参数高效微调#
参数高效微调 (PEFT) 方法能够有效地将大型预训练模型适配到新任务。NVIDIA NIM for LLMs (NIM for LLMs) 支持由 NeMo 框架和 Hugging Face Transformers 库训练的 LoRA PEFT 适配器。当向 NIM 提交推理请求时,服务器支持动态多 LoRA 推理,从而能够使用不同的 LoRA 模型同时进行推理请求。
以下框图说明了使用 NIM 的动态多 LoRA 架构
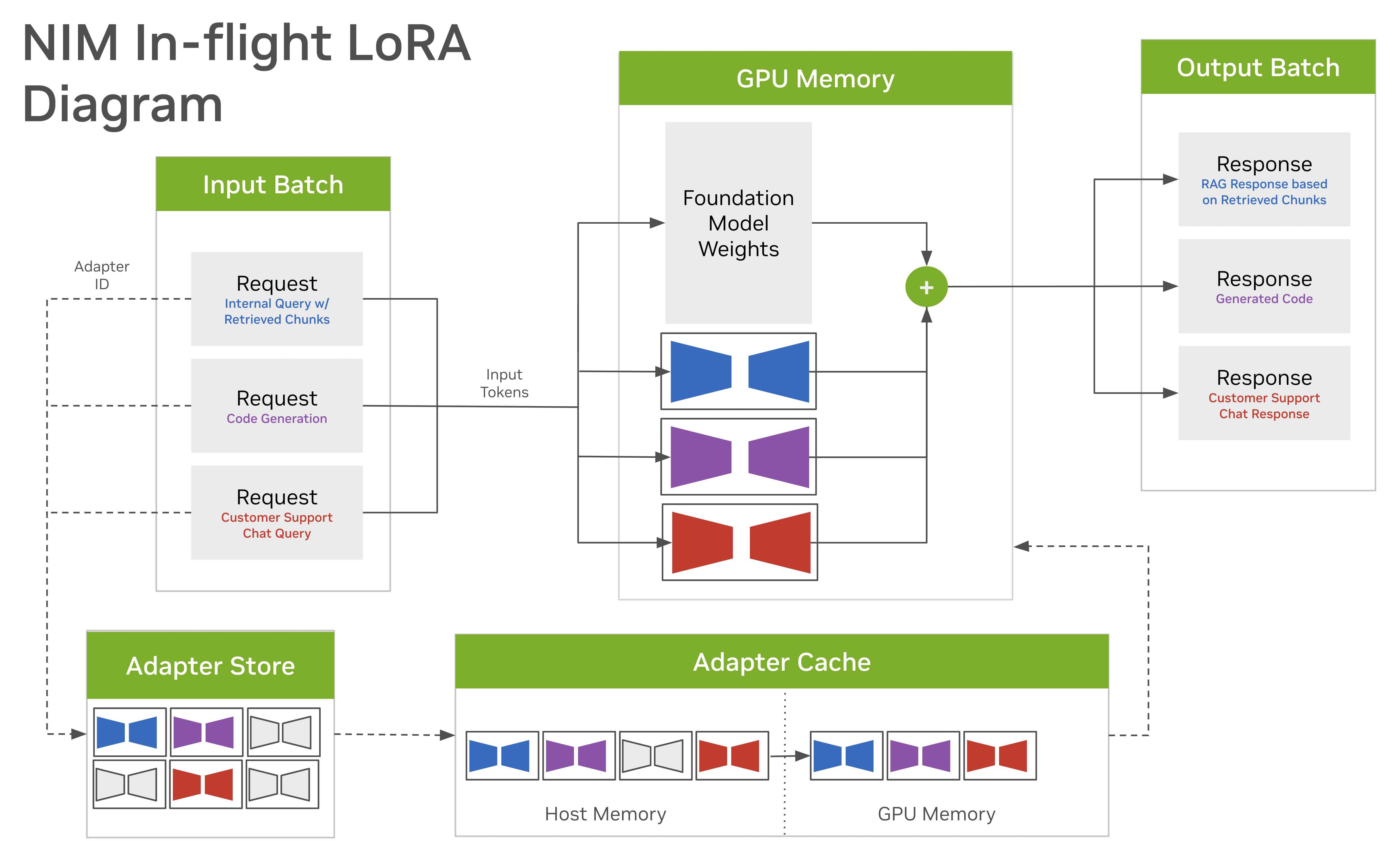
使用 NVIDIA NeMo 框架或 Hugging Face PEFT 库训练的适配器被放置到适配器存储中,并被赋予唯一的名称。
当向 NIM 发出请求时,客户端可以通过包含 LoRA 模型名称来指定他们想要的特定自定义。
当 NIM 收到自定义模型的请求时,它会从适配器存储中将关联的适配器拉取到多层缓存中。一些适配器驻留在 GPU 内存中,而一些适配器驻留在主机内存中,这取决于它们最近的使用频率。
在执行期间,NIM 运行专门的 GPU 内核,使数据能够同时流经基础模型和多个不同的低秩适配器。这项技术使 NIM 能够同时响应对多个不同自定义模型的需求。
LoRA 设置概述#
您可以使用环境变量中定义的配置来扩展 NIM 以服务 LoRA 模型。您使用的底层 NIM 必须与 LoRA 的基础模型相匹配。例如,要设置与 llama3-8b-instruct 兼容的 LoRA 适配器,例如 llama3-8b-instruct-lora:hf-math-v1,请配置 nvcr.io/nim/meta/llama3-8b-instruct NIM。以下部分描述了配置 NIM 以服务兼容 LoRA 的过程。
LoRA 适配器#
从 NGC 或 Hugging Face 下载 LoRA 适配器,或使用您自己的自定义 LoRA 适配器。LoRA 适配器必须存储在单独的目录中,并且一个或多个 LoRA 目录位于 LOCAL_PEFT_DIRECTORY 目录中。加载的 LoRA 适配器的名称必须与适配器目录的名称匹配。NIM for LLMs 支持 NeMo 格式和 Hugging Face Transformers 兼容格式。
NeMo 格式#
NeMo 格式的 LoRA 目录必须包含一个带有 .nemo 扩展名的文件。.nemo 文件的名称不需要与其父目录的名称匹配。支持的目标模块为 ["gate_proj", "o_proj", "up_proj", "down_proj", "k_proj", "q_proj", "v_proj", "attention_qkv"]。
Hugging Face Transformers 格式#
支持使用 Hugging Face Transformers 训练的 LoRA 适配器。LoRA 必须包含一个 adapter_config.json 文件和 {adapter_model.safetensors, adapter_model.bin} 文件之一。NIM 支持的目标模块为 ["gate_proj", "o_proj", "up_proj", "down_proj", "k_proj", "q_proj", "v_proj"]。
LoRA 模型目录结构#
