简介
NVIDIA HGX A100 结合了 NVIDIA A100 Tensor Core GPU 与下一代 NVIDIA® NVLink® 和 NVSwitch™ 高速互连,打造了世界上最强大的服务器。HGX A100 提供单基板四颗或八颗 A100 GPU 的配置。四 GPU 配置 (HGX A100 4-GPU) 通过 NVIDIA NVLink 完全互连,八 GPU 配置 (HGX A100 8-GPU) 通过 NVSwitch 互连。两个 NVIDIA HGX A100 8-GPU 基板也可以使用 NVSwitch 互连组合,以创建一个强大的 16 GPU 单节点。
更多信息请访问产品网站。
本文档概述了 NVIDIA 提供的用于开始使用配备 NVIDIA HGX A100 系统的基础软件。
软件配置
请注意,HGX A100 4-GPU 系统不包含 NVSwitch,因此 FM 不是此系统配置上的必需组件。
为了方便起见,NVIDIA 在网络存储库上提供了软件包,以便使用 Linux 软件包管理器 (apt/dnf/zypper) 进行安装,并使用软件包依赖关系按顺序安装这些软件组件。
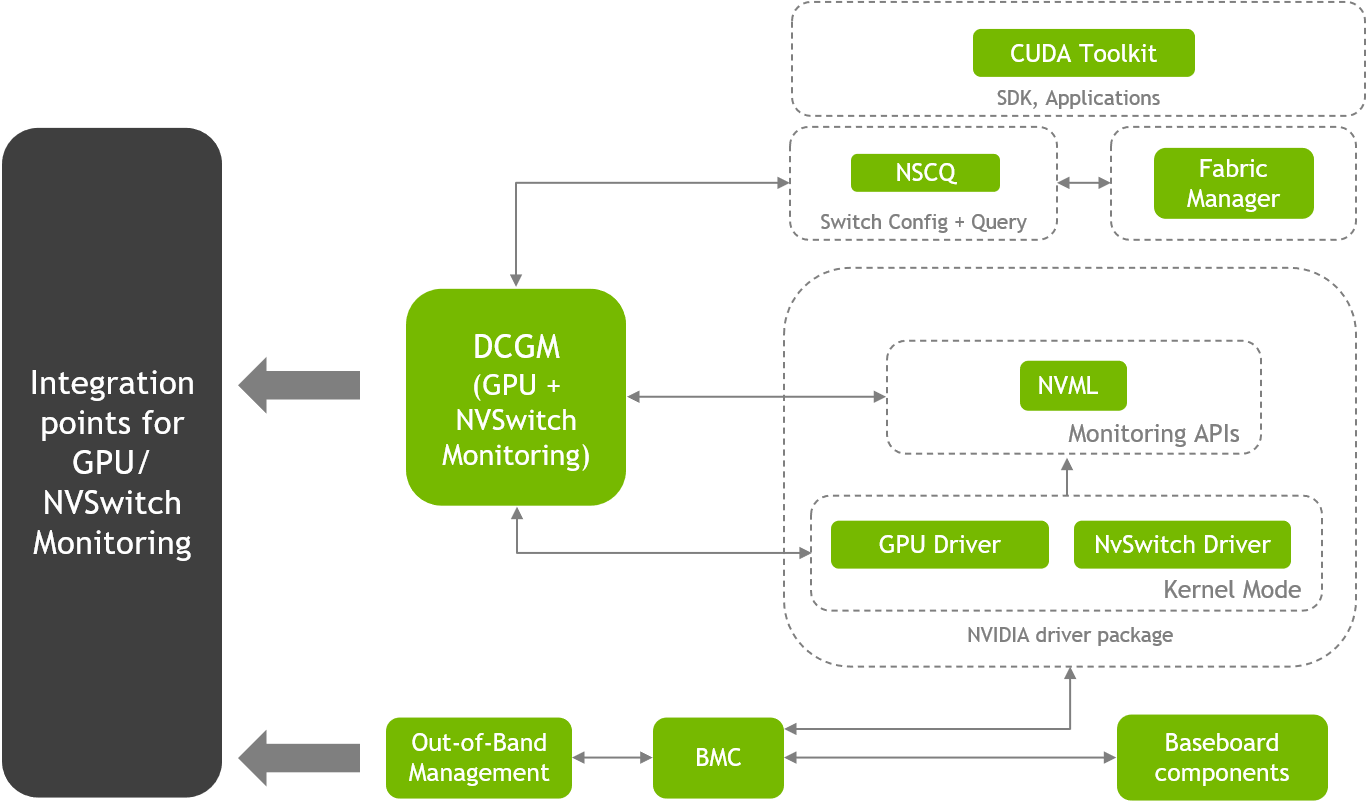
NVIDIA 数据中心驱动程序
NVIDIA 发布了适用于企业和数据中心 GPU 的合格驱动程序。门户网站包括发行说明、软件生命周期(包括活动驱动程序分支)、安装和用户指南。
根据软件生命周期,用于 NVIDIA HGX A100 生产的最低推荐驱动程序是 R450。有关活动和受支持的驱动程序分支,请参阅生命周期。
下表列出了当前积极支持的数据中心驱动程序。
| R418 | R440 | R450 | |
|---|---|---|---|
| 分支名称 | 长期服务分支 | 新功能分支 | 长期服务分支 |
| 生命周期结束 | 2022 年 3 月 | 2020 年 11 月 | 2023 年 7 月 |
| 支持的最大 CUDA 版本 | CUDA 10.1。 此驱动程序分支通过 CUDA 兼容性平台支持 CUDA 10.2 和 CUDA 11.0。 |
CUDA 10.2。 此驱动程序分支通过 CUDA 兼容性平台支持 CUDA 11.0。 |
CUDA 11.0 |
| 支持的架构 | Turing 及更低版本。 | Turing 及更低版本。 | NVIDIA Ampere 及更低版本。 |
对于基于 A100 (NVIDIA Ampere 架构) 的系统(如 HGX A100),R450 驱动程序是最低要求。在设置 HGX A100 系统之前,请确保您已完成先决条件 - 具体而言,您正在运行受支持的 Linux 发行版,系统具有构建工具(例如 gcc/make)和内核头文件。更多信息请访问此处。
要开始安装驱动程序和 NVIDIA Fabric Manager (FM),首先设置 CUDA 网络存储库和存储库优先级
distribution=$(. /etc/os-release;echo $ID$VERSION_ID | sed -e 's/\.//g') \
&& wget https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/cuda-$distribution.pin \
&& sudo mv cuda-$distribution.pin /etc/apt/preferences.d/cuda-repository-pin-600
设置 GPG 密钥
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/7fa2af80.pub \
&& echo "deb http://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64 /" | sudo tee /etc/apt/sources.list.d/cuda.list \
&& sudo apt-get update
由于 FM 和 NSCQ 与驱动程序版本锁定,NVIDIA 提供了一个名为 cuda-drivers-fabricmanager-<branch-number> 的元软件包,以确保使用依赖关系一起安装 FM 和驱动程序。
由于我们使用的是 HGX A100,我们将选择 R450 驱动程序分支。例如,下面显示了此软件包的依赖关系树
├─ cuda-drivers-fabricmanager-450
│ ├─ cuda-drivers-450 (= 450.80.02-1)
│ └─ nvidia-fabricmanager-450 (= 450.80.02-1)
可以使用 apt-cache 查看可用的软件包版本
sudo apt-cache madison cuda-drivers-fabricmanager-450
cuda-drivers-fabricmanager-450 | 450.80.02-1 | http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Packages
cuda-drivers-fabricmanager-450 | 450.51.06-1 | http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Packages
