指针,其中包含 Q、O 和 K、V 序列长度。请注意,相同的信息也通过主机端的 cudnnSeqDataDescriptor_t 类型的相应描述符传递。需要额外设备数组的原因在于 cuDNN 调用的异步性质以及专用于 GPU 内核参数的常量内存大小有限。当 cudnnMultiHeadAttnForward() API 返回时,可以立即修改描述符中存储的序列长度数组以进行下一次迭代。但是,前向调用启动的 GPU 内核可能此时尚未启动。因此,需要在设备端创建序列数组的副本,以便 GPU 内核直接访问。对于非常大的 K、V 输入,这些副本无法在 cudnnMultiHeadAttnForward() 函数内部创建,而无需设备内存分配和 CUDA 流同步。
为了减少 cudnnMultiHeadAttnForward() API 开销,devSeqLengthsQO[] 和 devSeqLengthsKV[] 设备数组未经验证是否包含与序列数据描述符中的 seqLengthArray[] 相同的设置。
kDesc 和 vDesc 描述符中的序列长度应相同。同样,qDesc 和 oDesc 描述符中的序列长度应匹配。用户可以在 qDesc、kDesc、vDesc 和 oDesc 描述符中定义六种不同的数据布局。有关这些布局的讨论,请参阅 cudnnSetSeqDataDescriptor() 函数。所有多头注意力 API 调用都要求在所有序列数据描述符中使用相同的布局。
在 Transformer 模型中,多头注意力块与层归一化和残差连接紧密耦合。cudnnMultiHeadAttnForward() 不包含层归一化,但可用于处理残差连接,如下图所示。
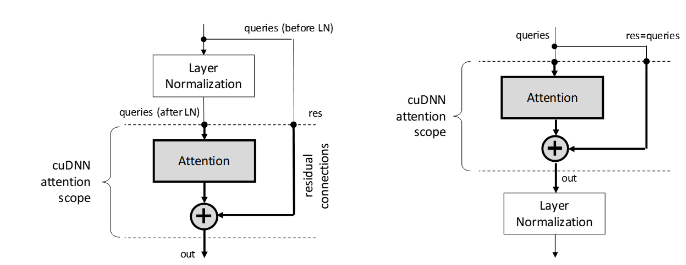
在 cudnnMultiHeadAttnForward() 中,查询和残差共享相同的 qDesc 描述符。当禁用残差连接时,残差指针应为 NULL。启用残差连接后,qDesc 中的向量长度应与 oDesc 描述符中指定的向量长度匹配,以便向量加法可行。
即使 K 和 V 是相同的输入,或者 Q、K、V 是相同的输入,也不允许 queries、keys 和 values 指针为 NULL。
参数
handle输入。当前的 cuDNN 上下文句柄。
attnDesc输入。先前初始化的注意力描述符。
currIdx输入。要处理的查询中的时间步。当
currIdx参数为负数时,将处理所有 Q 时间步。当currIdx为零或正数时,仅为选定的时间步计算前向响应。后一个输入只能在推理模式下使用,以处理一个时间步,同时在调用之间更新下一个注意力窗口和 Q、R、K、V 输入。loWinIdx[],hiWinIdx[]输入。两个主机整数数组,用于指定每个 Q 时间步的注意力窗口的起始和结束索引。K、V 集合中的起始索引是包含的,结束索引是排除的。
devSeqLengthsQO[]输入。设备数组,指定查询、残差和输出序列数据的序列长度。
devSeqLengthsKV[]输入。设备数组,指定键和值输入数据的序列长度。
qDesc输入。查询和残差序列数据的描述符。
queries输入。指向设备内存中查询数据的指针。
residuals输入。指向设备内存中残差数据的指针。如果不需要残差连接,请将此参数设置为
NULL。kDesc输入。键序列数据的描述符。
keys输入。指向设备内存中
keys数据的指针。vDesc输入。
values序列数据的描述符。values输入。指向设备内存中
values数据的指针。oDesc输入。多头注意力输出序列数据的描述符。
out输出。指向设备内存的指针,应在其中写入输出响应。
weightSizeInBytes输入。
weight缓冲区的字节大小,其中存储了所有多头注意力可训练参数。weights输入。指向设备内存中
weight缓冲区的指针。workSpaceSizeInBytes输入。用于临时 API 存储的工作区缓冲区的字节大小。
workSpace输入/输出。指向设备内存中工作区缓冲区的指针。
reserveSpaceSizeInBytes输入。用于前向和后向(梯度)API 调用之间数据交换的保留空间缓冲区的大小(以字节为单位)。此参数在推理模式下应为零,在训练模式下应为非零。
reserveSpace输入/输出。指向设备内存中保留空间缓冲区的指针。此参数在推理模式下应为
NULL,在训练模式下应为non-NULL。
返回值
CUDNN_STATUS_SUCCESS在处理 API 输入参数和启动 GPU 内核时未检测到错误。
CUDNN_STATUS_BAD_PARAM遇到无效或不兼容的输入参数。一些示例包括
所需的输入指针为
NULLcurrIdx超出范围attention、query、key、value和output的描述符值彼此不兼容
CUDNN_STATUS_EXECUTION_FAILED启动 GPU 内核的过程返回错误,或者较早的内核未成功完成。
CUDNN_STATUS_INTERNAL_ERROR遇到不一致的内部状态。
CUDNN_STATUS_NOT_SUPPORTED不支持请求的选项或输入参数组合。
CUDNN_STATUS_ALLOC_FAILED共享内存不足,无法启动 GPU 内核。
cudnnRNNBackwardData_v8()#
此函数计算 RNN 模型关于其输入(x、hx,以及对于 LSTM 单元类型,还有 cx)的精确一阶导数。如果 o = [y, hy, cy] = F(x, hx, cx) = F(z) 是一个向量值函数,表示整个 RNN 模型,并且它将向量 x(对于所有时间步)和向量 hx、cx(对于所有层)作为输入,连接成 \(\textbf{z}\epsilon\mathbb{R}^{n}\)(假设网络权重和偏差为常数),并输出向量 y、hy、cy,连接成向量 \(\textbf{o}\epsilon\mathbb{R}^{m}\),那么 cudnnRNNBackwardData_v8() 计算 \(\left(\partial o_{i}/\partial z_{j}\right)^{T} \delta_{out}\) 的结果,其中 \(\delta_{out}\) 是损失函数关于所有 RNN 输出的 mx1 梯度。\(\delta_{out}\) 梯度通过深度学习模型的先前层反向传播,从模型输出开始。\(\partial o_{i}/\partial z_{j}\) 是 F(z) 的 mxn Jacobian 矩阵。\(\delta_{out}\) 输入通过 dy、dhy 和 dcy 参数提供,梯度结果 \(\left(\partial o_{i}/\partial z_{j}\right)^{T} \delta_{out}\) 写入 dx、dhx 和 dcx 缓冲区。
cudnnStatus_t cudnnRNNBackwardData_v8( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, const int32_t devSeqLengths[], cudnnRNNDataDescriptor_t yDesc, const void *y, const void *dy, cudnnRNNDataDescriptor_t xDesc, void *dx, cudnnTensorDescriptor_t hDesc, const void *hx, const void *dhy, void *dhx, cudnnTensorDescriptor_t cDesc, const void *cx, const void *dcy, void *dcx, size_t weightSpaceSize, const void *weightSpace, size_t workSpaceSize, void *workSpace, size_t reserveSpaceSize, void *reserveSpace);
多层 RNN 模型中 x、y、hx、cx、hy、cy、dx、dy、dhx、dcx、dhy 和 dcy 信号的位置如下图所示。请注意,cudnnRNNBackwardData_v8() 函数未公开内部 RNN 信号(时间步之间和层之间)。
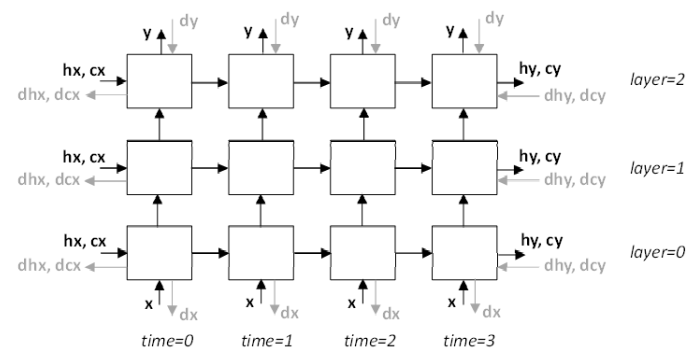
指向主 RNN 输出 y、初始隐藏状态 hx 和初始单元状态 cx(仅适用于 LSTM)的内存地址应指向与之前的 cudnnRNNForward() 调用中相同的数据。dy 和 dx 指针不能为 NULL。
cudnnRNNBackwardData_v8() 函数接受 dhy、dhx、dcy、dcx 缓冲区地址的任何组合为 NULL 的情况。当 dhy 或 dcy 为 NULL 时,假定这些输入为零。当 dhx 或 dcx 指针为 NULL 时,cudnnRNNBackwardData_v8() 不会写入相应的结果。当所有 hx、dhy、dhx 指针都为 NULL 时,则相应的张量描述符 hDesc 也可以为 NULL。相同的规则适用于 cx、dcy、dcx 指针和 cDesc 张量描述符。
cudnnRNNBackwardData_v8() 函数允许用户对输入 y、dy 和输出 dx 使用填充布局。在填充或解包布局(CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_UNPACKED、CUDNN_RNN_DATA_LAYOUT_BATCH_MAJOR_UNPACKED)中,小批量中的每个向量序列都具有由 cudnnSetRNNDataDescriptor() 函数中的 maxSeqLength 参数定义的固定长度。“解包”一词在此处指的是填充向量的存在,而不是连续向量之间未使用的地址范围。
每个填充的固定长度序列都从一段有效向量开始。有效向量计数存储在传递给 cudnnSetRNNDataDescriptor() 的 seqLengthArray 中,使得对于小批量中的所有序列(即对于 i=0..batchSize-1),0 < seqLengthArray[i] <= maxSeqLength。剩余的填充向量使组合序列长度等于 maxSeqLength。支持序列主序和批次主序填充布局。此外,还支持打包序列主序布局:CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_PACKED。