用于存储一个或多个 LoRA 的目录(您的 LOCAL_PEFT_DIRECTORY)应按照以下示例进行组织。在此示例中,loras 是您作为 LOCAL_PEFT_DIRECTORY 的值传递到 docker 容器中的目录名称。然后,加载的 LoRA 将被称为 llama3-8b-math、llama3-8b-math-hf、llama3-8b-squad 和 llama3-8b-squad-hf。
loras
├── llama3-8b-math
│ └── llama3_8b_math.nemo
├── llama3-8b-math-hf
│ ├── adapter_config.json
│ └── adapter_model.bin
├── llama3-8b-squad
│ └── squad.nemo
└── llama3-8b-squad-hf
├── adapter_config.json
└── adapter_model.safetensors
获取 LoRA 模型#
您可以从模型注册表下载预训练的适配器,或使用流行的框架(如 Hugging Face Transformers 和 NVIDIA NeMo)微调自定义适配器,以便与 NIM for LLMs 一起使用。请注意,LoRA 模型权重与特定的基础模型相关联。您必须仅部署使用与 NIM 正在服务的基础模型相同的模型进行调整的 LoRA 模型。
从 NGC 下载 LoRA 适配器#
llama3-8b-instruct 的 LoRA 适配器#
export LOCAL_PEFT_DIRECTORY=~/loras
mkdir $LOCAL_PEFT_DIRECTORY
pushd $LOCAL_PEFT_DIRECTORY
# downloading NeMo-format loras
ngc registry model download-version "nim/meta/llama3-8b-instruct-lora:nemo-math-v1"
ngc registry model download-version "nim/meta/llama3-8b-instruct-lora:nemo-squad-v1"
# downloading vLLM-format loras
ngc registry model download-version "nim/meta/llama3-8b-instruct-lora:hf-math-v1"
ngc registry model download-version "nim/meta/llama3-8b-instruct-lora:hf-squad-v1"
popd
chmod -R 777 $LOCAL_PEFT_DIRECTORY
llama3-70b-instruct 的 LoRA 适配器#
export LOCAL_PEFT_DIRECTORY=~/loras
mkdir $LOCAL_PEFT_DIRECTORY
pushd $LOCAL_PEFT_DIRECTORY
# downloading NeMo-format loras
ngc registry model download-version "nim/meta/llama3-70b-instruct-lora:nemo-math-v1"
ngc registry model download-version "nim/meta/llama3-70b-instruct-lora:nemo-squad-v1"