cuda-drivers-fabricmanager-450 | 450.51.06-1 | http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Packages
现在使用 cuda-drivers-fabricmanager-450 安装驱动程序
sudo apt-get -y cuda-drivers-fabricmanager-450
驱动程序安装完成后,您可能需要重启系统。系统可用后,运行 nvidia-smi 命令以观察系统中的所有 8 个 GPU 和 6 个 NVSwitch
nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.80.02 Driver Version: 450.80.02 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 A100-SXM4-40GB On | 00000000:07:00.0 Off | Off |
| N/A 22C P0 52W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 1 A100-SXM4-40GB On | 00000000:0F:00.0 Off | Off |
| N/A 22C P0 49W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 2 A100-SXM4-40GB On | 00000000:47:00.0 Off | Off |
| N/A 21C P0 49W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 3 A100-SXM4-40GB On | 00000000:4E:00.0 Off | Off |
| N/A 23C P0 53W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 4 A100-SXM4-40GB On | 00000000:87:00.0 Off | Off |
| N/A 24C P0 51W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 5 A100-SXM4-40GB On | 00000000:90:00.0 Off | Off |
| N/A 23C P0 49W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 6 A100-SXM4-40GB On | 00000000:B7:00.0 Off | Off |
| N/A 23C P0 51W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 7 A100-SXM4-40GB On | 00000000:BD:00.0 Off | Off |
| N/A 25C P0 52W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
NVIDIA Fabric Manager
Fabric Manager 是一个代理,用于配置 NVSwitch 以在所有参与的 GPU 之间形成单个内存 Fabric,并监控支持内存 Fabric 的 NVLink。有关使用和配置(包括高级选项)的更多信息,请参阅Fabric Manager 用户指南。
在上一节中安装软件包后,检查已安装的 FM 版本
/usr/bin/nv-fabricmanager --version
Fabric Manager version is : 450.80.02
使用提供的 systemd 服务文件启动 FM 服务
sudo systemctl status nvidia-fabricmanager.service
● nvidia-fabricmanager.service - NVIDIA fabric manager service
Loaded: loaded (/lib/systemd/system/nvidia-fabricmanager.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2020-10-12 11:23:25 PDT; 11min ago
Process: 10981 ExecStart=/usr/bin/nv-fabricmanager -c /usr/share/nvidia/nvswitch/fabricmanager.cfg (code=exited, status=0/SUCCESS)
Main PID: 10992 (nv-fabricmanage)
Tasks: 18 (limit: 39321)
CGroup: /system.slice/nvidia-fabricmanager.service
└─10992 /usr/bin/nv-fabricmanager -c /usr/share/nvidia/nvswitch/fabricmanager.cfg
Oct 12 11:23:09 ubuntu1804 systemd[1]: Starting NVIDIA fabric manager service...