在后一种布局中,小批量中的向量序列根据序列长度按降序排序。首先存储时间步零的所有向量。然后是时间步一的所有向量,依此类推。此布局不使用填充向量。
必须在 xDesc 和 yDesc 描述符中指定相同的布局类型。
xDesc 和 yDesc RNN 数据描述符中名为 seqLengthArray 的两个主机数组必须相同。此外,seqLengthArray 在设备内存中的副本必须通过 devSeqLengths 参数传递。此数组直接提供给 GPU 内核。从 cuDNN 8.9.1 开始,不再需要 devSeqLengths 参数,可以将其设置为 NULL。可变序列长度数组由 cudnnRNNBackwardData_v8() 函数自动传输到 GPU 内存。
cudnnRNNBackwardData_v8() 函数不验证 GPU 内存中 devSeqLengths 中存储的序列长度是否与 CPU 内存中 xDesc 和 yDesc 描述符中的序列长度相同。但是,会检查 xDesc 和 yDesc 描述符中的序列长度数组的一致性。
cudnnRNNBackwardData_v8() 函数必须在 cudnnRNNForward() 之后调用。cudnnRNNForward() 函数应使用类型为 cudnnForwardMode_t 的 fwdMode 参数设置为 CUDNN_FWD_MODE_TRAINING 来调用。
参数
handle输入。当前的 cuDNN 上下文句柄。
rnnDesc输入。先前初始化的 RNN 描述符。
devSeqLengths输入。
seqLengthArray在xDesc或yDescRNN 数据描述符中的副本。devSeqLengths数组必须存储在 GPU 内存中,因为它由 GPU 内核异步访问,可能在cudnnRNNBackwardData_v8()函数存在之后。在 cuDNN 8.9.1 及更高版本中,devSeqLengths应为NULL。yDesc输入。先前初始化的描述符,对应于 RNN 模型主输出。
dataType、layout、maxSeqLength、batchSize和seqLengthArray需要与xDesc的匹配。y,dy输入。指向 GPU 缓冲区的指针,这些缓冲区保存 RNN 模型主输出和梯度增量(损失函数关于
y的梯度)。y输出应由之前的 cudnnRNNForward() 调用生成。y和dy向量预计会根据yDesc指定的布局在内存中布局。张量中的元素(包括填充向量中的元素)必须密集打包。y和dy参数不能为NULL。xDesc输入。先前初始化的 RNN 数据描述符,对应于损失函数关于 RNN 主模型输入的梯度。
dataType、layout、maxSeqLength、batchSize和seqLengthArray必须与yDesc的匹配。参数vectorSize必须与传递给 cudnnSetRNNDescriptor_v8() 函数的inputSize参数匹配。dx输出。指向 GPU 内存的数据指针,应在其中存储反向传播的损失函数关于 RNN 主输入 x 的梯度。向量预计会根据
xDesc指定的布局在内存中排列。张量中的元素(包括填充向量)必须密集打包。此参数不能为NULL。hDesc输入。张量描述符,描述初始 RNN 隐藏状态
hx和损失函数的梯度增量dhy, dhx。隐藏状态数据和梯度必须完全打包。张量的第一个维度取决于传递给 cudnnSetRNNDescriptor_v8() 函数的dirMode参数。如果
dirMode为CUDNN_UNIDIRECTIONAL,则第一个维度应与传递给 cudnnSetRNNDescriptor_v8() 的numLayers参数匹配。如果
dirMode为CUDNN_BIDIRECTIONAL,则第一个维度应为传递给 cudnnSetRNNDescriptor_v8() 的numLayers参数的两倍。
第二个维度必须与
xDesc中描述的batchSize参数匹配。第三个维度取决于 RNN 模式是否为CUDNN_LSTM以及是否启用了 LSTM 投影。具体来说:如果 RNN 模式为
CUDNN_LSTM且启用了 LSTM 投影,则第三个维度必须与projSize参数匹配。否则,第三个维度必须与
hiddenSize参数匹配。
hx,dhy输入。 包含 RNN 初始隐藏状态
hx和梯度变化量dhy的 GPU 缓冲区地址。数据维度由hDesc张量描述符描述。如果在hx或dhy参数中传递了NULL指针,则假定相应的缓冲区包含全零。dhx输出。 指向 GPU 缓冲区的指针,该缓冲区应存储与初始隐藏状态变量对应的一阶导数。数据维度由
hDesc张量描述符描述。如果将NULL指针分配给dhx,则不会保存反向传播的导数。cDesc输入。 仅适用于 LSTM 网络。对于
RELU、TANH或GRU单元类型,此参数应为NULL。cDesc是一个张量描述符,用于指定初始细胞状态cx和损失函数的梯度变化量dcy, dcx的缓冲区布局。细胞状态数据必须完全 packed。张量的第一个维度取决于传递给 cudnnSetRNNDescriptor_v8() 调用的dirMode参数。如果
dirMode为CUDNN_UNIDIRECTIONAL,则第一个维度应与传递给 cudnnSetRNNDescriptor_v8() 的numLayers参数匹配。如果
dirMode为CUDNN_BIDIRECTIONAL,则第一个维度应为传递给 cudnnSetRNNDescriptor_v8() 的numLayers参数的两倍。
第二个张量维度必须与
xDesc中的batchSize参数匹配。第三个维度必须与传递给 cudnnSetRNNDescriptor_v8() 调用的hiddenSize参数匹配。cx,dcy输入。 仅适用于 LSTM 网络。包含初始 LSTM 状态数据和梯度变化量
dcy的 GPU 缓冲区地址。数据维度由cDesc张量描述符描述。如果在cx或dcy参数中传递了NULL指针,则假定相应的缓冲区包含全零。dcx输出。 仅适用于 LSTM 网络。指向 GPU 缓冲区的指针,该缓冲区应存储与初始 LSTM 状态变量对应的一阶导数。数据维度由
cDesc张量描述符描述。如果将NULL指针分配给dcx,则不会保存反向传播的导数。weightSpaceSize输入。 指定提供的权重空间缓冲区的大小(以字节为单位)。
weightSpace输入。 GPU 内存中权重空间缓冲区的地址。
workSpaceSize输入。 指定提供的工作区缓冲区的大小(以字节为单位)。
workSpace输入/输出。 GPU 内存中工作区缓冲区的地址,用于存储临时数据。
reserveSpaceSize输入。 指定预留空间缓冲区的大小(以字节为单位)。
reserveSpace输入/输出。 GPU 内存中预留空间缓冲区的地址。
返回值
CUDNN_STATUS_SUCCESS在处理 API 输入参数和启动 GPU 内核时未检测到错误。
CUDNN_STATUS_NOT_SUPPORTED满足以下至少一个条件
当指定
CUDNN_RNN_ALGO_PERSIST_STATIC、CUDNN_RNN_ALGO_PERSIST_DYNAMIC或CUDNN_RNN_ALGO_PERSIST_STATIC_SMALL_H时,会传递可变序列长度输入在 pre-Pascal 设备上请求
CUDNN_RNN_ALGO_PERSIST_STATIC或CUDNN_RNN_ALGO_PERSIST_DYNAMIC输入/输出使用了 ‘double’ 浮点类型,并且使用了
CUDNN_RNN_ALGO_PERSIST_STATIC算法
CUDNN_STATUS_BAD_PARAM遇到无效或不兼容的输入参数。一些示例包括
某些描述符或数据缓冲区地址为
NULLrnnDesc、xDesc、yDesc、hDesc或cDesc描述符中的设置无效weightSpaceSize、workSpaceSize或reserveSpaceSize太小
CUDNN_STATUS_MAPPING_ERRORGPU/CUDA 资源(例如纹理对象、共享内存或零拷贝内存)在所需大小中不可用,或者用户资源与 cuDNN 内部资源之间存在不匹配。例如,当调用 cudnnSetStream() 时,可能会发生资源不匹配。当调用 cudnnCreate() 时,用户提供的 CUDA 流与 cuDNN 句柄中实例化的内部 CUDA 事件之间可能存在不匹配。
当此错误状态与纹理维度、共享内存大小或零拷贝内存可用性相关时,可能无法纠正。如果 cudnnSetStream() 返回
CUDNN_STATUS_MAPPING_ERROR,则通常可以纠正,但是,这意味着 cuDNN 句柄是在一个 GPU 上创建的,而传递给此函数的用户流与另一个 GPU 相关联。CUDNN_STATUS_EXECUTION_FAILED启动 GPU 内核的过程返回错误,或者较早的内核未成功完成。
CUDNN_STATUS_ALLOC_FAILED该函数无法分配 CPU 内存。
cudnnRNNBackwardWeights_v8()#
此函数计算 RNN 模型相对于所有可训练参数(权重和偏置)的精确一阶导数。如果 o = [y, hy, cy] = F(w) 是一个向量值函数,表示多层 RNN 模型,它接受某个向量 \(\textbf{w}\epsilon\mathbb{R}^{n}\) 作为输入(包含所有“扁平化”的权重或偏置,以及所有其他数据输入常量),并输出向量 \(\textbf{o}\epsilon\mathbb{R}^{m}\),那么 cudnnRNNBackwardWeights_v8() 计算 \(\left(\partial o_{i}/\partial w_{j}\right)^{T} \delta_{out}\) 的结果,其中 \(\delta_{out}\) 是损失函数相对于所有 RNN 输出的 mx1 梯度。\(\delta_{out}\) 梯度通过深度学习模型的先前层反向传播,从模型输出开始。\(\partial o_{i}/\partial w_{j}\) 是 F(w) 的 mxn Jacobian 矩阵。\(\delta_{out}\) 输入通过 cudnnRNNBackwardData_v8() 函数中的 dy、dhy 和 dcy 参数提供。
