NVIDIA NVSwitch 系统 Fabric Manager
本文档描述了用于 NVSwitch™ 系统的 NVIDIA® Fabric Manager。
1. 概述
1.1. 简介
随着深度学习神经网络变得越来越复杂,它们的规模和复杂性持续扩展。结果是对计算能力呈指数级增长的需求,这些计算能力是在合理的时间段内训练这些网络所必需的。为了应对这一挑战,应用程序已转向多 GPU 实现。
NVIDIA NVLink® 最初被引入以连接多个 GPU,它是一种直接的 GPU 到 GPU 互连,可在服务器中扩展多 GPU 输入/输出 (IO)。为了进一步扩展性能并连接多个 GPU,NVIDIA 推出了 NVIDIA NVSwitch,它连接多个 NVLink,以在总 NVLink 速度下提供所有 GPU 之间的通信。
1.2. 基于 NVSwitch 的系统
多年来,NVIDIA 推出了三代 NVSwitch 以及相关的 DGX 和 NVIDIA HGX™ 服务器系统。
NVIDIA DGX-2™ 和 NVIDIA HGX-2 系统由两个相同的 GPU 基板组成,每个基板上有八个 NVIDIA V100 GPU 和六个第一代 NVSwitch。每个 V100 GPU 都有一个 NVLink 连接到同一 GPU 基板上的每个 NVSwitch。两个 GPU 基板连接在一起以构建一个 16 GPU 系统。在两个 GPU 基板之间,唯一的 NVLink 连接是在 NVSwitch 之间,其中一个 GPU 基板上的每个 NVSwitch 连接到第二个 GPU 基板上的一个 NVSwitch,总共有八个 NVLink 连接。
NVIDIA DGX™ A100 和 NVIDIA HGX A100 8-GPU 系统由一个 GPU 基板组成,该基板具有八个 NVIDIA A100 GPU 和六个第二代 NVSwitch。GPU 基板 NVLink 拓扑类似于第一代版本,其中每个 A100 GPU 都有两个 NVLink 连接到同一 GPU 基板上的每个 NVSwitch。这一代支持连接两个 GPU 基板,基板之间总共有 16 个 NVLink 连接。
第三代 NVSwitch 用于 DGX H100 和 NVIDIA HGX H100 8-GPU 服务器系统中。此服务器变体由一个 GPU 基板组成,该基板具有八个 NVIDIA H100 GPU 和四个 NVSwitch。相应的 NVLink 拓扑与上一代不同,因为每个 GPU 都有四个 NVLink 连接到两个 NVSwitch,以及五个 NVLink 连接到其余两个 NVSwitch。这一代已弃用使用 NVLink 连接两个 GPU 基板的支持。
1.3. 术语
术语 |
定义 |
|---|---|
FM |
Fabric Manager |
MMIO |
内存映射 I/O |
VM |
虚拟机 |
GPU 寄存器 |
GPU MMIO 空间中的位置 |
SBR |
辅助总线复位 |
DCGM |
NVIDIA 数据中心 GPU 管理器 |
NVML |
NVIDIA 管理库 |
服务 VM |
运行 NVIDIA NVSwitch 软件栈的特权 VM |
访问 NVLink |
GPU 和 NVSwitch 之间的 NVLink |
中继 NVLink |
两个 GPU 基板之间的 NVLink |
SMBPBI |
NVIDIA SMBus 邮箱接口 |
vGPU |
NVIDIA GRID 虚拟 GPU |
MIG |
多实例 GPU |
SR-IOV |
单根 I/O 虚拟化 |
PF |
物理功能 |
VF |
虚拟功能 |
GFID |
GPU 功能标识 |
分区 |
允许执行 NVLink 的 GPU 集合 彼此之间的对等通信 |
ALI |
自主链路初始化 |
1.4. NVSwitch 核心软件栈
NVSwitch 管理的核心软件栈包括 NVSwitch 内核驱动程序和一个名为 NVIDIA Fabric Manager (FM) 的特权进程。内核驱动程序响应 FM 请求执行低级硬件管理。该软件栈还提供带内和带外监控解决方案,以报告 NVSwitch 和 GPU 错误和状态信息。

图 1 NVSwitch 核心软件栈
1.5. 什么是 Fabric Manager?
FM 配置 NVSwitch 内存结构,以在所有参与的 GPU 之间形成一个内存结构,并监控支持该结构的 NVLink。在较高的层面上,FM 具有以下职责:
配置 NVSwitch 端口之间的路由。
与 GPU 驱动程序协调以初始化 GPU。
监控结构中的 NVLink 和 NVSwitch 错误。
在不具备基于自主链路初始化 (ALI) 的 NVLink 训练的系统(第一代和第二代基于 NVSwitch 的系统)上,FM 还具有以下附加职责:
与 NVSwitch 驱动程序协调以训练 NVSwitch 到 NVSwitch 的 NVLink 互连。
与 GPU 驱动程序协调以初始化和训练 NVSwitch 到 GPU 的 NVLink 互连。
本文档概述了 FM 的各种功能,旨在为基于 NVSwitch 的服务器系统的系统管理员和个人用户提供参考。
2. Fabric Manager 入门
2.1. 基本组件
本节提供有关 FM 中基本组件的信息。
2.1.1. Fabric Manager 服务
FM 的核心组件实现为作为 Unix 守护进程运行的独立可执行文件。FM 安装包将安装所需的核心组件,并将守护进程注册为名为 nvidia-fabricmanager 的系统服务。
2.1.2. 软件开发工具包
FM 还提供共享库、一组 C/C++ API (SDK) 和相应的头文件。这些 API 用于在 FM 以共享 NVSwitch 和 vGPU 多租户模式运行时,与 Fabric Manager 服务接口以查询/激活/停用 GPU 分区。所有这些 SDK 组件都通过单独的开发包安装。有关更多信息,请参阅 共享 NVSwitch 虚拟化模型 和 vGPU 虚拟化模型。
2.2. NVSwitch 和 NVLink 初始化
NVIDIA GPU 和 NVSwitch 内存结构是需要使用 NVIDIA 内核驱动程序的 PCIe 端点设备。
在没有 ALI 支持的 DGX-2、NVIDIA HGX-2、DGX A100 和 NVIDIA HGX A100 系统上,系统启动后,在加载 NVIDIA 内核驱动程序后启用 NVLink 连接,并且 FM 配置这些连接。如果应用程序在 FM 完全初始化系统之前或 FM 未能初始化系统时启动,CUDA 初始化将失败并显示 cudaErrorSystemNotReady 错误。
在具有 ALI 支持的 DGX H100 和 NVIDIA HGX H100 系统上,NVLink 在 GPU 和 NVSwitch 硬件级别进行训练,无需 FM。为了启用 NVLink 对等支持,GPU 必须在 NVLink 结构中注册。如果 GPU 未能在结构中注册,它将失去其 NVLink 对等功能,并且可用于非对等用例。CUDA 初始化过程将在 GPU 完成其在 NVLink 结构中的注册过程后开始。
GPU 结构注册状态通过 NVML API 公开,并且作为 nvidia-smi -q 命令的一部分。有关更多信息,请参阅以下 nvidia-smi 命令输出。
以下是 GPU 正在注册时的结构状态输出
nvidia-smi -q -i 0 | grep -i -A 2 Fabric Fabric State : In Progress Status : N/A以下是 GPU 成功注册后的结构状态输出
nvidia-smi -q -i 0 | grep -i -A 2 Fabric Fabric State : Completed Status : Success
Fabric Manager 在基于 NVSwitch 的系统的功能中起着至关重要的作用,这些系统通常在系统启动或工作负载激活期间启动。间歇性地重启服务是不必要的;但是,如果由于工作流程要求或作为 GPU 重置操作的一部分而必须重启,请完成以下适用于 DGX H100 和 NVIDIA HGX H100 系统的步骤,以确保系统恢复到一致状态。
停止所有 CUDA 应用程序和 GPU 相关服务。
停止所有正在运行的 CUDA 应用程序和服务(例如,DCGM),这些应用程序和服务正在积极使用 GPU。
您可以保持 nvidia-persistenced 服务运行。
通过终止 Fabric Manager 服务来停止 Fabric Manager 服务。
通过发出
nvidia-smi -r命令并执行 GPU 重置来执行 GPU 重置。再次启动 Fabric Manager 服务,方法是重启 Fabric Manager 服务并恢复其功能。
通过重启在步骤 1 中停止的任何服务(例如 DCGM 或其他 GPU 相关服务)来恢复停止的服务。
启动 CUDA 应用程序。
完成这些步骤后,根据需要启动您的 CUDA 应用程序。
注意
系统管理员可以将他们的 GPU 应用程序启动器服务(例如 SSHD、Docker 等)设置为在 FM 服务启动后启动。有关设置服务依赖项和服务启动顺序的更多信息,请参阅您的 Linux 发行版手册。
2.3. 支持的平台
本节提供有关 FM 当前支持的产品和环境的信息。
2.3.1. 硬件架构
x86_64
AArch64
2.3.2. NVIDIA 服务器架构
使用 V100 GPU 和第一代 NVSwitch 的 DGX-2 和 NVIDIA HGX-2 系统。
使用 A100 GPU 和第二代 NVSwitch 的 DGX A100 和 NVIDIA HGX A100 系统。
使用 A800 GPU 和第二代 NVSwitch 的 NVIDIA HGX A800 系统。
使用 H100 GPU 和第三代 NVSwitch 的 DGX H100 和 NVIDIA HGX H100 系统。
使用 H800 GPU 和第三代 NVSwitch 的 NVIDIA HGX H800 系统。
注意
除非另有说明,否则 NVIDIA HGX A800 和 NVIDIA HGX H800 的步骤与 NVIDIA HGX A100 和 NVIDIA HGX H100 的步骤相同。唯一的区别是 GPU NVLink 的数量将根据实际平台而有所不同。
2.3.3. 操作系统环境
FM 在以下主要的 Linux 操作系统发行版上受支持:
RHEL/CentOS 7.x 和 RHEL/CentOS 8.x
Ubuntu 18.04.x、Ubuntu 20.04.x 和 Ubuntu 22.04.x
2.4. 支持的部署模型
基于 NVSwitch 的系统可以部署为裸金属服务器或虚拟化(完全直通、共享 NVSwitch 或 vGPU)多租户环境。FM 支持这些部署模型。有关更多信息,请参阅以下章节:
2.5. 其他 NVIDIA 软件包
要运行 FM 服务,目标系统必须包含兼容的驱动程序,从 R450 版本开始,适用于 NVIDIA 数据中心 GPU。
注意
在初始化期间,FM 服务检查当前加载的内核驱动程序堆栈版本是否兼容,如果加载的驱动程序堆栈版本不兼容,则中止该过程。
2.6. 安装
2.6.1. 在基于 NVSwitch 的 DGX 服务器系统上
FM 服务已预安装在所有基于 NVSwitch 的 DGX-2、DGX A100 和 DGXH100 系统中,作为受支持的 DGX 操作系统软件包的一部分。该服务已启用并在操作系统启动时启动。
2.6.2. 在基于 NVSwitch 的 NVIDIA HGX 服务器系统上
在基于 NVSwitch 的 NVIDIA HGX 系统上,要配置 NVLink 和 NVSwitch 内存结构以支持一个内存结构,需要手动安装 FM 服务。FM 软件包通过 NVIDIA CUDA 网络存储库提供。有关设置系统软件包管理器以及从所需的 CUDA 网络存储库下载软件包的更多信息,请参阅 NVIDIA 驱动程序安装指南。
每个发布版本的 Fabric Manager 都包含以下软件包:
nvidia-fabricmanager-<版本>
此软件包包含必要的组件,例如核心独立的 FM 服务进程、服务单元文件和拓扑文件。对于裸金属,您可以仅安装此软件包。
nvidia-fabricmanager-devel-<版本>
“devel”软件包包含 FM 共享库及其关联的头文件。当您实现共享 NVSwitch 和 vGPU 多租户虚拟化模型时,此软件包非常重要。
通过将功能拆分为这些软件包,用户可以选择性地安装与其需求最相关的组件。
在设置软件包管理器网络存储库后,使用以下特定于发行版的 FM 安装命令:
注意
在以下命令中,<driver-branch> 应替换为符合条件的数据中心驱动程序所需的 NVIDIA 驱动程序分支号(例如,560)。
对于基于 Debian 和 Ubuntu 的操作系统发行版:
sudo apt-get install -V nvidia-open-<driver-branch> sudo apt-get install -V nvidia-fabricmanager-<driver-branch> nvidia-fabricmanager-dev-<driver-branch>
对于基于 Red Hat Enterprise Linux 8 的操作系统发行版:
sudo dnf module install nvidia-driver:<driver-branch>-open/fm
SUSE Linux 基于操作系统发行版:
sudo zypper install nvidia-open-<driver-branch>-<kernel-flavor> sudo zypper install nvidia-fabricmanager-<driver-branch> nvidia-fabricmanager-devel-<driver-branch>
注意
在基于 NVSwitch 的 NVIDIA HGX 系统上,在安装 FM 之前,请安装适用于 NVIDIA 数据中心 GPU 的兼容驱动程序。作为安装的一部分,FM 服务单元文件 (nvidia-fabricmanager.service) 将复制到 systemd。但是,系统管理员必须手动启用并启动 FM 服务。
2.7. 管理 Fabric Manager 服务
2.7.1. 启动 Fabric Manager
要启动 FM,请运行以下命令:
# For Linux based OS distributions
sudo systemctl start nvidia-fabricmanager
2.7.2. 停止 Fabric Manager
要停止 FM,请运行以下命令:
# For Linux based OS distributions
sudo systemctl stop nvidia-fabricmanager
2.7.3. 检查 Fabric Manager 状态
要检查 FM 状态,请运行以下命令:
# For Linux based OS distributions
sudo systemctl status nvidia-fabricmanager
2.7.4. 启用 Fabric Manager 服务以在启动时自动启动
要启用 FM 服务以在启动时自动启动,请运行以下命令:
# For Linux based OS distributions
sudo systemctl enable nvidia-fabricmanager
2.7.5. 禁用 Fabric Manager 服务在启动时自动启动
要禁用 FM 服务以在启动时自动启动,请运行以下命令:
# For Linux based OS distributions
sudo systemctl disable nvidia-fabricmanager
2.7.6. 检查 Fabric Manager 系统日志消息
要检查 FM 系统日志消息,请运行以下命令:
# For Linux based OS distributions
sudo journalctl -u nvidia-fabricmanager
2.8. Fabric Manager 启动选项
FM 支持以下命令行选项:
./nv-fabricmanager -h
NVIDIA Fabric Manager
Runs as a background process to configure the NVSwitches to form
a single memory fabric among all participating GPUs.
Usage: nv-fabricmanager [options]
Options include:
[-h | --help]: Displays help information
[-v | --version]: Displays the Fabric Manager version and exit.
[-c | --config]: Provides Fabric Manager config file path/name which controls all the config options.
[-r | --restart]: Restart Fabric Manager after exit. Applicable to Shared NVSwitch and vGPU multitenancy modes.