Oct 12 11:23:25 ubuntu1804 nv-fabricmanager[10992]: Successfully configured all the available GPUs and NVSwitches.
Oct 12 11:23:25 ubuntu1804 systemd[1]: Started NVIDIA fabric manager service.
检查服务状态
sudo systemctl start nvidia-fabricmanager.service
确保 Fabric Manager 日志(在 /var/log/fabricmanager.log 下)不包含任何错误。
现在查看拓扑,确保对等 GPU 之间出现“NV12”。这表明所有 12 个 NVLink 都已训练并可用于全双向带宽。可以使用 nvidia-smi topo -m 命令完成此操作。
nvidia-smi topo -m
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 mlx5_0 mlx5_1 mlx5_2 mlx5_3 mlx5_4 mlx5_5 mlx5_6 mlx5_7 mlx5_8 mlx5_9 CPU Affinity NUMA Affinity
GPU0 X NV12 NV12 NV12 NV12 NV12 NV12 NV12 PXB PXB SYS SYS SYS SYS SYS SYS SYS SYS 48-63,176-191 3
GPU1 NV12 X NV12 NV12 NV12 NV12 NV12 NV12 PXB PXB SYS SYS SYS SYS SYS SYS SYS SYS 48-63,176-191 3
GPU2 NV12 NV12 X NV12 NV12 NV12 NV12 NV12 SYS SYS PXB PXB SYS SYS SYS SYS SYS SYS 16-31,144-159 1
GPU3 NV12 NV12 NV12 X NV12 NV12 NV12 NV12 SYS SYS PXB PXB SYS SYS SYS SYS SYS SYS 16-31,144-159 1
GPU4 NV12 NV12 NV12 NV12 X NV12 NV12 NV12 SYS SYS SYS SYS PXB PXB SYS SYS SYS SYS 112-127,240-255 7
GPU5 NV12 NV12 NV12 NV12 NV12 X NV12 NV12 SYS SYS SYS SYS PXB PXB SYS SYS SYS SYS 112-127,240-255 7
GPU6 NV12 NV12 NV12 NV12 NV12 NV12 X NV12 SYS SYS SYS SYS SYS SYS PXB PXB SYS SYS 80-95,208-223 5
GPU7 NV12 NV12 NV12 NV12 NV12 NV12 NV12 X SYS SYS SYS SYS SYS SYS PXB PXB SYS SYS 80-95,208-223 5
mlx5_0 PXB PXB SYS SYS SYS SYS SYS SYS X PXB SYS SYS SYS SYS SYS SYS SYS SYS
mlx5_1 PXB PXB SYS SYS SYS SYS SYS SYS PXB X SYS SYS SYS SYS SYS SYS SYS SYS
mlx5_2 SYS SYS PXB PXB SYS SYS SYS SYS SYS SYS X PXB SYS SYS SYS SYS SYS SYS
mlx5_3 SYS SYS PXB PXB SYS SYS SYS SYS SYS SYS PXB X SYS SYS SYS SYS SYS SYS
mlx5_4 SYS SYS SYS SYS PXB PXB SYS SYS SYS SYS SYS SYS X PXB SYS SYS SYS SYS
mlx5_5 SYS SYS SYS SYS PXB PXB SYS SYS SYS SYS SYS SYS PXB X SYS SYS SYS SYS
mlx5_6 SYS SYS SYS SYS SYS SYS PXB PXB SYS SYS SYS SYS SYS SYS X PXB SYS SYS
mlx5_7 SYS SYS SYS SYS SYS SYS PXB PXB SYS SYS SYS SYS SYS SYS PXB X SYS SYS
mlx5_8 SYS SYS SYS SYS SYS SYS SYS SYS SYS SYS SYS SYS SYS SYS SYS SYS X PIX
mlx5_9 SYS SYS SYS SYS SYS SYS SYS SYS SYS SYS SYS SYS SYS SYS SYS SYS PIX X
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
NVSwitch 配置和查询库 (NSCQ)
NSCQ 库当前向库的客户端(如 DCGM)提供 NVSwitch 和 GPU 的拓扑信息。
请注意,目前 DCGM 是 NSCQ 的唯一客户端。将来,NSCQ 将包含用于收集 NVSwitch 信息的公共 API。为了允许 DCGM 等客户端访问 NSCQ,应在系统上安装该库 - 请注意,在不久的将来,该库软件包将作为驱动程序的一部分安装,类似于 FM。
使用 libnvidia-nscq-450 软件包设置库。
sudo apt-get install -y libnvidia-nscq-450
安装软件包后,您应该能够在系统上的标准安装路径中验证库
ls -ol /usr/lib/x86_64-linux-gnu/libnvidia-nscq*
lrwxrwxrwx 1 root 24 Sep 29 13:01 /usr/lib/x86_64-linux-gnu/libnvidia-nscq-dcgm.so -> libnvidia-nscq-dcgm.so.1
lrwxrwxrwx 1 root 26 Sep 29 13:01 /usr/lib/x86_64-linux-gnu/libnvidia-nscq-dcgm.so.1 -> libnvidia-nscq-dcgm.so.1.0
lrwxrwxrwx 1 root 32 Sep 29 13:01 /usr/lib/x86_64-linux-gnu/libnvidia-nscq-dcgm.so.1.0 -> libnvidia-nscq-dcgm.so.450.51.06
-rwxr-xr-x 1 root 1041416 Sep 29 12:56 /usr/lib/x86_64-linux-gnu/libnvidia-nscq-dcgm.so.450.51.06
lrwxrwxrwx 1 root 19 Sep 22 21:48 /usr/lib/x86_64-linux-gnu/libnvidia-nscq.so -> libnvidia-nscq.so.1
lrwxrwxrwx 1 root 21 Sep 22 21:48 /usr/lib/x86_64-linux-gnu/libnvidia-nscq.so.1 -> libnvidia-nscq.so.1.0
lrwxrwxrwx 1 root 27 Sep 22 21:48 /usr/lib/x86_64-linux-gnu/libnvidia-nscq.so.1.0 -> libnvidia-nscq.so.450.80.02