cudnnStatus_t cudnnRNNBackwardWeights_v8( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, cudnnWgradMode_t addGrad, const int32_t devSeqLengths[], cudnnRNNDataDescriptor_t xDesc, const void *x, cudnnTensorDescriptor_t hDesc, const void *hx, cudnnRNNDataDescriptor_t yDesc, const void *y, size_t weightSpaceSize, void *dweightSpace, size_t workSpaceSize, void *workSpace, size_t reserveSpaceSize, void *reserveSpace);
相对于权重和偏置的所有梯度结果 \(\left(\partial o_{i}/\partial w_{j}\right)^{T} \delta_{out}\) 都写入 dweightSpace 缓冲区。dweightSpace 缓冲区的大小和组织方式与保存 RNN 权重和偏置的 weightSpace 缓冲区相同。
损失函数相对于权重和偏置的梯度通常在多个小批量上计算。在这种情况下,应聚合为每个小批量计算的部分结果。addGrad 参数指定是否应将当前小批量的梯度添加到先前计算的结果中 (CUDNN_WGRAD_MODE_ADD),或者应使用新结果覆盖 dweightSpace 缓冲区 (CUDNN_WGRAD_MODE_SET)。目前,cudnnRNNBackwardWeights_v8() 函数仅支持 CUDNN_WGRAD_MODE_ADD 模式,因此用户应在首次调用该例程之前将 dweightSpace 缓冲区清零。
必须在 xDesc 描述符和设备数组 devSeqLengths 中指定相同的序列长度。从 cuDNN 8.9.1 开始,不再需要 devSeqLengths 参数,可以将其设置为 NULL。可变序列长度数组由 cudnnRNNBackwardWeights_v8() 函数自动传输到 GPU 内存。
cudnnRNNBackwardWeights_v8() 函数应在 cudnnRNNBackwardData_v8() 之后调用。
参数
handle输入。当前的 cuDNN 上下文句柄。
rnnDesc输入。先前初始化的 RNN 描述符。
addGrad输入。 权重梯度输出模式。有关更多详细信息,请参阅 cudnnWgradMode_t 枚举类型的描述。目前,
cudnnRNNBackwardWeights_v8()函数仅支持CUDNN_WGRAD_MODE_ADD模式。devSeqLengths输入。 来自
xDescRNN 数据描述符的seqLengthArray的副本。devSeqLengths数组必须存储在 GPU 内存中,因为它由 GPU 内核异步访问,可能在cudnnRNNBackwardWeights_v8()函数退出后访问。在 cuDNN 8.9.1 及更高版本中,devSeqLengths应为NULL。xDesc输入。 先前初始化的描述符,对应于 RNN 模型输入数据。这与在先前的 cudnnRNNForward() 和 cudnnRNNBackwardData_v8() 调用中使用的 RNN 数据描述符相同。
x输入。 指向 GPU 缓冲区的指针,该缓冲区包含主要的 RNN 输入。应在先前的 cudnnRNNForward() 和 cudnnRNNBackwardData_v8() 调用中提供相同的缓冲区地址
x。hDesc输入。 描述初始 RNN 隐藏状态的张量描述符。隐藏状态数据完全 packed。这与在先前的 cudnnRNNForward() 和 cudnnRNNBackwardData_v8() 调用中使用的张量描述符相同。
hx输入。 指向 GPU 缓冲区的指针,该缓冲区包含 RNN 初始隐藏状态。应在先前的 cudnnRNNForward() 和 cudnnRNNBackwardData_v8() 调用中提供相同的缓冲区地址
hx。yDesc输入。 先前初始化的描述符,对应于 RNN 模型输出数据。这与在先前的 cudnnRNNForward() 和 cudnnRNNBackwardData_v8() 调用中使用的 RNN 数据描述符相同。
y输出。 指向 GPU 缓冲区的指针,该缓冲区包含先前 cudnnRNNForward() 调用生成的主要 RNN 输出。
y缓冲区中的数据由yDesc描述符描述。y张量中的元素(包括填充向量中的元素)必须是密集 packed 的。weightSpaceSize输入。 指定提供的权重空间缓冲区的大小(以字节为单位)。
dweightSpace输出。 GPU 内存中权重空间缓冲区的地址。
workSpaceSize输入。 指定提供的工作区缓冲区的大小(以字节为单位)。
workSpace输入/输出。 GPU 内存中工作区缓冲区的地址,用于存储临时数据。
reserveSpaceSize输入。 指定预留空间缓冲区的大小(以字节为单位)。
reserveSpace输入/输出。 GPU 内存中预留空间缓冲区的地址。
返回值
CUDNN_STATUS_SUCCESS在处理 API 输入参数和启动 GPU 内核时未检测到错误。
CUDNN_STATUS_NOT_SUPPORTED该函数不支持提供的配置。
CUDNN_STATUS_BAD_PARAM遇到无效或不兼容的输入参数。一些示例包括
某些描述符或数据缓冲区地址为
NULLrnnDesc、xDesc、yDesc或hDesc描述符中的设置无效weightSpaceSize、workSpaceSize或reserveSpaceSize值太小addGrad参数不等于CUDNN_WGRAD_MODE_ADD
CUDNN_STATUS_EXECUTION_FAILED启动 GPU 内核的过程返回错误,或者较早的内核未成功完成。
CUDNN_STATUS_ALLOC_FAILED该函数无法分配 CPU 内存
cudnnRNNForward()#
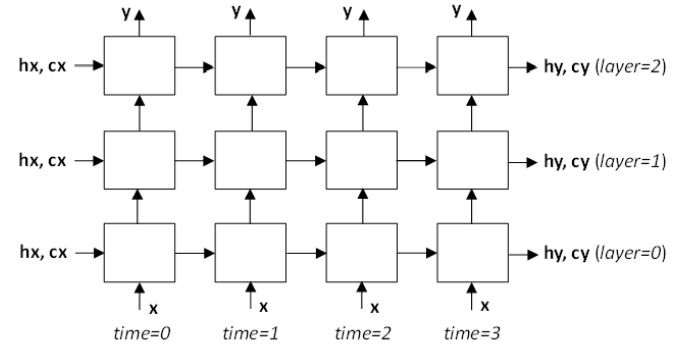
此例程计算由 rnnDesc 描述的循环神经网络的前向响应,输入在 x、hx、cx 中,权重/偏置在 weightSpace 缓冲区中。RNN 输出写入 y、hy 和 cy 缓冲区。多层 RNN 模型中 x、y、hx、cx、hy 和 cy 信号的位置如下图所示。请注意,时间步之间和层之间的内部 RNN 信号不会暴露给用户。
cudnnStatus_t cudnnRNNForward( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, cudnnForwardMode_t fwdMode, const int32_t devSeqLengths[], cudnnRNNDataDescriptor_t xDesc, const void *x, cudnnRNNDataDescriptor_t yDesc, void *y, cudnnTensorDescriptor_t hDesc, const void *hx, void *hy, cudnnTensorDescriptor_t cDesc, const void *cx, void *cy, size_t weightSpaceSize, const void *weightSpace, size_t workSpaceSize, void *workSpace, size_t reserveSpaceSize, void *reserveSpace);
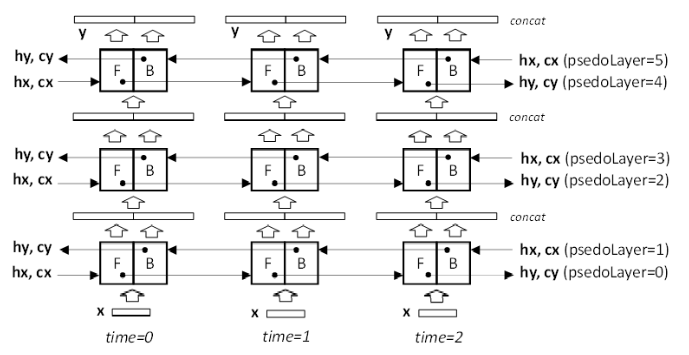
下图描述了 RNN 模型为双向时的数据流。在这种模式下,每个 RNN 物理层由两个连续的伪层组成,每个伪层都有自己的权重、偏置、初始隐藏状态 hx,对于 LSTM,还有初始细胞状态 cx。偶数伪层 0、2、4 从左到右或沿前向 (F) 方向处理输入向量。奇数伪层 1、3、5 从右到左或沿反向 (R) 方向处理输入向量。两个连续的伪层对相同的输入向量进行操作,只是顺序不同。伪层 0 和 1 访问存储在 x 缓冲区中的原始序列。F 和 R 单元的输出被连接起来,因此馈送到接下来的两个伪层的向量的长度为 2x hiddenSize 或 2x projSize。后续伪层中的输入 GEMM 将向量长度调整为 1x hiddenSize。
当 fwdMode 参数设置为 CUDNN_FWD_MODE_TRAINING 时,cudnnRNNForward() 函数会将计算一阶导数所需的中间数据存储在预留空间缓冲区中。工作区和预留空间缓冲区大小应由 cudnnGetRNNTempSpaceSizes() 函数计算,其 fwdMode 设置与 cudnnRNNForward() 调用中使用的设置相同。
必须在 xDesc 和 yDesc 描述符中指定相同的布局类型。必须在 xDesc、yDesc 和设备数组 devSeqLengths 中配置相同的序列长度。从 cuDNN 8.9.1 开始,不再需要 devSeqLengths 参数,可以将其设置为 NULL。可变序列长度数组由 cudnnRNNForward() 函数自动传输到 GPU 内存。
cudnnRNNForward() 函数不验证 GPU 内存中 devSeqLengths 中存储的序列长度是否与 CPU 内存中 xDesc 和 yDesc 描述符中的序列长度相同。但是,会检查来自 xDesc 和 yDesc 描述符的序列长度数组的一致性。
参数
handle输入。当前的 cuDNN 上下文句柄。
rnnDesc输入。先前初始化的 RNN 描述符。
fwdMode输入。 指定推理或训练模式 (
CUDNN_FWD_MODE_INFERENCE和CUDNN_FWD_MODE_TRAINING)。在训练模式下,其他数据存储在预留空间缓冲区中。此信息在反向传播中用于计算导数。devSeqLengths输入。 来自
xDesc或yDescRNN 数据描述符的seqLengthArray的副本。devSeqLengths数组必须存储在 GPU 内存中,因为它由 GPU 内核异步访问,可能在cudnnRNNForward()函数退出后访问。在 cuDNN 8.9.1 及更高版本中,devSeqLengths应为NULL。xDesc输入。 先前初始化的描述符,对应于 RNN 模型主输入。
