性能分析器用户指南
NVIDIA 性能分析工具用户手册,用于优化 CUDA 应用程序的性能。
性能分析概述
本文档介绍了 NVIDIA 性能分析工具,使您能够理解和优化 CUDA、OpenACC 或 OpenMP 应用程序的性能。Visual Profiler 是一款图形化性能分析工具,可显示应用程序 CPU 和 GPU 活动的时间线,并包含自动分析引擎以识别优化机会。nvprof 性能分析工具使您能够从命令行收集和查看性能分析数据。
请注意,Visual Profiler 和 nvprof 已被弃用,并将在未来的 CUDA 版本中移除。 NVIDIA Volta 平台是完全支持这些工具的最后一个架构。建议使用下一代工具 NVIDIA Nsight Systems 进行 GPU 和 CPU 采样与跟踪,以及 NVIDIA Nsight Compute 进行 GPU 内核性能分析。
有关更多详细信息,请参阅 从 Visual Profiler 和 nvprof 迁移到 Nsight Tools 部分。
术语表
事件是设备上可计数的活动、动作或事件。它对应于在内核执行期间收集的单个硬件计数器值。要查看特定 NVIDIA GPU 上所有可用事件的列表,请键入 nvprof --query-events。
指标是根据一个或多个事件值计算出的应用程序的特征。要查看特定 NVIDIA GPU 上所有可用指标的列表,请键入 nvprof --query-metrics。您还可以参考 指标参考 。
1. 准备应用程序以进行性能分析
CUDA 性能分析工具不需要对应用程序进行任何更改即可启用性能分析;但是,通过进行一些简单的修改和添加,您可以大大提高性能分析的可用性和有效性。本节介绍这些修改以及它们如何改进您的性能分析结果。
1.1. 聚焦性能分析
默认情况下,性能分析工具会在应用程序的整个运行过程中收集性能分析数据。但是,如下所述,您通常只想对应用程序中包含部分或全部性能关键代码的区域进行性能分析。将性能分析限制在性能关键区域可以减少您和工具必须处理的性能分析数据量,并将注意力集中在优化将带来最大性能提升的代码上。
在几种常见情况下,对应用程序的某个区域进行性能分析会很有帮助。
应用程序是一个测试工具,其中包含算法的全部或部分 CUDA 实现。测试工具初始化数据,调用 CUDA 函数来执行算法,然后检查结果的正确性。使用测试工具是快速迭代和测试算法更改的常用且高效的方法。在进行性能分析时,您希望收集实现算法的 CUDA 函数的性能分析数据,而不是初始化数据或检查结果的测试工具代码的性能分析数据。
应用程序分阶段运行,每个阶段都有一组不同的算法处于活动状态。当应用程序每个阶段的性能可以独立于其他阶段进行优化时,您需要分别对每个阶段进行性能分析,以集中您的优化工作。
应用程序包含在大量迭代中运行的算法,但算法的性能在这些迭代中没有显着变化。在这种情况下,您可以从迭代的子集中收集性能分析数据。
为了将性能分析限制在应用程序的某个区域,CUDA 提供了启动和停止性能分析数据收集的函数。cudaProfilerStart() 用于启动性能分析,cudaProfilerStop() 用于停止性能分析(使用 CUDA 驱动程序 API,您可以使用 cuProfilerStart() 和 cuProfilerStop() 获得相同的功能)。要使用这些函数,您必须包含 cuda_profiler_api.h(或驱动程序 API 的 cudaProfiler.h)。
当使用启动和停止函数时,您还需要指示性能分析工具在应用程序启动时禁用性能分析。对于 nvprof,您可以使用 --profile-from-start off 标志来执行此操作。对于 Visual Profiler,您可以使用设置视图中的“启动执行时启用性能分析”复选框。
1.2. 标记 CPU 活动区域
Visual Profiler 可以收集应用程序发出的 CUDA 函数调用的跟踪。Visual Profiler 在时间线视图中显示这些调用,使您可以查看应用程序中每个 CPU 线程在何处调用 CUDA 函数。要了解应用程序的 CPU 线程在 CUDA 函数调用之外执行的操作,您可以使用 NVIDIA 工具扩展 API (NVTX)。当您向应用程序添加 NVTX 标记和范围时,时间线视图会显示您的 CPU 线程何时在这些区域内执行。
nvprof 也支持 NVTX 标记和范围。标记和范围显示在时间线中的 API 跟踪输出中。在摘要模式下,每个范围都显示与该范围关联的 CUDA 活动。
1.3. 命名 CPU 和 CUDA 资源
Visual Profiler 时间线视图显示 CPU 线程和 GPU 设备、上下文和流的默认命名。对于具有许多主机线程、设备、上下文或流的 CUDA 应用程序,为这些资源使用自定义名称可以提高对应用程序行为的理解。您可以使用 NVIDIA 工具扩展 API 为您的 CPU 和 GPU 资源分配自定义名称。然后,您的自定义名称将显示在时间线视图中。
nvprof 也支持 NVTX 命名。CUDA 设备、上下文和流的名称显示在摘要和跟踪模式下。线程名称显示在摘要模式下。
1.4. 刷新性能分析数据
为了减少性能分析开销,性能分析工具会将性能分析信息收集并记录到内部缓冲区中。然后,这些缓冲区会以低优先级异步刷新到磁盘,以避免扰乱应用程序行为。为了避免丢失尚未刷新的性能分析信息,被性能分析的应用程序应在退出之前确保所有 GPU 工作已完成(使用 CUDA 同步调用),然后调用 cudaProfilerStop() 或 cuProfilerStop()。这样做会强制刷新相应上下文中的缓冲性能分析信息。
如果您的 CUDA 应用程序包含使用显示或主循环运行的图形,则必须注意在执行该循环的线程调用 exit() 之前调用 cudaProfilerStop() 或 cuProfilerStop()。未能调用这些 API 之一可能会导致丢失部分或全部收集的性能分析数据。
对于某些图形应用程序(如使用 OpenGL 的应用程序),应用程序会在按下 Esc 键时退出。在退出前调用上述函数不可行的情况下,请使用 nvprof 选项 --timeout 或在 Visual Profiler 中设置“执行超时”。性能分析器将在超时之前强制刷新数据。
1.5. 性能分析 CUDA Fortran 应用程序
使用 PGI CUDA Fortran 编译器编译的 CUDA Fortran 应用程序可以通过 nvprof 和 Visual Profiler 进行性能分析。如果性能分析器需要源文件和行信息(内核性能分析、全局内存访问模式分析、发散执行分析等),请在编译时使用 “-Mcuda=lineinfo” 选项。此选项在 PGI 2019 版本 19.1 或更高版本的 Linux 64 位目标上受支持。
2. Visual Profiler
NVIDIA Visual Profiler 使您可以可视化和优化应用程序的性能。Visual Profiler 显示应用程序在 CPU 和 GPU 上的活动时间线,以便您可以识别性能改进的机会。此外,Visual Profiler 将分析您的应用程序以检测潜在的性能瓶颈,并指导您如何采取措施消除或减少这些瓶颈。
Visual Profiler 既可以作为独立应用程序使用,也可以作为 Nsight Eclipse Edition 的一部分使用。Visual Profiler 的独立版本 nvvp 包含在所有受支持操作系统的 CUDA 工具包中。在 Nsight Eclipse Edition 中,Visual Profiler 位于 Profile Perspective 中,并在应用程序以性能分析模式运行时激活。
2.1. 入门指南
本节介绍您在开始性能分析时可能采取的步骤。
2.1.1. 设置 Java 运行时环境
Visual Profiler 需要 Java 运行时环境 (JRE) 1.8 在本地系统上可用。但是,从 CUDA 工具包 10.1 Update 2 版本开始,由于 Oracle 升级许可变更,JRE 不再包含在 CUDA 工具包中。用户必须安装所需版本的 JRE 1.8 才能使用 Visual Profiler。请参阅安装 JRE。
-
在 OpenSUSE15 或 SLES15 上运行 Visual Profiler
-
确保使用如下所示的命令行选项调用 Visual Profiler
nvvp -vm /usr/lib64/jvm/jre-1.8.0/bin/java
注意
仅当 JRE 1.8 不在默认路径中时,才需要
-vm选项。
-
-
在 Ubuntu 18.04 或 Ubuntu 18.10 上运行 Visual Profiler
-
确保使用如下所示的命令行选项调用 Visual Profiler
nvvp -vm /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
注意
仅当 JRE 1.8 不在默认路径中时,才需要
-vm选项。 -
在 Ubuntu 18.10 上,如果在运行 Visual Profiler 时收到错误 “
no swt-pi-gtk in java.library.path”,则需要安装 GTK2。键入以下命令以安装所需的 GTK2。apt-get install libgtk2.0-0
-
-
在 Fedora 29 上运行 Visual Profiler
-
确保使用如下所示的命令行选项调用 Visual Profiler
nvvp -vm /usr/bin/java
注意
仅当 JRE 1.8 不在默认路径中时,才需要
-vm选项。
-
-
在 Windows 上运行 Visual Profiler
-
确保使用如下所示的命令行选项调用 Visual Profiler
nvvp -vm "C:\Program Files\Java\jdk1.8.0_77\jre\bin\java"
注意
仅当 JRE 1.8 不在默认路径中时,才需要
-vm选项。
-
2.1.2. 安装 JRE
Visual Profiler 需要 Java 运行时环境 (JRE) 1.8 在本地系统上可用。但是,从 CUDA 工具包 10.1 Update 2 版本开始,由于 Oracle 升级许可变更,JRE 不再包含在 CUDA 工具包中。用户必须安装 JRE 1.8 才能使用 Visual Profiler。请参阅以下可用选项。另请参阅Java Platform, Standard Edition 8 Names and Versions。
Windows
Oracle JRE 1.8(可能需要付费更新)
OpenJDK JRE 1.8
Linux
Oracle JRE 1.8(可能需要付费更新)
-
OpenJDK JRE 1.8
注意
Visual Profiler 不支持 JRE 1.8u152 或更高版本。您可以在 Oracle 下载存档站点上找到 JRE update 151:https://www.oracle.com/technetwork/java/javase/downloads/java-archive-javase8-2177648.html?printOnly=1。
2.1.3. 修改您的应用程序以进行性能分析
Visual Profiler 不需要对应用程序进行任何更改;但是,通过进行一些简单的修改和添加,您可以大大提高其可用性和有效性。准备应用程序以进行性能分析部分介绍了如何集中您的性能分析工作,以及向应用程序添加额外的注释,这将大大改善您的性能分析体验。
2.1.4. 创建会话
使用 Visual Profiler 分析您的应用程序的第一步是创建一个新的性能分析会话。会话包含与您的应用程序关联的设置、数据和结果。会话部分提供了有关会话使用的更多信息。
您可以通过选择“欢迎”页面上的“性能分析应用程序”链接,或从“文件”菜单中选择“新建会话”来创建新会话。在“创建新会话”对话框中,输入应用程序的可执行文件。或者,您还可以指定工作目录、参数、多进程性能分析选项和环境。
多进程性能分析选项包括
性能分析子进程 - 如果选中,则分析指定应用程序启动的所有进程。
性能分析所有进程 - 如果选中,则分析由启动 nvprof 的同一用户在同一系统上启动的每个 CUDA 进程。在此模式下,Visual Profiler 将启动 nvprof,用户需要在 Visual Profiler 之外的另一个终端中运行其应用程序。用户可以通过按 Visual Profiler 进度对话框上的“取消”按钮退出此模式以加载性能分析数据
仅性能分析当前进程 - 如果选中,则仅分析指定的应用程序。
按“下一步”选择一些其他性能分析选项。
CUDA 选项
启动执行时启用性能分析 - 如果选中,则从应用程序执行开始收集性能分析数据。如果未选中,则在应用程序中调用
cudaProfilerStart()之前不会收集性能分析数据。有关cudaProfilerStart()的更多信息,请参阅聚焦性能分析。启用并发内核性能分析 - 对于使用 CUDA 流启动可以并发执行的内核的应用程序,应选择此选项。如果应用程序仅使用单个流(因此无法进行并发内核执行),则取消选择此选项可能会减少性能分析开销。
在时间线中启用 CUDA API 跟踪 - 如果选中,则会收集 CUDA 驱动程序和运行时 API 调用跟踪,并在时间线上显示。
启用功耗、时钟和热性能分析 - 如果选中,则将对 GPU 上的功耗、时钟和热条件进行采样,并在时间线上显示。并非所有 GPU 都支持收集此数据。有关更多信息,请参阅时间线视图中设备时间线的描述。
启用统一内存性能分析 - 如果为支持统一内存的 GPU 选中此项,则会收集与统一内存相关的每个 GPU 的内存流量,并在时间线上显示。
重放应用程序以收集事件和指标 - 如果选中,则会重新运行整个应用程序,而不是重放每个内核,以便收集所有事件/指标。
运行引导式分析 - 如果选中,则会在创建新会话后立即运行引导式分析。取消选中此选项可禁用此行为。
CPU(主机)选项
对 CPU 上的执行进行性能分析 - 如果选中,则会对 CPU 线程进行采样,并在CPU 详细信息视图中显示有关 CPU 性能的收集数据。
启用 OpenACC 性能分析 - 如果选中并对 OpenACC 应用程序进行性能分析,则 OpenACC 活动将被记录并在新的 OpenACC 时间线上显示。仅 Linux 和 PGI 19.1 或更高版本支持收集此数据。有关更多信息,请参阅时间线视图中 OpenACC 时间线的描述。
启用 CPU 线程跟踪 - 如果启用,则选定的 CPU 线程 API 调用将被记录并在新的线程 API 时间线上显示。这目前包括 Pthread API、互斥锁和条件变量。出于性能原因,仅记录影响并发执行的那些 API 调用,并且 Windows 不支持收集此数据。有关更多信息,请参阅时间线视图中线程时间线的描述。对于使用 CUDA 的多个 CPU 线程的应用程序的依赖关系分析,应选择此选项。
时间线选项
加载时间范围内的数据 - 如果选中,则可以指定要加载的数据范围的开始和结束时间戳。此选项对于选择大型数据的子集很有用。
在会话中启用时间线 - 默认情况下,所有时间线都已启用。如果取消选中时间线,则不会加载与该时间线关联的数据,并且不会显示该时间线。
注意
如果通过取消选中选项禁用某些时间线,则使用此时间线数据的分析结果将不正确。
按“完成”。
2.1.5. 分析您的应用程序
如果您在创建会话时未选择“不运行引导式分析”选项,Visual Profiler 将立即运行您的应用程序以收集引导式分析第一阶段所需的数据。如分析视图部分所述,您可以使用引导式分析系统来获取有关应用程序中限制性能的行为的建议。
2.1.6. 探索时间线
除了引导式分析结果外,您还会看到应用程序的时间线,其中显示了应用程序执行时发生的 CPU 和 GPU 活动。阅读时间线视图和属性视图,了解如何探索时间线中可用的性能分析信息。导航时间线介绍了如何缩放和滚动时间线以关注应用程序的特定区域。
2.1.7. 查看详细信息
除了分析视图中提供的结果外,您还可以查看作为分析一部分收集的特定指标和事件值。指标和事件值显示在GPU 详细信息视图中。您可以收集特定的指标和事件值,以揭示应用程序中内核的行为方式。您可以按照GPU 详细信息视图部分中的描述收集指标和事件。
2.1.8. 改进大型配置文件的加载
某些应用程序启动许多微小的内核,即使应用程序运行几秒钟,也容易产生非常大(数百兆字节或更大)的输出。Visual Profiler 大约需要与其打开/导入的配置文件的容量相同的内存。如果未指定“最大堆大小”设置,则 Java 虚拟机可能会使用一小部分主内存。因此,根据主内存的大小,Visual Profiler 可能无法加载某些大型文件。
如果 Visual Profiler 无法加载大型配置文件,请尝试根据主内存大小设置 JVM 允许使用的最大堆大小。您可以修改工具包安装目录中的配置文件 libnvvp/nvvp.ini。nvvp.ini 配置文件如下所示
-startup
plugins/org.eclipse.equinox.launcher_1.3.0.v20140415-2008.jar
--launcher.library
plugins/org.eclipse.equinox.launcher.gtk.linux.x86_64_1.1.200.v20140603-1326
-data
@user.home/nvvp_workspace
-vm
../jre/bin/java
-vmargs
-Dorg.eclipse.swt.browser.DefaultType=mozilla
例如,要强制 JVM 使用 3 GB 内存,请在 ‑vmargs 之后添加包含 ‑Xmx3G 的新行。-Xmx 设置应根据可用的系统内存和输入大小进行调整。例如,如果您的系统具有 24GB 的系统内存,并且您碰巧知道您无需在 Visual Profiler 的同时运行任何其他内存密集型应用程序,那么性能分析器占用大部分空间是可以的。因此,您可以选择例如 22GB 作为最大堆大小,为操作系统、GUI 和可能正在运行的任何其他程序留下几 GB。
还可以修改其他一些 nvvp.ini 配置设置
将默认堆大小(Java 自动启动的大小)增加到例如 2GB。(
-Xms)告诉 Java 以 64 位模式而不是默认的 32 位模式运行(仅在 64 位系统上有效);如果您想要大于 4GB 的堆大小,则这是必需的。(
-d64)启用 Java 的并行垃圾回收系统,这有助于减少给定输入大小所需的内存空间,并更优雅地捕获内存不足错误。(
-XX:+UseConcMarkSweepGC -XX:+CMSIncrementalMode)
注意:大多数安装需要管理员/root 级别的访问权限才能修改此文件。
根据上述示例,修改后的 nvvp.ini 文件如下
-data
@user.home/nvvp_workspace
-vm
../jre/bin/java
-d64
-vmargs
-Xms2g
-Xmx22g
-XX:+UseConcMarkSweepGC
-XX:+CMSIncrementalMode
-Dorg.eclipse.swt.browser.DefaultType=Mozilla
有关 JVM 设置的更多详细信息,请查阅 Java 虚拟机手册。
除了这一点,您还可以使用时间线选项“加载时间范围数据”和“在会话中启用时间线”,这两个选项在创建会话章节中提到,以限制加载和显示的数据。
2.2. 会话
会话包含与您的应用程序关联的设置、数据和性能分析结果。每个会话都保存在一个单独的文件中;因此,您可以通过简单地删除、移动、复制或共享会话文件来删除、移动、复制或共享会话。按照惯例,文件扩展名 .nvvp 用于 Visual Profiler 会话文件。
会话有两种类型:可执行会话,它与从 Visual Profiler 内部执行和性能分析的应用程序相关联;以及导入会话,它是通过导入 nvprof 生成的数据而创建的。
2.2.1. 可执行会话
您可以通过选择“欢迎”页面上的“性能分析应用程序”链接,或者从“文件”菜单中选择“新建会话”来为您的应用程序创建新的可执行会话。创建会话后,您可以按照设置视图中的描述编辑会话的设置。
您可以使用“文件”菜单中的打开和保存选项来打开和保存现有会话。
为了分析您的应用程序并收集指标和事件值,Visual Profiler 将多次执行您的应用程序。为了获得准确的性能分析结果,重要的是您的应用程序符合应用程序要求中详述的要求。
2.2.2. 导入会话
您可以通过使用“文件”菜单中的“导入…”选项从 nvprof 的输出创建导入会话。选择此选项将打开导入对话框,该对话框将引导您完成导入过程。
由于可执行应用程序未与导入会话关联,因此 Visual Profiler 无法执行该应用程序来收集额外的性能分析数据。因此,分析只能使用导入的数据执行。此外,GPU 详细信息视图将显示任何导入的事件和指标值,但无法为导入会话选择和收集新的指标和事件。
2.2.2.1. 导入单进程 nvprof 会话
使用导入对话框,您可以选择一个或多个 nvprof 数据文件以导入到新会话中。
您必须有一个 nvprof 数据文件,其中包含会话的时间线信息。此数据文件应通过使用 --export-profile 选项运行 nvprof 来收集。您可以选择性地启用其他选项,例如 --system-profiling on,但不应收集任何事件或指标,因为这会扭曲时间线,使其不能代表应用程序的真实行为。
您可以选择性地指定一个或多个事件/指标数据文件,其中包含应用程序的事件和指标值。这些数据文件应通过使用 --events 和 --metrics 选项之一或两者运行 nvprof 来收集。要收集分析系统所需的所有事件和指标,您可以简单地将 --analysis-metrics 选项与 --kernels 选项一起使用,以选择要收集事件和指标的内核。有关更多信息,请参阅远程性能分析。
如果您要将多个 nvprof 输出文件导入到会话中,则重要的是您的应用程序符合应用程序要求中详述的要求。
2.2.2.2. 导入多进程 nvprof 会话
使用导入向导,您可以选择多个 nvprof 数据文件以导入到新的多进程会话中。
每个 nvprof 数据文件必须包含其中一个进程的时间线信息。此数据文件应通过使用 --export-profile 选项运行 nvprof 来收集。您可以选择性地启用其他选项,例如 --system-profiling on,但不应收集任何事件或指标,因为这会扭曲时间线,使其不能代表应用程序的真实行为。
在“导入 nvprof 数据”对话框中选择“多进程”选项,如下图所示。
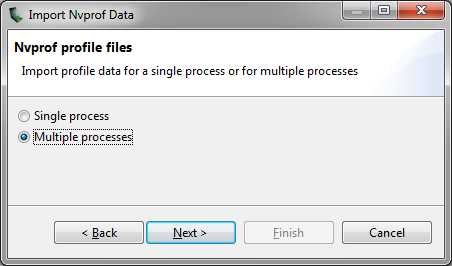
从多个进程导入时间线数据时,您不得为这些进程指定任何事件/指标数据文件。多进程性能分析仅支持时间线数据。
2.2.2.3. 导入命令行性能分析器会话
已删除对命令行性能分析器(使用环境变量 COMPUTE_PROFILE)的支持,但仍可以导入使用早期版本生成的 CSV 文件。
使用导入向导,您可以选择一个或多个命令行性能分析器生成的 CSV 文件以导入到新会话中。当您导入多个 CSV 文件时,它们的内容将被合并并在单个时间线中显示。
命令行性能分析器 CSV 文件必须使用 gpustarttimestamp 和 streamid 配置参数生成。包含其他配置参数(包括事件)也是可以的。
2.3. 应用程序要求
为了收集有关您的应用程序的性能数据,Visual Profiler 必须能够以确定性的方式重复执行您的应用程序。由于软件和硬件的限制,不可能在应用程序的单次执行中收集所有必要的性能分析数据。每次运行您的应用程序时,它都必须对相同的数据进行操作,并以相同的顺序执行相同的内核和内存复制调用。具体来说:
对于设备,每次执行应用程序时,上下文创建的顺序必须相同。对于多线程应用程序,其中每个线程创建自己的上下文,必须注意确保这些上下文创建的顺序在多次运行中保持一致。例如,可能需要在单个线程上创建上下文,然后将上下文传递给其他线程。或者,可以使用 NVIDIA Tools Extension API 为每个上下文提供自定义名称。只要在每次执行应用程序时将相同的自定义名称应用于相同的上下文,Visual Profiler 就能够跨多次运行正确地关联这些上下文。
对于上下文,每次执行应用程序时,流创建的顺序必须相同。或者,可以使用 NVIDIA Tools Extension API 为每个流提供自定义名称。只要在每次执行应用程序时将相同的自定义名称应用于相同的流,Visual Profiler 就能够跨多次运行正确地关联这些流。
在流中,每次执行应用程序时,内核和 memcpy 调用的顺序必须相同。
2.4. Visual Profiler 视图
Visual Profiler 被组织成多个视图。这些视图共同使您能够分析和可视化您的应用程序的性能。本节介绍每个视图以及如何在性能分析应用程序时使用它。
2.4.1. 时间线视图
时间线视图显示在对您的应用程序进行性能分析时发生的 CPU 和 GPU 活动。可以在 Visual Profiler 中同时打开多个时间线,它们位于不同的选项卡中。下图显示了 CUDA 应用程序的时间线视图。
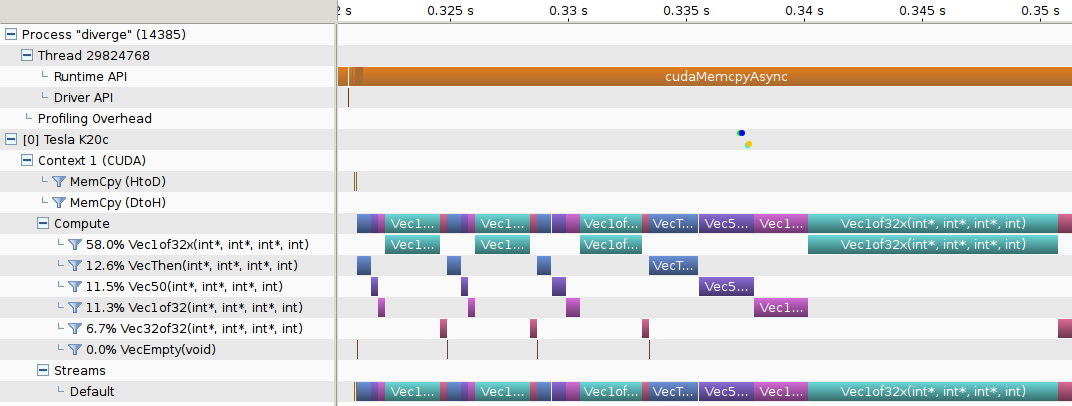
视图顶部是水平标尺,显示自应用程序性能分析开始以来经过的时间。视图左侧是垂直标尺,描述每行时间线显示的内容,并包含时间线的各种控件。这些控件在时间线控件中描述。
时间线视图由时间线行组成。每一行显示间隔,这些间隔表示与该行类型对应的活动的开始和结束时间。例如,表示内核的时间线行具有表示该内核执行的开始和结束时间的间隔。在某些情况下(如下所述),时间线行可以显示多个活动子行。当存在重叠活动时,将使用子行。这些子行是根据活动重叠的程度动态创建的。间隔在某些子行中的位置不传达任何特定含义。间隔只是使用一种启发式方法打包到子行中,该方法尝试最大限度地减少所需的子行数量。子行的高度被缩放以保持合理的垂直空间。
时间线视图中显示的时间线行类型为:
- 进程
-
时间线将为每个性能分析的应用程序包含一个“进程”行。进程标识符表示进程的 pid。进程的时间线行不包含任何活动间隔。进程中的线程显示为进程的子项。
- 线程
-
时间线将为性能分析的应用程序中执行了 CUDA 驱动程序或 CUDA 运行时 API 调用的每个 CPU 线程包含一个“线程”行。线程标识符是该 CPU 线程的唯一 ID。线程的时间线行不包含任何活动间隔。
- 运行时 API
-
时间线将为执行 CUDA 运行时 API 调用的每个 CPU 线程包含一个“运行时 API”行。行中的每个间隔表示相应线程上调用的持续时间。
- 驱动程序 API
-
时间线将为执行 CUDA 驱动程序 API 调用的每个 CPU 线程包含一个“驱动程序 API”行。行中的每个间隔表示相应线程上调用的持续时间。
- OpenACC
-
时间线将为每个调用 OpenACC 指令的 CPU 线程包含一个或多个 OpenACC 行。行中的每个间隔表示相应线程上调用的持续时间。每个 OpenACC 时间线可能由多行组成。在一个时间线内,较低行上的 OpenACC 活动是从较高行上的活动内部调用的。
- OpenMP
-
时间线将为每个调用 OpenMP 的 CPU 线程包含一个 OpenMP 行。行中的每个间隔表示应用程序在给定的 OpenMP 区域或状态中花费的时间长度。应用程序可能同时处于多种状态,这通过绘制多个行(其中一些间隔重叠)来显示。
- Pthread
-
时间线将为执行 Pthread API 调用的每个 CPU 线程包含一个 Pthread 行,前提是在测量期间已记录主机线程 API 调用。行中的每个间隔表示调用的持续时间。请注意,出于性能原因,可能只记录了选定的 Pthread API 调用。
- 标记和范围
-
时间线将为每个使用 NVIDIA Tools Extension API 注释时间范围或标记的 CPU 线程包含一个“标记和范围”行。行中的每个间隔表示时间范围的持续时间,或标记的瞬时点。如果存在重叠范围,则此行将具有子行。
- 性能分析开销
-
时间线将为每个进程包含一个“性能分析开销”行。行中的每个间隔表示性能分析所需的某些活动的执行持续时间。这些间隔表示在未对应用程序进行性能分析时不会发生的活动。
- 设备
-