-rw-r--r-- 1 root 1041416 Sep 22 21:48 /usr/lib/x86_64-linux-gnu/libnvidia-nscq.so.450.80.02
CUDA 工具包
安装 NVIDIA 驱动程序、Fabric Manager 和 NSCQ 后,您可以继续在系统上安装 CUDA 工具包以构建 CUDA 应用程序。请注意,如果您仅部署 CUDA 应用程序,则 CUDA 工具包不是必需的,因为 CUDA 应用程序应包含其所需的依赖项。
要安装 CUDA 工具包,让我们使用 cuda-toolkit-11-0 元软件包。对于其他元软件包,请查看文档中的此表。此元软件包仅安装 CUDA 工具包(不安装 NVIDIA 驱动程序)。
使用以下命令检查可用的元软件包
sudo apt-cache madison cuda-toolkit-11-
cuda-toolkit-11-0 cuda-toolkit-11-1
APT 显示有两个可用的 CUDA 版本。为了本文档的目的,让我们选择 CUDA 11.0
sudo apt-cache madison cuda-toolkit-11-0
cuda-toolkit-11-0 | 11.0.3-1 | http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Packages
cuda-toolkit-11-0 | 11.0.3-1 | http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Packages
cuda-toolkit-11-0 | 11.0.3-1 | http://international.download.nvidia.com/dgx/repos/bionic bionic-4.99/multiverse amd64 Packages
cuda-toolkit-11-0 | 11.0.2-1 | http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Packages
cuda-toolkit-11-0 | 11.0.2-1 | http://international.download.nvidia.com/dgx/repos/bionic bionic-4.99/multiverse amd64 Packages
cuda-toolkit-11-0 | 11.0.1-1 | http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Packages
cuda-toolkit-11-0 | 11.0.1-1 | http://international.download.nvidia.com/dgx/repos/bionic bionic-4.99/multiverse amd64 Packages
cuda-toolkit-11-0 | 11.0.0-1 | http://international.download.nvidia.com/dgx/repos/bionic bionic-4.99/multiverse amd64 Packages
您现在可以继续安装 CUDA 工具包:
sudo apt-get install -y cuda-toolkit-11-0
安装 CUDA 后,让我们构建包含的 CUDA p2pBandwidthLatencyTest 示例。二进制文件可用后,我们可以运行它来检查单向和双向带宽。
./bin/x86_64/linux/release/p2pBandwidthLatencyTest
[P2P (Peer-to-Peer) GPU Bandwidth Latency Test]
Device: 0, A100-SXM4-40GB, pciBusID: 7, pciDeviceID: 0, pciDomainID:0
Device: 1, A100-SXM4-40GB, pciBusID: f, pciDeviceID: 0, pciDomainID:0
Device: 2, A100-SXM4-40GB, pciBusID: 47, pciDeviceID: 0, pciDomainID:0
Device: 3, A100-SXM4-40GB, pciBusID: 4e, pciDeviceID: 0, pciDomainID:0
Device: 4, A100-SXM4-40GB, pciBusID: 87, pciDeviceID: 0, pciDomainID:0
Device: 5, A100-SXM4-40GB, pciBusID: 90, pciDeviceID: 0, pciDomainID:0
Device: 6, A100-SXM4-40GB, pciBusID: b7, pciDeviceID: 0, pciDomainID:0
Device: 7, A100-SXM4-40GB, pciBusID: bd, pciDeviceID: 0, pciDomainID:0
Device=0 CAN Access Peer Device=1
Device=0 CAN Access Peer Device=2
Device=0 CAN Access Peer Device=3
Device=0 CAN Access Peer Device=4
Device=0 CAN Access Peer Device=5
Device=0 CAN Access Peer Device=6
Device=0 CAN Access Peer Device=7
Device=1 CAN Access Peer Device=0
Device=1 CAN Access Peer Device=2
Device=1 CAN Access Peer Device=3
Device=1 CAN Access Peer Device=4
Device=1 CAN Access Peer Device=5
Device=1 CAN Access Peer Device=6
Device=1 CAN Access Peer Device=7
Device=2 CAN Access Peer Device=0
Device=2 CAN Access Peer Device=1
Device=2 CAN Access Peer Device=3
Device=2 CAN Access Peer Device=4
Device=2 CAN Access Peer Device=5
Device=2 CAN Access Peer Device=6
Device=2 CAN Access Peer Device=7
Device=3 CAN Access Peer Device=0
Device=3 CAN Access Peer Device=1
Device=3 CAN Access Peer Device=2
Device=3 CAN Access Peer Device=4
Device=3 CAN Access Peer Device=5
Device=3 CAN Access Peer Device=6
Device=3 CAN Access Peer Device=7
Device=4 CAN Access Peer Device=0
