CUDA 二进制工具
cuobjdump、nvdisasm、cu++filt 和 nvprune 的应用说明。
1. 概述
本文档介绍了 cuobjdump、nvdisasm、cu++filt 和 nvprune,这四个 CUDA 二进制工具,适用于 Linux (x86、ARM 和 P9)、Windows、Mac OS 和 Android。
1.1. 什么是 CUDA 二进制文件?
CUDA 二进制文件(也称为 cubin)文件是一种 ELF 格式的文件,它由 CUDA 可执行代码段以及包含符号、重定位器、调试信息等的其他段组成。默认情况下,CUDA 编译器驱动程序 nvcc 将 cubin 文件嵌入到主机可执行文件中。但是,也可以使用 nvcc 的 “-cubin” 选项单独生成它们。cubin 文件在运行时由 CUDA 驱动程序 API 加载。
注意
有关 cubin 文件或 CUDA 编译轨迹的更多详细信息,请参阅 NVIDIA CUDA 编译器驱动程序 NVCC。
1.2. cuobjdump 和 nvdisasm 之间的区别
CUDA 提供了两个二进制实用程序,用于检查和反汇编 cubin 文件和主机可执行文件:cuobjdump 和 nvdisasm。基本上,cuobjdump 接受 cubin 文件和主机二进制文件,而 nvdisasm 仅接受 cubin 文件;但 nvdisasm 提供了更丰富的输出选项。
以下是这两个工具的快速比较
|
|
|
|---|---|---|
反汇编 cubin |
是 |
是 |
从以下输入文件中提取 ptx 并提取和反汇编 cubin
|
是 |
否 |
控制流分析和输出 |
否 |
是 |
高级显示选项 |
否 |
是 |
1.3. 命令选项类型和表示法
本文档的本节提供了有关以下工具的命令行选项的常用详细信息
每个命令行选项都有一个长名称和一个短名称,它们可以互换使用。这两种变体通过必须放在选项名称前面的连字符的数量来区分,即长名称必须以两个连字符开头,而短名称必须以单个连字符开头。例如,-I 是 --include-path 的短名称。长选项旨在用于构建脚本,其中选项的大小不如描述性值重要,而短选项旨在用于交互式使用。
上述工具识别三种类型的命令选项:布尔选项、单值选项和列表选项。
布尔选项没有参数,它们要么在命令行上指定,要么不指定。单值选项最多只能指定一次,列表选项可以重复。每种选项类型的示例如下:
Boolean option : nvdisams --print-raw <file>
Single value : nvdisasm --binary SM70 <file>
List options : cuobjdump --function "foo,bar,foobar" <file>
单值选项和列表选项必须具有参数,这些参数必须在选项名称后跟一个或多个空格或等号字符。当使用诸如 -I、-l 和 -L 之类的单字符短名称时,选项的值也可以紧跟在选项本身之后,而无需用空格或等号字符分隔。列表选项的各个值可以用逗号在选项的单个实例中分隔,或者可以重复该选项,或者可以是这两种情况的任意组合。
因此,对于上述可能取值的两个示例选项,以下表示法是合法的:
-o file
-o=file
-Idir1,dir2 -I=dir3 -I dir4,dir5
对于采用单值的选项,如果多次指定,则命令行中最右边的值将被视为该选项。在下面的示例中,将反汇编 test.bin 二进制文件,并假定架构为 SM75。
nvdisasm.exe -b SM70 -b SM75 test.bin
nvdisasm warning : incompatible redefinition for option 'binary', the last value of this option was used
对于采用值列表的选项,如果多次指定,则这些值将附加到列表中。如果指定了重复的值,则会忽略它们。在下面的示例中,函数 foo 和 bar 被视为选项 --function 的有效值,并且重复值 foo 被忽略。
cuobjdump --function "foo" --function "bar" --function "foo" -sass test.cubin
2. cuobjdump
cuobjdump 从 CUDA 二进制文件(独立的和嵌入在主机二进制文件中的)中提取信息,并以人类可读的格式呈现它们。cuobjdump 的输出包括每个内核的 CUDA 汇编代码、CUDA ELF 节头、字符串表、重定位器和其他 CUDA 特定节。它还从主机二进制文件中提取嵌入的 ptx 文本。
有关每个 GPU 架构的 CUDA 汇编指令集列表,请参阅 指令集参考。
2.1. 用法
cuobjdump 每次运行时接受单个输入文件。基本用法如下:
cuobjdump [options] <file>
要反汇编独立的 cubin 或嵌入在主机可执行文件中的 cubin,并显示内核的 CUDA 汇编代码,请使用以下命令:
cuobjdump -sass <input file>
要以人类可读的格式从 cubin 文件中转储 cuda elf 节,请使用以下命令:
cuobjdump -elf <cubin file>
要从主机二进制文件中提取 ptx 文本,请使用以下命令:
cuobjdump -ptx <host binary>
以下是 cuobjdump 的示例输出:
$ cuobjdump a.out -sass -ptx
Fatbin elf code:
================
arch = sm_70
code version = [1,7]
producer = cuda
host = linux
compile_size = 64bit
identifier = add.cu
code for sm_70
Function : _Z3addPiS_S_
.headerflags @"EF_CUDA_SM70 EF_CUDA_PTX_SM(EF_CUDA_SM70)"
/*0000*/ IMAD.MOV.U32 R1, RZ, RZ, c[0x0][0x28] ; /* 0x00000a00ff017624 */
/* 0x000fd000078e00ff */
/*0010*/ @!PT SHFL.IDX PT, RZ, RZ, RZ, RZ ; /* 0x000000fffffff389 */
/* 0x000fe200000e00ff */
/*0020*/ IMAD.MOV.U32 R2, RZ, RZ, c[0x0][0x160] ; /* 0x00005800ff027624 */
/* 0x000fe200078e00ff */
/*0030*/ MOV R3, c[0x0][0x164] ; /* 0x0000590000037a02 */
/* 0x000fe20000000f00 */
/*0040*/ IMAD.MOV.U32 R4, RZ, RZ, c[0x0][0x168] ; /* 0x00005a00ff047624 */
/* 0x000fe200078e00ff */
/*0050*/ MOV R5, c[0x0][0x16c] ; /* 0x00005b0000057a02 */
/* 0x000fcc0000000f00 */
/*0060*/ LDG.E.SYS R2, [R2] ; /* 0x0000000002027381 */
/* 0x000ea800001ee900 */
/*0070*/ LDG.E.SYS R5, [R4] ; /* 0x0000000004057381 */
/* 0x000ea200001ee900 */
/*0080*/ IMAD.MOV.U32 R6, RZ, RZ, c[0x0][0x170] ; /* 0x00005c00ff067624 */
/* 0x000fe200078e00ff */
/*0090*/ MOV R7, c[0x0][0x174] ; /* 0x00005d0000077a02 */
/* 0x000fe40000000f00 */
/*00a0*/ IADD3 R9, R2, R5, RZ ; /* 0x0000000502097210 */
/* 0x004fd00007ffe0ff */
/*00b0*/ STG.E.SYS [R6], R9 ; /* 0x0000000906007386 */
/* 0x000fe2000010e900 */
/*00c0*/ EXIT ; /* 0x000000000000794d */
/* 0x000fea0003800000 */
/*00d0*/ BRA 0xd0; /* 0xfffffff000007947 */
/* 0x000fc0000383ffff */
/*00e0*/ NOP; /* 0x0000000000007918 */
/* 0x000fc00000000000 */
/*00f0*/ NOP; /* 0x0000000000007918 */
/* 0x000fc00000000000 */
.......................
Fatbin ptx code:
================
arch = sm_70
code version = [7,0]
producer = cuda
host = linux
compile_size = 64bit
compressed
identifier = add.cu
.version 7.0
.target sm_70
.address_size 64
.visible .entry _Z3addPiS_S_(
.param .u64 _Z3addPiS_S__param_0,
.param .u64 _Z3addPiS_S__param_1,
.param .u64 _Z3addPiS_S__param_2
)
{
.reg .s32 %r<4>;
.reg .s64 %rd<7>;
ld.param.u64 %rd1, [_Z3addPiS_S__param_0];
ld.param.u64 %rd2, [_Z3addPiS_S__param_1];
ld.param.u64 %rd3, [_Z3addPiS_S__param_2];
cvta.to.global.u64 %rd4, %rd3;
cvta.to.global.u64 %rd5, %rd2;
cvta.to.global.u64 %rd6, %rd1;
ld.global.u32 %r1, [%rd6];
ld.global.u32 %r2, [%rd5];
add.s32 %r3, %r2, %r1;
st.global.u32 [%rd4], %r3;
ret;
}
如输出所示,a.out 主机二进制文件包含用于 sm_70 的 cubin 和 ptx 代码。
要列出主机二进制文件中的 cubin 文件,请使用 -lelf 选项:
$ cuobjdump a.out -lelf
ELF file 1: add_new.sm_70.cubin
ELF file 2: add_new.sm_75.cubin
ELF file 3: add_old.sm_70.cubin
ELF file 4: add_old.sm_75.cubin
要从主机二进制文件中提取所有 cubin 作为文件,请使用 -xelf all 选项:
$ cuobjdump a.out -xelf all
Extracting ELF file 1: add_new.sm_70.cubin
Extracting ELF file 2: add_new.sm_75.cubin
Extracting ELF file 3: add_old.sm_70.cubin
Extracting ELF file 4: add_old.sm_75.cubin
要提取名为 add_new.sm_70.cubin 的 cubin:
$ cuobjdump a.out -xelf add_new.sm_70.cubin
Extracting ELF file 1: add_new.sm_70.cubin
要仅提取名称中包含 _old 的 cubin:
$ cuobjdump a.out -xelf _old
Extracting ELF file 1: add_old.sm_70.cubin
Extracting ELF file 2: add_old.sm_75.cubin
您可以将任何子字符串传递给 -xelf 和 -xptx 选项。只有名称中包含该子字符串的文件才会从输入二进制文件中提取。
要转储通用和每个函数的资源使用信息:
$ cuobjdump test.cubin -res-usage
Resource usage:
Common:
GLOBAL:56 CONSTANT[3]:28
Function calculate:
REG:24 STACK:8 SHARED:0 LOCAL:0 CONSTANT[0]:472 CONSTANT[2]:24 TEXTURE:0 SURFACE:0 SAMPLER:0
Function mysurf_func:
REG:38 STACK:8 SHARED:4 LOCAL:0 CONSTANT[0]:532 TEXTURE:8 SURFACE:7 SAMPLER:0
Function mytexsampler_func:
REG:42 STACK:0 SHARED:0 LOCAL:0 CONSTANT[0]:472 TEXTURE:4 SURFACE:0 SAMPLER:1
请注意,REG、TEXTURE、SURFACE 和 SAMPLER 的值表示计数,而其他资源的值表示使用的字节数。
2.2. 命令行选项
表 2 包含 cuobjdump 的受支持命令行选项,以及每个选项的功能描述。每个选项都有一个长名称和一个短名称,可以互换使用。
选项(长) |
选项(短) |
描述 |
|---|---|---|
|
|
转储所有 fatbin 节。默认情况下,仅转储可执行 fatbin 的内容(如果存在),否则如果不存在可执行 fatbin,则转储可重定位 fatbin。 |
|
|
转储 ELF 对象节。 |
|
|
转储 ELF 符号名称。 |
|
|
转储所有列出的设备函数的 PTX。 |
|
|
转储单个 cubin 文件或嵌入在二进制文件中的所有 cubin 文件的 CUDA 汇编代码。 |
|
|
转储每个 ELF 的资源使用情况。有助于在一个位置获取所有资源使用信息。 |
|
|
提取包含 <部分文件名> 的 ELF 文件,并另存为文件。使用 |
|
|
提取包含 <部分文件名> 的 PTX 文件,并另存为文件。使用 |
|
|
提取包含 <部分文件名> 的文本二进制编码文件,并另存为文件。使用“all”提取所有文件。要获取文本二进制编码的列表,请使用 -ltext 选项。所有“dump”和“list”选项都将使用此选项忽略。 |
|
|
指定必须转储其 fat binary 结构的设备函数的名称。 |
|
|
指定必须转储其 fat binary 结构的函数的符号表索引。 |
|
|
指定应转储信息的 GPU 架构。此选项的允许值为: |
|
|
打印有关此工具的帮助信息。 |
|
|
列出 fatbin 中所有可用的 ELF 文件。适用于主机可执行文件/对象/库和外部 fatbin。所有其他选项都将使用此标志忽略。这可以用于稍后使用 -xelf 选项选择特定的 ELF。 |
|
|
列出 fatbin 中所有可用的 PTX 文件。适用于主机可执行文件/对象/库和外部 fatbin。所有其他选项都将使用此标志忽略。这可以用于稍后使用 -xptx 选项选择特定的 PTX。 |
|
|
列出 fatbin 中所有可用的文本二进制函数名称。所有其他选项都将使用此标志忽略。这可以用于稍后使用 -xtext 选项选择特定的函数。 |
|
|
从指定的文件中包含命令行选项。 |
|
|
转储 sass 时对函数进行排序。 |
|
|
打印有关此工具的版本信息。 |
3. nvdisasm
nvdisasm 从独立的 cubin 文件中提取信息,并以人类可读的格式呈现它们。nvdisasm 的输出包括每个内核的 CUDA 汇编代码、ELF 数据节的列表和其他 CUDA 特定节。输出样式和选项通过 nvdisasm 命令行选项控制。nvdisasm 还执行控制流分析以注释跳转/分支目标,并使输出更易于阅读。
注意
nvdisasm 需要完整的重定位信息才能执行控制流分析。如果 CUDA 二进制文件中缺少此信息,请使用 nvdisasm 选项 -ndf 关闭控制流分析,或使用 ptxas 和 nvlink 选项 -preserve-relocs 重新生成 cubin 文件。
有关每个 GPU 架构的 CUDA 汇编指令集列表,请参阅 指令集参考。
3.1. 用法
nvdisasm 每次运行时接受单个输入文件。基本用法如下:
nvdisasm [options] <input cubin file>
以下是 nvdisasm 的示例输出:
.headerflags @"EF_CUDA_TEXMODE_UNIFIED EF_CUDA_64BIT_ADDRESS EF_CUDA_SM70
EF_CUDA_VIRTUAL_SM(EF_CUDA_SM70)"
.elftype @"ET_EXEC"
//--------------------- .nv.info --------------------------
.section .nv.info,"",@"SHT_CUDA_INFO"
.align 4
......