时间线将为性能分析的应用程序使用的每个 GPU 设备包含一个“设备”行。时间线行的名称指示方括号中的设备 ID,后跟设备名称。运行“计算利用率”分析后,该行将包含设备随时间推移的计算利用率的估计值。如果启用了功耗、时钟和热性能分析,则该行还将包含表示这些读数的点。
- 统一内存
-
时间线将为每个使用统一内存的 CPU 线程和设备包含一个“统一内存”行。统一内存可能包含“CPU 页面错误”、“GPU 页面错误”、“数据迁移 (DtoH)”和“数据迁移 (HtoD)”行。创建会话时,用户可以选择统一内存时间线的段模式或非段模式。在段模式下,时间线被分成相等宽度的段,并且仅显示每个时间段的聚合数据值。可以更改段的数量。在非段模式下,时间线上的每个间隔将表示实际收集的数据,并且可以查看每个间隔的属性。段使用热图颜色方案着色。在时间线的属性下,给出了用于选择颜色的属性,并且图例还显示了颜色到不同属性值范围的映射。
- CPU 页面错误
-
这将为每个 CPU 线程包含一个“CPU 页面错误”行。在非段模式下,时间线上的每个间隔对应于一个 CPU 页面错误。
- 数据迁移 (DtoH)
-
时间线将为每个设备包含一个“数据迁移 (DtoH)”行。在非段模式下,时间线上的每个间隔对应于从设备到主机的单次数据迁移。
- GPU 页面错误
-
时间线将为每个 CPU 线程包含“GPU 页面错误”行。在非段模式下,时间线上的每个间隔对应于一个 GPU 页面错误组。
- 数据迁移 (DtoH)
-
时间线将为每个设备包含一个“数据迁移 (HtoD)”行。在非段模式下,时间线上的每个间隔对应于从主机到设备的单次数据迁移。
- 上下文
-
时间线将为 GPU 设备上的每个 CUDA 上下文包含一个“上下文”行。时间线行的名称指示上下文 ID 或自定义上下文名称(如果使用 NVIDIA Tools Extension API 命名上下文)。上下文的行不包含任何活动间隔。
- Memcpy
-
时间线将为每个执行 memcpys 的上下文包含内存复制行。一个上下文最多可以包含四个 memcpy 行,分别用于设备到主机、主机到设备、设备到设备和对等设备到对等设备的内存复制。行中的每个间隔表示在 GPU 上执行 memcpy 的持续时间。
- 计算
-
时间线将为每个在 GPU 上执行计算的上下文包含一个“计算”行。行中的每个间隔表示 GPU 设备上内核的持续时间。“计算”行指示上下文的所有计算活动。当在上下文中并发执行内核时,将使用子行。“计算”行上显示所有内核活动,包括使用 CUDA 动态并行性启动的内核。“计算”行之后的“内核”行显示每个单独应用程序内核的活动。
- 内核
-
时间线将为应用程序执行的每个内核包含一个“内核”行。行中的每个间隔表示包含上下文中的该内核实例的执行持续时间。每行都标有百分比,该百分比指示该内核的所有实例的总执行时间与所有内核的总执行时间相比。对于每个上下文,内核按此执行时间百分比从上到下排序。子行用于显示并发内核执行。对于 CUDA 动态并行性应用程序,内核被组织在一个层次结构中,该层次结构表示内核之间的父/子关系。主机启动的内核显示为“上下文”行的直接子项。可以使用 CUDA 动态并行性启动其他内核的内核可以使用“+”图标展开,以显示表示这些子内核的内核行。对于不启动子内核的内核,内核执行由实心间隔表示,显示该内核实例在 GPU 上执行的时间。对于启动子内核的内核,间隔还可以在末尾包含空心部分。空心部分表示内核完成执行后等待子内核完成执行的时间。CUDA 动态并行性执行模型要求父内核在所有子内核完成之前不完成,这就是空心部分所显示的内容。时间线控件中描述的“焦点”控件可用于控制父/子时间线的显示。
- 流
-
时间线将为应用程序使用的每个流(包括默认流和任何应用程序创建的流)包含一个“流”行。“流”行中的每个间隔表示在该流上执行的 memcpy 或内核执行的持续时间。
2.4.1.1. 时间线控件
时间线视图有多个控件,您可以使用这些控件来控制时间线的显示方式。其中一些控件还会影响GPU 详细信息视图和分析视图中数据的呈现。
调整垂直时间线标尺的大小
可以通过将鼠标指针放在垂直标尺的右边缘上来调整垂直标尺的宽度。当出现双箭头指针时,单击并按住鼠标左键进行拖动。垂直标尺宽度与您的会话一起保存。
重新排序时间线
可以重新排序“内核”和“流”时间线行。您可能希望重新排序这些行以帮助可视化相关的内核和流,或将不重要的内核和流移动到时间线的底部。要重新排序行,请左键单击并按住行标签。当出现双箭头指针时,向上或向下拖动以定位行。时间线顺序与您的会话一起保存。
过滤时间线
可以过滤 Memcpy 和内核行,以将它们的活动从 GPU 详细信息视图和 分析视图中的呈现中排除。要过滤掉一行,请左键单击行标签左侧的过滤器图标。要过滤所有“内核”或“Memcpy”行,请按住 Shift 键并左键单击其中一行。当一行被过滤时,该行上的任何间隔都会变暗以指示其已过滤状态。
展开和折叠时间线
可以使用行标签左侧的 [+] 和 [-] 控件展开和折叠时间线行组。有三种展开/折叠状态:
- 已折叠
-
不显示折叠行中包含的时间线行。
- 已展开
-
显示所有未过滤的时间线行。
- 全部展开
-
显示所有时间线行,包括已过滤和未过滤的。
与折叠行关联的间隔可能不会显示在 GPU 详细信息视图和 分析视图中,具体取决于为这些视图设置的过滤模式(有关更多信息,请参阅视图文档)。例如,如果折叠设备行,则与该设备关联的所有 memcpys、memsets 和内核都将从这些视图中显示的结果中排除。
为时间线着色
时间线着色有三种模式。可以在“视图”菜单、时间线上下文菜单(通过在时间线视图中单击鼠标右键访问)和性能分析器工具栏中选择着色模式。在内核着色模式下,每种类型的内核都被分配一个唯一的颜色(即,内核行中的所有活动间隔都具有相同的颜色)。在流着色模式下,每个流都被分配一个唯一的颜色(即,流上发生的所有 memcpy 和内核活动都被分配相同的颜色)。在进程着色模式下,每个进程都被分配一个唯一的颜色(即,进程中发生的所有 memcpy 和内核活动都被分配相同的颜色)。
聚焦内核时间线
对于使用 CUDA 动态并行性的应用程序,时间线视图显示内核活动层次结构,该层次结构显示内核之间的父/子关系。默认情况下,所有父/子关系都同时显示。焦点时间线控件可用于将显示的父/子关系聚焦到特定的、有限的“族谱”集合。可以在时间线上下文菜单(通过在时间线视图中单击鼠标右键访问)和性能分析器工具栏中选择和取消选择焦点时间线模式。
要查看特定内核的“族谱”,请选择一个内核,然后启用“焦点”模式。除所选内核的祖先或后代之外的所有内核都将被隐藏。可以在启用“焦点”模式之前使用 Ctrl-选择来选择多个内核。使用“不聚焦”选项禁用焦点模式并将所有内核恢复到时间线视图。
依赖关系分析控件
时间线中有两种模式用于可视化依赖关系分析结果:“聚焦关键路径”和“突出显示执行依赖关系”。可以在“视图”菜单、时间线上下文菜单(通过在时间线视图中单击鼠标右键访问)和 Visual Profiler 工具栏中选择这些模式。
在运行“依赖关系分析”应用程序分析阶段后,这些选项才可用(请参阅非引导式应用程序分析)。依赖关系分析控件中提供了对这些模式的详细说明。
2.4.1.3. 时间线刷新
性能分析器在读取数据时逐步加载时间线。如果正在加载的数据文件很大,或者应用程序生成了大量数据,则这一点更加明显。在这种情况下,时间线可能仅部分呈现。同时,旋转圆圈将替换当前会话选项卡的图标,指示时间线未完全加载。当图标变回时,加载完成。
为了减少其内存占用,如果性能分析器在当前缩放级别下不可见某些时间线内容,则可能会跳过加载这些内容。当这些内容在新缩放级别上变得可见时,将自动加载它们。
2.4.1.4. 依赖性分析控件
性能分析器允许在时间线中可视化依赖性分析结果,前提是已运行相应的分析阶段。有关依赖性分析工作原理的详细描述,请参阅依赖性分析。
“聚焦关键路径”通过聚焦关键路径上的所有区间并淡化其他区间,从而可视化应用程序的关键路径。当启用此模式并选择任何时间线区间(通过单击鼠标左键)时,选定的区间将获得焦点。但是,关键路径仍将以空心区间的形式可见。这使您可以“跟随”执行的关键路径并检查各个区间。
“高亮显示执行依赖项”允许您分析每个区间的执行依赖项(请注意,对于某些区间,不会收集依赖项信息)。启用此模式后,高亮颜色将从黄色(表示相关的区间)变为红色(表示依赖项)。选定的区间以及所有传入和传出的依赖项都将被高亮显示。
2.4.2. 分析视图
“分析视图”用于控制应用程序分析并显示分析结果。有两种分析模式:引导模式和非引导模式。在引导模式下,分析系统将引导您完成多个分析阶段,以帮助您了解应用程序中可能的性能限制因素和优化机会。在非引导模式下,您可以手动浏览为您的应用程序收集的所有分析结果。下图显示了引导分析模式下的分析视图。视图的左侧部分提供逐步指导,以帮助您分析和优化您的应用程序。视图的右侧部分显示适用于每个分析部分的详细分析结果。
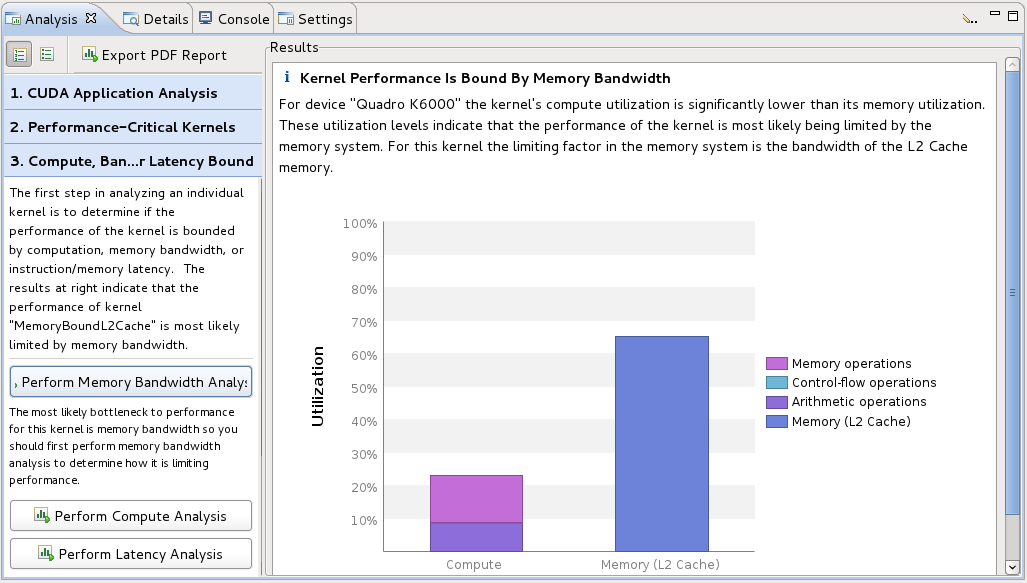
2.4.2.1. 引导式应用程序分析
在引导模式下,分析视图将逐步引导您完成整个应用程序的分析,并为应用程序中的每个内核提供特定的分析指导。引导式分析从 CUDA 应用程序分析开始,并从那里引导您找到应用程序中的优化机会。
2.4.2.2. 非引导式应用程序分析
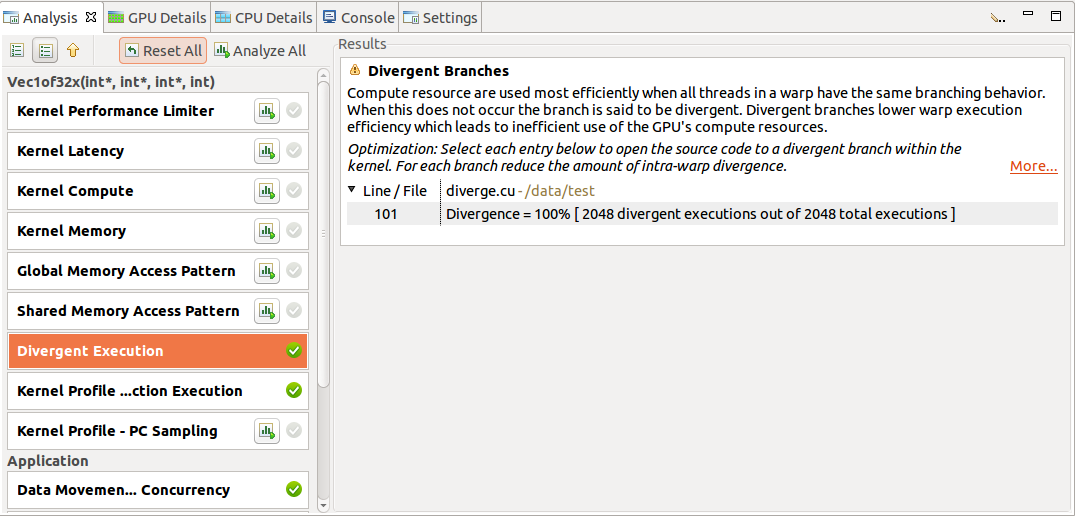
在非引导式分析模式下,每个应用程序分析阶段都有一个“运行分析”按钮,可用于生成该阶段的分析结果。选择“运行分析”按钮后,性能分析器将执行应用程序以收集执行分析所需的性能分析数据。分析阶段旁边的绿色对勾标记表示该阶段的分析结果可用。“每个分析结果都包含分析的简要描述以及指向分析详细文档的“更多…”链接。当您选择分析结果时,与该结果关联的时间线行或区间将在时间线视图中高亮显示。
当在时间线中选择单个内核实例时,将提供其他特定于内核的分析阶段。每个特定于内核的分析阶段都有一个“运行分析”按钮,其操作方式与应用程序分析阶段相同。下图显示了“发散执行”分析阶段的分析结果。某些内核实例分析结果(如“发散执行”)与内核中的特定源代码行相关联。要查看与每个结果关联的源代码,请从表中选择一个条目。将打开与该条目关联的源文件。
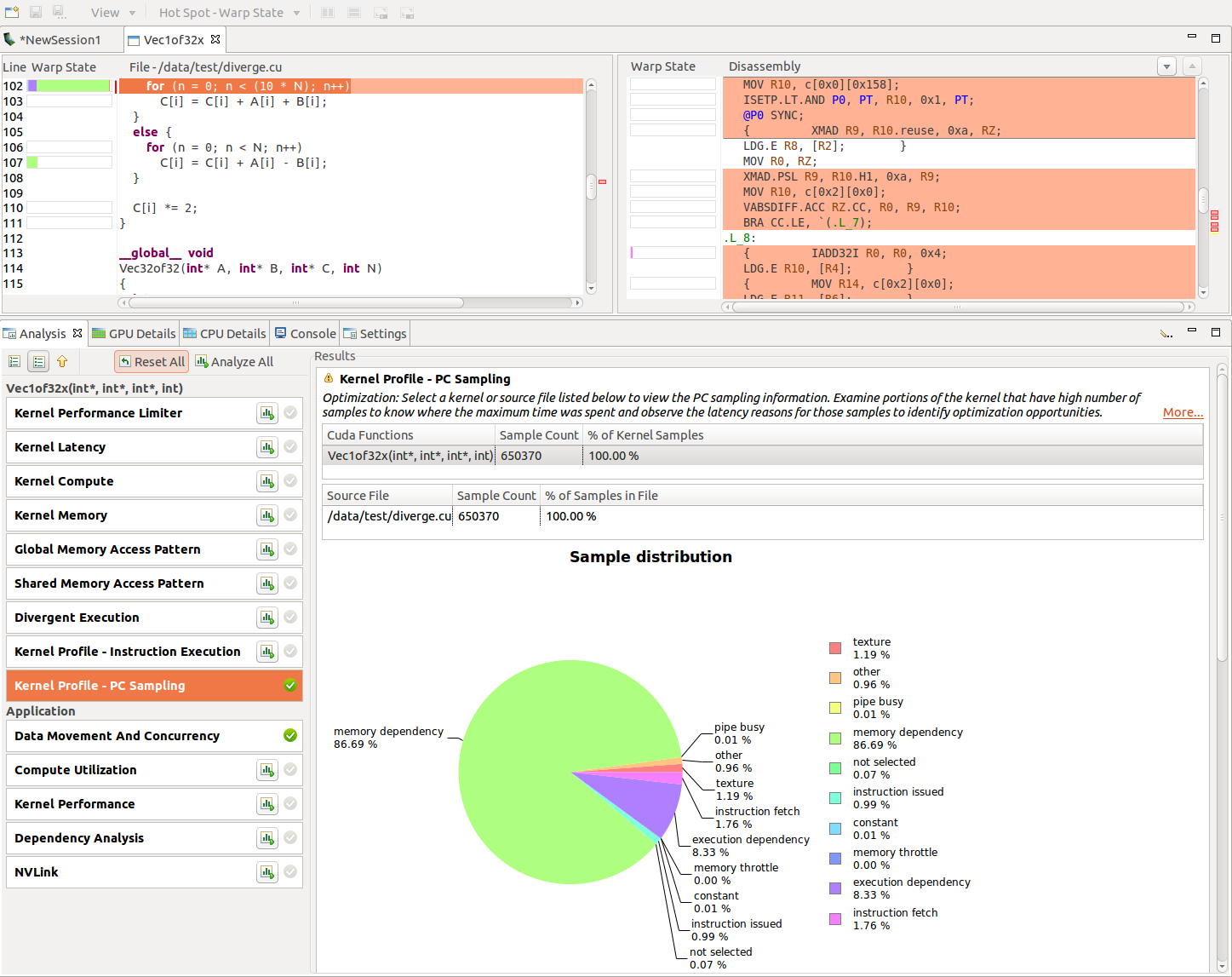
2.4.2.3. PC 采样视图
计算能力为 5.2 及更高版本的设备(不包括移动设备)具有 PC 采样功能。在此功能中,以固定间隔对每个 SM 的活动 warp 之一的 PC 和 warp 状态进行采样。warp 状态指示该 warp 是否在一个周期内发出指令,或者指示其停顿且无法发出指令的原因。当采样的 warp 停顿时,有可能在同一周期内,某些其他 warp 正在发出指令。因此,采样的 warp 的停顿不一定表示指令发出管道中存在空洞。有关不同状态的描述,请参阅Warp 状态部分。
计算能力为 6.0 及更高版本的设备具有一项新功能,可以提供延迟原因。延迟样本指示发出管道中空洞的原因。在收集这些样本时,相应的 warp 调度器中没有发出指令,因此这些样本给出了延迟原因。延迟原因将是Warp 状态部分中的停顿原因之一,但“未选择”停顿原因除外。
性能分析器会收集此信息,并在“内核性能分析 - PC 采样”视图中显示它。在此视图中,表格中给出了所有函数和内核的样本分布。饼图显示了为每个内核收集的停顿原因的分布。单击源文件或设备函数后,将打开“内核性能分析 - PC 采样”视图。垂直滚动条旁边显示的热点由为每个源代码和汇编行收集的样本数确定。停顿原因的分布以每个源代码和汇编行的堆叠条形图形式显示。这有助于精确定位源代码级别的延迟原因。
对于计算能力为 6.0 及更高版本的设备,Visual Profiler 显示两个视图:“内核性能分析 - PC 采样”(提供 warp 状态视图)和“内核性能分析 - PC 采样 - 延迟”(提供延迟原因)。可以选择热点以指向“Warp 状态”或“延迟原因”的热点。结果部分中的表格给出了总延迟样本、指令管道繁忙样本和指令发出样本的百分比分布。
博客文章使用指令级性能分析精确定位性能问题展示了如何使用 PC 采样来优化 CUDA 内核。
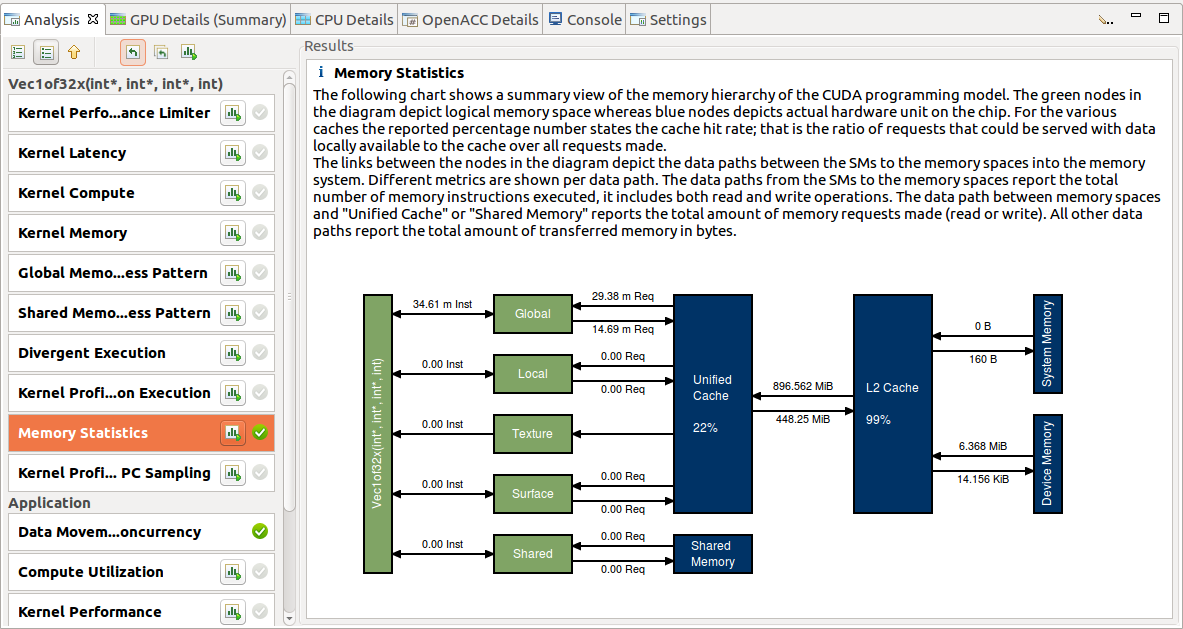
2.4.2.4. 内存统计信息
计算能力为 5.0 及更高版本的设备具有一项功能,可以在内核执行期间显示内存子系统的使用情况。图表显示了 CUDA 编程模型的内存层级结构的摘要视图。图中的绿色节点描述逻辑内存空间,而蓝色节点描述芯片上的实际硬件单元。对于各种缓存,报告的百分比数字表示缓存命中率;即可以使用本地缓存中可用的数据满足的请求与所有发出的请求的比率。
图表中节点之间的链接描述了 SM 到内存空间以及到内存系统的数据路径。每个数据路径显示不同的指标。从 SM 到内存空间(全局、本地、纹理、表面和共享)的数据路径报告执行的内存指令总数,包括读取和写入操作。内存空间和“统一缓存”或“共享内存”之间的数据路径报告发出的内存请求总数。所有其他数据路径报告传输的内存总量(以字节为单位)。指向右方向的箭头表示写入操作,而指向左方向的箭头表示读取操作。
2.4.2.5. NVLink 视图
NVIDIA NVLink 是一种高带宽、高能效的互连技术,可在 CPU 和 GPU 之间以及 GPU 之间实现快速通信。
Visual Profiler 收集 NVLink 拓扑和 NVLink 发射/接收吞吐量指标,并将这些指标映射到拓扑上。拓扑默认与时间线一起收集。吞吐量/利用率指标仅在选择 NVLink 选项时生成。
NVLink 信息在引导式分析的 CUDA 应用程序分析中的“检查 GPU 使用情况”的结果部分中显示。“NVLink 分析”显示拓扑,该拓扑显示不同设备之间的逻辑 NVLink 连接。逻辑链路包含 1 到 4 个物理 NVLink,这些物理 NVLink 具有连接在两个设备之间的相同属性。Visual Profiler 在“逻辑 NVLink 属性”表中列出了逻辑 NVLink 的属性和实现的利用率。它还在“逻辑 NVLink 吞吐量”表中列出了逻辑 NVLink 的发射和接收吞吐量。
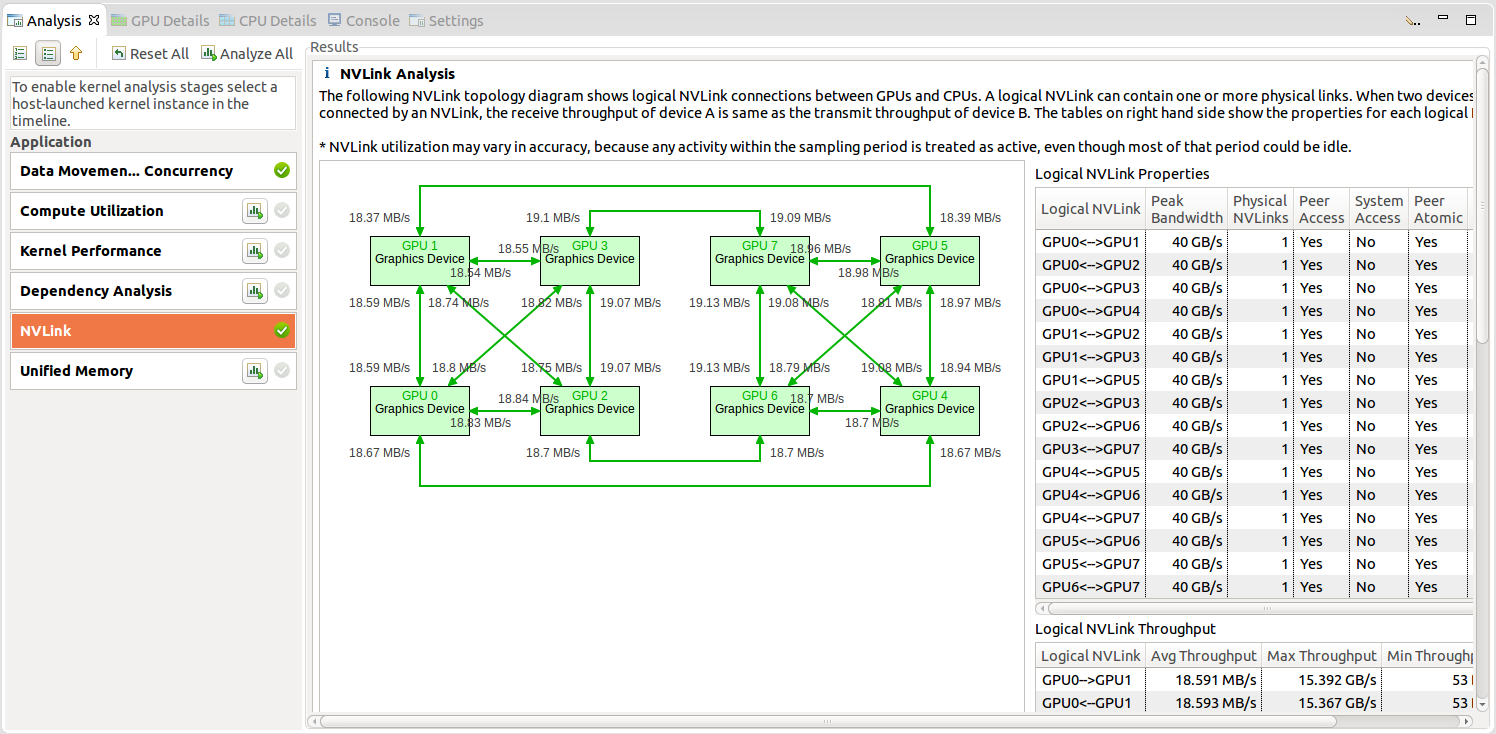
2.4.3. 源代码-反汇编视图
“源代码-反汇编视图”用于在源代码和汇编指令级别显示内核的分析结果。要能够查看内核源代码,您需要使用-lineinfo选项编译代码。如果未使用此编译器选项,则只会显示反汇编视图。
此视图显示用于以下类型的分析
全局内存访问模式分析
共享内存访问模式分析
发散执行分析
内核性能分析 - 指令执行分析
内核性能分析 - PC 采样分析
作为内核的引导式分析或非引导式分析的一部分,分析结果显示在“分析”视图下。单击源文件或设备函数后,将打开“源代码-反汇编”视图。如果未找到源文件,则会打开一个对话框,用于选择并指向源文件的新位置。例如,当在不同的系统上进行性能分析时,可能会发生这种情况。
“源代码-反汇编”视图包含
高级源代码
汇编指令
源代码级别的热点
汇编指令级别的热点
聚合到源代码级别的性能分析数据列
在汇编指令级别收集的性能分析数据列
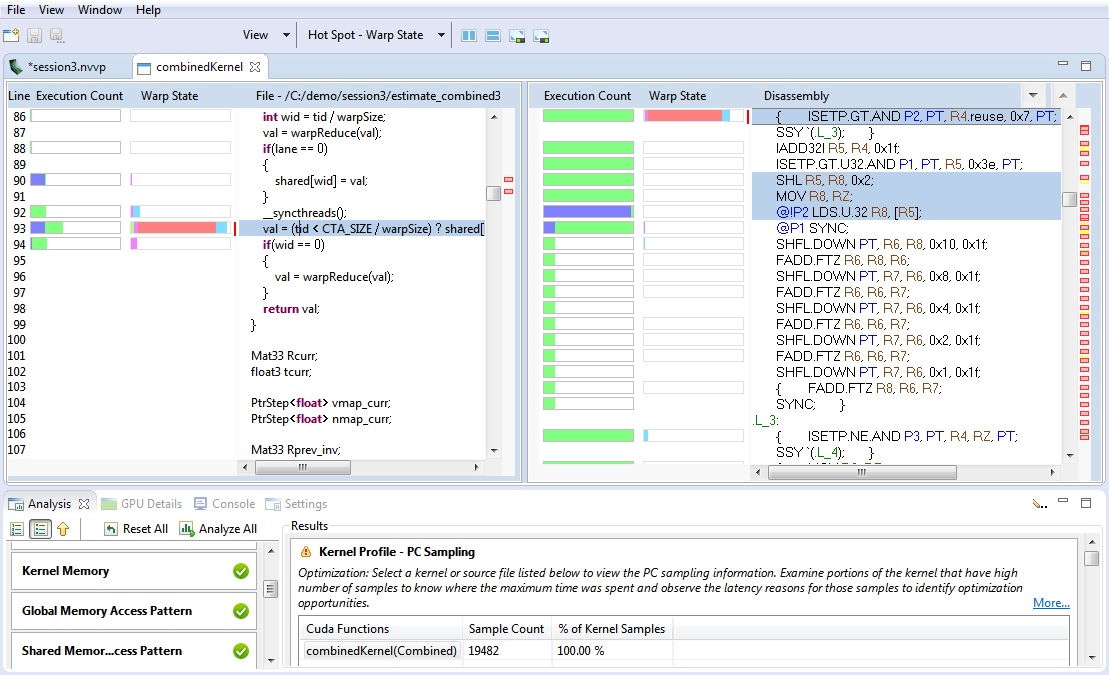
可以通过以下工具栏选项自定义“源代码-反汇编”视图中显示的信息
“视图”菜单 - 选择要显示的一个或多个可用性能分析器数据列。默认情况下,根据分析类型选择此项。
“热点”菜单 - 选择要用于热点的性能分析器数据。默认情况下,根据分析类型选择此项。
并排显示源代码视图和反汇编视图。
上下显示源代码视图和反汇编视图。
最大化源代码视图
最大化反汇编视图
热点根据重要性级别进行着色 - 低、中或高。将鼠标悬停在热点上会显示性能分析器数据的值、重要性级别以及源代码或反汇编行。您可以单击源代码级别或汇编指令级别的热点,以查看与热点对应的源代码或反汇编行。
在反汇编视图中,与选定的源代码行对应的汇编指令将被高亮显示。您可以单击反汇编列标题右侧显示的向上和向下箭头按钮,以导航到下一个或上一个指令块。
2.4.4. GPU 详情视图
“GPU 详情视图”显示表中每个内存复制和内核执行的性能分析应用程序的信息。下图显示了包含多个内存复制和内核执行的表格。表格的每一行都包含内核执行或内存复制的常规信息。对于内核,该表还将包含为该内核收集的每个指标或事件值的列。在该图中,“实际占用率”列显示了每个内核执行的该指标的值。
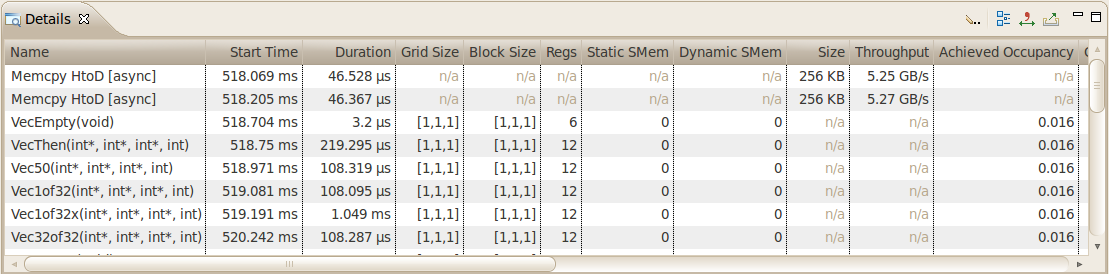
您可以通过单击列标题来按列对数据进行排序,并且可以通过单击列标题并将其拖动到新位置来重新排列列。如果您在表格中选择一行,则将在时间线视图中选择相应的区间。同样,如果您在时间线视图中选择内核或内存复制区间,则表格将滚动以显示相应的数据。
如果您将鼠标悬停在列标题上,则工具提示将显示该列中显示的数据。对于包含事件或指标数据的列,工具提示将描述相应的事件或指标。指标参考部分包含有关每个指标的更多详细信息。
可以使用从“详情视图”工具栏访问的菜单以各种方式过滤“GPU 详情视图”中显示的信息。以下模式可用
“按选择过滤” - 如果选中,则“GPU 详情视图”仅显示选定的内核和内存复制区间的数据。
“显示隐藏的时间线数据” - 如果未选中,则仅显示时间线中可见的内核和内存复制的数据。由于内核和内存复制位于时间线的折叠部分内而不可见,因此不会显示这些内核和内存复制。
“显示已过滤的时间线数据” - 如果未选中,则仅显示时间线行中未过滤的内核和内存复制的数据。
收集事件和指标
可以为每个内核收集特定的事件和指标值,并在详细信息表中显示。使用视图右上角的工具栏图标来配置要为每个设备收集的事件和指标,并运行应用程序以收集这些事件和指标。
显示摘要数据
默认情况下,该表为每个内存复制和内核调用显示一行。或者,该表可以显示每个内核函数的摘要结果。使用视图右上角的工具栏图标来选择或取消选择摘要格式。
格式化表格内容
表格中的数字可以使用或不使用分组分隔符显示。使用视图右上角的工具栏图标来选择或取消选择分组分隔符。
导出详细信息
可以使用视图右上角的工具栏图标以 CSV 格式导出表格的内容。
2.4.5. CPU 详情视图
CPU 详情视图
此视图详细说明了您的应用程序在 CPU 上执行函数所花费的时间量。定期对每个线程进行采样以捕获其调用堆栈,并且这些测量的摘要将在此视图中显示。您可以通过选择组织调用堆栈的不同方向来操作视图:自顶向下、自底向上、代码结构 (3)、选择要查看的线程 (1) 以及通过对特定线程进行排序或高亮显示 (7, 8)。
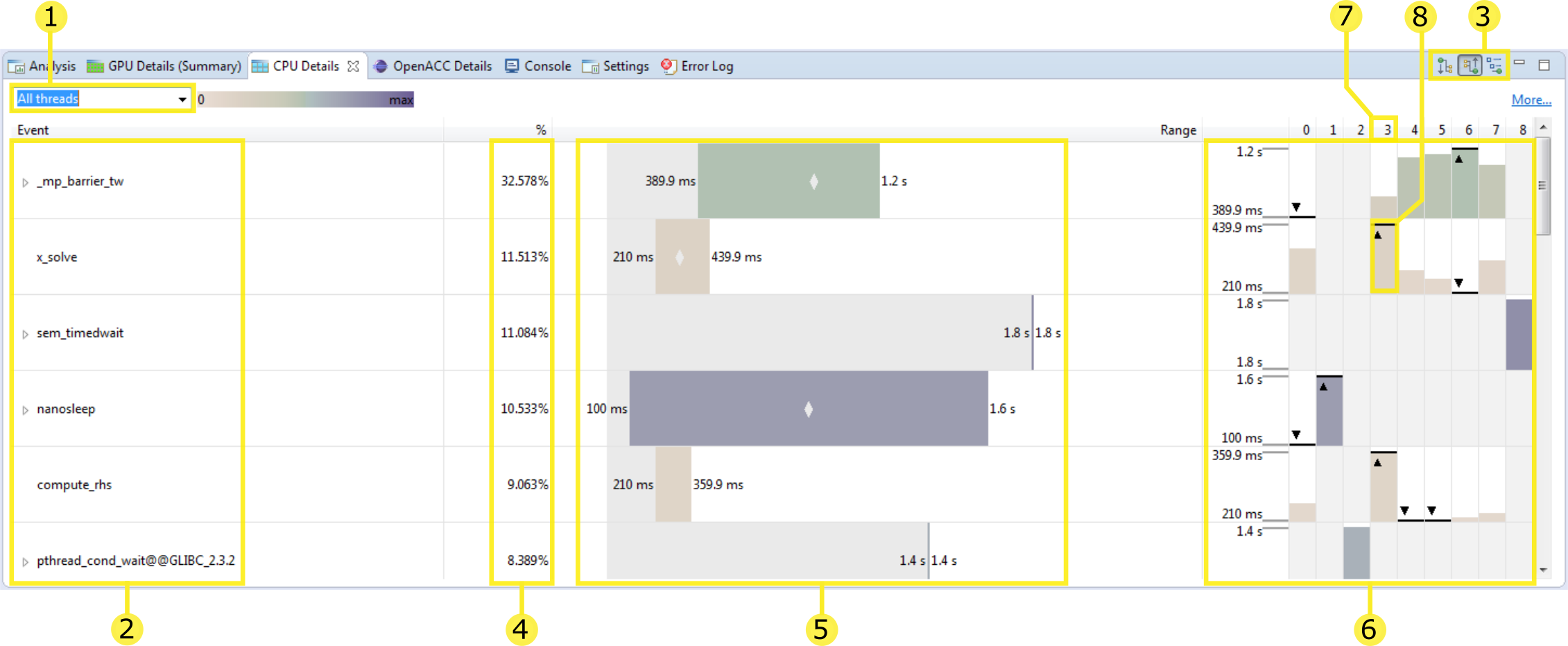
当选择“所有线程”选项(默认)时,将在一个视图中显示所有性能分析的线程。您可以使用此下拉菜单来改为选择单个线程。
此列显示事件树,该事件树表示应用程序在 CPU 上的执行结构。其余列中的每一列都显示为此事件收集的测量值。此处显示的事件由选择的树方向模式 (3) 确定。
-
树的组织方式旨在显示函数之间的调用层次结构。以下模式可用
自顶向下(调用方优先)调用树视图 - CPU 详情树组织为调用树,每个函数都显示为其调用方的子项。在此模式下,您可以查看从“main”函数开始的调用堆栈。
自底向上(被调用方优先)调用树视图 - CPU 详情树的组织方式使每个函数都显示为其调用的任何函数的子项。在此模式下,您可以快速识别为应用程序的执行贡献最多时间的调用路径。
代码结构(文件和行)树视图 - CPU 详情树显示哪些函数属于每个源文件和库,以及应用程序的执行有多少归因于给定的源代码行。
在每种模式下,为每个函数列出的时间都是“包含性的”,并且包括在此函数及其调用的任何函数中花费的时间。对于代码结构视图,代码区域是包含性的(即,文件条目列出了在文件中包含的每个函数中花费的时间)。
此列显示所有线程在此事件中花费的总时间量,占所有事件中花费的总时间量的百分比。
此列显示一个条,该条表示任何线程在事件中花费的时间量始终在此范围内的范围。左侧写入最小值,右侧写入最大值。此外,如果有空间,则会在条的中间绘制一个小“菱形”,其中绘制了所有线程在此事件中花费的平均时间。
这些列为每个事件显示一个不同的图表。左侧是垂直比例,显示与范围图表上显示的相同的最小值和最大值。以下各列分别显示线程在此事件中花费的时间量。如果给定事件/线程组合的单元格灰显,则表示此线程在此事件中没有花费时间(在此示例中,线程 1 和线程 2 都没有在事件“x_solve”中花费时间)。此外,在所有线程中,在事件中花费的时间量最少或最多的线程都使用“三角形/线”进行注释。在此示例中,线程 3 花费的时间最多,线程 6 花费的时间最少在事件“x_solve”中。
要按给定线程花费的时间重新排序行,请单击线程列标题。
要高亮显示给定线程,请单击其在此图表中的条之一。
对此视图的此更改是按线程 3 (7) 排序并高亮显示它 (8) 的结果。
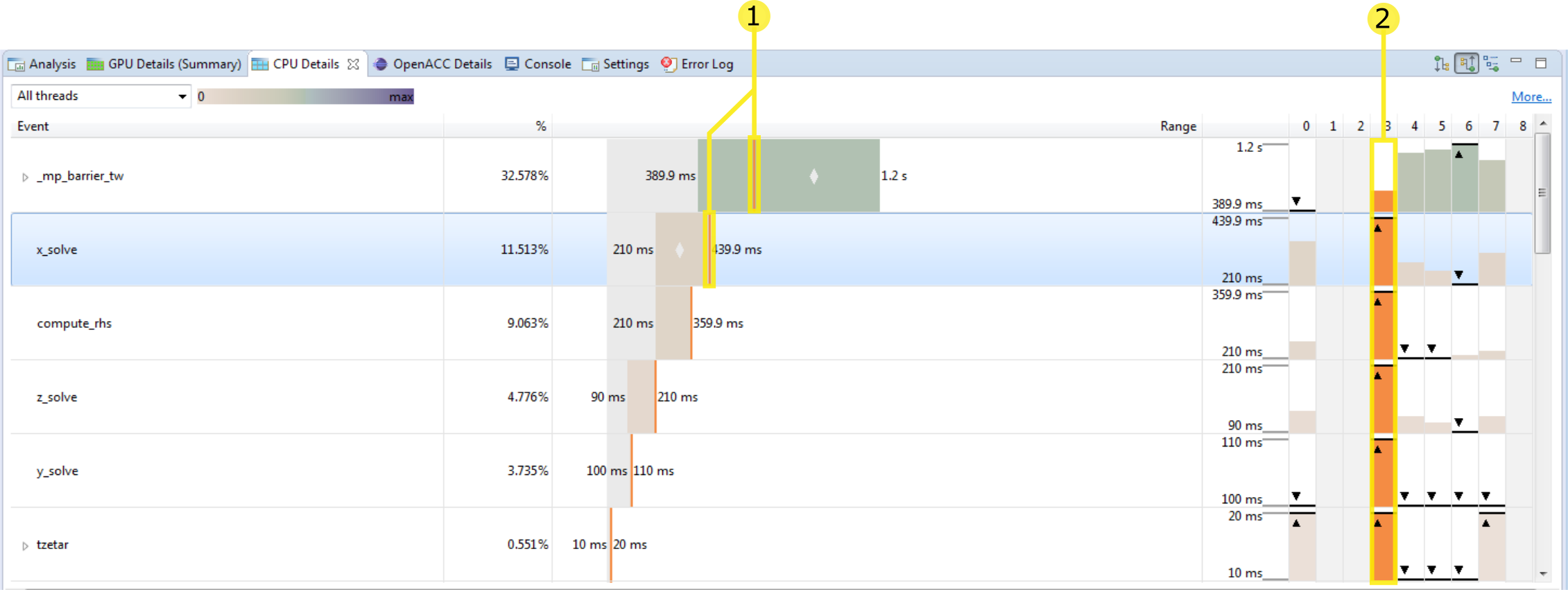
高亮显示线程 3 后,我们现在在范围图表上看到一条垂直线,显示此线程在此事件中花费的时间量,与所有线程的范围相比。
此线程也在每一行上高亮显示。
CPU 线程
CPU 源代码
您可以通过双击树中的任何函数来打开CPU 源代码视图。要显示源文件,源文件必须位于本地文件系统中。默认情况下,将搜索包含可执行文件或性能分析文件的目录。如果找不到源文件,将出现提示,要求提供其位置。有时,正在搜索特定目录中的文件,在这种情况下,您应提供此目录所在的路径。
提示
CPU 性能分析是通过定期采样运行应用程序的状态来收集的。因此,只有在执行期间对其进行采样时,函数才会在此视图中显示。不太可能对短时间运行或非常不频繁调用的函数进行采样。如果未对函数进行采样,则将其运行时间计入调用它的函数。为了收集代表应用程序性能的 CPU 性能分析,感兴趣的代码必须执行足够长的时间才能收集足够的样本。通常,一分钟的运行时就足够了。
提示
文件和行信息是从编译器获得的应用程序的调试信息中收集的。为确保此信息可用,建议您使用“-g”或类似的选项进行编译。
2.4.6. OpenACC 详情视图
OpenACC 表格视图
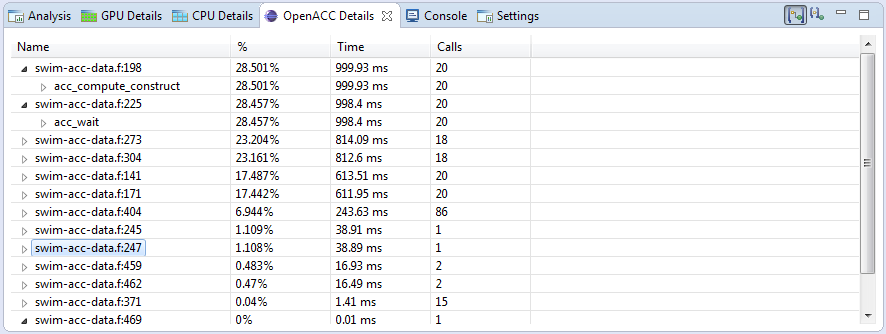
“OpenACC 详情视图”显示性能分析应用程序执行的每个 OpenACC 运行时活动。每个活动按源位置分组:在应用程序源代码中的同一文件和行号处发生的每个活动都放置在标有源位置的节点下。每个活动都显示性能分析应用程序花费的时间量,既显示为时间单位,又显示为此应用程序执行任何 OpenACC 活动的总时间的百分比。此外,还显示了此活动被调用的次数。有两种方法可以计算在特定 OpenACC 活动中花费了多少时间
在 OpenACC 详情视图中显示包含性持续时间(计算同时运行的任何其他 OpenACC 活动) - OpenACC 详情视图显示每个活动中花费的总时间,包括作为此活动结果执行的任何活动。在这种情况下,将在给定应用程序源位置发生的每个活动中花费的时间量进行汇总,并在显示源位置的行上显示。
在 OpenACC 详情视图中显示排除性持续时间(排除同时运行的任何其他 OpenACC 活动) - OpenACC 详情视图仅显示在给定活动中花费的时间。在这种情况下,在给定源位置花费的时间量始终为零 — 时间仅归因于在此源位置发生的每个活动。
2.4.7. OpenMP 详情视图
OpenMP 表格视图

“OpenMP 详情视图”显示 CPU 上 OpenMP 运行时的活动。您的应用程序在并行区域或空闲状态下花费的时间既在时间线上显示,又在此视图中进行汇总。每种活动类型花费的时间百分比的参考是从第一个并行区域的开始到最后一个并行区域的结束的时间。每种活动类型的百分比总和通常超过 100%,因为 OpenMP 运行时可以同时处于多种状态。
2.4.8. 属性视图
“属性视图”显示有关在时间线视图中高亮显示或选择的行或区间的信息。如果未选择行或区间,则显示的信息会跟踪鼠标指针的移动。如果选择了行或区间,则显示的信息将固定到该行或区间。
当选择具有关联源文件的 OpenACC 区间时,此文件名将显示在“源文件”表条目中。双击文件名将在文件系统上可用时打开相应的源文件。
2.4.9. 控制台视图
“控制台视图”显示应用程序每次执行时的 stdout 和 stderr 输出。如果您需要为应用程序提供 stdin 输入,请在控制台视图中键入。
2.4.10. 设置视图
“设置视图”允许您为正在性能分析的应用程序指定执行设置。如下图所示,“可执行文件设置”选项卡允许您指定可执行文件、工作目录、命令行参数和应用程序的环境。仅可执行文件是必需的,所有其他字段都是可选的。
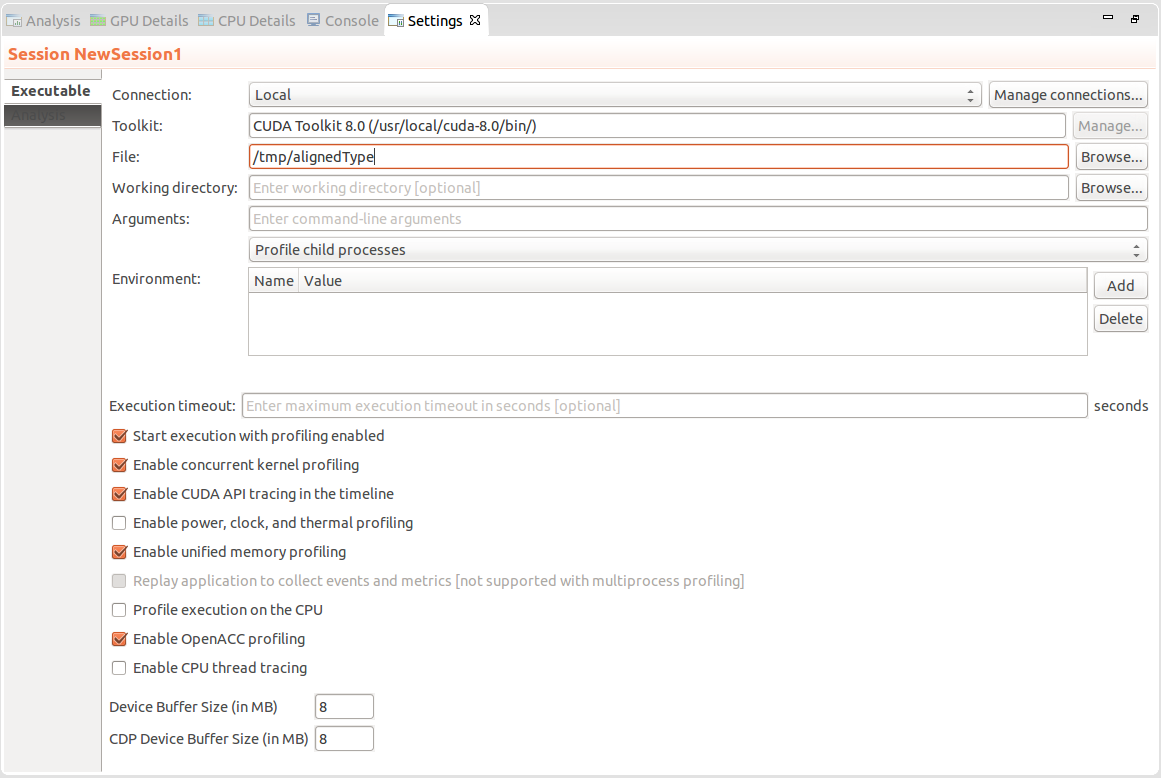
执行超时
“可执行文件设置”选项卡还允许您指定可选的执行超时。如果指定了执行超时,则应用程序执行将在该秒数后终止。如果未指定执行超时,则将允许应用程序继续执行,直到其正常终止。
注意
计时器从 CUDA 驱动程序初始化的那一刻开始计数。如果应用程序未调用任何 CUDA API,则不会触发超时。
启用性能分析后开始执行
默认情况下,选中“启用性能分析后开始执行”复选框,以指示应用程序性能分析在应用程序执行开始时开始。如果您正在使用cudaProfilerStart()和cudaProfilerStop()来控制应用程序内的性能分析,如聚焦性能分析中所述,则应取消选中此框。
启用并发内核性能分析
默认情况下,选中“启用并发内核性能分析”复选框以启用对利用并发内核执行的应用程序的性能分析。如果取消选中此复选框,则性能分析器将禁用并发内核执行。在某些情况下,禁用并发内核执行可以减少性能分析开销,因此可能适用于不利用并发内核的应用程序。
启用功耗、时钟和热力性能分析
可以设置“启用功耗、时钟和热力性能分析”复选框,以启用对应用程序使用的每个 GPU 的功耗、时钟和热力行为的低频采样。
2.4.11. CPU 源代码视图
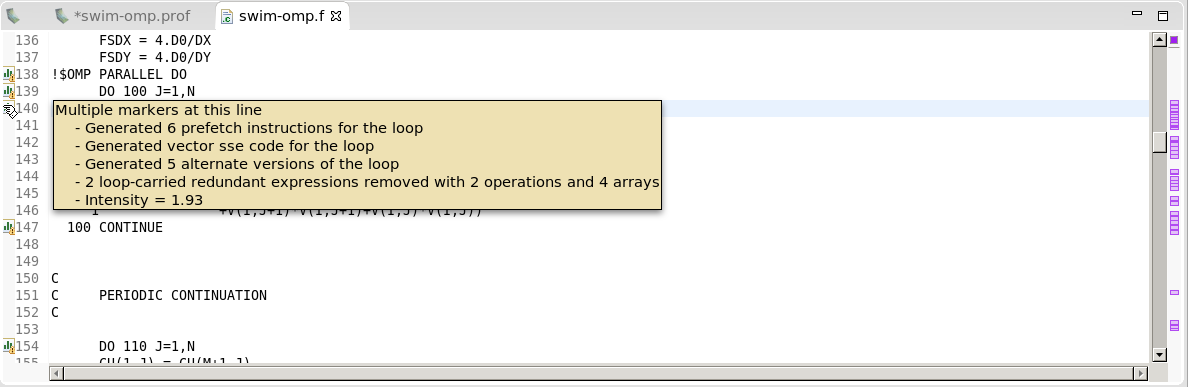
“CPU 源代码视图”允许您检查构成性能分析应用程序的 CPU 源代码的文件。可以通过在树中双击一个函数,在CPU 详情视图中打开此视图,然后将打开与此函数对应的源文件。可以通过右键单击左侧标尺来启用行号。
当使用 PGI® 编译器进行编译时,可以将注释添加到此视图(有关更多信息,请参阅常用编译器反馈格式)。这些注释是关于如何编译给定代码行的注释。PGI 编译器保存有关如何优化程序的信息,或为什么未进行特定优化的信息。这可以与CPU 详情视图结合使用,以帮助确定某些代码行执行方式的原因。例如,该消息可能会告诉您以下内容
编译器生成的向量指令。
循环的计算密集度,计算与内存操作的比率 - 数字越高表示计算量大于内存加载和存储。
有关并行化的信息,以及如果编译器无法自动并行化循环,如何使循环并行运行的提示。
2.5. 自定义性能分析器
当您首次启动 Visual Profiler, 并在关闭 欢迎页面后,您将看到视图的默认放置位置。通过移动和调整视图大小,您可以自定义性能分析器以满足您的开发需求。您所做的任何更改都会在您下次启动性能分析器时恢复。
2.5.1. 调整视图大小
要调整视图大小,只需单击鼠标左键并拖动视图之间的分隔区域即可。在一个区域中堆叠在一起的所有视图将同时调整大小。
2.5.2. 重新排序视图
要在堆叠视图集中重新排序视图,请单击鼠标左键并拖动视图标签到视图堆叠中的新位置。
2.5.3. 移动视图
要移动视图,左键单击视图选项卡,然后将其拖动到新的位置。当您拖动视图时,轮廓将显示视图的目标位置。您可以将视图放置在新位置,或者将其与其他视图堆叠在同一位置。
2.5.4. 取消停靠视图
您可以从分析器窗口取消停靠视图,以便该视图占用其自身的独立窗口。您可能希望这样做以利用多个显示器或最大化单个视图的大小。要取消停靠视图,左键单击视图选项卡并将其拖动到分析器窗口外部。要停靠视图,左键单击视图选项卡(不是窗口装饰)并将其拖动到分析器窗口中。
2.5.5. 打开和关闭视图
使用视图选项卡上的 X 图标关闭视图。要打开视图,请使用“视图”菜单。
2.6. 命令行参数
当从命令行启动 Visual Profiler 时,可以使用命令行参数来指定要启动新会话的可执行文件,或者导入使用以下模式之一从 nvprof 导出的配置文件
-
通过使用可执行文件的名称启动 nvvp(可选地后跟其参数)来启动新的可执行会话
nvvp executableName [[executableArguments]...]
-
通过使用单个 .nvprof 文件作为参数启动 nvvp 来导入单进程 nvprof 会话(有关更多详细信息,请参阅nvprof 的导出/导入选项部分)