大多数 FM 可配置参数和选项通过文本配置文件指定。FM 安装会将默认配置文件复制到预定义的位置,并且默认情况下将使用该文件。要使用不同的配置文件位置,请使用 [-c | --config] 命令行参数指定相同的位置。
注意
在基于 Linux 的安装中,默认的 FM 配置文件将位于 /usr/share/nvidia/nvswitch/fabricmanager.cfg 目录中。如果系统上的默认配置文件被修改,为了管理现有的配置文件,后续的 FM 软件包更新将提供诸如合并/保留/覆盖之类的选项。
2.9. Fabric Manager 服务文件
2.9.1. 在基于 Linux 的系统上
在基于 Linux 的系统上,安装包将使用以下 systemd 服务单元文件注册 FM 服务。要更改 FM 服务启动选项,请在 /lib/systemd/system/nvidia-fabricmanager.service 目录中修改此服务单元文件。
[Unit]
Description=FabricManager service
After=network-online.target
Requires=network-online.target
[Service]
User=root
PrivateTmp=false
Type=forking
ExecStart=/usr/bin/nv-fabricmanager -c /usr/share/nvidia/nvswitch/fabricmanager.cfg
[Install]
WantedBy=multi-user.target
2.10. 以非 Root 用户身份运行 Fabric Manager
在基于 Linux 的系统上,默认情况下,FM 服务需要管理(root)权限才能配置所有 GPU NVLink 和 NVSwitch 以支持内存结构。但是,系统管理员和高级用户可以完成以下步骤,以从非 root 帐户运行 FM:
如果 FM 实例正在运行,请停止它。
FM 需要访问以下目录/文件,因此请将相应的目录/文件访问权限调整为您所需的用户/用户组。
/var/run/nvidia-fabricmanager此选项提供了一个固定位置来保存运行时信息。
/var/log/此选项提供了一个可配置的位置来保存 FM 日志文件。
/usr/share/nvidia/nvswitch此选项为结构拓扑文件提供了一个可配置的位置。
此可配置的目录/文件信息基于默认的 FM 配置文件选项。如果默认配置值已更改,请相应地调整目录/文件信息。
NVIDIA 驱动程序将使用默认权限 root 创建以下 proc 条目。
将其读/写访问权限更改为您所需的用户/用户组。
/proc/driver/nvidia-nvlink/capabilities/fabric-mgmtFM 还需要访问以下设备节点文件:
在所有基于 NVSwitch 的 NVIDIA HGX 系统上:
/dev/nvidia-nvlink/dev/nvidia-nvswitchctl/dev/nvidia-nvswitchX (每个 NVSwitch 设备一个)
以下是在 DGX-2 和 NVIDIA HGX A100 系统上的其他设备节点文件:
/dev/nvidiactl/dev/nvidiaX(每个 GPU 设备一个)
默认情况下,这些设备节点文件由
nvidia-modprobe实用程序创建,该实用程序作为 NVIDIA 数据中心 GPU 驱动程序包的一部分安装,并具有所有用户的访问权限。如果这些设备节点文件是手动创建的或在nvidia-modprobe之外创建的,请为用户/用户组分配读/写访问权限。在分配了所需的权限后,从用户/用户组帐户手动启动 FM 进程。
NVIDIA 驱动程序将在驱动程序加载期间创建/重新创建上述
/proc条目,因此请在每次驱动程序重新加载或系统启动时重复步骤 1-6。
当 FM 配置为 systemd 服务时,系统管理员必须编辑 FM 服务单元文件,以指示 systemd 从特定用户/用户组运行 FM 服务。此特定用户/用户组可以通过 FM 服务单元文件的 [Service] 部分中的 User= 和 Group= 指令指定。系统管理员必须确保在 FM 服务在系统启动时启动之前,将 proc 条目和关联的文件节点权限更改为所需的用户/用户组。
当 FM 配置为从上述指定的特定用户/用户组运行时,应从同一用户/用户组帐户启动 nvswitch-audit 命令行实用程序。
注意
系统管理员可以设置必要的 udev 规则,以自动化更改这些 proc 条目权限的过程。
2.11. Fabric Manager 配置选项
FM 使用的可配置参数和选项通过文本配置文件指定。以下部分列出了当前支持的所有可配置参数和选项。
注意
FM 配置文件在 FM 服务启动时读取。如果您更改了任何配置文件选项,要使新设置生效,请重启 FM 服务。
2.11.3. 杂项配置项
2.11.3.1. 阻止 Fabric Manager 守护进程化
配置项
DAEMONIZE=<值>支持/可能的值
0- 不守护进程化,并将 FM 作为普通进程运行。1- 将 FM 进程作为 Unix 守护进程运行。
默认值
DAEMONIZE=1
2.11.3.2. Fabric Manager 通信套接字接口
配置项
BIND_INTERFACE_IP=<值>支持/可能的值
用于监听 FM 内部通信/IPC 的网络接口,此值应为有效的 IPv4 地址。
默认值
BIND_INTERFACE_IP=127.0.0.1
2.11.3.3. Fabric Manager 通信 TCP 端口
配置项
STARTING_TCP_PORT=<值>支持/可能的值
FM 内部通信/IPC 的起始 TCP 端口号,此值应介于 0 和 65535 之间。
默认值
STARTING_TCP_PORT=16000
2.11.3.4. 用于 Fabric Manager 通信的 Unix 域套接字
配置项
UNIX_SOCKET_PATH=<值>支持/可能的值
使用 Unix 域套接字而不是 TCP/IP 套接字进行 FM 内部通信/IPC。空值表示不使用 Unix 域套接字。
默认值
UNIX_SOCKET_PATH=<空 值>
2.11.3.5. Fabric Manager 系统拓扑文件位置
配置项
TOPOLOGY_FILE_PATH =<值>支持/可能的值
用于指定 FM 拓扑文件目录路径信息的配置选项。
默认值
TOPOLOGY_FILE_PATH=/usr/share/nvidia/nvswitch
3. 裸机模式
3.1. 简介
基于 NVSwitch 的 DGX 和 NVIDIA HGX 服务器系统的默认软件配置是将系统作为裸机机器运行,用于 AI、机器学习等工作负载。本章提供有关 FM 安装要求的信息,以支持裸机配置。
3.2. Fabric Manager 安装
3.2.1. 在基于 NVSwitch 的 DGX 服务器系统上
作为受支持的 DGX OS 包安装的一部分,FM 服务已预安装在所有基于 NVSwitch 的 DGX 系统中。该服务在操作系统启动时启用并启动,默认安装配置旨在支持裸机模式。
3.2.2. 在基于 NVSwitch 的 NVIDIA HGX 服务器系统上
要为裸机模式配置基于 NVSwitch 的 NVIDIA HGX 系统,系统管理员必须安装 NVIDIA FM 包,该包的版本与驱动程序包的版本相同。
驱动程序包适用于 NVIDIA 数据中心 GPU(NVIDIA HGX-2 和 NVIDIA HGX A100 系统的 450.xx 及更高版本)。对于 NVIDIA HGX H100 系统,需要 525.xx 及更高版本。
FM 默认安装模式和配置文件选项支持裸机模式。
3.3. 运行时 NVSwitch 和 GPU 错误
当 NVSwitch 端口或 GPU 生成运行时错误时,相应的信息将被记录到操作系统的内核日志或事件日志中。来自 NVSwitch 的错误报告将以 SXid 前缀记录,而 GPU 错误报告将由 NVIDIA 驱动程序以 Xid 前缀记录。
NVSwitch SXids 错误使用以下报告约定
<nvidia-nvswitchX: SXid (PCI:<switch_pci_bdf>): <SXid_Value>, <Fatal
or Non-Fatal>, <Link No> < Error Description>
<raw error information for additional troubleshooting>
The following is an example of a SXid error log
[...] nvidia-nvswitch3: SXid (PCI:0000:c1:00.0): 28006, Non-fatal, Link
46 MC TS crumbstore MCTO (First)
[...] nvidia-nvswitch3: SXid (PCI:0000:c1:00.0): 28006, Severity 0
Engine instance 46 Sub-engine instance 00
[...] nvidia-nvswitch3: SXid (PCI:0000:c1:00.0): 28006, Data
{0x00140004, 0x00100000, 0x00140004, 0x00000000, 0x00000000,
0x00000000, 0x00000000, 0x00000000}
GPU Xids 错误使用以下报告约定
NVRM: GPU at PCI:<gpu_pci_bdf>: <gpu_uuid>
NVRM: GPU Board Serial Number: <gpu_serial_number>
NVRM: Xid (PCI:<gpu_pci_bdf>): <Xid_Value>, <raw error information>
The following is an example of a Xid error log
[...] NVRM: GPU at PCI:0000:34:00: GPU-c43f0536-e751-7211-d7a7-78c95249ee7d
[...] NVRM: GPU Board Serial Number: 0323618040756
[...] NVRM: Xid (PCI:0000:34:00): 45, Ch 00000010
根据严重性(致命与非致命)和受影响的端口,SXid 和 Xid 错误可能会中止现有 CUDA 作业并阻止新的 CUDA 作业启动。下一节提供有关 SXid 和 Xid 错误的潜在影响以及相应的恢复过程的信息。
3.3.1. NVSwitch SXid 错误
3.3.1.1. NVSwitch 非致命 SXid 错误
NVSwitch 非致命 SXids 仅供参考,FM 不会终止正在运行的 CUDA 作业或阻止新的 CUDA 作业启动。现有 CUDA 作业应恢复;但根据具体错误,CUDA 作业可能会遇到性能下降、短暂时间无进展等问题。
3.3.1.2. NVSwitch 致命 SXid 错误
当在连接 GPU 和 NVSwitch 的 NVSwitch 端口上报告致命 SXid 错误时,相应的错误将传播到 GPU。在该 GPU 上运行的 CUDA 作业将被中止,GPU 可能会报告 Xid 74 和 Xid 45 错误。FM 服务将在其日志文件和 syslog 中记录相应的 GPU 索引和 PCI 总线信息。系统管理员必须使用以下恢复过程来清除错误状态,然后才能将 GPU 用于其他 CUDA 工作负载。
通过 NVIDIA 系统管理接口 (
nvidia-smi) 命令行实用程序重置指定的 GPU(以及受影响工作负载中的所有参与 GPU)。有关更多信息和单个 GPU 重置操作,请参阅
nvidia-smi中的-r或--gpu-reset选项。如果问题仍然存在,请重启或断电重启系统。当在连接两个 GPU 基板的 NVSwitch 端口上报告致命 SXid 错误时,FM 将中止所有正在运行的 CUDA 作业,并阻止任何新的 CUDA 作业启动。作为中止 CUDA 作业的一部分,GPU 也会报告 Xid 45 错误。FM 服务将在其日志文件和 syslog 中记录相应的错误信息。
系统管理员必须使用以下恢复过程来清除错误状态,并随后成功启动 CUDA 作业
重置所有 GPU 和 NVSwitch。
停止 FM 服务。
停止所有正在使用 GPU 的应用程序。
使用带有
-r或--gpu-reset选项的 nvidia-smi 命令行实用程序重置所有 GPU 和 NVSwitch。请勿使用
-i或-id选项。重置操作完成后,再次启动 FM 服务。
如果问题仍然存在,请重启或断电重启系统。
3.3.2. GPU Xid 错误
GPU Xid 消息指示发生了常规 GPU 错误。这些消息可能指示硬件问题、NVIDIA 软件问题或用户应用程序问题。当 GPU 遇到 Xid 错误时,在该 GPU 上运行的 CUDA 作业通常会被中止。完成上一节中的 GPU 重置过程以进行其他故障排除。
在 DGX H100 和 NVIDIA HGX H100 系统上,FM 不再监视和记录 GPU 错误。NVIDIA 驱动程序将继续在 syslog 中监视和记录 GPU 错误。
3.4. 与 MIG 的互操作性
多实例 GPU (MIG) 将 NVIDIA A100 或 H100 GPU 分区为多个独立的 GPU 实例。这些实例同时运行,每个实例都有自己的内存、缓存和流式多处理器。但是,当您启用 MIG 模式时,GPU NVLink 将被禁用,GPU 将失去其 NVLink 对等 (P2P) 功能。成功禁用 MIG 模式后,GPU NVLink 将再次启用,GPU NVLink P2P 功能将恢复。在基于 NVSwitch 的 DGX 和 NVIDIA HGX 系统上,FM 服务可以与 GPU MIG 实例协同工作。此外,在这些系统上,要在禁用 MIG 模式后成功恢复 GPU NVLink 对等功能,FM 服务必须正在运行。在 DGX A100 和 NVIDIA HGX A100 系统上,当启用 MIG 模式时,相应的 GPU NVLink 和 NVSwitch 侧 NVLink 会被关闭,并在禁用 MIG 模式时重新训练。但是,在 DGX H100 和 NVIDIA HGX H100 系统上,GPU NVLink 在 MIG 模式期间将保持活动状态。
4. 虚拟化模型
4.1. 简介
基于 NVSwitch 的系统支持多种模型,以隔离多租户环境中的 NVLink 互连。在虚拟化环境中,VM 工作负载通常不可信任,必须彼此隔离,并与主机或 Hypervisor 隔离。用于维护此隔离的交换机不能由不可信任的 VM 直接控制,而必须由可信任的软件控制。
本章提供了受支持的虚拟化模型的高级概述。
4.2. 支持的虚拟化模型
基于 NVSwitch 的系统支持以下虚拟化模型
完全直通
GPU 和 NVSwitch 内存 Fabric 被传递到客户机操作系统。
易于部署,并且对 Hypervisor/主机操作系统的更改最小。
对于两个和四个 GPU VM,NVLink 带宽降低。
共享 NVSwitch 多租户模式
仅 GPU 直通到客户机。
NVSwitch 内存 Fabric 由称为服务 VM的专用可信任 VM 管理。
NVSwitch 内存 Fabric 由客户机 VM 共享,但 Fabric 对客户机不可见。
需要与 Hypervisor 最紧密的集成。
两个和四个 GPU VM 的完整带宽。
无需客户机 VM 和服务 VM 之间的直接通信。
vGPU 多租户模式
仅 SR-IOV GPU VF 直通到客户机。
GPU PF 和 NVSwitch 内存 Fabric 由 vGPU 主机管理。
NVSwitch 内存 Fabric 由所有客户机 VM 共享,但 Fabric 对客户机不可见。
两个和四个 GPU VM 的完整带宽。
此模式与 vGPU 软件堆栈紧密耦合。
5. Fabric Manager SDK
FM 提供共享库、一组 C/C++ API (SDK) 以及相应的头文件。当 FM 在共享 NVSwitch 和 vGPU 多租户模式下运行时,库和 API 用于与 FM 接口,以查询/激活/停用 GPU 分区。所有 FM 接口 API 定义、库、示例代码和关联的数据结构定义都作为单独的开发包 (RPM/Debian) 交付。要编译本用户指南中提供的示例代码,必须安装此包。
5.1. 数据结构
以下是数据结构
// max number of GPU/fabric partitions supported by FM
#define FM_MAX_FABRIC_PARTITIONS 64
// max number of GPUs supported by FM
#define FM_MAX_NUM_GPUS 16
// Max number of ports per NVLink device supported by FM
#define FM_MAX_NUM_NVLINK_PORTS 64
// connection options for fmConnect()
typedef struct
{
unsigned int version;
char addressInfo[FM_MAX_STR_LENGTH];
unsigned int timeoutMs;
unsigned int addressIsUnixSocket;
} fmConnectParams_v1;
typedef fmConnectParams_v1 fmConnectParams_t;
// VF PCI Device Information
typedef struct
{
unsigned int domain;
unsigned int bus;
unsigned int device;
unsigned int function;
} fmPciDevice_t;
// structure to store information about a GPU belonging to fabric partition
typedef struct
{
unsigned int physicalId;
char uuid[FM_UUID_BUFFER_SIZE];
char pciBusId[FM_DEVICE_PCI_BUS_ID_BUFFER_SIZE];
unsigned int numNvLinksAvailable;
unsigned int maxNumNvLinks;
unsigned int nvlinkLineRateMBps;
} fmFabricPartitionGpuInfo_t;
// structure to store information about a fabric partition
typedef struct
{
fmFabricPartitionId_t partitionId;
unsigned int isActive;
unsigned int numGpus;
fmFabricPartitionGpuInfo_t gpuInfo[FM_MAX_NUM_GPUS];
} fmFabricPartitionInfo_t;
// structure to store information about all the supported fabric partitions
typedef struct
{
unsigned int version;
unsigned int numPartitions;
unsigned int maxNumPartitions;
fmFabricPartitionInfo_t partitionInfo[FM_MAX_FABRIC_PARTITIONS];
} fmFabricPartitionList_v2;
typedef fmFabricPartitionList_v2 fmFabricPartitionList_t;
// structure to store information about all the activated fabric partitionIds
typedef struct
{
unsigned int version;
unsigned int numPartitions;
fmFabricPartitionId_t partitionIds[FM_MAX_FABRIC_PARTITIONS];
} fmActivatedFabricPartitionList_v1;
typedef fmActivatedFabricPartitionList_v1 fmActivatedFabricPartitionList_t;
// Structure to store information about an NVSwitch or GPU with failed NVLinks
typedef struct
{
char uuid[FM_UUID_BUFFER_SIZE];
char pciBusId[FM_DEVICE_PCI_BUS_ID_BUFFER_SIZE];
unsigned int numPorts;
unsigned int portNum[FM_MAX_NUM_NVLINK_PORTS];
} fmNvlinkFailedDeviceInfo_t;
// Structure to store a list of NVSwitches and GPUs with failed NVLinks
typedef struct
{
unsigned int version;
unsigned int numGpus;
unsigned int numSwitches;
fmNvlinkFailedDeviceInfo_t gpuInfo[FM_MAX_NUM_GPUS];
fmNvlinkFailedDeviceInfo_t switchInfo[FM_MAX_NUM_NVSWITCHES];
} fmNvlinkFailedDevices_v1;
typedef fmNvlinkFailedDevices_v1 fmNvlinkFailedDevices_t;
/**
* Structure to store information about a unsupported fabric partition
*/
typedef struct
{
fmFabricPartitionId_t partitionId; //!< a unique id assigned to
reference this partition
unsigned int numGpus; //!< number of GPUs in this partition
unsigned int gpuPhysicalIds[FM_MAX_NUM_GPUS]; //!< physicalId of
each GPU assigned to this partition.
} fmUnsupportedFabricPartitionInfo_t;
/**
* Structure to store information about all the unsupported fabric partitions
*/
typedef struct
{
unsigned int version; //!< version number. Use fmFabricPartitionList_version
unsigned int numPartitions; //!< total number of unsupported partitions
fmUnsupportedFabricPartitionInfo_t
partitionInfo[FM_MAX_FABRIC_PARTITIONS]; /*!< detailed information of
each unsupported partition*/
} fmUnsupportedFabricPartitionList_v1;
typedef fmUnsupportedFabricPartitionList_v1 fmUnsupportedFabricPartitionList_t;
#define fmUnsupportedFabricPartitionList_version1
MAKE_FM_PARAM_VERSION(fmUnsupportedFabricPartitionList_v1, 1)
#define fmUnsupportedFabricPartitionList_version
fmUnsupportedFabricPartitionList_version1
注意
在 DGX H100 和 NVIDIA HGX H100 系统上,GPU 物理 ID 信息与 nvidia-smi-q 输出返回的 GPU 模块 ID 信息具有相同的值。在这些系统上,当报告分区信息时,GPU 信息(例如 UUID、PCI 设备 (BDF))将为空。Hypervisor 堆栈应使用 GPU 物理 ID 信息来关联分区中的 GPU,并且需要将实际 GPU 分配给相应分区的客户机 VM。
5.2. 初始化 Fabric Manager API 接口
要初始化 FM API 接口库,请运行以下命令
fmReturn_t fmLibInit(void)
Parameters
None
Return Values
FM_ST_SUCCESS - if FM API interface library has been properly initialized
FM_ST_IN_USE - FM API interface library is already in initialized state.
