Virtual GPU 软件用户指南
Virtual GPU 软件用户指南
面向管理员的文档,介绍了如何安装和配置 NVIDIA Virtual GPU 管理器,如何在直通模式下配置虚拟 GPU 软件,以及如何在客户操作系统上安装驱动程序。
NVIDIA vGPU 软件是一个图形虚拟化平台,为虚拟机 (VM) 提供对 NVIDIA GPU 技术的访问。
1.1. NVIDIA vGPU 软件的使用方式
1.1.1. NVIDIA vGPU
NVIDIA Virtual GPU (vGPU) 使多个虚拟机 (VM) 能够同时直接访问单个物理 GPU,使用与部署在非虚拟化操作系统上的相同的 NVIDIA 图形驱动程序。通过这样做,NVIDIA vGPU 为虚拟机提供了无与伦比的图形性能、计算性能和应用程序兼容性,以及通过在多个工作负载之间共享 GPU 而带来的成本效益和可扩展性。
有关更多信息,请参阅安装和配置 NVIDIA Virtual GPU 管理器。
1.1.2. GPU 直通
在 GPU 直通模式下,整个物理 GPU 直接分配给一个 VM,绕过 NVIDIA Virtual GPU 管理器。在这种运行模式下,GPU 由 VM 中运行的 NVIDIA 驱动程序独占访问。GPU 不在 VM 之间共享。
有关更多信息,请参阅使用 GPU 直通。
1.1.3. 裸机部署
在裸机部署中,您可以将 NVIDIA vGPU 软件图形驱动程序与 vWS 和 vApps 许可证结合使用,以交付远程虚拟桌面和应用程序。如果您打算在没有虚拟机监控程序的情况下将 Tesla 板用于此目的,请使用 NVIDIA vGPU 软件图形驱动程序,而不是其他 NVIDIA 驱动程序。
要将 NVIDIA vGPU 软件驱动程序用于裸机部署,请完成以下任务
-
在物理主机上安装驱动程序。
有关说明,请参阅安装 NVIDIA vGPU 软件图形驱动程序。
-
许可您正在使用的任何 NVIDIA vGPU 软件。
有关说明,请参阅Virtual GPU 客户端许可用户指南。
-
配置平台以进行远程访问。
要将图形功能与 Tesla GPU 结合使用,您必须使用受支持的远程解决方案,例如 RemoteFX、Citrix Virtual Apps and Desktops、VNC 或类似技术。
-
使用主机操作系统的显示设置功能将 Tesla GPU 配置为主显示器。
NVIDIA Tesla 通常在裸机平台上作为辅助设备运行。
-
如果系统有多个显示适配器,请禁用通过非 NVIDIA 适配器连接的显示设备。
您可以使用主机操作系统的显示设置功能或远程解决方案来实现此目的。在包括 Tesla GPU 在内的 NVIDIA GPU 上,默认情况下会启用默认显示设备。
只有在启用由 NVIDIA 适配器驱动的显示器后,用户才能启动需要 NVIDIA GPU 技术以增强用户体验的应用程序。
1.2. NVIDIA vGPU 软件部署的主显示适配器要求
设置为主显示适配器的 GPU 不能用于 NVIDIA vGPU 部署或 GPU 直通部署。主显示器是虚拟机监控程序主机的启动显示器,它显示 SBIOS 控制台消息,然后启动操作系统或虚拟机监控程序。
任何用于 NVIDIA vGPU 部署或 GPU 直通部署的 GPU 都必须设置为辅助显示适配器。
XenServer 提供了一个特定设置,允许将主显示适配器用于 GPU 直通部署。

仅支持以下 GPU 作为主显示适配器
- Tesla M6
- Quadro RTX 6000
- Quadro RTX 8000
所有其他支持 NVIDIA vGPU 软件的 GPU 都不能用作主显示适配器,因为它们是 3D 控制器,而不是 VGA 设备。
如果虚拟机监控程序主机没有额外的图形适配器,请考虑安装一个低端显示适配器用作主显示适配器。如有必要,请确保在虚拟机监控程序主机的 BIOS 选项中正确设置了主显示适配器。
1.3. NVIDIA vGPU 软件功能
NVIDIA vGPU 软件包括 vWS、vPC 和 vApps。
1.3.1. NVIDIA vGPU 上的 API 支持
NVIDIA vGPU 包括对以下 API 的支持
- Open Computing Language (OpenCL™ 软件) 3.0
- OpenGL® 4.6
- Vulkan® 1.3
- DirectX 11
- DirectX 12 (Windows 10)
- Direct2D
- DirectX 视频加速 (DXVA)
- NVIDIA® CUDA® 12.4
- NVIDIA vGPU 软件 SDK(远程图形加速)
- NVIDIA RTX(基于 NVIDIA Volta 图形架构和更高版本的架构的 GPU 上)
这些 API 向后兼容。也支持旧版本的 API。
1.3.2. NVIDIA CUDA Toolkit 和 OpenCL 对 NVIDIA vGPU 软件的支持
NVIDIA CUDA Toolkit 和 OpenCL 仅在 vGPU 类型和受支持 GPU 的子集上受 NVIDIA vGPU 支持。
有关 NVIDIA CUDA Toolkit 的更多信息,请参阅CUDA Toolkit 12.4 文档。
如果您在 Linux 上将 NVIDIA vGPU 软件与 CUDA 结合使用,请通过从独立于发行版的 runfile 软件包安装 CUDA 来避免安装方法冲突。请勿从特定于发行版的 RPM 或 Deb 软件包安装 CUDA。
为确保在安装 CUDA 时 NVIDIA vGPU 软件图形驱动程序不会被覆盖,请在选择要安装的 CUDA 组件时取消选择 CUDA 驱动程序。
有关更多信息,请参阅NVIDIA CUDA Linux 安装指南。
OpenCL 和 CUDA 应用程序支持
以下 NVIDIA vGPU 类型支持 OpenCL 和 CUDA 应用程序
- Tesla M10 GPU 上的 8Q vGPU 类型
- 以下 GPU 上的所有 Q 系列 vGPU 类型
- NVIDIA L2
- NVIDIA L4
- NVIDIA L20
- NVIDIA L40
- NVIDIA L40S
- NVIDIA RTX 5000 Ada
- NVIDIA RTX 6000 Ada
- NVIDIA A2
- NVIDIA A10
- NVIDIA A16
- NVIDIA A40
- NVIDIA RTX A5000
- NVIDIA RTX A5500
- NVIDIA RTX A6000
- Tesla V100 SXM2
- Tesla V100 SXM2 32GB
- Tesla V100 PCIe
- Tesla V100 PCIe 32GB
- Tesla V100S PCIe 32GB
- Tesla V100 FHHL
- Tesla T4
- Quadro RTX 6000
- Quadro RTX 6000 无源
- Quadro RTX 8000
- Quadro RTX 8000 无源
NVIDIA CUDA Toolkit 开发工具支持
NVIDIA vGPU 在某些 GPU 上支持以下 NVIDIA CUDA Toolkit 开发工具
- 调试器
- CUDA-GDB
- Compute Sanitizer
- 分析器
- CUDA 性能分析工具接口 (CUPTI) 的 Activity、Callback 和 Profiling API
不支持其他 CUPTI API,例如 Event 和 Metric API。
- NVIDIA Nsight™ Compute
- NVIDIA Nsight Systems
- NVIDIA Nsight 插件
- NVIDIA Nsight Visual Studio 插件
不支持其他 CUDA 分析器,例如 nvprof 和 NVIDIA Visual Profiler。
- CUDA 性能分析工具接口 (CUPTI) 的 Activity、Callback 和 Profiling API
这些工具仅在 Linux 客户虚拟机中受支持。
NVIDIA CUDA Toolkit 分析器受支持,并且可以在启用了统一内存的 VM 上启用。
默认情况下,NVIDIA CUDA Toolkit 开发工具在 NVIDIA vGPU 上处于禁用状态。如果使用,您必须通过设置 vGPU 插件参数为每个需要它们的 VM 单独启用 NVIDIA CUDA Toolkit 开发工具。有关说明,请参阅为 NVIDIA vGPU 启用 NVIDIA CUDA Toolkit 开发工具。
下表列出了 NVIDIA vGPU 支持这些调试器和分析器的 GPU。
| GPU | vGPU 模式 | 调试器 | 分析器 |
|---|---|---|---|
| NVIDIA L2 | 时间分片 | ✓ | ✓ |
| NVIDIA L4 | 时间分片 | ✓ | ✓ |
| NVIDIA L20 | 时间分片 | ✓ | ✓ |
| NVIDIA L40 | 时间分片 | ✓ | ✓ |
| NVIDIA L40S | 时间分片 | ✓ | ✓ |
| NVIDIA RTX 5000 Ada | 时间分片 | ✓ | ✓ |
| NVIDIA RTX 6000 Ada | 时间分片 | ✓ | ✓ |
| NVIDIA A2 | 时间分片 | ✓ | ✓ |
| NVIDIA A10 | 时间分片 | ✓ | ✓ |
| NVIDIA A16 | 时间分片 | ✓ | ✓ |
| NVIDIA A40 | 时间分片 | ✓ | ✓ |
| NVIDIA RTX A5000 | 时间分片 | ✓ | ✓ |
| NVIDIA RTX A5500 | 时间分片 | ✓ | ✓ |
| NVIDIA RTX A6000 | 时间分片 | ✓ | ✓ |
| Tesla T4 | 时间分片 | ✓ | ✓ |
| Quadro RTX 6000 | 时间分片 | ✓ | ✓ |
| Quadro RTX 6000 无源 | 时间分片 | ✓ | ✓ |
| Quadro RTX 8000 | 时间分片 | ✓ | ✓ |
| Quadro RTX 8000 无源 | 时间分片 | ✓ | ✓ |
| Tesla V100 SXM2 | 时间分片 | ✓ | ✓ |
| Tesla V100 SXM2 32GB | 时间分片 | ✓ | ✓ |
| Tesla V100 PCIe | 时间分片 | ✓ | ✓ |
| Tesla V100 PCIe 32GB | 时间分片 | ✓ | ✓ |
| Tesla V100S PCIe 32GB | 时间分片 | ✓ | ✓ |
| Tesla V100 FHHL | 时间分片 | ✓ | ✓ |
✓ 表示支持该功能
- 表示不支持该功能
受支持的 NVIDIA CUDA Toolkit 功能
如果 vGPU 类型、物理 GPU 和虚拟机监控程序软件版本支持该功能,则 NVIDIA vGPU 支持以下 NVIDIA CUDA Toolkit 功能
- 纠错码 (ECC) 内存
- 通过 NVLink 的对等 CUDA 传输注意
要确定主机中物理 GPU 或分配给 VM 的 vGPU 之间的 NVLink 拓扑,请从主机或 VM 运行以下命令
$ nvidia-smi topo -m
- 统一内存注意
默认情况下,统一内存处于禁用状态。如果使用,您必须通过设置 vGPU 插件参数为每个需要它的 vGPU 单独启用统一内存。有关说明,请参阅为 vGPU 启用统一内存。
- NVIDIA Nsight Systems GPU 上下文切换跟踪
动态页面停用功能适用于支持 ECC 内存的物理 GPU 上的所有 vGPU 类型,即使物理 GPU 上禁用了 ECC 内存也是如此。
NVIDIA vGPU 不支持的 NVIDIA CUDA Toolkit 功能
NVIDIA vGPU 不支持 NVIDIA CUDA Toolkit 的 NVIDIA Nsight Graphics 功能。
NVIDIA Nsight Graphics 功能在 GPU 直通模式和裸机部署中受支持。
1.3.3. 其他 vWS 功能
除了 vPC 和 vApps 的功能外,vWS 还提供以下功能
- 工作站特定的图形功能和加速
- 专业应用程序的认证驱动程序
- 用于工作站或专业 3D 图形的 GPU 直通
在直通模式下,vWS 支持高达 8K 分辨率的多个虚拟显示头,以及基于可用像素数的灵活虚拟显示分辨率。有关详细信息,请参阅物理 GPU 的显示分辨率。
- 适用于 Windows 用户的 10 位颜色。(Linux 上目前不支持 HDR/10 位颜色,支持 NvFBC 捕获,但已弃用。)
1.3.4. NVIDIA GPU Cloud (NGC) 容器对 NVIDIA vGPU 软件的支持
NVIDIA vGPU 软件在所有受支持的虚拟机监控程序上的 NVIDIA vGPU 和 GPU 直通部署中都支持 NGC 容器。
在 NVIDIA vGPU 部署中,仅在基于 Maxwell 架构之后的 NVIDIA GPU 架构的 GPU 上支持 Q 系列 vGPU 类型。
在 GPU 直通部署中,支持 NVIDIA vGPU 软件的基于 NVIDIA Maxwell™ 架构之后的所有 NVIDIA GPU 架构的 GPU 都受支持。
NVIDIA vGPU 软件在受支持的平台 - NVIDIA 容器工具包中列出的任何客户操作系统上都支持 NGC 容器,该客户操作系统也受 NVIDIA vGPU 软件支持。
有关设置 NVIDIA vGPU 软件以与 NGC 容器一起使用的更多信息,请参阅将 NGC 与 NVIDIA Virtual GPU 软件设置指南结合使用。
1.3.5. NVIDIA GPU Operator 支持
NVIDIA GPU Operator 简化了在由 Kubernetes 容器编排引擎管理的软件容器平台上部署 NVIDIA vGPU 软件的过程。它自动化了在配置了 NVIDIA vGPU 的客户虚拟机中运行的容器平台的 NVIDIA vGPU 软件图形驱动程序的安装和更新。
NVIDIA GPU Operator 要安装的任何驱动程序都必须从 NVIDIA 许可门户下载到本地计算机。NVIDIA GPU Operator 不支持自动访问 NVIDIA 许可门户。
NVIDIA GPU Operator 支持 NVIDIA vGPU 软件的自动配置,并通过在客户虚拟机中运行的 DCGM Exporter 提供遥测支持。
NVIDIA GPU Operator 仅在虚拟机监控程序软件版本、容器平台、vGPU 类型和客户操作系统版本的特定组合上受支持。要确定您的配置是否支持 NVIDIA GPU Operator 与 NVIDIA vGPU 部署,请查阅您选择的虚拟机监控程序的发行说明:NVIDIA Virtual GPU 软件文档。
有关更多信息,请参阅 NVIDIA 文档门户上的NVIDIA GPU Operator 概述。
1.4. 本指南的组织结构
Virtual GPU 软件用户指南按如下方式组织
- 本章介绍了 NVIDIA vGPU 软件的功能和特性。
- 安装和配置 NVIDIA Virtual GPU 管理器提供了在受支持的虚拟机监控程序上安装和配置 vGPU 的分步指南。
- 使用 GPU 直通介绍了如何在受支持的虚拟机监控程序上配置 GPU 以进行直通。
- 安装 NVIDIA vGPU 软件图形驱动程序 介绍了如何在 Windows 和 Linux 操作系统上安装 NVIDIA vGPU 软件图形驱动程序。
- NVIDIA vGPU 许可 介绍了如何在 Windows 和 Linux 操作系统上为 NVIDIA vGPU 许可产品进行许可。
- 修改虚拟机的 NVIDIA vGPU 配置 介绍了如何删除虚拟机的 vGPU 配置以及如何修改启用 vGPU 的虚拟机的 GPU 分配。
- 监控 GPU 性能 涵盖了从虚拟机监控程序和各个客户机虚拟机内部监控物理 GPU 和虚拟 GPU 的性能。
- 更改分时 vGPU 的调度行为 描述了 NVIDIA vGPU 的调度行为以及如何更改它。
- 故障排除 提供了故障排除指南。
- 虚拟 GPU 类型参考 提供了每个受支持 GPU 提供的每个 vGPU 的详细信息,并提供了 B 系列和 Q 系列 vGPU 的混合虚拟显示配置示例。
- 配置 x11vnc 以检查 Linux 服务器中的 GPU 介绍了如何使用 x11vnc 确认未直接连接显示设备的 Linux 服务器中的 NVIDIA GPU 是否按预期工作。
- 禁用 Citrix 发布应用程序用户会话的 NVIDIA 通知图标 介绍了如何确保 NVIDIA 通知图标应用程序不会阻止 Citrix 发布应用程序用户会话注销,即使在用户退出所有其他应用程序后也是如此。
- XenServer 基础知识 介绍了如何在 XenServer 上执行基本操作以安装和配置 NVIDIA vGPU 软件并优化 XenServer 与 vGPU 的操作。
- XenServer vGPU 管理 涵盖了 XenServer 上的 vGPU 管理。
- XenServer 性能调优 涵盖了 XenServer 上的 vGPU 性能优化。
安装和配置 NVIDIA 虚拟 GPU 管理器的过程取决于您使用的虚拟机监控程序。完成此过程后,您可以为您的客户机操作系统安装显示驱动程序,并为正在使用的任何 NVIDIA vGPU 软件许可产品进行许可。
2.1. 关于 NVIDIA 虚拟 GPU
2.1.1. NVIDIA vGPU 架构
图 1 说明了 NVIDIA vGPU 的高级架构。在虚拟机监控程序下运行的 NVIDIA 虚拟 GPU 管理器的控制下,NVIDIA 物理 GPU 能够支持多个虚拟 GPU 设备 (vGPU),这些设备可以直接分配给客户机虚拟机。
客户机虚拟机以与虚拟机监控程序直通的物理 GPU 相同的方式使用 NVIDIA vGPU:加载在客户机虚拟机中的 NVIDIA 驱动程序为性能关键的快速路径提供对 GPU 的直接访问,而与 NVIDIA 虚拟 GPU 管理器的准虚拟化接口用于非性能管理操作。
图 1. NVIDIA vGPU 系统架构

每个 NVIDIA vGPU 都类似于传统的 GPU,它具有固定数量的 GPU 帧缓冲区以及一个或多个虚拟显示输出或“头”。 vGPU 的帧缓冲区在创建 vGPU 时从物理 GPU 的帧缓冲区中分配,并且 vGPU 保留对该帧缓冲区的独占使用权,直到它被销毁。根据物理 GPU 和 GPU 虚拟化软件,NVIDIA 虚拟 GPU 管理器在物理 GPU 上支持不同类型的 vGPU
- 在所有支持 NVIDIA vGPU 软件的 GPU 上,都可以创建分时 vGPU。
- 此外,在支持多实例 GPU (MIG) 功能和 NVIDIA AI Enterprise 的 GPU 上,支持 MIG 支持的 vGPU。 MIG 功能是在基于 NVIDIA Ampere GPU 架构的 GPU 上引入的。注意
虽然早期版本的 NVIDIA vGPU 软件支持支持 MIG 功能的 GPU,但此版本的 NVIDIA vGPU 软件不支持此类 GPU。支持 MIG 功能的 GPU 仅在 NVIDIA AI Enterprise 上受支持。
2.1.1.1. 分时 NVIDIA vGPU 内部架构
分时 vGPU 是驻留在未分区为多个 GPU 实例的物理 GPU 上的 vGPU。驻留在 GPU 上的所有分时 vGPU 共享对 GPU 引擎(包括图形 (3D)、视频解码和视频编码引擎)的访问。
在分时 vGPU 中,在 vGPU 上运行的进程被调度为串行运行。每个 vGPU 在其他进程在其他 vGPU 上运行时等待。当进程在 vGPU 上运行时,vGPU 独占使用 GPU 的引擎。您可以更改默认调度行为,如 更改分时 vGPU 的调度行为 中所述。
图 2. 分时 NVIDIA vGPU 内部架构

2.1.2. 关于虚拟 GPU 类型
板卡拥有的物理 GPU 数量取决于板卡。每个物理 GPU 可以支持几种不同类型的虚拟 GPU (vGPU)。 vGPU 类型具有固定数量的帧缓冲区、支持的显示头数和最大分辨率1。它们根据优化的不同类别的工作负载分为不同的系列。每个系列都由 vGPU 类型名称的最后一个字母标识。
| 系列 | 最佳工作负载 |
|---|---|
| Q 系列 | 适用于需要 Quadro 技术性能和功能的创意和技术专业人士的虚拟工作站 |
| B 系列 | 适用于商务专业人士和知识工作者的虚拟桌面 |
| A 系列 | 适用于虚拟应用程序用户的应用流式传输或基于会话的解决方案4 |
vGPU 类型名称中板卡类型后的数字表示分配给该类型 vGPU 的帧缓冲区大小。例如,A16-4Q 类型的 vGPU 在 NVIDIA A16 板卡上分配了 4096 MB 的帧缓冲区。
由于其不同的资源要求,可以在物理 GPU 上同时创建的最大 vGPU 数量因 vGPU 类型而异。例如,NVDIA A16 板卡在其两个物理 GPU 中的每个上最多可以支持 4 个 A16-4Q vGPU,总共 16 个 vGPU,但只能支持 2 个 A16-8Q vGPU,总共 8 个 vGPU。启用后,帧速率限制器 (FRL) 将 vGPU 的最大帧速率限制为每秒帧数 (FPS),如下所示
- 对于 B 系列 vGPU,最大帧速率为 45 FPS。
- 对于 Q 系列和 A 系列 vGPU,最大帧速率为 60 FPS。
默认情况下,FRL 对所有 GPU 启用。当 vGPU 调度行为从支持备用 vGPU 调度器的 GPU 上的默认尽力而为调度器更改时,FRL 将被禁用。有关详细信息,请参阅 更改分时 vGPU 的调度行为。在 vGPU 上使用尽力而为调度器时,可以禁用 FRL,如您选择的虚拟机监控程序的发行说明中所述,网址为 NVIDIA 虚拟 GPU 软件文档。
NVIDIA vGPU 是所有受支持 GPU 板卡上的许可产品。需要软件许可证才能启用客户机虚拟机中的所有 vGPU 功能。所需的许可证类型取决于 vGPU 类型。
- Q 系列 vGPU 类型需要 vWS 许可证。
- B 系列 vGPU 类型需要 vPC 许可证,但也可以与 vWS 许可证一起使用。
- A 系列 vGPU 类型需要 vApps 许可证。
有关每个受支持 GPU 提供的虚拟 GPU 类型的详细信息,请参阅 受支持 GPU 的虚拟 GPU 类型。
2.1.3. Q 系列和 B 系列 vGPU 的虚拟显示分辨率
Q 系列和 B 系列 vGPU 不支持每个显示器的固定最大分辨率,而是支持基于可用像素数的最大组合分辨率,这由它们的帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量低分辨率显示器与这些 vGPU 一起使用。
您可以使用的虚拟显示器数量取决于以下因素的组合
- 虚拟 GPU 系列
- GPU 架构
- vGPU 帧缓冲区大小
- 显示分辨率
即使显示器的组合分辨率小于 vGPU 的可用像素数,您也不能使用超过 vGPU 支持的最大显示器数量。例如,由于 -0Q 和 -0B vGPU 最多仅支持两个显示器,因此即使显示器的组合分辨率 (6220800) 小于这些 vGPU 的可用像素数 (8192000),您也不能将四个 1280×1024 显示器与这些 vGPU 一起使用。
各种因素会影响 GPU 帧缓冲区的消耗,这可能会影响用户体验。这些因素包括但不限于显示器数量、显示分辨率、部署的工作负载和应用程序、远程解决方案和客户机操作系统。 vGPU 驱动特定显示器组合的能力并不能保证有足够的帧缓冲区可用于运行所有应用程序。如果应用程序耗尽帧缓冲区,请考虑通过以下方式之一更改您的设置
- 切换到具有更多帧缓冲区的 vGPU 类型
- 使用更少的显示器
- 使用较低分辨率的显示器
受支持 GPU 的虚拟 GPU 类型 中列出的每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关混合显示分辨率配置的示例,请参阅 B 系列和 Q 系列 vGPU 的混合显示配置。
2.1.4. 单个 GPU 上的有效分时虚拟 GPU 配置
NVIDIA vGPU 软件支持在同一物理 GPU 上混合使用不同类型的分时 vGPU。任何具有任何帧缓冲区大小的 A 系列、B 系列和 Q 系列 vGPU 的组合都可以同时驻留在同一物理 GPU 上。分配给物理 GPU 上的 vGPU 的帧缓冲区总大小不得超过物理 GPU 拥有的帧缓冲区大小。
例如,以下 vGPU 组合可以同时驻留在同一物理 GPU 上
- A40-2B 和 A40-2Q
- A40-2Q 和 A40-4Q
- A40-2B 和 A40-4Q
默认情况下,GPU 仅支持具有相同帧缓冲区大小的 vGPU,因此处于等大小模式。为了支持具有不同帧缓冲区大小的 vGPU,必须将 GPU 置于混合大小模式。当 GPU 处于混合大小模式时,允许在 GPU 上使用的某些类型 vGPU 的最大数量小于 GPU 处于等大小模式时的最大数量。有关更多信息,请参阅以下主题
并非所有虚拟机监控程序和 GPU 都支持在同一物理 GPU 上混合使用不同类型的分时 vGPU。要确定您选择的虚拟机监控程序是否支持您选择的 GPU 的此功能,请查阅您的虚拟机监控程序的发行说明,网址为 NVIDIA 虚拟 GPU 软件文档。
2.1.5. 客户机虚拟机支持
NVIDIA vGPU 支持 Windows 和 Linux 客户机虚拟机操作系统。受支持的 vGPU 类型取决于客户机虚拟机操作系统。
有关受支持的 Windows 和 Linux 版本以及有关受支持配置的更多信息,请参阅您的虚拟机监控程序的驱动程序发行说明,网址为 NVIDIA 虚拟 GPU 软件文档。
2.1.5.1. Windows 客户机虚拟机支持
所有 NVIDIA vGPU 类型都支持 Windows 客户机虚拟机,即:Q 系列、B 系列和 A 系列 NVIDIA vGPU 类型。
2.1.5.2. Linux 客户机虚拟机支持
所有 NVIDIA vGPU 类型都支持 Linux 客户机虚拟机,即:Q 系列、B 系列和 A 系列 NVIDIA vGPU 类型。
2.2. 使用 NVIDIA vGPU 的先决条件
在继续之前,请确保满足以下先决条件
- 您拥有一个服务器平台,该平台能够托管您选择的虚拟机监控程序和支持 NVIDIA vGPU 软件的 NVIDIA GPU。
- 您的服务器平台中安装了一个或多个支持 NVIDIA vGPU 软件的 NVIDIA GPU。
-
如果您使用的是基于 NVIDIA Ampere 架构或更高架构的 GPU,则在您的服务器平台上启用以下 BIOS 设置
- VT-D/IOMMU
- SR-IOV
- 备用路由 ID 解释 (ARI)
- 您已下载适用于您选择的虚拟机监控程序的 NVIDIA vGPU 软件包,其中包含以下软件
- 适用于您的虚拟机监控程序的 NVIDIA 虚拟 GPU 管理器
- 适用于受支持客户机操作系统的 NVIDIA vGPU 软件图形驱动程序
- 以下软件已按照软件供应商文档中的说明进行安装
- 您选择的虚拟机监控程序,例如,XenServer、红帽企业 Linux KVM 或 VMware vSphere Hypervisor (ESXi)
- 用于管理您选择的虚拟机监控程序的软件,例如,Citrix XenCenter 管理 GUI 或 VMware vCenter Server
- 您将与运行 NVIDIA 虚拟 GPU 的虚拟机 (VM) 一起使用的虚拟桌面软件,例如,Citrix Virtual Apps and Desktops 或 Omnissa Horizon
注意如果您使用的是 VMware vSphere Hypervisor (ESXi),请确保您将在其上配置具有 NVIDIA vGPU 的虚拟机的 ESXi 主机不是完全自动化的 VMware Distributed Resource Scheduler (DRS) 集群的成员。有关更多信息,请参阅 安装和配置 VMware vSphere 的 NVIDIA 虚拟 GPU 管理器。
- 已创建要启用一个或多个虚拟 GPU 的虚拟机。注意
如果虚拟机使用 UEFI 启动,并且您计划在虚拟机中安装 Linux 客户机操作系统,请确保安全启动处于禁用状态。
- 您选择的客户机操作系统已安装在虚拟机中。
有关受支持的硬件和软件,以及此版本的 NVIDIA vGPU 软件的任何已知问题的信息,请参阅您选择的虚拟机监控程序的发行说明
- Virtual GPU Software for XenServer Release Notes
- Virtual GPU Software for Microsoft Azure Local Release Notes
- Virtual GPU Software for Red Hat Enterprise Linux with KVM Release Notes
- Virtual GPU Software for Ubuntu Release Notes
- Virtual GPU Software for VMware vSphere Release Notes
2.3. 切换支持多种显示模式的 GPU 的模式
某些 GPU 支持关闭显示和启用显示模式,但必须在 NVIDIA vGPU 软件部署中以关闭显示模式使用。
下表列出的 GPU 支持多种显示模式。如表所示,某些 GPU 在出厂时以关闭显示模式供货,而其他 GPU 则以启用显示模式供货。
| GPU | 出厂供货模式 |
|---|---|
| NVIDIA A40 | 关闭显示 |
| NVIDIA L40 | 关闭显示 |
| NVIDIA L40S | 关闭显示 |
| NVIDIA L20 | 关闭显示 |
| NVIDIA L20 液冷 | 关闭显示 |
| NVIDIA RTX 5000 Ada | 启用显示 |
| NVIDIA RTX 6000 Ada | 启用显示 |
| NVIDIA RTX A5000 | 启用显示 |
| NVIDIA RTX A5500 | 启用显示 |
| NVIDIA RTX A6000 | 启用显示 |
出厂时以关闭显示模式供货的 GPU,例如 NVIDIA A40 GPU,如果其模式之前已更改,则可能处于启用显示模式。
要更改支持多种显示模式的 GPU 的模式,请使用 displaymodeselector 工具,您可以从 NVIDIA 开发者网站上的NVIDIA Display Mode Selector Tool页面请求该工具。
只有表中列出的 GPU 支持 displaymodeselector 工具。其他支持 NVIDIA vGPU 软件的 GPU 不支持 displaymodeselector 工具,除非另有说明,否则不需要切换显示模式。
2.4. 为 XenServer 安装和配置 NVIDIA Virtual GPU Manager
以下主题将逐步指导您完成设置单个 XenServer VM 以使用 NVIDIA vGPU 的过程。完成此过程后,您可以为您的客户操作系统安装图形驱动程序,并许可您正在使用的任何 NVIDIA vGPU 软件许可产品。
这些设置步骤假定您熟悉XenServer 基础知识中涵盖的 XenServer 技能。
2.4.1. 为 XenServer 安装和更新 NVIDIA Virtual GPU Manager
NVIDIA Virtual GPU Manager 在 XenServer dom0 域中运行。用于 XenServer 的 NVIDIA Virtual GPU Manager 以 RPM 文件和 Supplemental Pack 的形式提供。
NVIDIA Virtual GPU Manager 和客户 VM 驱动程序必须兼容。如果您将 vGPU Manager 更新到与客户 VM 驱动程序不兼容的版本,则客户 VM 将在禁用 vGPU 的情况下启动,直到其客户 vGPU 驱动程序更新到兼容版本。有关更多详细信息,请参阅Virtual GPU Software for XenServer Release Notes。
2.4.1.1. 为 XenServer 安装 RPM 软件包
RPM 文件必须在安装前复制到 XenServer dom0 域(请参阅将文件复制到 dom0)。
- 使用 rpm 命令安装软件包
[root@xenserver ~]# rpm -iv NVIDIA-vGPU-NVIDIA-vGPU-CitrixHypervisor-8.2-550.144.02.x86_64.rpm Preparing packages for installation... NVIDIA-vGPU-NVIDIA-vGPU-CitrixHypervisor-8.2-550.144.02 [root@xenserver ~]#
- 重新启动 XenServer 平台
[root@xenserver ~]# shutdown –r now Broadcast message from root (pts/1) (Fri Jan 17 14:24:11 2025): The system is going down for reboot NOW! [root@xenserver ~]#
2.4.1.2. 为 XenServer 更新 RPM 软件包
如果系统上已安装现有的 NVIDIA Virtual GPU Manager 并且您想要升级,请按照以下步骤操作
- 关闭任何正在使用 NVIDIA vGPU 的 VM。
- 使用 rpm 命令的 –U 选项安装新软件包,以从先前安装的软件包升级
[root@xenserver ~]# rpm -Uv NVIDIA-vGPU-NVIDIA-vGPU-CitrixHypervisor-8.2-550.144.02.x86_64.rpm Preparing packages for installation... NVIDIA-vGPU-NVIDIA-vGPU-CitrixHypervisor-8.2-550.144.02 [root@xenserver ~]#
注意您可以使用 rpm –q 命令查询当前 NVIDIA Virtual GPU Manager 软件包的版本
[root@xenserver ~]# rpm –q NVIDIA-vGPU-NVIDIA-vGPU-CitrixHypervisor-8.2-550.144.02 [root@xenserver ~]# If an existing NVIDIA GRID package is already installed and you don’t select the upgrade (-U) option when installing a newer GRID package, the rpm command will return many conflict errors. Preparing packages for installation... file /usr/bin/nvidia-smi from install of NVIDIA-vGPU-NVIDIA-vGPU-CitrixHypervisor-8.2-550.144.02.x86_64 conflicts with file from package NVIDIA-vGPU-xenserver-8.2-550.127.06.x86_64 file /usr/lib/libnvidia-ml.so from install of NVIDIA-vGPU-NVIDIA-vGPU-CitrixHypervisor-8.2-550.144.02.x86_64 conflicts with file from package NVIDIA-vGPU-xenserver-8.2-550.127.06.x86_64 ...
- 重新启动 XenServer 平台
[root@xenserver ~]# shutdown –r now Broadcast message from root (pts/1) (Fri Jan 17 14:24:11 2025): The system is going down for reboot NOW! [root@xenserver ~]#
2.4.1.3. 为 XenServer 安装或更新 Supplemental Pack
XenCenter 可用于在 XenServer 主机上安装或更新 Supplemental Pack。NVIDIA Virtual GPU Manager supplemental pack 以 ISO 形式提供。
- 从工具菜单中选择 Install Update(安装更新)。
- 在浏览完Before You Start(开始之前)部分的说明后,单击 Next(下一步)。
- 在 Select Update(选择更新)部分单击 Select update or supplemental pack from disk(从磁盘中选择更新或 supplemental pack),然后打开 NVIDIA 的 XenServer Supplemental Pack ISO。
图 3. 在 XenCenter 中选择的 NVIDIA vGPU Manager supplemental pack
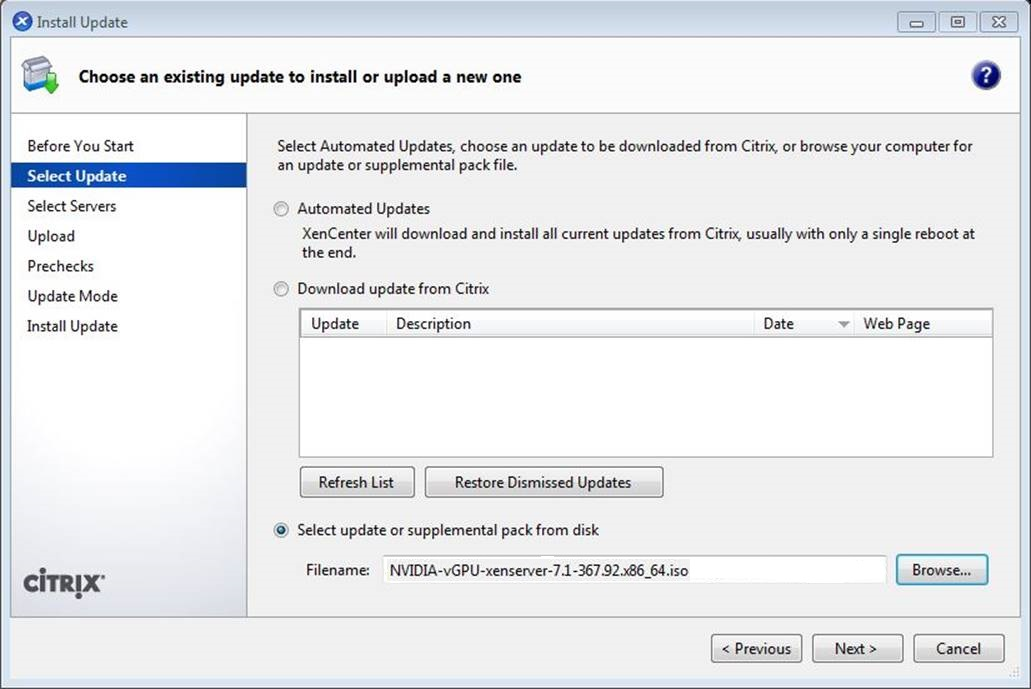
- 在 Select Update(选择更新)部分单击 Next(下一步)。
- 在 Select Servers(选择服务器)部分,选择所有要安装 Supplemental Pack 的 XenServer 主机,然后单击 Next(下一步)。
- Supplemental Pack 上传到所有 XenServer 主机后,在 Upload(上传)部分单击 Next(下一步)。
- 在 Prechecks(预检)部分单击 Next(下一步)。
- 在 Update Mode(更新模式)部分单击 Install Update(安装更新)。
- 在 Install Update(安装更新)部分单击 Finish(完成)。

图 4. 成功安装 NVIDIA vGPU Manager supplemental pack

2.4.1.4. 验证 NVIDIA vGPU Software for XenServer 软件包的安装
XenServer 平台重新启动后,验证 NVIDIA vGPU software package for XenServer 的安装。
- 通过检查内核加载模块列表中是否存在 NVIDIA 内核驱动程序,验证 NVIDIA vGPU 软件包是否已安装并正确加载。
[root@xenserver ~]# lsmod | grep nvidia nvidia 9522927 0 i2c_core 20294 2 nvidia,i2c_i801 [root@xenserver ~]#
- 通过运行 nvidia-smi 命令,验证 NVIDIA 内核驱动程序是否可以与系统中的 NVIDIA 物理 GPU 成功通信。有关 nvidia-smi 命令的更详细描述,请参阅NVIDIA System Management Interface nvidia-smi。
运行 nvidia-smi 命令应生成平台中 GPU 的列表。
[root@xenserver ~]# nvidia-smi
Fri Jan 17 18:46:50 2025
+------------------------------------------------------+
| NVIDIA-SMI 550.144.02 Driver Version: 550.144.02 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla M60 On | 00000000:05:00.0 Off | Off |
| N/A 25C P8 24W / 150W | 13MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla M60 On | 00000000:06:00.0 Off | Off |
| N/A 24C P8 24W / 150W | 13MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla M60 On | 00000000:86:00.0 Off | Off |
| N/A 25C P8 25W / 150W | 13MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla M60 On | 00000000:87:00.0 Off | Off |
| N/A 28C P8 24W / 150W | 13MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
[root@xenserver ~]#
如果 nvidia-smi 无法运行或未针对系统中的所有 NVIDIA GPU 生成预期输出,请参阅故障排除以获取故障排除步骤。
2.4.2. 使用 Virtual GPU 配置 XenServer VM
为了支持计算或图形密集型应用程序和工作负载,您可以向单个 VM 添加多个 vGPU。
有关哪些 XenServer 版本和 NVIDIA vGPU 支持将多个 vGPU 分配给 VM 的详细信息,请参阅Virtual GPU Software for XenServer Release Notes。
XenServer 支持使用 XenCenter 或在 XenServer dom0 shell 中运行的 xe 命令行工具配置和管理虚拟 GPU。以下部分介绍了使用 XenCenter 进行的基本配置。使用 xe 的命令行管理在XenServer vGPU 管理中进行了描述。
如果您使用的是 Citrix Hypervisor 8.1 或更高版本,并且需要分配插件配置参数,请使用 xe 命令创建 vGPU,如使用 xe 创建 vGPU中所述。
- 确保 VM 已关闭电源。
- 在 XenCenter 中右键单击 VM,选择 Properties(属性)以打开 VM 的属性,然后选择 GPU 属性。可用 GPU 类型在 GPU 类型下拉列表中列出:
图 5. 使用 Citrix XenCenter 配置带有 vGPU 的 VM
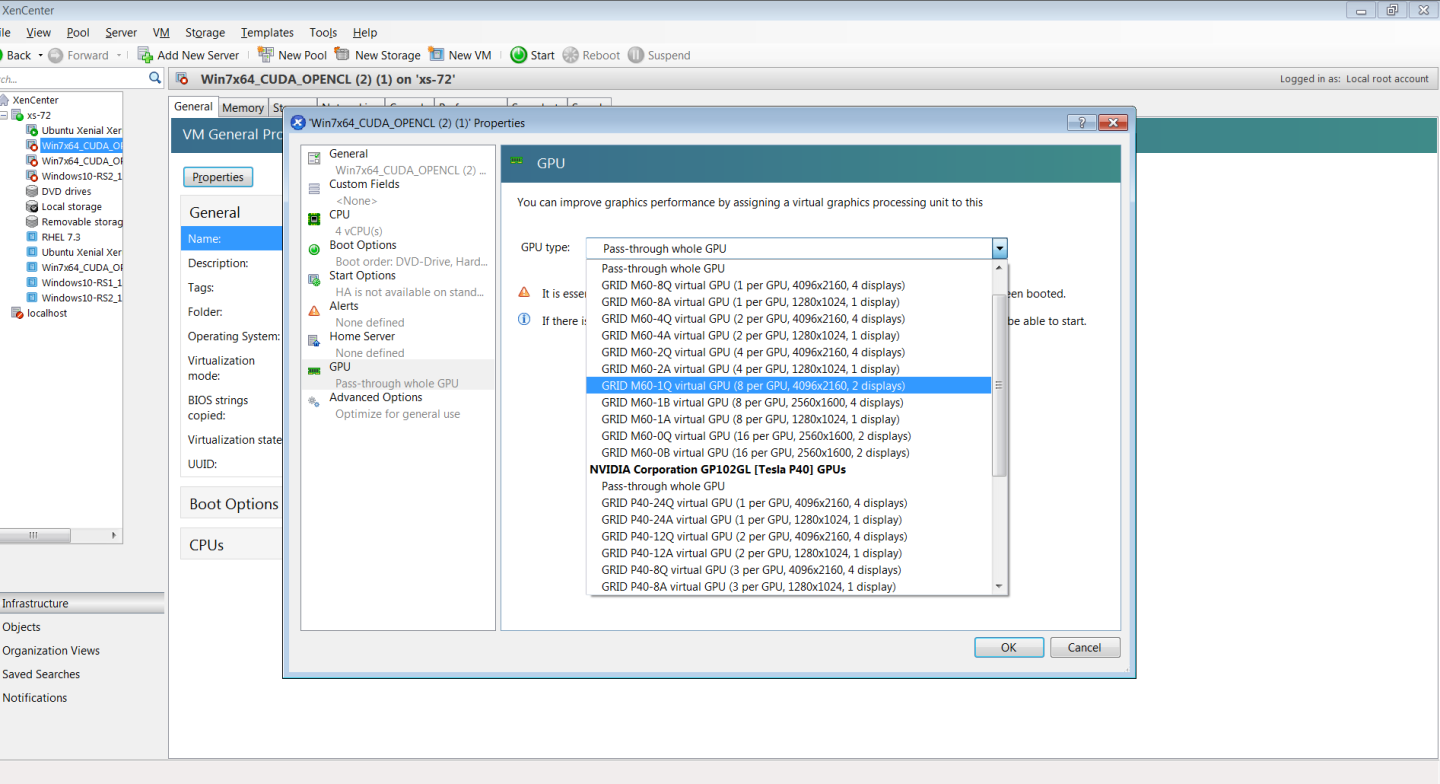