nvvp data.nvprof
-
通过使用多个 .nvprof 文件作为参数启动 nvvp 来导入多进程 nvprof 会话
nvvp data1.nvprof data2.nvprof ...
3. nvprof
nvprof 性能分析工具使您能够从命令行收集和查看性能分析数据。nvprof 能够收集 CPU 和 GPU 上 CUDA 相关活动的时间线,包括内核执行、内存传输、内存设置和 CUDA API 调用以及 CUDA 内核的事件或指标。通过命令行选项为 nvprof 提供性能分析选项。性能分析结果在收集性能分析数据后显示在控制台中,也可以保存以供以后通过 nvprof 或 Visual Profiler 查看。
注意
默认情况下,分析器的文本输出重定向到 stderr。使用 --log-file 将输出重定向到另一个文件。请参阅重定向输出。
要从命令行分析应用程序
nvprof [options] [application]
[application-arguments]
要查看完整的帮助页面,请键入 nvprof --help。
3.1. 命令行选项
3.1.1. CUDA 性能分析选项
选项 |
值 |
默认值 |
描述 |
|---|---|---|---|
aggregate-mode |
on, off |
on |
为后续 有关更多信息,请参阅事件/指标跟踪模式。 |
analysis-metrics |
N/A |
N/A |
收集可以导入到 Visual Profiler 的“分析”模式的性能分析数据。注意:使用 |
annotate-mpi |
off, openmpi, mpich |
off |
使用 NVTX 标记自动注释 MPI 调用。指定安装在您机器上的 MPI 实现。目前,支持 Open MPI 和 MPICH 实现。 有关更多信息,请参阅使用 NVTX 自动进行 MPI 注释。 |
concurrent-kernels |
on, off |
on |
启用/禁用并发内核执行。如果并发内核执行关闭,则在一个设备上运行的所有内核将被串行化。 |
continuous-sampling-interval |
{毫秒间隔} |
2 毫秒 |
设置连续模式采样间隔(以毫秒为单位)。最小值为 1 毫秒。 |
cpu-thread-tracing |
on, off |
off |
收集有关 CPU 线程 API 活动的信息。 有关更多信息,请参阅CPU 线程跟踪。 |
dependency-analysis |
N/A |
N/A |
生成主机和设备活动的事件依赖关系图并运行依赖关系分析。 有关更多信息,请参阅依赖关系分析。 |
device-buffer-size |
{MB 为单位的大小} |
8 MB |
设置设备内存大小(以 MB 为单位),该大小保留用于存储非 CDP 操作(特别是并发内核跟踪)的性能分析数据,用于上下文中的每个缓冲区。大小应为正整数。 |
device-cdp-buffer-size |
{MB 为单位的大小} |
8 MB |
设置设备内存大小(以 MB 为单位),该大小保留用于存储 CDP 操作的性能分析数据,用于上下文中的每个缓冲区。大小应为正整数。 |
devices |
{逗号分隔的设备 ID}, all |
N/A |
更改后续 有关更多信息,请参阅性能分析范围。 |
event-collection-mode |
kernel, continuous |
kernel |
为所有事件/指标选择事件收集模式。
|
events (e) |
{逗号分隔的事件名称}, all |
N/A |
指定要在某些设备上分析的事件。可以指定多个以逗号分隔的事件名称。分析哪个设备由 |
kernel-latency-timestamps |
on, off |
off |
启用/禁用内核延迟时间戳的收集,即排队和提交的时间戳。排队时间戳在内核启动命令排队到 CPU 命令缓冲区时捕获。提交时间戳表示包含此内核启动的 CPU 命令缓冲区何时提交到 GPU。启用此选项可能会在性能分析期间产生开销。 |
kernels |
{内核名称}, {[上下文 ID/名称]:[流 ID/名称]:[内核名称]:[调用]} |
N/A |
更改后续
示例: 有关更多信息,请参阅性能分析范围。 |
metrics (m) |
{逗号分隔的指标名称}, all |
N/A |
指定要在某些设备上分析的指标。可以指定多个以逗号分隔的指标名称。分析哪个设备由 |
pc-sampling-period |
{周期,以周期为单位} |
根据设置,介于 5 到 12 之间 |
指定 PC 采样周期,以周期为单位,采样记录将在此周期转储。周期的允许值是 5 到 31 之间的整数,包括 5 和 31。这将采样周期设置为(2^周期)个周期。注意:仅适用于 GM20X+。 |
profile-all-processes |
N/A |
N/A |
分析由启动此 nvprof 实例的同一用户启动的所有进程。注意:在这种模式下,一次只能运行一个 nvprof 实例。在这种模式下,无需指定要运行的应用程序。 有关更多信息,请参阅多进程性能分析。 |
profile-api-trace |
none, runtime, driver, all |
all |
启用/禁用 CUDA 运行时/驱动程序 API 跟踪。
|
profile-child-processes |
N/A |
N/A |
分析应用程序及其启动的所有子进程。 有关更多信息,请参阅多进程性能分析。 |
profile-from-start |
on, off |
on |
启用/禁用从应用程序启动时开始性能分析。如果禁用,应用程序可以使用 {cu,cuda}Profiler{Start,Stop} 来启用/禁用性能分析。 有关更多信息,请参阅聚焦性能分析。 |
profiling-semaphore-pool-size |
{计数} |
65536 |
设置性能分析信号量池大小,该大小保留用于存储每个上下文中串行化内核和内存操作的性能分析数据。大小应为正整数。 |
query-events |
N/A |
N/A |
列出设备上所有可用的事件。查询的设备可以通过 |
query-metrics |
N/A |
N/A |
列出设备上所有可用的指标。查询的设备可以通过 |
replay-mode |
disabled, kernel, application |
kernel |
选择在无法在单次运行中收集所有事件/指标时使用的重放模式。
|
skip-kernel-replay-save-restore |
on, off |
off |
如果启用,此选项可以大大提高内核重放速度,因为将跳过每次内核传递的可变状态的保存和恢复。跳过输入/输出缓冲区的保存/恢复允许您指定上下文上的所有分析内核在执行期间都不会更改其输入缓冲区的内容,或者调用设备 malloc/free 或 new/delete,这些操作会使设备堆处于不同的状态。具体而言,内核可以在同一次启动中 malloc 和 free 缓冲区,但它不能调用不匹配的 malloc 或不匹配的 free。注意:如果在一个内核确实修改输入缓冲区或使用不匹配的 malloc/free 时错误地使用此模式,将导致未定义的行为,包括内核执行失败和/或设备数据损坏。
|
source-level-analysis (a) |
global_access, shared_access, branch, instruction_execution, pc_sampling |
N/A |
指定要在特定内核调用上分析的源代码级别指标。使用
注意:使用 有关更多信息,请参阅源代码-反汇编视图。 |
system-profiling |
on, off |
off |
启用/禁用功耗、时钟和热性能分析。 有关更多信息,请参阅系统性能分析。 |
timeout (t) |
{秒} |
N/A |
为 CUDA 应用程序设置执行超时(以秒为单位)。注意:超时从 CUDA 驱动程序初始化时开始计数。如果应用程序不调用任何 CUDA API,则不会触发超时。 |
track-memory-allocations |
on, off |
off |
启用/禁用内存操作的跟踪,这涉及记录内存分配和释放的时间戳、内存大小、内存类型和程序计数器。启用此选项可能会在性能分析期间产生开销。 |
unified-memory-profiling |
per-process-device, off |
per-process-device |
配置统一内存性能分析。
有关更多信息,请参阅统一内存性能分析。 |
3.1.2. CPU 性能分析选项
选项 |
值 |
默认值 |
描述 |
|---|---|---|---|
cpu-profiling |
on, off |
off |
启用 CPU 性能分析。注意:多进程模式不支持 CPU 性能分析。 |
cpu-profiling-explain-ccff |
{文件名} |
N/A |
设置 PGI pgexplain.xml 文件的路径,该文件应用于解释通用编译器反馈格式 (CCFF) 消息。 |
cpu-profiling-frequency |
{频率} |
100Hz |
设置 CPU 性能分析频率,以每秒样本数为单位。最大值为 500Hz。 |
cpu-profiling-max-depth |
{深度} |
0 (即无限制) |
设置每个调用堆栈的最大深度。 |
cpu-profiling-mode |
flat, top-down, bottom-up |
bottom-up |
设置 CPU 性能分析的输出模式。
|
cpu-profiling-percentage-threshold |
{阈值} |
0 (即无限制) |
过滤掉低于设置的百分比阈值的条目。限制应为 0 到 100 之间的整数,包括 0 和 100。 |
cpu-profiling-scope |
function, instruction |
function |
选择性能分析范围。
|
cpu-profiling-show-ccff |
on, off |
off |
选择是否打印嵌入在二进制文件中的通用编译器反馈格式 (CCFF) 消息。注意:此选项暗示 |
cpu-profiling-show-library |
on, off |
off |
选择是否为每个样本打印库名称。 |
cpu-profiling-thread-mode |
separated, aggregated |
aggregated |
设置 CPU 性能分析的线程模式。
|
cpu-profiling-unwind-stack |
on, off |
on |
选择是否在每个采样点展开 CPU 调用堆栈。 |
openacc-profiling |
on, off |
on |
启用/禁用从 OpenACC 性能分析接口记录信息。注意:OpenACC 性能分析接口是否可用取决于 OpenACC 运行时。 有关更多信息,请参阅OpenACC。 |
openmp-profiling |
on, off |
off |
启用/禁用从 OpenMP 性能分析接口记录信息。注意:OpenMP 性能分析接口是否可用取决于 OpenMP 运行时。 有关更多信息,请参阅OpenMP。 |
3.1.3. 打印选项
选项 |
值 |
默认值 |
描述 |
|---|---|---|---|
context-name |
{名称} |
N/A |
CUDA 上下文的名称。 上下文名称字符串中的 上下文名称字符串中的 上下文名称字符串中的 上下文名称字符串中的 上下文名称字符串中的 |
csv |
N/A |
N/A |
在输出中使用逗号分隔值。 有关更多信息,请参阅CSV。 |
demangling |
on, off |
on |
启用/禁用函数名称的 C++ 名称反修饰。 有关更多信息,请参阅反修饰。 |
normalized-time-unit (u) |
s, ms, us, ns, col, auto |
auto |
指定将在输出中使用的时间单位。
有关更多信息,请参阅调整单位。 |
openacc-summary-mode |
exclusive, inclusive |
exclusive |
设置如何在 OpenACC 摘要中计算持续时间。 有关更多信息,请参阅OpenACC 摘要模式。 |
trace |
api, gpu |
N/A |
指定要跟踪的选项(或以逗号分隔的选项)。
|
print-api-summary |
N/A |
N/A |
打印 CUDA 运行时/驱动程序 API 调用的摘要。 |
print-api-trace |
N/A |
N/A |
打印 CUDA 运行时/驱动程序 API 跟踪。 有关更多信息,请参阅GPU 跟踪和 API 跟踪模式。 |
print-dependency-analysis-trace |
N/A |
N/A |
打印依赖关系分析跟踪。 有关更多信息,请参阅依赖关系分析。 |
print-gpu-summary |
N/A |
N/A |
打印 GPU 上活动(包括 CUDA 内核和 memcpy/memset)的摘要。 有关更多信息,请参阅摘要模式。 |
print-gpu-trace |
N/A |
N/A |
打印单个内核调用(包括 CUDA memcpy/memset),并按时间顺序对其进行排序。在事件/指标性能分析模式下,显示每个内核调用的事件/指标。 有关更多信息,请参阅GPU 跟踪和 API 跟踪模式。 |
print-openacc-constructs |
N/A |
N/A |
在 OpenACC 配置文件中包含父构造名称。 有关更多信息,请参阅OpenACC 选项。 |
print-openacc-summary |
N/A |
N/A |
打印 OpenACC 配置文件的摘要。 |
print-openacc-trace |
N/A |
N/A |
打印 OpenACC 配置文件的跟踪。 |
print-openmp-summary |
N/A |
N/A |
打印 OpenMP 配置文件的摘要。 |
print-summary (s) |
N/A |
N/A |
在屏幕上打印性能分析结果的摘要。注意:除非使用 |
print-summary-per-gpu |
N/A |
N/A |
打印每个 GPU 的性能分析结果摘要。 |
process-name |
{名称} |
N/A |
进程的名称。 进程名称字符串中的 进程名称字符串中的 进程名称字符串中的 进程名称字符串中的 |
quiet |
N/A |
N/A |
禁止所有 nvprof 输出。 |
stream-name |
{名称} |
N/A |
CUDA 流的名称。 流名称字符串中的 流名称字符串中的 流名称字符串中的 流名称字符串中的 流名称字符串中的 |
3.1.4. IO 选项
选项 |
值 |
默认值 |
描述 |
|---|---|---|---|
export-profile (o) |
{文件名} |
N/A |
导出结果文件,该文件可以稍后导入或由 NVIDIA Visual Profiler 打开。 文件名字符串中的 文件名字符串中的 文件名字符串中的 文件名字符串中的 默认情况下,此选项禁用摘要输出。注意:如果正在分析的应用程序创建子进程,或者如果使用 有关更多信息,请参阅导出/导入。 |
force-overwrite (f) |
N/A |
N/A |
强制覆盖所有输出文件(任何现有文件都将被覆盖)。 |
import-profile (i) |
{文件名} |
N/A |
从之前的运行中导入结果配置文件。 有关更多信息,请参阅导出/导入。 |
log-file |
{文件名} |
N/A |
使 nvprof 将其所有输出发送到指定的文件或标准通道之一。该文件将被覆盖。如果该文件不存在,将创建一个新文件。 作为完整文件名的 作为完整文件名的 文件名字符串中的 文件名字符串中的 文件名字符串中的 文件名中的 有关更多信息,请参阅重定向输出。 |
print-nvlink-topology |
N/A |
N/A |
打印 nvlink 拓扑 |
print-pci-topology |
N/A |
N/A |
打印 PCI 拓扑 |
help (h) |
N/A |
N/A |
打印帮助信息。 |
version (V) |
N/A |
N/A |
打印此工具的版本信息。 |
3.2. 性能分析模式
nvprof 在下面列出的模式之一中运行。
3.2.1. 摘要模式
摘要模式是 nvprof 的默认操作模式。在此模式下,nvprof 为每个内核函数和应用程序执行的每种类型的 CUDA 内存复制/设置输出单行结果。对于每个内核,nvprof 输出内核或内存复制类型的所有实例的总时间以及平均时间、最短时间和最长时间。内核的时间是设备上的内核执行时间。默认情况下,nvprof 还打印所有 CUDA 运行时/驱动程序 API 调用的摘要。nvprof 的输出(表除外)以 ==<pid>== 为前缀,<pid> 是正在分析的应用程序的进程 ID。
这是一个在 CUDA 示例 matrixMul 上运行 nvprof 的简单示例
$ nvprof matrixMul
[Matrix Multiply Using CUDA] - Starting...
==27694== NVPROF is profiling process 27694, command: matrixMul
GPU Device 0: "GeForce GT 640M LE" with compute capability 3.0
MatrixA(320,320), MatrixB(640,320)
Computing result using CUDA Kernel...
done
Performance= 35.35 GFlop/s, Time= 3.708 msec, Size= 131072000 Ops, WorkgroupSize= 1024 threads/block
Checking computed result for correctness: OK
Note: For peak performance, please refer to the matrixMulCUBLAS example.
==27694== Profiling application: matrixMul
==27694== Profiling result:
Time(%) Time Calls Avg Min Max Name
99.94% 1.11524s 301 3.7051ms 3.6928ms 3.7174ms void matrixMulCUDA<int=32>(float*, float*, float*, int, int)
0.04% 406.30us 2 203.15us 136.13us 270.18us [CUDA memcpy HtoD]
0.02% 248.29us 1 248.29us 248.29us 248.29us [CUDA memcpy DtoH]
==27964== API calls:
Time(%) Time Calls Avg Min Max Name
49.81% 285.17ms 3 95.055ms 153.32us 284.86ms cudaMalloc
25.95% 148.57ms 1 148.57ms 148.57ms 148.57ms cudaEventSynchronize
22.23% 127.28ms 1 127.28ms 127.28ms 127.28ms cudaDeviceReset
1.33% 7.6314ms 301 25.353us 23.551us 143.98us cudaLaunch
0.25% 1.4343ms 3 478.09us 155.84us 984.38us cudaMemcpy
0.11% 601.45us 1 601.45us 601.45us 601.45us cudaDeviceSynchronize
0.10% 564.48us 1505 375ns 313ns 3.6790us cudaSetupArgument
0.09% 490.44us 76 6.4530us 307ns 221.93us cuDeviceGetAttribute
0.07% 406.61us 3 135.54us 115.07us 169.99us cudaFree
0.02% 143.00us 301 475ns 431ns 2.4370us cudaConfigureCall
0.01% 42.321us 1 42.321us 42.321us 42.321us cuDeviceTotalMem
0.01% 33.655us 1 33.655us 33.655us 33.655us cudaGetDeviceProperties
0.01% 31.900us 1 31.900us 31.900us 31.900us cuDeviceGetName
0.00% 21.874us 2 10.937us 8.5850us 13.289us cudaEventRecord
0.00% 16.513us 2 8.2560us 2.6240us 13.889us cudaEventCreate
0.00% 13.091us 1 13.091us 13.091us 13.091us cudaEventElapsedTime
0.00% 8.1410us 1 8.1410us 8.1410us 8.1410us cudaGetDevice
0.00% 2.6290us 2 1.3140us 509ns 2.1200us cuDeviceGetCount
0.00% 1.9970us 2 998ns 520ns 1.4770us cuDeviceGet
注意
如果不需要 API 跟踪,可以使用 --profile-api-trace none 关闭 API 跟踪。这减少了一些性能分析开销,尤其是在内核较短时。
如果分析了多个支持 CUDA 的设备,则可以使用 nvprof --print-summary-per-gpu 为每个 GPU 打印一个摘要。
nvprof 在摘要模式下支持 CUDA 动态并行性。如果您的应用程序使用动态并行性,则输出将包含一列用于主机启动的内核数量,一列用于设备启动的内核数量。这是一个在 CUDA 动态并行性示例 cdpSimpleQuicksort 上运行 nvprof 的示例
$ nvprof cdpSimpleQuicksort
==27325== NVPROF is profiling process 27325, command: cdpSimpleQuicksort
Running on GPU 0 (Tesla K20c)
Initializing data:
Running quicksort on 128 elements
Launching kernel on the GPU
Validating results: OK
==27325== Profiling application: cdpSimpleQuicksort
==27325== Profiling result:
Time(%) Time Calls (host) Calls (device) Avg Min Max Name
99.71% 1.2114ms 1 14 80.761us 5.1200us 145.66us cdp_simple_quicksort(unsigned int*, int, int, int)
0.18% 2.2080us 1 - 2.2080us 2.2080us 2.2080us [CUDA memcpy DtoH]
0.11% 1.2800us 1 - 1.2800us 1.2800us 1.2800us [CUDA memcpy HtoD]
3.2.2. GPU 跟踪和 API 跟踪模式
GPU 跟踪和 API 跟踪模式可以单独或一起启用。GPU 跟踪模式按时间顺序提供 GPU 上发生的所有活动的时间线。输出中显示每个内核执行和内存复制/设置实例。对于每个内核或内存复制,都会显示详细信息,例如内核参数、共享内存使用情况和内存传输吞吐量。内核名称后方括号中显示的数字与启动该内核的 CUDA API 相关联。
这是一个示例
$ nvprof --print-gpu-trace matrixMul
==27706== NVPROF is profiling process 27706, command: matrixMul
==27706== Profiling application: matrixMul
[Matrix Multiply Using CUDA] - Starting...
GPU Device 0: "GeForce GT 640M LE" with compute capability 3.0
MatrixA(320,320), MatrixB(640,320)
Computing result using CUDA Kernel...
done
Performance= 35.36 GFlop/s, Time= 3.707 msec, Size= 131072000 Ops, WorkgroupSize= 1024 threads/block
Checking computed result for correctness: OK
Note: For peak performance, please refer to the matrixMulCUBLAS example.
==27706== Profiling result:
Start Duration Grid Size Block Size Regs* SSMem* DSMem* Size Throughput Device Context Stream Name
133.81ms 135.78us - - - - - 409.60KB 3.0167GB/s GeForce GT 640M 1 2 [CUDA memcpy HtoD]
134.62ms 270.66us - - - - - 819.20KB 3.0267GB/s GeForce GT 640M 1 2 [CUDA memcpy HtoD]
134.90ms 3.7037ms (20 10 1) (32 32 1) 29 8.1920KB 0B - - GeForce GT 640M 1 2 void matrixMulCUDA<int=32>(float*, float*, float*, int, int) [94]
138.71ms 3.7011ms (20 10 1) (32 32 1) 29 8.1920KB 0B - - GeForce GT 640M 1 2 void matrixMulCUDA<int=32>(float*, float*, float*, int, int) [105]
<...more output...>
1.24341s 3.7011ms (20 10 1) (32 32 1) 29 8.1920KB 0B - - GeForce GT 640M 1 2 void matrixMulCUDA<int=32>(float*, float*, float*, int, int) [2191]
1.24711s 3.7046ms (20 10 1) (32 32 1) 29 8.1920KB 0B - - GeForce GT 640M 1 2 void matrixMulCUDA<int=32>(float*, float*, float*, int, int) [2198]
1.25089s 248.13us - - - - - 819.20KB 3.3015GB/s GeForce GT 640M 1 2 [CUDA memcpy DtoH]
Regs: Number of registers used per CUDA thread. This number includes registers used internally by the CUDA driver and/or tools and can be more than what the compiler shows.
SSMem: Static shared memory allocated per CUDA block.