FM_ST_GENERIC_ERROR - A generic, unspecified error occurred
5.3. 关闭 Fabric Manager API 接口
以下方法用于关闭 FM API 接口库,通过 fmConnect() 建立的远程连接也将被关闭。
fmReturn_t fmLibShutdown(void)
Parameters
None
Return Values
FM_ST_SUCCESS - if FM API interface library has been properly shut down
FM_ST_UNINITIALIZED - interface library was not in initialized state.
5.4. 连接到正在运行的 Fabric Manager 实例
要连接到正在运行的 FM 实例,FM 实例将作为系统服务的一部分启动,或由系统管理员手动启动。API 将使用此连接来交换信息到正在运行的 FM 实例。
fmReturn_t fmConnect(fmConnectParams_t *connectParams, fmHandle_t *pFmHandle)
Parameters
connectParams
Valid IP address for the remote host engine to connect to. If ipAddress
is specified as x.x.x.x it will attempt to connect to the default port
specified by FM_CMD_PORT_NUMBER.If ipAddress is specified as x.x.x.x:yyyy
it will attempt to connect to the port specified by yyyy. To connect to
an FM instance that was started with unix domain socket fill the socket
path in addressInfo member and set addressIsUnixSocket flag.
pfmHandle
Fabric Manager API interface abstracted handle for subsequent API calls
Return Values
FM_ST_SUCCESS - successfully connected to the FM instance
FM_ST_CONNECTION_NOT_VALID - if the FM instance could not be reached
FM_ST_UNINITIALIZED - FM interface library has not been initialized
FM_ST_BADPARAM - pFmHandle is NULL or IP Address/format is invalid
FM_ST_VERSION_MISMATCH - provided versions of params do not match
5.5. 断开与正在运行的 Fabric Manager 实例的连接
要断开与 FM 实例的连接,请运行以下命令。
fmReturn_t fmDisconnect(fmHandle_t pFmHandle)
Parameters
pfmHandle
Handle that came from fmConnect
Return Values
FM_ST_SUCCESS - successfully disconnected from the FM instance
FM_ST_UNINITIALIZED - FM interface library has not been initialized
FM_ST_BADPARAM - if pFmHandle is not a valid handle
FM_ST_GENERIC_ERROR - an unspecified internal error occurred
5.6. 获取支持的分区
要在基于 NVSwitch 的系统中查询支持的(静态)GPU Fabric 分区列表,请运行以下命令。
fmReturn_t fmGetSupportedFabricPartitions(fmHandle_t pFmHandle,
fmFabricPartitionList_t *pFmFabricPartition)
Parameters
pFmHandle
Handle returned by fmConnect()
pFmFabricPartition
Pointer to fmFabricPartitionList_t structure. On success, the list of
supported (static) partition information will be populated in this structure.
Return Values
M_ST_SUCCESS – successfully queried the list of supported partitions
FM_ST_UNINITIALIZED - FM interface library has not been initialized.
FM_ST_BADPARAM – Invalid input parameters
FM_ST_GENERIC_ERROR – an unspecified internal error occurred
FM_ST_NOT_SUPPORTED - requested feature is not supported or enabled
FM_ST_NOT_CONFIGURED - Fabric Manager is initializing and no data
FM_ST_VERSION_MISMATCH - provided versions of params do not match
5.7. 激活 GPU 分区
要在基于 NVSwitch 的系统中激活受支持的 GPU Fabric 分区,请运行以下命令。
注意
此 API 仅在共享 NVSwitch 多租户模式下受支持。
fmReturn_t fmActivateFabricPartition((fmHandle_t pFmHandle,
fmFabricPartitionId_t partitionId)
Parameters
pFmHandle
Handle returned by fmConnect()
partitionId
The partition id to be activated.
Return Values
FM_ST_SUCCESS – successfully queried the list of supported partitions
FM_ST_UNINITIALIZED - FM interface library has not been initialized.
FM_ST_BADPARAM – Invalid input parameters or unsupported partition id
FM_ST_GENERIC_ERROR – an unspecified internal error occurred
FM_ST_NOT_SUPPORTED - requested feature is not supported or enabled
FM_ST_NOT_CONFIGURED - Fabric Manager is initializing and no data
FM_ST_IN_USE - specified partition is already active or the GPUs are in
use by other partitions.
5.8. 激活具有虚拟功能的 GPU 分区
在 vGPU 虚拟化模式下,要激活具有 vGPU 虚拟功能 (VF) 的可用 GPU Fabric 分区,请运行此命令。
fmReturn_t fmActivateFabricPartitionWithVFs((fmHandle_t pFmHandle,
fmFabricPartitionId_t partitionId, fmPciDevice_t *vfList, unsigned int numVfs)
Parameters:
pFmHandle
Handle returned by fmConnect()
partitionId
The partition id to be activated.
*vfList
List of VFs associated with physical GPUs in the partition. The
ordering of VFs passed to this call is significant, especially for
migration/suspend/resume compatibility, the same ordering should be used each
time the partition is activated.
numVfs
Number of VFs
Return Values:
FM_ST_SUCCESS – successfully queried the list of supported partitions
FM_ST_UNINITIALIZED - FM interface library has not been initialized.
FM_ST_BADPARAM – Invalid input parameters or unsupported partition id
FM_ST_GENERIC_ERROR – an unspecified internal error occurred
FM_ST_NOT_SUPPORTED - requested feature is not supported or enabled
FM_ST_NOT_CONFIGURED - Fabric Manager is initializing and no data
FM_ST_IN_USE - specified partition is already active or the GPUs are in
use by other partitions.
注意
在启动 vGPU VM 之前,即使只有一个 vGPU 分区,也必须调用此 API。
如果相应的 GPU 上启用了 MIG 模式,则多 vGPU 分区激活将失败。
5.9. 停用 GPU 分区
要在 FM 在共享 NVSwitch 或 vGPU 多租户模式下运行时,在基于 NVSwitch 的系统中停用先前激活的 GPU Fabric 分区,请运行以下命令。
fmReturn_t fmDeactivateFabricPartition((fmHandle_t pFmHandle,
fmFabricPartitionId_t partitionId)
Parameters
pFmHandle
Handle returned by fmConnect()
partitionId
The partition id to be deactivated.
Return Values
FM_ST_SUCCESS – successfully queried the list of supported partitions
FM_ST_UNINITIALIZED - FM interface library has not been initialized.
FM_ST_BADPARAM – Invalid input parameters or unsupported partition id
FM_ST_GENERIC_ERROR – an unspecified internal error occurred
FM_ST_NOT_SUPPORTED - requested feature is not supported or enabled
FM_ST_NOT_CONFIGURED - Fabric Manager is initializing and no data
FM_ST_UNINITIALIZED - specified partition is not activated
5.10. 在 Fabric Manager 重启后设置激活的分区列表
要在 FM 重启后向其发送当前激活的 Fabric 分区列表,请运行以下命令。
注意
如果在 FM 重启时没有活动分区,则必须使用分区数为零进行此调用。
fmReturn_t fmSetActivatedFabricPartitions(fmHandle_t pFmHandle,
fmActivatedFabricPartitionList_t *pFmActivatedPartitionList)
Parameters
pFmHandle
Handle returned by fmConnect()
pFmActivatedPartitionList
List of currently activated fabric partitions.
Return Values
FM_ST_SUCCESS – FM state is updated with active partition information
FM_ST_UNINITIALIZED - FM interface library has not been initialized.
FM_ST_BADPARAM – Invalid input parameters
FM_ST_GENERIC_ERROR – an unspecified internal error occurred
FM_ST_NOT_SUPPORTED - requested feature is not supported or enabled
5.11. 获取 NVLink 故障设备
要查询所有在 FM 初始化时具有 NVLink 故障的 GPU 和 NVSwitch,请运行以下命令。
注意
当 FM 在共享 NVSwitch 或 vGPU 多租户弹性重启 (--restart) 模式下运行时,不支持此 API。
fmReturn_t fmGetNvlinkFailedDevices(fmHandle_t pFmHandle,
fmNvlinkFailedDevices_t *pFmNvlinkFailedDevices)
Parameters
pFmHandle
Handle returned by fmConnect()
pFmNvlinkFailedDevices
List of GPU or NVSwitch devices that have failed NVLinks.
Return Values
FM_ST_SUCCESS – successfully queried list of devices with failed NVLinks
FM_ST_UNINITIALIZED - FM interface library has not been initialized.
FM_ST_BADPARAM – Invalid input parameters
FM_ST_GENERIC_ERROR – an unspecified internal error occurred
FM_ST_NOT_SUPPORTED - requested feature is not supported or enabled
FM_ST_NOT_CONFIGURED - Fabric Manager is initializing and no data
FM_ST_VERSION_MISMATCH - provided versions of params do not match
注意
在 DGX H100 和 NVIDIA HGX H100 系统上,NVLink 在 GPU 和 NVSwitch 硬件级别使用 ALI 功能进行训练,而无需 FM 协调。在这些系统上,对于此 API,FM 将始终返回 FM_ST_SUCCESS 和一个空列表。
5.12. 获取不支持的分区
要在 FM 在共享 NVSwitch 或 vGPU 多租户模式下运行时,查询所有不支持的 Fabric 分区,请运行以下命令。
fmReturn_tfmGetUnsupportedFabricPartitions(fmHandle_t pFmHandle,
fmUnsupportedFabricPartitionList_t *pFmUnupportedFabricPartition)
Parameters
pFmHandle
Handle returned by fmConnect()
pFmUnupportedFabricPartition
List of unsupported fabric partitions on the system.
Return Values
FM_ST_SUCCESS – successfully queried list of devices with failed NVLinks
FM_ST_UNINITIALIZED - FM interface library has not been initialized.
FM_ST_BADPARAM – Invalid input parameters
FM_ST_GENERIC_ERROR – an unspecified internal error occurred
FM_ST_NOT_SUPPORTED - requested feature is not supported or enabled
FM_ST_NOT_CONFIGURED - Fabric Manager is initializing and no data
FM_ST_VERSION_MISMATCH - provided versions of params do not match
注意
在 DGX H100 和 NVIDIA HGX H100 系统上,此 API 将始终返回 FM_ST_SUCCESS 和一个空的不支持分区列表。
6. 完全直通虚拟化模型