使用 vGPU 配置 XenServer VM 后,从 XenCenter 或通过在 dom0 shell 中使用 xe vm-start 启动 VM。您可以在 XenCenter 中查看 VM 的控制台。
VM 启动后,按照安装 NVIDIA vGPU 软件图形驱动程序中的说明安装 NVIDIA vGPU 软件图形驱动程序。
2.4.3. 在 XenServer 上设置 vGPU 插件参数
vGPU 的插件参数控制 vGPU 的行为,例如帧速率限制器 (FRL) 配置(以每秒帧数为单位)或是否启用 vGPU 的控制台虚拟网络计算 (VNC)。分配了 vGPU 的 VM 将使用这些参数启动。如果为分配给同一 VM 的多个 vGPU 设置了参数,则 VM 将使用分配给每个 vGPU 的参数启动。
对于要为其设置插件参数的每个 vGPU,请在 XenServer dom0 域的命令 shell 中执行此任务。
- 获取 hypervisor 主机上所有 VM 的 UUID,并使用命令的输出识别分配了 vGPU 的 VM。
[root@xenserver ~] xe vm-list ... uuid ( RO) : 7f6c855d-5635-2d57-9fbc-b1200172162f name-label ( RW): RHEL8.3 power-state ( RO): running ...
- 获取 hypervisor 主机上所有 vGPU 的 UUID,并从分配了 vGPU 的 VM 的 UUID 中,确定 vGPU 的 UUID。
[root@xenserver ~] xe vgpu-list ... uuid ( RO) : d15083f8-5c59-7474-d0cb-fbc3f7284f1b vm-uuid ( RO): 7f6c855d-5635-2d57-9fbc-b1200172162f device ( RO): 0 gpu-group-uuid ( RO): 3a2fbc36-827d-a078-0b2f-9e869ae6fd93 ...
- 使用 xe 命令设置您想要设置的每个 vGPU 插件参数。
[root@xenserver ~] xe vgpu-param-set uuid=vgpu-uuid extra_args='parameter=value'
- vgpu-uuid
- vGPU 的 UUID,您在上一步中获得。
- parameter
- 您要设置的 vGPU 插件参数的名称。
- value
- 您要将 vGPU 插件参数设置为何值。
此示例将 UUID 为
d15083f8-5c59-7474-d0cb-fbc3f7284f1b的 vGPU 的 enable_uvm vGPU 插件参数设置为 1。此参数设置启用 vGPU 的统一内存。[root@xenserver ~] xe vgpu-param-set uuid=d15083f8-5c59-7474-d0cb-fbc3f7284f1b extra_args='enable_uvm=1'
2.5. 为 Linux KVM 安装 Virtual GPU Manager 软件包
用于 Linux Kernel-based Virtual Machine (KVM)(Linux KVM)的 NVIDIA vGPU 软件仅 适用于受支持版本的 Linux KVM hypervisor。有关支持哪些 Linux KVM hypervisor 版本的详细信息,请参阅Virtual GPU Software for Generic Linux with KVM Release Notes。
如果您使用的是 Red Hat Enterprise Linux KVM,请按照为 Red Hat Enterprise Linux KVM 安装和配置 NVIDIA Virtual GPU Manager中的说明进行操作。
在为 Linux KVM 安装 Virtual GPU Manager 软件包之前,请确保满足以下先决条件
-
以下软件包已安装在 Linux KVM 服务器上
- GNU Compiler Collection (GCC) 的
x86_64版本 - Linux 内核标头
- GNU Compiler Collection (GCC) 的
-
软件包文件已复制到 Linux KVM 服务器文件系统中的目录。
如果存在用于 NVIDIA 显卡的 Nouveau 驱动程序,请在安装软件包之前禁用它。
- 切换到 Linux KVM 服务器上包含软件包文件的目录。
# cd package-file-directory
- package-file-directory
- 包含软件包文件的目录的路径。
- 使软件包文件可执行。
# chmod +x package-file-name
- package-file-name
- 包含用于 Linux KVM 的 Virtual GPU Manager 软件包的文件名,例如 NVIDIA-Linux-x86_64-390.42-vgpu-kvm.run。
- 以 root 用户身份运行软件包文件。
# sudo sh./package-file-name
- 接受许可协议以继续安装。
- 安装完成后,选择 OK(确定)退出安装程序。
- 重新启动 Linux KVM 服务器。
# systemctl reboot
2.6. 为 Microsoft Azure Local 安装和配置 NVIDIA Virtual GPU Manager
在开始之前,请确保满足使用 NVIDIA vGPU 的先决条件中的先决条件,并按如下方式配置 Microsoft Azure Local 主机
- Microsoft Azure Local OS 按照 Microsoft 文档网站上的部署 Azure Stack HCI 操作系统中的说明进行安装。
- 启用以下 BIOS 设置
- 虚拟化支持,例如,Intel Virtualization Technology (VT-D) 或 AMD Virtualization (AMD-V)
- SR-IOV
- 4G 以上解码
- 对于 Supermicro 服务器:ASPM 支持
- 对于具有 AMD CPU 的服务器
- 备用路由 ID 解释 (ARI)
- 访问控制服务 (ACS)
- 高级错误报告 (AER)
按照此指令顺序设置单个 Microsoft Azure Local VM 以使用 NVIDIA vGPU。
- 为 Microsoft Azure Local 安装 NVIDIA Virtual GPU Manager
- 在 GPU 上设置允许的 vGPU 系列
- 向 Microsoft Azure Local VM 添加 vGPU
这些说明假定您熟悉 Microsoft 文档网站上的使用 Windows PowerShell 在 Azure Local 上管理 VM中涵盖的 Microsoft Windows PowerShell 命令。
设置完成后,您可以为您的客户操作系统安装图形驱动程序,并许可您正在使用的任何 NVIDIA vGPU 软件许可产品。
2.6.1. 为 Microsoft Azure Local 安装 NVIDIA Virtual GPU Manager
Virtual GPU Manager 的驱动程序软件包以存档文件形式分发。您必须解压缩此存档文件的内容,才能从安装信息文件将软件包添加到驱动程序存储。
以管理员用户身份在 Windows PowerShell 窗口中执行此任务。
- 下载 Virtual GPU Manager 的驱动程序软件包分发的存档文件。
- 将存档文件的内容解压缩到可从 Microsoft Azure Local 主机访问的目录。
- 切换到您从存档文件中解压缩的 GridSW-Azure-Local 目录。注意
对于 NVIDIA vGPU 软件版本 17.0-17.4,请切换到 GridSW-Azure-Stack-HCI 目录。
- 使用 PnPUtil 工具从 nvgridswhci.inf 安装信息文件将 Virtual GPU Manager 的驱动程序软件包添加到驱动程序存储。在用于添加驱动程序软件包的命令中,还要设置选项以遍历驱动程序软件包的子目录,并在必要时重新启动 Microsoft Azure Local 主机以完成操作。
PS C:> pnputil /add-driver nvgridswhci.inf /subdirs /install /reboot
- 主机重新启动后,验证 NVIDIA Virtual GPU Manager 是否可以与系统中的 NVIDIA 物理 GPU 成功通信。为此目的,请运行不带参数的 nvidia-smi 命令。运行 nvidia-smi 命令应生成平台中 GPU 的列表。
- 通过列出支持 GPU-P 的 GPU,确认 Microsoft Azure Local 主机具有可以分区的 GPU 适配器。
PS C:> Get-VMHostPartitionableGpu
- 对于每个 GPU,将 GPU 应支持的分区数设置为可以添加到 GPU 的最大 vGPU 数。
PS C:> Set-VMHostPartitionableGpu -Name "gpu-name" -PartitionCount partitions
- gpu-name
- 您在上一步中获得的用于引用 GPU 的唯一名称。
- partitions
- 可以添加到 GPU 的最大 vGPU 数。此数字取决于虚拟 GPU 类型。例如,可以添加到 NVIDIA A16 GPU 的每种类型的 vGPU 的最大数量如下所示
虚拟 GPU 类型 每个 GPU 的最大 vGPU 数 A16-16Q
A16-16A
1 A16-8Q
A16-8A
2 A16-4Q
A16-4A
4 A16-2Q
A16-2B
A16-2A
8 A16-1Q
A16-1B
A16-1A
16
2.6.2. 在 GPU 上设置允许的 vGPU 系列
Virtual GPU Manager 允许仅从一个 vGPU 系列在 GPU 上创建虚拟 GPU (vGPU)。默认情况下,只能在 GPU 上创建 Q 系列 vGPU。您可以通过在 Windows 注册表中为 GPU 设置 GridGpupProfileType 值来更改 GPU 上允许的 vGPU 系列。
此任务需要管理员用户权限。
- 使用 Windows PowerShell 获取您要在其上设置允许的 vGPU 系列的 GPU 的驱动程序密钥。在下一步中,您将需要此信息来识别 Windows 注册表项,其中存储了有关 GPU 的信息。
- 获取您要在其上设置允许的 vGPU 系列的 GPU 的
InstanceID属性。PS C:\> Get-PnpDevice -PresentOnly | >> Where-Object {$_.InstanceId -like "PCI\VEN_10DE*" } | >> Select-Object -Property FriendlyName,InstanceId | >> Format-List FriendlyName : NVIDIA A100 InstanceId : PCI\VEN_10DE&DEV_2236&SUBSYS_148210DE&REV_A1\6&17F903&0&00400000
- 从您在上一步中获得的
InstanceID属性中获取 GPU 的DEVPKEY_Device_Driver属性。PS C:\> Get-PnpDeviceProperty -InstanceId "instance-id" | >> where {$_.KeyName -eq "DEVPKEY_Device_Driver"} | >> Select-Object -Property Data Data ---- {4d36e968-e325-11ce-bfc1-08002be10318}\0001
- instance-id
- 您在上一步中获得的 GPU 的
InstanceID属性,例如,PCI\VEN_10DE&DEV_2236&SUBSYS_148210DE&REV_A1\6&17F903&0&00400000。
- 获取您要在其上设置允许的 vGPU 系列的 GPU 的
- 在 Windows 注册表项
HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Control\Class\<i>driver-key</i>中设置GridGpupProfileTypeDWord (REG_DWORD) 注册表值。- driver-key
- 您在上一步中获得的 GPU 的驱动程序密钥,例如,
{4d36e968-e325-11ce-bfc1-08002be10318}\0001。
要设置的值取决于您希望在 GPU 上允许的 vGPU 系列。
vGPU 系列 值 Q 系列 1 A 系列 2 B 系列 3
2.6.3. 向 Microsoft Azure Local VM 添加 vGPU
您可以通过向 Microsoft Azure Local VM 添加 GPU-P 适配器来向 VM 添加 vGPU。
以管理员用户身份在 Windows PowerShell 窗口中执行此任务。
- 将变量
$vm设置为您要向其添加 vGPU 的虚拟机的名称。PS C:> $vm = "vm-name"
- vm-name
- 您要向其添加 vGPU 的虚拟机的名称。
- 允许 VM 控制 MMIO 访问的缓存类型。
PS C:> Set-VM -GuestControlledCacheTypes $true -VMName $vm
- 将较低 MMIO 空间设置为 1 GB,以便允许映射足够的 MMIO 空间。
PS C:> Set-VM -LowMemoryMappedIoSpace 1Gb -VMName $vm
此数量是设备必须允许对齐数量的两倍。较低 MMIO 空间是 4 GB 以下的地址空间,并且是任何具有 32 位 BAR 内存的设备所必需的。
- 将较高 MMIO 空间设置为 32 GB,以便允许映射足够的 MMIO 空间。
PS C:> Set-VM –HighMemoryMappedIoSpace 32GB –VMName $vm
此数量是设备必须允许对齐数量的两倍。较高 MMIO 空间是大约 64 GB 以上的地址空间。
- 确认 Microsoft Azure Local 主机具有支持您要创建的 GPU-P 适配器的 GPU。
PS C:> get-VMHostPartitionableGpu
- 向 VM 添加 GPU-P 适配器。
PS C:> Add-VMGpuPartitionAdapter –VMName $vm ` –MinPartitionVRAM min-ram ` -MaxPartitionVRAM max-ram ` -OptimalPartitionVRAM opt-ram ` -MinPartitionEncode min-enc ` -MaxPartitionEncode max-enc ` -OptimalPartitionEncode opt-enc ` -MinPartitionDecode min-dec ` -MaxPartitionDecode max-dec ` -OptimalPartitionDecode opt-dec ` -MinPartitionCompute min-compute ` -MaxPartitionCompute max-compute ` -OptimalPartitionCompute opt-compute
注意由于分区仅在 VM 启动时才解析,因此此命令无法验证 Microsoft Azure Local 主机是否具有支持您要创建的 GPU-P 适配器的 GPU。您指定的值必须在在上一步中列出的最大值和最小值范围内。
- 列出分配给 VM 的适配器,以确认 GPU-P 适配器已添加到 VM。
PS C:> Get-VMGpuPartitionAdapter –VMName $vm
此命令还会返回适配器 ID,用于重新配置或删除 GPU 分区。
- 连接并启动 VM。
2.6.4. 卸载用于 Microsoft Azure Local 的 NVIDIA Virtual GPU Manager
如果您不再需要在 Microsoft Azure Local 服务器上使用 Virtual GPU Manager,您可以卸载 Virtual GPU Manager 的驱动程序软件包。
以管理员用户身份在 Windows PowerShell 窗口中执行此任务。
- 通过枚举驱动程序存储中的所有第三方驱动程序软件包,确定 Virtual GPU Manager 的驱动程序软件包的已发布名称。
PS C:> pnputil /enum-drivers
Microsoft PnP Utility ... Published name : oem5.inf Driver package provider : NVIDIA Class : Display adapters Driver date and version : 01/01/2023 31.0.15.2807 Signer name : Microsoft Windows Hardware Compatibility Publisher ...
- 删除并卸载 Virtual GPU Manager 的驱动程序软件包。
PS C:> pnputil /delete-driver vgpu-manager-package-published-name /uninstall /reboot
- vgpu-manager-package-published-name
- 您在上一步中获得的 Virtual GPU Manager 的驱动程序软件包的已发布名称,例如,oem5.inf。
此示例删除并卸载已发布名称为 oem5.inf 的驱动程序软件包。
PS C:> pnputil.exe /delete-driver oem5.inf /uninstall /reboot Microsoft PnP Utility Driver package uninstalled. Driver package deleted successfully.
如有必要,Microsoft Azure Local 服务器将重新启动。
2.7. 为 Red Hat Enterprise Linux KVM 安装和配置 NVIDIA Virtual GPU Manager
以下主题将逐步指导您完成设置单个 Red Hat Enterprise Linux Kernel-based Virtual Machine (KVM) VM 以使用 NVIDIA vGPU 的过程。
VM 控制台的输出不适用于正在运行 vGPU 的 VM。在配置 vGPU 之前,请确保您已安装访问 VM 的替代方法(例如 VNC 服务器)。
按照此指令顺序操作
- 为 Red Hat Enterprise Linux KVM 安装 Virtual GPU Manager 软件包
- 验证 NVIDIA vGPU Software for Red Hat Enterprise Linux KVM 的安装
- 仅支持 SR-IOV 的 vGPU:为 Linux with KVM Hypervisor 上的支持 SR-IOV 的 NVIDIA vGPU 准备虚拟功能
- 可选:将 GPU 置于混合大小模式
- 获取 Linux with KVM Hypervisor 上 GPU 的 BDF 和域
- 在 Linux with KVM Hypervisor 上创建 NVIDIA vGPU
- 向 Linux with KVM Hypervisor VM 添加一个或多个 vGPU
- 可选:在 Linux with KVM Hypervisor 上将 vGPU 放置在混合大小模式的物理 GPU 上
- 在 Linux with KVM Hypervisor 上设置 vGPU 插件参数
完成此过程后,您可以为您的客户操作系统安装图形驱动程序,并许可您正在使用的任何 NVIDIA vGPU 软件许可产品。
如果您使用的是通用 Linux KVM hypervisor,请按照为 Linux KVM 安装 Virtual GPU Manager 软件包中的说明进行操作。
2.7.1. 为 Red Hat Enterprise Linux KVM 安装 Virtual GPU Manager 软件包
用于 Red Hat Enterprise Linux KVM 的 NVIDIA Virtual GPU Manager 以 .rpm 文件的形式提供。
NVIDIA Virtual GPU Manager 和客户 VM 驱动程序必须兼容。如果您将 vGPU Manager 更新到与客户 VM 驱动程序不兼容的版本,则客户 VM 将在禁用 vGPU 的情况下启动,直到其客户 vGPU 驱动程序更新到兼容版本。有关更多详细信息,请参阅Virtual GPU Software for Red Hat Enterprise Linux with KVM Release Notes。
在为 Red Hat Enterprise Linux KVM 安装 RPM 软件包之前,请确保 Red Hat Enterprise Linux KVM 服务器上的 sshd 服务配置为允许 root 登录。如果存在用于 NVIDIA 显卡的 Nouveau 驱动程序,请在安装软件包之前禁用它。有关说明,请参阅How to disable the Nouveau driver and install the Nvidia driver in RHEL 7(需要 Red Hat 订阅)。
某些版本的 Red Hat Enterprise Linux KVM 具有 z-stream 更新,这些更新会破坏内核应用程序二进制接口 (kABI) 与先前内核或 GA 内核的兼容性。对于这些版本的 Red Hat Enterprise Linux KVM,提供了以下 Virtual GPU Manager RPM 软件包
- 用于 GA Linux KVM 内核的软件包
- 用于更新的 z-stream 内核的软件包
为了区分这些软件包,每个 RPM 软件包的名称都包含内核版本。确保您安装的 RPM 软件包与您的 Linux KVM 内核版本兼容。
- 将 RPM 文件从您下载该文件的系统安全地复制到 Red Hat Enterprise Linux KVM 服务器。
- 从 Windows 系统,使用安全复制客户端,例如 WinSCP。
- 从 Linux 系统,使用 scp 命令。
- 使用安全 shell (SSH) 以 root 身份登录到 Red Hat Enterprise Linux KVM 服务器。
# ssh root@kvm-server
- kvm-server
- Red Hat Enterprise Linux KVM 服务器的主机名或 IP 地址。
- 切换到 Red Hat Enterprise Linux KVM 服务器上您复制 RPM 文件的目录。
# cd rpm-file-directory
- rpm-file-directory
- 您复制 RPM 文件的目录的路径。
- 使用 rpm 命令安装软件包。
# rpm -iv NVIDIA-vGPU-rhel-8.9-550.144.02.x86_64.rpm Preparing packages for installation... NVIDIA-vGPU-rhel-8.9-550.144.02 #
- 重新启动 Red Hat Enterprise Linux KVM 服务器。
# systemctl reboot
2.7.2. 验证 NVIDIA vGPU Software for Red Hat Enterprise Linux KVM 的安装
Red Hat Enterprise Linux KVM 服务器重新启动后,验证 NVIDIA vGPU software package for Red Hat Enterprise Linux KVM 的安装。
- 通过检查内核加载模块列表中是否存在 VFIO 驱动程序,验证 NVIDIA vGPU 软件包是否已安装并正确加载。
# lsmod | grep vfio nvidia_vgpu_vfio 27099 0 nvidia 12316924 1 nvidia_vgpu_vfio vfio_mdev 12841 0 mdev 20414 2 vfio_mdev,nvidia_vgpu_vfio vfio_iommu_type1 22342 0 vfio 32331 3 vfio_mdev,nvidia_vgpu_vfio,vfio_iommu_type1 #
- 验证 libvirtd 服务是否处于活动状态并正在运行。
# service libvirtd status
- 通过运行 nvidia-smi 命令,验证 NVIDIA 内核驱动程序是否可以与系统中的 NVIDIA 物理 GPU 成功通信。有关 nvidia-smi 命令的更详细描述,请参阅NVIDIA System Management Interface nvidia-smi。
运行 nvidia-smi 命令应生成平台中 GPU 的列表。
# nvidia-smi
Fri Jan 17 18:46:50 2025
+------------------------------------------------------+
| NVIDIA-SMI 550.144.02 Driver Version: 550.144.02 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla M60 On | 0000:85:00.0 Off | Off |
| N/A 23C P8 23W / 150W | 13MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla M60 On | 0000:86:00.0 Off | Off |
| N/A 29C P8 23W / 150W | 13MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla P40 On | 0000:87:00.0 Off | Off |
| N/A 21C P8 18W / 250W | 53MiB / 24575MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
#
如果 nvidia-smi 无法运行或未针对系统中的所有 NVIDIA GPU 生成预期输出,请参阅故障排除以获取故障排除步骤。
2.8. 为 Ubuntu 安装和配置 NVIDIA Virtual GPU Manager
按照此指令顺序设置单个 Ubuntu VM 以使用 NVIDIA vGPU。
- 为 Ubuntu 安装 NVIDIA Virtual GPU Manager
- 获取 Linux with KVM Hypervisor 上 GPU 的 BDF 和域
- 仅支持 SR-IOV 的 vGPU:为 Linux with KVM Hypervisor 上的支持 SR-IOV 的 NVIDIA vGPU 准备虚拟功能
- 可选:将 GPU 置于混合大小模式
- 在 Linux with KVM Hypervisor 上创建 NVIDIA vGPU
- 向 Linux with KVM Hypervisor VM 添加一个或多个 vGPU
- 可选:在 Linux with KVM Hypervisor 上将 vGPU 放置在混合大小模式的物理 GPU 上
- 在 Linux with KVM Hypervisor 上设置 vGPU 插件参数
VM 控制台的输出不适用于正在运行 vGPU 的 VM。在配置 vGPU 之前,请确保您已安装访问 VM 的替代方法(例如 VNC 服务器)。
完成此过程后,您可以为您的客户操作系统安装图形驱动程序,并许可您正在使用的任何 NVIDIA vGPU 软件许可产品。
2.8.1. 为 Ubuntu 安装 NVIDIA Virtual GPU Manager
用于 Ubuntu 的 NVIDIA Virtual GPU Manager 以 Debian 软件包 (.deb) 文件的形式提供。
NVIDIA Virtual GPU Manager 和客户虚拟机 (VM) 驱动程序必须兼容。如果您将 vGPU Manager 更新到与客户虚拟机驱动程序不兼容的版本,则客户虚拟机将在 vGPU 禁用的情况下启动,直到其客户 vGPU 驱动程序更新到兼容版本。有关更多详细信息,请参阅 Ubuntu 版 Virtual GPU 软件发行说明。
2.8.1.1. 为 Ubuntu 安装 Virtual GPU Manager 软件包
在为 Ubuntu 安装 Debian 软件包之前,请确保 Ubuntu 服务器上的 sshd 服务配置为允许 root 登录。如果存在 NVIDIA 显卡的 Nouveau 驱动程序,请在安装软件包之前禁用它。
- 将 Debian 软件包文件从您下载该文件的系统安全地复制到 Ubuntu 服务器。
- 从 Windows 系统,使用安全复制客户端,例如 WinSCP。
- 从 Linux 系统,使用 scp 命令。
- 使用安全外壳 (SSH) 以 root 身份登录到 Ubuntu 服务器。
# ssh root@ubuntu-server
- ubuntu-server
- Ubuntu 服务器的主机名或 IP 地址。
- 更改到 Ubuntu 服务器上您复制 Debian 软件包文件的目录。
# cd deb-file-directory
- deb-file-directory
- 您复制 Debian 软件包文件的目录路径。
- 使用 apt 命令安装软件包。
# apt install ./nvidia-vgpu-ubuntu-550.144.02_amd64.deb
- 重启 Ubuntu 服务器。
# systemctl reboot
2.8.1.2. 验证 NVIDIA vGPU 软件 for Ubuntu 的安装
在 Ubuntu 服务器重启后,验证 NVIDIA vGPU 软件 for Ubuntu 软件包的安装。
- 通过检查内核加载模块列表中是否存在 VFIO 驱动程序,验证 NVIDIA vGPU 软件包是否已安装并正确加载。
# lsmod | grep vfio nvidia_vgpu_vfio 27099 0 nvidia 12316924 1 nvidia_vgpu_vfio vfio_mdev 12841 0 mdev 20414 2 vfio_mdev,nvidia_vgpu_vfio vfio_iommu_type1 22342 0 vfio 32331 3 vfio_mdev,nvidia_vgpu_vfio,vfio_iommu_type1 #
- 验证 libvirtd 服务是否处于活动状态并正在运行。
# service libvirtd status
- 通过运行 nvidia-smi 命令,验证 NVIDIA 内核驱动程序是否可以与系统中的 NVIDIA 物理 GPU 成功通信。有关 nvidia-smi 命令的更详细描述,请参阅NVIDIA System Management Interface nvidia-smi。
运行 nvidia-smi 命令应生成平台中 GPU 的列表。
# nvidia-smi
Fri Jan 17 18:46:50 2025
+------------------------------------------------------+
| NVIDIA-SMI 550.144.02 Driver Version: 550.144.02 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla M60 On | 0000:85:00.0 Off | Off |
| N/A 23C P8 23W / 150W | 13MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla M60 On | 0000:86:00.0 Off | Off |
| N/A 29C P8 23W / 150W | 13MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla P40 On | 0000:87:00.0 Off | Off |
| N/A 21C P8 18W / 250W | 53MiB / 24575MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
#
如果 nvidia-smi 无法运行或未针对系统中的所有 NVIDIA GPU 生成预期输出,请参阅故障排除以获取故障排除步骤。
2.9. 为 VMware vSphere 安装和配置 NVIDIA Virtual GPU Manager
您可以使用 NVIDIA Virtual GPU Manager for VMware vSphere 设置 VMware vSphere 虚拟机以使用 NVIDIA vGPU。
某些服务器,例如 Dell R740,如果服务器上禁用了 SR-IOV SBIOS 设置,则不会配置 SR-IOV 功能。如果您在这样的服务器上将 Tesla T4 GPU 与 VMware vSphere 一起使用,则必须确保服务器上启用了 SR-IOV SBIOS 设置。
但是,对于任何服务器硬件,请勿在 VMware vCenter Server 中为 Tesla T4 GPU 启用 SR-IOV。如果在 VMware vCenter Server 中为 T4 启用了 SR-IOV,VMware vCenter Server 会将 GPU 的状态列为需要重启。您可以忽略此状态消息。
NVIDIA vGPU 说明
在 NVIDIA vGPU 模式下,图形设备不需要 Xorg 服务。有关更多信息,请参阅 为 VMware vSphere 安装和更新 NVIDIA Virtual GPU Manager。
要设置 VMware vSphere 虚拟机以使用 NVIDIA vGPU,请按照以下步骤顺序进行操作
- 为 VMware vSphere 安装和更新 NVIDIA Virtual GPU Manager
- 为 VMware vSphere 配置带有 vGPU 的 VMware vMotion
- 在 VMware vSphere 中更改默认图形类型
- 配置带有 NVIDIA vGPU 的 vSphere 虚拟机
- 可选:在 VMware vSphere 上设置 vGPU 插件参数
在配置 vSphere 虚拟机以使用 NVIDIA vGPU 后,您可以为您的客户操作系统安装 NVIDIA vGPU 软件图形驱动程序,并为您正在使用的任何 NVIDIA vGPU 软件许可产品进行许可。
在 DRS 集群中配置 NVIDIA vGPU 的要求
您可以在 VMware Distributed Resource Scheduler (DRS) 集群中的 ESXi 主机上配置带有 NVIDIA vGPU 的虚拟机。但是,为了确保集群的自动化级别支持配置了 NVIDIA vGPU 的虚拟机,您必须将自动化级别设置为部分自动化或手动。
有关这些设置的更多信息,请参阅 VMware 文档中的 编辑集群设置。
2.9.1. 为 VMware vSphere 安装和更新 NVIDIA Virtual GPU Manager
NVIDIA Virtual GPU Manager 在 ESXi 主机上运行。它作为 ZIP 存档中的多个软件组件分发。
NVIDIA Virtual GPU Manager 软件组件如下
- NVIDIA vGPU hypervisor 主机驱动程序的软件组件
- NVIDIA GPU 管理守护程序的软件组件
您可以通过以下方式之一安装这些软件组件
- 通过将软件组件复制到 ESXi 主机,然后按照 在 VMware vSphere 上安装 NVIDIA Virtual GPU Manager 中所述的方式安装它们
- 通过手动导入软件组件,如 VMware vSphere 文档中的 手动导入补丁 中所述
NVIDIA Virtual GPU Manager 和客户虚拟机驱动程序必须兼容。如果您将 vGPU Manager 更新到与客户虚拟机驱动程序不兼容的版本,则客户虚拟机将在 vGPU 禁用的情况下启动,直到其客户 vGPU 驱动程序更新到兼容版本。有关更多详细信息,请参阅 VMware vSphere 版 Virtual GPU 软件发行说明。
2.9.1.1. 在 VMware vSphere 上安装 NVIDIA Virtual GPU Manager
要安装 NVIDIA Virtual GPU Manager,您需要通过 ESXi Shell 或 SSH 访问 ESXi 主机。请参阅 VMware 关于如何为 ESXi 主机启用 ESXi Shell 或 SSH 的文档。
在开始之前,请确保满足以下先决条件
- 包含 NVIDIA vGPU 软件的 ZIP 存档已从 NVIDIA 许可门户下载。
- NVIDIA Virtual GPU Manager 的软件组件已从下载的 ZIP 存档中提取。
- 将 NVIDIA Virtual GPU Manager 组件文件复制到 ESXi 主机。
- 将 ESXi 主机置于维护模式。
$ esxcli system maintenanceMode set –-enable true
- 从其软件组件文件安装 NVIDIA vGPU hypervisor 主机驱动程序和 NVIDIA GPU 管理守护程序。
- 运行 esxcli 命令以从其软件组件文件安装 NVIDIA vGPU hypervisor 主机驱动程序。
$ esxcli software vib install -d /vmfs/volumes/datastore/host-driver-component.zip
- 运行 esxcli 命令以从其软件组件文件安装 NVIDIA GPU 管理守护程序。
$ esxcli software vib install -d /vmfs/volumes/datastore/gpu-management-daemon-component.zip
- datastore
- 您将软件组件复制到的 VMFS 数据存储的名称。
- host-driver-component
- 包含 NVIDIA vGPU hypervisor 主机驱动程序的文件名,格式为软件组件。确保指定从下载的 ZIP 存档中提取的文件。例如,对于 VMware vSphere 7.0.2,host-driver-component 是 NVD-VMware-x86_64-550.144.02-1OEM.702.0.0.17630552-bundle-build-number。
- gpu-management-daemon-component
- 包含 NVIDIA GPU 管理守护程序的文件名,格式为软件组件。确保指定从下载的 ZIP 存档中提取的文件。例如,对于 VMware vSphere 7.0.2,gpu-management-daemon-component 是 VMW-esx-7.0.2-nvd-gpu-mgmt-daemon-1.0-0.0.0001。
- 运行 esxcli 命令以从其软件组件文件安装 NVIDIA vGPU hypervisor 主机驱动程序。
- 退出维护模式。
$ esxcli system maintenanceMode set –-enable false
- 重启 ESXi 主机。
$ reboot
2.9.1.2. 为 VMware vSphere 更新 NVIDIA Virtual GPU Manager
如果您想在已安装现有版本的系统上安装新版本的 NVIDIA Virtual GPU Manager,请更新 NVIDIA Virtual GPU Manager。
要更新 vGPU Manager VIB,您需要通过 ESXi Shell 或 SSH 访问 ESXi 主机。请参阅 VMware 关于如何为 ESXi 主机启用 ESXi Shell 或 SSH 的文档。
在继续 vGPU Manager 更新之前,请确保所有虚拟机都已关闭电源,并且 ESXi 主机已置于维护模式。请参阅 VMware 关于如何将 ESXi 主机置于维护模式的文档
- 停止 NVIDIA GPU 管理守护程序。
$ /etc/init.d/nvdGpuMgmtDaemon stop
- 更新 NVIDIA vGPU hypervisor 主机驱动程序和 NVIDIA GPU 管理守护程序。
- 运行 esxcli 命令以从其软件组件文件更新 NVIDIA vGPU hypervisor 主机驱动程序。
$ esxcli software vib update -d /vmfs/volumes/datastore/host-driver-component.zip
- 运行 esxcli 命令以从其软件组件文件更新 NVIDIA GPU 管理守护程序。
$ esxcli software vib update -d /vmfs/volumes/datastore/gpu-management-daemon-component.zip
- datastore
- 您将软件组件复制到的 VMFS 数据存储的名称。
- host-driver-component
- 包含 NVIDIA vGPU hypervisor 主机驱动程序的文件名,格式为软件组件。确保指定从下载的 ZIP 存档中提取的文件。例如,对于 VMware vSphere 7.0.2,host-driver-component 是 NVD-VMware-x86_64-550.144.02-1OEM.702.0.0.17630552-bundle-build-number。
- gpu-management-daemon-component
- 包含 NVIDIA GPU 管理守护程序的文件名,格式为软件组件。确保指定从下载的 ZIP 存档中提取的文件。例如,对于 VMware vSphere 7.0.2,gpu-management-daemon-component 是 VMW-esx-7.0.2-nvd-gpu-mgmt-daemon-1.0-0.0.0001。
- 运行 esxcli 命令以从其软件组件文件更新 NVIDIA vGPU hypervisor 主机驱动程序。
- 重启 ESXi 主机并将其从维护模式中移除。
2.9.1.3. 验证 vSphere 版 NVIDIA vGPU 软件包的安装
在 ESXi 主机重启后,验证 vSphere 版 NVIDIA vGPU 软件包的安装。
- 通过检查内核加载模块列表中是否存在 NVIDIA 内核驱动程序,验证 NVIDIA vGPU 软件包是否已正确安装和加载。
[root@esxi:~] vmkload_mod -l | grep nvidia nvidia 5 8420
- 如果输出中未列出 NVIDIA 驱动程序,请检查 dmesg 以查看驱动程序报告的任何加载时错误。
- 验证 NVIDIA GPU 管理守护程序是否已启动。
$ /etc/init.d/nvdGpuMgmtDaemon status
- 通过运行 nvidia-smi 命令,验证 NVIDIA 内核驱动程序是否可以与系统中的 NVIDIA 物理 GPU 成功通信。有关 nvidia-smi 命令的更详细描述,请参阅NVIDIA System Management Interface nvidia-smi。
运行 nvidia-smi 命令应生成平台中 GPU 的列表。
[root@esxi:~] nvidia-smi
Fri Jan 17 17:56:22 2025
+------------------------------------------------------+
| NVIDIA-SMI 550.144.02 Driver Version: 550.144.02 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla M60 On | 00000000:05:00.0 Off | Off |
| N/A 25C P8 24W / 150W | 13MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla M60 On | 00000000:06:00.0 Off | Off |
| N/A 24C P8 24W / 150W | 13MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla M60 On | 00000000:86:00.0 Off | Off |
| N/A 25C P8 25W / 150W | 13MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla M60 On | 00000000:87:00.0 Off | Off |
| N/A 28C P8 24W / 150W | 13MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
如果 nvidia-smi 未能报告系统中所有 NVIDIA GPU 的预期输出,请参阅 故障排除 以获取故障排除步骤。
2.9.1.4. 管理 VMware vSphere 版 NVIDIA GPU 管理守护程序
VMware vSphere 版 NVIDIA GPU 管理守护程序是一项服务,它通过 /etc/init.d 目录中的脚本进行控制。您可以使用这些脚本来启动守护程序、停止守护程序并获取其状态。
- 要启动 NVIDIA GPU 管理守护程序,请输入以下命令
$ /etc/init.d/nvdGpuMgmtDaemon start
- 要停止 NVIDIA GPU 管理守护程序,请输入以下命令
$ /etc/init.d/nvdGpuMgmtDaemon stop
- 要获取 NVIDIA GPU 管理守护程序的状态,请输入以下命令
$ /etc/init.d/nvdGpuMgmtDaemon status
2.9.2. 为 VMware vSphere 配置带有 vGPU 的 VMware vMotion
NVIDIA vGPU 软件支持 vGPU 迁移,其中包括 VMware vMotion 和挂起-恢复,适用于配置了 vGPU 的虚拟机。要启用带有 vGPU 的 VMware vMotion,必须启用高级 vCenter Server 设置。但是,默认情况下,为配置了 vGPU 的虚拟机启用挂起-恢复。
有关哪些 VMware vSphere 版本、NVIDIA GPU 和客户操作系统版本支持 vGPU 迁移的详细信息,请参阅 VMware vSphere 版 Virtual GPU 软件发行说明。
在为 ESXi 主机配置带有 vGPU 的 VMware vMotion 之前,请确保主机上已安装当前的 VMware vSphere 版 NVIDIA Virtual GPU Manager 软件包。
- 使用 vSphere Web Client 登录到 vCenter Server。
- 在“主机和集群”视图中,选择 vCenter Server 实例。注意
确保您选择的是 vCenter Server 实例,而不是 vCenter Server 虚拟机。
- 单击配置选项卡。
- 在设置部分中,选择高级设置,然后单击编辑。
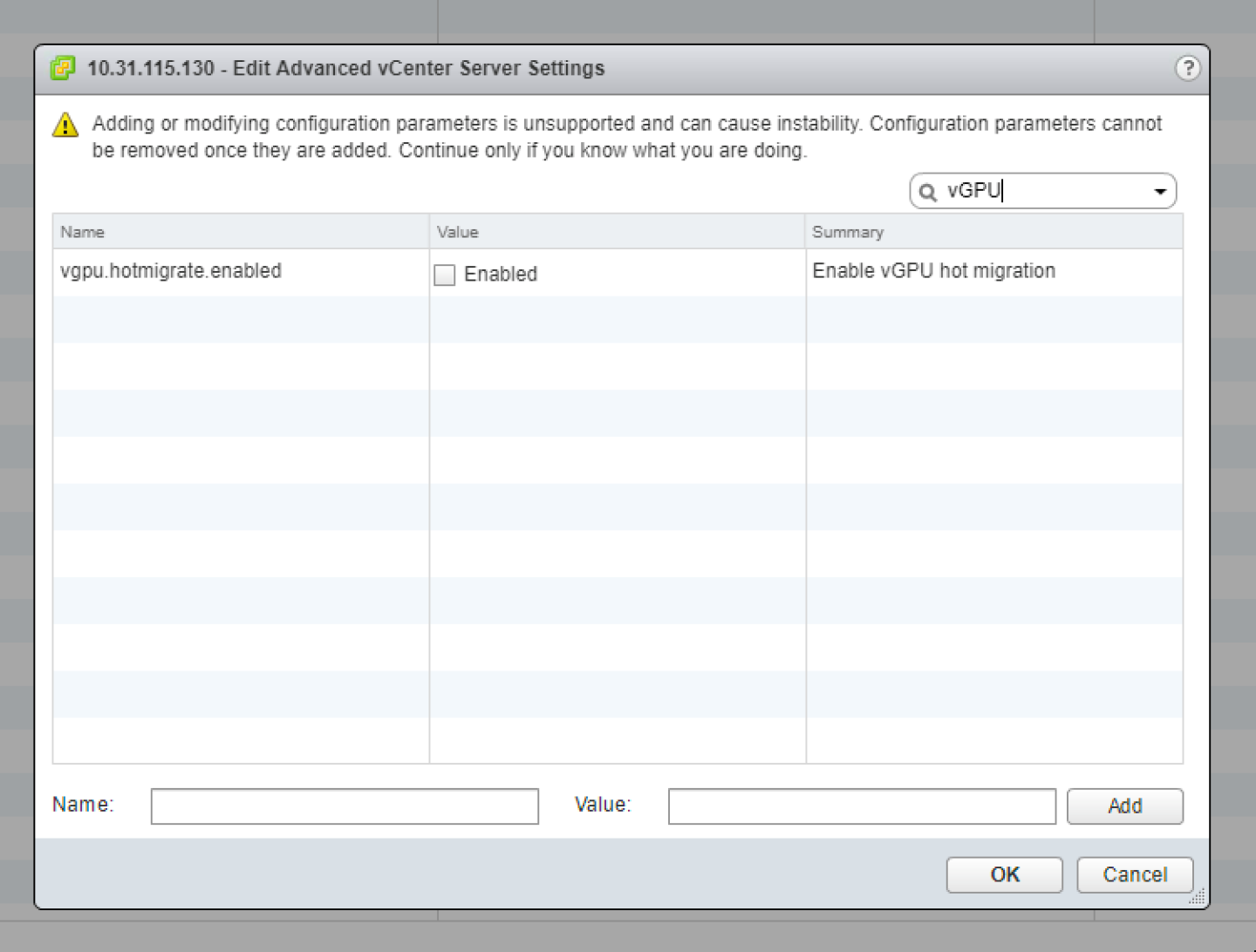
- 在打开的“编辑高级 vCenter Server 设置”窗口中,在搜索字段中键入 vGPU。
- 当出现 vgpu.hotmigrate.enabled 设置时,设置已启用选项,然后单击确定。

2.9.3. 在 VMware vSphere 中更改默认图形类型
安装 VMware vSphere 版 vGPU Manager VIB 后,默认图形类型为“共享”。要在 VMware vSphere 中为虚拟机启用 vGPU 支持,您必须将默认图形类型更改为“共享直通”。
如果您不更改默认图形类型,则分配了 vGPU 的虚拟机将无法启动,并且会显示以下错误消息
The amount of graphics resource available in the parent resource pool is insufficient for the operation.
在配置 vGPU 之前更改默认图形类型。对于正在运行 vGPU 的虚拟机,VMware vSphere Web Client 中的虚拟机控制台输出不可用。
在更改默认图形类型之前,请确保 ESXi 主机正在运行,并且主机上的所有虚拟机都已关闭电源。
- 使用 vSphere Web Client 登录到 vCenter Server。
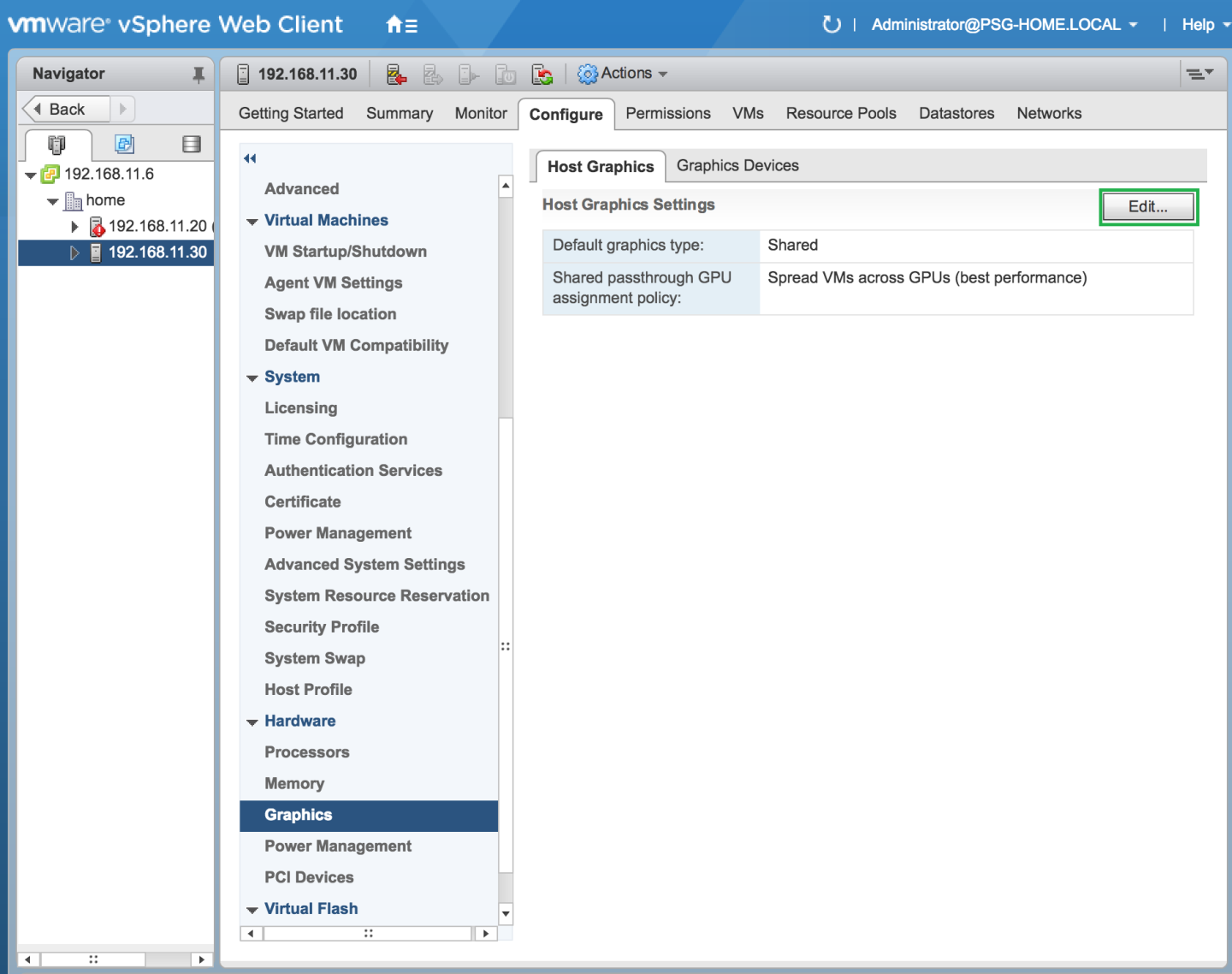
- 在导航树中,选择您的 ESXi 主机,然后单击配置选项卡。
- 从菜单中,选择图形,然后单击主机图形选项卡。
- 在主机图形选项卡上,单击编辑。
图 6. 共享默认图形类型
- 在打开的“编辑主机图形设置”对话框中,选择共享直通,然后单击确定。
图 7. vGPU 的主机图形设置
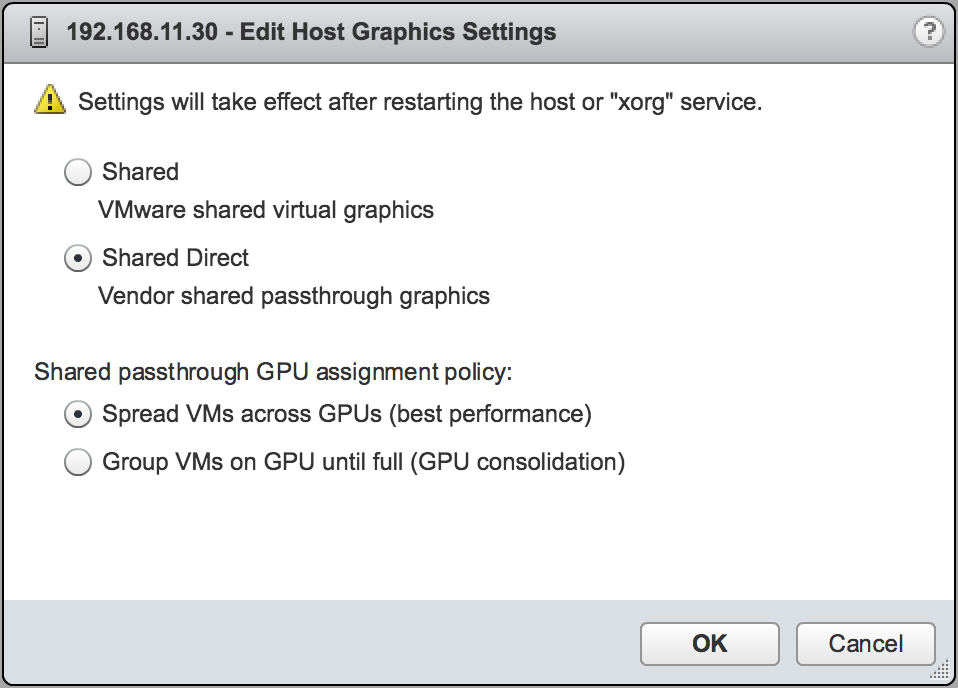 注意
注意在此对话框中,您还可以更改启用 vGPU 的虚拟机的分配方案。有关更多信息,请参阅 修改 VMware vSphere 上的 GPU 分配策略。
单击“确定”后,默认图形类型将更改为“共享直通”。
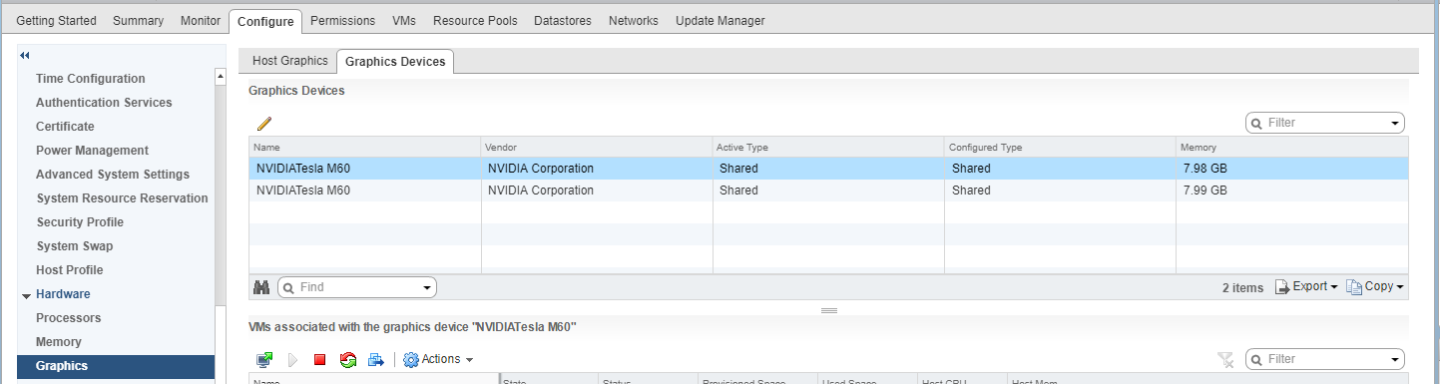
- 单击图形设备选项卡以验证您要配置 vGPU 的每个物理 GPU 的配置类型。每个物理 GPU 的配置类型必须为“共享直通”。对于配置类型为“共享”的任何物理 GPU,请按如下方式更改配置类型
- 在图形设备选项卡上,选择物理 GPU,然后单击编辑图标。
图 8. 共享图形类型
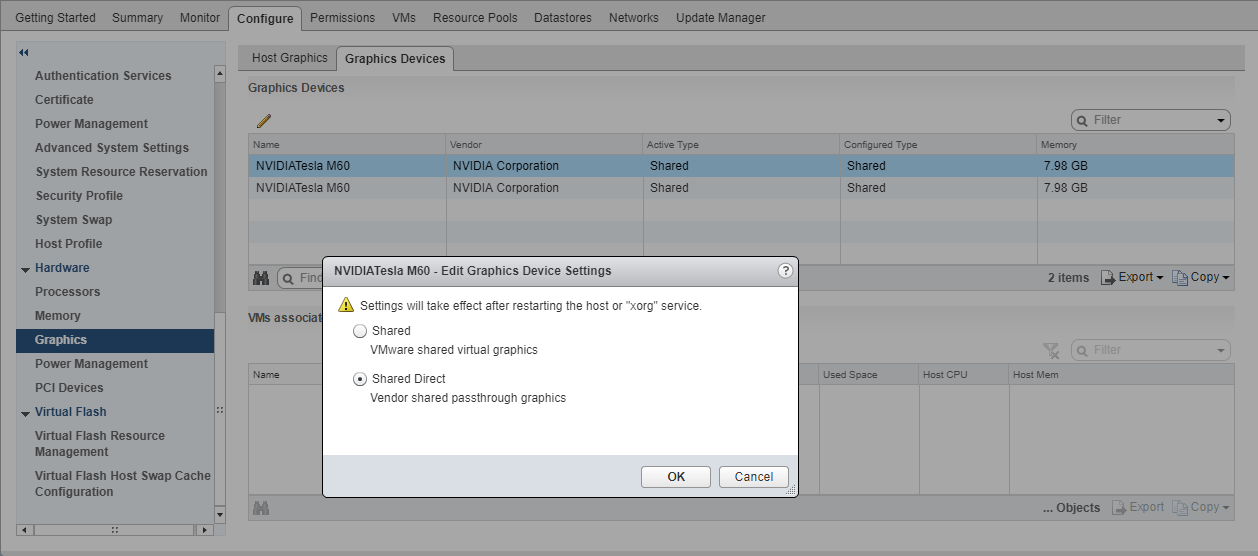
- 在打开的编辑图形设备设置对话框中,选择共享直通,然后单击确定。
图 9. 物理 GPU 的图形设备设置
- 在图形设备选项卡上,选择物理 GPU,然后单击编辑图标。
- 重启 ESXi 主机,或在必要时停止并重启 ESXi 主机上的 Xorg 服务和 nv-hostengine。
要停止并重启 Xorg 服务和 nv-hostengine,请执行以下步骤
- 仅限 7.0 Update 1 之前的 VMware vSphere 版本:停止 Xorg 服务。
在 NVIDIA vGPU 模式下,图形设备不需要 Xorg 服务。
- 停止 nv-hostengine。
[root@esxi:~] nv-hostengine -t
- 等待 1 秒钟以允许 nv-hostengine 停止。
- 启动 nv-hostengine。
[root@esxi:~] nv-hostengine -d
- 仅限 7.0 Update 1 之前的 VMware vSphere 版本:启动 Xorg 服务。
在 NVIDIA vGPU 模式下,图形设备不需要 Xorg 服务。
[root@esxi:~] /etc/init.d/xorg start
- 仅限 7.0 Update 1 之前的 VMware vSphere 版本:停止 Xorg 服务。
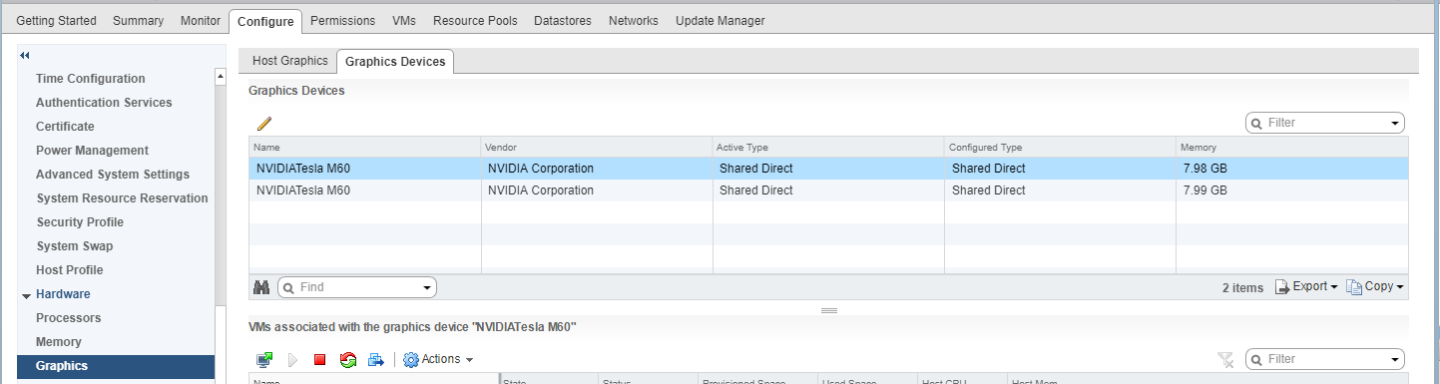
- 在 VMware vCenter Web UI 的图形设备选项卡中,确认每个物理 GPU 的活动类型和配置类型均为“共享直通”。
图 10. 共享直通图形类型





更改默认图形类型后,按照 配置带有 NVIDIA vGPU 的 vSphere 虚拟机 中所述配置 vGPU。
另请参阅 VMware vSphere 文档中的以下主题
2.9.4. 配置带有 NVIDIA vGPU 的 vSphere 虚拟机
为了支持计算或图形密集型应用程序和工作负载,您可以向单个 VM 添加多个 vGPU。
有关哪些 VMware vSphere 版本和 NVIDIA vGPU 支持将多个 vGPU 分配给虚拟机的详细信息,请参阅 VMware vSphere 版 Virtual GPU 软件发行说明。
对于正在运行 vGPU 的虚拟机,VMware vSphere Web Client 中的虚拟机控制台输出不可用。在配置 vGPU 之前,请确保您已安装访问虚拟机的替代方法(例如 Omnissa Horizon 或 VNC 服务器)。
从虚拟机配置中删除 vGPU 参数后,vSphere Web Client 中的虚拟机控制台将再次变为活动状态。
如何使用 vGPU 配置 vSphere 虚拟机取决于您的 VMware vSphere 版本,如下列主题中所述
在配置带有 vGPU 的 vSphere 虚拟机后,启动虚拟机。此 vGPU 版本不支持 vSphere Web Client 中的虚拟机控制台。因此,请使用 Omnissa Horizon 或 VNC 访问虚拟机的桌面。
VM 启动后,按照安装 NVIDIA vGPU 软件图形驱动程序中的说明安装 NVIDIA vGPU 软件图形驱动程序。
2.9.4.1. 配置带有 NVIDIA vGPU 的 vSphere 8 虚拟机
- 打开 vCenter Web UI。
- 在 vCenter Web UI 中,右键单击虚拟机,然后选择编辑设置。
- 在打开的“编辑设置”窗口中,配置您要添加到虚拟机的 vGPU。按如下方式添加您要添加到虚拟机的每个 vGPU
- 返回“编辑设置”窗口,单击确定。


2.9.4.2. 配置带有 NVIDIA vGPU 的 vSphere 7 虚拟机
如果您要向单个虚拟机添加多个 vGPU,请为您要添加到虚拟机的每个 vGPU 执行此任务。
- 打开 vCenter Web UI。
- 在 vCenter Web UI 中,右键单击虚拟机,然后选择编辑设置。
- 单击虚拟硬件选项卡。
- 在新设备列表中,选择共享 PCI 设备,然后单击添加。PCI 设备字段应自动填充 NVIDIA GRID vGPU。
图 13. vGPU 的虚拟机设置
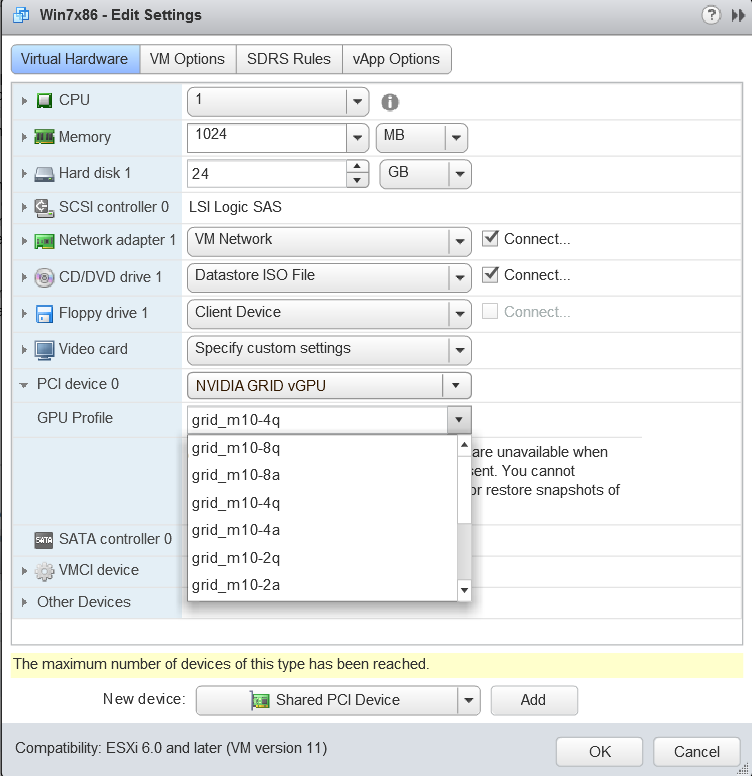
- 从GPU 配置文件下拉菜单中,选择您要配置的 vGPU 类型,然后单击确定。注意
NVIDIA vGPU 软件不支持 VMware vSphere 上的 vCS。因此,C 系列 vGPU 类型无法从GPU 配置文件下拉菜单中选择。
- 确保运行 vGPU 的虚拟机已预留所有内存
- 从 vCenter Web UI 中选择编辑虚拟机设置。
- 展开内存部分,然后单击预留所有客户机内存(全部锁定)。