dataType、layout、maxSeqLength、batchSize和seqLengthArray必须与yDesc的匹配。vectorSize参数必须与传递给 cudnnSetRNNDescriptor_v8() 函数的inputSize参数匹配。x输入。 指向与 RNN 数据描述符
xDesc关联的 GPU 内存的数据指针。向量应根据xDesc指定的布局排列在内存中。张量中的元素(包括填充向量)必须是密集 packed 的。yDesc输入。 先前初始化的 RNN 数据描述符。
dataType、layout、maxSeqLength、batchSize和seqLengthArray必须与xDesc的匹配。vectorSize参数取决于是否启用了 LSTM 投影以及网络是否为双向。具体来说:对于单向模型,
vectorSize参数必须与传递给 cudnnSetRNNDescriptor_v8() 的hiddenSize参数匹配。如果启用了 LSTM 投影,则vectorSize必须与传递给 cudnnSetRNNDescriptor_v8() 的projSize参数相同。对于双向模型,如果 RNN
cellMode为CUDNN_LSTM并且启用了投影功能,则vectorSize参数必须是传递给 cudnnSetRNNDescriptor_v8() 的projSize参数的 2 倍。否则,它应为hiddenSize值的 2 倍。
y输出。 指向与 RNN 数据描述符
yDesc关联的 GPU 内存的数据指针。向量应根据yDesc指定的布局排列在内存中。张量中的元素(包括填充向量中的元素)必须是密集 packed 的,并且不支持步幅。hDesc输入。 一个张量描述符,用于指定初始或最终隐藏状态缓冲区 (hx, hy) 的布局。隐藏状态数据必须完全 packed。张量的第一个维度取决于传递给 cudnnSetRNNDescriptor_v8() 函数的
dirMode参数。如果
dirMode为CUDNN_UNIDIRECTIONAL,则第一个维度应与传递给 cudnnSetRNNDescriptor_v8() 的numLayers参数匹配。如果
dirMode为CUDNN_BIDIRECTIONAL,则第一个维度应为传递给 cudnnSetRNNDescriptor_v8() 的numLayers参数的两倍。
第二个维度必须与
xDesc中描述的batchSize参数匹配。第三个维度取决于 RNN 模式是否为CUDNN_LSTM以及是否启用了 LSTM 投影。具体来说:如果 RNN 模式为
CUDNN_LSTM且启用了 LSTM 投影,则第三个维度必须与projSize参数匹配。否则,第三个维度必须与用于初始化
rnnDesc的 cudnnSetRNNDescriptor_v8() 调用传递的hiddenSize参数匹配。
hx输入。 指向 GPU 缓冲区的指针,该缓冲区包含 RNN 初始隐藏状态。数据维度由
hDesc张量描述符描述。如果传递了NULL指针,则网络的初始隐藏状态将初始化为零。hy输出。 指向 GPU 缓冲区的指针,该缓冲区应存储最终 RNN 隐藏状态。数据维度由
hDesc张量描述符描述。如果传递了NULL指针,则不会保存网络的最终隐藏状态。cDesc输入。 仅适用于 LSTM 网络。对于
RELU、TANH或GRU单元类型,此参数应为NULL。cDesc是一个张量描述符,用于指定 LSTM 网络使用的初始或最终细胞状态缓冲区 (cx, cy) 的布局。细胞状态数据必须完全 packed。张量的第一个维度取决于传递给 cudnnSetRNNDescriptor_v8() 调用的dirMode参数。如果
dirMode为CUDNN_UNIDIRECTIONAL,则第一个维度应与传递给 cudnnSetRNNDescriptor_v8() 的numLayers参数匹配。如果
dirMode为CUDNN_BIDIRECTIONAL,则第一个维度应与传递给 cudnnSetRNNDescriptor_v8() 的numLayers参数的两倍匹配。
第二个张量维度必须与
xDesc中的batchSize参数匹配。第三个维度必须与传递给 cudnnSetRNNDescriptor_v8() 调用的hiddenSize参数匹配。cx输入。 仅适用于 LSTM 网络。指向 GPU 缓冲区的指针,该缓冲区包含初始 LSTM 状态数据。数据维度由
cDesc张量描述符描述。如果传递了NULL指针,则网络的初始细胞状态将初始化为零。cy输出。 仅适用于 LSTM 网络。指向 GPU 缓冲区的指针,该缓冲区应存储最终 LSTM 状态数据。数据维度由
cDesc张量描述符描述。如果传递了NULL指针,则不会保存最终 LSTM 细胞状态。weightSpaceSize输入。 指定提供的权重空间缓冲区的大小(以字节为单位)。
weightSpace输入。 GPU 内存中权重空间缓冲区的地址。
workSpaceSize输入。 指定提供的工作区缓冲区的大小(以字节为单位)。
workSpace输入/输出。 GPU 内存中工作区缓冲区的地址,用于存储临时数据。
reserveSpaceSize输入。 指定预留空间缓冲区的大小(以字节为单位)。
reserveSpace输入/输出。 GPU 内存中预留空间缓冲区的地址。
返回值
CUDNN_STATUS_SUCCESS在处理 API 输入参数和启动 GPU 内核时未检测到错误。
CUDNN_STATUS_NOT_SUPPORTED满足以下至少一个条件
当指定
CUDNN_RNN_ALGO_PERSIST_STATIC、CUDNN_RNN_ALGO_PERSIST_DYNAMIC或CUDNN_RNN_ALGO_PERSIST_STATIC_SMALL_H时,会传递可变序列长度输入在 pre-Pascal 设备上请求
CUDNN_RNN_ALGO_PERSIST_STATIC或CUDNN_RNN_ALGO_PERSIST_DYNAMIC输入/输出使用了 ‘double’ 浮点类型,并且使用了
CUDNN_RNN_ALGO_PERSIST_STATIC算法
CUDNN_STATUS_BAD_PARAM遇到无效或不兼容的输入参数。一些示例包括
某些输入描述符为
NULLrnnDesc、xDesc、yDesc、hDesc或cDesc描述符中至少有一个设置无效weightSpaceSize、workSpaceSize或reserveSpaceSize太小
CUDNN_STATUS_EXECUTION_FAILED启动 GPU 内核的过程返回错误,或者较早的内核未成功完成。
CUDNN_STATUS_ALLOC_FAILED该函数无法分配 CPU 内存。
cudnnRNNGetClip_v8()#
此函数已在 cuDNN 9.0 中弃用;请改用 cudnnRNNGetClip_v9()。
检索当前的 LSTM 细胞裁剪参数,并将它们存储在提供的参数中。当不需要检索的值时,用户可以将 NULL 分配给除 rnnDesc 之外的任何指针。该函数不检查检索到的参数的有效性。
cudnnStatus_t cudnnRNNGetClip_v8( cudnnRNNDescriptor_t rnnDesc, cudnnRNNClipMode_t *clipMode, cudnnNanPropagation_t *clipNanOpt, double *lclip, double *rclip);
参数
rnnDesc输入。先前初始化的 RNN 描述符。
clipMode输出。 指向存储检索到的 cudnnRNNClipMode_t 值的位置的指针。
clipMode可以是CUDNN_RNN_CLIP_NONE,在这种情况下,不执行 LSTM 细胞状态裁剪;或者是CUDNN_RNN_CLIP_MINMAX,在这种情况下,细胞状态激活到其他单元将被裁剪。clipNanOpt输出。 指向存储检索到的 cudnnNanPropagation_t 值的位置的指针。
lclip,rclip输出。 指向存储检索到的 LSTM 细胞裁剪范围
[lclip, rclip]的位置的指针。
返回值
CUDNN_STATUS_SUCCESSLSTM 裁剪参数已成功从 RNN 描述符中检索。
CUDNN_STATUS_BAD_PARAM找到无效的输入参数(
rnnDesc为NULL)。
cudnnRNNGetClip_v9()#
检索当前的 LSTM 细胞裁剪参数,并将它们存储在提供的参数中。当不需要检索的值时,用户可以将 NULL 分配给除 rnnDesc 之外的任何指针。该函数不检查检索到的参数的有效性。
cudnnStatus_t cudnnRNNGetClip_v9( cudnnRNNDescriptor_t rnnDesc, cudnnRNNClipMode_t *clipMode, double *lclip, double *rclip);
参数
rnnDesc输入。先前初始化的 RNN 描述符。
clipMode输出。 指向存储检索到的 cudnnRNNClipMode_t 值的位置的指针。
clipMode可以是CUDNN_RNN_CLIP_NONE,在这种情况下,不执行 LSTM 细胞状态裁剪;或者是CUDNN_RNN_CLIP_MINMAX,在这种情况下,细胞状态激活到其他单元将被裁剪。lclip,rclip输出。 指向存储检索到的 LSTM 细胞裁剪范围
[lclip, rclip]的位置的指针。
返回值
CUDNN_STATUS_SUCCESSLSTM 裁剪参数已成功从 RNN 描述符中检索。
CUDNN_STATUS_BAD_PARAM找到无效的输入参数(
rnnDesc为NULL)。
cudnnRNNSetClip_v8()#
此函数已在 cuDNN 9.0 中弃用;请使用 cudnnRNNSetClip_v9() 代替。
设置 LSTM 单元裁剪模式。LSTM 裁剪默认禁用。启用后,裁剪将应用于所有层。此 cudnnRNNSetClip_v8() 函数不影响工作区、保留区和权重空间缓冲区的大小,并且可以多次调用。
cudnnStatus_t cudnnRNNSetClip_v8( cudnnRNNDescriptor_t rnnDesc, cudnnRNNClipMode_t clipMode, cudnnNanPropagation_t clipNanOpt, double lclip, double rclip);
