2. 用法
2.1. CUPTI 兼容性和要求
CUPTI,即 CUDA 分析工具接口,确保 CUDA 应用程序在各种 GPU 架构和 CUDA 驱动程序版本之间的无缝分析兼容性。作为 CUDA 工具包的一部分,CUPTI 遵守 CUDA 工具包与 CUDA 驱动程序的兼容性要求,其中包括对后向、前向和增强兼容性的支持。例如,基于旧版本 CUPTI 的分析工具仍然可以与更新的 CUDA 驱动程序一起运行。
务必参考 CUDA 工具包和 兼容驱动程序版本表,以确定与 CUDA 工具包版本对应的每个 CUPTI 版本所需的最低 CUDA 驱动程序版本。尝试使用与不兼容的 CUDA 驱动程序版本的 CUPTI 调用将导致 CUPTI_ERROR_NOT_INITIALIZED 错误代码。
2.2. CUPTI 初始化
CUPTI 初始化在您首次调用任何 CUPTI 函数时延迟发生。对于 Activity、Event、Metric 和 Callback API,对初始化何时发生没有要求(即,您可以在任何时候调用第一个 CUPTI 函数)。有关 activity API 的 CUPTI 初始化要求的更多信息,请参阅 CUPTI Activity API 部分。
建议 CUPTI 客户端在开始分析会话之前调用 API cuptiSubscribe(),即应在调用任何其他 CUPTI API 之前调用 API cuptiSubscribe()。当另一个 CUPTI 客户端已订阅时,此 API 将返回错误代码 CUPTI_ERROR_MULTIPLE_SUBSCRIBERS_NOT_SUPPORTED。如果 cuptiSubscribe() 返回错误,CUPTI 客户端应报错并停止进行进一步的 CUPTI 调用。这将防止多个 CUPTI 客户端同时处于活动状态,否则它们可能会相互干扰分析状态。
2.3. CUPTI Activity API
CUPTI Activity API 允许您异步收集应用程序的 CPU 和 GPU CUDA 活动的跟踪。活动 API 使用以下术语。
- 活动记录
CPU 和 GPU 活动在名为活动记录的 C 数据结构中报告。每种活动类型都有不同的 C 结构类型(例如
CUpti_ActivityAPI)。记录通常使用CUpti_Activity类型引用。此类型仅包含一个字段,指示活动记录的类型。使用此类型,可以将对象从通用CUpti_Activity类型强制转换为表示特定活动的类型。有关示例,请参阅 activity_trace_async 示例中的printActivity函数。- 活动缓冲区
活动缓冲区用于将一个或多个活动记录从 CUPTI 传输到客户端。当 CPU 和 GPU 上发生相应的活动时,CUPTI 会用活动记录填充活动缓冲区。但是,CUPTI 不保证活动缓冲区中活动的任何排序,因为某些活动类型的活动记录是延迟添加的。CUPTI 客户端负责根据需要提供空的活动缓冲区,以确保不会丢失任何记录。
异步缓冲 API 由 cuptiActivityRegisterCallbacks 和 cuptiActivityFlushAll 实现。
不需要在 CUDA 初始化之前初始化 activity API。将收集初始化 activity API 后发生的所有相关活动。您可以使用 cuptiActivityEnable 或 cuptiActivityEnableContext 启用一种或多种活动类型来强制初始化 activity API,如 activity_trace_async 示例的 initTrace 函数中所示。某些活动类型无法直接启用,有关详细信息,请参阅 CUpti_ActivityKind 的 API 文档。cuptiActivityEnable 和 cuptiActivityEnableContext 函数将在请求的活动类型无法启用时返回 CUPTI_ERROR_NOT_COMPATIBLE。
活动缓冲区 API 使用回调来请求和返回活动记录缓冲区。要使用异步缓冲 API,您必须首先使用 cuptiActivityRegisterCallbacks 注册两个回调。每当 CUPTI 需要空活动缓冲区时,将调用其中一个回调。另一个回调用于向客户端传递包含一个或多个活动记录的缓冲区。为了最大限度地减少分析开销,客户端应尽可能快地从这些回调返回。客户端可以预先分配一个活动缓冲区池,并在 CUPTI 请求时从池中返回一个空缓冲区。应仔细选择活动缓冲区大小,较小的缓冲区可能导致 CUPTI 的频繁请求,而较大的缓冲区可能会延迟已完成活动缓冲区的自动传递。对于典型的工作负载,建议选择 1 到 10 MB 之间的大小。cuptiActivityGetAttribute 和 cuptiActivitySetAttribute 函数可用于读取和写入控制缓冲 API 行为的属性。有关更多信息,请参阅 API 文档。
活动缓冲区的刷新
CUPTI 预计在活动缓冲区满且其中的所有活动记录都完成时自动传递活动缓冲区。出于性能原因,CUPTI 基于某些启发式方法调用底层方法,因此可能会导致缓冲区传递延迟。但是,客户端可以随时请求传递活动缓冲区,这可以使用 API cuptiActivityFlushAll 和 cuptiActivityFlushPeriod 来实现。这些 API 的行为如下
对于使用 API
cuptiActivityFlushAll且标志设置为 0 的按需刷新,CUPTI 返回所有已完成所有活动记录的活动缓冲区,缓冲区不必是满的。它不会返回具有一个或多个未完成记录的缓冲区。此刷新可以在单独的线程中以规则的时间间隔完成。对于使用 API
cuptiActivityFlushAll且标志设置为 CUPTI_ACTIVITY_FLAG_FLUSH_FORCED 的按需强制刷新,CUPTI 返回所有活动缓冲区,包括具有一个或多个未完成活动记录的缓冲区。建议在分析会话终止之前进行强制刷新,以允许传递剩余的缓冲区。对于使用 API
cuptiActivityFlushPeriod的定期刷新,CUPTI 仅返回那些已满且已完成所有活动记录的活动缓冲区。即使客户端设置了定期刷新,也允许使用 APIcuptiActivityFlushAll按需刷新缓冲区。
请注意,如果活动记录已填写所有信息,包括时间戳(如果有),则视为已完成。
activity_trace_async 示例演示了如何使用活动缓冲区 API 收集简单应用程序的 CPU 和 GPU 活动的跟踪。
CUPTI 线程
CUPTI 创建一个工作线程,以最大限度地减少对应用程序创建的线程的干扰。CUPTI 将某些操作从应用程序线程卸载到工作线程,这包括主机和设备之间分析资源的同步,以及使用在 API cuptiActivityRegisterCallbacks 等中注册的缓冲区完成回调将活动缓冲区传递给客户端。为了最大限度地减少开销,CUPTI 基于某些启发式方法唤醒工作线程。CUDA 11.1 中引入的 API cuptiActivityFlushPeriod 可用于控制工作线程的刷新周期。此设置会覆盖 CUPTI 启发式方法。即使客户端设置了定期刷新,也允许使用 API cuptiActivityFlushAll 按需刷新数据。
此外,当启用某些活动类型时,CUPTI 会创建单独的线程。例如,CUPTI 为活动类型 CUPTI_ACTIVITY_KIND_UNIFIED_MEMORY_COUNTER 和 CUPTI_ACTIVITY_KIND_ENVIRONMENT 各创建一个线程,以从后端收集信息。
2.3.1. SASS 源码关联
虽然用于 GPU 编程的高级语言(如 CUDA C)提供了有用的抽象级别、便利性和可维护性,但它们本质上隐藏了硬件上执行的一些细节。有时,在汇编指令级别分析内核的性能问题会很有帮助。阅读汇编语言既繁琐又具有挑战性;CUPTI 可以帮助您构建高级源代码行与执行的汇编指令之间的关联。
构建 PC 的 SASS 源码关联可以分为两个部分
PC 与 SASS 指令的关联 - 订阅
CUPTI_CBID_RESOURCE_MODULE_LOADED、CUPTI_CBID_RESOURCE_MODULE_UNLOAD_STARTING或CUPTI_CBID_RESOURCE_MODULE_PROFILED回调中的任何一个。这将返回一个包含 CUDA 二进制文件的CUpti_ModuleResourceData结构。可以使用 CUDA 工具包附带的 nvdisasm 实用程序反汇编该二进制文件。应用程序可以有多个函数和模块,为了唯一标识,所有源级别活动记录中都有一个functionId字段。这唯一对应于CUPTI_ACTIVITY_KIND_FUNCTION,它在模块中具有唯一的模块 ID 和函数 ID。SASS 指令与 CUDA 源代码行的关联 - 每个源级别活动都有一个
sourceLocatorId字段,该字段唯一映射到CUPTI_ACTIVITY_KIND_SOURCE_LOCATOR类型的记录,其中包含行号和文件名信息。请注意,多个 PC 可以对应于单个源代码行。
当启用任何源级别活动(全局访问、分支、PC 采样等)时,将为具有源级别结果的 PC 生成源定位器记录。记录 CUpti_ActivityInstructionCorrelation 可以与源级别活动一起使用,以生成 SASS 汇编指令到 CUDA C 源代码的映射,用于函数的所有 PC,而不仅仅是具有源级别结果的 PC。可以使用活动类型 CUPTI_ACTIVITY_KIND_INSTRUCTION_CORRELATION 启用此功能。
sass_source_map 示例演示了如何将 SASS 汇编指令映射到 CUDA C 源代码。
2.3.2. PC 采样
CUPTI 支持设备范围的程序计数器 (PC) 采样。PC 采样提供每个源和汇编行在各种停顿原因下的样本数。使用此信息,您可以查明内核中引入延迟的部分以及延迟的原因。无论 warp 是否正在发出指令,都会以循环方式在固定数量的周期内对所有活动 warp 进行采样。
计算能力为 6.0 及更高的设备具有一项新功能,可提供延迟原因。延迟样本指示 issue pipeline 中出现空洞的原因。在收集这些样本时,相应的 warp 调度程序中没有发出指令,因此这些样本给出了延迟原因。延迟原因将是枚举 CUpti_ActivityPCSamplingStallReason 中列出的停顿原因之一,但停顿原因 CUPTI_ACTIVITY_PC_SAMPLING_STALL_NOT_SELECTED 除外。
活动记录 CUpti_ActivityPCSampling3,通过活动类型 CUPTI_ACTIVITY_KIND_PC_SAMPLING 启用,输出停顿原因以及 PC 和其他相关信息。枚举 CUpti_ActivityPCSamplingStallReason 列出了所有停顿原因。采样周期是可配置的,可以使用 API cuptiActivityConfigurePCSampling 进行调整。支持范围广泛的采样周期,从每个样本 2^5 个周期到 2^31 个周期。这可以通过 PC 采样配置结构 CUpti_ActivityPCSamplingConfig 中的字段 samplingPeriod2 进行控制。活动记录 CUpti_ActivityPCSamplingRecordInfo 提供针对 PC 采样分析的每个内核的总样本数和丢弃样本数。
此功能在计算能力为 5.2 及更高版本的设备上可用,但不包括移动设备。对于 Pascal 和更旧的芯片,必须在启用活动类型 CUPTI_ACTIVITY_KIND_PC_SAMPLING 之前调用 cuptiActivityConfigurePCSampling API,对于 Volta 和更新的芯片,顺序无关紧要。对于 Volta 和更新的 GPU 架构,如果在执行过程中调用 cuptiActivityConfigurePCSampling API,PC 采样配置将针对后续内核启动进行更新。PC 采样可能会显着改变应用程序的整体性能特征,因为所有内核执行都在 GPU 上序列化。
pc_sampling 示例演示了如何使用这些 API 收集内核的 PC 采样分析信息。
注意
CUDA 11.3 版本中引入了一组新的 PC 采样 API,它支持连续模式数据收集,而无需序列化内核执行,并具有更低的运行时开销。有关更多详细信息,请参阅 CUPTI PC 采样 API 部分。来自头文件 cupti_activity.h 的 PC 采样 API 将被称为 PC 采样 Activity API,而来自头文件 cupti_pcsampling.h 的 API 将被称为 PC 采样 API。
2.3.3. NVLink
NVIDIA NVLink 是一种高带宽、节能的互连技术,可在 CPU 和 GPU 之间以及 GPU 之间实现快速通信。CUPTI 提供 NVLink 拓扑信息和 NVLink 发送/接收吞吐量指标。
活动记录 CUpti_ActivityNVLink4,通过活动类型 CUPTI_ACTIVITY_KIND_NVLink 启用,以逻辑 NVLink 的形式输出 NVLink 拓扑信息。逻辑 NVLink 连接在 2 个设备之间,设备可以是 NPU(NVLink 处理单元)类型,可以是 CPU 或 GPU。每个设备最多可以支持 18 个 NVLink,因此一个逻辑链路可以包含 1 到 18 个物理 NVLink。physicalNvLinkCount 字段给出了此逻辑链路中物理链路的数量。portDev0 和 portDev1 字段提供了有关物理 NVLink 连接到逻辑链路的插槽的信息。此端口与从设备分析的 NVLink 指标的实例相同。因此,端口和实例信息应用于将每个实例的指标值与物理 NVLink 相关联,进而与拓扑相关联。flag 字段给出了逻辑链路的属性,无论该链路是否可以访问系统内存或对等设备内存,以及是否具有执行系统内存或对等内存原子操作的功能。bandwidth 字段给出了逻辑链路的带宽,单位为千字节/秒。
CUPTI 为每个物理链路提供了一些指标。为每个物理 NVLink 提供了数据发送/接收、发送/接收吞吐量以及标头与用户数据开销的指标。这些指标也按数据包类型(读取/写入/原子/响应)提供,以更详细地了解 NVLink 流量。
nvlink_bandwidth 示例演示了如何使用这些 API 收集 NVLink 指标和拓扑,以及如何将指标与拓扑相关联。
2.3.4. OpenACC
CUPTI 支持使用 PGI 运行时的 OpenACC 工具接口实现来收集 OpenACC 应用程序的信息。OpenACC 分析仅在 Linux x86_64、IBM POWER 和 Arm 服务器平台 (arm64 SBSA) 平台上可用。此功能还需要 PGI 运行时版本 19.1 或更高版本。
创建了活动记录 CUpti_ActivityOpenAccData、CUpti_ActivityOpenAccLaunch 和 CUpti_ActivityOpenAccOther,表示 OpenACC 工具接口中指定的三组回调事件。可以启用 CUPTI_ACTIVITY_KIND_OPENACC_DATA、CUPTI_ACTIVITY_KIND_OPENACC_LAUNCH 和 CUPTI_ACTIVITY_KIND_OPENACC_OTHER 以收集相应的活动记录。
由于 OpenACC 工具接口的限制,CUPTI 无法从客户端应用程序内部记录 OpenACC 记录。相反,必须实现一个共享库,该库导出 OpenACC 工具接口规范中定义的 acc_register_library 函数。从 OpenACC 运行时传递到此函数的参数可用于使用 cuptiOpenACCInitialize 初始化 CUPTI OpenACC 测量。在启动客户端应用程序之前,必须设置环境变量 ACC_PROFLIB 以指向此共享库。
cuptiOpenACCInitialize 在 cupti_openacc.h 中定义,该文件包含在 cupti_activity.h 中。由于 CUPTI OpenACC 标头仅在受支持的平台上可用,因此 CUPTI 客户端在编译时必须定义 CUPTI_OPENACC_SUPPORT。
openacc_trace 示例演示了如何使用 CUPTI API 进行 OpenACC 数据收集。
2.3.5. CUDA Graphs
CUPTI 可以收集 CUDA Graphs 应用程序的跟踪,而不会破坏驱动程序性能优化。CUPTI 在内核、memcpy 和 memset 活动记录中添加了字段 graphId 和 graphNodeId,以分别表示 GPU 活动的图和图节点的唯一 ID。CUPTI 为图操作(如图和图节点创建/销毁/克隆)以及可执行图创建/销毁发出回调。cuda_graphs_trace 示例演示了如何收集 CUDA Graphs 的 GPU 跟踪和 API 跟踪,以及如何通过使用 CUPTI 回调进行图操作将图节点启动与节点创建 API 相关联。
2.3.6. 外部关联
CUPTI 支持将 CUDA API 活动记录与外部 API 相关联。此类 API 包括 OpenACC、OpenMP 和 MPI。这会将 CUPTI 关联 ID 与外部 API 提供的 ID 相关联。这两个 ID 都存储在 CUpti_ActivityExternalCorrelation 类型的新活动记录中。
CUPTI 为每个 CPU 线程和每个 CUpti_ExternalCorrelationKind 维护一个外部关联 ID 堆栈。客户端必须使用 cuptiActivityPushExternalCorrelationId 将特定类型的外部 ID 推送到此堆栈,并使用 cuptiActivityPopExternalCorrelationId 删除最新的 ID。如果在同一 CPU 线程上的任何 CUpti_ExternalCorrelationKind 堆栈为非空时生成 CUDA API 活动记录,则在相应的 CUDA API 活动记录之前,会将每个 CUpti_ExternalCorrelationKind 堆栈的一个 CUpti_ActivityExternalCorrelation 记录插入到活动缓冲区中。CUPTI 客户端负责跟踪传递的外部 API 关联 ID,以便最终将外部 API 调用与 CUDA API 调用相关联。除了活动类型 CUPTI_ACTIVITY_KIND_EXTERNAL_CORRELATION 之外,还需要启用 CUDA API 活动类型,即 CUPTI_ACTIVITY_KIND_RUNTIME 和 CUPTI_ACTIVITY_KIND_DRIVER,以生成外部关联活动记录。
如果同时启用了 CUPTI_ACTIVITY_KIND_EXTERNAL_CORRELATION 和任何 CUPTI_ACTIVITY_KIND_OPENACC_* 活动类型,CUPTI 将为 OpenACC 生成外部关联活动记录,其中 externalKind 为 CUPTI_EXTERNAL_CORRELATION_KIND_OPENACC。
cupti_external_correlation 示例演示了如何使用 CUPTI API 进行外部关联。
2.3.7. 动态连接和分离
CUPTI 提供了连接或分离正在运行的进程的机制,以支持按需分析。CUPTI 可以通过调用任何 CUPTI API 进行连接,因为 CUPTI 支持延迟初始化。要分离 CUPTI,请调用 API cuptiFinalize(),该 API 会销毁并清理当前进程中与 CUPTI 关联的所有资源。CUPTI 从进程分离后,该进程将继续运行,而没有连接 CUPTI。任何后续的 CUPTI API 调用都将重新初始化 CUPTI。您可以多次连接和分离 CUPTI。为了 API 的安全操作,建议从任何 CUDA 驱动程序或运行时 API 的退出调用站点调用 API cuptiFinalize()。否则,CUPTI 客户端需要确保在调用 API cuptiFinalize() 之前完成 CUDA 同步和 CUPTI 活动缓冲区刷新。要理解从代码流中的特定点调用 API cuptiFinalize() 的必要性,请考虑执行各种 CUDA 活动的多个应用程序线程。当一个线程处于 cuptiFinalize() 的中间时,其他线程很可能继续调用 CUPTI 并尝试访问 CUPTI 维护的各种对象(设备、上下文、线程状态等)的状态,这些状态可能会在 cuptiFinalize() 的过程中变为无效,从而导致崩溃。我们必须阻止其他线程,直到通过 cuptiFinalize() 完成 CUPTI 拆卸。API 退出调用站点是我们可以确保所有线程提交的工作已完成并且可以安全地拆卸 CUPTI 的位置之一。cuptiFinalize() 是一项繁重的操作,因为它对所有活动的 CUDA 上下文进行上下文同步,并阻止所有应用程序线程,直到 CUPTI 拆卸完成。示例代码显示了在 cupti 回调处理程序代码中 API cuptiFinalize() 的用法
void CUPTIAPI
cuptiCallbackHandler(void *userdata, CUpti_CallbackDomain domain,
CUpti_CallbackId cbid, void *cbdata)
{
const CUpti_CallbackData *cbInfo = (CUpti_CallbackData *)cbdata;
// Take this code path when CUPTI detach is requested
if (detachCupti) {
switch(domain)
{
case CUPTI_CB_DOMAIN_RUNTIME_API:
case CUPTI_CB_DOMAIN_DRIVER_API:
if (cbInfo->callbackSite == CUPTI_API_EXIT) {
// call the CUPTI detach API
cuptiFinalize();
}
break;
default:
break;
}
}
}
完整代码可以在 cupti_finalize 示例中找到。
2.3.8. 设备内存分配源跟踪
CUDA 应用程序利用各种共享库,例如 cuBLAS、cuFFT、cuDNN 等,每个库都服务于不同的目的。这些库可以在编译时静态集成,也可以在运行时动态加载。在动态加载的情况下,CUPTI 可以精确地将内存分配归因于它们各自的共享库。这可以通过调用 cuptiActivityEnableAllocationSource() API 来实现。负责任的共享对象的文件路径在活动记录 CUpti_ActivityMemory4 中的 source 字段中分配,该活动记录使用活动类型 CUPTI_ACTIVITY_KIND_MEMORY2 启用。此功能目前仅限于 Linux x86_64 平台。但是,如果库是静态链接的,则源被标识为主应用程序可执行文件,而不是库。
2.4. CUPTI Callback API
CUPTI Callback API 允许您在自己的代码中注册回调。当正在分析的应用程序调用 CUDA 运行时或驱动程序函数,或者 CUDA 驱动程序中发生某些事件时,将调用您的回调。回调 API 使用以下术语。
- 回调域
回调被分组到域中,以便更轻松地将您的回调函数与相关 CUDA 函数或事件组关联。目前有四个回调域,由
CUpti_CallbackDomain定义:CUDA 运行时函数的域、CUDA 驱动程序函数的域、CUDA 资源跟踪的域和 CUDA 同步通知的域。- 回调 ID
每个回调在相应的回调域内都获得一个唯一的 ID,以便您可以在回调函数中识别它。CUDA 驱动程序 API ID 在
cupti_driver_cbid.h中定义,CUDA 运行时 API ID 在cupti_runtime_cbid.h中定义。当您包含cupti.h时,这两个标头都包含在内。CUDA 资源回调 ID 由CUpti_CallbackIdResource定义,CUDA 同步回调 ID 由CUpti_CallbackIdSync定义。- 回调函数
您的回调函数必须是
CUpti_CallbackFunc类型。此函数类型有两个参数,用于指定回调域和 ID,以便您知道回调发生的原因。该类型还有一个cbdata参数,用于传递特定于回调的数据。- 订阅者
订阅器用于将您的每个回调函数与一个或多个 CUDA API 函数关联起来。在任何时候,最多只能有一个使用
cuptiSubscribe()初始化的订阅器。在初始化新的订阅器之前,必须使用cuptiUnsubscribe()最终完成现有订阅器的操作。
每个回调域在下面详细描述。除非明确声明,否则不支持从回调函数内部调用任何 CUDA 运行时或驱动程序 API。这样做可能会导致应用程序挂起。
2.4.1. 驱动程序和运行时 API 回调
通过将回调 API 与 CUPTI_CB_DOMAIN_DRIVER_API 或 CUPTI_CB_DOMAIN_RUNTIME_API 域一起使用,您可以将回调函数与一个或多个 CUDA API 函数关联起来。当这些 CUDA 函数在应用程序中被调用时,您的回调函数也会被调用。对于这些域,您的回调函数的 cbdata 参数类型将为 CUpti_CallbackData。
从驱动程序或运行时 API 回调函数内部调用 cudaThreadSynchronize()、cudaDeviceSynchronize()、cudaStreamSynchronize()、cuCtxSynchronize() 和 cuStreamSynchronize() 是合法的。
以下代码显示了将回调函数与一个或多个 CUDA API 函数关联的典型序列。为了简化演示,错误检查代码已被删除。
CUpti_SubscriberHandle subscriber;
MyDataStruct *my_data = ...;
...
cuptiSubscribe(&subscriber,
(CUpti_CallbackFunc)my_callback , my_data);
cuptiEnableDomain(1, subscriber,
CUPTI_CB_DOMAIN_RUNTIME_API);
首先,cuptiSubscribe 用于初始化一个带有 my_callback 回调函数的订阅器。接下来,cuptiEnableDomain 用于将该回调与所有 CUDA 运行时 API 函数关联起来。使用此代码序列将导致每次调用任何 CUDA 运行时 API 函数时,my_callback 被调用两次,一次在进入 CUDA 函数时,一次在即将退出 CUDA 函数之前。CUPTI 回调 API 函数 cuptiEnableCallback 和 cuptiEnableAllDomains 也可用于将 CUDA API 函数与回调关联(有关更多信息,请参阅下面的参考资料)。
以下代码显示了一个典型的回调函数。
void CUPTIAPI
my_callback(void *userdata, CUpti_CallbackDomain domain,
CUpti_CallbackId cbid, const void *cbdata)
{
const CUpti_CallbackData *cbInfo = (CUpti_CallbackData *)cbdata;
MyDataStruct *my_data = (MyDataStruct *)userdata;
if ((domain == CUPTI_CB_DOMAIN_RUNTIME_API) &&
(cbid == CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy_v3020)) {
if (cbInfo->callbackSite == CUPTI_API_ENTER) {
cudaMemcpy_v3020_params *funcParams =
(cudaMemcpy_v3020_params *)(cbInfo->
functionParams);
size_t count = funcParams->count;
enum cudaMemcpyKind kind = funcParams->kind;
...
}
...
在您的回调函数中,您可以使用 CUpti_CallbackDomain 和 CUpti_CallbackID 参数来确定哪个 CUDA API 函数调用正在导致此回调。在上面的示例中,我们正在检查 CUDA 运行时 cudaMemcpy 函数。cbdata 参数保存了一个有用的信息结构,可以在回调中使用。在本例中,我们使用结构的 callbackSite 成员来检测回调是否发生在进入 cudaMemcpy 时,并使用 functionParams 成员来访问传递给 cudaMemcpy 的参数。要访问参数,我们首先将 functionParams 强制转换为与 cudaMemcpy 函数对应的结构类型。这些参数结构包含在 generated_cuda_runtime_api_meta.h、generated_cuda_meta.h 和许多其他文件中。在可能的情况下,cupti.h 会为您包含这些文件。
在示例页面上描述的 callback_event 和 callback_timestamp 示例都展示了如何将回调 API 用于驱动程序和运行时 API 域。
2.4.2. 资源回调
通过将回调 API 与 CUPTI_CB_DOMAIN_RESOURCE 域一起使用,您可以将回调函数与一些 CUDA 资源创建和销毁事件关联起来。例如,当创建 CUDA 上下文时,您的回调函数将被调用,回调 ID 等于 CUPTI_CBID_RESOURCE_CONTEXT_CREATED。对于此域,您的回调函数的 cbdata 参数类型将为 CUpti_ResourceData。
请注意,从使用回调 ID CUPTI_CBID_RESOURCE_STREAM_DESTROY_STARTING 标识的流销毁开始回调中调用 API cuptiActivityFlush 和 cuptiActivityFlushAll 将导致死锁。
2.4.3. 同步回调
通过将回调 API 与 CUPTI_CB_DOMAIN_SYNCHRONIZE 域一起使用,您可以将回调函数与 CUDA 上下文和流同步关联起来。例如,当 CUDA 上下文同步时,您的回调函数将被调用,回调 ID 等于 CUPTI_CBID_SYNCHRONIZE_CONTEXT_SYNCHRONIZED。对于此域,您的回调函数的 cbdata 参数类型将为 CUpti_SynchronizeData。
2.4.4. NVIDIA 工具扩展回调
通过将回调 API 与 CUPTI_CB_DOMAIN_NVTX 域一起使用,您可以将回调函数与 NVIDIA 工具扩展 (NVTX) API 函数关联起来。当 NVTX 函数在应用程序中被调用时,您的回调函数也会被调用。对于这些域,您的回调函数的 cbdata 参数类型将为 CUpti_NvtxData。
NVTX 库有其自身的约定来发现将提供 NVTX 回调实现的分析库。要接收回调,您必须正确设置 NVTX 环境变量,以便当应用程序调用 NVTX 函数时,您的分析库可以接收到回调。以下代码序列显示了启用 NVTX 回调和活动记录的典型初始化序列。
/* Set env so CUPTI-based profiling library loads on first nvtx call. */
char *inj32_path = "/path/to/32-bit/version/of/cupti/based/profiling/library";
char *inj64_path = "/path/to/64-bit/version/of/cupti/based/profiling/library";
setenv("NVTX_INJECTION32_PATH", inj32_path, 1);
setenv("NVTX_INJECTION64_PATH", inj64_path, 1);
以下代码显示了将回调函数与一个或多个 NVTX 函数关联的典型序列。为了简化演示,错误检查代码已被删除。
CUpti_SubscriberHandle subscriber;
MyDataStruct *my_data = ...;
...
cuptiSubscribe(&subscriber,
(CUpti_CallbackFunc)my_callback , my_data);
cuptiEnableDomain(1, subscriber,
CUPTI_CB_DOMAIN_NVTX);
首先,cuptiSubscribe 用于初始化一个带有 my_callback 回调函数的订阅器。接下来,cuptiEnableDomain 用于将该回调与所有 NVTX 函数关联起来。使用此代码序列将导致每次调用任何 NVTX 函数时,my_callback 被调用一次。CUPTI 回调 API 函数 cuptiEnableCallback 和 cuptiEnableAllDomains 也可用于将 NVTX API 函数与回调关联(有关更多信息,请参阅下面的参考资料)。
以下代码显示了一个典型的回调函数。
void CUPTIAPI
my_callback(void *userdata, CUpti_CallbackDomain domain,
CUpti_CallbackId cbid, const void *cbdata)
{
const CUpti_NvtxData *nvtxInfo = (CUpti_NvtxData *)cbdata;
MyDataStruct *my_data = (MyDataStruct *)userdata;
if ((domain == CUPTI_CB_DOMAIN_NVTX) &&
(cbid == CUPTI_CBID_NVTX_nvtxRangeStartEx)) {
nvtxRangeStartEx_params *params = (nvtxRangeStartEx_params *)nvtxInfo->
functionParams;
nvtxRangeId_t *id = (nvtxRangeId_t *)nvtxInfo->functionReturnValue;
...
}
...