Device=4 CAN Access Peer Device=1
Device=4 CAN Access Peer Device=2
Device=4 CAN Access Peer Device=3
Device=4 CAN Access Peer Device=5
Device=4 CAN Access Peer Device=6
Device=4 CAN Access Peer Device=7
Device=5 CAN Access Peer Device=0
Device=5 CAN Access Peer Device=1
Device=5 CAN Access Peer Device=2
Device=5 CAN Access Peer Device=3
Device=5 CAN Access Peer Device=4
Device=5 CAN Access Peer Device=6
Device=5 CAN Access Peer Device=7
Device=6 CAN Access Peer Device=0
Device=6 CAN Access Peer Device=1
Device=6 CAN Access Peer Device=2
Device=6 CAN Access Peer Device=3
Device=6 CAN Access Peer Device=4
Device=6 CAN Access Peer Device=5
Device=6 CAN Access Peer Device=7
Device=7 CAN Access Peer Device=0
Device=7 CAN Access Peer Device=1
Device=7 CAN Access Peer Device=2
Device=7 CAN Access Peer Device=3
Device=7 CAN Access Peer Device=4
Device=7 CAN Access Peer Device=5
Device=7 CAN Access Peer Device=6
***NOTE: In case a device doesn't have P2P access to other one, it falls back to normal memcopy procedure.
So you can see lesser Bandwidth (GB/s) and unstable Latency (us) in those cases.
P2P Connectivity Matrix
D\D 0 1 2 3 4 5 6 7
0 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1
2 1 1 1 1 1 1 1 1
3 1 1 1 1 1 1 1 1
4 1 1 1 1 1 1 1 1
5 1 1 1 1 1 1 1 1
6 1 1 1 1 1 1 1 1
7 1 1 1 1 1 1 1 1
Unidirectional P2P=Disabled Bandwidth Matrix (GB/s)
D\D 0 1 2 3 4 5 6 7
0 1277.60 14.69 17.62 17.69 18.52 18.14 18.66 17.72
1 14.96 1276.55 17.66 17.72 18.23 18.23 18.66 17.65
2 17.58 17.59 1277.60 14.61 18.18 18.61 17.80 17.97
3 17.53 17.73 14.68 1275.51 18.20 17.74 18.63 17.42
4 17.79 17.62 17.84 17.93 1291.32 15.95 17.77 17.97
5 17.46 17.85 17.79 17.93 16.51 1290.26 18.63 17.24
6 17.35 17.78 17.65 17.81 18.51 18.85 1289.19 15.43
7 17.44 17.82 17.87 18.11 17.49 18.74 15.90 1290.26
Unidirectional P2P=Enabled Bandwidth (P2P Writes) Matrix (GB/s)
D\D 0 1 2 3 4 5 6 7
0 1275.51 263.60 267.07 273.62 273.73 273.54 272.89 273.45
1 263.77 1288.13 265.92 273.83 274.13 273.33 273.76 274.06
2 263.38 265.44 1284.95 273.68 274.70 273.48 274.19 274.15
3 265.34 266.87 266.85 1299.92 272.81 273.92 273.38 274.47
4 266.56 266.66 268.40 275.25 1305.35 273.76 275.42 275.17
5 266.49 266.64 266.40 275.85 273.77 1305.35 272.82 274.67
6 265.32 267.78 269.32 266.30 274.32 275.12 1298.84 274.21
7 267.13 266.07 269.01 266.72 275.14 274.46 274.83 1304.26
Bidirectional P2P=Disabled Bandwidth Matrix (GB/s)
D\D 0 1 2 3 4 5 6 7
0 1290.79 15.65 19.52 19.53 20.00 20.39 20.34 20.03
1 15.97 1304.80 19.37 19.42 19.93 19.92 20.04 19.91
2 19.09 19.21 1302.08 15.54 19.92 19.93 20.01 19.77
3 19.17 19.28 15.65 1304.80 20.04 20.06 20.03 19.85
4 19.48 19.63 19.71 19.85 1304.80 17.55 19.91 19.69
5 19.45 19.65 19.76 19.94 18.19 1306.44 20.11 19.84
6 19.49 19.73 19.73 19.95 19.59 20.09 1303.17 17.84
7 19.29 19.48 19.56 19.60 19.88 19.62 18.31 1304.80
Bidirectional P2P=Enabled Bandwidth Matrix (GB/s)
D\D 0 1 2 3 4 5 6 7
0 1289.72 411.91 414.96 413.53 415.59 417.36 417.43 415.88
1 410.46 1290.26 411.43 410.63 411.75 412.08 412.41 411.97
2 414.04 412.75 1288.66 413.25 415.37 416.25 414.85 415.15
3 409.55 410.13 411.32 1287.60 412.18 412.30 412.62 411.75
4 414.31 414.14 417.84 413.87 1304.26 436.86 436.86 437.60
5 413.65 414.87 417.28 414.35 437.48 1310.27 517.97 518.83