//--------------------- .text._Z9acos_main10acosParams --------------------------
.section .text._Z9acos_main10acosParams,"ax",@progbits
.sectioninfo @"SHI_REGISTERS=14"
.align 128
.global _Z9acos_main10acosParams
.type _Z9acos_main10acosParams,@function
.size _Z9acos_main10acosParams,(.L_21 - _Z9acos_main10acosParams)
.other _Z9acos_main10acosParams,@"STO_CUDA_ENTRY STV_DEFAULT"
_Z9acos_main10acosParams:
.text._Z9acos_main10acosParams:
/*0000*/ MOV R1, c[0x0][0x28] ;
/*0010*/ NOP;
/*0020*/ S2R R0, SR_CTAID.X ;
/*0030*/ S2R R3, SR_TID.X ;
/*0040*/ IMAD R0, R0, c[0x0][0x0], R3 ;
/*0050*/ ISETP.GE.AND P0, PT, R0, c[0x0][0x170], PT ;
/*0060*/ @P0 EXIT ;
.L_1:
/*0070*/ MOV R11, 0x4 ;
/*0080*/ IMAD.WIDE R2, R0, R11, c[0x0][0x160] ;
/*0090*/ LDG.E.SYS R2, [R2] ;
/*00a0*/ MOV R7, 0x3d53f941 ;
/*00b0*/ FADD.FTZ R4, |R2|.reuse, -RZ ;
/*00c0*/ FSETP.GT.FTZ.AND P0, PT, |R2|.reuse, 0.5699, PT ;
/*00d0*/ FSETP.GEU.FTZ.AND P1, PT, R2, RZ, PT ;
/*00e0*/ FADD.FTZ R5, -R4, 1 ;
/*00f0*/ IMAD.WIDE R2, R0, R11, c[0x0][0x168] ;
/*0100*/ FMUL.FTZ R5, R5, 0.5 ;
/*0110*/ @P0 MUFU.SQRT R4, R5 ;
/*0120*/ MOV R5, c[0x0][0x0] ;
/*0130*/ IMAD R0, R5, c[0x0][0xc], R0 ;
/*0140*/ FMUL.FTZ R6, R4, R4 ;
/*0150*/ FFMA.FTZ R7, R6, R7, 0.018166976049542427063 ;
/*0160*/ FFMA.FTZ R7, R6, R7, 0.046756859868764877319 ;
/*0170*/ FFMA.FTZ R7, R6, R7, 0.074846573173999786377 ;
/*0180*/ FFMA.FTZ R7, R6, R7, 0.16667014360427856445 ;
/*0190*/ FMUL.FTZ R7, R6, R7 ;
/*01a0*/ FFMA.FTZ R7, R4, R7, R4 ;
/*01b0*/ FADD.FTZ R9, R7, R7 ;
/*01c0*/ @!P0 FADD.FTZ R9, -R7, 1.5707963705062866211 ;
/*01d0*/ ISETP.GE.AND P0, PT, R0, c[0x0][0x170], PT ;
/*01e0*/ @!P1 FADD.FTZ R9, -R9, 3.1415927410125732422 ;
/*01f0*/ STG.E.SYS [R2], R9 ;
/*0200*/ @!P0 BRA `(.L_1) ;
/*0210*/ EXIT ;
.L_2:
/*0220*/ BRA `(.L_2);
.L_21:
要获取内核的控制流图,请使用以下命令:
nvdisasm -cfg <input cubin file>
nvdisasm 能够以 DOT 图形描述语言的格式生成 CUDA 汇编的控制流。nvdisasm 的控制流输出可以直接导入到 DOT 图形可视化工具(如 Graphviz)中。
以下是如何使用 nvdisasm 和 Graphviz 生成上述 cubin (a.cubin) 的控制流 PNG 图像 (cfg.png):
nvdisasm -cfg a.cubin | dot -ocfg.png -Tpng
以下是生成的图形:
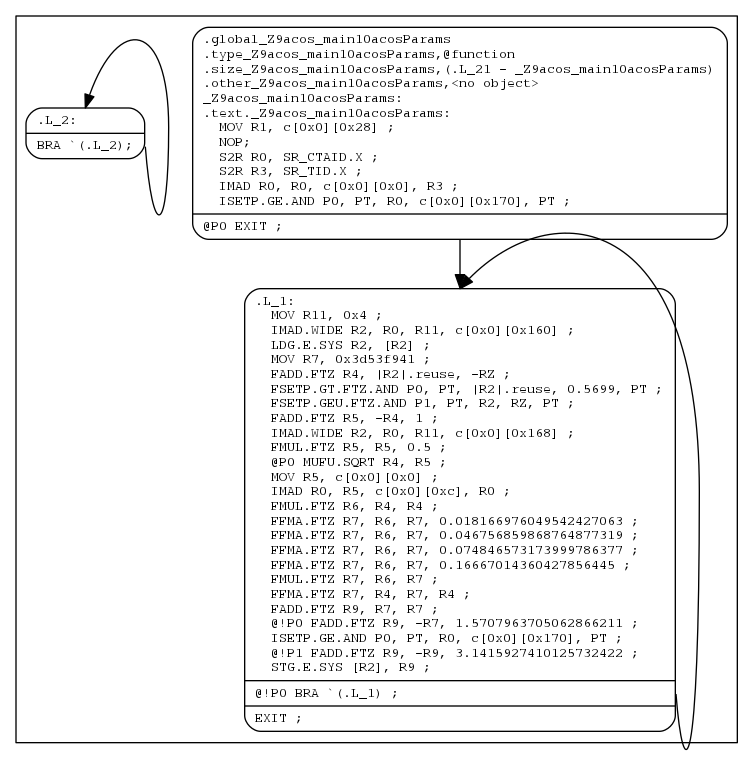
控制流图
要使用 nvdisasm 和 Graphviz 生成上述 cubin (a.cubin) 的基本块控制流 PNG 图像 (bbcfg.png):
nvdisasm -bbcfg a.cubin | dot -obbcfg.png -Tpng
以下是生成的图形:
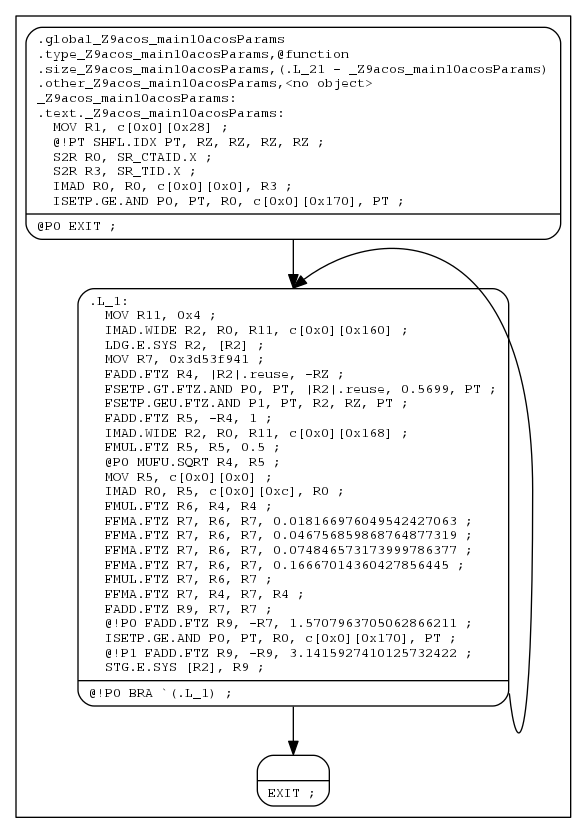
基本块控制流图
nvdisasm 能够显示寄存器(通用和谓词)的生命周期范围信息。对于 CUDA 汇编的每一行,nvdisasm 显示给定的设备寄存器是否已分配、访问、处于活动状态或重新分配。它还显示了使用的寄存器总数。如果用户对任何特定寄存器的生命周期范围或一般寄存器使用情况感兴趣,这将非常有用。
以下是示例输出(为简洁起见,输出已修剪):
// +-----------------+------+
// | GPR | PRED |
// | | |
// | | |
// | 000000000011 | |
// | # 012345678901 | # 01 |
// +-----------------+------+
.global acos // | | |
.type acos,@function // | | |
.size acos,(.L_21 - acos) // | | |
.other acos,@"STO_CUDA_ENTRY STV_DEFAULT" // | | |
acos: // | | |
.text.acos: // | | |
MOV R1, c[0x0][0x28] ; // | 1 ^ | |
NOP; // | 1 ^ | |
S2R R0, SR_CTAID.X ; // | 2 ^: | |
S2R R3, SR_TID.X ; // | 3 :: ^ | |
IMAD R0, R0, c[0x0][0x0], R3 ; // | 3 x: v | |
ISETP.GE.AND P0, PT, R0, c[0x0][0x170], PT ; // | 2 v: | 1 ^ |
@P0 EXIT ; // | 2 :: | 1 v |
.L_1: // | 2 :: | |
MOV R11, 0x4 ; // | 3 :: ^ | |
IMAD.WIDE R2, R0, R11, c[0x0][0x160] ; // | 5 v:^^ v | |
LDG.E.SYS R2, [R2] ; // | 4 ::^ : | |
MOV R7, 0x3d53f941 ; // | 5 ::: ^ : | |
FADD.FTZ R4, |R2|.reuse, -RZ ; // | 6 ::v ^ : : | |
FSETP.GT.FTZ.AND P0, PT, |R2|.reuse, 0.5699, PT; // | 6 ::v : : : | 1 ^ |
FSETP.GEU.FTZ.AND P1, PT, R2, RZ, PT ; // | 6 ::v : : : | 2 :^ |
FADD.FTZ R5, -R4, 1 ; // | 6 :: v^ : : | 2 :: |
IMAD.WIDE R2, R0, R11, c[0x0][0x168] ; // | 8 v:^^:: : v | 2 :: |
FMUL.FTZ R5, R5, 0.5 ; // | 5 :: :x : | 2 :: |
@P0 MUFU.SQRT R4, R5 ; // | 5 :: ^v : | 2 v: |
MOV R5, c[0x0][0x0] ; // | 5 :: :^ : | 2 :: |
IMAD R0, R5, c[0x0][0xc], R0 ; // | 5 x: :v : | 2 :: |
FMUL.FTZ R6, R4, R4 ; // | 5 :: v ^: | 2 :: |
FFMA.FTZ R7, R6, R7, 0.018166976049542427063 ; // | 5 :: : vx | 2 :: |
FFMA.FTZ R7, R6, R7, 0.046756859868764877319 ; // | 5 :: : vx | 2 :: |
FFMA.FTZ R7, R6, R7, 0.074846573173999786377 ; // | 5 :: : vx | 2 :: |
FFMA.FTZ R7, R6, R7, 0.16667014360427856445 ; // | 5 :: : vx | 2 :: |
FMUL.FTZ R7, R6, R7 ; // | 5 :: : vx | 2 :: |
FFMA.FTZ R7, R4, R7, R4 ; // | 4 :: v x | 2 :: |
FADD.FTZ R9, R7, R7 ; // | 4 :: v ^ | 2 :: |
@!P0 FADD.FTZ R9, -R7, 1.5707963705062866211 ; // | 4 :: v ^ | 2 v: |
ISETP.GE.AND P0, PT, R0, c[0x0][0x170], PT ; // | 3 v: : | 2 ^: |
@!P1 FADD.FTZ R9, -R9, 3.1415927410125732422 ; // | 3 :: x | 2 :v |
STG.E.SYS [R2], R9 ; // | 3 :: v | 1 : |
@!P0 BRA `(.L_1) ; // | 2 :: | 1 v |
EXIT ; // | 1 : | |
.L_2: // +.................+......+
BRA `(.L_2); // | | |
.L_21: // +-----------------+------+
// Legend:
// ^ : Register assignment
// v : Register usage
// x : Register usage and reassignment
// : : Register in use
// <space> : Register not in use
// # : Number of occupied registers
nvdisasm 能够显示 CUDA 源文件的行号信息,这对于调试非常有用。
要获取内核的行信息,请使用以下命令:
nvdisasm -g <input cubin file>
以下是使用 nvdisasm -g 命令的内核的示例输出:
//--------------------- .text._Z6kernali --------------------------
.section .text._Z6kernali,"ax",@progbits
.sectioninfo @"SHI_REGISTERS=24"
.align 128
.global _Z6kernali
.type _Z6kernali,@function
.size _Z6kernali,(.L_4 - _Z6kernali)
.other _Z6kernali,@"STO_CUDA_ENTRY STV_DEFAULT"
_Z6kernali:
.text._Z6kernali:
/*0000*/ MOV R1, c[0x0][0x28] ;
/*0010*/ NOP;
//## File "/home/user/cuda/sample/sample.cu", line 25
/*0020*/ MOV R0, 0x160 ;
/*0030*/ LDC R0, c[0x0][R0] ;
/*0040*/ MOV R0, R0 ;
/*0050*/ MOV R2, R0 ;
//## File "/home/user/cuda/sample/sample.cu", line 26
/*0060*/ MOV R4, R2 ;
/*0070*/ MOV R20, 32@lo((_Z6kernali + .L_1@srel)) ;
/*0080*/ MOV R21, 32@hi((_Z6kernali + .L_1@srel)) ;
/*0090*/ CALL.ABS.NOINC `(_Z3fooi) ;
.L_1:
/*00a0*/ MOV R0, R4 ;
/*00b0*/ MOV R4, R2 ;
/*00c0*/ MOV R2, R0 ;
/*00d0*/ MOV R20, 32@lo((_Z6kernali + .L_2@srel)) ;