在您的回调函数中,您可以使用 CUpti_CallbackDomain 和 CUpti_CallbackID 参数来确定哪个 NVTX API 函数调用正在导致此回调。在上面的示例中,我们正在检查 nvtxRangeStartEx 函数。cbdata 参数保存了一个有用的信息结构,可以在回调中使用。在本例中,我们使用 functionParams 成员来访问传递给 nvtxRangeStartEx 的参数。要访问参数,我们首先将 functionParams 强制转换为与 nvtxRangeStartEx 函数对应的结构类型。这些参数结构包含在 generated_nvtx_meta.h 中。我们还使用 functionReturnValue 成员来访问 nvtxRangeStartEx 返回的值。要访问返回值,我们首先将 functionReturnValue 强制转换为与 nvtxRangeStartEx 函数对应的返回类型。如果 NVTX 函数没有返回值,则 functionReturnValue 为 NULL。
示例 cupti_nvtx 展示了启用 NVTX 回调和活动记录的初始化序列。
如果您的基于 CUPTI 的分析库链接了静态 CUPTI 库,您可以定义和导出您自己的 NvtxInitializeInjection 和 NvtxInitializeInjection2 函数,这些函数可以通过设置 NVTX 环境变量来调用。
如果您希望 CUPTI 处理 NVTX 调用,这些函数应调用 CUPTI 对应的初始化函数,如下例所示,以便当应用程序调用 NVTX 函数时,您的分析库可以接收到回调。以下代码序列显示了如何在链接静态 CUPTI 库时完成此操作以接收回调和活动记录。
/* Set env so CUPTI-based profiling library loads on first nvtx call. */
char *inj32_path = "/path/to/32-bit/version/of/cupti/based/profiling/library";
char *inj64_path = "/path/to/64-bit/version/of/cupti/based/profiling/library";
setenv("NVTX_INJECTION32_PATH", inj32_path, 1);
setenv("NVTX_INJECTION64_PATH", inj64_path, 1);
/* Extern the CUPTI NVTX initialization APIs. The APIs are thread-safe */
extern "C" CUptiResult CUPTIAPI cuptiNvtxInitialize(void* pfnGetExportTable);
extern "C" CUptiResult CUPTIAPI cuptiNvtxInitialize2(void* pfnGetExportTable);
extern "C" int InitializeInjectionNvtx(void* p)
{
CUptiResult res = cuptiNvtxInitialize(p);
return (res == CUPTI_SUCCESS) ? 1 : 0;
}
extern "C" int InitializeInjectionNvtx2(void* p)
{
CUptiResult res = cuptiNvtxInitialize2(p);
return (res == CUPTI_SUCCESS) ? 1 : 0;
}
或者,如果您希望直接在您的分析库中处理 NVTX 调用,您可以在这些函数中将您自己的回调附加到 NVTX 客户端。
NVTX v1 和 v2 都将初始化代码放在由整个进程中所有 NVTX 用户共享的单个注入库中,因此初始化在每个进程中只会发生一次。NVTX v3 将初始化代码嵌入到您自己的二进制文件中,因此如果 NVTX v3 位于多个动态库中,则每个站点将在首次从该动态库进行 NVTX 调用时进行初始化。这些首次调用可能发生在不同的线程上。因此,如果您要连接您自己的 NVTX 处理程序,则应确保代码在从多个线程同时调用时是线程安全的。
2.4.5. 状态回调
显式 CUPTI API 调用遇到的任何致命错误都由 API 本身返回,而 CUPTI 在后台遇到的错误仅在下一次显式 CUPTI API 调用期间返回给用户。通过将回调 API 与 CUPTI_CB_DOMAIN_STATE 域一起使用,您可以将回调函数与 CUPTI 中的错误关联,并立即接收报告的错误。例如,当 CUPTI 遇到致命错误时,您的回调函数将被调用,回调 ID 等于 CUPTI_CBID_STATE_FATAL_ERROR。对于此域,您的回调函数的 cbdata 参数类型将为 CUpti_StateData。
作为 CUpti_StateData 的一部分,您可以接收故障的错误代码,以及包含可能原因或指向文档的相应链接的错误消息。这些回调的示例用法可以在 CUPTI 跟踪示例中找到。
2.5. CUPTI 分析器主机 API
CUPTI 在 CUDA 12.6 版本中引入了一组新的分析器主机 API cuptiProfilerHost*。这些 API 可用于执行通过 PM 采样 API 或新的范围分析器 API 收集分析数据所需的各种主机端任务。
这些新的 API 取代了旧的 Perfworks API,并且与之前的 NVPW 原始指标和指标评估器 API 相比,它们更高级。它们保留了关键功能,同时抽象出了底层细节,从而提供了一种更精简高效的方式来收集性能指标。
在 CUPTI 分析中,有三种类型的主机操作,即枚举、配置和评估。
2.5.1. 枚举
指标是一种可量化的度量,用于评估 CUDA 内核的性能和效率。指标可以提供对各种计算特性的深入了解,例如执行时间、指令吞吐量或缓存效率。
在分析内核时,指标是预定义的,用于捕获特定的性能数据。分析完成后,与这些指标关联的值允许开发人员分析内核的行为,识别性能瓶颈,并做出明智的优化。
例如,内核分析期间的常见指标可能包括
执行时间:内核完成所需的持续时间。
内存带宽:单元之间传输的数据量。
指令吞吐量:每秒执行的指令数。
缓存命中率:由缓存服务的内存访问百分比。
指标提供了内核性能的详细、量化的视图,使其对于性能调优和优化至关重要。
CUPTI 引入了多个 API,用于查询各种芯片支持的指标,并检索这些指标的属性,例如指标类型和每个指标代表的含义的描述。
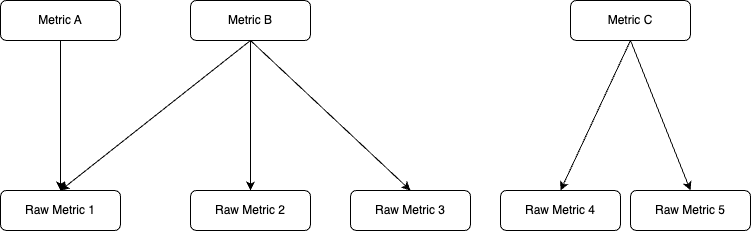
每个指标都可以被视为单个或多个原始指标(也称为原始计数器)的函数。CUPTI 将调度(参考配置)和分析关联的原始指标,并将其存储在计数器数据镜像中(参考评估)。
指标类型
CUPTI 中所有支持的指标可以分为 3 组,分别是 计数器、比率 和 吞吐量 指标。为了分析指标,用户需要根据要收集分析数据的指标类型添加汇总或子指标,有时两者都需要。计数器指标类型需要有一个汇总,但拥有子指标是可选的。对于比率指标类型,不支持汇总,因此只会添加一个子指标作为有效分析指标的后缀。对于吞吐量指标,汇总和子指标都是必需的。
CUPTI 支持四种类型的汇总,分别是 *sum、avg、min 和 max*。
汇总表 汇总类型
指标详细信息
.sum
所有单元实例的计数器值之和。
.avg
所有单元实例的计数器值的平均值。
.min
所有单元实例的计数器值的最小值。
.max
所有单元实例的计数器值的最大值。
对于 计数器 指标类型,请参考下表,了解可以添加到基本指标以进行分析的可选子指标列表。
计数器指标支持的子指标 子指标
描述
.peak_sustained
峰值持续速率。
.peak_sustained_active
单元活动周期内的峰值持续速率。
.peak_sustained_active.per_second
单元活动周期内的峰值持续速率,每秒。
.peak_sustained_elapsed
单元经过周期内的峰值持续速率。
.peak_sustained_active.per_second
单元经过周期内的峰值持续速率,每秒。
.per_second
每秒操作数。
.per_cycle_active
每个单元活动周期的操作数。
.per_cycle_elapsed
每个单元经过周期的操作数。
.pct_of_peak_sustained_active
单元活动周期内达到的峰值持续速率的百分比。
.pct_of_peak_sustained_elapsed
单元经过周期内达到的峰值持续速率的百分比。
例如,
smsp__warps_launched.sum.per_second
基本指标:
smsp__warps_launched汇总:
.sum子指标:
.per_second比率 指标仅支持以下三个子指标。
比率指标支持的子指标 子指标
描述
.pct
以百分比表示的值。
.ratio
以比率表示的值。
.max_rate
比率的最大值。
例如,
smsp__average_inst_executed_per_warp.max_rate
基本指标:
smsp__average_inst_executed_per_warp汇总:
不允许子指标:
.max_rate对于 吞吐量 指标,用户需要添加带有以下子指标之一的汇总。
吞吐量指标支持的子指标 子指标
描述
.pct_of_peak_sustained_active
单元活动周期内达到的峰值持续速率的百分比。
.pct_of_peak_sustained_elapsed
单元经过周期内达到的峰值持续速率的百分比。
例如,
sm__throughput.sum.pct_of_peak_sustained_active
基本指标:
sm__throughput汇总:
.sum子指标:
.pct_of_peak_sustained_active注意
为了解码指标名称,用户可以参考 Nsight Compute 文档中提到的内核分析指南中的指标解码器部分。
API
cuptiProfilerHostGetBaseMetrics()API 用于列出指标类型(计数器、吞吐量和比率)的基本指标。
cuptiProfilerHostGetSubMetrics()API 用于列出指标的子指标。
cuptiProfilerHostGetMetricProperties()API 用于查询有关指标的详细信息,例如关联的硬件单元、指标类型以及关于指标的简短描述。代码示例
// Initialize profiler host CUptiResult GetSupportedBaseMetrics(std::vector<std::string>& metricsList) { for (size_t metricTypeIndex = 0; metricTypeIndex < CUPTI_METRIC_TYPE__COUNT; ++metricTypeIndex) { CUpti_Profiler_Host_GetBaseMetrics_Params getBaseMetricsParams {CUpti_Profiler_Host_GetBaseMetrics_Params_STRUCT_SIZE}; getBaseMetricsParams.pHostObject = m_pHostObject; getBaseMetricsParams.metricType = (CUpti_MetricType)metricTypeIndex; cuptiProfilerHostGetBaseMetrics(&getBaseMetricsParams); for (size_t metricIndex = 0; metricIndex < getBaseMetricsParams.numMetrics; ++metricIndex) { metricsList.push_back(getBaseMetricsParams.ppMetricNames[metricIndex]); } } return CUPTI_SUCCESS; } CUptiResult GetMetricProperties(const std::string& metricName, CUpti_MetricType& metricType, std::string& metricDescription) { CUpti_Profiler_Host_GetMetricProperties_Params getMetricPropertiesParams {CUpti_Profiler_Host_GetMetricProperties_Params_STRUCT_SIZE}; getMetricPropertiesParams.pHostObject = m_pHostObject; getMetricPropertiesParams.pMetricName = metricName.c_str(); cuptiProfilerHostGetMetricProperties(&getMetricPropertiesParams); metricType = getMetricPropertiesParams.metricType; metricDescription = getMetricPropertiesParams.pDescription; return CUPTI_SUCCESS; } CUptiResult GetSubMetrics(const std::string& metricName, std::vector<std::string>& subMetricsList) { CUpti_MetricType metricType; std::string metricDescription; GetMetricProperties(metricName, metricType, metricDescription); CUpti_Profiler_Host_GetSubMetrics_Params getSubMetricsParams {CUpti_Profiler_Host_GetSubMetrics_Params_STRUCT_SIZE}; getSubMetricsParams.pHostObject = m_pHostObject; getSubMetricsParams.pMetricName = metricName.c_str(); getSubMetricsParams.metricType = metricType; cuptiProfilerHostGetSubMetrics(&getSubMetricsParams); for (size_t subMetricIndex = 0;subMetricIndex < getSubMetricsParams.numOfSubmetrics; ++subMetricIndex) { subMetricsList.push_back(getSubMetricsParams.ppSubMetrics[subMetricIndex]); } return CUPTI_SUCCESS; } // Deinitialize profiler host
2.5.2. 配置
用户选择要分析的指标后,必须在开始分析会话之前创建配置镜像。此镜像包含指定指标的调度详细信息,包括收集分析数据所需的pass次数以及在每个pass期间将收集哪些指标。用户可以离线存储配置镜像,并可以重复使用它来分析相同的指标列表以及相同的芯片。
下图显示了配置镜像内容的一个非常高级的概述。我们可以看到,当一起收集 3 个指标(M1、M2、M3)时,配置镜像具有调度信息,这需要 3 个pass。每个指标都定义了原始指标 (RM-X),这些原始指标被调度在相应的pass中收集。
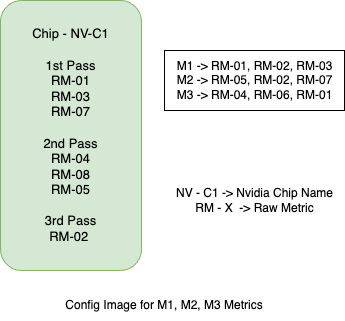
注意
对于 PM 采样,配置镜像应该能够调度指标以在单个pass中收集分析数据,否则 CUPTI 将报告 CUPTI_ERROR_NOT_SUPPORTED 错误。
API
cuptiProfilerHostConfigAddMetrics():添加将在配置镜像中调度用于分析的指标列表。cuptiProfilerHostGetConfigImageSize():添加指标列表后,用户可以调用此 API 来获取将为存储配置镜像信息分配多少内存。cuptiProfilerHostGetConfigImage():配置镜像将存储在用户分配的缓冲区中。
代码示例
// Initialize profiler host CUpti_Profiler_Host_ConfigAddMetrics_Params configAddMetricsParams {CUpti_Profiler_Host_ConfigAddMetrics_Params_STRUCT_SIZE}; configAddMetricsParams.pHostObject = profilerHostObjectPtr; configAddMetricsParams.ppMetricNames = metricNames.data(); configAddMetricsParams.numMetrics = metricNames.size(); cuptiProfilerHostConfigAddMetrics(&configAddMetricsParams); CUpti_Profiler_Host_GetConfigImageSize_Params getConfigImageSizeParams {CUpti_Profiler_Host_GetConfigImageSize_Params_STRUCT_SIZE}; getConfigImageSizeParams.pHostObject = profilerHostObjectPtr; cuptiProfilerHostGetConfigImageSize(&getConfigImageSizeParams); configImage.resize(getConfigImageSizeParams.configImageSize, 0); CUpti_Profiler_Host_GetConfigImage_Params initializeConfigImageParams {CUpti_Profiler_Host_GetConfigImage_Params_STRUCT_SIZE}; initializeConfigImageParams.pHostObject = profilerHostObjectPtr; initializeConfigImageParams.pConfigImage = configImage.data(); initializeConfigImageParams.configImageSize = configImage.size(); cuptiProfilerHostGetConfigImage(&initializeConfigImageParams); // Deinitialize profiler host
2.5.3. 评估
收集分析数据后,用户必须为每种分析类型(范围分析或 PM 采样)调用解码 API,以将存储在硬件缓冲区中的数据解码到用户分配的主机缓冲区中,称为 计数器数据镜像。此计数器数据镜像包含查询指标的分析数据,格式为内部格式,用户需要调用评估 API 以提取人类可读格式的数据。
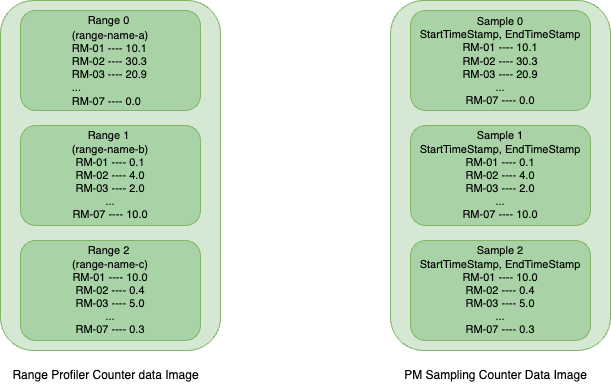
如上图所示,它表示计数器数据镜像中数据存储方式的非常高级的概述。对于范围分析,每个范围都由唯一的范围名称标识,而在 PM 采样中,每个样本都通过其开始和结束时间戳来区分。
API
cuptiRangeProfilerGetCounterDataInfo():在范围分析中,此 API 报告已分析并存储在计数器数据中的范围数量。
cuptiRangeProfilerCounterDataGetRangeInfo():用户可以使用此 API 查询计数器数据中特定范围索引的范围名称。
cuptiProfilerHostEvaluateToGpuValues():报告范围索引或样本索引的指标列表的分析数据。代码示例
// Initialize profiler host CUpti_RangeProfiler_GetCounterDataInfo_Params getCounterDataInfoParams {CUpti_RangeProfiler_GetCounterDataInfo_Params_STRUCT_SIZE}; getCounterDataInfoParams.pCounterDataImage = counterData; getCounterDataInfoParams.counterDataImageSize = counterDataSize; cuptiRangeProfilerGetCounterDataInfo(&getCounterDataInfoParams); size_t numOfRanges = getCounterDataInfoParams.numTotalRanges; metricNameValueMap.resize(metricNames.size()); for (size_t rangeIndex = 0; rangeIndex < numOfRanges; ++rangeIndex) { CUpti_RangeProfiler_CounterData_GetRangeInfo_Params getRangeInfoParams {CUpti_RangeProfiler_CounterData_GetRangeInfo_Params_STRUCT_SIZE}; getRangeInfoParams.pCounterDataImage = counterData; getRangeInfoParams.counterDataImageSize = counterDataSize; getRangeInfoParams.rangeIndex = rangeIndex; getRangeInfoParams.rangeDelimiter = "/"; cuptiRangeProfilerCounterDataGetRangeInfo(&getRangeInfoParams); std::vector<double> metricValues(metricNames.size()); CUpti_Profiler_Host_EvaluateToGpuValues_Params evalauateToGpuValuesParams {CUpti_Profiler_Host_EvaluateToGpuValues_Params_STRUCT_SIZE}; evalauateToGpuValuesParams.pHostObject = profilerHostObjectPtr; evalauateToGpuValuesParams.pCounterDataImage = counterData; evalauateToGpuValuesParams.counterDataImageSize = counterDataSize; evalauateToGpuValuesParams.ppMetricNames = metricNames.data(); evalauateToGpuValuesParams.numMetrics = metricNames.size(); evalauateToGpuValuesParams.rangeIndex = rangeIndex; evalauateToGpuValuesParams.pMetricValues = metricValues.data(); cuptiProfilerHostEvaluateToGpuValues(&evalauateToGpuValuesParams); } // Deinitialize profiler host
2.6. CUPTI 范围分析 API
从 CUDA 12.6 Update 2 开始,CUPTI 推出了一套新的高级分析 API,称为 cuptiRangeProfiler*。这些 API 类似于之前的 cuptiProfiler* API,使用户能够在 CUDA 上下文级别收集指标的分析数据。API 调用的这种一致性确保了与 CUPTI 内的其他分析组件保持一致。用户可以在其应用程序中指定特定范围,以收集 GPU 上的分析数据。
新的 API 与 Volta 和更新的 GPU 架构(计算能力 7.0 及更高版本)兼容,并且只需要处理两种镜像类型:配置镜像(包含指标的调度信息)和计数器数据镜像(在从 GPU 解码后存储分析数据)。此方法类似于早期的分析器 API 和 PM 采样 API,涉及主机操作(枚举、配置和评估)和目标操作(数据收集)。
2.6.1. 用法
对于主机任务,例如枚举、配置和评估,请参阅 CUPTI 主机 API 用法部分。
收集分析数据(收集)
一旦您设置了包含所有基本调度详细信息的配置镜像,您就可以使用范围分析器 API 来收集分析数据。在使用这些 API 之前,熟悉与范围分析相关的特定概念非常重要。
范围模式
CUPTI 提供两种范围模式来确定分析器范围的定义
自动范围
在这种模式下,每个内核启动都被视为一个单独的范围。在评估收集的数据时,CUPTI 为这些范围分配从 0 开始的数值。由于围绕内核边界定义,此模式在每个内核启动结束时都包含上下文同步,使操作同步。如果两个内核启动之间存在依赖关系,这可能会导致诸如挂起状态的问题。
用户范围
在这种模式下,用户可以使用 Push/Pop API 显式定义范围,允许范围跨越多个内核启动。因此,内核可以在此模式下异步启动。
重放模式
一个指标包括各种原始计数器,CUPTI 收集这些计数器以生成最终指标值。由于硬件限制,某些指标需要多次重放。重放模式对于分析多pass指标集合至关重要。对于单pass指标,不需要重放;因此,可以忽略重放模式。
内核重放
在这种模式下,内核被多次执行以收集完整的分析数据,CUPTI 管理保存/恢复操作并多次启动内核。此重放模式仅在自动范围模式下受支持。
用户重放
用户必须在重放范围之前保存和恢复上下文状态。此模式支持自动和用户范围模式。CUPTI 具有检查点 API,用于管理给定时间的上下文数据的保存和恢复。
应用程序重放
适用于内存有限的设备,用户使用相同的配置镜像和中间计数器数据文件重新启动应用程序以收集分析数据。此模式支持自动和用户范围模式。
注意
应用程序需要具有确定性的运行时工作负载,否则分析数据将不正确。
嵌套范围
CUPTI 允许嵌套的 Push/Pop 范围 API 调用,这对于详细分析非常有用。例如,范围 A 可以包含内核 A、B 和 C,而范围 B 包含 B 和 C,范围 C 仅包含 C。每个范围都有一个关联的嵌套级别,例如范围 A 处于基本级别,分配给级别 1,范围 B 和 C 的嵌套级别分别为 2 和 3。
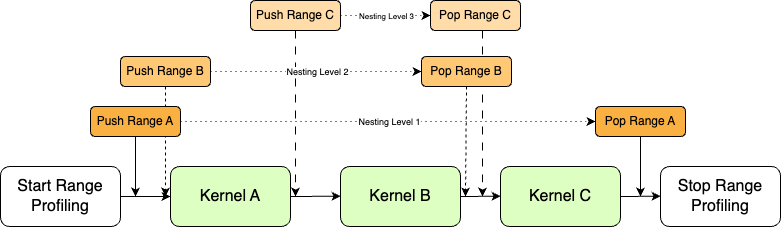
嵌套范围仅在用户范围模式下允许,并且随着嵌套级别的增加,收集嵌套范围的分析数据所需的重放次数也会增加。在
CUpti_RangeProfiler_SetConfig_Params结构中,numNestingLevels 和 minNestingLevel 专门用于嵌套范围,其中 minNestingLevel 将设置分析会话的基本级别。numNestingLevels 参数设置在一个分析会话中要分析多少个级别,从基本级别开始;如果设置为 2,则仅分析嵌套级别 1 和 2 中的范围。
2.6.2. API 用法
启用范围分析
在开始范围分析之前,使用
cuptiRangeProfilerEnable()为 CUDA 上下文启用它。这将创建一个CUpti_RangeProfiler_Object,它存储中间数据并标识上下文的其他分析器 API。创建计数器数据镜像
用户需要分配一个 CPU 缓冲区,用于存储在 GPU 中收集的解码后的分析数据。缓冲区必须采用特定格式才能存储数据,为此,CUPTI 公开了一组 API,用于获取存储分析数据所需的缓冲区大小,一旦分配了缓冲区,CUPTI 会将数据初始化为默认值。
cuptiRangeProfilerGetCounterDataSize(): 用于获取基于指标和应用程序中要分析的范围数量所需的缓冲区大小。cuptiRangeProfilerCounterDataImageInitialize(): 此 API 初始化用户分配的缓冲区。它也可用于重置计数器数据镜像。
设置配置
使用
cuptiRangeProfilerSetConfig()API 自定义分析配置。用户必须提供配置和计数器数据镜像,以及范围模式、重放模式和每次传递的范围数量等参数。启动范围分析
设置配置后,调用
cuptiRangeProfilerStart()API 以定义分析会话的边界。此边界之外的 Kernel 将不会被分析。推入范围
对于用户范围模式,调用
cuptiRangeProfilerPushRange()API 以定义范围的开始。在 Push/Pop API 调用之间启动的 Kernel 将被分析。弹出范围
使用
cuptiRangeProfilerPopRange()API 标记范围的结束。确保 Pop 范围 API 调用的数量与 Push 范围调用的数量匹配,以避免错误。注意
CUPTI 允许嵌套的 Push/Pop API 调用,用于嵌套范围分析。请参阅嵌套范围分析。
停止范围分析
cuptiRangeProfilerStop()API 设置范围分析的边界结束。同时,它还会报告是否已完成收集请求指标的分析数据的所有传递。如果未完成,则用户需要重放应用程序或 Start/Stop 边界,直到完成所有传递。对于 Kernel 重放模式,CUPTI 内部重放 Kernel,因此 allPassSubmitted 参数将始终为 1。对于应用程序重放模式,它会报告当前的 passIndex 和 targetNestingLevel,用户需要在下次重放时在cuptiRangeProfilerSetConfig()API 中设置这些参数。解码范围分析数据
存储在 GPU 缓冲区中的分析数据必须使用
cuptiRangeProfilerDecodeData()API 进行解码。此 API 在解码之前添加了 CUDA 上下文同步。注意
如果一次传递中分析的范围数量大于计数器数据镜像中可以存储的最大范围限制,则范围将被丢弃,并在
cuptiRangeProfilerDecodeData()API 中报告。禁用范围分析
用户需要调用
cuptiRangeProfilerDisable()API 来销毁 CUPTI 为范围分析分配的所有资源。
2.6.3. 示例代码
CUPTI 提供了一个示例,即 range_profiling,它展示了 API 的用法。该示例包含两个文件 range_profiler.h 和 range_profiler.cu。对于早期原型,用户可以简单地获取 range_profiler.h 头文件,该文件包含用于主机和目标操作的所有包装函数,并在其应用程序中使用它来收集分析数据。
// Enable Range profiler
pRangeProfilerTarget->EnableRangeProfiler();
// Create CounterData Image
std::vector<uint8_t> counterDataImage;
pRangeProfilerTarget->CreateCounterDataImage(args.metrics, counterDataImage);
// Set range profiler configuration
pRangeProfilerTarget->SetConfig(CUPTI_AutoRange, CUPTI_KernelReplay, configImage,counterDataImage);
do
{
// Start Range Profiling
pRangeProfilerTarget->StartRangeProfiler();
{
// Push Range (Level 1)
pRangeProfilerTarget->PushRange("VectorAdd");
// Launch CUDA workload
vectorLaunchWorkLoad.LaunchKernel();
{
// Push Range (Level 2)
pRangeProfilerTarget->PushRange("Nested VectorAdd");
vectorLaunchWorkLoad.LaunchKernel();
// Pop Range (Level 2)
pRangeProfilerTarget->PopRange();
}
// Pop Range (Level 1)
pRangeProfilerTarget->PopRange();
}
vectorLaunchWorkLoad.LaunchKernel();
// Stop Range Profiling
pRangeProfilerTarget->StopRangeProfiler();
}
while (!pRangeProfilerTarget->IsAllPassSubmitted());
// Get Profiler Data
pRangeProfilerTarget->DecodeCounterData();
// Evaluate the results
size_t numRanges = 0;
pCuptiProfilerHost->GetNumOfRanges(counterDataImage, numRanges);
for (size_t rangeIndex = 0; rangeIndex < numRanges; ++rangeIndex) {
pCuptiProfilerHost->EvaluateCounterData(rangeIndex, args.metrics, counterDataImage);
}
pCuptiProfilerHost->PrintProfilerRanges();
// Clean up
pRangeProfilerTarget->DisableRangeProfiler();
2.7. CUPTI PC 采样 API
CUPTI 支持对 Warp 程序计数器和 Warp 调度器状态进行周期性采样。在固定的周期间隔,每个流式多处理器 (SM) 中的采样器选择一个活动的 Warp,并记录其程序计数器和 Warp 调度器状态。采样器选择一个随机的活动 Warp,而调度器可能会在同一周期中选择不同的 Warp 来发出指令。收集的指标可以与执行的指令相关联,但它们缺乏时间分辨率。
指标可以在连续模式下收集,这种模式不会中断 Kernel 执行,并且运行时开销极小。
这些 API 在头文件 cupti_pcsampling.h 中提供。此外,实用程序库在头文件 cupti_pcsampling_util.h 中提供,其中包含用于将 GPU 汇编代码与 CUDA-C 源代码关联,以及用于读取和写入 PC 采样数据到文件的 API。
PC 采样 API 在 Volta 及更高版本的 GPU 架构(计算能力 7.0 及以上)上可用。
功能概述
两种采样模式 – 连续(并发 Kernel)或串行化(一次一个 Kernel)。
收集特定停顿原因的选项。
能够收集整个应用程序持续时间或特定 CPU 代码范围(由启动和停止 API 定义)的 GPU PC 采样数据。
刷新 GPU PC 采样数据的 API。
支持 GPU PC 采样与 CUDA C 源代码行和 GPU 汇编指令的离线和运行时关联的 API。
提供了示例,演示如何编写注入库以收集 PC 采样信息,以及如何使用实用程序 API 解析生成的文件,以打印停顿原因计数器值并将这些值与 GPU 汇编指令和 CUDA-C 源代码相关联。请参阅示例 pc_sampling_continuous、pc_sampling_utility 和 pc_sampling_start_stop。
注意
来自头文件 cupti_activity.h 的 PC 采样 API 将被称为 *PC 采样活动 API*,而来自头文件 cupti_pcsampling.h 的 API 将被称为 *PC 采样 API*。
2.7.1. 配置属性
下表列出了可以使用 cuptiPCSamplingSetConfigurationAttribute() API 设置的 PC 采样配置属性。
配置属性 |
描述 |
默认值 |
PC 采样 API 与 CUPTI PC 采样活动 API 的比较 |
调整配置选项的指南 |
|---|---|---|---|---|
收集模式 |
PC 采样收集模式 - 连续或 Kernel 串行化 |
连续 |
连续模式是新的。 Kernel 串行化模式等同于 CUPTI PC 采样活动 API 提供的 Kernel 级别功能。 |
|
采样周期 |
PC 采样的采样周期。采样周期的有效值介于 5 到 31 之间(包括 5 和 31)。这将采样周期设置为 (2^samplingPeriod) 个周期。 例如,对于采样周期 = 5 到 31,周期 = 32, 64, 128,…, 2^31 |