参数
rnnDesc输入。先前初始化的 RNN 描述符。
clipMode输入。启用或禁用 LSTM 单元裁剪。当
clipMode设置为CUDNN_RNN_CLIP_NONE时,不执行 LSTM 单元状态裁剪。当clipMode为CUDNN_RNN_CLIP_MINMAX时,单元状态激活值将被裁剪到其他单元。clipNanOpt输入。当设置为
CUDNN_PROPAGATE_NAN时(请参阅 cudnnNanPropagation_t 的描述),NaN将从 LSTM 单元传播,或者可以将其设置为裁剪范围边界值之一,而不是传播。lclip,rclip输入。裁剪 LSTM 单元状态应设置到的范围
[lclip, rclip]。
返回值
CUDNN_STATUS_SUCCESS函数已成功完成。
CUDNN_STATUS_BAD_PARAM找到无效的输入参数,例如
rnnDesc为NULLlclip>rcliplclip或rclip为NaN
cudnnRNNSetClip_v9()#
设置 LSTM 单元裁剪模式。LSTM 裁剪默认禁用。启用后,裁剪将应用于所有层。此 cudnnRNNSetClip_v8() 函数不影响工作区、保留区和权重空间缓冲区的大小,并且可以多次调用。
cudnnStatus_t cudnnRNNSetClip_v9( cudnnRNNDescriptor_t rnnDesc, cudnnRNNClipMode_t clipMode, double lclip, double rclip);
参数
rnnDesc输入。先前初始化的 RNN 描述符。
clipMode输入。启用或禁用 LSTM 单元裁剪。当
clipMode设置为CUDNN_RNN_CLIP_NONE时,不执行 LSTM 单元状态裁剪。当clipMode为CUDNN_RNN_CLIP_MINMAX时,单元状态激活值将被裁剪到其他单元。lclip,rclip输入。裁剪 LSTM 单元状态应设置到的范围
[lclip, rclip]。
返回值
CUDNN_STATUS_SUCCESS函数已成功完成。
CUDNN_STATUS_BAD_PARAM找到无效的输入参数,例如
rnnDesc为NULLlclip>rcliplclip或rclip为NaN
cudnnSetAttnDescriptor()#
此函数已在 cuDNN 9.0 中弃用。
此函数配置一个多头注意力描述符,该描述符先前使用 cudnnCreateAttnDescriptor() 函数创建。此函数设置计算内部缓冲区大小、权重和偏置张量维度或选择优化代码路径所需的注意力参数。
cudnnStatus_t cudnnSetAttnDescriptor( cudnnAttnDescriptor_t attnDesc, unsigned attnMode, int nHeads, double smScaler, cudnnDataType_t dataType, cudnnDataType_t computePrec, cudnnMathType_t mathType, cudnnDropoutDescriptor_t attnDropoutDesc, cudnnDropoutDescriptor_t postDropoutDesc, int qSize, int kSize, int vSize, int qProjSize, int kProjSize, int vProjSize, int oProjSize, int qoMaxSeqLength, int kvMaxSeqLength, int maxBatchSize, int maxBeamSize);
cudnnMultiHeadAttnForward()、cudnnMultiHeadAttnBackwardData() 和 cudnnMultiHeadAttnBackwardWeights() 函数中的输入序列数据描述符将根据存储在注意力描述符中的配置参数进行检查。某些参数必须完全匹配,而 max 参数(如 maxBatchSize 或 qoMaxSeqLength)则为相应的维度建立上限。
多头注意力模型可以用以下公式描述
\(\textbf{h}_{i}=\left( \textbf{W}_{V,i} \textbf{V}\right)softmax\left( smScaler\left( \textbf{K}^{\textbf{T}}\mathrm{\textbf{W}}_{K,i}^{T} \right)\left( \textbf{W}_{Q,i} \textbf{q}\right) \right), for i=0 \cdots nHeads -1\)
\(MultiHeadAttn\left( \textbf{q},\textbf{K},\textbf{V},\textbf{W}_{Q},\textbf{W}_{K},\textbf{W}_{V},\textbf{W}_{O} \right)=\sum_{i=0}^{nHeads-1}\textbf{W}_{O,i}\textbf{h}_{i}\)
其中
nHeads是评估 h i 向量的独立注意力头的数量q 是主输入,单个查询列向量
K、V 是
key和value列向量的两个矩阵
query、key 和 value 向量的长度分别由 qSize、kSize 和 vSize 参数定义。
为简单起见,以上公式使用单个嵌入向量 q 呈现,但 cuDNN API 可以处理波束搜索方案中的多个 q 候选,处理批处理中捆绑的多个序列的 q 向量,或自动迭代序列的所有嵌入向量(时间步)。因此,通常,q、K、V 输入是具有额外信息的张量,例如每个序列的活动长度或应如何保存未使用的填充向量。
在某些出版物中,W O,i 矩阵被组合成一个输出投影矩阵,并且 h i 向量被显式合并为单个向量。这是一个等效的表示法。在 cuDNN 库中,W O,i 矩阵在概念上被视为与 W Q,i、W K,i 或 W V,i 输入投影权重相同的方式。有关更多详细信息,请参阅 cudnnGetMultiHeadAttnWeights() 函数的描述。
权重矩阵 W Q,i、W K,i、W V,i 和 W O,i 起着相似的作用,调整 q、K、V 输入和多头注意力最终输出中的向量长度。用户可以通过将 qProjSize、kProjSize、vProjSize 或 oProjSize 参数设置为零来禁用任何或所有投影。
需要以使上述矩阵乘法可行的这种方式选择 q、K、V 中的嵌入向量大小以及投影后的向量长度。否则,cudnnSetAttnDescriptor() 函数将返回 CUDNN_STATUS_BAD_PARAM。当希望保持矩阵的秩亏 \(\textbf{W}_{KQ,i}=\mathrm{\textbf{W}}_{K,i}^{T}\textbf{W}_{Q,i}\) 或 \(\textbf{W}_{OV,i}=\textbf{W}_{O,i}\textbf{W}_{V,i}\) 以消除每个头中线性变换期间的一个或多个维度时,将使用所有四个权重矩阵。这是一种特征提取形式。在这种情况下,投影大小小于原始向量长度。
对于每个注意力头,权重矩阵大小定义如下
W Q,i - 大小
[qProjSize x qSize],i = 0 .. nHeads-1W K,i - 大小
[kProjSize x kSize],i = 0 .. nHeads-1,kProjSize=qProjSizeW V,i - 大小
[vProjSize x vSize],i = 0 .. nHeads-1W O,i - 大小
[oProjSize x (vProjSize > 0 ? vProjSize : vSize)],i = 0 .. nHeads-1
当禁用输出投影 (oProjSize=0) 时,输出向量长度为 nHeads * (vProjSize > 0 ? vProjSize : vSize),这意味着输出是所有 h i 向量的串联。在另一种解释中,串联矩阵 W O = [W O,0, W O,1, W O,2, …] 形成单位矩阵。
Softmax 是归一化的指数向量函数,它接受并输出相同大小的向量。多头注意力 API 使用 CUDNN_SOFTMAX_ACCURATE 类型的 softmax 来降低浮点溢出的可能性。
smScaler 参数是 softmax 锐化/平滑系数。当 smScaler=1.0 时,softmax 使用自然指数函数 exp(x) 或 2.7183*。当 smScaler<1.0 时,例如 smScaler=0.2,softmax 块使用的函数增长速度不会那么快,因为 exp(0.2*x) ≈ 1.2214 x。
可以调整 smScaler 参数以处理馈送到 softmax 的更大范围的值。当范围太大(或者对于给定范围,smScaler 不够小)时,softmax 块的输出向量变为分类的,这意味着,一个向量元素接近 1.0,而其他输出为零或非常接近于零。当发生这种情况时,softmax 块的 Jacobian 矩阵也接近于零,因此除了通过残差连接(如果启用了这些连接),增量不会在训练期间从输出反向传播到输入。用户可以将 smScaler 设置为任何正浮点值甚至零。smScaler 参数不可训练。
qoMaxSeqLength、kvMaxSeqLength、maxBatchSize 和 maxBeamSize 参数分别声明了 cudnnSeqDataDescriptor_t 容器中的最大序列长度、最大批大小和最大波束大小。提供给前向和后向(梯度)API 函数的实际维度不应超过 max 限制。应仔细设置 max 参数,因为值过大将导致工作区和保留空间缓冲区过大,从而导致过多的内存使用。
attnMode 参数被视为二进制掩码,其中设置了各种开/关选项。这些选项会影响内部缓冲区大小、强制执行某些参数检查、选择优化的代码执行路径或启用不需要其他数值参数的注意力变体。此类选项的一个示例是在输入和输出投影中包含偏置。
attnDropoutDesc 和 postDropoutDesc 参数是描述在训练模式中处于活动状态的两个 dropout 层的描述符。由 attnDropoutDesc 定义的第一个 dropout 操作直接应用于 softmax 输出。由 postDropoutDesc 指定的第二个 dropout 操作会更改多头注意力输出,就在添加残差连接的点之前。