基于 NVSwitch 的系统的第一个受支持的虚拟化模型是 GPU 和 NVSwitch 内存 Fabric(交换机)的直通设备分配。具有 16、8、4、2 和 1 个 GPU 的 VM 在每个 VM 大小使用的 GPU 和 NVSwitch 的预定义子集下受支持。
GPU 和 NVSwitch 的子集称为系统分区。非重叠分区可以混合和匹配,这允许您在具有两个 GPU 基板的基于 NVSwitch 的系统上同时支持例如一个 8-GPU VM、一个 4-GPU VM 和两个 2-GPU VM。具有 16 和 8 个 GPU 的 VM 没有带宽损失,而在较小的 VM 中,通过使用专用交换机进行隔离,会存在一些带宽权衡。
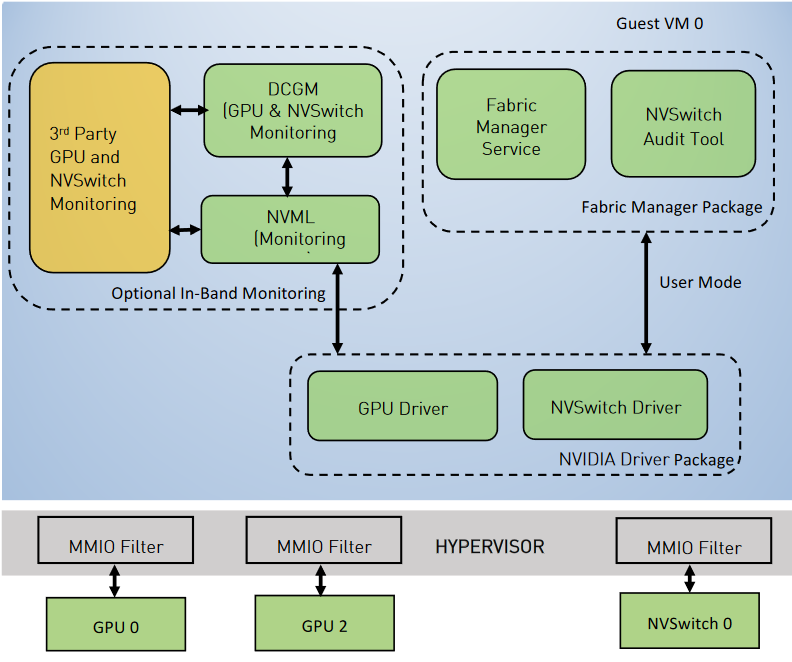
图 2 双 GPU 虚拟机中的软件堆栈(完全直通模型)
6.1. 支持的虚拟机配置
分配给 VM 的 GPU 数量 |
NVSwitch 数量 |
启用的 NVLink 互连 |
启用的 NVLink 每个 GPU |
每个 NVSwitch |
|---|---|---|---|---|
16 |
12 |
约束 |
6/6 |
16/18 |
8 |
6 |
约束 |
无 |
8/18 |
4 |
3 |
来自每个 GPU 基板的一组八个 GPU |
3/6 |
4/18 |
2 |
1 |
来自每个 GPU 基板的两组四个 GPU |
1/6 |
2/18 |
1 |
0 |
来自每个 GPU 基板的四组两个 GPU |
0/6 |
16/18 |
分配给 VM 的 GPU 数量 |
NVSwitch 数量 |
启用的 NVLink 互连 |
启用的 NVLink 每个 GPU |
每个 NVSwitch |
|---|---|---|---|---|
16 |
12 |
表 2 两个 DGX A100 和 NVIDIA HGX A100 系统设备分配 |
12/12 |
16/18 |
8 |
6 |
表 2 两个 DGX A100 和 NVIDIA HGX A100 系统设备分配 |
32/36 |
8/18 |
4 |
3 |
16/36 |
6/12 |
4/18 |
2 |
1 |
6/36 |
2/12 |
2/18 |
1 |
0 |
4/36 |
0/12 |
16/18 |
分配给 VM 的 GPU 数量 |
NVSwitch 数量 |
启用的 NVLink 互连 |
启用的 NVLink 每个 GPU |
每个 NVSwitch |
|---|---|---|---|---|
8 |
4 |
表 3 DGX H100 和 NVIDIA HGX H100 系统设备分配 |
18/18 两个 NVSwitch 为 32/64。 |
16/18 |
1 |
0 |
0/6 |
其他两个 NVSwitch 为 40/64。 |
0/64 |
需要禁用 GPU NVLink。
6.2. 具有 16 个 GPU 的虚拟机
可用的 GPU 和 NVSwitch 分配给客户机 VM。NVSwitch 或 GPU 上没有禁用的 NVLink 互连。要支持 16 GPU 分区,系统必须配置两个 GPU 基板。
6.3. 具有八个 GPU 的虚拟机
每个 VM 有八个 GPU,并且必须将同一基板上的 NVSwitch(DGX A100 和 NVIDIA HGX A100 为六个,DGX H100 和 NVIDIA HGX H100 为四个)分配给客户机 VM。每个 GPU 都启用了所有 NVLink 互连。如果系统有两个 GPU 基板,则将有两个系统分区可用,可以在其中创建八个 GPU VM。否则,只有一个分区可用。GPU 基板之间的所有 NVLink 连接均被禁用。
6.4. 具有四个 GPU 的虚拟机
如果支持此配置,则每个 VM 获取四个 GPU 和三个交换机。如表 3 所示,每个 GPU 仅启用 NVLink 互连的子集。如果系统配置了两个 GPU 基板,则系统上将有四个分区可用。对于单基板系统,将有两个分区可用。GPU 基板之间的所有 NVLink 连接均被禁用。
如果支持此配置,则每个 VM 将获得两个 GPU 和一个 NVSwitch。此外,每个 GPU 启用 GPU NVLink 互连的子集。如果系统填充了两个 GPU 基板,则系统上将有八个分区可用。对于单基板系统,有四个分区可用。GPU 基板之间的所有 NVLink 连接均已禁用。
6.6. 具有一个 GPU 的虚拟机
每个 VM 具有一个 GPU,没有交换机。如果系统填充了两个 GPU 基板,则系统上将有 16 个分区可用。对于单基板系统,有八个分区可用。GPU 基板之间的所有 NVLink 连接均已禁用。
6.7. 其他要求
以下是一些其他要求
虚拟机监控程序需要维护分区配置,包括在每个 GPU 和交换机上为每个分区阻止哪些 NVLink 连接。
虚拟机监控程序需要为 NVSwitch 实施 MMIO 过滤。
虚拟机监控程序需要精细控制为 GPU 和交换机配置的 IOMMU 映射。
具有多个 GPU 的 Guest VM 需要运行核心 NVSwitch 软件堆栈,例如,NVIDIA 驱动程序和 FM,以配置交换机和 NVLink 连接。
6.8. 虚拟机监控程序序列
虚拟机监控程序完成以下步骤来启动、关闭和重新启动 Guest VM。
启动 Guest VM。
选择 GPU 和交换机的未使用分区。
重置分区中的 GPU 和交换机。
通过执行指定的 MMIO 配置来阻止每个 GPU 上禁用的 NVLink 连接。
通过配置 MMIO 拦截来阻止每个交换机上禁用的 NVLink 连接。
避免在 GPU 和交换机之间配置任何 IOMMU 映射。
交换机不能被 Guest VM 控制的任何其他 PCIe 设备访问。这样,交换机就无法绕过为 CPU 实施的 MMIO 限制。
GPU 不需要被任何其他 GPU 或交换机访问。
GPU 需要被第三方设备访问,以支持 NVIDIAGPUDirect™ RDMA。
为避免额外的 GPU 重置,请启动 Guest VM。
关闭 Guest VM。
照常关闭 Guest VM。
重置属于该分区的 GPU 和交换机。
重新启动 Guest VM。
重复步骤 1a 到 1f,但这次分区已选定。
6.9. 监控错误
NVSwitch、GPU 和 NVLink 错误对 Guest VM 可见。如果您希望虚拟机监控程序监控相同的项,请使用以下方法之一
带内监控
在 Guest VM 上运行 NVIDIA Data Center GPU Manager (DCGM),或使用 NVIDIA Management Library (NVML) API 进行 GPU 特定的监控。
带外监控
使用基于 GPU 和 NVSwitch SMBus Post Box Interface (SMBPBI) 的 OOB 命令。
6.10. 限制
NVSwitch 错误对 Guest VM 可见。
Windows 仅支持单 GPU VM。
7. 共享 NVSwitch 虚拟化模型
共享 NVSwitch 虚拟化模型通过从永久运行的一个服务 VM 管理交换机,额外扩展了 GPU 直通模型。GPU 可供服务 VM 访问以进行链路训练,并重新分配给 Guest VM。在 Guest VM 之间共享交换机允许 FM 为在 GPU 直通模型中观察到带宽降低的 2 个和 4 个 GPU VM 启用更多 NVLink 连接。
7.1. 软件堆栈
NVSwitch 管理所需的软件堆栈在服务 VM 中运行。
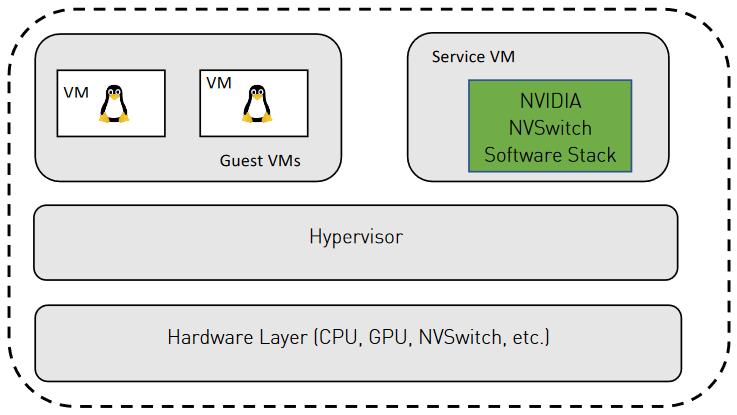
图 3 共享 NVSwitch 软件堆栈
NVSwitch 单元始终作为 PCIe 直通设备分配给服务 VM。GPU 根据需要(作为 PCI 直通)热插拔到服务 VM。
在较高层面上,服务 VM 具有以下功能
提供一个接口来查询可用的 GPU VM 分区(分组)和相应的 GPU 信息。
提供一个接口来激活 GPU VM 分区,这涉及以下内容
训练 NVSwitch 到 NVSwitch NVLink 互连(如果需要)。
训练相应的 GPU NVLink 接口(如果适用)。
编程 NVSwitch 以拒绝访问未分配给分区的 GPU。
提供一个接口来停用 GPU VM 分区,这涉及以下内容
取消训练(断电)NVSwitch 到 NVSwitch NVLink 互连。
取消训练(断电)相应的 GPU NVLink 接口。
禁用相应的 NVSwitch 路由和 GPU 访问。
通过带内和带外机制报告 NVSwitch 错误。
7.2. Guest VM 到服务 VM 交互
对于 NVIDIA HGX-2、NVIDIA HGX A100 和 NVIDIA HGX A800 服务器系统,启用 NVLink 通信所需的 GPU 配置是在初始分区激活过程中建立的,该过程发生在将 GPU 控制权转移到 Guest VM 之前。因此,在工作负载运行时,Guest VM 无需启动与服务 VM 的通信。
但是,在 NVIDIA HGX H100 和 NVIDIA HGX H800 系统上,需要采用不同的方法。在这些系统中,GPU 在分区激活期间未分配给服务 VM。因此,GPU NVLink 通信的配置必须传递到 Guest VM。此外,H100 和 H800 世代中新引入的 NVLink Sharp 功能需要根据 Guest VM 的工作负载需求动态调整 NVSwitch 配置。
为了在 NVIDIA HGX H100 和 NVIDIA HGX H800 系统上促进这些功能,Guest VM 中的 GPU 通过将专用数据包传输到在服务 VM 上运行的 FM 来通过 NVLink 进行通信。为了简化集成工作,通过 NVLink 传达这些请求是最佳解决方案,因为它可以在 NVIDIA 的软件和固件中完全管理,而无需为客户进行自定义集成。此通信协议也是版本不可知的,这允许 Guest VM 和服务 VM 上不同版本的 NVIDIA 驱动程序之间的兼容性。
7.3. 准备服务虚拟机
7.3.1. 操作系统镜像
在内部,NVIDIA 使用 Ubuntu 发行版作为服务 VM 操作系统镜像。但是,其他主要 Linux 操作系统发行版没有已知的限制。有关更多信息,请参阅操作系统环境。
7.3.2. 资源要求
有关确切的服务 VM 资源要求的更多信息,请参阅相应的操作系统发行版最低资源指南。除了指定的最低指南外,NVIDIA 内部还为服务 VM 使用以下硬件资源。
注意
如果服务 VM 用于其他功能(例如执行 GPU 健康检查),则服务 VM 的资源要求可能会有所不同。特定的内存和 vCPU 需求也可能根据您选择的 Linux 发行版和您启用的操作系统功能而波动。我们建议您根据需要对分配的内存和 vCPU 资源进行必要的调整。
资源 |
数量/大小 |
|---|---|
vCPU |
2 |
系统内存 |
4 GB |
7.3.3. NVIDIA 软件包
服务 VM 镜像必须安装以下 NVIDIA 软件包。
NVIDIA Data Center GPU 驱动程序(NVIDIA HGX-2 和 NVIDIA HGX A100 系统的 450.xx 及更高版本)。
对于 NVIDIA HGX H100 系统,需要 525.xx 及更高版本。
NVIDIA Fabric Manager 软件包(与驱动程序软件包版本相同)。
7.3.4. Fabric Manager 配置文件修改
为了支持共享 NVSwitch 模式,通过设置 FM 配置项 FABRIC_MODE=1 在共享 NVSwitch 模式下启动 FM 服务。
注意
NVIDIA HGX-2 和 NVIDIA HGX A100 系统上的 NVSwitch 和 GPU 必须在 FM 服务启动之前绑定到 nvidia.ko。如果 GPU 和 NVSwitch 未作为操作系统启动的一部分插入服务 VM,请在 NVSwitch 和 GPU 绑定到 nvidia.ko 后手动启动 FM 服务或直接通过运行相应的命令行选项来启动该过程。
在共享 NVSwitch 模式下,FM 支持弹性功能,该功能允许在服务 VM 中 FM 正常或非正常退出后,在活动 Guest VM 上的 GPU 之间不停地转发 NVLink 流量。为了支持此功能,FM 使用 /tmp/fabricmanager.state 来保存某些元数据信息。要使用不同的位置/文件来存储此元数据信息,请使用路径和文件名修改 STATE_FILE_NAME FM 配置文件项。FM 使用基于 TCP I/P 回环 (127.0.0.1) 的套接字接口进行通信。要改为使用 Unix 域套接字,请使用 Unix 域套接字名称修改 FM FM_CMD_UNIX_SOCKET_PATH 和 UNIX_SOCKET_PATH 配置文件选项。
7.3.5. 其他 NVIDIA 软件包
在共享 NVSwitch 模式下,除了 FM 之外,在激活或停用分区时,任何进程或实体都不应打开 GPU 并与之交互。此外,所有 GPU 健康检查应用程序必须在激活分区后启动,并且必须在从 nvidia.ko 解绑定 GPU 之前关闭。
7.5. Fabric Manager 弹性
有关共享虚拟化模式下 FM 弹性的更多信息,请参阅弹性。
7.6. 服务虚拟机生命周期管理
7.6.2. 构建 GPU 到分区的映射
在服务 VM 和虚拟机监控程序上运行的 FM 实例必须使用通用的编号方案(GPU 物理 ID)来唯一标识每个 GPU。在此版本中,物理 ID 编号与基板引脚排列设计附带材料中的编号相同。
虚拟机监控程序应维护 GPU 物理 ID 列表和相应的 PCI BDF 映射信息,以识别虚拟机监控程序中的每个 GPU。此信息是识别属于分区的 GPU 以及在 Guest VM 激活过程中将 GPU 热添加到服务 VM 所必需的。
7.6.3. 启动服务虚拟机
作为服务 VM 启动的一部分,虚拟机监控程序必须执行以下操作
将可用的 NVSwitch 作为 PCI 直通设备分配/插入到服务 VM,而无需 MMIO 过滤。
在 NVIDIA HGX-2 和 NVIDIA HGX A100 系统上,将可用的 GPU 作为 PCI 直通设备分配/插入到服务 VM,而无需 MMIO 过滤。
启动并等待 FM 完全初始化 GPU 和交换机。在 fabric 初始化并准备就绪之前,FM API 将返回
FM_ST_NOT_CONFIGURED。查询当前支持的 VM 分区列表,并相应地构建可用的 Guest VM 组合。
对于 NVIDIA HGX-2 和 NVIDIA HGX A100 系统,从服务 VM 取消分配/拔出 GPU。
7.6.4. 重新启动服务虚拟机
NVSwitch 内核软件堆栈在服务 VM 启动时加载并初始化 NVSwitch 和 GPU,因此重新启动服务 VM 会影响当前激活的 GPU 分区。虚拟机监控程序必须遵循与启动服务虚拟机中描述的相同的过程和步骤。
7.6.5. 关闭服务
当前激活的 VM 分区不会作为服务 VM 关闭的一部分受到影响,因为 NVSwitch 配置已保留。但是,如果虚拟机监控程序或 PCIe 直通驱动程序在服务 VM 关闭时向 NVSwitch 设备发出辅助总线重置 (SBR),则激活的分区将受到影响。由于 FM 未运行且驱动程序已卸载,因此将不会进行主动错误监控和相应的补救。
注意
请勿将 Guest VM 在此状态下保留较长时间。
7.7. Guest 虚拟机生命周期管理
7.7.1. Guest 虚拟机 NVIDIA 驱动程序软件包
要使用 GPU NVLink 互连,请确保 Guest VM 上安装了以下 NVIDIA Data Center GPU 的驱动程序软件包之一
NVIDIA HGX-2 和 NVIDIA HGX A100 系统的 450.xx 及更高版本。
NVIDIA HGX H100 系统的 525.xx 及更高版本。
7.7.2. 启动 Guest 虚拟机
要启动 Guest VM,虚拟机监控程序必须完成以下过程之一
注意
序列将因系统中使用的 NVSwitch 世代而异。主要区别在于 GPU 是否需要连接到服务 VM 并绑定到 nvidia.ko。
在 NVIDIA HGX-2 和 NVIDIA HGX A100 系统上
根据 Guest VM GPU 需求选择支持的 GPU 分区之一。
使用 GPU 物理 ID 到 PCI BDF 映射来识别相应的 GPU。
重置 (SBR) 选定的 GPU。
将选定的 GPU 热插拔到服务 VM。
确保 GPU 绑定到
nvidia.ko。请求 FM 使用
fmActivateFabricPartition()API 激活请求的 GPU 分区。从
nvidia.ko解绑定 GPU。从服务 VM 热拔出 GPU(如果需要)。
启动 Guest VM,无需重置 GPU。
注意
如果 GPU 作为 Guest VM 启动的一部分进行 PCIe 重置,则 GPU NVLink 在 Guest VM 上将处于 InActive 状态。此外,在不进行 GPU 重置的情况下启动 Guest VM 可能需要在您的虚拟机监控程序 VM 启动序列路径中进行修改。
在 NVIDIA HGX H100 系统上
根据 Guest VM GPU 需求选择支持的 GPU 分区之一。
使用 GPU 物理 ID 到 PCI BDF 映射来识别相应的 GPU。
请求 FM 使用
fmActivateFabricPartition()API 激活请求的 GPU 分区。启动 Guest VM。
7.7.3. 关闭 Guest 虚拟机
要关闭 Guest VM,虚拟机监控程序必须执行以下操作。
注意
序列将因系统中使用的 NVSwitch 世代而异。
在 NVIDIA HGX-2 和 NVIDIA HGX A100 系统上
关闭 Guest VM,但为避免任何 NVSwitch 侧 NVLink 错误,请避免 GPU 重置。
使用
fmDeactivateFabricPartition()API 并请求 FM 停用特定的 GPU 分区。在停用分区请求完成后重置 GPU。
在 NVIDIA HGX H100 系统上
关闭 Guest VM。
使用
fmDeactivateFabricPartition()API 并请求 FM 停用特定的 GPU 分区。如果 Guest VM 关闭过程未完成显式 GPU 重置,请在停用分区请求完成后重置 GPU。
7.7.4. 重新启动 Guest 虚拟机