CUPTI 定义的值基于 SM 的数量 |
已删除对 5 个级别(MIN、LOW、MID、HIGH、MAX)采样周期的当前支持。 新的“采样周期”等同于 CUpti_ActivityPCSamplingConfig 中的“samplingPeriod2”字段。 |
低采样周期意味着高采样频率,这可能会导致样本丢失。极高的采样周期可能会导致低采样频率,并且不生成样本。 |
停顿原因 |
要收集的停顿原因 输入是指向要收集的停顿原因索引数组的指针。 |
将收集所有停顿原因 |
使用 CUPTI PC 采样活动 API,没有选择要收集哪些停顿原因的选项。此外,支持的停顿原因列表已更改。 |
|
暂存缓冲区大小 |
用于从硬件缓冲区下载的原始 PC 计数器数据的 SW 缓冲区大小。 大约需要 16 字节(和一些固定大小的内存)来容纳一个 PC 和一个停顿原因 例如,1 个 PC 和 1 个停顿原因 = 32 字节 1 个 PC 和 2 个停顿原因 = 48 字节 1 个 PC 和 4 个停顿原因 = 96 字节 |
1 MB (可以容纳大约 5500 个包含所有停顿原因的 PC) |
新的 |
客户端可以根据内存预算选择暂存缓冲区大小。非常小的暂存缓冲区大小可能会导致运行时开销,因为需要更多迭代来容纳和处理更多 PC 样本 |
硬件缓冲区大小 |
硬件缓冲区的大小(以字节为单位)。 如果采样周期太小,硬件缓冲区可能会溢出并丢弃 PC 数据 |
512 MB |
新的 |
设备可访问的样本缓冲区。采样周期较小时,较小的硬件缓冲区大小可能会导致溢出并丢弃 PC 数据。较高的硬件缓冲区大小可能会影响应用程序执行,因为可用的设备内存量较少 |
启用启动/停止控制 |
控制 PC 采样数据收集范围。 1 - 允许用户使用 API 启动和停止 PC 采样 |
0(禁用) |
新的 |
2.7.2. 停顿原因映射表
下表列出了从 PC 采样活动 API 到 PC 采样 API 的停顿原因映射。注意:带有后缀 _not_issued 的停顿原因表示延迟样本。这些样本表明,在该周期内,Warp 被采样的 Warp 调度器未发出任何指令。
PC 采样活动 API 停顿原因 (通用前缀:CUPTI_ACTIVITY_PC_SAMPLING_STALL_) |
PC 采样 API 停顿原因 (通用前缀:smsp__pcsamp_warps_issue_stalled_) |
|---|---|
NONE |
selected selected_not_issued |
INST_FETCH |
branch_resolving branch_resolving_not_issued no_instructions no_instructions_not_issued |
EXEC_DEPENDENCY |
short_scoreboard short_scoreboard_not_issued wait wait_not_issued |
MEMORY_DEPENDENCY |
long_scoreboard long_scoreboard_not_issued |
TEXTURE |
tex_throttle tex_throttle_not_issued |
SYNC |
barrier barrier_not_issued membar membar_not_issued |
CONSTANT_MEMORY_DEPENDENCY |
imc_miss imc_miss_not_issued |
PIPE_BUSY |
mio_throttle mio_throttle_not_issued math_pipe_throttle math_pipe_throttle_not_issued |
MEMORY_THROTTLE |
drain drain_not_issued lg_throttle lg_throttle_not_issued |
NOT_SELECTED |
not_selected not_selected_not_issued |
OTHER |
misc misc_not_issued dispatch_stall dispatch_stall_not_issued |
SLEEPING |
sleeping sleeping_not_issued |
对于 PC 采样 API,默认情况下会收集总计 (smsp__pcsamp_sample_count) 和丢弃 (smsp__pcsamp_samples_data_dropped) 的样本计数。
2.7.3. 数据结构映射表
下表列出了从 PC 采样活动 API 到 PC 采样 API 的数据结构映射。
PC 采样活动 API 结构 |
PC 采样 API 结构 |
|---|---|
CUpti_ActivityPCSamplingConfig |
CUpti_PCSamplingConfigurationInfo |
CUpti_ActivityPCSamplingStallReason |
CUpti_PCSamplingStallReason 请参阅 停顿原因映射表 |
CUpti_ActivityPCSampling3 |
CUpti_PCSamplingPCData |
CUpti_ActivityPCSamplingRecordInfo |
CUpti_PCSamplingData |
2.7.4. 数据刷新
CUPTI 客户端可以使用 API cuptiPCSamplingGetData() 定期刷新 GPU PC 采样数据。除了定期刷新 GPU PC 采样数据外,CUPTI 客户端还需要在以下时间点刷新 GPU PC 采样数据,以保持 PC 的唯一性
对于连续收集模式 CUPTI_PC_SAMPLING_COLLECTION_MODE_CONTINUOUS - 在每个模块加载-卸载-加载序列之后。
对于串行化收集模式 CUPTI_PC_SAMPLING_COLLECTION_MODE_KERNEL_SERIALIZED - 在每个 Kernel 完成之后。
对于使用配置选项 CUPTI_PC_SAMPLING_CONFIGURATION_ATTR_TYPE_ENABLE_START_STOP_CONTROL 的范围分析 - 在范围结束时,即在
cuptiPCSamplingStop()API 之后。
如果应用程序在禁用范围分析的连续收集模式下进行分析,并且没有模块卸载,则 CUPTI 客户端可以通过两种方式收集数据
通过定期使用
cuptiPCSamplingGetData()API。通过在应用程序退出时使用
cuptiPCSamplingDisable(),并从配置期间传递的采样数据缓冲区读取 GPU PC 采样数据。
注意
如果未定期调用 cuptiPCSamplingGetData() API,则配置期间传递的采样数据缓冲区应足够大,以容纳所有 PC 的数据。
注意
结构 CUpti_PCSamplingData 的字段 remainingNumPcs 有助于识别 CUPTI 中可用的 PC 记录数量。用户可以根据它调整定期刷新间隔。此外,用户需要确保所有剩余记录都可以容纳在配置期间传递的采样数据缓冲区中,然后再禁用 PC 采样。
2.7.5. SASS 源代码关联
构建 PC 的 SASS 源码关联可以分为两个部分
PC 与 SASS 指令的关联 - PC 到 SASS 的关联在 PC 采样期间运行时完成,SASS 数据在 PC 记录中可用。PC 记录中的字段
cubinCrc、pcOffset和functionName有助于将 PC 与 SASS 指令关联。您可以使用cuobjdump实用程序,通过执行命令cuobjdump -xelf all exe/lib从应用程序可执行文件或库中提取 cubin。cuobjump 实用程序版本应与用于构建 CUDA 应用程序可执行文件或库文件的 CUDA 工具包版本匹配。您可以使用cuptiGetCubinCrc()API 查找提取的 cubin 的 cubinCrc。借助 cubinCrc,您可以找出 PC 所属的 cubin。可以使用 CUDA 工具包附带的nvdisasm实用程序反汇编 cubin。SASS 指令与 CUDA 源代码行的关联 - 借助
cuptiGetSassToSourceCorrelation()API,可以离线以及在运行时完成 GPU PC 样本与 CUDA C 源代码行的关联。
JIT 编译的 cubin - 对于 JIT 编译的 cubin,无法从可执行文件或库中提取 cubin。对于这种情况,可以订阅 CUPTI_CBID_RESOURCE_MODULE_LOADED 或 CUPTI_CBID_RESOURCE_MODULE_UNLOAD_STARTING 或 CUPTI_CBID_RESOURCE_MODULE_PROFILED 回调之一。它返回一个包含 CUDA 二进制文件的 CUpti_ModuleResourceData 结构。此二进制文件可以存储在文件中,并可用于离线 CUDA C 源代码关联。
2.7.6. API 用法
这是一个伪代码,展示了如何收集特定 CPU 代码范围的 PC 采样数据
void Collection()
{
// Select collection mode
CUpti_PCSamplingConfigurationInfoParams pcSamplingConfigurationInfoParams = {};
CUpti_PCSamplingConfigurationInfo collectionMode = {};
collectionMode.attributeData.collectionModeData.collectionMode = CUPTI_PC_SAMPLING_COLLECTION_MODE_CONTINUOUS;
pcSamplingConfigurationInfoParams.numAttributes = 1;
pcSamplingConfigurationInfoParams.pPCSamplingConfigurationInfo = &collectionMode;
cuptiPCSamplingSetConfigurationAttribute(&pcSamplingConfigurationInfoParams);
// Select stall reasons to collect
{
// Get number of supported stall reasons
cuptiPCSamplingGetNumStallReasons();
// Get number of supported stall reason names and corresponding indexes
cuptiPCSamplingGetStallReasons();
// Set selected stall reasons
cuptiPCSamplingSetConfigurationAttribute();
}
// Select code range using start/stop APIs
// Opt-in for start and stop PC Sampling using APIs cuptiPCSamplingStart and cuptiPCSamplingStop
CUpti_PCSamplingConfigurationInfo enableStartStop = {};
enableStartStop.attributeType = CUPTI_PC_SAMPLING_CONFIGURATION_ATTR_TYPE_ENABLE_START_STOP_CONTROL;
enableStartStop.attributeData.enableStartStopControlData.enableStartStopControl = true;
pcSamplingConfigurationInfoParams.numAttributes = 1;
pcSamplingConfigurationInfoParams.pPCSamplingConfigurationInfo = &enableStartStop;
cuptiPCSamplingSetConfigurationAttribute(&pcSamplingConfigurationInfoParams);
// Enable PC Sampling
cuptiPCSamplingEnable();
kernelA <<<blocks, threads, 0, s0>>>(...); // KernelA is not sampled
// Start PC sampling collection
cuptiPCSamplingStart();
{
// KernelB and KernelC might run concurrently since 'continuous' sampling collection mode is selected
kernelB <<<blocks, threads, 0, s0>>>(...); // KernelB is sampled
kernelC <<<blocks, threads, 0, s1>>>(...); // KernelC is sampled
}
// Stop PC sampling collection
cuptiPCSamplingStop();
// Flush PC sampling data
cuptiPCSamplingGetData();
kernelD <<<blocks, threads, 0, s0>>>(...); // KernelD is not sampled
// Start PC sampling collection
cuptiPCSamplingStart();
{
kernelE <<<blocks, threads, 0, s0>>>(...); // KernelE is sampled
}
// Stop PC sampling collection
cuptiPCSamplingStop();
// Flush PC sampling data
cuptiPCSamplingGetData();
// Disable PC Sampling
cuptiPCSamplingDisable();
}
2.7.7. 局限性
已知局限性和问题
PC 采样 API 不支持在 GPU 上同时采样多个 CUDA 上下文。但是,支持在每个 GPU 上同时采样单个 CUDA 上下文。在同一 GPU 上的不同 CUDA 上下文上启用和配置 PC 采样之前,需要在另一个上下文中禁用 PC 采样。
2.8. CUPTI SASS 指标 API
SASS 指标 API 支持在 SASS 汇编指令级别收集指标数据。与 CUPTI 活动 API 相比,这些 API 支持更大的 SASS 指令级别指标集。可以查询每个 GPU 架构支持的 sass 指标集。这些 API 在 Volta 及更高版本的 GPU 架构(即计算能力 7.0 及更高的设备)上受支持。
这些 API 支持 SASS 指令到 CUDA C 源代码行的离线模式关联。因此,数据收集期间的运行时开销较低。
2.8.1. API 用法
枚举指标: 使用 API
cuptiSassMetricsGetNumOfMetrics()获取芯片支持的指标数量。然后分配CUpti_SassMetrics_MetricDetails类型的缓冲区,并将其传递给 APIcuptiSassMetricsGetMetrics(),CUPTI 将在其中列出所有 SASS 指标并将其放入用户分配的缓冲区中。创建配置镜像: 对于所有选定的 SASS 指标,创建
CUpti_SassMetrics_Config结构的列表。要为指标创建配置缓冲区,我们需要指标 ID 和指标的输出粒度。可以使用 APIcuptiSassMetricsGetProperties()查询指标 ID。输出粒度指示将在哪个级别收集数据。CUPTI 支持在三个级别进行收集 -CUPTI_SASS_METRICS_OUTPUT_GRANULARITY_GPU(在 GPU 级别),
CUPTI_SASS_METRICS_OUTPUT_GRANULARITY_SM(在流式多处理器级别,指标实例计数将是芯片中存在的 SM 数量),
CUPTI_SASS_METRICS_OUTPUT_GRANULARITY_SMSP(SM 子分区级别,实例数量将是芯片中存在的所有 SMSP 的总和,即 SM 数量 * 每个 SM 中的子分区数量)
为 CUDA 设备设置配置: API
cuptiSassMetricsSetConfig()应用于在设备上设置 SASS 指标收集的配置。此 API 接受设备索引和CUpti_SassMetrics_Config结构列表作为输入参数。然后为 Kernel 运行的设备设置配置,否则 CUPTI 将报告CUPTI_ERROR_INVALID_OPERATION错误。启用 SASS 指标分析: 为 CUDA 设备设置配置后,需要使用 API
cuptSassMetricsEnable()启用将在其上启动 Kernel 的上下文的 SASS 补丁。CUPTI 提供了对 Kernel 何时被打补丁的控制。对于延迟补丁模式,CUPTI 将仅在首次启动实例时为 Kernel 打补丁,然后在调用 APIcuptiSassMetricsDisable时取消 Kernel 补丁。否则,CUPTI 将为上下文中模块中的所有 Kernel 打补丁,无论 Kernel 是否会在启用/禁用范围内启动。设置enableLazyPatching标志以启用延迟补丁模式进行分析。延迟补丁适用于模块中具有大量 Kernel 且只启动少量 Kernel 的应用程序。刷新 SASS 指标分析数据: Kernel 执行完成后,指标数据以内部格式存储。需要查询缓冲区的大小以存储指标数据。API
cuptiSassMetricsGetDataProperties()可用于查询已打补丁指令的数量和硬件实例的数量。然后根据检索到的数据分配缓冲区,CUPTI 将在其中刷新分析的指标数据。要刷新数据,请调用 APIcuptiSassMetricsFlushData()。禁用 SASS 指标分析: Kernel 分析完成后,调用 API
cuptiSassMetricsDisable()以重置已打补丁的 Kernel 并删除为 Kernel 收集的所有分析指标数据。需要注意的一点是,CUPTI 将删除自上次调用 APIcuptiSassMetricsFlushData()以来为启动的 Kernel 收集的所有指标数据。因此,用户有责任调用刷新数据 API 以检索所有指标数据。在cuptiSassMetricsDisable()之后调用 APIcuptiSassMetricsFlushData()将报告错误CUPTI_ERROR_INVALID_OPERATION。取消 CUDA 设备的配置: CUPTI 为每个启用了 SASS 指标收集的 CUDA 设备维护内部状态。应调用 API
cuptiSassMetricsUnsetConfig()以清理状态。对于已配置 SASS 指标收集的每个设备,都应调用此 API。
2.8.2. 示例代码
CUPTI 示例 sass_metric 有两个核心函数 – 函数 ListSupportedMetrics() 展示了如何枚举芯片支持的所有指标,函数 CollectSassMetrics() 展示了如何收集 SASS 指标。用于枚举 SASS 指标的代码片段(请参阅 CUPTI sass_metric 示例中的 ListSupportedMetrics() 函数)
CUpti_Device_GetChipName_Params getChipParams{ CUpti_Device_GetChipName_Params_STRUCT_SIZE };
cuptiDeviceGetChipName(&getChipParams);
CUpti_SassMetrics_GetNumOfMetrics_Params getNumOfMetricParams;
getNumOfMetricParams.pChipName = getChipParams.pChipName;
cuptiSassMetricsGetNumOfMetrics(&getNumOfMetricParams);
std::vector<CUpti_SassMetrics_MetricDetails> supportedMetrics(getNumOfMetricParams.numOfMetrics);
CUpti_SassMetrics_GetMetrics_Params getMetricsParams {CUpti_SassMetrics_GetMetrics_Params_STRUCT_SIZE};
getMetricsParams.pChipName = getChipParams.pChipName;
getMetricsParams.pMetricsList = supportedMetrics.data();
getMetricsParams.numOfMetrics = supportedMetrics.size();
cuptiSassMetricsGetMetrics(&getMetricsParams);
for (size_t i = 0; i < supportedMetrics.size(); ++i)
{
std::cout << "Metric Name: " << supportedMetrics[i].pMetricName
<< ", MetricID: " << supportedMetrics[i].metricId
<< ", Metric Description: " << supportedMetrics[i].pMetricDescription << "\n";
}
用于收集 SASS 指标的代码片段(请参阅 CUPTI sass_metric 示例中的 CollectSassMetrics() 函数)
cuptiSassMetricsSetConfig();
// Enable SASS Patching
sassMetricsEnableParams.enableLazyPatching = 1;
cuptiSassMetricsEnable();
// As lazy patching has been enabled, VectorAdd will be patched here at the first launch instance
VectorAdd<<<gridSize, blockSize>>>();
cuptiSassMetricsGetDataProperties();
if (getDataPropParams.numOfInstances != 0 && getDataPropParams.numOfPatchedInstructionRecords != 0)
{
// allocate memory for getting patched data.
flushDataParams.numOfInstances = getDataPropParams.numOfInstances;
flushDataParams.numOfPatchedInstructionRecords = getDataPropParams.numOfPatchedInstructionRecords;
flushDataParams.pMetricsData =
(CUpti_SassMetrics_Data*)malloc(getDataPropParams.numOfPatchedInstructionRecords * sizeof(CUpti_SassMetrics_Data));
for (size_t recordIndex = 0;
recordIndex < getDataPropParams.numOfPatchedInstructionRecords;
++recordIndex)
{
flushDataParams.pMetricsData[recordIndex].pInstanceValues =
(CUpti_SassMetrics_InstanceValue*) malloc(getDataPropParams.numOfInstances * sizeof(CUpti_SassMetrics_InstanceValue));
}
cuptiSassMetricsFlushData();
// Store the data for post-processing the data (e.g. SASS to source correlation)
// Cleanup memory
}
// As this is the first VectorSub launch, the patching will be done here.
VectorSub<<<gridSize, blockSize>>>();
// As cuptiSassMetricsFlushData() API is not called, VectorSub SASS metric data will be discarded.
// All the kernels which were patched earlier will be reset to its original state.
cuptiSassMetricsDisable();
// VectorMultiply function will not get patched as it is called outside the enable/disable range.
VectorMultiply<<<gridSize, blockSize>>>();
cuptiSassMetricsUnsetConfig();
2.9. CUPTI PM 采样 API
在 CUDA 12.6 版本中,CUPTI 引入了新的 PM 采样 API,这些 API 包含在头文件 cupti_pmsampling.h 中,用于通过以固定间隔定期采样 GPU 的性能监视器 (PM) 来收集一组指标。每个样本都由指标值和收集时的 GPU 时间戳(以纳秒为单位)组成。
这些 API 在 Turing 及更高版本的 GPU 架构(即计算能力 7.5 及更高的设备)上受支持。
PM 采样遵循与范围分析类似的方法,其中该过程分为 2 种类型的操作,即主机(枚举、配置、评估)和目标(收集)。
2.9.1. API 用法
枚举指标(枚举)
CUPTI 发布了一组新的带有
cuptiProfilerHost前缀的主机 API,用户需要为所有主机操作创建一个分析器主机对象。对于 PM 采样特定的主机操作,用户需要在CUpti_Profiler_Host_Initialize_Params对象中将 profilerType 设置为CUPTI_PROFILER_TYPE_PM_SAMPLING。CUPTI 具有以下用于枚举指标及其属性的主机 API
cuptiProfilerHostGetBaseMetrics()用于列出指标类型(计数器、吞吐量和比率)的基本指标。cuptiProfilerHostGetSubMetrics()用于列出指标的子指标。cuptiProfilerHostGetMetricProperties()用于查询有关指标的详细信息,例如关联的硬件单元、指标类型和有关指标的简短描述。CUPTI 在 PM 采样指标表 中列出了一些有用的指标,这些指标可用于初始指标选择,其中列出了各种 GPU 及其组件属性,例如 SM 活动周期、GPC 和 SYS 时钟频率等等。
创建配置镜像(配置)
与范围分析器类似,为了收集 PM 采样数据,用户需要创建一个配置镜像 blob,其中将包含为收集而选择的指标的调度信息。由于配置是类似于枚举的主机操作,因此用户需要在调用任何配置 API 之前初始化分析器主机对象。
为了创建配置镜像,CUPTI 公开了新的分析器主机 API,例如
cuptiProfilerHostConfigAddMetrics()API,用户将在其中传递指标列表作为输入,然后调用cuptiProfilerHostGetConfigImageSize()API 以获取配置镜像的大小,用户需要分配该大小,最后调用cuptiProfilerHostGetConfigImage()API,用户可以在其中传递分配的缓冲区以将调度信息存储在配置镜像中。CUPTI 还添加了另一个可选 API,即
cuptiProfilerHostGetNumOfPasses(),用于检查收集给定配置镜像的采样数据所需的传递次数。注意
不支持需要多次传递才能收集采样数据的配置镜像。
收集采样数据(收集)
此操作指示 CUPTI 开始在 CUDA 设备上以特定间隔或周期收集采样数据,这些间隔或周期由
cuptiPmSamplingSetConfig()API 中指定的触发类型确定。收集阶段可以分为 6 个子部分
启用 PM 采样
这是 PM 采样过程的入口点,用户在其中传递将在其上收集采样数据的设备索引。使用
cuptiPmSamplingEnable()API 创建CUpti_PmSampling_Object对象。这存储所有中间数据,并充当其他目标 API 的标识符。设置配置
CUPTI 具有
cuptiPmSamplingSetConfig()API,用于自定义 PM 采样过程的配置,例如硬件缓冲区大小(原始采样数据将存储在该缓冲区中),采样间隔指定采样触发器将收集采样数据的频率。这将根据配置 API 中设置的触发模式而有所不同。除了这些参数外,用户还需要传递配置镜像,其中包含配置阶段早期创建的调度信息。没有缓冲区溢出事件的最大采样频率取决于 GPU(SM 计数)、GPU 负载强度和整体系统负载。芯片越大,负载越高,最大频率越低。如果需要更高的频率,您可以增加频率,直到出现溢出事件,该事件可以在使用
cuptiPmSamplingDecodeData()API 解码 pm 采样数据时查询。CUPTI 支持两种触发模式,
GPU_SYSCLK_INTERVAL基于系统时钟频率,采样间隔以时钟周期为单位。第二种是GPU_TIME_INTERVAL,它具有固定频率,间隔以纳秒为单位。注意
Turing 和 GA100 芯片不支持
GPU_TIME_INTERVAL触发器。启动 PM 采样
在启用并设置 PM 采样的配置后,用户需要调用
cuptiPmSamplingStart()API,该 API 向 CUPTI 发出信号以开始收集,原始采样数据将存储在硬件缓冲区中。停止 PM 采样
用户需要调用
cuptiPmSamplingStop()API 以停止采样数据的收集。解码 PM 采样数据
在收集阶段,所有原始采样数据都将存储在硬件缓冲区中。CUPTI 公开了
cuptiPmSamplingDecodeData()API,该 API 解码原始数据并将其存储在计数器数据镜像中,用户需要将计数器数据镜像作为输入传递到 API 中。有关创建计数器数据镜像的信息,请参阅此处。用户有责任调用此解码 API 以释放硬件缓冲区,以便允许新的原始数据存储在硬件缓冲区中。此 API 还输出一些属性,例如硬件缓冲区溢出状态、解码停止原因(例如所有原始数据结束或传递的计数器数据镜像已满)。因此,对于长时间运行的工作负载,用户可以在 Start 和 Stop API 之间调用此解码 API。理想的方法是在单独的线程中调用它。请参阅 pm_sampling 公共示例,该示例展示了解码操作与收集并行运行。
禁用 PM 采样
为了销毁为 PM 采样分配的所有资源并结束 PM 采样,用户可以调用
cuptiPmSamplingDisable()API。创建 Counter 数据映像
为了存储解码后的数据并在评估阶段使用它,用户需要分配一个缓冲区,CUPTI 将其称为计数器数据映像。创建计数器数据映像是一个目标操作,应在启用 PM 采样之后和调用解码 API 之前完成。为了创建计数器缓冲区映像,首先用户需要调用
cuptiPmSamplingGetCounterDataSize()API 来获取分配所需的缓冲区大小。一旦用户分配了缓冲区,该缓冲区需要是计数器数据格式,样本将存储在其中,因此为了初始化缓冲区,用户必须调用cuptiPmSamplingCounterDataImageInitialize()API。这个相同的 API 也可以用于重置计数器缓冲区映像。
评估 Counter 数据(评估)
一旦原始数据被解码到计数器缓冲区映像中,用户需要使用分析器主机 API 来评估计数器数据,以获取可读格式的样本数据。用户可以使用
cuptiPmSamplingGetCounterDataInfo()API 查询计数器数据中已完成的样本数量。对于 PM 采样,每个样本都由其开始和结束时间戳定义。为了获取样本信息,如开始和结束时间戳,CUPTI 提供了cuptiPmSamplingCounterDataGetSampleInfo()API。报告的时间戳是基于 CPU 的时间戳。然后,为了获取样本的收集指标值,使用cuptiProfilerHostEvaluateToGpuValues()API。
2.9.2. 示例代码
CUPTI 示例 pm_sampling 有两个核心函数 – 函数 PmSamplingQueryMetrics() 展示了如何枚举芯片支持的所有指标,函数 PmSamplingCollection() 展示了如何在启动 CUDA 工作负载时收集指标列表的 PM 采样数据。用于枚举支持的 PM 采样指标的代码片段(参考 CUPTI pm_sampling 示例中的 PmSamplingQueryMetrics() 函数)
CUpti_Device_GetChipName_Params getChipParams{ CUpti_Device_GetChipName_Params_STRUCT_SIZE };
cuptiDeviceGetChipName(&getChipParams);
CUpti_Profiler_Host_Initialize_Params hostInitializeParams = {CUpti_Profiler_Host_Initialize_Params_STRUCT_SIZE};
hostInitializeParams.profilerType = CUPTI_PROFILER_TYPE_PM_SAMPLING;
hostInitializeParams.pChipName = m_chipName.c_str();
hostInitializeParams.pCounterAvailabilityImage = counterAvailibilityImage.data();
cuptiProfilerHostInitialize(&hostInitializeParams);
m_pHostObject = hostInitializeParams.pHostObject;
for (size_t metricTypeIndex = 0; metricTypeIndex < CUPTI_METRIC_TYPE__COUNT; ++metricTypeIndex)
{
CUpti_Profiler_Host_GetBaseMetrics_Params getBaseMetricsParams {CUpti_Profiler_Host_GetBaseMetrics_Params_STRUCT_SIZE};
getBaseMetricsParams.pHostObject = m_pHostObject;
getBaseMetricsParams.metricType = (CUpti_MetricType)metricTypeIndex;
cuptiProfilerHostGetBaseMetrics(&getBaseMetricsParams);
for (size_t metricIndex = 0; metricIndex < getBaseMetricsParams.numMetrics; ++metricIndex) {
metricsList.push_back(getBaseMetricsParams.ppMetricNames[metricIndex]);
}
}
CUpti_Profiler_Host_Deinitialize_Params deinitializeParams = {CUpti_Profiler_Host_Deinitialize_Params_STRUCT_SIZE};
deinitializeParams.pHostObject = m_pHostObject;
cuptiProfilerHostDeinitialize(&deinitializeParams);
用于收集 PM 采样数据的代码片段(参考 CUPTI pm_sampling 示例中的 PmSamplingCollection() 函数)
void PmSamplingCollection()
{
// 1. Create config image
std::vector<uint8_t> configImage;
CreateConfigImage(configImage, metrics);
// 2. Enable PM sampling and set config for the PM sampling data collection.