DSMem: Dynamic shared memory allocated per CUDA block.
nvprof 在 GPU 跟踪模式下支持 CUDA 动态并行性。对于主机内核启动,将显示内核 ID。对于设备内核启动,将显示内核 ID、父内核 ID 和父块。这是一个示例
$nvprof --print-gpu-trace cdpSimpleQuicksort
==28128== NVPROF is profiling process 28128, command: cdpSimpleQuicksort
Running on GPU 0 (Tesla K20c)
Initializing data:
Running quicksort on 128 elements
Launching kernel on the GPU
Validating results: OK
==28128== Profiling application: cdpSimpleQuicksort
==28128== Profiling result:
Start Duration Grid Size Block Size Regs* SSMem* DSMem* Size Throughput Device Context Stream ID Parent ID Parent Block Name
192.76ms 1.2800us - - - - - 512B 400.00MB/s Tesla K20c (0) 1 2 - - - [CUDA memcpy HtoD]
193.31ms 146.02us (1 1 1) (1 1 1) 32 0B 0B - - Tesla K20c (0) 1 2 2 - - cdp_simple_quicksort(unsigned int*, int, int, int) [171]
193.41ms 110.53us (1 1 1) (1 1 1) 32 0B 256B - - Tesla K20c (0) 1 2 -5 2 (0 0 0) cdp_simple_quicksort(unsigned int*, int, int, int)
193.45ms 125.57us (1 1 1) (1 1 1) 32 0B 256B - - Tesla K20c (0) 1 2 -6 2 (0 0 0) cdp_simple_quicksort(unsigned int*, int, int, int)
193.48ms 9.2480us (1 1 1) (1 1 1) 32 0B 256B - - Tesla K20c (0) 1 2 -7 -5 (0 0 0) cdp_simple_quicksort(unsigned int*, int, int, int)
193.52ms 107.23us (1 1 1) (1 1 1) 32 0B 256B - - Tesla K20c (0) 1 2 -8 -5 (0 0 0) cdp_simple_quicksort(unsigned int*, int, int, int)
193.53ms 93.824us (1 1 1) (1 1 1) 32 0B 256B - - Tesla K20c (0) 1 2 -9 -6 (0 0 0) cdp_simple_quicksort(unsigned int*, int, int, int)
193.57ms 117.47us (1 1 1) (1 1 1) 32 0B 256B - - Tesla K20c (0) 1 2 -10 -6 (0 0 0) cdp_simple_quicksort(unsigned int*, int, int, int)
193.58ms 5.0560us (1 1 1) (1 1 1) 32 0B 256B - - Tesla K20c (0) 1 2 -11 -8 (0 0 0) cdp_simple_quicksort(unsigned int*, int, int, int)
193.62ms 108.06us (1 1 1) (1 1 1) 32 0B 256B - - Tesla K20c (0) 1 2 -12 -8 (0 0 0) cdp_simple_quicksort(unsigned int*, int, int, int)
193.65ms 113.34us (1 1 1) (1 1 1) 32 0B 256B - - Tesla K20c (0) 1 2 -13 -10 (0 0 0) cdp_simple_quicksort(unsigned int*, int, int, int)
193.68ms 29.536us (1 1 1) (1 1 1) 32 0B 256B - - Tesla K20c (0) 1 2 -14 -12 (0 0 0) cdp_simple_quicksort(unsigned int*, int, int, int)
193.69ms 22.848us (1 1 1) (1 1 1) 32 0B 256B - - Tesla K20c (0) 1 2 -15 -10 (0 0 0) cdp_simple_quicksort(unsigned int*, int, int, int)
193.71ms 130.85us (1 1 1) (1 1 1) 32 0B 256B - - Tesla K20c (0) 1 2 -16 -13 (0 0 0) cdp_simple_quicksort(unsigned int*, int, int, int)
193.73ms 62.432us (1 1 1) (1 1 1) 32 0B 256B - - Tesla K20c (0) 1 2 -17 -12 (0 0 0) cdp_simple_quicksort(unsigned int*, int, int, int)
193.76ms 41.024us (1 1 1) (1 1 1) 32 0B 256B - - Tesla K20c (0) 1 2 -18 -13 (0 0 0) cdp_simple_quicksort(unsigned int*, int, int, int)
193.92ms 2.1760us - - - - - 512B 235.29MB/s Tesla K20c (0) 1 2 - - - [CUDA memcpy DtoH]
Regs: Number of registers used per CUDA thread. This number includes registers used internally by the CUDA driver and/or tools and can be more than what the compiler shows.
SSMem: Static shared memory allocated per CUDA block.
DSMem: Dynamic shared memory allocated per CUDA block.
API 跟踪模式按时间顺序显示主机上调用的所有 CUDA 运行时和驱动程序 API 调用的时间线。这是一个示例
$nvprof --print-api-trace matrixMul
==27722== NVPROF is profiling process 27722, command: matrixMul
==27722== Profiling application: matrixMul
[Matrix Multiply Using CUDA] - Starting...
GPU Device 0: "GeForce GT 640M LE" with compute capability 3.0
MatrixA(320,320), MatrixB(640,320)
Computing result using CUDA Kernel...
done
Performance= 35.35 GFlop/s, Time= 3.708 msec, Size= 131072000 Ops, WorkgroupSize= 1024 threads/block
Checking computed result for correctness: OK
Note: For peak performance, please refer to the matrixMulCUBLAS example.
==27722== Profiling result:
Start Duration Name
108.38ms 6.2130us cuDeviceGetCount
108.42ms 840ns cuDeviceGet
108.42ms 22.459us cuDeviceGetName
108.45ms 11.782us cuDeviceTotalMem
108.46ms 945ns cuDeviceGetAttribute
149.37ms 23.737us cudaLaunch (void matrixMulCUDA<int=32>(float*, float*, float*, int, int) [2198])
149.39ms 6.6290us cudaEventRecord
149.40ms 1.10156s cudaEventSynchronize
<...more output...>
1.25096s 21.543us cudaEventElapsedTime
1.25103s 1.5462ms cudaMemcpy
1.25467s 153.93us cudaFree
1.25483s 75.373us cudaFree
1.25491s 75.564us cudaFree
1.25693s 10.901ms cudaDeviceReset
注意
由于分析器的设置方式,第一个 “cuInit()” 驱动程序 API 调用永远不会被跟踪。
3.2.3. 事件/指标摘要模式
要查看特定 NVIDIA GPU 上所有可用事件的列表,请使用 --query-events 选项。要查看特定 NVIDIA GPU 上所有可用指标的列表,请使用 --query-metrics 选项。nvprof 能够同时收集多个事件/指标。这是一个示例
$ nvprof --events warps_launched,local_load --metrics ipc matrixMul
[Matrix Multiply Using CUDA] - Starting...
==6461== NVPROF is profiling process 6461, command: matrixMul
GPU Device 0: "GeForce GTX TITAN" with compute capability 3.5
MatrixA(320,320), MatrixB(640,320)
Computing result using CUDA Kernel...
==6461== Warning: Some kernel(s) will be replayed on device 0 in order to collect all events/metrics.
done
Performance= 6.39 GFlop/s, Time= 20.511 msec, Size= 131072000 Ops, WorkgroupSize= 1024 threads/block
Checking computed result for correctness: Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
==6461== Profiling application: matrixMul
==6461== Profiling result:
==6461== Event result:
Invocations Event Name Min Max Avg
Device "GeForce GTX TITAN (0)"
Kernel: void matrixMulCUDA<int=32>(float*, float*, float*, int, int)
301 warps_launched 6400 6400 6400
301 local_load 0 0 0
==6461== Metric result:
Invocations Metric Name Metric Description Min Max Avg
Device "GeForce GTX TITAN (0)"
Kernel: void matrixMulCUDA<int=32>(float*, float*, float*, int, int)
301 ipc Executed IPC 1.282576 1.299736 1.291500
如果指定的事件/指标无法在应用程序的单次运行中进行分析,则默认情况下,nvprof 会多次重放每个内核,直到收集到所有事件/指标。
可以使用 --replay-mode <mode> 选项更改重放模式。在“应用程序重放”模式下,nvprof 重新运行整个应用程序而不是重放每个内核,以便收集所有事件/指标。在某些情况下,如果应用程序分配大量设备内存,则此模式可能比内核重放模式更快。也可以完全关闭重放,在这种情况下,分析器将不会收集某些事件/指标。
要收集每个设备上所有可用的事件,请使用选项 --events all。
要收集每个设备上所有可用的指标,请使用选项 --metrics all。
注意
事件或指标收集可能会显着改变应用程序的整体性能特征,因为所有内核执行都在 GPU 上串行化。
注意
如果请求大量事件或指标,无论选择哪种重放模式,整体应用程序执行时间都可能会显着增加。
3.2.4. 事件/指标跟踪模式
在事件/指标跟踪模式下,将显示每次内核执行的事件和指标值。默认情况下,事件和指标值在 GPU 中的所有单元上进行聚合。例如,特定于多处理器的事件将在 GPU 上的所有多处理器上进行聚合。如果指定了 --aggregate-mode off,则会显示每个单元的值。例如,在以下示例中,将显示 GPU 上每个多处理器的 “branch” 事件值。
$ nvprof --aggregate-mode off --events local_load --print-gpu-trace matrixMul
[Matrix Multiply Using CUDA] - Starting...
==6740== NVPROF is profiling process 6740, command: matrixMul
GPU Device 0: "GeForce GTX TITAN" with compute capability 3.5
MatrixA(320,320), MatrixB(640,320)
Computing result using CUDA Kernel...
done
Performance= 16.76 GFlop/s, Time= 7.822 msec, Size= 131072000 Ops, WorkgroupSize= 1024 threads/block
Checking computed result for correctness: Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
==6740== Profiling application: matrixMul
==6740== Profiling result:
Device Context Stream Kernel local_load (0) local_load (1) ...
GeForce GTX TIT 1 7 void matrixMulCUDA<i 0 0 ...
GeForce GTX TIT 1 7 void matrixMulCUDA<i 0 0 ...
<...more output...>
注意
虽然 --aggregate-mode 适用于指标,但某些指标仅在聚合模式下可用,而某些指标仅在非聚合模式下可用。
3.3. 性能分析控制
3.3.1. 超时
可以为 nvprof 提供超时时间(以秒为单位)。在超时后,被分析的 CUDA 应用程序将被 nvprof 终止。超时前收集的性能分析结果将显示出来。
注意
超时时间从 CUDA 驱动程序初始化的那一刻开始计算。如果应用程序没有调用任何 CUDA API,则不会触发超时。
3.3.2. 并发内核
支持并发内核性能分析,并且默认情况下处于启用状态。要关闭此功能,请使用选项 --concurrent-kernels off。当使用 nvprof 运行 CUDA 应用程序时,这将强制并发内核执行串行化。
3.3.3. 性能分析范围
当收集事件/指标时,默认情况下 nvprof 会分析所有可见 CUDA 设备上启动的所有内核。此性能分析范围可以通过以下选项进行限制。
--devices <device IDs> 应用于其后的 --events、--metrics、--query-events 和 --query-metrics 选项。它将这些选项限制为仅在 <device IDs> 指定的设备上收集事件/指标,<device IDs> 可以是由逗号分隔的设备 ID 号列表。
--kernels <kernel filter> 应用于其后的 --events 和 --metrics 选项。它将这些选项限制为仅在 <kernel filter> 指定的内核上收集事件/指标,<kernel filter> 具有以下语法
<kernel name>
或
<context id/name>:<stream id/name>:<kernel
name>:<invocation>
尖括号中的每个字符串都可以是标准的 Perl 正则表达式。空字符串匹配任何数字或字符组合。
调用号 n 表示内核的第 n 次调用。如果调用号是正数,则它与内核的调用严格匹配。否则,它将被视为正则表达式。调用号是为每个内核单独计数的。例如,:::3 将匹配每个内核的第 3 次调用。
如果上下文/流字符串是正数,则它与 CUDA 上下文/流 ID 严格匹配。否则,它将被视为正则表达式,并与 NVIDIA Tools Extension 提供的上下文/流名称匹配。
可以多次指定 --devices 和 --kernels,并关联不同的事件/指标。
--events、--metrics、--query-events 和 --query-metrics 受其之前最近的范围选项控制。
例如,以下命令,
nvprof --devices 0 --metrics ipc
--kernels "1:foo:bar:2" --events local_load a.out
在设备 0 上启动的所有内核上收集指标 ipc。它还在名称包含 bar 的任何内核上收集事件 local_load,并且是设备 0 上上下文 1 和名为 foo 的流中启动的第 2 个实例。
3.3.4. 多进程性能分析
默认情况下,nvprof 仅分析命令行参数指定的应用程序。它不跟踪该进程启动的子进程。要分析应用程序启动的所有进程,请使用 --profile-child-processes 选项。
注意
nvprof 无法分析 fork() 但之后不 exec() 的进程。
nvprof 还具有“分析所有进程”模式,在该模式下,它会分析同一系统上由启动 nvprof 的同一用户启动的每个 CUDA 进程。通过键入 “Ctrl-c” 退出此模式。
注意
多进程模式下不支持 CPU 性能分析。
3.3.5. 系统性能分析
对于支持系统性能分析的设备,nvprof 可以启用对应用程序使用的每个 GPU 的功耗、时钟和热行为的低频采样。此功能默认情况下处于关闭状态。要启用此功能,请使用 --system-profiling on。要查看每个采样点的详细信息,请将上述选项与 --print-gpu-trace 结合使用。
3.3.6. 统一内存性能分析
对于支持统一内存的 GPU,nvprof 会收集与统一内存相关的内存流量,这些流量进出系统上的每个 GPU。此功能默认情况下处于启用状态。可以使用 --unified-memory-profiling off 禁用此功能。要查看启用此功能时每次内存传输的详细信息,请使用 --print-gpu-trace。
在多 GPU 配置中,如果任何一对支持统一内存的设备之间没有 P2P 支持,则托管内存分配将放置在零复制内存中。在这种情况下,不支持统一内存性能分析。在某些情况下,可以设置环境变量 CUDA_MANAGED_FORCE_DEVICE_ALLOC 以强制托管分配位于设备内存中,并在这些硬件配置上启用迁移。在这种情况下,支持统一内存性能分析。通常,建议使用环境变量 CUDA_VISIBLE_DEVICES 将 CUDA 限制为仅使用那些具有 P2P 支持的 GPU。有关更多详细信息,请参阅 CUDA C++ 编程指南 中的环境变量部分。
3.3.7. CPU 线程跟踪
为了允许正确的 依赖性分析,nvprof 可以收集有关 CPU 端线程 API 的信息。可以通过在测量期间指定 --cpu-thread-tracing on 来启用此功能。如果满足以下条件,则记录此信息是必要的:
应用程序使用多个 CPU 线程,并且
这些线程中至少有两个调用了 CUDA API。
目前,仅支持 POSIX 线程 (Pthreads)。出于性能原因,可能只记录选定的 Pthread API 调用。nvprof 尝试检测哪些调用对于建模执行行为是必要的,并过滤掉其他调用。过滤掉的调用包括 pthread_mutex_lock 和 pthread_mutex_unlock,当这些调用不会导致任何并发线程阻塞时。
注意
Windows 上不可用 CPU 线程跟踪。
注意
CPU 线程跟踪在第一个 CUDA API 调用之后开始,从发出此调用的线程开始。因此,应用程序必须从其主线程调用例如 cuInit,然后再生成任何其他调用 CUDA API 的用户线程。
3.4. 输出
3.4.1. 调整单位
默认情况下,nvprof 会自动调整时间单位,以获得最精确的时间值。--normalized-time-unit 选项可用于在整个结果中获得固定的时间单位。
3.4.2. CSV
对于每种性能分析模式,选项 --csv 可用于生成逗号分隔值 (CSV) 格式的输出。结果可以直接导入到电子表格软件(如 Excel)。
3.4.3. 导出/导入
对于每种性能分析模式,选项 --export-profile 可用于生成结果文件。此文件不可人工读取,但可以使用选项 --import-profile 导入回 nvprof,或导入到 Visual Profiler 中。
注意
性能分析器使用 SQLite 作为导出配置文件的格式。以这种格式写入文件可能需要比写入纯文件更多的磁盘操作。因此,将配置文件导出到较慢的设备(如网络驱动器)可能会减慢应用程序的执行速度。
3.4.4. 符号解析
默认情况下,nvprof 会解析 C++ 函数名称。使用选项 --demangling off 关闭此功能。
3.4.5. 重定向输出
默认情况下,nvprof 将其大部分输出发送到 stderr。要重定向输出,请使用 --log-file。--log-file %1 告诉 nvprof 将所有输出重定向到 stdout。--log-file <filename> 将输出重定向到文件。在文件名中使用 %p 以替换为 nvprof 的进程 ID,%h 替换为主机名,%q{ENV} 替换为环境变量 ENV 的值,%% 替换为 %。
3.4.6. 依赖性分析
nvprof 可以在应用程序完成性能分析后运行 依赖性分析,使用 --dependency-analysis 选项。此分析也可以应用于导入的配置文件。它需要在测量期间收集完整的 CUDA API 和 GPU 活动跟踪。如果未使用 --profile-api-trace none 禁用,则这是 nvprof 的默认设置。
对于从多个 CPU 线程使用 CUDA 的应用程序,也应启用 CPU 线程跟踪。可以指定选项 --print-dependency-analysis-trace,以将摘要输出更改为跟踪输出,显示计算出的指标,例如每个函数实例而不是每个函数类型的关键路径上的时间。
下面显示了依赖性分析摘要输出的示例,其中所有计算的指标都按函数类型聚合。该表首先按关键路径上的时间排序,然后按等待时间排序。摘要包含一个名为 Other 的条目,指的是未被 nvprof 跟踪的所有 CPU 活动(例如应用程序的 main 函数)。
==20704== Dependency Analysis:
==20704== Analysis progress: 100%
Critical path(%) Critical path Waiting time Name
% s s
92.06 4.061817 0.000000 clock_block(long*, long)
4.54 0.200511 0.000000 cudaMalloc
3.25 0.143326 0.000000 cudaDeviceReset
0.13 5.7273280e-03 0.000000 <Other>
0.01 2.7200900e-04 0.000000 cudaFree
0.00 0.000000 4.062506 pthread_join
0.00 0.000000 4.061790 cudaStreamSynchronize
0.00 0.000000 1.015485 pthread_mutex_lock
0.00 0.000000 1.013711 pthread_cond_wait
0.00 0.000000 0.000000 pthread_mutex_unlock
0.00 0.000000 0.000000 pthread_exit
0.00 0.000000 0.000000 pthread_enter
0.00 0.000000 0.000000 pthread_create
0.00 0.000000 0.000000 pthread_cond_signal
0.00 0.000000 0.000000 cudaLaunch
3.5. CPU 采样
有时,对应用程序的 CPU 部分进行性能分析很有用,以便更好地了解瓶颈并识别整个 CUDA 应用程序的潜在热点。对于应用程序的 CPU 部分,nvprof 能够以一定的频率对程序计数器和调用堆栈进行采样。然后,这些数据用于构建图形,节点是每个调用堆栈中的帧。如果可用,还会提取函数和库符号。下面显示了一个示例图
======== CPU profiling result (bottom up):
45.45% cuInit
| 45.45% cudart::globalState::loadDriverInternal(void)
| 45.45% cudart::__loadDriverInternalUtil(void)
| 45.45% pthread_once
| 45.45% cudart::cuosOnce(int*, void (*) (void))
| 45.45% cudart::globalState::loadDriver(void)
| 45.45% cudart::globalState::initializeDriver(void)
| 45.45% cudaMalloc
| 45.45% main
33.33% cuDevicePrimaryCtxRetain
| 33.33% cudart::contextStateManager::initPrimaryContext(cudart::device*)
| 33.33% cudart::contextStateManager::tryInitPrimaryContext(cudart::device*)
| 33.33% cudart::contextStateManager::initDriverContext(void)
| 33.33% cudart::contextStateManager::getRuntimeContextState(cudart::contextState**, bool)
| 33.33% cudart::getLazyInitContextState(cudart::contextState**)
| 33.33% cudart::doLazyInitContextState(void)
| 33.33% cudart::cudaApiMalloc(void**, unsigned long)
| 33.33% cudaMalloc
| 33.33% main
18.18% cuDevicePrimaryCtxReset
| 18.18% cudart::device::resetPrimaryContext(void)
| 18.18% cudart::cudaApiThreadExit(void)
| 18.18% cudaThreadExit
| 18.18% main
3.03% cudbgGetAPIVersion
3.03% start_thread
3.03% clone
该图可以以不同的“视图”(top-down、bottom-up 或 flat)呈现,允许用户从不同的角度分析采样数据。例如,bottom-up 视图(如上所示)可用于识别应用程序花费大部分时间的“热”函数。top-down 视图给出了应用程序执行时间的细分,从 main 函数开始,使您可以找到频繁执行的“调用路径”。
默认情况下,CPU 采样功能处于禁用状态。要启用它,请使用选项 --cpu-profiling on。下一节介绍了控制 CPU 采样行为的所有选项。
Linux 和 Windows 上的 Intel x86/x86_64 架构支持 CPU 采样。
注意
在 POSIX 系统上使用 CPU 性能分析功能时,性能分析器通过发送周期性信号来采样应用程序。因此,应用程序应确保在中断时正确处理系统调用。
注意
在 Windows 上,nvprof 需要安装 Visual Studio(2010 或更高版本)和编译器生成的 .PDB(程序数据库)文件才能解析符号信息。构建应用程序时,请确保创建 .PDB 文件并将其放置在性能分析的可执行文件和库旁边。
3.5.1. CPU 采样限制
以下是当前版本中已知的 issues。
移动设备上不支持 CPU 采样。
多进程性能分析模式下目前不支持 CPU 采样。
在某些编译器优化(特别是帧指针省略和函数内联)下,结果堆栈跟踪可能不完整。
CPU 采样结果不支持 CSV 模式。
3.6. OpenACC
在 64 位 Linux 平台上,nvprof 支持使用 CUPTI Activity API 记录 OpenACC 活动。这允许在 OpenACC 构造级别以及底层编译器生成的 CUDA API 调用中调查性能。
nvprof 中的 OpenACC 性能分析要求目标应用程序使用 PGI OpenACC 运行时 19.1 或更高版本。
即使仅在 x86_64 Linux 系统上支持记录 OpenACC 活动,导入和查看先前生成的性能分析数据在 nvprof 支持的所有平台上都可用。
下面显示了 OpenACC 摘要输出的示例。CUPTI OpenACC 活动使用其源文件和行信息映射到原始 OpenACC 构造。对于 acc_enqueue_launch 活动,它还将进一步显示由 OpenACC 编译器生成的启动 CUDA 内核名称。默认情况下,nvprof 将解析 OpenACC 编译器生成的内核名称。您可以传递 --demangling off 以禁用此行为。
==20854== NVPROF is profiling process 20854, command: ./acc_saxpy
==20854== Profiling application: ./acc_saxpy
==20854== Profiling result:
==20854== OpenACC (excl):
Time(%) Time Calls Avg Min Max Name
33.16% 1.27944s 200 6.3972ms 24.946us 12.770ms acc_implicit_wait@acc_saxpy.cpp:42
33.12% 1.27825s 100 12.783ms 12.693ms 12.787ms acc_wait@acc_saxpy.cpp:54
33.12% 1.27816s 100 12.782ms 12.720ms 12.786ms acc_wait@acc_saxpy.cpp:61
0.14% 5.4550ms 100 54.549us 51.858us 71.461us acc_enqueue_download@acc_saxpy.cpp:43
0.07% 2.5190ms 100 25.189us 23.877us 60.269us acc_enqueue_launch@acc_saxpy.cpp:50 (kernel2(int, float, float*, float*)_50_gpu)
0.06% 2.4988ms 100 24.987us 24.161us 29.453us acc_enqueue_launch@acc_saxpy.cpp:60 (kernel3(int, float, float*, float*)_60_gpu)
0.06% 2.2799ms 100 22.798us 21.654us 56.674us acc_enqueue_launch@acc_saxpy.cpp:42 (kernel1(int, float, float*, float*)_42_gpu)
0.05% 2.1068ms 100 21.068us 20.444us 33.159us acc_enqueue_download@acc_saxpy.cpp:51
0.05% 2.0854ms 100 20.853us 19.453us 23.697us acc_enqueue_download@acc_saxpy.cpp:61
0.04% 1.6265ms 100 16.265us 15.284us 49.632us acc_enqueue_upload@acc_saxpy.cpp:50
0.04% 1.5963ms 100 15.962us 15.052us 19.749us acc_enqueue_upload@acc_saxpy.cpp:60
0.04% 1.5393ms 100 15.393us 14.592us 56.414us acc_enqueue_upload@acc_saxpy.cpp:42
0.01% 558.54us 100 5.5850us 5.3700us 6.2090us acc_implicit_wait@acc_saxpy.cpp:43
0.01% 266.13us 100 2.6610us 2.4630us 4.7590us acc_compute_construct@acc_saxpy.cpp:42
0.01% 211.77us 100 2.1170us 1.9980us 4.1770us acc_compute_construct@acc_saxpy.cpp:50
0.01% 209.14us 100 2.0910us 1.9880us 2.2500us acc_compute_construct@acc_saxpy.cpp:60
0.00% 55.066us 1 55.066us 55.066us 55.066us acc_enqueue_launch@acc_saxpy.cpp:70 (initVec(int, float, float*)_70_gpu)
0.00% 13.209us 1 13.209us 13.209us 13.209us acc_compute_construct@acc_saxpy.cpp:70
0.00% 10.901us 1 10.901us 10.901us 10.901us acc_implicit_wait@acc_saxpy.cpp:70
0.00% 0ns 200 0ns 0ns 0ns acc_delete@acc_saxpy.cpp:61
0.00% 0ns 200 0ns 0ns 0ns acc_delete@acc_saxpy.cpp:43
0.00% 0ns 200 0ns 0ns 0ns acc_create@acc_saxpy.cpp:60
0.00% 0ns 200 0ns 0ns 0ns acc_create@acc_saxpy.cpp:42
0.00% 0ns 200 0ns 0ns 0ns acc_delete@acc_saxpy.cpp:51
0.00% 0ns 200 0ns 0ns 0ns acc_create@acc_saxpy.cpp:50
0.00% 0ns 2 0ns 0ns 0ns acc_alloc@acc_saxpy.cpp:42
3.6.1. OpenACC 选项
表 1 包含 nvprof 的 OpenACC 性能分析相关命令行选项。
选项 |
描述 |
|---|---|
|
打开/关闭 OpenACC 性能分析。注意:OpenACC 性能分析仅在 x86_64 Linux 上受支持。默认为打开。 |
|
打印所有记录的 OpenACC 活动的摘要。 |
|
打印所有记录的 OpenACC 活动的详细跟踪,包括每个活动的时间戳和持续时间。 |
|
包括导致发出 OpenACC 活动的 OpenACC 父构造的名称。请注意,对于使用 19.1 之前的 PGI OpenACC 运行时的应用程序,此值将始终为 |
|
指定如何在 OpenACC 摘要中显示活动持续时间。允许的值:“exclusive” - 独占持续时间(默认)。“inclusive” - 包含持续时间。有关更多信息,请参阅 OpenACC 摘要模式。 |
3.6.2. OpenACC 摘要模式
nvprof 支持两种模式,用于在 OpenACC 摘要模式(使用 --print-openacc-summary 启用)中呈现 OpenACC 活动持续时间:“exclusive” 和 “inclusive”。
包含 (Inclusive):在此模式下,所有持续时间都表示活动的实际运行时。这包括在此活动中花费的时间以及在其所有子项(被调用者)中花费的时间。
独占 (Exclusive):在此模式下,所有持续时间都表示仅在此活动中花费的时间。这包括在此活动中花费的时间,但不包括其所有子项(被调用者)的运行时。
例如,考虑 OpenACC acc_compute_construct,它本身调用 acc_enqueue_launch 以将内核启动到设备,并调用 acc_implicit_wait,后者等待此内核完成。在 “inclusive” 模式下,acc_compute_construct 的持续时间将包括在 acc_enqueue_launch 和 acc_implicit_wait 中花费的时间。在 “exclusive” 模式下,这两个持续时间将被减去。在摘要配置文件中,这有助于识别长时间的 acc_compute_construct 是表示启动开销高还是等待(同步)时间长。
3.7. OpenMP
在 64 位 Linux 平台上,nvprof 支持记录 OpenMP 活动
nvprof 中的 OpenMP 性能分析要求目标应用程序使用支持 OpenMP Tools 接口 (OMPT) 的运行时。(使用 LLVM 代码生成器的 PGI 版本 19.1 或更高版本支持 OMPT)。
即使仅在 x86_64 Linux 系统上支持记录 OpenMP 活动,导入和查看先前生成的性能分析数据在 nvprof 支持的所有平台上都可用。
下面显示了 OpenMP 摘要输出的示例
==20854== NVPROF is profiling process 20854, command: ./openmp
==20854== Profiling application: ./openmp
==20854== Profiling result:
No kernels were profiled.
No API activities were profiled.