2.9.5. 在 VMware vSphere 上设置 vGPU 插件参数
vGPU 的插件参数控制 vGPU 的行为,例如帧速率限制器 (FRL) 配置(以每秒帧数为单位)或是否启用 vGPU 的控制台虚拟网络计算 (VNC)。分配了 vGPU 的 VM 将使用这些参数启动。如果为分配给同一 VM 的多个 vGPU 设置了参数,则 VM 将使用分配给每个 vGPU 的参数启动。
确保分配了 vGPU 的虚拟机已关闭电源。
对于您要设置插件参数的每个 vGPU,请在 vSphere Client 中执行此任务。vGPU 插件参数是高级虚拟机属性中的 PCI 直通配置参数。
- 在 vSphere Client 中,浏览到分配了 vGPU 的虚拟机。
- 右键单击虚拟机,然后选择编辑设置。
- 在“编辑设置”窗口中,单击 VM 选项选项卡。
- 从高级下拉列表中,选择编辑配置。
- 在“配置参数”对话框中,单击添加行。
- 在名称字段中,键入参数名称 pciPassthruvgpu-id.cfg.parameter,在值字段中键入参数值,然后单击确定。
- vgpu-id
- 标识分配给虚拟机的 vGPU 的正整数。对于分配给虚拟机的第一个 vGPU,vgpu-id 为 0。例如,如果将两个 vGPU 分配给虚拟机,并且您要为这两个 vGPU 设置插件参数,请设置以下参数
- pciPassthru0.cfg.parameter
- pciPassthru1.cfg.parameter
- parameter
- 您要设置的 vGPU 插件参数的名称。例如,用于启用统一内存的 vGPU 插件参数的名称为 enable_uvm。
要为分配给虚拟机的两个 vGPU 启用统一内存,请将 pciPassthru0.cfg.enable_uvm 和 pciPassthru1.cfg.enable_uvm 设置为 1。
2.10. 为带有 KVM Hypervisor 的 Linux 配置 vGPU Manager
NVIDIA vGPU 软件支持以下带有 KVM hypervisor 的 Linux:带有 KVM 的 Red Hat Enterprise Linux 和 Ubuntu。
如果您要配置需要 UEFI 虚拟机上大型 BAR 地址空间的 NVIDIA vGPU,请参阅 NVIDIA vGPU 软件图形驱动程序无法在基于 KVM 的 hypervisor 上加载,以获取确保 BAR 资源映射到虚拟机中的解决方法。
此解决方法涉及设置实验性 QEMU 参数。
2.10.1. 在带有 KVM Hypervisor 的 Linux 上获取 GPU 的 BDF 和域
有时,在配置物理 GPU 以与 NVIDIA vGPU 软件一起使用时,您必须找出 sysfs 文件系统中哪个目录代表 GPU。此目录由 GPU 的域、总线、插槽和功能标识。
有关 sysfs 文件系统中代表物理 GPU 的目录的更多信息,请参阅 sysfs 文件系统中的 NVIDIA vGPU 信息。
- 获取物理 GPU 的 PCI 设备总线/设备/功能 (BDF)。
# lspci | grep NVIDIA
此示例中列出的 NVIDIA GPU 具有 PCI 设备 BDF
06:00.0和07:00.0。# lspci | grep NVIDIA 06:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [Tesla M10] (rev a1) 07:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [Tesla M10] (rev a1)
- 从 GPU 的 PCI 设备 BDF 获取 GPU 的完整标识符。
# virsh nodedev-list --cap pci| grep transformed-bdf
- transformed-bdf
- GPU 的 PCI 设备 BDF,其中冒号和句点替换为下划线,例如
06_00_0。
此示例获取 PCI 设备 BDF 为
06:00.0的 GPU 的完整标识符。# virsh nodedev-list --cap pci| grep 06_00_0 pci_0000_06_00_0
- 从 GPU 的完整标识符中获取 GPU 的域、总线、插槽和功能。
virsh nodedev-dumpxml full-identifier| egrep 'domain|bus|slot|function'
- full-identifier
- 您在上一步中获取的 GPU 的完整标识符,例如
pci_0000_06_00_0。
此示例获取 PCI 设备 BDF 为
06:00.0的 GPU 的域、总线、插槽和功能。# virsh nodedev-dumpxml pci_0000_06_00_0| egrep 'domain|bus|slot|function' <domain>0x0000</domain> <bus>0x06</bus> <slot>0x00</slot> <function>0x0</function> <address domain='0x0000' bus='0x06' slot='0x00' function='0x0'/>
2.10.2. 为支持 SR-IOV 的 NVIDIA vGPU 准备带有 KVM Hypervisor 的 Linux 上的虚拟功能
支持 SR-IOV 的 NVIDIA vGPU 位于支持 SR-IOV 的物理 GPU 上,例如基于 NVIDIA Ampere 架构的 GPU。在支持 SR-IOV 的 GPU 上创建 NVIDIA vGPU 之前,您必须启用 GPU 的虚拟功能,并获取您要在其上创建 vGPU 的特定虚拟功能的域、总线、插槽和功能。
在执行此任务之前,请确保 GPU 未被任何其他进程使用,例如 CUDA 应用程序、监控应用程序或 nvidia-smi 命令。
- 在 sysfs 文件系统中启用物理 GPU 的虚拟功能。注意
在 hypervisor 主机重启后,或者如果驱动程序重新加载或升级,则 sysfs 文件系统中物理 GPU 的虚拟功能将被禁用。
仅使用 NVIDIA vGPU 软件提供的自定义脚本 sriov-manage 用于此目的。不要尝试通过任何其他方式启用 GPU 的虚拟功能。
# /usr/lib/nvidia/sriov-manage -e domain:bus:slot.function
- domain
- bus
- slot
- function
- GPU 的域、总线、插槽和功能,不带
0x前缀。
注意只能在一个虚拟功能上创建一个
mdev设备文件。此示例为域
00、总线41、插槽0000和功能0的 GPU 启用虚拟功能。# /usr/lib/nvidia/sriov-manage -e 00:41:0000.0
- 获取 GPU 上可用虚拟功能的域、总线、插槽和功能。
# ls -l /sys/bus/pci/devices/domain\:bus\:slot.function/ | grep virtfn
- domain
- bus
- slot
- function
- GPU 的域、总线、插槽和功能,不带
0x前缀。
此示例显示了插槽
00、总线41、域0000和功能0的物理 GPU 的此命令的输出。# ls -l /sys/bus/pci/devices/0000:41:00.0/ | grep virtfn lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn0 -> ../0000:41:00.4 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn1 -> ../0000:41:00.5 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn10 -> ../0000:41:01.6 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn11 -> ../0000:41:01.7 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn12 -> ../0000:41:02.0 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn13 -> ../0000:41:02.1 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn14 -> ../0000:41:02.2 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn15 -> ../0000:41:02.3 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn16 -> ../0000:41:02.4 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn17 -> ../0000:41:02.5 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn18 -> ../0000:41:02.6 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn19 -> ../0000:41:02.7 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn2 -> ../0000:41:00.6 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn20 -> ../0000:41:03.0 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn21 -> ../0000:41:03.1 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn22 -> ../0000:41:03.2 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn23 -> ../0000:41:03.3 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn24 -> ../0000:41:03.4 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn25 -> ../0000:41:03.5 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn26 -> ../0000:41:03.6 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn27 -> ../0000:41:03.7 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn28 -> ../0000:41:04.0 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn29 -> ../0000:41:04.1 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn3 -> ../0000:41:00.7 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn30 -> ../0000:41:04.2 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn31 -> ../0000:41:04.3 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn4 -> ../0000:41:01.0 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn5 -> ../0000:41:01.1 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn6 -> ../0000:41:01.2 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn7 -> ../0000:41:01.3 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn8 -> ../0000:41:01.4 lrwxrwxrwx. 1 root root 0 Jul 16 04:42 virtfn9 -> ../0000:41:01.5
- 选择您要在其上创建 vGPU 的可用虚拟功能,并记下其域、总线、插槽和功能。
自 17.4 起:在配置了 NVLink 的系统上,sriov-manage 脚本可能无法启用物理 GPU 的虚拟功能,因为 Virtual GPU Manager 的初始化尚未完成。在这种情况下,sriov-manage 脚本会将以下错误消息写入 hypervisor 主机上的日志文件
NVRM: Timeout occurred in event processing by vgpu_mgr daemon
如果日志文件中出现此错误消息,请稍后重试运行 sriov-manage 脚本以启用物理 GPU 的虚拟功能。
2.10.3. 在带有 KVM Hypervisor 的 Linux 上创建 NVIDIA vGPU
对于您要创建的每个 vGPU,请在带有 KVM hypervisor 主机的 Linux 命令 shell 中执行此任务。
在开始之前,请确保您拥有要在其上创建 vGPU 的 GPU 的域、总线、插槽和功能。有关说明,请参阅 在带有 KVM Hypervisor 的 Linux 上获取 GPU 的 BDF 和域。
如何在带有 KVM hypervisor 的 Linux 上创建 NVIDIA vGPU 取决于以下因素
- NVIDIA vGPU 是否支持单根 I/O 虚拟化 (SR-IOV)
- hypervisor 是否为支持 SR-IOV 的 NVIDIA vGPU 使用供应商特定的虚拟功能 I/O (VFIO) 框架注意
使用供应商特定的 VFIO 框架的 hypervisor 仅将其用于支持 SR-IOV 的 NVIDIA vGPU。hypervisor 仍然为旧版 NVIDIA vGPU 使用中介 VFIO
mdev驱动程序框架。供应商特定的 VFIO 框架不支持中介 VFIO
mdev驱动程序框架。
对于支持 SR-IOV 的 GPU,供应商特定的 VFIO 框架在 Ubuntu 24.04 版本中引入。
要确定您正在创建的 NVIDIA vGPU 应遵循哪些说明,请参阅下表。
| NVIDIA vGPU 类型 | VFIO 框架 | 说明 |
|---|---|---|
| 旧版:不支持 SR-IOV | mdev |
在带有 KVM Hypervisor 的 Linux 上创建旧版 NVIDIA vGPU |
| 支持 SR-IOV | mdev |
在带有 KVM Hypervisor 的 Linux 上创建支持 SR-IOV 的 NVIDIA vGPU |
| 支持 SR-IOV | 供应商特定 | 在带有使用供应商特定 VFIO 框架的 KVM Hypervisor 的 Linux 上创建 NVIDIA vGPU |
自 17.4 起:在配置了 NVLink 的系统上,可能无法创建 vGPU,因为 Virtual GPU Manager 的初始化尚未完成。在这种情况下,以下错误消息将写入 hypervisor 主机上的日志文件
NVRM: kvgpumgrCreateRequestVgpu: GPU is not initialized yet
如果日志文件中出现此错误消息,请稍后重试创建 vGPU。
2.10.3.1. 在带有 KVM Hypervisor 的 Linux 上创建旧版 NVIDIA vGPU
旧版 NVIDIA vGPU 不支持 SR-IOV。
- 更改为物理 GPU 的 mdev_supported_types 目录。
# cd /sys/class/mdev_bus/domain\:bus\:slot.function/mdev_supported_types/
- domain
- bus
- slot
- function
- GPU 的域、总线、插槽和功能,不带
0x前缀。
此示例更改为域
0000和 PCI 设备 BDF06:00.0的 GPU 的 mdev_supported_types 目录。# cd /sys/bus/pci/devices/0000\:06\:00.0/mdev_supported_types/
- 找出 mdev_supported_types 的哪个子目录包含您要创建的 vGPU 类型的注册信息。
# grep -l "vgpu-type" nvidia-*/name
- vgpu-type
- vGPU 类型,例如
M10-2Q。
此示例显示 M10-2Q vGPU 类型的注册信息包含在 mdev_supported_types 的 nvidia-41 子目录中。
# grep -l "M10-2Q" nvidia-*/name nvidia-41/name
- 确认您可以在物理 GPU 上创建 vGPU 类型的实例。
# cat subdirectory/available_instances
- subdirectory
- 您在上一步中找到的子目录,例如
nvidia-41。
可用实例数必须至少为 1。如果数字为 0,则物理 GPU 上已存在另一个 vGPU 类型的实例,或者已创建允许的最大实例数。
此示例显示可以在物理 GPU 上创建另外四个 M10-2Q vGPU 类型的实例。
# cat nvidia-41/available_instances 4
- 为 vGPU 生成格式正确的通用唯一标识符 (UUID)。
# uuidgen aa618089-8b16-4d01-a136-25a0f3c73123
- 将您在上一步中获得的 UUID 写入您要创建的 vGPU 类型的注册信息目录中的 create 文件。
# echo "uuid"> subdirectory/create
- uuid
- 您在上一步中生成的 UUID,它将成为您要创建的 vGPU 的 UUID。
- subdirectory
- 您要创建的 vGPU 类型的注册信息目录,例如
nvidia-41。
此示例创建 UUID 为
aa618089-8b16-4d01-a136-25a0f3c73123的 M10-2Q vGPU 类型的实例。# echo "aa618089-8b16-4d01-a136-25a0f3c73123" > nvidia-41/create
vGPU 的
mdev设备文件已添加到 vGPU 的父物理设备目录中。vGPU 由其 UUID 标识。/sys/bus/mdev/devices/ 目录包含指向
mdev设备文件的符号链接。 - 使您创建的表示 vGPU 的
mdev设备文件持久化。# mdevctl define --auto --uuid uuid
- uuid
- 您在上一步中为要创建的 vGPU 指定的 UUID。
注意并非所有带有 KVM hypervisor 的 Linux 版本都包含 mdevctl 命令。如果您的版本不包含 mdevctl 命令,您可以使用操作系统的标准功能来自动化在主机启动时重新创建此设备文件。例如,您可以编写在主机重启时执行的自定义脚本。
- 确认 vGPU 已创建。
- 确认 /sys/bus/mdev/devices/ 目录包含 vGPU 的
mdev设备文件。# ls -l /sys/bus/mdev/devices/ total 0 lrwxrwxrwx. 1 root root 0 Nov 24 13:33 aa618089-8b16-4d01-a136-25a0f3c73123 -> ../../../devices/pci0000:00/0000:00:03.0/0000:03:00.0/0000:04:09.0/0000:06:00.0/aa618089-8b16-4d01-a136-25a0f3c73123
- 如果您的版本包含 mdevctl 命令,请列出 hypervisor 主机上的活动中介设备。
# mdevctl list aa618089-8b16-4d01-a136-25a0f3c73123 0000:06:00.0 nvidia-41
- 确认 /sys/bus/mdev/devices/ 目录包含 vGPU 的
2.10.3.2. 在带有 KVM Hypervisor 的 Linux 上创建支持 SR-IOV 的 NVIDIA vGPU
支持 SR-IOV 的 NVIDIA vGPU 位于支持 SR-IOV 的物理 GPU 上,例如基于 NVIDIA Ampere 架构的 GPU。
在执行此任务之前,请确保您要创建 vGPU 的虚拟功能已按照在具有 KVM Hypervisor 的 Linux 上为支持 SR-IOV 的 NVIDIA vGPU 准备虚拟功能中所述进行准备。
如果您想要支持具有不同帧缓冲区大小的 vGPU,还请确保 GPU 已按照在具有 KVM Hypervisor 的 Linux 上为支持 SR-IOV 的 NVIDIA vGPU 准备虚拟功能中所述置于混合大小模式。
- 更改到您要创建 vGPU 的虚拟功能的 mdev_supported_types 目录。
# cd /sys/class/mdev_bus/domain\:bus\:vf-slot.v-function/mdev_supported_types/
- domain
- bus
- GPU 的域和总线,不带
0x前缀。 - vf-插槽
- v-功能
- 您在在具有 KVM Hypervisor 的 Linux 上为支持 SR-IOV 的 NVIDIA vGPU 准备虚拟功能中记录的虚拟功能的插槽和功能。
此示例更改到域为
0000和总线为41的 GPU 的第一个虚拟功能 (virtfn0) 的 mdev_supported_types 目录。第一个虚拟功能 (virtfn0) 的插槽为00,功能为4。# cd /sys/class/mdev_bus/0000\:41\:00.4/mdev_supported_types
- 找出 mdev_supported_types 的哪个子目录包含您要创建的 vGPU 类型的注册信息。
# grep -l "vgpu-type" nvidia-*/name
- vgpu-type
- vGPU 类型,例如
A40-2Q。
此示例显示 A40-2Q vGPU 类型的注册信息包含在 mdev_supported_types 的 nvidia-558 子目录中。
# grep -l "A40-2Q" nvidia-*/name nvidia-558/name
- 确认您可以在虚拟功能上创建 vGPU 类型的实例。
# cat subdirectory/available_instances
- subdirectory
- 您在上一步中找到的子目录,例如
nvidia-558。
可用实例的数量必须为 1。如果数量为 0,则已在虚拟功能上创建了 vGPU。任何 vGPU 类型只能在虚拟功能上创建一个实例。
此示例显示可以在虚拟功能上创建 A40-2Q vGPU 类型的实例。
# cat nvidia-558/available_instances 1
- 为 vGPU 生成格式正确的通用唯一标识符 (UUID)。
# uuidgen aa618089-8b16-4d01-a136-25a0f3c73123
- 将您在上一步中获得的 UUID 写入您要创建的 vGPU 类型的注册信息目录中的 create 文件。
# echo "uuid"> subdirectory/create
- uuid
- 您在上一步中生成的 UUID,它将成为您要创建的 vGPU 的 UUID。
- subdirectory
- 您要创建的 vGPU 类型的注册信息目录,例如
nvidia-558。
此示例创建 UUID 为
aa618089-8b16-4d01-a136-25a0f3c73123的 A40-2Q vGPU 类型的实例。# echo "aa618089-8b16-4d01-a136-25a0f3c73123" > nvidia-558/create
vGPU 的
mdev设备文件被添加到 vGPU 的父虚拟功能目录中。vGPU 由其 UUID 标识。 - 仅限分时 vGPU:使您创建的用于表示 vGPU 的
mdev设备文件持久化。# mdevctl define --auto --uuid uuid
- uuid
- 您在上一步中为要创建的 vGPU 指定的 UUID。
注意- 如果您使用的是支持 SR-IOV 的 GPU,则
mdev设备文件仅在主机重启后持久存在,前提是您在重启配置了 GPU 上 vGPU 的任何 VM 之前,按照在具有 KVM Hypervisor 的 Linux 上为支持 SR-IOV 的 NVIDIA vGPU 准备虚拟功能中所述启用 GPU 的虚拟功能。 - 您 不能 使用 mdevctl 命令使 MIG 支持的 vGPU 的
mdev设备文件持久化。MIG 支持的 vGPU 的mdev设备文件在主机重启后不会保留,因为 MIG 实例不再可用。 - 并非所有带有 KVM hypervisor 的 Linux 版本都包含 mdevctl 命令。如果您的版本不包含 mdevctl 命令,您可以使用操作系统的标准功能来自动化在主机启动时重新创建此设备文件。例如,您可以编写在主机重启时执行的自定义脚本。
- 确认 vGPU 已创建。
- 确认 /sys/bus/mdev/devices/ 目录包含指向
mdev设备文件的符号链接。# ls -l /sys/bus/mdev/devices/ total 0 lrwxrwxrwx. 1 root root 0 Jul 16 05:57 aa618089-8b16-4d01-a136-25a0f3c73123 -> ../../../devices/pci0000:40/0000:40:01.1/0000:41:00.4/aa618089-8b16-4d01-a136-25a0f3c73123
- 如果您的版本包含 mdevctl 命令,请列出 hypervisor 主机上的活动中介设备。
# mdevctl list aa618089-8b16-4d01-a136-25a0f3c73123 0000:06:00.0 nvidia-558
- 确认 /sys/bus/mdev/devices/ 目录包含指向
2.10.3.3. 在 Linux 上使用特定于供应商的 VFIO 框架的 KVM Hypervisor 上创建 NVIDIA vGPU
对于支持 SR-IOV 的 NVIDIA vGPU,hypervisor 仅 使用特定于供应商的 VFIO 框架。对于旧版 NVIDIA vGPU,hypervisor 使用标准 VFIO 框架。特定于供应商的 VFIO 框架不支持中介 VFIO mdev 驱动程序框架。
对于支持 SR-IOV 的 GPU,供应商特定的 VFIO 框架在 Ubuntu 24.04 版本中引入。
在执行此任务之前,请确保您要创建 vGPU 的虚拟功能已按照在具有 KVM Hypervisor 的 Linux 上为支持 SR-IOV 的 NVIDIA vGPU 准备虚拟功能中所述进行准备。
如果您想要支持具有不同帧缓冲区大小的 vGPU,还请确保 GPU 已按照在具有 KVM Hypervisor 的 Linux 上为支持 SR-IOV 的 NVIDIA vGPU 准备虚拟功能中所述置于混合大小模式。
- 更改到 sysfs 文件系统中包含要在其上创建 vGPU 的虚拟功能的 vGPU 管理文件的目录。
# cd /sys/bus/pci/devices/domain\:bus\:vf-slot.v-function/nvidia
- domain
- bus
- GPU 的域和总线,不带
0x前缀。 - vf-插槽
- v-功能
- 您在在具有 KVM Hypervisor 的 Linux 上为支持 SR-IOV 的 NVIDIA vGPU 准备虚拟功能中记录的虚拟功能的插槽和功能。
此示例更改到域为
0000和总线为3d的 GPU 的第一个虚拟功能 (virtfn0) 的 nvidia 目录。第一个虚拟功能 (virtfn0) 的插槽为00,功能为4。# cd /sys/bus/pci/devices/0000\:3d\:00.4/nvidia
- 确认该目录包含虚拟功能上的 vGPU 管理文件,即 creatable_vgpu_types 和 current_vgpu_type。
# ll -r--r--r-- 1 root root 4096 Aug 3 00:39 creatable_vgpu_types -rw-r--r-- 1 root root 4096 Aug 3 00:39 current_vgpu_type ...
- 确认尚未在虚拟功能上创建 vGPU。
# cat current_vgpu_type 0
如果当前 vGPU 类型为 0,则尚未在虚拟功能上创建 vGPU。
注意如果当前 vGPU 类型不为 0,则 不能 在虚拟功能上创建 vGPU,因为已在其上创建了 vGPU,并且只能在虚拟功能上创建一个 vGPU。
- 确定可以在虚拟功能上创建的 NVIDIA vGPU 类型以及在 sysfs 文件系统中表示每种 vGPU 类型的整数 ID。
# cat creatable_vgpu_types NVIDIA A40-1Q 557 NVIDIA A40-2Q 558 NVIDIA A40-3Q 559 NVIDIA A40-4Q 560 NVIDIA A40-6Q 561
- 将表示您要创建的 NVIDIA vGPU 类型的 ID 写入 current_vgpu_type 文件。
# echo vgpu-type-id > current_vgpu_type
- vgpu-type-id
- 表示您要在 sysfs 文件系统中创建的 NVIDIA vGPU 类型的 ID。
注意您必须指定有效的 ID。如果您指定无效的 ID,则写入操作将失败,并且当前 vGPU 类型将设置为
0。此示例创建 A40-4Q vGPU 类型的实例。
# echo 560 > current_vgpu_type
- 确认虚拟功能上的当前 vGPU 类型与您在上一步中创建的 vGPU 类型匹配。
# cat current_vgpu_type 560
- 确认 creatable_vgpu_types 文件为空,表示无法在虚拟功能上创建 vGPU。
# cat creatable_vgpu_types
要重新配置虚拟功能上的 vGPU,必须首先删除现有 vGPU,如在使用特定于供应商的 VFIO 框架的 Linux 上的 KVM Hypervisor 上删除 vGPU中所述。
2.10.4. 向 Linux 上的 KVM Hypervisor VM 添加一个或多个 vGPU
为了支持计算或图形密集型应用程序和工作负载,您可以向单个 VM 添加多个 vGPU。
有关哪些 hypervisor 版本和 NVIDIA vGPU 支持向 VM 分配多个 vGPU 的详细信息,请参阅适用于 Red Hat Enterprise Linux with KVM 发行说明的虚拟 GPU 软件和适用于 Ubuntu 发行说明的虚拟 GPU 软件。
确保满足以下先决条件
- 您要向其添加 vGPU 的 VM 已关闭。
- 您要添加的 vGPU 已按照在 Linux 上的 KVM Hypervisor 上创建 NVIDIA vGPU中所述创建。
您可以使用以下任何工具向 Linux 上的 KVM hypervisor VM 添加 vGPU
- virsh 命令
- QEMU 命令行
向 Linux 上的 KVM hypervisor VM 添加 vGPU 后,启动 VM。
# virsh start vm-name
- vm-name
- 您向其添加 vGPU 的 VM 的名称。
VM 启动后,按照安装 NVIDIA vGPU 软件图形驱动程序中的说明安装 NVIDIA vGPU 软件图形驱动程序。
2.10.4.1. 通过使用 virsh 向 Linux 上的 KVM Hypervisor VM 添加一个或多个 vGPU
- 在 virsh 中,打开要向其添加 vGPU 的 VM 的 XML 文件进行编辑。
# virsh edit vm-name
- vm-name
- 您要向其添加 vGPU 的 VM 的名称。
- 对于要添加到 VM 的每个 vGPU,以
address元素的形式在source元素内添加设备条目,以将 vGPU 添加到访客 VM。设备条目的内容取决于 hypervisor 是否对支持 SR-IOV 的 NVIDIA vGPU 使用特定于供应商的 VFIO 框架。
对于支持 SR-IOV 的 GPU,供应商特定的 VFIO 框架在 Ubuntu 24.04 版本中引入。
-
对于使用
mdevVFIO 框架的 hypervisor,添加一个通过其 UUID 标识 vGPU 的设备条目,如下所示<device> ... <hostdev mode='subsystem' type='mdev' model='vfio-pci'> <source> <address uuid='uuid'/> </source> </hostdev> </device>
- uuid
- 在创建 vGPU 时分配给 vGPU 的 UUID。
此示例添加 UUID 为
a618089-8b16-4d01-a136-25a0f3c73123的 vGPU 的设备条目。<device> ... <hostdev mode='subsystem' type='mdev' model='vfio-pci'> <source> <address uuid='a618089-8b16-4d01-a136-25a0f3c73123'/> </source> </hostdev> </device>
此示例添加了以下两个 UUID 的 vGPU 的设备条目
-
c73f1fa6-489e-4834-9476-d70dabd98c40 -
3b356d38-854e-48be-b376-00c72c7d119c
<device> ... <hostdev mode='subsystem' type='mdev' model='vfio-pci'> <source> <address uuid='c73f1fa6-489e-4834-9476-d70dabd98c40'/> </source> </hostdev> <hostdev mode='subsystem' type='mdev' model='vfio-pci'> <source> <address uuid='3b356d38-854e-48be-b376-00c72c7d119c'/> </source> </hostdev> </device>
-
对于使用 特定于供应商的 VFIO 框架的 hypervisor,添加一个通过在其上创建 vGPU 的虚拟功能标识 vGPU 的设备条目,如下所示
<hostdev mode='subsystem' type='pci' managed='no'> <source> <address domain='domain' bus='bus' slot='vf-slot' function='v-function'/> </source> </hostdev>
- domain
- bus
- GPU 的域和总线,包括
0x前缀。 - vf-插槽
- v-功能
- 您在在具有 KVM Hypervisor 的 Linux 上为支持 SR-IOV 的 NVIDIA vGPU 准备虚拟功能中记录的虚拟功能的插槽和功能。
注意vGPU 仅在非托管
libvirt模式下受支持。因此,请确保在hostdev元素中,managed属性设置为no。此示例添加了在虚拟功能
0000:3d:00.4上创建的 vGPU 的设备条目。<device> ... <hostdev mode='subsystem' type='pci' managed='no'> <source> <address domain='0x0000' bus='0x3d' slot='0x00' function='0x4'/> </source> </hostdev> </device>
此示例添加了在以下虚拟功能上创建的两个 vGPU 的设备条目
-
0000:3d:00.4 -
0000:3d:00.5
<device> ... <hostdev mode='subsystem' type='pci' managed='no'> <source> <address domain='0x0000' bus='0x3d' slot='0x00' function='0x4'/> </source> </hostdev> <hostdev mode='subsystem' type='pci' managed='no'> <source> <address domain='0x0000' bus='0x3d' slot='0x00' function='0x5'/> </source> </hostdev> </device>
-
- 可选:添加一个
video元素,该元素包含一个model元素,其中type属性设置为none。<video> <model type='none'/> </video>
添加此
video元素可防止libvirt添加的默认视频设备加载到 VM 中。如果您不添加此video元素,则必须配置 Xorg 服务器或您的远程解决方案以仅加载您添加的 vGPU 设备,而不是默认视频设备。
2.10.4.2. 通过使用 QEMU 命令行向 Linux 上的 KVM Hypervisor VM 添加一个或多个 vGPU
此任务涉及向 QEMU 命令行添加选项,这些选项标识您要添加的 vGPU 以及您要向其添加 vGPU 的 VM。
- 对于要添加到 VM 的每个 vGPU,添加一个 -device 选项,该选项标识 vGPU。
每个 -device 选项的格式取决于 hypervisor 是否对支持 SR-IOV 的 NVIDIA vGPU 使用特定于供应商的 VFIO 框架。
对于支持 SR-IOV 的 GPU,供应商特定的 VFIO 框架在 Ubuntu 24.04 版本中引入。
-
对于使用
mdevVFIO 框架的 hypervisor 上的每个 vGPU,添加一个 -device 选项,该选项通过其 UUID 标识 vGPU。-device vfio-pci,sysfsdev=/sys/bus/mdev/devices/vgpu-uuid
- vgpu-uuid
- 在创建 vGPU 时分配给 vGPU 的 UUID。
-
对于使用 特定于供应商的 VFIO 框架的 hypervisor 上的每个 vGPU,添加一个 -device 选项,该选项通过在其上创建 vGPU 的虚拟功能标识 vGPU。
-device vfio-pci,sysfsdev=/sys/bus/pci/devices/domain\:bus\:vf-slot.v-function/
- domain
- bus
- GPU 的域和总线,不带
0x前缀。 - vf-插槽
- v-功能
- 您在在具有 KVM Hypervisor 的 Linux 上为支持 SR-IOV 的 NVIDIA vGPU 准备虚拟功能中记录的虚拟功能的插槽和功能。
-
- 添加一个 -uuid 选项以指定您要向其添加 vGPU 的 VM。
-uuid vm-uuid
- vm-uuid
- 在创建 VM 时分配给 VM 的 UUID。
在使用 mdev VFIO 框架的 Hypervisor 上的 VM 中添加一个 vGPU
此示例将 UUID 为 aa618089-8b16-4d01-a136-25a0f3c73123 的 vGPU 添加到 UUID 为 ebb10a6e-7ac9-49aa-af92-f56bb8c65893 的 VM。
-device vfio-pci,sysfsdev=/sys/bus/mdev/devices/aa618089-8b16-4d01-a136-25a0f3c73123 \
-uuid ebb10a6e-7ac9-49aa-af92-f56bb8c65893
在使用 mdev VFIO 框架的 Hypervisor 上的 VM 中添加两个 vGPU
此示例添加了以下两个 UUID 的 vGPU 的设备条目
-
676428a0-2445-499f-9bfd-65cd4a9bd18f -
6c5954b8-5bc1-4769-b820-8099fe50aaba
这些条目已添加到 UUID 为 ec5e8ee0-657c-4db6-8775-da70e332c67e 的 VM。
-device vfio-pci,sysfsdev=/sys/bus/mdev/devices/676428a0-2445-499f-9bfd-65cd4a9bd18f \
-device vfio-pci,sysfsdev=/sys/bus/mdev/devices/6c5954b8-5bc1-4769-b820-8099fe50aaba \
-uuid ec5e8ee0-657c-4db6-8775-da70e332c67e
在使用特定于供应商的 VFIO 框架的 Hypervisor 上的 VM 中添加一个 vGPU
此示例将虚拟功能 0000:3d:00.4 上创建的 vGPU 添加到 UUID 为 ebb10a6e-7ac9-49aa-af92-f56bb8c65893 的 VM。
-device vfio-pci,sysfsdev=/sys/bus/pci/devices/0000\:3d\:00.4 \
-uuid ebb10a6e-7ac9-49aa-af92-f56bb8c65893
在在使用特定于供应商的 VFIO 框架的 Hypervisor 上的 VM 中添加两个 vGPU
此示例添加了在以下虚拟功能上创建的两个 vGPU 的设备条目
-
0000:3d:00.4 -
0000:3d:00.5
这些条目已添加到 UUID 为 ec5e8ee0-657c-4db6-8775-da70e332c67e 的 VM。
-device vfio-pci,sysfsdev=/sys/bus/pci/devices/0000\:3d\:00.4 \
-device vfio-pci,sysfsdev=/sys/bus/pci/devices/0000\:3d\:00.5 \
-uuid ec5e8ee0-657c-4db6-8775-da70e332c67e
2.10.5. 在 Linux 上的 KVM Hypervisor 上设置 vGPU 插件参数
vGPU 的插件参数控制 vGPU 的行为,例如帧速率限制器 (FRL) 配置(以每秒帧数为单位)或是否启用 vGPU 的控制台虚拟网络计算 (VNC)。分配了 vGPU 的 VM 将使用这些参数启动。如果为分配给同一 VM 的多个 vGPU 设置了参数,则 VM 将使用分配给每个 vGPU 的参数启动。
对于要设置插件参数的每个 vGPU,在 Linux 上的 KVM hypervisor 主机上的 Linux 命令 shell 中执行此任务。
- 更改到 sysfs 文件系统中包含您要为其设置 vGPU 插件参数的 vGPU 的 vgpu_params 文件的目录。
目录取决于 hypervisor 是否对支持 SR-IOV 的 NVIDIA vGPU 使用特定于供应商的 VFIO 框架。
对于支持 SR-IOV 的 GPU,供应商特定的 VFIO 框架在 Ubuntu 24.04 版本中引入。
-
对于使用
mdevVFIO 框架的 hypervisor,更改到表示 vGPU 的mdev设备目录的 nvidia 子目录。# cd /sys/bus/mdev/devices/uuid/nvidia
- uuid
- vGPU 的 UUID,例如
aa618089-8b16-4d01-a136-25a0f3c73123。
-
对于使用 特定于供应商的 VFIO 框架的 hypervisor,更改到 sysfs 文件系统中包含在其上创建 vGPU 的虚拟功能的 vGPU 管理文件的目录。
# cd /sys/bus/pci/devices/domain\:bus\:vf-slot.v-function/nvidia
- domain
- bus
- GPU 的域和总线,不带
0x前缀。 - vf-插槽
- v-功能
- 您在在具有 KVM Hypervisor 的 Linux 上为支持 SR-IOV 的 NVIDIA vGPU 准备虚拟功能中记录的虚拟功能的插槽和功能。
此示例更改到域为
0000和总线为3d的 GPU 的第一个虚拟功能 (virtfn0) 的 nvidia 目录。第一个虚拟功能 (virtfn0) 的插槽为00,功能为4。# cd /sys/bus/pci/devices/0000\:3d\:00.4/nvidia
-
- 将您要设置的插件参数写入您在上一步中更改到的目录中的 vgpu_params 文件。
# echo "plugin-config-params" > vgpu_params
- plugin-config-params
- 参数值对的逗号分隔列表,其中每对的形式为 parameter-name=value。
此示例禁用 vGPU 的帧速率限制和控制台 VNC。
# echo "frame_rate_limiter=0, disable_vnc=1" > vgpu_params
此示例为 vGPU 启用统一内存。
# echo "enable_uvm=1" > vgpu_params
此示例为 vGPU 启用 NVIDIA CUDA Toolkit 调试器。
# echo "enable_debugging=1" > vgpu_params
此示例为 vGPU 启用 NVIDIA CUDA Toolkit 分析器。
# echo "enable_profiling=1" > vgpu_params
要清除先前设置的任何 vGPU 插件参数,请将空格写入 vGPU 的 vgpu_params 文件。
# echo " " > vgpu_params
2.10.6. 在 Linux 上的 KVM Hypervisor 上删除 vGPU
如何在 Linux 上的 KVM hypervisor 上删除 vGPU 取决于 hypervisor 是否对支持 SR-IOV 的 NVIDIA vGPU 使用特定于供应商的 VFIO 框架。
对于支持 SR-IOV 的 NVIDIA vGPU,hypervisor 仅 使用特定于供应商的 VFIO 框架。对于旧版 NVIDIA vGPU,hypervisor 仍然使用中介 VFIO mdev 驱动程序框架。
对于支持 SR-IOV 的 GPU,供应商特定的 VFIO 框架在 Ubuntu 24.04 版本中引入。
要确定要删除的 NVIDIA vGPU 应遵循哪些说明,请参阅下表。
| NVIDIA vGPU 类型 | VFIO 框架 | 说明 |
|---|---|---|
| 旧版:不支持 SR-IOV | mdev |
在使用 mdev VFIO 框架的 Linux 上的 KVM Hypervisor 上删除 vGPU |
| 支持 SR-IOV | mdev |
|
| 支持 SR-IOV | 供应商特定 | 在使用特定于供应商的 VFIO 框架的 Linux 上的 KVM Hypervisor 上删除 vGPU |
2.10.6.1. 在使用 mdev VFIO 框架的 Linux 上的 KVM Hypervisor 上删除 vGPU
对于要删除的每个 vGPU,在 Linux 上的 KVM hypervisor 主机上的 Linux 命令 shell 中执行此任务。
在开始之前,请确保满足以下先决条件
- 您拥有要删除的 vGPU 所在的 GPU 的域、总线、插槽和功能。有关说明,请参阅在 Linux 上的 KVM Hypervisor 上获取 GPU 的 BDF 和域。
- 分配了 vGPU 的 VM 已关闭。
- 更改为物理 GPU 的 mdev_supported_types 目录。
# cd /sys/class/mdev_bus/domain\:bus\:slot.function/mdev_supported_types/
- domain
- bus
- slot
- function
- GPU 的域、总线、插槽和功能,不带
0x前缀。
此示例更改到 PCI 设备 BDF 为
06:00.0的 GPU 的 mdev_supported_types 目录。# cd /sys/bus/pci/devices/0000\:06\:00.0/mdev_supported_types/
- 更改到 mdev_supported_types 的子目录,该子目录包含 vGPU 的注册信息。
# cd `find . -type d -name uuid`
- uuid
- vGPU 的 UUID,例如
aa618089-8b16-4d01-a136-25a0f3c73123。
- 将值
1写入您要删除的 vGPU 的注册信息目录中的 remove 文件。# echo "1" > remove
2.10.6.2. 在使用特定于供应商的 VFIO 框架的 Linux 上的 KVM Hypervisor 上删除 vGPU
对于支持 SR-IOV 的 NVIDIA vGPU,hypervisor 仅 使用特定于供应商的 VFIO 框架。对于旧版 NVIDIA vGPU,hypervisor 使用 mdev VFIO 框架。特定于供应商的 VFIO 框架不支持中介 VFIO mdev 驱动程序框架。
对于支持 SR-IOV 的 GPU,供应商特定的 VFIO 框架在 Ubuntu 24.04 版本中引入。
在开始之前,请确保满足以下先决条件
- 您具有以下信息
- 您要删除的 vGPU 所在的 GPU 的域和总线。有关说明,请参阅在 Linux 上的 KVM Hypervisor 上获取 GPU 的 BDF 和域。
- 在其上创建要删除的 vGPU 的虚拟功能的插槽和功能。
- 分配了 vGPU 的 VM 已关闭。
- 更改到 sysfs 文件系统中包含在其上创建 vGPU 的虚拟功能的 vGPU 管理文件的目录。
# cd /sys/bus/pci/devices/domain\:bus\:vf-slot.v-function/nvidia
- domain
- bus
- GPU 的域和总线,不带
0x前缀。 - vf-插槽
- v-功能
- 您在在具有 KVM Hypervisor 的 Linux 上为支持 SR-IOV 的 NVIDIA vGPU 准备虚拟功能中记录的虚拟功能的插槽和功能。
此示例更改到域为
0000和总线为3d的 GPU 的第一个虚拟功能 (virtfn0) 的 nvidia 目录。第一个虚拟功能 (virtfn0) 的插槽为00,功能为4。# cd /sys/bus/pci/devices/0000\:3d\:00.4/nvidia
- 确认该目录包含虚拟功能上的 vGPU 管理文件,即 creatable_vgpu_types 和 current_vgpu_type。
# ll -r--r--r-- 1 root root 4096 Aug 3 00:39 creatable_vgpu_types -rw-r--r-- 1 root root 4096 Aug 3 00:39 current_vgpu_type ...
- 确认虚拟功能上的当前 vGPU 类型是表示您要删除的 vGPU 类型的 ID。
# cat current_vgpu_type 560
- 将
0写入 current_vgpu_type 文件。# echo 0 > current_vgpu_type
- 确认虚拟功能上的当前 vGPU 类型为
0,表示 vGPU 已被删除。# cat current_vgpu_type 0
- 确认 creatable_vgpu_types 文件不再为空,表示 vGPU 已被删除,并且可以在虚拟功能上再次创建 vGPU。
# cat creatable_vgpu_types NVIDIA A40-1Q 557 NVIDIA A40-2Q 558 NVIDIA A40-3Q 559 NVIDIA A40-4Q 560 NVIDIA A40-6Q 561
2.10.7. 准备配置为直通的 GPU 以用于 vGPU
物理 GPU 使用的模式决定了 GPU 绑定的 Linux 内核模块。如果您要切换 GPU 使用的模式,则必须从其当前内核模块中解除绑定 GPU,并将其绑定到新模式的内核模块。将 GPU 绑定到正确的内核模块后,您可以将其配置为 vGPU。
传递到 VM 的物理 GPU 绑定到 vfio-pci 内核模块。绑定到 vfio-pci 内核模块的物理 GPU 只能用于直通。要使 GPU 可以用于 vGPU,必须从 vfio-pci 内核模块解除绑定 GPU,并将其绑定到 nvidia 内核模块。
在开始之前,请确保您具有要准备用于 vGPU 的 GPU 的域、总线、插槽和功能。有关说明,请参阅在 Linux 上的 KVM Hypervisor 上获取 GPU 的 BDF 和域。
- 通过在主机上的 NVIDIA GPU 上运行带有 -k 选项的 lspci 命令,确定 GPU 绑定的内核模块。
# lspci -d 10de: -k
Kernel driver in use:字段指示 GPU 绑定的内核模块。以下示例显示 BDF 为
06:00.0的 NVIDIA Tesla M60 GPU 绑定到vfio-pci内核模块,并用于 GPU 直通。06:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [Tesla M60] (rev a1) Subsystem: NVIDIA Corporation Device 115e Kernel driver in use: vfio-pci
- 从
vfio-pci内核模块解除绑定 GPU。- 更改到表示
vfio-pci内核模块的 sysfs 目录。# cd /sys/bus/pci/drivers/vfio-pci
- 将 GPU 的域、总线、插槽和功能写入此目录中的 unbind 文件。
# echo domain:bus:slot.function > unbind
- domain
- bus
- slot
- function
- GPU 的域、总线、插槽和功能,不带
0x前缀。
此示例写入域为
0000且 PCI 设备 BDF 为06:00.0的 GPU 的域、总线、插槽和功能。# echo 0000:06:00.0 > unbind
- 更改到表示
- 将 GPU 绑定到
nvidia内核模块。- 更改到 sysfs 目录,该目录包含物理 GPU 的 PCI 设备信息。
# cd /sys/bus/pci/devices/domain\:bus\:slot.function
- domain
- bus
- slot
- function
- GPU 的域、总线、插槽和功能,不带
0x前缀。
此示例更改到 sysfs 目录,该目录包含域为
0000且 PCI 设备 BDF 为06:00.0的 GPU 的 PCI 设备信息。# cd /sys/bus/pci/devices/0000\:06\:00.0
- 将内核模块名称
nvidia写入此目录中的 driver_override 文件。# echo nvidia > driver_override
- 更改到表示
nvidia内核模块的 sysfs 目录。# cd /sys/bus/pci/drivers/nvidia
- 将 GPU 的域、总线、插槽和功能写入此目录中的 bind 文件。
# echo domain:bus:slot.function > bind
- domain
- bus
- slot
- function
- GPU 的域、总线、插槽和功能,不带
0x前缀。
此示例写入域为
0000且 PCI 设备 BDF 为06:00.0的 GPU 的域、总线、插槽和功能。# echo 0000:06:00.0 > bind
- 更改到 sysfs 目录,该目录包含物理 GPU 的 PCI 设备信息。
现在,您可以按照为 Red Hat Enterprise Linux KVM 安装和配置 NVIDIA 虚拟 GPU 管理器中所述,使用 vGPU 配置 GPU。
2.10.8. sysfs 文件系统中的 NVIDIA vGPU 信息
有关 Linux 上的 KVM hypervisor 主机中每个物理 GPU 支持的 NVIDIA vGPU 类型的信息存储在 sysfs 文件系统中。
NVIDIA vGPU 信息在 sysfs 文件系统中的存储方式取决于 hypervisor 是否对支持 SR-IOV 的 NVIDIA vGPU 使用特定于供应商的 VFIO 框架。
对于支持 SR-IOV 的 NVIDIA vGPU,hypervisor 使用特定于供应商的 VFIO 框架,对于旧版 NVIDIA vGPU,则使用 mdev VFIO 框架。
对于支持 SR-IOV 的 GPU,Ubuntu 24.04 发行版中引入了特定于供应商的 VFIO 框架的使用。有关 NVIDIA vGPU 信息如何在 sysfs 文件系统中存储的更多详细信息,请参阅以下主题
- 适用于使用 mdev VFIO 框架的 Hypervisor 的 sysfs 文件系统中的 NVIDIA vGPU 信息
- 适用于使用特定于供应商的 VFIO 框架的 Hypervisor 的 sysfs 文件系统中的 NVIDIA vGPU 信息
2.10.8.1. 适用于使用 mdev VFIO 框架的 Hypervisor 的 sysfs 文件系统中的 NVIDIA vGPU 信息
主机上的所有物理 GPU 都在 mdev 内核模块中注册。有关物理 GPU 以及可以在每个物理 GPU 上创建的 vGPU 类型的信息存储在 /sys/class/mdev_bus/ 目录下的目录和文件中。
每个物理 GPU 的 sysfs 目录位于以下位置
- /sys/bus/pci/devices/
- /sys/class/mdev_bus/
这两个目录都是指向 sysfs 文件系统中 PCI 设备的真实目录的符号链接。
每个物理 GPU 的 sysfs 目录的组织结构如下
/sys/class/mdev_bus/
|-parent-physical-device
|-mdev_supported_types
|-nvidia-vgputype-id
|-available_instances
|-create
|-description
|-device_api
|-devices
|-name
- 父物理设备
-
主机上的每个物理 GPU 由 /sys/class/mdev_bus/ 目录的子目录表示。
每个子目录的名称如下
域\:总线\:插槽.功能
域、总线、插槽、功能 是 GPU 的域、总线、插槽和功能,例如
0000\:06\:00.0。每个目录都是指向 sysfs 文件系统中 PCI 设备的真实目录的符号链接。例如
# ll /sys/class/mdev_bus/ total 0 lrwxrwxrwx. 1 root root 0 Dec 12 03:20 0000:05:00.0 -> ../../devices/pci0000:00/0000:00:03.0/0000:03:00.0/0000:04:08.0/0000:05:00.0 lrwxrwxrwx. 1 root root 0 Dec 12 03:20 0000:06:00.0 -> ../../devices/pci0000:00/0000:00:03.0/0000:03:00.0/0000:04:09.0/0000:06:00.0 lrwxrwxrwx. 1 root root 0 Dec 12 03:20 0000:07:00.0 -> ../../devices/pci0000:00/0000:00:03.0/0000:03:00.0/0000:04:10.0/0000:07:00.0 lrwxrwxrwx. 1 root root 0 Dec 12 03:20 0000:08:00.0 -> ../../devices/pci0000:00/0000:00:03.0/0000:03:00.0/0000:04:11.0/0000:08:00.0
- mdev_supported_types
- 在将配置 NVIDIA vGPU 的每个物理 GPU 的 sysfs 目录下都需要一个名为 mdev_supported_types 的目录。为 GPU 创建此目录的方式取决于 GPU 是否支持 SR-IOV。
- 对于不支持 SR-IOV 的 GPU,在主机上安装虚拟 GPU 管理器并重启主机后,将自动创建此目录。
- 对于支持 SR-IOV 的 GPU,例如基于 NVIDIA Ampere 架构的 GPU,您必须通过启用 GPU 的虚拟功能来创建此目录,如在 Linux 上的 KVM Hypervisor 上创建 NVIDIA vGPU中所述。mdev_supported_types 目录本身在物理功能上永远不可见。
mdev_supported_types 目录包含物理 GPU 支持的每种 vGPU 类型的子目录。每个子目录的名称为 nvidia-vgputype-id,其中 vgputype-id 是一个无符号整数序列号。例如
# ll mdev_supported_types/ total 0 drwxr-xr-x 3 root root 0 Dec 6 01:37 nvidia-35 drwxr-xr-x 3 root root 0 Dec 5 10:43 nvidia-36 drwxr-xr-x 3 root root 0 Dec 5 10:43 nvidia-37 drwxr-xr-x 3 root root 0 Dec 5 10:43 nvidia-38 drwxr-xr-x 3 root root 0 Dec 5 10:43 nvidia-39 drwxr-xr-x 3 root root 0 Dec 5 10:43 nvidia-40 drwxr-xr-x 3 root root 0 Dec 5 10:43 nvidia-41 drwxr-xr-x 3 root root 0 Dec 5 10:43 nvidia-42 drwxr-xr-x 3 root root 0 Dec 5 10:43 nvidia-43 drwxr-xr-x 3 root root 0 Dec 5 10:43 nvidia-44 drwxr-xr-x 3 root root 0 Dec 5 10:43 nvidia-45
- nvidia-vgputype-id
- 每个目录代表一个单独的 vGPU 类型,并包含以下文件和目录
- available_instances
- 本文档介绍了仍可创建的此 vGPU 类型的实例数量。每当在此物理 GPU 上创建或删除此类型的 vGPU 时,此文件都会更新。注意
当创建时间分片 vGPU 时,物理 GPU 上所有其他时间分片 vGPU 类型的 available_instances 的内容都将设置为 0。此行为强制要求物理 GPU 上的所有时间分片 vGPU 必须是相同类型。但是,此要求不适用于 MIG 支持的 vGPU。因此,当创建 MIG 支持的 vGPU 时,物理 GPU 上所有其他 MIG 支持的 vGPU 类型的 available_instances 不会设置为 0。
- 创建
- 此文件用于创建 vGPU 实例。通过将 vGPU 的 UUID 写入此文件来创建 vGPU 实例。此文件为只写文件。
- 描述
- 此文件包含 vGPU 类型的以下详细信息
- vGPU 类型支持的最大虚拟显示头数
- 帧速率限制器 (FRL) 配置,单位为帧/秒
- 帧缓冲区大小,单位为 Mbytes
- 每个显示头的最大分辨率
- 每个物理 GPU 的最大 vGPU 实例数
例如
# cat description num_heads=4, frl_config=60, framebuffer=2048M, max_resolution=4096x2160, max_instance=4
- device_api
- 此文件包含字符串
vfio_pci,指示 vGPU 是 PCI 设备。 - devices
- 此目录包含为 vGPU 类型创建的所有
mdev设备。例如# ll devices total 0 lrwxrwxrwx 1 root root 0 Dec 6 01:52 aa618089-8b16-4d01-a136-25a0f3c73123 -> ../../../aa618089-8b16-4d01-a136-25a0f3c73123
- name
- 此文件包含 vGPU 类型的名称。例如
# cat name GRID M10-2Q
2.10.8.2. 使用供应商特定 VFIO 框架的虚拟机监控程序在 sysfs 文件系统中的 NVIDIA vGPU 信息
供应商特定的 VFIO 框架不支持中介 VFIO mdev 驱动程序框架。有关物理 GPU 以及可在每个物理 GPU 上创建的 vGPU 类型的信息存储在 /sys/bus/pci/devices/ 目录下的目录和文件中。
每个物理 GPU 上的每个虚拟功能的 sysfs 目录的组织结构如下
/sys/bus/pci/devices/
|-virtual-function
|-nvidia
|-creatable_vgpu_types
|-current_vgpu_type
|-vgpu_params
- virtual-function
-
主机上每个物理 GPU 上的每个虚拟功能都由 /sys/bus/pci/devices/ 目录的子目录表示。
每个子目录的名称如下
域\:总线\:vf-插槽.v-功能
域和总线是 GPU 的域和总线。vf-插槽和v-功能是虚拟功能的插槽和功能。例如:
0000\:3d\:00.4。您必须通过启用 GPU 的虚拟功能来创建此目录,如在 Linux 上使用 KVM 虚拟机监控程序创建 NVIDIA vGPU中所述。此目录不会自动创建。
- nvidia
- nvidia 目录包含用于虚拟功能上的 vGPU 管理的文件。这些文件如下
- creatable_vgpu_types
- 此文件包含可在虚拟功能上创建的 NVIDIA vGPU 类型以及表示 sysfs 文件系统中每种 vGPU 类型的整数 ID。例如
# cat creatable_vgpu_types NVIDIA A40-1Q 557 NVIDIA A40-2Q 558 NVIDIA A40-3Q 559 NVIDIA A40-4Q 560 NVIDIA A40-6Q 561
- 如果已在此虚拟功能上创建 vGPU,则此文件为空。
- 如果已在同一 GPU 上的另一个虚拟功能上创建 vGPU,则此文件仅包含可以与现有 vGPU 驻留在同一 GPU 上的 vGPU 类型。
- 如果 GPU 支持的最大 vGPU 数量已在 GPU 的其他虚拟功能上创建,则此文件为空。
注意当在等大小模式下在 GPU 上创建时间分片 vGPU 时,物理 GPU 上所有虚拟功能的 creatable_vgpu_types 的内容都将设置为仅与已创建的 vGPU 具有相同帧缓冲区大小的 vGPU 类型。此行为强制要求物理 GPU 上的所有时间分片 vGPU 必须具有相同的帧缓冲区大小。但是,此要求不适用于在混合大小模式下创建的 GPU 上的时间分片 vGPU 或 MIG 支持的 vGPU。
- current_vgpu_type
- 此文件包含整数 ID,该 ID 表示在此虚拟功能上创建的 vGPU 的 sysfs 文件系统中的 vGPU 类型。例如,如果已在此虚拟功能上创建 NVIDIA A40-4Q vGPU,则此文件包含整数
560# cat current_vgpu_type 560
如果未在虚拟功能上创建 vGPU,则此文件包含整数 0。创建此文件时,其内容将设置为默认值 0。
此文件用于在虚拟功能上创建和删除 vGPU。
- 通过将表示 sysfs 文件系统中 vGPU 类型的整数 ID 写入此文件来创建 vGPU。
- 通过将 0 写入此文件来删除 vGPU。
- vgpu_params
- 此文件用于为虚拟功能上的 vGPU 设置插件参数,以控制其行为。插件参数通过将参数-值对列表写入此文件来设置。有关详细信息,请参阅在 Linux 上使用 KVM 虚拟机监控程序设置 vGPU 插件参数。
2.11. 将 GPU 置于混合大小模式
默认情况下,GPU 仅支持具有相同帧缓冲区大小的 vGPU,因此处于等大小模式。要支持具有不同帧缓冲区大小的 vGPU,必须将 GPU 置于混合大小模式。当 GPU 处于混合大小模式时,GPU 上允许的某些类型的 vGPU 的最大数量小于 GPU 处于等大小模式时的最大数量。
- 如果虚拟机监控程序主机重新启动、NVIDIA Virtual GPU Manager 重新加载或 GPU 重置,则混合大小模式下的 GPU 的行为取决于虚拟机监控程序
- 在 Linux 上使用 KVM 虚拟机监控程序时,混合大小模式下的 GPU 会恢复为其默认模式。
- 在 VMware vSphere 上,混合大小模式下的 GPU 保持在混合大小模式。GPU 不会恢复为其默认模式。
- 当 GPU 处于混合大小模式时,仅支持尽力而为和等份额调度程序。不支持固定份额调度程序。
在执行此任务之前,请确保 GPU 上没有正在运行的 vGPU,并且 GPU 未被任何其他进程(例如 CUDA 应用程序、监控应用程序或 nvidia-smi 命令)使用。
如何将 GPU 置于混合大小模式取决于您正在使用的虚拟机监控程序,如下列主题中所述
2.11.1. 在 Linux 上使用 KVM 虚拟机监控程序将 GPU 置于混合大小模式
如果您使用的是支持 SR-IOV 的 GPU,请确保已启用 sysfs 文件系统中物理 GPU 的虚拟功能,如在 Linux 上使用 KVM 虚拟机监控程序为支持 SR-IOV 的 NVIDIA vGPU 准备虚拟功能中所述。
- 使用 nvidia-smi 列出所有物理 GPU 的状态,并检查是否已注明支持异构时间分片 vGPU 大小。
# nvidia-smi -q ... Attached GPUs : 1 GPU 00000000:41:00.0 ... Heterogeneous Time-Slice Sizes : Supported ...
- 将您要支持具有不同帧缓冲区大小的 vGPU 的每个 GPU 置于混合大小模式。
# nvidia-smi vgpu -i id -shm 1
- id
- nvidia-smi 报告的 GPU 索引。
此示例将索引为
00000000:41:00.0的 GPU 置于混合大小模式。# nvidia-smi vgpu -i 0 -shm 1 Enabled vGPU heterogeneous mode for GPU 00000000:41:00.0
- 使用 nvidia-smi 检查是否已启用 vGPU 异构模式,以确认 GPU 现在处于混合大小模式。
# nvidia-smi -q ... vGPU Heterogeneous Mode : Enabled ...
2.11.2. 在 VMware vSphere 上将 GPU 置于混合大小模式
在 VMware vSphere 上,您可以使用 vCenter Server 或 esxcli 命令将 GPU 置于混合大小模式。
有关说明,请参阅以下主题
2.11.2.1. 通过使用 vCenter Server 在 VMware vSphere 上将 GPU 置于混合大小模式
- 使用 vSphere Web Client 登录到 vCenter Server。
- 在导航树中,选择您的 ESXi 主机,然后单击配置选项卡。
- 在配置选项卡的导航树中,选择硬件 > 图形。
- 选择 GPU,然后单击编辑。
- 在打开的弹出窗口中,将 vGPU 模式设置为 混合大小。注意
不要将选项设置为重新启动 Xorg 服务器。仅当设备类型更改时才需要此选项,当 GPU 的 vGPU 模式更改时不需要此选项。
2.11.2.2. 通过使用 esxcli 命令在 VMware vSphere 上将 GPU 置于混合大小模式
从虚拟机监控程序主机上的 ESXi Shell 执行此任务。
- 运行 esxcli 命令以将 GPU 的 vGPU 模式更改为混合大小。
$ esxcli graphics device set --device-id=slot:bus:domain.function --type SharedPassthru --vgpu-mode=MixedSize
- slot
- bus
- domain
- function
- GPU 的域、总线、插槽和功能,不带
0x前缀。
注意要将 GPU 置于等大小模式,请使用 --vgpu-mode=SameSize 选项运行此命令。
- 刷新主机并重建可分配硬件树。
$ esxcli graphics host refresh
- 确认 GPU 的 vGPU 模式已更改。
$ esxcli graphics device list
2.12. 在 Linux 上使用 KVM 虚拟机监控程序在混合大小模式下将 vGPU 放置在物理 GPU 上
默认情况下,Virtual GPU Manager 确定 vGPU 在 GPU 上的放置位置。在 Linux 上使用 KVM 虚拟机监控程序时,您可以控制混合大小模式下 GPU 上 vGPU 的放置位置,以便在 GPU 上容纳尽可能多的 vGPU。通过控制 vGPU 在 GPU 上的放置位置,您可以确保 GPU 上的放置区域中没有可以被 vGPU 占据的空白。
混合大小模式下的 GPU 支持的 vGPU 放置位置取决于 GPU 拥有的帧缓冲区总量。有关详细信息,请参阅混合大小模式下 GPU 的 vGPU 放置位置。
- 在 Linux 上使用 KVM 虚拟机监控程序时,此任务是可选的。如果您希望 Virtual GPU Manager 确定 vGPU 在 GPU 上的放置位置,请忽略此任务。
- 在 VMware vSphere 上,您不能控制混合大小模式下 GPU 上 vGPU 的放置位置。VMware vSphere 软件确定 vGPU 在 GPU 上的放置位置。
在执行此任务之前,请确保满足以下先决条件
- GPU 已置于混合大小模式,如将 GPU 置于混合大小模式中所述。
- 您要放置在物理 GPU 上的 vGPU 已创建,如在 Linux 上使用 KVM 虚拟机监控程序创建 NVIDIA vGPU中所述。
在虚拟机监控程序主机上的命令 shell 中执行此任务。
- 使用 nvidia-smi 列出 vGPU 类型的放置大小和可用放置 ID。
# nvidia-smi vgpu -c -v ... vGPU Type ID : 0x392 Name : NVIDIA L4-6Q ... Placement Size : 6 Creatable Placement IDs : 6 18 ...
注意某些 vGPU 类型支持的放置 ID 可能不可用,因为它们已被另一个 vGPU 使用。要列出 vGPU 类型的放置大小和所有支持的放置 ID,请运行以下命令
# nvidia-smi vgpu -s -v ... vGPU Type ID : 0x392 Name : NVIDIA L4-6Q ... Placement Size : 6 Supported Placement IDs : 0 6 12 18 ...
支持的放置 ID 数量是混合大小模式下 GPU 上允许的该类型 vGPU 的最大数量。
- 将 vGPU 的 vgpu-placement-id vGPU 插件参数设置为您想要的放置 ID。
对于 Linux 上使用 KVM 虚拟机监控程序,将参数写入表示 vGPU 的 mdev 设备目录的 nvidia 子目录中的 vgpu_params 文件。
# echo "vgpu-placement-id=placement-id" > /sys/bus/mdev/devices/uuid/nvidia/vgpu_params
- placement-id
- 您要为 vGPU 设置的放置 ID。
- uuid
- vGPU 的 UUID,例如
aa618089-8b16-4d01-a136-25a0f3c73123。
此示例将 UUID 为
aa618089-8b16-4d01-a136-25a0f3c73123的 vGPU 的放置 ID 设置为 6。# echo "vgpu-placement-id=6" > \ /sys/bus/mdev/devices/aa618089-8b16-4d01-a136-25a0f3c73123/nvidia/vgpu_params
当分配了 vGPU 的 VM 重新启动时,Virtual GPU Manager 会验证您分配给 vGPU 的放置 ID。如果放置 ID 无效或不可用,则 VM 启动失败。
在分配了 vGPU 的 VM 重新启动后,您可以确认 vGPU 已分配了正确的放置 ID。
# nvidia-smi vgpu -q
GPU 00000000:41:00.0
Active vGPUs : 1
vGPU ID : 3251719533
VM ID : 2150987
...
Placement ID : 6
...
2.13. 禁用和启用 ECC 内存
某些支持 NVIDIA vGPU 软件的 GPU 支持带有 NVIDIA vGPU 的纠错码 (ECC) 内存。ECC 内存通过检测和处理双位错误来提高数据完整性。但是,并非所有 GPU、vGPU 类型和虚拟机监控程序软件版本都支持带有 NVIDIA vGPU 的 ECC 内存。
在支持带有 NVIDIA vGPU 的 ECC 内存的 GPU 上,C 系列和 Q 系列 vGPU 支持 ECC 内存,但 A 系列和 B 系列 vGPU 不支持。尽管 A 系列和 B 系列 vGPU 在启用了 ECC 内存的物理 GPU 上启动,但在不支持 ECC 的 vGPU 上启用 ECC 可能会产生一些成本。
在没有 HBM2 内存的物理 GPU 上,vGPU 可用的帧缓冲区量会减少。所有类型的 vGPU 都会受到影响,而不仅仅是支持 ECC 内存的 vGPU。
在物理 GPU 上启用 ECC 内存的效果如下
- ECC 内存作为物理 GPU 上所有受支持 vGPU 的一项功能公开。
- 在支持 ECC 内存的 VM 中,ECC 内存已启用,并可以选择在 VM 中禁用 ECC。
- 可以为单个 VM 启用或禁用 ECC 内存。在 VM 中启用或禁用 ECC 内存不会影响 vGPU 可用的帧缓冲区量。
基于 Pascal GPU 架构和更高版本 GPU 架构的 GPU 支持带有 NVIDIA vGPU 的 ECC 内存。要确定是否为 GPU 启用了 ECC 内存,请为 GPU 运行 nvidia-smi -q。
Tesla M60 和 M6 GPU 在不使用 GPU 虚拟化时支持 ECC 内存,但 NVIDIA vGPU 不支持这些 GPU 的 ECC 内存。在图形模式下,这些 GPU 在出厂时默认禁用 ECC 内存。
某些虚拟机监控程序软件版本不支持带有 NVIDIA vGPU 的 ECC 内存。
如果您正在使用不支持带有 NVIDIA vGPU 的 ECC 内存的虚拟机监控程序软件版本或 GPU,并且启用了 ECC 内存,则 NVIDIA vGPU 将无法启动。在这种情况下,如果您正在使用 NVIDIA vGPU,则必须确保在所有 GPU 上禁用 ECC 内存。
2.13.1. 禁用 ECC 内存
如果 ECC 内存不适合您的工作负载,但在您的 GPU 上已启用,请禁用它。如果您正在使用 NVIDIA vGPU 以及不支持带有 NVIDIA vGPU 的 ECC 内存的虚拟机监控程序软件版本或 GPU,您还必须确保在所有 GPU 上禁用 ECC 内存。如果您的虚拟机监控程序软件版本或 GPU 不支持 ECC 内存,并且启用了 ECC 内存,则 NVIDIA vGPU 将无法启动。
执行此任务的位置取决于您是更改物理 GPU 还是 vGPU 的 ECC 内存设置。
- 对于物理 GPU,请从虚拟机监控程序主机执行此任务。
- 对于 vGPU,请从分配了 vGPU 的 VM 执行此任务。注意
必须在 vGPU 所在的物理 GPU 上启用 ECC 内存。
在开始之前,请确保您的虚拟机监控程序上已安装 NVIDIA Virtual GPU Manager。如果您要更改 vGPU 的 ECC 内存设置,还请确保已在分配了 vGPU 的 VM 中安装 NVIDIA vGPU 软件图形驱动程序。
- 使用 nvidia-smi 列出所有物理 GPU 或 vGPU 的状态,并检查是否已注明 ECC 已启用。
# nvidia-smi -q ==============NVSMI LOG============== Timestamp : Mon Jan 20 18:36:45 2025 Driver Version : 550.144.02 Attached GPUs : 1 GPU 0000:02:00.0 [...] Ecc Mode Current : Enabled Pending : Enabled [...]
- 将每个已启用 ECC 的 GPU 的 ECC 状态更改为关闭。
- 如果您想将主机上所有 GPU 或分配给 VM 的 vGPU 的 ECC 状态更改为关闭,请运行此命令
# nvidia-smi -e 0
- 如果您想将特定 GPU 或 vGPU 的 ECC 状态更改为关闭,请运行此命令
# nvidia-smi -i id -e 0
id 是 nvidia-smi 报告的 GPU 或 vGPU 的索引。
此示例禁用索引为
0000:02:00.0的 GPU 的 ECC。# nvidia-smi -i 0000:02:00.0 -e 0
- 如果您想将主机上所有 GPU 或分配给 VM 的 vGPU 的 ECC 状态更改为关闭,请运行此命令
- 重新启动主机或重新启动 VM。
- 确认 GPU 或 vGPU 的 ECC 现在已禁用。
# nvidia—smi —q ==============NVSMI LOG============== Timestamp : Mon Jan 20 18:37:53 2025 Driver Version : 550.144.02 Attached GPUs : 1 GPU 0000:02:00.0 [...] Ecc Mode Current : Disabled Pending : Disabled [...]
如果您稍后需要启用 GPU 或 vGPU 上的 ECC,请按照启用 ECC 内存中的说明进行操作。
2.13.2. 启用 ECC 内存
如果 ECC 内存适合您的工作负载,并且您的虚拟机监控程序软件和 GPU 支持 ECC 内存,但您的 GPU 或 vGPU 上已禁用 ECC 内存,请启用它。
执行此任务的位置取决于您是更改物理 GPU 还是 vGPU 的 ECC 内存设置。
- 对于物理 GPU,请从虚拟机监控程序主机执行此任务。
- 对于 vGPU,请从分配了 vGPU 的 VM 执行此任务。注意
必须在 vGPU 所在的物理 GPU 上启用 ECC 内存。
在开始之前,请确保您的虚拟机监控程序上已安装 NVIDIA Virtual GPU Manager。如果您要更改 vGPU 的 ECC 内存设置,还请确保已在分配了 vGPU 的 VM 中安装 NVIDIA vGPU 软件图形驱动程序。
- 使用 nvidia-smi 列出所有物理 GPU 或 vGPU 的状态,并检查是否已注明 ECC 已禁用。
# nvidia-smi -q ==============NVSMI LOG============== Timestamp : Mon Jan 20 18:36:45 2025 Driver Version : 550.144.02 Attached GPUs : 1 GPU 0000:02:00.0 [...] Ecc Mode Current : Disabled Pending : Disabled [...]
- 将每个已启用 ECC 的 GPU 或 vGPU 的 ECC 状态更改为开启。
- 如果您想将主机上所有 GPU 或分配给 VM 的 vGPU 的 ECC 状态更改为开启,请运行此命令
# nvidia-smi -e 1
- 如果您想将特定 GPU 或 vGPU 的 ECC 状态更改为开启,请运行此命令
# nvidia-smi -i id -e 1
id 是 nvidia-smi 报告的 GPU 或 vGPU 的索引。
此示例启用索引为
0000:02:00.0的 GPU 的 ECC。# nvidia-smi -i 0000:02:00.0 -e 1
- 如果您想将主机上所有 GPU 或分配给 VM 的 vGPU 的 ECC 状态更改为开启,请运行此命令
- 重新启动主机或重新启动 VM。
- 确认 GPU 或 vGPU 的 ECC 现在已启用。
# nvidia—smi —q ==============NVSMI LOG============== Timestamp : Mon Jan 20 18:37:53 2025 Driver Version : 550.144.02 Attached GPUs : 1 GPU 0000:02:00.0 [...] Ecc Mode Current : Enabled Pending : Enabled [...]
如果您稍后需要禁用 GPU 或 vGPU 上的 ECC,请按照禁用 ECC 内存中的说明进行操作。
2.14. 配置 vGPU VM 以与 NVIDIA GPUDirect Storage 技术配合使用
要将 NVIDIA® GPUDirect Storage® 技术与 NVIDIA vGPU 结合使用,您必须在配置了 NVIDIA vGPU 的 VM 中安装所有必需的软件。
确保满足使用 NVIDIA vGPU 的先决条件中的先决条件。
- 按照安装和配置 Red Hat Enterprise Linux KVM 的 NVIDIA Virtual GPU Manager中所述安装和配置 NVIDIA Virtual GPU Manager。
- 以 root 用户身份登录到您在上一步中配置了 NVIDIA vGPU 的 VM。
- 按照安装 Mellanox OFED中的安装步骤中所述,在 VM 中安装 Mellanox OpenFabrics Enterprise Distribution for Linux (MLNX_OFED)。
在运行安装脚本的命令中,指定以下选项
- --with-nvmf
- --with-nfsrdma
- --enable-gds
- --add-kernel-support
- 从特定于分发的软件包在 VM 中安装适用于 Linux 的 NVIDIA vGPU 软件图形驱动程序。注意
GPUDirect Storage 技术不支持从 .run 文件安装适用于 Linux 的 NVIDIA vGPU 软件图形驱动程序。
按照 VM 中安装的 Linux 发行版的说明进行操作
- 从 .run 文件安装 NVIDIA CUDA Toolkit,在选择要安装的 CUDA 组件时取消选择 CUDA 驱动程序。注意
为避免覆盖您在上一步中安装的 NVIDIA vGPU 软件图形驱动程序,不要从特定于分发的软件包安装 NVIDIA CUDA Toolkit。
有关说明,请参阅适用于 Linux 的 NVIDIA CUDA 安装指南中的Runfile 安装。
- 使用 VM 中安装的 Linux 发行版的软件包管理器安装 GPUDirect Storage 技术软件包,省略 NVIDIA CUDA Toolkit 软件包的安装。
按照适用于 Linux 的 NVIDIA CUDA 安装指南中 VM 中安装的 Linux 发行版的说明进行操作
-
在安装 CUDA 的步骤中,仅执行包含所有 GPUDirect Storage 技术软件包的命令
sudo dnf install nvidia-gds
- Ubuntu 在安装 CUDA 的步骤中,仅执行包含所有 GPUDirect Storage 技术软件包的命令
sudo apt-get install nvidia-gds
-
在您配置 vGPU VM 以与 NVIDIA GPUDirect Storage 技术配合使用后,您可以为您正在使用的 NVIDIA vGPU 软件许可产品授权。有关说明,请参阅Virtual GPU Client Licensing User Guide。
GPU 直通用于将整个物理 GPU 直接分配给一个 VM,绕过 NVIDIA Virtual GPU Manager。在这种操作模式下,GPU 由 VM 中运行的 NVIDIA 驱动程序独占访问;GPU 不在 VM 之间共享。
在直通模式下,基于 Maxwell 架构之后的 NVIDIA GPU 架构的 GPU 支持纠错码 (ECC)。
GPU 直通可以与 NVIDIA vGPU 一起在服务器平台上使用,但有一些限制
- 一个物理 GPU 可以托管 NVIDIA vGPU,也可以用于直通,但不能同时进行。某些虚拟机监控程序(例如 VMware vSphere ESXi)需要重新启动主机才能将 GPU 从直通模式更改为 vGPU 模式。
- 单个 VM 不能同时配置 vGPU 和 GPU 直通。
- 直通到 VM 的物理 GPU 的性能只能从 VM 内部进行监控。通过虚拟机监控程序(例如 XenCenter 或 nvidia-smi)操作的工具无法监控此类 GPU(请参阅监控 GPU 性能)。
-
必须在您的服务器平台上启用以下 BIOS 设置
- VT-D/IOMMU
- 高级选项中的 SR-IOV
- 通过 NVLink 直接相互连接的所有 GPU 必须分配给同一个 VM。
您可以将多个物理 GPU 分配给一个 VM。您可以分配给 VM 的物理 GPU 的最大数量取决于您选择的虚拟机监控程序可以支持的每个 VM 的 PCIe 直通设备的最大数量。有关更多信息,请参阅您的虚拟机监控程序的文档,例如
- XenServer:配置限制
- Red Hat Enterprise Linux
- Red Hat Enterprise Linux 9 版本:将 GPU 分配给虚拟机,已知问题
- Red Hat Enterprise Linux 8 版本:将 GPU 分配给虚拟机,已知问题
- Red Hat Enterprise Linux 7 版本:GPU PCI 设备分配
- VMware vSphere:vSphere 7.0 配置限制
如果您打算将服务器平台中的所有 GPU 配置为直通,则无需安装 NVIDIA Virtual GPU Manager。
3.1. 物理 GPU 的显示分辨率
物理 GPU 支持的显示分辨率取决于 NVIDIA GPU 架构和应用于 GPU 的 NVIDIA vGPU 软件许可证。
vWS 物理 GPU 分辨率
使用 vWS 许可证许可的 GPU 支持基于可用像素数的最大组合分辨率,该像素数由 NVIDIA GPU 架构确定。您可以选择使用少量高分辨率显示器或大量低分辨率显示器来使用这些 GPU。
下表列出了每个 GPU 在每个支持的显示分辨率下的最大显示器数量,其中所有显示器都具有相同的分辨率。
| NVIDIA GPU 架构 | 可用像素 | 显示分辨率 | 每个 GPU 的显示器数 |
|---|---|---|---|
| Pascal 及更高版本 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||
| Maxwell | 35389440 | 5120×2880 | 2 |
| 4096×2160 或更低 | 4 |
下表提供了具有混合显示分辨率的配置示例。
| NVIDIA GPU 架构 | 可用像素 | 可用像素基数 | 最大显示器数 | 混合显示配置示例 |
|---|---|---|---|---|
| Pascal 及更高版本 | 66355200 | 2 个 7680×4320 显示器 | 4 | 1 个 7680×4320 显示器加 2 个 5120×2880 显示器 |
| 1 个 7680×4320 显示器加 3 个 4096×2160 显示器 | ||||
| Maxwell | 35389440 | 4 个 4096×2160 显示器 | 4 | 1 个 5120×2880 显示器加 2 个 4096×2160 显示器 |
即使显示器的组合分辨率小于 GPU 的可用像素数,您也不能使用超过四个显示器。例如,即使显示器的组合分辨率 (44236800) 小于 GPU 的可用像素数 (66355200),您也不能将五个 4096×2160 显示器与基于 NVIDIA Pascal 架构的 GPU 一起使用。
vApps 或 vCS 物理 GPU 分辨率
使用 vApps 或 vCS 许可证许可的 GPU 支持具有固定最大分辨率的单个显示器。最大分辨率取决于以下因素
- NVIDIA GPU 架构
- 应用于 GPU 的 NVIDIA vGPU 软件许可证
- 在分配了 GPU 的系统上运行的操作系统
| 许可证 | NVIDIA GPU 架构 | 操作系统 | 最大显示分辨率 | 每个 GPU 的显示器数 |
|---|---|---|---|---|
| vApps | Pascal 或更高版本 | Linux | 2560×1600 | 1 |
| Pascal 或更高版本 | Windows | 1280×1024 | 1 | |
| Maxwell | Windows 和 Linux | 2560×1600 | 1 |
3.2. 在 XenServer 上使用 GPU 直通
您可以使用 XenCenter 或 xe 命令在 XenServer 上配置 GPU 以进行直通。
当 GPU 直通与 NVIDIA vGPU 一起在服务器平台上使用时,以下附加限制适用
- 通过 XenCenter 无法监控直通到 VM 的物理 GPU 的性能。
- dom0 中的 nvidia-smi 不再有权访问 GPU。
- 直通 GPU 不通过 XenCenter 的 VM 控制台选项卡提供控制台输出。直接使用远程图形连接到 VM 以访问 VM 的操作系统。
3.2.1. 通过使用 XenCenter 配置 VM 以进行 GPU 直通
在 VM 的属性中选择直通整个 GPU选项作为 GPU 类型:
图 14. 使用 XenCenter 配置直通 GPU