EnablePmSampling(deviceIndex);
SetConfig(configImage, hardwareBufferSize, samplingInterval);
// 3. Create counter data image
std::vector<uint8_t> counterDataImage;
CreateCounterDataImage(maxSamples, metrics, counterDataImage);
VectorLaunchWorkLoad vectorWorkLoad;
vectorWorkLoad.SetUp();
// 4. Start the PM sampling and launch the CUDA workload
StartPmSampling();
// 5. Launch the kernel NUM_OF_ITERATIONS times
const size_t NUM_OF_ITERATIONS = 100000;
for (size_t ii = 0; ii < NUM_OF_ITERATIONS; ++ii)
{
vectorWorkLoad.LaunchKernel();
}
cudaDeviceSynchronize();
// 6. Stop the PM sampling and join the decode thread
StopPmSampling();
// 7. Decode PM Sampling Data
DecodeCounterData(counterDataImage);
// 8. Print the sample ranges for the collected metrics
PrintSampleRanges(counterDataImage);
// 9. Disable PM Sampling
DisablePmSampling();
}
// PrintSampleRanges function
void PrintSampleRanges(std::vector<uint8_t> counterDataImage)
{
CUpti_PmSampling_GetCounterDataInfo_Params counterDataInfo {CUpti_PmSampling_GetCounterDataInfo_Params_STRUCT_SIZE};
counterDataInfo.pCounterDataImage = counterDataImage.data();
counterDataInfo.counterDataImageSize = counterDataImage.size();
cuptiPmSamplingGetCounterDataInfo(&counterDataInfo);
for (size_t sampleIndex = 0; sampleIndex < counterDataInfo.numCompletedSamples; ++sampleIndex)
{
pmSamplingHost.EvaluateCounterData(sampleIndex, metricsList, counterDataImage);
}
// For reusing the counter data image, reset the counter data image
ResetCounterDataImage(counterDataImage);
}
2.9.3. 指标表
PM 采样支持收集各种各样的指标。下表列出了一些有用的指标,这些指标提供了对 GPU 中不同单元利用率的深入了解。
指标名称 |
指标详细信息 |
|---|---|
gpc__cycles_elapsed.avg.per_second |
GPC 时钟频率 平均 GPC 时钟频率,单位为赫兹。 |
sys__cycles_elapsed.avg.per_second |
SYS 时钟频率 平均 SYS 时钟频率,单位为赫兹。GPU 前端(命令处理器)、复制引擎和性能监视器在 SYS 时钟下运行。在 Turing 和 NVIDIA GA100 GPU 上,采样频率基于 SYS 时钟周期(而不是时间),因此每秒样本数将随 SYS 时钟而变化。在 NVIDIA GA10x GPU 上,采样频率基于固定频率时钟。最大频率与 SYS 时钟线性缩放。 |
gr__cycles_active.sum.pct_of_peak_sustained_elapsed |
GR 活动 计算引擎处于活动状态的周期百分比。如果计算管道中有任何工作,则计算引擎处于活动状态。 |
gr__dispatch_count.avg.pct_of_peak_sustained_elapsed |
调度启动 计算网格启动(调度)到计算管道的最大持续速率的比率。 |
tpc__warps_inactive_sm_active_realtime.avg.pct_of_peak_sustained_elapsed |
活动 SM 未使用 Warp 插槽 SM 上非活动 warp 插槽与每个 SM 的最大 warp 数的比率,以百分比表示。这表明如果占用率不受着色器类型的最大 warp 数、共享内存、每个线程的寄存器或每个 SM 的线程块等资源限制,则 SM 上可能容纳多少 warp。 |
tpc__warps_inactive_sm_idle_realtime.avg.pct_of_peak_sustained_elapsed |
空闲 SM 未使用 Warp 插槽 由于空闲 SM 导致的非活动 warp 插槽与每个 SM 的最大 warp 数的比率,以百分比表示。 这表明 SM 上的当前工作负载不足以将工作负载分配到所有 SM 上。这可能是由于 CPU 使 GPU 饥饿,当前工作太小而无法使 GPU 饱和,或者当前工作正在拖尾但阻止了下一个工作。 |
sm__cycles_active.avg.pct_of_peak_sustained_elapsed |
SM 活动 SM 至少有 1 个 warp 在飞行(在 SM 上分配)的周期数与周期数的比率,以百分比表示。值为 0 表示所有 SM 都处于空闲状态(没有 warp 在飞行)。值为 50% 可能表示所有 SM 在样本期间 50% 的时间内处于活动状态,或者 50% 的 SM 在样本期间 100% 的时间内处于活动状态之间的某种梯度。 |
sm__inst_executed_realtime.avg.pct_of_peak_sustained_elapsed |
SM 发射 SM 子分区(warp 调度器)发出指令的周期数与样本期间周期数的比率,以百分比表示。 |
sm__pipe_tensor_cycles_active_realtime.avg.pct_of_peak_sustained_elapsed |
Tensor 活动 SM tensor 管道处于活动状态,发出 tensor 指令的周期数与样本期间周期数的比率,以百分比表示。 此指标在 Turing GPU 上不适用于周期性采样。 |
sm__pipe_shared_cycles_active_realtime.avg.pct_of_peak_sustained_elapsed |
Tensor 活动 / FP16 活动 SM tensor 管道或 FP16x2 管道处于活动状态,发出 tensor 指令的周期数与样本期间周期数的比率,以百分比表示。 此指标仅适用于 Turing GPU 的周期性采样。 |
dramc__read_throughput.avg.pct_of_peak_sustained_elapsed |
DRAM 读取带宽 DRAM 接口处于活动状态读取数据的周期数与同一期间经过的周期数的比率,以百分比表示。 |
dramc__write_throughput.avg.pct_of_peak_sustained_elapsed |
DRAM 写入带宽 DRAM 接口处于活动状态写入数据的周期数与同一期间经过的周期数的比率,以百分比表示。 |
pcie__read_bytes.avg.pct_of_peak_sustained_elapsed |
PCIe 读取吞吐量 在 PCIe 接口上接收的字节数与样本期间可接收的最大字节数的比率,以百分比表示。理论值是根据 PCIe 代数和通道数计算得出的。 |
pcie__write_bytes.avg.pct_of_peak_sustained_elapsed |
PCIe 写入吞吐量 在 PCIe 接口上发送的字节数与样本期间可接收的最大字节数的比率,以百分比表示。理论值是根据 PCIe 代数和通道数计算得出的。 |
nvlrx__bytes.avg.pct_of_peak_sustained_elapsed |
NVLink 接收的字节数 在 NVLink 接口上接收的字节数与样本期间可接收的最大字节数的比率,以百分比表示。 |
nvltx__bytes.avg.pct_of_peak_sustained_elapsed |
NVLink 发送的字节数 在 NVLink 接口上发送的字节数与样本期间可发送的最大字节数的比率,以百分比表示。 |
pcie__rx_requests_aperture_bar1_op_read.sum pcie__rx_requests_aperture_bar1_op_write.sum |
PCIe 到 BAR1 的读取/写入请求 BAR1 是一个 PCI Express (PCIe) 接口,用于允许 CPU 或其他设备直接访问 GPU 内存。GPU 通常使用其复制引擎传输内存,这不会显示为 BAR1 活动。CPU 上的 GPU 驱动程序会进行少量 BAR1 访问,但更重的流量通常来自其他技术。 |
2.10. CUPTI Checkpoint API
从 CUDA 11.5 开始,CUPTI 附带了一个新的库,以协助希望在直接控制下重放内核的工具开发人员,例如使用 Profiling API User Replay 模式的工具。这个新的 Checkpoint 库为许多常见用途提供了自动保存和恢复设备状态的支持。
设备检查点是设备功能状态的托管副本 - 包括内存中的值,以及设备的一些(但不是全部)其他用户可见状态。当保存检查点时,此状态将保存到内部缓冲区,优先使用空闲设备空间,然后是主机空间,最后是文件系统空间来保存数据。用户工具维护检查点的句柄,并且能够通过单个调用恢复检查点,从而恢复状态,以便内核可以重新执行并期望具有与保存检查点时相同的设备状态。
一旦保存,检查点可以随时恢复,包括在启动多个内核之后,尽管目前对于在 Save 和 Restore 之间已验证可以工作的用户调用(CUDA 或驱动程序 API 调用)存在限制。目前已知在恢复检查点之前,在上下文中启动多个内核和执行 memcpy 调用是安全的。未来版本的 CUPTI 将扩展此功能,以支持在 Save 和 Restore 之间进行额外的 API 调用。
检查点可以在注入的内核启动回调期间保存,也可以直接编码到目标应用程序中。
某些 API 已知与 CUPTI 11.5 附带的 Checkpoint API 版本不兼容,包括流捕获模式。
2.10.1. 用法
该库有一个头文件 cupti_checkpoint.h,需要包含它,并且 libcheckpoint 需要链接到应用程序或注入库中。尽管 checkpoint 库不依赖于 cupti,但 API 返回的错误代码与 cupti 共享,因此需要链接 libcupti 以将返回代码转换为字符串表示形式。
Checkpoint API 遵循与其他 CUPTI API 类似的设计。API 行为通过结构 CUpti_Checkpoint 控制,该结构由工具或应用程序初始化,然后传递给 cuptiCheckpointSave。如果调用成功,该结构将保存检查点的句柄。此时,应用程序可以进行一系列修改设备状态的调用(更新内存的内核、内存复制等),当应恢复设备状态时,工具可以在调用 cuptiCheckpointRestore 中使用相同的结构,最后调用 cuptiCheckpointFree 以释放检查点对象使用的资源。
可以同时保存多个检查点。如果存在多个检查点,它们将完全独立地运行 - 每个检查点都消耗恢复保存时设备状态所需的全部资源。API 不强制执行多个检查点之间的操作顺序 - 虽然多个检查点的常见用途可能是嵌套模式,但也可以交错检查点操作。
在 cuptiCheckpointSave 和 cuptiCheckpointRestore 之间,可以进行任意数量的标准内核启动(或等效的 API 调用,如 cuLaunchKernel)或 memcpy 调用。此外,可以进行任何不影响设备状态的主机 (cpu) 端调用。可以进行其他 CUDA 或驱动程序 API 调用,但尚未在 11.5 版本中进行验证。
CUpti_Checkpoint 结构中存在几个选项。它们必须在使用该结构的初始 cuptiCheckpointSave 之前设置。对结构的任何进一步更改都将被忽略,直到调用 cuptiCheckpointFree 之后,此时可以重新配置和重复使用该结构。
每个检查点的重要选项
structSize- 必须设置为CUpti_Checkpoint_STRUCT_SIZE的值ctx- 如果为 NULL,则检查点将是默认 CUDA 上下文的检查点,否则,指定上下文reserveDeviceMB- 限制检查点保存至少使用这么多设备内存reserveHostMB- 限制检查点保存至少使用这么多主机内存allowOverwrite- 通常,使用现有检查点句柄(尚未 Free 的句柄)调用 Save 是错误的。设置此选项后,允许在句柄上多次调用 Save 操作。请注意,使用此选项时,不会在任何后续 Save 上重新读取CUpti_Checkpoint选项。要读取新选项,句柄必须在cuptiCheckpointSave调用之前传递给cuptiCheckpointFree。optimizations- 检查点行为的选项位掩码CUPTI_CHECKPOINT_OPT_TRANSFER- 通常,在恢复检查点时,将恢复保存时所有现有的设备内存。此优化添加了一个测试,以查看内存块是否已更改,然后再恢复它,并将结果缓存以供后续调用 Restore 使用。使用此选项需要所有 Restore 调用在应用程序中的给定检查点的同一点完成。由于优化在计算上可能很昂贵,因此当有大量数据可以跳过并且将多次调用 Restore 检查点时,它最有用。
2.10.2. 限制
在流捕获期间可能无法进行 Checkpoint API 调用。它们也可能无法插入到图中。除了内核启动 (cuLaunchKernel、标准 kernel<<<>>> 启动等) 和 memcpy 调用之外,其余的 CUDA 和驱动程序 API 调用尚未在 Checkpoint Save 和 Restore 区域内进行验证。任何其他 CUDA 或驱动程序 API 调用(例如 - 设备 malloc 或 free)可能有效,也可能导致不确定的行为。未来的版本中将验证更多 API 以与 Checkpoint API 一起工作。
Checkpoint API 无法了解在 cuptiCheckpointSave 和 cuptiCheckpointRestore 调用之间进行了哪些 API 调用,并且如果进行了不受支持的调用,可能无法正确检测到错误情况。在这种情况下,设备状态可能仅由 cuptiCheckpointRestore 部分恢复,这可能会在后续设备调用中导致功能不正确的行为。
Checkpoint API 仅恢复功能可见的设备状态,而不是性能关键状态。某些性能特征(例如缓存状态)不会被检查点保存,并且保存或恢复检查点可能会更改占用率并改变后续设备调用的性能。
Checkpoint API 不会尝试恢复主机(非设备)状态,除了在调用 cuptiCheckpointFree 期间释放其内部使用的资源之外。
Checkpoint API 默认使用设备内存、主机内存,最后使用文件系统来备份设备状态。可能添加 cuptiCheckpointSave 会导致稍后的设备分配由于设备内存使用量增加而失败。(类似地,也使用主机内存,并且可能受到检查点的影响)。为了允许用户保证一定数量的设备或主机内存保持可用以供以后使用,可以设置 CUpti_Checkpoint 结构中的 reserveDeviceMB 和 reserveHostMB 字段。使用这些字段将保证设备或主机内存将在 cuptiCheckpointSave 调用期间留下那么多可用内存,但可能会由于更多地使用较慢的存储空间而导致 Checkpoint API 调用性能下降。
2.10.3. 示例
Checkpoint API 不需要任何其他 CUPTI 调用。一个简单的用例可能是比较内核的三个不同实现的输出。此示例的伪代码可能如下所示
CUpti_Checkpoint cp = { CUpti_Checkpoint_STRUCT_SIZE };
int kernel = 0;
do
{
if (kernel == 0)
cuptiCheckpointSave(&cp);
else
cuptiCheckpointRestore(&cp);
if (kernel == 0)
kernel_1<<<>>>(...);
else if (kernel == 1)
kernel_2<<<>>>(...);
else if (kernel == 2)
kernel_3<<<>>>(...);
} while (kernel++ < 3);
cuptiCheckpointFree(&cp);
在此示例中,即使任何内核修改了它们自己的输入数据,通过循环的后续传递仍然可以正确运行 - 修改后的输入数据仍将通过每次调用 cuptiCheckpointRestore 在下一个内核运行之前恢复。当程序员不知道内核调用之前的设备确切状态时,这尤其有用 - Checkpoint API 确保所有需要的数据都被保存和恢复,否则在某些复杂情况下这将是不切实际的,甚至是不可能的。
另一个可能的用例可能是用于模糊测试 - 随机修改内核的输入,并确保其按预期执行。Checkpoint API 可以初始化一个良好的状态,而不是手动将设备状态恢复到已知的良好点,并且模糊器可以仅修改所需的内容。
CUpti_Checkpoint cp = { CUpti_Checkpoint_STRUCT_SIZE };
int i = 0;
do
{
if (i == 0)
cuptiCheckpointSave(&cp);
else
cuptiCheckpointRestore(&cp);
setup_test<<<>>>(i, ...);
kernel<<<>>>(...);
validate_result<<<>>>(i, ...);
} while (i++ < num_tests);
cuptiCheckpointFree(&cp);
最后,Checkpoint API 对于 CUPTI Profiling API 的 User Replay 模式非常有用。User Replay 模式可能非常理想,因为它允许内核并发运行,而 Kernel Replay 模式则不允许,并且只重放性能区域内的应用程序部分,这与 Applicatin Replay 模式不同。但是,在这种模式下,内核可能需要多次启动才能收集所有请求的指标。当内核可能修改其自身的某些输入数据时,这会变得很复杂,并且如果没有 Checkpoint API,则需要工具开发人员手动处理恢复任何修改后的输入数据。工具很难自动知道在每次迭代之前是否需要恢复任何数据,甚至设备现有状态是什么。使用 Checkpoint API,工具可以保证输入数据将在每次传递时恢复。
CUpti_Checkpoint cp = { CUpti_Checkpoint_STRUCT_SIZE };
// Pseudocode - assume all Profiling API structures are already initialized correctly
cuptiProfilerBeginSession(&beginSessionParams);
cuptiProfilerSetConfig(&setConfigParams);
int numPasses = 0;
bool lastPass = false;
do
{
if (numPasses == 0)
cuptiCheckpointSave(&cp);
else
cuptiCheckpointRestore(&cp);
cuptiProfilerBeginPass(&beginPassParams);
cuptiProfilerEnableProfiling(&enableProfilingParams);
cuptiProfilerPushRange(&pushRangeParams);
// Kernel launch on N separate streams - will be profiled while running concurrently
kernel<<<..., stream0>>>(...);
kernel<<<..., stream1>>>(...);
...
kernel<<<..., streamN>>>(...);
cudaStreamSynchronize(stream0);
cudaStreamSynchronize(stream1);
...
cudaStreamSynchronize(streamN);
cuptiProfilerPopRange(&popRangeParams);
cuptiProfilerDisableProfiling(&disableProfilingParams);
lastPass = cuptiProfilerEndPass(&endPassParams);
} while (lastPass == false);
cuptiProfilerFlushCounterData(&flushCounterDataParams);
cuptiProfilerUnsetConfig(&unsetConfigParams);
cuptiProfilerEndSession(&endSessionParams);
在此示例中,分析器范围将跨越所有并发运行的内核,这些内核可能会修改它们自己的输入数据 - 每次通过循环都将恢复初始值。
2.11. CUPTI Profiling API
从 CUDA 10.0 开始,为计算能力为 7.0 及更高版本的设备添加了一组新的指标 API。这些 API 在目标系统上提供低且确定性的分析开销。这些 API 在除 Android 以外的所有 CUDA 支持的平台上都受支持,并且在 MPS(多进程服务)、机密计算或 SLI 配置的系统下不受支持。为了确定设备是否与此 API 兼容,CUDA 11.5 中引入了一个新函数 cuptiProfilerDeviceSupported,它公开了整体 Profiling API 支持以及给定设备的特定要求。Profiling API 必须通过调用 cuptiProfilerInitialize 初始化,然后才能测试设备支持。
本节介绍用于 CUDA 的性能分析主机和目标 API。广义上,分析 API 分为以下四个部分
枚举(主机)
配置(主机)
收集(目标)
评估(主机)
主机 API 为枚举、配置和评估提供了一个 指标 接口,该接口不需要计算 (GPU) 设备,并且也可以在离线模式下运行。在 扩展 下的示例部分中,分析器主机实用程序涵盖了主机 API 的用法。目标 API 用于指标的数据收集,并且需要计算 (GPU) 设备。有关分析 API 的用法,请参阅示例 auto_rangeProfiling 和 userrange_profiling。
指标列表已从早期代的指标和事件 API 进行了修改,以支持基于 unit__(subunit?)_(pipestage?)_quantity_qualifiers 的标准命名约定
注意
在 CUDA 12.6 版本中,CUPTI 引入了一组新的目标 API CUPTI Range Profiling API 和主机 API CUPTI Profiler Host API。对于分析,强烈建议用户,尤其是那些刚接触该领域的用户,使用这些新的主机和目标 API。现有的 Profiling API 可能会被弃用,并可能在未来的版本中删除。
2.11.1. 多轮次收集
NVIDIA GPU 硬件的计数器寄存器数量有限,无法同时收集所有可能的计数器。对于哪些计数器可以在单个 轮次 中一起收集,也存在限制。这可以通过多次重放完全相同的 GPU 工作负载来解决,其中每次重放都称为一个 轮次。在每个轮次中,收集请求的计数器的不同子集。一旦收集了所有轮次,数据就可以用于评估。某些指标有许多计数器作为输入;添加单个指标可能需要多个轮次才能收集。CUPTI API 通过不同的收集属性支持多轮次收集。
示例 cupti_metric_properties 展示了如何查询收集一组计数器所需的轮次数。
2.11.2. 范围分析
每个分析会话运行一系列重放轮次,其中每个轮次包含一系列范围。会话配置中启用的每个指标都会在轮次中为每个唯一的范围堆栈单独收集。CUPTI 支持自动和用户定义的范围。
2.11.2.1. 自动范围
在具有自动范围模式的会话中,范围在每个内核周围自动定义,并在启用分析时为每个范围分配唯一的名称。此模式对于围绕每个内核的严格指标收集非常有用。用户可以选择一种受支持的重放模式,下面描述了每种模式的伪代码
内核重放
重放逻辑(如果需要,多轮次)由 CUPTI 隐式完成(对用户不透明),并且在此模式下,CUPTI 重放 API cuptiProfilerBeginPass 和 cuptiProfilerEndPass 的使用将是空操作。此模式对于严格控制下收集内核周围的指标非常有用。每个内核启动都同步以将其指标隔离到单独的范围中,并进行 CPU-GPU 同步以确保从 GPU 收集分析数据。可以使用 cuptiProfilerEnableProfiling 和 cuptiProfilerDisableProfiling 启用和禁用计数器收集。请参阅示例 autorange_profiling
/* Assume Inputs(counterDataImagePrefix and configImage) from configuration phase at host */
void Collection(std::vector<uint8_t>& counterDataImagePrefix, std::vector<uint8_t>& configImage)
{
CUpti_Profiler_Initialize_Params profilerInitializeParams = { CUpti_Profiler_Initialize_Params_STRUCT_SIZE };
cuptiProfilerInitialize(&profilerInitializeParams);
std::vector<uint8_t> counterDataImages;
std::vector<uint8_t> counterDataScratchBuffer;
CreateCounterDataImage(counterDataImages, counterDataScratchBuffer, counterDataImagePrefix);
CUpti_Profiler_BeginSession_Params beginSessionParams = { CUpti_Profiler_BeginSession_Params_STRUCT_SIZE };
CUpti_ProfilerRange profilerRange = CUPTI_AutoRange;
CUpti_ProfilerReplayMode profilerReplayMode = CUPTI_KernelReplay;
beginSessionParams.ctx = NULL;
beginSessionParams.counterDataImageSize = counterDataImage.size();
beginSessionParams.pCounterDataImage = &counterDataImage[0];
beginSessionParams.counterDataScratchBufferSize = counterDataScratchBuffer.size();
beginSessionParams.pCounterDataScratchBuffer = &counterDataScratchBuffer[0];
beginSessionParams.range = profilerRange;
beginSessionParams.replayMode = profilerReplayMode;
beginSessionParams.maxRangesPerPass = num_ranges;
beginSessionParams.maxLaunchesPerPass = num_ranges;
cuptiProfilerBeginSession(&beginSessionParams));
CUpti_Profiler_SetConfig_Params setConfigParams = { CUpti_Profiler_SetConfig_Params_STRUCT_SIZE };
setConfigParams.pConfig = &configImage[0];
setConfigParams.configSize = configImage.size();
cuptiProfilerSetConfig(&setConfigParams));
kernelA <<<grid, tids >>>(...); // KernelA not profiled
CUpti_Profiler_EnableProfiling_Params enableProfilingParams = { CUpti_Profiler_EnableProfiling_Params_STRUCT_SIZE };
cuptiProfilerEnableProfiling(&enableProfilingParams);
{
kernelB <<<grid, tids >>>(...); // KernelB profiled and captured in an unique range.
kernelC <<<grid, tids >>>(...); // KernelC profiled and captured in an unique range.
kernelD <<<grid, tids >>>(...); // KernelD profiled and captured in an unique range.
}
CUpti_Profiler_DisableProfiling_Params disableProfilingParams = { CUpti_Profiler_DisableProfiling_Params_STRUCT_SIZE };
cuptiProfilerDisableProfiling(&disableProfilingParams);
kernelE <<<grid, tids >>>(...); // KernelE not profiled
CUpti_Profiler_UnsetConfig_Params unsetConfigParams = { CUpti_Profiler_UnsetConfig_Params_STRUCT_SIZE };
cuptiProfilerUnsetConfig(&unsetConfigParams);
CUpti_Profiler_EndSession_Params endSessionParams = { CUpti_Profiler_EndSession_Params_STRUCT_SIZE };
cuptiProfilerEndSession(&endSessionParams);
}
用户重放
重放(如果需要,多轮次)由用户使用重放 API cuptiProfilerBeginPass 和 cuptiProfilerEndPass 完成。用户有责任在结束会话之前刷新计数器数据 cuptiProfilerFlushCounterData,以确保在 CPU 中收集指标数据。可以使用 cuptiProfilerEnableProfiling/ cuptiProfilerDisableProfiling 启用/禁用计数器收集。请参阅示例 autorange_profiling
/* Assume Inputs(counterDataImagePrefix and configImage) from configuration phase at host */
void Collection(std::vector<uint8_t>& counterDataImagePrefix, std::vector<uint8_t>& configImage)
{
CUpti_Profiler_Initialize_Params profilerInitializeParams = {CUpti_Profiler_Initialize_Params_STRUCT_SIZE};
cuptiProfilerInitialize(&profilerInitializeParams);
std::vector<uint8_t> counterDataImages;
std::vector<uint8_t> counterDataScratchBuffer;
CreateCounterDataImage(counterDataImages, counterDataScratchBuffer, counterDataImagePrefix);
CUpti_Profiler_BeginSession_Params beginSessionParams = {CUpti_Profiler_BeginSession_Params_STRUCT_SIZE};
CUpti_ProfilerRange profilerRange = CUPTI_AutoRange;
CUpti_ProfilerReplayMode profilerReplayMode = CUPTI_UserReplay;
beginSessionParams.ctx = NULL;
beginSessionParams.counterDataImageSize = counterDataImage.size();
beginSessionParams.pCounterDataImage = &counterDataImage[0];
beginSessionParams.counterDataScratchBufferSize = counterDataScratchBuffer.size();
beginSessionParams.pCounterDataScratchBuffer = &counterDataScratchBuffer[0];
beginSessionParams.range = profilerRange;
beginSessionParams.replayMode = profilerReplayMode;
beginSessionParams.maxRangesPerPass = num_ranges;
beginSessionParams.maxLaunchesPerPass = num_ranges;
cuptiProfilerBeginSession(&beginSessionParams));
CUpti_Profiler_SetConfig_Params setConfigParams = {CUpti_Profiler_SetConfig_Params_STRUCT_SIZE};
setConfigParams.pConfig = &configImage[0];
setConfigParams.configSize = configImage.size();
cuptiProfilerSetConfig(&setConfigParams));
CUpti_Profiler_FlushCounterData_Params cuptiFlushCounterDataParams = {CUpti_Profiler_FlushCounterData_Params_STRUCT_SIZE};
CUpti_Profiler_EnableProfiling_Params enableProfilingParams = {CUpti_Profiler_EnableProfiling_Params_STRUCT_SIZE};
CUpti_Profiler_DisableProfiling_Params disableProfilingParams = {CUpti_Profiler_DisableProfiling_Params_STRUCT_SIZE};
kernelA<<<grid, tids>>>(...); // KernelA neither profiled, nor replayed
CUpti_Profiler_BeginPass_Params beginPassParams = {CUpti_Profiler_BeginPass_Params_STRUCT_SIZE};
CUpti_Profiler_EndPass_Params endPassParams = {CUpti_Profiler_EndPass_Params_STRUCT_SIZE};
cuptiProfilerBeginPass(&beginPassParams);
{
kernelB<<<grid, tids>>>(...); // KernelB replayed but not profiled
cuptiProfilerEnableProfiling(&enableProfilingParams);
kernelC<<<grid, tids>>>(...); // KernelC profiled and captured in an unique range.
kernelD<<<grid, tids>>>(...); // KernelD profiled and captured in an unique range.