/*00e0*/ MOV R21, 32@hi((_Z6kernali + .L_2@srel)) ;
/*00f0*/ CALL.ABS.NOINC `(_Z3bari) ;
.L_2:
/*0100*/ MOV R4, R4 ;
/*0110*/ IADD3 R4, R2, R4, RZ ;
/*0120*/ MOV R2, 32@lo(arr) ;
/*0130*/ MOV R3, 32@hi(arr) ;
/*0140*/ MOV R2, R2 ;
/*0150*/ MOV R3, R3 ;
/*0160*/ ST.E.SYS [R2], R4 ;
//## File "/home/user/cuda/sample/sample.cu", line 27
/*0170*/ ERRBAR ;
/*0180*/ EXIT ;
.L_3:
/*0190*/ BRA `(.L_3);
.L_4:
nvdisasm 能够显示带有附加函数内联信息的行号信息(如果有)。在没有任何函数内联的情况下,输出与使用 nvdisasm -g 命令的输出相同。
以下是使用 nvdisasm -gi 命令的内核的示例输出:
//--------------------- .text._Z6kernali --------------------------
.section .text._Z6kernali,"ax",@progbits
.sectioninfo @"SHI_REGISTERS=16"
.align 128
.global _Z6kernali
.type _Z6kernali,@function
.size _Z6kernali,(.L_18 - _Z6kernali)
.other _Z6kernali,@"STO_CUDA_ENTRY STV_DEFAULT"
_Z6kernali:
.text._Z6kernali:
/*0000*/ IMAD.MOV.U32 R1, RZ, RZ, c[0x0][0x28] ;
//## File "/home/user/cuda/inline.cu", line 17 inlined at "/home/user/cuda/inline.cu", line 23
//## File "/home/user/cuda/inline.cu", line 23
/*0010*/ UMOV UR4, 32@lo(arr) ;
/*0020*/ UMOV UR5, 32@hi(arr) ;
/*0030*/ IMAD.U32 R2, RZ, RZ, UR4 ;
/*0040*/ MOV R3, UR5 ;
/*0050*/ ULDC.64 UR4, c[0x0][0x118] ;
//## File "/home/user/cuda/inline.cu", line 10 inlined at "/home/user/cuda/inline.cu", line 17
//## File "/home/user/cuda/inline.cu", line 17 inlined at "/home/user/cuda/inline.cu", line 23
//## File "/home/user/cuda/inline.cu", line 23
/*0060*/ LDG.E R4, [R2.64] ;
/*0070*/ LDG.E R5, [R2.64+0x4] ;
//## File "/home/user/cuda/inline.cu", line 17 inlined at "/home/user/cuda/inline.cu", line 23
//## File "/home/user/cuda/inline.cu", line 23
/*0080*/ LDG.E R0, [R2.64+0x8] ;
//## File "/home/user/cuda/inline.cu", line 23
/*0090*/ UMOV UR6, 32@lo(ans) ;
/*00a0*/ UMOV UR7, 32@hi(ans) ;
//## File "/home/user/cuda/inline.cu", line 10 inlined at "/home/user/cuda/inline.cu", line 17
//## File "/home/user/cuda/inline.cu", line 17 inlined at "/home/user/cuda/inline.cu", line 23
//## File "/home/user/cuda/inline.cu", line 23
/*00b0*/ IADD3 R7, R4, c[0x0][0x160], RZ ;
//## File "/home/user/cuda/inline.cu", line 23
/*00c0*/ IMAD.U32 R4, RZ, RZ, UR6 ;
//## File "/home/user/cuda/inline.cu", line 10 inlined at "/home/user/cuda/inline.cu", line 17
//## File "/home/user/cuda/inline.cu", line 17 inlined at "/home/user/cuda/inline.cu", line 23
//## File "/home/user/cuda/inline.cu", line 23
/*00d0*/ IADD3 R9, R5, c[0x0][0x160], RZ ;
//## File "/home/user/cuda/inline.cu", line 23
/*00e0*/ MOV R5, UR7 ;
//## File "/home/user/cuda/inline.cu", line 10 inlined at "/home/user/cuda/inline.cu", line 17
//## File "/home/user/cuda/inline.cu", line 17 inlined at "/home/user/cuda/inline.cu", line 23
//## File "/home/user/cuda/inline.cu", line 23
/*00f0*/ IADD3 R11, R0.reuse, c[0x0][0x160], RZ ;
//## File "/home/user/cuda/inline.cu", line 17 inlined at "/home/user/cuda/inline.cu", line 23
//## File "/home/user/cuda/inline.cu", line 23
/*0100*/ IMAD.IADD R13, R0, 0x1, R7 ;
//## File "/home/user/cuda/inline.cu", line 10 inlined at "/home/user/cuda/inline.cu", line 17
//## File "/home/user/cuda/inline.cu", line 17 inlined at "/home/user/cuda/inline.cu", line 23
//## File "/home/user/cuda/inline.cu", line 23
/*0110*/ STG.E [R2.64+0x4], R9 ;
/*0120*/ STG.E [R2.64], R7 ;
/*0130*/ STG.E [R2.64+0x8], R11 ;
//## File "/home/user/cuda/inline.cu", line 23
/*0140*/ STG.E [R4.64], R13 ;
//## File "/home/user/cuda/inline.cu", line 24
/*0150*/ EXIT ;
.L_3:
/*0160*/ BRA (.L_3);
.L_18:
nvdisasm 可以生成 JSON 格式的反汇编。
有关 JSON 格式的详细信息,请参阅附录。
要获取 JSON 格式的反汇编,请使用以下命令:
nvdisasm -json <input cubin file>
nvdisasm -json 的输出将采用最小化格式。下面的示例是美化后的示例:
[
{
"ELF": {
"layout-id": 4,
"ei_osabi": 51,
"ei_abiversion": 7
},
"SM": {
"version": {
"major": 9,
"minor": 0
}
},
"SchemaVersion": {
"major": 12,
"minor": 8,
"revision": 0
},
"Producer": "nvdisasm V12.8.14 Build r570_00.r12.8/compiler.35033008_0",
"Description": ""
},
[
{
"function-name": "foo",
"start": 0,
"length": 96,
"other-attributes": [],
"sass-instructions": [
{
"opcode": "LDC",
"operands": "R1,c[0x0][0x28]"
},
{
"opcode": "MOV",
"operands": "R6,0x60"
},
{
"opcode": "ISETP.NE.U32.AND",
"operands": "P0,PT,R1,0x1,PT"
},
{
"opcode": "CALL.REL.NOINC",
"operands": "`(bar)",
"other-attributes": {
"control-flow": "True"
}
},
{
"opcode": "MOV",
"operands": "R8,R7"
},
{
"opcode": "EXIT",
"other-attributes": {
"control-flow": "True"
}
}
]
},
{
"function-name": "bar",
"start": 96,
"length": 32,
"other-attributes": [],
"sass-instructions": [
{
"opcode": "STS.128",
"operands": "[UR5+0x400],RZ"
},
{
"opcode": "RET.REL.NODEC",
"operands": "R18,`(foo)",
"other-attributes": {
"control-flow": "True"
}
}
]
}
]
]
3.2. 命令行选项
表 3 包含 nvdisasm 的受支持命令行选项,以及每个选项的功能描述。每个选项都有一个长名称和一个短名称,可以互换使用。
选项(长) |
选项(短) |
描述 |
|---|---|---|
|
|
指定要反汇编的映像的逻辑基地址。此选项仅在反汇编原始指令二进制文件时有效(请参阅选项 |
|
|
指定此选项后,假定输入文件包含原始指令二进制文件,即指令内存中出现的二进制指令编码序列。此选项的值必须是原始二进制文件的断言架构。此选项的允许值为: |
|
|
将输出限制为由具有给定索引的符号表示的 CUDA 函数。给定符号的 CUDA 函数是封闭节。这仅限制可执行节;所有其他节仍将被打印。 |
|
|
以 JSON 格式打印反汇编。这可以与选项 |
|
|
打印有关此工具的帮助信息。 |
|
|
此选项隐含选项 |
|
|
禁用反汇编后的数据流分析。通常启用数据流分析以执行分支堆栈分析,并使用推断的分支目标标签注释所有通过 GPU 分支堆栈跳转的指令。但是,当不满足输入 nvelf/cubin 的某些限制时,它有时可能会失败。 |
|
|
常规模式;以正常语法而不是 VLIW 语法反汇编配对的指令。 |
|
|
从指定的文件中包含命令行选项。 |
|
|
指定时,输出控制流图,其中每个节点都是一个超块,格式可供 graphviz 工具(如 dot)使用。 |
|
|
指定时,输出控制流图,其中每个节点都是一个基本块,格式可供 graphviz 工具(如 dot)使用。 |
|
|
仅打印代码节。 |
|
|
指定时,在控制流图中打印指令偏移量。这应与选项 |
|
|
指定时,在每个反汇编操作后打印编码字节。 |
|
|
在生成的反汇编的尾随列中打印寄存器生命周期范围信息。 |
|
|
如果存在,则使用从 .debug_line 节获取的源行信息注释反汇编。 |
|
|
如果存在,则使用从 .debug_line 节获取的源行信息以及函数内联信息注释反汇编。 |
|
|
如果存在,则使用从 .nv_debug_line_sass 节获取的源行信息注释反汇编。 |
|
|
打印反汇编,而不尝试美化它。 |
|
|
用一些换行符分隔与函数符号对应的代码,以使其在打印的反汇编中突出显示。 |
|
|
打印有关此工具的版本信息。 |
4. 指令集参考
本节包含 NVIDIA® GPU 架构的指令集参考。
4.1. Maxwell 和 Pascal 指令集
Maxwell(计算能力 5.x)和 Pascal(计算能力 6.x)架构具有以下指令集格式:
(instruction) (destination) (source1), (source2) ...