在为 GPU 直通配置 XenServer VM 后,按照安装 NVIDIA vGPU 软件图形驱动程序中所述,在 VM 上的客户机操作系统中安装 NVIDIA 图形驱动程序。
3.2.2. 通过使用 xe 配置 VM 以进行 GPU 直通
使用 passthrough vGPU 类型创建 vgpu 对象
[root@xenserver ~]# xe vgpu-type-list model-name="passthrough"
uuid ( RO) : fa50b0f0-9705-6c59-689e-ea62a3d35237
vendor-name ( RO):
model-name ( RO): passthrough
framebuffer-size ( RO): 0
[root@xenserver ~]# xe vgpu-create vm-uuid=753e77a9-e10d-7679-f674-65c078abb2eb vgpu-type-uuid=fa50b0f0-9705-6c59-689e-ea62a3d35237 gpu-group-uuid=585877ef-5a6c-66af-fc56-7bd525bdc2f6
6aa530ec-8f27-86bd-b8e4-fe4fde8f08f9
[root@xenserver ~]#
不要使用旧版 other-config:pci 参数设置来分配直通 GPU。XenCenter UI 和 xe vgpu 机制不支持此机制,尝试使用它可能会导致未定义的后果。
在为 GPU 直通配置 XenServer VM 后,按照安装 NVIDIA vGPU 软件图形驱动程序中所述,在 VM 上的客户机操作系统中安装 NVIDIA 图形驱动程序。
3.3. 在 Linux 上使用 KVM 虚拟机监控程序使用 GPU 直通
NVIDIA vGPU 软件支持以下带有 KVM hypervisor 的 Linux:带有 KVM 的 Red Hat Enterprise Linux 和 Ubuntu。
您可以使用以下任何工具在 Linux 上使用 KVM 虚拟机监控程序配置 GPU 以进行直通
- Virtual Machine Manager (virt-manager) 图形工具
- virsh 命令
- QEMU 命令行
在 Red Hat Enterprise Linux KVM 或 Ubuntu 上配置 GPU 以进行直通之前,请确保满足以下先决条件
- 已安装 Red Hat Enterprise Linux KVM 或 Ubuntu。
- 已创建虚拟磁盘。注意
请勿在 /root 中创建任何虚拟磁盘。
- 已创建虚拟机。
如果您要配置需要 UEFI VM 上大型 BAR 地址空间的直通 GPU,请参阅NVIDIA vGPU 软件图形驱动程序在基于 KVM 的虚拟机监控程序上加载失败,以获取确保 BAR 资源映射到 VM 中的解决方法。
此解决方法涉及设置实验性 QEMU 参数。
3.3.1. 通过使用 Virtual Machine Manager (virt-manager) 配置 VM 以进行 GPU 直通
有关使用 Virtual Machine Manager 的更多信息,请参阅 Red Hat Enterprise Linux 7 文档中的以下主题
- 启动 virt-manager。
- 在 virt-manager 主窗口中,选择您要配置直通的虚拟机 (VM)。
- 从编辑菜单中,选择虚拟机详情。
- 在打开的虚拟机硬件信息窗口中,单击添加硬件。
- 在打开的“添加新虚拟硬件”对话框中,在左侧的硬件列表中,选择 PCI 主机设备。
- 从出现的主机设备列表中,选择您要分配给虚拟机的 GPU,然后单击完成。
如果您想从已分配 GPU 的虚拟机中移除 GPU,请在虚拟机硬件信息窗口中选择该 GPU,然后单击移除。
在为 GPU 直通配置虚拟机后,按照安装 NVIDIA vGPU 软件图形驱动程序中的说明,在虚拟机上的客户机操作系统中安装 NVIDIA 图形驱动程序。
3.3.2. 使用 virsh 配置 GPU 直通虚拟机
有关使用 virsh 的更多信息,请参阅 Red Hat Enterprise Linux 7 文档中的以下主题
- 验证
vfio-pci模块是否已加载。# lsmod | grep vfio-pci
- 获取您想要在直通模式下分配给虚拟机的 GPU 的 PCI 设备总线/设备/功能 (BDF)。
# lspci | grep NVIDIA
此示例中列出的 NVIDIA GPU 的 PCI 设备 BDF 为
85:00.0和86:00.0。# lspci | grep NVIDIA 85:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [Tesla M60] (rev a1) 86:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [Tesla M60] (rev a1)
- 从 GPU 的 PCI 设备 BDF 获取 GPU 的完整标识符。
# virsh nodedev-list --cap pci| grep transformed-bdf
- transformed-bdf
- GPU 的 PCI 设备 BDF,其中冒号和句点替换为下划线,例如
85_00_0。
此示例获取 PCI 设备 BDF 为
85:00.0的 GPU 的完整标识符。# virsh nodedev-list --cap pci| grep 85_00_0 pci_0000_85_00_0
- 获取 GPU 的域、总线、插槽和功能。
virsh nodedev-dumpxml full-identifier| egrep 'domain|bus|slot|function'
- full-identifier
- 您在上一步中获得的 GPU 的完整标识符,例如
pci_0000_85_00_0。
此示例获取 PCI 设备 BDF 为
85:00.0的 GPU 的域、总线、插槽和功能。# virsh nodedev-dumpxml pci_0000_85_00_0| egrep 'domain|bus|slot|function' <domain>0x0000</domain> <bus>0x85</bus> <slot>0x00</slot> <function>0x0</function> <address domain='0x0000' bus='0x85' slot='0x00' function='0x0'/>
- 在 virsh 中,打开要将 GPU 分配到的虚拟机的 XML 文件进行编辑。
# virsh edit vm-name
- vm-name
- 您要将 GPU 分配到的虚拟机的名称。
- 在
source元素内添加address元素形式的设备条目,以将 GPU 分配给客户机虚拟机。 您可以选择在source元素之后添加第二个 address 元素,以在客户机操作系统中为 GPU 设置固定的 PCI 设备 BDF。<hostdev mode='subsystem' type='pci' managed='yes'> <source> <address domain='domain' bus='bus' slot='slot' function='function'/> </source> <address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/> </hostdev>
- domain
- bus
- slot
- function
- 您在上一步中获得的 GPU 的域、总线、插槽和功能。
此示例为 PCI 设备 BDF 为
85:00.0的 GPU 添加设备条目,并为客户机操作系统中的 GPU 固定 BDF。<hostdev mode='subsystem' type='pci' managed='yes'> <source> <address domain='0x0000' bus='0x85' slot='0x00' function='0x0'/> </source> <address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/> </hostdev>
- 启动您已分配 GPU 的虚拟机。
# virsh start vm-name
- vm-name
- 您已分配 GPU 的虚拟机的名称。
在为 GPU 直通配置虚拟机后,按照安装 NVIDIA vGPU 软件图形驱动程序中的说明,在虚拟机上的客户机操作系统中安装 NVIDIA 图形驱动程序。
3.3.3. 使用 QEMU 命令行配置 GPU 直通虚拟机
- 获取您想要在直通模式下分配给虚拟机的 GPU 的 PCI 设备总线/设备/功能 (BDF)。
# lspci | grep NVIDIA
此示例中列出的 NVIDIA GPU 的 PCI 设备 BDF 为
85:00.0和86:00.0。# lspci | grep NVIDIA 85:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [Tesla M60] (rev a1) 86:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [Tesla M60] (rev a1)
- 将以下选项添加到 QEMU 命令行
-device vfio-pci,host=bdf
- bdf
- 您想要在直通模式下分配给虚拟机的 GPU 的 PCI 设备 BDF,例如
85:00.0。
此示例将 PCI 设备 BDF 为
85:00.0的 GPU 以直通模式分配给虚拟机。-device vfio-pci,host=85:00.0
在为 GPU 直通配置虚拟机后,按照安装 NVIDIA vGPU 软件图形驱动程序中的说明,在虚拟机上的客户机操作系统中安装 NVIDIA 图形驱动程序。
3.3.4. 准备配置为 vGPU 的 GPU 以用于直通模式
物理 GPU 使用的模式决定了 GPU 绑定的 Linux 内核模块。 如果您想要切换 GPU 的使用模式,您必须将 GPU 从其当前的内核模块解绑,并将其绑定到新模式的内核模块。 将 GPU 绑定到正确的内核模块后,您可以将其配置为直通。
当 Virtual GPU Manager 安装在 Red Hat Enterprise Linux KVM 或 Ubuntu 主机上时,主机上的物理 GPU 将绑定到 nvidia 内核模块。 绑定到 nvidia 内核模块的物理 GPU 只能用于 vGPU。 要使 GPU 能够直通到虚拟机,必须将 GPU 从 nvidia 内核模块解绑,并绑定到 vfio-pci 内核模块。
在开始之前,请确保您拥有要准备用于直通模式的 GPU 的域、总线、插槽和功能。 有关说明,请参阅在具有 KVM Hypervisor 的 Linux 上获取 GPU 的 BDF 和域。
- 如果您使用的是支持 SR-IOV 的 GPU,例如基于 NVIDIA Ampere 架构的 GPU,请在 sysfs 文件系统中禁用 GPU 的虚拟功能。
如果您的 GPU 不支持 SR-IOV,请省略此步骤。
注意在执行此步骤之前,请确保 GPU 未被任何其他进程使用,例如 CUDA 应用程序、监控应用程序或 nvidia-smi 命令。
为此目的,请使用 NVIDIA vGPU 软件提供的自定义脚本 sriov-manage。
# /usr/lib/nvidia/sriov-manage -d domain:bus:slot.function
- domain
- bus
- slot
- function
- GPU 的域、总线、插槽和功能,不带
0x前缀。
此示例禁用域
00、总线06、插槽0000和功能0的 GPU 的虚拟功能。# /usr/lib/nvidia/sriov-manage -d 00:06:0000.0
- 通过在主机上的 NVIDIA GPU 上运行带有 -k 选项的 lspci 命令,确定 GPU 绑定的内核模块。
# lspci -d 10de: -k
Kernel driver in use:字段指示 GPU 绑定的内核模块。以下示例显示 BDF 为
06:00.0的 NVIDIA Tesla M60 GPU 已绑定到nvidia内核模块,并且正在用于 vGPU。06:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [Tesla M60] (rev a1) Subsystem: NVIDIA Corporation Device 115e Kernel driver in use: nvidia
- 为确保没有客户端正在使用 GPU,请获取 GPU 的解绑锁。
- 确保没有虚拟机正在运行,并且没有主机上运行的进程正在使用该 GPU (分配了物理 GPU 上的 vGPU 的虚拟机)。 主机上使用 GPU 的进程包括 nvidia-smi 命令和所有基于 NVIDIA Management Library (NVML) 的进程。
- 更改到 proc 文件系统中代表 GPU 的目录。
# cd /proc/driver/nvidia/gpus/domain\:bus\:slot.function
- domain
- bus
- slot
- function
- GPU 的域、总线、插槽和功能,不带
0x前缀。
此示例更改到 proc 文件系统中代表域为
0000且 PCI 设备 BDF 为06:00.0的 GPU 的目录。# cd /proc/driver/nvidia/gpus/0000\:06\:00.0
- 将值
1写入此目录中的 unbindLock 文件。# echo 1 > unbindLock
- 确认 unbindLock 文件现在包含值
1。# cat unbindLock 1
如果 unbindLock 文件包含值
0,则无法获取解绑锁,因为进程或客户端正在使用 GPU。
- 将 GPU 从
nvidia内核模块解绑。- 更改到表示
nvidia内核模块的 sysfs 目录。# cd /sys/bus/pci/drivers/nvidia
- 将 GPU 的域、总线、插槽和功能写入此目录中的 unbind 文件。
# echo domain:bus:slot.function > unbind
- domain
- bus
- slot
- function
- GPU 的域、总线、插槽和功能,不带
0x前缀。
此示例写入域为
0000且 PCI 设备 BDF 为06:00.0的 GPU 的域、总线、插槽和功能。# echo 0000:06:00.0 > unbind
- 更改到表示
- 将 GPU 绑定到
vfio-pci内核模块。- 更改到 sysfs 目录,该目录包含物理 GPU 的 PCI 设备信息。
# cd /sys/bus/pci/devices/domain\:bus\:slot.function
- domain
- bus
- slot
- function
- GPU 的域、总线、插槽和功能,不带
0x前缀。
此示例更改到 sysfs 目录,该目录包含域为
0000且 PCI 设备 BDF 为06:00.0的 GPU 的 PCI 设备信息。# cd /sys/bus/pci/devices/0000\:06\:00.0
- 将内核模块名称
vfio-pci写入此目录中的 driver_override 文件。# echo vfio-pci > driver_override
- 更改到表示
nvidia内核模块的 sysfs 目录。# cd /sys/bus/pci/drivers/vfio-pci
- 将 GPU 的域、总线、插槽和功能写入此目录中的 bind 文件。
# echo domain:bus:slot.function > bind
- domain
- bus
- slot
- function
- GPU 的域、总线、插槽和功能,不带
0x前缀。
此示例写入域为
0000且 PCI 设备 BDF 为06:00.0的 GPU 的域、总线、插槽和功能。# echo 0000:06:00.0 > bind
- 更改回包含物理 GPU 的 PCI 设备信息的 sysfs 目录。
# cd /sys/bus/pci/devices/domain\:bus\:slot.function
- 清除此目录中 driver_override 文件的内容。
# echo > driver_override
- 更改到 sysfs 目录,该目录包含物理 GPU 的 PCI 设备信息。
现在您可以按照在带有 KVM 虚拟化程序的 Linux 上使用 GPU 直通中的说明,配置 GPU 以用于直通模式。
3.4. 在 Microsoft Windows Server 上使用 GPU 直通
在支持的带有 Hyper-V 角色的 Microsoft Windows Server 版本上,您可以使用离散设备分配 (DDA) 来使虚拟机能够直接访问 GPU。
3.4.1. 在带有 Hyper-V 的 Microsoft Windows Server 上将 GPU 分配给虚拟机
在 Windows PowerShell 中执行此任务。 如果您不知道要分配给虚拟机的 GPU 的位置路径,请使用设备管理器获取它。
如果您使用的是主动散热的 NVIDIA Quadro 显卡,例如 RTX 8000 或 RTX 6000,您还必须直通显卡上的音频设备。
确保满足以下先决条件
-
服务器平台上已安装并配置了带有桌面体验的 Windows Server 和 Hyper-V 角色,并且已创建虚拟机。
有关说明,请参阅 Microsoft 技术文档站点上的以下文章
- 客户机操作系统已安装在虚拟机中。
- 虚拟机已关闭电源。
- 获取您要分配给虚拟机的 GPU 的位置路径。
- 在设备管理器中,右键单击 GPU,然后从弹出的菜单中选择属性。
- 在打开的“属性”窗口中,单击详细信息选项卡,然后在属性下拉列表中,选择位置路径。
位置路径示例如下
PCIROOT(80)#PCI(0200)#PCI(0000)#PCI(1000)#PCI(0000)
- 如果您使用的是主动散热的 NVIDIA Quadro 显卡,请获取显卡上音频设备的位置路径并禁用该设备。
- 在设备管理器中,从查看菜单中,选择按连接列出设备。
- 导航到 ACPI x64-based PC > Microsoft ACPI-Compliant System > PCI Express Root Complex > PCI-to-PCI Bridge。
- 右键单击高清音频控制器,然后从弹出的菜单中选择属性。
- 在打开的“属性”窗口中,单击详细信息选项卡,然后在属性下拉列表中,选择位置路径。
- 再次右键单击高清音频控制器,然后从弹出的菜单中选择禁用设备。
- 从主机卸载 GPU 以及(如果存在)音频设备,使其对主机不可用,以便它们只能由虚拟机使用。
对于您要卸载的每个设备,键入以下命令
Dismount-VMHostAssignableDevice -LocationPath gpu-device-location -force
- gpu-device-location
- 您先前获得的 GPU 或音频设备的位置路径。
此示例卸载位置路径为
PCIROOT(80)#PCI(0200)#PCI(0000)#PCI(1000)#PCI(0000)的 GPU。Dismount-VMHostAssignableDevice -LocationPath "PCIROOT(80)#PCI(0200)#PCI(0000)#PCI(1000)#PCI(0000)" -force
- 将您在上一步中卸载的 GPU 以及(如果存在)音频设备分配给虚拟机。
对于您要分配的每个设备,键入以下命令
Add-VMAssignableDevice -LocationPath gpu-device-location -VMName vm-name
- gpu-device-location
- 您在上一步中卸载的 GPU 或音频设备的位置路径。
- vm-name
- 您要附加 GPU 或音频设备的虚拟机的名称。
注意您一次只能将一个直通 GPU 以及(如果存在)其音频设备分配给 一台虚拟机。
此示例将位置路径为
PCIROOT(80)#PCI(0200)#PCI(0000)#PCI(1000)#PCI(0000)的 GPU 分配给虚拟机VM1。Add-VMAssignableDevice -LocationPath "PCIROOT(80)#PCI(0200)#PCI(0000)#PCI(1000)#PCI(0000)" -VMName VM1
- 开启虚拟机电源。 客户机操作系统现在应该能够使用 GPU 以及(如果存在)音频设备。
在将 GPU 分配给虚拟机后,按照安装 NVIDIA vGPU 软件图形驱动程序中的说明,在虚拟机上的客户机操作系统中安装 NVIDIA 图形驱动程序。
3.4.2. 在带有 Hyper-V 的 Windows Server 上从虚拟机将 GPU 返回到主机操作系统
在 Windows PowerShell 中执行此任务。
如果您使用的是主动散热的 NVIDIA Quadro 显卡,例如 RTX 8000 或 RTX 6000,您还必须返回显卡上的音频设备。
- 列出当前分配给虚拟机 (VM) 的 GPU 以及(如果存在)音频设备。
Get-VMAssignableDevice -VMName vm-name
- vm-name
- 您要列出已分配的 GPU 和音频设备的虚拟机的名称。
- 关闭已分配 GPU 和任何音频设备的虚拟机。
- 从已分配 GPU 和(如果存在)音频设备的虚拟机中移除它们。
对于您要移除的每个设备,键入以下命令
Remove-VMAssignableDevice –LocationPath gpu-device-location -VMName vm-name
- gpu-device-location
- 您先前获得的要移除的 GPU 或音频设备的位置路径。
- vm-name
- 您要从中移除 GPU 或音频设备的虚拟机的名称。
此示例从虚拟机
VM1中移除位置路径为PCIROOT(80)#PCI(0200)#PCI(0000)#PCI(1000)#PCI(0000)的 GPU。Remove-VMAssignableDevice –LocationPath "PCIROOT(80)#PCI(0200)#PCI(0000)#PCI(1000)#PCI(0000)" -VMName VM1
从虚拟机中移除 GPU 以及(如果存在)其音频设备后,在您将它们重新挂载到主机操作系统 (OS) 上之前,它们对主机操作系统不可用。
- 将 GPU 以及(如果存在)音频设备重新挂载到主机操作系统上。
对于您要重新挂载的每个设备,键入以下命令
Mount-VMHostAssignableDevice –LocationPath gpu-device-location
- gpu-device-location
- 您在上一步中指定的要从虚拟机中移除 GPU 或音频设备的位置路径 (用于移除)。
此示例将位置路径为
PCIROOT(80)#PCI(0200)#PCI(0000)#PCI(1000)#PCI(0000)的 GPU 重新挂载到主机操作系统上。Mount-VMHostAssignableDevice -LocationPath "PCIROOT(80)#PCI(0200)#PCI(0000)#PCI(1000)#PCI(0000)"
主机操作系统现在应该能够使用 GPU 以及(如果存在)音频设备。
3.5. 在 VMware vSphere 上使用 GPU 直通
在 VMware vSphere 上,您可以使用虚拟专用图形加速 (vDGA) 来使虚拟机能够直接访问 GPU。 vDGA 是 VMware vSphere 的一项功能,它将 ESXi 主机上的单个物理 GPU 专用于单个虚拟机。
在配置具有 vDGA 的 vSphere 虚拟机之前,请确保满足以下先决条件
- 虚拟机和 ESXi 主机已按照 VMware Horizon 文档中的准备 vDGA 功能中的说明进行配置。
- 虚拟机已关闭电源。
- 打开 vCenter Web UI。
- 在 vCenter Web UI 中,右键单击 ESXi 主机,然后选择配置。
- 从硬件菜单中,选择 PCI 设备。
- 在打开的“PCI 设备”页面上,单击所有 PCI 设备,然后在设备表中,选择 GPU。注意
选择要直通的 GPU 时,您必须仅选择物理设备。 要仅列出 NVIDIA 物理设备,请将供应商名称字段上的过滤器设置为 NVIDIA,并通过将 ID 字段上的过滤器设置为 00.0 来过滤掉 GPU 的任何虚拟功能设备。
- 单击切换直通。
- 重启 ESXi 主机。
- 在 ESXi 主机启动后,右键单击虚拟机,然后选择编辑设置。
- 从新设备菜单中,选择 PCI 设备,然后单击添加。
- 在打开的页面上,从新设备下拉列表中,选择 GPU。
- 单击预留所有内存,然后单击确定。
- 启动虚拟机。

有关 vDGA 的更多信息,请参阅 VMware Horizon 文档中的以下主题
在配置具有 vDGA 的 vSphere 虚拟机后,按照安装 NVIDIA vGPU 软件图形驱动程序中的说明,在虚拟机上的客户机操作系统中安装 NVIDIA 图形驱动程序。
安装 NVIDIA vGPU 软件图形驱动程序的过程取决于您使用的操作系统。 但是,对于任何操作系统,在配置了 vGPU 的虚拟机、运行直通 GPU 的虚拟机或裸机部署中的物理主机上安装驱动程序的过程都是相同的。
在安装 NVIDIA vGPU 软件图形驱动程序后,您可以许可您正在使用的任何 NVIDIA vGPU 软件许可产品。
4.1. 在 Windows 上安装 NVIDIA vGPU 软件图形驱动程序和 NVIDIA 控制面板
要完全启用虚拟机或裸机主机中的 GPU 操作,必须安装 NVIDIA vGPU 软件图形驱动程序。 如果在安装图形驱动程序时未安装 NVIDIA 控制面板应用程序,您可以从图形驱动程序单独安装它。
4.1.1. 在 Windows 上安装 NVIDIA vGPU 软件图形驱动程序
在虚拟机中安装:在 Hypervisor 上创建 Windows 虚拟机并启动虚拟机后,虚拟机应以 800×600 分辨率的 VGA 模式启动到标准 Windows 桌面。 您可以使用 Windows 屏幕分辨率控制面板将分辨率提高到其他标准分辨率,但要完全启用 GPU 操作,必须安装 NVIDIA vGPU 软件图形驱动程序。 所有 NVIDIA vGPU 类型(即:Q 系列、B 系列和 A 系列 NVIDIA vGPU 类型)均支持 Windows 客户机虚拟机。
在裸机上安装:在安装 NVIDIA vGPU 软件图形驱动程序之前启动物理主机时,启动和主显示器由板载图形适配器处理。 要安装 NVIDIA vGPU 软件图形驱动程序,请使用通过板载图形适配器连接的显示器访问主机上的 Windows 桌面。
在虚拟机和裸机上安装驱动程序的过程是相同的。
- 将 NVIDIA Windows 驱动程序包复制到您要安装驱动程序的客户机虚拟机或物理主机。
- 执行该软件包以解压缩并运行驱动程序安装程序。
图 15. NVIDIA 驱动程序安装
- 单击以浏览许可协议。
- 选择快速安装,然后单击下一步。 驱动程序安装完成后,安装程序可能会提示您重新启动平台。
- 如果提示您重新启动平台,请执行以下操作之一
- 选择立即重新启动以重新启动虚拟机或物理主机。
- 退出安装程序,并在准备就绪时重新启动虚拟机或物理主机。
虚拟机或物理主机重新启动后,它将启动到 Windows 桌面。
- 验证 NVIDIA 驱动程序是否正在运行。


在虚拟机中安装:安装 NVIDIA vGPU 软件图形驱动程序后,您可以许可您正在使用的任何 NVIDIA vGPU 软件许可产品。 有关说明,请参阅虚拟 GPU 客户端许可用户指南。
此 NVIDIA vGPU 软件版本中的 Windows 图形驱动程序以符合 DCH 标准的软件包分发。 符合 DCH 标准的软件包与不符合 DCH 标准的驱动程序软件包在以下方面有所不同
- 符合 DCH 标准的软件包的许可证设置的 Windows 注册表项与不符合 DCH 标准的驱动程序软件包的项不同。 如果您从先前已许可的虚拟机中不符合 DCH 标准的驱动程序软件包升级,则必须重新配置虚拟机的许可证设置。 现有许可证设置不会传播到符合 DCH 标准的软件包的新 Windows 注册表项。
- NVIDIA 系统管理界面 nvidia-smi 安装在默认可执行路径中的文件夹中。
- NVWMI 二进制文件安装在 %SystemDrive%:\Windows\System32\DriverStore\FileRepository\ 下的 Windows 驱动程序存储中。
- Windows 帮助格式的 NVWMI 帮助信息未与 Windows 客户机操作系统的图形驱动程序一起安装。
在裸机上安装:安装 NVIDIA vGPU 软件图形驱动程序后,按照裸机部署中的说明完成裸机部署。
4.1.2. 安装独立的 NVIDIA 控制面板应用程序
NVIDIA 控制面板应用程序现在通过 Microsoft Store 分发。 如果您的系统不允许从 Microsoft Store 安装应用程序,则在安装 Windows 的 NVIDIA vGPU 软件图形驱动程序时,不会安装 NVIDIA 控制面板应用程序。
您的系统可能因以下任何原因不允许从 Microsoft Store 安装应用程序
- Microsoft Store 应用程序已禁用。
- 您的系统未连接到 Internet
- 从 Microsoft Store 安装应用程序被您的系统设置阻止。
您可以从 NVIDIA Licensing Portal 下载并运行独立的 NVIDIA 控制面板安装程序,从而从图形驱动程序单独安装 NVIDIA 控制面板应用程序。
- 从 NVIDIA Licensing Portal 下载并解压缩独立的 NVIDIA 控制面板安装程序。
- 将解压缩的独立的 NVIDIA 控制面板安装程序复制到您要安装 NVIDIA 控制面板应用程序的客户机虚拟机或物理主机。
- 双击安装程序可执行文件以启动安装程序。
- 当询问您是否要允许安装程序应用程序对您的设备进行更改时,单击是。
- 接受 NVIDIA 软件许可协议。
- 选择快速安装选项,然后单击下一步。
- 安装完成后,单击关闭以关闭安装程序。 NVIDIA 控制面板应用程序将打开。
4.2. 在 Linux 上安装 NVIDIA vGPU 软件图形驱动程序
Linux 的 NVIDIA vGPU 软件图形驱动程序以 .run 文件形式分发,可以在所有受支持的 Linux 发行版上安装。 该驱动程序也以 Debian 软件包形式分发用于 Ubuntu 发行版,并以 RPM 软件包形式分发用于 Red Hat 发行版。
在虚拟机中安装:在 Hypervisor 上创建 Linux 虚拟机并启动虚拟机后,在虚拟机中安装 NVIDIA vGPU 软件图形驱动程序以完全启用 GPU 操作。 所有 NVIDIA vGPU 类型(即:Q 系列、B 系列和 A 系列 NVIDIA vGPU 类型)均支持 Linux 客户机虚拟机。
裸机安装:在安装 NVIDIA vGPU 软件图形驱动程序之前启动物理主机时,vesa Xorg 驱动程序会启动 X 服务器。如果主显示设备已连接到主机,请使用该设备访问桌面。否则,请使用安全外壳 (SSH) 从远程主机登录到该主机。除了 NVIDIA vGPU 软件 Linux 图形驱动程序的专有版本之外,还提供基于 NVIDIA Linux 开源 GPU 内核模块的版本。基于 NVIDIA Linux 开源 GPU 内核模块的版本与以下 NVIDIA vGPU 软件部署兼容:
- 基于 NVIDIA Ada Lovelace GPU 架构或更高架构的 GPU 上的 NVIDIA vGPU 部署
- 基于 NVIDIA Turing GPU 架构或更高架构的 GPU 上的裸机部署
基于 NVIDIA Linux 开源 GPU 内核模块的版本仅能从 .run 文件安装,不能从 Debian 软件包或 RPM 软件包安装。
在虚拟机和裸机上安装驱动程序的过程是相同的。
在安装 NVIDIA vGPU 软件图形驱动程序之前,请确保满足以下先决条件:
- 虚拟机中已安装 OpenSSL。如果未安装 OpenSSL,虚拟机将无法获取 NVIDIA vGPU 软件许可证。
- NVIDIA Direct Rendering Manager Kernel Modesetting (DRM KMS) 已禁用。默认情况下,DRM KMS 处于禁用状态。但是,如果已启用,请从内核命令行选项中删除
nvidia-drm.modeset=1。 - 如果虚拟机使用 UEFI 启动,请确保安全启动处于禁用状态。
- 如果存在 Nouveau NVIDIA 显卡驱动程序,请将其禁用。有关说明,请参阅禁用 Nouveau NVIDIA 显卡驱动程序中的说明。
- 如果您使用的 Linux 操作系统默认启用了 Wayland 显示服务器协议,请按照为 Red Hat Enterprise Linux 禁用 Wayland 显示服务器协议中的说明禁用它。
如何在 Linux 上安装 NVIDIA vGPU 软件图形驱动程序取决于您从中安装驱动程序的分发格式。有关详细说明,请参阅:
- 从 .run 文件在 Linux 上安装 NVIDIA vGPU 软件图形驱动程序
- 从 Debian 软件包在 Ubuntu 上安装 NVIDIA vGPU 软件图形驱动程序
- 从 RPM 软件包在 Red Hat 发行版上安装 NVIDIA vGPU 软件图形驱动程序
在虚拟机中安装:安装 NVIDIA vGPU 软件图形驱动程序后,您可以许可您正在使用的任何 NVIDIA vGPU 软件许可产品。 有关说明,请参阅虚拟 GPU 客户端许可用户指南。
在裸机上安装:安装 NVIDIA vGPU 软件图形驱动程序后,按照裸机部署中的说明完成裸机部署。
4.2.1. 从 .run 文件在 Linux 上安装 NVIDIA vGPU 软件图形驱动程序
您可以使用 .run 文件在任何受支持的 Linux 发行版上安装 NVIDIA vGPU 软件图形驱动程序。
从 .run 文件安装 NVIDIA vGPU 软件 Linux 图形驱动程序需要:
- 编译器工具链
- 内核头文件
如果先前已从 Debian 软件包或 RPM 软件包在客户虚拟机或物理主机上安装了驱动程序,请先卸载该驱动程序,然后再从 .run 文件安装驱动程序。
如果启用了动态内核模块支持 (DKMS),请确保已安装 dkms 软件包。
- 复制 NVIDIA vGPU 软件 Linux 驱动程序包,例如 NVIDIA-Linux_x86_64-550.144.03-grid.run,到您要安装驱动程序的客户虚拟机或物理主机。
- 在尝试运行驱动程序安装程序之前,退出 X 服务器并终止所有 OpenGL 应用程序。
- 在 Red Hat Enterprise Linux 和 CentOS 系统上,通过转换为运行级别 3 来退出 X 服务器。
[nvidia@localhost ~]$ sudo init 3
- 在 Ubuntu 平台上,请执行以下操作:
- 切换到控制台登录提示符。
- 如果您可以访问终端的功能键,请按 CTRL-ALT-F1。
- 如果您通过 VNC 或 Web 浏览器访问客户虚拟机或物理主机,并且无法访问终端的功能键,请以 root 用户身份运行操作系统的 chvt 命令。
[nvidia@localhost ~]$ sudo chvt 3
- 登录并关闭显示管理器。
-
对于 Ubuntu 18 及更高版本,停止 gdm 服务。
[nvidia@localhost ~]$ sudo service gdm stop
-
对于早于 Ubuntu 18 的版本,停止 lightdm 服务。
[nvidia@localhost ~]$ sudo service lightdm stop
-
- 切换到控制台登录提示符。
- 在 Red Hat Enterprise Linux 和 CentOS 系统上,通过转换为运行级别 3 来退出 X 服务器。
- 从控制台 shell 中,以 root 用户身份运行驱动程序安装程序。
- 要安装驱动程序的专有版本,请在不使用任何附加选项的情况下运行驱动程序安装程序。
sudo sh ./NVIDIA-Linux_x86_64-550.144.03-grid.run
- 要安装基于 NVIDIA Linux 开源 GPU 内核模块的版本,请使用 -m=kernel-open 选项运行驱动程序安装程序。
sudo sh ./NVIDIA-Linux_x86_64-550.144.03-grid.run -m=kernel-open
如果启用了 DKMS,请设置 -dkms 选项。此选项需要安装
dkms软件包。sudo sh ./NVIDIA-Linux_x86_64-550.144.03-grid.run -dkms
在某些情况下,安装程序可能无法检测到已安装的内核头文件和源文件。在这种情况下,请重新运行安装程序,并使用 --kernel-source-path 选项指定内核源路径。
sudo sh ./NVIDIA-Linux_x86_64-550.144.03-grid.run \ –kernel-source-path=/usr/src/kernels/3.10.0-229.11.1.el7.x86_64
- 要安装驱动程序的专有版本,请在不使用任何附加选项的情况下运行驱动程序安装程序。
- 出现提示时,接受更新 X 配置文件 (xorg.conf) 的选项。
图 17. 更新 xorg.conf 设置
- 安装完成后,选择确定以退出安装程序。
- 验证 NVIDIA 驱动程序是否正常运行。
- 重新启动系统并登录。
- 运行 nvidia-settings。
[nvidia@localhost ~]$ nvidia-settings

4.2.2. 从 Debian 软件包在 Ubuntu 上安装 NVIDIA vGPU 软件图形驱动程序
适用于 Ubuntu 的 NVIDIA vGPU 软件图形驱动程序以 Debian 软件包文件的形式分发。
此任务需要 sudo 权限。
- 复制 NVIDIA vGPU 软件 Linux 驱动程序包,例如 nvidia-linux-grid-550_550.144.03_amd64.deb,到您要安装驱动程序的客户虚拟机。
- 以具有 sudo 权限的用户身份登录到客户虚拟机。
- 打开命令 shell 并更改到包含 NVIDIA vGPU 软件 Linux 驱动程序包的目录。
- 从命令 shell 中,运行命令以安装软件包。
$ sudo apt-get install ./nvidia-linux-grid-550_550.144.03_amd64.deb
- 验证 NVIDIA 驱动程序是否正常运行。
- 重新启动系统并登录。
- 系统重新启动后,确认您可以在 nvidia-smi 命令的输出中看到您的 NVIDIA vGPU 设备。
$ nvidia-smi
4.2.3. 从 RPM 软件包在 Red Hat 发行版上安装 NVIDIA vGPU 软件图形驱动程序
适用于 Red Hat 发行版的 NVIDIA vGPU 软件图形驱动程序以 RPM 软件包文件的形式分发。
此任务需要 root 用户权限。
- 复制 NVIDIA vGPU 软件 Linux 驱动程序包,例如 nvidia-linux-grid-550_550.144.03_amd64.rpm,到您要安装驱动程序的客户虚拟机。
- 以具有
root用户权限的用户身份登录到客户虚拟机。 - 打开命令 shell 并更改到包含 NVIDIA vGPU 软件 Linux 驱动程序包的目录。
- 从命令 shell 中,运行命令以安装软件包。
$ rpm -iv ./nvidia-linux-grid-550_550.144.03_amd64.rpm
- 验证 NVIDIA 驱动程序是否正常运行。
- 重新启动系统并登录。
- 系统重新启动后,确认您可以在 nvidia-smi 命令的输出中看到您的 NVIDIA vGPU 设备。
$ nvidia-smi
4.2.4. 禁用 Nouveau NVIDIA 显卡驱动程序
如果存在 Nouveau NVIDIA 显卡驱动程序,请在安装 NVIDIA vGPU 软件图形驱动程序之前将其禁用。
如果您使用的是 SUSE Linux Enterprise Server,则可以跳过此任务,因为 Nouveau 驱动程序在 SUSE Linux Enterprise Server 中不存在。
运行以下命令,如果该命令打印任何输出,则表示 Nouveau 驱动程序存在,必须将其禁用。
$ lsmod | grep nouveau
- 创建文件 /etc/modprobe.d/blacklist-nouveau.conf,内容如下:
blacklist nouveau options nouveau modeset=0
- 重新生成内核初始 RAM 文件系统 (initramfs)。用于重新生成内核 initramfs 的命令取决于您使用的 Linux 发行版。
Linux 发行版 命令 CentOS $ sudo dracut --force
Debian $ sudo update-initramfs -u
Red Hat Enterprise Linux $ sudo dracut --force
Ubuntu $ sudo update-initramfs -u
- 重新启动主机或客户虚拟机。
4.2.5. 为 Red Hat Enterprise Linux 禁用 Wayland 显示服务器协议
从 Red Hat Enterprise Linux Desktop 8.0 开始,在受支持的 GPU 和图形驱动程序配置上,默认使用 Wayland 显示服务器协议。但是,NVIDIA vGPU 软件 Linux 图形驱动程序需要 X Window 系统。在安装驱动程序之前,您必须禁用 Wayland 显示服务器协议以恢复到 X Window 系统。
从运行 Red Hat Enterprise Linux Desktop 的主机或客户虚拟机执行此任务。
此任务需要管理权限。
- 在纯文本编辑器中,编辑文件 /etc/gdm/custom.conf,并删除选项
WaylandEnable=false的注释。 - 将您的更改保存到 /etc/gdm/custom.conf。
- 重新启动主机或客户虚拟机。
4.2.6. 禁用 GSP 固件
某些 GPU 包括 GPU 系统处理器 (GSP),可用于卸载 GPU 初始化和管理任务。在 Linux 上的 GPU 直通和裸机部署中,仅 vCS 支持 GSP。如果您在 Linux 上的 GPU 直通或裸机部署中使用任何其他产品,则必须禁用 GSP 固件。
对于 Linux 上的 NVIDIA vGPU 部署以及 Windows 上的所有 NVIDIA vGPU 软件部署,请忽略此任务。
基于 NVIDIA Ada Lovelace GPU 架构的 GPU 上的 NVIDIA vGPU 部署支持 GSP 固件。对于 Linux 上的 NVIDIA vGPU 部署以及 Windows 上基于早期 GPU 架构的 GPU 上的所有 NVIDIA vGPU 软件部署,也不支持 GSP,但 GSP 固件已禁用。
对于每种 NVIDIA vGPU 软件产品,下表列出了在可以启用 GSP 固件的部署中是否支持 GSP。该表还总结了当虚拟机或主机在启用 GSP 固件时请求许可证时 NVIDIA vGPU 软件的行为。可以启用 GSP 固件的部署是 Linux 上的 GPU 直通和裸机部署。
| 产品 | GSP | 许可证请求 | 错误消息 |
|---|---|---|---|
| vCS | 支持 | 允许 | 不适用 |
| vApps | 不支持 | 阻止 | 已打印 |
| vWS | 不支持 | 阻止 | 已打印 |
当许可证请求被阻止时,以下错误消息将写入许可证事件日志文件,位置在虚拟 GPU 客户端许可用户指南中给出。
Invalid feature requested for the underlying GSP firmware configuration.
Disable GSP firmware to use this feature.
在 GPU 直通到的虚拟机或裸机主机上执行此任务。
确保虚拟机或裸机主机上已安装 NVIDIA vGPU 软件 Linux 图形驱动程序。
- 登录到虚拟机或裸机主机并打开命令 shell。
- 确定是否启用了 GSP 固件。
$ nvidia-smi -q
- 如果启用了 GSP 固件,该命令将显示 GSP 固件版本,例如:
GSP Firmware Version : 550.144.03
- 否则,该命令将显示 N/A 作为 GSP 固件版本。
- 如果启用了 GSP 固件,该命令将显示 GSP 固件版本,例如:
- 如果启用了 GSP 固件,请通过将 NVIDIA 模块参数
NVreg_EnableGpuFirmware设置为 0 来禁用它。通过将以下条目添加到 /etc/modprobe.d/nvidia.conf 文件来设置此参数:
options nvidia NVreg_EnableGpuFirmware=0
如果 /etc/modprobe.d/nvidia.conf 文件尚不存在,请创建它。
- 重新启动虚拟机或裸机主机。
如果您以后需要启用 GSP 固件,请将 NVIDIA 模块参数 NVreg_EnableGpuFirmware 设置为 1。
NVIDIA vGPU 是一种许可产品。当在受支持的 GPU 上启动时,vGPU 最初以全部功能运行,但如果虚拟机未能获得许可证,其性能会随着时间的推移而降低。如果 vGPU 的性能已降低,则在获得许可证后,vGPU 的全部功能将恢复。有关未许可 vGPU 的性能如何降低的信息,请参阅虚拟 GPU 客户端许可用户指南。
在您许可 NVIDIA vGPU 后,设置为使用 NVIDIA vGPU 的虚拟机能够运行全系列的 DirectX 和 OpenGL 图形应用程序。
如果配置了许可,虚拟机 (VM) 在这些 GPU 上启动 vGPU 时,会从许可证服务器获取许可证。虚拟机保留许可证,直到关闭。然后,它将许可证释放回许可证服务器。许可设置在重新启动后仍然存在,只有在许可证服务器地址更改或虚拟机切换到运行 GPU 直通时才需要修改。
有关配置和使用 NVIDIA vGPU 软件许可功能(包括 vGPU)的完整信息,请参阅虚拟 GPU 客户端许可用户指南。
5.1. 配置 NVIDIA 许可证系统的许可客户端的先决条件
具有网络连接的客户端通过从 NVIDIA 许可证系统服务实例租用许可证来获取许可证。服务实例通过网络从 NVIDIA 许可门户获得的浮动许可证池中向客户端提供许可证。当许可客户端不再需要许可证时,许可证将返回到服务实例。
在配置许可客户端之前,请确保满足以下先决条件:
- 客户端上已安装 NVIDIA vGPU 软件图形驱动程序。
- 您要部署在客户端上的客户端配置令牌已从 NVIDIA 许可门户或 DLS 创建,如NVIDIA 许可证系统用户指南中的生成客户端配置令牌中所述。
- 防火墙或代理中的端口 443 和 80 必须打开,以允许服务实例及其许可客户端之间的 HTTPS 流量。这些端口对于 CLS 实例和 DLS 实例都必须打开。注意
对于 DLS 1.1 之前的 DLS 版本,还需要打开端口 8081 和 8082,以允许 DLS 实例及其许可客户端之间的 HTTPS 流量。尽管不再需要这些端口,但它们仍然受支持以实现向后兼容性。
图形驱动程序会创建一个默认位置,用于在客户端上存储客户端配置令牌。
配置许可客户端的过程对于 CLS 和 DLS 实例是相同的,但取决于客户端上运行的操作系统。
5.2. 使用默认设置在 Windows 上配置许可客户端
从客户端执行此任务。
- 将客户端配置令牌复制到 %SystemDrive%:\Program Files\NVIDIA Corporation\vGPU Licensing\ClientConfigToken 文件夹。
- 重新启动 NvDisplayContainer 服务。
客户端上的 NVIDIA 服务现在应自动从 CLS 或 DLS 实例获取许可证。
5.3. 使用默认设置在 Linux 上配置许可客户端
从客户端执行此任务。
- 以 root 用户身份,在纯文本编辑器(如 vi)中打开文件 /etc/nvidia/gridd.conf。
$ sudo vi /etc/nvidia/gridd.conf
注意您可以通过复制提供的模板文件 /etc/nvidia/gridd.conf.template 来创建 /etc/nvidia/gridd.conf 文件。
- 将
FeatureType配置参数添加到文件 /etc/nvidia/gridd.conf 的新行,格式为FeatureType="<i>value</i>"。value 取决于分配给您要配置的许可客户端的 GPU 类型。
GPU 类型 值 NVIDIA vGPU 1. NVIDIA vGPU 软件会自动根据 vGPU 类型选择正确的许可证类型。 物理 GPU 直通模式或裸机部署中 GPU 的功能类型 - 0:NVIDIA Virtual Applications
- 2:NVIDIA RTX Virtual Workstation
注意您也可以从 NVIDIA X Server Settings 执行此步骤。在使用 NVIDIA X Server Settings 执行此步骤之前,请确保已启用此选项,如虚拟 GPU 客户端许可用户指南中所述。
此示例显示如何为 NVIDIA RTX Virtual Workstation 配置许可的 Linux 客户端。
# /etc/nvidia/gridd.conf.template - Configuration file for NVIDIA Grid Daemon … # Description: Set Feature to be enabled # Data type: integer # Possible values: # 0 => for unlicensed state # 1 => for NVIDIA vGPU # 2 => for NVIDIA RTX Virtual Workstation # 4 => for NVIDIA Virtual Compute Server FeatureType=2 ...
- 将客户端配置令牌复制到 /etc/nvidia/ClientConfigToken 目录。
- 确保客户端配置令牌的文件访问模式允许所有者读取、写入和执行令牌,而组和其他人只能读取令牌。
- 确定客户端配置令牌的当前文件访问模式。
# ls -l client-configuration-token-directory
- 如有必要,将客户端配置令牌的模式更改为 744。
# chmod 744 client-configuration-token-directory/client_configuration_token_*.tok
- 客户端配置令牌目录
- 您在上一步中将客户端配置令牌复制到的目录。
- 确定客户端配置令牌的当前文件访问模式。
- 将您的更改保存到 /etc/nvidia/gridd.conf 文件并关闭该文件。
- 重新启动 nvidia-gridd 服务。
客户端上的 NVIDIA 服务现在应自动从 CLS 或 DLS 实例获取许可证。
5.4. 验证许可客户端的 NVIDIA vGPU 软件许可证状态
使用 NVIDIA vGPU 软件许可证配置客户端后,通过显示许可产品名称和状态来验证许可证状态。
要验证许可客户端的许可证状态,请从许可客户端(而不是 hypervisor 主机)运行带有 –q 或 --query 选项的 nvidia-smi。如果产品已获得许可,则许可证状态中会显示到期日期。
nvidia-smi -q
==============NVSMI LOG==============
Timestamp : Wed Nov 23 10:52:59 2022
Driver Version : 525.60.06
CUDA Version : 12.0
Attached GPUs : 2
GPU 00000000:02:03.0
Product Name : NVIDIA A2-8Q
Product Brand : NVIDIA RTX Virtual Workstation
Product Architecture : Ampere
Display Mode : Enabled
Display Active : Disabled
Persistence Mode : Enabled
MIG Mode
Current : Disabled
Pending : Disabled
Accounting Mode : Disabled
Accounting Mode Buffer Size : 4000
Driver Model
Current : N/A
Pending : N/A
Serial Number : N/A
GPU UUID : GPU-ba5b1e9b-1dd3-11b2-be4f-98ef552f4216
Minor Number : 0
VBIOS Version : 00.00.00.00.00
MultiGPU Board : No
Board ID : 0x203
Board Part Number : N/A
GPU Part Number : 25B6-890-A1
Module ID : N/A
Inforom Version
Image Version : N/A
OEM Object : N/A
ECC Object : N/A
Power Management Object : N/A
GPU Operation Mode
Current : N/A
Pending : N/A
GSP Firmware Version : N/A
GPU Virtualization Mode
Virtualization Mode : VGPU
Host VGPU Mode : N/A
vGPU Software Licensed Product Product Name : NVIDIA RTX Virtual Workstation License Status : Licensed (Expiry: 2022-11-23 10:41:16 GMT)
…
…
您可以通过从虚拟机中删除 NVIDIA vGPU 配置或修改 GPU 分配策略来修改虚拟机的 NVIDIA vGPU 配置。
6.1. 删除虚拟机的 NVIDIA vGPU 配置
当您不再需要虚拟机使用虚拟 GPU 时,请删除虚拟机的 NVIDIA vGPU 配置。
6.1.1. 删除 Citrix Virtual Apps and Desktops 虚拟机的 vGPU 配置
您可以使用 XenCenter 或 xe 命令从虚拟机中删除虚拟 GPU 分配,从而使其不再使用虚拟 GPU。
虚拟机必须处于关闭电源状态,才能修改或删除其 vGPU 配置。
6.1.1.1. 使用 XenCenter 删除虚拟机的 vGPU 配置
- 在虚拟机的 GPU 属性中,将GPU 类型设置为无,如图 18所示。
图 18. 使用 XenCenter 从虚拟机中删除 vGPU 配置
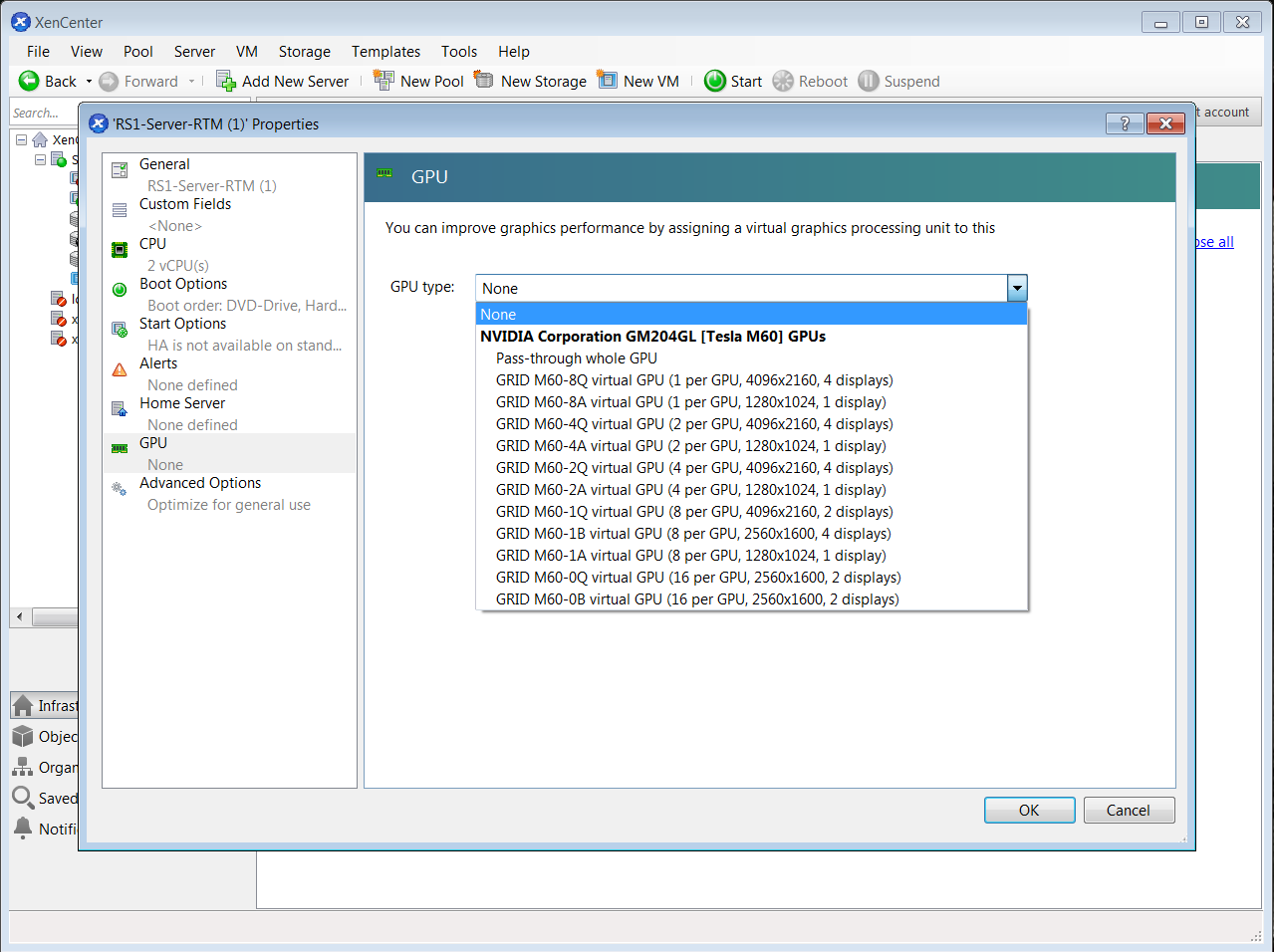
- 单击确定。