注意
cudnnSetAttnDescriptor()函数执行attnDropoutDesc和postDropoutDesc的浅拷贝,这意味着,注意力描述符中存储的是两个 dropout 描述符的地址,而不是整个结构。因此,用户应在注意力描述符的整个生命周期内保留 dropout 描述符。
参数
attnDesc输出。要配置的注意力描述符。
attnMode输入。启用不需要其他数值的各种注意力选项。有关支持的标志列表,请参阅下表。用户应为此参数分配一组首选的按位
OR运算的标志。nHeads输入。注意力头的数量。
smScaler输入。Softmax 平滑 (
1.0 >= smScaler >= 0.0) 或锐化 (smScaler > 1.0) 系数。不接受负值。dataType输入。用于表示注意力输入、注意力权重和注意力输出的数据类型。
computePrec输入。计算精度。
mathType输入。NVIDIA Tensor Core 设置。
attnDropoutDesc输入。应用于 softmax 输出的 dropout 操作的描述符。有关不支持的功能列表,请参阅下表。
postDropoutDesc输入。应用于多头注意力输出的 dropout 操作的描述符,就在添加残差连接的点之前。有关不支持的功能列表,请参阅下表。
qSize、kSize、vSize输入。Q、K、V 嵌入向量长度。
qProjSize、kProjSize、vProjSize输入。输入投影后 Q、K、V 嵌入向量长度。使用零禁用相应的投影。
oProjSize输入。输出投影后 h i 向量长度。使用零禁用此投影。
qoMaxSeqLength输入。与 Q、O、dQ 和 dO 输入和输出相关的序列数据描述符中预期的最大序列长度。
kvMaxSeqLength输入。与 K、V、dK 和 dV 输入和输出相关的序列数据描述符中预期的最大序列长度。
maxBatchSize输入。任何 cudnnSeqDataDescriptor_t 容器中预期的最大批大小。
maxBeamSize输入。任何 cudnnSeqDataDescriptor_t 容器中预期的最大波束大小。
支持的 ``attnMode`` 标志
CUDNN_ATTN_QUERYMAP_ALL_TO_ONE当 Q 输入中的波束大小大于一时,Q 和 K、V 向量之间映射的前向声明。来自同一波束束的多个 Q 向量映射到相同的 K、V 向量。这意味着 K、V 集中的波束大小等于一。
CUDNN_ATTN_QUERYMAP_ONE_TO_ONE当 Q 输入中的波束大小大于一时,Q 和 K、V 向量之间映射的前向声明。来自同一波束束的多个 Q 向量映射到不同的 K、V 向量。这要求 K、V 集中的波束大小与 Q 输入中的波束大小相同。
CUDNN_ATTN_DISABLE_PROJ_BIASES在注意力输入和输出投影中不使用偏置。
CUDNN_ATTN_ENABLE_PROJ_BIASES在注意力输入和输出投影中使用额外的偏置。在这种情况下,投影的 \(\bar{\textbf{K}}\) 向量计算为 \(\bar{\textbf{K}}_{i}=\textbf{W}_{K,i}\textbf{K}+\textbf{b}\ast \left[ 1,1,\cdots ,1 \right]_{1xn}\),其中 n 是 K 矩阵中的列数。换句话说,在权重矩阵乘法后,相同的列向量 b 被添加到 K 的所有列中。
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
不支持的功能
cudnnSeqDataDescriptor_t 中的
paddingFill参数当前被所有多头注意力函数忽略。
返回值
CUDNN_STATUS_SUCCESS注意力描述符已成功配置。
CUDNN_STATUS_BAD_PARAM遇到无效的输入参数。一些示例包括
后投影 Q 和 K 大小不相等
dataType、computePrec或mathType无效以下一个或多个参数为负数或零:
nHeads、qSize、kSize、vSize、qoMaxSeqLength、kvMaxSeqLength、maxBatchSize、maxBeamSize以下一个或多个参数为负数:
qProjSize、kProjSize、vProjSize、smScaler
CUDNN_STATUS_NOT_SUPPORTED不支持请求的选项或输入参数组合。
cudnnSetCTCLossDescriptor()#
此函数已在 cuDNN 9.0 中弃用;请使用 cudnnSetCTCLossDescriptor_v9() 代替。
此函数设置 CTC 损失函数描述符。请参阅扩展版本 cudnnSetCTCLossDescriptorEx() 以设置输入归一化模式。
cudnnStatus_t cudnnSetCTCLossDescriptor( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t compType)
当扩展版本 cudnnSetCTCLossDescriptorEx() 与设置为 CUDNN_LOSS_NORMALIZATION_NONE 的 normMode 和设置为 CUDNN_NOT_PROPAGATE_NAN 的 gradMode 一起使用时,它与当前函数 cudnnSetCTCLossDescriptor() 相同,意味着
cudnnSetCtcLossDescriptor(*) = cudnnSetCtcLossDescriptorEx(*, normMode=CUDNN_LOSS_NORMALIZATION_NONE, gradMode=CUDNN_NOT_PROPAGATE_NAN)
参数
ctcLossDesc输出。要设置的 CTC 损失描述符。
compType输入。此 CTC 损失函数的计算类型。
返回值
CUDNN_STATUS_SUCCESS函数成功返回。
CUDNN_STATUS_BAD_PARAM至少传递的输入参数之一无效。
cudnnSetCTCLossDescriptor_v8()#
此函数已在 cuDNN 9.0 中弃用;请使用 cudnnSetCTCLossDescriptor_v9() 代替。
许多 CTC API 函数在 v8 中更新以支持 CUDA 图。为此,需要一个新的参数 maxLabelLength。现在标签和输入数据被假定在 GPU 内存中,否则此信息不易获得。
cudnnStatus_t cudnnSetCTCLossDescriptor_v8( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t compType, cudnnLossNormalizationMode_t normMode, cudnnNanPropagation_t gradMode, int maxLabelLength)
参数
ctcLossDesc输出。要设置的 CTC 损失描述符。
compType输入。此 CTC 损失函数的计算类型。
normMode输入。此 CTC 损失函数的输入归一化类型。有关更多信息,请参阅 cudnnLossNormalizationMode_t。
gradMode输入。此 CTC 损失函数的
NaN传播类型。对于序列长度L,序列中重复字母的数量R,以及序列数据长度T,以下情况适用:当在梯度计算期间遇到L+R > T的样本时,如果gradMode设置为CUDNN_PROPAGATE_NAN(请参阅 cudnnNanPropagation_t),则 CTC 损失函数不会写入该样本的梯度缓冲区。相反,保留当前值,即使不是有限值。如果gradMode设置为CUDNN_NOT_PROPAGATE_NAN,则该样本的梯度设置为零。这保证了有限梯度。maxLabelLength输入。来自标签数据的最大标签长度。
返回值
CUDNN_STATUS_SUCCESS函数成功返回。
CUDNN_STATUS_BAD_PARAM至少传递的输入参数之一无效。
cudnnSetCTCLossDescriptor_v9()#
此函数设置 CTC 损失函数描述符。
cudnnStatus_t cudnnSetCTCLossDescriptor_v9( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t compType, cudnnLossNormalizationMode_t normMode, cudnnCTCGradMode_t ctcGradMode, int maxLabelLength)
参数
ctcLossDesc输出。要设置的 CTC 损失描述符。
compType输入。此 CTC 损失函数的计算类型。
normMode输入。此 CTC 损失函数的输入归一化类型。有关更多信息,请参阅 cudnnLossNormalizationMode_t。
ctcGradMode超出边界 (OOB) 样本的行为。OOB 样本是在梯度计算期间遇到 L+R > T 的样本。
如果
ctcGradMode设置为CUDNN_CTC_SKIP_OOB_GRADIENTS,则 CTC 损失函数不会写入该样本的梯度缓冲区。相反,保留当前值,即使不是有限值。如果
ctcGradMode设置为CUDNN_CTC_ZERO_OOB_GRADIENTS,则该样本的梯度设置为零。这保证了有限梯度。
maxLabelLength输入。来自标签数据的最大标签长度。
返回值
CUDNN_STATUS_SUCCESS函数成功返回。
CUDNN_STATUS_BAD_PARAM至少传递的输入参数之一无效。
cudnnSetCTCLossDescriptorEx()#
此函数已在 cuDNN 9.0 中弃用;请使用 cudnnSetCTCLossDescriptor_v9() 代替。
此函数是 cudnnSetCTCLossDescriptor() 的扩展。此函数提供了一个额外的接口 normMode,用于设置 CTC 损失函数的输入归一化模式,以及 gradMode,用于控制 NaN 传播类型。
cudnnStatus_t cudnnSetCTCLossDescriptorEx( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t compType, cudnnLossNormalizationMode_t normMode, cudnnNanPropagation_t gradMode)