有效的目标和源位置包括:
RX 用于寄存器
SRX 用于特殊系统控制寄存器
PX 用于条件寄存器
c[X][Y] 用于常量内存
表 4 列出了 Maxwell 和 Pascal GPU 的有效指令。
操作码 |
描述 |
|---|---|
浮点指令 |
|
FADD |
FP32 加法 |
FCHK |
单精度 FP 除法范围检查 |
FCMP |
FP32 与零比较并选择源 |
FFMA |
FP32 融合乘加 |
FMNMX |
FP32 最小值/最大值 |
FMUL |
FP32 乘法 |
FSET |
FP32 比较和设置 |
FSETP |
FP32 比较和设置谓词 |
FSWZADD |
用于 FSWZ 仿真的 FP32 加法 |
MUFU |
多功能操作 |
RRO |
范围缩减运算符 FP |
DADD |
FP64 加法 |
DFMA |
FP64 融合乘加 |
DMNMX |
FP64 最小值/最大值 |
DMUL |
FP64 乘法 |
DSET |
FP64 比较和设置 |
DSETP |
FP64 比较和设置谓词 |
HADD2 |
FP16 加法 |
HFMA2 |
FP16 融合乘加 |
HMUL2 |
FP16 乘法 |
HSET2 |
FP16 比较和设置 |
HSETP2 |
FP16 比较和设置谓词 |
整数指令 |
|
BFE |
位字段提取 |
BFI |
位字段插入 |
FLO |
查找前导 1 |
IADD |
整数加法 |
IADD3 |
3 输入整数加法 |
ICMP |
整数与零比较并选择源 |
IMAD |
整数乘加 |
IMADSP |
提取的整数乘加。 |
IMNMX |
整数最小值/最大值 |
IMUL |
整数乘法 |
ISCADD |
缩放整数加法 |
ISET |
整数比较和设置 |
ISETP |
整数比较和设置谓词 |
LEA |
计算有效地址 |
LOP |
逻辑运算 |
LOP3 |
3 输入逻辑运算 |
POPC |
人口计数 |
SHF |
漏斗移位 |
SHL |
左移 |
SHR |
右移 |
XMAD |
整数短乘加 |
转换指令 |
|
F2F |
浮点到浮点转换 |
F2I |
浮点到整数转换 |
I2F |
整数到浮点转换 |
I2I |
整数到整数转换 |
移动指令 |
|
MOV |
移动 |
PRMT |
置换寄存器对 |
SEL |
使用谓词选择源 |
SHFL |
Warp 宽度寄存器 Shuffle |
谓词/CC 指令 |
|
CSET |
测试条件代码和设置 |
CSETP |
测试条件代码和设置谓词 |
PSET |
组合谓词和设置 |
PSETP |
组合谓词和设置谓词 |
P2R |
将谓词寄存器移动到寄存器 |
R2P |
将寄存器移动到谓词/CC寄存器 |
纹理指令 |
|
TEX |
纹理Fetch |
TLD |
纹理加载 |
TLD4 |
纹理加载 4 |
TXQ |
纹理查询 |
TEXS |
纹理Fetch,带标量/非vec4源/目标 |
TLD4S |
纹理加载 4,带标量/非vec4源/目标 |
TLDS |
纹理加载,带标量/非vec4源/目标 |
计算加载/存储指令 |
|
LD |
从通用内存加载 |
LDC |
加载常量 |
LDG |
从全局内存加载 |
LDL |
在本地内存窗口内加载 |
LDS |
本地共享内存窗口内 |
ST |
存储到通用内存 |
STG |
存储到全局内存 |
STL |
存储到本地内存 |
STS |
存储到共享内存 |
ATOM |
通用内存上的原子操作 |
ATOMS |
共享内存上的原子操作 |
RED |
通用内存上的归约操作 |
CCTL |
缓存控制 |
CCTLL |
缓存控制 |
MEMBAR |
内存屏障 |
CCTLT |
纹理缓存控制 |
表面内存指令 |
|
SUATOM |
表面内存上的原子操作 |
SULD |
表面加载 |
SURED |
表面内存上的归约操作 |
SUST |
表面存储 |
控制指令 |
|
BRA |
相对分支 |
BRX |
相对分支间接 |
JMP |
绝对跳转 |
JMX |
绝对跳转间接 |
SSY |
设置同步点 |
SYNC |
条件分支后收敛线程 |
CAL |
相对调用 |
JCAL |
绝对调用 |
PRET |
从子程序预返回 |
RET |
从子程序返回 |
BRK |
中断 |
PBK |
预中断 |
CONT |
继续 |
PCNT |
预继续 |
EXIT |
退出程序 |
PEXIT |
预退出 |
BPT |
断点/陷阱 |
杂项指令 |
|
NOP |
空操作 |
CS2R |
将特殊寄存器移动到寄存器 |
S2R |
将特殊寄存器移动到寄存器 |
B2R |
将屏障移动到寄存器 |
BAR |
屏障同步 |
R2B |
将寄存器移动到屏障 |
VOTE |
跨SIMD线程组投票 |
4.2. Volta 指令集
Volta 架构(计算能力 7.0 和 7.2)具有以下指令集格式
(instruction) (destination) (source1), (source2) ...
有效的目标和源位置包括:
RX 用于寄存器
SRX 用于特殊系统控制寄存器
用于谓词寄存器的 PX
c[X][Y] 用于常量内存
表 5 列出了 Volta GPU 的有效指令。
操作码 |
描述 |
|---|---|
浮点指令 |
|
FADD |
FP32 加法 |
FADD32I |
FP32 加法 |
FCHK |
浮点范围检查 |
FFMA32I |
FP32 融合乘加 |
FFMA |
FP32 融合乘加 |
FMNMX |
FP32 最小值/最大值 |
FMUL |
FP32 乘法 |
FMUL32I |
FP32 乘法 |
FSEL |
浮点选择 |
FSET |
FP32 比较和设置 |
FSETP |
FP32 比较和设置谓词 |
FSWZADD |
FP32 混洗加法 |
MUFU |
FP32 多功能操作 |
HADD2 |
FP16 加法 |
HADD2_32I |
FP16 加法 |
HFMA2 |
FP16 融合乘加 |
HFMA2_32I |
FP16 融合乘加 |
HMMA |
矩阵乘法和累加 |
HMUL2 |
FP16 乘法 |
HMUL2_32I |
FP16 乘法 |
HSET2 |
FP16 比较和设置 |
HSETP2 |
FP16 比较和设置谓词 |
DADD |
FP64 加法 |
DFMA |
FP64 融合乘加 |
DMUL |
FP64 乘法 |
DSETP |
FP64 比较和设置谓词 |
整数指令 |
|
BMSK |
位域掩码 |
BREV |
位反转 |
FLO |
查找前导 1 |
IABS |
整数绝对值 |
IADD |
整数加法 |
IADD3 |
3 输入整数加法 |
IADD32I |
整数加法 |
IDP |
整数点积和累加 |
IDP4A |
整数点积和累加 |
IMAD |
整数乘加 |
IMMA |
整数矩阵乘法和累加 |
IMNMX |
整数最小值/最大值 |
IMUL |
整数乘法 |
IMUL32I |
整数乘法 |
ISCADD |
缩放整数加法 |
ISCADD32I |
缩放整数加法 |
ISETP |
整数比较和设置谓词 |
LEA |
加载有效地址 |
LOP |
逻辑运算 |
LOP3 |
逻辑运算 |
LOP32I |
逻辑运算 |
POPC |
人口计数 |
SHF |
漏斗移位 |
SHL |
左移 |
SHR |
右移 |
VABSDIFF |
绝对差 |
VABSDIFF4 |
绝对差 |
转换指令 |
|
F2F |
浮点到浮点转换 |
F2I |
浮点到整数转换 |
I2F |
整数到浮点转换 |
I2I |
整数到整数转换 |
I2IP |
整数到整数转换和打包 |
FRND |
舍入为整数 |
移动指令 |
|
MOV |
移动 |
MOV32I |
移动 |
PRMT |
置换寄存器对 |
SEL |
使用谓词选择源 |
SGXT |
符号扩展 |
SHFL |
Warp 宽度寄存器 Shuffle |
谓词指令 |
|
PLOP3 |
谓词逻辑运算 |
PSETP |
组合谓词和设置谓词 |
P2R |
将谓词寄存器移动到寄存器 |
R2P |
将寄存器移动到谓词寄存器 |
加载/存储指令 |
|
LD |
从通用内存加载 |
LDC |
加载常量 |
LDG |
从全局内存加载 |
LDL |
在本地内存窗口内加载 |
LDS |
在共享内存窗口内加载 |
ST |
存储到通用内存 |
STG |
存储到全局内存 |
STL |
存储到本地内存 |
STS |
存储到共享内存 |
MATCH |
跨线程组匹配寄存器值 |
QSPC |
查询空间 |
ATOM |
通用内存上的原子操作 |
ATOMS |
共享内存上的原子操作 |
ATOMG |
全局内存上的原子操作 |
RED |
通用内存上的归约操作 |
CCTL |
缓存控制 |
CCTLL |
缓存控制 |
ERRBAR |
错误屏障 |
MEMBAR |
内存屏障 |
CCTLT |
纹理缓存控制 |
纹理指令 |
|
TEX |
纹理Fetch |
TLD |
纹理加载 |
TLD4 |
纹理加载 4 |
TMML |
纹理mipmap层级 |
TXD |
带导数的纹理Fetch |
TXQ |
纹理查询 |
表面指令 |
|
SUATOM |
表面内存上的原子操作 |
SULD |
表面加载 |
SURED |
表面内存上的归约操作 |
SUST |
表面存储 |
控制指令 |
|
BMOV |
移动收敛屏障状态 |
BPT |
断点/陷阱 |
BRA |
相对分支 |
BREAK |
跳出指定的收敛屏障 |
BRX |
相对分支间接 |
BSSY |
屏障设置收敛同步点 |
BSYNC |
在收敛屏障上同步线程 |
CALL |
调用函数 |
EXIT |
退出程序 |
JMP |
绝对跳转 |
JMX |
绝对跳转间接 |
KILL |
终止线程 |
NANOSLEEP |
暂停执行 |
RET |
从子程序返回 |
RPCMOV |
PC 寄存器移动 |
RTT |
从陷阱返回 |
WARPSYNC |
同步 Warp 中的线程 |
YIELD |
Yield 控制 |
杂项指令 |
|
B2R |
将屏障移动到寄存器 |
BAR |
屏障同步 |
CS2R |
将特殊寄存器移动到寄存器 |
DEPBAR |
依赖屏障 |
GETLMEMBASE |
获取本地内存基地址 |
LEPC |
加载有效 PC |
NOP |
空操作 |
PMTRIG |
性能监视器触发器 |
R2B |
将寄存器移动到屏障 |
S2R |
将特殊寄存器移动到寄存器 |
SETCTAID |
设置 CTA ID |
SETLMEMBASE |
设置本地内存基地址 |
VOTE |
跨SIMD线程组投票 |
4.3. Turing 指令集
Turing 架构(计算能力 7.5)具有以下指令集格式
(instruction) (destination) (source1), (source2) ...