6 413.25 414.44 418.48 415.52 437.24 521.41 1301.54 519.75
7 414.79 414.89 418.19 413.95 438.69 517.46 517.80 1301.54
P2P=Disabled Latency Matrix (us)
GPU 0 1 2 3 4 5 6 7
0 3.09 24.91 25.81 25.55 24.70 24.73 24.68 24.75
1 25.33 3.07 25.70 25.59 24.82 24.67 24.48 24.70
2 25.60 25.69 3.17 25.60 24.95 24.64 24.86 24.63
3 25.68 25.52 25.35 3.30 24.68 24.69 24.66 24.67
4 25.58 25.27 25.58 25.59 2.91 24.60 24.60 24.59
5 25.68 25.54 25.59 25.42 24.57 3.01 24.60 24.60
6 25.68 25.59 25.60 25.59 24.59 24.56 2.47 24.65
7 25.59 25.33 25.62 25.61 24.59 24.59 24.65 2.66
CPU 0 1 2 3 4 5 6 7
0 4.40 13.76 13.47 13.62 12.74 12.75 12.67 12.86
1 13.81 4.82 13.60 13.53 12.57 12.70 12.89 13.02
2 13.69 13.43 4.40 13.41 12.62 12.70 12.62 12.82
3 13.66 13.36 13.76 4.42 12.87 12.64 12.59 12.56
4 12.80 12.78 12.91 12.88 4.13 12.17 12.04 12.06
5 12.93 12.78 12.86 12.86 12.18 4.15 12.14 12.01
6 12.74 12.81 12.91 12.87 12.06 12.02 4.41 12.01
7 12.90 12.83 12.99 13.07 11.97 12.16 12.20 4.12
P2P=Enabled Latency (P2P Writes) Matrix (us)
GPU 0 1 2 3 4 5 6 7
0 3.19 3.63 3.57 3.55 3.60 3.56 3.56 3.58
1 3.63 3.06 3.62 3.59 3.56 3.57 3.55 3.62
2 3.62 3.58 3.16 3.56 3.57 3.65 3.56 3.63
3 3.58 3.60 3.62 3.30 3.64 3.56 3.59 3.61
4 3.49 3.46 3.53 3.46 2.93 3.47 3.53 3.53
5 3.47 3.54 3.56 3.53 3.53 3.00 3.53 3.46
6 2.91 2.96 2.92 2.93 2.94 2.98 2.46 2.98
7 3.03 3.04 3.06 3.03 3.06 3.09 3.14 2.66
CPU 0 1 2 3 4 5 6 7
0 4.46 3.81 3.92 3.87 3.85 3.88 3.88 3.92
1 3.96 4.49 3.93 3.93 3.96 3.97 3.91 3.87
2 4.00 4.03 4.52 3.93 3.93 3.93 4.12 4.23
3 4.01 3.95 4.11 4.50 4.23 4.20 3.95 3.93
4 4.09 3.96 3.71 3.70 4.41 3.70 3.68 3.66
5 3.76 3.69 3.72 3.71 3.72 4.23 3.68 3.65
6 3.77 3.63 3.65 3.94 3.64 3.71 4.20 3.60
7 3.94 4.00 3.69 3.70 3.72 3.74 3.73 4.21
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
上述值显示 GPU 到 GPU 的单向传输带宽范围为 263GB/s 到 275GB/s。双向带宽范围为 413GB/s 到 521GB/s。在同一 GPU 内(对角线输出),显示同一 GPU 内的带宽约为 1,300GB/s。这些数字接近 GPU 对之间可以实现的理论上完整的 600GB/s 双向 NVLink 带宽。
NVIDIA A100 支持 PCIe Gen 4.0,我们可以使用 CUDA 安装目录 (/usr/local/cuda/extras/demo_suite) 中提供的 bandwidthTest 来观察 CPU 和 GPU 之间的总线速度。
测试显示设备和主机之间的带宽约为 23GB/s
./bandwidthTest
[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: A100-SXM4-40GB
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 22865.7
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 22554.8
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 1173168.2
Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
NVIDIA DCGM
NVIDIA DCGM 是一套用于管理和监控集群环境中数据中心 GPU 的工具。有关更多信息,请查看产品页面。
要为您的 Linux 发行版安装 DCGM,请下载安装程序软件包。
wget --no-check-certificate https://developer.download.nvidia.com/compute/redist/dcgm/2.0.13/DEBS/datacenter-gpu-manager_2.0.13_amd64.deb
--2020-10-12 12:12:21-- https://developer.download.nvidia.com/compute/redist/dcgm/2.0.13/DEBS/datacenter-gpu-manager_2.0.13_amd64.deb
Resolving developer.download.nvidia.com (developer.download.nvidia.com)... 152.195.19.142
Connecting to developer.download.nvidia.com (developer.download.nvidia.com)|152.195.19.142|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 184133216 (176M) [application/x-deb]
Saving to: ‘datacenter-gpu-manager_2.0.13_amd64.deb’
datacenter-gpu-manager_2.0.13_amd64.deb 100%[==============================================================================================================>] 175.60M 105MB/s in 1.7s