当此函数 cudnnSetCTCLossDescriptorEx() 与设置为 CUDNN_LOSS_NORMALIZATION_NONE 的 normMode 和设置为 CUDNN_NOT_PROPAGATE_NAN 的 gradMode 一起使用时,它与 cudnnSetCTCLossDescriptor() 相同,意味着
cudnnSetCtcLossDescriptor(*) = cudnnSetCtcLossDescriptorEx(*, normMode=CUDNN_LOSS_NORMALIZATION_NONE, gradMode=CUDNN_NOT_PROPAGATE_NAN)
参数
ctcLossDesc输出。要设置的 CTC 损失描述符。
compType输入。此 CTC 损失函数的计算类型。
normMode输入。此 CTC 损失函数的输入归一化类型。有关更多信息,请参阅 cudnnLossNormalizationMode_t。
gradMode输入。此 CTC 损失函数的 NaN 传播类型。对于序列长度
L,序列中重复字母的数量R,以及序列数据长度T,以下情况适用:当在梯度计算期间遇到L+R > T的样本时,如果gradMode设置为CUDNN_PROPAGATE_NAN(请参阅 cudnnNanPropagation_t),则 CTC 损失函数不会写入该样本的梯度缓冲区。相反,保留当前值,即使不是有限值。如果gradMode设置为CUDNN_NOT_PROPAGATE_NAN,则该样本的梯度设置为零。这保证了有限梯度。
返回值
CUDNN_STATUS_SUCCESS函数成功返回。
CUDNN_STATUS_BAD_PARAM至少传递的输入参数之一无效。
cudnnSetRNNDataDescriptor()#
此函数初始化先前创建的 RNN 数据描述符对象。此数据结构旨在支持扩展 RNN 推理和训练函数的输入和输出的解包(填充)布局。为了向后兼容,也支持打包(非填充)布局。
cudnnStatus_t cudnnSetRNNDataDescriptor( cudnnRNNDataDescriptor_t RNNDataDesc, cudnnDataType_t dataType, cudnnRNNDataLayout_t layout, int maxSeqLength, int batchSize, int vectorSize, const int seqLengthArray[], void *paddingFill);
参数
RNNDataDesc输入/输出。先前创建的 RNN 描述符。有关更多信息,请参阅 cudnnRNNDataDescriptor_t。
dataType输入。RNN 数据张量的数据类型。有关更多信息,请参阅 cudnnDataType_t。
layout输入。RNN 数据张量的内存布局。
maxSeqLength输入。此 RNN 数据张量中的最大序列长度。在解包(填充)布局中,这应包括每个序列中的填充向量。在打包(非填充)布局中,这应等于
seqLengthArray中的最大元素。batchSize输入。小批量中的序列数。
vectorSize输入。每个时间步的输入或输出张量的向量长度(嵌入大小)。
seqLengthArray输入。一个整数数组,包含
batchSize个元素。描述每个序列的长度(时间步数)。seqLengthArray中的每个元素都必须大于或等于 0,但小于或等于maxSeqLength。在打包布局中,元素应按降序排序,类似于非扩展 RNN 计算函数所需的布局。paddingFill输入。用户定义的符号,用于填充 RNN 输出中的填充位置。这仅在描述 RNN 输出并且指定了解包布局时才有效。该符号应位于主机内存中,并解释为与 RNN 数据张量的数据类型相同的数据类型。如果传入
NULL指针,则输出中的填充位置将未定义。
返回值
CUDNN_STATUS_SUCCESS对象已成功设置。
CUDNN_STATUS_NOT_SUPPORTED以下任何一种情况均会发生
dataType不是CUDNN_DATA_HALF、CUDNN_DATA_FLOAT或CUDNN_DATA_DOUBLE中的一种。maxSeqLength大于 65535 (0xffff)。
CUDNN_STATUS_BAD_PARAM以下任何一种情况均会发生
RNNDataDesc为NULL。maxSeqLength、batchSize或vectorSize中任何一个小于或等于零。seqLengthArray的一个元素小于零或大于maxSeqLength。布局不是
CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_UNPACKED、CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_PACKED或CUDNN_RNN_DATA_LAYOUT_BATCH_MAJOR_UNPACKED中的一种。
CUDNN_STATUS_ALLOC_FAILED内部数组存储的分配失败。
cudnnSetRNNDescriptor_v8()#
此函数初始化先前创建的 RNN 描述符对象。由 cudnnSetRNNDescriptor_v8() 配置的 RNN 描述符已得到增强,可以存储计算 RNN 模型中可调整权重/偏置总数所需的所有信息。
cudnnStatus_t cudnnSetRNNDescriptor_v8( cudnnRNNDescriptor_t rnnDesc, cudnnRNNAlgo_t algo, cudnnRNNMode_t cellMode, cudnnRNNBiasMode_t biasMode, cudnnDirectionMode_t dirMode, cudnnRNNInputMode_t inputMode, cudnnDataType_t dataType, cudnnDataType_t mathPrec, cudnnMathType_t mathType, int32_t inputSize, int32_t hiddenSize, int32_t projSize, int32_t numLayers, cudnnDropoutDescriptor_t dropoutDesc, uint32_t auxFlags);
参数
rnnDesc输入。先前初始化的 RNN 描述符。
algo输入。RNN 算法 (
CUDNN_RNN_ALGO_STANDARD、CUDNN_RNN_ALGO_PERSIST_STATIC、CUDNN_RNN_ALGO_PERSIST_DYNAMIC或CUDNN_RNN_ALGO_PERSIST_STATIC_SMALL_H)。cellMode输入。指定整个模型中的 RNN 单元类型 (
CUDNN_RNN_RELU、CUDNN_RNN_TANH、CUDNN_RNN_LSTM、CUDNN_RNN_GRU)。biasMode输入。设置偏置向量的数量 (
CUDNN_RNN_NO_BIAS、CUDNN_RNN_SINGLE_INP_BIAS、CUDNN_RNN_SINGLE_REC_BIAS、CUDNN_RNN_DOUBLE_BIAS)。对于RELU、TANH和LSTM单元类型,两种单偏置设置在功能上是相同的。有关 GRU 单元的差异,请参阅 cudnnRNNMode_t 枚举类型中CUDNN_GRU的描述。CUDNN_RNN_ALGO_STANDARD接受所有偏置模式。其余 RNN 算法仅适用于CUDNN_RNN_DOUBLE_BIAS。dirMode输入。指定循环模式:
CUDNN_UNIDIRECTIONAL或CUDNN_BIDIRECTIONAL。在双向 RNN 中,在物理层之间传递的隐藏状态是前向和后向隐藏状态的串联。inputMode输入。指定 RNN 模型的输入如何由第一层处理。当
inputMode为CUDNN_LINEAR_INPUT时,大小为inputSize的原始输入向量与权重矩阵相乘,以获得大小为hiddenSize的向量。当inputMode为CUDNN_SKIP_INPUT时,第一层的原始输入向量按原样使用,而无需与权重矩阵相乘。dataType输入。指定 RNN 权重/偏置以及输入和输出数据的数据类型。
mathPrec输入。此参数用于控制 RNN 模型中的计算数学精度。以下适用
对于 FP16 中的输入/输出,参数
mathPrec可以是CUDNN_DATA_HALF或CUDNN_DATA_FLOAT。对于 FP32 中的输入/输出,参数
mathPrec只能是CUDNN_DATA_FLOAT。对于 FP64 中的输入/输出,双精度类型,参数
mathPrec只能是CUDNN_DATA_DOUBLE。
mathType输入。设置在 Volta (SM 7.0) 或更高版本的 GPU 上使用 NVIDIA Tensor Cores 加速器的首选选项。
当
dataType为CUDNN_DATA_HALF时,mathType参数可以是CUDNN_DEFAULT_MATH或CUDNN_TENSOR_OP_MATH。ALLOW_CONVERSION设置对于此数据类型被视为与CUDNN_TENSOR_OP_MATH相同。当
dataType为CUDNN_DATA_FLOAT时,mathType参数可以是CUDNN_DEFAULT_MATH或CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION。当使用后一种设置时,原始权重和中间结果将在另一次递归迭代中使用之前下转换为CUDNN_DATA_HALF。当
dataType为CUDNN_DATA_DOUBLE时,mathType参数可以是CUDNN_DEFAULT_MATH。
此选项具有建议性质,意味着 Tensor Cores 可能并不总是被利用,例如,由于特定的 GEMM 维度限制。
inputSize输入。RNN 模型中输入向量的大小。当
inputMode=CUDNN_SKIP_INPUT时,inputSize应与hiddenSize值匹配。hiddenSize输入。RNN 模型中隐藏状态向量的大小。所有 RNN 层都使用相同的隐藏大小。
projSize输入。LSTM 单元在循环投影后的输出大小。启用 LSTM 投影后,此值应小于