6.1.1.2. 使用 xe 删除虚拟机的 vGPU 配置
- 使用 vgpu-list 发现与给定虚拟机关联的 vGPU 对象 UUID。
[root@xenserver ~]# xe vgpu-list vm-uuid=e71afda4-53f4-3a1b-6c92-a364a7f619c2 uuid ( RO) : c1c7c43d-4c99-af76-5051-119f1c2b4188 vm-uuid ( RO): e71afda4-53f4-3a1b-6c92-a364a7f619c2 gpu-group-uuid ( RO): d53526a9-3656-5c88-890b-5b24144c3d96
- 使用 vgpu-destroy 删除与虚拟机关联的虚拟 GPU 对象。
[root@xenserver ~]# xe vgpu-destroy uuid=c1c7c43d-4c99-af76-5051-119f1c2b4188 [root@xenserver ~]#
6.1.2. 删除 vSphere 虚拟机的 vGPU 配置
要从虚拟机中删除 vSphere vGPU 配置:
- 在 vCenter Web UI 中右键单击虚拟机后,选择编辑设置。
- 选择虚拟硬件选项卡。
- 将鼠标悬停在显示NVIDIA GRID vGPU的 PCI 设备条目上,然后单击 (X) 图标以标记设备以进行删除。
- 单击确定以删除设备并更新虚拟机设置。
6.2. 修改 GPU 分配策略
XenServer 和 VMware vSphere 都支持用于启用 vGPU 的虚拟机的广度优先和深度优先 GPU 分配策略。
- 广度优先
- 广度优先分配策略尝试最大限度地减少在每个物理 GPU 上运行的 vGPU 的数量。新创建的 vGPU 将放置在可以支持新 vGPU 并且在其上已驻留最少 vGPU 的物理 GPU 上。此策略通常会带来更高的性能,因为它尝试最大限度地减少物理 GPU 的共享,但它可能会人为地限制可以运行的 vGPU 总数。
- 深度优先
- 深度优先分配策略尝试最大限度地增加在每个物理 GPU 上运行的 vGPU 的数量。新创建的 vGPU 将放置在可以支持新 vGPU 并且在其上已驻留最多 vGPU 的物理 GPU 上。此策略通常会带来更高的 vGPU 密度,尤其是在运行不同类型的 vGPU 时,但可能会导致较低的性能,因为它尝试最大限度地增加物理 GPU 的共享。
每个 hypervisor 默认使用不同的 GPU 分配策略。
- XenServer 使用深度优先分配策略。
- VMware vSphere ESXi 使用广度优先分配策略。
如果默认 GPU 分配策略不能满足您对性能或 vGPU 密度的要求,您可以更改它。
6.2.1. 在 XenServer 上修改 GPU 分配策略
您可以使用 XenCenter 或 xe 命令在 XenServer 上修改 GPU 分配策略。
6.2.1.1. 使用 xe 修改 GPU 分配策略
GPU 组的分配策略存储在 gpu-group 对象的 allocation-algorithm 参数中。
要更改 GPU 组的分配策略,请使用 gpu-group-param-set。
[root@xenserver ~]# xe gpu-group-param-get uuid=be825ba2-01d7-8d51-9780-f82cfaa64924 param-name=allocation-algorithmdepth-first
[root@xenserver ~]# xe gpu-group-param-set uuid=be825ba2-01d7-8d51-9780-f82cfaa64924 allocation-algorithm=breadth-first
[root@xenserver ~]#
6.2.1.2. 使用 XenCenter 修改 GPU 分配策略 GPU
您可以从 XenCenter 中的GPU选项卡修改 GPU 分配策略。
图 19. 在 XenCenter 中修改 GPU 放置策略

6.2.2. 在 VMware vSphere 上修改 GPU 分配策略
在使用 vSphere Web Client 更改分配方案之前,请确保 ESXi 主机正在运行,并且主机上的所有虚拟机都已关闭电源。
- 使用 vSphere Web Client 登录到 vCenter Server。
- 在导航树中,选择您的 ESXi 主机,然后单击配置选项卡。
- 从菜单中,选择图形,然后单击主机图形选项卡。
- 在主机图形选项卡上,单击编辑。
图 20. 启用 vGPU 的虚拟机的广度优先分配方案设置
- 在打开的“编辑主机图形设置”对话框中,选择这些选项,然后单击确定。
- 如果尚未选择,请选择共享直通。
- 选择将虚拟机分组到 GPU 直至满载。
图 21. 适用于 vGPU 的主机图形设置
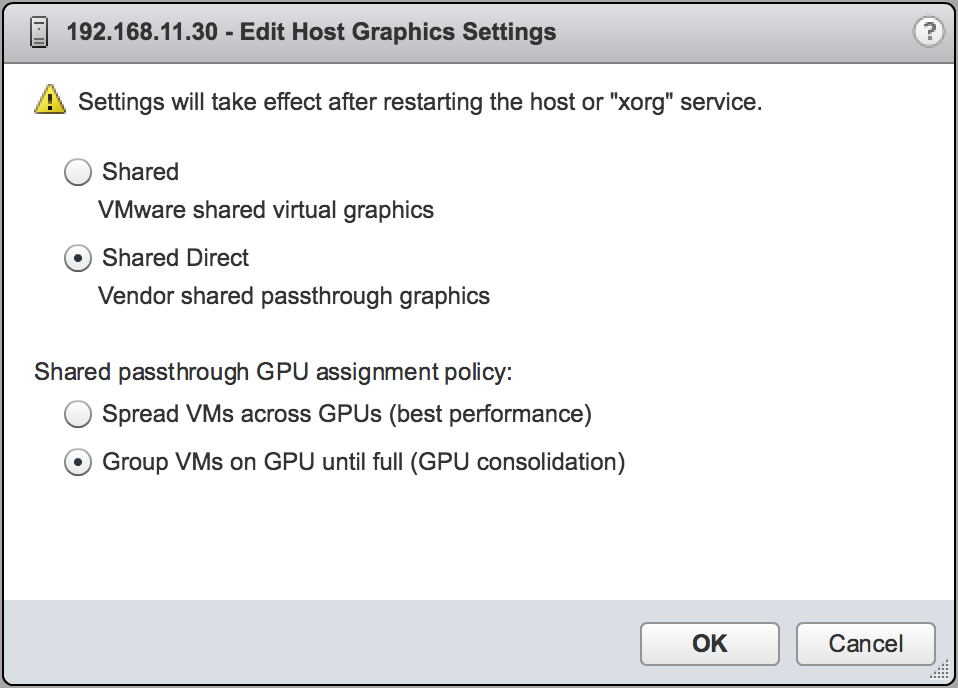
单击“确定”后,默认图形类型将更改为“共享直通”,并且启用 vGPU 的虚拟机的分配方案为广度优先。
图 22. 启用 vGPU 的虚拟机的深度优先分配方案设置
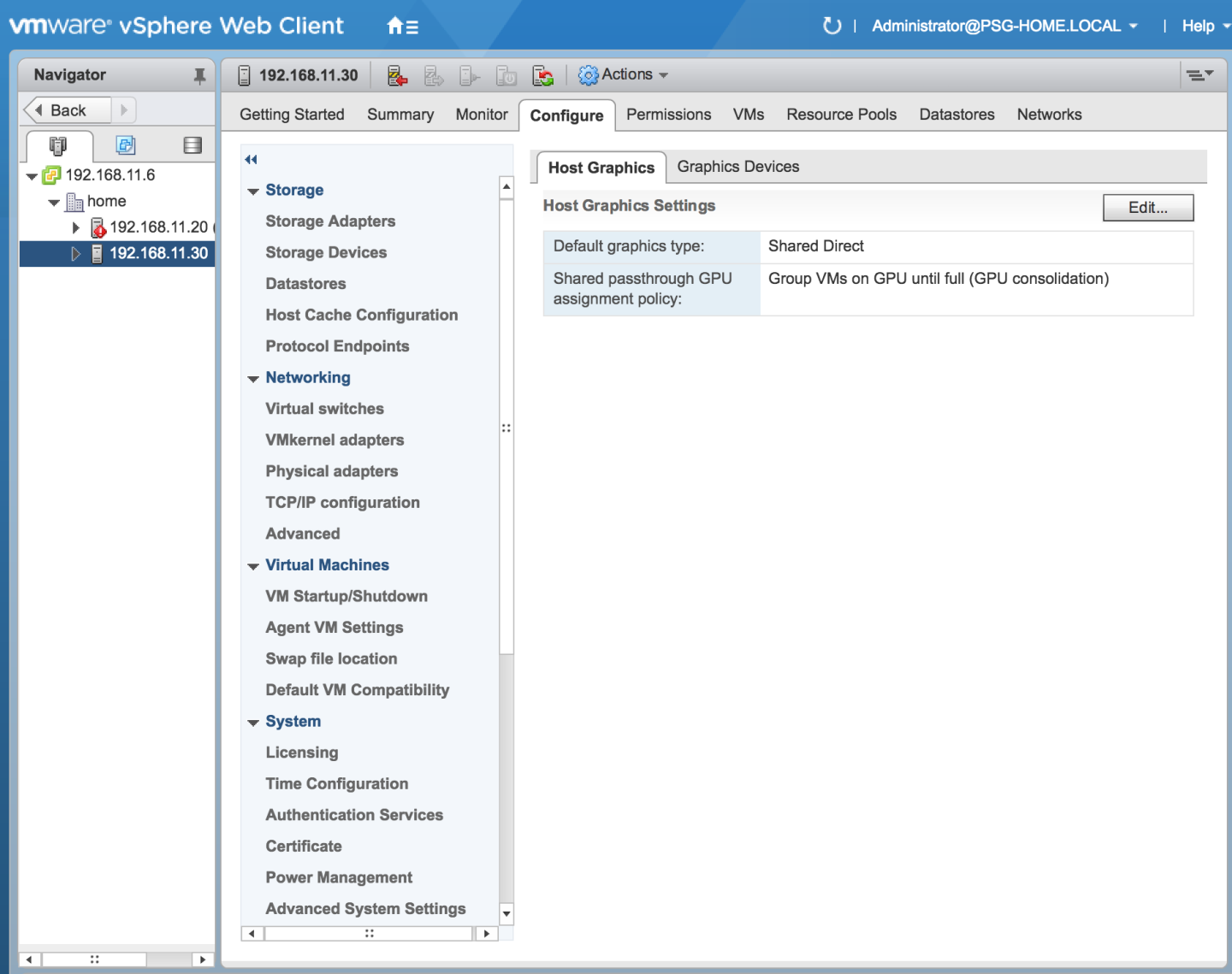
- 重新启动 ESXi 主机或主机上的 Xorg 服务。


6.3. 迁移配置了 vGPU 的虚拟机
在某些 hypervisor 上,NVIDIA vGPU 软件支持迁移配置了 vGPU 的虚拟机。
在迁移配置了 vGPU 的虚拟机之前,请确保满足以下先决条件:
- 虚拟机已配置 vGPU。
- 虚拟机正在运行。
- 虚拟机在启动时获得了合适的 vGPU 许可证。
- 目标主机具有与 vGPU 当前所在 GPU 相同类型的物理 GPU。
- 源主机和目标主机上的 ECC 内存配置(启用或禁用)必须相同。
- 源主机和目标主机上的 GPU 拓扑(包括 NVLink 宽度)必须相同。
如何迁移配置了 vGPU 的虚拟机取决于您使用的 hypervisor。
迁移后,vGPU 的 vGPU 类型保持不变。
迁移所需的时间取决于 vGPU 拥有的帧缓冲区大小。具有大量帧缓冲区的 vGPU 的迁移速度比具有少量帧缓冲区的 vGPU 的迁移速度慢。
6.3.1. 在 XenServer 上迁移配置了 vGPU 的虚拟机
NVIDIA vGPU 软件支持用于配置了 vGPU 的虚拟机的 XenMotion。XenMotion 使您能够将正在运行的虚拟机从一台物理主机移动到另一台主机,且几乎没有中断或停机时间。对于配置了 vGPU 的虚拟机,vGPU 将随虚拟机迁移到另一台主机上的 NVIDIA GPU。两台主机上的 NVIDIA GPU 必须是同一类型。
有关哪些 XenServer 版本、NVIDIA GPU 和客户操作系统版本支持带有 vGPU 的 XenMotion 的详细信息,请参阅适用于 XenServer 发行说明的虚拟 GPU 软件。
为了获得最佳性能,应将物理主机配置为使用以下各项:
- 共享存储,例如 NFS、iSCSI 或光纤通道
如果未使用共享存储,则迁移可能需要很长时间,因为 vDISK 也必须迁移。
- 10 GB 网络。
- 在 Citrix XenCenter 中,右键单击虚拟机,然后从打开的菜单中选择迁移。
- 从可用主机列表中,选择要将虚拟机迁移到的目标主机。目标主机必须具有与 vGPU 当前所在 GPU 相同类型的物理 GPU。此外,物理 GPU 必须能够托管 vGPU。如果未满足这些要求,则不会列出任何可用主机。
6.3.2. 自 17.2 起:在带有 KVM Hypervisor 的 Linux 上迁移配置了 vGPU 的虚拟机
NVIDIA vGPU 软件支持用于配置了 vGPU 的虚拟机的 vGPU 迁移。vGPU 迁移使您能够将正在运行的虚拟机从一台物理主机移动到另一台主机,且几乎没有中断或停机时间。对于配置了 vGPU 的虚拟机,vGPU 将随虚拟机迁移到另一台主机上的 NVIDIA GPU。两台主机上的 NVIDIA GPU 必须是同一类型。
NVIDIA vGPU 软件支持以下带有 KVM hypervisor 的 Linux:带有 KVM 的 Red Hat Enterprise Linux 和 Ubuntu。有关哪些带有 KVM hypervisor 版本的 Linux、NVIDIA GPU 和客户操作系统版本支持 vGPU 迁移的详细信息,请参阅以下文档:
- Virtual GPU Software for Red Hat Enterprise Linux with KVM Release Notes
- Virtual GPU Software for Ubuntu Release Notes
在要迁移的虚拟机正在运行的带有 KVM hypervisor 的 Linux 主机上的 Linux 命令 shell 中执行此任务。
在带有 KVM hypervisor 的 Linux 上迁移配置了 vGPU 的虚拟机之前,请确保满足迁移配置了 vGPU 的虚拟机中为所有受支持的 hypervisor 列出的先决条件。
- 将虚拟机的最大停机时间设置为大于完成迁移所需的时间长度。
如果虚拟机负载很重,则迁移可能无法在默认最大停机时间内完成。为了确保虚拟机迁移完成,请确保最大停机时间超过完成迁移所需的时间。
# virsh migrate-setmaxdowntime --domain vm-name --downtime length
- vm-name
- 虚拟机名称
- 您要迁移的本地主机上的虚拟机的名称。
- 长度
虚拟机的最大停机时间,以毫秒为单位。
# virsh migrate-setmaxdowntime --domain guestvm --downtime 10000
- 此示例将本地主机上名为
guestvm的虚拟机的最大停机时间设置为 10 秒(10,000 毫秒)。# virsh migrate --live vm-name destination-url --verbose
- vm-name
- 虚拟机名称
- 运行以下 virsh migrate 命令:
- 目标 URL
要将虚拟机迁移到的远程主机的连接 URL。例如,要通过 SSH 隧道将虚拟机迁移到 IP v4 地址为 192.0.2.12 的远程主机的系统连接,请将目标 URL 指定为 qemu+ssh://root@192.0.2.12/system。
# virsh migrate --live guestvm qemu+ssh://root@192.0.2.12/system --verbose
此示例使用 SSH 隧道将本地主机上名为 guestvm 的虚拟机迁移到 IP v4 地址为 192.0.2.12 的远程主机的系统连接。
有关更多信息,请参阅 Red Hat Enterprise Linux 9 产品文档中的迁移虚拟机。
6.3.3. 自 17.2 起:在带有 KVM Hypervisor 的 Linux 上挂起和恢复配置了 vGPU 的虚拟机
NVIDIA vGPU 软件支持用于配置了 vGPU 的虚拟机的挂起和恢复。
- Virtual GPU Software for Red Hat Enterprise Linux with KVM Release Notes
- Virtual GPU Software for Ubuntu Release Notes
NVIDIA vGPU 软件支持以下带有 KVM hypervisor 的 Linux:带有 KVM 的 Red Hat Enterprise Linux 和 Ubuntu。有关哪些带有 KVM hypervisor 版本的 Linux、NVIDIA GPU 和客户操作系统版本支持挂起和恢复的详细信息,请参阅以下文档:
- 在要挂起的虚拟机正在运行或要恢复的虚拟机将要运行的带有 KVM hypervisor 的 Linux 主机上的 Linux 命令 shell 中执行此任务。
# virsh save vm-name vm-state-file
- vm-name
- 要挂起虚拟机,请使用 virsh save 命令将虚拟机的状态保存到文件。
- 虚拟机名称
- 您要挂起的本地主机上的虚拟机的名称。
虚拟机状态文件
# virsh save guestvm guestvm-state.save
- 要将虚拟机状态保存到的文件的名称。
# virsh restore vm-state-file
- 虚拟机名称
- 此示例通过将其状态保存到文件 guestvm-state.save,来挂起本地主机上名为
guestvm的虚拟机。
要恢复虚拟机,请使用 virsh restore 命令从先前保存虚拟机状态的文件中恢复虚拟机。
# virsh restore guestvm-state.save
先前已保存虚拟机状态的文件的名称。
此示例通过从文件 guestvm-state.save 恢复其状态,来恢复本地主机上名为 guestvm 的虚拟机。
6.3.4. 在 VMware vSphere 上迁移配置了 vGPU 的虚拟机
NVIDIA vGPU 软件支持用于配置了 vGPU 的虚拟机的 VMware vMotion。VMware vMotion 使您能够将正在运行的虚拟机从一台物理主机移动到另一台主机,且几乎没有中断或停机时间。对于配置了 vGPU 的虚拟机,vGPU 将随虚拟机迁移到另一台主机上的 NVIDIA GPU。两台主机上的 NVIDIA GPU 必须是同一类型。
有关哪些 VMware vSphere 版本、NVIDIA GPU 和客户操作系统版本支持挂起和恢复的详细信息,请参阅适用于 VMware vSphere 发行说明的虚拟 GPU 软件。
- 通过使用迁移向导在 VMware vSphere Web Client 中执行此任务。
- 在 VMware vSphere 上迁移配置了 vGPU 的虚拟机之前,请确保满足以下先决条件:
- 您的主机已正确配置用于 VMware vMotion。请参阅 VMware 文档中的vMotion 的主机配置。
- 满足迁移配置了 vGPU 的虚拟机中为所有受支持的 hypervisor 列出的先决条件。
- NVIDIA vGPU 迁移已配置。请参阅为 VMware vSphere 配置带有 vGPU 的 VMware vMotion。
- 右键单击虚拟机,然后从打开的菜单中选择迁移。
- 对于迁移类型,选择仅更改计算资源,然后单击下一步。如果选择同时更改计算资源和存储,则迁移所需的时间会增加。
- 选择目标主机,然后单击下一步。目标主机必须具有与 vGPU 当前所在 GPU 相同类型的物理 GPU。此外,物理 GPU 必须能够托管 vGPU。如果未满足这些要求,则不会列出任何可用主机。
- 选择目标网络,然后单击下一步。
有关更多信息,请参阅 VMware 文档中的以下主题
如果未配置 NVIDIA vGPU 迁移,则任何尝试迁移具有 NVIDIA vGPU 的虚拟机的操作都将失败,并显示包含以下错误消息的窗口
Compatibility Issue/Host
Migration was temporarily disabled due to another
migration activity.
vGPU hot migration is not enabled.
窗口显示如下

如果您看到此错误,请按照为 VMware vSphere 配置带有 vGPU 的 VMware vMotion中的说明配置 NVIDIA vGPU 迁移。
如果您的 VMware vSpehere ESXi 版本不支持为配置了 NVIDIA vGPU 的虚拟机使用 vMotion,则任何尝试迁移具有 NVIDIA vGPU 的虚拟机的操作都将失败,并显示包含以下错误消息的窗口
Compatibility Issues
...
A required migration feature is not supported on the "Source" host 'host-name'.
A warning or error occurred when migrating the virtual machine.
Virtual machine relocation, or power on after relocation or cloning can fail if
vGPU resources are not available on the destination host.
窗口显示如下

6.3.4. 在 VMware vSphere 上迁移配置了 vGPU 的虚拟机
6.3.5. 在 VMware vSphere 上挂起和恢复配置了 vGPU 的虚拟机
6.3.3. 自 17.2 起:在带有 KVM Hypervisor 的 Linux 上挂起和恢复配置了 vGPU 的虚拟机
6.3.4. 在 VMware vSphere 上迁移配置了 vGPU 的虚拟机
在 VMware vSphere Web Client 中执行此任务。
- 要挂起虚拟机,请右键单击要挂起的虚拟机,然后从弹出的上下文菜单中选择电源 > 挂起。
- 要恢复虚拟机,请右键单击要恢复的虚拟机,然后从弹出的上下文菜单中选择电源 > 开启电源。
6.4. 为 vGPU 启用统一内存
默认情况下,统一内存处于禁用状态。 如果使用统一内存,您必须通过设置 vGPU 插件参数,为每个需要它的 vGPU 单独启用统一内存。 为 vGPU 启用统一内存的方式取决于您使用的 hypervisor。
6.4.1. 在 XenServer 上为 vGPU 启用统一内存
在 XenServer 上,通过设置 enable_uvm vGPU 插件参数来启用统一内存。
使用 xe 命令为每个需要统一内存的 vGPU 执行此任务。
将 vGPU 的 enable_uvm vGPU 插件参数设置为 1,如在 XenServer 上设置 vGPU 插件参数中所述。
此示例为 UUID 为 d15083f8-5c59-7474-d0cb-fbc3f7284f1b 的 vGPU 启用统一内存。
[root@xenserver ~] xe vgpu-param-set uuid=d15083f8-5c59-7474-d0cb-fbc3f7284f1b extra_args='enable_uvm=1'
6.4.2. 在 Red Hat Enterprise Linux KVM 上为 vGPU 启用统一内存
在 Red Hat Enterprise Linux KVM 上,通过设置 enable_uvm vGPU 插件参数来启用统一内存。
确保已创建代表 vGPU 的 mdev 设备文件,如在带有 KVM Hypervisor 的 Linux 上创建 NVIDIA vGPU中所述。
为每个需要统一内存的 vGPU 执行此任务。
将代表 vGPU 的 mdev 设备文件的 enable_uvm vGPU 插件参数设置为 1,如在带有 KVM Hypervisor 的 Linux 上设置 vGPU 插件参数中所述。
6.4.3. 在 VMware vSphere 上为 vGPU 启用统一内存
在 VMware vSphere 上,通过在高级虚拟机属性中设置 pciPassthruvgpu-id.cfg.enable_uvm 配置参数来启用统一内存。
确保分配了 vGPU 的虚拟机已关闭电源。
在 vSphere Client 中为每个需要统一内存的 vGPU 执行此任务。
在高级虚拟机属性中,将 vGPU 的 pciPassthruvgpu-id.cfg.enable_uvm vGPU 插件参数设置为 1,如在 VMware vSphere 上设置 vGPU 插件参数中所述。
- vgpu-id
- 一个正整数,用于标识分配给虚拟机的 vGPU。 对于分配给虚拟机的第一个 vGPU,vgpu-id 为 0。 例如,如果将两个 vGPU 分配给一个虚拟机,并且您要为这两个 vGPU 启用统一内存,请将 pciPassthru0.cfg.enable_uvm 和 pciPassthru1.cfg.enable_uvm 设置为 1。
6.5. 为 NVIDIA vGPU 启用 NVIDIA CUDA Toolkit 开发工具
默认情况下,NVIDIA CUDA Toolkit 开发工具在 NVIDIA vGPU 上处于禁用状态。 如果使用开发工具,您必须通过设置 vGPU 插件参数,为每个需要它们的虚拟机单独启用 NVIDIA CUDA Toolkit 开发工具。 必须设置一个参数以启用 NVIDIA CUDA Toolkit 调试器,并且必须设置另一个不同的参数以启用 NVIDIA CUDA Toolkit 性能分析器。
6.5.1. 为 NVIDIA vGPU 启用 NVIDIA CUDA Toolkit 调试器
默认情况下,NVIDIA CUDA Toolkit 调试器处于禁用状态。 如果使用调试器,您必须通过设置 vGPU 插件参数,为每个需要它们的 vGPU 虚拟机启用调试器。 为 vGPU 虚拟机设置参数以启用 NVIDIA CUDA Toolkit 调试器的方式取决于您使用的 hypervisor。
您可以为同一 GPU 上配置了 vGPU 的任意数量的虚拟机启用 NVIDIA CUDA Toolkit 调试器。 当为虚拟机启用 NVIDIA CUDA Toolkit 调试器后,该虚拟机无法迁移。
为您要启用 NVIDIA CUDA Toolkit 调试器的每个虚拟机执行此任务。
在 XenServer 上为 NVIDIA vGPU 启用 NVIDIA CUDA Toolkit 调试器
将分配给虚拟机的 vGPU 的 enable_debugging vGPU 插件参数设置为 1,如在 XenServer 上设置 vGPU 插件参数中所述。
此示例为 UUID 为 d15083f8-5c59-7474-d0cb-fbc3f7284f1b 的 vGPU 启用 NVIDIA CUDA Toolkit 调试器。
[root@xenserver ~] xe vgpu-param-set uuid=d15083f8-5c59-7474-d0cb-fbc3f7284f1b extra_args='enable_debugging=1'
重新启动客户机虚拟机和重新启动 hypervisor 主机后,此参数的设置将保留。
在 Red Hat Enterprise Linux KVM 上为 NVIDIA vGPU 启用 NVIDIA CUDA Toolkit 调试器
将分配给虚拟机的 vGPU 的 mdev 设备文件的 enable_debugging vGPU 插件参数设置为 1,如在带有 KVM Hypervisor 的 Linux 上设置 vGPU 插件参数中所述。
重新启动客户机虚拟机后,此参数的设置将保留。 但是,重新启动 hypervisor 主机后,此参数将重置为其默认值。
在 VMware vSphere 上为 NVIDIA vGPU 启用 NVIDIA CUDA Toolkit 调试器
确保您要为其启用 NVIDIA CUDA Toolkit 调试器的虚拟机已关闭电源。
在高级虚拟机属性中,将分配给虚拟机的 vGPU 的 pciPassthruvgpu-id.cfg.enable_debugging vGPU 插件参数设置为 1,如在 VMware vSphere 上设置 vGPU 插件参数中所述。
- vgpu-id
- 一个正整数,用于标识分配给虚拟机的 vGPU。 对于分配给虚拟机的第一个 vGPU,vgpu-id 为 0。 例如,如果将两个 vGPU 分配给一个虚拟机,并且您要为这两个 vGPU 启用调试器,请将 pciPassthru0.cfg.enable_debugging 和 pciPassthru1.cfg.enable_debugging 设置为 1。
重新启动客户机虚拟机后,此参数的设置将保留。 但是,重新启动 hypervisor 主机后,此参数将重置为其默认值。
6.5.2. 为 NVIDIA vGPU 启用 NVIDIA CUDA Toolkit 性能分析器
默认情况下,仅启用 GPU 工作负载跟踪。 如果您要使用 NVIDIA vGPU 支持的所有 NVIDIA CUDA Toolkit 性能分析器功能,则必须为每个需要它们的 vGPU 虚拟机启用这些功能。
为虚拟机启用性能分析将使该虚拟机能够访问 GPU 的全局性能计数器,其中可能包括在同一 GPU 上执行的其他虚拟机的活动。 为虚拟机启用性能分析还允许虚拟机锁定 GPU 上的时钟,这会影响在同一 GPU 上执行的所有其他虚拟机。
6.5.2.1. 支持的 NVIDIA CUDA Toolkit 性能分析器功能
您可以为 vGPU 虚拟机启用以下 NVIDIA CUDA Toolkit 性能分析器功能
- NVIDIA Nsight™ Compute
- NVIDIA Nsight Systems
- CUDA 性能分析工具接口 (CUPTI)
6.5.2.2. 为启用了 NVIDIA CUDA Toolkit 性能分析器的 vGPU 虚拟机进行时钟管理
对于定期采样用例(例如 NVIDIA Nsight Systems 性能分析),时钟不会锁定。
对于多通道性能分析(例如
- NVIDIA Nsight Compute 内核性能分析
- CUPTI 范围性能分析
时钟在性能分析开始时自动锁定,并在性能分析结束时自动解锁。
6.5.2.3. 在 NVIDIA vGPU 中使用 NVIDIA CUDA Toolkit 性能分析器的限制
为 NVIDIA vGPU 启用 NVIDIA CUDA Toolkit 性能分析器时,适用以下限制
- NVIDIA CUDA Toolkit 性能分析器一次只能在一个虚拟机上使用。
- 无法同时分析多个 CUDA 上下文。
- 性能分析数据是为每个上下文单独收集的。
- 为虚拟机启用 NVIDIA CUDA Toolkit 性能分析器后,该虚拟机无法迁移。
由于 NVIDIA CUDA Toolkit 性能分析器一次只能在一个虚拟机上使用,因此您应该仅为分配了 GPU 上的 vGPU 的一个虚拟机启用它们。 但是,NVIDIA vGPU 软件无法强制执行此要求。 如果在分配了 GPU 上的 vGPU 的多个虚拟机上启用了 NVIDIA CUDA Toolkit 性能分析器,则仅为启动性能分析器的第一个虚拟机收集性能分析数据。
6.5.2.4. 为 vGPU 虚拟机启用 NVIDIA CUDA Toolkit 性能分析器
您可以通过设置 vGPU 插件参数,为 vGPU 虚拟机启用 NVIDIA CUDA Toolkit 性能分析器。 为 vGPU 虚拟机设置参数以启用 NVIDIA CUDA Toolkit 性能分析器的方式取决于您使用的 hypervisor。
为您要启用 NVIDIA CUDA Toolkit 性能分析器的虚拟机执行此任务。
在 XenServer 上为 NVIDIA vGPU 启用 NVIDIA CUDA Toolkit 性能分析器
将分配给虚拟机的 vGPU 的 enable_profiling vGPU 插件参数设置为 1,如在 XenServer 上设置 vGPU 插件参数中所述。
此示例为 UUID 为 d15083f8-5c59-7474-d0cb-fbc3f7284f1b 的 vGPU 启用 NVIDIA CUDA Toolkit 性能分析器。
[root@xenserver ~] xe vgpu-param-set uuid=d15083f8-5c59-7474-d0cb-fbc3f7284f1b extra_args='enable_profiling=1'
重新启动客户机虚拟机和重新启动 hypervisor 主机后,此参数的设置将保留。
在 Red Hat Enterprise Linux KVM 上为 NVIDIA vGPU 启用 NVIDIA CUDA Toolkit 性能分析器
将分配给虚拟机的 vGPU 的 mdev 设备文件的 enable_profiling vGPU 插件参数设置为 1,如在带有 KVM Hypervisor 的 Linux 上设置 vGPU 插件参数中所述。
重新启动客户机虚拟机后,此参数的设置将保留。 但是,重新启动 hypervisor 主机后,此参数将重置为其默认值。
在 VMware vSphere 上为 NVIDIA vGPU 启用 NVIDIA CUDA Toolkit 性能分析器
确保您要为其启用 NVIDIA CUDA Toolkit 性能分析器的虚拟机已关闭电源。
在高级虚拟机属性中,将分配给虚拟机的 vGPU 的 pciPassthruvgpu-id.cfg.enable_profiling vGPU 插件参数设置为 1,如在 VMware vSphere 上设置 vGPU 插件参数中所述。
- vgpu-id
- 一个正整数,用于标识分配给虚拟机的 vGPU。 对于分配给虚拟机的第一个 vGPU,vgpu-id 为 0。 例如,如果将两个 vGPU 分配给一个虚拟机,并且您要为第二个 vGPU 启用性能分析器,请将 pciPassthru1.cfg.enable_profiling 设置为 1。
重新启动客户机虚拟机后,此参数的设置将保留。 但是,重新启动 hypervisor 主机后,此参数将重置为其默认值。
6.6. 为 vGPU 启用 TCC 驱动程序模型
Tesla 计算集群 (TCC) 驱动程序模型支持 CUDA C/C++ 应用程序。 此模型针对计算应用程序进行了优化,并缩短了 Windows 上的内核启动时间。 默认情况下,分配给 Windows 虚拟机的 vGPU 的驱动程序模型是 Windows 显示驱动程序模型 (WDDM)。 如果您要使用 TCC 驱动程序模型,则必须显式启用它。
此任务需要管理员权限。
从分配了 vGPU 的虚拟机执行此任务。
只有 Q 系列 vGPU 支持 TCC 驱动程序模型。
- 登录到分配了 vGPU 的虚拟机。
- 将 vGPU 的驱动程序模型设置为 TCC 驱动程序模型。
nvidia-smi -g vgpu-id -dm 1
- vgpu-id
- 要为其启用 TCC 驱动程序模型的 vGPU 的 ID。 如果省略 -g,则为分配给虚拟机的全部 vGPU 启用 TCC 驱动程序模型。
- 重新启动虚拟机。
借助 NVIDIA vGPU 软件,您可以从 hypervisor 和各个客户机虚拟机内部监控物理 GPU 和虚拟 GPU 的性能。 您可以使用多种工具来监控 GPU 性能
- 从任何受支持的 hypervisor 以及运行 64 位 Windows 或 Linux 版本的客户机虚拟机,您都可以使用 NVIDIA 系统管理界面 nvidia-smi。
- 从 XenServer,您可以使用 Citrix XenCenter。
- 从 Windows 客户机虚拟机,您可以使用以下工具
- Windows 性能监视器
- Windows Management Instrumentation (WMI)
7.1. NVIDIA 系统管理界面 nvidia-smi
NVIDIA 系统管理界面 nvidia-smi 是一种命令行工具,用于报告 NVIDIA GPU 的管理信息。
- 每个受支持 hypervisor 的 NVIDIA Virtual GPU Manager 软件包
- 每个受支持客户机操作系统的 NVIDIA 驱动程序软件包
报告的管理信息的范围取决于您从何处运行 nvidia-smi:
-
从 hypervisor 命令行 shell(例如 XenServer dom0 shell 或 VMware ESXi 主机 shell),nvidia-smi 报告系统中存在的 NVIDIA 物理 GPU 和虚拟 GPU 的管理信息。
注意从 hypervisor 命令行 shell 运行时,nvidia-smi 不会列出当前为 GPU 直通分配的任何 GPU。
-
从客户机虚拟机,nvidia-smi 检索分配给虚拟机的 vGPU 或直通 GPU 的使用情况统计信息。
在 Windows 客户机虚拟机中,nvidia-smi 安装在默认可执行路径中的文件夹中。 因此,您可以通过运行 nvidia-smi.exe 命令从任何文件夹的命令提示符运行 nvidia-smi。
7.2. 从 Hypervisor 监控 GPU 性能
您可以使用 NVIDIA 系统管理界面 nvidia-smi 命令行实用程序从任何受支持的 hypervisor 监控 GPU 性能。 在 XenServer 平台上,您还可以使用 Citrix XenCenter 监控 GPU 性能。
您无法从 hypervisor 监控用于 GPU 直通的 GPU 的性能。 您只能从正在使用直通 GPU 的客户机虚拟机内部监控直通 GPU 的性能。
7.2.1. 使用 nvidia-smi 从 Hypervisor 监控 GPU 性能
您可以通过从 hypervisor 命令行 shell(例如 XenServer dom0 shell 或 VMware ESXi 主机 shell)运行 nvidia-smi,来获取系统中存在的 NVIDIA 物理 GPU 和虚拟 GPU 的管理信息。
在没有子命令的情况下,nvidia-smi 提供物理 GPU 的管理信息。 要更详细地检查虚拟 GPU,请将 nvidia-smi 与 vgpu 子命令结合使用。
从命令行,您可以获取有关 nvidia-smi 工具和 vgpu 子命令的帮助信息。
| 帮助信息 | 命令 |
|---|---|
| nvidia-smi 工具支持的子命令列表。 请注意,并非所有子命令都适用于支持 NVIDIA vGPU 软件的 GPU。 | nvidia-smi -h |
| vgpu 子命令支持的所有选项的列表。 | nvidia-smi vgpu –h |
7.2.1.1. 获取系统中所有物理 GPU 的摘要
要获取系统中所有物理 GPU 的摘要,以及 PCI 总线 ID、电源状态、温度、当前内存使用情况等,请在不带其他参数的情况下运行 nvidia-smi。
每个 vGPU 实例都在“计算进程”部分中报告,同时报告其物理 GPU 索引和分配给它的帧缓冲区内存量。
在以下示例中,系统中共运行了三个 vGPU:每个物理 GPU 0、1 和 2 上各运行一个 vGPU。
[root@vgpu ~]# nvidia-smi
Fri Jan 17 09:26:18 2025
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 550.144.02 Driver Version: 550.144.02 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla M60 On | 0000:83:00.0 Off | Off |
| N/A 31C P8 23W / 150W | 1889MiB / 8191MiB | 7% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla M60 On | 0000:84:00.0 Off | Off |
| N/A 26C P8 23W / 150W | 926MiB / 8191MiB | 9% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla M10 On | 0000:8A:00.0 Off | N/A |
| N/A 23C P8 10W / 53W | 1882MiB / 8191MiB | 12% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla M10 On | 0000:8B:00.0 Off | N/A |
| N/A 26C P8 10W / 53W | 10MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 4 Tesla M10 On | 0000:8C:00.0 Off | N/A |
| N/A 34C P8 10W / 53W | 10MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 5 Tesla M10 On | 0000:8D:00.0 Off | N/A |
| N/A 32C P8 10W / 53W | 10MiB / 8191MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 11924 C+G /usr/lib64/xen/bin/vgpu 1856MiB |
| 1 11903 C+G /usr/lib64/xen/bin/vgpu 896MiB |
| 2 11908 C+G /usr/lib64/xen/bin/vgpu 1856MiB |
+-----------------------------------------------------------------------------+
[root@vgpu ~]#
7.2.1.2. 获取系统中所有 vGPU 的摘要
要获取系统中当前在每个物理 GPU 上运行的 vGPU 的摘要,请在不带其他参数的情况下运行 nvidia-smi vgpu。
[root@vgpu ~]# nvidia-smi vgpu
Fri Jan 17 09:27:06 2025
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 550.144.02 Driver Version: 550.144.02 |
|-------------------------------+--------------------------------+------------+
| GPU Name | Bus-Id | GPU-Util |
| vGPU ID Name | VM ID VM Name | vGPU-Util |
|===============================+================================+============|
| 0 Tesla M60 | 0000:83:00.0 | 7% |
| 11924 GRID M60-2Q | 3 Win7-64 GRID test 2 | 6% |
+-------------------------------+--------------------------------+------------+
| 1 Tesla M60 | 0000:84:00.0 | 9% |
| 11903 GRID M60-1B | 1 Win8.1-64 GRID test 3 | 8% |
+-------------------------------+--------------------------------+------------+
| 2 Tesla M10 | 0000:8A:00.0 | 12% |
| 11908 GRID M10-2Q | 2 Win7-64 GRID test 1 | 10% |
+-------------------------------+--------------------------------+------------+
| 3 Tesla M10 | 0000:8B:00.0 | 0% |
+-------------------------------+--------------------------------+------------+
| 4 Tesla M10 | 0000:8C:00.0 | 0% |
+-------------------------------+--------------------------------+------------+
| 5 Tesla M10 | 0000:8D:00.0 | 0% |
+-------------------------------+--------------------------------+------------+
[root@vgpu ~]#
7.2.1.3. 获取物理 GPU 详细信息
要获取有关平台上所有物理 GPU 的详细信息,请使用 –q 或 --query 选项运行 nvidia-smi。
[root@vgpu ~]# nvidia-smi -q
==============NVSMI LOG==============
Timestamp : Tue Nov 22 10:33:26 2022
Driver Version : 525.60.06
CUDA Version : Not Found
vGPU Driver Capability
Heterogenous Multi-vGPU : Supported
Attached GPUs : 3
GPU 00000000:C1:00.0
Product Name : Tesla T4
Product Brand : NVIDIA
Product Architecture : Turing
Display Mode : Enabled
Display Active : Disabled
Persistence Mode : Enabled
vGPU Device Capability
Fractional Multi-vGPU : Supported
Heterogeneous Time-Slice Profiles : Supported
Heterogeneous Time-Slice Sizes : Not Supported
MIG Mode
Current : N/A
Pending : N/A
Accounting Mode : Enabled
Accounting Mode Buffer Size : 4000
Driver Model
Current : N/A
Pending : N/A
Serial Number : 1321120031291
GPU UUID : GPU-9084c1b2-624f-2267-4b66-345583fbd981
Minor Number : 1
VBIOS Version : 90.04.38.00.03
MultiGPU Board : No
Board ID : 0xc100
Board Part Number : 900-2G183-0000-001
GPU Part Number : 1EB8-895-A1
Module ID : 0
Inforom Version
Image Version : G183.0200.00.02
OEM Object : 1.1
ECC Object : 5.0
Power Management Object : N/A
GPU Operation Mode
Current : N/A
Pending : N/A
GSP Firmware Version : N/A
GPU Virtualization Mode
Virtualization Mode : Host VGPU
Host VGPU Mode : Non SR-IOV
IBMNPU
Relaxed Ordering Mode : N/A
PCI
Bus : 0xC1
Device : 0x00
Domain : 0x0000
Device Id : 0x1EB810DE
Bus Id : 00000000:C1:00.0
Sub System Id : 0x12A210DE
GPU Link Info
PCIe Generation
Max : 3
Current : 1
Device Current : 1
Device Max : 3
Host Max : N/A
Link Width
Max : 16x
Current : 16x
Bridge Chip
Type : N/A
Firmware : N/A
Replays Since Reset : 0
Replay Number Rollovers : 0
Tx Throughput : 0 KB/s
Rx Throughput : 0 KB/s
Atomic Caps Inbound : N/A
Atomic Caps Outbound : N/A
Fan Speed : N/A
Performance State : P8
Clocks Throttle Reasons
Idle : Active
Applications Clocks Setting : Not Active
SW Power Cap : Not Active
HW Slowdown : Not Active
HW Thermal Slowdown : Not Active
HW Power Brake Slowdown : Not Active
Sync Boost : Not Active
SW Thermal Slowdown : Not Active
Display Clock Setting : Not Active
FB Memory Usage
Total : 15360 MiB
Reserved : 0 MiB
Used : 3859 MiB
Free : 11500 MiB
BAR1 Memory Usage
Total : 256 MiB
Used : 17 MiB
Free : 239 MiB
Compute Mode : Default
Utilization
Gpu : 0 %
Memory : 0 %
Encoder : 0 %
Decoder : 0 %
Encoder Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
FBC Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
Ecc Mode
Current : Enabled
Pending : Enabled
ECC Errors
Volatile
SRAM Correctable : 0
SRAM Uncorrectable : 0
DRAM Correctable : 0
DRAM Uncorrectable : 0
Aggregate
SRAM Correctable : 0
SRAM Uncorrectable : 0
DRAM Correctable : 0
DRAM Uncorrectable : 0
Retired Pages
Single Bit ECC : 0
Double Bit ECC : 0
Pending Page Blacklist : No
Remapped Rows : N/A
Temperature
GPU Current Temp : 35 C
GPU Shutdown Temp : 96 C
GPU Slowdown Temp : 93 C
GPU Max Operating Temp : 85 C
GPU Target Temperature : N/A
Memory Current Temp : N/A
Memory Max Operating Temp : N/A
Power Readings
Power Management : Supported
Power Draw : 16.57 W
Power Limit : 70.00 W
Default Power Limit : 70.00 W
Enforced Power Limit : 70.00 W
Min Power Limit : 60.00 W
Max Power Limit : 70.00 W
Clocks
Graphics : 300 MHz
SM : 300 MHz
Memory : 405 MHz
Video : 540 MHz
Applications Clocks
Graphics : 585 MHz
Memory : 5001 MHz
Default Applications Clocks
Graphics : 585 MHz
Memory : 5001 MHz
Deferred Clocks
Memory : N/A
Max Clocks
Graphics : 1590 MHz
SM : 1590 MHz
Memory : 5001 MHz
Video : 1470 MHz
Max Customer Boost Clocks
Graphics : 1590 MHz
Clock Policy
Auto Boost : N/A
Auto Boost Default : N/A
Voltage
Graphics : N/A
Fabric
State : N/A
Status : N/A
Processes
GPU instance ID : N/A
Compute instance ID : N/A
Process ID : 2103065
Type : C+G
Name : Win11SV2_View87
Used GPU Memory : 3810 MiB
[root@vgpu ~]#
7.2.1.4. 获取 vGPU 详细信息
要获取有关平台上所有 vGPU 的详细信息,请使用 –q 或 --query 选项运行 nvidia-smi vgpu。
要将检索到的信息限制为平台上的 GPU 子集,请使用 –i 或 --id 选项选择一个或多个 GPU。
[root@vgpu ~]# nvidia-smi vgpu -q -i 1
GPU 00000000:C1:00.0
Active vGPUs : 1
vGPU ID : 3251634327
VM ID : 2103066
VM Name : Win11SV2_View87
vGPU Name : GRID T4-4Q
vGPU Type : 232
vGPU UUID : afdcf724-1dd2-11b2-8534-624f22674b66
Guest Driver Version : 527.15
License Status : Licensed (Expiry: 2022-11-23 5:2:12 GMT)
GPU Instance ID : N/A
Accounting Mode : Disabled
ECC Mode : Enabled
Accounting Buffer Size : 4000
Frame Rate Limit : 60 FPS
PCI
Bus Id : 00000000:02:04.0
FB Memory Usage
Total : 4096 MiB
Used : 641 MiB
Free : 3455 MiB
Utilization
Gpu : 0 %
Memory : 0 %
Encoder : 0 %
Decoder : 0 %
Encoder Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
FBC Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
[root@vgpu ~]#
7.2.1.5. 监控 vGPU 引擎使用率
要跨多个 vGPU 监控 vGPU 引擎使用率,请使用 –u 或 --utilization 选项运行 nvidia-smi vgpu。
对于每个 vGPU,下表中的使用情况统计信息每秒报告一次。 该表还显示了命令输出中报告每个统计信息的列的名称。
| 统计信息 | 列 |
|---|---|
| 3D/计算 | sm |
| 内存控制器带宽 | mem |
| 视频编码器 | enc |
| 视频解码器 | dec |
每个报告的百分比是 vGPU 正在使用的物理 GPU 容量的百分比。 例如,使用 GPU 图形引擎 20% 容量的 vGPU 将报告 20%。
要修改报告频率,请使用 –l 或 --loop 选项。
要将监控限制为平台上的 GPU 子集,请使用 –i 或 --id 选项选择一个或多个 GPU。
[root@vgpu ~]# nvidia-smi vgpu -u
# gpu vgpu sm mem enc dec
# Idx Id % % % %
0 11924 6 3 0 0
1 11903 8 3 0 0
2 11908 10 4 0 0
3 - - - - -
4 - - - - -
5 - - - - -
0 11924 6 3 0 0
1 11903 9 3 0 0
2 11908 10 4 0 0
3 - - - - -
4 - - - - -
5 - - - - -
0 11924 6 3 0 0
1 11903 8 3 0 0
2 11908 10 4 0 0
3 - - - - -
4 - - - - -
5 - - - - -
^C[root@vgpu ~]#
7.2.1.6. 按应用程序监控 vGPU 引擎使用率
要跨多个 vGPU 按应用程序监控 vGPU 引擎使用率,请使用 –p 选项运行 nvidia-smi vgpu。
对于每个 vGPU 上的每个应用程序,下表中的使用情况统计信息每秒报告一次。 每个应用程序都通过其进程 ID 和进程名称进行标识。 该表还显示了命令输出中报告每个统计信息的列的名称。
| 统计信息 | 列 |
|---|---|
| 3D/计算 | sm |
| 内存控制器带宽 | mem |
| 视频编码器 | enc |
| 视频解码器 | dec |
每个报告的百分比是物理 GPU 的容量百分比,该容量由在物理 GPU 上的 vGPU 上运行的应用程序使用。 例如,使用 GPU 图形引擎 20% 容量的应用程序将报告 20%。
要修改报告频率,请使用 –l 或 --loop 选项。
要将监控限制为平台上的 GPU 子集,请使用 –i 或 --id 选项选择一个或多个 GPU。
[root@vgpu ~]# nvidia-smi vgpu -p
# GPU vGPU process process sm mem enc dec
# Idx Id Id name % % % %
0 38127 1528 dwm.exe 0 0 0 0
1 37408 4232 DolphinVS.exe 32 25 0 0
1 257869 4432 FurMark.exe 16 12 0 0
1 257969 4552 FurMark.exe 48 37 0 0
0 38127 1528 dwm.exe 0 0 0 0
1 37408 4232 DolphinVS.exe 16 12 0 0
1 257911 656 DolphinVS.exe 32 24 0 0
1 257969 4552 FurMark.exe 48 37 0 0
0 38127 1528 dwm.exe 0 0 0 0
1 257869 4432 FurMark.exe 38 30 0 0
1 257911 656 DolphinVS.exe 19 14 0 0
1 257969 4552 FurMark.exe 38 30 0 0
0 38127 1528 dwm.exe 0 0 0 0
1 257848 3220 Balls64.exe 16 12 0 0
1 257869 4432 FurMark.exe 16 12 0 0
1 257911 656 DolphinVS.exe 16 12 0 0
1 257969 4552 FurMark.exe 48 37 0 0
0 38127 1528 dwm.exe 0 0 0 0
1 257911 656 DolphinVS.exe 32 25 0 0
1 257969 4552 FurMark.exe 64 50 0 0
0 38127 1528 dwm.exe 0 0 0 0
1 37408 4232 DolphinVS.exe 16 12 0 0
1 257911 656 DolphinVS.exe 16 12 0 0
1 257969 4552 FurMark.exe 64 49 0 0
0 38127 1528 dwm.exe 0 0 0 0
1 37408 4232 DolphinVS.exe 16 12 0 0
1 257869 4432 FurMark.exe 16 12 0 0
1 257969 4552 FurMark.exe 64 49 0 0
[root@vgpu ~]#
7.2.1.7. 监控编码器会话
编码器会话仅可针对分配给 Windows 虚拟机的 vGPU 进行监控。 对于分配给 Linux 虚拟机的 vGPU,不报告任何编码器会话统计信息。
要监控在多个 vGPU 上运行的进程的编码器会话,请使用 –es 或 --encodersessions 选项运行 nvidia-smi vgpu。
对于每个编码器会话,以下统计信息每秒报告一次
- GPU ID
- vGPU ID
- 编码器会话 ID
- 在虚拟机中创建编码器会话的进程的 PID
- 编解码器类型,例如 H.264 或 H.265
- 编码水平分辨率
- 编码垂直分辨率
- 一秒钟尾随平均编码 FPS
- 一秒钟尾随平均编码延迟(以微秒为单位)
要修改报告频率,请使用 –l 或 --loop 选项。
要将监控限制为平台上的 GPU 子集,请使用 –i 或 --id 选项选择一个或多个 GPU。
[root@vgpu ~]# nvidia-smi vgpu -es
# GPU vGPU Session Process Codec H V Average Average
# Idx Id Id Id Type Res Res FPS Latency(us)
1 21211 2 2308 H.264 1920 1080 424 1977
1 21206 3 2424 H.264 1920 1080 0 0
1 22011 1 3676 H.264 1920 1080 374 1589
1 21211 2 2308 H.264 1920 1080 360 807
1 21206 3 2424 H.264 1920 1080 325 1474
1 22011 1 3676 H.264 1920 1080 313 1005
1 21211 2 2308 H.264 1920 1080 329 1732
1 21206 3 2424 H.264 1920 1080 352 1415
1 22011 1 3676 H.264 1920 1080 434 1894
1 21211 2 2308 H.264 1920 1080 362 1818
1 21206 3 2424 H.264 1920 1080 296 1072
1 22011 1 3676 H.264 1920 1080 416 1994
1 21211 2 2308 H.264 1920 1080 444 1912
1 21206 3 2424 H.264 1920 1080 330 1261
1 22011 1 3676 H.264 1920 1080 436 1644
1 21211 2 2308 H.264 1920 1080 344 1500
1 21206 3 2424 H.264 1920 1080 393 1727
1 22011 1 3676 H.264 1920 1080 364 1945
1 21211 2 2308 H.264 1920 1080 555 1653
1 21206 3 2424 H.264 1920 1080 295 925
1 22011 1 3676 H.264 1920 1080 372 1869
1 21211 2 2308 H.264 1920 1080 326 2206
1 21206 3 2424 H.264 1920 1080 318 1366
1 22011 1 3676 H.264 1920 1080 464 2015
1 21211 2 2308 H.264 1920 1080 305 1167
1 21206 3 2424 H.264 1920 1080 445 1892
1 22011 1 3676 H.264 1920 1080 361 906
1 21211 2 2308 H.264 1920 1080 353 1436
1 21206 3 2424 H.264 1920 1080 354 1798
1 22011 1 3676 H.264 1920 1080 373 1310
^C[root@vgpu ~]#
7.2.1.8. 监控帧缓冲区捕获 (FBC) 会话
要监控在多个 vGPU 上运行的进程的 FBC 会话,请使用 -fs 或 --fbcsessions 选项运行 nvidia-smi vgpu。
对于每个 FBC 会话,以下统计信息每秒报告一次
- GPU ID
- vGPU ID
- FBC 会话 ID
- 在虚拟机中创建 FBC 会话的进程的 PID
- 与 FBC 会话关联的显示序号。
- FBC 会话类型
- FBC 会话标志
- 捕获模式
- 会话支持的最大水平分辨率
- 会话支持的最大垂直分辨率
- 调用方在捕获调用中请求的水平分辨率
- 调用方在捕获调用中请求的垂直分辨率
- 会话每秒捕获的新帧的移动平均值
- 会话的新帧捕获延迟的移动平均值(以微秒为单位)
要修改报告频率,请使用 –l 或 --loop 选项。
要将监控限制为平台上的 GPU 子集,请使用 –i 或 --id 选项选择一个或多个 GPU。
[root@vgpu ~]# nvidia-smi vgpu -fs
# GPU vGPU Session Process Display Session Diff. Map Class. Map Capture Max H Max V H V Average Average
# Idx Id Id Id Ordinal Type State State Mode Res Res Res Res FPS Latency(us)
0 - - - - - - - - - - - - - -
1 3251634178 - - - - - - - - - - - - -
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 - - - - - - - - - - - - -
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 - - - - - - - - - - - - -
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 - - - - - - - - - - - - -
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 - - - - - - - - - - - - -
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Unknown 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Unknown 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
# GPU vGPU Session Process Display Session Diff. Map Class. Map Capture Max H Max V H V Average Average
# Idx Id Id Id Ordinal Type State State Mode Res Res Res Res FPS Latency(us)
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Unknown 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Unknown 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Unknown 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Unknown 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Unknown 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Unknown 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Unknown 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 1600 900 25 39964
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 1600 900 25 39964
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
# GPU vGPU Session Process Display Session Diff. Map Class. Map Capture Max H Max V H V Average Average
# Idx Id Id Id Ordinal Type State State Mode Res Res Res Res FPS Latency(us)
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 1600 900 135 7400
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 1600 900 227 4403
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 1600 900 227 4403
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
# GPU vGPU Session Process Display Session Diff. Map Class. Map Capture Max H Max V H V Average Average
# Idx Id Id Id Ordinal Type State State Mode Res Res Res Res FPS Latency(us)
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
0 - - - - - - - - - - - - - -
1 3251634178 1 3984 0 ToSys Disabled Disabled Blocking 4096 2160 0 0 0 0
2 - - - - - - - - - - - - - -
^C[root@vgpu ~]#
7.2.1.9. 列出支持的 vGPU 类型
要列出系统中 GPU 支持的虚拟 GPU 类型,请使用 –s 或 --supported 选项运行 nvidia-smi vgpu。
要将检索到的信息限制为平台上的 GPU 子集,请使用 –i 或 --id 选项选择一个或多个 GPU。
[root@vgpu ~]# nvidia-smi vgpu -s -i 0
GPU 0000:83:00.0
GRID M60-0B
GRID M60-0Q
GRID M60-1A
GRID M60-1B
GRID M60-1Q
GRID M60-2A
GRID M60-2Q
GRID M60-4A
GRID M60-4Q
GRID M60-8A
GRID M60-8Q
[root@vgpu ~]#
要查看有关支持的 vGPU 类型的详细信息,请添加 –v 或 --verbose 选项
[root@vgpu ~]# nvidia-smi vgpu -s -i 0 -v | less
GPU 00000000:40:00.0
vGPU Type ID : 0xc
Name : GRID M60-0Q
Class : Quadro
GPU Instance Profile ID : N/A
Max Instances : 16
Max Instances Per VM : 1
Multi vGPU Exclusive : False
vGPU Exclusive Type : False
vGPU Exclusive Size : False
Device ID : 0x13f210de
Sub System ID : 0x13f2114c
FB Memory : 512 MiB
Display Heads : 2
Maximum X Resolution : 2560
Maximum Y Resolution : 1600
Frame Rate Limit : 60 FPS
GRID License : Quadro-Virtual-DWS,5.0;GRID-Virtual-WS,2.0;GRID-Virtual-WS-Ext,2.0
vGPU Type ID : 0xf
Name : GRID M60-1Q
Class : Quadro
GPU Instance Profile ID : N/A
Max Instances : 8
Max Instances Per VM : 1
Multi vGPU Exclusive : False
vGPU Exclusive Type : False
vGPU Exclusive Size : False
Device ID : 0x13f210de
Sub System ID : 0x13f2114d
FB Memory : 1024 MiB
Display Heads : 4
Maximum X Resolution : 5120
Maximum Y Resolution : 2880
Frame Rate Limit : 60 FPS
GRID License : Quadro-Virtual-DWS,5.0;GRID-Virtual-WS,2.0;GRID-Virtual-WS-Ext,2.0
vGPU Type ID : 0x12
Name : GRID M60-2Q
Class : Quadro
GPU Instance Profile ID : N/A
Max Instances : 4
Max Instances Per VM : 1
Multi vGPU Exclusive : False
vGPU Exclusive Type : False
vGPU Exclusive Size : False
…
[root@vgpu ~]#
7.2.1.10. 列出当前可以创建的 vGPU 类型
要列出当前可以在系统中 GPU 上创建的虚拟 GPU 类型,请使用 –c 或 --creatable 选项运行 nvidia-smi vgpu。 此属性是一个动态属性,它反映了 GPU 上已运行的 vGPU 的数量和类型。
- 如果 GPU 上未运行任何 vGPU,则会列出 GPU 支持的所有 vGPU 类型。
- 如果 GPU 上运行着一个或多个 vGPU,但 GPU 未完全加载,则只会列出已运行的 vGPU 的类型。
- 如果 GPU 已完全加载,则不会列出任何 vGPU 类型。
要将检索到的信息限制为平台上的 GPU 子集,请使用 –i 或 --id 选项选择一个或多个 GPU。
[root@vgpu ~]# nvidia-smi vgpu -c -i 0
GPU 0000:83:00.0
GRID M60-2Q
[root@vgpu ~]#
要查看有关当前可以创建的 vGPU 类型的详细信息,请添加 –v 或 --verbose 选项。
7.2.2. 使用 Citrix XenCenter 监控 GPU 性能
如果您正在使用 XenServer 作为 hypervisor,则可以在 XenCenter 中监控 GPU 性能。
- 单击服务器的性能选项卡。
- 右键单击图表窗口,然后选择操作和新建图表。
- 为图表提供名称。
- 在可用计数器资源列表中,选择一个或多个 GPU 计数器。
计数器将为当前未用于 GPU 直通的每个物理 GPU 列出。
图 23. 使用 Citrix XenCenter 监控 GPU 性能