Type Time(%) Time Calls Avg Min Max Name
OpenMP (incl): 99.97% 277.10ms 20 13.855ms 13.131ms 18.151ms omp_parallel
0.03% 72.728us 19 3.8270us 2.9840us 9.5610us omp_idle
0.00% 7.9170us 7 1.1310us 1.0360us 1.5330us omp_wait_barrier
3.7.1. OpenMP 选项
表 2 包含 nvprof 的 OpenMP 性能分析相关命令行选项。
选项 |
描述 |
|---|---|
|
打印所有记录的 OpenMP 活动的摘要。 |
4. 远程性能分析
远程性能分析是从远程系统(与查看和分析性能分析数据的主机系统不同)收集性能分析数据的过程。有两种方法可以执行远程性能分析。您可以直接从 nsight 或 Visual Profiler 分析远程应用程序。或者,您可以使用 nvprof 在远程系统上收集性能分析数据,然后使用主机系统上的 nvvp 查看和分析数据。
4.1. 使用 Visual Profiler 进行远程性能分析
本节介绍如何使用 nsight 和 Visual Profiler 的远程功能执行远程性能分析。
Nsight Eclipse Edition 支持完整的远程开发,包括远程构建、调试和性能分析。使用这些功能,您可以创建一个项目和启动配置,使您能够远程分析您的应用程序。有关更多信息,请参阅 Nsight Eclipse Edition 文档。
Visual Profiler 也支持远程性能分析。如下图所示,在创建新会话或编辑现有会话时,您可以指定要分析的应用程序驻留在远程系统上。将您的会话配置为使用远程应用程序后,您可以像使用本地应用程序一样执行所有性能分析器功能,包括时间线生成、引导式分析以及事件和指标收集。
要使用 Visual Profiler 远程性能分析,您必须在主机和远程系统上安装相同版本的 CUDA 工具包。主机系统不必具有 NVIDIA GPU,但请确保主机系统上安装的 CUDA 工具包支持目标设备。主机和远程系统可以运行不同的操作系统或具有不同的 CPU 架构。仅支持运行 Linux 的远程系统。远程系统必须可通过 SSH 访问。
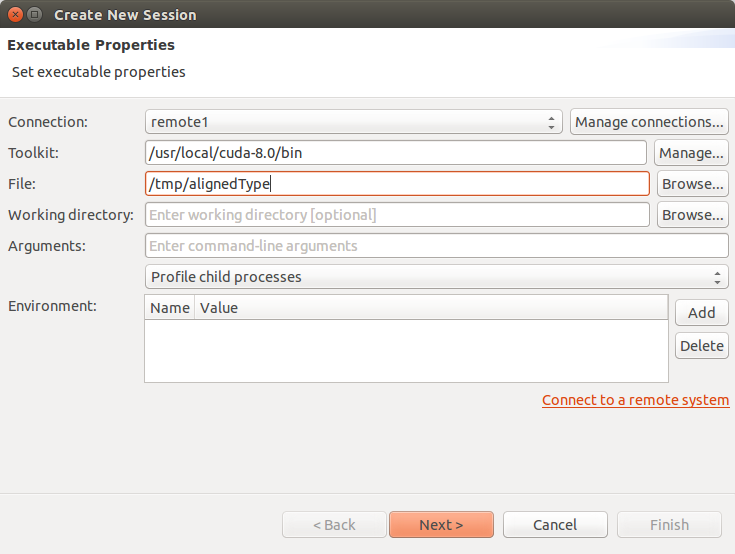
4.1.1. 单跳远程性能分析
在某些远程性能分析设置中,运行实际 CUDA 程序的机器无法从运行 Visual Profiler 的机器访问。这两台机器通过中间机器连接,我们将其称为登录节点。
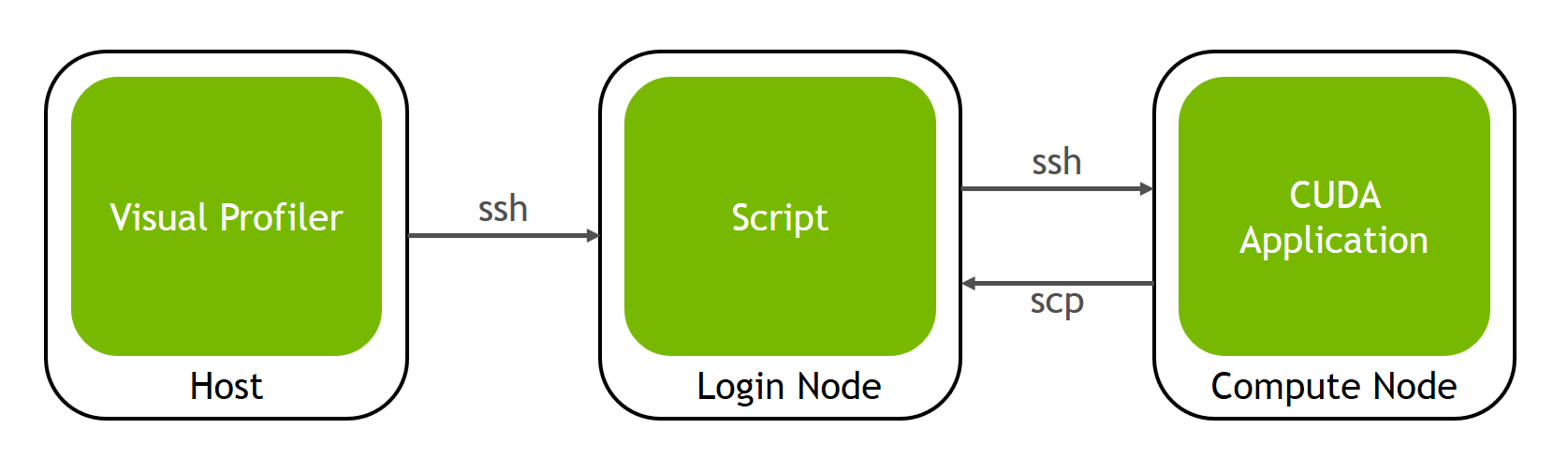
主机是运行 Visual Profiler 的机器。
登录节点是单跳性能分析脚本将运行的位置。我们只需要此机器上的 ssh、scp 和 perl。
计算节点是实际 CUDA 应用程序将运行和分析的位置。生成的性能分析数据将被复制到登录节点,以便主机上的 Visual Profiler 可以使用它。
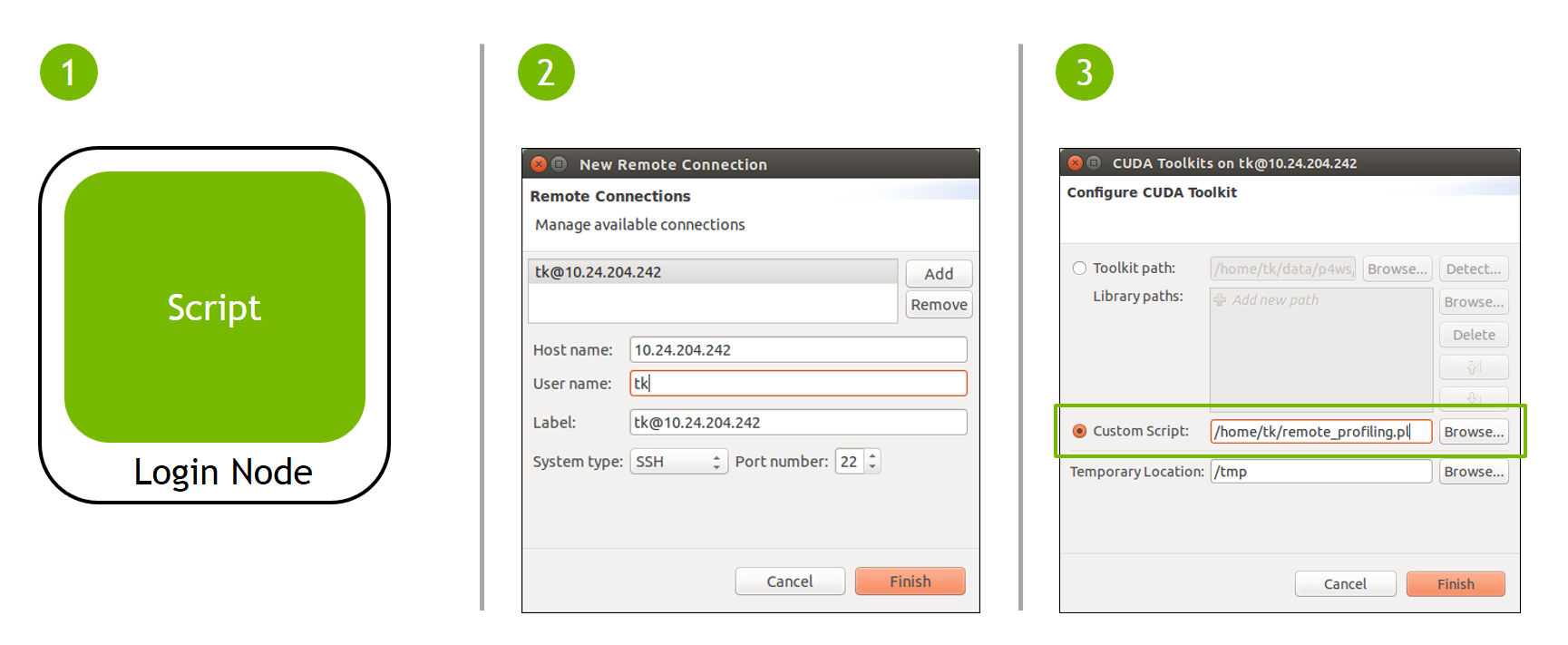
要配置单跳性能分析,您需要执行以下一次性设置
将 单跳性能分析 Perl 脚本 复制到登录节点上。
在 Visual Profiler 中,将登录节点添加为新的远程连接。
在 Visual Profiler 的新建会话向导中,使用“配置”按钮打开工具包配置窗口。在此处,使用单选按钮选择自定义脚本选项,然后浏览以指向登录节点上的 Perl 脚本。
完成此设置后,您可以像在任何远程机器上一样分析应用程序。往返于登录节点和计算节点的所有数据复制都是透明且自动的。
4.2. 使用 nvprof 进行远程性能分析
本节介绍如何通过在远程系统上手动运行 nvprof,然后将收集的性能分析数据导入到 Visual Profiler 中来执行远程性能分析。
4.2.1. 在远程系统上收集数据
可以通过使用 nvprof 和 Visual Profiler 来解决三个常见的远程性能分析用例。
时间线
第一个用例是收集在远程系统上执行的应用程序的时间线。应以最准确反映应用程序行为的方式收集时间线。要在远程系统上收集时间线,请执行以下操作。有关 nvprof 选项的更多信息,请参阅 nvprof。
$ nvprof --export-profile timeline.prof <app> <app args>
性能分析数据将收集在 timeline.prof 中。您应该将此文件复制回主机系统,然后将其导入到 Visual Profiler 中,如下一节所述。
指标和事件
第二个用例是为应用程序中已收集时间线的所有内核收集事件或指标。为所有内核收集事件或指标将显着改变应用程序的整体性能特征,因为所有内核执行将在 GPU 上串行化。即使整体应用程序性能发生了变化,但单个内核的事件或指标值仍然是正确的,因此您可以将收集的事件和指标值合并到先前收集的时间线上,以获得应用程序行为的准确图片。要收集事件或指标,请使用 --events 或 --metrics 标志。以下示例仅使用 --metrics 标志来收集两个指标。
$ nvprof --metrics achieved_occupancy,ipc -o metrics.prof <app> <app args>
您可以为每个 nvprof 调用收集任意数量的事件和指标,并且可以多次调用 nvprof 以收集多个 metrics.prof 文件。为了获得准确的性能分析结果,您的应用程序必须符合 应用程序要求 中详述的要求。
性能分析数据将收集在 metrics.prof 文件中。您应该将这些文件复制回主机系统,然后将其导入到 Visual Profiler 中,如下一节所述。
单个内核的分析
第三个常见的远程性能分析用例是收集分析系统所需的指标,以用于分析单个内核。导入到 Visual Profiler 后,此数据将使分析系统能够分析内核并报告该内核的优化机会。要收集分析数据,请在远程系统上执行以下操作。重要的是,--kernels 选项必须出现在 --analysis-metrics 选项之前,以便仅为 kernel specifier 指定的内核收集指标。有关 --kernels 选项的更多信息,请参阅 性能分析范围。
$ nvprof --kernels <kernel specifier> --analysis-metrics -o analysis.prof <app> <app args>
性能分析数据将收集在 analysis.prof 中。您应该将此文件复制回主机系统,然后将其导入到 Visual Profiler 中,如下一节所述。
4.2.2. 查看和分析数据
通过将收集的性能分析数据导入到主机系统上的 Visual Profiler 中来查看和分析数据。有关导入的更多信息,请参阅 导入会话。
时间线、指标和事件
要查看收集的时间线数据,可以将 timeline.prof 文件导入到 Visual Profiler 中,如 导入单进程 nvprof 会话 中所述。如果还为应用程序收集了指标或事件数据,则可以将相应的 metrics.prof 文件与时间线一起导入到 Visual Profiler 中,以便为每个内核收集的事件和指标与时间线中相应的内核相关联。
单个内核的引导式分析
要查看单个内核的收集分析数据,可以将 analysis.prof 文件导入到 Visual Profiler 中,如导入单进程 nvprof 会话中所述。analysis.prof 必须单独导入。时间线将仅显示我们在数据收集期间指定的单个内核。导入后,可以使用引导式分析系统来探索内核的优化机会。
5. NVIDIA 工具扩展
NVIDIA 工具扩展 (NVTX) 是一个基于 C 的应用程序编程接口 (API),用于注释应用程序中的事件、代码范围和资源。集成了 NVTX 的应用程序可以使用 Visual Profiler 来捕获和可视化这些事件和范围。NVTX API 提供两项核心服务
CPU 事件和时间范围的跟踪。
OS 和 CUDA 资源的命名。
NVTX 可以快速集成到应用程序中。下面的示例程序展示了标记事件、范围事件和资源命名的用法。
void Wait(int waitMilliseconds) {
nvtxNameOsThread(“MAIN”);
nvtxRangePush(__FUNCTION__);
nvtxMark("Waiting...");
Sleep(waitMilliseconds);
nvtxRangePop();
}
int main(void) {
nvtxNameOsThread("MAIN");
nvtxRangePush(__FUNCTION__);
Wait();
nvtxRangePop();
}
5.1. NVTX API 概述
文件
核心 NVTX API 在文件 nvToolsExt.h 中定义,而 NVTX 接口的 CUDA 特定扩展在 nvToolsExtCuda.h 和 nvToolsExtCudaRt.h 中定义。在 Linux 上,NVTX 共享库名为 libnvToolsExt.so,在 macOS 上,共享库名为 libnvToolsExt.dylib。在 Windows 上,库 (.lib) 和运行时组件 (.dll) 被命名为 nvToolsExt[bitness=32|64]_[version].{dll|lib}。
函数调用
所有 NVTX API 函数都以 nvtx 名称前缀开头,并且可能以三个后缀之一结尾:A、W 或 Ex。具有这些后缀的 NVTX 函数存在多个变体,它们使用不同的参数编码执行相同的核心功能。根据 NVTX 库的版本,可用的编码可能包括 ASCII (A)、Unicode (W) 或事件结构 (Ex)。
NVTX 的 CUDA 实现仅实现了 API 的 ASCII (A) 和事件结构 (Ex) 变体,Unicode (W) 版本不受支持,调用时无效。
返回值
一些 NVTX 函数被定义为具有返回值。例如,nvtxRangeStart() 函数返回唯一的范围标识符,而 nvtxRangePush() 函数输出当前的堆栈级别。建议不要将返回值用作检测应用程序中条件代码的一部分。返回值可能因 NVTX 库的各种实现而异,因此,添加对返回值的依赖性可能在一个工具中有效,但在另一个工具中可能失败。
5.2. NVTX API 事件
标记用于描述在应用程序执行期间特定时间发生的事件,而范围详细说明事件发生的时间跨度。此信息与所有其他捕获的数据一起呈现,这使得更容易理解收集的信息。所有标记和范围都由消息字符串标识。标记和范围 API 的 Ex 版本还允许使用事件属性结构将类别、颜色和有效负载属性与事件关联。
5.2.1. NVTX 标记
标记用于描述瞬时事件。标记可以包含文本消息或使用事件属性结构指定其他信息。使用 nvtxMarkA 创建包含 ASCII 消息的标记。使用 nvtxMarkEx() 创建包含事件属性结构指定的其他属性的标记。nvtxMarkW() 函数在 NVTX 的 CUDA 实现中不受支持,如果调用则无效。
代码示例
nvtxMarkA("My mark");
nvtxEventAttributes_t eventAttrib = {0};
eventAttrib.version = NVTX_VERSION;
eventAttrib.size = NVTX_EVENT_ATTRIB_STRUCT_SIZE;
eventAttrib.colorType = NVTX_COLOR_ARGB;
eventAttrib.color = COLOR_RED;
eventAttrib.messageType = NVTX_MESSAGE_TYPE_ASCII;
eventAttrib.message.ascii = "my mark with attributes";
nvtxMarkEx(&eventAttrib);
5.2.2. NVTX 范围开始/停止
开始/结束范围用于表示任意的、可能非嵌套的时间跨度。范围的开始可能与范围的结束发生在不同的线程上。范围可以包含文本消息或使用事件属性结构指定其他信息。使用 nvtxRangeStartA() 创建包含 ASCII 消息的标记。使用 nvtxRangeStartEx() 创建包含事件属性结构指定的其他属性的范围。nvtxRangeStartW() 函数在 NVTX 的 CUDA 实现中不受支持,如果调用则无效。对于开始/结束对的相关性,将创建一个唯一的关联 ID,该 ID 从 nvtxRangeStartA() 或 nvtxRangeStartEx() 返回,然后传递到 nvtxRangeEnd() 中。
代码示例
// non-overlapping range
nvtxRangeId_t id1 = nvtxRangeStartA("My range");
nvtxRangeEnd(id1);
nvtxEventAttributes_t eventAttrib = {0};
eventAttrib.version = NVTX_VERSION;
eventAttrib.size = NVTX_EVENT_ATTRIB_STRUCT_SIZE;
eventAttrib.colorType = NVTX_COLOR_ARGB;
eventAttrib.color = COLOR_BLUE;
eventAttrib.messageType = NVTX_MESSAGE_TYPE_ASCII;
eventAttrib.message.ascii = "my start/stop range";
nvtxRangeId_t id2 = nvtxRangeStartEx(&eventAttrib);
nvtxRangeEnd(id2);
// overlapping ranges
nvtxRangeId_t r1 = nvtxRangeStartA("My range 0");
nvtxRangeId_t r2 = nvtxRangeStartA("My range 1");
nvtxRangeEnd(r1);
nvtxRangeEnd(r2);
5.2.3. NVTX 范围推送/弹出
推送/弹出范围用于表示嵌套的时间跨度。范围的开始必须与范围的结束发生在同一线程上。范围可以包含文本消息或使用事件属性结构指定其他信息。使用 nvtxRangePushA() 创建包含 ASCII 消息的标记。使用 nvtxRangePushEx() 创建包含事件属性结构指定的其他属性的范围。nvtxRangePushW() 函数在 NVTX 的 CUDA 实现中不受支持,如果调用则无效。每个推送函数都会返回正在启动的范围的从零开始的深度。nvtxRangePop() 函数用于结束线程最近推送的范围。nvtxRangePop() 返回正在结束的范围的从零开始的深度。如果弹出没有匹配的推送,则返回负值以指示错误。
代码示例
nvtxRangePushA("outer");
nvtxRangePushA("inner");
nvtxRangePop(); // end "inner" range
nvtxRangePop(); // end "outer" range
nvtxEventAttributes_t eventAttrib = {0};
eventAttrib.version = NVTX_VERSION;
eventAttrib.size = NVTX_EVENT_ATTRIB_STRUCT_SIZE;
eventAttrib.colorType = NVTX_COLOR_ARGB;
eventAttrib.color = COLOR_GREEN;
eventAttrib.messageType = NVTX_MESSAGE_TYPE_ASCII;
eventAttrib.message.ascii = "my push/pop range";
nvtxRangePushEx(&eventAttrib);
nvtxRangePop();
5.2.4. 事件属性结构
事件属性结构 nvtxEventAttributes_t 用于描述事件的属性。结构的布局由特定版本的 NVTX 定义,并且可能在工具扩展库的不同版本之间更改。
属性
标记和范围可以使用属性为事件提供附加信息或指导工具对数据的可视化。每个属性都是可选的,如果未指定,则属性将回退到默认值。
- 消息
-
消息字段可用于指定可选字符串。调用者必须同时设置
messageType和message字段。默认值为NVTX_MESSAGE_UNKNOWN。NVTX 的 CUDA 实现仅支持 ASCII 类型消息。 - 类别
-
类别属性是用户控制的 ID,可用于对事件进行分组。该工具可以使用类别 ID 来改进过滤或对事件进行分组。默认值为 0。
- 颜色
-
颜色属性用于帮助在工具中以可视方式识别事件。调用者必须同时设置
colorType和color字段。 - 有效负载
-
有效负载属性可用于为标记和范围提供附加数据。范围事件只能在范围的开始处指定值。调用者必须为
payloadType和payload字段指定有效值。
初始化
调用者在使用属性时应始终执行以下三项任务
将结构清零
设置版本字段
设置大小字段
将结构清零会将所有事件属性类型和值设置为默认值。NVTX 使用版本和大小字段来处理属性结构的多个版本。
建议调用者使用以下方法来初始化事件属性结构。
nvtxEventAttributes_t eventAttrib = {0};
eventAttrib.version = NVTX_VERSION;
eventAttrib.size = NVTX_EVENT_ATTRIB_STRUCT_SIZE;
eventAttrib.colorType = NVTX_COLOR_ARGB;
eventAttrib.color = ::COLOR_YELLOW;
eventAttrib.messageType = NVTX_MESSAGE_TYPE_ASCII;
eventAttrib.message.ascii = "My event";
nvtxMarkEx(&eventAttrib);
5.2.5. NVTX 同步标记
NVTX 同步模块提供函数来支持跟踪目标应用程序的附加同步详细信息。命名 OS 同步原语可以让用户更好地理解通过跟踪同步 API 收集的数据。此外,注释用户定义的同步对象可以让用户告知工具,何时用户正在构建自己的同步系统,该系统不依赖 OS 来提供行为,而是使用原子操作和自旋锁等技术。
注意
同步标记支持在 Windows 上不可用。
代码示例
class MyMutex
{
volatile long bLocked;
nvtxSyncUser_t hSync;
public:
MyMutex(const char* name, nvtxDomainHandle_t d) {
bLocked = 0;
nvtxSyncUserAttributes_t attribs = { 0 };
attribs.version = NVTX_VERSION;
attribs.size = NVTX_SYNCUSER_ATTRIB_STRUCT_SIZE;
attribs.messageType = NVTX_MESSAGE_TYPE_ASCII;
attribs.message.ascii = name;
hSync = nvtxDomainSyncUserCreate(d, &attribs);
}
~MyMutex() {
nvtxDomainSyncUserDestroy(hSync);
}
bool Lock() {
nvtxDomainSyncUserAcquireStart(hSync);
//atomic compiler intrinsic
bool acquired = __sync_bool_compare_and_swap(&bLocked, 0, 1);
if (acquired) {
nvtxDomainSyncUserAcquireSuccess(hSync);
}
else {
nvtxDomainSyncUserAcquireFailed(hSync);
}
return acquired;
}
void Unlock() {
nvtxDomainSyncUserReleasing(hSync);
bLocked = false;
}
};
5.3. NVTX 域
域使开发人员能够限定注释的范围。默认情况下,所有事件和注释都在默认域中。可以注册其他域。这允许开发人员限定标记和范围的范围,以避免冲突。
函数 nvtxDomainCreateA() 或 nvtxDomainCreateW() 用于创建命名域。
每个域都维护自己的
类别
线程范围堆栈
注册的字符串
函数 nvtxDomainDestroy() 标记域的结束。销毁域会注销并销毁与其关联的所有对象,例如注册的字符串、资源对象、命名的类别和启动的范围。
注意
域支持在 Windows 上不可用。
代码示例
nvtxDomainHandle_t domain = nvtxDomainCreateA("Domain_A");
nvtxMarkA("Mark_A");
nvtxEventAttributes_t attrib = {0};
attrib.version = NVTX_VERSION;
attrib.size = NVTX_EVENT_ATTRIB_STRUCT_SIZE;
attrib.message.ascii = "Mark A Message";
nvtxDomainMarkEx(NULL, &attrib);
nvtxDomainDestroy(domain);
5.4. NVTX 资源命名
NVTX 资源命名允许将自定义名称与主机 OS 线程和 CUDA 资源(如设备、上下文和流)相关联。使用 NVTX 分配的名称由 Visual Profiler 显示。
OS 线程
nvtxNameOsThreadA() 函数用于命名主机 OS 线程。nvtxNameOsThreadW() 函数在 NVTX 的 CUDA 实现中不受支持,如果调用则无效。以下示例显示了如何命名当前主机 OS 线程。
// Windows
nvtxNameOsThread(GetCurrentThreadId(), "MAIN_THREAD");
// Linux/Mac
nvtxNameOsThread(pthread_self(), "MAIN_THREAD");
CUDA 运行时资源
nvtxNameCudaDeviceA() 和 nvtxNameCudaStreamA() 函数分别用于命名 CUDA 设备和流对象。nvtxNameCudaDeviceW() 和 nvtxNameCudaStreamW() 函数在 CUDA 实现的 NVTX 中不受支持,如果调用则无效。nvtxNameCudaEventA() 和 nvtxNameCudaEventW() 函数也不受支持。以下示例显示了如何命名 CUDA 设备和流。
nvtxNameCudaDeviceA(0, "my cuda device 0");
cudaStream_t cudastream;
cudaStreamCreate(&cudastream);
nvtxNameCudaStreamA(cudastream, "my cuda stream");
CUDA 驱动程序资源
nvtxNameCuDeviceA()、nvtxNameCuContextA() 和 nvtxNameCuStreamA() 函数分别用于命名 CUDA 驱动程序设备、上下文和流对象。nvtxNameCuDeviceW()、nvtxNameCuContextW() 和 nvtxNameCuStreamW() 函数在 CUDA 实现的 NVTX 中不受支持,如果调用则无效。nvtxNameCuEventA() 和 nvtxNameCuEventW() 函数也不受支持。以下示例显示了如何命名 CUDA 设备、上下文和流。
CUdevice device;
cuDeviceGet(&device, 0);
nvtxNameCuDeviceA(device, "my device 0");
CUcontext context;
cuCtxCreate(&context, 0, device);
nvtxNameCuContextA(context, "my context");
cuStream stream;
cuStreamCreate(&stream, 0);
nvtxNameCuStreamA(stream, "my stream");
5.5. NVTX 字符串注册
注册字符串旨在通过降低检测开销来提高性能。字符串可以注册一次,句柄可以代替字符串传递到 API 可能允许的位置。
nvtxDomainRegisterStringA() 函数用于注册字符串。nvtxDomainRegisterStringW() 函数在 NVTX 的 CUDA 实现中不受支持,如果调用则无效。
nvtxDomainHandle_t domain = nvtxDomainCreateA("Domain_A");
nvtxStringHandle_t message = nvtxDomainRegisterStringA(domain, "registered string");
nvtxEventAttributes_t eventAttrib = {0};
eventAttrib.version = NVTX_VERSION;
eventAttrib.size = NVTX_EVENT_ATTRIB_STRUCT_SIZE;
eventAttrib.messageType = NVTX_MESSAGE_TYPE_REGISTERED;
eventAttrib.message.registered = message;
6. MPI 分析
6.1. 使用 NVTX 自动 MPI 注释
您可以使用 NVTX 标记注释 MPI 调用以进行分析、跟踪和可视化。将每个 MPI 调用与 NVTX 标记包装起来可能很繁琐,但有两种方法可以自动执行此操作
内置注释
nvprof 具有内置选项,支持两种 MPI 实现 - OpenMPI 和 MPICH。如果您的系统上安装了其中任何一个,您可以使用 --annotate-mpi 选项并指定您安装的 MPI 实现。
如果您使用此选项,nvprof 将在您的应用程序每次进行 MPI 调用时生成 NVTX 标记。只有同步 MPI 调用才使用此内置选项进行注释。此外,我们使用 NVTX 重命名当前线程和当前设备对象以指示 MPI 排名。
例如,如果您安装了 OpenMPI,您可以使用以下命令注释您的应用程序
$ mpirun -np 2 nvprof --annotate-mpi openmpi ./my_mpi_app
这将为您提供如下所示的输出
NVTX result:
Thread "MPI Rank 0" (id = 583411584)
Domain "<unnamed>"
Range "MPI_Reduce"
Type Time(%) Time Calls Avg Min Max Name
Range: 100.00% 16.652us 1 16.652us 16.652us 16.652us MPI_Reduce
...
Range "MPI_Scatter"
Type Time(%) Time Calls Avg Min Max Name
Range: 100.00% 3.0320ms 1 3.0320ms 3.0320ms 3.0320ms MPI_Scatter
...
NVTX result:
Thread "MPI Rank 1" (id = 199923584)
Domain "<unnamed>"
Range "MPI_Reduce"
Type Time(%) Time Calls Avg Min Max Name
Range: 100.00% 21.062us 1 21.062us 21.062us 21.062us MPI_Reduce
...
Range "MPI_Scatter"
Type Time(%) Time Calls Avg Min Max Name
Range: 100.00% 85.296ms 1 85.296ms 85.296ms 85.296ms MPI_Scatter
...
自定义注释
如果您的系统具有 nvprof 不支持的 MPI 版本,或者如果您想更好地控制注释哪些 MPI 函数以及如何生成 NVTX 标记,您可以创建自己的注释库,并使用环境变量 LD_PRELOAD 来拦截 MPI 调用并将它们与 NVTX 标记包装在一起。
您可以使用位于此处的文档和开源脚本方便地创建此注释库。
6.2. 手动 MPI 分析
要使用 nvprof 收集各个 MPI 进程的配置文件,您必须告诉 nvprof 将其输出发送到唯一的文件。在 CUDA 5.0 和更早版本中,建议使用脚本来执行此操作。但是,您现在可以轻松地利用 %h、%p 和 %q{ENV} 功能作为 nvprof 命令的 --export-profile 参数。以下是使用 Open MPI 的运行示例。
$ mpirun -np 2 -host c0-0,c0-1 nvprof -o output.%h.%p.%q{OMPI_COMM_WORLD_RANK} ./my_mpi_app
或者,可以使用新功能,通过 --profile-all-processes 参数到 nvprof 来打开感兴趣节点上的分析。为此,您首先登录到要分析的节点,并在那里启动 nvprof。
$ nvprof --profile-all-processes -o output.%h.%p
然后,您可以像平常一样运行 MPI 作业。
$ mpirun -np 2 -host c0-0,c0-1 ./my_mpi_app
在运行 --profile-all-processes 的节点上运行的任何进程都将自动进行分析。分析数据将写入输出文件。请注意,%q{OMPI_COMM_WORLD_RANK} 选项在这里不起作用,因为此环境变量在运行 nvprof 的 shell 中不可用。
从 CUDA 7.5 开始,您可以命名线程和 CUDA 上下文,就像使用选项 –process-name 和 –context-name 命名输出文件一样,方法是传递一个字符串,例如 "MPI Rank %q{OMPI_COMM_WORLD_RANK}" 作为参数。当用户将多个文件导入到 Visual Profiler 的同一时间线中时,此功能对于查找与特定排名关联的资源非常有用。
$ mpirun -np 2 -host c0-0,c0-1 nvprof --process-name "MPI Rank %q{OMPI_COMM_WORLD_RANK}" --context-name "MPI Rank %q{OMPI_COMM_WORLD_RANK}" -o output.%h.%p.%q{OMPI_COMM_WORLD_RANK} ./my_mpi_app
6.3. 进一步阅读
有关与 nvprof 一起使用的其他参数类型的详细信息,请参见多进程分析和重定向输出部分。有关如何使用 Visual Profiler 查看数据的更多信息,请参见导入单进程 nvprof 会话和导入多进程 nvprof 会话部分。
博客文章分析 MPI 应用程序展示了如何使用 CUDA 6.5 中引入的 nvprof 的新输出文件命名和 NVTX 库来命名各种资源,以分析 MPI 应用程序的性能。
博客文章在 Visual Profiler 中跟踪 MPI 调用展示了 Visual Profiler 与 PMPI 和 NVTX 结合使用如何为您的应用程序中的 MPI 调用如何与 GPU 交互提供有趣的见解。
7. MPS 分析
您可以使用 Multi-Process Service(MPS) 和 nvprof 收集 CUDA 应用程序的分析数据,然后在 Visual Profiler 中导入数据以查看时间线。
7.1. 使用 Visual Profiler 进行 MPS 分析
Visual Profiler 可以在特定的 MPS 客户端上运行,也可以在所有 MPS 客户端上运行。时间线分析可以为同一服务器上的所有 MPS 客户端完成。事件或指标分析会导致序列化 - 一次只有一个 MPS 客户端将执行。
要使用 MPS 分析 CUDA 应用程序
启动 MPS 守护程序。有关详细信息,请参阅 MPS 文档。
nvidia-cuda-mps-control -d
在 Visual Profiler 中,使用主菜单“文件->新建会话”打开“新建会话”向导。从下拉列表中选择“分析所有进程”选项,按“下一步”,然后按“完成”。
在单独的终端中运行应用程序
要结束分析,请按 Visual Profiler 中进度对话框上的“取消”按钮。
请注意,分析输出还包括 CUDA MPS 服务器进程的数据,这些进程的进程名称为 nvidia-cuda-mps-server。
7.2. 使用 nvprof 进行 MPS 分析
nvprof 可以在特定的 MPS 客户端上运行,也可以在所有 MPS 客户端上运行。时间线分析可以为同一服务器上的所有 MPS 客户端完成。事件或指标分析会导致序列化 - 一次只有一个 MPS 客户端将执行。
要使用 MPS 分析 CUDA 应用程序
启动 MPS 守护程序。有关详细信息,请参阅 MPS 文档。
nvidia-cuda-mps-control -d
运行
nvprof并使用--profile-all-processes参数,要为每个进程生成单独的输出文件,请使用--export-profile参数的%p功能。请注意,%p将被进程 ID 替换。
nvprof --profile-all-processes -o output_%p
在单独的终端中运行应用程序
通过键入“Ctrl-c”退出
nvprof。
请注意,分析输出还包括 CUDA MPS 服务器进程的数据,这些进程的进程名称为 nvidia-cuda-mps-server。
7.3. 在 Visual Profiler 中查看 nvprof MPS 时间线
使用多进程导入选项导入每个进程的 nvprof 生成的数据文件。请参阅导入多进程会话部分。
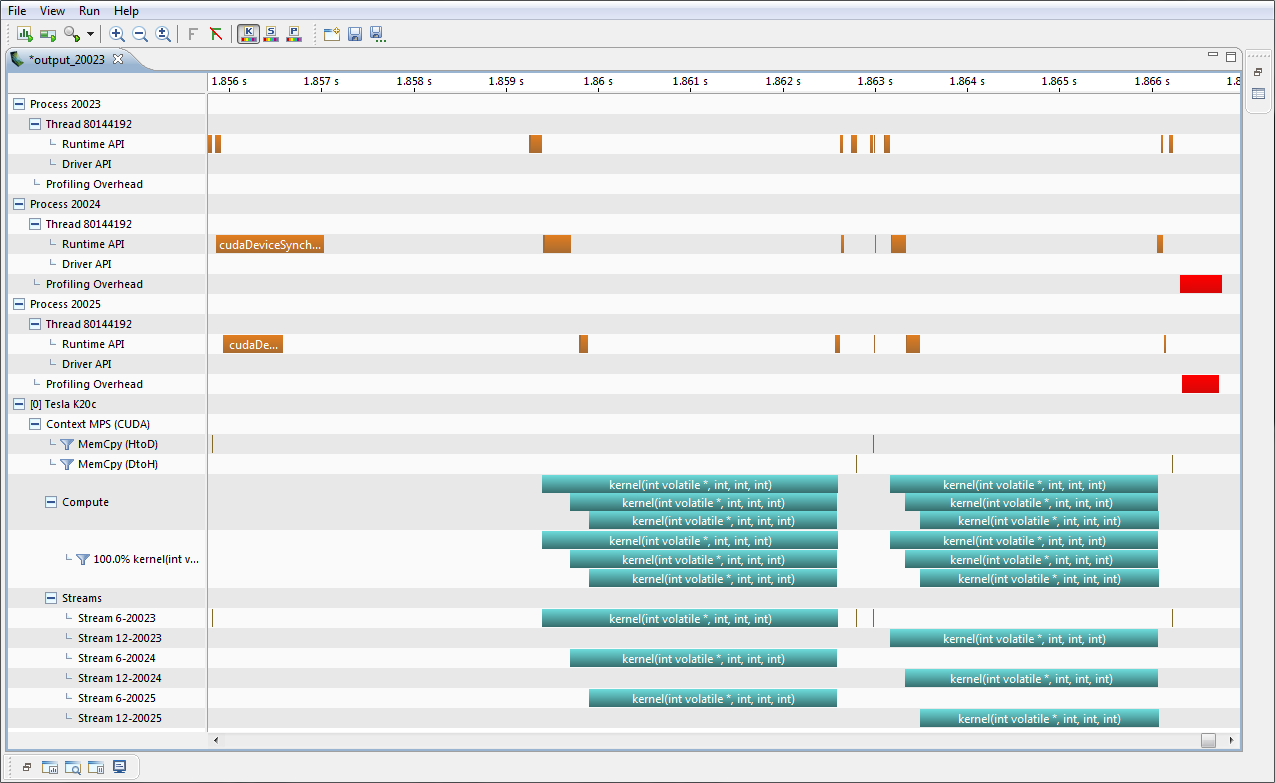
下图显示了三个进程的 MPS 时间线视图。MPS 上下文在时间线行标签中标识为 Context MPS。请注意,计算和内核时间线行显示了三个内核重叠。
8. 依赖性分析
依赖性分析功能可以优化程序运行时以及利用多个 CPU 线程和 CUDA 流的应用程序的并发性。它允许计算特定执行的关键路径,检测等待时间,并检查在不同线程或流中执行的函数之间的依赖关系。
8.1. 背景
nvprof 和 Visual Profiler 中的依赖性分析基于应用程序的执行跟踪。跟踪捕获所有相关活动,例如 API 函数调用或 CUDA 内核,以及它们的时间戳和持续时间。给定此执行跟踪和不同线程/流上这些活动之间依赖性的模型,可以构建依赖性图。在此图中建模的典型依赖性是,CUDA 内核不能在其各自的启动 API 调用之前启动,或者阻塞的 CUDA 流同步调用不能在其流中所有先前排队的工作完成之前返回。这些依赖性由 CUDA API 约定定义。
从此依赖性图和 API 模型中,可以计算等待状态。等待状态是 API 函数调用等活动被阻塞等待另一个线程或流中的事件的持续时间。给定先前的流同步示例,同步 API 调用被阻塞的时间是它必须等待相应 CUDA 流中任何 GPU 活动的时间。关于等待状态发生的位置以及函数被阻塞多长时间的知识有助于识别应用程序中更高级别并发性的优化机会。
除了单个等待状态之外,通过捕获的事件图的关键路径能够精确定位那些负责应用程序总运行时的函数调用、内核和内存副本。关键路径是不包含等待状态的事件图中的最长路径,即优化此路径上的活动可以直接改善执行时间。
8.2. 指标
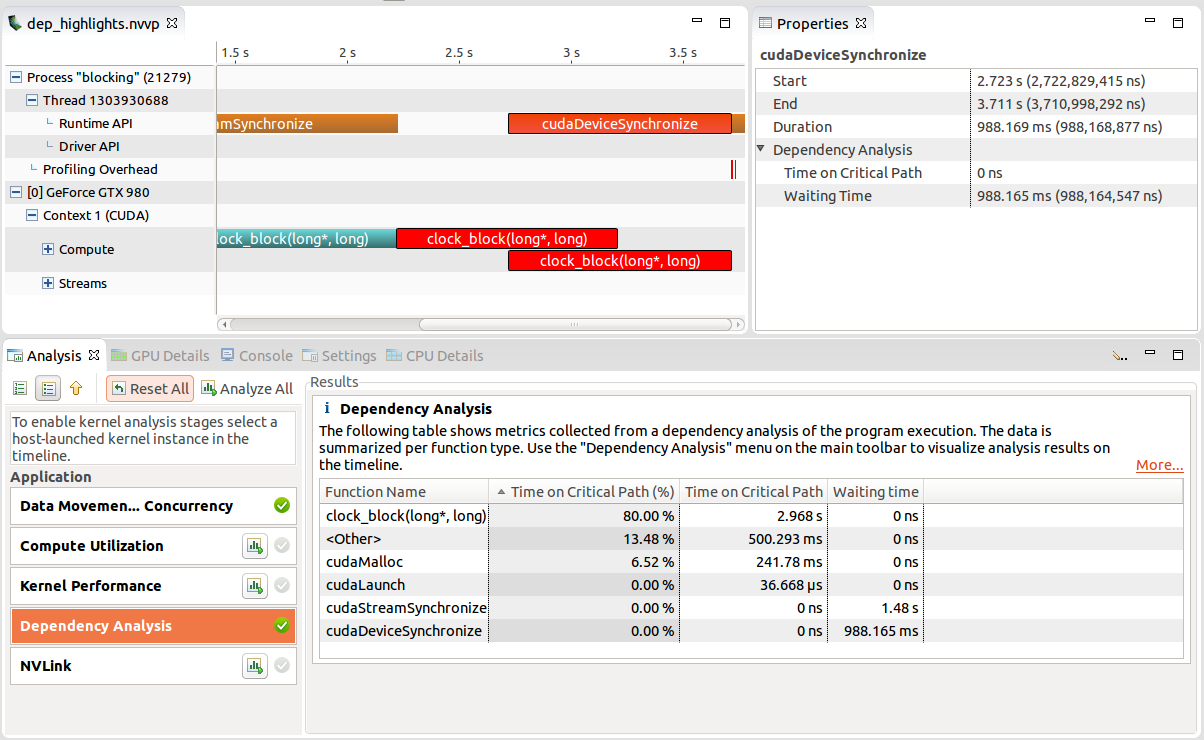
等待时间
等待状态是 API 函数调用等活动被阻塞等待另一个线程或流中的事件的持续时间。等待时间是执行流之间负载不平衡的指标。在下面的示例中,阻塞的 CUDA 同步 API 调用正在等待它们各自的内核完成在 GPU 上的执行。与其立即等待,不如尝试将内核执行与具有相似运行时的并发 CPU 工作重叠,从而减少任何计算设备(CPU 或 GPU)被阻塞的时间。
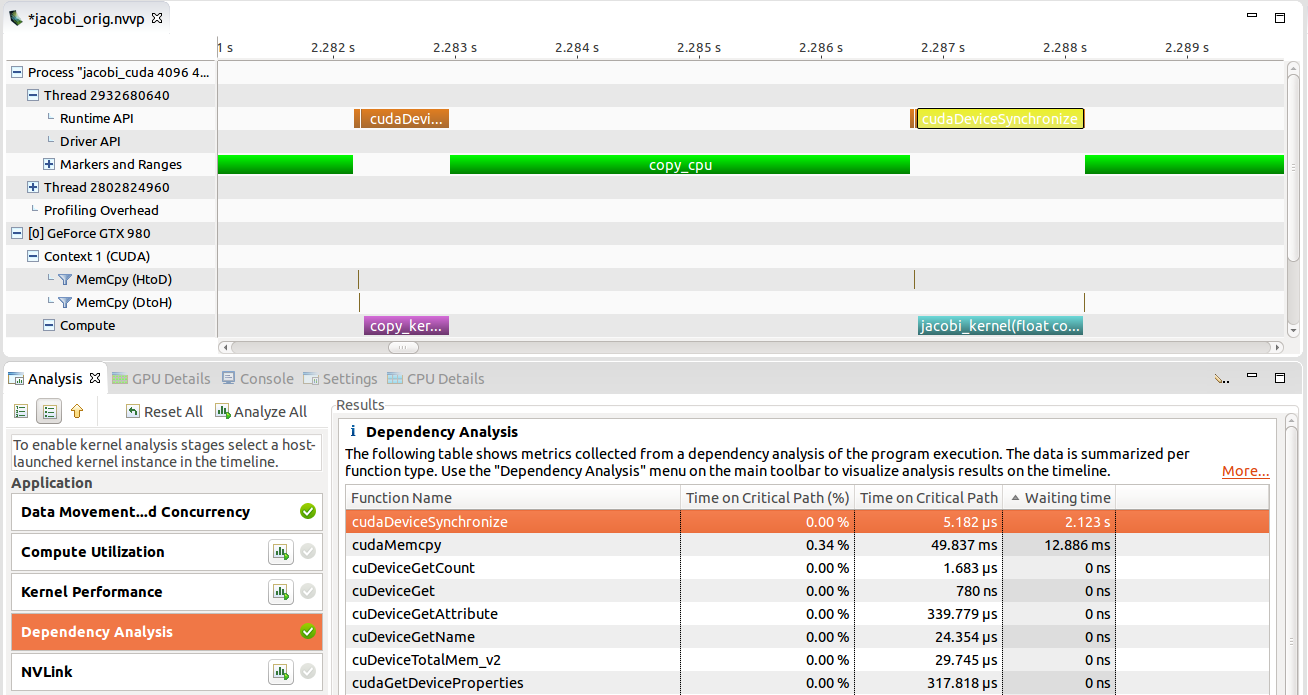
关键路径上的时间
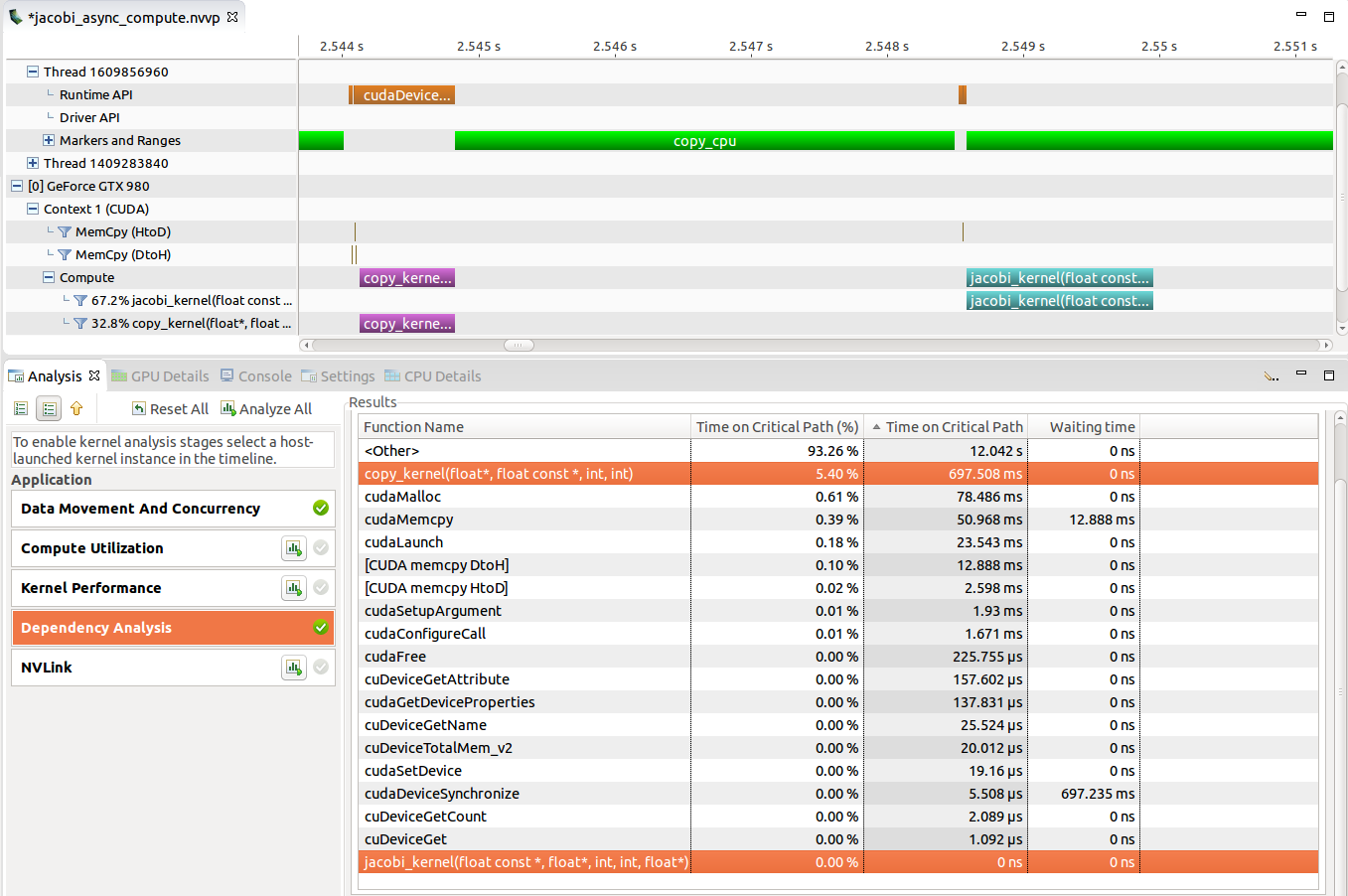
关键路径是不包含等待状态的事件图中的最长路径,即优化此路径上的活动可以直接改善执行时间。在关键路径上花费大量时间的活动对应用程序运行时具有较高的直接影响。在下图中,copy_kernel 位于关键路径上,因为 CPU 被阻塞,等待它在 cudeDeviceSynchronize 中完成。减少内核运行时允许 CPU 更早地从 API 调用返回并继续程序执行。另一方面,jacobi_kernel 与 CPU 工作完全重叠,即同步 API 调用在内核已完成之后触发。由于没有执行流等待此内核完成,因此减少其持续时间可能不会改善整体应用程序运行时。
8.3. 支持
以下编程 API 当前受支持用于依赖性分析
CUDA 运行时和驱动程序 API
POSIX 线程 (Pthreads)、POSIX 互斥锁和条件变量
依赖性分析在 Visual Profiler 和 nvprof 中可用。“依赖性分析”阶段可以在非引导式应用程序分析中选择,新的依赖性分析控件可用于时间线。请参阅依赖性分析部分,了解如何在 nvprof 中使用此功能。
8.4. 局限性
不同线程和 CUDA 流之间的依赖性和等待时间分析仅考虑各自支持的 API 约定中声明的执行依赖性。这尤其不包括由于资源争用而导致的同步。例如,即使具体的 GPU 只有一个复制引擎,排队到独立 CUDA 流中的异步内存副本也不会被标记为依赖项。此外,分析不考虑使用不受支持的 API 进行同步。例如,主动轮询某个内存位置的值的 CPU 线程(忙等待)将不被视为阻塞在另一个并发活动上。
依赖性分析对使用 CUDA 动态并行性 (CDP) 的应用程序的支持有限。CDP 内核可以使用来自 GPU 的 CUDA API 调用,这些调用未通过 CUPTI Activity API 跟踪。因此,分析无法确定 CDP 内核的完整依赖性和等待时间。但是,它利用了 CDP 内核之间的父子启动依赖性。因此,关键路径将始终包含每个主机启动的内核的最后一个 CDP 内核。
POSIX 信号量 API 当前不受支持。
依赖性分析不支持 API 函数 cudaLaunchCooperativeKernelMultiDevice 或 cuLaunchCooperativeKernelMultiDevice。通过这些 API 函数之一启动的内核可能无法正确跟踪。
9. 指标参考
本节包含有关 nvprof 和 Visual Profiler 可以收集的指标的详细描述。“单上下文”的范围值表示只有在单个上下文(CUDA 或图形)在 GPU 上执行时才能准确收集指标。“多上下文”的范围值表示当多个上下文在 GPU 上执行时可以准确收集指标。“设备”的范围值表示指标将在设备级别收集,即它将包括在 GPU 上执行的所有上下文的值。请注意,为内核模式收集的 NVLink 指标表现出“单上下文”的行为。
9.1. Capability 5.x 的指标
计算能力为 5.x 的设备实现了下表所示的指标。请注意,对于某些指标,“多上下文”范围仅对特定设备受支持。此类指标在“范围”列下标记为“多上下文*”。请参阅表底部的注释。
指标名称 |
描述 |
范围 |
|---|---|---|
achieved_occupancy |
每个活动周期平均活动 Warp 与多处理器上支持的最大 Warp 数之比 |
多上下文 |
atomic_transactions |
全局内存原子和归约事务 |
多上下文 |
atomic_transactions_per_request |
每个原子和归约指令执行的全局内存原子和归约事务的平均数 |
多上下文 |
branch_efficiency |
非发散分支与总分支的比率,以百分比表示 |
多上下文 |
cf_executed |
执行的控制流指令数 |