有效的目标和源位置包括:
RX 用于寄存器
用于统一寄存器的 URX
SRX 用于特殊系统控制寄存器
用于谓词寄存器的 PX
c[X][Y] 用于常量内存
表 6 列出了 Turing GPU 的有效指令。
操作码 |
描述 |
|---|---|
浮点指令 |
|
FADD |
FP32 加法 |
FADD32I |
FP32 加法 |
FCHK |
浮点范围检查 |
FFMA32I |
FP32 融合乘加 |
FFMA |
FP32 融合乘加 |
FMNMX |
FP32 最小值/最大值 |
FMUL |
FP32 乘法 |
FMUL32I |
FP32 乘法 |
FSEL |
浮点选择 |
FSET |
FP32 比较和设置 |
FSETP |
FP32 比较和设置谓词 |
FSWZADD |
FP32 混洗加法 |
MUFU |
FP32 多功能操作 |
HADD2 |
FP16 加法 |
HADD2_32I |
FP16 加法 |
HFMA2 |
FP16 融合乘加 |
HFMA2_32I |
FP16 融合乘加 |
HMMA |
矩阵乘法和累加 |
HMUL2 |
FP16 乘法 |
HMUL2_32I |
FP16 乘法 |
HSET2 |
FP16 比较和设置 |
HSETP2 |
FP16 比较和设置谓词 |
DADD |
FP64 加法 |
DFMA |
FP64 融合乘加 |
DMUL |
FP64 乘法 |
DSETP |
FP64 比较和设置谓词 |
整数指令 |
|
BMMA |
位矩阵乘法和累加 |
BMSK |
位域掩码 |
BREV |
位反转 |
FLO |
查找前导 1 |
IABS |
整数绝对值 |
IADD |
整数加法 |
IADD3 |
3 输入整数加法 |
IADD32I |
整数加法 |
IDP |
整数点积和累加 |
IDP4A |
整数点积和累加 |
IMAD |
整数乘加 |
IMMA |
整数矩阵乘法和累加 |
IMNMX |
整数最小值/最大值 |
IMUL |
整数乘法 |
IMUL32I |
整数乘法 |
ISCADD |
缩放整数加法 |
ISCADD32I |
缩放整数加法 |
ISETP |
整数比较和设置谓词 |
LEA |
加载有效地址 |
LOP |
逻辑运算 |
LOP3 |
逻辑运算 |
LOP32I |
逻辑运算 |
POPC |
人口计数 |
SHF |
漏斗移位 |
SHL |
左移 |
SHR |
右移 |
VABSDIFF |
绝对差 |
VABSDIFF4 |
绝对差 |
转换指令 |
|
F2F |
浮点到浮点转换 |
F2I |
浮点到整数转换 |
I2F |
整数到浮点转换 |
I2I |
整数到整数转换 |
I2IP |
整数到整数转换和打包 |
FRND |
舍入为整数 |
移动指令 |
|
MOV |
移动 |
MOV32I |
移动 |
MOVM |
带转置或扩展的移动矩阵 |
PRMT |
置换寄存器对 |
SEL |
使用谓词选择源 |
SGXT |
符号扩展 |
SHFL |
Warp 宽度寄存器 Shuffle |
谓词指令 |
|
PLOP3 |
谓词逻辑运算 |
PSETP |
组合谓词和设置谓词 |
P2R |
将谓词寄存器移动到寄存器 |
R2P |
将寄存器移动到谓词寄存器 |
加载/存储指令 |
|
LD |
从通用内存加载 |
LDC |
加载常量 |
LDG |
从全局内存加载 |
LDL |
在本地内存窗口内加载 |
LDS |
在共享内存窗口内加载 |
LDSM |
从共享内存加载矩阵,带元素大小扩展 |
ST |
存储到通用内存 |
STG |
存储到全局内存 |
STL |
存储到本地内存 |
STS |
存储到共享内存 |
MATCH |
跨线程组匹配寄存器值 |
QSPC |
查询空间 |
ATOM |
通用内存上的原子操作 |
ATOMS |
共享内存上的原子操作 |
ATOMG |
全局内存上的原子操作 |
RED |
通用内存上的归约操作 |
CCTL |
缓存控制 |
CCTLL |
缓存控制 |
ERRBAR |
错误屏障 |
MEMBAR |
内存屏障 |
CCTLT |
纹理缓存控制 |
统一数据路径指令 |
|
R2UR |
从向量寄存器移动到统一寄存器 |
S2UR |
将特殊寄存器移动到统一寄存器 |
UBMSK |
统一位域掩码 |
UBREV |
统一位反转 |
UCLEA |
加载常量的有效地址 |
UFLO |
统一查找前导一 |
UIADD3 |
统一整数加法 |
UIADD3.64 |
统一整数加法 |
UIMAD |
统一整数乘法 |
UISETP |
整数比较和设置统一谓词 |
ULDC |
从常量内存加载到统一寄存器 |
ULEA |
统一加载有效地址 |
ULOP |
逻辑运算 |
ULOP3 |
逻辑运算 |
ULOP32I |
逻辑运算 |
UMOV |
统一移动 |
UP2UR |
统一谓词到统一寄存器 |
UPLOP3 |
统一谓词逻辑运算 |
UPOPC |
统一人口计数 |
UPRMT |
统一字节置换 |
UPSETP |
统一谓词逻辑运算 |
UR2UP |
统一寄存器到统一谓词 |
USEL |
统一选择 |
USGXT |
统一符号扩展 |
USHF |
统一漏斗移位 |
USHL |
统一左移 |
USHR |
统一右移 |
VOTEU |
跨 SIMD 线程组投票,结果在统一目标中 |
纹理指令 |
|
TEX |
纹理Fetch |
TLD |
纹理加载 |
TLD4 |
纹理加载 4 |
TMML |
纹理mipmap层级 |
TXD |
带导数的纹理Fetch |
TXQ |
纹理查询 |
表面指令 |
|
SUATOM |
表面内存上的原子操作 |
SULD |
表面加载 |
SURED |
表面内存上的归约操作 |
SUST |
表面存储 |
控制指令 |
|
BMOV |
移动收敛屏障状态 |
BPT |
断点/陷阱 |
BRA |
相对分支 |
BREAK |
跳出指定的收敛屏障 |
BRX |
相对分支间接 |
BRXU |
相对分支,带基于统一寄存器的偏移量 |
BSSY |
屏障设置收敛同步点 |
BSYNC |
在收敛屏障上同步线程 |
CALL |
调用函数 |
EXIT |
退出程序 |
JMP |
绝对跳转 |
JMX |
绝对跳转间接 |
JMXU |
绝对跳转,带基于统一寄存器的偏移量 |
KILL |
终止线程 |
NANOSLEEP |
暂停执行 |
RET |
从子程序返回 |
RPCMOV |
PC 寄存器移动 |
RTT |
从陷阱返回 |
WARPSYNC |
同步 Warp 中的线程 |
YIELD |
Yield 控制 |
杂项指令 |
|
B2R |
将屏障移动到寄存器 |
BAR |
屏障同步 |
CS2R |
将特殊寄存器移动到寄存器 |
DEPBAR |
依赖屏障 |
GETLMEMBASE |
获取本地内存基地址 |
LEPC |
加载有效 PC |
NOP |
空操作 |
PMTRIG |
性能监视器触发器 |
R2B |
将寄存器移动到屏障 |
S2R |
将特殊寄存器移动到寄存器 |
SETCTAID |
设置 CTA ID |
SETLMEMBASE |
设置本地内存基地址 |
VOTE |
跨SIMD线程组投票 |
4.4. NVIDIA Ampere GPU 和 Ada 指令集
NVIDIA Ampere GPU 和 Ada 架构(计算能力 8.0 和 8.6)具有以下指令集格式
(instruction) (destination) (source1), (source2) ...
有效的目标和源位置包括:
RX 用于寄存器
用于统一寄存器的 URX
SRX 用于特殊系统控制寄存器
用于谓词寄存器的 PX
用于统一谓词寄存器的 UPX
c[X][Y] 用于常量内存
表 7 列出了 NVIDIA Ampere 架构和 Ada GPU 的有效指令。
操作码 |
描述 |
|---|---|
浮点指令 |
|
FADD |
FP32 加法 |
FADD32I |
FP32 加法 |
FCHK |
浮点范围检查 |
FFMA32I |
FP32 融合乘加 |
FFMA |
FP32 融合乘加 |
FMNMX |
FP32 最小值/最大值 |
FMUL |
FP32 乘法 |
FMUL32I |
FP32 乘法 |
FSEL |
浮点选择 |
FSET |
FP32 比较和设置 |
FSETP |
FP32 比较和设置谓词 |
FSWZADD |
FP32 混洗加法 |
MUFU |
FP32 多功能操作 |
HADD2 |
FP16 加法 |
HADD2_32I |
FP16 加法 |
HFMA2 |
FP16 融合乘加 |
HFMA2_32I |
FP16 融合乘加 |
HMMA |
矩阵乘法和累加 |
HMNMX2 |
FP16 最小值/最大值 |
HMUL2 |
FP16 乘法 |
HMUL2_32I |
FP16 乘法 |
HSET2 |
FP16 比较和设置 |
HSETP2 |
FP16 比较和设置谓词 |
DADD |
FP64 加法 |
DFMA |
FP64 融合乘加 |
DMMA |
矩阵乘法和累加 |
DMUL |
FP64 乘法 |
DSETP |
FP64 比较和设置谓词 |
整数指令 |
|
BMMA |
位矩阵乘法和累加 |
BMSK |
位域掩码 |
BREV |
位反转 |
FLO |
查找前导 1 |
IABS |
整数绝对值 |
IADD |
整数加法 |
IADD3 |
3 输入整数加法 |
IADD32I |
整数加法 |
IDP |
整数点积和累加 |
IDP4A |
整数点积和累加 |
IMAD |
整数乘加 |
IMMA |
整数矩阵乘法和累加 |
IMNMX |
整数最小值/最大值 |
IMUL |
整数乘法 |
IMUL32I |
整数乘法 |
ISCADD |
缩放整数加法 |
ISCADD32I |
缩放整数加法 |
ISETP |
整数比较和设置谓词 |
LEA |
加载有效地址 |
LOP |
逻辑运算 |
LOP3 |
逻辑运算 |
LOP32I |
逻辑运算 |
POPC |
人口计数 |
SHF |
漏斗移位 |
SHL |
左移 |
SHR |
右移 |
VABSDIFF |
绝对差 |
VABSDIFF4 |
绝对差 |
转换指令 |
|
F2F |
浮点到浮点转换 |
F2I |
浮点到整数转换 |
I2F |
整数到浮点转换 |
I2I |
整数到整数转换 |
I2IP |
整数到整数转换和打包 |
I2FP |
整数到 FP32 转换和打包 |
F2IP |
FP32 向下转换为整数并打包 |
FRND |
舍入为整数 |
移动指令 |
|
MOV |
移动 |
MOV32I |
移动 |
MOVM |
带转置或扩展的移动矩阵 |
PRMT |
置换寄存器对 |
SEL |
使用谓词选择源 |
SGXT |
符号扩展 |
SHFL |
Warp 宽度寄存器 Shuffle |
谓词指令 |
|
PLOP3 |
谓词逻辑运算 |
PSETP |
组合谓词和设置谓词 |
P2R |
将谓词寄存器移动到寄存器 |
R2P |
将寄存器移动到谓词寄存器 |
加载/存储指令 |
|
LD |
从通用内存加载 |
LDC |
加载常量 |
LDG |
从全局内存加载 |
LDGDEPBAR |
全局加载依赖屏障 |
LDGSTS |
异步全局到共享内存复制 |
LDL |
在本地内存窗口内加载 |
LDS |
在共享内存窗口内加载 |
LDSM |
从共享内存加载矩阵,带元素大小扩展 |
ST |
存储到通用内存 |
STG |
存储到全局内存 |
STL |
存储到本地内存 |
STS |
存储到共享内存 |
MATCH |
跨线程组匹配寄存器值 |
QSPC |
查询空间 |
ATOM |
通用内存上的原子操作 |
ATOMS |
共享内存上的原子操作 |
ATOMG |
全局内存上的原子操作 |
RED |
通用内存上的归约操作 |
CCTL |
缓存控制 |
CCTLL |
缓存控制 |
ERRBAR |
错误屏障 |
MEMBAR |
内存屏障 |
CCTLT |
纹理缓存控制 |
统一数据路径指令 |
|
R2UR |
从向量寄存器移动到统一寄存器 |
REDUX |
将向量寄存器归约到统一寄存器 |
S2UR |
将特殊寄存器移动到统一寄存器 |
UBMSK |
统一位域掩码 |
UBREV |
统一位反转 |
UCLEA |
加载常量的有效地址 |
UF2FP |
统一 FP32 向下转换和打包 |
UFLO |
统一查找前导一 |
UIADD3 |
统一整数加法 |
UIADD3.64 |
统一整数加法 |
UIMAD |
统一整数乘法 |
UISETP |
整数比较和设置统一谓词 |
ULDC |
从常量内存加载到统一寄存器 |
ULEA |
统一加载有效地址 |
ULOP |
逻辑运算 |
ULOP3 |
逻辑运算 |
ULOP32I |
逻辑运算 |
UMOV |
统一移动 |
UP2UR |
统一谓词到统一寄存器 |
UPLOP3 |
统一谓词逻辑运算 |
UPOPC |
统一人口计数 |
UPRMT |
统一字节置换 |
UPSETP |
统一谓词逻辑运算 |
UR2UP |
统一寄存器到统一谓词 |
USEL |
统一选择 |
USGXT |
统一符号扩展 |
USHF |
统一漏斗移位 |
USHL |
统一左移 |
USHR |
统一右移 |
VOTEU |
跨 SIMD 线程组投票,结果在统一目标中 |
纹理指令 |
|
TEX |
纹理Fetch |
TLD |
纹理加载 |
TLD4 |
纹理加载 4 |
TMML |
纹理mipmap层级 |
TXD |
带导数的纹理Fetch |
TXQ |
纹理查询 |
表面指令 |
|
SUATOM |
表面内存上的原子操作 |
SULD |
表面加载 |
SURED |
表面内存上的归约操作 |
SUST |
表面存储 |
控制指令 |
|
BMOV |
移动收敛屏障状态 |
BPT |
断点/陷阱 |
BRA |
相对分支 |
BREAK |
跳出指定的收敛屏障 |
BRX |
相对分支间接 |
BRXU |
相对分支,带基于统一寄存器的偏移量 |
BSSY |
屏障设置收敛同步点 |
BSYNC |
在收敛屏障上同步线程 |
CALL |
调用函数 |
EXIT |
退出程序 |
JMP |
绝对跳转 |
JMX |
绝对跳转间接 |
JMXU |
绝对跳转,带基于统一寄存器的偏移量 |
KILL |
终止线程 |
NANOSLEEP |
暂停执行 |
RET |
从子程序返回 |
RPCMOV |
PC 寄存器移动 |
WARPSYNC |
同步 Warp 中的线程 |
YIELD |
Yield 控制 |
杂项指令 |
|
B2R |
将屏障移动到寄存器 |
BAR |
屏障同步 |
CS2R |
将特殊寄存器移动到寄存器 |
DEPBAR |
依赖屏障 |
GETLMEMBASE |
获取本地内存基地址 |
LEPC |
加载有效 PC |
NOP |
空操作 |
PMTRIG |
性能监视器触发器 |
S2R |
将特殊寄存器移动到寄存器 |
SETCTAID |
设置 CTA ID |
SETLMEMBASE |
设置本地内存基地址 |
VOTE |
跨SIMD线程组投票 |
4.5. Hopper 指令集
Hopper 架构(计算能力 9.0)具有以下指令集格式
(instruction) (destination) (source1), (source2) ...