7.3. 从客户机虚拟机监控 GPU 性能
您可以使用各个客户机虚拟机中的监控工具来监控分配给虚拟机的 vGPU 或直通 GPU 的性能。 这些工具的范围仅限于您在其中使用它们的客户机虚拟机。 您不能使用各个客户机虚拟机中的监控工具来监控平台中的任何其他 GPU。
对于 vGPU,客户机虚拟机中仅报告以下指标
- 3D/计算
- 内存控制器
- 视频编码器
- 视频解码器
- 帧缓冲区使用率
GPU 中通常存在的其他指标不适用于 vGPU,并且根据您使用的工具,报告为零或 N/A。
7.3.1. 使用 nvidia-smi 从客户机虚拟机监控 GPU 性能
在客户机虚拟机中,您可以使用 nvidia-smi 命令检索虚拟机中运行的所有应用程序的总使用情况统计信息,以及各个应用程序对以下资源的使用情况统计信息
- GPU
- 视频编码器
- 视频解码器
- 帧缓冲区
要使用 nvidia-smi 检索虚拟机中运行的所有应用程序的总资源使用情况统计信息,请运行以下命令
nvidia-smi dmon
以下示例显示了从 Windows 客户机虚拟机中运行 nvidia-smi dmon 的结果。
图 24. 使用 Windows 客户机虚拟机中的 nvidia-smi 获取所有应用程序的总资源使用情况

要使用 nvidia-smi 检索虚拟机中运行的各个应用程序的资源使用情况统计信息,请运行以下命令
nvidia-smi pmon
图 25. 使用 Windows 客户机虚拟机中的 nvidia-smi 获取各个应用程序的资源使用情况

7.3.2. 使用 Windows 性能计数器监控 GPU 性能
在 Windows 虚拟机中,GPU 指标可通过 Windows 性能计数器 以 NVIDIA GPU 对象的形式提供。
任何启用读取性能计数器的应用程序都可以访问这些指标。您可以使用 Windows 操作系统自带的 Windows 性能监视器 应用程序直接访问这些指标。
以下示例显示了性能监视器应用程序中的 GPU 指标。
图 26. 使用 Windows 性能监视器监控 GPU 性能

在 vGPU 上,以下 GPU 性能计数器读数为 0,因为它们不适用于 vGPU:
- % 总线使用率
- % 散热器速率
- 核心时钟频率 MHz
- 风扇转速
- 内存时钟频率 MHz
- PCI-E 当前速度至 GPU Mbps
- PCI-E 当前宽度至 GPU
- PCI-E 下行宽度至 GPU
- 功耗 mW
- 温度 C
7.3.3. 使用 NVWMI 监控 GPU 性能
在 Windows 虚拟机中,Windows Management Instrumentation (WMI) 通过 NVWMI 在 ROOT\CIMV2\NV 命名空间中公开 GPU 指标。NVWMI 包含在 NVIDIA 驱动程序包中。NVWMI API 参考 Windows 帮助格式可从 NVIDIA 网站下载。
任何启用 WMI 的应用程序都可以访问这些指标。以下示例显示了第三方应用程序 WMI Explorer 中的 GPU 指标,该应用程序可从 CodePlex WMI Explorer 页面下载。
图 27. 使用 WMI Explorer 监控 GPU 性能

在 vGPU 上,以下类的一些实例属性不适用于 vGPU
- Gpu
- PcieLink
不适用于 vGPU 的 Gpu 实例属性
| Gpu 实例属性 | vGPU 上报告的值 |
|---|---|
| gpuCoreClockCurrent | -1 |
| memoryClockCurrent | -1 |
| pciDownstreamWidth | 0 |
| pcieGpu.curGen | 0 |
| pcieGpu.curSpeed | 0 |
| pcieGpu.curWidth | 0 |
| pcieGpu.maxGen | 1 |
| pcieGpu.maxSpeed | 2500 |
| pcieGpu.maxWidth | 0 |
| power | -1 |
| powerSampleCount | -1 |
| powerSamplingPeriod | -1 |
| verVBIOS.orderedValue | 0 |
| verVBIOS.strValue | - |
| verVBIOS.value | 0 |
不适用于 vGPU 的 PcieLink 实例属性
vGPU 没有报告 PcieLink 实例。
基于 NVIDIA Maxwell™ 图形架构的 NVIDIA GPU 实施了一种尽力而为的 vGPU 调度程序,旨在平衡 vGPU 之间的性能。尽力而为调度程序允许 vGPU 使用其他 vGPU 未使用的 GPU 处理周期。在某些情况下,运行图形密集型应用程序的虚拟机可能会对在其他虚拟机中运行的图形轻负载应用程序的性能产生不利影响。
基于 Maxwell 架构 之后 的 NVIDIA GPU 架构的 GPU 还支持均等共享和固定共享 vGPU 调度程序。这些调度程序限制了 vGPU 使用的 GPU 处理周期,从而防止在一个虚拟机中运行的图形密集型应用程序影响在其他虚拟机中运行的图形轻负载应用程序的性能。在支持多个 vGPU 调度程序的 GPU 上,您可以选择要使用的 vGPU 调度程序。您还可以设置均等共享和固定共享 vGPU 调度程序的时间片长度。
如果您使用均等共享或固定共享 vGPU 调度程序,则帧速率限制器 (FRL) 将被禁用。
尽力而为调度程序是所有受支持 GPU 架构的默认调度程序。
如果您不确定您的 GPU 的 NVIDIA GPU 架构,请参阅您的 hypervisor 的发行说明,网址为 NVIDIA Virtual GPU 软件文档。
8.1. 分时 vGPU 的调度策略
除了默认的尽力而为调度程序外,基于 Maxwell 架构 之后 的 NVIDIA GPU 架构的 GPU 还支持均等共享和固定共享 vGPU 调度程序。
- 均等共享调度程序
- 物理 GPU 在其上运行的 vGPU 之间平均分配。当 vGPU 添加到 GPU 或从 GPU 中移除时,分配给每个 vGPU 的 GPU 处理周期份额也会相应变化。因此,当同一 GPU 上的其他 vGPU 停止时,vGPU 的性能可能会提高,或者当同一 GPU 上启动其他 vGPU 时,vGPU 的性能可能会降低。
- 固定共享调度程序
- 每个 vGPU 都被赋予物理 GPU 处理周期的固定份额,份额的大小取决于 vGPU 类型,而 vGPU 类型又决定了每个物理 GPU 的最大 vGPU 数量。例如,每个物理 GPU 的 T4-4Q vGPU 的最大数量为 4。当调度策略为固定共享时,每个 T4-4Q vGPU 被赋予物理 GPU 处理周期的四分之一或 25%。当 vGPU 添加到 GPU 或从 GPU 中移除时,分配给每个 vGPU 的 GPU 处理周期份额保持不变。因此,当同一 GPU 上停止或启动其他 vGPU 时,vGPU 的性能保持不变。
对于在同一物理 GPU 上具有不同帧缓冲区大小的分时 vGPU,仅支持尽力而为和均等共享调度程序。 不 支持固定共享调度程序。
默认情况下,这些调度程序实施严格的循环调度策略。当实施此策略时,调度程序通过调整为配置了 NVIDIA vGPU 的每个虚拟机的时间片来维持调度公平性。严格的循环调度策略确保了为配置了 NVIDIA vGPU 的虚拟机更一致地调度工作,并限制了一个虚拟机中运行的 GPU 密集型应用程序对在其他虚拟机中运行的应用程序的影响。
您可以不使用严格的循环调度策略,而是通过调度在计划状态中花费时间最少的 vGPU 的工作来确保调度公平性。此行为是 15.0 之前的 NVIDIA vGPU 软件版本中的默认调度行为。
当实施严格的循环调度策略时,时间片的调整基于 调度频率 和 平均因子 。
- 调度频率
- 为特定 vGPU 调度工作的每秒次数。默认调度频率取决于驻留在物理 GPU 上的 vGPU 数量
- 如果物理 GPU 上驻留的 vGPU 少于 8 个,则默认值为 480 Hz。
- 如果物理 GPU 上驻留的 vGPU 为 8 个或更多,则默认值为 960 Hz。
- 平均因子
- 一个数字,用于确定每个 vGPU 累积的时间片超额的移动平均值。此平均值控制实施调度频率的严格程度。平均因子的值越高,实施调度频率的严格程度越低。
发生偏离指定调度频率的原因是,调度程序分配给虚拟机的实际时间量可能会超过或超出为虚拟机指定的时间片。调度程序通过缩短每个 vGPU 虚拟机的下一个时间片来补偿虚拟机的累积超额时间,从而实施调度频率。
为了计算缩短 vGPU 虚拟机下一个时间片的量,调度程序维护每个 vGPU 虚拟机累积超额时间的运行总计。此量等于运行总计除以您指定的平均因子。计算出的量也从累积超额时间中减去。平均因子的值越高,实施调度频率的严格程度越低,通过在较长时间段内分摊累积超额时间的补偿。
8.2. 分时 vGPU 的调度程序时间片
当多个虚拟机访问单个 GPU 上的 vGPU 时,GPU 串行 执行每个虚拟机的工作。vGPU 调度程序时间片表示在虚拟机的工作被抢占并且执行下一个虚拟机的工作之前,允许虚拟机的工作在 GPU 上运行的时间量。
对于均等共享和固定共享 vGPU 调度程序,您可以设置时间片的长度。时间片的长度会影响延迟和吞吐量。时间片的最佳长度取决于 GPU 正在处理的工作负载。
-
对于需要低延迟的工作负载,较短的时间片是最佳的。通常,这些工作负载是必须以固定间隔生成输出的应用程序,例如以 60 FPS 帧速率生成输出的图形应用程序。这些工作负载对延迟敏感,应允许每个间隔至少运行一次。较短的时间片通过使调度程序更频繁地在虚拟机之间切换来减少延迟并提高响应速度。
- 对于需要最大吞吐量的工作负载,较长的时间片是最佳的。通常,这些工作负载是必须尽快完成其工作并且不需要响应速度的应用程序,例如 CUDA 应用程序。较长的时间片通过防止虚拟机之间频繁切换来提高吞吐量。
8.3. 获取有关分时 vGPU 调度行为的信息
nvidia-smi 命令提供了用于获取有关分时 vGPU 调度行为的详细信息的选项。您还可以使用 hypervisor 的 dmesg 命令来获取所有 GPU 的当前分时 vGPU 调度策略。
8.3.1. 获取分时 vGPU 调度程序功能
分时 vGPU 的调度程序功能是一组值,这些值定义了如何配置 vGPU 以为配置了 NVIDIA vGPU 的每个虚拟机分配工作。这些功能值取决于 vGPU 引擎类型,并且对于支持多种调度策略的 vGPU,取决于 vGPU 是否支持并实施严格的循环调度策略。
- 如果 vGPU 引擎类型为图形,则 vGPU 调度程序功能值由支持的调度策略和其他影响如何为配置了 NVIDIA vGPU 的每个虚拟机分配工作的值组成。适用的功能值取决于 vGPU 是否支持并实施严格的循环调度策略。
- 如果 vGPU 支持并实施严格的循环调度策略,则调度频率和平均因子的值适用。
- 否则,支持的时间片范围的值适用。
- 如果 vGPU 引擎类型为图形以外的任何类型 其他类型 ,则唯一的 vGPU 调度程序功能值指示对尽力而为调度策略的支持。所有其他功能值均为零。
要获取平台上所有分时 vGPU 的调度程序功能,请运行带有 –sc 或 --schedulercaps 选项的 nvidia-smi vgpu。
要将检索到的信息限制为平台上的 GPU 子集,请使用 –i 或 --id 选项选择一个或多个 GPU。
[root@vgpu ~]# nvidia-smi vgpu -sc
vGPU scheduler capabilities
Supported Policies : Best Effort
Equal Share
Fixed Share
ARR Mode : Supported
Supported Timeslice Range
Maximum Timeslice : 30000000 ns
Minimum Timeslice : 1000000 ns
Supported Scheduling Frequency
Maximum Frequency : 960
Minimum Frequency : 63
Supported ARR Averaging Factor
Maximum Avg Factor : 60
Minimum Avg Factor : 1
8.3.2. 获取分时 vGPU 调度程序状态信息
分时 vGPU 的调度程序状态信息包括为 vGPU 设置的调度策略以及控制如何为配置了 vGPU 的虚拟机分配工作的属性值。可用的属性取决于为 vGPU 设置的调度策略。
可以为 vGPU 检索的调度程序状态信息取决于配置了 vGPU 的虚拟机是否正在运行。
要获取平台上所有分时 vGPU 的调度程序状态信息,请运行带有 –ss 或 --schedulerstate 选项的 nvidia-smi vgpu。
要将检索到的信息限制为平台上的 GPU 子集,请使用 –i 或 --id 选项选择一个或多个 GPU。
以下示例显示了当配置了 vGPU 的虚拟机未运行和正在运行时,为 vGPU 检索的调度程序状态信息。在这些示例中,调度策略是具有严格循环调度策略和默认时间片长度、调度频率和平均因子的均等共享调度程序。
未运行虚拟机的 vGPU 调度程序状态信息
对于未运行的虚拟机,未列出 ARR 模式、平均因子和时间片。
[root@vgpu ~]# nvidia-smi vgpu -ss
GPU 00000000:65:00.0
Active vGPUs : 0
Scheduler Policy : Equal Share
正在运行虚拟机的 vGPU 调度程序状态信息
[root@vgpu ~]# nvidia-smi vgpu -ss
GPU 00000000:65:00.0
Active vGPUs : 1
Scheduler Policy : Equal Share
ARR Mode : Enabled
Average Factor : 33
Time Slice(ns) : 2083333
8.3.3. 获取分时 vGPU 调度程序工作日志
分时 vGPU 的调度程序工作日志提供有关配置了 vGPU 的虚拟机的工作在运行时的分配信息。
可以为 vGPU 检索的调度程序工作日志中的信息取决于配置了 vGPU 的虚拟机是否正在运行。
要获取平台上所有分时 vGPU 的调度程序工作日志,请运行带有 –sl 或 --schedulerlogs 选项的 nvidia-smi vgpu。
要将检索到的信息限制为平台上的 GPU 子集,请使用 –i 或 --id 选项选择一个或多个 GPU。
未运行虚拟机的 vGPU 调度程序工作日志
[root@vgpu ~]# nvidia-smi vgpu -sl
+---------------------------------------------------------------------------------------------------------+
Engine Id 1
Scheduler Policy Equal Share
GPU at deviceIndex 0 has no active VM runlist.
+---------------------------------------------------------------------------------------------------------+
正在运行虚拟机的 vGPU 调度程序工作日志
[root@vgpu ~]# nvidia-smi vgpu -sl
+---------------------------------------------------------------------------------------------------------+
GPU Id 0
Engine Id 1
Scheduler Policy Equal Share
ARR Mode Enabled
Avg Factor 33
Time Slice 2083333
+---------------------------------------------------------------------------------------------------------+
GPU SW Runlist Time Cumulative Prev Timeslice Target Time Cumulative
Idx Id Stamp Run Time Runtime Slice Preempt Time
0 0 1673362687729708384 2619237216 2083840 2005425 2493060
0 0 1673362687731793472 2621322304 2085088 2005372 2494762
0 0 1673362687733877664 2623406496 2084192 2005346 2495595
8.3.4. 获取所有 GPU 的当前分时 vGPU 调度策略
您可以使用 hypervisor 的 dmesg 命令来获取所有 GPU 的当前分时 vGPU 调度策略。在更改一个或多个 GPU 的调度行为之前获取此信息,以确定是否需要更改它,或者在更改之后获取此信息以确认更改。
在您的 hypervisor 命令行 shell 中执行此任务。
- 在您的 hypervisor 主机上打开一个命令行 shell。在所有受支持的 hypervisor 上,您可以使用安全外壳 (SSH) 来实现此目的。各个 hypervisor 可能会提供其他登录方式。有关详细信息,请参阅您的 hypervisor 的文档。
- 使用 dmesg 命令显示来自内核的消息,其中包含字符串
NVRM和scheduler。$ dmesg | grep NVRM | grep scheduler
调度策略在这些消息中由以下字符串指示
-
BEST_EFFORT -
EQUAL_SHARE -
FIXED_SHARE
如果调度策略是均等共享或固定共享,则还会显示调度程序时间片,单位为毫秒。
此示例获取系统中 GPU 的调度策略,其中一个 GPU 的策略设置为尽力而为,一个 GPU 的策略设置为均等共享,一个 GPU 的策略设置为固定共享。
$ dmesg | grep NVRM | grep scheduler 2020-10-05T02:58:08.928Z cpu79:2100753)NVRM: GPU at 0000:3d:00.0 has software scheduler DISABLED with policy BEST_EFFORT. 2020-10-05T02:58:09.818Z cpu79:2100753)NVRM: GPU at 0000:5e:00.0 has software scheduler ENABLED with policy EQUAL_SHARE. NVRM: Software scheduler timeslice set to 1 ms. 2020-10-05T02:58:12.115Z cpu79:2100753)NVRM: GPU at 0000:88:00.0 has software scheduler ENABLED with policy FIXED_SHARE. NVRM: Software scheduler timeslice set to 1 ms.
-
8.4. 用于更改分时 vGPU 调度行为的工具
要更改分时 vGPU 的调度行为,您可以使用 nvidia-smi 命令或 RmPVMRL 注册表项。要使用的工具取决于您是否需要立即应用更改,或者是否需要更改是持久的。
- 如果您需要立即应用更改,请使用 nvidia-smi 命令。如果您使用 nvidia-smi 命令,则无需重新加载驱动程序或重新启动 hypervisor 主机即可应用您的更改。但是,您的更改是易失性的,并且在以下情况下不会持久存在
- 驱动程序已重新加载。
- hypervisor 主机已重新启动。
- sriov-manage 脚本已运行以启用 sysfs 文件系统中物理 GPU 的虚拟功能。
- 如果您需要更改是持久的,请使用 RmPVMRL 注册表项。
但是,如果您使用 RmPVMRL 注册表项,则必须重新加载驱动程序或重新启动 hypervisor 主机才能应用您的更改。
有关如何使用这些工具来更改分时 vGPU 的调度行为的信息,请参阅以下主题
8.5. 使用 nvidia-smi 命令更改分时 vGPU 的调度行为
nvidia-smi 命令提供了 vgpu set-scheduler-state 子命令和相关选项,用于更改分时 vGPU 的调度行为。
确保您要更改分时 vGPU 调度行为的任何物理 GPU 上都不存在 vGPU。您所做的任何更改都会影响在您进行更改后在物理 GPU 上创建的 vGPU。如果您尝试在已存在 vGPU 的物理 GPU 上更改分时 vGPU 的调度行为,则更改调度行为的尝试将失败,并且 nvidia-smi 命令将显示类似于以下示例的错误消息
Unable to set the vGPU scheduler state on GPU "00000000:1A:00.0".
vGPU scheduler state cannot be configured, if vGPU instance is currently active on the device.
要更改分时 vGPU 的调度行为,请运行 nvidia-smi vgpu set-scheduler-state 及其相关选项。
有关这些选项的更多信息,请参阅 分时 vGPU 的调度策略。
- –igpu-id
- --idgpu-id
-
gpu-id 是您要更改分时 vGPU 调度行为的 GPU 的标识符,格式为以下之一
- 驱动程序返回的自然枚举中 GPU 的从 0 开始的索引
- GPU 的通用唯一标识符 (UUID)
- 十六进制形式的 GPU 的 PCI 总线 ID domain:bus:device.function。
此选项不是强制性的。如果省略,则会更改平台上所有 GPU 的分时 vGPU 调度行为。
- -pS
- --policyS
-
S 是范围为 1-3 的十进制整数,用于设置要使用的调度程序
- 1:尽力而为调度程序(默认)
- 2:均等共享调度程序
- 3:固定共享调度程序
如果 S 不是 范围为 1-3 的十进制整数,则设置要使用的调度程序的尝试将失败,并且 nvidia-smi 命令将显示以下错误消息
Unable to set the vGPU scheduler state. Not supported
- -aR
- --arr-modeR
-
R 是一个布尔参数,用于启用或禁用调度程序的严格循环调度策略
- 0:禁用调度程序的严格循环调度策略
- 1:启用调度程序的严格循环调度策略
如果为调度程序启用了严格的循环调度策略,则还可以使用 -asf 和 -aavg 选项来设置调度频率和平均因子。
对于均等共享和固定共享调度程序,此参数是可选的。如果省略,则 --arr-mode 设置为 1 以启用调度程序的严格循环调度策略。对于尽力而为调度程序,此参数不适用。
如果 R 不是 0 或 1,则启用或禁用严格循环调度策略的尝试将失败,并且 nvidia-smi 命令将显示以下错误消息
Option passed to set Adaptive Round Robin scheduler is invalid.
- -asffrequency
- --arr-sched-frequencyfrequency
-
frequency 是范围为 63 到 960 的十进制整数,用于为具有严格循环调度策略的均等共享和固定共享调度程序设置调度频率,单位为 Hz。如果 frequency 超出 63 到 960 的范围,则调度频率设置如下
- 如果未设置 frequency,则调度频率设置为 表 1 中列出的 vGPU 类型的默认调度频率。
- 如果 frequency 小于 63,则调度频率将提高到 63。
- 如果 frequency 大于 960,则调度频率上限为 960。
- -aavgaveraging-factor
- --arr-avg-factoraveraging-factor
-
averaging-factor 是范围为 1 到 60 的十进制整数,用于设置平均因子,以确保具有严格循环调度策略的均等共享和固定共享调度程序的调度公平性。应用于累积超额时间的补偿的时间片数量取决于 averaging-factor 的值
- 如果 averaging-factor 为 1,则累积超额时间的补偿将在单个时间片中应用。
- 如果 averaging-factor 为 60,则累积超额时间的补偿将分散在 60 个时间片中。
- 如果未设置 averaging-factor,则使用默认值 33。
- 如果 averaging-factor 大于 60,则应用补偿的时间片数量上限为 60。
- -tstime-slice-length
- --time-slicetime-slice-length
-
time-slice-length 是范围为 1,000,000 到 30,000,000 的十进制整数,用于为 不带 严格循环调度策略的均等共享和固定共享调度程序设置时间片长度,单位为纳秒 (ns)。 仅 当 --arr-mode 设置为 0 以禁用调度程序的严格循环调度策略时,才设置此参数。最小长度为 1,000,000 ns (1 ms),最大长度为 30,000,000 ns (30 ms)。如果 time-slice-length 超出 1,000,000 到 30,000,000 的范围,则长度设置如下
- 如果未设置 time-slice-length,则长度设置为 表 1 中列出的 vGPU 类型的默认时间片长度。
- 如果 time-slice-length 小于 1,000,000,则长度将提高到 1,000,000 ns (1 ms)。
- 如果 time-slice-length 大于 30,000,000,则长度上限为 30,000,000 ns (30 ms)。
为单个 GPU 设置调度策略
此示例将 PCI 域 0000 和 BDF 15:00.0 处的 GPU 的调度策略设置为 不带 严格循环调度策略的固定共享调度程序,并使用默认时间片长度。
# nvidia-smi vgpu set-scheduler-state –i 0000:15:00.0 -p 3 -a 0
为单个 GPU 设置调度策略和时间片
此示例将 PCI 域 0000 和 BDF 86:00.0 处的 GPU 的调度策略设置为 不带 严格循环调度策略的固定共享调度程序,并使用 24 毫秒(24,000,000 纳秒)的时间片长度。
# nvidia-smi vgpu set-scheduler-state -i 0000:86:00.0 -p 3 -a 0 -ts 24,000,000
为所有 GPU 设置调度策略和时间片
此示例将 vGPU 调度程序设置为 不带 严格循环调度策略的均等共享调度程序,并为平台上所有 GPU 设置 3 毫秒(3,000,000 纳秒)的时间片长度。
# nvidia-smi vgpu set-scheduler-state -p 2 -a 0 -ts 3,000,000
为所有 GPU 的均等共享调度程序启用严格循环调度策略
此示例将 vGPU 调度程序设置为具有严格循环调度策略的均等共享调度程序,并为平台上所有 GPU 设置默认时间片长度、调度频率和平均因子。
# nvidia-smi vgpu set-scheduler-state -p 2 -a 1
为所有 GPU 的固定共享调度程序启用严格循环调度策略
此示例将 vGPU 调度程序设置为具有严格循环调度策略的固定共享调度程序,并为平台上所有 GPU 设置默认时间片长度、调度频率和平均因子。
# nvidia-smi vgpu set-scheduler-state -p 3 -a 1
禁用固定共享调度程序的严格循环调度策略并为所有 GPU 设置时间片
此示例将 vGPU 调度程序设置为 不带 严格循环调度策略的固定共享调度程序,并为平台上所有 GPU 设置 24 毫秒(24,000,000 纳秒)的时间片长度。
# nvidia-smi vgpu set-scheduler-state -p 3 -a 0 -ts 24,000,000
为具有自定义属性的所有 GPU 的均等共享调度程序启用严格循环调度策略
此示例将 vGPU 调度程序设置为具有严格循环调度策略、平均因子为 60 和调度频率为 960 Hz 的均等共享调度程序,并为平台上所有 GPU 设置这些属性。
# nvidia-smi vgpu set-scheduler-state -p 2 -a 1 -aavg 60-asf 960
为具有自定义属性的所有 GPU 的固定共享调度程序启用严格循环调度策略
此示例将 vGPU 调度程序设置为具有严格循环调度策略、平均因子为 60 和调度频率为 960 Hz 的固定共享调度程序,并为平台上所有 GPU 设置这些属性。
# nvidia-smi vgpu set-scheduler-state -p 3 -a 1 -aavg 60-asf 960
恢复默认分时 vGPU 调度程序设置
此示例通过将 vGPU 调度程序设置为尽力而为调度程序来恢复默认分时 vGPU 调度程序设置。
# nvidia-smi vgpu set-scheduler-state -p 1
8.6. 使用 RmPVMRL 注册表项更改分时 vGPU 的调度行为
要使用 RmPVMRL 注册表项更改分时 vGPU 的调度行为,请使用您的 hypervisor 的标准接口来设置 RmPVMRL 注册表项值。 RmPVMRL 注册表项通过设置调度策略、具有严格循环调度策略的调度程序的平均因子和调度频率以及 不带 严格循环调度策略的调度程序的时间片长度来控制 NVIDIA vGPU 的调度行为。
8.6.1. 使用 RmPVMRL 注册表项更改所有 GPU 的分时 vGPU 调度行为
您只能在支持多个 vGPU 调度程序的 GPU 上更改 vGPU 调度行为,即基于 Maxwell 架构 之后 的 NVIDIA GPU 架构的 GPU。
在您的 hypervisor 命令行 shell 中执行此任务。
- 在您的 hypervisor 主机上打开一个命令行 shell。在所有受支持的 hypervisor 上,您可以使用安全外壳 (SSH) 来实现此目的。各个 hypervisor 可能会提供其他登录方式。有关详细信息,请参阅您的 hypervisor 的文档。
- 将
RmPVMRL注册表项设置为设置 GPU 调度策略和您想要的时间片长度的值。-
在 XenServer 或 Red Hat Enterprise Linux KVM 上,将以下条目添加到 /etc/modprobe.d/nvidia.conf 文件。
options nvidia NVreg_RegistryDwords="RmPVMRL=value"
如果 /etc/modprobe.d/nvidia.conf 文件尚不存在,请创建它。
-
在 VMware vSphere 上,使用 esxcli set 命令。
# esxcli system module parameters set -m nvidia -p "NVreg_RegistryDwords=RmPVMRL=value"
- value
-
设置 GPU 调度策略和您想要的时间片长度的值,例如
-
0x01 - 将 vGPU 调度策略设置为具有默认时间片长度的均等共享调度程序。
-
0x00030001 - 将 GPU 调度策略设置为时间片长度为 3 毫秒的均等共享调度程序。
-
0x11 - 将 vGPU 调度策略设置为具有默认时间片长度的固定共享调度程序。
-
0x00180011 - 将 GPU 调度策略设置为时间片长度为 24 (0x18) 毫秒的固定共享调度程序。
-
对于所有支持的值,请参阅 RmPVMRL 注册表项。
-
- 重新启动您的 hypervisor 主机。
确认已按要求更改调度行为,如获取所有 GPU 的当前时间分片 vGPU 调度策略中所述。
8.6.2. 更改 时间分片 vGPU 调度 行为 ,通过使用 RmPVMRL 注册表项
您只能在支持多个 vGPU 调度程序的 GPU 上更改 vGPU 调度行为,即基于 Maxwell 架构 之后 的 NVIDIA GPU 架构的 GPU。
在您的 hypervisor 命令行 shell 中执行此任务。
- 在您的 hypervisor 主机上打开一个命令行 shell。在所有受支持的 hypervisor 上,您可以使用安全外壳 (SSH) 来实现此目的。各个 hypervisor 可能会提供其他登录方式。有关详细信息,请参阅您的 hypervisor 的文档。
- 使用 lspci 命令获取要更改调度行为的每个 GPU 的 PCI 域和总线/设备/功能 (BDF)。
- 在 XenServer 或 Red Hat Enterprise Linux KVM 上,添加 -D 选项以显示 PCI 域,并添加 -d 10de: 选项以仅显示 NVIDIA GPU 的信息。
# lspci -D -d 10de:
- 在 VMware vSphere 上,将 lspci 的输出管道传输到 grep 命令,以仅显示 NVIDIA GPU 的信息。
# lspci | grep NVIDIA
此示例中列出的 NVIDIA GPU 的 PCI 域为
0000,BDF 为86:00.0。0000:86:00.0 3D controller: NVIDIA Corporation GP104GL [Tesla P4] (rev a1)
- 在 XenServer 或 Red Hat Enterprise Linux KVM 上,添加 -D 选项以显示 PCI 域,并添加 -d 10de: 选项以仅显示 NVIDIA GPU 的信息。
- 使用模块参数
NVreg_RegistryDwordsPerDevice为每个 GPU 设置pci和RmPVMRL注册表项。-
在 XenServer 或 Red Hat Enterprise Linux KVM 上,将以下条目添加到 /etc/modprobe.d/nvidia.conf 文件。
options nvidia NVreg_RegistryDwordsPerDevice="pci=pci-domain:pci-bdf;RmPVMRL=value [;pci=pci-domain:pci-bdf;RmPVMRL=value...]"
如果 /etc/modprobe.d/nvidia.conf 文件尚不存在,请创建它。
-
在 VMware vSphere 上,使用 esxcli set 命令。
# esxcli system module parameters set -m nvidia \ -p "NVreg_RegistryDwordsPerDevice=pci=pci-domain:pci-bdf;RmPVMRL=value\ [;pci=pci-domain:pci-bdf;RmPVMRL=value...]"
对于每个 GPU,请提供以下信息
- pci-domain
- GPU 的 PCI 域。
- pci-bdf
- GPU 的 PCI 设备 BDF。
- value
-
设置 GPU 调度策略和您想要的时间片长度的值,例如
-
0x01 - 将 GPU 调度策略设置为具有默认时间片长度的均等共享调度器。
-
0x00030001 - 将 GPU 调度策略设置为时间片长度为 3 毫秒的均等共享调度程序。
-
0x11 - 将 GPU 调度策略设置为具有默认时间片长度的固定共享调度器。
-
0x00180011 - 将 GPU 调度策略设置为时间片长度为 24 (0x18) 毫秒的固定共享调度程序。
对于所有支持的值,请参阅 RmPVMRL 注册表项。
-
此示例向 /etc/modprobe.d/nvidia.conf 文件添加一个条目,以更改单个 GPU 的调度行为。该条目将 PCI 域为
0000且 BDF 为86:00.0的 GPU 的调度策略设置为具有默认时间片长度的固定共享调度器。options nvidia NVreg_RegistryDwordsPerDevice= "pci=0000:86:00.0;RmPVMRL=0x11"
此示例向 /etc/modprobe.d/nvidia.conf 文件添加一个条目,以更改单个 GPU 的调度行为。该条目将 PCI 域为
0000且 BDF 为86:00.0的 GPU 的调度策略设置为具有 24 (0x18) 毫秒时间片的固定共享调度器。options nvidia NVreg_RegistryDwordsPerDevice= "pci=0000:86:00.0;RmPVMRL=0x00180011"
此示例更改了在运行 VMware vSphere 的虚拟机监控程序主机上单个 GPU 的调度行为。该命令将 PCI 域为
0000且 BDF 为15:00.0的 GPU 的调度策略设置为具有默认时间片长度的固定共享调度器。# esxcli system module parameters set -m nvidia -p \ "NVreg_RegistryDwordsPerDevice=pci=0000:15:00.0;RmPVMRL=0x11[;pci=0000:15:00.0;RmPVMRL=0x11]"
此示例更改了在运行 VMware vSphere 的虚拟机监控程序主机上单个 GPU 的调度行为。该命令将 PCI 域为
0000且 BDF 为15:00.0的 GPU 的调度策略设置为具有 24 (0x18) 毫秒时间片的固定共享调度器。# esxcli system module parameters set -m nvidia -p \ "NVreg_RegistryDwordsPerDevice=pci=0000:15:00.0;RmPVMRL=0x11[;pci=0000:15:00.0;RmPVMRL=0x00180011]"
-
- 重新启动您的 hypervisor 主机。
确认已按要求更改调度行为,如获取所有 GPU 的当前时间分片 vGPU 调度策略中所述。
8.6.3. 恢复默认 时间分片 vGPU 调度器设置,通过使用 RmPVMRL 注册表项
在您的 hypervisor 命令行 shell 中执行此任务。
- 在您的 hypervisor 主机上打开一个命令行 shell。在所有受支持的 hypervisor 上,您可以使用安全外壳 (SSH) 来实现此目的。各个 hypervisor 可能会提供其他登录方式。有关详细信息,请参阅您的 hypervisor 的文档。
- 取消设置
RmPVMRL注册表项。-
在 XenServer 或 Red Hat Enterprise Linux KVM 上,注释掉 /etc/modprobe.d/nvidia.conf 文件中设置
RmPVMRL的条目,方法是在每个条目前面加上#字符。 -
在 VMware vSphere 上,将模块参数设置为空字符串。
# esxcli system module parameters set -m nvidia -p "module-parameter="
- module-parameter
- 要设置的模块参数,这取决于是否更改了所有 GPU 或选定 GPU 的调度行为
- 对于所有 GPU,设置
NVreg_RegistryDwords模块参数。 - 对于选定 GPU,设置
NVreg_RegistryDwordsPerDevice模块参数。
- 对于所有 GPU,设置
例如,要恢复为所有 GPU 更改后的默认 vGPU 调度器设置,请输入以下命令
# esxcli system module parameters set -m nvidia -p "NVreg_RegistryDwords="
-
- 重新启动您的 hypervisor 主机。
8.6.4. RmPVMRL 注册表项
RmPVMRL 注册表项通过设置调度策略、具有严格循环调度策略的调度器的平均因子和调度频率,以及不具有严格循环调度策略的调度器的时间片长度来控制 NVIDIA vGPU 的调度行为。
您只能在支持多个 vGPU 调度程序的 GPU 上更改 vGPU 调度行为,即基于 Maxwell 架构 之后 的 NVIDIA GPU 架构的 GPU。
类型
Dword
内容
| 值 | 含义 |
|---|---|
0x00(默认) |
尽力而为调度器 |
0x01 |
具有严格循环调度策略和默认时间片长度、调度频率和平均因子的均等共享调度器 |
0x03 |
不具有严格循环调度策略和默认时间片长度的均等共享调度器 |
0x<i>AA</i><i>FFF</i>001 |
具有严格循环调度策略以及用户定义的平均因子 AA 和用户定义的调度频率 FFF 的均等共享调度器 |
0x00<i>TT</i>0003 |
不具有严格循环调度策略且具有用户定义的时间片长度 TT 的均等共享调度器 |
0x11 |
具有严格循环调度策略以及默认时间片长度、调度频率和平均因子的固定共享调度器 注意
此值不能为混合大小模式下物理 GPU 上的时间分片 vGPU 设置。 |
0x13 |
不具有严格循环调度策略且具有默认时间片长度的固定共享调度器 注意
此值不能为混合大小模式下物理 GPU 上的时间分片 vGPU 设置。 |
0x<i>AA</i><i>FFF</i>011 |
具有严格循环调度策略以及用户定义的平均因子 AA 和用户定义的调度频率 FFF 的固定共享调度器 注意
此值不能为混合大小模式下物理 GPU 上的时间分片 vGPU 设置。 |
0x00<i>TT</i>0013 |
不具有严格循环调度策略且具有用户定义的时间片长度 TT 的固定共享调度器 注意
此值不能为混合大小模式下物理 GPU 上的时间分片 vGPU 设置。 |
默认时间片长度和调度频率取决于每物理 GPU 允许的最大 vGPU 数量(针对 vGPU 类型)。
- AA
- 范围为 0x01 到 0x3C(十进制 1-60)的两位十六进制数字,用于设置具有严格循环调度策略的均等共享和固定共享调度器的平均因子。应用累积超额时间补偿的时间片数量取决于 AA 的值
- 如果 AA 为 0x01,则在单个时间片中应用累积超额时间的补偿。
- 如果 AA 为 0x3C,则累积超额时间的补偿将分散在 60 (0x3C) 个时间片中。
- 如果 AA 为 0x00,则使用默认值 33。
- 如果 AA 大于 0x3C,则该值上限为 0x3C。
- FFF
- 范围为 0x3F 到 0x3C0(十进制 63-960)的三位十六进制数字,用于设置具有严格循环调度策略的均等共享和固定共享调度器的调度频率。时间片是调度频率的倒数。例如,频率 0x3F(63 赫兹)产生的时间片为 1/63 秒,或 15.873 毫秒。
FFF 的值 0x100 将调度频率设置为 256。
如果 FFF 超出 0x3F 到 0x3C0 的范围,则调度频率设置如下
- 如果 FFF 为 000,则调度频率设置为 vGPU 类型的默认调度频率,如表 1中所列。
- 如果 FFF 大于 000 但小于 0x3F,则调度频率将提高到 0x3F(十进制 63)。
- 如果 FFF 大于 0x3C0,则调度频率上限为 0x3C0(十进制 960)。
- TT
- 范围为 0x01 到 0x1E(十进制 1-30)的两位十六进制数字,用于设置均等共享和固定共享调度器的时间片长度(以毫秒为单位)。最小长度为 1 毫秒,最大长度为 30 毫秒。如果 TT 超出 01 到 1E 的范围,则长度设置如下
- 如果 TT 为 00,则长度设置为 vGPU 类型的默认时间片长度,如表 1中所列。
- 如果 TT 大于 0x1E(十进制 30),则长度上限为 30 毫秒。
示例
此示例将 vGPU 调度器设置为具有严格循环调度策略以及默认时间片长度、调度频率和平均因子的均等共享调度器。
RmPVMRL=0x01
此示例将 vGPU 调度器设置为不具有严格循环调度策略且具有 3 毫秒时间片的均等共享调度器。
RmPVMRL=0x00030003
此示例将 vGPU 调度器设置为具有严格循环调度策略以及默认时间片长度、调度频率和平均因子的固定共享调度器。
RmPVMRL=0x11
此示例将 vGPU 调度器设置为不具有严格循环调度策略且具有 24 (0x18) 毫秒时间片的固定共享调度器。
RmPVMRL=0x00180011
此示例将 vGPU 调度器设置为具有严格循环调度策略、平均因子为 60 (0x3C) 和调度频率为 960 (0x3C0) 赫兹的均等共享调度器。
RmPVMRL=0x3c3c0001
此示例将 vGPU 调度器设置为具有严格循环调度策略、平均因子为 60 (0x3C) 和调度频率为 960 (0x3C0) 赫兹的固定共享调度器。
RmPVMRL=0x3c3c0011
本章介绍 Linux 风格虚拟机监控程序上 NVIDIA vGPU 的基本故障排除步骤,以及如何在提交错误报告时收集调试信息。
9.1. 已知问题
在进行故障排除或提交错误报告之前,请查看每个驱动程序版本随附的发行说明,以获取有关当前版本的已知问题和潜在解决方法的信息。
9.2. 故障排除步骤
如果启用 vGPU 的虚拟机无法启动,或者在启动时未显示任何输出,请按照以下步骤缩小可能的原因范围。
9.2.1. 验证 NVIDIA 内核驱动程序是否已加载
- 使用虚拟机监控程序提供的命令来验证内核驱动程序是否已加载
- 在 VMware vSphere 以外的 Linux 风格虚拟机监控程序上,使用 lsmod
[root@xenserver ~]# lsmod|grep nvidia nvidia 9604895 84 i2c_core 20294 2 nvidia,i2c_i801 [root@xenserver ~]#
- 在 VMware vSphere 上,使用 vmkload_mod
[root@esxi:~] vmkload_mod -l | grep nvidia nvidia 5 8420
- 在 VMware vSphere 以外的 Linux 风格虚拟机监控程序上,使用 lsmod
- 如果输出中未列出 nvidia 驱动程序,请检查 dmesg 以查找驱动程序报告的任何加载时错误(请参阅检查 NVIDIA 内核驱动程序输出)。
- 在 XenServer 和 Red Hat Enterprise Linux KVM 上,还使用 rpm -q 命令来验证 NVIDIA GPU 管理器软件包是否已正确安装。
rpm -q vgpu-manager-rpm-package-name
- vgpu-manager-rpm-package-name
- NVIDIA GPU 管理器软件包的 RPM 软件包名称,例如 XenServer 的
NVIDIA-vGPU-NVIDIA-vGPU-CitrixHypervisor-8.2-550.144.02。
此示例验证 XenServer 的 NVIDIA GPU 管理器软件包是否已正确安装。
[root@xenserver ~]# rpm –q NVIDIA-vGPU-NVIDIA-vGPU-CitrixHypervisor-8.2-550.144.02 [root@xenserver ~]# If an existing NVIDIA GRID package is already installed and you don’t select the upgrade (-U) option when installing a newer GRID package, the rpm command will return many conflict errors. Preparing packages for installation... file /usr/bin/nvidia-smi from install of NVIDIA-vGPU-NVIDIA-vGPU-CitrixHypervisor-8.2-550.144.02.x86_64 conflicts with file from package NVIDIA-vGPU-xenserver-8.2-550.127.06.x86_64 file /usr/lib/libnvidia-ml.so from install of NVIDIA-vGPU-NVIDIA-vGPU-CitrixHypervisor-8.2-550.144.02.x86_64 conflicts with file from package NVIDIA-vGPU-xenserver-8.2-550.127.06.x86_64 ...
9.2.2. 验证 nvidia-smi 是否工作
如果 NVIDIA 内核驱动程序已在物理 GPU 上正确加载,请运行 nvidia-smi 并验证当前未用于 GPU 直通的所有物理 GPU 是否都列在输出中。有关预期输出的详细信息,请参阅NVIDIA 系统管理界面 nvidia-smi。
如果 nvidia-smi 未能报告预期的输出,请检查 dmesg 以查找 NVIDIA 内核驱动程序消息。
9.2.3. 检查 NVIDIA 内核驱动程序输出
来自 NVIDIA 内核驱动程序的信息和调试消息记录在内核日志中,前缀为 NVRM 或 nvidia。
在受支持的 Linux 风格虚拟机监控程序上运行 dmesg,并检查 NVRM 和 nvidia 前缀
[root@xenserver ~]# dmesg | grep -E "NVRM|nvidia"
[ 22.054928] nvidia: module license 'NVIDIA' taints kernel.
[ 22.390414] NVRM: loading
[ 22.829226] nvidia 0000:04:00.0: enabling device (0000 -> 0003)
[ 22.829236] nvidia 0000:04:00.0: PCI INT A -> GSI 32 (level, low) -> IRQ 32
[ 22.829240] NVRM: This PCI I/O region assigned to your NVIDIA device is invalid:
[ 22.829241] NVRM: BAR0 is 0M @ 0x0 (PCI:0000:00:04.0)
[ 22.829243] NVRM: The system BIOS may have misconfigured your GPU.
9.2.4. 检查 NVIDIA 虚拟 GPU 管理器消息
来自 NVIDIA 虚拟 GPU 管理器的信息和调试消息记录到虚拟机监控程序的日志文件中,前缀为 vmiop。
9.2.4.1. 检查 XenServer vGPU 管理器消息
对于 XenServer,NVIDIA 虚拟 GPU 管理器消息写入 /var/log/messages。
在 /var/log/messages 文件中查找 vmiop 前缀
[root@xenserver ~]# grep vmiop /var/log/messages
Jan 20 10:34:03 localhost vgpu-ll[25698]: notice: vmiop_log: gpu-pci-id : 0000:05:00.0
Jan 20 10:34:03 localhost vgpu-ll[25698]: notice: vmiop_log: vgpu_type : quadro
Jan 20 10:34:03 localhost vgpu-ll[25698]: notice: vmiop_log: Framebuffer: 0x74000000
Jan 20 10:34:03 localhost vgpu-ll[25698]: notice: vmiop_log: Virtual Device Id: 0xl3F2:0xll4E
Jan 20 10:34:03 localhost vgpu-ll[25698]: notice: vmiop_log: ######## vGPU Manager Information: ########
Jan 20 10:34:03 localhost vgpu-ll[25698]: notice: vmiop_log: Driver Version: 550.144.02
Jan 20 10:34:03 localhost vgpu-ll[25698]: notice: vmiop_log: Init frame copy engine: syncing...
Jan 20 10:35:31 localhost vgpu-ll[25698]: notice: vmiop_log: ######## Guest NVIDIA Driver Information: ########
Jan 20 10:35:31 localhost vgpu-ll[25698]: notice: vmiop_log: Driver Version: 553.62
Jan 20 10:35:36 localhost vgpu-ll[25698]: notice: vmiop_log: Current max guest pfn = 0xllbc84!
Jan 20 10:35:40 localhost vgpu-ll[25698]: notice: vmiop_log: Current max guest pfn = 0xlleff0!
[root@xenserver ~]#
9.2.4.2. 检查 Red Hat Enterprise Linux KVM vGPU 管理器消息
对于 Red Hat Enterprise Linux KVM,NVIDIA 虚拟 GPU 管理器消息写入 /var/log/messages。
在这些文件中查找 vmiop_log: 前缀
# grep vmiop_log: /var/log/messages
[2025-01-17 04:46:12] vmiop_log: [2025-01-17 04:46:12] notice: vmiop-env: guest_max_gpfn:0x11f7ff
[2025-01-17 04:46:12] vmiop_log: [2025-01-17 04:46:12] notice: pluginconfig: /usr/share/nvidia/vgx/grid_m60-1q.conf,gpu-pci-id=0000:06:00.0
[2025-01-17 04:46:12] vmiop_log: [2025-01-17 04:46:12] notice: Loading Plugin0: libnvidia-vgpu
[2025-01-17 04:46:12] vmiop_log: [2025-01-17 04:46:12] notice: Successfully update the env symbols!
[2025-01-17 04:46:12] vmiop_log: [2025-01-17 04:46:12] notice: vmiop_log: gpu-pci-id : 0000:06:00.0
[2025-01-17 04:46:12] vmiop_log: [2025-01-17 04:46:12] notice: vmiop_log: vgpu_type : quadro
[2025-01-17 04:46:12] vmiop_log: [2025-01-17 04:46:12] notice: vmiop_log: Framebuffer: 0x38000000
[2025-01-17 04:46:12] vmiop_log: [2025-01-17 04:46:12] notice: vmiop_log: Virtual Device Id: 0x13F2:0x114D
[2025-01-17 04:46:12] vmiop_log: [2025-01-17 04:46:12] notice: vmiop_log: ######## vGPU Manager Information: ########
[2025-01-17 04:46:12] vmiop_log: [2025-01-17 04:46:12] notice: vmiop_log: Driver Version: 550.144.02
[2025-01-17 04:46:12] vmiop_log: [2025-01-17 04:46:12] notice: vmiop_log: Init frame copy engine: syncing...
[2025-01-17 05:09:14] vmiop_log: [2025-01-17 05:09:14] notice: vmiop_log: ######## Guest NVIDIA Driver Information: ########
[2025-01-17 05:09:14] vmiop_log: [2025-01-17 05:09:14] notice: vmiop_log: Driver Version: 553.62
[2025-01-17 05:09:14] vmiop_log: [2025-01-17 05:09:14] notice: vmiop_log: Current max guest pfn = 0x11a71f!
[2025-01-17 05:12:09] vmiop_log: [2025-01-17 05:12:09] notice: vmiop_log: vGPU license state: (0x00000001)
#
9.2.4.3. 检查 VMware vSphere vGPU 管理器消息
对于 VMware vSphere,NVIDIA 虚拟 GPU 管理器消息写入访客虚拟机的存储目录中的 vmware.log 文件。
在 vmware.log 文件中查找 vmiop 前缀
[root@esxi:~] grep vmiop /vmfs/volumes/datastore1/win7-vgpu-test1/vmware.log
2025-01-17T14:02:21.275Z| vmx| I120: DICT pciPassthru0.virtualDev = "vmiop"
2025-01-17T14:02:21.344Z| vmx| I120: GetPluginPath testing /usr/lib64/vmware/plugin/libvmx-vmiop.so
2025-01-17T14:02:21.344Z| vmx| I120: PluginLdr_LoadShared: Loaded shared plugin libvmx-vmiop.so from /usr/lib64/vmware/plugin/libvmx-vmiop.so
2025-01-17T14:02:21.344Z| vmx| I120: VMIOP: Loaded plugin libvmx-vmiop.so:VMIOP_InitModule
2025-01-17T14:02:21.359Z| vmx| I120: VMIOP: Initializing plugin vmiop-display
2025-01-17T14:02:21.365Z| vmx| I120: vmiop_log: gpu-pci-id : 0000:04:00.0
2025-01-17T14:02:21.365Z| vmx| I120: vmiop_log: vgpu_type : quadro
2025-01-17T14:02:21.365Z| vmx| I120: vmiop_log: Framebuffer: 0x74000000
2025-01-17T14:02:21.365Z| vmx| I120: vmiop_log: Virtual Device Id: 0x11B0:0x101B
2025-01-17T14:02:21.365Z| vmx| I120: vmiop_log: ######## vGPU Manager Information: ########
2025-01-17T14:02:21.365Z| vmx| I120: vmiop_log: Driver Version: 550.144.02
2025-01-17T14:02:21.365Z| vmx| I120: vmiop_log: VGX Version: 17.5
2025-01-17T14:02:21.445Z| vmx| I120: vmiop_log: Init frame copy engine: syncing...
2025-01-17T14:02:37.031Z| vthread-12| I120: vmiop_log: ######## Guest NVIDIA Driver Information: ########
2025-01-17T14:02:37.031Z| vthread-12| I120: vmiop_log: Driver Version: 553.62
2025-01-17T14:02:37.031Z| vthread-12| I120: vmiop_log: VGX Version: 17.5
2025-01-17T14:02:37.093Z| vthread-12| I120: vmiop_log: Clearing BAR1 mapping
2025-01-20T23:39:55.726Z| vmx| I120: VMIOP: Shutting down plugin vmiop-display
[root@esxi:~]
9.3. 捕获配置数据以提交错误报告
向 NVIDIA 提交错误报告时,请通过以下方式之一捕获展示错误的平台的相关配置数据
- 在任何受支持的虚拟机监控程序上,运行 nvidia-bug-report.sh。
- 在 Citrix XenServer 上,创建 XenServer 服务器状态报告。
9.3.1. 通过运行 nvidia-bug-report.sh 捕获配置数据
nvidia-bug-report.sh 脚本将调试信息捕获到服务器上的 gzip 压缩日志文件中。
从 XenServer dom0 shell、支持 KVM 虚拟机监控程序的 Linux 主机 shell 或 VMware ESXi 主机 shell 运行 nvidia-bug-report.sh。
此示例在 XenServer 上运行 nvidia-bug-report.sh,但在任何受支持的具有 KVM 虚拟机监控程序或 VMware vSphere ESXi 的 Linux 上,过程都是相同的。
[root@xenserver ~]# nvidia-bug-report.sh
nvidia-bug-report.sh will now collect information about your
system and create the file 'nvidia-bug-report.log.gz' in the current
directory. It may take several seconds to run. In some
cases, it may hang trying to capture data generated dynamically
by the Linux kernel and/or the NVIDIA kernel module. While
the bug report log file will be incomplete if this happens, it
may still contain enough data to diagnose your problem.
For Xen open source/XCP users, if you are reporting a domain issue,
please run: nvidia-bug-report.sh --domain-name <"domain_name">
Please include the 'nvidia-bug-report.log.gz' log file when reporting
your bug via the NVIDIA Linux forum (see devtalk.nvidia.com)
or by sending email to 'linux-bugs@nvidia.com'.
Running nvidia-bug-report.sh...
If the bug report script hangs after this point consider running with
--safe-mode command line argument.
complete
[root@xenserver ~]#
9.3.2. 通过创建 XenServer 状态报告捕获配置数据
- 在 XenCenter 中,从工具菜单中,选择服务器状态报告。
- 选择要从中收集状态报告的 XenServer 实例。
- 选择要包含在报告中的数据。
- 要包含 NVIDIA vGPU 调试信息,请在报告内容项列表中选择 NVIDIA-logs。
- 生成报告。
图 28. 在 XenServer 状态报告中包含 NVIDIA 日志