2020-10-12 12:12:22 (105 MB/s) - ‘datacenter-gpu-manager_2.0.13_amd64.deb’ saved [184133216/184133216]
然后继续使用 systemd 安装并启动 DCGM 服务
sudo dpkg -i datacenter-gpu-manager_2.0.13_amd64.deb
(Reading database ... 174123 files and directories currently installed.)
Preparing to unpack datacenter-gpu-manager_2.0.13_amd64.deb ...
Unpacking datacenter-gpu-manager (1:2.0.13) over (1:2.0.10) ...
Setting up datacenter-gpu-manager (1:2.0.13) ...
$ nv-hostengine --version
Version : 2.0.13
Build ID : 18
Build Date : 2020-09-29
Build Type : Release
Commit ID : v2.0.12-6-gbf6e6238
Branch Name : rel_dcgm_2_0
CPU Arch : x86_64
Build Platform : Linux 4.4.0-116-generic #140-Ubuntu SMP Mon Feb 12 21:23:04 UTC 2018 x86_64
检查 DCGM 服务状态,以确保 nv-hostengine 代理已成功启动且没有错误
sudo systemctl start dcgm.service
● dcgm.service - DCGM service
Loaded: loaded (/usr/lib/systemd/system/dcgm.service; disabled; vendor preset: enabled)
Active: active (running) since Mon 2020-10-12 12:18:57 PDT; 14s ago
Main PID: 32847 (nv-hostengine)
Tasks: 7 (limit: 39321)
CGroup: /system.slice/dcgm.service
└─32847 /usr/bin/nv-hostengine -n
Oct 12 12:18:57 ubuntu1804 systemd[1]: Started DCGM service.
Oct 12 12:18:58 ubuntu1804 nv-hostengine[32847]: DCGM initialized
Oct 12 12:18:58 ubuntu1804 nv-hostengine[32847]: Host Engine Listener Started
现在检查 DCGM 是否可以枚举系统的拓扑
dcgmi discovery -l
8 GPUs found.
+--------+----------------------------------------------------------------------+
| GPU ID | Device Information |
+--------+----------------------------------------------------------------------+
| 0 | Name: A100-SXM4-40GB |
| | PCI Bus ID: 00000000:07:00.0 |
| | Device UUID: GPU-1d82f4df-3cf9-150d-088b-52f18f8654e1 |
+--------+----------------------------------------------------------------------+
| 1 | Name: A100-SXM4-40GB |
| | PCI Bus ID: 00000000:0F:00.0 |
| | Device UUID: GPU-94168100-c5d5-1c05-9005-26953dd598e7 |
+--------+----------------------------------------------------------------------+
| 2 | Name: A100-SXM4-40GB |
| | PCI Bus ID: 00000000:47:00.0 |
| | Device UUID: GPU-9387e4b3-3640-0064-6b80-5ace1ee535f6 |
+--------+----------------------------------------------------------------------+
| 3 | Name: A100-SXM4-40GB |
| | PCI Bus ID: 00000000:4E:00.0 |
| | Device UUID: GPU-cefd0e59-c486-c12f-418c-84ccd7a12bb2 |
+--------+----------------------------------------------------------------------+
| 4 | Name: A100-SXM4-40GB |
| | PCI Bus ID: 00000000:87:00.0 |
| | Device UUID: GPU-1501b26d-f3e4-8501-421d-5a444b17eda8 |
+--------+----------------------------------------------------------------------+
| 5 | Name: A100-SXM4-40GB |
| | PCI Bus ID: 00000000:90:00.0 |
| | Device UUID: GPU-f4180a63-1978-6c56-9903-ca5aac8af020 |
+--------+----------------------------------------------------------------------+
| 6 | Name: A100-SXM4-40GB |
| | PCI Bus ID: 00000000:B7:00.0 |
| | Device UUID: GPU-8b354e3e-0145-6cfc-aec6-db2c28dae134 |
+--------+----------------------------------------------------------------------+
| 7 | Name: A100-SXM4-40GB |
| | PCI Bus ID: 00000000:BD:00.0 |
| | Device UUID: GPU-a16e3b98-8be2-6a0c-7fac-9cb024dbc2df |
+--------+----------------------------------------------------------------------+