多上下文 |
cf_fu_utilization |
多处理器功能单元的利用率,以 0 到 10 的等级执行控制流指令 |
多上下文 |
cf_issued |
发出的控制流指令数 |
多上下文 |
double_precision_fu_utilization |
多处理器功能单元的利用率,以 0 到 10 的等级执行双精度浮点指令 |
多上下文 |
dram_read_bytes |
从 DRAM 读取到 L2 缓存的总字节数。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
dram_read_throughput |
设备内存读取吞吐量。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
dram_read_transactions |
设备内存读取事务。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
dram_utilization |
设备内存的利用率,相对于峰值利用率,等级为 0 到 10 |
多上下文* |
dram_write_bytes |
从 L2 缓存写入到 DRAM 的总字节数。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
dram_write_throughput |
设备内存写入吞吐量。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
dram_write_transactions |
设备内存写入事务。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
ecc_throughput |
从 L2 到 DRAM 的 ECC 吞吐量。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
ecc_transactions |
L2 和 DRAM 之间 ECC 事务的数量。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
eligible_warps_per_cycle |
每个活动周期内有资格发出的 warp 的平均数量 |
多上下文 |
flop_count_dp |
非谓词线程执行的双精度浮点运算次数(加法、乘法和乘加)。每个乘加运算计为 2。 |
多上下文 |
flop_count_dp_add |
非谓词线程执行的双精度浮点加法运算次数。 |
多上下文 |
flop_count_dp_fma |
非谓词线程执行的双精度浮点乘加运算次数。每个乘加运算计为 1。 |
多上下文 |
flop_count_dp_mul |
非谓词线程执行的双精度浮点乘法运算次数。 |
多上下文 |
flop_count_hp |
非谓词线程执行的半精度浮点运算次数(加法、乘法和乘加)。每个乘加运算计为 2。这适用于计算能力 5.3。 |
多上下文* |
flop_count_hp_add |
非谓词线程执行的半精度浮点加法运算次数。这适用于计算能力 5.3。 |
多上下文* |
flop_count_hp_fma |
非谓词线程执行的半精度浮点乘加运算次数。每个乘加运算计为 1。这适用于计算能力 5.3。 |
多上下文* |
flop_count_hp_mul |
非谓词线程执行的半精度浮点乘法运算次数。这适用于计算能力 5.3。 |
多上下文* |
flop_count_sp |
非谓词线程执行的单精度浮点运算次数(加法、乘法和乘加)。每个乘加运算计为 2。计数不包括特殊运算。 |
多上下文 |
flop_count_sp_add |
非谓词线程执行的单精度浮点加法运算次数。 |
多上下文 |
flop_count_sp_fma |
非谓词线程执行的单精度浮点乘加运算次数。每个乘加运算计为 1。 |
多上下文 |
flop_count_sp_mul |
非谓词线程执行的单精度浮点乘法运算次数。 |
多上下文 |
flop_count_sp_special |
非谓词线程执行的单精度浮点特殊运算次数。 |
多上下文 |
flop_dp_efficiency |
实现的双精度浮点运算与峰值双精度浮点运算的比率 |
多上下文 |
flop_hp_efficiency |
实现的半精度浮点运算与峰值半精度浮点运算的比率。这适用于计算能力 5.3。 |
多上下文* |
flop_sp_efficiency |
实现的单精度浮点运算与峰值单精度浮点运算的比率 |
多上下文 |
gld_efficiency |
请求的全局内存加载吞吐量与所需的全局内存加载吞吐量的比率,以百分比表示。 |
多上下文* |
gld_requested_throughput |
请求的全局内存加载吞吐量 |
多上下文 |
gld_throughput |
全局内存加载吞吐量 |
多上下文* |
gld_transactions |
全局内存加载事务的数量 |
多上下文* |
gld_transactions_per_request |
每次全局内存加载执行的全局内存加载事务的平均数量。 |
多上下文* |
global_atomic_requests |
来自多处理器的全局原子(Atom 和 Atom CAS)请求总数 |
多上下文 |
global_hit_rate |
统一 L1/纹理缓存中全局加载的命中率。如果在内核中使用 malloc,则指标值可能错误。 |
多上下文* |
global_load_requests |
来自多处理器的全局加载请求总数 |
多上下文 |
global_reduction_requests |
来自多处理器的全局归约请求总数 |
多上下文 |
global_store_requests |
来自多处理器的全局存储请求总数。这不包括原子请求。 |
多上下文 |
gst_efficiency |
请求的全局内存存储吞吐量与所需的全局内存存储吞吐量的比率,以百分比表示。 |
多上下文* |
gst_requested_throughput |
请求的全局内存存储吞吐量 |
多上下文 |
gst_throughput |
全局内存存储吞吐量 |
多上下文* |
gst_transactions |
全局内存存储事务的数量 |
多上下文* |
gst_transactions_per_request |
每次全局内存存储执行的全局内存存储事务的平均数量 |
多上下文* |
half_precision_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行 16 位浮点指令和整数指令。这适用于计算能力 5.3。 |
多上下文* |
inst_bit_convert |
非谓词线程执行的位转换指令的数量 |
多上下文 |
inst_compute_ld_st |
非谓词线程执行的计算加载/存储指令的数量 |
多上下文 |
inst_control |
非谓词线程执行的控制流指令的数量(跳转、分支等) |
多上下文 |
inst_executed |
执行的指令数 |
多上下文 |
inst_executed_global_atomics |
用于全局原子和原子 cas 的 Warp 级别指令 |
多上下文 |
inst_executed_global_loads |
用于全局加载的 Warp 级别指令 |
多上下文 |
inst_executed_global_reductions |
用于全局归约的 Warp 级别指令 |
多上下文 |
inst_executed_global_stores |
用于全局存储的 Warp 级别指令 |
多上下文 |
inst_executed_local_loads |
用于本地加载的 Warp 级别指令 |
多上下文 |
inst_executed_local_stores |
用于本地存储的 Warp 级别指令 |
多上下文 |
inst_executed_shared_atomics |
用于原子和原子 CAS 的 Warp 级别共享指令 |
多上下文 |
inst_executed_shared_loads |
用于共享加载的 Warp 级别指令 |
多上下文 |
inst_executed_shared_stores |
用于共享存储的 Warp 级别指令 |
多上下文 |
inst_executed_surface_atomics |
用于表面原子和原子 cas 的 Warp 级别指令 |
多上下文 |
inst_executed_surface_loads |
用于表面加载的 Warp 级别指令 |
多上下文 |
inst_executed_surface_reductions |
用于表面归约的 Warp 级别指令 |
多上下文 |
inst_executed_surface_stores |
用于表面存储的 Warp 级别指令 |
多上下文 |
inst_executed_tex_ops |
用于纹理的 Warp 级别指令 |
多上下文 |
inst_fp_16 |
非谓词线程执行的半精度浮点指令的数量(算术、比较等)。这适用于计算能力 5.3。 |
多上下文* |
inst_fp_32 |
非谓词线程执行的单精度浮点指令的数量(算术、比较等)。 |
多上下文 |
inst_fp_64 |
非谓词线程执行的双精度浮点指令的数量(算术、比较等)。 |
多上下文 |
inst_integer |
非谓词线程执行的整数指令的数量 |
多上下文 |
inst_inter_thread_communication |
非谓词线程执行的线程间通信指令的数量 |
多上下文 |
inst_issued |
发出的指令数 |
多上下文 |
inst_misc |
非谓词线程执行的杂项指令的数量 |
多上下文 |
inst_per_warp |
每个 warp 执行的平均指令数 |
多上下文 |
inst_replay_overhead |
每个执行的指令的平均重放次数 |
多上下文 |
ipc |
每个周期执行的指令数 |
多上下文 |
issue_slot_utilization |
在所有周期中平均,至少发出一条指令的发出槽的百分比 |
多上下文 |
issue_slots |
使用的发出槽的数量 |
多上下文 |
issued_ipc |
每个周期发出的指令数 |
多上下文 |
l2_atomic_throughput |
在 L2 缓存中看到的原子和归约请求的内存读取吞吐量 |
多上下文 |
l2_atomic_transactions |
在 L2 缓存中看到的原子和归约请求的内存读取事务 |
多上下文* |
l2_global_atomic_store_bytes |
从统一缓存写入到 L2 的全局原子(ATOM 和 ATOM CAS)字节数 |
多上下文* |
l2_global_load_bytes |
从 L2 读取的用于全局加载的统一缓存未命中字节数 |
多上下文* |
l2_global_reduction_bytes |
从统一缓存写入到 L2 的全局归约字节数 |
多上下文* |
l2_local_global_store_bytes |
从统一缓存写入到 L2 的本地和全局存储字节数。这不包括全局原子。 |
多上下文* |
l2_local_load_bytes |
从 L2 读取的用于本地加载的统一缓存未命中字节数 |
多上下文* |
l2_read_throughput |
在 L2 缓存中看到的所有读取请求的内存读取吞吐量 |
多上下文* |
l2_read_transactions |
在 L2 缓存中看到的所有读取请求的内存读取事务 |
多上下文* |
l2_surface_atomic_store_bytes |
在统一缓存和 L2 之间为表面原子(ATOM 和 ATOM CAS)传输的字节数 |
多上下文* |
l2_surface_load_bytes |
从 L2 读取的用于表面加载的统一缓存未命中字节数 |
多上下文* |
l2_surface_reduction_bytes |
从统一缓存写入到 L2 的表面归约字节数 |
多上下文* |
l2_surface_store_bytes |
从统一缓存写入到 L2 的表面存储字节数。这不包括表面原子。 |
多上下文* |
l2_tex_hit_rate |
来自纹理缓存的所有请求在 L2 缓存中的命中率 |
多上下文* |
l2_tex_read_hit_rate |
来自纹理缓存的所有读取请求在 L2 缓存中的命中率。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
l2_tex_read_throughput |
在 L2 缓存中看到的来自纹理缓存的读取请求的内存读取吞吐量 |
多上下文* |
l2_tex_read_transactions |
在 L2 缓存中看到的来自纹理缓存的读取请求的内存读取事务 |
多上下文* |
l2_tex_write_hit_rate |
来自纹理缓存的所有写入请求在 L2 缓存中的命中率。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
l2_tex_write_throughput |
在 L2 缓存中看到的来自纹理缓存的写入请求的内存写入吞吐量 |
多上下文* |
l2_tex_write_transactions |
在 L2 缓存中看到的来自纹理缓存的写入请求的内存写入事务 |
多上下文* |
l2_utilization |
L2 缓存相对于峰值利用率的利用率水平,范围为 0 到 10 |
多上下文* |
l2_write_throughput |
在 L2 缓存中看到的所有写入请求的内存写入吞吐量 |
多上下文* |
l2_write_transactions |
在 L2 缓存中看到的所有写入请求的内存写入事务 |
多上下文* |
ldst_executed |
执行的本地、全局、共享和纹理内存加载和存储指令的数量 |
多上下文 |
ldst_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行共享加载、共享存储和常量加载指令 |
多上下文 |
ldst_issued |
发出的本地、全局、共享和纹理内存加载和存储指令的数量 |
多上下文 |
local_hit_rate |
本地加载和存储的命中率 |
多上下文* |
local_load_requests |
来自多处理器的本地加载请求总数 |
多上下文* |
local_load_throughput |
本地内存加载吞吐量 |
多上下文* |
local_load_transactions |
本地内存加载事务的数量 |
多上下文* |
local_load_transactions_per_request |
每次本地内存加载执行的本地内存加载事务的平均数量 |
多上下文* |
local_memory_overhead |
L1 和 L2 缓存之间本地内存流量与总内存流量的比率,以百分比表示 |
多上下文* |
local_store_requests |
来自多处理器的本地存储请求总数 |
多上下文* |
local_store_throughput |
本地内存存储吞吐量 |
多上下文* |
local_store_transactions |
本地内存存储事务的数量 |
多上下文* |
local_store_transactions_per_request |
每次本地内存存储执行的本地内存存储事务的平均数量 |
多上下文* |
pcie_total_data_received |
通过 PCIe 接收的总数据字节数 |
设备 |
pcie_total_data_transmitted |
通过 PCIe 传输的总数据字节数 |
设备 |
shared_efficiency |
请求的共享内存吞吐量与所需的共享内存吞吐量的比率,以百分比表示 |
多上下文* |
shared_load_throughput |
共享内存加载吞吐量 |
多上下文* |
shared_load_transactions |
共享内存加载事务的数量 |
多上下文* |
shared_load_transactions_per_request |
每次共享内存加载执行的共享内存加载事务的平均数量 |
多上下文* |
shared_store_throughput |
共享内存存储吞吐量 |
多上下文* |
shared_store_transactions |
共享内存存储事务的数量 |
多上下文* |
shared_store_transactions_per_request |
每次共享内存存储执行的共享内存存储事务的平均数量 |
多上下文* |
shared_utilization |
共享内存相对于峰值利用率的利用率水平,范围为 0 到 10 |
多上下文* |
single_precision_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行单精度浮点指令和整数指令 |
多上下文 |
sm_efficiency |
在特定多处理器上至少有一个 warp 处于活动状态的时间百分比 |
多上下文* |
special_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行 sin、cos、ex2、popc、flo 和类似指令 |
多上下文 |
stall_constant_memory_dependency |
由于立即常量缓存未命中而发生的停顿百分比 |
多上下文 |
stall_exec_dependency |
由于指令所需的输入尚不可用而发生的停顿百分比 |
多上下文 |
stall_inst_fetch |
由于尚未获取下一条汇编指令而发生的停顿百分比 |
多上下文 |
stall_memory_dependency |
由于内存操作无法执行,原因是所需资源不可用或未充分利用,或者给定类型的请求过多而发生的停顿百分比 |
多上下文 |
stall_memory_throttle |
由于内存节流而发生的停顿百分比 |
多上下文 |
stall_not_selected |
由于 warp 未被选中而发生的停顿百分比 |
多上下文 |
stall_other |
由于其他原因而发生的停顿百分比 |
多上下文 |
stall_pipe_busy |
由于计算流水线繁忙而无法执行计算操作而发生的停顿百分比 |
多上下文 |
stall_sync |
由于 warp 在 __syncthreads() 调用处被阻止而发生的停顿百分比 |
多上下文 |
stall_texture |
由于纹理子系统已完全利用或未完成请求过多而发生的停顿百分比 |
多上下文 |
surface_atomic_requests |
来自多处理器的表面原子(Atom 和 Atom CAS)请求总数 |
多上下文 |
surface_load_requests |
来自多处理器的表面加载请求总数 |
多上下文 |
surface_reduction_requests |
来自多处理器的表面归约请求总数 |
多上下文 |
surface_store_requests |
来自多处理器的表面存储请求总数 |
多上下文 |
sysmem_read_bytes |
从系统内存读取的字节数 |
多上下文* |
sysmem_read_throughput |
系统内存读取吞吐量 |
多上下文* |
sysmem_read_transactions |
系统内存读取事务的数量 |
多上下文* |
sysmem_read_utilization |
系统内存相对于峰值利用率的读取利用率水平,范围为 0 到 10。这适用于计算能力 5.0 和 5.2。 |
多上下文 |
sysmem_utilization |
系统内存相对于峰值利用率的利用率水平,范围为 0 到 10。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
sysmem_write_bytes |
写入系统内存的字节数 |
多上下文* |
sysmem_write_throughput |
系统内存写入吞吐量 |
多上下文* |
sysmem_write_transactions |
系统内存写入事务的数量 |
多上下文* |
sysmem_write_utilization |
系统内存相对于峰值利用率的写入利用率水平,范围为 0 到 10。这适用于计算能力 5.0 和 5.2。 |
多上下文* |
tex_cache_hit_rate |
统一缓存命中率 |
多上下文* |
tex_cache_throughput |
统一缓存吞吐量 |
多上下文* |
tex_cache_transactions |
统一缓存读取事务 |
多上下文* |
tex_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行全局、本地和纹理内存指令 |
多上下文 |
tex_utilization |
统一缓存相对于峰值利用率的利用率水平,范围为 0 到 10 |
多上下文* |
texture_load_requests |
来自多处理器的纹理加载请求总数 |
多上下文 |
warp_execution_efficiency |
每个 warp 的平均活动线程数与多处理器上支持的每个 warp 的最大线程数的比率 |
多上下文 |
warp_nonpred_execution_efficiency |
每个 warp 执行非谓词指令的平均活动线程数与多处理器上支持的每个 warp 的最大线程数的比率 |
多上下文 |
* 此指标的“多上下文”范围仅在计算能力为 5.0 和 5.2 的设备上受支持。
9.2. Capability 6.x 的指标
计算能力为 6.x 的设备实现下表所示的指标。
指标名称 |
描述 |
范围 |
|---|---|---|
achieved_occupancy |
每个活动周期平均活动 Warp 与多处理器上支持的最大 Warp 数之比 |
多上下文 |
atomic_transactions |
全局内存原子和归约事务 |
多上下文 |
atomic_transactions_per_request |
每个原子和归约指令执行的全局内存原子和归约事务的平均数 |
多上下文 |
branch_efficiency |
非发散分支与总分支的比率,以百分比表示 |
多上下文 |
cf_executed |
执行的控制流指令数 |
多上下文 |
cf_fu_utilization |
多处理器功能单元的利用率,以 0 到 10 的等级执行控制流指令 |
多上下文 |
cf_issued |
发出的控制流指令数 |
多上下文 |
double_precision_fu_utilization |
多处理器功能单元的利用率,以 0 到 10 的等级执行双精度浮点指令 |
多上下文 |
dram_read_bytes |
从 DRAM 读取到 L2 缓存的总字节数 |
多上下文 |
dram_read_throughput |
设备内存读取吞吐量。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
dram_read_transactions |
设备内存读取事务。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
dram_utilization |
设备内存的利用率,相对于峰值利用率,等级为 0 到 10 |
多上下文 |
dram_write_bytes |
从 L2 缓存写入到 DRAM 的总字节数 |
多上下文 |
dram_write_throughput |
设备内存写入吞吐量。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
dram_write_transactions |
设备内存写入事务。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
ecc_throughput |
从 L2 到 DRAM 的 ECC 吞吐量。这适用于计算能力 6.1。 |
多上下文 |
ecc_transactions |
L2 和 DRAM 之间 ECC 事务的数量。这适用于计算能力 6.1。 |
多上下文 |
eligible_warps_per_cycle |
每个活动周期内有资格发出的 warp 的平均数量 |
多上下文 |
flop_count_dp |
非谓词线程执行的双精度浮点运算次数(加法、乘法和乘加)。每个乘加运算计为 2。 |
多上下文 |
flop_count_dp_add |
非谓词线程执行的双精度浮点加法运算次数。 |
多上下文 |
flop_count_dp_fma |
非谓词线程执行的双精度浮点乘加运算次数。每个乘加运算计为 1。 |
多上下文 |
flop_count_dp_mul |
非谓词线程执行的双精度浮点乘法运算次数。 |
多上下文 |
flop_count_hp |
非谓词线程执行的半精度浮点运算次数(加法、乘法和乘加)。每个乘加运算计为 2。 |
多上下文 |
flop_count_hp_add |
非谓词线程执行的半精度浮点加法运算次数。 |
多上下文 |
flop_count_hp_fma |
非谓词线程执行的半精度浮点乘加运算次数。每个乘加运算计为 1。 |
多上下文 |
flop_count_hp_mul |
非谓词线程执行的半精度浮点乘法运算次数。 |
多上下文 |
flop_count_sp |
非谓词线程执行的单精度浮点运算次数(加法、乘法和乘加)。每个乘加运算计为 2。计数不包括特殊运算。 |
多上下文 |
flop_count_sp_add |
非谓词线程执行的单精度浮点加法运算次数。 |
多上下文 |
flop_count_sp_fma |
非谓词线程执行的单精度浮点乘加运算次数。每个乘加运算计为 1。 |
多上下文 |
flop_count_sp_mul |
非谓词线程执行的单精度浮点乘法运算次数。 |
多上下文 |
flop_count_sp_special |
非谓词线程执行的单精度浮点特殊运算次数。 |
多上下文 |
flop_dp_efficiency |
实现的双精度浮点运算与峰值双精度浮点运算的比率 |
多上下文 |
flop_hp_efficiency |
实现的半精度浮点运算与峰值半精度浮点运算的比率 |
多上下文 |
flop_sp_efficiency |
实现的单精度浮点运算与峰值单精度浮点运算的比率 |
多上下文 |
gld_efficiency |
请求的全局内存加载吞吐量与所需的全局内存加载吞吐量的比率,以百分比表示。 |
多上下文 |
gld_requested_throughput |
请求的全局内存加载吞吐量 |
多上下文 |
gld_throughput |
全局内存加载吞吐量 |
多上下文 |
gld_transactions |
全局内存加载事务的数量 |
多上下文 |
gld_transactions_per_request |
每次全局内存加载执行的全局内存加载事务的平均数量。 |
多上下文 |
global_atomic_requests |
来自多处理器的全局原子(Atom 和 Atom CAS)请求总数 |
多上下文 |
global_hit_rate |
统一 L1/纹理缓存中全局加载的命中率。如果在内核中使用 malloc,则指标值可能错误。 |
多上下文 |
global_load_requests |
来自多处理器的全局加载请求总数 |
多上下文 |
global_reduction_requests |
来自多处理器的全局归约请求总数 |
多上下文 |
global_store_requests |
来自多处理器的全局存储请求总数。这不包括原子请求。 |
多上下文 |
gst_efficiency |
请求的全局内存存储吞吐量与所需的全局内存存储吞吐量的比率,以百分比表示。 |
多上下文 |
gst_requested_throughput |
请求的全局内存存储吞吐量 |
多上下文 |
gst_throughput |
全局内存存储吞吐量 |
多上下文 |
gst_transactions |
全局内存存储事务的数量 |
多上下文 |
gst_transactions_per_request |
每次全局内存存储执行的全局内存存储事务的平均数量 |
多上下文 |
half_precision_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行 16 位浮点指令 |
多上下文 |
inst_bit_convert |
非谓词线程执行的位转换指令的数量 |
多上下文 |
inst_compute_ld_st |
非谓词线程执行的计算加载/存储指令的数量 |
多上下文 |
inst_control |
非谓词线程执行的控制流指令的数量(跳转、分支等) |
多上下文 |
inst_executed |
执行的指令数 |
多上下文 |
inst_executed_global_atomics |
用于全局原子和原子 cas 的 Warp 级别指令 |
多上下文 |
inst_executed_global_loads |
用于全局加载的 Warp 级别指令 |
多上下文 |
inst_executed_global_reductions |
用于全局归约的 Warp 级别指令 |
多上下文 |
inst_executed_global_stores |
用于全局存储的 Warp 级别指令 |
多上下文 |
inst_executed_local_loads |
用于本地加载的 Warp 级别指令 |
多上下文 |
inst_executed_local_stores |
用于本地存储的 Warp 级别指令 |
多上下文 |
inst_executed_shared_atomics |
用于原子和原子 CAS 的 Warp 级别共享指令 |
多上下文 |
inst_executed_shared_loads |
用于共享加载的 Warp 级别指令 |
多上下文 |
inst_executed_shared_stores |
用于共享存储的 Warp 级别指令 |
多上下文 |
inst_executed_surface_atomics |
用于表面原子和原子 cas 的 Warp 级别指令 |
多上下文 |
inst_executed_surface_loads |
用于表面加载的 Warp 级别指令 |
多上下文 |
inst_executed_surface_reductions |
用于表面归约的 Warp 级别指令 |
多上下文 |
inst_executed_surface_stores |
用于表面存储的 Warp 级别指令 |
多上下文 |
inst_executed_tex_ops |
用于纹理的 Warp 级别指令 |
多上下文 |
inst_fp_16 |
非谓词线程执行的半精度浮点指令的数量(算术、比较等)。 |
多上下文 |
inst_fp_32 |
非谓词线程执行的单精度浮点指令的数量(算术、比较等)。 |
多上下文 |
inst_fp_64 |
非谓词线程执行的双精度浮点指令的数量(算术、比较等)。 |
多上下文 |
inst_integer |
非谓词线程执行的整数指令的数量 |
多上下文 |
inst_inter_thread_communication |
非谓词线程执行的线程间通信指令的数量 |
多上下文 |
inst_issued |
发出的指令数 |
多上下文 |
inst_misc |
非谓词线程执行的杂项指令的数量 |
多上下文 |
inst_per_warp |
每个 warp 执行的平均指令数 |
多上下文 |
inst_replay_overhead |
每个执行的指令的平均重放次数 |
多上下文 |
ipc |
每个周期执行的指令数 |
多上下文 |
issue_slot_utilization |
在所有周期中平均,至少发出一条指令的发出槽的百分比 |
多上下文 |
issue_slots |
使用的发出槽的数量 |
多上下文 |
issued_ipc |
每个周期发出的指令数 |
多上下文 |
l2_atomic_throughput |
在 L2 缓存中看到的原子和归约请求的内存读取吞吐量 |
多上下文 |
l2_atomic_transactions |
在 L2 缓存中看到的原子和归约请求的内存读取事务 |
多上下文 |
l2_global_atomic_store_bytes |
从统一缓存写入到 L2 的全局原子(ATOM 和 ATOM CAS)字节数 |
多上下文 |
l2_global_load_bytes |
从 L2 读取的用于全局加载的统一缓存未命中字节数 |
多上下文 |
l2_global_reduction_bytes |
从统一缓存写入到 L2 的全局归约字节数 |
多上下文 |
l2_local_global_store_bytes |
从统一缓存写入到 L2 的本地和全局存储字节数。这不包括全局原子。 |
多上下文 |
l2_local_load_bytes |
从 L2 读取的用于本地加载的统一缓存未命中字节数 |
多上下文 |
l2_read_throughput |
在 L2 缓存中看到的所有读取请求的内存读取吞吐量 |
多上下文 |
l2_read_transactions |
在 L2 缓存中看到的所有读取请求的内存读取事务 |
多上下文 |
l2_surface_atomic_store_bytes |
在统一缓存和 L2 之间为表面原子(ATOM 和 ATOM CAS)传输的字节数 |
多上下文 |
l2_surface_load_bytes |
从 L2 读取的用于表面加载的统一缓存未命中字节数 |
多上下文 |
l2_surface_reduction_bytes |
从统一缓存写入到 L2 的表面归约字节数 |
多上下文 |
l2_surface_store_bytes |
从统一缓存写入到 L2 的表面存储字节数。这不包括表面原子。 |
多上下文 |
l2_tex_hit_rate |
来自纹理缓存的所有请求在 L2 缓存中的命中率 |
多上下文 |
l2_tex_read_hit_rate |
来自纹理缓存的所有读取请求在 L2 缓存中的命中率。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
l2_tex_read_throughput |
在 L2 缓存中看到的来自纹理缓存的读取请求的内存读取吞吐量 |
多上下文 |
l2_tex_read_transactions |
在 L2 缓存中看到的来自纹理缓存的读取请求的内存读取事务 |
多上下文 |
l2_tex_write_hit_rate |
来自纹理缓存的所有写入请求在 L2 缓存中的命中率。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
l2_tex_write_throughput |
在 L2 缓存中看到的来自纹理缓存的写入请求的内存写入吞吐量 |
多上下文 |
l2_tex_write_transactions |
在 L2 缓存中看到的来自纹理缓存的写入请求的内存写入事务 |
多上下文 |
l2_utilization |
L2 缓存相对于峰值利用率的利用率水平,范围为 0 到 10 |
多上下文 |
l2_write_throughput |
在 L2 缓存中看到的所有写入请求的内存写入吞吐量 |
多上下文 |
l2_write_transactions |
在 L2 缓存中看到的所有写入请求的内存写入事务 |
多上下文 |
ldst_executed |
执行的本地、全局、共享和纹理内存加载和存储指令的数量 |
多上下文 |
ldst_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行共享加载、共享存储和常量加载指令 |
多上下文 |
ldst_issued |
发出的本地、全局、共享和纹理内存加载和存储指令的数量 |
多上下文 |
local_hit_rate |
本地加载和存储的命中率 |
多上下文 |
local_load_requests |
来自多处理器的本地加载请求总数 |
多上下文 |
local_load_throughput |
本地内存加载吞吐量 |
多上下文 |
local_load_transactions |
本地内存加载事务的数量 |
多上下文 |
local_load_transactions_per_request |
每次本地内存加载执行的本地内存加载事务的平均数量 |
多上下文 |
local_memory_overhead |
L1 和 L2 缓存之间本地内存流量与总内存流量的比率,以百分比表示 |
多上下文 |
local_store_requests |
来自多处理器的本地存储请求总数 |
多上下文 |
local_store_throughput |
本地内存存储吞吐量 |
多上下文 |
local_store_transactions |
本地内存存储事务的数量 |
多上下文 |
local_store_transactions_per_request |
每次本地内存存储执行的本地内存存储事务的平均数量 |
多上下文 |
nvlink_overhead_data_received |
通过 NVLink 接收的开销数据与总数据的比率。这适用于计算能力 6.0。 |
设备 |
nvlink_overhead_data_transmitted |
通过 NVLink 传输的开销数据与总数据的比率。这适用于计算能力 6.0。 |
设备 |
nvlink_receive_throughput |
每秒通过 NVLink 接收的字节数。这适用于计算能力 6.0。 |
设备 |
nvlink_total_data_received |
通过 NVLink 接收的总数据字节数,包括标头。这适用于计算能力 6.0。 |
设备 |
nvlink_total_data_transmitted |
通过 NVLink 传输的总数据字节数,包括标头。这适用于计算能力 6.0。 |
设备 |
nvlink_total_nratom_data_transmitted |
通过 NVLink 传输的非归约原子数据字节总数。这适用于计算能力 6.0。 |
设备 |
nvlink_total_ratom_data_transmitted |
通过 NVLink 传输的归约原子数据字节总数。这适用于计算能力 6.0。 |
设备 |
nvlink_total_response_data_received |
通过 NVLink 接收的响应数据字节总数,响应数据包括读取请求的数据和非归约原子请求的结果。这适用于计算能力 6.0。 |
设备 |
nvlink_total_write_data_transmitted |
通过 NVLink 传输的写入数据字节总数。这适用于计算能力 6.0。 |
设备 |
nvlink_transmit_throughput |
每秒通过 NVLink 传输的字节数。这适用于计算能力 6.0。 |
设备 |
nvlink_user_data_received |
通过 NVLink 接收的用户数据字节数,不包括标头。这适用于计算能力 6.0。 |
设备 |
nvlink_user_data_transmitted |
通过 NVLink 传输的用户数据字节数,不包括标头。这适用于计算能力 6.0。 |
设备 |
nvlink_user_nratom_data_transmitted |
通过 NVLink 传输的非归约原子用户数据字节总数。这适用于计算能力 6.0。 |
设备 |
nvlink_user_ratom_data_transmitted |
通过 NVLink 传输的归约原子用户数据字节总数。这适用于计算能力 6.0。 |
设备 |
nvlink_user_response_data_received |
通过 NVLink 接收的用户响应数据字节总数,响应数据包括读取请求的数据和非归约原子请求的结果。这适用于计算能力 6.0。 |