9.4. 自 17.2 版本起:收集 XID 119 错误的故障排除信息
如果您遇到 XID 119 错误,请确保已将 NVIDIA vGPU 软件图形驱动程序升级到提供专门用于排除这些错误的信息的版本。您可以向 NVIDIA 企业支持提供此信息以排除这些错误。升级 NVIDIA vGPU 软件图形驱动程序不能修复这些错误。
XID 119 错误是由 GPU 系统处理器 (GSP) RPC 超时引起的。因此,这些错误仅在使用基于 NVIDIA Ada Lovelace 和 Hopper GPU 架构的 GPU 的 NVIDIA vGPU 部署中才会发生。
要收集 NVIDIA vGPU 软件图形驱动程序提供的关于 XID 119 错误的附加信息,请从 NVIDIA 企业支持处下载并运行用于此目的的脚本。有关此脚本的更多信息,请参阅 NVIDIA 知识库中关于捕获 XID 119 和 XID 120 错误信息的文章。
A.1. 受支持 GPU 的虚拟 GPU 类型
NVIDIA vGPU 作为许可产品在受支持的 NVIDIA GPU 上提供。有关推荐的服务器平台和受支持的 GPU 列表,请查阅受支持虚拟机监控程序的发行说明,网址为NVIDIA 虚拟 GPU 软件文档。
A.1.1. NVIDIA A40 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
NVIDIA A40 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| A40-48Q | 49152 | 1 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| A40-24Q | 24576 | 2 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| A40-16Q | 16384 | 3 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| A40-12Q | 12288 | 4 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| A40-8Q | 8192 | 6 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| A40-6Q | 6144 | 8 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| A40-4Q | 4096 | 12 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| A40-3Q | 3072 | 16 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| A40-2Q | 2048 | 24 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| A40-1Q | 1024 | 325 | 30 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 |
NVIDIA A40 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| A40-2B | 2048 | 24 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 | |||||
| A40-1B | 1024 | 32 | 32 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | |||||
| 3840×2160 | 1 | |||||
| 2560×1600 或更低 | 43 |
NVIDIA A40 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| A40-48A | 49152 | 1 | 1 | 1280×10244 | 14 |
| A40-24A | 24576 | 2 | 2 | 1280×10244 | 14 |
| A40-16A | 16384 | 3 | 2 | 1280×10244 | 14 |
| A40-12A | 12288 | 4 | 4 | 1280×10244 | 14 |
| A40-8A | 8192 | 6 | 4 | 1280×10244 | 14 |
| A40-6A | 6144 | 8 | 8 | 1280×10244 | 14 |
| A40-4A | 4096 | 12 | 8 | 1280×10244 | 14 |
| A40-3A | 3072 | 16 | 16 | 1280×10244 | 14 |
| A40-2A | 2048 | 24 | 16 | 1280×10244 | 14 |
| A40-1A | 1024 | 325 | 32 | 1280×10244 | 14 |
A.1.2. NVIDIA A16 虚拟 GPU 类型
每板物理 GPU:4
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
NVIDIA A16 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| A16-16Q | 16384 | 1 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| A16-8Q | 8192 | 2 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| A16-4Q | 4096 | 4 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| A16-2Q | 2048 | 8 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| A16-1Q | 1024 | 16 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 |
NVIDIA A16 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| A16-2B | 2048 | 8 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 | |||||
| A16-1B | 1024 | 16 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | |||||
| 3840×2160 | 1 | |||||
| 2560×1600 或更低 | 43 |
NVIDIA A16 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
A.1.3. NVIDIA A10 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
NVIDIA A10 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| A10-24Q | 24576 | 1 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| A10-12Q | 12288 | 2 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| A10-8Q | 8192 | 3 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| A10-6Q | 6144 | 4 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| A10-4Q | 4096 | 6 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| A10-3Q | 3072 | 8 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| A10-2Q | 2048 | 12 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| A10-1Q | 1024 | 24 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 |
NVIDIA A10 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| A10-2B | 2048 | 12 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 | |||||
| A10-1B | 1024 | 24 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | |||||
| 3840×2160 | 1 | |||||
| 2560×1600 或更低 | 43 |
NVIDIA A10 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| A10-24A | 24576 | 1 | 1 | 1280×10244 | 14 |
| A10-12A | 12288 | 2 | 2 | 1280×10244 | 14 |
| A10-8A | 8192 | 3 | 2 | 1280×10244 | 14 |
| A10-6A | 6144 | 4 | 4 | 1280×10244 | 14 |
| A10-4A | 4096 | 6 | 4 | 1280×10244 | 14 |
| A10-3A | 3072 | 8 | 8 | 1280×10244 | 14 |
| A10-2A | 2048 | 12 | 8 | 1280×10244 | 14 |
| A10-1A | 1024 | 24 | 16 | 1280×10244 | 14 |
A.1.4. NVIDIA A2 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
NVIDIA A2 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| A2-16Q | 16384 | 1 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| A2-8Q | 8192 | 2 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| A2-4Q | 4096 | 4 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| A2-2Q | 2048 | 8 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| A2-1Q | 1024 | 16 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 |
NVIDIA A2 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| A2-2B | 2048 | 8 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 | |||||
| A2-1B | 1024 | 16 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | |||||
| 3840×2160 | 1 | |||||
| 2560×1600 或更低 | 43 |
NVIDIA A2 的 A 系列虚拟 GPU 类型
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
A.1.5. NVIDIA L40 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
NVIDIA L40 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| L40-48Q | 49152 | 1 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L40-24Q | 24576 | 2 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L40-16Q | 16384 | 3 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L40-12Q | 12288 | 4 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L40-8Q | 8192 | 6 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L40-6Q | 6144 | 8 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| L40-4Q | 4096 | 12 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| L40-3Q | 3072 | 16 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| L40-2Q | 2048 | 24 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| L40-1Q | 1024 | 326 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 |
NVIDIA L40 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| L40-2B | 2048 | 24 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 | |||||
| L40-1B | 1024 | 32 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | |||||
| 3840×2160 | 1 | |||||
| 2560×1600 或更低 | 43 |
NVIDIA L40 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| L40-48A | 49152 | 1 | 1 | 1280×10244 | 14 |
| L40-24A | 24576 | 2 | 2 | 1280×10244 | 14 |
| L40-16A | 16384 | 3 | 2 | 1280×10244 | 14 |
| L40-12A | 12288 | 4 | 4 | 1280×10244 | 14 |
| L40-8A | 8192 | 6 | 4 | 1280×10244 | 14 |
| L40-6A | 6144 | 8 | 8 | 1280×10244 | 14 |
| L40-4A | 4096 | 12 | 8 | 1280×10244 | 14 |
| L40-3A | 3072 | 16 | 16 | 1280×10244 | 14 |
| L40-2A | 2048 | 24 | 16 | 1280×10244 | 14 |
| L40-1A | 1024 | 326 | 16 | 1280×10244 | 14 |
A.1.6. NVIDIA L40S 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
NVIDIA L40S 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| L40S-48Q | 49152 | 1 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L40S-24Q | 24576 | 2 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L40S-16Q | 16384 | 3 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L40S-12Q | 12288 | 4 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L40S-8Q | 8192 | 6 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L40S-6Q | 6144 | 8 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| L40S-4Q | 4096 | 12 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| L40S-3Q | 3072 | 16 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| L40S-2Q | 2048 | 24 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| L40S-1Q | 1024 | 327 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 |
NVIDIA L40S 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| L40S-2B | 2048 | 24 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 | |||||
| L40S-1B | 1024 | 32 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | |||||
| 3840×2160 | 1 | |||||
| 2560×1600 或更低 | 43 |
NVIDIA L40S 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| L40S-48A | 49152 | 1 | 1 | 1280×10244 | 14 |
| L40S-24A | 24576 | 2 | 2 | 1280×10244 | 14 |
| L40S-16A | 16384 | 3 | 2 | 1280×10244 | 14 |
| L40S-12A | 12288 | 4 | 4 | 1280×10244 | 14 |
| L40S-8A | 8192 | 6 | 4 | 1280×10244 | 14 |
| L40S-6A | 6144 | 8 | 8 | 1280×10244 | 14 |
| L40S-4A | 4096 | 12 | 8 | 1280×10244 | 14 |
| L40S-3A | 3072 | 16 | 16 | 1280×10244 | 14 |
| L40S-2A | 2048 | 24 | 16 | 1280×10244 | 14 |
| L40S-1A | 1024 | 327 | 16 | 1280×10244 | 14 |
A.1.7. NVIDIA L20 和 NVIDIA L20 液冷虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
NVIDIA L20 和 NVIDIA L20 液冷 GPU 的虚拟 GPU 类型是相同的。
NVIDIA L20 和 NVIDIA L20 液冷的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| L20-48Q | 49152 | 1 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L20-24Q | 24576 | 2 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L20-16Q | 16384 | 3 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L20-12Q | 12288 | 4 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L20-8Q | 8192 | 6 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L20-6Q | 6144 | 8 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| L20-4Q | 4096 | 12 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| L20-3Q | 3072 | 16 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| L20-2Q | 2048 | 24 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| L20-1Q | 1024 | 328 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 |
NVIDIA L20 和 NVIDIA L20 液冷的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| L20-2B | 2048 | 24 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 | |||||
| L20-1B | 1024 | 32 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | |||||
| 3840×2160 | 1 | |||||
| 2560×1600 或更低 | 43 |
NVIDIA L20 和 NVIDIA L20 液冷的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| L20-48A | 49152 | 1 | 1 | 1280×10244 | 14 |
| L20-24A | 24576 | 2 | 2 | 1280×10244 | 14 |
| L20-16A | 16384 | 3 | 2 | 1280×10244 | 14 |
| L20-12A | 12288 | 4 | 4 | 1280×10244 | 14 |
| L20-8A | 8192 | 6 | 4 | 1280×10244 | 14 |
| L20-6A | 6144 | 8 | 8 | 1280×10244 | 14 |
| L20-4A | 4096 | 12 | 8 | 1280×10244 | 14 |
| L20-3A | 3072 | 16 | 16 | 1280×10244 | 14 |
| L20-2A | 2048 | 24 | 16 | 1280×10244 | 14 |
| L20-1A | 1024 | 328 | 16 | 1280×10244 | 14 |
A.1.8. NVIDIA L4 虚拟 GPU 类型
每板物理 GPU:1
NVIDIA L4 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| L4-24Q | 24576 | 1 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L4-12Q | 12288 | 2 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L4-8Q | 8192 | 3 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L4-6Q | 6144 | 4 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| L4-4Q | 4096 | 6 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| L4-3Q | 3072 | 8 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| L4-2Q | 2048 | 12 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| L4-1Q | 1024 | 24 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 |
NVIDIA L4 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| L4-2B | 2048 | 12 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 | |||||
| L4-1B | 1024 | 24 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | |||||
| 3840×2160 | 1 | |||||
| 2560×1600 或更低 | 43 |
NVIDIA L4 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| L4-24A | 24576 | 1 | 1 | 1280×10244 | 14 |
| L4-12A | 12288 | 2 | 2 | 1280×10244 | 14 |
| L4-8A | 8192 | 3 | 2 | 1280×10244 | 14 |
| L4-6A | 6144 | 4 | 4 | 1280×10244 | 14 |
| L4-4A | 4096 | 6 | 4 | 1280×10244 | 14 |
| L4-3A | 3072 | 8 | 8 | 1280×10244 | 14 |
| L4-2A | 2048 | 12 | 8 | 1280×10244 | 14 |
| L4-1A | 1024 | 24 | 16 | 1280×10244 | 14 |
A.1.9. NVIDIA L2 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
NVIDIA L2 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| L2-24Q | 24576 | 1 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L2-12Q | 12288 | 2 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L2-8Q | 8192 | 3 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| L2-6Q | 6144 | 4 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| L2-4Q | 4096 | 6 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| L2-3Q | 3072 | 8 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| L2-2Q | 2048 | 12 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| L2-1Q | 1024 | 24 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 |
NVIDIA L2 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| L2-2B | 2048 | 12 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 | |||||
| L2-1B | 1024 | 24 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | |||||
| 3840×2160 | 1 | |||||
| 2560×1600 或更低 | 43 |
NVIDIA L2 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| L2-24A | 24576 | 1 | 1 | 1280×10244 | 14 |
| L2-12A | 12288 | 2 | 2 | 1280×10244 | 14 |
| L2-8A | 8192 | 3 | 2 | 1280×10244 | 14 |
| L2-6A | 6144 | 4 | 4 | 1280×10244 | 14 |
| L2-4A | 4096 | 6 | 4 | 1280×10244 | 14 |
| L2-3A | 3072 | 8 | 8 | 1280×10244 | 14 |
| L2-2A | 2048 | 12 | 8 | 1280×10244 | 14 |
| L2-1A | 1024 | 24 | 16 | 1280×10244 | 14 |
A.1.10. NVIDIA RTX 6000 Ada 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
NVIDIA RTX 6000 Ada 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| RTX 6000 Ada-48Q | 49152 | 1 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTX 6000 Ada-24Q | 24576 | 2 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTX 6000 Ada-16Q | 16384 | 3 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTX 6000 Ada-12Q | 12288 | 4 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTX 6000 Ada-8Q | 8192 | 6 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTX 6000 Ada-6Q | 6144 | 8 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| RTX 6000 Ada-4Q | 4096 | 12 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| RTX 6000 Ada-3Q | 3072 | 16 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| RTX 6000 Ada-2Q | 2048 | 24 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| RTX 6000 Ada-1Q | 1024 | 329 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 |
NVIDIA RTX 6000 Ada 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| RTX 6000 Ada-2B | 2048 | 24 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 | |||||
| RTX 6000 Ada-1B | 1024 | 32 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | |||||
| 3840×2160 | 1 | |||||
| 2560×1600 或更低 | 43 |
NVIDIA RTX 6000 Ada 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| RTX 6000 Ada-48A | 49152 | 1 | 1 | 1280×10244 | 14 |
| RTX 6000 Ada-24A | 24576 | 2 | 2 | 1280×10244 | 14 |
| RTX 6000 Ada-16A | 16384 | 3 | 2 | 1280×10244 | 14 |
| RTX 6000 Ada-12A | 12288 | 4 | 4 | 1280×10244 | 14 |
| RTX 6000 Ada-8A | 8192 | 6 | 4 | 1280×10244 | 14 |
| RTX 6000 Ada-6A | 6144 | 8 | 8 | 1280×10244 | 14 |
| RTX 6000 Ada-4A | 4096 | 12 | 8 | 1280×10244 | 14 |
| RTX 6000 Ada-3A | 3072 | 16 | 16 | 1280×10244 | 14 |
| RTX 6000 Ada-2A | 2048 | 24 | 16 | 1280×10244 | 14 |
| RTX 6000 Ada-1A | 1024 | 329 | 16 | 1280×10244 | 14 |
A.1.11. NVIDIA RTX 5880 Ada 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
NVIDIA RTX 5880 Ada 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| RTX 5880 Ada-48Q | 49152 | 1 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTX 5880 Ada-24Q | 24576 | 2 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTX 5880 Ada-16Q | 16384 | 3 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTX 5880 Ada-12Q | 12288 | 4 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTX 5880 Ada-8Q | 8192 | 6 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTX 5880 Ada-6Q | 6144 | 8 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| RTX 5880 Ada-4Q | 4096 | 12 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| RTX 5880 Ada-3Q | 3072 | 16 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| RTX 5880 Ada-2Q | 2048 | 24 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| RTX 5880 Ada-1Q | 1024 | 3210 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 |
NVIDIA RTX 5880 Ada 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| RTX 5880 Ada-2B | 2048 | 24 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 | |||||
| RTX 5880 Ada-1B | 1024 | 32 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | |||||
| 3840×2160 | 1 | |||||
| 2560×1600 或更低 | 43 |
NVIDIA RTX 5880 Ada 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| RTX 5880 Ada-48A | 49152 | 1 | 1 | 1280×10244 | 14 |
| RTX 5880 Ada-24A | 24576 | 2 | 2 | 1280×10244 | 14 |
| RTX 5880 Ada-16A | 16384 | 3 | 2 | 1280×10244 | 14 |
| RTX 5880 Ada-12A | 12288 | 4 | 4 | 1280×10244 | 14 |
| RTX 5880 Ada-8A | 8192 | 6 | 4 | 1280×10244 | 14 |
| RTX 5880 Ada-6A | 6144 | 8 | 8 | 1280×10244 | 14 |
| RTX 5880 Ada-4A | 4096 | 12 | 8 | 1280×10244 | 14 |
| RTX 5880 Ada-3A | 3072 | 16 | 16 | 1280×10244 | 14 |
| RTX 5880 Ada-2A | 2048 | 24 | 16 | 1280×10244 | 14 |
| RTX 5880 Ada-1A | 1024 | 3210 | 16 | 1280×10244 | 14 |
A.1.12. NVIDIA RTX 5000 Ada 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
NVIDIA RTX 5000 Ada 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| RTX 5000 Ada-32Q | 32768 | 1 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTX 5000 Ada-16Q | 16384 | 2 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTX 5000 Ada-8Q | 8192 | 4 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTX 5000 Ada-4Q | 4096 | 8 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| RTX 5000 Ada-2Q | 2048 | 16 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| RTX 5000 Ada-1Q | 1024 | 32 | 32 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 |
NVIDIA RTX 5000 Ada 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| RTX 5000 Ada-2B | 2048 | 16 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 | |||||
| RTX 5000 Ada-1B | 1024 | 32 | 32 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | |||||
| 3840×2160 | 1 | |||||
| 2560×1600 或更低 | 43 |
NVIDIA RTX 5000 Ada 的 A 系列虚拟 GPU 类型
所需许可证版本:vApps
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| RTX 5000 Ada-32A | 32768 | 1 | 1 | 1280×10244 | 14 |
| RTX 5000 Ada-16A | 16384 | 2 | 2 | 1280×10244 | 14 |
| RTX 5000 Ada-8A | 8192 | 4 | 4 | 1280×10244 | 14 |
| RTX 5000 Ada-4A | 4096 | 8 | 8 | 1280×10244 | 14 |
| RTX 5000 Ada-2A | 2048 | 16 | 16 | 1280×10244 | 14 |
| RTX 5000 Ada-1A | 1024 | 32 | 32 | 1280×10244 | 14 |
A.1.13. NVIDIA RTX A6000 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
NVIDIA RTX A6000 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| RTXA6000-48Q | 49152 | 1 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTXA6000-24Q | 24576 | 2 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTXA6000-16Q | 16384 | 3 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTXA6000-12Q | 12288 | 4 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTXA6000-8Q | 8192 | 6 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTXA6000-6Q | 6144 | 8 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| RTXA6000-4Q | 4096 | 12 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| RTXA6000-3Q | 3072 | 16 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| RTXA6000-2Q | 2048 | 24 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| RTXA6000-1Q | 1024 | 3211 | 30 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 |
NVIDIA RTX A6000 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| RTXA6000-2B | 2048 | 24 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 | |||||
| RTXA6000-1B | 1024 | 32 | 30 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | |||||
| 3840×2160 | 1 | |||||
| 2560×1600 或更低 | 43 |
NVIDIA RTX A6000 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| RTXA6000-48A | 49152 | 1 | 1 | 1280×10244 | 14 |
| RTXA6000-24A | 24576 | 2 | 2 | 1280×10244 | 14 |
| RTXA6000-16A | 16384 | 3 | 2 | 1280×10244 | 14 |
| RTXA6000-12A | 12288 | 4 | 4 | 1280×10244 | 14 |
| RTXA6000-8A | 8192 | 6 | 4 | 1280×10244 | 14 |
| RTXA6000-6A | 6144 | 8 | 8 | 1280×10244 | 14 |
| RTXA6000-4A | 4096 | 12 | 8 | 1280×10244 | 14 |
| RTXA6000-3A | 3072 | 16 | 16 | 1280×10244 | 14 |
| RTXA6000-2A | 2048 | 24 | 16 | 1280×10244 | 14 |
| RTXA6000-1A | 1024 | 3211 | 30 | 1280×10244 | 14 |
A.1.14. NVIDIA RTX A5500 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
NVIDIA RTX A5500 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| RTXA5500-24Q | 24576 | 1 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTXA5500-12Q | 12288 | 2 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTXA5500-8Q | 8192 | 3 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTXA5500-6Q | 6144 | 4 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| RTXA5500-4Q | 4096 | 6 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| RTXA5500-3Q | 3072 | 8 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| RTXA5500-2Q | 2048 | 12 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| RTXA5500-1Q | 1024 | 24 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 |
NVIDIA RTX A5500 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| RTXA5500-2B | 2048 | 12 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 | |||||
| RTXA5500-1B | 1024 | 24 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | |||||
| 3840×2160 | 1 | |||||
| 2560×1600 或更低 | 43 |
NVIDIA RTX A5500 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| RTXA5500-24A | 24576 | 1 | 1 | 1280×10244 | 14 |
| RTXA5500-12A | 12288 | 2 | 2 | 1280×10244 | 14 |
| RTXA5500-8A | 8192 | 3 | 2 | 1280×10244 | 14 |
| RTXA5500-6A | 6144 | 4 | 4 | 1280×10244 | 14 |
| RTXA5500-4A | 4096 | 6 | 4 | 1280×10244 | 14 |
| RTXA5500-3A | 3072 | 8 | 8 | 1280×10244 | 14 |
| RTXA5500-2A | 2048 | 12 | 8 | 1280×10244 | 14 |
| RTXA5500-1A | 1024 | 24 | 16 | 1280×10244 | 14 |
A.1.15. NVIDIA RTX A5000 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
此 GPU不支持混合大小模式。
NVIDIA RTX A5000 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| RTXA5000-24Q | 24576 | 1 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTXA5000-12Q | 12288 | 2 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTXA5000-8Q | 8192 | 3 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | |||||
| RTXA5000-6Q | 6144 | 4 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| RTXA5000-4Q | 4096 | 6 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | |||||
| RTXA5000-3Q | 3072 | 8 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| RTXA5000-2Q | 2048 | 12 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | |||||
| 3840×2400 或更低 | 4 | |||||
| RTXA5000-1Q | 1024 | 24 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 |
NVIDIA RTX A5000 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|---|
| RTXA5000-2B | 2048 | 12 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | |||||
| 3840×2160 | 2 | |||||
| 2560×1600 或更低 | 4 | |||||
| RTXA5000-1B | 1024 | 24 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | |||||
| 3840×2160 | 1 | |||||
| 2560×1600 或更低 | 43 |
NVIDIA RTX A5000 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| RTXA5000-24A | 24576 | 1 | 1 | 1280×10244 | 14 |
| RTXA5000-12A | 12288 | 2 | 2 | 1280×10244 | 14 |
| RTXA5000-8A | 8192 | 3 | 2 | 1280×10244 | 14 |
| RTXA5000-6A | 6144 | 4 | 4 | 1280×10244 | 14 |
| RTXA5000-4A | 4096 | 6 | 4 | 1280×10244 | 14 |
| RTXA5000-3A | 3072 | 8 | 8 | 1280×10244 | 14 |
| RTXA5000-2A | 2048 | 12 | 8 | 1280×10244 | 14 |
| RTXA5000-1A | 1024 | 24 | 16 | 1280×10244 | 14 |
A.1.16. Tesla M10 虚拟 GPU 类型
每板物理 GPU:4
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
此 GPU不支持混合大小模式。
Tesla M10 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| M10-8Q | 8192 | 1 | 36864000 | 5120×2880 | 2 |
| 3840×2400 或更低 | 4 | ||||
| M10-4Q | 4096 | 2 | 36864000 | 5120×2880 | 2 |
| 3840×2400 或更低 | 4 | ||||
| M10-2Q | 2048 | 4 | 36864000 | 5120×2880 | 2 |
| 3840×2400 或更低 | 4 | ||||
| M10-1Q | 1024 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| M10-0Q | 512 | 16 | 8192000 | 2560×1600 | 21 |
Tesla M10 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| M10-2B | 2048 | 4 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| M10-2B42 | 2048 | 4 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| M10-1B | 1024 | 8 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 | ||||
| M10-1B42 | 1024 | 8 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 | ||||
| M10-0B | 512 | 16 | 8192000 | 2560×1600 | 21 |
Tesla M10 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
A.1.17. Tesla T4 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
此 GPU不支持混合大小模式。
Tesla T4 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| T4-16Q | 16384 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| T4-8Q | 8192 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| T4-4Q | 4096 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | ||||
| T4-2Q | 2048 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | ||||
| 3840×2400 或更低 | 4 | ||||
| T4-1Q | 1024 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 |
Tesla T4 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| T4-2B | 2048 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| T4-2B42 | 2048 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| T4-1B | 1024 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 | ||||
| T4-1B42 | 1024 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 |
Tesla T4 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
A.1.18. Tesla V100 SXM2 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
此 GPU不支持混合大小模式。
Tesla V100 SXM2 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| V100X-16Q | 16384 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| V100X-8Q | 8192 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| V100X-4Q | 4096 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | ||||
| V100X-2Q | 2048 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | ||||
| 3840×2400 或更低 | 4 | ||||
| V100X-1Q | 1024 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 |
Tesla V100 SXM2 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| V100X-2B | 2048 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| V100X-2B42 | 2048 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| V100X-1B | 1024 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 | ||||
| V100X-1B42 | 1024 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 |
Tesla V100 SXM2 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
A.1.19. Tesla V100 SXM2 32GB 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
此 GPU不支持混合大小模式。
Tesla V100 SXM2 32GB 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| V100DX-32Q | 32768 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| V100DX-16Q | 16384 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| V100DX-8Q | 8192 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| V100DX-4Q | 4096 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | ||||
| V100DX-2Q | 2048 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | ||||
| 3840×2400 或更低 | 4 | ||||
| V100DX-1Q | 1024 | 32 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 |
Tesla V100 SXM2 32GB 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| V100DX-2B | 2048 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| V100DX-2B42 | 2048 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| V100DX-1B | 1024 | 32 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 | ||||
| V100DX-1B42 | 1024 | 32 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 |
Tesla V100 SXM2 32GB 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
A.1.20. Tesla V100 PCIe 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
此 GPU不支持混合大小模式。
Tesla V100 PCIe 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| V100-16Q | 16384 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| V100-8Q | 8192 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| V100-4Q | 4096 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | ||||
| V100-2Q | 2048 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | ||||
| 3840×2400 或更低 | 4 | ||||
| V100-1Q | 1024 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 |
Tesla V100 PCIe 的 B 系列虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| V100-2B | 2048 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| V100-2B42 | 2048 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| V100-1B | 1024 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 | ||||
| V100-1B42 | 1024 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 |
Tesla V100 PCIe 的 A 系列虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
A.1.21. Tesla V100 PCIe 32GB 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
此 GPU不支持混合大小模式。
Tesla V100 PCIe 32GB 的 Q 系列虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| V100D-32Q | 32768 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| V100D-16Q | 16384 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| V100D-8Q | 8192 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| V100D-4Q | 4096 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | ||||
| V100D-2Q | 2048 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | ||||
| 3840×2400 或更低 | 4 | ||||
| V100D-1Q | 1024 | 32 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 |
B 系列 Tesla V100 PCIe 32GB 虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| V100D-2B | 2048 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| V100D-2B42 | 2048 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| V100D-1B | 1024 | 32 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 | ||||
| V100D-1B42 | 1024 | 32 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 |
A 系列 Tesla V100 PCIe 32GB 虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
A.1.22. Tesla V100S PCIe 32GB 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
此 GPU不支持混合大小模式。
Q 系列 Tesla V100S PCIe 32GB 虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| V100S-32Q | 32768 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| V100S-16Q | 16384 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| V100S-8Q | 8192 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| V100S-4Q | 4096 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | ||||
| V100S-2Q | 2048 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | ||||
| 3840×2400 或更低 | 4 | ||||
| V100S-1Q | 1024 | 32 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 |
B 系列 Tesla V100S PCIe 32GB 虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| V100S-2B | 2048 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| V100S-1B | 1024 | 32 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 |
A 系列 Tesla V100S PCIe 32GB 虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
A.1.23. Tesla V100 FHHL 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
此 GPU不支持混合大小模式。
Q 系列 Tesla V100 FHHL 虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| V100L-16Q | 16384 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| V100L-8Q | 8192 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| V100L-4Q | 4096 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | ||||
| V100L-2Q | 2048 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | ||||
| 3840×2400 或更低 | 4 | ||||
| V100L-1Q | 1024 | 16 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 |
B 系列 Tesla V100 FHHL 虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| V100L-2B | 2048 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| V100L-2B42 | 2048 | 8 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| V100L-1B | 1024 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 | ||||
| V100L-1B42 | 1024 | 16 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 |
A 系列 Tesla V100 FHHL 虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
A.1.24. Quadro RTX 8000 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
此 GPU不支持混合大小模式。
Q 系列 Quadro RTX 8000 虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| RTX8000-48Q | 49152 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX8000-24Q | 24576 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX8000-16Q | 16384 | 3 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX8000-12Q | 12288 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX8000-8Q | 8192 | 6 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX8000-6Q | 6144 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | ||||
| RTX8000-4Q | 4096 | 12 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | ||||
| RTX8000-3Q | 3072 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | ||||
| 3840×2400 或更低 | 4 | ||||
| RTX8000-2Q | 2048 | 24 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | ||||
| 3840×2400 或更低 | 4 | ||||
| RTX8000-1Q | 1024 | 3212 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 |
B 系列 Quadro RTX 8000 虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| RTX8000-2B | 2048 | 24 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| RTX8000-1B | 1024 | 32 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 |
A 系列 Quadro RTX 8000 虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|
| RTX8000-48A | 49152 | 1 | 1280×10244 | 14 |
| RTX8000-24A | 24576 | 2 | 1280×10244 | 14 |
| RTX8000-16A | 16384 | 3 | 1280×10244 | 14 |
| RTX8000-12A | 12288 | 4 | 1280×10244 | 14 |
| RTX8000-8A | 8192 | 6 | 1280×10244 | 14 |
| RTX8000-6A | 6144 | 8 | 1280×10244 | 14 |
| RTX8000-4A | 4096 | 12 | 1280×10244 | 14 |
| RTX8000-3A | 3072 | 16 | 1280×10244 | 14 |
| RTX8000-2A | 2048 | 24 | 1280×10244 | 14 |
| RTX8000-1A | 1024 | 3212 | 1280×10244 | 14 |
A.1.25. Quadro RTX 8000 Passive 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
此 GPU不支持混合大小模式。
Q 系列 Quadro RTX 8000 Passive 虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| RTX8000P-48Q | 49152 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX8000P-24Q | 24576 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX8000P-16Q | 16384 | 3 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX8000P-12Q | 12288 | 4 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX8000P-8Q | 8192 | 6 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX8000P-6Q | 6144 | 8 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | ||||
| RTX8000P-4Q | 4096 | 12 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | ||||
| RTX8000P-3Q | 3072 | 16 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | ||||
| 3840×2400 或更低 | 4 | ||||
| RTX8000P-2Q | 2048 | 24 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | ||||
| 3840×2400 或更低 | 4 | ||||
| RTX8000P-1Q | 1024 | 3213 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 |
B 系列 Quadro RTX 8000 Passive 虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| RTX8000P-2B | 2048 | 24 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| RTX8000P-1B | 1024 | 32 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 |
A 系列 Quadro RTX 8000 Passive 虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|
| RTX8000P-48A | 49152 | 1 | 1280×10244 | 14 |
| RTX8000P-24A | 24576 | 2 | 1280×10244 | 14 |
| RTX8000P-16A | 16384 | 3 | 1280×10244 | 14 |
| RTX8000P-12A | 12288 | 4 | 1280×10244 | 14 |
| RTX8000P-8A | 8192 | 6 | 1280×10244 | 14 |
| RTX8000P-6A | 6144 | 8 | 1280×10244 | 14 |
| RTX8000P-4A | 4096 | 12 | 1280×10244 | 14 |
| RTX8000P-3A | 3072 | 16 | 1280×10244 | 14 |
| RTX8000P-2A | 2048 | 24 | 1280×10244 | 14 |
| RTX8000P-1A | 1024 | 3213 | 1280×10244 | 14 |
A.1.26. Quadro RTX 6000 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
此 GPU不支持混合大小模式。
Q 系列 Quadro RTX 6000 虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| RTX6000-24Q | 24576 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX6000-12Q | 12288 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX6000-8Q | 8192 | 3 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX6000-6Q | 6144 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | ||||
| RTX6000-4Q | 4096 | 6 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | ||||
| RTX6000-3Q | 3072 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | ||||
| 3840×2400 或更低 | 4 | ||||
| RTX6000-2Q | 2048 | 12 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | ||||
| 3840×2400 或更低 | 4 | ||||
| RTX6000-1Q | 1024 | 24 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 |
B 系列 Quadro RTX 6000 虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| RTX6000-2B | 2048 | 12 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| RTX6000-1B | 1024 | 24 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 |
A 系列 Quadro RTX 6000 虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|
| RTX6000-24A | 24576 | 1 | 1280×10244 | 14 |
| RTX6000-12A | 12288 | 2 | 1280×10244 | 14 |
| RTX6000-8A | 8192 | 3 | 1280×10244 | 14 |
| RTX6000-6A | 6144 | 4 | 1280×10244 | 14 |
| RTX6000-4A | 4096 | 6 | 1280×10244 | 14 |
| RTX6000-3A | 3072 | 8 | 1280×10244 | 14 |
| RTX6000-2A | 2048 | 12 | 1280×10244 | 14 |
| RTX6000-1A | 1024 | 24 | 1280×10244 | 14 |
A.1.27. Quadro RTX 6000 Passive 虚拟 GPU 类型
每板物理 GPU:1
每板最大 vGPU 数量是每 GPU 最大 vGPU 数量和每板物理 GPU 数量的乘积。
此 GPU不支持混合大小模式。
Q 系列 Quadro RTX 6000 Passive 虚拟 GPU 类型
预期用例:虚拟工作站
所需许可证版本:vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| RTX6000P-24Q | 24576 | 1 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX6000P-12Q | 12288 | 2 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX6000P-8Q | 8192 | 3 | 66355200 | 7680×4320 | 2 |
| 5120×2880 或更低 | 4 | ||||
| RTX6000P-6Q | 6144 | 4 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | ||||
| RTX6000P-4Q | 4096 | 6 | 58982400 | 7680×4320 | 1 |
| 5120×2880 或更低 | 4 | ||||
| RTX6000P-3Q | 3072 | 8 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | ||||
| 3840×2400 或更低 | 4 | ||||
| RTX6000P-2Q | 2048 | 12 | 36864000 | 7680×4320 | 1 |
| 5120×2880 | 2 | ||||
| 3840×2400 或更低 | 4 | ||||
| RTX6000P-1Q | 1024 | 24 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 |
B 系列 Quadro RTX 6000 Passive 虚拟 GPU 类型
预期用例:虚拟桌面
所需许可证版本:vPC 或 vWS
这些 vGPU 类型支持基于可用像素数量的最大组合分辨率,该分辨率由其帧缓冲区大小决定。您可以选择使用少量高分辨率显示器或大量较低分辨率显示器与这些 vGPU 类型。每个 vGPU 的最大显示器数量基于所有显示器都具有相同分辨率的配置。有关显示器分辨率混合配置的示例,请参阅B 系列和 Q 系列 vGPU 的混合显示配置。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 可用像素 | 显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|---|
| RTX6000P-2B | 2048 | 12 | 18432000 | 5120×2880 | 1 |
| 3840×2400 | 2 | ||||
| 3840×2160 | 2 | ||||
| 2560×1600 或更低 | 4 | ||||
| RTX6000P-1B | 1024 | 24 | 16384000 | 5120×2880 | 1 |
| 3840×2400 | 1 | ||||
| 3840×2160 | 1 | ||||
| 2560×1600 或更低 | 43 |
A 系列 Quadro RTX 6000 Passive 虚拟 GPU 类型
预期用例:虚拟应用程序
所需许可证版本:vApps
这些 vGPU 类型支持具有固定最大分辨率的单个显示器。
| 虚拟 GPU 类型 | 帧缓冲区 (MB) | 每个 GPU 的最大 vGPU 数 | 最大显示分辨率 | 每个 vGPU 的虚拟显示器 |
|---|---|---|---|---|
| RTX6000P-24A | 24576 | 1 | 1280×10244 | 14 |
| RTX6000P-12A | 12288 | 2 | 1280×10244 | 14 |
| RTX6000P-8A | 8192 | 3 | 1280×10244 | 14 |
| RTX6000P-6A | 6144 | 4 | 1280×10244 | 14 |
| RTX6000P-4A | 4096 | 6 | 1280×10244 | 14 |
| RTX6000P-3A | 3072 | 8 | 1280×10244 | 14 |
| RTX6000P-2A | 2048 | 12 | 1280×10244 | 14 |
| RTX6000P-1A | 1024 | 24 | 1280×10244 | 14 |
A.2. B 系列和 Q 系列 vGPU 的混合显示配置
A.2.1. B 系列 vGPU 的混合显示配置
| 虚拟 GPU 类型 | 可用像素 | 可用像素基数 | 最大显示器数 | 混合显示配置示例 |
|---|---|---|---|---|
| -2B | 17694720 | 2 个 4096×2160 显示器 | 4 | 1 个 4096×2160 显示器加 2 个 2560×1600 显示器 |
| -2B4 | 17694720 | 2 个 4096×2160 显示器 | 4 | 1 个 4096×2160 显示器加 2 个 2560×1600 显示器 |
| -1B | 16384000 | 4 个 2560×1600 显示器 | 4 | 1 个 4096×2160 显示器加 1 个 2560×1600 显示器 |
| -1B4 | 16384000 | 4 个 2560×1600 显示器 | 4 | 1 个 4096×2160 显示器加 1 个 2560×1600 显示器 |
| -0B | 8192000 | 2 个 2560×1600 显示器 | 2 | 1 个 2560×1600 显示器加 1 个 1280×1024 显示器 |
A.2.2. 基于 NVIDIA Maxwell 架构的 Q 系列 vGPU 的混合显示配置
| 虚拟 GPU 类型 | 可用像素 | 可用像素基数 | 最大显示器数 | 混合显示配置示例 |
|---|---|---|---|---|
| -8Q | 35389440 | 4 个 4096×2160 显示器 | 4 | 1 个 5120×2880 显示器加 2 个 4096×2160 显示器 |
| -4Q | 35389440 | 4 个 4096×2160 显示器 | 4 | 1 个 5120×2880 显示器加 2 个 4096×2160 显示器 |
| -2Q | 35389440 | 4 个 4096×2160 显示器 | 4 | 1 个 5120×2880 显示器加 2 个 4096×2160 显示器 |
| -1Q | 17694720 | 2 个 4096×2160 显示器 | 4 | 1 个 4096×2160 显示器加 2 个 2560×1600 显示器 |
| -0Q | 8192000 | 2 个 2560×1600 显示器 | 2 | 1 个 2560×1600 显示器加 1 个 1280×1024 显示器 |
A.2.3. 基于 NVIDIA Maxwell 之后架构的 Q 系列 vGPU 的混合显示配置
| 虚拟 GPU 类型 | 可用像素 | 可用像素基数 | 最大显示器数 | 混合显示配置示例 |
|---|---|---|---|---|
| -8Q 及以上 | 66355200 | 2 个 7680×4320 显示器 | 4 | 1 个 7680×4320 显示器加 2 个 5120×2880 显示器 |
| 1 个 7680×4320 显示器加 3 个 4096×2160 显示器 | ||||
| -6Q | 58982400 | 4 个 5120×2880 显示器 | 4 | 1 个 7680×4320 显示器加 1 个 5120×2880 显示器 |
| -4Q | 58982400 | 4 个 5120×2880 显示器 | 4 | 1 个 7680×4320 显示器加 1 个 5120×2880 显示器 |
| -3Q | 35389440 | 4 个 4096×2160 显示器 | 4 | 1 个 5120×2880 显示器加 2 个 4096×2160 显示器 |
| -2Q | 35389440 | 4 个 4096×2160 显示器 | 4 | 1 个 5120×2880 显示器加 2 个 4096×2160 显示器 |
| -1Q | 17694720 | 2 个 4096×2160 显示器 | 4 | 1 个 4096×2160 显示器加 2 个 2560×1600 显示器 |
A.3. 混合大小模式下 GPU 的 vGPU 放置
混合大小模式下 GPU 支持的 vGPU 放置取决于 GPU 拥有的帧缓冲区总量。
A.3.1. 具有 94 GB 帧缓冲区的 GPU 的 vGPU 放置
放置区域大小:94
| vGPU 大小(MB 帧缓冲区) | 放置大小 | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 支持的放置 ID |
|---|---|---|---|---|
| 96246 | 94 | 1 | 1 | 0 |
| 48128 | 47 | 2 | 2 | 0, 47 |
| 23552 | 23 | 4 | 4 | 0, 24, 47, 71 |
| 15360 | 15 | 6 | 4 | 0, 32, 47, 79 |
| 11264 | 11 | 8 | 8 | 0, 12, 23, 36, 47, 59, 70, 83 |
| 6,144 | 6 | 15 | 8 | 0, 17, 23, 41, 47, 64, 70, 88 |
| 4,096 | 4 | 23 | 16 | 0, 7, 11, 19, 23, 31, 35, 43, 47, 54, 58, 66, 70, 78, 82, 90 |
下图显示了在混合大小模式下,具有 94 GB 总帧缓冲区的 GPU 上,每种大小的 vGPU 支持的放置。

A.3.2. 具有 80 GB 帧缓冲区的 GPU 的 vGPU 放置
放置区域大小:80
| vGPU 大小(MB 帧缓冲区) | 放置大小 | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 支持的放置 ID |
|---|---|---|---|---|
| 81920 | 80 | 1 | 1 | 0 |
| 40960 | 40 | 2 | 2 | 0, 40 |
| 20480 | 20 | 4 | 4 | 0, 20, 40, 60 |
| 16384 | 16 | 5 | 4 | 0, 24, 40, 64 |
| 10240 | 10 | 8 | 8 | 0, 10, 20, 30, 40, 50, 60, 70 |
| 8192 | 8 | 10 | 8 | 0, 12, 20, 32, 40, 52, 60, 72 |
| 5120 | 5 | 16 | 16 | 0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75 |
| 4096 | 4 | 20 | 16 | 0, 6, 10, 16, 20, 26, 30, 36, 40, 46, 50, 56, 60, 66, 70, 76 |
下图显示了在混合大小模式下,具有 80 GB 总帧缓冲区的 GPU 上,每种大小的 vGPU 支持的放置。

A.3.3. 具有 48 GB 帧缓冲区的 GPU 的 vGPU 放置
放置区域大小:48
在混合大小模式下,基于 Ada Lovelace GPU 架构的 GPU 上允许的最大帧缓冲区为 1024 MB 的 vGPU 数量低于其他 GPU 架构。因此,这些 vGPU 在基于 Ada Lovelace GPU 架构的 GPU 上的支持放置 ID 与其他 GPU 架构不同。
| vGPU 大小(MB 帧缓冲区) | 放置大小 | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 支持的放置 ID |
|---|---|---|---|---|
| 49152 | 48 | 1 | 1 | 0 |
| 24576 | 24 | 2 | 2 | 0, 24 |
| 16384 | 16 | 3 | 2 | 0, 32 |
| 12288 | 12 | 4 | 4 | 0, 12, 24, 36 |
| 8192 | 8 | 6 | 4 | 0, 16, 24, 40 |
| 6144 | 6 | 8 | 8 | 0, 6, 12, 18, 24, 30, 36, 42 |
| 4096 | 4 | 12 | 8 | 0, 8, 12, 20, 24, 32, 36, 44 |
| 3072 | 3 | 16 | 16 | 0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36, 39, 42, 45 |
| 2048 | 2 | 24 | 16 | 0, 4, 6, 10, 12, 16, 18, 22, 24, 28, 30, 34, 36, 40, 42, 46 |
| 1024 | 1 | 32 | GPU 架构 除 Ada Lovelace 外:30 | GPU 架构 除 Ada Lovelace 外:0、2、3、5、6、9、11、12、14、15、17、18、20、21、23、24、26、27、29、30、33、35、36、38、39、41、42、44、45、47 |
| Ada Lovelace GPU 架构:16 | Ada Lovelace GPU 架构:0、5、6、11、12、17、18、23、24、29、30、35、36、41、42、47 |
下图显示了在混合大小模式下,基于 除 Ada Lovelace 外的 GPU 架构且具有 48 GB 总帧缓冲区的 GPU 上,每种大小的 vGPU 支持的放置。

下图显示了在混合大小模式下,基于 Ada Lovelace GPU 架构且具有 48 GB 总帧缓冲区的 GPU 上,每种大小的 vGPU 支持的放置。

A.3.4. 具有 40 GB 帧缓冲区的 GPU 的 vGPU 放置
放置区域大小:40
| vGPU 大小(MB 帧缓冲区) | 放置大小 | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 支持的放置 ID |
|---|---|---|---|---|
| 40960 | 40 | 1 | 1 | 0 |
| 20480 | 20 | 2 | 2 | 0, 20 |
| 10240 | 10 | 4 | 4 | 0, 10, 20, 30 |
| 8192 | 8 | 5 | 4 | 0, 12, 20, 32 |
| 5120 | 5 | 8 | 8 | 0, 5, 10, 15, 20, 25, 30, 35 |
| 4096 | 4 | 10 | 8 | 0, 6, 10, 16, 20, 26, 30, 36 |
下图显示了在混合大小模式下,具有 40 GB 总帧缓冲区的 GPU 上,每种大小的 vGPU 支持的放置。

A.3.5. 具有 32 GB 帧缓冲区的 GPU 的 vGPU 放置
放置区域大小:32
| vGPU 大小(MB 帧缓冲区) | 放置大小 | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 支持的放置 ID |
|---|---|---|---|---|
| 32768 | 32 | 1 | 1 | 0 |
| 16384 | 16 | 2 | 2 | 0, 16 |
| 8192 | 8 | 4 | 4 | 0, 8, 16, 24 |
| 4096 | 4 | 8 | 8 | 0, 4, 8, 12, 16, 20, 24, 28 |
| 2048 | 2 | 16 | 16 | 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30 |
| 1024 | 1 | 32 | 32 | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 |
下图显示了在混合大小模式下,具有 32 GB 总帧缓冲区的 GPU 上,每种大小的 vGPU 支持的放置。

A.3.6. 具有 24 GB 帧缓冲区的 GPU 的 vGPU 放置
放置区域大小:24
| vGPU 大小(MB 帧缓冲区) | 放置大小 | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 支持的放置 ID |
|---|---|---|---|---|
| 24576 | 24 | 1 | 1 | 0 |
| 12288 | 12 | 2 | 2 | 0, 12 |
| 8192 | 8 | 3 | 2 | 0, 16 |
| 6144 | 6 | 4 | 4 | 0, 6, 12, 18 |
| 4096 | 4 | 6 | 4 | 0, 8, 12, 20 |
| 3072 | 3 | 8 | 8 | 0, 3, 6, 9, 12, 15, 18, 21 |
| 2048 | 2 | 12 | 8 | 0, 4, 6, 10, 12, 16, 18, 22 |
| 1024 | 1 | 24 | 16 | 0, 2, 3, 5, 6, 8, 9, 11, 12, 14, 15, 17, 18, 20, 21, 23 |
下图显示了在混合大小模式下,具有 24 GB 总帧缓冲区的 GPU 上,每种大小的 vGPU 支持的放置。

A.3.7. 具有 20 GB 帧缓冲区的 GPU 的 vGPU 放置
放置区域大小:20
| vGPU 大小(MB 帧缓冲区) | 放置大小 | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 支持的放置 ID |
|---|---|---|---|---|
| 20480 | 20 | 1 | 1 | 0 |
| 10240 | 10 | 2 | 2 | 0, 10 |
| 5120 | 5 | 4 | 4 | 0, 5, 10, 15 |
| 4096 | 4 | 5 | 4 | 0, 6, 10, 16 |
| 2048 | 2 | 10 | 8 | 0, 3, 5, 8, 10, 13, 15, 18 |
| 1024 | 1 | 20 | 16 | 0, 1, 2, 4, 5, 6, 7, 9, 10, 11, 12, 14, 15, 16, 17, 19 |
下图显示了在混合大小模式下,具有 20 GB 总帧缓冲区的 GPU 上,每种大小的 vGPU 支持的放置。

A.3.8. 具有 16 GB 帧缓冲区的 GPU 的 vGPU 放置
放置区域大小:16
| vGPU 大小(MB 帧缓冲区) | 放置大小 | 等大小模式下每 GPU 的最大 vGPU 数量 | 混合大小模式下每 GPU 的最大 vGPU 数量 | 支持的放置 ID |
|---|---|---|---|---|
| 16384 | 16 | 1 | 1 | 0 |
| 8192 | 8 | 2 | 2 | 0, 8 |
| 4096 | 4 | 4 | 4 | 0, 4, 8, 12 |
| 2048 | 2 | 8 | 8 | 0, 2, 4, 6, 8, 10, 12, 14 |
| 1024 | 1 | 16 | 16 | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 |
下图显示了在混合大小模式下,具有 16 GB 总帧缓冲区的 GPU 上,每种大小的 vGPU 支持的放置。

用于将物理硬件资源分配给 VM 和 vGPU 的策略可以提高运行 NVIDIA vGPU 的 VM 的性能。其中包括将 VM CPU 核心绑定到非统一内存访问 (NUMA) 平台上的物理核心、将 VM 分配给 CPU 以及将 vGPU 分配给物理 GPU 的策略。XenServer 和 VMware vSphere vSphere 支持这些分配策略。
B.1. NUMA 注意事项
服务器平台通常实现多个 CPU 插槽,系统内存和 PCI Express 扩展槽在每个 CPU 插槽本地,如图 图 29 所示:
图 29. NUMA 服务器平台

这些平台通常配置为在非一致性内存访问 (NUMA) 模式下运行;物理内存按顺序排列在地址空间中,连接到每个插槽的所有内存都显示在单个连续的地址块中。从 CPU 或 GPU 访问某个内存范围的成本各不相同;连接到与 CPU 或 GPU 同一插槽的内存比另一 CPU 插槽上的内存具有更低的延迟,因为对远程内存的访问还必须遍历 CPU 插槽之间的互连。
B.1.1. 在具有 XenServer 的 NUMA 平台上获得最佳性能
为了在 NUMA 平台上获得最佳性能,NVIDIA 建议将 VM vCPU 核心绑定到物理 GPU(托管 VM 的 vGPU)所连接的同一 CPU 插槽上的物理核心。例如,以作为参考,在物理 GPU 0 或 1 上分配了 vGPU 的 VM 应将其 vCPU 绑定到 CPU 插槽 0 上的 CPU 核心。同样,在物理 GPU 2 或 3 上分配了 vGPU 的 VM 应将其 vCPU 绑定到插槽 1 上的 CPU 核心。
有关绑定 vCPU 的指南,请参阅将 VM 绑定到特定 CPU 插槽和核心,有关确定 GPU 本地性的指南,请参阅如何确定 GPU 本地性。控制在特定物理 GPU 上启用的 vGPU 类型介绍了如何通过为特定物理 GPU 创建 GPU 组来精确控制用于托管 vGPU 的物理 GPU。
B.1.2. 在具有 VMware vSphere ESXi 的 NUMA 平台上获得最佳性能
对于某些类型的工作负载或系统配置,您可以通过显式指定 VM 的放置来优化性能。为了获得最佳性能,请将每个 VM 绑定到托管 VM 的 vGPU 的物理 GPU 所连接的 NUMA 节点。
以下类型的工作负载和系统配置受益于 VM 的显式放置
- 内存密集型工作负载,例如内存数据库或具有大型数据集的 HPC 应用程序
- 配置了少量虚拟机的虚拟机监控程序主机
VMware vSphere ESXi 提供了NUMA 节点亲缘性选项,用于显式指定 VM 的放置。有关 VMware vSphere ESXi 中用于 NUMA 放置的选项的常规信息,请参阅 VMware 文档中的指定 NUMA 控制。
在设置NUMA 节点亲缘性选项之前,请在 ESXi 主机 shell 中运行 nvidia-smi topo -m 命令,以确定 GPU 设备的 NUMA 亲缘性。
在确定 GPU 设备的 NUMA 亲缘性后,按照 VMware 文档中的将虚拟机与指定的 NUMA 节点关联中的说明设置NUMA 节点亲缘性选项。
B.2. 最大化性能
为了在平台上 vGPU 启用的 VM 数量增加时最大化性能,NVIDIA 建议采用广度优先分配:在负载最轻的 CPU 插槽上分配新 VM,并在通过该插槽连接的可用、负载最轻的物理 GPU 上分配 VM 的 vGPU。
XenServer 和 VMware vSphere ESXi 默认使用不同的 GPU 分配策略。
-
XenServer 创建 GPU 组,默认分配策略为深度优先。
有关将分配策略切换为广度优先的详细信息,请参阅在 XenServer 上修改 GPU 分配策略。
-
VMware vSphere ESXi 创建 GPU 组,默认分配策略为广度优先。
有关将分配策略切换为深度优先的详细信息,请参阅在 VMware vSphere 上修改 GPU 分配策略。
由于 vGPU 要求在任何给定时间只有一个 vGPU 类型可以在物理 GPU 上运行,因此并非所有物理 GPU 都可用于托管新 VM 所需的 vGPU 类型。
x11vnc 是一个虚拟网络计算 (VNC) 服务器,它使用任何 VNC 查看器提供对现有 X 会话的远程访问。您可以使用 x11vnc 来确认未直接连接显示设备的 Linux 服务器中的 NVIDIA GPU 是否按预期工作。未直接连接显示设备的服务器示例包括配置了 NVIDIA vGPU 的 VM、配置了直通 GPU 的 VM 以及裸机部署中的无头物理主机。
在开始之前,请确保满足以下先决条件
- Linux 的 NVIDIA vGPU 软件图形驱动程序安装在服务器上。
- 安全外壳 (SSH) 客户端安装在您的本地系统上
- 在 Windows 上,您必须使用第三方 SSH 客户端,例如 PuTTY。
- 在 Linux 上,您可以从 shell 或终端窗口运行操作系统附带的 SSH 客户端。
配置 x11vnc 涉及按照以下各节中的说明顺序操作
连接到服务器后,您可以使用 NVIDIA X Server Settings 来确认 NVIDIA GPU 是否按预期工作。
C.1. 在 Linux 服务器上配置 Xorg 服务器
您必须配置 Xorg 服务器以指定 Xorg 服务器要使用哪个 GPU 或 vGPU(如果服务器中安装了多个 GPU),并允许 Xorg 服务器即使在未检测到已连接的显示设备的情况下也能启动。
- 登录到 Linux 服务器。
- 确定服务器上 GPU 或 vGPU 的 PCI 总线标识符。
# nvidia-xconfig --query-gpu-info Number of GPUs: 1 GPU #0: Name : GRID T4-2Q UUID : GPU-ea80de2d-1dd8-11b2-8305-c955f034e718 PCI BusID : PCI:2:2:0 Number of Display Devices: 0
- 在纯文本编辑器中,编辑 /etc/X11/xorg.conf 文件以指定 Xorg 服务器要使用的 GPU,并允许 Xorg 服务器即使在未检测到已连接的显示设备的情况下也能启动。
- 在
Device部分中,添加 Xorg 服务器要使用的 GPU 的 PCI 总线标识符。Section "Device" Identifier "Device0" Driver "nvidia" VendorName "NVIDIA Corporation" BusID "PCI:2:2:0" EndSection
注意nvidia-xconfig 在上一步中获得的 PCI BusID 中的三个数字是十六进制数。它们必须在
Device部分的 PCI 总线标识符中转换为十进制数。例如,如果在上一步中获得的 PCI 总线标识符是 PCI:A:10:0,则在Device部分的 PCI 总线标识符中必须将其指定为 PCI:10:16:0。 - 在
Screen部分中,确保AllowEmptyInitialConfiguration选项设置为True。Section "Screen" Identifier "Screen0" Device "Device0" Option "AllowEmptyInitialConfiguration" "True" EndSection
- 在
- 通过以下方式之一重启 Xorg 服务器
- 重启服务器。
- 运行 startx 命令。
- 如果 Linux 服务器处于运行级别 3,请运行 init 5 命令以在图形模式下运行服务器。
- 确认 Xorg 服务器正在运行。
# ps -ef | grep X
在 Ubuntu 上,此命令显示类似于以下示例的输出。
root 16500 16499 2 03:01 tty2 00:00:00 /usr/lib/xorg/Xorg -nolisten tcp :0 -auth /tmp/serverauth.s7CE4mMeIz root 1140 1126 0 18:46 tty1 00:00:00 /usr/lib/xorg/Xorg vt1 -displayfd 3 -auth /run/user/121/gdm/Xauthority -background none -noreset -keeptty -verbose 3 root 17011 17108 0 18:50 pts/0 00:00:00 grep --color=auto X
在 Red Hat Enterprise Linux 上,此命令显示类似于以下示例的输出。
root 5285 5181 0 16:29 pts/0 00:00:00 grep --color=auto X root 5880 1 0 Jun13 ? 00:00:00 /usr/bin/abrt-watch-log -F Backtrace /var/log/Xorg.0.log -- /usr/bin/abrt-dump-xorg -xD root 7039 6289 0 Jun13 tty1 00:00:03 /usr/bin/X :0 -background none -noreset -audit 4 -verbose -auth /run/gdm/auth-for-gdm-vr4MFC/database -seat seat0 vt1
C.2. 在 Linux 服务器上安装和配置 x11vnc
与其他 VNC 服务器(例如 TigerVNC 或 Vino)不同,x11vnc 不会创建额外的 X 会话以进行远程访问。相反,x11vnc 提供对 Linux 服务器上现有 X 会话的远程访问。
- 安装所需的
x11vnc包和任何依赖包。-
对于基于 Red Hat 的发行版,请使用 yum 包管理器安装
x11vnc包。# yum install x11vnc
-
对于基于 Debian 的发行版,请使用 apt 包管理器安装
x11vnc包。# sudo apt install x11vnc
-
对于 SuSE Linux 发行版,请从 x11vnc openSUSE 软件页面安装 x11vnc。
-
- 获取 Xorg 服务器的服务器显示编号。
# cat /proc/*/environ 2>/dev/null | tr '\0' '\n' | grep '^DISPLAY=:' | uniq DISPLAY=:0 DISPLAY=:100
- 启动 x11vnc 服务器,指定要使用的显示编号。
以下示例在运行 Gnome 桌面的 Linux 服务器上的显示 0 上启动 x11vnc 服务器。
# x11vnc -display :0 -auth /run/user/121/gdm/Xauthority -forever \ -shared -ncache -bg
注意如果您使用的是 C 系列 vGPU,请省略 -ncache 选项。
x11vnc 服务器在显示 hostname:0 上启动,例如,
my-linux-host:0。26/03/20200 04:23:13 The VNC desktop is: my-linux-host:0 PORT=5900
C.3. 使用 VNC 客户端连接到 Linux 服务器
- 在您的客户端计算机上,安装 VNC 客户端,例如 TightVNC。
- 启动 VNC 客户端并连接到 Linux 服务器。
服务器上的 X 会话将在 VNC 客户端中打开。