重新启动 Guest VM 时,如果 GPU 作为 VM 重新启动的一部分获得 SBR,则虚拟机监控程序必须完成:ref:starting-a-guest-virtual-machine和关闭 Guest 虚拟机中的步骤。
7.7.5. 验证 GPU 路由
nvswitch-audit 命令行实用程序(作为 FM 软件包的一部分安装)可以输出 NVSwitch 编程为每个 GPU 处理的 NVLink 数量。该工具通过读取和解码内部 NVSwitch 硬件路由表信息来重建此信息。我们建议您在每个 VM 分区激活和停用周期中定期验证 GPU 可达性矩阵,方法是在服务 VM 中运行此工具。
nvswitch-audit 命令行实用程序支持以下选项。
root@host1-servicevm:~# ./nvswitch-audit -h
NVIDIA NVSwitch audit tool
Reads NVSwitch hardware tables and outputs the current number of
NVlink connections between each pair of GPUs
Usage: nvswitch-audit [options]
Options include:
[-h | --help]: Displays help information
[-v | --verbose]: Verbose output including all Request and Response table entries
[-f | --full-matrix]: Display All possible GPUs including those with no connecting paths
[-c | --csv]: Output the GPU Reachability Matrix as Comma Separated Values
[-s | --src]: Source GPU for displaying number of unidirectional connections
[-d | --dst]: Destination GPU for displaying number of unidirectional connections
以下示例输出显示在 NVIDIA HGX A100 上激活 8-GPU VM 分区时的最大 GPU NVLink 连接。
root@host1-servicevm:~# ./nvswitch-audit
GPU Reachability Matrix
GPU 1 2 3 4 5 6 7 8
1 X 12 12 12 12 12 12 12
2 12 X 12 12 12 12 12 12
3 12 12 X 12 12 12 12 12
4 12 12 12 X 12 12 12 12
5 12 12 12 12 X 12 12 12
6 12 12 12 12 12 X 12 12
7 12 12 12 12 12 12 X 12
8 12 12 12 12 12 12 X 12
7.8. 错误处理
有关 FM 初始化、分区和硬件特定错误及其处理的信息,请参阅错误处理。
7.8.1. Guest 虚拟机 GPU 错误
当 Guest VM 处于活动状态时,所有 GPU 运行时错误都将作为 Xid 错误记录在 Guest VM 系统日志中。在 NVIDIA HGX-2 和 NVIDIA HGX A100 系统上,此环境中不支持需要重新训练的 GPU NVLink 错误,要恢复,必须完成启动 Guest 虚拟机和关闭 Guest 虚拟机中的步骤。
7.8.2. 处理服务虚拟机崩溃
当服务 VM 遇到内核崩溃时,剩余的已激活 Guest VM 将继续按预期运行。但是,VM 分区激活和停用生命周期将受到影响。要从此状态恢复,需要重新启动服务 VM 或重新启动。
7.9. 与多实例 GPU 的互操作性
共享 NVSwitch 虚拟化模型可以与 NVIDIA A100 和 H100 GPU 上支持的 MIG 功能互操作。但是,要向 Guest VM 公开具有启用 MIG 的 GPU 的共享 NVSwitch 分区,请维护本节中的选项之一。由于启用 MIG 后,NVLink 未在 H100 GPU 上进行训练,因此这些选项不适用于 NVIDIA HGX H100 系统。
7.9.1. 初始化服务虚拟机
当 FM 在服务 VM 上初始化时,如果不使用 --restart 选项进行弹性流程,则必须禁用可用 GPU 的 MIG 模式。如果任何 GPU 启用了 MIG 模式,则 FM 服务初始化将中止。
7.9.2. 激活 Guest 虚拟机
FM 共享 NVSwitch 分区激活和停用序列可以处理启用 MIG 的 GPU。但是,在激活分区之前已启用 MIG 的 GPU(例如,在 VM 重新启动之前由 VM 启用)将不会在分区激活期间训练 NVLink。激活/停用流程按预期工作。
8. vGPU 虚拟化模型
vGPU 虚拟化模型通过在所有受支持的 GPU 中启用 SR-IOV 功能并将特定的 VF 或 VF 集分配给 VM 来支持 VF 直通。
GPU NVLink 一次仅分配给一个 VF。
不支持属于不同 VM 或分区的 GPU 之间的 NVLink P2P。
有关支持的 vGPU 功能、特性和配置的更多信息,请参阅vGPU 软件用户指南。
8.1. 软件堆栈
在 vGPU 虚拟化模型中,NVSwitch 软件堆栈(FM 和交换机驱动程序)在 vGPU 主机中运行。与裸机模式一样,物理 GPU 和 NVSwitch 由 vGPU 主机拥有和管理。GPU 和 NVSwitch NVLink 作为 FM 初始化的一部分进行训练和配置。交换机路由表已初始化,以防止任何 GPU-GPU 通信。
注意
基于 vGPU 的部署模型在基于第一代 NVSwitch 的系统(如 DGX-2 和 NVIDIA HGX-2)上不受支持。
注意
基于 vGPU 的部署模型在当前版本的 DGX H100 和 NVIDIA HGX H100 系统上不受支持。NVIDIA 计划在未来的软件版本中添加此支持。
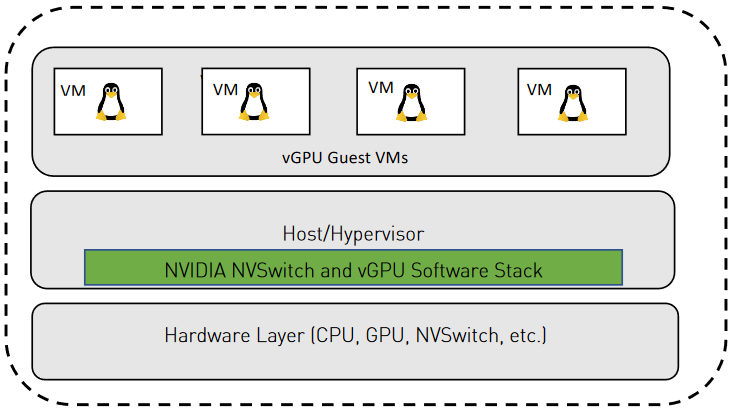
图 4 vGPU 软件堆栈
8.2. 准备 vGPU 主机
8.2.1. 操作系统镜像
有关支持的操作系统、虚拟机监控程序以及有关安装和配置 vGPU 主机驱动程序软件的信息,请参阅vGPU 软件用户指南。
8.2.2. NVIDIA 软件包
除了 NVIDIA vGPU 主机驱动程序软件外,vGPU 主机镜像还必须安装以下 NVIDIA 软件包
NVIDIA FM 软件包
NVIDIA Fabric Manager SDK 软件包
注意
这两个软件包的版本必须与驱动程序软件包的版本相同。
8.2.3. Fabric Manager 配置文件修改
为了支持 vGPU 虚拟化,通过设置 FABRIC_MODE=2 FM 配置项,在 vGPU 虚拟化模式下启动 FM 服务。
注意
NVSwitch 必须在 FM 服务启动之前绑定到 nvidia.ko。在 DGX A100 和 NVIDIA HGX A100 系统上,所有 GPU 也必须在 FM 服务启动之前绑定到 nvidia.ko。
在 vGPU 虚拟化模式下,FM 支持弹性功能,该功能允许在 vGPU 主机上 FM 退出(正常或非正常)后,在活动 Guest VM 上的 GPU 之间连续转发 NVLink 流量。为了支持此功能,FM 使用 /tmp/fabricmanager.state 来保存某些元数据信息。要使用不同的位置/文件来存储此元数据信息,请使用新路径和文件名修改 STATE_FILE_NAME FM 配置文件项。
默认情况下,FM 使用基于 TCP I/P 回环 (127.0.0.1) 的套接字接口进行通信。要改为使用 Unix 域套接字,请使用新的 Unix 域套接字名称修改 FM_CMD_UNIX_SOCKET_PATH 和 UNIX_SOCKET_PATH FM 配置文件选项。
8.4. Fabric Manager 弹性
有关 vGPU 虚拟化模式下 FM 弹性的更多信息,请参阅弹性。
8.5. vGPU 分区
有关 vGPU 虚拟化模型的默认支持分区,请参阅GPU 分区。
8.6. Guest 虚拟机生命周期管理
以下是 Guest VM 生命周期概述
系统通电并初始化。
vGPU 主机驱动程序加载。
SR-IOV 已启用。
FM 在 vGPU 虚拟化模式下初始化。
NVlink 已训练。
分区已使用选定的 SR-IOV VF 激活。
启用 vGPU 的 VM 使用步骤 2 中选择的 VF 完成其生命周期。
此生命周期可能涉及启动、重新启动、关闭、挂起、恢复和迁移活动。
分区已停用。
以下部分将更详细地解释这些步骤。
8.6.1. 激活分区并启动虚拟机
在激活分区并启动 vGPU VM 之前,必须在物理 GPU 上启用 SR-IOV VF。
启动 Guest VM 时,虚拟机监控程序必须执行以下操作
选择一个可用的 GPU 分区,其中包含 Guest VM 所需数量的 GPU,并选择将在这些 GPU 上使用的 VF。
使用
fmActivateFabricPartitionWithVFs()API 并请求 FM 激活 GPU 分区,以及选定的一组 VF。使用选定的 VF 启动 Guest VM。
注意
即使对于仅使用一个 vGPU 的 VM,也始终需要在启动 vGPU VM 之前进行分区激活。
分区激活期间使用的 VF 顺序和 VM 分配必须保持一致,以确保正确的挂起、恢复和迁移操作。
有关 SR-IOV VF 启用和将 VF 分配给 VM 的更多信息,请参阅安装和配置用于 Red Hat Enterprise Linux KVM 的 NVIDIA Virtual GPU Manager <https://docs.nvda.net.cn/vgpu/latest/grid-vgpu-user-guide/index.html#red-hat-el-kvm-install-configure-vgpu>__。
8.6.2. 停用分区
仅当分区中的 GPU 上没有 VM 正在执行时才停用分区。要停用分区
关闭当前在分区中运行的 Guest VM。
使用
fmDeactivateFabricPartition()API 并请求 FM 停用分区。
8.6.3. 迁移虚拟机
仅在具有相同数量、GPU 类型和 NvLink 拓扑的分区之间支持 VM 迁移。
有关更多信息,请参阅迁移配置了 vGPU 的 VM。
8.6.4. 在 GPU 模式下验证 NVSwitch 路由
在验证 GPU 路由中引用的 nvswitch-audit 命令行实用程序也可用于验证 vGPU 模式下的 NVSwitch 路由信息。我们建议您运行此工具,以定期验证每个 VM 分区激活和停用周期的 GPU 可达性矩阵。
8.7. 错误处理
有关 FM 初始化、分区、硬件特定错误及其处理的信息,请参阅:ref:error-handling。
8.7.1. Guest 虚拟机 GPU 错误
当 Guest VM 处于活动状态时,GPU 运行时错误将像 Xid 错误一样记录在 vGPU 主机系统日志中。在 DGX A100 和 NVIDIA HGX A100 系统上,此环境中不支持需要重新训练的 GPU NVLink 错误,并且必须完成 Guest VM 关闭和启动序列才能恢复。
8.8. GPU 重置
如果 GPU 生成运行时错误或出现 Xid NVLink 错误,则系统管理员可以清除相应的错误状态,并使用 GPU 重置操作恢复 GPU。此操作必须在虚拟机(VM)关闭且使用该 GPU 的相应分区停用后,从 vGPU 主机启动。有关更多信息,请参阅 nvidia-smi 命令行实用程序文档。
8.9. 与 MIG 的互操作性
在 NVIDIA A100 和 NVIDIA HGX A100 上,由 MIG 支持的 vGPU 无法使用 NVlink。FM 的 vGPU 虚拟化模式仍然可以与 MIG 功能互操作,以支持在 MIG 模式下使用 GPU 子集的使用案例。
8.9.1. 在启动 Fabric Manager 服务之前启用 MIG
如果在启动 FM 之前在 GPU 上启用了 MIG,则 FM 会从包含 MIG 模式 GPU 的可用分区列表中删除该 GPU 分区。
这些 GPU 分区将不可用于部署虚拟机(VM)。
要在禁用 GPU 上的 MIG 模式后启用分区,请重启系统。
8.9.2. 在启动 Fabric Manager 服务之后启用 MIG
MIG 功能可以在启动 FM 服务之后,但在包含 GPU 的分区激活之前,在任何 GPU 上启用。
即使 GPU 处于 MIG 模式,激活 GPU 分区也会返回成功。
如果分区中的任何 GPU 在 DGX A100 和 NVIDIA HGX A100 系统上处于 MIG 模式,则激活多 GPU 分区将失败。
此过程在 DGX H100 和 NVIDIA HGX H100 系统上将成功。
9. 支持的高可用性模式
FM 提供了几种高可用性模式(降级模式)配置,允许系统管理员在基于 NVSwitch 的系统上出现硬件故障(例如 GPU 故障、NVSwitch 故障、NVLink 连接故障等)时设置适当的策略。借助此功能,系统管理员可以保留可用的 GPU 子集,以便在等待更换故障 GPU、基板等时使用。
DGX A100、NVIDIA HGX A100 和 DGX H100、NVIDIA HGX H100 系统具有不同的行为。请参阅:ref:error-handling 以获取更多信息。
9.1. 常用术语
GPU 访问 NVLink 是 GPU 和 NVSwitch 之间的 NVLink 连接。
GPU 访问 NVLink 故障是 GPU 和 NVSwitch 之间连接中发生的故障。
故障可能是 GPU/NVSwitch 引脚故障、GPU 基板中的机械故障或类似故障的结果。
Trunk NVLink 是连接两个 GPU 基板的链路。Trunk NVLink 仅发生在 NVSwitch 之间,并通过 NVLink 桥接 PCB 和连接器传输。
Trunk NVLink 故障 是在两个 GPU 基板托盘之间横向传输的 trunk NVLink 故障。
此故障可能是背板连接器引脚不良或类似问题的结果。
NVSwitch 故障 是 NVSwitch 故障,被归类为 NVSwitch 的内部故障。此故障可能是 NVSwitch 未显示在 PCIe 总线上、DBE 错误或类似问题的结果。
GPU 故障 是 GPU 发生故障的 GPU 故障。
此故障可能是 NVLink 连接、PCIe 故障或类似问题的结果。
注意
这些高可用性模式及其相应的基于 NVSwitch 的系统的动态重新配置应用于响应在 FM 初始化期间检测到的错误。在系统初始化后或 GPU 作业运行时发生的运行时错误不会触发这些高可用性模式策略。
9.2. GPU 访问 NVLink 故障
9.2.1. Fabric Manager 配置项
GPU 访问 NVLink 故障模式通过此 FM 配置文件项控制
ACCESS_LINK_FAILURE_MODE=<值>
9.2.2. 裸机行为
ACCESS_LINK_FAILURE_MODE=0在此模式下,FM 从 NVSwitch 路由中删除具有访问 NVLink 故障的 GPU,并将其余 GPU 配置为形成一个内存 fabric。这意味着具有访问 NVLink 故障的 GPU 将失去与其他 GPU 的 NVLink P2P 功能。故障 GPU 对于 NVIDIA 软件堆栈(例如 CUDA、NVML、NVIDIA-SMI 等)仍然可见,并且可以用于非 NVLink 工作负载。
ACCESS_LINK_FAILURE_MODE=1在此模式下,如果存在两个 GPU 基板(GPU 访问 NVLink 连接到这两个基板),则 FM 将禁用 NVSwitch 及其一对 Trunk NVLink。这会将 fabric 中的 NVLink P2P 带宽降低到 5/6。如果 GPU 可以访问多个 NVSwitch 的 NVLink 故障,则此选项将从 NVSwitch 路由配置中删除该 GPU 并禁用其 NVLink P2P 功能。
此过程将使其他 GPU 具有完整的 NVLink P2P 带宽。如果多个 GPU 访问 NVLink 故障指向同一 NVSwitch,则该 NVSwitch 将被禁用。
此模式仅在基于 NVSwitch 的 DGX A100 和 NVIDIA HGX A100 系统上有效。
9.2.3. 共享 NVSwitch 和 vGPU 虚拟化行为
ACCESS_LINK_FAILURE_MODE=0在此模式下,FM 从当前支持的 GPU 分区列表中删除具有访问 NVLink 故障的 GPU。图 4 显示了在双 GPU 基板系统中,一个 GPU 发生访问 NVLink 故障的效果。故障 GPU 将可用于单 GPU 分区。
此模式仅在基于 NVSwitch 的 DGX A100 和 NVIDIA HGX A100 系统上有效。
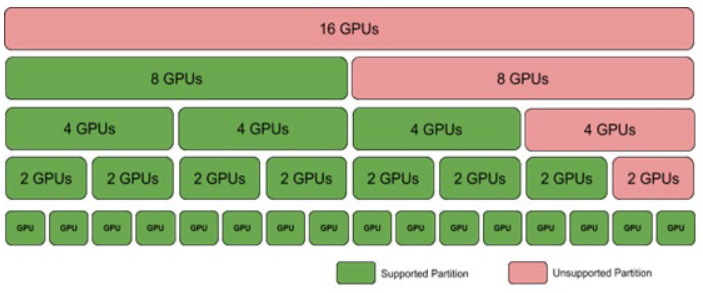
图 5 GPU 访问 NVLink 故障时的共享 NVSwitch 和 vGPU 分区
ACCESS_LINK_FAILURE_MODE=1在共享 NVSwitch 模式下,所有 GPU 分区都将可用,但分区会将 fabric 中的可用带宽降低到 5/6。如果一个 GPU 上发生多个访问 NVLink 故障,则将删除该 GPU,并且将如前所述调整可用的 GPU 分区。故障 GPU 将可用于单 GPU 分区。
此模式仅在基于 NVSwitch 的 DGX A100 和 NVIDIA HGX A100 系统上有效。
注意
目前,vGPU 多租户模式不支持 ACCESS_LINK_FAILURE_MODE=1 配置。
9.3. Trunk NVLink 故障
9.3.1. Fabric Manager 配置项
Trunk NVLink 故障模式通过此 FM 配置文件项控制
TRUNK_LINK_FAILURE_MODE=<值>
注意
此选项仅适用于具有两个 GPU 基板的系统。
9.3.2. 裸机行为
TRUNK_LINK_FAILURE_MODE=0在此模式下,当存在 trunk NVLink 故障时,FM 会中止并使系统保持未初始化状态,并且所有 CUDA 应用程序启动都将失败,并显示