设备 |
nvlink_user_write_data_transmitted |
通过 NVLink 传输的用户写入数据字节数。这适用于计算能力 6.0。 |
设备 |
pcie_total_data_received |
通过 PCIe 接收的总数据字节数 |
设备 |
pcie_total_data_transmitted |
通过 PCIe 传输的总数据字节数 |
设备 |
shared_efficiency |
请求的共享内存吞吐量与所需的共享内存吞吐量的比率,以百分比表示 |
多上下文 |
shared_load_throughput |
共享内存加载吞吐量 |
多上下文 |
shared_load_transactions |
共享内存加载事务的数量 |
多上下文 |
shared_load_transactions_per_request |
每次共享内存加载执行的共享内存加载事务的平均数量 |
多上下文 |
shared_store_throughput |
共享内存存储吞吐量 |
多上下文 |
shared_store_transactions |
共享内存存储事务的数量 |
多上下文 |
shared_store_transactions_per_request |
每次共享内存存储执行的共享内存存储事务的平均数量 |
多上下文 |
shared_utilization |
共享内存相对于峰值利用率的利用率水平,范围为 0 到 10 |
多上下文 |
single_precision_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行单精度浮点指令和整数指令 |
多上下文 |
sm_efficiency |
在特定多处理器上至少有一个 warp 处于活动状态的时间百分比 |
多上下文 |
special_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行 sin、cos、ex2、popc、flo 和类似指令 |
多上下文 |
stall_constant_memory_dependency |
由于立即常量缓存未命中而发生的停顿百分比 |
多上下文 |
stall_exec_dependency |
由于指令所需的输入尚不可用而发生的停顿百分比 |
多上下文 |
stall_inst_fetch |
由于尚未获取下一条汇编指令而发生的停顿百分比 |
多上下文 |
stall_memory_dependency |
由于内存操作无法执行,原因是所需资源不可用或未充分利用,或者给定类型的请求过多而发生的停顿百分比 |
多上下文 |
stall_memory_throttle |
由于内存节流而发生的停顿百分比 |
多上下文 |
stall_not_selected |
由于 warp 未被选中而发生的停顿百分比 |
多上下文 |
stall_other |
由于其他原因而发生的停顿百分比 |
多上下文 |
stall_pipe_busy |
由于计算流水线繁忙而无法执行计算操作而发生的停顿百分比 |
多上下文 |
stall_sync |
由于 warp 在 __syncthreads() 调用处被阻止而发生的停顿百分比 |
多上下文 |
stall_texture |
由于纹理子系统已完全利用或未完成请求过多而发生的停顿百分比 |
多上下文 |
surface_atomic_requests |
来自多处理器的表面原子(Atom 和 Atom CAS)请求总数 |
多上下文 |
surface_load_requests |
来自多处理器的表面加载请求总数 |
多上下文 |
surface_reduction_requests |
来自多处理器的表面归约请求总数 |
多上下文 |
surface_store_requests |
来自多处理器的表面存储请求总数 |
多上下文 |
sysmem_read_bytes |
从系统内存读取的字节数 |
多上下文 |
sysmem_read_throughput |
系统内存读取吞吐量 |
多上下文 |
sysmem_read_transactions |
系统内存读取事务的数量 |
多上下文 |
sysmem_read_utilization |
系统内存相对于峰值利用率的读取利用率水平,范围为 0 到 10。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
sysmem_utilization |
系统内存相对于峰值利用率的利用率水平,范围为 0 到 10。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
sysmem_write_bytes |
写入系统内存的字节数 |
多上下文 |
sysmem_write_throughput |
系统内存写入吞吐量 |
多上下文 |
sysmem_write_transactions |
系统内存写入事务的数量 |
多上下文 |
sysmem_write_utilization |
系统内存相对于峰值利用率的写入利用率水平,范围为 0 到 10。这适用于计算能力 6.0 和 6.1。 |
多上下文 |
tex_cache_hit_rate |
统一缓存命中率 |
多上下文 |
tex_cache_throughput |
统一缓存吞吐量 |
多上下文 |
tex_cache_transactions |
统一缓存读取事务 |
多上下文 |
tex_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行全局、本地和纹理内存指令 |
多上下文 |
tex_utilization |
统一缓存相对于峰值利用率的利用率水平,范围为 0 到 10 |
多上下文 |
texture_load_requests |
来自多处理器的纹理加载请求总数 |
多上下文 |
unique_warps_launched |
启动的 warp 数量。值不受计算抢占的影响。 |
多上下文 |
warp_execution_efficiency |
每个 warp 的平均活动线程数与多处理器上支持的每个 warp 的最大线程数的比率 |
多上下文 |
warp_nonpred_execution_efficiency |
每个 warp 执行非谓词指令的平均活动线程数与多处理器上支持的每个 warp 的最大线程数的比率 |
多上下文 |
9.3. Capability 7.x 的指标
计算能力为 7.x 的设备实现下表所示的指标。(7.x 在这里指的是 7.0 和 7.2。)
指标名称 |
描述 |
范围 |
|---|---|---|
achieved_occupancy |
每个活动周期平均活动 Warp 与多处理器上支持的最大 Warp 数之比 |
多上下文 |
atomic_transactions |
全局内存原子和归约事务 |
多上下文 |
atomic_transactions_per_request |
每个原子和归约指令执行的全局内存原子和归约事务的平均数 |
多上下文 |
branch_efficiency |
分支指令与分支指令和发散分支指令之和的比率 |
多上下文 |
cf_executed |
执行的控制流指令数 |
多上下文 |
cf_fu_utilization |
多处理器功能单元的利用率,以 0 到 10 的等级执行控制流指令 |
多上下文 |
cf_issued |
发出的控制流指令数 |
多上下文 |
double_precision_fu_utilization |
多处理器功能单元的利用率,以 0 到 10 的等级执行双精度浮点指令 |
多上下文 |
dram_read_bytes |
从 DRAM 读取到 L2 缓存的总字节数 |
多上下文 |
dram_read_throughput |
设备内存读取吞吐量 |
多上下文 |
dram_read_transactions |
设备内存读取事务 |
多上下文 |
dram_utilization |
设备内存的利用率,相对于峰值利用率,等级为 0 到 10 |
多上下文 |
dram_write_bytes |
从 L2 缓存写入到 DRAM 的总字节数 |
多上下文 |
dram_write_throughput |
设备内存写入吞吐量 |
多上下文 |
dram_write_transactions |
设备内存写入事务 |
多上下文 |
eligible_warps_per_cycle |
每个活动周期内有资格发出的 warp 的平均数量 |
多上下文 |
flop_count_dp |
非谓词线程执行的双精度浮点运算次数(加法、乘法和乘加)。每个乘加运算计为 2。 |
多上下文 |
flop_count_dp_add |
非谓词线程执行的双精度浮点加法运算次数。 |
多上下文 |
flop_count_dp_fma |
非谓词线程执行的双精度浮点乘加运算次数。每个乘加运算计为 1。 |
多上下文 |
flop_count_dp_mul |
非谓词线程执行的双精度浮点乘法运算次数。 |
多上下文 |
flop_count_hp |
非谓词线程执行的半精度浮点运算次数(加法、乘法和乘加)。每个乘加运算根据输入数量计为 2 或 4。 |
多上下文 |
flop_count_hp_add |
非谓词线程执行的半精度浮点加法运算次数。 |
多上下文 |
flop_count_hp_fma |
非谓词线程执行的半精度浮点乘加运算次数。每个乘加运算根据输入数量计为 2 或 4。 |
多上下文 |
flop_count_hp_mul |
非谓词线程执行的半精度浮点乘法运算次数。 |
多上下文 |
flop_count_sp |
非谓词线程执行的单精度浮点运算次数(加法、乘法和乘加)。每个乘加运算计为 2。计数不包括特殊运算。 |
多上下文 |
flop_count_sp_add |
非谓词线程执行的单精度浮点加法运算次数。 |
多上下文 |
flop_count_sp_fma |
非谓词线程执行的单精度浮点乘加运算次数。每个乘加运算计为 1。 |
多上下文 |
flop_count_sp_mul |
非谓词线程执行的单精度浮点乘法运算次数。 |
多上下文 |
flop_count_sp_special |
非谓词线程执行的单精度浮点特殊运算次数。 |
多上下文 |
flop_dp_efficiency |
实现的双精度浮点运算与峰值双精度浮点运算的比率 |
多上下文 |
flop_hp_efficiency |
实现的半精度浮点运算与峰值半精度浮点运算的比率 |
多上下文 |
flop_sp_efficiency |
实现的单精度浮点运算与峰值单精度浮点运算的比率 |
多上下文 |
gld_efficiency |
请求的全局内存加载吞吐量与所需的全局内存加载吞吐量的比率,以百分比表示。 |
多上下文 |
gld_requested_throughput |
请求的全局内存加载吞吐量 |
多上下文 |
gld_throughput |
全局内存加载吞吐量 |
多上下文 |
gld_transactions |
全局内存加载事务的数量 |
多上下文 |
gld_transactions_per_request |
每次全局内存加载执行的全局内存加载事务的平均数量。 |
多上下文 |
global_atomic_requests |
来自多处理器的全局原子(Atom 和 Atom CAS)请求总数 |
多上下文 |
global_hit_rate |
统一 L1/纹理缓存中全局加载和存储的命中率 |
多上下文 |
global_load_requests |
来自多处理器的全局加载请求总数 |
多上下文 |
global_reduction_requests |
来自多处理器的全局归约请求总数 |
多上下文 |
global_store_requests |
来自多处理器的全局存储请求总数。这不包括原子请求。 |
多上下文 |
gst_efficiency |
请求的全局内存存储吞吐量与所需的全局内存存储吞吐量的比率,以百分比表示。 |
多上下文 |
gst_requested_throughput |
请求的全局内存存储吞吐量 |
多上下文 |
gst_throughput |
全局内存存储吞吐量 |
多上下文 |
gst_transactions |
全局内存存储事务的数量 |
多上下文 |
gst_transactions_per_request |
每次全局内存存储执行的全局内存存储事务的平均数量 |
多上下文 |
half_precision_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行 16 位浮点指令。请注意,这没有指定张量核心单元的利用率水平 |
多上下文 |
inst_bit_convert |
非谓词线程执行的位转换指令的数量 |
多上下文 |
inst_compute_ld_st |
非谓词线程执行的计算加载/存储指令的数量 |
多上下文 |
inst_control |
非谓词线程执行的控制流指令的数量(跳转、分支等) |
多上下文 |
inst_executed |
执行的指令数 |
多上下文 |
inst_executed_global_atomics |
用于全局原子和原子 cas 的 Warp 级别指令 |
多上下文 |
inst_executed_global_loads |
用于全局加载的 Warp 级别指令 |
多上下文 |
inst_executed_global_reductions |
用于全局归约的 Warp 级别指令 |
多上下文 |
inst_executed_global_stores |
用于全局存储的 Warp 级别指令 |
多上下文 |
inst_executed_local_loads |
用于本地加载的 Warp 级别指令 |
多上下文 |
inst_executed_local_stores |
用于本地存储的 Warp 级别指令 |
多上下文 |
inst_executed_shared_atomics |
用于原子和原子 CAS 的 Warp 级别共享指令 |
多上下文 |
inst_executed_shared_loads |
用于共享加载的 Warp 级别指令 |
多上下文 |
inst_executed_shared_stores |
用于共享存储的 Warp 级别指令 |
多上下文 |
inst_executed_surface_atomics |
用于表面原子和原子 cas 的 Warp 级别指令 |
多上下文 |
inst_executed_surface_loads |
用于表面加载的 Warp 级别指令 |
多上下文 |
inst_executed_surface_reductions |
用于表面归约的 Warp 级别指令 |
多上下文 |
inst_executed_surface_stores |
用于表面存储的 Warp 级别指令 |
多上下文 |
inst_executed_tex_ops |
用于纹理的 Warp 级别指令 |
多上下文 |
inst_fp_16 |
非谓词线程执行的半精度浮点指令的数量(算术、比较等)。 |
多上下文 |
inst_fp_32 |
非谓词线程执行的单精度浮点指令的数量(算术、比较等)。 |
多上下文 |
inst_fp_64 |
非谓词线程执行的双精度浮点指令的数量(算术、比较等)。 |
多上下文 |
inst_integer |
非谓词线程执行的整数指令的数量 |
多上下文 |
inst_inter_thread_communication |
非谓词线程执行的线程间通信指令的数量 |
多上下文 |
inst_issued |
发出的指令数 |
多上下文 |
inst_misc |
非谓词线程执行的杂项指令的数量 |
多上下文 |
inst_per_warp |
每个 warp 执行的平均指令数 |
多上下文 |
inst_replay_overhead |
每个执行的指令的平均重放次数 |
多上下文 |
ipc |
每个周期执行的指令数 |
多上下文 |
issue_slot_utilization |
在所有周期中平均,至少发出一条指令的发出槽的百分比 |
多上下文 |
issue_slots |
使用的发出槽的数量 |
多上下文 |
issued_ipc |
每个周期发出的指令数 |
多上下文 |
l2_atomic_throughput |
在 L2 缓存中看到的原子和归约请求的内存读取吞吐量 |
多上下文 |
l2_atomic_transactions |
在 L2 缓存中看到的原子和归约请求的内存读取事务 |
多上下文 |
l2_global_atomic_store_bytes |
从 L1 写入到 L2 的全局原子(ATOM 和 ATOM CAS)字节数 |
多上下文 |
l2_global_load_bytes |
从 L2 读取的用于全局加载的 L1 未命中字节数 |
多上下文 |
l2_local_global_store_bytes |
从 L1 写入到 L2 的本地和全局存储字节数。这不包括全局原子。 |
多上下文 |
l2_local_load_bytes |
从 L2 读取的用于本地加载的 L1 未命中字节数 |
多上下文 |
l2_read_throughput |
在 L2 缓存中看到的所有读取请求的内存读取吞吐量 |
多上下文 |
l2_read_transactions |
在 L2 缓存中看到的所有读取请求的内存读取事务 |
多上下文 |
l2_surface_load_bytes |
从 L2 读取的用于表面加载的 L1 未命中字节数 |
多上下文 |
l2_surface_store_bytes |
从 L2 读取的用于表面存储的 L1 未命中字节数 |
多上下文 |
l2_tex_hit_rate |
来自纹理缓存的所有请求在 L2 缓存中的命中率 |
多上下文 |
l2_tex_read_hit_rate |
来自纹理缓存的所有读取请求在 L2 缓存中的命中率 |
多上下文 |
l2_tex_read_throughput |
在 L2 缓存中看到的来自纹理缓存的读取请求的内存读取吞吐量 |
多上下文 |
l2_tex_read_transactions |
在 L2 缓存中看到的来自纹理缓存的读取请求的内存读取事务 |
多上下文 |
l2_tex_write_hit_rate |
来自纹理缓存的所有写入请求在 L2 缓存中的命中率 |
多上下文 |
l2_tex_write_throughput |
在 L2 缓存中看到的来自纹理缓存的写入请求的内存写入吞吐量 |
多上下文 |
l2_tex_write_transactions |
在 L2 缓存中看到的来自纹理缓存的写入请求的内存写入事务 |
多上下文 |
l2_utilization |
L2 缓存相对于峰值利用率的利用率水平,范围为 0 到 10 |
多上下文 |
l2_write_throughput |
在 L2 缓存中看到的所有写入请求的内存写入吞吐量 |
多上下文 |
l2_write_transactions |
在 L2 缓存中看到的所有写入请求的内存写入事务 |
多上下文 |
ldst_executed |
执行的本地、全局、共享和纹理内存加载和存储指令的数量 |
多上下文 |
ldst_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行共享加载、共享存储和常量加载指令 |
多上下文 |
ldst_issued |
发出的本地、全局、共享和纹理内存加载和存储指令的数量 |
多上下文 |
local_hit_rate |
本地加载和存储的命中率 |
多上下文 |
local_load_requests |
来自多处理器的本地加载请求总数 |
多上下文 |
local_load_throughput |
本地内存加载吞吐量 |
多上下文 |
local_load_transactions |
本地内存加载事务的数量 |
多上下文 |
local_load_transactions_per_request |
每次本地内存加载执行的本地内存加载事务的平均数量 |
多上下文 |
local_memory_overhead |
L1 和 L2 缓存之间本地内存流量与总内存流量的比率,以百分比表示 |
多上下文 |
local_store_requests |
来自多处理器的本地存储请求总数 |
多上下文 |
local_store_throughput |
本地内存存储吞吐量 |
多上下文 |
local_store_transactions |
本地内存存储事务的数量 |
多上下文 |
local_store_transactions_per_request |
每次本地内存存储执行的本地内存存储事务的平均数量 |
多上下文 |
nvlink_overhead_data_received |
通过 NVLink 接收的开销数据与总数据的比率。 |
设备 |
nvlink_overhead_data_transmitted |
通过 NVLink 传输的开销数据与总数据的比率。 |
设备 |
nvlink_receive_throughput |
每秒通过 NVLink 接收的字节数。 |
设备 |
nvlink_total_data_received |
通过 NVLink 接收的总数据字节数,包括标头。 |
设备 |
nvlink_total_data_transmitted |
通过 NVLink 传输的总数据字节数,包括标头。 |
设备 |
nvlink_total_nratom_data_transmitted |
通过 NVLink 传输的非归约原子数据字节总数。 |
设备 |
nvlink_total_ratom_data_transmitted |
通过 NVLink 传输的归约原子数据字节总数。 |
设备 |
nvlink_total_response_data_received |
通过 NVLink 接收的响应数据字节总数,响应数据包括读取请求的数据和非归约原子请求的结果。 |
设备 |
nvlink_total_write_data_transmitted |
通过 NVLink 传输的写入数据字节总数。 |
设备 |
nvlink_transmit_throughput |
每秒通过 NVLink 传输的字节数。 |
设备 |
nvlink_user_data_received |
通过 NVLink 接收的用户数据字节数,不包括标头。 |
设备 |
nvlink_user_data_transmitted |
通过 NVLink 传输的用户数据字节数,不包括标头。 |
设备 |
nvlink_user_nratom_data_transmitted |
通过 NVLink 传输的非归约原子用户数据字节总数。 |
设备 |
nvlink_user_ratom_data_transmitted |
通过 NVLink 传输的归约原子用户数据字节总数。 |
设备 |
nvlink_user_response_data_received |
通过 NVLink 接收的用户响应数据字节总数,响应数据包括读取请求的数据和非归约原子请求的结果。 |
设备 |
nvlink_user_write_data_transmitted |
通过 NVLink 传输的用户写入数据字节数。 |
设备 |
pcie_total_data_received |
通过 PCIe 接收的总数据字节数 |
设备 |
pcie_total_data_transmitted |
通过 PCIe 传输的总数据字节数 |
设备 |
shared_efficiency |
请求的共享内存吞吐量与所需的共享内存吞吐量的比率,以百分比表示 |
多上下文 |
shared_load_throughput |
共享内存加载吞吐量 |
多上下文 |
shared_load_transactions |
共享内存加载事务的数量 |
多上下文 |
shared_load_transactions_per_request |
每次共享内存加载执行的共享内存加载事务的平均数量 |
多上下文 |
shared_store_throughput |
共享内存存储吞吐量 |
多上下文 |
shared_store_transactions |
共享内存存储事务的数量 |
多上下文 |
shared_store_transactions_per_request |
每次共享内存存储执行的共享内存存储事务的平均数量 |
多上下文 |
shared_utilization |
共享内存相对于峰值利用率的利用率水平,范围为 0 到 10 |
多上下文 |
single_precision_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行单精度浮点指令 |
多上下文 |
sm_efficiency |
在特定多处理器上至少有一个 warp 处于活动状态的时间百分比 |
多上下文 |
special_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行 sin、cos、ex2、popc、flo 和类似指令 |
多上下文 |
stall_constant_memory_dependency |
由于立即常量缓存未命中而发生的停顿百分比 |
多上下文 |
stall_exec_dependency |
由于指令所需的输入尚不可用而发生的停顿百分比 |
多上下文 |
stall_inst_fetch |
由于尚未获取下一条汇编指令而发生的停顿百分比 |
多上下文 |
stall_memory_dependency |
由于内存操作无法执行,原因是所需资源不可用或未充分利用,或者给定类型的请求过多而发生的停顿百分比 |
多上下文 |
stall_memory_throttle |
由于内存节流而发生的停顿百分比 |
多上下文 |
stall_not_selected |
由于 warp 未被选中而发生的停顿百分比 |
多上下文 |
stall_other |
由于其他原因而发生的停顿百分比 |
多上下文 |
stall_pipe_busy |
由于计算流水线繁忙而无法执行计算操作而发生的停顿百分比 |
多上下文 |
stall_sleeping |
由于 warp 处于休眠状态而发生的停顿百分比 |
多上下文 |
stall_sync |
由于 warp 在 __syncthreads() 调用处被阻止而发生的停顿百分比 |
多上下文 |
stall_texture |
由于纹理子系统已完全利用或未完成请求过多而发生的停顿百分比 |
多上下文 |
surface_atomic_requests |
来自多处理器的表面原子(Atom 和 Atom CAS)请求总数 |
多上下文 |
surface_load_requests |
来自多处理器的表面加载请求总数 |
多上下文 |
surface_reduction_requests |
来自多处理器的表面归约请求总数 |
多上下文 |
surface_store_requests |
来自多处理器的表面存储请求总数 |
多上下文 |
sysmem_read_bytes |
从系统内存读取的字节数 |
多上下文 |
sysmem_read_throughput |
系统内存读取吞吐量 |
多上下文 |
sysmem_read_transactions |
系统内存读取事务的数量 |
多上下文 |
sysmem_read_utilization |
系统内存相对于峰值利用率的读取利用率水平,范围为 0 到 10 |
多上下文 |
sysmem_utilization |
系统内存相对于峰值利用率的利用率水平,范围为 0 到 10 |
多上下文 |
sysmem_write_bytes |
写入系统内存的字节数 |
多上下文 |
sysmem_write_throughput |
系统内存写入吞吐量 |
多上下文 |
sysmem_write_transactions |
系统内存写入事务的数量 |
多上下文 |
sysmem_write_utilization |
系统内存相对于峰值利用率的写入利用率水平,范围为 0 到 10 |
多上下文 |
tensor_precision_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行张量核心指令 |
多上下文 |
tensor_int_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行张量核心 int8 指令。此指标仅适用于计算能力为 7.2 的设备。 |
多上下文 |
tex_cache_hit_rate |
统一缓存命中率 |
多上下文 |
tex_cache_throughput |
统一缓存到多处理器读取吞吐量 |
多上下文 |
tex_cache_transactions |
统一缓存到多处理器读取事务 |
多上下文 |
tex_fu_utilization |
多处理器功能单元的利用率水平,这些单元在 0 到 10 的范围内执行全局、本地和纹理内存指令 |
多上下文 |
tex_utilization |
统一缓存相对于峰值利用率的利用率水平,范围为 0 到 10 |
多上下文 |
texture_load_requests |
来自多处理器的纹理加载请求总数 |
多上下文 |
warp_execution_efficiency |
每个 warp 的平均活动线程数与多处理器上支持的每个 warp 的最大线程数的比率 |
多上下文 |
warp_nonpred_execution_efficiency |
每个 warp 执行非谓词指令的平均活动线程数与多处理器上支持的每个 warp 的最大线程数的比率 |
多上下文 |
10. Warp 状态
本节包含每个 warp 状态的描述。warp 可以具有以下状态
指令已发出 - 已从 warp 发出一条指令或一对独立指令。
-
已停顿 - Warp 可能因以下原因之一而停顿。停顿原因分布可以在 PC 采样视图 中的源代码级别或使用“检查停顿原因”的延迟分析中的内核级别查看
-
指令获取停顿 - 下一条指令尚不可用。
为了减少指令获取停顿
如果内核中已展开大型循环,请尝试减少它们。
如果内核包含对小型函数的多次调用,请尝试使用 __inline__ 或 __forceinline__ 限定符内联更多函数。相反,如果内联许多函数或大型函数,请尝试 __noinline__ 以禁用对这些函数的内联。
对于非常短的内核,请考虑合并为单个内核。
如果使用线程数较少的块,请考虑使用线程数较多的较少块。然后,偶尔调用 __syncthreads() 将使 warp 保持同步,这可能会提高指令缓存命中率。
-
执行依赖停顿 - 下一条指令正在等待由较早的指令计算出的一个或多个输入。
为了减少执行依赖停顿,请尝试增加指令级并行性 (ILP)。这可以通过例如增加循环展开或每个线程处理多个元素来完成。这可以防止线程在每个指令的完整延迟中空闲。
-
内存依赖停顿 - 下一条指令正在等待先前的内存访问完成。
为了减少内存依赖停顿
尝试提高内存合并和/或获取字节的效率(对齐等)。查看源代码级别的分析“全局内存访问模式”和/或指标 gld_efficiency 和 gst_efficiency。
尝试增加内存级并行性 (MLP):每个线程的正在进行的独立内存操作的数量。循环展开、加载向量类型(如 float4)以及每个线程处理多个元素都是增加内存级并行性的方法。
考虑将频繁访问的数据移动到更靠近 SM 的位置,例如通过使用共享内存或只读数据缓存。
考虑在可能的情况下重新计算数据,而不是从设备内存中加载数据。
如果本地内存访问量很高,请考虑增加每个线程的寄存器计数以减少溢出,即使以占用率为代价,因为对于计算能力主版本号 = 5 的 GPU,本地内存访问仅在 L2 中缓存。
-
内存节流停顿 - 大量未完成的内存请求阻止了向前推进。在计算能力主版本号 = 3 的 GPU 上,内存节流指示内存重放次数过多。
为了减少内存节流停顿
尝试找到将多个内存事务组合为一个的方法(例如,使用 64 位内存请求而不是两个 32 位请求)。
使用源代码级别的分析“全局内存访问模式”和/或分析器指标 gld_efficiency 和 gst_efficiency 检查未合并的内存访问;尽可能地减少它们。
在计算能力主版本号 >= 3 的 GPU 上,考虑对未合并的全局读取使用 LDG 的只读数据缓存
-
纹理停顿 - 纹理子系统已完全利用或未完成请求过多。
为了减少纹理停顿
考虑将多个纹理获取操作组合为一个(例如,在纹理中打包数据并在 SM 中解包或使用向量加载)。
考虑通过使用共享内存将频繁访问的数据移动到更靠近 SM 的位置。
考虑在可能的情况下重新计算数据,而不是从内存中获取数据。
在计算能力主版本号 < 5 的 GPU 上:考虑将某些纹理访问更改为常规全局加载,以减少纹理单元的压力,特别是如果您不使用纹理特定功能(如插值)。
在计算能力主版本号 = 3 的 GPU 上:如果通过只读数据缓存 (LDG) 的全局加载是此内核的纹理访问源,请考虑将其中一些改回常规全局加载。请注意,如果 LDG 是由于使用 __ldg() 内在函数而生成的,这仅意味着改回正常的指针解引用,但如果 LDG 是由于使用 const 和 __restrict__ 限定符而由编译器自动生成的,则这可能更困难。
-
同步停顿 - warp 正在等待所有线程在屏障指令后同步。
为了减少同步停顿
尝试改善负载平衡,即尝试增加同步点之间完成的工作;考虑减少线程块大小。
尽量减少 threadfence_*() 的使用。
在计算能力主版本号 >= 3 的 GPU 上:如果由于线程块内通过共享内存进行数据交换而使用 __syncthreads(),请考虑是否可以使用 warp shuffle 操作来代替某些交换/同步序列。
-
常量内存依赖停顿 - warp 因 __constant__ 内存和立即数的缓存未命中而停顿。
首次访问每个常量时(例如,在内核开始时),这可能是高延迟操作。为了减少这些停顿,
考虑减少 __constant__ 的使用,或通过增加块计数来增加内核运行时
考虑增加每个线程处理的项目数量
考虑合并使用相同 __constant__ 数据的多个内核,以分摊常量缓存未命中的成本。
尝试使用常规全局内存访问代替常量内存访问。
-
管道忙停顿 - Warp 停顿是因为执行下一条指令所需的功能单元正忙。
为了减少管道忙导致的停顿
优先选择高吞吐量操作而不是低吞吐量操作。如果精度不重要,请使用 float 而不是双精度算术。
寻找可能在数学上有效,但编译器自动执行可能不安全的算术改进(例如,运算顺序更改)。例如,由于浮点非结合性。
未被选中停顿 - Warp 已准备就绪,但由于选择了其他 Warp 进行发布而没有机会发布。此原因通常表明内核可能已得到很好的优化,但在某些情况下,您或许可以在不影响延迟隐藏的情况下降低占用率,这样做可能有助于提高缓存命中率。
其他原因停顿 - Warp 由于编译器或硬件原因等不常见的原因而被阻止。开发人员无法控制这些停顿。
-
11. 从 Visual Profiler 和 nvprof 迁移到 Nsight Tools
Visual Profiler 和 nvprof 已被弃用,并将在未来的 CUDA 版本中移除。建议使用下一代工具 NVIDIA Nsight Systems 进行 GPU 和 CPU 采样和跟踪,以及 NVIDIA Nsight Compute 进行 GPU 内核分析。新工具仍然提供相同的分析/优化/部署工作流程。您需要查看的数据类型是相同的。命令已更改,输出看起来有些不同。新工具功能强大、快速且功能丰富,使您能够更快地找到解决方案。
NVIDIA Nsight Systems 是一款系统范围的性能分析工具,旨在可视化应用程序的算法,帮助您确定最大的优化机会,并调整以在任何数量或大小的 CPU 和 GPU 上高效扩展;从大型服务器到我们最小的 SoC。请参阅 NVIDIA Nsight Systems 用户指南中的 从 NVIDIA nvprof 迁移部分。
NVIDIA Nsight Compute 是一款用于 CUDA 应用程序的交互式内核分析器。它通过用户界面和命令行工具提供详细的性能指标和 API 调试。此外,其基线功能允许用户在工具内比较结果。Nsight Compute 提供可自定义的、数据驱动的用户界面和指标收集,并且可以通过分析脚本进行扩展以进行后处理结果。请参阅 Nsight Compute CLI 文档中的 nvprof 过渡指南 部分。请参阅 Nsight Compute 文档中的 Visual Profiler 过渡指南 部分。
另请参阅有关如何将您的开发迁移到下一代工具的博客文章
GPU 架构 |
Visual Profiler 和 nvprof |
Nsight Systems |
Nsight Compute |
|---|---|---|---|
Maxwell |
是 |
否 |
否 |
Pascal |
是 |
是 |
否 |
Volta |
是 |
是 |
是 |
Turing |
是*(仅限跟踪) |
是 |
是 |
Ampere 及更高版本的 GPU 架构 |
否 |
是 |
是 |
* 仅支持跟踪功能 - 时间线、活动、API。不支持 CUDA 内核分析功能,即收集 GPU 性能指标。
Visual Profiler/nvprof 功能类别 |
Nsight Systems |
Nsight Compute |
|---|---|---|
时间线/活动/API 跟踪 |
是 |
|
CPU 采样 |
是 |
|
OpenACC |
是 |
|
OpenMP |
是 |
|
MPI |
是 |
|
MPS |
是 |
|
应用程序依赖性分析 |
||
统一内存传输 |
是 |
|
统一内存页面错误 |
是 |
|
应用程序统一内存分析 |
||
应用程序 NVLink 分析 |
是(每个内核) |
|
事件和指标(每个内核) |
是 |
|
引导式和非引导式内核分析 |
是 |
|
内核源代码-反汇编视图 |
是 |
|
内核 PC 采样 |
是 |
|
NVTX |
是 |
是 |
远程分析 |
是 |
是 |
12. Profiler 已知问题
以下是当前版本中已知的 issues。
Visual Profiler 和 nvprof 不支持计算能力为 8.0 及更高的设备。应使用下一代工具 NVIDIA Nsight Compute 和 NVIDIA Nsight Systems。
从 CUDA 11.0 开始,Visual Profiler 和 nvprof 不再支持 macOS 作为目标平台。然而,Visual Profiler 在 CUDA 12.5 版本之前一直支持从 macOS 主机进行远程分析。此支持在 CUDA 12.6 版本中被移除。Visual Profiler 在一个单独的安装包中提供,以维护 macOS 上 CUDA 开发人员的远程分析工作流程。请参阅 macOS 开发者工具 以获取下载说明。
从 CUDA 10.2 开始,Visual Profiler 和 nvprof 使用动态/共享 CUPTI 库。因此,在 Windows 上启动 Visual Profiler 和 nvprof 之前,需要设置 CUPTI 库的路径。CUPTI 库可以在 Windows 的
"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\<cuda-toolkit>\extras\CUPTI\lib64"找到。-
一个安全漏洞问题要求分析工具在使用 Windows 419.17 或 Linux 418.43 或更高版本驱动程序时,禁用非 root 或非管理员用户的 GPU 性能计数器功能。默认情况下,NVIDIA 驱动程序需要提升的权限才能访问 GPU 性能计数器。在 Tegra 平台上,以 root 用户或使用 sudo 进行分析。在其他平台上,您可以 root 用户或使用 sudo 启动分析,或者启用非管理员分析。有关该问题和解决方案的更多详细信息,请访问 ERR_NVGPUCTRPERM 网页。
注意
Visual Profiler 和 nvprof 允许在桌面平台上为非 root 和非管理员用户进行跟踪功能,Tegra 平台需要 root 或 sudo 访问权限。