cuptiProfilerDisableProfiling(&disableProfilingParams);
}
cuptiProfilerEndPass(&endPassParams);
cuptiProfilerFlushCounterData(&cuptiFlushCounterDataParams);
kernelE<<<grid, tids>>>(...); // KernelE not profiled
CUpti_Profiler_UnsetConfig_Params unsetConfigParams = {CUpti_Profiler_UnsetConfig_Params_STRUCT_SIZE};
cuptiProfilerUnsetConfig(&unsetConfigParams);
CUpti_Profiler_EndSession_Params endSessionParams = {CUpti_Profiler_EndSession_Params_STRUCT_SIZE};
cuptiProfilerEndSession(&endSessionParams);
}
应用程序重放
此重放模式与用户重放模式相同,您可以重放整个进程,而不是进程内重放。您需要在设置配置 cuptiProfilerSetConfig 时更新轮次索引,并在每个轮次中重新加载中间 counterDataImage。
2.11.2.2. 用户范围
在具有用户范围模式的会话中,范围由您定义,cuptiProfilerPushRange 和 cuptiProfilerPopRange。内核启动在范围内是并发的。此模式对于围绕特定代码段收集指标数据非常有用,而不是每个内核的指标收集。用户范围模式不支持内核重放。您拥有使用 cuptiProfilerBeginPass 和 cuptiProfilerEndPass 进行重放的责任。
用户重放
重放(如果需要,多轮次)由用户使用重放 API cuptiProfilerBeginPass 和 cuptiProfilerEndPass 完成。您有责任在结束会话之前使用 cuptiProfilerFlushCounterData 刷新计数器数据。可以使用 cuptiProfilerEnableProfiling 和 cuptiProfilerDisableProfiling 启用/禁用计数器收集。请参阅示例 userrange_profiling
/* Assume Inputs(counterDataImagePrefix and configImage) from configuration phase at host */
void Collection(std::vector<uint8_t>& counterDataImagePrefix, std::vector<uint8_t>& configImage)
{
CUpti_Profiler_Initialize_Params profilerInitializeParams = {CUpti_Profiler_Initialize_Params_STRUCT_SIZE};
cuptiProfilerInitialize(&profilerInitializeParams);
std::vector<uint8_t> counterDataImages;
std::vector<uint8_t> counterDataScratchBuffer;
CreateCounterDataImage(counterDataImages, counterDataScratchBuffer, counterDataImagePrefix);
CUpti_Profiler_BeginSession_Params beginSessionParams = {CUpti_Profiler_BeginSession_Params_STRUCT_SIZE};
CUpti_ProfilerRange profilerRange = CUPTI_UserRange;
CUpti_ProfilerReplayMode profilerReplayMode = CUPTI_UserReplay;
beginSessionParams.ctx = NULL;
beginSessionParams.counterDataImageSize = counterDataImage.size();
beginSessionParams.pCounterDataImage = &counterDataImage[0];
beginSessionParams.counterDataScratchBufferSize = counterDataScratchBuffer.size();
beginSessionParams.pCounterDataScratchBuffer = &counterDataScratchBuffer[0];
beginSessionParams.range = profilerRange;
beginSessionParams.replayMode = profilerReplayMode;
beginSessionParams.maxRangesPerPass = num_ranges;
beginSessionParams.maxLaunchesPerPass = num_ranges;
cuptiProfilerBeginSession(&beginSessionParams));
CUpti_Profiler_SetConfig_Params setConfigParams = {CUpti_Profiler_SetConfig_Params_STRUCT_SIZE};
setConfigParams.pConfig = &configImage[0];
setConfigParams.configSize = configImage.size();
cuptiProfilerSetConfig(&setConfigParams));
CUpti_Profiler_FlushCounterData_Params cuptiFlushCounterDataParams = {CUpti_Profiler_FlushCounterData_Params_STRUCT_SIZE};
kernelA<<<grid, tids>>>(...); // KernelA neither profiled, nor replayed
CUpti_Profiler_BeginPass_Params beginPassParams = {CUpti_Profiler_BeginPass_Params_STRUCT_SIZE};
CUpti_Profiler_EndPass_Params endPassParams = {CUpti_Profiler_EndPass_Params_STRUCT_SIZE};
cuptiProfilerBeginPass(&beginPassParams);
{
kernelB<<<grid, tids>>>(...); // KernelB replayed but not profiled
CUpti_Profiler_PushRange_Params enableProfilingParams = {CUpti_Profiler_PushRange_Params_STRUCT_SIZE};
pushRangeParams.pRangeName = "RangeA";
cuptiProfilerPushRange(&pushRangeParams);
kernelC<<<grid, tids>>>(...);
kernelD<<<grid, tids>>>(...);
cuptiProfilerPopRange(&popRangeParams); // Kernel C and Kernel D are captured in rangeA without any serialization introduced by profiler
}
cuptiProfilerEndPass(&endPassParams);
cuptiProfilerFlushCounterData(&cuptiFlushCounterDataParams);
kernelE<<<grid, tids>>>(...); // KernelE not Profiled
CUpti_Profiler_UnsetConfig_Params unsetConfigParams = {CUpti_Profiler_UnsetConfig_Params_STRUCT_SIZE};
cuptiProfilerUnsetConfig(&unsetConfigParams);
CUpti_Profiler_EndSession_Params endSessionParams = {CUpti_Profiler_EndSession_Params_STRUCT_SIZE};
cuptiProfilerEndSession(&endSessionParams);
}
应用程序重放
此重放模式与用户重放模式相同,您可以重放整个进程,而不是进程内重放。您需要在使用 cuptiProfilerSetConfig API 设置配置时更新轮次索引,并在每个轮次中重新加载中间 counterDataImage。
2.11.3. CUPTI 分析器定义
本节中使用的术语表的定义。
- CounterData 映像
包含收集的计数器值的 Blob
- CounterData 前缀
CounterData 映像的元数据标头
- 设备
物理 NVIDIA GPU。
- 事件
事件是设备上可计数的活动、动作或发生的事情。
- 指标
从计数器值派生的高级值。
- 轮次
一组可重复的操作,带有标记一致的范围。
- 范围
执行的标记区域
- 重放
执行可重复的操作集。
- 会话
一个分析会话,其中分配了分析所需的 GPU 资源。分析器在会话边界处于准备就绪状态,并且可能在会话边界禁用电源管理。在会话之外,GPU 将恢复到其正常运行状态。
2.11.4. 与事件和指标 API 的区别
以下是事件和指标 API 支持但 Profiling API 不支持的功能列表
2.12. Perfworks 指标 API
简介
Perfworks 指标 API 支持指标的枚举、配置和评估。配置阶段的二进制输出是 CUPTI Profiling API 的 Range API 的输入。范围分析的输出是 CounterData,它被传递到派生指标评估 API。
GPU 指标通常表示为计数、比率和百分比。从硬件收集的底层值是原始计数器(类似于 CUPTI 事件),但这些细节隐藏在派生指标公式之后。
指标 API 分为两层:派生指标和原始指标。派生指标包含命名指标列表并执行评估以获得数值结果,其作用与之前的 CUPTI 指标 API 类似。大多数用户交互将使用派生指标。原始指标包含原始计数器列表,并生成类似于之前的 CUPTI 事件 API 的配置文件镜像。
指标枚举
指标枚举是列出可用计数器和指标的过程。
请参阅 List.cpp 文件,该文件由 cupti_metric_properties 示例使用。
指标分为三种类型,即计数器、比率和吞吐量。除了比率指标类型外,每个指标还具有四种子指标类型,也称为汇总指标,即总和、平均值、最小值、最大值。
为了枚举芯片支持的指标,我们需要计算主机操作所需的暂存缓冲区,并初始化指标评估器。
调用
NVPW_CUDA_MetricsEvaluator_CalculateScratchBufferSize以计算分配主机操作内存所需的暂存缓冲区大小。调用
NVPW_CUDA_MetricsEvaluator_Initialize以初始化指标评估器,该评估器创建一个 NVPW_MetricsEvaluator 对象。
用于枚举芯片支持的计数器指标的outline
调用
NVPW_MetricsEvaluator_GetMetricNames以获取 NVPW_METRIC_TYPE_COUNTER 指标类型,以列出所有支持的计数器指标。调用
NVPW_MetricsEvaluator_GetSupportedSubmetrics以列出 NVPW_METRIC_TYPE_COUNTER 指标类型支持的所有子指标。调用
NVPW_MetricsEvaluator_GetCounterProperties以提供计数器的描述和收集硬件单元。
类似地,为了枚举比率和吞吐量指标,我们需要将 NVPW_METRIC_TYPE_RATIO 和 NVPW_METRIC_TYPE_THROUGHPUT 作为指标类型传递给 NVPW_MetricsEvaluator_GetMetricNames 和 NVPW_MetricsEvaluator_GetSupportedSubmetrics。
有关指标属性的更多详细信息,请分别调用 NVPW_MetricsEvaluator_GetRatioMetricProperties 和 NVPW_MetricsEvaluator_GetThroughputMetricProperties。
配置工作流程
配置是指定将要收集的指标以及应如何收集这些指标的过程。此阶段的输入是指标名称和指标收集属性。此阶段的输出是 ConfigImage 和 CounterDataPrefix 镜像。
请参阅 Metric.cpp 文件,该文件由 userrange_profiling 示例使用。
用于配置指标的outline
作为输入,获取指标名称列表。
在创建 ConfigImage 或 CounterDataPrefixImage 之前,我们需要一个 NVPA_RawMetricRequest 列表,用于列出的要收集的指标。
我们需要计算主机操作所需的暂存缓冲区大小,并像在枚举阶段一样初始化指标评估器。
对于每个指标,调用
NVPW_MetricsEvaluator_ConvertMetricNameToMetricEvalRequest以创建 NVPW_MetricEvalRequest。调用
NVPW_MetricsEvaluator_GetMetricRawDependencies,它将 NVPW_MetricsEvaluator 和 NVPW_MetricEvalRequest 作为输入,以获取给定指标的原始依赖项。
使用
keepInstances=true和isolated=true创建一个NVPA_RawMetricRequest将
NVPA_RawMetricRequest传递给NVPW_RawMetricsConfig_AddMetrics以获取 ConfigImage。将
NVPA_RawMetricRequest传递给NVPW_CounterDataBuilder_AddMetrics以获取 CounterDataPrefix。生成二进制配置“镜像”(内存中的文件格式)
来自
NVPW_RawMetricsConfig_GetConfigImage的 ConfigImage来自
NVPW_CounterDataBuilder_GetCounterDataPrefix的 CounterDataPrefix
指标评估
指标评估是从 CounterData 镜像中存储的计数器形成指标的过程。
请参阅 Eval.cpp 文件,该文件由 userrange_profiling 示例使用。
用于配置指标的outline
作为输入,采用与配置期间使用的指标名称相同的列表。
作为输入,获取在目标设备上收集的 CounterDataImage。
我们需要计算主机操作所需的暂存缓冲区大小,并像在枚举阶段一样初始化指标评估器。
通过
NVPW_CounterData_GetNumRanges查询收集的范围数。对于每个指标
调用
NVPW_MetricsEvaluator_ConvertMetricNameToMetricEvalRequest以创建 NVPW_MetricEvalRequest对于每个范围
调用
NVPW_Profiler_CounterData_GetRangeDescriptions以检索范围的描述,该描述最初由cuptiProfilerPushRange设置。调用
NVPW_MetricsEvaluator_SetDeviceAttributes以在 NVPW_MetricEvalRequest 上设置当前评估范围。调用
NVPW_MetricsEvaluator_EvaluateToGpuValues以查询与每个输入指标对应的数值数组。
2.12.1. 派生指标
指标概述
PerfWorks API 配备了先进的指标计算系统,旨在帮助您确定发生了什么(计数器和指标),以及程序接近 GPU 峰值性能的程度(吞吐量以百分比表示)。每个计数器在数据库中都有相关的峰值速率,以允许计算其吞吐量百分比。
吞吐量指标返回其组成计数器的最大百分比值。可以通过 NVPW_MetricsEvaluator_GetMetricNames 和 NVPW_METRIC_TYPE_THROUGHPUT 作为指标类型以编程方式查询成分。这些成分经过精心选择,以表示控制峰值性能的 GPU 管道部分。虽然所有计数器都可以转换为峰值的百分比,但并非所有计数器都适用于峰值性能分析;不适用计数器的示例包括活动限定子集和工作负载驻留计数器。使用吞吐量指标可确保有意义且可操作的分析。
每个计数器有两种类型的峰值速率可用:突发和持续。突发速率是单个时钟周期内可报告的最大速率。持续速率是在无限长的测量周期内针对“典型”操作可实现的最大速率。对于许多计数器,突发 == 持续。由于突发速率无法超过,因此突发速率的百分比将始终小于 100%。在极端情况下,持续速率的百分比有时可能会超过 100%。突发指标仅受 MetricsContext API 支持,并且将在未来的 CUDA 版本中弃用。这些指标不受 NVPW_MetricsEvaluator API 支持。
指标实体
指标层有 3 种主要类型的实体
指标:这些是计算量,具有以下静态属性
描述字符串。
量纲单位:量纲分析风格的('名称',指数)列表。示例字符串表示形式:
pixels / gpc_clk。原始指标依赖项:为了评估指标而必须收集的原始指标列表。
每个指标都内置了以下子指标。
.peak_sustained峰值持续速率
.peak_sustained_active单元活动周期内的峰值持续速率
.peak_sustained_active.per_second单元活动周期内的峰值持续速率,每秒 *
.peak_sustained_elapsed单元经过周期内的峰值持续速率
.peak_sustained_elapsed.per_second单元经过周期内的峰值持续速率,每秒 *
.peak_sustained_region用户指定的“范围”内的峰值持续速率
.peak_sustained_region.per_second用户指定的“范围”内的峰值持续速率,每秒 *
.peak_sustained_frame用户指定的“帧”内的峰值持续速率
.peak_sustained_frame.per_second用户指定的“帧”内的峰值持续速率,每秒 *
.per_cycle_active每个单元活动周期的操作数
.per_cycle_elapsed每个单元经过周期的操作数
.per_cycle_in_region每个用户指定的“范围”周期的操作数
.per_cycle_in_frame每个用户指定的“帧”周期的操作数
.per_second每秒的操作数
.pct_of_peak_sustained_active单元活动周期内达到的峰值持续速率的百分比
.pct_of_peak_sustained_elapsed单元经过周期内达到的峰值持续速率的百分比
.pct_of_peak_sustained_region用户指定的“范围”时间内达到的峰值持续速率的百分比
.pct_of_peak_sustained_frame用户指定的“帧”时间内达到的峰值持续速率的百分比
* CUPTI 11.3 中添加的子指标。
计数器可以是来自 GPU 的原始计数器,也可以是计算的计数器值。每个计数器下都有四种子指标,也称为汇总
.sum所有单元实例的计数器值之和。
.avg所有单元实例的平均计数器值。
.min所有单元实例的最小计数器值。
.max所有单元实例的最大计数器值。
比率在其下有三种子指标
.pct以百分比表示的值。
.ratio以比率表示的值。
.max_rate比率的最大值。
吞吐量指示 GPU 的一部分接近峰值速率的程度。每个吞吐量都有以下子指标
.pct_of_peak_sustained_active单元活动周期内达到的峰值持续速率的百分比
.pct_of_peak_sustained_elapsed单元经过周期内达到的峰值持续速率的百分比
.pct_of_peak_sustained_region用户指定的“范围”时间内达到的峰值持续速率的百分比
.pct_of_peak_sustained_frame用户指定的“帧”时间内达到的峰值持续速率的百分比
在配置步骤中,您必须指定指标名称。计数器、比率和吞吐量不是直接可调度的。
注意: 突发指标仅受 MetricsContext API 支持。
从 CUPTI 11.3 开始,由于对性能优化没有用处,以下计数器子指标在 MetricEvaluator API 中不存在,仅受 MetricsContext API 支持
|
峰值突发速率 |
|
单元活动周期内达到的峰值突发速率的百分比 |
|
单元经过周期内达到的峰值突发速率的百分比 |
|
用户指定的“范围”内达到的峰值突发速率的百分比 |
|
用户指定的“帧”内达到的峰值突发速率的百分比 |
从 CUPTI 11.3 开始,由于对性能优化没有用处,以下吞吐量子指标在 MetricEvaluator API 中不存在,仅受 MetricsContext API 支持
|
单元活动周期内达到的峰值突发速率的百分比 |
|
单元经过周期内达到的峰值突发速率的百分比 |
|
用户指定的“范围”时间内达到的峰值突发速率的百分比 |
|
用户指定的“帧”时间内达到的峰值突发速率的百分比 |
指标示例
## non-metric names -- *not* directly evaluable
sm__inst_executed # counter
smsp__average_warp_latency # ratio
sm__throughput # throughput
## a counter's four roll-ups as sub-metrics -- all evaluable
sm__inst_executed.sum # metric
sm__inst_executed.avg # metric
sm__inst_executed.min # metric
sm__inst_executed.max # metric
## all names below are metrics -- all evaluable
l1tex__data_bank_conflicts_pipe_lsu.sum
l1tex__data_bank_conflicts_pipe_lsu.sum.peak_burst
l1tex__data_bank_conflicts_pipe_lsu.sum.peak_sustained
l1tex__data_bank_conflicts_pipe_lsu.sum.per_cycle_active
l1tex__data_bank_conflicts_pipe_lsu.sum.per_cycle_elapsed
l1tex__data_bank_conflicts_pipe_lsu.sum.per_cycle_in_region
l1tex__data_bank_conflicts_pipe_lsu.sum.per_cycle_in_frame
l1tex__data_bank_conflicts_pipe_lsu.sum.per_second
l1tex__data_bank_conflicts_pipe_lsu.sum.pct_of_peak_sustained_active
l1tex__data_bank_conflicts_pipe_lsu.sum.pct_of_peak_sustained_elapsed
l1tex__data_bank_conflicts_pipe_lsu.sum.pct_of_peak_sustained_region
l1tex__data_bank_conflicts_pipe_lsu.sum.pct_of_peak_sustained_frame
指标命名约定
计数器和指标_通常_遵守命名方案
单元级计数器:
unit__(subunit?)_(pipestage?)_quantity_(qualifiers?)接口计数器:
unit__(subunit?)_(pipestage?)_(interface)_quantity_(qualifiers?)单元指标:
(counter_name).(rollup_metric)子指标:
(counter_name).(rollup_metric).(submetric)
其中
unit:GPU 的逻辑或物理单元
subunit:测量计数器的单元内的子单元。有时这是一个管道模式。
pipestage:测量计数器的子单元内的管道阶段。
quantity:正在测量的量。通常与“量纲单位”匹配。
qualifiers:应用于计数器的任何其他谓词或过滤器。通常,非限定计数器可以分解为几个限定子组件。
interface:形式为
sender2receiver,其中sender是源单元,receiver是目标单元。rollup_metric:sum、avg、min、max 之一。
submetric:请参阅 指标实体 部分
组件并非总是存在。大多数顶级计数器没有限定符。子单元和管道阶段可能在不相关的地方不存在,或者对于详细的计数器可能存在许多子单元说明符。
周期指标
名称中使用术语 cycles 的计数器报告单元时钟域中的周期数。单元级周期指标包括
unit__cycles_elapsed:范围内的周期数。周期的 DimUnits 特定于单元的时钟域。unit__cycles_active:单元正在处理数据的周期数。unit__cycles_stalled:由于其输出接口被阻塞,单元无法处理新数据的周期数。unit__cycles_idle:单元空闲的周期数。
接口级周期计数器通常(并非总是)在以下变体中可用
unit__(interface)_active:数据从源单元传输到目标单元的周期。unit__(interface)_stalled:源单元有数据,但目标单元无法接受数据的周期。
2.12.2. 原始指标
原始指标层包含底层 GPU 计数器列表,以及编程硬件所需的“调度”逻辑。二进制输出文件(ConfigImage 和 CounterDataPrefix)可以离线生成、存储在磁盘上,并在任何兼容的 GPU 上使用。它们不需要在 GPU 可用的机器上生成。
请参阅指标配置,以了解原始指标在分析器的整体数据流中的位置。
2.12.3. 指标映射表
下表列出了计算能力为 7.0 的设备的 CUPTI 指标。对于每个 CUPTI 指标,都给出了最接近的等效 Perfworks 指标或公式。如果没有可用的等效 Perfworks 指标,则该列留空。请注意,CUPTI 指标和 Perfworks 指标之间的指标值可能存在一些差异。
以 sm__ 开头的 Perfworks 指标是按 SM 收集的。以 smsp__ 开头的指标是按 SM 子分区收集的。但是,所有相应的 CUPTI 指标仅按 SM 收集。
CUPTI 指标 |
Perfworks 指标或公式 |
|---|---|
achieved_occupancy |
sm__warps_active.avg.pct_of_peak_sustained_active |
atomic_transactions |
l1tex__t_set_accesses_pipe_lsu_mem_global_op_atom.sum + l1tex__t_set_accesses_pipe_lsu_mem_global_op_red.sum |
atomic_transactions_per_request |
(l1tex__t_sectors_pipe_lsu_mem_global_op_atom.sum + l1tex__t_sectors_pipe_lsu_mem_global_op_red.sum) / (l1tex__t_requests_pipe_lsu_mem_global_op_atom.sum + l1tex__t_requests_pipe_lsu_mem_global_op_red.sum) |
branch_efficiency |
smsp__sass_average_branch_targets_threads_uniform.pct |
cf_executed |
smsp__inst_executed_pipe_cbu.sum + smsp__inst_executed_pipe_adu.sum |
cf_fu_utilization |
|
cf_issued |
|
double_precision_fu_utilization |
smsp__inst_executed_pipe_fp64.avg.pct_of_peak_sustained_active |
dram_read_bytes |
dram__bytes_read.sum |
dram_read_throughput |
dram__bytes_read.sum.per_second |
dram_read_transactions |
dram__sectors_read.sum |
dram_utilization |
dram__throughput.avg.pct_of_peak_sustained_elapsed |
dram_write_bytes |
dram__bytes_write.sum |
dram_write_throughput |
dram__bytes_write.sum.per_second |
dram_write_transactions |
dram__sectors_write.sum |
eligible_warps_per_cycle |
smsp__warps_eligible.sum.per_cycle_active |
flop_count_dp |
smsp__sass_thread_inst_executed_op_dadd_pred_on.sum + smsp__sass_thread_inst_executed_op_dmul_pred_on.sum + smsp__sass_thread_inst_executed_op_dfma_pred_on.sum * 2 |
flop_count_dp_add |
smsp__sass_thread_inst_executed_op_dadd_pred_on.sum |
flop_count_dp_fma |
smsp__sass_thread_inst_executed_op_dfma_pred_on.sum |
flop_count_dp_mul |
smsp__sass_thread_inst_executed_op_dmul_pred_on.sum |
flop_count_hp |
smsp__sass_thread_inst_executed_op_hadd_pred_on.sum + smsp__sass_thread_inst_executed_op_hmul_pred_on.sum + smsp__sass_thread_inst_executed_op_hfma_pred_on.sum * 2 |
flop_count_hp_add |
smsp__sass_thread_inst_executed_op_hadd_pred_on.sum |
flop_count_hp_fma |
smsp__sass_thread_inst_executed_op_hfma_pred_on.sum |
flop_count_hp_mul |
smsp__sass_thread_inst_executed_op_hmul_pred_on.sum |
flop_count_sp |
smsp__sass_thread_inst_executed_op_fadd_pred_on.sum + smsp__sass_thread_inst_executed_op_fmul_pred_on.sum + smsp__sass_thread_inst_executed_op_ffma_pred_on.sum * 2 |
flop_count_sp_add |
smsp__sass_thread_inst_executed_op_fadd_pred_on.sum |
flop_count_sp_fma |
smsp__sass_thread_inst_executed_op_ffma_pred_on.sum |
flop_count_sp_mul |
smsp__sass_thread_inst_executed_op_fmul_pred_on.sum |
flop_count_sp_special |
|
flop_dp_efficiency |
smsp__sass_thread_inst_executed_ops_dadd_dmul_dfma_pred_on.avg.pct_of_peak_sustained_elapsed |
flop_hp_efficiency |
smsp__sass_thread_inst_executed_ops_hadd_hmul_hfma_pred_on.avg.pct_of_peak_sustained_elapsed |
flop_sp_efficiency |
smsp__sass_thread_inst_executed_ops_fadd_fmul_ffma_pred_on.avg.pct_of_peak_sustained_elapsed |
gld_efficiency |
smsp__sass_average_data_bytes_per_sector_mem_global_op_ld.pct |
gld_requested_throughput |
|
gld_throughput |
l1tex__t_bytes_pipe_lsu_mem_global_op_ld.sum.per_second |
gld_transactions |
l1tex__t_sectors_pipe_lsu_mem_global_op_ld.sum |
gld_transactions_per_request |
l1tex__average_t_sectors_per_request_pipe_lsu_mem_global_op_ld.ratio |
global_atomic_requests |
l1tex__t_requests_pipe_lsu_mem_global_op_atom.sum |
global_hit_rate |
l1tex__t_sectors_pipe_lsu_mem_global_op_{op}_lookup_hit.sum / l1tex__t_sectors_pipe_lsu_mem_global_op_{op}.sum |
global_load_requests |
l1tex__t_requests_pipe_lsu_mem_global_op_ld.sum |
global_reduction_requests |
l1tex__t_requests_pipe_lsu_mem_global_op_red.sum |
global_store_requests |
l1tex__t_requests_pipe_lsu_mem_global_op_st.sum |
gst_efficiency |
smsp__sass_average_data_bytes_per_sector_mem_global_op_st.pct |
gst_requested_throughput |
|
gst_throughput |
l1tex__t_bytes_pipe_lsu_mem_global_op_st.sum.per_second |
gst_transactions |
l1tex__t_bytes_pipe_lsu_mem_global_op_st.sum |
gst_transactions_per_request |
l1tex__average_t_sectors_per_request_pipe_lsu_mem_global_op_st.ratio |
half_precision_fu_utilization |
smsp__inst_executed_pipe_fp16.avg.pct_of_peak_sustained_active |
inst_bit_convert |
smsp__sass_thread_inst_executed_op_conversion_pred_on.sum |
inst_compute_ld_st |
smsp__sass_thread_inst_executed_op_memory_pred_on.sum |
inst_control |
smsp__sass_thread_inst_executed_op_control_pred_on.sum |
inst_executed |
smsp__inst_executed.sum |
inst_executed_global_atomics |
smsp__sass_inst_executed_op_global_atom.sum |
inst_executed_global_loads |
smsp__inst_executed_op_global_ld.sum |
inst_executed_global_reductions |
smsp__inst_executed_op_global_red.sum |
inst_executed_global_stores |
smsp__inst_executed_op_global_st.sum |
inst_executed_local_loads |
smsp__inst_executed_op_local_ld.sum |
inst_executed_local_stores |
smsp__inst_executed_op_local_st.sum |
inst_executed_shared_atomics |
smsp__inst_executed_op_shared_atom.sum + smsp__inst_executed_op_shared_atom_dot_alu.sum + smsp__inst_executed_op_shared_atom_dot_cas.sum |
inst_executed_shared_loads |
smsp__inst_executed_op_shared_ld.sum |
inst_executed_shared_stores |
smsp__inst_executed_op_shared_st.sum |
inst_executed_surface_atomics |
smsp__inst_executed_op_surface_atom.sum |
inst_executed_surface_loads |
smsp__inst_executed_op_surface_ld.sum + smsp__inst_executed_op_shared_atom_dot_alu.sum + smsp__inst_executed_op_shared_atom_dot_cas.sum |
inst_executed_surface_reductions |
smsp__inst_executed_op_surface_red.sum |
inst_executed_surface_stores |
smsp__inst_executed_op_surface_st.sum |
inst_executed_tex_ops |
smsp__inst_executed_op_texture.sum |
inst_fp_16 |
smsp__sass_thread_inst_executed_op_fp16_pred_on.sum |
inst_fp_32 |
smsp__sass_thread_inst_executed_op_fp32_pred_on.sum |
inst_fp_64 |
smsp__sass_thread_inst_executed_op_fp64_pred_on.sum |
inst_integer |
smsp__sass_thread_inst_executed_op_integer_pred_on.sum |
inst_inter_thread_communication |
smsp__sass_thread_inst_executed_op_inter_thread_communication_pred_on.sum |
inst_issued |
smsp__inst_issued.sum |
inst_misc |
smsp__sass_thread_inst_executed_op_misc_pred_on.sum |
inst_per_warp |
smsp__average_inst_executed_per_warp.ratio |
inst_replay_overhead |
|
ipc |
smsp__inst_executed.avg.per_cycle_active |
issue_slot_utilization |
smsp__issue_active.avg.pct_of_peak_sustained_active |
issue_slots |
smsp__inst_issued.sum |
issued_ipc |
smsp__inst_issued.avg.per_cycle_active |
l2_atomic_throughput |
lts__t_sectors_srcunit_l1_op_atom.sum.per_second |
l2_atomic_transactions |
lts__t_sectors_srcunit_l1_op_atom.sum |
l2_global_atomic_store_bytes |
lts__t_bytes_equiv_l1sectormiss_pipe_lsu_mem_global_op_atom.sum |
l2_global_load_bytes |
lts__t_bytes_equiv_l1sectormiss_pipe_lsu_mem_global_op_ld.sum |
l2_local_global_store_bytes |
lts__t_bytes_equiv_l1sectormiss_pipe_lsu_mem_local_op_st.sum + lts__t_bytes_equiv_l1sectormiss_pipe_lsu_mem_global_op_st.sum |
l2_local_load_bytes |
lts__t_bytes_equiv_l1sectormiss_pipe_lsu_mem_local_op_ld.sum |
l2_read_throughput |
lts__t_sectors_op_read.sum.per_second |
l2_read_transactions |
lts__t_sectors_op_read.sum |
l2_surface_load_bytes |
lts__t_bytes_equiv_l1sectormiss_pipe_tex_mem_surface_op_ld.sum |
l2_surface_store_bytes |
lts__t_bytes_equiv_l1sectormiss_pipe_tex_mem_surface_op_st.sum |
l2_tex_hit_rate |