cudaErrorSystemNotReady状态。但是,当FM_STAY_RESIDENT_ON_FAILURES =1时,将启用continue with error config选项,并且 FM 服务继续运行,并且 CUDA 应用程序启动将失败,并显示cudaErrorSystemNotReady状态。此模式仅在基于 NVSwitch 的 DGX A100 和 NVIDIA HGX A100 系统上有效。
TRUNK_LINK_FAILURE_MODE=1在此模式下,如果 NVSwitch 有一个或多个 trunk NVLink 故障,则该 NVSwitch 将与其对等 NVSwitch 一起禁用。这会将 fabric 中的可用带宽降低到 5/6。如果多个 NVSwitch 具有 trunk NVLink 故障,则 FM 将回退到上述
TRUNK_LINK_FAILURE_MODE=0行为。此模式仅在基于 NVSwitch 的 DGX A100 和 NVIDIA HGX A100 系统上有效。
9.3.3. 共享 NVSwitch 和 vGPU 虚拟化行为
TRUNK_LINK_FAILURE_MODE=0在此模式下,FM 从当前支持的 GPU 分区列表中删除使用 trunk NVLink 的 GPU 分区。这意味着将删除跨基板的 16 个 GPU 分区和 8 个 GPU 分区。剩余分区将以完整的 NVLink 带宽运行。此选项将支持连接的 NVSwitch 对上的无限数量的 trunk NVLink 故障。
此模式仅在基于 NVSwitch 的 DGX A100 和 NVIDIA HGX A100 系统上有效。
TRUNK_LINK_FAILURE_MODE=1在共享 NVSwitch 模式下,GPU 分区将可用,但分区会将 fabric 中的可用带宽降低到 5/6。当同一 NVSwitch 对上存在多个 trunk NVLink 故障时,将支持此选项。如果多个 trunk NVLink 故障影响不同的 NVSwitch 对,则 FM 将回退到上述
TRUNK_LINK_FAILURE_MODE=0行为。此模式仅在基于 NVSwitch 的 DGX A100 和 NVIDIA HGX A100 系统上有效。
注意
目前,vGPU 多租户模式不支持 TRUNK_LINK_FAILURE_MODE=1 配置。
9.4. NVSwitch 故障
9.4.1. Fabric Manager 配置项
NVSwitch 故障模式通过此 FM 配置文件项控制
NVSWITCH_FAILURE_MODE=<值>
9.4.2. 裸机行为
NVSWITCH_FAILURE_MODE=0在此模式下,当存在 NVSwitch 故障时,FM 会中止并使系统保持未初始化状态,并且所有 CUDA 应用程序启动都将失败,并显示
cudaErrorSystemNotReady状态。但是,当FM_STAY_RESIDENT_ON_FAILURES =1时,将启用 continue with error config 选项,FM 服务继续运行,并且 CUDA 应用程序启动将失败,并显示cudaErrorSystemNotReady状态。NVSWITCH_FAILURE_MODE =1在此模式下,当存在 NVSwitch 故障时,该 NVSwitch 将与其对等 NVSwitch 一起禁用。这会将 fabric 中的可用带宽降低到 5/6。如果发生多个 NVSwitch 故障,则 FM 将回退到上述
NVSWITCH_FAILURE_MODE=0行为。此模式仅在基于 NVSwitch 的 DGX A100 和 NVIDIA HGX A100 系统上有效。
9.4.3. 共享 NVSwitch 和 vGPU 虚拟化行为
NVSWITCH_FAILURE_MODE=0在此模式下,FM 将从具有故障 NVSwitch 的基板中删除多 GPU 分区,并删除跨基板的 8 个 GPU 分区。在一个基板系统中,仅支持单 GPU 分区。图 5 显示了当 NVSwitch 发生故障时支持的分区。
此模式仅在基于 NVSwitch 的 DGX A100 和 NVIDIA HGX A100 系统上有效。
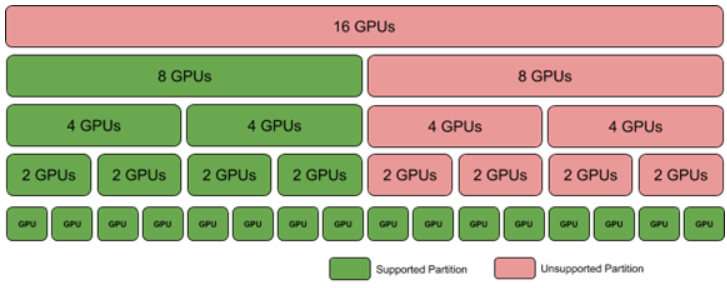
图 6 NVSwitch 发生故障时的共享 NVSwitch 和 vGPU 分区
NVSWITCH_FAILURE_MODE=1在共享 NVSwitch 模式下,所有 GPU 分区都将可用,但分区会将 fabric 中的可用带宽降低到 5/6。如果发生多个 NVSwitch 故障,则 FM 将回退到上述
NVSWITCH_FAILURE_MODE =0行为。此模式仅在基于 NVSwitch 的 DGX A100 和 NVIDIA HGX A100 系统上有效。
注意
目前,vGPU 多租户模式不支持 NVSWITCH_FAILURE_MODE=1 配置。
9.5. GPU 故障
9.5.1. 裸机行为
FM 将忽略初始化失败、未显示在 PCI 总线上的 GPU 等。FM 将在可用的 GPU 之间设置路由并启用 NVLink P2P。
9.5.2. 共享 NVSwitch 和 vGPU 虚拟化行为
FM 将继续初始化并通过排除故障 GPU 分区来调整当前支持的分区列表。图 6 显示了 GPU 丢失或初始化失败时支持的分区。
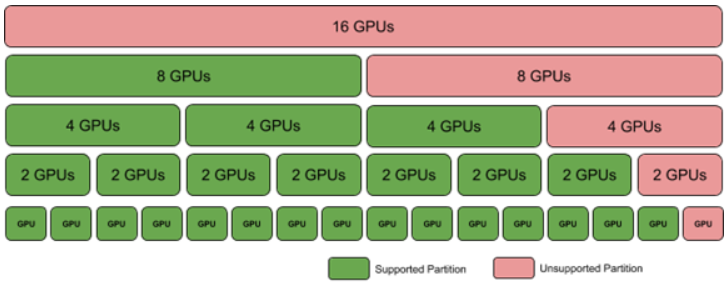
图 7 GPU 丢失/故障时的共享 NVSwitch 和 vGPU 分区
9.6. 手动降级
手动降级可防止 NVSwitch 系统软件堆栈枚举持续发生故障的 GPU、NVSwitch 或基板。根据故障组件,系统管理员必须配置适当的操作。
9.6.1. GPU 排除
根据错误,某些 GPU 可能是从系统中排除的候选对象,以便 FM 可以成功初始化和配置其余 GPU 子集。根据上一代 GPU 的故障分析数据,要排除 GPU,以下是建议的错误条件
GPU 双位 ECC 错误。
GPU 从 PCIe 总线上掉线。
GPU 无法在 PCIe 总线上枚举。
GPU 侧 NVLink 训练错误。
GPU 侧意外 XID。此类别也可能是由应用程序引起的。
对于完全直通虚拟化,管理员必须识别应排除的 GPU。虚拟机监控程序必须确保不在已识别为排除候选对象的 GPU 上创建虚拟机(VM)。
9.6.1.1. GPU 排除流程
GPU 排除流程可以分解为以下阶段
运行应用程序错误处理。
诊断 GPU 故障。
修复错误。
这些阶段的步骤可能因系统是在裸机模式还是在虚拟化模式下运行而异。以下部分描述了裸机和虚拟化平台的流程。
9.6.1.2. 运行应用程序错误处理
GPU 在活动执行期间遇到的错误(例如 GPU ECC 错误、GPU 从总线上掉线等)通过以下方式报告
/var/log/syslog作为 XID 消息DCGM
NVIDIA 管理库(NVML)
基于 GPU SMBPBI 的 OOB 命令
FM 日志文件
错误条件 |
运行应用程序上的错误签名 |
|---|---|
GPU 双位错误 |
GPU 驱动程序输出 XID 48 |
GPU 从 PCIe 总线上掉线 |
GPU 驱动程序输出 XID 79 |
GPU 无法在总线上枚举 |
GPU 不对应用程序显示(CUDA 应用程序或 |
GPU 侧 NVLink 训练错误 |
FM 输出到 |
GPU 侧错误 |
GPU 驱动程序输出的其他 XID。这也可能是由应用程序引起的。 |
GPU 双位错误 |
GPU 驱动程序输出 XID 48 |
9.6.1.3. 诊断 GPU 故障
系统管理员可以创建自己的 GPU 监控/健康检查脚本来查找错误跟踪。此过程需要查找至少一个上述来源(syslog、NVML API 等)以收集必要的数据。
DCGM 包括一个排除建议脚本,系统管理员可以调用该脚本来收集 GPU 错误信息。此脚本查询 DCGM 执行的被动监控中的信息,以确定自上次 DCGM 守护程序启动以来是否发生了任何可能需要排除 GPU 的情况。作为执行的一部分,该脚本调用一个验证测试,该测试
确定已知良好应用程序的执行是否正在生成意外的 XID。用户可以阻止运行验证测试,并选择仅监控被动信息。
DCGM 排除建议脚本代码作为系统管理员的参考提供,以便根据需要进行扩展或构建自己的监控/健康检查脚本。
注意
有关排除建议脚本(例如其位置和支持的选项)的更多信息,请参阅 NVIDIA DCGM 文档。
9.6.1.4. 带内 GPU 排除机制
可以配置基于 NVSwitch 的系统上的 GPU 内核驱动程序以忽略一组 GPU,即使这些 GPU 已在 PCIe 总线上枚举。要排除的 GPU 通过内核模块参数按 GPU 的唯一标识符(GPU UUID)标识。在确定系统中是否存在 GPU 排除候选对象后,GPU 内核模块驱动程序将排除该 GPU,使其不被应用程序使用。如果 GPU UUID 在排除候选对象列表中,但在运行时未检测到该 UUID,因为该 UUID 属于系统上不存在的 GPU,或者因为 GPU 板的 PCIe 枚举失败,则该 GPU 不被视为已排除。
通过使用文件系统中的 .conf 文件指定模块参数,可以将排除候选 GPU 列表跨重启持久保存。排除机制特定于 GPU,而不是基板上的物理位置。因此,如果 GPU 在排除候选对象列表中,并且稍后被新 GPU 替换,则新 GPU 将对系统可见,而无需更新排除候选对象。相反,如果 GPU 已在系统上排除,则将其放置在不同的 PCIe 插槽中仍将阻止 GPU 对应用程序可见,除非更新排除候选对象列表。
更新 GPU 排除候选对象需要系统管理员手动干预。
9.6.1.5. 内核模块参数
要排除的候选 GPU UUID 集通过内核模块参数指定,该参数由一组逗号分隔的 GPU UUID 组成。
内核参数可以在内核模块加载
nvidia.ko时指定。insmod nvidia.ko NVreg_ExcludedGpus=uuid1,uuid2…为了使 GPU UUID 持久化,还可以通过使用
/etc/modprobe.d中的nvidia.conf文件来指定排除候选 GPU UUID 集。options nvidia NVreg_ExcludedGpus=uuid1, uuid2…
将 GPU 添加到排除候选对象列表是一个手动步骤,必须由系统管理员完成。
注意
先前支持的 NVreg_GpuBlacklist 模块参数选项已被弃用,将在未来的版本中删除。
9.6.1.6. 从排除候选对象列表中添加/删除 GPU
要从排除候选对象列表中添加 GPU 或从中删除 GPU,系统管理员必须完成以下步骤
如果 conf 文件不存在,则为
nvidia内核模块参数创建 conf 文件。完成以下任务之一
将排除的 GPU 的 UUID 添加到 .conf 文件中。
从列表中删除 GPU 的 UUID。
重启系统以加载具有更新模块参数的内核驱动程序。
9.6.1.7. 列出排除的 GPU
排除的 GPU 在 CUDA 应用程序或使用 nvidia-smi -q 或通过 NVML 的基本查询中不可见。本节提供有关识别 GPU 何时被排除的选项的信息,例如,GPU 的 UUID 在排除候选对象列表中,并且 GPU 在系统中被检测到。
9.6.1.8. nvidia-smi
新命令 nvidia-smi -B 或 nvidia-smi --list-excluded-gpus 可用于获取排除的 GPU 列表。
9.6.1.9. Procfs
procfs 条目 /proc/driver/nvidia/gpus/<PCI_ID>/information 可以指定 GPU 是否已被排除。
9.6.1.10. 带外查询
有关更多信息,请参阅 *NVIDIA GPU SMBus Post-Box Interface (SMBPBI)* 文档。
9.6.1.11. 运行 GPU 排除脚本
以下部分提供有关系统管理员应遵循的推荐流程的信息,以便在各种系统配置上运行 GPU 监控健康检查或 DCGM 排除建议脚本。
9.6.1.12. 裸机和 vGPU 配置
在裸机和 vGPU 虚拟化配置中,系统管理员将在与应用程序相同的操作系统实例中运行配置。以下是系统管理员将遵循的一般流程
定期为系统上的所有 GPU 和 NVSwitch 运行健康检查脚本或 DCGM 排除建议脚本。
(可选)监控系统日志以触发运行健康检查脚本或 DCGM 排除建议脚本。
根据健康检查或排除建议脚本的输出,将 GPU UUID 添加到排除候选对象列表。
此外,如果您正在使用 DCGM 排除建议脚本,请使用新预期的 GPU 计数更新排除建议脚本的定期运行。
重启系统以加载具有更新模块参数的内核驱动程序。
9.6.1.13. 完全直通虚拟化配置
虚拟化配置中的主要区别在于,GPU 内核驱动程序留给来宾虚拟机(VM)。因此,GPU 诊断和修复阶段的执行必须由具有 VM 预配机制的虚拟机监控程序执行。
以下是虚拟机监控程序将遵循的一般流程
来宾虚拟机(VM)完成并返回一组 GPU 和交换机的控制权给虚拟机监控程序。
虚拟机监控程序调用一个特殊的测试虚拟机(VM),该虚拟机(VM)受虚拟机监控程序信任。在测试虚拟机(VM)中,应存在 NVIDIA NVSwitch 核心软件堆栈的完整实例,包括 GPU 驱动程序和 FM。
在此测试虚拟机(VM)上,运行健康检查脚本或 DCGM 排除建议脚本。
根据健康检查或排除建议脚本的输出,将 GPU UUID 添加到虚拟机监控程序可读数据库。
虚拟机监控程序关闭测试虚拟机(VM)。
虚拟机监控程序读取数据库以识别排除的候选对象,并更新其资源分配机制,以防止将该 GPU 分配给未来的 VM 请求。
更换 GPU 板后,要使 GPU 再次可用,虚拟机监控程序会更新数据库。
9.6.2. NVSwitch 排除
在 DGX A100 和 NVIDIA HGX A100 系统中,如果 NVSwitch 持续发生故障,系统管理员可以显式排除 NVSwitch。
9.6.2.1. 带内 NVSwitch 排除
可以配置基于 NVSwitch 的系统上的 NVSwitch 内核驱动程序以忽略 NVSwitch,即使系统像 GPU 排除功能一样在 PCIe 总线上枚举。如果系统中存在 NVSwitch 排除候选对象,则 NVSwitch 内核模块驱动程序将排除 NVSwitch,使其不被应用程序使用。如果 NVSwitch UUID 在排除候选对象列表中,但在运行时未检测到该 UUID,因为该 UUID 属于系统上不存在的 NVSwitch,或者因为 NVSwitch 的 PCIe 枚举失败,则该 NVSwitch 不被视为已排除。
此外,在具有两个 GPU 基板的 NVIDIA HGX A100 系统中,如果显式排除 NVSwitch,FM 将手动排除其跨 Trunk NVLink 的对等 NVSwitch。此行为可以使用 NVSWITCH_FAILURE_MODE 高可用性配置文件项进行配置。
9.6.2.2. 内核模块参数
要将候选 NVSwitch UUID 指定为内核模块参数,请运行以下命令
insmod nvidia.ko NvSwitchExcludelist=<NVSwitch_uuid>
要使 NVSwitch UUID 持久化,请使用
/etc/modprobe.d中的nvidia.conf文件指定 UUIDoptions nvidia NvSwitchExcludelist=<NVSwitch_uuid>
系统管理员可以从 FM 日志文件中获取 NVSwitch UUID,并将 UUID 添加到排除候选对象列表中。
注意
先前支持的 NvSwitchBlacklist 模块参数选项已被弃用,将在未来的版本中删除。
9.6.2.3. 带外 NVSwitch 排除
有关 NVSwitch 的更多信息,请参阅 *SMBus Post Box Interface (SMBPBI)*。
10. NVLink 拓扑
以下部分列出了每个 GPU 用于连接到不同版本 NVIDIA HGX 基板上的每个 NVSwitch 的链路 ID。
10.1. NVIDIA HGX-2 GPU 基板
每个 NVSwitch 都使用 0/1、2/3、8/9 和 10/11 链路进行 GPU 基板间连接,并且未列出这些链路。其他 NVLink 连接(每个 NVSwitch 两个)未使用。
GPU |
GPU 链路 |
NVSwitch |
NVSwitch 链路 |
|---|---|---|---|
1 |
0 |
4 |
16 |
1 |
1 |
1 |
5 |
1 |
2 |
6 |
6 |
1 |
3 |
3 |
15 |
1 |
4 |
5 |
15 |
1 |
5 |
2 |
6 |
2 |
0 |
4 |
15 |
2 |
1 |
1 |
16 |
2 |
2 |
3 |
6 |
2 |
3 |
6 |
12 |
2 |
4 |
2 |
17 |
2 |
5 |
5 |
7 |
3 |
0 |
4 |
14 |
3 |
1 |
1 |
17 |
3 |
2 |
3 |
17 |
3 |
3 |
6 |
13 |
3 |
4 |
5 |
6 |
3 |
5 |
2 |
4 |
4 |
0 |
4 |
17 |
4 |
1 |
1 |
4 |
4 |
2 |
3 |
7 |
4 |
3 |
6 |
7 |
4 |
4 |
2 |
7 |
4 |
5 |
5 |
17 |
5 |
0 |
4 |
13 |
5 |
1 |
1 |
13 |
5 |
2 |
5 |
13 |
5 |
3 |
3 |
13 |
5 |
4 |
6 |
14 |
5 |
5 |
2 |
6 |
6 |
0 |
4 |
5 |
6 |
1 |
1 |
14 |
6 |
2 |
6 |
5 |
6 |
3 |
3 |
4 |
6 |
4 |
2 |
12 |
6 |
5 |
5 |
14 |
7 |
0 |
4 |
12 |
7 |
1 |
1 |
15 |
7 |
2 |
5 |
5 |
7 |
3 |
3 |
5 |
7 |
4 |
2 |
13 |
7 |
5 |
6 |
17 |
8 |
0 |
4 |
4 |
8 |
1 |
1 |
12 |
8 |
2 |
6 |
15 |
8 |
3 |
5 |
12 |
8 |
4 |
3 |
14 |
8 |
5 |
2 |
5 |
10.2. NVIDIA HGX A100 GPU 基板
每个 NVSwitch 都使用链路 0 到 7 和 16 到 23 进行 GPU 基板间连接,并且未列出这些链路。其他 NVLink 连接(每个 NVSwitch 四个)未使用。表 7 中的 GPU 编号与 *HGX A100 基板引脚排列* 设计文档中使用的编号相同。