使用环境变量 LD_PRELOAD 加载某些版本的 MPI 库可能会导致 Linux 平台崩溃。解决方法是以 root 用户身份启动分析会话。对于普通用户,必须设置
nvprof的 SUID 权限。为确保收集所有分析数据并刷新到文件,应在应用程序退出之前调用 cudaDeviceSynchronize(),然后调用 cudaProfilerStop() 或 cuProfilerStop()。请参阅 刷新分析数据 部分。
如果并发内核模式用于执行大量块且执行时间短的内核,则可能会增加显著的开销。
如果内核启动速率非常高,则用于收集分析数据的设备内存可能会耗尽。在这种情况下,可能会丢弃一些分析数据。这将通过警告指示。
-
当分析使用 CUDA 动态并行性 (CDP) 的应用程序时,分析工具存在一些限制。
CDP 内核启动跟踪对计算能力为 7.0 及更高的设备存在限制。分析器跟踪所有主机启动的内核,直到遇到启动子内核的主机启动内核。随后的内核将不会被跟踪。
在计算能力为 7.0 及更高的设备上不支持源代码级别分析。
Visual Profiler 时间线不显示从设备启动的内核内部调用的 CUDA API 调用。
Visual Profiler 不显示设备启动内核的详细事件、指标和源代码级别结果。为 CPU 启动内核收集的事件、指标和源代码级别结果将包括从该内核内部启动的内核的整个调用树的事件、指标和源代码级别结果。
nvprof事件/指标输出不包括设备启动内核的结果。为 CPU 启动内核收集的事件/指标将包括从该内核内部启动的内核的整个调用树的事件/指标。
不支持分析 APK 二进制文件。
在 ARM 架构 (aarch64) 上不支持统一内存分析。
当分析应用程序时,如果设备内核由于断言而停止,则分析数据将不完整,并显示警告或错误消息。但该消息不精确,因为未检测到故障的确切原因。
对于依赖性分析,如果在跟踪中的活动时间戳略有失真,以至于违反了编程模型约束,则无法分析依赖性或等待时间。
-
计算能力为 6.0 及更高的设备引入了一项新功能:计算抢占,以便在运行长时间任务时为所有计算上下文提供公平的机会。借助计算抢占功能 -
如果多个上下文并行运行,则长时间运行的内核可能会被抢占。
某些内核可能会因上下文的时间片到期而偶尔被抢占。
如果内核已被抢占,则内核花费的抢占时间仍计入内核持续时间。由于抢占引入了随机性,这可能会影响 Visual Profiler 给出的内核优化优先级。
计算抢占会影响事件和指标收集。以下是当前版本中的已知问题
对于 MPS 客户端,事件和指标收集可能会导致计算能力为 7.0 及更高的设备上出现高于预期的计数,因为 MPS 客户端可能会由于另一个 MPS 客户端的终止而被抢占。
事件 warps_launched 和 sm_cta_launched 以及指标 inst_per_warp 在计算能力为 6.0 和 6.1 的设备上可能会提供高于预期的计数。指标 unique_warps_launched 可以代替 warps_launched 使用,以获得已启动的实际 warp 的正确计数,因为它不受计算抢占的影响。
-
为避免计算抢占影响分析器结果,请尝试隔离正在分析的上下文
在未连接显示器的辅助 GPU 上运行应用程序。
在 Linux 上,如果应用程序在连接显示驱动程序的主 GPU 上运行,则卸载显示驱动程序。
一次只运行一个使用 GPU 的进程。
计算能力为 6.0 及更高的设备支持按需分页。当内核首次被调度时,所有使用 cudaMallocManaged 分配且内核执行所需的页面都会在生成 GPU 错误时被提取到全局内存中。Profiler 需要多次传递才能收集内核分析所需的所有指标。内核状态需要为每个内核重放传递保存和恢复。对于计算能力为 6.0 及更高版本且支持统一内存的平台,在第一次内核迭代中,将生成 GPU 页面错误,并且所有页面都将被提取到全局内存中。从第二次迭代开始,将不会发生 GPU 页面错误。这将显著影响内存相关事件和计时。从跟踪中获取的时间将包括提取页面所需的时间,但多次迭代中分析的大多数指标将不包括提取页面所需的时间/周期。这会导致分析器结果不一致。
CUDA 设备枚举和顺序,通常通过环境变量
CUDA_VISIBLE_DEVICES和CUDA_DEVICE_ORDER控制,对于分析器和应用程序应保持一致。CUDA 分析可能无法在包含受支持和不受支持 GPU 混合的系统上工作。在此类系统上,要么在
nvprof中将选项--devices设置为受支持的设备,要么在启动nvprof或 Visual Profiler 之前设置环境变量CUDA_VISIBLE_DEVICES。由于 Windows 上计时器的分辨率较低,因此在 Windows 上执行时间短的活动,开始和结束时间戳可能相同。因此,
nvprof和 Visual Profiler 报告以下警告:“在结果中找到 N 个无效记录。”Profiler 无法与其他 Nvidia 工具(如 cuda-gdb、cuda-memcheck、Nsight Systems 和 Nsight Compute)互操作。
当 OpenACC 库在用户应用程序中静态链接时,OpenACC 分析可能会失败。发生这种情况的原因是缺少 OpenACC 分析所需的 OpenACC API 例程的定义,因为编译器可能会忽略应用程序中未使用的函数的定义。可以通过动态链接 OpenACC 库来缓解此问题。
CUDA Toolkit 11.7 和 CUDA Toolkit 11.8 中提供的 Visual Profiler 和 nvprof 版本不支持 Kepler (sm_35 和 sm_37) 设备。可以通过升级 CUPTI 库来解决此问题。请参阅网页 CUPTI 11.7 和 CUPTI 11.8,了解有关支持这些 Kepler 设备的 CUPTI 软件包的位置。
从 CUDA 12.4 版本开始,使用 Optix SDK 的应用程序无法使用 Visual Profiler 和 nvprof 进行分析。
-
Profiler 在以下系统配置上不受支持
64 位 ARM 服务器 CPU 架构 (arm64 SBSA)。
虚拟 GPU (vGPU)。
Windows Linux 子系统 (WSL)。
NVIDIA 加密货币挖矿处理器 (CMP)。有关更多信息,请访问 网页。
Visual Profiler
以下是与 Visual Profiler 相关的已知问题
Visual Profiler 需要本地系统上提供 Java Runtime Environment (JRE) 1.8。但是,从 CUDA Toolkit 10.1 Update 2 版本开始,由于 Oracle 升级许可变更,JRE 不再包含在 CUDA Toolkit 中。用户必须安装所需版本的 JRE 1.8 才能使用 Visual Profiler。请参阅 设置 Java Runtime Environment 部分以获取更多信息。
某些分析结果需要并非在所有设备上都可用的指标。当在指标不可用的设备上尝试这些分析时,分析结果将显示所需数据“不可用”。
在 Windows 上的 Visual Profiler 中,使用鼠标滚轮按钮滚动不起作用。
由于 Visual Profiler 使用
nvprof收集分析数据,因此nvprof的限制也适用于 Visual Profiler。Visual Profiler 无法加载大于 JVM 限制的内存大小或系统可用内存的分析器数据。有关更多信息,请参阅 改进大型配置文件的加载。
在某些版本的 Ubuntu 上,Visual Profiler 全局菜单未正确显示或为空。一种解决方法是在运行 Visual Profiler 之前设置环境变量 “UBUNTU_MENUPROXY=0”
在 Visual Profiler 中,滚动图表后,NVLink 分析图表可能不正确。可以通过水平调整图表面板大小来纠正此问题。
当收集大量样本时,Visual Profiler 可能无法在时间线上显示 NVLink 事件。要解决此问题,请通过放大或缩小来刷新时间线。另一种解决方案是保存并打开会话。
对于在远程设置上进行统一内存分析,如果 GCC 版本与主机不同,则 Visual Profiler 可能无法显示 CPU 页面错误事件的源代码位置。
对于在远程设置上进行统一内存分析,如果架构与主机不同(x86 与 POWER),则 Visual Profiler 可能无法显示 CPU 页面错误和分配跟踪事件的源代码位置。
Visual Profiler 在 ARM 架构 (aarch64) 上不受支持。您可以使用远程分析。有关更多信息,请参阅 远程分析 部分。
Visual Profiler 不支持 Android 目标的远程分析。解决方法是在目标上运行 nvprof,并在 Visual Profiler 中加载 nvprof 输出。
对于远程分析,主机系统上安装的 CUDA Toolkit 必须支持远程系统上的目标设备。
Visual Profiler 可能会在未安装所需字体的平台上显示奇怪的符号字体。
-
当使用远程分析时,如果由于密钥交换失败而导致连接失败,您将收到错误消息 “无法建立与 ‘user@xxx’ 的 shell 连接”。您可以按照以下步骤来缓解此问题。
检查目标上的 SSH 守护程序配置文件(默认路径为 /etc/ssh/sshd_config)
-
注释掉以 开头的行
KexAlgorithms
HostbasedAcceptedKeyTypes
Ciphers
HostKey
AuthorizedKeysFile
-
重新生成密钥
sudo ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
-
重启 sshd 服务
sudo services sshd restart
从 Visual Profiler 访问本地帮助文档会导致 HTTP 错误 500。解决方法是参考本文档(在线文档或 pdf)。
Visual Profiler 无法远程连接到运行 Ubuntu 20.04 及更高版本的目标计算机。
nvprof
以下是与 nvprof 相关的已知问题
nvprof无法分析fork()但之后不exec()的进程。nvprof假定它可以访问系统上的临时目录,它使用该目录来存储临时分析数据。在 Linux 上,默认为/tmp。在 Windows 上,它由系统环境变量指定。要指定自定义位置,请在 Linux 上更改$TMPDIR,或在 Windows 上更改%TMP%。当在同一节点上同时运行多个
nvprof进程时,临时目录下的文件会发生争用问题。一种解决方法是为每个进程设置不同的临时目录。使用应用程序重放并发运行的多个
nvprof进程可能会生成不正确的结果或根本没有结果。要解决此问题,您需要为每个进程设置唯一的临时目录。在启动nvprof之前设置 NVPROF_TMPDIR。要在 Android 上分析应用程序,必须定义
$TMPDIR环境变量并指向用户可写入的文件夹。启用自动加速时,分析结果可能不一致。
nvprof默认尝试禁用自动加速,但在某些情况下可能无法禁用,但分析将继续进行。nvprof将在无法禁用自动加速时报告警告。请注意,自动加速仅在 Kepler+ 系列的某些 Tesla 设备上受支持。分析在全局范围内重载 new 运算符并在重载的 new 运算符内部使用任何 CUDA API(如
cudaMalloc()或cudaMallocManaged())的 C++ 应用程序将导致挂起。当使用
nvprof选项--profile-all-processes分析所有进程时,NVTX 注释将不起作用。建议在启动应用程序之前,设置环境变量 NVTX_INJECTION64_PATH 以指向分析器注入库,Linux 上的 libcuinj64.so 和 Windows 上的 cuinj64_*.dll。
事件和指标
以下是与事件和指标分析相关的已知问题
对于计算能力为 7.5 及更高的设备,在 NVIDIA Nsight Compute 中支持分析功能。Visual Profiler 不支持引导式分析、非引导式分析下的某些阶段以及计算能力为 7.5 及更高的设备的事件和指标收集。可以从 Visual Profiler 启动计算能力为 7.5 及更高版本的设备的 NVIDIA Nsight Compute UI。此外,nvprof 不支持查询和收集事件和指标、源代码级别分析以及用于在计算能力为 7.5 及更高版本的设备上进行分析的其他选项。NVIDIA Nsight Compute 命令行界面可用于这些功能。
事件或指标收集可能会显着改变应用程序的整体性能特征,因为所有内核执行都在 GPU 上串行化。
在事件或指标分析中,内核启动是阻塞的。因此,等待主机或其他内核更新的内核可能会挂起。这包括主机和设备之间基于基于值的 CUDA 流同步 API(如
cuStreamWaitValue32()和cuStreamWriteValue32())构建的同步。需要多次传递的事件和指标收集将不适用于任何执行 IPC 或内核与 CPU 之间、内核与常规 CPU 分配内存之间、内核与对等 GPU 之间或内核与其他对等设备(例如,GPU direct)之间数据通信的
nvprof内核重放选项。对于某些指标,所需的事件只能为一个 CUDA 上下文收集。对于使用多个 CUDA 上下文的应用程序,这些指标将仅为一个上下文收集。只能为一个 CUDA 上下文收集的指标在 指标参考表 中指示。
某些指标值是在假设内核足够大,可以占用所有设备多处理器且工作量大致相同的情况下计算的。如果内核启动不具有此特征,则这些指标值可能不准确。
某些指标并非在所有设备上都可用。要查看特定 NVIDIA GPU 上所有可用指标的列表,请键入
nvprof --query-metrics。您还可以参考 指标参考表。当“应用程序重放”模式打开时,分析器可能无法收集事件或指标。如果应用程序是多线程且不确定的,则最有可能发生这种情况。在这种情况下,请改用“内核重放”模式。
对于分配大量设备内存的应用程序,当使用“内核重放”模式时,分析器可能需要很长时间才能收集所有事件或指标。在这种情况下,请改用“应用程序重放”模式。
-
以下是 Visual Profiler 可能无法收集指标或事件信息的几个原因。
多个工具尝试访问 GPU。要解决此问题,请确保在任何给定时间只有一个工具在使用 GPU。工具包括 Nsight Compute、Nsight Systems、Nsight Graphics 以及使用 CUPTI 或 PerfKit API (NVPM) 读取事件值的应用程序。
在 Visual Profiler 分析 CUDA 应用程序的同时,多个应用程序正在使用 GPU。要解决此问题,请关闭所有应用程序,只运行 Visual Profiler 的应用程序。在应用程序生成事件信息时,应避免与活动桌面交互。请注意,对于某些类型的事件,如果应用程序在同一应用程序中使用多个上下文,则 Visual Profiler 仅为一个上下文收集事件。
当使用
--events、--metrics或--analysis-metrics选项收集事件或指标时,nvprof将使用内核重放来多次执行每个内核,以根据需要收集所有请求的数据。如果请求大量事件或指标,则可能需要大量重放,从而导致应用程序执行时间显著增加。某些事件并非在所有设备上都可用。要查看特定设备上所有可用事件的列表,请键入
nvprof --query-events。-
启用某些事件可能会导致 GPU 内核运行时间超过驱动程序的看门狗超时限制。在这些情况下,驱动程序将终止 GPU 内核,从而导致应用程序错误,并且分析数据将不可用。请在分析此类长时间运行的 CUDA 内核之前禁用驱动程序看门狗超时。
在 Linux 上,建议将 X Config 选项 Interactive 设置为 false。
对于 Windows,有关 TDR(超时检测和恢复)以及如何禁用它的详细信息,请访问 https://docs.microsoft.com/en-us/windows-hardware/drivers/display/timeout-detection-and-recovery
nvprof可能会为事件和指标分析提供内存不足错误,这可能是由于内核中指令数量过多造成的。对于使用早于 9.0 的 nvcc 版本为计算能力为 6.0 和 6.1 的设备编译的 CUDA 应用程序,分析结果可能不正确。建议使用 nvcc 版本 9.0 或更高版本重新编译应用程序。如果代码已使用推荐的 nvcc 版本编译,请忽略此警告。
PC 采样在 Tegra 平台上不受支持。
多设备协同内核(即使用 API 函数 cudaLaunchCooperativeKernelMultiDevice 或 cuLaunchCooperativeKernelMultiDevice 启动的内核)不支持分析。
CUDA 图形启动的 CUDA 内核节点不支持分析。
13. 更新日志
CUDA 12.8 中的 Profiler 更改
作为 CUDA Toolkit 12.8 版本的一部分完成的更改列表。
Visual Profiler 和 nvprof 已被弃用,并将在未来的 CUDA 版本中移除。
常规错误修复。此版本中未添加新功能。
CUDA 12.6 中的 Profiler 更改
作为 CUDA Toolkit 12.6 版本的一部分完成的更改列表。
移除了 Visual Profiler 从 macOS 主机进行的远程分析支持。
常规错误修复。此版本中未添加新功能。
CUDA 12.5 中的 Profiler 更改
作为 CUDA Toolkit 12.5 版本的一部分完成的更改列表。
Visual Profiler 从 macOS 主机进行的远程分析支持已被弃用。它将在即将发布的版本中移除。
对 IBM Power 架构的支持已移除。
常规错误修复。此版本中未添加新功能。
CUDA 12.4 中的 Profiler 更改
作为 CUDA Toolkit 12.4 版本的一部分完成的更改列表。
常规错误修复。此版本中未添加新功能。
CUDA 12.3 中的 Profiler 更改
作为 CUDA Toolkit 12.3 版本的一部分完成的更改列表。
常规错误修复。此版本中未添加新功能。
CUDA 12.2 中的 Profiler 更改
作为 CUDA Toolkit 12.2 版本的一部分完成的更改列表。
常规错误修复。此版本中未添加新功能。
CUDA 12.1 中的 Profiler 更改
作为 CUDA Toolkit 12.1 版本的一部分完成的更改列表。
常规错误修复。此版本中未添加新功能。
CUDA 12.0 中的 Profiler 更改
作为 CUDA Toolkit 12.0 版本的一部分完成的更改列表。
常规错误修复。此版本中未添加新功能。
CUDA 11.8 中的 Profiler 更改
作为 CUDA Toolkit 11.8 版本的一部分完成的更改列表。
常规错误修复。此版本中未添加新功能。
CUDA 11.7 中的 Profiler 更改
作为 CUDA Toolkit 11.7 版本的一部分完成的更改列表。
常规错误修复。此版本中未添加新功能。
CUDA 11.6 中的 Profiler 更改
作为 CUDA Toolkit 11.6 版本的一部分完成的更改列表。
常规错误修复。此版本中未添加新功能。
CUDA 11.5 中的 Profiler 更改
作为 CUDA Toolkit 11.5 版本的一部分完成的更改列表。
常规错误修复。此版本中未添加新功能。
CUDA 11.4 中的 Profiler 更改
作为 CUDA Toolkit 11.4 版本的一部分完成的更改列表。
常规错误修复。此版本中未添加新功能。
CUDA 11.3 中的 Profiler 更改
作为 CUDA Toolkit 11.3 版本的一部分完成的更改列表。
Visual Profiler 将远程分析支持扩展到在 Intel x86_64 架构上运行版本 11 (Big Sur) 的 macOS 主机。
常规错误修复。
CUDA 11.2 中的 Profiler 更改
作为 CUDA Toolkit 11.2 版本的一部分完成的更改列表。
常规错误修复。此版本中未添加新功能。
CUDA 11.1 中的 Profiler 更改
作为 CUDA Toolkit 11.1 版本的一部分完成的更改列表。
常规错误修复。此版本中未添加新功能。
CUDA 11.0 中的 Profiler 更改
作为 CUDA Toolkit 11.0 版本的一部分完成的更改列表。
Visual Profiler 和 nvprof 不支持计算能力为 8.0 及更高的设备。应使用下一代工具 NVIDIA Nsight Compute 和 NVIDIA Nsight Systems。
从 CUDA 11.0 开始,Visual Profiler 和 nvprof 将不再支持 Mac 作为目标平台。但是,Visual Profiler 将继续支持从 Mac 主机进行远程分析。Visual Profiler 将在一个单独的安装包中提供,以维护 Mac 上 CUDA 开发人员的远程分析工作流程。
添加了对跟踪 Optix 应用程序的支持。
修复了自 CUDA 10.0 以来已损坏的 nvprof 选项 –annotate-mpi。
CUDA 10.2 中的 Profiler 更改
作为 CUDA Toolkit 10.2 版本的一部分完成的更改列表。
Visual Profiler 和 nvprof 允许桌面平台上为非 root 和非管理员用户进行跟踪功能。请注意,事件和指标分析仍然限制为非 root 和非管理员用户。有关该问题和解决方案的更多详细信息,请访问此 网页。
从 CUDA 10.2 开始,Visual Profiler 和 nvprof 使用动态/共享 CUPTI 库。因此,在启动 Visual Profiler 和 nvprof 之前,需要设置 CUPTI 库的路径。CUPTI 库可以在 POSIX 平台的
/usr/local/<cuda-toolkit>/extras/CUPTI/lib64或/usr/local/<cuda-toolkit>/targets/<arch>/lib和 Windows 的"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\<cuda-toolkit>\extras\CUPTI\lib64"找到。Profiler 在跟踪应用程序时不再关闭 CUDA 图形的性能特征。
在 Visual Profiler 中添加了启用/禁用 OpenMP 分析的选项。
修复了异步 cuMemset/cudaMemset 活动的错误计时问题。
CUDA 10.1 Update 2 中的 Profiler 更改
作为 CUDA Toolkit 10.1 Update 2 版本的一部分完成的更改列表。
此版本专注于分析工具的错误修复和稳定性。
由于安全漏洞问题,需要分析工具禁用所有非 root 或非管理员用户的功能。因此,当使用 Windows 419.17 或 Linux 418.43 或更高版本的驱动程序时,Visual Profiler 和 nvprof 无法分析应用程序。有关此问题和解决方案的更多详细信息,请访问此网页。
Visual Profiler 需要本地系统上提供 Java Runtime Environment (JRE) 1.8。但是,从 CUDA Toolkit 10.1 Update 2 版本开始,由于 Oracle 升级许可变更,JRE 不再包含在 CUDA Toolkit 中。用户必须安装所需版本的 JRE 1.8 才能使用 Visual Profiler。请参阅 设置 Java Runtime Environment 部分以获取更多信息。
CUDA 10.1 中的 Profiler 更改
作为 CUDA Toolkit 10.1 版本的一部分完成的更改列表。
此版本专注于分析工具的错误修复和稳定性。
支持 NVTX 字符串注册 API nvtxDomainRegisterStringA()。
CUDA 10.0 中的 Profiler 更改
作为 CUDA Toolkit 10.0 版本的一部分完成的更改列表。
为计算能力为 7.5 的设备添加了追踪支持。
对于计算能力为 7.5 及更高的设备,在 NVIDIA Nsight Compute 中支持分析功能。Visual Profiler 不支持引导式分析、非引导式分析下的某些阶段以及计算能力为 7.5 及更高的设备的事件和指标收集。可以从 Visual Profiler 启动计算能力为 7.5 及更高版本的设备的 NVIDIA Nsight Compute UI。此外,nvprof 不支持查询和收集事件和指标、源代码级别分析以及用于在计算能力为 7.5 及更高版本的设备上进行分析的其他选项。NVIDIA Nsight Compute 命令行界面可用于这些功能。
Visual Profiler 和 nvprof 现在支持 OpenMP 分析(如果可用)。有关更多信息,请参阅 OpenMP。
为 CUDA Graph 启动的 CUDA 内核、memcpy 和 memset 节点提供追踪支持。
Profiler 支持 NVIDIA Tools Extension API (NVTX) 的版本 3。这是 NVTX 版本 2 的仅头文件实现。
CUDA 9.2 中的 Profiler 更改
作为 CUDA Toolkit 9.2 版本的一部分完成的更改列表。
Visual Profiler 允许在时间轴上将多个分段切换到非分段模式,以便进行统一内存分析。以前仅限于单个分段。
Visual Profiler 显示 CUDA 编程模型的内存层次结构的摘要视图。这适用于计算能力为 5.0 及更高的设备。有关更多信息,请参阅 内存统计信息。
当使用选项
--kernels kernel-filter时,Visual Profiler 可以正确导入 nvprof 生成的分析器数据。nvprof 支持显示基本的 PCIe 拓扑,包括 NVIDIA GPU 和主机桥之间的 PCI 桥。
为了查看和分析 PCIe 拓扑上的内存传输带宽,添加了一组新的指标来收集通过 PCIe 传输和接收的总数据字节数。这些指标给出了系统中所有设备的累积计数。这些指标在设备级别为整个应用程序收集。这些指标适用于计算能力为 5.2 及更高的设备。
-
Visual Profiler 和 nvprof 添加了对新指标的支持
为不同类型的加载和存储执行的指令
从 SM 到纹理缓存的缓存全局/本地加载请求总数
从纹理缓存写入到 L2 缓存的全局原子/非原子/规约字节数
从纹理缓存写入到 L2 缓存的表面原子/非原子/规约字节数
来自纹理缓存的所有请求在 L2 缓存中的命中率
设备内存 (DRAM) 读取和写入字节数
计算能力为 7.0 的设备执行张量核心指令的多处理器功能单元的利用率水平
nvprof 允许在同一次运行中收集追踪信息和分析信息。使用新选项
--trace <api|gpu>以在收集事件/指标的同时启用追踪。
CUDA 9.1 中的 Profiler 更改
作为 CUDA Toolkit 9.1 版本的一部分完成的更改列表。
Visual Profiler 在CPU 详细信息视图中显示每个线程在 CPU 上花费的时间的细分。
Visual Profiler 支持选择 PC 采样频率的新选项。
Visual Profiler 在 NVLink 拓扑中显示 NVLink 版本。
nvprof在 CSV 格式生成分析数据时提供相关 ID。
CUDA 9.0 中的 Profiler 更改
作为 CUDA Toolkit 9.0 版本的一部分完成的更改列表。
Visual Profiler 和
nvprof现在支持在计算能力为 7.0 的设备上进行分析。用于分析的工具和扩展托管在 Github 上,网址为 https://github.com/NVIDIA/cuda-profiler
-
统一内存分析有几项增强功能
Visual Profiler 现在将统一内存事件与分配内存的源代码关联起来。
Visual Profiler 现在将 CPU 页面错误与导致页面错误的源代码相关联。
添加了用于页面抖动、节流和远程映射的新统一内存分析事件。
Visual Profiler 提供了一个选项,可以在时间轴上在分段模式和非分段模式之间切换。
Visual Profiler 支持基于虚拟地址、迁移原因或页面错误访问类型来筛选统一内存分析事件。
CPU 页面错误支持已扩展到 Mac 平台。
支持协同内核启动的追踪和分析。
Visual Profiler 在时间轴上显示 NVLink 事件。
Visual Profiler 根据吞吐量对 NVLink 拓扑图中的链接进行颜色编码。
Visual Profiler 支持新选项,使其更容易进行多跳远程分析。
nvprof支持选择 PC 采样频率的新选项。Visual Profiler 支持远程分析到支持密钥长度为 2048 位的
ssh密钥交换算法的系统。OpenACC 分析现在也支持在非 NVIDIA 系统上进行。
nvprof在遇到SIGINT或SIGKILL信号时会刷新所有分析数据。
CUDA 8.0 中的 Profiler 更改
作为 CUDA Toolkit 8.0 版本的一部分完成的更改列表。
Visual Profiler 和 nvprof 现在支持对计算能力为 6.0 的设备进行 NVLink 分析。有关更多信息,请参阅 NVLink 视图。
Visual Profiler 和 nvprof 现在支持依赖性分析,这可以优化程序运行时和利用多个 CPU 线程和 CUDA 流的应用程序的并发性。它允许计算特定执行的关键路径,检测等待时间,并检查在不同线程或流中执行的函数之间的依赖关系。有关更多信息,请参阅 依赖性分析。
Visual Profiler 和 nvprof 现在支持 OpenACC 分析。有关更多信息,请参阅 OpenACC。
Visual Profiler 现在支持 CPU 分析。有关更多信息,请参阅 CPU 详细信息视图 和 CPU 源代码视图。
统一内存分析现在在计算能力为 6.0 的设备和 64 位 Linux 平台上提供 GPU 页面错误信息。
统一内存分析现在在 64 位 Linux 平台上提供 CPU 页面错误信息。
统一内存分析支持已扩展到 Mac 平台。
Visual Profiler 源代码-反汇编视图进行了一些增强。现在,对于为内核实例收集的不同源代码级别分析结果,有一个单一的集成视图。可以一起查看不同分析步骤的结果。有关更多信息,请参阅 源代码-反汇编视图。
PC 采样功能得到增强,可以指出计算能力为 6.0 及更高设备的真正延迟问题。
支持 16 位浮点 (FP16) 数据格式分析。
如果使用了域的新 NVIDIA Tools Extension API(NVTX) 功能,那么 Visual Profiler 和 nvprof 将显示按域分组的 NVTX 标记和范围。
Visual Profiler 现在添加默认文件扩展名
.nvvp,如果在保存或打开会话文件时未指定扩展名。Visual Profiler 现在在创建新会话和导入对话框中支持时间轴过滤选项。有关更多详细信息,请参阅 创建会话 下的“时间轴选项”部分。
CUDA 7.5 中的 Profiler 更改
作为 CUDA Toolkit 7.5 版本的一部分完成的更改列表。
Visual Profiler现在支持计算能力为 5.2 的设备的 PC 采样。Warp 状态(包括停顿原因)在源代码级别显示,用于内核延迟分析。有关更多信息,请参阅 PC 采样视图。Visual Profiler现在支持分析子进程和分析在同一系统上启动的所有进程。有关新的多进程分析选项的更多信息,请参阅 创建会话。有关使用多进程服务 (MPS) 分析 CUDA 应用程序的信息,请参阅 使用 Visual Profiler 进行 MPS 分析Visual Profiler导入现在支持浏览和选择远程系统上的文件。nvprof现在支持 CPU 分析。有关更多信息,请参阅 CPU 采样。现在可以在 GPU 上存在多个上下文的情况下准确收集计算能力为 5.2 的设备的所有事件和指标。
CUDA 7.0 中的 Profiler 更改
作为 CUDA Toolkit 7.0 版本的一部分,分析工具包含许多更改和新功能。
-
Visual Profiler 已更新,包含多项增强功能
加载大型数据文件时性能得到提升。内存使用量也减少了。
Visual Profiler 时间轴得到改进,可以查看多 GPU MPS 分析数据。
统一内存分析通过提供与 GPU 之间更精细的数据传输以及每次传输更准确的时间戳而得到增强。
-
nvprof已更新,包含多项增强功能现在可以在 GPU 上存在多个上下文的情况下准确收集计算能力为 3.x 和 5.0 的设备的所有事件和指标。
CUDA 6.5 中的 Profiler 更改
作为 CUDA Toolkit 6.5 版本的一部分完成的更改列表。
-
Visual Profiler 内核内存分析已更新,包含多项增强功能
添加了 ECC 开销,它提供了 ECC 所需的内存事务计数
在 L2 缓存下,显示了 L1 读取、L1 写入、纹理读取、原子和非相干读取的事务拆分
在 L1 缓存下,显示了原子事务的计数
-
Visual Profiler 内核分析视图已更新,包含多项增强功能
最初,执行计数最多的指令会被突出显示
在“执行计数”列的计数器值的背景中显示了一个条形图,以便更容易识别具有高执行计数的指令
当前汇编指令块使用块周围的两条水平线突出显示。还添加了“下一个”和“上一个”按钮,以移动到下一个或上一个汇编指令块。
为 CUDA C 源代码添加了语法突出显示。
添加了用于显示或隐藏列的支持。
添加了描述每列的工具提示。
nvprof现在支持新的应用程序重放模式,用于收集多个事件和指标。在此模式下,应用程序会多次运行,而不是使用内核重放。这对于内核使用大量设备内存的情况非常有用,并且由于为每次内核重放运行保存和恢复设备内存的开销很高,因此使用内核重放可能会很慢。有关更多信息,请参阅 事件/指标摘要模式。Visual Profiler 也支持这种新的应用程序重放模式,可以在 Visual Profiler “新建会话”对话框中启用它。Visual Profiler 现在在设备属性下显示 GPU 的峰值单精度浮点运算次数和双精度浮点运算次数。
改进了 PGI CUDA Fortran 编译器编译的 CUDA Fortran 应用程序的源代码到汇编代码的相关性。
CUDA 6.0 中的 Profiler 更改
作为 CUDA Toolkit 6.0 版本的一部分完成的更改列表。
Visual Profiler 和
nvprof都完全支持统一内存。这两个分析器都允许您查看与系统上每个 GPU 之间往来的统一内存相关内存流量。独立的 Visual Profiler
nvvp现在提供多进程时间轴视图。您可以将使用nvprof收集的多个时间轴数据集导入到nvvp中,并在同一时间轴上查看它们,以了解它们如何共享 GPU。此多进程导入功能还包括对使用 MPS 的 CUDA 应用程序的支持。有关更多信息,请参阅 MPS 分析。Visual Profiler 现在支持远程分析模式,允许您在远程 Linux 系统上收集分析数据,并在本地 Linux、Mac 或 Windows 系统上查看时间轴、分析结果和详细结果。有关更多信息,请参阅 远程分析。
Visual Profiler 分析系统现在包含一个并排的源代码和反汇编视图,其中注释了指令执行计数、非活动线程计数和谓词指令计数。这个新视图使您能够在内核中找到热点和低效的代码序列。
Visual Profiler 分析系统已更新了几个新的分析过程:1) 内核指令被分类,以便您可以查看指令混合是否符合您的预期;2) 检测并报告低效的共享内存访问模式;3) 显示每个 SM 的活动级别,以帮助您检测内核块之间的负载平衡问题。
Visual Profiler 引导式分析系统现在可以生成内核分析报告。该报告是引导式分析系统提供的每个内核信息的 PDF 版本。
nvvp和nvprof现在都可以在没有 NVIDIA GPU 的系统上运行。您可以导入从另一个系统收集的分析数据,并在没有 GPU 的系统上查看和分析它。nvvp和nvprof的分析开销已大大降低。
14. 声明
14.1. 通知
本文档仅供参考,不应被视为对产品的特定功能、状况或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含的信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对因使用此类信息或因使用此类信息而可能导致的侵犯第三方专利或其他权利的行为的后果不承担任何责任。本文档不构成开发、发布或交付任何材料(如下所定义)、代码或功能的承诺。
NVIDIA 保留随时更正、修改、增强、改进和对本文档进行任何其他更改的权利,恕不另行通知。
客户在下订单前应获取最新的相关信息,并应核实此类信息是最新且完整的。
NVIDIA 产品的销售受 NVIDIA 标准销售条款和条件(在订单确认时提供)的约束,除非 NVIDIA 和客户的授权代表签署的个别销售协议(“销售条款”)另有约定。NVIDIA 特此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档不直接或间接地构成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空器、航天或生命支持设备,也不适用于 NVIDIA 产品的故障或 malfunction 可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在上述设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不作任何陈述或保证,保证基于本文档的产品将适用于任何特定用途。NVIDIA 不一定会对每个产品的所有参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合并满足客户计划的应用,并为该应用执行必要的测试,以避免应用或产品的缺陷。客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同条件和/或要求。NVIDIA 对可能基于或归因于以下原因的任何缺陷、损害、成本或问题不承担任何责任:(i)以任何违反本文档的方式使用 NVIDIA 产品;或(ii)客户产品设计。
本文档未授予任何 NVIDIA 专利权、版权或其他 NVIDIA 知识产权的明示或暗示的许可。NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成 NVIDIA 对其的保证或认可。使用此类信息可能需要从第三方获得其专利或其他知识产权的许可,或从 NVIDIA 获得 NVIDIA 专利或其他知识产权的许可。
只有在事先获得 NVIDIA 书面批准的情况下,才允许复制本文档中的信息,并且复制必须未经修改,完全符合所有适用的出口法律和法规,并附带所有相关的条件、限制和声明。
本文档和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均按“原样”提供。NVIDIA 对材料不作任何明示、暗示、法定或其他形式的保证,并且明确否认所有关于非侵权、适销性和特定用途适用性的默示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对任何损害(包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害)负责,无论其因何种原因引起,也无论其责任理论如何,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因遭受任何损害,但 NVIDIA 对本文所述产品的客户的累计总责任应根据产品的销售条款进行限制。
14.2. OpenCL
OpenCL 是 Apple Inc. 的商标,已获得 Khronos Group Inc. 的许可使用。
14.3. 商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其关联的各自公司的商标。