lts__t_sector_hit_rate.pct |
l2_tex_read_hit_rate |
lts__t_sector_op_read_hit_rate.pct |
l2_tex_read_throughput |
lts__t_sectors_srcunit_tex_op_read.sum.per_second |
l2_tex_read_transactions |
lts__t_sectors_srcunit_tex_op_read.sum |
l2_tex_write_hit_rate |
lts__t_sector_op_write_hit_rate.pct |
l2_tex_write_throughput |
lts__t_sectors_srcunit_tex_op_read.sum.per_second |
l2_tex_write_transactions |
lts__t_sectors_srcunit_tex_op_read.sum |
l2_utilization |
lts__t_sectors.avg.pct_of_peak_sustained_elapsed |
l2_write_throughput |
lts__t_sectors_op_write.sum.per_second |
l2_write_transactions |
lts__t_sectors_op_write.sum |
ldst_executed |
|
ldst_fu_utilization |
smsp__inst_executed_pipe_lsu.avg.pct_of_peak_sustained_active |
ldst_issued |
|
local_hit_rate |
|
local_load_requests |
l1tex__t_requests_pipe_lsu_mem_local_op_ld.sum |
local_load_throughput |
l1tex__t_bytes_pipe_lsu_mem_local_op_ld.sum.per_second |
local_load_transactions |
l1tex__t_sectors_pipe_lsu_mem_local_op_ld.sum |
local_load_transactions_per_request |
l1tex__average_t_sectors_per_request_pipe_lsu_mem_local_op_ld.ratio |
local_memory_overhead |
|
local_store_requests |
l1tex__t_requests_pipe_lsu_mem_local_op_st.sum |
local_store_throughput |
l1tex__t_sectors_pipe_lsu_mem_local_op_st.sum.per_second |
local_store_transactions |
l1tex__t_sectors_pipe_lsu_mem_local_op_st.sum |
local_store_transactions_per_request |
l1tex__average_t_sectors_per_request_pipe_lsu_mem_local_op_st.ratio |
nvlink_data_receive_efficiency |
|
nvlink_data_transmission_efficiency |
|
nvlink_overhead_data_received |
|
nvlink_overhead_data_transmitted |
|
nvlink_receive_throughput |
|
nvlink_total_data_received |
|
nvlink_total_data_transmitted |
|
nvlink_total_nratom_data_transmitted |
|
nvlink_total_ratom_data_transmitted |
|
nvlink_total_response_data_received |
|
nvlink_total_write_data_transmitted |
|
nvlink_transmit_throughput |
|
nvlink_user_data_received |
|
nvlink_user_data_transmitted |
|
nvlink_user_nratom_data_transmitted |
|
nvlink_user_ratom_data_transmitted |
|
nvlink_user_response_data_received |
|
nvlink_user_write_data_transmitted |
|
pcie_total_data_received |
pcie__read_bytes.sum |
pcie_total_data_transmitted |
pcie__write_bytes.sum |
shared_efficiency |
smsp__sass_average_data_bytes_per_wavefront_mem_shared.pct |
shared_load_throughput |
l1tex__data_pipe_lsu_wavefronts_mem_shared_op_ld.sum.per_second |
shared_load_transactions |
l1tex__data_pipe_lsu_wavefronts_mem_shared_op_ld.sum |
shared_load_transactions_per_request |
|
shared_store_throughput |
l1tex__data_pipe_lsu_wavefronts_mem_shared_op_st.sum.per_second |
shared_store_transactions |
l1tex__data_pipe_lsu_wavefronts_mem_shared_op_st.sum |
shared_store_transactions_per_request |
|
shared_utilization |
l1tex__data_pipe_lsu_wavefronts_mem_shared.avg.pct_of_peak_sustained_elapsed |
single_precision_fu_utilization |
smsp__pipe_fma_cycles_active.avg.pct_of_peak_sustained_active |
sm_efficiency |
smsp__cycles_active.avg.pct_of_peak_sustained_elapsed |
sm_tex_utilization |
l1tex__texin_sm2tex_req_cycles_active.avg.pct_of_peak_sustained_elapsed |
special_fu_utilization |
smsp__inst_executed_pipe_xu.avg.pct_of_peak_sustained_active |
stall_constant_memory_dependency |
smsp__warp_issue_stalled_imc_miss_per_warp_active.pct |
stall_exec_dependency |
smsp__warp_issue_stalled_short_scoreboard_per_warp_active.pct + smsp__warp_issue_stalled_wait_per_warp_active.pct |
stall_inst_fetch |
smsp__warp_issue_stalled_no_instruction_per_warp_active.pct |
stall_memory_dependency |
smsp__warp_issue_stalled_long_scoreboard_per_warp_active.pct |
stall_memory_throttle |
smsp__warp_issue_stalled_drain_per_warp_active.pct + smsp__warp_issue_stalled_lg_throttle_per_warp_active.pct |
stall_not_selected |
smsp__warp_issue_stalled_not_selected_per_warp_active.pct |
stall_other |
smsp__warp_issue_stalled_misc_per_warp_active.pct + smsp__warp_issue_stalled_dispatch_stall_per_warp_active.pct |
stall_pipe_busy |
smsp__warp_issue_stalled_mio_throttle_per_warp_active.pct + smsp__warp_issue_stalled_math_pipe_throttle_per_warp_active.pct |
stall_sleeping |
smsp__warp_issue_stalled_sleeping_per_warp_active.pct |
stall_sync |
smsp__warp_issue_stalled_membar_per_warp_active.pct + smsp__warp_issue_stalled_barrier_per_warp_active.pct |
stall_texture |
smsp__warp_issue_stalled_tex_throttle_per_warp_active.pct |
surface_atomic_requests |
l1tex__t_requests_pipe_tex_mem_surface_op_atom.sum |
surface_load_requests |
l1tex__t_requests_pipe_tex_mem_surface_op_ld.sum |
surface_reduction_requests |
l1tex__t_requests_pipe_tex_mem_surface_op_red.sum |
surface_store_requests |
l1tex__t_requests_pipe_tex_mem_surface_op_st.sum |
sysmem_read_bytes |
lts__t_sectors_aperture_sysmem_op_read* 32 |
sysmem_read_throughput |
lts__t_sectors_aperture_sysmem_op_read.sum.per_second |
sysmem_read_transactions |
lts__t_sectors_aperture_sysmem_op_read.sum |
sysmem_read_utilization |
|
sysmem_utilization |
|
sysmem_write_bytes |
lts__t_sectors_aperture_sysmem_op_write * 32 |
sysmem_write_throughput |
lts__t_sectors_aperture_sysmem_op_write.sum.per_second |
sysmem_write_transactions |
lts__t_sectors_aperture_sysmem_op_write.sum |
sysmem_write_utilization |
|
tensor_precision_fu_utilization |
sm__pipe_tensor_cycles_active.avg.pct_of_peak_sustained_active |
tex_cache_hit_rate |
l1tex__t_sector_hit_rate.pct |
tex_cache_throughput |
|
tex_cache_transactions |
l1tex__lsu_writeback_active.avg.pct_of_peak_sustained_active + l1tex__tex_writeback_active.avg.pct_of_peak_sustained_active |
tex_fu_utilization |
smsp__inst_executed_pipe_tex.avg.pct_of_peak_sustained_active |
tex_sm_tex_utilization |
l1tex__f_tex2sm_cycles_active.avg.pct_of_peak_sustained_elapsed |
tex_sm_utilization |
sm__mio2rf_writeback_active.avg.pct_of_peak_sustained_elapsed |
tex_utilization |
|
texture_load_requests |
l1tex__t_requests_pipe_tex_mem_texture.sum |
warp_execution_efficiency |
smsp__thread_inst_executed_per_inst_executed.ratio |
warp_nonpred_execution_efficiency |
smsp__thread_inst_executed_per_inst_executed.pct |
2.12.4. 事件映射表
下表列出了计算能力为 7.0 的设备的 CUPTI 事件。对于每个 CUPTI 事件,都给出了最接近的等效 Perfworks 指标或公式。如果没有可用的等效 Perfworks 指标,则该列留空。请注意,CUPTI 事件和 Perfworks 指标之间的值可能存在一些差异。
以 sm__ 开头的 Perfworks 指标是按 SM 收集的。以 smsp__ 开头的指标是按 SM 子分区收集的。但是,所有相应的 CUPTI 事件仅按 SM 收集。
CUPTI 事件 |
Perfworks 指标或公式 |
|---|---|
active_cycles |
sm__cycles_active.sum |
active_cycles_pm |
sm__cycles_active.sum |
active_cycles_sys |
sys__cycles_active.sum |
active_warps |
sm__warps_active.sum |
active_warps_pm |
sm__warps_active.sum |
atom_count |
smsp__inst_executed_op_generic_atom_dot_alu.sum |
elapsed_cycles_pm |
sm__cycles_elapsed.sum |
elapsed_cycles_sm |
sm__cycles_elapsed.sum |
elapsed_cycles_sys |
sys__cycles_elapsed.sum |
fb_subp0_read_sectors |
dram__sectors_read.sum |
fb_subp1_read_sectors |
dram__sectors_read.sum |
fb_subp0_write_sectors |
dram__sectors_write.sum |
fb_subp1_write_sectors |
dram__sectors_write.sum |
global_atom_cas |
smsp__inst_executed_op_generic_atom_dot_cas.sum |
gred_count |
smsp__inst_executed_op_global_red.sum |
inst_executed |
sm__inst_executed.sum |
inst_executed_fma_pipe_s0 |
smsp__inst_executed_pipe_fma.sum |
inst_executed_fma_pipe_s1 |
smsp__inst_executed_pipe_fma.sum |
inst_executed_fma_pipe_s2 |
smsp__inst_executed_pipe_fma.sum |
inst_executed_fma_pipe_s3 |
smsp__inst_executed_pipe_fma.sum |
inst_executed_fp16_pipe_s0 |
smsp__inst_executed_pipe_fp16.sum |
inst_executed_fp16_pipe_s1 |
smsp__inst_executed_pipe_fp16.sum |
inst_executed_fp16_pipe_s2 |
smsp__inst_executed_pipe_fp16.sum |
inst_executed_fp16_pipe_s3 |
smsp__inst_executed_pipe_fp16.sum |
inst_executed_fp64_pipe_s0 |
smsp__inst_executed_pipe_fp64.sum |
inst_executed_fp64_pipe_s1 |
smsp__inst_executed_pipe_fp64.sum |
inst_executed_fp64_pipe_s2 |
smsp__inst_executed_pipe_fp64.sum |
inst_executed_fp64_pipe_s3 |
smsp__inst_executed_pipe_fp64.sum |
inst_issued1 |
sm__inst_issued.sum |
l2_subp0_read_sector_misses |
lts__t_sectors_op_read_lookup_miss.sum |
l2_subp1_read_sector_misses |
lts__t_sectors_op_read_lookup_miss.sum |
l2_subp0_read_sysmem_sector_queries |
lts__t_sectors_aperture_sysmem_op_read.sum |
l2_subp1_read_sysmem_sector_queries |
lts__t_sectors_aperture_sysmem_op_read.sum |
l2_subp0_read_tex_hit_sectors |
lts__t_sectors_srcunit_tex_op_read_lookup_hit.sum |
l2_subp1_read_tex_hit_sectors |
lts__t_sectors_srcunit_tex_op_read_lookup_hit.sum |
l2_subp0_read_tex_sector_queries |
lts__t_sectors_srcunit_tex_op_read.sum |
l2_subp1_read_tex_sector_queries |
lts__t_sectors_srcunit_tex_op_read.sum |
l2_subp0_total_read_sector_queries |
lts__t_sectors_op_read.sum + lts__t_sectors_op_atom.sum + lts__t_sectors_op_red.sum |
l2_subp1_total_read_sector_queries |
lts__t_sectors_op_read.sum + lts__t_sectors_op_atom.sum + lts__t_sectors_op_red.sum |
l2_subp0_total_write_sector_queries |
lts__t_sectors_op_write.sum + lts__t_sectors_op_atom.sum + lts__t_sectors_op_red.sum |
l2_subp1_total_write_sector_queries |
lts__t_sectors_op_write.sum + lts__t_sectors_op_atom.sum + lts__t_sectors_op_red.sum |
l2_subp0_write_sector_misses |
lts__t_sectors_op_write_lookup_miss.sum |
l2_subp1_write_sector_misses |
lts__t_sectors_op_write_lookup_miss.sum |
l2_subp0_write_sysmem_sector_queries |
lts__t_sectors_aperture_sysmem_op_write.sum |
l2_subp1_write_sysmem_sector_queries |
lts__t_sectors_aperture_sysmem_op_write.sum |
l2_subp0_write_tex_hit_sectors |
lts__t_sectors_srcunit_tex_op_write_lookup_hit.sum |
l2_subp1_write_tex_hit_sectors |
lts__t_sectors_srcunit_tex_op_write_lookup_hit.sum |
l2_subp0_write_tex_sector_queries |
lts__t_sectors_srcunit_tex_op_write.sum |
l2_subp1_write_tex_sector_queries |
lts__t_sectors_srcunit_tex_op_write.sum |
not_predicated_off_thread_inst_executed |
smsp__线程_指令_已执行_谓词_开启.sum |
pcie_rx_活动_脉冲 |
|
pcie_tx_活动_脉冲 |
|
prof_触发_00 |
|
prof_触发_01 |
|
prof_触发_02 |
|
prof_触发_03 |
|
prof_触发_04 |
|
prof_触发_05 |
|
prof_触发_06 |
|
prof_触发_07 |
|
inst_已发出0 |
smsp__issue_inst0.sum |
sm_cta_已启动 |
sm__ctas_已启动.sum |
共享_加载 |
smsp__inst_executed_op_shared_ld.sum |
共享_存储 |
smsp__inst_executed_op_shared_st.sum |
通用_加载 |
smsp__inst_executed_op_generic_ld.sum |
通用_存储 |
smsp__inst_executed_op_generic_st.sum |
全局_加载 |
smsp__inst_executed_op_global_ld.sum |
全局_存储 |
smsp__inst_executed_op_global_st.sum |
本地_加载 |
smsp__inst_executed_op_local_ld.sum |
本地_存储 |
smsp__inst_executed_op_local_st.sum |
共享_原子 |
smsp__inst_executed_op_shared_atom.sum |
共享_原子_cas |
smsp__inst_executed_op_shared_atom_dot_cas.sum |
共享_ld_bank_冲突 |
l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_ld.sum |
共享_st_bank_冲突 |
l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_st.sum |
共享_ld_事务 |
l1tex__data_pipe_lsu_wavefronts_mem_shared_op_ld.sum |
共享_st_事务 |
l1tex__data_pipe_lsu_wavefronts_mem_shared_op_st.sum |
张量_管道_活动_周期_s0 |
smsp__pipe_tensor_cycles_active.sum |
张量_管道_活动_周期_s1 |
smsp__pipe_tensor_cycles_active.sum |
张量_管道_活动_周期_s2 |
smsp__pipe_tensor_cycles_active.sum |
张量_管道_活动_周期_s3 |
smsp__pipe_tensor_cycles_active.sum |
线程_指令_已执行 |
smsp__thread_inst_executed.sum |
warp_已启动 |
smsp__warps_launched.sum |
2.13. CUPTI 事件 API
CUPTI 事件 API 允许您查询、配置、启动、停止和读取 CUDA 启用设备上的事件计数器。事件 API 使用以下术语。
- 事件
事件是设备上可计数的活动、动作或发生。
- 事件 ID
每个事件都被分配一个唯一的标识符。命名事件将代表所有设备类型上的相同活动、动作或发生。但是,命名事件在不同的设备系列上可能具有不同的 ID。使用
cuptiEventGetIdFromName获取特定设备上命名事件的 ID。- 事件类别
每个事件都放置在
CUpti_EventCategory定义的类别之一中。该类别指示事件测量的活动、动作或发生的一般类型。- 事件域
设备公开一个或多个事件域。每个事件域代表该设备上可用的一组相关事件。一个设备可能具有一个域的多个实例,表明该设备可以同时记录该域内每个事件的多个实例。
- 事件组
事件组是共同管理的一组事件。可以添加到事件组的事件数量和类型受设备特定限制的约束。在任何给定时间,设备可能被配置为仅计数来自有限数量事件组的事件。事件组中的所有事件必须属于同一事件域。
- 事件组集
事件组集是可以同时启用的事件组的集合。事件组集由
cuptiEventGroupSetsCreate和cuptiMetricCreateEventGroupSets创建。
您可以使用 cuptiDeviceEnumEventDomains 和 cuptiEventDomainEnumEvents 函数确定设备上可用的事件。 示例页面 上描述的 cupti_query 示例展示了如何使用这些函数。您还可以使用 cuptiEnumEventDomains 函数枚举任何设备上可用的所有 CUPTI 事件。
配置和读取事件计数需要以下步骤。首先,选择您的事件收集模式。如果您想计算内核执行期间发生的事件,请使用 cuptiSetEventCollectionMode 将模式设置为 CUPTI_EVENT_COLLECTION_MODE_KERNEL。如果您想连续采样事件计数,请使用模式 CUPTI_EVENT_COLLECTION_MODE_CONTINUOUS。接下来,确定您要计数的事件的名称,然后使用 cuptiEventGroupCreate、cuptiEventGetIdFromName 和 cuptiEventGroupAddEvent 函数创建事件组并使用这些事件初始化事件组。如果您无法将所有事件添加到单个事件组,那么您将需要创建多个事件组。或者,您可以使用 cuptiEventGroupSetsCreate 函数自动创建一组事件所需的事件组。
由于硬件或软件限制,所有请求的事件可能无法在单次传递中收集,因此需要多次重放完全相同的 GPU 工作负载。可以使用 API cuptiEventGroupSetsCreate 查询传递次数。分析一个事件始终需要单次传递。当我们想要一起分析多个事件时,可能需要多次传递。代码片段展示了如何查询传递次数
CUpti_EventGroupSets *eventGroupSets = NULL;
size_t eventIdArraySize = sizeof(CUpti_EventID) * numEvents;
CUpti_EventID *eventIdArray = (CUpti_EventID *)malloc(sizeof(CUpti_EventID) * numEvents);
// fill in event Ids
cuptiEventGroupSetsCreate(context, eventIdArraySize, eventIdArray, &eventGroupSets);
// number of passes required to collect all the events
passes = eventGroupSets->numSets;
要开始计数一组事件,请使用 cuptiEventGroupEnable 函数启用包含这些事件的事件组。如果您的事件包含在多个事件组中,您可能无法同时启用所有事件组,即在同一次传递中。在这种情况下,您可以跨应用程序的多次执行收集事件,或者您可以启用内核重放。如果您使用 cuptiEnableKernelReplayMode 启用内核重放,您将能够启用任意数量的事件组,并且将收集所有包含的事件。
使用 cuptiEventGroupReadEvent 和/或 cuptiEventGroupReadAllEvents 函数读取事件值。当您完成事件收集后,使用 cuptiEventGroupDisable 函数停止计数事件组中包含的事件。 示例页面 上描述的 callback_event 示例展示了如何使用这些函数创建、启用和禁用事件组,以及如何读取事件计数。
注意
对于事件收集模式 CUPTI_EVENT_COLLECTION_MODE_KERNEL,事件或指标收集可能会显着改变应用程序的整体性能特征,因为在 cuptiEventGroupEnable 和 cuptiEventGroupDisable 调用之间发生的所有内核执行都在 GPU 上串行化。可以通过使用模式 CUPTI_EVENT_COLLECTION_MODE_CONTINUOUS 并将分析限制为可以在单次传递中收集的事件和指标来避免这种情况。
注意
除 NVLink 指标外,所有事件和指标都在上下文级别收集,而与事件收集模式无关。也就是说,当多个上下文在 GPU 上执行时,事件或指标可以归因于正在分析的上下文,并且可以准确地收集值。 NVLink 指标在设备级别针对所有事件收集模式收集。
在具有多个 GPU 的系统中,可以在所有 GPU 上同时收集事件;换句话说,事件分析不会强制跨 GPU 的任何工作串行化。 event_multi_gpu 示例展示了如何在这些设置上使用 CUPTI 事件和 CUDA API。
注意
对于计算能力为 7.5 及更高的设备,不支持来自头文件 cupti_events.h 的事件 API。建议改用 CUPTI 范围分析 API。有关更多详细信息,请参阅 分析 API 的演变 部分。
2.13.1. 收集内核执行事件
事件 API 的常见用途是在内核执行期间计数一组事件(如 callback_event 示例所示)。以下代码显示了用于此目的的典型回调。假设回调仅针对使用 CUDA 运行时的内核启动启用(即,通过 cuptiEnableCallback(1, subscriber, CUPTI_CB_DOMAIN_RUNTIME_API, CUPTI_RUNTIME_TRACE_CBID_cudaLaunch_v3020))。为了简化演示,已删除错误检查代码。
static void CUPTIAPI
getEventValueCallback(void *userdata,
CUpti_CallbackDomain domain,
CUpti_CallbackId cbid,
const void *cbdata)
{
const CUpti_CallbackData *cbData =
(CUpti_CallbackData *)cbdata;
if (cbData->callbackSite == CUPTI_API_ENTER) {
cudaDeviceSynchronize();
cuptiSetEventCollectionMode(cbInfo->context,
CUPTI_EVENT_COLLECTION_MODE_KERNEL);
cuptiEventGroupEnable(eventGroup);
}
if (cbData->callbackSite == CUPTI_API_EXIT) {
cudaDeviceSynchronize();
cuptiEventGroupReadEvent(eventGroup,
CUPTI_EVENT_READ_FLAG_NONE,
eventId,
&bytesRead, &eventVal);
cuptiEventGroupDisable(eventGroup);
}
}
使用两个同步点来确保仅针对内核的执行计数事件。如果应用程序包含其他启动内核的线程,则还必须引入额外的线程级同步,以确保这些线程在回调收集事件时不会启动内核。当 cudaLaunch API 进入时(即,在内核实际在设备上启动之前),使用 cudaDeviceSynchronize 等待直到 GPU 空闲。事件收集模式设置为 CUPTI_EVENT_COLLECTION_MODE_KERNEL,以便事件计数器在内核执行之前和之后自动启动和停止。然后使用 cuptiEventGroupEnable 启用事件收集。
当 cudaLaunch API 退出时(即,在内核排队等待在 GPU 上执行之后),另一个 cudaDeviceSynchronize 用于使 CPU 线程等待内核完成执行。最后,使用 cuptiEventGroupReadEvent 读取事件计数。
2.13.2. 采样事件
事件 API 也可用于在内核执行时采样事件值(如 event_sampling 示例所示)。该示例展示了一种可能的执行采样的方法。事件收集模式设置为 CUPTI_EVENT_COLLECTION_MODE_CONTINUOUS,以便事件计数器连续运行。 event_sampling 中使用了两个线程:一个线程调度内核和执行计算的 memcopy,而另一个线程定期唤醒以采样事件计数器。在此示例中,事件样本与 GPU 上发生的事情之间没有关联。
2.14. CUPTI 指标 API
CUPTI 指标 API 允许您收集从一个或多个事件值计算出的应用程序指标。指标 API 使用以下术语。
- 指标
从一个或多个事件值计算出的应用程序的特性。
- 指标 ID
每个指标都被分配一个唯一的标识符。命名指标将代表所有设备类型上的相同特性。但是,命名指标在不同的设备系列上可能具有不同的 ID。使用
cuptiMetricGetIdFromName获取特定设备上命名指标的 ID。- 指标类别
每个指标都放置在
CUpti_MetricCategory定义的类别之一中。该类别指示指标测量的特性的一般类型。- 指标属性
每个指标都从输入值计算得出。这些输入值可以是事件或设备或系统的属性。可用属性由
CUpti_MetricPropertyID定义。- 指标值
每个指标都有一个值,该值表示
CUpti_MetricValueKind定义的类型之一。对于每种值类型,CUpti_MetricValue联合中都有一个对应的成员,用于保存指标的值。
本节中包含的表格列出了每个设备可用的指标,由设备的计算能力决定。您还可以使用 cuptiDeviceEnumMetrics 函数确定设备上可用的指标。 示例页面 上描述的 cupti_query 示例展示了如何使用此函数。您还可以使用 cuptiEnumMetrics 函数枚举任何设备上可用的所有 CUPTI 指标。
CUPTI 提供了两个用于计算指标值的函数。当设备不可用时,可以使用 cuptiMetricGetValue2 计算指标值。所有必需的事件值和指标属性必须由调用者提供。当设备可用时(作为 CUdevice 对象),可以使用 cuptiMetricGetValue 计算指标值。所有必需的事件值必须由调用者提供,但 CUPTI 将从 CUdevice 对象确定适当的属性值。
配置和计算指标值需要以下步骤。首先,确定您要收集的指标的名称,然后使用 cuptiMetricGetIdFromName 获取指标 ID。使用 cuptiMetricEnumEvents 获取计算指标所需的事件,并按照 CUPTI 事件 API 部分中的说明创建这些事件的事件组。以这种方式创建事件组时,重要的是使用 cuptiMetricGetRequiredEventGroupSets 的结果来正确地将必须在同一次传递中收集的事件分组在一起,以确保正确的指标计算。
或者,您可以使用 cuptiMetricCreateEventGroupSets 函数自动创建指标事件所需的事件组。当使用此函数时,事件将根据需要分组,以最准确地计算指标;因此,没有必要使用 cuptiMetricGetRequiredEventGroupSets。
如果您正在使用 cuptiMetricGetValue2,那么您还必须使用 cuptiMetricEnumProperties 收集所需的指标属性值。
按照 CUPTI 事件 API 部分中的描述收集事件计数,然后使用 cuptiMetricGetValue 或 cuptiMetricGetValue2 从收集的事件和属性值计算指标值。 示例页面 上描述的 callback_metric 示例展示了如何使用这些函数计算事件值以及如何使用 cuptiMetricGetValue 计算指标。请注意,如示例所示,您应从所有域实例收集事件计数,并对计数进行归一化以获得最准确的指标值。有必要对事件计数进行归一化,因为事件计数器实例的数量因设备和正在计数的事件而异。
例如,一个设备可能有 8 个多处理器,但只有 4 个多处理器的事件计数器,并且可能有 3 个内存单元,但只有一个内存单元的事件计数器。当计算需要多处理器事件和内存单元事件的指标时,应将 4 个多处理器计数器相加并乘以 2,以将事件计数归一化到整个设备。类似地,一个内存单元计数器应乘以 3,以将事件计数归一化到整个设备。然后可以将归一化的值传递给 cuptiMetricGetValue 或 cuptiMetricGetValue2 以计算指标值。
如所述,归一化假设内核执行足够数量的块以完全加载设备。如果内核只有少量块,则跨整个设备进行归一化可能会扭曲结果。
由于硬件或软件限制,所有请求的指标可能无法在单次传递中收集,因此需要多次重放完全相同的 GPU 工作负载。可以使用 API cuptiMetricCreateEventGroupSets 查询传递次数。分析单个指标也可能需要多次传递,具体取决于它从中计算出的事件的数量和类型。代码片段展示了如何查询传递次数
CUpti_EventGroupSets *eventGroupSets = NULL;
size_t metricIdArraySize = sizeof(CUpti_MetricID) * numMetrics;
CUpti_MetricID metricIdArray = (CUpti_MetricID *)malloc(sizeof(CUpti_MetricID) * numMetrics);
// fill in metric Ids
cuptiMetricCreateEventGroupSets(context, metricIdArraySize, metricIdArray, &eventGroupSets);
// number of passes required to collect all the metrics
passes = eventGroupSets->numSets;
注意
对于计算能力为 7.5 及更高的设备,不支持来自头文件 cupti_metrics.h 的指标 API。建议改用 CUPTI 范围分析 API。有关更多详细信息,请参阅 分析 API 的演变 部分。
2.14.1. 指标参考
本节包含 CUPTI 可以收集的指标的详细描述。“单上下文”范围值表示只有当单个上下文(CUDA 或图形)在 GPU 上执行时,才能准确收集该指标。“多上下文”范围值表示当多个上下文在 GPU 上执行时,可以准确收集该指标。“设备”范围值表示将在设备级别收集指标,也就是说,它将包括在 GPU 上执行的所有上下文的值。
2.14.1.1. 能力 5.x 的指标
计算能力为 5.x 的设备实现了下表所示的指标。请注意,对于某些指标,仅特定设备支持“多上下文”范围。此类指标在“范围”列下标记为“多上下文*”。请参阅表格底部的注释。
指标名称 |
描述 |
范围 |
|---|---|---|
achieved_occupancy |
每个活动周期中平均活动线程束与多处理器上支持的最大线程束数的比率 |
多上下文 |
atomic_transactions |
全局内存原子和归约事务 |
多上下文 |
atomic_transactions_per_request |
每个原子和归约指令执行的全局内存原子和归约事务的平均数 |
多上下文 |
branch_efficiency |
非发散分支与总分支的比率,以百分比表示 |
多上下文 |
cf_executed |
已执行的控制流指令数 |
多上下文 |
cf_fu_utilization |
多处理器功能单元的利用率水平,在 0 到 10 的范围内,用于执行控制流指令 |
多上下文 |
cf_issued |
已发出的控制流指令数 |
多上下文 |
double_precision_fu_utilization |
多处理器功能单元的利用率水平,在 0 到 10 的范围内,用于执行双精度浮点指令 |
多上下文 |
dram_read_bytes |
从 DRAM 读取到 L2 缓存的总字节数。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
dram_read_throughput |
设备内存读取吞吐量。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
dram_read_transactions |
设备内存读取事务。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
dram_utilization |
设备内存的利用率水平,相对于峰值利用率,在 0 到 10 的范围内 |
多上下文* |
dram_write_bytes |
从 L2 缓存写入到 DRAM 的总字节数。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
dram_write_throughput |
设备内存写入吞吐量。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
dram_write_transactions |
设备内存写入事务。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
ecc_吞吐量 |
从 L2 到 DRAM 的 ECC 吞吐量。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
ecc_事务 |
L2 和 DRAM 之间的 ECC 事务数。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
eligible_warps_per_cycle |