GPU |
GPU 链路 |
NVSwitch |
NVSwitch 链路 |
|---|---|---|---|
1 |
0, 1 |
4 |
8, 9 |
1 |
2, 3 |
1 |
24, 25 |
1 |
4, 5 |
3 |
30, 31 |
1 |
6, 7 |
6 |
12, 13 |
1 |
8, 9 |
2 |
12, 13 |
1 |
10, 11 |
5 |
30, 31 |
2 |
0, 1 |
4 |
30, 31 |
2 |
2, 3 |
1 |
26, 27 |
2 |
4, 5 |
3 |
12, 13 |
2 |
6, 7 |
6 |
24, 25 |
2 |
8, 9 |
2 |
34, 35 |
2 |
10, 11 |
5 |
14, 15 |
3 |
0, 1 |
4 |
28, 29 |
3 |
2, 3 |
1 |
34, 35 |
3 |
4, 5 |
3 |
34, 35 |
3 |
6, 7 |
6 |
26, 27 |
3 |
8, 9 |
2 |
8, 9 |
3 |
10, 11 |
5 |
12, 13 |
4 |
0, 1 |
4 |
34, 35 |
4 |
2, 3 |
1 |
32, 33 |
4 |
4, 5 |
3 |
14, 15 |
4 |
6, 7 |
6 |
14, 15 |
4 |
8, 9 |
2 |
14, 15 |
4 |
10, 11 |
5 |
34, 35 |
5 |
0, 1 |
4 |
26, 27 |
5 |
2, 3 |
1 |
10, 11 |
5 |
4, 5 |
3 |
28, 29 |
5 |
6, 7 |
6 |
28, 29 |
5 |
8, 9 |
2 |
10, 11 |
5 |
10, 11 |
5 |
26, 27 |
6 |
0, 1 |
4 |
10, 11 |
6 |
2, 3 |
1 |
28, 29 |
6 |
4, 5 |
3 |
8, 9 |
6 |
6, 7 |
6 |
10, 11 |
6 |
8, 9 |
2 |
24, 25 |
6 |
10, 11 |
5 |
28, 29 |
7 |
0, 1 |
4 |
24, 25 |
7 |
2, 3 |
1 |
30, 31 |
7 |
4, 5 |
3 |
26, 27 |
7 |
6, 7 |
6 |
30, 31 |
7 |
8, 9 |
2 |
26, 27 |
7 |
10, 11 |
5 |
10, 11 |
8 |
0, 1 |
4 |
32, 33 |
8 |
2, 3 |
1 |
8, 9 |
8 |
4, 5 |
3 |
10, 11 |
8 |
6, 7 |
6 |
34, 35 |
8 |
8, 9 |
2 |
32, 33 |
8 |
10, 11 |
5 |
24, 25 |
10.3. NVIDIA HGX H100 GPU 基板
表 8 中的 GPU 编号与通过 nvidia-smi 返回的模块 ID 相同,该模块 ID 基于基板上的 GPIO 连接派生而来。
GPU |
GPU 链路 |
NVSwitch |
NVSwitch 链路 |
|---|---|---|---|
1 |
2,3,12,13 |
1 |
40,41,44,45 |
1 |
0,1,11,16,17 |
2 |
36,37,40,46,47 |
1 |
15,14,10,6,7 |
3 |
42,43,45,62,63 |
1 |
4,5,9,8 |
4 |
58,59,62,63 |
2 |
15,14,8,9 |
1 |
42,43,46,47 |
2 |
2,3,7,6,11 |
2 |
2,3,4,5,32 |
2 |
10,5,4,0,1 |
3 |
34,40,41,46,47 |
2 |
12,13,16,17 |
4 |
34,35,38,39 |
3 |
13,12,7,6 |
1 |
48,49,52,53 |
3 |
17,16,10,3,2 |
2 |
0,1,33,38,39 |
3 |
14,15,8,9,11 |
3 |
16,17,50,51,52 |
3 |
5,4,1,0 |
4 |
56,57,60,61 |
4 |
9,8,13,12 |
1 |
32,33,36,37 |
4 |
2,3,10,14,15 |
2 |
50,51,53,62,63 |
4 |
7,6,11,16,17 |
3 |
2,3,35,38,39 |
4 |
5,4,1,0 |
4 |
42,43,46,47 |
5 |
7,6,12,13 |
1 |
58,59,62,63 |
5 |
17,16,11,1,0 |
2 |
48,49,52,56,57 |
5 |
15,14,10,2,3 |
3 |
36,37,44,60,61 |
5 |
4,5,9,8 |
4 |
48,49,52,53 |
6 |
6,7,15,14 |
1 |
34,35,38,39 |
6 |
8,9,17,16,11 |
2 |
6,7,34,35,42 |
6 |
4,5,10,1,0 |
3 |
0,1,19,32,33 |
6 |
13,12,3,2 |
4 |
32,33,36,37 |
7 |
17,16,13,12 |
1 |
50,51,54,55 |
7 |
10,0,1,4,5 |
2 |
43,54,55,58,59 |
7 |
15,14,11,8,9 |
3 |
48,49,53,56,57 |
7 |
7,6,3,2 |
4 |
40,41,44,45 |
8 |
12,13,17,16 |
1 |
56,57,60,61 |
8 |
10,5,4,0,1 |
2 |
41,44,45,60,61 |
8 |
11,14,15,7,6 |
3 |
18,54,55,58,59 |
8 |
2,3,8,9 |
4 |
50,51,54,55 |
11. GPU 分区
本章提供有关各种 GPU 基板的 =默认共享 NVSwitch 和 vGPU 分区的信息。
11.1. DGX-2 和 NVIDIA HGX-2
分区 ID |
分配给 VM 的 GPU 数量 |
GPU 物理 ID |
NVLink 数量 每个 GPU 的互连数 |
|---|---|---|---|
0 |
16 |
1 到 16 |
6 |
1 |
8 |
1 到 8 |
6 |
2 |
8 |
9 到 1 |
6 |
3 |
8 |
来自底板 1 的 1, 4, 6, 7 来自底板 2 的 9, 12, 14, 15 |
5 |
4 |
8 |
来自底板 1 的 2, 3, 5, 8 来自底板 2 的 10, 11, 13, 16 |
5 |
5 |
4 |
1,4,6,7 |
5 |
6 |
4 |
2,3,5,8 |
5 |
7 |
4 |
9,12,14,15 |
5 |
8 |
4 |
10,11,13,16 |
5 |
9 |
2 |
1,4 |
5 |
10 |
2 |
2,3 |
5 |
11 |
2 |
5,8 |
5 |
12 |
2 |
6,7 |
5 |
13 |
2 |
9,12 |
5 |
14 |
2 |
10,11 |
5 |
15 |
2 |
13,16 |
5 |
16 |
2 |
14,15 |
5 |
17 到 32 |
1 |
分区 ID 17 的物理 ID 1, 分区 ID 18 的物理 ID 2, 依此类推 |
0 |
在本代 NVSwitch 中,NVLink 端口复位(链路的奇偶对)必须成对发出。因此,NVIDIA HGX-2 和 DGX-2 仅支持共享 NVSwitch 分区的固定映射。由于此限制,四 GPU 和双 GPU VM 每个 GPU 只能启用六个 NVLink 中的五个。
11.2. DGX A100 和 NVIDIA HGX A100
11.2.1. 默认 GPU 分区
根据高可用性模式配置,当 GPU 不可用时(由于故障、列入黑名单等),相应的分区将从当前支持的分区列表中删除。但是,对于其余支持的分区,分区 ID 和 GPU 物理 ID 将保持不变。
注意
GPU 物理 ID 基于 GPU 底板 NVSwitch GPIO 的配置方式。如果仅存在一个底板,并且 GPIO 配置为底部托架,则 GPU 物理 ID 范围介于 1 到 8 之间。如果底板配置为顶部托架,则 GPU 物理 ID 范围介于 9 到 16 之间。
分区 ID |
分配给 VM 的 GPU 数量 |
GPU 物理 ID |
NVLink 数量 每个 GPU 的互连数 |
|---|---|---|---|
0 |
16 |
1 到 16 |
12 |
1 |
8 |
1 到 8 |
12 |
2 |
8 |
9 到 16 |
12 |
3 |
8 |
1 到 4 & 9 到 12 |
12 |
4 |
8 |
5 到 8 & 13 到 16 |
12 |
5 |
8 |
1 到 4 & 13 到 16 |
12 |
6 |
8 |
5 到 8 & 9 到 12 |
12 |
7 |
4 |
1, 2, 3, 4 |
12 |
8 |
4 |
5, 6, 7, 8 |
12 |
9 |
4 |
9, 10, 11, 12 |
12 |
10 |
4 |
13, 14, 15, 16 |
12 |
11 |
2 |
1, 2 |
12 |
12 |
2 |
3, 4 |
12 |
13 |
2 |
5, 6 |
12 |
14 |
2 |
7, 8 |
12 |
15 |
2 |
9, 10 |
12 |
16 |
2 |
11, 12 |
12 |
17 |
2 |
13, 14 |
12 |
18 |
2 |
15, 16 |
12 |
19 |
1 |
1 |
0 |
20 到 34 |
1 |
分区 ID 20 的物理 ID 2, 分区 ID 21 的物理 ID 3,等等。 |
0 |
11.2.2. 支持的 GPU 分区
在 DGX A100 和 NVIDIA HGX A100 系统中,不再适用早期版本的奇偶对 NVSwitch NVLink 复位要求。因此,如果上述默认 GPU 分区并非基于系统的 PCIe 拓扑的最佳分区,则可以更改分区映射。但是,NVIDIA 对分区定义有以下限制
双 GPU NVLink 分区必须位于同一 GPU 底板中。
四 GPU NVLink 分区必须位于同一 GPU 底板中。
对于跨越两个 GPU 底板的八 GPU NVLink 分区,每个底板必须有四个 GPU。
注意
NVIDIA 将根据具体情况评估任何自定义分区定义请求以及上述策略的变体,并将提供必要的信息来配置/覆盖默认 GPU 分区。
11.3. DGX H100 和 HGX H100
11.3.1. 默认 GPU 分区
分区 ID |
分配给 VM 的 GPU 数量 |
GPU 物理 ID 模块 ID |
NVLink 数量 每个 GPU 的互连数 |
|---|---|---|---|
0 |
8 |
1 到 8 |
18 |
1 |
4 |
1 到 4 |
18 |
2 |
4 |
5 到 8 |
18 |
3 |
2 |
1,3 |
18 |
4 |
2 |
2,4 |
18 |
5 |
2 |
5,7 |
18 |
6 |
2 |
6,8 |
18 |
7 |
1 |
1 |
0 |
8 |
1 |
2 |
0 |
9 |
1 |
3 |
0 |
10 |
1 |
4 |
0 |
11 |
1 |
5 |
0 |
12 |
1 |
6 |
0 |
13 |
1 |
7 |
0 |
14 |
1 |
8 |
0 |
11.3.2. 支持的 GPU 分区
在 DGX H100 和 NVIDIA HGX H100 系统中,无论 GPU 降级状态如何,上述 GPU 分区都会在 get support partition API 中返回。
12. 弹性
共享 NVSwitch 和 vGPU 模型中的 FM 弹性功能允许系统管理员在 Service VM 中 FM 正常或非正常退出后恢复正常运行。借助此功能,即使 FM 未运行,当前激活的访客 VM 仍将继续转发 NVLink 流量。FM 成功重启后,FM 将支持典型的访客 VM 激活/停用工作流程。
在 FM 未运行时检测到的 NVSwitch 和 GPU NVLink 错误将被缓存到 NVSwitch 驱动程序中,并在 FM 成功重启后报告。此外,不支持在 FM 未运行时更改 FM 版本。
12.1. 高级流程
在 FM 崩溃或正常退出后,hypervisor 将运行
-restart命令行选项以启动 FM 并恢复操作。重启 FM 后,在 60 秒内,hypervisor 将使用
fmSetActivatedFabricPartitions()API 并提供当前激活的访客 VM 分区列表。这是因为 FM 在未运行时不知道访客 VM 的更改。如果在 FM 重启时没有激活的访客 VM 分区正在运行,则 hypervisor 将调用
fmSetActivatedFabricPartitions()API,并将分区数设置为零。要使用典型流程启动 Fabric Manager,或重新初始化软件和硬件状态,hypervisor 将遵循典型的 Service VM 启动序列,而无需
--restart选项。
12.2. 详细的弹性流程
当 FM 在正常模式下启动时,在初始化所有 NVLink 设备并发现 NVLink 连接后,FM 将在 /tmp/fabricmanger.state 文件中保存所需的元数据信息。但是,可以通过将新文件位置设置为 STATE_FILE_NAME FM 配置文件项来更改此位置。保存的状态是检测到的 GPU 信息(UUID、物理 ID)和当前支持的访客 VM 分区元数据的快照。
当 FM 使用 --restart 命令行选项启动时,它将跳过其大部分 NVLink 和 NVSwitch 初始化步骤,并从存储的文件中填充所需的信息。FM 将等待 hypervisor 提供当前激活的访客 VM 分区列表。在此期间,典型的分区操作(例如查询支持的访客 VM 分区列表、激活和停用访客 VM 分区等)将被拒绝。从 hypervisor 收到活动访客 VM 分区信息列表后,FM 将确保仅为这些分区启用路由。完成这些步骤后,FM 将启用典型的访客 VM 分区激活和停用工作流程。
如果 FM 无法从当前状态恢复,或者 hypervisor 未在超时期限之前提供当前激活的访客 VM 分区列表,则重启操作将中止,并且 FM 将退出。
图 8 显示了 FM 在使用典型命令行选项和 --restart 选项启动时的高级流程。
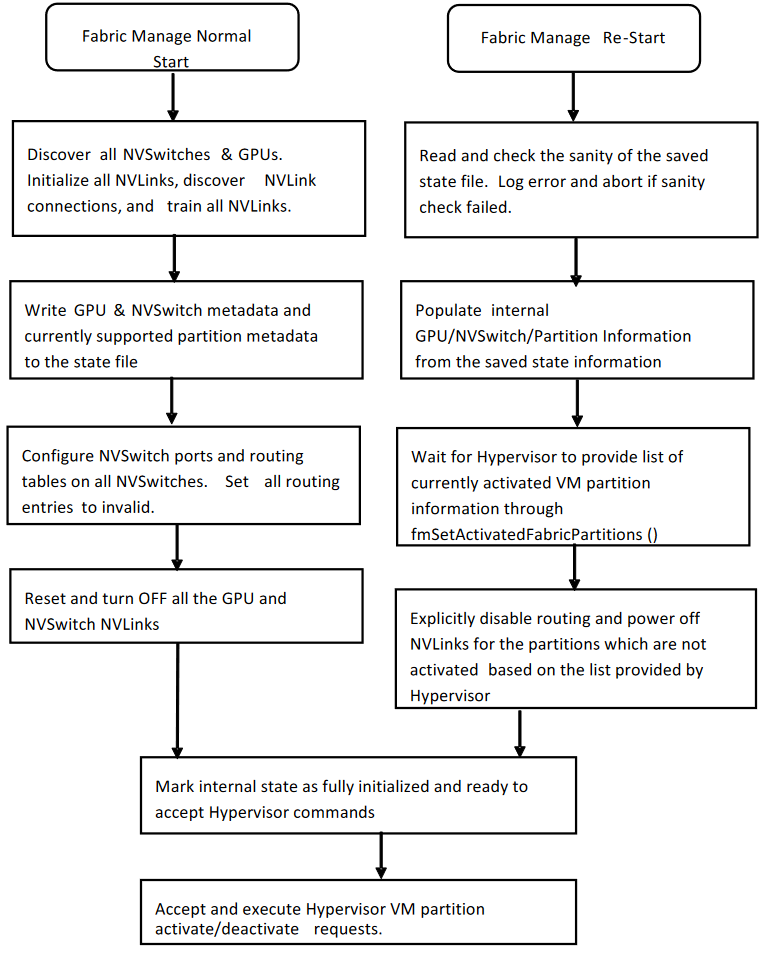
图 8 Fabric Manager 流程:典型和重启选项
13. 错误处理
13.1. FM 初始化错误
以下错误可能在 FM 初始化和拓扑发现期间发生。这些错误仅在主机启动时(vGPU 模式)或 Service VM 初始化时(共享 NVSwitch 模式)发生,并且假设没有访客 VM 正在运行。
错误条件 |
错误影响 |
恢复 |
|---|---|---|
访问 NVLink 连接 (GPU 到 NVSwitch)训练失败 |
根据 |
重启 FM 服务(vGPU 模式)或 Service VM(共享 NVSwitch 模式) 如果错误仍然存在,请 RMA GPU。 |
Trunk NVLink 连接(NVSwitch 到 NVSwitch)训练失败 |
根据 |
重启 FM 服务(vGPU 模式)或 Service VM(共享 NVSwitch 模式) 如果错误仍然存在,请检查/重新安装 NVLink Trunk 背板连接器。 |
任何 NVSwitch 或 GPU 编程/配置失败以及典型的软件错误 |
被视为致命错误,FM 服务将中止。但是,如果设置了 |
重启主机和 FM 服务(vGPU 模式)或 Service VM(NVSwitch 模式) 如果错误仍然存在,则需要进行技术故障排除。 |
13.2. 分区生命周期错误
表 13 总结了在查询支持的分区或激活/停用 VM 分区时,FM SDK API 可能返回的错误。
返回代码 |
错误条件/影响 |
恢复 |
|---|---|---|
|
提供给 API 的分区 ID 或其他参数无效。 |
仅使用 |
|
FM 未使用所需的配置选项启动。 |
确保在 FM 配置文件中启用了共享 fabric 模式。如果未启用,请设置所需的值并重启
|
|
在 FM 完全初始化之前发出 FM API。 |
等待 FM 服务完全初始化。 |
|
FM 接口库尚未初始化。 |
确保 FM 接口库已通过调用 |
|
提供的分区 ID 已激活,或者指定分区所需的 GPU 正在其他激活的分区上使用。 |
|
|
提供的分区 ID 已停用。 |
提供一个已激活的分区 ID。 |
|
在激活/停用 VM 分区时发生了一般错误。 |
检查相关的系统日志以获取特定和详细的错误信息。 |
|
GPU 或 NVSwitch 配置设置超时。 |
检查相关的系统日志以获取特定和详细的错误信息。 |
|
使用 FM API 的客户端应用程序可能已使用与 Service VM 上运行的 FM 包不同的版本进行编译/链接。 |
确保客户端应用程序使用与 Service VM 上安装的 FM 包相同或兼容的 FM 包进行编译和链接。 |
13.3. 运行时 NVSwitch 错误
可以使用以下选项检索或监控 NVSwitch 运行时错误
通过主机或 Service VM 系统日志和 Fabric Manager 日志文件(作为 SXid 错误)。
通过 NVSwitch 公共 API 接口。
通过基于 NVSwitch SMBPBI 的 OOB 命令。
当 NVSwitch 端口生成 SXid 错误时,相应的错误信息和受影响的 GPU 分区信息将记录到主机或 Service VM 系统日志中。根据 SXid 错误的类型和受影响的端口,相应访客 VM 上的 GPU 或所有其他访客 VM 可能会受到影响。通常,如果影响是本地于访客 VM,则其他正在运行的访客 VM 不会受到影响,并且应正常运行。
13.4. 非致命 NVSwitch SXid 错误
表 14 列出了可能在现场发生的潜在 NVSwitch 非致命 SXid 错误及其影响。
SXid & 错误字符串 |
访客 VM 影响 |
访客 VM 恢复 |
其他访客 VM 影响 |
|---|---|---|---|
11004(入口无效 ACL) 此 SXid 错误可能仅由于不正确的 FM 分区配置而发生,预计不会在现场发生。 |