故障排除: 如果您的 VNC 客户端无法连接到服务器,请在 Linux 服务器上更改权限,如下所示
- 通过进行以下更改之一,允许 VNC 客户端连接到服务器
- 禁用防火墙和 iptables 服务。
- 在防火墙中打开 VNC 端口。
- 确保为 Security Enhanced Linux (SELinux) 启用 permissive 模式。
连接到服务器后,您可以使用 NVIDIA X Server Settings 来确认 NVIDIA GPU 是否按预期工作。

默认情况下,在 Windows Server 操作系统上,NVIDIA 通知图标应用程序会随每个 Citrix 发布应用程序用户会话一起启动。即使在用户退出所有其他应用程序后,此应用程序也可能会阻止 Citrix 发布应用程序用户会话注销。
NVIDIA 通知图标应用程序会显示在运行 Citrix Receiver 或 Citrix Workspace 的端点客户端上的 Citrix Connection Center 中。
下图显示了在 Citrix Connection Center 中,已发布 Adobe Acrobat Reader DC 和 Google Chrome 应用程序的用户会话中的 NVIDIA 通知图标。

管理员可以为所有用户的会话禁用 NVIDIA 通知图标应用程序,如为所有用户的 Citrix 发布应用程序会话禁用 NVIDIA 通知图标中所述。
个人用户可以为自己的会话禁用 NVIDIA 通知图标应用程序,如为您的 Citrix 发布应用程序用户会话禁用 NVIDIA 通知图标中所述。
如果管理员为其自己的会话启用了 NVIDIA 通知图标应用程序,则该应用程序将为所有用户的会话启用,即使是以前禁用该应用程序的用户的会话也是如此。
D.1. 为所有用户的 Citrix 发布应用程序会话禁用 NVIDIA 通知图标
管理员可以设置注册表项,为 VM 上所有用户的 Citrix 发布应用程序会话禁用 NVIDIA 通知图标应用程序。要确保在从主映像创建的任何虚拟交付代理 (VDA) 上禁用 NVIDIA 通知图标应用程序,请在主映像中设置此项。
从将在其上创建 Citrix 发布应用程序会话的 VM 执行此任务。
在开始之前,请确保 VM 中安装了 NVIDIA vGPU 软件图形驱动程序。
- 将系统级 StartOnLogin Windows 注册表项设置为 0。
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\nvlddmkm\NvTray] Value: "StartOnLogin" Type: DWORD Data: 00000000
数据值 0 禁用 NVIDIA 通知图标,数据值 1 启用它。
- 重启 VM。您必须重启 VM 以确保在用户会话中的 NVIDIA 服务启动之前设置注册表项。
D.2. 为您的 Citrix 发布应用程序用户会话禁用 NVIDIA 通知图标
个人用户可以为自己的 Citrix 发布应用程序会话禁用 NVIDIA 通知图标。
在开始之前,请确保您已登录到 Citrix 发布应用程序会话。
- 将当前用户的 StartOnLogin Windows 注册表项设置为 0。
[HKEY_CURRENT_USER\SOFTWARE\NVIDIA Corporation\NvTray\] Value: "StartOnLogin" Type: DWORD Data: 00000000
数据值 0 禁用 NVIDIA 通知图标,数据值 1 启用它。
- 注销并重新登录或重启 VM。您必须注销并重新登录或重启 VM 以确保在用户会话中的 NVIDIA 服务启动之前设置注册表项。
要安装和配置 NVIDIA vGPU 软件并优化 XenServer 与 vGPU 的操作,需要对 XenServer 进行一些基本操作。
E.1. 打开 dom0 shell
大多数配置命令必须在 XenServer dom0 域的命令行 shell 中运行。您可以通过以下任何方式在 XenServer dom0 域中打开 shell
- 使用 XenCenter 中的控制台窗口
- 使用独立的 Secure Shell (SSH) 客户端
E.1.1. 通过 XenCenter 访问 dom0 shell
- 在 XenCenter 窗口的左侧窗格中,选择要连接的 XenServer 主机。
- 单击控制台选项卡以打开 XenServer 控制台。
- 按 Enter 键启动 shell 提示符。
图 30. 使用 XenCenter 连接到 dom0 shell

E.1.2. 通过 SSH 客户端访问 dom0 shell
- 确保您在 Windows 上有 SSH 客户端套件(例如 PuTTY),或者在 Linux 上有来自 OpenSSH 的 SSH 客户端。
- 将您的 SSH 客户端连接到 XenServer 主机的管理 IP 地址。
- 以 root 用户身份登录。
E.2. 将文件复制到 dom0
您可以通过以下任何方式轻松地将文件复制到 XenServer dom0 和从 XenServer dom0 复制文件
- 使用安全复制协议 (SCP) 客户端
- 使用网络挂载文件系统
E.2.1. 使用 SCP 客户端复制文件
用于将文件复制到 dom0 的 SCP 客户端取决于您从何处运行客户端。
-
如果您从 dom0 运行客户端,请使用安全复制命令 scp。
scp 命令是 SSH 应用程序套件的一部分。它在 dom0 中实现,可用于从远程启用 SSH 的服务器复制
[root@xenserver ~]# scp root@10.31.213.96:/tmp/somefile . The authenticity of host '10.31.213.96 (10.31.213.96)' can't be established. RSA key fingerprint is 26:2d:9b:b9:bf:6c:81:70:36:76:13:02:c1:82:3d:3c. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '10.31.213.96' (RSA) to the list of known hosts. root@10.31.213.96's password: somefile 100% 532 0.5KB/s 00:00 [root@xenserver ~]#
-
如果您从 Windows 运行客户端,请使用 pscp 程序。
pscp 程序是 PuTTY 套件的一部分,可用于将文件从远程 Windows 系统复制到 XenServer
C:\Users\nvidia>pscp somefile root@10.31.213.98:/tmp root@10.31.213.98's password: somefile | 80 kB | 80.1 kB/s | ETA: 00:00:00 | 100% C:\Users\nvidia>
E.2.2. 使用 CIFS 挂载文件系统复制文件
您可以通过从 dom0 挂载 CIFS/SMB 文件共享来复制文件到 CIFS/SMB 文件共享和从 CIFS/SMB 文件共享复制文件。
以下示例说明了如何在 dom0 上将网络共享 \\myserver.example.com\myshare 挂载到 /mnt/myshare,以及如何复制文件到该共享和从该共享复制文件。该示例假设文件共享是名为 example.com 的 Active Directory 域的一部分,并且用户 myuser 具有访问该共享的权限。
- 在 dom0 上创建目录 /mnt/myshare。
[root@xenserver ~]# mkdir /mnt/myshare
- 在 dom0 上将网络共享 \\myserver.example.com\myshare 挂载到 /mnt/myshare。
[root@xenserver ~]# mount -t cifs -o username=myuser,workgroup=example.com //myserver.example.com/myshare /mnt/myshare Password: [root@xenserver ~]#
- 当提示输入密码时,输入
example.com域中myuser的密码。 - 挂载共享后,通过使用 cp 命令将文件复制到 /mnt/myshare 和从 /mnt/myshare 复制文件,从而复制文件到文件共享和从文件共享复制文件
[root@xenserver ~]# cp /mnt/myshare/NVIDIA-vGPU-NVIDIA-vGPU-CitrixHypervisor-8.2-550.144.02.x86_64.rpm . [root@xenserver ~]#
E.3. 确定 VM 的 UUID
您可以通过以下任何方式确定虚拟机的 UUID
- 在 dom0 shell 中使用 xe vm-list 命令
- 使用 XenCenter
E.3.1. 使用 xe vm-list 确定 VM 的 UUID
使用 xe vm-list 命令列出所有 VM 及其关联的 UUID,或查找特定命名 VM 的 UUID。
-
要列出所有 VM 及其关联的 UUID,请使用不带任何参数的
xe vm-list[root@xenserver ~]# xe vm-list uuid ( RO) : 6b5585f6-bd74-2e3e-0e11-03b9281c3ade name-label ( RW): vgx-base-image-win7-64 power-state ( RO): halted uuid ( RO) : fa3d15c7-7e88-4886-c36a-cdb23ed8e275 name-label ( RW): test-image-win7-32 power-state ( RO): halted uuid ( RO) : 501bb598-a9b3-4afc-9143-ff85635d5dc3 name-label ( RW): Control domain on host: xenserver power-state ( RO): running uuid ( RO) : 8495adf7-be9d-eee1-327f-02e4f40714fc name-label ( RW): vgx-base-image-win7-32 power-state ( RO): halted
-
要查找特定命名 VM 的 UUID,请使用
name-label参数 xe vm-list[root@xenserver ~]# xe vm-list name-label=test-image-win7-32 uuid ( RO) : fa3d15c7-7e88-4886-c36a-cdb23ed8e275 name-label ( RW): test-image-win7-32 power-state ( RO): halted
E.3.2. 使用 XenCenter 确定 VM 的 UUID
- 在 XenCenter 窗口的左侧窗格中,选择要确定其 UUID 的 VM。
- 在 XenCenter 窗口的右侧窗格中,单击常规选项卡。
图 31. 使用 XenCenter 确定 VM 的 UUID

E.4. Windows 客户端 VM 使用两个以上的 vCPU
Windows 客户端操作系统最多支持两个 CPU 插槽。在客户 VM 中为虚拟插槽分配 vCPU 时,XenServer 默认情况下每个插槽分配一个 vCPU。分配给 VM 的 vCPU 超过两个将不会被 Windows 客户端操作系统识别。
为确保识别所有已分配的 vCPU,请将 platform:cores-per-socket 设置为分配给 VM 的 vCPU 数量
[root@xenserver ~]# xe vm-param-set uuid=vm-uuid platform:cores-per-socket=4 VCPUs-max=4 VCPUs-at-startup=4
vm-uuid 是 VM 的 UUID,您可以按照确定 VM 的 UUID中的说明获取。
E.5. 将 VM 绑定到特定 CPU 插槽和核心
- 使用 xe host-cpu-info 确定服务器平台中 CPU 插槽和逻辑 CPU 核心的数量。在此示例中,服务器在两个插槽中实现了 32 个逻辑 CPU 核心
[root@xenserver ~]# xe host-cpu-info cpu_count : 32 socket_count: 2 vendor: GenuineIntel speed: 2600.064 modelname: Intel(R) Xeon(R) CPU E5-2670 0 @ 2.60GHz family: 6 model: 45 stepping: 7 flags: fpu de tsc msr pae mce cx8 apic sep mtrr mca cmov pat clflush acpi mmx fxsr sse sse2 ss ht nx constant_tsc nonstop_tsc aperfmperf pni pclmulqdq vmx est ssse3 sse4_1 sse4_2 x2apic popcnt aes hypervisor ida arat tpr_shadow vnmi flexpriority ept vpid features: 17bee3ff-bfebfbff-00000001-2c100800 features_after_reboot: 17bee3ff-bfebfbff-00000001-2c100800 physical_features: 17bee3ff-bfebfbff-00000001-2c100800 maskable: full
- 设置
VCPUs-params:mask以将 VM 的 vCPU 绑定到特定的插槽或插槽内的特定核心。此设置在 VM 重启和关机后仍然保留。在具有 32 个总核心的双插槽平台中,核心 0-15 位于插槽 0 上,核心 16-31 位于插槽 1 上。在以下示例中,vm-uuid 是 VM 的 UUID,您可以通过 确定 VM 的 UUID 中所述的方法获取。- 要将 VM 限制为仅在插槽 0 上运行,请设置掩码以指定核心 0-15
[root@xenserver ~]# xe vm-param-set uuid=vm-uuid VCPUs-params:mask=0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15
- 要将 VM 限制为仅在插槽 1 上运行,请设置掩码以指定核心 16-31
[root@xenserver ~]# xe vm-param-set uuid=vm-uuid VCPUs-params:mask=16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31
- 要将 vCPU 绑定到插槽内的特定核心,请设置掩码以直接指定核心
[root@xenserver ~]# xe vm-param-set uuid=vm-uuid VCPUs-params:mask=16,17,18,19
- 要将 VM 限制为仅在插槽 0 上运行,请设置掩码以指定核心 0-15
- 使用 xl vcpu-list 列出 vCPU 当前到物理 CPU 的分配
[root@xenserver ~]# xl vcpu-list Name ID VCPU CPU State Time(s) CPU Affinity Domain-0 0 0 25 -b- 9188.4 any cpu Domain-0 0 1 19 r-- 8908.4 any cpu Domain-0 0 2 30 -b- 6815.1 any cpu Domain-0 0 3 17 -b- 4881.4 any cpu Domain-0 0 4 22 -b- 4956.9 any cpu Domain-0 0 5 20 -b- 4319.2 any cpu Domain-0 0 6 28 -b- 5720.0 any cpu Domain-0 0 7 26 -b- 5736.0 any cpu test-image-win7-32 34 0 9 -b- 17.0 4-15 test-image-win7-32 34 1 4 -b- 13.7 4-15
E.6. 更改 dom0 vCPU 默认配置
默认情况下,dom0 vCPU 配置如下
- 分配给 dom0 的 vCPU 数量为 8。
- dom0 shell 的 vCPU 未绑定,并且能够在系统中的任何物理 CPU 上运行。
E.6.1. 更改 dom0 vCPU 的数量
分配给 dom0 的默认 vCPU 数量为 8。
- 修改 Xen 启动行中的
dom0_max_vcpus参数。例如
[root@xenserver ~]# /opt/xensource/libexec/xen-cmdline --set-xen dom0_max_vcpus=4
- 应用此设置后,重启系统以使设置生效,方法是执行以下操作之一
- 运行以下命令
shutdown –r
- 从 XenCenter 重启系统。
- 运行以下命令
E.6.2. 绑定 dom0 vCPU
默认情况下,dom0 的 vCPU 未绑定,并且能够在系统中的任何物理 CPU 上运行。
- 要将 dom0 vCPU 绑定到特定的物理 CPU,请使用 xl vcpu-pin。
例如,要将 dom0 的 vCPU 0 绑定到物理 CPU 18,请使用以下命令
[root@xenserver ~]# xl vcpu-pin Domain-0 0 18
以这种方式应用的 CPU 绑定会立即生效,但不会在重启后保留。
- 要使设置持久化,请将 xl vcpu-pin 命令添加到 /etc/rc.local 中。
例如
xl vcpu-pin 0 0 0-15 xl vcpu-pin 0 1 0-15 xl vcpu-pin 0 2 0-15 xl vcpu-pin 0 3 0-15 xl vcpu-pin 0 4 16-31 xl vcpu-pin 0 5 16-31 xl vcpu-pin 0 6 16-31 xl vcpu-pin 0 7 16-31
E.7. GPU 局部性如何确定
如 NUMA 考虑事项 中所述,当前的多插槽服务器通常在每个 CPU 插槽本地实现 PCIe 扩展槽,将 VM 绑定到与其关联的物理 GPU 连接的同一插槽是有利的。
对于当前的 Intel 平台,CPU 插槽 0 通常将其 PCIe 根端口位于总线 0 上,因此任何低于位于总线 0 上的根端口的 GPU 都连接到插槽 0。CPU 插槽 1 的根端口位于更高的总线号上,通常为总线 0x20 或总线 0x80,具体取决于特定的服务器平台。
您可以使用 XenCenter 和 xe 命令行操作来执行 XenServer 高级 vGPU 管理技术。
F.1. GPU 的管理对象
XenServer 使用四个底层管理对象来管理 GPU:物理 GPU、vGPU 类型、GPU 组和 vGPU。当使用 xe 管理 vGPU 时,会直接使用这些对象;当使用 XenCenter 管理 vGPU 时,会间接使用这些对象。
F.1.1. pgpu - 物理 GPU
pgpu 对象代表一个物理 GPU,例如 Tesla M60 或 M10 卡上存在的多个 GPU 之一。 XenServer 在启动时自动创建 pgpu 对象,以表示平台上存在的每个物理 GPU。
F.1.1.1. 列出平台上存在的 pgpu 对象
要列出平台上存在的物理 GPU 对象,请使用 xe pgpu-list。
例如,此平台包含一个具有单个物理 GPU 的 Tesla P40 卡和一个具有两个物理 GPU 的 Tesla M60 卡
[root@xenserver ~]# xe pgpu-list
uuid ( RO) : f76d1c90-e443-4bfc-8f26-7959a7c85c68
vendor-name ( RO): NVIDIA Corporation
device-name ( RO): GP102GL [Tesla P40]
gpu-group-uuid ( RW): 134a7b71-5ceb-8066-ef1b-3b319fb2bef3
uuid ( RO) : 4c5e05d9-60fa-4fe5-9cfc-c641e95c8e85
vendor-name ( RO): NVIDIA Corporation
device-name ( RO): GM204GL [Tesla M60]
gpu-group-uuid ( RW): 3df80574-c303-f020-efb3-342f969da5de
uuid ( RO) : 4960e63c-c9fe-4a25-add4-ee697263e04c
vendor-name ( RO): NVIDIA Corporation
device-name ( RO): GM204GL [Tesla M60]
gpu-group-uuid ( RW): d32560f2-2158-42f9-d201-511691e1cb2b
[root@xenserver ~]#
F.1.1.2. 查看关于 pgpu 对象的详细信息
要查看关于 pgpu 的详细信息,请使用 xe pgpu-param-list
[root@xenserver ~]# xe pgpu-param-list uuid=4960e63c-c9fe-4a25-add4-ee697263e04c
uuid ( RO) : 4960e63c-c9fe-4a25-add4-ee697263e04c
vendor-name ( RO): NVIDIA Corporation
device-name ( RO): GM204GL [Tesla M60]
dom0-access ( RO): enabled
is-system-display-device ( RO): false
gpu-group-uuid ( RW): d32560f2-2158-42f9-d201-511691e1cb2b
gpu-group-name-label ( RO): 86:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [Tesla M60] (rev a1)
host-uuid ( RO): b55452df-1ee4-4e4e-bd97-3aee97b2123a
host-name-label ( RO): xs7.1
pci-id ( RO): 0000:86:00.0
dependencies (SRO):
other-config (MRW):
supported-VGPU-types ( RO): 5b9acd25-06fa-43e1-8b53-c35bceb8515c; 16326fcb-543f-4473-a4ae-2d30516a2779; 0f9fc39a-0758-43c8-88cc-54c8491aa4d4; cecb2033-3b4a-437c-a0c0-c9dfdb692d9b; 095d8939-5f84-405d-a39a-684738f9b957; 56c335be-4036-4a38-816c-c246a60556ac; ef0a94fd-2230-4fd4-aee0-d6d3f6ced4ef; 11615f73-47b8-4494-806e-2a7b5e1d7bea; dbd8f2ac-f548-4c40-804b-9133cfda8090; a33189f1-1417-4593-aa7d-978c4f25b953; 3f437337-3682-4897-a7ba-6334519f4c19; 99900aab-42b0-4cc4-8832-560ff6b60231
enabled-VGPU-types (SRW): 5b9acd25-06fa-43e1-8b53-c35bceb8515c; 16326fcb-543f-4473-a4ae-2d30516a2779; 0f9fc39a-0758-43c8-88cc-54c8491aa4d4; cecb2033-3b4a-437c-a0c0-c9dfdb692d9b; 095d8939-5f84-405d-a39a-684738f9b957; 56c335be-4036-4a38-816c-c246a60556ac; ef0a94fd-2230-4fd4-aee0-d6d3f6ced4ef; 11615f73-47b8-4494-806e-2a7b5e1d7bea; dbd8f2ac-f548-4c40-804b-9133cfda8090; a33189f1-1417-4593-aa7d-978c4f25b953; 3f437337-3682-4897-a7ba-6334519f4c19; 99900aab-42b0-4cc4-8832-560ff6b60231
resident-VGPUs ( RO):
[root@xenserver ~]#
F.1.1.3. 在 XenCenter 中查看物理 GPU
要在 XenCenter 中查看物理 GPU,请单击服务器的 GPU 选项卡:
图 32. XenCenter 中的物理 GPU 显示

F.1.2. vgpu-type - 虚拟 GPU 类型
vgpu-type 表示一种虚拟 GPU 类型,例如 M60-0B、P40-8A 和 P100-16Q。定义了一个额外的直通 vGPU 类型,用于表示可以直接分配给单个客户 VM 的物理 GPU。
XenServer 在启动时自动创建 vgpu-type 对象,以表示平台上存在的物理 GPU 支持的每种虚拟类型。
F.1.2.1. 列出平台上存在的 vgpu-type 对象
要列出平台上存在的 vgpu-type 对象,请使用 xe vgpu-type-list。
例如,由于此平台包含 Tesla P100、Tesla P40 和 Tesla M60 卡,因此报告的 vGPU 类型是这些卡支持的类型
[root@xenserver ~]# xe vgpu-type-list
uuid ( RO) : d27f84a2-53f8-4430-ad15-0eca225cd974
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-12A
max-heads ( RO): 1
max-resolution ( RO): 1280x1024
uuid ( RO) : 57bb231f-f61b-408e-a0c0-106bddd91019
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-3Q
max-heads ( RO): 4
max-resolution ( RO): 4096x2160
uuid ( RO) : 9b2eaba5-565f-4cb4-ad9b-6347cfb03e93
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-2Q
max-heads ( RO): 4
max-resolution ( RO): 4096x2160
uuid ( RO) : af593219-0800-42da-a51d-d13b35f589e1
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-4A
max-heads ( RO): 1
max-resolution ( RO): 1280x1024
uuid ( RO) : 5b9acd25-06fa-43e1-8b53-c35bceb8515c
vendor-name ( RO):
model-name ( RO): passthrough
max-heads ( RO): 0
max-resolution ( RO): 0x0
uuid ( RO) : af121387-0b58-498a-8d04-fe0305e4308f
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-3A
max-heads ( RO): 1
max-resolution ( RO): 1280x1024
uuid ( RO) : 3b28a628-fd6c-4cda-b0fb-80165699229e
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P100-4Q
max-heads ( RO): 4
max-resolution ( RO): 4096x2160
uuid ( RO) : 99900aab-42b0-4cc4-8832-560ff6b60231
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID M60-1Q
max-heads ( RO): 2
max-resolution ( RO): 4096x2160
uuid ( RO) : 0f9fc39a-0758-43c8-88cc-54c8491aa4d4
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID M60-4A
max-heads ( RO): 1
max-resolution ( RO): 1280x1024
uuid ( RO) : 4017c9dd-373f-431a-b36f-50e4e5c9f0c0
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-6A
max-heads ( RO): 1
max-resolution ( RO): 1280x1024
uuid ( RO) : 125fbbdf-406e-4d7c-9de8-a7536aa1a838
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-24A
max-heads ( RO): 1
max-resolution ( RO): 1280x1024
uuid ( RO) : 88162a34-1151-49d3-98ae-afcd963f3105
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-2A
max-heads ( RO): 1
max-resolution ( RO): 1280x1024
uuid ( RO) : ad00a95c-d066-4158-b361-487abf57dd30
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-1A
max-heads ( RO): 1
max-resolution ( RO): 1280x1024
uuid ( RO) : 11615f73-47b8-4494-806e-2a7b5e1d7bea
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID M60-0Q
max-heads ( RO): 2
max-resolution ( RO): 2560x1600
uuid ( RO) : 6ea0cd56-526c-4966-8f53-7e1721b95a5c
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-4Q
max-heads ( RO): 4
max-resolution ( RO): 4096x2160
uuid ( RO) : 095d8939-5f84-405d-a39a-684738f9b957
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID M60-4Q
max-heads ( RO): 4
max-resolution ( RO): 4096x2160
uuid ( RO) : 9626e649-6802-4396-976d-94c0ead1f835
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-12Q
max-heads ( RO): 4
max-resolution ( RO): 4096x2160
uuid ( RO) : a33189f1-1417-4593-aa7d-978c4f25b953
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID M60-0B
max-heads ( RO): 2
max-resolution ( RO): 2560x1600
uuid ( RO) : dbd8f2ac-f548-4c40-804b-9133cfda8090
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID M60-1A
max-heads ( RO): 1
max-resolution ( RO): 1280x1024
uuid ( RO) : ef0a94fd-2230-4fd4-aee0-d6d3f6ced4ef
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID M60-8Q
max-heads ( RO): 4
max-resolution ( RO): 4096x2160
uuid ( RO) : 67fa06ab-554e-452b-a66e-a4048a5bfdf7
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-6Q
max-heads ( RO): 4
max-resolution ( RO): 4096x2160
uuid ( RO) : 739d7b8e-50e2-48a1-ae0d-5047aa490f0e
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-8A
max-heads ( RO): 1
max-resolution ( RO): 1280x1024
uuid ( RO) : 9fb62f31-7dfb-46f8-a4a9-cca8db48147e
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P100-8Q
max-heads ( RO): 4
max-resolution ( RO): 4096x2160
uuid ( RO) : 56c335be-4036-4a38-816c-c246a60556ac
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID M60-1B
max-heads ( RO): 4
max-resolution ( RO): 2560x1600
uuid ( RO) : 3f437337-3682-4897-a7ba-6334519f4c19
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID M60-8A
max-heads ( RO): 1
max-resolution ( RO): 1280x1024
uuid ( RO) : 25dbb2d3-a074-4f9f-92ce-b42d8b3d1de2
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-1B
max-heads ( RO): 4
max-resolution ( RO): 2560x1600
uuid ( RO) : cecb2033-3b4a-437c-a0c0-c9dfdb692d9b
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID M60-2Q
max-heads ( RO): 4
max-resolution ( RO): 4096x2160
uuid ( RO) : 16326fcb-543f-4473-a4ae-2d30516a2779
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID M60-2A
max-heads ( RO): 1
max-resolution ( RO): 1280x1024
uuid ( RO) : 7ca2399f-89ab-49dd-bf96-75071ced28fc
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-24Q
max-heads ( RO): 4
max-resolution ( RO): 4096x2160
uuid ( RO) : 9611a3f4-d130-4a66-a61b-21d4a2ca4663
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-8Q
max-heads ( RO): 4
max-resolution ( RO): 4096x2160
uuid ( RO) : d0e4a116-a944-42ef-a8dc-62a54c4d2d77
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-1Q
max-heads ( RO): 2
max-resolution ( RO): 4096x2160
[root@xenserver ~]#
F.1.2.2. 查看关于 vgpu-type 对象的详细信息
要查看关于 vgpu-type 的详细信息,请使用 xe vgpu-type-param-list
[root@xenserver ~]# xe xe vgpu-type-param-list uuid=7ca2399f-89ab-49dd-bf96-75071ced28fc
uuid ( RO) : 7ca2399f-89ab-49dd-bf96-75071ced28fc
vendor-name ( RO): NVIDIA Corporation
model-name ( RO): GRID P40-24Q
framebuffer-size ( RO): 24092082176
max-heads ( RO): 4
max-resolution ( RO): 4096x2160
supported-on-PGPUs ( RO): f76d1c90-e443-4bfc-8f26-7959a7c85c68
enabled-on-PGPUs ( RO): f76d1c90-e443-4bfc-8f26-7959a7c85c68
supported-on-GPU-groups ( RO): 134a7b71-5ceb-8066-ef1b-3b319fb2bef3
enabled-on-GPU-groups ( RO): 134a7b71-5ceb-8066-ef1b-3b319fb2bef3
VGPU-uuids ( RO):
experimental ( RO): false
[root@xenserver ~]#
F.1.3. gpu-group - 物理 GPU 的集合
gpu-group 是物理 GPU 的集合,所有物理 GPU 都属于同一类型。 XenServer 在启动时自动创建 gpu-group 对象,以表示平台上存在的不同类型的物理 GPU。
F.1.3.1. 列出平台上存在的 gpu-group 对象
要列出平台上存在的 gpu-group 对象,请使用 xe gpu-group-list。
例如,具有单个 Tesla P100 卡、单个 Tesla P40 卡和两个 Tesla M60 卡的系统包含一个 Tesla P100 类型的 GPU 组、一个 Tesla P40 类型的 GPU 组和两个 Tesla M60 类型的 GPU 组
[root@xenserver ~]# xe gpu-group-list
uuid ( RO) : 3d652a59-beaf-ddb3-3b19-c8c77ef60605
name-label ( RW): Group of NVIDIA Corporation GP100GL [Tesla P100 PCIe 16GB] GPUs
name-description ( RW):
uuid ( RO) : 3df80574-c303-f020-efb3-342f969da5de
name-label ( RW): 85:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [Tesla M60] (rev a1)
name-description ( RW): 85:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [Tesla M60] (rev a1)
uuid ( RO) : 134a7b71-5ceb-8066-ef1b-3b319fb2bef3
name-label ( RW): 87:00.0 3D controller: NVIDIA Corporation GP102GL [TESLA P40] (rev a1)
name-description ( RW): 87:00.0 3D controller: NVIDIA Corporation GP102GL [TESLA P40] (rev a1)
uuid ( RO) : d32560f2-2158-42f9-d201-511691e1cb2b
name-label ( RW): 86:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [Tesla M60] (rev a1)
name-description ( RW): 86:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [Tesla M60] (rev a1)
[root@xenserver ~]#
F.1.3.2. 查看关于 gpu-group 对象的详细信息
要查看关于 gpu-group 的详细信息,请使用 xe gpu-group-param-list
[root@xenserver ~]# xe gpu-group-param-list uuid=134a7b71-5ceb-8066-ef1b-3b319fb2bef3
uuid ( RO) : 134a7b71-5ceb-8066-ef1b-3b319fb2bef3
name-label ( RW): 87:00.0 3D controller: NVIDIA Corporation GP102GL [TESLA P40] (rev a1)
name-description ( RW): 87:00.0 3D controller: NVIDIA Corporation GP102GL [TESLA P40] (rev a1)
VGPU-uuids (SRO): 101fb062-427f-1999-9e90-5a914075e9ca
PGPU-uuids (SRO): f76d1c90-e443-4bfc-8f26-7959a7c85c68
other-config (MRW):
enabled-VGPU-types ( RO): d0e4a116-a944-42ef-a8dc-62a54c4d2d77; 9611a3f4-d130-4a66-a61b-21d4a2ca4663; 7ca2399f-89ab-49dd-bf96-75071ced28fc; 25dbb2d3-a074-4f9f-92ce-b42d8b3d1de2; 739d7b8e-50e2-48a1-ae0d-5047aa490f0e; 67fa06ab-554e-452b-a66e-a4048a5bfdf7; 9626e649-6802-4396-976d-94c0ead1f835; 6ea0cd56-526c-4966-8f53-7e1721b95a5c; ad00a95c-d066-4158-b361-487abf57dd30; 88162a34-1151-49d3-98ae-afcd963f3105; 125fbbdf-406e-4d7c-9de8-a7536aa1a838; 4017c9dd-373f-431a-b36f-50e4e5c9f0c0; af121387-0b58-498a-8d04-fe0305e4308f; 5b9acd25-06fa-43e1-8b53-c35bceb8515c; af593219-0800-42da-a51d-d13b35f589e1; 9b2eaba5-565f-4cb4-ad9b-6347cfb03e93; 57bb231f-f61b-408e-a0c0-106bddd91019; d27f84a2-53f8-4430-ad15-0eca225cd974
supported-VGPU-types ( RO): d0e4a116-a944-42ef-a8dc-62a54c4d2d77; 9611a3f4-d130-4a66-a61b-21d4a2ca4663; 7ca2399f-89ab-49dd-bf96-75071ced28fc; 25dbb2d3-a074-4f9f-92ce-b42d8b3d1de2; 739d7b8e-50e2-48a1-ae0d-5047aa490f0e; 67fa06ab-554e-452b-a66e-a4048a5bfdf7; 9626e649-6802-4396-976d-94c0ead1f835; 6ea0cd56-526c-4966-8f53-7e1721b95a5c; ad00a95c-d066-4158-b361-487abf57dd30; 88162a34-1151-49d3-98ae-afcd963f3105; 125fbbdf-406e-4d7c-9de8-a7536aa1a838; 4017c9dd-373f-431a-b36f-50e4e5c9f0c0; af121387-0b58-498a-8d04-fe0305e4308f; 5b9acd25-06fa-43e1-8b53-c35bceb8515c; af593219-0800-42da-a51d-d13b35f589e1; 9b2eaba5-565f-4cb4-ad9b-6347cfb03e93; 57bb231f-f61b-408e-a0c0-106bddd91019; d27f84a2-53f8-4430-ad15-0eca225cd974
allocation-algorithm ( RW): depth-first
[root@xenserver ~]
F.1.4. vgpu - 虚拟 GPU
vgpu 对象代表一个虚拟 GPU。与其他 GPU 管理对象不同,vgpu 对象不是由 XenServer 自动创建的。相反,它们是按如下方式创建的
- 当通过 XenCenter 或 xe 将 VM 配置为使用 vGPU 时
- 通过克隆配置为使用 vGPU 的 VM,如 克隆启用 vGPU 的 VM 中所述
F.2. 使用 xe 创建 vGPU
使用 xe vgpu-create 创建 vgpu 对象,指定所需的 vGPU 类型、将从中分配 vGPU 的 GPU 组以及与其关联的 VM
[root@xenserver ~]# xe vgpu-create vm-uuid=e71afda4-53f4-3a1b-6c92-a364a7f619c2 gpu-group-uuid=be825ba2-01d7-8d51-9780-f82cfaa64924 vgpu-type-uuid=3f318889-7508-c9fd-7134-003d4d05ae56b73cbd30-096f-8a9a-523e-a800062f4ca7
[root@xenserver ~]#
为 VM 创建 vgpu 对象不会立即导致在物理 GPU 上创建虚拟 GPU。相反,每当与其关联的 VM 启动时,就会创建 vgpu 对象。有关 vGPU 如何在 VM 启动时创建的更多详细信息,请参阅 控制 vGPU 分配。
拥有 VM 必须处于关机状态,vgpu-create 命令才能成功。
vgpu 对象的拥有 VM、关联的 GPU 组和 vGPU 类型在创建时是固定的,之后无法更改。要更改分配给 VM 的 vGPU 类型,请删除现有的 vgpu 对象并创建另一个。
F.3. 控制 vGPU 分配
在 XenCenter 中配置 VM 以使用 vGPU,或使用 xe 为 VM 创建 vgpu 对象,不会立即导致创建虚拟 GPU;相反,虚拟 GPU 在下次 VM 启动时创建,步骤如下
- 检查与
vgpu对象关联的 GPU 组中是否存在可以托管所需类型 vGPU 的物理 GPU(即vgpu对象关联的vgpu-type)。由于 vGPU 类型不能在单个物理 GPU 上混合使用,因此新的 vGPU 只能在没有驻留 vGPU 或仅驻留相同类型的 vGPU 且数量少于物理 GPU 可以支持的该类型 vGPU 限制的物理 GPU 上创建。 - 如果组中不存在此类物理 GPU,则
vgpu创建失败,并且 VM 启动中止。 - 否则,如果组中存在多个此类物理 GPU,则根据 GPU 组的分配策略选择一个物理 GPU,如 修改 GPU 分配策略 中所述。
F.3.1. 确定虚拟 GPU 驻留的物理 GPU
vgpu 对象的 resident-on 参数返回 vGPU 驻留的物理 GPU 的 pgpu 对象的 UUID。
要确定虚拟 GPU 驻留的物理 GPU,请使用 vgpu-param-get
[root@xenserver ~]# xe vgpu-param-get uuid=101fb062-427f-1999-9e90-5a914075e9ca param-name=resident-on
f76d1c90-e443-4bfc-8f26-7959a7c85c68
[root@xenserver ~]# xe pgpu-param-list uuid=f76d1c90-e443-4bfc-8f26-7959a7c85c68
uuid ( RO) : f76d1c90-e443-4bfc-8f26-7959a7c85c68
vendor-name ( RO): NVIDIA Corporation
device-name ( RO): GP102GL [Tesla P40]
gpu-group-uuid ( RW): 134a7b71-5ceb-8066-ef1b-3b319fb2bef3
gpu-group-name-label ( RO): 87:00.0 3D controller: NVIDIA Corporation GP102GL [TESLA P40] (rev a1)
host-uuid ( RO): b55452df-1ee4-4e4e-bd97-3aee97b2123a
host-name-label ( RO): xs7.1-krish
pci-id ( RO): 0000:87:00.0
dependencies (SRO):
other-config (MRW):
supported-VGPU-types ( RO): 5b9acd25-06fa-43e1-8b53-c35bceb8515c; 88162a34-1151-49d3-98ae-afcd963f3105; 9b2eaba5-565f-4cb4-ad9b-6347cfb03e93; 739d7b8e-50e2-48a1-ae0d-5047aa490f0e; d0e4a116-a944-42ef-a8dc-62a54c4d2d77; 7ca2399f-89ab-49dd-bf96-75071ced28fc; 67fa06ab-554e-452b-a66e-a4048a5bfdf7; 9611a3f4-d130-4a66-a61b-21d4a2ca4663; d27f84a2-53f8-4430-ad15-0eca225cd974; 125fbbdf-406e-4d7c-9de8-a7536aa1a838; 4017c9dd-373f-431a-b36f-50e4e5c9f0c0; 6ea0cd56-526c-4966-8f53-7e1721b95a5c; af121387-0b58-498a-8d04-fe0305e4308f; 9626e649-6802-4396-976d-94c0ead1f835; ad00a95c-d066-4158-b361-487abf57dd30; af593219-0800-42da-a51d-d13b35f589e1; 25dbb2d3-a074-4f9f-92ce-b42d8b3d1de2; 57bb231f-f61b-408e-a0c0-106bddd91019
enabled-VGPU-types (SRW): 5b9acd25-06fa-43e1-8b53-c35bceb8515c; 88162a34-1151-49d3-98ae-afcd963f3105; 9b2eaba5-565f-4cb4-ad9b-6347cfb03e93; 739d7b8e-50e2-48a1-ae0d-5047aa490f0e; d0e4a116-a944-42ef-a8dc-62a54c4d2d77; 7ca2399f-89ab-49dd-bf96-75071ced28fc; 67fa06ab-554e-452b-a66e-a4048a5bfdf7; 9611a3f4-d130-4a66-a61b-21d4a2ca4663; d27f84a2-53f8-4430-ad15-0eca225cd974; 125fbbdf-406e-4d7c-9de8-a7536aa1a838; 4017c9dd-373f-431a-b36f-50e4e5c9f0c0; 6ea0cd56-526c-4966-8f53-7e1721b95a5c; af121387-0b58-498a-8d04-fe0305e4308f; 9626e649-6802-4396-976d-94c0ead1f835; ad00a95c-d066-4158-b361-487abf57dd30; af593219-0800-42da-a51d-d13b35f589e1; 25dbb2d3-a074-4f9f-92ce-b42d8b3d1de2; 57bb231f-f61b-408e-a0c0-106bddd91019
resident-VGPUs ( RO): 101fb062-427f-1999-9e90-5a914075e9ca
[root@xenserver ~]#
如果 vGPU 当前未运行,则不会为 vGPU 实例化 resident-on 参数,并且 vgpu-param-get 操作返回
<not in database>
F.3.2. 控制在特定物理 GPU 上启用的 vGPU 类型
物理 GPU 支持多种 vGPU 类型,如 支持的 GPU 的虚拟 GPU 类型 和用于将整个物理 GPU 分配给 VM 的“直通”类型(请参阅 在 XenServer 上使用 GPU 直通)。
F.3.2.1. 使用 XenCenter 控制在特定物理 GPU 上启用的 vGPU 类型
要限制可以在特定物理 GPU 上创建的 vGPU 类型
- 在 XenCenter 中打开服务器的 GPU 选项卡。
- 选中要限制 vGPU 类型的 一个或多个 GPU 旁边的框。
- 选择 编辑选定的 GPU。
图 33. 使用 XenCenter 编辑 GPU 的已启用 vGPU 类型

F.3.2.2. 使用 xe 控制在特定物理 GPU 上启用的 vGPU 类型
物理 GPU 的 pgpu 对象的 enabled-vGPU-types 参数控制在特定物理 GPU 上启用的 vGPU 类型。
要修改 pgpu 对象的 enabled-vGPU-types 参数,请使用 xe pgpu-param-set
[root@xenserver ~]# xe pgpu-param-list uuid=cb08aaae-8e5a-47cb-888e-60dcc73c01d3
uuid ( RO) : cb08aaae-8e5a-47cb-888e-60dcc73c01d3
vendor-name ( RO): NVIDIA Corporation
device-name ( RO): GP102GL [Tesla P40]
domO-access ( RO): enabled
is-system-display-device ( RO): false
gpu-group-uuid ( RW): bfel603d-c526-05f3-e64f-951485ef3b49
gpu-group-name-label ( RO): 87:00.0 3D controller: NVIDIA Corporation GP102GL [Tesla P40] (rev al)
host-uuid ( RO): fdeb6bbb-e460-4cfl-ad43-49ac81c20540
host-name-label ( RO): xs-72
pci-id ( RO): 0000:87:00.0
dependencies (SRO):
other-config (MRW):
supported-VGPU-types ( RO): 23e6b80b-le5e-4c33-bedb-e6dlae472fec; f5583e39-2540-440d-a0ee-dde9f0783abf; al8e46ff-4d05-4322-b040-667ce77d78a8; adell9a9-84el-435f-b0e9-14cl62e212fb; 2560d066-054a-48a9-a44d-3f3f90493a00; 47858f38-045d-4a05-9blc-9128fee6b0ab; Ifb527f6-493f-442b-abe2-94a6fafd49ce; 78b8e044-09ae-4a4c-8a96-b20c7a585842; 18ed7e7e-f8b7-496e-9784-8ba4e35acaa3; 48681d88-c4e5-4e39-85ff-c9bal2e8e484 ; cc3dbbfb-4b83-400d-8c52-811948b7f8c4; 8elad75a-ed5f-4609-83ff-5f9bca9aaca2; 840389a0-f511-4f90-8153-8a749d85b09e; a2042742-da67-4613-a538-ldl7d30dccb9; 299e47c2-8fcl-4edf-aa31-e29db84168c6; e95c636e-06e6-4 47e-8b49-14b37d308922; 0524a5d0-7160-48c5-a9el-cc33e76dc0de; 09043fb2-6d67-4443-b312-25688f13e012
enabled-VGPU-types (SRW): 23e6b80b-le5e-4c33-bedb-e6dlae472fec; f5583e39-2540-440d-a0ee-dde9f0783abf; al8e46ff-4d05-4322-b040-667ce77d78a8; adell9a9-84el-435f-b0e9-14cl62e212fb; 2560d066-054a-48a9-a44d-3f3f90493a00; 47858f38-045d-4a05-9blc-9128fee6b0ab; Ifb527f6-493f-442b-abe2-94a6fafd49ce; 78b8e044-09ae-4a4c-8a96-b20c7a585842; 18ed7e7e-f8b7-496e-9784-8ba4e35acaa3; 48681d88-c4e5-4e39-85ff-c9bal2e8e484 ; cc3dbbfb-4b83-400d-8c52-811948b7f8c4; 8elad75a-ed5f-4609-83ff-5f9bca9aaca2; 840389a0-f511-4f90-8153-8a749d85b09e; a2042742-da67-4613-a538-ldl7d30dccb9; 299e47c2-8fcl-4edf-aa31-e29db84168c6; e95c636e-06e6-4 47e-8b49-14b37d308922; 0524a5d0-7160-48c5-a9el-cc33e76dc0de; 09043fb2-6d67-4443-b312-25688f13e012
resident-VGPUs ( RO):
[root@xenserver-vgx-test ~]# xe pgpu-param-set uuid=cb08aaae-8e5a-47cb-888e-60dcc73c01d3 enabled-VGPU-types=23e6b80b-le5e-4c33-bedb-e6dlae472fec
F.3.3. 在特定物理 GPU 上创建 vGPU
要在特定物理 GPU 上精确控制 vGPU 的分配,请为您希望在其上分配 vGPU 的物理 GPU 创建单独的 GPU 组。创建虚拟 GPU 时,请在包含您希望在其上分配 vGPU 的物理 GPU 的 GPU 组上创建它。
例如,要为 PCI 总线 ID 为 0000:87:00.0 的物理 GPU 创建新的 GPU 组,请按照以下步骤操作
- 使用适当的名称创建新的 GPU 组
[root@xenserver ~]# xe gpu-group-create name-label="GRID P40 87:0.0" 3f870244-41da-469f-71f3-22bc6d700e71 [root@xenserver ~]#
- 找到您要分配给新 GPU 组的
0000:87:0.0处的物理 GPU 的 UUID[root@xenserver ~]# xe pgpu-list pci-id=0000:87:00.0 uuid ( RO) : f76d1c90-e443-4bfc-8f26-7959a7c85c68 vendor-name ( RO): NVIDIA Corporation device-name ( RO): GP102GL [Tesla P40] gpu-group-uuid ( RW): 134a7b71-5ceb-8066-ef1b-3b319fb2bef3 [root@xenserver ~]
注意传递给 pgpu-list 命令的
pci-id参数必须采用所示的精确格式,其中 PCI 域已完全指定(例如,0000),并且 PCI 总线和设备号均为两位数字(例如,87:00.0)。 - 通过检查
resident-VGPUs参数,确保当前没有 vGPU 在物理 GPU 上运行[root@xenserver ~]# xe pgpu-param-get uuid=f76d1c90-e443-4bfc-8f26-7959a7c85c68 param-name=resident-VGPUs [root@xenserver ~]#
- 如果列出了任何 vGPU,请关闭与其关联的 VM。
- 将物理 GPU 的
gpu-group-uuid参数更改为新创建的 GPU 组的 UUID[root@xenserver ~]# xe pgpu-param-set uuid=7c1e3cff-1429-0544-df3d-bf8a086fb70a gpu-group-uuid=585877ef-5a6c-66af-fc56-7bd525bdc2f6 [root@xenserver ~]#
现在创建的任何指定此 GPU 组 UUID 的 vgpu 对象都将始终在其 PCI 总线 ID 为 0000:05:0.0 的 GPU 上创建 vGPU。
您可以将多个物理 GPU 添加到手动创建的 GPU 组中 - 例如,表示多插槽服务器平台中连接到同一 CPU 插槽的所有 GPU - 但与自动创建的 GPU 组一样,组中的所有物理 GPU 必须属于同一类型。
在 XenCenter 中,手动创建的 GPU 组会显示在 VM 的 GPU 属性中的 GPU 类型列表中。从您希望从中分配 vGPU 的组中选择一个 GPU 类型:
图 34. 在 XenCenter 中使用自定义 GPU 组

F.4. 克隆启用 vGPU 的 VM
XenServer 的快速克隆或复制功能可用于从“黄金”基本 VM 映像快速创建新的 VM,该映像已配置 NVIDIA vGPU、NVIDIA 驱动程序、应用程序和远程图形软件。
克隆 VM 时,与基本 VM 关联的任何 vGPU 配置都会复制到克隆的 VM。启动克隆的 VM 将创建与原始 VM 类型相同的 vGPU 实例,并从与原始 vGPU 相同的 GPU 组中创建。
F.4.1. 使用 xe 克隆启用 vGPU 的 VM
要从 dom0 shell 克隆启用 vGPU 的 VM,请使用 vm-clone
[root@xenserver ~]# xe vm-clone new-name-label="new-vm" vm="base-vm-name" 7f7035cb-388d-1537-1465-1857fb6498e7
[root@xenserver ~]#
F.4.2. 使用 XenCenter 克隆启用 vGPU 的 VM
要使用 XenCenter 克隆启用 vGPU 的 VM,请使用 VM 的 复制 VM 命令,如图 图 35 所示。
图 35. 使用 XenCenter 克隆 VM

本章提供了关于优化在 XenServer 上使用 NVIDIA vGPU 运行的 VM 性能的建议。
G.1. XenServer Tools
为了最大限度地发挥在 XenServer 上运行的 VM 的性能,无论您是否使用 NVIDIA vGPU,都必须在 VM 中安装 XenServer tools。如果没有 XenServer tools 提供的优化网络和存储驱动程序,在 NVIDIA vGPU 上运行的远程图形应用程序将无法提供最佳性能。
G.2. 使用远程图形
NVIDIA vGPU 实现了一个控制台 VGA 接口,允许通过 XenCenter 的 控制台 选项卡查看 VM 的图形输出。此功能允许在虚拟机中加载任何 NVIDIA 图形驱动程序之前在 XenCenter 中看到启用 vGPU 的 VM 的桌面,但这仅旨在作为管理便利;它仅支持 vGPU 主显示的输出,并且并非设计或优化为提供高帧率。
为了从 vGPU 上的多个显示器提供高帧率,NVIDIA 建议您安装高性能远程图形堆栈,例如 Citrix Virtual Apps and Desktops with HDX 3D Pro 远程图形,并在安装堆栈后禁用 vGPU 的控制台 VGA。
G.2.1. 禁用控制台 VGA
vGPU 中的控制台 VGA 接口经过优化,可消耗最少的资源,但是当系统加载大量 VM 时,完全禁用控制台 VGA 接口可能会产生一些性能优势。
一旦您安装了访问 VM 的替代方法(例如 Citrix Virtual Apps and Desktops 或 VNC 服务器),就可以按如下方式禁用其 vGPU 控制台 VGA 接口,具体取决于您使用的 XenServer 版本
- Citrix Hypervisor 8.1 或更高版本:使用
xe命令创建 vGPU,并为 vGPU 所属的组指定插件参数- 创建 vGPU。
[root@xenserver ~]# xe vgpu-create gpu-group-uuid=gpu-group-uuid vgpu-type-uuid=vgpu-type-uuid vm-uuid=vm-uuid
- 为 vGPU 所属的组指定插件参数。
[root@xenserver ~]# xe vgpu-param-set uuid=vgpu-uuid extra_args=disable_vnc=1
- 创建 vGPU。
- 早于 8.1 的 Citrix Hypervisor:在 VM 的
platform:vgpu_extra_args参数中指定disable_vnc=1[root@xenserver ~]# xe vm-param-set uuid=vm-uuid platform:vgpu_extra_args="disable_vnc=1"
如果您在安装或启用访问 VM 的替代机制(例如 Citrix Virtual Apps and Desktops)之前禁用了控制台 VGA,则一旦 VM 启动,您将无法与其交互。
您可以通过进行以下更改之一来恢复控制台 VGA 访问
- 删除 vGPU 插件的参数
- Citrix Hypervisor 8.1 或更高版本:从 vGPU 所属的组中删除
extra_args键 - 早于 8.1 的 Citrix Hypervisor:从
platform参数中删除vgpu_extra_args键
- Citrix Hypervisor 8.1 或更高版本:从 vGPU 所属的组中删除
- 从
extra_args或vgpu_extra_args键中删除disable_vnc=1 - 设置
disable_vnc=0,例如- Citrix Hypervisor 8.1 或更高版本
[root@xenserver ~]# xe vgpu-param-set uuid=vgpu-uuid extra_args=disable_vnc=0
- 早于 8.1 的 Citrix Hypervisor
[root@xenserver ~]# xe vm-param-set uuid=vm-uuid platform:vgpu_extra_args="disable_vnc=0"
- Citrix Hypervisor 8.1 或更高版本
声明
本文档仅供参考,不应视为对产品的特定功能、条件或质量的保证。 NVIDIA Corporation(“NVIDIA”)对本文档中包含的信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。 NVIDIA 对使用此类信息造成的后果或使用此类信息,或因使用此类信息而可能导致的侵犯第三方专利或其他权利的行为不承担任何责任。 本文档并非承诺开发、发布或交付任何材料(如下定义)、代码或功能。
NVIDIA 保留随时更正、修改、增强、改进和对本文档进行任何其他更改的权利,恕不另行通知。
客户在下订单前应获取最新的相关信息,并应验证此类信息是否为最新且完整。
NVIDIA 产品根据订单确认时提供的 NVIDIA 标准销售条款和条件进行销售,除非 NVIDIA 和客户的授权代表签署的单独销售协议(“销售条款”)另有约定。 NVIDIA 特此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。 本文档不直接或间接地形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空器、太空或生命维持设备,也不适用于 NVIDIA 产品的故障或失灵可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。 NVIDIA 对在上述设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不保证或声明基于本文档的产品将适用于任何特定用途。 NVIDIA 不一定会对每种产品的所有参数进行测试。 客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合且适用于客户计划的应用,并为该应用执行必要的测试,以避免应用或产品的缺陷。 客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的额外或不同的条件和/或要求。 NVIDIA 对可能基于或归因于以下原因的任何缺陷、损坏、成本或问题不承担任何责任:(i) 以任何违反本文档的方式使用 NVIDIA 产品;或 (ii) 客户产品设计。
本文档未授予 NVIDIA 专利权、版权或本文档项下的其他 NVIDIA 知识产权的任何明示或暗示的许可。 NVIDIA 发布的关于第三方产品或服务的信息不构成 NVIDIA 授予的使用此类产品或服务的许可,也不构成 NVIDIA 对其的保证或认可。 使用此类信息可能需要获得第三方在其专利或其他知识产权下的许可,或获得 NVIDIA 在其专利或其他知识产权下的许可。
只有在事先获得 NVIDIA 书面批准的情况下,才允许复制本文档中的信息,并且复制时不得进行更改,必须完全遵守所有适用的出口法律和法规,并附带所有相关的条件、限制和声明。
本文档和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均按“原样”提供。 NVIDIA 对材料不作任何明示、暗示、法定或其他形式的保证,并明确否认对非侵权性、适销性和特定用途适用性的所有默示保证。 在法律未禁止的范围内,在任何情况下,NVIDIA 均不对因使用本文档而引起的任何损害(包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害,无论何种原因造成,也无论责任理论如何)承担责任,即使 NVIDIA 已被告知可能发生此类损害。 尽管客户可能因任何原因遭受任何损害,但 NVIDIA 对本文所述产品的对客户的总累积责任应根据产品的销售条款中的规定进行限制。
VESA DisplayPort
DisplayPort 和 DisplayPort Compliance Logo、DisplayPort Compliance Logo for Dual-mode Sources 以及 DisplayPort Compliance Logo for Active Cables 是视频电子标准协会在美国和其他国家/地区的商标。
HDMI
HDMI、HDMI 标志和 High-Definition Multimedia Interface 是 HDMI Licensing LLC 的商标或注册商标。
OpenCL
OpenCL 是 Apple Inc. 的商标,已授权 Khronos Group Inc. 使用。
商标
NVIDIA、NVIDIA 徽标、NVIDIA GRID、NVIDIA GRID vGPU、NVIDIA Maxwell、NVIDIA Pascal、NVIDIA Turing、NVIDIA Volta、GPUDirect、Quadro 和 Tesla 是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。 其他公司和产品名称可能是与其关联的各自公司的商标。
- 使用 -1B vGPU 类型代替 -1B4 vGPU 类型。
- 使用 -2B vGPU 类型代替 -2B4 vGPU 类型。