hiddenSize。禁用 LSTM 投影时,对于所有其他 RNN 单元类型(CUDNN_RNN_RELU、CUDNN_RNN_TANH和CUDNN_RNN_GRU),projSize必须等于hiddenSize。循环投影是 LSTM 单元中的一个额外的矩阵乘法,用于将隐藏状态向量 h t 投影(压缩)为较小的向量 r t = W r h t,其中 W r 是一个具有projSize行和hiddenSize列的矩形矩阵。启用循环投影后,LSTM 单元的输出(到下一层和及时展开)是 r t 而不是 h t。循环投影只能为 LSTM 单元和CUDNN_RNN_ALGO_STANDARD启用。numLayers输入。深度 RNN 模型中堆叠的物理层数。当
dirMode= CUDNN_BIDIRECTIONAL时,物理层由两个伪层组成,分别对应于前向和后向方向。dropoutDesc输入。先前创建和初始化的 dropout 描述符的句柄。Dropout 操作将在物理层之间应用。单层网络将不应用 dropout。Dropout 仅在训练模式下使用。
auxFlags输入。此参数用于传递不需要额外数值来配置相应功能的各种开关。在未来的 cuDNN 版本中,此参数将用于扩展 RNN 功能,而无需添加新的 API 函数(适用的选项应按位
OR运算)。目前,此参数用于启用或禁用填充的输入/输出 (CUDNN_RNN_PADDED_IO_DISABLED、CUDNN_RNN_PADDED_IO_ENABLED)。启用填充 I/O 后,RNN 数据描述符中允许使用布局CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_UNPACKED和CUDNN_RNN_DATA_LAYOUT_BATCH_MAJOR_UNPACKED。
返回值
CUDNN_STATUS_SUCCESSRNN 描述符已成功配置。
CUDNN_STATUS_BAD_PARAM检测到无效的输入参数。
CUDNN_STATUS_NOT_SUPPORTED检测到不兼容或不支持的输入参数组合。
cudnnSetSeqDataDescriptor()#
此函数已在 cuDNN 9.0 中弃用。
此函数初始化先前创建的序列数据描述符对象。在最简化的视图中,此描述符定义了四维张量的维度 (dimA) 和数据布局 (axes)。
cudnnStatus_t cudnnSetSeqDataDescriptor( cudnnSeqDataDescriptor_t seqDataDesc, cudnnDataType_t dataType, int nbDims, const int dimA[], const cudnnSeqDataAxis_t axes[], size_t seqLengthArraySize, const int seqLengthArray[], void *paddingFill);
序列数据描述符的所有四个维度都具有唯一标识符,可用于索引 dimA[] 数组
CUDNN_SEQDATA_TIME_DIM CUDNN_SEQDATA_BATCH_DIM CUDNN_SEQDATA_BEAM_DIM CUDNN_SEQDATA_VECT_DIM
例如,要表达我们序列数据缓冲区中的向量长度为五个元素的信息,我们需要在 dimA[] 数组中赋值 dimA[CUDNN_SEQDATA_VECT_DIM]=5。
dimA[] 和 axes[] 数组中活动维度的数量由 nbDims 参数定义。目前,此参数的值应为四。 dimA[] 和 axes[] 数组的实际大小应使用 CUDNN_SEQDATA_DIM_COUNT 宏声明。
cudnnSeqDataDescriptor_t 容器被视为形成序列的固定长度向量的集合,类似于单词(字符向量)构造句子。TIME 维度跨越序列长度。不同的序列捆绑在一起成一个批次。BATCH 可以是一组单独的序列或束。BEAM 是备选序列或候选序列的集群。在考虑束时,请考虑从一种语言到另一种语言的翻译任务。您可能希望保留并尝试原始句子的几个翻译版本,然后再选择最佳版本。保留的候选版本数量就是 BEAM 大小。
每个序列可以具有不同的长度,即使在同一束内也是如此,因此序列末尾的向量可能只是填充。paddingFill 参数指定填充向量应如何写入输出序列数据缓冲区。paddingFill 参数指向 dataType 类型的一个值,该值应复制到填充向量中的所有元素。目前,paddingFill 唯一支持的值是 NULL,这意味着应忽略此选项。在这种情况下,输出缓冲区中填充向量的元素将具有未定义的值。
假设非空序列始终从时间索引零开始。seqLengthArray[] 必须指定容器中的所有序列长度,因此此数组的总大小应为 dimA[CUDNN_SEQDATA_BATCH_DIM] * dimA[CUDNN_SEQDATA_BEAM_DIM]。seqLengthArray[] 数组的每个元素都应具有非负值,小于或等于 dimA[CUDNN_SEQDATA_TIME_DIM];最大序列长度。seqLengthArray[] 中的元素始终以相同的批次主顺序排列,这意味着,在考虑 BEAM 和 BATCH 维度时,当我们以地址升序遍历数组时,BATCH 是外部索引或变化较慢的索引。使用一个简单的示例,seqLengthArray[] 数组应按以下顺序保存序列长度
{batch_idx=0, beam_idx=0} {batch_idx=0, beam_idx=1} {batch_idx=1, beam_idx=0} {batch_idx=1, beam_idx=1} {batch_idx=2, beam_idx=0} {batch_idx=2, beam_idx=1}
当 dimA[CUDNN_SEQDATA_BATCH_DIM]=3 且 dimA[CUDNN_SEQDATA_BEAM_DIM]=2 时。
存储在 cudnnSeqDataDescriptor_t 容器中的数据必须符合以下约束
所有数据都完全打包。各个向量元素或连续向量之间没有未使用的空间或间隙。
容器的最内层维度是向量。换句话说,第一个连续的
dimA[CUDNN_SEQDATA_VECT_DIM]元素组属于第一个向量,然后是第二个向量的元素,依此类推。
cudnnSeqDataDescriptor_t 函数中的 axes 参数有点复杂。此数组应具有与 dimA[] 相同的容量。axes[] 数组指定 GPU 内存中的实际数据布局。在此函数中,布局按以下方式描述:当我们通过递增元素指针从一个向量的元素移动到内存中的另一个元素时,我们遇到的 VECT、TIME、BATCH 和 BEAM 维度的顺序是什么。假设我们要定义以下数据布局
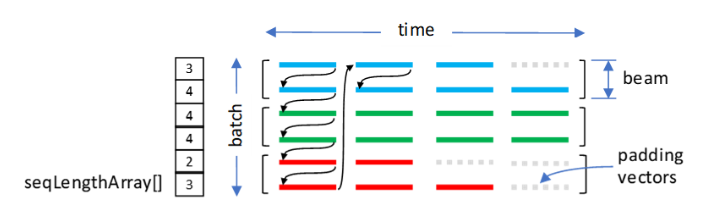
这对应于张量维度
int dimA[CUDNN_SEQDATA_DIM_COUNT]; dimA[CUDNN_SEQDATA_TIME_DIM] = 4; dimA[CUDNN_SEQDATA_BATCH_DIM] = 3; dimA[CUDNN_SEQDATA_BEAM_DIM] = 2; dimA[CUDNN_SEQDATA_VECT_DIM] = 5;
现在,让我们初始化 axes[] 数组。请注意,最内层维度由 axes[] 的最后一个活动元素描述。这里只有一个有效的配置,因为我们总是首先遍历整个向量。因此,我们需要在 axes[] 的最后一个活动元素中写入 CUDNN_SEQDATA_VECT_DIM。
cudnnSeqDataAxis_t axes[CUDNN_SEQDATA_DIM_COUNT]; axes[3] = CUDNN_SEQDATA_VECT_DIM; // 3 = nbDims-1
现在,让我们处理 axes[] 的其余三个元素。当我们到达第一个向量的末尾时,我们跳转到下一个 BEAM,因此
axes[2] = CUDNN_SEQDATA_BEAM_DIM;
当我们接近第二个向量的末尾时,我们移动到下一个批次,因此
axes[1] = CUDNN_SEQDATA_BATCH_DIM;
最后一个(最外层)维度是 TIME
axes[0] = CUDNN_SEQDATA_TIME_DIM;
axes[] 数组的四个值完全描述了图中描绘的数据布局。
序列数据描述符允许用户选择 3! = 6 种不同的数据布局或 BEAM、BATCH 和 TIME 维度的排列。多头注意力 API 支持所有六种布局。
参数
seqDataDesc输出。指向先前创建的序列数据描述符的指针。
dataType输入。序列数据缓冲区的数据类型 (
CUDNN_DATA_HALF、CUDNN_DATA_FLOAT或CUDNN_DATA_DOUBLE)。nbDims输入。必须为 4。
dimA[]和axes[]数组中活动维度的数量。这两个数组都应声明为至少包含CUDNN_SEQDATA_DIM_COUNT个元素。dimA[]输入。指定序列数据维度的整数数组。使用 cudnnSeqDataAxis_t 枚举类型来索引所有活动的
dimA[]元素。axes[]输入。cudnnSeqDataAxis_t 数组,用于定义内存中序列数据的布局。
axes[]的前nbDims个元素应使用axes[0]中的最外层维度和axes[nbDims-1]中的最内层维度进行初始化。seqLengthArraySize输入。序列长度数组
seqLengthArray[]中的元素数量。seqLengthArray[]输入。一个整数数组,用于定义容器的所有序列长度。
paddingFill输入。必须为
NULL。指向dataType类型值的指针,该值用于填充超出每个序列有效长度的输出向量,或者为NULL以忽略此设置。
返回值
CUDNN_STATUS_SUCCESS所有输入参数均已验证,序列数据描述符已成功更新。
CUDNN_STATUS_BAD_PARAM找到无效的输入参数。一些示例包括
seqDataDesc=NULLdateType不是 cudnnDataType_t 的有效类型nbDims为负数或零seqLengthArraySize与预期长度不匹配seqLengthArray[]的某些元素无效
CUDNN_STATUS_NOT_SUPPORTED遇到不支持的输入参数。一些示例包括
nbDims不等于 4paddingFill不是NULL
CUDNN_STATUS_ALLOC_FAILED无法为序列数据描述符对象分配存储空间。