相应的 GPU NVLink 流量将被阻止,随后的 GPU 访问将挂起。访客 VM 上的 GPU 驱动程序将中止 Xid 45 的 CUDA 作业。 |
|
如果在 Trunk 端口上观察到错误,则使用 NVSwitch trunk 端口的分区将受到影响。 |
11012、11021、11022、11023、12021、12023、15008、15011、19049、19055、19057、19059、19062、19065、19068、19071、24001、24002、24003(单位 ECC 错误) |
没有访客 VM 影响,因为 NVSwitch 硬件将自动纠正 ECC 错误。 |
不适用。 |
无影响 |
20001(TX 重放错误) |
NVLink 数据包需要重新传输。此错误可能会影响指定端口的 NVLink 吞吐量。 |
不适用 |
如果在 Trunk 端口上观察到错误,则使用 NVSwitch trunk 端口的分区可能会看到吞吐量影响。 |
12028(出口非发布发布 PRIV 错误) |
相应的 GPU NVLink 流量将被阻止,随后的 GPU 访问将挂起。访客 VM 上的 GPU 驱动程序将中止 Xid 45 的 CUDA 作业。 |
重启访客 VM |
如果在 Trunk 端口上观察到错误,则使用 NVSwitch trunk 端口的分区将受到影响。 |
19084(AN1 心跳超时错误) |
此错误通常伴随致命的 SXid 错误,该错误将影响相应的 GPU NVLink 流量。 |
重置所有 GPU 和所有 NVSwitch(请参阅 D.9 节) |
如果在 Trunk 端口上观察到错误,则使用 NVSwitch trunk 端口的分区将受到影响。 |
22013(Minion Link DLREQ 中断) |
可以安全地忽略此 SXid。 |
不适用 |
无影响。 |
20012 |
此错误可能是由于连接断开/不一致或协调不一致的关机引起的。 |
如果此问题不是由于协调不一致的关机引起的,请检查链路机械连接。 |
如果错误仅限于单个 GPU,则无影响。 |
13.5. 致命 NVSwitch SXid 错误
表 15 列出了可能在现场发生的潜在 NVSwitch 致命 SXid 错误。hypervisor 必须跟踪这些 SXid 源端口 (NVLink),以确定错误是发生在 NVSwitch trunk 端口还是 NVSwitch 访问端口上。致命 SXid 将在适用时作为 Xid 74 传播到 GPU。除非另有说明,否则以下建议操作适用于表 15 中的所有 SXid。
如果错误发生在 NVSwitch 访问端口上,则影响将仅限于相应的访客 VM。
要恢复,请关闭访客 VM。
如果错误发生在 NVSwitch trunk 端口上,要重置 trunk 端口并恢复,请关闭跨越 trunk 端口的访客 VM 分区。
可以重新创建分区。目前,使用 NVSwitch trunk 端口的分区是 16x GPU 分区和每个底板四个 GPU 的 8x GPU 分区。
SXid |
SXid 错误字符串 |
|---|---|
11001 |
入口无效命令 |
11009 |
入口无效 VCSet |
11013 |
入口标头 DBE |
11018 |
入口 RID DBE |
11019 |
入口 RLAN DBE |
11020 |
入口控制奇偶校验 |
12001 |
出口交叉开关溢出 |
12002 |
出口数据包路由 |
12022 |
出口输入 ECC DBE 错误 |
12024 |
出口输出 ECC DBE 错误 |
12025 |
出口信用溢出 |
12026 |
出口目标请求 ID 错误 |
12027 |
出口目标响应 ID 错误 |
12030 |
出口控制奇偶校验错误 |
12031 |
出口信用奇偶校验错误 |
12032 |
出口 flit 类型不匹配 |
14017 |
TS ATO 超时 |
15001 |
路由缓冲区上溢/下溢 |
15006 |
路由 transdone 上溢/下溢 |
15009 |
路由 GLT DBE |
15010 |
路由奇偶校验 |
15012 |
路由传入 DBE |
15013 |
路由信用奇偶校验 |
19047 |
NCISOC HDR ECC DBE 错误 |
19048 |
NCISOC DAT ECC DBE 错误 |
19054 |
HDR RAM ECC DBE 错误 |
19056 |
DAT0 RAM ECC DBE 错误 |
19058 |
DAT1 RAM ECC DBE 错误 |
19060 |
CREQ RAM HDR ECC DBE 错误 |
19061 |
CREQ RAM DAT ECC DBE 错误 |
19063 |
Response RAM HDR ECC DBE 错误 |
19064 |
Response RAM DAT ECC DBE 错误 |
19066 |
COM RAM HDR ECC DBE 错误 |
19067 |
COM RAM DAT ECC DBE 错误 |
19069 |
RSP1 RAM HDR ECC DBE 错误 |
19070 |
RSP1 RAM DAT ECC DBE 错误 |
20034 |
LTSSM 故障向上 访客 VM 影响:每当关联的链路从活动状态变为关闭状态时,都会触发此 SXid。此中断通常与其他 NVLink 错误相关联。 访客 VM 恢复:在 A100 的情况下,重启 VM。在 H100 的情况下,重置 GPU(请参阅 GPU/VM/系统重置功能和限制)。如果问题仍然存在,请报告 GPU 问题。 其他访客 VM 影响:如果错误仅限于单个 GPU,则无影响。 |
22012 |
Minion Link NA 中断 |
24004 |
sourcetrack TCEN0 crubmstore DBE |
24005 |
sourcetrack TCEN0 TD crubmstore DBE |
24006 |
sourcetrack TCEN1 crubmstore DBE |
24007 |
sourcetrack 超时错误 |
13.6. 始终致命的 NVSwitch SXid 错误
表 16 列出了可能对整个 fabric/系统始终致命的潜在 NVSwitch 致命 SXid 错误。在发生始终致命的 SXid 错误后,需要关闭访客 VM 分区,并且必须执行以下任务之一
需要重启主机。
在 NVSwitch 和 GPU SBR 后,重启 Service VM 重启。
SXid |
SXid 错误字符串 |
|---|---|
12020 |
出口序列 ID 错误 |
22003 |
Minion Halt |
22011 |
Minion exterror |
23001 |
入口 SRC-VC 缓冲区溢出 |
23002 |
入口 SRC-VC 缓冲区下溢 |
23003 |
出口 DST-VC 信用溢出 |
23004 |
出口 DST-VC 信用下溢 |
23005 |
入口数据包突发错误 |
23006 |
入口数据包粘滞错误 |
23007 |
入口可能存在气泡 |
23008 |
入口数据包无效 dst 错误 |
23009 |
入口数据包奇偶校验错误 |
23010 |
入口 SRC-VC 缓冲区溢出 |
23011 |
入口 SRC-VC 缓冲区下溢 |
23012 |
出口 DST-VC 信用溢出 |
23013 |
出口 DST-VC 信用下溢 |
23014 |
入口数据包突发错误 |
23015 |
入口数据包粘滞错误 |
23016 |
入口可能存在气泡 |
23017 |
入口信用奇偶校验错误 |
13.7. 其他值得注意的 NVSwitch SXid 错误
表 17 提供了可能影响整个 fabric/系统的其他 SXid 错误。
SXid |
SXid 错误字符串 |
注释/描述 |
|---|---|---|
10001 |
|
这些错误对 fabric/系统不是致命的,但它们之后可能会出现其他致命事件。 |
10002 |
|
这些错误对 fabric/系统不是致命的,但它们之后可能会出现其他致命事件。 |
10003 |
|
永远不会预期发生此 SXid 错误。 如果发生,则对 fabric/系统是致命的,要恢复,需要重置所有 GPU 和 NVSwitch(请参阅 GPU/VM/系统重置功能和限制)。 如果在 Trunk 端口上观察到错误,则使用 NVSwitch trunk 端口的分区将受到影响。 |
10004 |
|
与热事件相关,热事件对 fabric/系统不是直接致命的,但它们表明系统冷却可能不足。 此错误可能会强制指定的 NVSwitch 链路进入省电模式(单通道模式),并影响 NVLink 吞吐量。 |
10005 |
|
与热事件相关,热事件对 fabric/系统不是直接致命的,但它们确实表明系统冷却可能不足。 |
有关其他 NVSwitch SXid 错误的完整列表,请转到 https://github.com/NVIDIA/open-gpu-kernel-modules/blob/4397463e738d2d90aa1164cc5948e723701f7b53/src/common/nvswitch/interface/ctrl_dev_nvswitch.h
13.8. 高可用性模式比较
表 18 提供了有关 DGX A100/NVIDIA HGX A100 和 DGX H100/NVIDIA HGX H100 系统上现有 FM 高可用性模式配置选项的预期行为的信息。
配置 |
DGX A100/ NVIDIA HGX A100 |
DGX H100/ NVIDIA HGX H100 |
|---|---|---|
当存在 Trunk 链路故障(NVSwitch 到 NVSwitch NVLink 故障)时的高可用性模式选项。 |
在裸机或完全直通虚拟化模式下
在共享 NVSwitch 或基于 vGPU 的多租户模式下
所有分区都将可用,但 NVLink P2P 带宽会降低。 |
此配置不适用于 DGX H100 和 NVIDIA HGX H100 NVLink 在这些系统上。同样在系统上,由于没有 trunk,因此这些系统会忽略此配置值。 |
当存在 NVSwitch 故障或 NVSwitch 被排除时的高可用性模式选项。 |
在裸机或完全直通虚拟化模式下
在共享 NVSwitch 或基于 vGPU 的多租户模式下
所有分区都将可用,但 NVLink P2P 带宽会降低。 |
此配置不适用于 DGX H100 和 NVIDIA HGXH100 系统。同样在这些系统上,此配置值将被忽略。 在裸机或完全直通虚拟化模式下 底板上的四个 NVSwitch 应可供 FM 访问。如果某个 NVSwitch 不可用,FM 将中止并使系统保持未初始化状态。 根据故障的性质,GPU NVLink 可能会处于活动状态。但是,GPU 将无法完成与 NVLink fabric 的注册,并且 CUDA 应用程序启动将失败。 在共享 NVSwitch 或基于 vGPU 的多租户模式下 底板上的四个 NVSwitch 应可供 FM 访问。如果某个 NVSwitch 不可用,FM 将中止并使系统保持未初始化状态,并且与共享 NVSwitch 相关的分区 API 将失败/返回错误。 |
当存在访问链路故障(GPU 到 NVSwitch NVLink 故障)时的高可用性模式选项 |
在裸机或完全直通虚拟化模式下
基于 vGPU 的多租户模式
|
此配置不适用于 DGX H100 和 NVIDIA HGX H100 系统,并且配置的值将被忽略。 在裸机或完全直通虚拟化模式下 当存在访问链路故障时,相应的 在共享 NVSwitch 或基于 vGPU 的多租户模式下 FM 将报告所有分区都可用,并且允许分区激活。但是,访客 VM 上的相应 GPU 将报告某些 NVLink 为 |
控制 FM 服务停止或终止时正在运行的 CUDA 作业的行为。 |
|
此配置不适用于 DGX H100 和 NVIDIA HGX H100 系统,并且配置的值将被忽略。 在这些系统上,FM 退出后,将发生以下情况
但是,如果 GPU 启用了持久模式,则新的 CUDA 作业启动将成功。此外,在 GPU 重置操作之后,即使 GPU 启用了持久模式,CUDA 作业启动也会失败。 |
13.9. GPU/VM/系统重置功能和限制
请参阅 nvidia-smi 手册页中的以下摘录
用于触发一个或多个 GPU 的重置。可用于清除 GPU HW 和 SW 状态,否则需要机器重启的情况。
通常在发生双位 ECC 错误时很有用。
-i选项可用于定位一个或多个特定设备。如果不使用此选项,则将重置所有 GPU,并且需要 root 权限。
应用程序(例如 CUDA 应用程序)、图形应用程序(例如 X 服务器)、监控应用程序(例如
nvidia-smi的其他实例)无法使用这些设备。
FM 状态 |
裸机 |
完全直通虚拟化 (同一 VM 中的所有设备) |
共享 NVSwitch 虚拟化 (不同 VM 中的 GPU 和 NVSwitch) |
|
|---|---|---|---|---|
NVIDIA Ampere 架构及更高版本,具有直接 NVLink 连接。 |
不适用 |
可以单独重置一个 GPU。此外,无需指定任何设备即可重置所有 GPU。 |
VM 中不支持 GPU 重置。重启 VM。 |
不适用 |
NVIDIA Ampere 架构 + NVSwitch |
运行 |
可以单独重置一个 GPU。作为 GPU 重置操作的一部分,FM 也会重置相应的 NVSwitch 侧链路。 |
VM 中不支持 GPU 重置。重启 VM。 |
重启 VM。service VM 流程应确保通过与 FM 通信来正确重置 NVSwitch 链路。 |
未运行 |
不支持单独的 GPU 重置。重置通过 NVLink 连接在一起的所有 GPU 和 NVSwitch。 |
VM 中不支持 GPU 重置。重启 VM。 |
||
Hopper 及更高版本 + NVSwitch |
不适用 |
可以单独重置 GPU,而无需 FM 依赖项。此外,无需指定任何设备即可重置所有 GPU 和 NVSwitch。 |
GPU 重置能力取决于 hypervisor 允许 VM 的权限。如果不允许,请重启 VM。 |
GPU 重置能力取决于 hypervisor 允许 VM 的权限。如果不允许,请重启 VM。 |
14. 声明
14.1. 声明
本文档仅供参考,不得视为对产品的特定功能、条件或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含的信息的准确性或完整性不做任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对使用此类信息造成的后果或使用,或因使用此类信息而可能导致的侵犯第三方专利或其他权利的行为不承担任何责任。本文档不构成开发、发布或交付任何材料(以下定义)、代码或功能的承诺。
NVIDIA 保留随时更正、修改、增强、改进和对本文档进行任何其他更改的权利,恕不另行通知。
客户在下订单前应获取最新的相关信息,并应验证此类信息是否为最新且完整。
NVIDIA 产品的销售受订单确认时提供的 NVIDIA 标准销售条款和条件的约束,除非 NVIDIA 和客户的授权代表签署的个别销售协议(“销售条款”)另有约定。NVIDIA 在此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档未直接或间接形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命支持设备,也不适用于 NVIDIA 产品的故障或故障可以合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在这些设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不保证基于本文档的产品适用于任何特定用途。NVIDIA 不一定会对每种产品的所有参数进行测试。客户全权负责评估和确定本文档中任何信息的适用性,确保产品适合客户计划的应用,并为该应用执行必要的测试,以避免应用或产品出现缺陷。客户产品设计的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档所载的附加或不同的条件和/或要求。对于因以下原因引起或归因于以下原因的任何缺陷、损坏、成本或问题,NVIDIA 概不负责:(i) 以违反本文档的方式使用 NVIDIA 产品或 (ii) 客户产品设计。
本文档未授予任何明示或暗示的许可,以使用任何 NVIDIA 专利权、版权或其他 NVIDIA 知识产权。NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予的使用此类产品或服务的许可,也不构成对此类产品或服务的保证或认可。使用此类信息可能需要获得第三方的专利或其他知识产权许可,或者获得 NVIDIA 的专利或其他知识产权许可。
只有在事先获得 NVIDIA 书面批准的情况下,才可以复制本文档中的信息,且复制必须未经修改,完全遵守所有适用的出口法律法规,并附带所有相关的条件、限制和声明。
本文档以及所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”,单独或合并)均按“原样”提供。NVIDIA 对这些材料不作任何明示、暗示、法定或其他形式的保证,并明确声明不承担所有关于不侵权、适销性和特定用途适用性的默示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对因使用本文档而引起的任何损害(包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害,无论何种原因造成,也无论基于何种责任理论)承担责任,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因遭受任何损害,NVIDIA 对本文所述产品的客户承担的总体和累积责任应根据产品的销售条款进行限制。
14.2. OpenCL
OpenCL 是 Apple Inc. 的商标,已授权 Khronos Group Inc. 使用。
14.3. 商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。