每个活动周期中有资格发出的线程束的平均数 |
多上下文 |
flop_count_dp |
非谓词线程执行的双精度浮点运算数(加法、乘法和乘加)。每个乘加运算贡献 2 到计数。 |
多上下文 |
flop_count_dp_add |
非谓词线程执行的双精度浮点加法运算数。 |
多上下文 |
flop_count_dp_fma |
非谓词线程执行的双精度浮点乘加运算数。每个乘加运算贡献 1 到计数。 |
多上下文 |
flop_count_dp_mul |
非谓词线程执行的双精度浮点乘法运算数。 |
多上下文 |
flop_count_hp |
非谓词线程执行的半精度浮点运算数(加法、乘法和乘加)。每个乘加运算贡献 2 到计数。这适用于计算能力 5.3。 |
多上下文* |
flop_count_hp_add |
非谓词线程执行的半精度浮点加法运算数。这适用于计算能力 5.3。 |
多上下文* |
flop_count_hp_fma |
非谓词线程执行的半精度浮点乘加运算数。每个乘加运算贡献 1 到计数。这适用于计算能力 5.3。 |
多上下文* |
flop_count_hp_mul |
非谓词线程执行的半精度浮点乘法运算数。这适用于计算能力 5.3。 |
多上下文* |
flop_count_sp |
非谓词线程执行的单精度浮点运算数(加法、乘法和乘加)。每个乘加运算贡献 2 到计数。计数不包括特殊运算。 |
多上下文 |
flop_count_sp_add |
非谓词线程执行的单精度浮点加法运算数。 |
多上下文 |
flop_count_sp_fma |
非谓词线程执行的单精度浮点乘加运算数。每个乘加运算贡献 1 到计数。 |
多上下文 |
flop_count_sp_mul |
非谓词线程执行的单精度浮点乘法运算数。 |
多上下文 |
flop_count_sp_special |
非谓词线程执行的单精度浮点特殊运算数。 |
多上下文 |
flop_dp_efficiency |
实现的双精度浮点运算与峰值双精度浮点运算的比率 |
多上下文 |
flop_hp_efficiency |
实现的半精度浮点运算与峰值半精度浮点运算的比率。这适用于计算能力 5.3。 |
多上下文* |
flop_sp_efficiency |
实现的单精度浮点运算与峰值单精度浮点运算的比率 |
多上下文 |
gld_efficiency |
请求的全局内存加载吞吐量与所需的全局内存加载吞吐量的比率,以百分比表示。 |
多上下文* |
gld_requested_throughput |
请求的全局内存加载吞吐量 |
多上下文 |
gld_throughput |
全局内存加载吞吐量 |
多上下文* |
gld_transactions |
全局内存加载事务数 |
多上下文* |
gld_transactions_per_request |
每个全局内存加载执行的全局内存加载事务的平均数。 |
多上下文* |
global_atomic_requests |
来自多处理器的全局原子(Atom 和 Atom CAS)请求的总数 |
多上下文 |
global_hit_rate |
统一 l1/tex 缓存中全局加载的命中率。如果在内核中使用 malloc,指标值可能不正确。 |
多上下文* |
global_load_requests |
来自多处理器的全局加载请求的总数 |
多上下文 |
global_reduction_requests |
来自多处理器的全局归约请求的总数 |
多上下文 |
global_store_requests |
来自多处理器的全局存储请求的总数。这不包括原子请求。 |
多上下文 |
gst_efficiency |
请求的全局内存存储吞吐量与所需的全局内存存储吞吐量的比率,以百分比表示。 |
多上下文* |
gst_requested_throughput |
请求的全局内存存储吞吐量 |
多上下文 |
gst_throughput |
全局内存存储吞吐量 |
多上下文* |
gst_transactions |
全局内存存储事务数 |
多上下文* |
gst_transactions_per_request |
每个全局内存存储执行的全局内存存储事务的平均数 |
多上下文* |
half_precision_fu_utilization |
多处理器功能单元的利用率水平,在 0 到 10 的范围内,用于执行 16 位浮点指令和整数指令。这适用于计算能力 5.3。 |
多上下文* |
inst_bit_convert |
非谓词线程执行的位转换指令数 |
多上下文 |
inst_compute_ld_st |
非谓词线程执行的计算加载/存储指令数 |
多上下文 |
inst_control |
非谓词线程执行的控制流指令数(跳转、分支等) |
多上下文 |
inst_executed |
已执行的指令数 |
多上下文 |
inst_executed_global_atomics |
用于全局原子和原子 cas 的 Warp 级别指令 |
多上下文 |
inst_executed_global_loads |
用于全局加载的 Warp 级别指令 |
多上下文 |
inst_executed_global_reductions |
用于全局归约的 Warp 级别指令 |
多上下文 |
inst_executed_global_stores |
用于全局存储的 Warp 级别指令 |
多上下文 |
inst_executed_local_loads |
用于本地加载的 Warp 级别指令 |
多上下文 |
inst_executed_local_stores |
用于本地存储的 Warp 级别指令 |
多上下文 |
inst_executed_shared_atomics |
用于原子和原子 CAS 的 Warp 级别共享指令 |
多上下文 |
inst_executed_shared_loads |
用于共享加载的 Warp 级别指令 |
多上下文 |
inst_executed_shared_stores |
用于共享存储的 Warp 级别指令 |
多上下文 |
inst_executed_surface_atomics |
用于表面原子和原子 cas 的 Warp 级别指令 |
多上下文 |
inst_executed_surface_loads |
用于表面加载的 Warp 级别指令 |
多上下文 |
inst_executed_surface_reductions |
用于表面归约的 Warp 级别指令 |
多上下文 |
inst_executed_surface_stores |
用于表面存储的 Warp 级别指令 |
多上下文 |
inst_executed_tex_ops |
用于纹理的 Warp 级别指令 |
多上下文 |
inst_fp_16 |
非谓词线程执行的半精度浮点指令数(算术、比较等)。这适用于计算能力 5.3。 |
多上下文* |
inst_fp_32 |
非谓词线程执行的单精度浮点指令数(算术、比较等) |
多上下文 |
inst_fp_64 |
非谓词线程执行的双精度浮点指令数(算术、比较等) |
多上下文 |
inst_integer |
非谓词线程执行的整数指令数 |
多上下文 |
inst_inter_thread_communication |
非谓词线程执行的线程间通信指令数 |
多上下文 |
inst_issued |
已发出的指令数 |
多上下文 |
inst_misc |
非谓词线程执行的杂项指令数 |
多上下文 |
inst_per_warp |
每个线程束执行的指令的平均数 |
多上下文 |
inst_replay_overhead |
每个执行的指令的重放平均数 |
多上下文 |
ipc |
每个周期的指令执行数 |
多上下文 |
issue_slot_utilization |
至少发出一条指令的发出槽的百分比,在所有周期中平均 |
多上下文 |
issue_slots |
使用的发出槽数 |
多上下文 |
issued_ipc |
每个周期的指令发出数 |
多上下文 |
l2_atomic_throughput |
在 L2 缓存中看到的原子和归约请求的内存读取吞吐量 |
多上下文 |
l2_atomic_transactions |
在 L2 缓存中看到的原子和归约请求的内存读取事务 |
多上下文* |
l2_global_atomic_store_bytes |
从统一缓存写入到 L2 的全局原子(ATOM 和 ATOM CAS)字节数 |
多上下文* |
l2_global_load_bytes |
从 L2 读取的统一缓存中全局加载未命中的字节数 |
多上下文* |
l2_global_reduction_bytes |
从统一缓存写入到 L2 的全局归约字节数 |
多上下文* |
l2_local_global_store_bytes |
从统一缓存写入到 L2 的本地和全局存储字节数。这不包括全局原子。 |
多上下文* |
l2_local_load_bytes |
从 L2 读取的统一缓存中本地加载未命中的字节数 |
多上下文* |
l2_read_throughput |
在 L2 缓存中看到的所有读取请求的内存读取吞吐量 |
多上下文* |
l2_read_transactions |
在 L2 缓存中看到的所有读取请求的内存读取事务 |
多上下文* |
l2_surface_atomic_store_bytes |
统一缓存和 L2 之间为表面原子(ATOM 和 ATOM CAS)传输的字节数 |
多上下文* |
l2_surface_load_bytes |
从 L2 读取的统一缓存中表面加载未命中的字节数 |
多上下文* |
l2_surface_reduction_bytes |
从统一缓存写入到 L2 的表面归约字节数 |
多上下文* |
l2_surface_store_bytes |
从统一缓存写入到 L2 的表面存储字节数。这不包括表面原子。 |
多上下文* |
l2_tex_hit_rate |
纹理缓存的所有请求在 L2 缓存中的命中率 |
多上下文* |
l2_tex_read_hit_rate |
纹理缓存的所有读取请求在 L2 缓存中的命中率。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
l2_tex_read_throughput |
在 L2 缓存中看到的来自纹理缓存的读取请求的内存读取吞吐量 |
多上下文* |
l2_tex_read_transactions |
在 L2 缓存中看到的来自纹理缓存的读取请求的内存读取事务 |
多上下文* |
l2_tex_write_hit_rate |
纹理缓存的所有写入请求在 L2 缓存中的命中率。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
l2_tex_write_throughput |
在 L2 缓存中看到的来自纹理缓存的写入请求的内存写入吞吐量 |
多上下文* |
l2_tex_write_transactions |
在 L2 缓存中看到的来自纹理缓存的写入请求的内存写入事务 |
多上下文* |
l2_utilization |
L2 缓存的利用率水平,相对于峰值利用率,在 0 到 10 的范围内 |
多上下文* |
l2_write_throughput |
在 L2 缓存中看到的所有写入请求的内存写入吞吐量 |
多上下文* |
l2_write_transactions |
L2 缓存中所有写入请求的内存写入事务 |
多上下文* |
ldst_executed |
执行的本地、全局、共享和纹理内存加载和存储指令数量 |
多上下文 |
ldst_fu_utilization |
多处理器功能单元的利用率,该功能单元在 0 到 10 的等级范围内执行共享加载、共享存储和常量加载指令 |
多上下文 |
ldst_issued |
发出的本地、全局、共享和纹理内存加载和存储指令数量 |
多上下文 |
local_hit_rate |
本地加载和存储的命中率 |
多上下文* |
local_load_requests |
来自多处理器的本地加载请求总数 |
多上下文* |
local_load_throughput |
本地内存加载吞吐量 |
多上下文* |
local_load_transactions |
本地内存加载事务数量 |
多上下文* |
local_load_transactions_per_request |
为每个本地内存加载执行的平均本地内存加载事务数 |
多上下文* |
local_memory_overhead |
L1 和 L2 缓存之间本地内存流量与总内存流量的比率,以百分比表示 |
多上下文* |
local_store_requests |
来自多处理器的本地存储请求总数 |
多上下文* |
local_store_throughput |
本地内存存储吞吐量 |
多上下文* |
local_store_transactions |
本地内存存储事务数量 |
多上下文* |
local_store_transactions_per_request |
为每个本地内存存储执行的平均本地内存存储事务数 |
多上下文* |
pcie_total_data_received |
通过 PCIe 接收的总数据字节数 |
设备 |
pcie_total_data_transmitted |
通过 PCIe 传输的总数据字节数 |
设备 |
shared_efficiency |
请求的共享内存吞吐量与要求的共享内存吞吐量的比率,以百分比表示 |
多上下文* |
shared_load_throughput |
共享内存加载吞吐量 |
多上下文* |
shared_load_transactions |
共享内存加载事务数量 |
多上下文* |
shared_load_transactions_per_request |
为每个共享内存加载执行的平均共享内存加载事务数 |
多上下文* |
shared_store_throughput |
共享内存存储吞吐量 |
多上下文* |
shared_store_transactions |
共享内存存储事务数量 |
多上下文* |
shared_store_transactions_per_request |
为每个共享内存存储执行的平均共享内存存储事务数 |
多上下文* |
shared_utilization |
共享内存相对于峰值利用率的利用率等级,范围为 0 到 10 |
多上下文* |
single_precision_fu_utilization |
多处理器功能单元的利用率等级,该功能单元在 0 到 10 的等级范围内执行单精度浮点指令和整数指令 |
多上下文 |
sm_efficiency |
在特定多处理器上至少一个 Warp 处于活动状态的时间百分比 |
多上下文* |
special_fu_utilization |
多处理器功能单元的利用率等级,该功能单元在 0 到 10 的等级范围内执行 sin、cos、ex2、popc、flo 和类似指令 |
多上下文 |
stall_constant_memory_dependency |
由于立即常量缓存未命中而发生的停顿百分比 |
多上下文 |
stall_exec_dependency |
由于指令所需的输入尚不可用而发生的停顿百分比 |
多上下文 |
stall_inst_fetch |
由于尚未获取下一条汇编指令而发生的停顿百分比 |
多上下文 |
stall_memory_dependency |
由于内存操作无法执行(因为所需资源不可用或未充分利用,或者因为给定类型的待处理请求过多)而发生的停顿百分比 |
多上下文 |
stall_memory_throttle |
由于内存节流而发生的停顿百分比 |
多上下文 |
stall_not_selected |
由于 Warp 未被选中而发生的停顿百分比 |
多上下文 |
stall_other |
由于其他原因而发生的停顿百分比 |
多上下文 |
stall_pipe_busy |
由于计算操作无法执行(因为计算流水线正忙)而发生的停顿百分比 |
多上下文 |
stall_sync |
由于 Warp 在 __syncthreads() 调用处被阻塞而发生的停顿百分比 |
多上下文 |
stall_texture |
由于纹理子系统已完全利用或有过多待处理请求而发生的停顿百分比 |
多上下文 |
surface_atomic_requests |
来自多处理器的表面原子(Atom 和 Atom CAS)请求总数 |
多上下文 |
surface_load_requests |
来自多处理器的表面加载请求总数 |
多上下文 |
surface_reduction_requests |
来自多处理器的表面归约请求总数 |
多上下文 |
surface_store_requests |
来自多处理器的表面存储请求总数 |
多上下文 |
sysmem_read_bytes |
从系统内存读取的字节数 |
多上下文* |
sysmem_read_throughput |
系统内存读取吞吐量 |
多上下文* |
sysmem_read_transactions |
系统内存读取事务数量 |
多上下文* |
sysmem_read_utilization |
系统内存相对于峰值利用率的读取利用率等级,范围为 0 到 10。这适用于计算能力 5.0 和 5.2。 |
多上下文 |
sysmem_utilization |
系统内存相对于峰值利用率的利用率等级,范围为 0 到 10。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
sysmem_write_bytes |
写入系统内存的字节数 |
多上下文* |
sysmem_write_throughput |
系统内存写入吞吐量 |
多上下文* |
sysmem_write_transactions |
系统内存写入事务数量 |
多上下文* |
sysmem_write_utilization |
系统内存相对于峰值利用率的写入利用率等级,范围为 0 到 10。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
tex_cache_hit_rate |
统一缓存命中率 |
多上下文* |
tex_cache_throughput |
统一缓存吞吐量 |
多上下文* |
tex_cache_transactions |
统一缓存读取事务 |
多上下文* |
tex_fu_utilization |
多处理器功能单元的利用率等级,该功能单元在 0 到 10 的等级范围内执行全局、本地和纹理内存指令 |
多上下文 |
tex_utilization |
统一缓存相对于峰值利用率的利用率等级,范围为 0 到 10 |
多上下文* |
texture_load_requests |
来自多处理器的纹理加载请求总数 |
多上下文 |
warp_execution_efficiency |
每个 Warp 的平均活动线程数与多处理器上支持的每个 Warp 的最大线程数的比率 |
多上下文 |
warp_nonpred_execution_efficiency |
每个 Warp 执行非谓词指令的平均活动线程数与多处理器上支持的每个 Warp 的最大线程数的比率 |
多上下文 |
* 此指标的“多上下文”范围仅在计算能力为 5.0 和 5.2 的设备上受支持。
2.14.1.2. Capability 6.x 的指标
计算能力为 6.x 的设备实现了下表所示的指标。
指标名称 |
描述 |
范围 |
|---|---|---|
achieved_occupancy |
每个活动周期中平均活动线程束与多处理器上支持的最大线程束数的比率 |
多上下文 |
atomic_transactions |
全局内存原子和归约事务 |
多上下文 |
atomic_transactions_per_request |
每个原子和归约指令执行的全局内存原子和归约事务的平均数 |
多上下文 |
branch_efficiency |
非发散分支与总分支的比率,以百分比表示 |
多上下文 |
cf_executed |
已执行的控制流指令数 |
多上下文 |
cf_fu_utilization |
多处理器功能单元的利用率水平,在 0 到 10 的范围内,用于执行控制流指令 |
多上下文 |
cf_issued |
已发出的控制流指令数 |
多上下文 |
double_precision_fu_utilization |
多处理器功能单元的利用率水平,在 0 到 10 的范围内,用于执行双精度浮点指令 |
多上下文 |
dram_read_bytes |
从 DRAM 读取到 L2 缓存的总字节数 |
多上下文 |
dram_read_throughput |
设备内存读取吞吐量。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
dram_read_transactions |
设备内存读取事务。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
dram_utilization |
设备内存的利用率水平,相对于峰值利用率,在 0 到 10 的范围内 |
多上下文 |
dram_write_bytes |
从 L2 缓存写入到 DRAM 的总字节数 |
多上下文 |
dram_write_throughput |
设备内存写入吞吐量。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
dram_write_transactions |
设备内存写入事务。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
ecc_吞吐量 |
从 L2 到 DRAM 的 ECC 吞吐量。这适用于计算能力 6.1。 |
多上下文 |
ecc_事务 |
L2 和 DRAM 之间的 ECC 事务数量。这适用于计算能力 6.1。 |
多上下文 |
eligible_warps_per_cycle |
每个活动周期中有资格发出的线程束的平均数 |
多上下文 |
flop_count_dp |
非谓词线程执行的双精度浮点运算数(加法、乘法和乘加)。每个乘加运算贡献 2 到计数。 |
多上下文 |
flop_count_dp_add |
非谓词线程执行的双精度浮点加法运算数。 |
多上下文 |
flop_count_dp_fma |
非谓词线程执行的双精度浮点乘加运算数。每个乘加运算贡献 1 到计数。 |
多上下文 |
flop_count_dp_mul |
非谓词线程执行的双精度浮点乘法运算数。 |
多上下文 |
flop_count_hp |
非谓词线程执行的半精度浮点运算数量(加法、乘法和乘加)。每个乘加运算贡献 2 到计数。 |
多上下文 |
flop_count_hp_add |
非谓词线程执行的半精度浮点加法运算数量。 |
多上下文 |
flop_count_hp_fma |
非谓词线程执行的半精度浮点乘加运算数量。每个乘加运算贡献 1 到计数。 |
多上下文 |
flop_count_hp_mul |
非谓词线程执行的半精度浮点乘法运算数量。 |
多上下文 |
flop_count_sp |
非谓词线程执行的单精度浮点运算数(加法、乘法和乘加)。每个乘加运算贡献 2 到计数。计数不包括特殊运算。 |
多上下文 |
flop_count_sp_add |
非谓词线程执行的单精度浮点加法运算数。 |
多上下文 |
flop_count_sp_fma |
非谓词线程执行的单精度浮点乘加运算数。每个乘加运算贡献 1 到计数。 |
多上下文 |
flop_count_sp_mul |
非谓词线程执行的单精度浮点乘法运算数。 |
多上下文 |
flop_count_sp_special |
非谓词线程执行的单精度浮点特殊运算数。 |
多上下文 |
flop_dp_efficiency |
实现的双精度浮点运算与峰值双精度浮点运算的比率 |
多上下文 |
flop_hp_efficiency |
实际与峰值半精度浮点运算之比 |
多上下文 |
flop_sp_efficiency |
实现的单精度浮点运算与峰值单精度浮点运算的比率 |
多上下文 |
gld_efficiency |
请求的全局内存加载吞吐量与所需的全局内存加载吞吐量的比率,以百分比表示。 |
多上下文 |
gld_requested_throughput |
请求的全局内存加载吞吐量 |
多上下文 |
gld_throughput |
全局内存加载吞吐量 |
多上下文 |
gld_transactions |
全局内存加载事务数 |
多上下文 |
gld_transactions_per_request |
每个全局内存加载执行的全局内存加载事务的平均数。 |
多上下文 |
global_atomic_requests |
来自多处理器的全局原子(Atom 和 Atom CAS)请求的总数 |
多上下文 |
global_hit_rate |
统一 l1/tex 缓存中全局加载的命中率。如果在内核中使用 malloc,指标值可能不正确。 |
多上下文 |
global_load_requests |
来自多处理器的全局加载请求的总数 |
多上下文 |
global_reduction_requests |
来自多处理器的全局归约请求的总数 |
多上下文 |
global_store_requests |
来自多处理器的全局存储请求的总数。这不包括原子请求。 |
多上下文 |
gst_efficiency |
请求的全局内存存储吞吐量与所需的全局内存存储吞吐量的比率,以百分比表示。 |
多上下文 |
gst_requested_throughput |
请求的全局内存存储吞吐量 |
多上下文 |
gst_throughput |
全局内存存储吞吐量 |
多上下文 |
gst_transactions |
全局内存存储事务数 |
多上下文 |
gst_transactions_per_request |
每个全局内存存储执行的全局内存存储事务的平均数 |
多上下文 |
half_precision_fu_utilization |
多处理器功能单元的利用率等级,该功能单元在 0 到 10 的等级范围内执行 16 位浮点指令 |
多上下文 |
inst_bit_convert |
非谓词线程执行的位转换指令数 |
多上下文 |
inst_compute_ld_st |
非谓词线程执行的计算加载/存储指令数 |
多上下文 |
inst_control |
非谓词线程执行的控制流指令数(跳转、分支等) |
多上下文 |
inst_executed |
已执行的指令数 |
多上下文 |
inst_executed_global_atomics |
用于全局原子和原子 cas 的 Warp 级别指令 |
多上下文 |
inst_executed_global_loads |
用于全局加载的 Warp 级别指令 |
多上下文 |
inst_executed_global_reductions |
用于全局归约的 Warp 级别指令 |
多上下文 |
inst_executed_global_stores |
用于全局存储的 Warp 级别指令 |
多上下文 |
inst_executed_local_loads |
用于本地加载的 Warp 级别指令 |
多上下文 |
inst_executed_local_stores |
用于本地存储的 Warp 级别指令 |
多上下文 |
inst_executed_shared_atomics |
用于原子和原子 CAS 的 Warp 级别共享指令 |
多上下文 |
inst_executed_shared_loads |
用于共享加载的 Warp 级别指令 |
多上下文 |
inst_executed_shared_stores |
用于共享存储的 Warp 级别指令 |
多上下文 |
inst_executed_surface_atomics |
用于表面原子和原子 cas 的 Warp 级别指令 |
多上下文 |
inst_executed_surface_loads |
用于表面加载的 Warp 级别指令 |
多上下文 |
inst_executed_surface_reductions |
用于表面归约的 Warp 级别指令 |
多上下文 |
inst_executed_surface_stores |
用于表面存储的 Warp 级别指令 |
多上下文 |
inst_executed_tex_ops |
用于纹理的 Warp 级别指令 |
多上下文 |
inst_fp_16 |
非谓词线程执行的半精度浮点指令数量(算术、比较等) |
多上下文 |
inst_fp_32 |
非谓词线程执行的单精度浮点指令数(算术、比较等) |
多上下文 |
inst_fp_64 |
非谓词线程执行的双精度浮点指令数(算术、比较等) |
多上下文 |
inst_integer |
非谓词线程执行的整数指令数 |
多上下文 |
inst_inter_thread_communication |
非谓词线程执行的线程间通信指令数 |
多上下文 |
inst_issued |
已发出的指令数 |
多上下文 |
inst_misc |
非谓词线程执行的杂项指令数 |
多上下文 |
inst_per_warp |
每个线程束执行的指令的平均数 |
多上下文 |
inst_replay_overhead |
每个执行的指令的重放平均数 |
多上下文 |
ipc |
每个周期的指令执行数 |
多上下文 |
issue_slot_utilization |
至少发出一条指令的发出槽的百分比,在所有周期中平均 |
多上下文 |
issue_slots |
使用的发出槽数 |
多上下文 |
issued_ipc |
每个周期的指令发出数 |
多上下文 |
l2_atomic_throughput |
在 L2 缓存中看到的原子和归约请求的内存读取吞吐量 |
多上下文 |
l2_atomic_transactions |
在 L2 缓存中看到的原子和归约请求的内存读取事务 |
多上下文 |
l2_global_atomic_store_bytes |
从统一缓存写入到 L2 的全局原子(ATOM 和 ATOM CAS)字节数 |
多上下文 |
l2_global_load_bytes |
从 L2 读取的统一缓存中全局加载未命中的字节数 |
多上下文 |
l2_global_reduction_bytes |
从统一缓存写入到 L2 的全局归约字节数 |
多上下文 |
l2_local_global_store_bytes |
从统一缓存写入到 L2 的本地和全局存储字节数。这不包括全局原子。 |
多上下文 |
l2_local_load_bytes |
从 L2 读取的统一缓存中本地加载未命中的字节数 |
多上下文 |
l2_read_throughput |
在 L2 缓存中看到的所有读取请求的内存读取吞吐量 |
多上下文 |
l2_read_transactions |
在 L2 缓存中看到的所有读取请求的内存读取事务 |
多上下文 |
l2_surface_atomic_store_bytes |
统一缓存和 L2 之间为表面原子(ATOM 和 ATOM CAS)传输的字节数 |
多上下文 |
l2_surface_load_bytes |
从 L2 读取的统一缓存中表面加载未命中的字节数 |
多上下文 |
l2_surface_reduction_bytes |
从统一缓存写入到 L2 的表面归约字节数 |
多上下文 |
l2_surface_store_bytes |
从统一缓存写入到 L2 的表面存储字节数。这不包括表面原子。 |
多上下文 |
l2_tex_hit_rate |
纹理缓存的所有请求在 L2 缓存中的命中率 |
多上下文 |
l2_tex_read_hit_rate |
来自纹理缓存的所有读取请求在 L2 缓存的命中率。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
l2_tex_read_throughput |
在 L2 缓存中看到的来自纹理缓存的读取请求的内存读取吞吐量 |
多上下文 |
l2_tex_read_transactions |
在 L2 缓存中看到的来自纹理缓存的读取请求的内存读取事务 |
多上下文 |
l2_tex_write_hit_rate |
来自纹理缓存的所有写入请求在 L2 缓存的命中率。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
l2_tex_write_throughput |
在 L2 缓存中看到的来自纹理缓存的写入请求的内存写入吞吐量 |
多上下文 |
l2_tex_write_transactions |
在 L2 缓存中看到的来自纹理缓存的写入请求的内存写入事务 |
多上下文 |
l2_utilization |
L2 缓存的利用率水平,相对于峰值利用率,在 0 到 10 的范围内 |
多上下文 |
l2_write_throughput |
在 L2 缓存中看到的所有写入请求的内存写入吞吐量 |
多上下文 |
l2_write_transactions |
L2 缓存中所有写入请求的内存写入事务 |
多上下文 |
ldst_executed |
执行的本地、全局、共享和纹理内存加载和存储指令数量 |
多上下文 |
ldst_fu_utilization |
多处理器功能单元的利用率,该功能单元在 0 到 10 的等级范围内执行共享加载、共享存储和常量加载指令 |
多上下文 |
ldst_issued |
发出的本地、全局、共享和纹理内存加载和存储指令数量 |
多上下文 |
local_hit_rate |
本地加载和存储的命中率 |
多上下文 |
local_load_requests |
来自多处理器的本地加载请求总数 |
多上下文 |
local_load_throughput |
本地内存加载吞吐量 |
多上下文 |
local_load_transactions |
本地内存加载事务数量 |
多上下文 |
local_load_transactions_per_request |
为每个本地内存加载执行的平均本地内存加载事务数 |
多上下文 |
local_memory_overhead |
L1 和 L2 缓存之间本地内存流量与总内存流量的比率,以百分比表示 |
多上下文 |
local_store_requests |
来自多处理器的本地存储请求总数 |
多上下文 |
local_store_throughput |
本地内存存储吞吐量 |
多上下文 |
local_store_transactions |
本地内存存储事务数量 |
多上下文 |
local_store_transactions_per_request |
为每个本地内存存储执行的平均本地内存存储事务数 |
多上下文 |
nvlink_overhead_data_received |
通过 NVLink 接收的开销数据与总数据的比率。这适用于计算能力 6.0。 |
设备 |
nvlink_overhead_data_transmitted |
通过 NVLink 传输的开销数据与总数据的比率。这适用于计算能力 6.0。 |
设备 |
nvlink_receive_throughput |
每秒通过 NVLinks 接收的字节数。这适用于计算能力 6.0。 |
设备 |
nvlink_total_data_received |
通过 NVLinks 接收的总数据字节数,包括标头。这适用于计算能力 6.0。 |
设备 |
nvlink_total_data_transmitted |
通过 NVLinks 传输的总数据字节数,包括标头。这适用于计算能力 6.0。 |
设备 |
nvlink_total_nratom_data_transmitted |
通过 NVLinks 传输的总非归约原子数据字节数。这适用于计算能力 6.0。 |
设备 |
nvlink_total_ratom_data_transmitted |
通过 NVLinks 传输的总归约原子数据字节数。这适用于计算能力 6.0。 |
设备 |
nvlink_total_response_data_received |
通过 NVLink 接收的总响应数据字节数,响应数据包括读取请求的数据和非归约原子请求的结果。这适用于计算能力 6.0。 |
设备 |
nvlink_total_write_data_transmitted |
通过 NVLinks 传输的总写入数据字节数。这适用于计算能力 6.0。 |
设备 |
nvlink_transmit_throughput |
每秒通过 NVLinks 传输的字节数。这适用于计算能力 6.0。 |
设备 |
nvlink_user_data_received |
通过 NVLinks 接收的用户数据字节数,不包括标头。这适用于计算能力 6.0。 |
设备 |
nvlink_user_data_transmitted |
通过 NVLinks 传输的用户数据字节数,不包括标头。这适用于计算能力 6.0。 |
设备 |
nvlink_user_nratom_data_transmitted |
通过 NVLinks 传输的总非归约原子用户数据字节数。这适用于计算能力 6.0。 |
设备 |
nvlink_user_ratom_data_transmitted |
通过 NVLinks 传输的总归约原子用户数据字节数。这适用于计算能力 6.0。 |
设备 |
nvlink_user_response_data_received |
通过 NVLink 接收的总用户响应数据字节数,响应数据包括读取请求的数据和非归约原子请求的结果。这适用于计算能力 6.0。 |
设备 |
nvlink_user_write_data_transmitted |
通过 NVLinks 传输的用户写入数据字节数。这适用于计算能力 6.0。 |
设备 |
pcie_total_data_received |
通过 PCIe 接收的总数据字节数 |
设备 |
pcie_total_data_transmitted |
通过 PCIe 传输的总数据字节数 |
设备 |
shared_efficiency |
请求的共享内存吞吐量与要求的共享内存吞吐量的比率,以百分比表示 |
多上下文 |
shared_load_throughput |
共享内存加载吞吐量 |
多上下文 |
shared_load_transactions |
共享内存加载事务数量 |
多上下文 |
shared_load_transactions_per_request |
为每个共享内存加载执行的平均共享内存加载事务数 |
多上下文 |
shared_store_throughput |
共享内存存储吞吐量 |
多上下文 |
shared_store_transactions |
共享内存存储事务数量 |
多上下文 |
shared_store_transactions_per_request |
为每个共享内存存储执行的平均共享内存存储事务数 |
多上下文 |
shared_utilization |
共享内存相对于峰值利用率的利用率等级,范围为 0 到 10 |
多上下文 |
single_precision_fu_utilization |
多处理器功能单元的利用率等级,该功能单元在 0 到 10 的等级范围内执行单精度浮点指令和整数指令 |
多上下文 |
sm_efficiency |
在特定多处理器上至少一个 Warp 处于活动状态的时间百分比 |
多上下文 |
special_fu_utilization |
多处理器功能单元的利用率等级,该功能单元在 0 到 10 的等级范围内执行 sin、cos、ex2、popc、flo 和类似指令 |
多上下文 |
stall_constant_memory_dependency |
由于立即常量缓存未命中而发生的停顿百分比 |
多上下文 |
stall_exec_dependency |
由于指令所需的输入尚不可用而发生的停顿百分比 |
多上下文 |
stall_inst_fetch |
由于尚未获取下一条汇编指令而发生的停顿百分比 |
多上下文 |
stall_memory_dependency |
由于内存操作无法执行(因为所需资源不可用或未充分利用,或者因为给定类型的待处理请求过多)而发生的停顿百分比 |
多上下文 |
stall_memory_throttle |
由于内存节流而发生的停顿百分比 |
多上下文 |
stall_not_selected |
由于 Warp 未被选中而发生的停顿百分比 |
多上下文 |
stall_other |
由于其他原因而发生的停顿百分比 |
多上下文 |
stall_pipe_busy |
由于计算操作无法执行(因为计算流水线正忙)而发生的停顿百分比 |
多上下文 |
stall_sync |
由于 Warp 在 __syncthreads() 调用处被阻塞而发生的停顿百分比 |
多上下文 |
stall_texture |
由于纹理子系统已完全利用或有过多待处理请求而发生的停顿百分比 |
多上下文 |
surface_atomic_requests |
来自多处理器的表面原子(Atom 和 Atom CAS)请求总数 |
多上下文 |
surface_load_requests |
来自多处理器的表面加载请求总数 |
多上下文 |
surface_reduction_requests |
来自多处理器的表面归约请求总数 |
多上下文 |
surface_store_requests |
来自多处理器的表面存储请求总数 |
多上下文 |
sysmem_read_bytes |
从系统内存读取的字节数 |
多上下文 |
sysmem_read_throughput |
系统内存读取吞吐量 |
多上下文 |
sysmem_read_transactions |
系统内存读取事务数量 |
多上下文 |
sysmem_read_utilization |
系统内存相对于峰值利用率的读取利用率等级,范围为 0 到 10。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
sysmem_utilization |
系统内存相对于峰值利用率的利用率等级,范围为 0 到 10。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
sysmem_write_bytes |
写入系统内存的字节数 |
多上下文 |
sysmem_write_throughput |
系统内存写入吞吐量 |
多上下文 |
sysmem_write_transactions |
系统内存写入事务数量 |
多上下文 |
sysmem_write_utilization |
系统内存相对于峰值利用率的写入利用率等级,范围为 0 到 10。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
tex_cache_hit_rate |
统一缓存命中率 |
多上下文 |
tex_cache_throughput |
统一缓存吞吐量 |
多上下文 |
tex_cache_transactions |
统一缓存读取事务 |
多上下文 |
tex_fu_utilization |
多处理器功能单元的利用率等级,该功能单元在 0 到 10 的等级范围内执行全局、本地和纹理内存指令 |
多上下文 |
tex_utilization |
统一缓存相对于峰值利用率的利用率等级,范围为 0 到 10 |
多上下文 |
texture_load_requests |
来自多处理器的纹理加载请求总数 |
多上下文 |
unique_warps_launched |
启动的 Warp 数量。值不受计算抢占的影响。 |
多上下文 |
warp_execution_efficiency |