6 NvSwitches found.
+-----------+
| Switch ID |
+-----------+
| 11 |
| 10 |
| 13 |
| 9 |
| 12 |
| 8 |
+-----------+
现在检查 DCGM 是否可以枚举系统中存在的 NVLink
dcgmi nvlink -s
+----------------------+
| NvLink Link Status |
+----------------------+
GPUs:
gpuId 0:
U U U U U U U U U U U U
gpuId 1:
U U U U U U U U U U U U
gpuId 2:
U U U U U U U U U U U U
gpuId 3:
U U U U U U U U U U U U
gpuId 4:
U U U U U U U U U U U U
gpuId 5:
U U U U U U U U U U U U
gpuId 6:
U U U U U U U U U U U U
gpuId 7:
U U U U U U U U U U U U
NvSwitches:
physicalId 11:
X X X X X X X X U U U U X X X X X X X X X X X X U U U U U U U U U U U U
physicalId 10:
X X X X X X X X U U U U U U U U X X X X X X X X X X U U U U U U X X U U
physicalId 13:
X X X X X X X X X X U U U U U U X X X X X X X X U U U U U U U U X X U U
physicalId 9:
X X X X X X X X U U U U U U U U X X X X X X X X U U U U X X X X U U U U
physicalId 12:
X X X X X X X X X X U U U U U U X X X X X X X X U U U U U U U U X X U U
physicalId 8:
X X X X X X X X U U U U X X X X X X X X X X X X U U U U U U U U U U U U
Key: Up=U, Down=D, Disabled=X, Not Supported=_
支持的软件版本
以下软件版本支持 HGX A100
| 软件 | 版本 |
|---|---|
| R450 | 450.80.02 |
| Fabric Manager | 450.80.02 |
| NSCQ | 450.80.02 |
| DCGM | 2.0.13 |
| CUDA 工具包 | 11.0+ |
声明
声明
本文档仅供参考,不应被视为对产品的特定功能、状况或质量的保证。NVIDIA Corporation(“NVIDIA”)不对本文档中包含的信息的准确性或完整性做任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对使用此类信息或因使用此类信息而可能导致的侵犯第三方专利或其他权利的行为的后果或使用不承担任何责任。本文档不构成对开发、发布或交付任何材料(如下定义)、代码或功能的承诺。
NVIDIA 保留随时修改、增强、改进和对本文档进行任何其他更改的权利,恕不另行通知。
客户在下订单前应获取最新的相关信息,并应验证此类信息是否为最新且完整。
除非 NVIDIA 和客户的授权代表签署的个别销售协议(“销售条款”)另有约定,否则 NVIDIA 产品的销售受订单确认时提供的 NVIDIA 标准销售条款和条件的约束。NVIDIA 在此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档未直接或间接形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命维持设备,也不适用于 NVIDIA 产品故障或失灵可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在上述设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不保证或声明基于本文档的产品适用于任何特定用途。NVIDIA 不一定对每个产品的所有参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合客户计划的应用,并为应用执行必要的测试,以避免应用或产品的默认设置。客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的其他或不同的条件和/或要求。NVIDIA 对可能基于或归因于以下原因的任何默认设置、损坏、成本或问题不承担任何责任:(i) 以任何违反本文档的方式使用 NVIDIA 产品,或 (ii) 客户产品设计。
本文档未授予 NVIDIA 专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予的使用此类产品或服务的许可,也不构成对其的保证或认可。使用此类信息可能需要获得第三方在其专利或其他知识产权下的许可,或获得 NVIDIA 在其专利或其他 NVIDIA 知识产权下的许可。
只有在事先获得 NVIDIA 书面批准的情况下,才允许复制本文档中的信息,并且复制必须不得更改,必须完全符合所有适用的出口法律和法规,并附带所有相关的条件、限制和声明。
本文档和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均按“原样”提供。NVIDIA 不对材料作出任何明示、暗示、法定或其他方面的保证,并且明确否认所有关于非侵权、适销性和特定用途适用性的默示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对任何损害(包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害)负责,无论其由何种原因引起,也无论责任理论如何,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因遭受任何损害,但 NVIDIA 对本文所述产品的客户承担的累计总责任应根据产品的销售条款进行限制。