有效的目标和源位置包括:
RX 用于寄存器
用于统一寄存器的 URX
SRX 用于特殊系统控制寄存器
用于谓词寄存器的 PX
用于统一谓词寄存器的 UPX
c[X][Y] 用于常量内存
用于内存描述符的 desc[URX][RY]
用于全局内存描述符的 gdesc[URX]
表 8 列出了 Hopper GPU 的有效指令。
操作码 |
描述 |
|---|---|
浮点指令 |
|
FADD |
FP32 加法 |
FADD32I |
FP32 加法 |
FCHK |
浮点范围检查 |
FFMA32I |
FP32 融合乘加 |
FFMA |
FP32 融合乘加 |
FMNMX |
FP32 最小值/最大值 |
FMUL |
FP32 乘法 |
FMUL32I |
FP32 乘法 |
FSEL |
浮点选择 |
FSET |
FP32 比较和设置 |
FSETP |
FP32 比较和设置谓词 |
FSWZADD |
FP32 混洗加法 |
MUFU |
FP32 多功能操作 |
HADD2 |
FP16 加法 |
HADD2_32I |
FP16 加法 |
HFMA2 |
FP16 融合乘加 |
HFMA2_32I |
FP16 融合乘加 |
HMMA |
矩阵乘法和累加 |
HMNMX2 |
FP16 最小值/最大值 |
HMUL2 |
FP16 乘法 |
HMUL2_32I |
FP16 乘法 |
HSET2 |
FP16 比较和设置 |
HSETP2 |
FP16 比较和设置谓词 |
DADD |
FP64 加法 |
DFMA |
FP64 融合乘加 |
DMMA |
矩阵乘法和累加 |
DMUL |
FP64 乘法 |
DSETP |
FP64 比较和设置谓词 |
整数指令 |
|
BMMA |
位矩阵乘法和累加 |
BMSK |
位域掩码 |
BREV |
位反转 |
FLO |
查找前导 1 |
IABS |
整数绝对值 |
IADD |
整数加法 |
IADD3 |
3 输入整数加法 |
IADD32I |
整数加法 |
IDP |
整数点积和累加 |
IDP4A |
整数点积和累加 |
IMAD |
整数乘加 |
IMMA |
整数矩阵乘法和累加 |
IMNMX |
整数最小值/最大值 |
IMUL |
整数乘法 |
IMUL32I |
整数乘法 |
ISCADD |
缩放整数加法 |
ISCADD32I |
缩放整数加法 |
ISETP |
整数比较和设置谓词 |
LEA |
加载有效地址 |
LOP |
逻辑运算 |
LOP3 |
逻辑运算 |
LOP32I |
逻辑运算 |
POPC |
人口计数 |
SHF |
漏斗移位 |
SHL |
左移 |
SHR |
右移 |
VABSDIFF |
绝对差 |
VABSDIFF4 |
绝对差 |
VHMNMX |
SIMD FP16 3 输入最小值/最大值 |
VIADD |
SIMD 整数加法 |
VIADDMNMX |
SIMD 整数加法和融合的最小值/最大值比较 |
VIMNMX |
SIMD 整数最小值/最大值 |
VIMNMX3 |
SIMD 整数 3 输入最小值/最大值 |
转换指令 |
|
F2F |
浮点到浮点转换 |
F2I |
浮点到整数转换 |
I2F |
整数到浮点转换 |
I2I |
整数到整数转换 |
I2IP |
整数到整数转换和打包 |
I2FP |
整数到 FP32 转换和打包 |
F2IP |
FP32 向下转换为整数并打包 |
FRND |
舍入为整数 |
移动指令 |
|
MOV |
移动 |
MOV32I |
移动 |
MOVM |
带转置或扩展的移动矩阵 |
PRMT |
置换寄存器对 |
SEL |
使用谓词选择源 |
SGXT |
符号扩展 |
SHFL |
Warp 宽度寄存器 Shuffle |
谓词指令 |
|
PLOP3 |
谓词逻辑运算 |
PSETP |
组合谓词和设置谓词 |
P2R |
将谓词寄存器移动到寄存器 |
R2P |
将寄存器移动到谓词寄存器 |
加载/存储指令 |
|
FENCE |
共享或全局内存的内存可见性保证 |
LD |
从通用内存加载 |
LDC |
加载常量 |
LDG |
从全局内存加载 |
LDGDEPBAR |
全局加载依赖屏障 |
LDGMC |
减少加载 |
LDGSTS |
异步全局到共享内存复制 |
LDL |
在本地内存窗口内加载 |
LDS |
在共享内存窗口内加载 |
LDSM |
从共享内存加载矩阵,带元素大小扩展 |
STSM |
将矩阵存储到共享内存 |
ST |
存储到通用内存 |
STG |
存储到全局内存 |
STL |
存储到本地内存 |
STS |
存储到共享内存 |
STAS |
异步存储到分布式共享内存,带显式同步 |
SYNCS |
同步单元 |
MATCH |
跨线程组匹配寄存器值 |
QSPC |
查询空间 |
ATOM |
通用内存上的原子操作 |
ATOMS |
共享内存上的原子操作 |
ATOMG |
全局内存上的原子操作 |
REDAS |
分布式共享内存上的异步归约,带显式同步 |
REDG |
通用内存上的归约操作 |
CCTL |
缓存控制 |
CCTLL |
缓存控制 |
ERRBAR |
错误屏障 |
MEMBAR |
内存屏障 |
CCTLT |
纹理缓存控制 |
统一数据路径指令 |
|
R2UR |
从向量寄存器移动到统一寄存器 |
REDUX |
将向量寄存器归约到统一寄存器 |
S2UR |
将特殊寄存器移动到统一寄存器 |
UBMSK |
统一位域掩码 |
UBREV |
统一位反转 |
UCGABAR_ARV |
CGA 屏障同步 |
UCGABAR_WAIT |
CGA 屏障同步 |
UCLEA |
加载常量的有效地址 |
UF2FP |
统一 FP32 向下转换和打包 |
UFLO |
统一查找前导一 |
UIADD3 |
统一整数加法 |
UIADD3.64 |
统一整数加法 |
UIMAD |
统一整数乘法 |
UISETP |
整数比较和设置统一谓词 |
ULDC |
从常量内存加载到统一寄存器 |
ULEA |
统一加载有效地址 |
ULEPC |
统一加载有效 PC |
ULOP |
逻辑运算 |
ULOP3 |
逻辑运算 |
ULOP32I |
逻辑运算 |
UMOV |
统一移动 |
UP2UR |
统一谓词到统一寄存器 |
UPLOP3 |
统一谓词逻辑运算 |
UPOPC |
统一人口计数 |
UPRMT |
统一字节置换 |
UPSETP |
统一谓词逻辑运算 |
UR2UP |
统一寄存器到统一谓词 |
USEL |
统一选择 |
USETMAXREG |
释放、取消分配和分配寄存器 |
USGXT |
统一符号扩展 |
USHF |
统一漏斗移位 |
USHL |
统一左移 |
USHR |
统一右移 |
VOTEU |
跨 SIMD 线程组投票,结果在统一目标中 |
Warpgroup 指令 |
|
BGMMA |
跨 Warp 的位矩阵乘法和累加 |
HGMMA |
跨 Warpgroup 的矩阵乘法和累加 |
IGMMA |
跨 Warpgroup 的整数矩阵乘法和累加 |
QGMMA |
跨 Warpgroup 的 FP8 矩阵乘法和累加 |
WARPGROUP |
Warpgroup 同步 |
WARPGROUPSET |
设置 Warpgroup 计数器 |
张量内存访问指令 |
|
UBLKCP |
批量数据复制 |
UBLKPF |
批量数据预取 |
UBLKRED |
从共享内存批量数据复制,带归约 |
UTMACCTL |
TMA 缓存控制 |
UTMACMDFLUSH |
TMA 命令刷新 |
UTMALDG |
从全局到共享内存的张量加载 |
UTMAPF |
张量预取 |
UTMAREDG |
从共享到全局内存的张量存储,带归约 |
UTMASTG |
从共享到全局内存的张量存储 |
纹理指令 |
|
TEX |
纹理Fetch |
TLD |
纹理加载 |
TLD4 |
纹理加载 4 |
TMML |
纹理mipmap层级 |
TXD |
带导数的纹理Fetch |
TXQ |
纹理查询 |
表面指令 |
|
SUATOM |
表面内存上的原子操作 |
SULD |
表面加载 |
SURED |
表面内存上的归约操作 |
SUST |
表面存储 |
控制指令 |
|
ACQBULK |
等待批量释放状态 Warp 状态 |
BMOV |
移动收敛屏障状态 |
BPT |
断点/陷阱 |
BRA |
相对分支 |
BREAK |
跳出指定的收敛屏障 |
BRX |
相对分支间接 |
BRXU |
相对分支,带基于统一寄存器的偏移量 |
BSSY |
屏障设置收敛同步点 |
BSYNC |
在收敛屏障上同步线程 |
CALL |
调用函数 |
CGAERRBAR |
CGA 错误屏障 |
ELECT |
选出一个 Leader 线程 |
ENDCOLLECTIVE |
重置 MCOLLECTIVE 掩码 |
EXIT |
退出程序 |
JMP |
绝对跳转 |
JMX |
绝对跳转间接 |
JMXU |
绝对跳转,带基于统一寄存器的偏移量 |
KILL |
终止线程 |
NANOSLEEP |
暂停执行 |
PREEXIT |
依赖任务启动提示 |
RET |
从子程序返回 |
RPCMOV |
PC 寄存器移动 |
WARPSYNC |
同步 Warp 中的线程 |
YIELD |
Yield 控制 |
杂项指令 |
|
B2R |
将屏障移动到寄存器 |
BAR |
屏障同步 |
CS2R |
将特殊寄存器移动到寄存器 |
DEPBAR |
依赖屏障 |
GETLMEMBASE |
获取本地内存基地址 |
LEPC |
加载有效 PC |
NOP |
空操作 |
PMTRIG |
性能监视器触发器 |
S2R |
将特殊寄存器移动到寄存器 |
SETCTAID |
设置 CTA ID |
SETLMEMBASE |
设置本地内存基地址 |
VOTE |
跨 SIMT 线程组投票 |
4.6. Blackwell 指令集
Blackwell 架构(计算能力 10.0 和 12.0)具有以下指令集格式
(instruction) (destination) (source1), (source2) ...