每个 Warp 的平均活动线程数与多处理器上支持的每个 Warp 的最大线程数的比率 |
多上下文 |
warp_nonpred_execution_efficiency |
每个 Warp 执行非谓词指令的平均活动线程数与多处理器上支持的每个 Warp 的最大线程数的比率 |
多上下文 |
2.14.1.3. Capability 7.0 的指标
计算能力为 7.0 的设备实现了下表所示的指标。
指标名称 |
描述 |
范围 |
|---|---|---|
achieved_occupancy |
每个活动周期中平均活动线程束与多处理器上支持的最大线程束数的比率 |
多上下文 |
atomic_transactions |
全局内存原子和归约事务 |
多上下文 |
atomic_transactions_per_request |
每个原子和归约指令执行的全局内存原子和归约事务的平均数 |
多上下文 |
branch_efficiency |
分支指令与分支指令和发散分支指令之和的比率 |
多上下文 |
cf_executed |
已执行的控制流指令数 |
多上下文 |
cf_fu_utilization |
多处理器功能单元的利用率水平,在 0 到 10 的范围内,用于执行控制流指令 |
多上下文 |
cf_issued |
已发出的控制流指令数 |
多上下文 |
double_precision_fu_utilization |
多处理器功能单元的利用率水平,在 0 到 10 的范围内,用于执行双精度浮点指令 |
多上下文 |
dram_read_bytes |
从 DRAM 读取到 L2 缓存的总字节数 |
多上下文 |
dram_read_throughput |
设备内存读取吞吐量 |
多上下文 |
dram_read_transactions |
设备内存读取事务 |
多上下文 |
dram_utilization |
设备内存的利用率水平,相对于峰值利用率,在 0 到 10 的范围内 |
多上下文 |
dram_write_bytes |
从 L2 缓存写入到 DRAM 的总字节数 |
多上下文 |
dram_write_throughput |
设备内存写入吞吐量 |
多上下文 |
dram_write_transactions |
设备内存写入事务 |
多上下文 |
eligible_warps_per_cycle |
每个活动周期中有资格发出的线程束的平均数 |
多上下文 |
flop_count_dp |
非谓词线程执行的双精度浮点运算数(加法、乘法和乘加)。每个乘加运算贡献 2 到计数。 |
多上下文 |
flop_count_dp_add |
非谓词线程执行的双精度浮点加法运算数。 |
多上下文 |
flop_count_dp_fma |
非谓词线程执行的双精度浮点乘加运算数。每个乘加运算贡献 1 到计数。 |
多上下文 |
flop_count_dp_mul |
非谓词线程执行的双精度浮点乘法运算数。 |
多上下文 |
flop_count_hp |
非谓词线程执行的半精度浮点运算数量(加法、乘法和乘加)。每个乘加运算根据输入数量贡献 2 或 4 到计数。 |
多上下文 |
flop_count_hp_add |
非谓词线程执行的半精度浮点加法运算数量。 |
多上下文 |
flop_count_hp_fma |
非谓词线程执行的半精度浮点乘加运算数量。每个乘加运算根据输入数量贡献 2 或 4 到计数。 |
多上下文 |
flop_count_hp_mul |
非谓词线程执行的半精度浮点乘法运算数量。 |
多上下文 |
flop_count_sp |
非谓词线程执行的单精度浮点运算数(加法、乘法和乘加)。每个乘加运算贡献 2 到计数。计数不包括特殊运算。 |
多上下文 |
flop_count_sp_add |
非谓词线程执行的单精度浮点加法运算数。 |
多上下文 |
flop_count_sp_fma |
非谓词线程执行的单精度浮点乘加运算数。每个乘加运算贡献 1 到计数。 |
多上下文 |
flop_count_sp_mul |
非谓词线程执行的单精度浮点乘法运算数。 |
多上下文 |
flop_count_sp_special |
非谓词线程执行的单精度浮点特殊运算数。 |
多上下文 |
flop_dp_efficiency |
实现的双精度浮点运算与峰值双精度浮点运算的比率 |
多上下文 |
flop_hp_efficiency |
实际与峰值半精度浮点运算之比 |
多上下文 |
flop_sp_efficiency |
实现的单精度浮点运算与峰值单精度浮点运算的比率 |
多上下文 |
gld_efficiency |
请求的全局内存加载吞吐量与所需的全局内存加载吞吐量的比率,以百分比表示。 |
多上下文 |
gld_requested_throughput |
请求的全局内存加载吞吐量 |
多上下文 |
gld_throughput |
全局内存加载吞吐量 |
多上下文 |
gld_transactions |
全局内存加载事务数 |
多上下文 |
gld_transactions_per_request |
每个全局内存加载执行的全局内存加载事务的平均数。 |
多上下文 |
global_atomic_requests |
来自多处理器的全局原子(Atom 和 Atom CAS)请求的总数 |
多上下文 |
global_hit_rate |
统一 L1/纹理缓存中全局加载和存储的命中率 |
多上下文 |
global_load_requests |
来自多处理器的全局加载请求的总数 |
多上下文 |
global_reduction_requests |
来自多处理器的全局归约请求的总数 |
多上下文 |
global_store_requests |
来自多处理器的全局存储请求的总数。这不包括原子请求。 |
多上下文 |
gst_efficiency |
请求的全局内存存储吞吐量与所需的全局内存存储吞吐量的比率,以百分比表示。 |
多上下文 |
gst_requested_throughput |
请求的全局内存存储吞吐量 |
多上下文 |
gst_throughput |
全局内存存储吞吐量 |
多上下文 |
gst_transactions |
全局内存存储事务数 |
多上下文 |
gst_transactions_per_request |
每个全局内存存储执行的全局内存存储事务的平均数 |
多上下文 |
half_precision_fu_utilization |
多处理器功能单元的利用率等级,该功能单元在 0 到 10 的等级范围内执行 16 位浮点指令。请注意,这不指定 Tensor Core 单元的利用率等级 |
多上下文 |
inst_bit_convert |
非谓词线程执行的位转换指令数 |
多上下文 |
inst_compute_ld_st |
非谓词线程执行的计算加载/存储指令数 |
多上下文 |
inst_control |
非谓词线程执行的控制流指令数(跳转、分支等) |
多上下文 |
inst_executed |
已执行的指令数 |
多上下文 |
inst_executed_global_atomics |
用于全局原子和原子 cas 的 Warp 级别指令 |
多上下文 |
inst_executed_global_loads |
用于全局加载的 Warp 级别指令 |
多上下文 |
inst_executed_global_reductions |
用于全局归约的 Warp 级别指令 |
多上下文 |
inst_executed_global_stores |
用于全局存储的 Warp 级别指令 |
多上下文 |
inst_executed_local_loads |
用于本地加载的 Warp 级别指令 |
多上下文 |
inst_executed_local_stores |
用于本地存储的 Warp 级别指令 |
多上下文 |
inst_executed_shared_atomics |
用于原子和原子 CAS 的 Warp 级别共享指令 |
多上下文 |
inst_executed_shared_loads |
用于共享加载的 Warp 级别指令 |
多上下文 |
inst_executed_shared_stores |
用于共享存储的 Warp 级别指令 |
多上下文 |
inst_executed_surface_atomics |
用于表面原子和原子 cas 的 Warp 级别指令 |
多上下文 |
inst_executed_surface_loads |
用于表面加载的 Warp 级别指令 |
多上下文 |
inst_executed_surface_reductions |
用于表面归约的 Warp 级别指令 |
多上下文 |
inst_executed_surface_stores |
用于表面存储的 Warp 级别指令 |
多上下文 |
inst_executed_tex_ops |
用于纹理的 Warp 级别指令 |
多上下文 |
inst_fp_16 |
非谓词线程执行的半精度浮点指令数量(算术、比较等) |
多上下文 |
inst_fp_32 |
非谓词线程执行的单精度浮点指令数(算术、比较等) |
多上下文 |
inst_fp_64 |
非谓词线程执行的双精度浮点指令数(算术、比较等) |
多上下文 |
inst_integer |
非谓词线程执行的整数指令数 |
多上下文 |
inst_inter_thread_communication |
非谓词线程执行的线程间通信指令数 |
多上下文 |
inst_issued |
已发出的指令数 |
多上下文 |
inst_misc |
非谓词线程执行的杂项指令数 |
多上下文 |
inst_per_warp |
每个线程束执行的指令的平均数 |
多上下文 |
inst_replay_overhead |
每个执行的指令的重放平均数 |
多上下文 |
ipc |
每个周期的指令执行数 |
多上下文 |
issue_slot_utilization |
至少发出一条指令的发出槽的百分比,在所有周期中平均 |
多上下文 |
issue_slots |
使用的发出槽数 |
多上下文 |
issued_ipc |
每个周期的指令发出数 |
多上下文 |
l2_atomic_throughput |
在 L2 缓存中看到的原子和归约请求的内存读取吞吐量 |
多上下文 |
l2_atomic_transactions |
在 L2 缓存中看到的原子和归约请求的内存读取事务 |
多上下文 |
l2_global_atomic_store_bytes |
从 L1 写入到 L2 的全局原子操作(ATOM 和 ATOM CAS)字节数 |
多上下文 |
l2_global_load_bytes |
从 L2 读取的全局加载在 L1 中未命中的字节数 |
多上下文 |
l2_local_global_store_bytes |
从 L1 写入到 L2 的本地和全局存储字节数。这不包括全局原子操作。 |
多上下文 |
l2_local_load_bytes |
从 L2 读取的本地加载在 L1 中未命中的字节数 |
多上下文 |
l2_read_throughput |
在 L2 缓存中看到的所有读取请求的内存读取吞吐量 |
多上下文 |
l2_read_transactions |
在 L2 缓存中看到的所有读取请求的内存读取事务 |
多上下文 |
l2_surface_load_bytes |
从 L2 读取的表面加载在 L1 中未命中的字节数 |
多上下文 |
l2_surface_store_bytes |
从 L2 读取的表面存储在 L1 中未命中的字节数 |
多上下文 |
l2_tex_hit_rate |
纹理缓存的所有请求在 L2 缓存中的命中率 |
多上下文 |
l2_tex_read_hit_rate |
来自纹理缓存的所有读取请求在 L2 缓存的命中率 |
多上下文 |
l2_tex_read_throughput |
在 L2 缓存中看到的来自纹理缓存的读取请求的内存读取吞吐量 |
多上下文 |
l2_tex_read_transactions |
在 L2 缓存中看到的来自纹理缓存的读取请求的内存读取事务 |
多上下文 |
l2_tex_write_hit_rate |
来自纹理缓存的所有写入请求在 L2 缓存的命中率 |
多上下文 |
l2_tex_write_throughput |
在 L2 缓存中看到的来自纹理缓存的写入请求的内存写入吞吐量 |
多上下文 |
l2_tex_write_transactions |
在 L2 缓存中看到的来自纹理缓存的写入请求的内存写入事务 |
多上下文 |
l2_utilization |
L2 缓存的利用率水平,相对于峰值利用率,在 0 到 10 的范围内 |
多上下文 |
l2_write_throughput |
在 L2 缓存中看到的所有写入请求的内存写入吞吐量 |
多上下文 |
l2_write_transactions |
L2 缓存中所有写入请求的内存写入事务 |
多上下文 |
ldst_executed |
执行的本地、全局、共享和纹理内存加载和存储指令数量 |
多上下文 |
ldst_fu_utilization |
多处理器功能单元的利用率,该功能单元在 0 到 10 的等级范围内执行共享加载、共享存储和常量加载指令 |
多上下文 |
ldst_issued |
发出的本地、全局、共享和纹理内存加载和存储指令数量 |
多上下文 |
local_hit_rate |
本地加载和存储的命中率 |
多上下文 |
local_load_requests |
来自多处理器的本地加载请求总数 |
多上下文 |
local_load_throughput |
本地内存加载吞吐量 |
多上下文 |
local_load_transactions |
本地内存加载事务数量 |
多上下文 |
local_load_transactions_per_request |
为每个本地内存加载执行的平均本地内存加载事务数 |
多上下文 |
local_memory_overhead |
L1 和 L2 缓存之间本地内存流量与总内存流量的比率,以百分比表示 |
多上下文 |
local_store_requests |
来自多处理器的本地存储请求总数 |
多上下文 |
local_store_throughput |
本地内存存储吞吐量 |
多上下文 |
local_store_transactions |
本地内存存储事务数量 |
多上下文 |
local_store_transactions_per_request |
为每个本地内存存储执行的平均本地内存存储事务数 |
多上下文 |
nvlink_overhead_data_received |
通过 NVLink 接收的开销数据与总数据的比率。 |
设备 |
nvlink_overhead_data_transmitted |
通过 NVLink 传输的开销数据与总数据的比率。 |
设备 |
nvlink_receive_throughput |
每秒通过 NVLinks 接收的字节数。 |
设备 |
nvlink_total_data_received |
通过 NVLinks 接收的总数据字节数,包括标头。 |
设备 |
nvlink_total_data_transmitted |
通过 NVLinks 传输的总数据字节数,包括标头。 |
设备 |
nvlink_total_nratom_data_transmitted |
通过 NVLinks 传输的总非归约原子数据字节数。 |
设备 |
nvlink_total_ratom_data_transmitted |
通过 NVLinks 传输的总归约原子数据字节数。 |
设备 |
nvlink_total_response_data_received |
通过 NVLink 接收的总响应数据字节数,响应数据包括读取请求的数据和非归约原子请求的结果。 |
设备 |
nvlink_total_write_data_transmitted |
通过 NVLinks 传输的总写入数据字节数。 |
设备 |
nvlink_transmit_throughput |
每秒通过 NVLinks 传输的字节数。 |
设备 |
nvlink_user_data_received |
通过 NVLinks 接收的用户数据字节数,不包括标头。 |
设备 |
nvlink_user_data_transmitted |
通过 NVLinks 传输的用户数据字节数,不包括标头。 |
设备 |
nvlink_user_nratom_data_transmitted |
通过 NVLinks 传输的总非归约原子用户数据字节数。 |
设备 |
nvlink_user_ratom_data_transmitted |
通过 NVLinks 传输的总归约原子用户数据字节数。 |
设备 |
nvlink_user_response_data_received |
通过 NVLink 接收的总用户响应数据字节数,响应数据包括读取请求的数据和非归约原子请求的结果。 |
设备 |
nvlink_user_write_data_transmitted |
通过 NVLinks 传输的用户写入数据字节数。 |
设备 |
pcie_total_data_received |
通过 PCIe 接收的总数据字节数 |
设备 |
pcie_total_data_transmitted |
通过 PCIe 传输的总数据字节数 |
设备 |
shared_efficiency |
请求的共享内存吞吐量与要求的共享内存吞吐量的比率,以百分比表示 |
多上下文 |
shared_load_throughput |
共享内存加载吞吐量 |
多上下文 |
shared_load_transactions |
共享内存加载事务数量 |
多上下文 |
shared_load_transactions_per_request |
为每个共享内存加载执行的平均共享内存加载事务数 |
多上下文 |
shared_store_throughput |
共享内存存储吞吐量 |
多上下文 |
shared_store_transactions |
共享内存存储事务数量 |
多上下文 |
shared_store_transactions_per_request |
为每个共享内存存储执行的平均共享内存存储事务数 |
多上下文 |
shared_utilization |
共享内存相对于峰值利用率的利用率等级,范围为 0 到 10 |
多上下文 |
single_precision_fu_utilization |
多处理器功能单元的利用率等级,该功能单元在 0 到 10 的等级范围内执行单精度浮点指令 |
多上下文 |
sm_efficiency |
在特定多处理器上至少一个 Warp 处于活动状态的时间百分比 |
多上下文 |
special_fu_utilization |
多处理器功能单元的利用率等级,该功能单元在 0 到 10 的等级范围内执行 sin、cos、ex2、popc、flo 和类似指令 |
多上下文 |
stall_constant_memory_dependency |
由于立即常量缓存未命中而发生的停顿百分比 |
多上下文 |
stall_exec_dependency |
由于指令所需的输入尚不可用而发生的停顿百分比 |
多上下文 |
stall_inst_fetch |
由于尚未获取下一条汇编指令而发生的停顿百分比 |
多上下文 |
stall_memory_dependency |
由于内存操作无法执行(因为所需资源不可用或未充分利用,或者因为给定类型的待处理请求过多)而发生的停顿百分比 |
多上下文 |
stall_memory_throttle |
由于内存节流而发生的停顿百分比 |
多上下文 |
stall_not_selected |
由于 Warp 未被选中而发生的停顿百分比 |
多上下文 |
stall_other |
由于其他原因而发生的停顿百分比 |
多上下文 |
stall_pipe_busy |
由于计算操作无法执行(因为计算流水线正忙)而发生的停顿百分比 |
多上下文 |
stall_sleeping |
由于 Warp 休眠而发生的停顿百分比 |
多上下文 |
stall_sync |
由于 Warp 在 __syncthreads() 调用处被阻塞而发生的停顿百分比 |
多上下文 |
stall_texture |
由于纹理子系统已完全利用或有过多待处理请求而发生的停顿百分比 |
多上下文 |
surface_atomic_requests |
来自多处理器的表面原子(Atom 和 Atom CAS)请求总数 |
多上下文 |
surface_load_requests |
来自多处理器的表面加载请求总数 |
多上下文 |
surface_reduction_requests |
来自多处理器的表面归约请求总数 |
多上下文 |
surface_store_requests |
来自多处理器的表面存储请求总数 |
多上下文 |
sysmem_read_bytes |
从系统内存读取的字节数 |
多上下文 |
sysmem_read_throughput |
系统内存读取吞吐量 |
多上下文 |
sysmem_read_transactions |
系统内存读取事务数量 |
多上下文 |
sysmem_read_utilization |
系统内存相对于峰值利用率的读取利用率等级,范围为 0 到 10 |
多上下文 |
sysmem_utilization |
系统内存相对于峰值利用率的利用率等级,范围为 0 到 10 |
多上下文 |
sysmem_write_bytes |
写入系统内存的字节数 |
多上下文 |
sysmem_write_throughput |
系统内存写入吞吐量 |
多上下文 |
sysmem_write_transactions |
系统内存写入事务数量 |
多上下文 |
sysmem_write_utilization |
系统内存相对于峰值利用率的写入利用率等级,范围为 0 到 10 |
多上下文 |
tensor_precision_fu_utilization |
多处理器功能单元的利用率等级,该功能单元在 0 到 10 的等级范围内执行 Tensor Core 指令 |
多上下文 |
tensor_int_fu_utilization |
多处理器功能单元的利用率等级,该功能单元在 0 到 10 的等级范围内执行 Tensor Core int8 指令。此指标仅适用于计算能力为 7.2 的设备。 |
多上下文 |
tex_cache_hit_rate |
统一缓存命中率 |
多上下文 |
tex_cache_throughput |
从统一缓存到多处理器的读取吞吐量 |
多上下文 |
tex_cache_transactions |
从统一缓存到多处理器的读取事务 |
多上下文 |
tex_fu_utilization |
多处理器功能单元的利用率等级,该功能单元在 0 到 10 的等级范围内执行全局、本地和纹理内存指令 |
多上下文 |
tex_utilization |
统一缓存相对于峰值利用率的利用率等级,范围为 0 到 10 |
多上下文 |
texture_load_requests |
来自多处理器的纹理加载请求总数 |
多上下文 |
warp_execution_efficiency |
每个 Warp 的平均活动线程数与多处理器上支持的每个 Warp 的最大线程数的比率 |
多上下文 |
warp_nonpred_execution_efficiency |
每个 Warp 执行非谓词指令的平均活动线程数与多处理器上支持的每个 Warp 的最大线程数的比率 |
多上下文 |
2.15. 分析 API 的演变
随着时间的推移,GPU 性能指标的收集已通过各种分析 API 集不断发展。最初,使用了 CUPTI 事件 API 和 CUPTI 指标 API,但这些 API 在 Turing 及更高版本的 GPU 架构上不受支持。在 CUDA 10.0 版本发布时,引入了用于目标 API 的 CUPTI 分析 API 和用于主机 API 的 Perfworks 指标 API,以提供低且确定的分析开销。这些 API 在 Volta 及更高版本的 GPU 架构上受支持。Perfworks API 是低级别的,并且会受到接口级别更改的影响。
随着 CUPTI 的发展,需要引入一组新的分析 API,以简化使用、使用户免受低级别概念的影响,并易于适应 Perfworks 指标 API 的更改。因此,CUPTI 在 CUDA 12.6 GA 版本中围绕 Perfworks 指标 API 添加了一组新的主机 API。这些主机 API 在头文件 cupti_profiler_host.h 中提供,被称为 CUPTI 分析器主机 API。作为补充,在 CUDA 12.6 Update 2 中添加了一组新的目标 API,以简化新用户的分析,并将调用结构与其他分析 API 对齐,以加快学习速度并提高适应性。这些目标 API 在头文件 cupti_range_profiler.h 中提供,被称为 CUPTI 范围分析 API。对于范围分析,强烈建议用户,尤其是该领域的新手,使用 CUDA 12.6 中引入的新主机和目标 API。引入新的 CUPTI 范围分析 API 是必要的,以解决现有分析 API 的局限性,并提供更用户友好和适应性强的分析体验。CUPTI 分析 API 可能会在未来版本中被弃用并可能移除。因此,过渡到新的主机和目标 API 将确保持续支持、与最新硬件的兼容性以及访问增强的分析能力。
不同 CUPTI API 支持的 GPU 架构在表格中列出。重要的是要注意,不能混合使用不同组的分析 API。
2.16. CUPTI 开销
当 CUPTI 用于 CUDA 应用程序的跟踪或分析时,会产生开销。开销在不同的应用程序之间可能会有很大差异。这主要取决于应用程序中 CUDA 活动的密度;CUDA 活动越少,CUPTI 开销越小。一般来说,跟踪(即活动 API)的开销远小于分析(即事件和指标 API)的开销。
2.16.1. 跟踪开销
跟踪 API 的目标之一是提供 CUDA 活动时间信息的非侵入式收集。跟踪是收集细粒度运行时信息的低开销机制。
2.16.1.1. 执行开销
考虑以下可能影响应用程序执行开销的几点:
仅启用感兴趣的活动和回调。
尽早从回调返回。回调从主机发出,如果未尽早返回,这些回调可能会阻止 GPU 上的工作提交,因为 CUPTI 以及 CUDA 驱动程序无法在发出回调的主机线程上取得向前进展。
API
cuptiActivityEnableDriverApi和cuptiActivityEnableRuntimeApi可用于限制对感兴趣的 CUDA API 的跟踪。对于 CUDA 图形,如果不需要节点级别的可见性,则从节点级别跟踪切换到图形级别跟踪可以显著帮助减少收集开销。使用活动类型
CUPTI_ACTIVITY_KIND_GRAPH_TRACE启用图形级别跟踪。对于活动缓冲区请求回调,客户端应尽快返回缓冲区,因为此回调是从应用程序线程发出的。客户端可以预先分配一个活动缓冲区池,并在 CUPTI 请求时从池中返回一个空缓冲区。
CUPTI 在使用新的活动缓冲区之前,会使用 memset 调用将其初始化为零值。如果用户提供零值缓冲区并设置枚举
CUpti_ActivityAttribute的属性CUPTI_ACTIVITY_ATTR_ZEROED_OUT_ACTIVITY_BUFFER,则可以跳过此操作。客户端可以请求 CUPTI 在线程级别而不是全局缓冲区级别维护活动缓冲区。可以通过设置枚举
CUpti_ActivityAttribute的选项CUPTI_ACTIVITY_ATTR_PER_THREAD_ACTIVITY_BUFFER来实现这一点。这可以帮助减少从多个主机线程启动 CUDA 活动的应用程序的收集开销。减少缓冲区刷新的频率,因为它可能是一项昂贵的操作。可以通过使用 API
cuptiActivityFlushPeriod设置较高的刷新周期以避免 CUPTI 完成的内部刷新,并通过降低 APIcuptiActivityFlushAll的频率来实现这一点。这种方法可能会导致主机和设备上的内存占用增加。对于设备缓冲区,当 CUPTI 从池中耗尽缓冲区时,CUPTI 会分配一个新的缓冲区,这发生在主应用程序线程中,这可能会导致关键路径中的停顿。可以通过预先分配更多设备缓冲区或使用枚举
CUpti_ActivityAttribute中的属性CUPTI_ACTIVITY_ATTR_DEVICE_BUFFER_POOL_LIMIT和CUPTI_ACTIVITY_ATTR_DEVICE_BUFFER_SIZE分别增加设备缓冲区的大小来避免这种情况。使用活动类型
CUPTI_ACTIVITY_KIND_KERNEL启用的串行内核跟踪可能会显着改变应用程序的整体性能特征,因为所有内核执行都在 GPU 上串行化。对于仅使用单个 CUDA 流且因此无法进行并发内核执行的应用程序,此模式可能很有用,因为它通常(并非总是)比并发内核模式产生的分析开销更少。使用活动类型
CUPTI_ACTIVITY_KIND_CONCURRENT_KERNEL启用的并发内核跟踪不会影响应用程序中内核的并发性。在此模式下,CUPTI 检测内核代码以收集时间信息。在加载 CUDA 模块时生成单个检测代码,并在内核执行期间应用于每个内核。检测代码生成开销在活动记录CUpti_ActivityOverhead2中归因于CUPTI_ACTIVITY_OVERHEAD_CUPTI_INSTRUMENTATION。由于代码检测,如果并发内核模式用于执行大量块且执行持续时间短的内核,则可能会增加显著的运行时开销。
2.16.1.2. 内存开销
CUPTI 分配设备和页面锁定系统内存以存储跟踪信息
静态内存分配: 默认情况下,CUPTI 在上下文创建阶段为每个 CUDA 上下文在页面锁定系统内存中分配 3 个 3 MB 的缓冲区。这用于存储并发内核、串行内核、内存复制和 memset 跟踪信息,这些缓冲区足以存储约 30 万个此类活动的信息。缓冲区的数量由属性
CUPTI_ACTIVITY_ATTR_DEVICE_BUFFER_PRE_ALLOCATE_VALUE控制,缓冲区的大小由属性CUPTI_ACTIVITY_ATTR_DEVICE_BUFFER_SIZE确定。用户可以在分析会话期间随时更改缓冲区大小,但此设置仅对新缓冲区分配生效。建议在创建任何 CUDA 上下文之前调整缓冲区大小,以确保所有预分配的缓冲区都具有调整后的大小。动态内存分配: 一旦用于存储跟踪信息的分析缓冲区耗尽,CUPTI 将分配另一个相同大小的缓冲区。请注意,内存占用不总是随内核、内存复制、memset 计数而扩展,因为 CUPTI 在处理缓冲区中的所有记录后会重用缓冲区。对于这些活动密度高的应用程序,CUPTI 可能会分配更多缓冲区。
与上下文关联的所有 CUPTI 分配的内存在上下文被销毁时都会被释放。内存分配开销在活动记录 CUpti_ActivityOverhead2 中归因于 CUPTI_ACTIVITY_OVERHEAD_CUPTI_RESOURCE。如果没有创建 CUDA 上下文,则 CUPTI 将不会分配相应的缓冲区。
CUPTI 分配内存以存储唯一的内核名称、NVTX 范围、CUDA 模块 cubin
内核跟踪: 对于使用活动类型
CUPTI_ACTIVITY_KIND_KERNEL或CUPTI_ACTIVITY_KIND_CONCURRENT_KERNEL启用的内核跟踪,CUPTI 会分配内存以存储记录中的内核名称。建议不要释放内核活动记录中为内核名称分配的内存,因为内核名称内存空间可能在具有相同内核名称的所有内核记录中是通用的。NVTX 范围: 对于使用活动类型
CUPTI_ACTIVITY_KIND_MARKER启用的 NVTX,CUPTI 会分配内存以存储记录中的范围名称。建议不要释放标记活动记录中为 NVTX 范围名称分配的内存,因为 NVTX 范围名称内存空间在具有相同名称的所有 NVTX 范围记录中将是通用的。CUDA 模块 cubin: CUPTI 在加载 CUDA 模块时缓存 cubin 镜像副本。这仅在启用了需要它的分析功能时完成。与模块的 cubin 镜像关联的所有 CUPTI 分配的内存在模块被卸载时都会被释放。
2.16.2. 分析开销
使用 CUPTI 收集事件和指标会产生运行时开销。此开销取决于选择的事件和指标的数量和类型。由于每个指标都是从一个或多个事件计算得出的,因此指标开销取决于底层事件的数量和类型。开销包括配置硬件事件和读取硬件事件值所花费的时间。
以下是影响分析下执行开销的因素:
硬件提供的事件和指标的开销较小。
对于事件和指标 API,使用收集方法
CUPTI_EVENT_COLLECTION_METHOD_PM或CUPTI_EVENT_COLLECTION_METHOD_SM收集的事件属于此类。对于分析 API,名称中不包含字符串“sass”的指标属于此类。
软件检测事件和指标很昂贵,因为 CUPTI 需要检测内核才能收集这些事件和指标。此外,这些事件和指标不能与同一遍中的任何其他事件或指标组合,否则检测代码也会贡献于事件值。
对于事件和指标 API,收集方法
CUPTI_EVENT_COLLECTION_METHOD_INSTRUMENTED属于此类。对于分析 API,名称中包含字符串“sass”的指标属于此类。
在串行模式下,分析可能会显着改变应用程序的整体性能特征,因为所有内核执行都在 GPU 上串行化。这样做是为了在每个内核周围启用紧密的事件或指标收集。
对于事件和指标 API,收集模式
CUPTI_EVENT_COLLECTION_MODE_KERNEL会串行化在 APIcuptiEventGroupEnable和cuptiEventGroupDisable之间发生的所有 GPU 上的内核执行。另一方面,可以通过使用收集模式CUPTI_EVENT_COLLECTION_MODE_CONTINUOUS并将分析限制为可以在单遍中收集的事件和指标来保持内核并发性。对于分析 API,自动范围模式会串行化 GPU 上的所有内核执行。另一方面,可以通过使用用户范围模式来保持内核并发性。
当由于硬件或软件限制而无法在单遍中收集所有请求的事件或指标时,需要多次重放完全相同的 GPU 工作负载集。这可以通过内核粒度来实现,方法是多次重放内核或多次启动整个应用程序。CUPTI 仅提供内核重放支持。应用程序重放可以由 CUPTI 客户端完成。
当使用内核重放时,为每次重放遍保存和恢复内核状态的开销取决于内核使用的设备内存量。对于内核使用的设备内存大小很高的情况,应用程序重放预计会比内核重放表现更好。
2.17. 可重复性
某些 CUPTI API 不能保证在运行之间返回完全可重复的结果。许多因素会在软件和硬件性能中引入可测量的运行到运行的变化。对于想要更可重复结果的用户,有以下几点建议。
2.17.1. 固定时钟频率
许多指标直接受 GPU SM 和内存时钟频率的影响。默认情况下,GPU 在工作启动之前保持低时钟频率,但时钟频率不会立即提升到全速,因此在空闲期后启动的初始工作可能以低时钟速度运行。此外,目标时钟频率可能因功率、热量和其他因素而异。系统不同部分之间复杂的交互意味着这些动态时钟频率在运行之间可能不可重复。
为了减少动态时钟频率的影响,可以设置固定时钟频率。GPU 将不再机会性地将时钟频率提升到此速率以上,但它将消除 GPU 空闲后以及功率和热变化影响的可变性。存在几种不同的方法来固定 SM 或内存时钟频率。最简单的方法可能是 nvidia-smi,但有关更多建议,请参阅 此 NVIDIA 博客条目。
2.17.2. 串行化
工作负载可以提交到 GPU 上执行,GPU 可以异步和并发地运行这些工作负载。通过同时使用更多的 GPU 资源,这可以提高性能,但也使性能分析变得复杂,这体现在两个方面:首先,并发运行的内核可能会通过争用共享资源而相互影响。对这些共享资源的测量将包括任何并发内核的影响,并且可能无法确定任何给定内核的具体影响。其次,由于与在没有精确保证时间的情况下运行的其他内核争用资源,给定内核的计时可能会以不可复现的方式受到影响。
当使用 CUPTI_ACTIVITY_KIND_CONCURRENT_KERNEL 来测量内核时序时,内核被允许在设备上并发运行。可以使用 CUPTI_ACTIVITY_KIND_KERNEL 来代替测量串行内核时序。这将消除此进程中的 GPU 并发,并应提供更好的运行间可重复性,但此时序可能不如在这种模式下真实——内核将不必争用共享资源,而这可能会影响它们的性能。
2.17.3. 其他问题
除了可变时钟频率和并发内核执行之外,还有其他几个因素会影响应用程序和内核性能。
驱动程序通常在不使用时不会保持加载状态。加载和初始化驱动程序需要一些时间,这可能会以明显且有些不可复现的方式影响性能。可以保持驱动程序持久加载,这将消除此初始化开销。nvidia-persistenced 是配置此项的工具之一;也可以通过 nvidia-smi 进行配置。
2.18. 示例
CUPTI 安装包包含多个示例,演示了 CUPTI API 的使用。可以参考这些示例来了解 CUPTI 支持的不同 API 的用法。并非所有 GPU 架构都支持某个示例,请参阅 GPU 支持 部分,了解示例中使用的不同 CUPTI API 支持的 GPU 架构。示例包括:
Activity API
- activity_trace_async
此示例展示了如何使用新的异步 activity 缓冲区 API 收集 CPU 和 GPU activity 的跟踪信息。
- callback_timestamp
此示例展示了如何使用回调 API 记录 API 启动和停止时间的跟踪信息。
- cuda_graphs_trace
此示例展示了如何收集 CUDA Graphs 的跟踪信息,并使用 CUPTI 回调将图节点启动与节点创建 API 相关联。
- cuda_memory_trace
此示例展示了如何收集 CUDA 内存操作的跟踪信息。该示例还跟踪通过默认内存池完成的 CUDA 内存操作。
- cupti_correlation
此示例展示了如何在 CUDA API 和相应的 GPU activity 之间进行关联。
- cupti_external_correlation
此示例展示了如何将 CUDA API activity 记录与外部 API 相关联。
- cupti_finalize
此示例展示了如何使用 API
cuptiFinalize()来动态地分离和附加 CUPTI。
- cupti_nvtx
此示例展示了如何在 CUPTI 中接收 NVTX 回调并收集 NVTX 记录。
- cupti_trace_injection
此示例展示了如何使用 CUPTI activity 和回调 API 构建注入库。它可以用于跟踪任何 CUDA 应用程序的 CUDA API 和 GPU activity。它不需要修改 CUDA 应用程序。
- nvlink_bandwidth
此示例展示了如何在连续模式下收集 NVLink 拓扑和 NVLink 吞吐量指标。
- openacc_trace
此示例展示了如何使用 CUPTI API 进行 OpenACC 数据收集。
- pc_sampling
此示例展示了如何使用 PC Sampling Activity API 收集内核的 PC Sampling 性能分析信息。
- sass_source_map
此示例展示了如何生成 CUpti_ActivityInstructionExecution 记录,以及如何将 SASS 汇编指令映射到 CUDA C 源代码。
- unified_memory
此示例展示了如何收集有关统一内存页传输的信息。
Event and Metric APIs
- callback_event
此示例展示了如何同时使用回调和事件 API 来记录简单内核执行期间发生的事件。该示例展示了同步所需的顺序,以及事件组的启用、禁用和读取所需的顺序。
- callback_metric
此示例展示了如何同时使用回调和指标 API 来记录简单内核执行期间的指标事件,然后使用这些事件来计算指标值。
- cupti_query
此示例展示了如何查询支持 CUDA 的设备的事件域、事件和指标。
- event_multi_gpu
此示例展示了如何在具有多个 GPU 的设置上使用 CUPTI 事件和 CUDA API 来采样事件。该示例展示了同步所需的顺序,以及事件组的启用、禁用和读取所需的顺序。
- event_sampling
此示例展示了如何使用事件 API 使用单独的主机线程来采样事件。
Profiling API
- extensions
这包括一些示例中使用的实用程序。
- autorange_profiling
此示例展示了如何使用性能分析 API 在自动范围模式下收集指标。
- callback_profiling
此示例展示了如何使用回调和性能分析 API 来收集内核执行期间的指标。它展示了如何在适当的回调中使用性能分析的不同阶段,即枚举、配置、收集和评估。
- concurrent_profiling
此示例展示了如何使用性能分析 API 记录以两种不同方式启动的并发内核的指标——在单个设备上使用多个流,以及使用多个线程和多个设备。
- cupti_metric_properties
此示例展示了如何使用性能分析 API 查询指标的各种属性。该示例展示了收集方法(硬件或软件)以及收集指标列表所需的pass次数。
- nested_range_profiling
此示例展示了如何使用性能分析 API 分析嵌套范围。
- profiling_injection
此 Linux 系统示例展示了如何构建一个注入库,该库可以使用自动范围和内核重放模式自动启用 CUPTI 的性能分析 API。它可以附加到未使用 CUPTI 进行检测的应用程序,并分析任何内核启动。
- userrange_profiling
此示例展示了如何使用性能分析 API 在用户指定范围模式下收集指标。
Range Profiling API
- range_profiling
此示例展示了如何使用范围性能分析 API 使用不同的范围模式(自动和用户)和重放模式(内核和用户)收集指标。
PC Sampling API
- pc_sampling_continuous
此注入示例展示了如何使用 PC Sampling API 收集 PC Sampling 性能分析信息。提供了一个 perl 脚本 libpc_sampling_continuous.pl,用于使用不同的 PC 采样选项运行 CUDA 应用程序。使用命令 ./libpc_sampling_continuous.pl –help 列出所有选项。CUDA 应用程序代码不需要修改。有关构建和使用注入库的说明,请参阅示例附带的 README.txt 文件。
- pc_sampling_start_stop
此示例展示了如何使用 PC Sampling 启动/停止 API 收集范围内内核的 PC Sampling 性能分析信息。
- pc_sampling_utility
此实用程序将 pc_sampling_continuous 注入库生成的 PC 采样数据文件作为输入。它在 GPU 汇编指令级别打印停顿原因计数器值。它还执行 GPU 汇编到 CUDA-C 源代码的关联,并显示 CUDA-C 源文件名和行号。有关构建和运行实用程序的说明,请参阅示例附带的 README.txt 文件。
PM Sampling API
- pm_sampling
此示例展示了如何使用 PM 采样 API 收集 PM 采样启动/停止 API 在范围内启动的内核的指标列表的采样数据。
SASS Metric API
- sass_metric
此示例展示了如何使用 SASS 指标 API 枚举设备支持的指标,以及如何使用 SASS 补丁在源代码级别收集指标。
Checkpoint API
- checkpoint_kernels
此示例展示了如何使用 Checkpoint API 恢复设备内存,从而允许内核被重放,即使它修改了其输入数据。