有效的目标和源位置包括:
RX 用于寄存器
用于统一寄存器的 URX
SRX 用于特殊系统控制寄存器
用于谓词寄存器的 PX
用于统一谓词寄存器的 UPX
c[X][Y] 用于常量内存
用于内存描述符的 desc[URX][RY]
用于全局内存描述符的 gdesc[URX]
用于张量内存的 tmem[URX]
表 8 列出了 Blackwell GPU 的有效指令。
操作码 |
描述 |
|---|---|
浮点指令 |
|
FADD |
FP32 加法 |
FADD2 |
FP32 加法 |
FADD32I |
FP32 加法 |
FCHK |
浮点范围检查 |
FFMA32I |
FP32 融合乘加 |
FFMA |
FP32 融合乘加 |
FFMA2 |
FP32 融合乘加 |
FHADD |
FP32 加法 |
FHFMA |
FP32 融合乘加 |
FMNMX |
FP32 最小值/最大值 |
FMNMX3 |
3 输入浮点最小值/最大值 |
FMUL |
FP32 乘法 |
FMUL2 |
FP32 乘法 |
FMUL32I |
FP32 乘法 |
FSEL |
浮点选择 |
FSET |
FP32 比较和设置 |
FSETP |
FP32 比较和设置谓词 |
FSWZADD |
FP32 混洗加法 |
MUFU |
FP32 多功能操作 |
HADD2 |
FP16 加法 |
HADD2_32I |
FP16 加法 |
HFMA2 |
FP16 融合乘加 |
HFMA2_32I |
FP16 融合乘加 |
HMMA |
矩阵乘法和累加 |
HMNMX2 |
FP16 最小值/最大值 |
HMUL2 |
FP16 乘法 |
HMUL2_32I |
FP16 乘法 |
HSET2 |
FP16 比较和设置 |
HSETP2 |
FP16 比较和设置谓词 |
DADD |
FP64 加法 |
DFMA |
FP64 融合乘加 |
DMMA |
矩阵乘法和累加 |
DMUL |
FP64 乘法 |
DSETP |
FP64 比较和设置谓词 |
OMMA |
跨 Warp 的 FP4 矩阵乘法和累加 |
QMMA |
跨 Warp 的 FP8 矩阵乘法和累加 |
整数指令 |
|
BMSK |
位域掩码 |
BREV |
位反转 |
FLO |
查找前导 1 |
IABS |
整数绝对值 |
IADD |
整数加法 |
IADD3 |
3 输入整数加法 |
IADD32I |
整数加法 |
IDP |
整数点积和累加 |
IDP4A |
整数点积和累加 |
IMAD |
整数乘加 |
IMMA |
整数矩阵乘法和累加 |
IMNMX |
整数最小值/最大值 |
IMUL |
整数乘法 |
IMUL32I |
整数乘法 |
ISCADD |
缩放整数加法 |
ISCADD32I |
缩放整数加法 |
ISETP |
整数比较和设置谓词 |
LEA |
加载有效地址 |
LOP |
逻辑运算 |
LOP3 |
逻辑运算 |
LOP32I |
逻辑运算 |
POPC |
人口计数 |
SHF |
漏斗移位 |
SHL |
左移 |
SHR |
右移 |
VABSDIFF |
绝对差 |
VABSDIFF4 |
绝对差 |
VHMNMX |
SIMD FP16 3 输入最小值/最大值 |
VIADD |
SIMD 整数加法 |
VIADDMNMX |
SIMD 整数加法和融合的最小值/最大值比较 |
VIMNMX |
SIMD 整数最小值/最大值 |
VIMNMX3 |
SIMD 整数 3 输入最小值/最大值 |
转换指令 |
|
F2F |
浮点到浮点转换 |
F2I |
浮点到整数转换 |
I2F |
整数到浮点转换 |
I2I |
整数到整数转换 |
I2IP |
整数到整数转换和打包 |
I2FP |
整数到 FP32 转换和打包 |
F2IP |
FP32 向下转换为整数并打包 |
FRND |
舍入为整数 |
移动指令 |
|
MOV |
移动 |
MOV32I |
移动 |
MOVM |
带转置或扩展的移动矩阵 |
PRMT |
置换寄存器对 |
SEL |
使用谓词选择源 |
SGXT |
符号扩展 |
SHFL |
Warp 宽度寄存器 Shuffle |
谓词指令 |
|
PLOP3 |
谓词逻辑运算 |
PSETP |
组合谓词和设置谓词 |
P2R |
将谓词寄存器移动到寄存器 |
R2P |
将寄存器移动到谓词寄存器 |
加载/存储指令 |
|
FENCE |
共享或全局内存的内存可见性保证 |
LD |
从通用内存加载 |
LDC |
加载常量 |
LDG |
从全局内存加载 |
LDGDEPBAR |
全局加载依赖屏障 |
LDGMC |
减少加载 |
LDGSTS |
异步全局到共享内存复制 |
LDL |
在本地内存窗口内加载 |
LDS |
在共享内存窗口内加载 |
LDSM |
从共享内存加载矩阵,带元素大小扩展 |
STSM |
将矩阵存储到共享内存 |
ST |
存储到通用内存 |
STG |
存储到全局内存 |
STL |
存储到本地内存 |
STS |
存储到共享内存 |
STAS |
异步存储到分布式共享内存,带显式同步 |
SYNCS |
同步单元 |
MATCH |
跨线程组匹配寄存器值 |
QSPC |
查询空间 |
ATOM |
通用内存上的原子操作 |
ATOMS |
共享内存上的原子操作 |
ATOMG |
全局内存上的原子操作 |
REDAS |
分布式共享内存上的异步归约,带显式同步 |
REDG |
通用内存上的归约操作 |
CCTL |
缓存控制 |
CCTLL |
缓存控制 |
ERRBAR |
错误屏障 |
MEMBAR |
内存屏障 |
CCTLT |
纹理缓存控制 |
统一数据路径指令 |
|
CREDUX |
耦合的向量寄存器归约到统一寄存器 |
CS2UR |
从常量内存加载值到统一寄存器 |
LDCU |
从常量内存加载值到统一寄存器 |
R2UR |
从向量寄存器移动到统一寄存器 |
REDUX |
将向量寄存器归约到统一寄存器 |
S2UR |
将特殊寄存器移动到统一寄存器 |
UBMSK |
统一位域掩码 |
UBREV |
统一位反转 |
UCGABAR_ARV |
CGA 屏障同步 |
UCGABAR_WAIT |
CGA 屏障同步 |
UCLEA |
加载常量的有效地址 |
UFADD |
统一统一 FP32 加法 |
UF2F |
统一浮点到浮点转换 |
UF2FP |
统一 FP32 向下转换和打包 |
UF2I |
统一浮点到整数转换 |
UF2IP |
统一 FP32 向下转换为整数并打包 |
UFFMA |
统一 FP32 融合乘加 |
UFLO |
统一查找前导一 |
UFMNMX |
统一浮点最小值/最大值 |
UFMUL |
统一 FP32 乘法 |
UFRND |
统一舍入为整数 |
UFSEL |
统一浮点选择 |
UFSET |
统一浮点比较和设置 |
UFSETP |
统一浮点比较和设置谓词 |
UI2F |
统一整数到浮点转换 |
UI2FP |
统一整数到 FP32 转换和打包 |
UI2I |
统一饱和整数到整数转换 |
UI2IP |
统一双饱和整数到整数转换和打包 |
UIABS |
统一整数绝对值 |
UIMNMX |
统一整数最小值/最大值 |
UIADD3 |
统一整数加法 |
UIADD3.64 |
统一整数加法 |
UIMAD |
统一整数乘法 |
UISETP |
统一整数比较和设置统一谓词 |
ULEA |
统一加载有效地址 |
ULEPC |
统一加载有效 PC |
ULOP |
统一逻辑运算 |
ULOP3 |
统一逻辑运算 |
ULOP32I |
统一逻辑运算 |
UMOV |
统一移动 |
UP2UR |
统一谓词到统一寄存器 |
UPLOP3 |
统一谓词逻辑运算 |
UPOPC |
统一人口计数 |
UPRMT |
统一字节置换 |
UPSETP |
统一谓词逻辑运算 |
UR2UP |
统一寄存器到统一谓词 |
USEL |
统一选择 |
USETMAXREG |
释放、取消分配和分配寄存器 |
USGXT |
统一符号扩展 |
USHF |
统一漏斗移位 |
USHL |
统一左移 |
USHR |
统一右移 |
UGETNEXTWORKID |
统一获取下一个工作 ID |
UMEMSETS |
初始化共享内存 |
UREDGR |
统一全局内存归约,带释放 |
USTGR |
统一存储到全局内存,带释放 |
UVIADD |
统一 SIMD 整数加法 |
UVIMNMX |
统一 SIMD 整数最小值/最大值 |
UVIRTCOUNT |
虚拟资源管理 |
VOTEU |
跨 SIMD 线程组投票,结果在统一目标中 |
张量内存访问指令 |
|
UBLKCP |
批量数据复制 |
UBLKPF |
批量数据预取 |
UBLKRED |
从共享内存批量数据复制,带归约 |
UTMACCTL |
TMA 缓存控制 |
UTMACMDFLUSH |
TMA 命令刷新 |
UTMALDG |
从全局到共享内存的张量加载 |
UTMAPF |
张量预取 |
UTMAREDG |
从共享到全局内存的张量存储,带归约 |
UTMASTG |
从共享到全局内存的张量存储 |
张量核心内存指令 |
|
LDT |
从张量内存加载矩阵到寄存器文件 |
LDTM |
从张量内存加载矩阵到寄存器文件 |
STT |
从寄存器文件将矩阵存储到张量内存 |
STTM |
从寄存器文件将矩阵存储到张量内存 |
UTCATOMSWS |
在 SW 状态寄存器上执行原子操作 |
UTCBAR |
张量核心屏障 |
UTCCP |
从共享内存到张量内存的异步数据复制 |
UTCHMMA |
统一矩阵乘法和累加 |
UTCIMMA |
统一矩阵乘法和累加 |
UTCOMMA |
统一矩阵乘法和累加 |
UTCQMMA |
统一矩阵乘法和累加 |
UTCSHIFT |
在张量内存中移动元素 |
纹理指令 |
|
TEX |
纹理Fetch |
TLD |
纹理加载 |
TLD4 |
纹理加载 4 |
TMML |
纹理mipmap层级 |
TXD |
带导数的纹理Fetch |
TXQ |
纹理查询 |
表面指令 |
|
SUATOM |
表面内存上的原子操作 |
SULD |
表面加载 |
SURED |
表面内存上的归约操作 |
SUST |
表面存储 |
控制指令 |
|
ACQBULK |
等待批量释放状态 Warp 状态 |
ACQSHMINIT |
等待共享内存初始化释放状态 Warp 状态 |
BMOV |
移动收敛屏障状态 |
BPT |
断点/陷阱 |
BRA |
相对分支 |
BREAK |
跳出指定的收敛屏障 |
BRX |
相对分支间接 |
BRXU |
相对分支,带基于统一寄存器的偏移量 |
BSSY |
屏障设置收敛同步点 |
BSYNC |
在收敛屏障上同步线程 |
CALL |
调用函数 |
CGAERRBAR |
CGA 错误屏障 |
ELECT |
选出一个 Leader 线程 |
ENDCOLLECTIVE |
重置 MCOLLECTIVE 掩码 |
EXIT |
退出程序 |
JMP |
绝对跳转 |
JMX |
绝对跳转间接 |
JMXU |
绝对跳转,带基于统一寄存器的偏移量 |
KILL |
终止线程 |
NANOSLEEP |
暂停执行 |
PREEXIT |
依赖任务启动提示 |
RET |
从子程序返回 |
RPCMOV |
PC 寄存器移动 |
WARPSYNC |
同步 Warp 中的线程 |
YIELD |
Yield 控制 |
杂项指令 |
|
B2R |
将屏障移动到寄存器 |
BAR |
屏障同步 |
CS2R |
将特殊寄存器移动到寄存器 |
DEPBAR |
依赖屏障 |
GETLMEMBASE |
获取本地内存基地址 |
LEPC |
加载有效 PC |
NOP |
空操作 |
PMTRIG |
性能监视器触发器 |
S2R |
将特殊寄存器移动到寄存器 |
SETCTAID |
设置 CTA ID |
SETLMEMBASE |
设置本地内存基地址 |
VOTE |
跨 SIMT 线程组投票 |
5. cu++filt
cu++filt 解码(反混淆)已被 CUDA C++ 混淆的低级标识符,使其成为用户可读的名称。对于每个输入的字母数字单词,cu++filt 的输出要么是反混淆的名称(如果名称解码为 CUDA C++ 名称),要么是原始名称本身。
5.1. 用法
cu++filt 接受一个或多个字母数字单词(由字母、数字、下划线、美元符号或句点组成),并尝试解密它们。基本用法如下
cu++filt [options] <symbol(s)>
要反混淆整个文件(如二进制文件),请将文件内容通过管道传递给 cu++filt,例如在以下命令中
nm <input file> | cu++filt
要在不打印参数类型的情况下反混淆函数名称,请使用以下命令
cu++filt -p <symbol(s)>
要跳过混淆符号的前导下划线,请使用以下命令
cu++filt -_ <symbol(s)>
这是 cu++filt 的示例输出
$ cu++filt _Z1fIiEbl
bool f<int>(long)
如输出所示,符号 _Z1fIiEbl 已成功反混淆。
要剥离函数签名和参数中的所有类型,请使用 -p 选项
$ cu++filt -p _Z1fIiEbl
f<int>
要跳过混淆符号的前导下划线,请使用 -_ 选项
$ cu++filt -_ __Z1fIiEbl
bool f<int>(long)
要反混淆整个文件,请将文件内容通过管道传递给 cu++filt
$ nm test.sm_70.cubin | cu++filt
0000000000000000 t hello(char *)
0000000000000070 t hello(char *)::display()
0000000000000000 T hello(int *)
无法反混淆的符号将按原样打印回 stdout
$ cu++filt _ZD2
_ZD2
可以从命令行反混淆多个符号
$ cu++filt _ZN6Scope15Func1Enez _Z3fooIiPFYneEiEvv _ZD2
Scope1::Func1(__int128, long double, ...)
void foo<int, __int128 (*)(long double), int>()
_ZD2
5.2. 命令行选项
表 9 包含 cu++filt 支持的命令行选项,以及每个选项的功能描述。
选项 |
描述 |
|---|---|
|
剥离下划线。在某些系统上,CUDA 编译器在每个名称前面都放置一个下划线。此选项删除初始下划线。cu++filt 是否默认删除下划线取决于目标。 |
|
在反混淆函数名称时,不显示函数参数的类型。 |
|
打印 cu++filt 选项的摘要并退出。 |
|
打印此工具的版本信息。 |
5.3. 库可用性
cu++filt 也可作为静态库 (libcufilt) 使用,可以链接到现有项目。以下接口描述了其用法
char* __cu_demangle(const char *id, char *output_buffer, size_t *length, int *status)
此接口可以在 SDK 中的文件 “nv_decode.h” 中找到。
输入参数
id 输入混淆字符串。
output_buffer 指向将存储反混淆缓冲区的指针。此内存必须使用 malloc 分配。如果 output-buffer 为 NULL,则将 malloc 内存以存储反混淆的名称,并通过函数返回值返回。如果 output-buffer 太小,则使用 realloc 扩展它。
length 如果用户提供预分配的内存,则必须提供输出缓冲区的大小。这是反混淆器在需要重新分配大小时所必需的。如果 length 为非空,则反混淆缓冲区的长度将放置在 length 中。
status *status 设置为以下值之一
0 - 反混淆操作成功
-1 - 发生内存分配失败
-2 - 不是有效的混淆 id
-3 - 发生输入验证失败(一个或多个参数无效)
返回值
指向 NUL 终止的反混淆名称的开头的指针,如果反混淆失败,则为 NULL。调用者负责使用 free 释放此内存。
注意:此函数是线程安全的。
用法示例
#include <stdio.h>
#include <stdlib.h>
#include "nv_decode.h"
int main()
{
int status;
const char *real_mangled_name="_ZN8clstmp01I5cls01E13clstmp01_mf01Ev";
const char *fake_mangled_name="B@d_iDentiFier";
char* realname = __cu_demangle(fake_mangled_name, 0, 0, &status);
printf("fake_mangled_name:\t result => %s\t status => %d\n", realname, status);
free(realname);
size_t size = sizeof(char)*1000;
realname = (char*)malloc(size);
__cu_demangle(real_mangled_name, realname, &size, &status);
printf("real_mangled_name:\t result => %s\t status => %d\n", realname, status);
free(realname);
return 0;
}
这将打印
fake_mangled_name: result => (null) status => -2
real_mangled_name: result => clstmp01<cls01>::clstmp01_mf01() status => 0
6. nvprune
nvprune 剪除主机对象文件和库,使其仅包含指定目标的设备代码。
6.1. 用法
nvprune 每次运行时接受单个输入文件,并发出新的输出文件。基本用法如下
nvprune [options] -o <outfile> <infile>
输入文件必须是可重定位的主机对象或静态库(而不是主机可执行文件),输出文件将是相同的格式。
必须使用 –arch 或 –generate-code 选项之一来指定要保留的目标。所有其他设备代码都将从文件中丢弃。目标可以是 sm_NN arch (cubin) 或 compute_NN arch (ptx)。
例如,以下命令将剪除 libcublas_static.a,使其仅包含 sm_70 cubin,而不是通常存在的所有目标
nvprune -arch sm_70 libcublas_static.a -o libcublas_static70.a
请注意,这意味着 libcublas_static70.a 将无法在任何其他架构上运行,因此仅应在为单个架构构建时使用。
6.2. 命令行选项
表 10 包含 nvprune 支持的命令行选项,以及每个选项的功能描述。每个选项都有一个长名称和一个短名称,可以互换使用。
选项(长) |
选项(短) |
描述 |
|---|---|---|
|
|
指定将保留在对象或库中的 NVIDIA GPU 架构的名称。 |
|
|
此选项的格式与 nvcc –generate-code 选项相同,并提供了一种指定应保留在对象或库中的多个架构的方法。只有 ‘code’ 值用作匹配的目标。此选项允许的关键字:‘arch’,‘code’。 |
|
|
不保留任何可重定位的 ELF。 |
|
|
指定输出文件的名称和位置。 |
|
|
打印有关此工具的帮助信息。 |
|
|
从指定的文件中包含命令行选项。 |
|
|
打印有关此工具的版本信息。 |
7. 附录
7.1. JSON 格式
nvdisasm 的输出是人类可读的文本,未针对机器消费进行格式化。任何使用 nvdisasm 输出的工具都必须解析人类可读的文本,这可能很慢,并且对文本的任何细微更改都可能破坏解析器。
基于 JSON 的格式提供了一种高效且可扩展的方法,用于从 nvdisasm 输出机器可读数据。选项 -json 可用于生成符合以下 JSON 模式定义的 JSON 文档。
{
"$id": "https://nvidia.com/cuda/cuda-binary-utilities/index.html#json-format",
"description": "A JSON schema for NVIDIA CUDA disassembler. The $id attribute is not a real URL but a unique identifier for the schema",
"$schema": "https://json-schema.fullstack.org.cn/draft/2020-12/schema",
"title": "A JSON schema for NVIDIA CUDA disassembler",
"version": "12-8-0",
"type": "array",
"minItems": 2,
"prefixItems": [
{
"$ref": "#/$defs/metadata"
},
{
"description": "A list of CUDA functions",
"type": "array",
"minItems": 1,
"items": {
"$ref": "#/$defs/function"
}
}
],
"$defs": {
"metadata": {
"type": "object",
"properties": {
"ELF": {
"$ref": "#/$defs/elf-metadata"
},
"SM": {
"type": "object",
"properties": {
"version": {
"$ref": "#/$defs/sm-version"
}
},
"required": [
"version"
]
},
"SchemaVersion": {
"$ref": "#/$defs/version"
},
"Producer": {
"type": "string",
"description": "Name and version of the CUDA disassembler tool",
"maxLength": 1024
},
"Description": {
"type": "string",
"description": "A description that may be empty",
"maxLength": 1024
},
".note.nv.tkinfo": {
"$ref": "#/$defs/Elf64_NV_TKinfo"
}
},
"required": [
"ELF",
"SM",
"SchemaVersion",
"Producer",
"Description"
]
},
"elf-metadata": {
"type": "object",
"properties": {
"layout-id": {
"description": "Indicates the layout of the ELF file, part of the ELF header flags. Undocumented enum",
"type": "integer"
},
"ei_osabi": {
"description": "Operating system/ABI identification",
"type": "integer"
},
"ei_abiversion": {
"description": "ABI version",
"type": "integer"
}
},
"required": [
"layout-id",
"ei_osabi",
"ei_abiversion"
]
},
"sm-version": {
"type": "object",
"properties": {
"major": {
"type": "integer"
},
"minor": {
"type": "integer"
}
},
"required": [
"major",
"minor"
]
},
"version": {
"type": "object",
"properties": {
"major": {
"type": "integer"
},
"minor": {
"type": "integer"
},
"revision": {
"type": "integer"
}
},
"required": [
"major",
"minor",
"revision"
]
},
"sass-instruction-attribute": {
"type": "object",
"additionalProperties": {
"type": "string"
}
},
"sass-instruction": {
"type": "object",
"properties": {
"predicate": {
"type": "string",
"description": "Instruction predicate"
},
"opcode": {
"type": "string",
"description": "The instruction opcode. May be empty to indicate a gap between non-contiguous instructions"
},
"operands": {
"type": "string",
"description": "Instruction operands separated by commas"
},
"extra": {
"type": "string",
"description": "Optional field"
},
"other-attributes": {
"type": "object",
"description": "Additional instruction attributes encoded as a map of string:string key-value pairs. Example: {'control-flow': 'True'}",
"items": {
"type": "string"
}
},
"other-flags": {
"type": "array",
"description": "Aditional instruction attributes encoded as a list strings",
"items": {
"type": "string"
}
}
},
"required": [
"opcode"
]
},
"function": {
"type": "object",
"properties": {
"function-name": {
"type": "string"
},
"start": {
"type": "integer",
"description": "The function's start virtual address"
},
"length": {
"type": "integer",
"description": "The function's length in bytes"
},
"other-attributes": {
"type": "array",
"items": {
"type": "string"
}
},
"sass-instructions": {
"type": "array",
"items": {
"$ref": "#/$defs/sass-instruction"
}
}
},
"required": [
"function-name",
"start",
"length",
"sass-instructions"
]
},
"Elf64_NV_TKinfo": {
"type": "object",
"properties": {
"tki_toolkitVersion": {
"type": "integer"
},
"tki_objFname": {
"type": "string"
},
"tki_toolName": {
"type": "string"
},
"tki_toolVersion": {
"type": "string"
},
"tki_toolBranch": {
"type": "string"
},
"tki_toolOptions": {
"type": "string"
}
},
"required": [
"tki_toolkitVersion",
"tki_objFname",
"tki_toolName",
"tki_toolVersion",
"tki_toolBranch",
"tki_toolOptions"
]
}
}
}
关于 sass-instruction 对象的说明
other-attributes可能包含"control-flow": "True"键值对,以指示控制流指令。第 n 个(从 0 开始)SASS 指令的地址可以计算为 start + n * 指令大小。在 Volta 和更高版本的架构上,指令大小为 16 字节,而在之前的架构上为 8 字节。
JSON 列表可能包含空指令对象;这些对象计入指令索引,因为它们指示不连续指令之间的间隙。
空指令对象具有单个字段
opcode,其值为空字符串:"opcode": ""
这是 nvdisasm -json 的示例输出
[
// First element in the list: Metadata
{
// ELF Metadata
"ELF": {
"layout-id": 4,
"ei_osabi": 51,
"ei_abiversion": 7
},
// SASS code SM version: SM89 (16 bytes instructions)
"SM": {
"version": {
"major": 8,
"minor": 9
}
},
"SchemaVersion": {
"major": 12,
"minor": 8,
"revision": 0
},
// Release details of nvdisasm
"Producer": "nvdisasm V12.8.14 Build r570_00.r12.8/compiler.35033008_0",
"Description": ""
},
// Second element in the list: Functions
[
{
"function-name": "_Z10exampleKernelv",
// Function start address
"start": 0,
// Function length in bytes
"length": 384,
"other-attributes": [],
// SASS instructions
"sass-instructions": [
{
// Instruction at 0x00
"opcode": "IMAD.MOV.U32",
"operands": "R1,RZ,RZ,c[0x0][0x28]"
},
{
// Instruction at 0x10 (16 bytes increment)
"opcode": "MOV",
"operands": "R0,0x0"
},
{
// Instruction at 0x20
"opcode": "IMAD.MOV.U32",
"operands": "R4,RZ,RZ,c[0x4][0x8]"
},
// [...]
{
"opcode": "CALL.ABS.NOINC",
"operands": "R2",
// other-attributes is an optional that can indicate control flow instructions
"other-attributes": {
"control-flow": "True"
}
},
{
"opcode": "EXIT",
"other-attributes": {
"control-flow": "True"
}
},
{
"opcode": "NOP"
}
]
}
]
]
8. 声明
8.1. 声明
本文档仅供参考,不应被视为对产品的特定功能、状况或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含的信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文中包含的任何错误不承担任何责任。NVIDIA 对使用此类信息或因使用此类信息而可能导致的侵犯第三方专利或其他权利的后果或用途不承担任何责任。本文档不构成开发、发布或交付任何材料(下文定义)、代码或功能的承诺。
NVIDIA 保留随时对此文档进行更正、修改、增强、改进和任何其他更改的权利,恕不另行通知。
客户应在下订单前获取最新的相关信息,并应验证此类信息是否为最新且完整。
NVIDIA 产品的销售受 NVIDIA 在订单确认时提供的标准销售条款和条件的约束,除非 NVIDIA 和客户的授权代表签署的个别销售协议(“销售条款”)另有约定。NVIDIA 在此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档未直接或间接形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命支持设备,也不适用于 NVIDIA 产品的故障或故障可以合理预期会导致人身伤害、死亡或财产或环境损害的应用。对于在上述设备或应用中包含和/或使用 NVIDIA 产品,NVIDIA 不承担任何责任,因此,此类包含和/或使用由客户自行承担风险。
NVIDIA 不作任何陈述或保证,保证基于本文档的产品将适用于任何特定用途。NVIDIA 不一定会对每种产品的所有参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适用于客户计划的应用并适合该应用,并为该应用执行必要的测试,以避免应用或产品的默认设置。客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同条件和/或要求。对于可能基于或归因于以下原因的任何默认、损坏、成本或问题,NVIDIA 不承担任何责任:(i)以任何违反本文档的方式使用 NVIDIA 产品,或(ii)客户产品设计。
本文档未授予任何 NVIDIA 专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。NVIDIA 发布的关于第三方产品或服务的信息不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成对此类产品或服务的保证或认可。使用此类信息可能需要获得第三方的专利或其他知识产权下的许可,或者获得 NVIDIA 的专利或其他知识产权下的 NVIDIA 许可。
仅在事先获得 NVIDIA 书面批准的情况下,才允许复制本文档中的信息,复制时不得进行更改,并且必须完全符合所有适用的出口法律和法规,并附带所有相关的条件、限制和声明。
本文档和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断程序、列表和其他文档(统称为“材料”)均按“原样”提供。NVIDIA 对材料不作任何明示、暗示、法定或其他形式的保证,并明确声明不承担所有关于不侵权、适销性和特定用途适用性的默示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对因使用本文档而引起的任何损害(包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害,无论因何种原因造成且无论责任理论如何)承担责任,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因遭受任何损害,但 NVIDIA 对本文所述产品的客户的累计责任应根据产品的销售条款进行限制。
8.2. OpenCL
OpenCL 是 Apple Inc. 的商标,已获得 Khronos Group Inc. 的许可使用。
8.3. 商标
NVIDIA 和 NVIDIA 徽标是 NVIDIA Corporation 在美国和其他国家/地区的商标或注册商标。其他公司和产品名称可能是与其相关的各自公司的商标。