# downloading vLLM-format loras
ngc registry model download-version "nim/meta/llama3-70b-instruct-lora:hf-math-v1"
ngc registry model download-version "nim/meta/llama3-70b-instruct-lora:hf-squad-v1"
popd
chmod -R 777 $LOCAL_PEFT_DIRECTORY
从 Hugging Face Hub 下载 LoRA 适配器#
如果您没有 huggingface-cli CLI 工具,请使用 pip install -U "huggingface_hub[cli]" 安装它。
export LOCAL_PEFT_DIRECTORY=~/loras
mkdir $LOCAL_PEFT_DIRECTORY
# download a LoRA from Hugging Face Hub
mkdir $LOCAL_PEFT_DIRECTORY/llama3-lora
huggingface-cli download <Hugging Face LoRA name> adapter_config.json adapter_model.safetensors --local-dir $LOCAL_PEFT_DIRECTORY/llama3-lora
chmod -R 777 $LOCAL_PEFT_DIRECTORY
使用您自己的自定义 LoRA 适配器#
如果您正在使用本地训练的自定义 LoRA 适配器,请创建一个 $LOCAL_PEFT_DIRECTORY 目录并将您的 LoRA 适配器复制到该目录。您的自定义 LoRA 适配器的名称必须遵循上一节中描述的命名约定。
从 NGC 下载 LoRA 示例中的 LoRA 模块使用 NeMo 框架来训练 LoRA 适配器。使用 NeMo 训练框架来自定义适配器瓶颈维度并指定应用 LoRA 的目标模块。LoRA 可以应用于 transformer 模型中的任何线性层,包括
Q、K、V 注意力投影
注意力输出层
两个 transformer MLP 层中的一个或两个
对于 QKV 投影,NeMo 的注意力实现将 QKV 融合到单个投影中,因此 LoRA 实现为组合的 QKV 学习单个低秩投影。
以下示例使用已训练并在 local_lora_path 存在的自定义 LoRA 适配器设置 NIM 的 PEFT 目录。
export LOCAL_PEFT_DIRECTORY=~/loras
mkdir $LOCAL_PEFT_DIRECTORY
# move a custom LoRA adapter to the local PEFT directory
cp local_lora_path $LOCAL_PEFT_DIRECTORY/llama3-lora
chmod -R 777 $LOCAL_PEFT_DIRECTORY
处理混合批次请求#
一个批次中的请求可能使用不同的 LoRA 适配器来支持不同的任务。因此,传统的 通用矩阵乘法 (GEMM) 不能用于一起计算所有请求。逐个顺序计算它们会导致显着的额外开销。为了解决这个问题,我们使用 NVIDIA CUTLASS 实现了批处理 GEMM,以将批处理的异构请求处理融合到单个内核中。这提高了 GPU 利用率和性能。
PEFT 环境变量#
您可以通过设置 NIM_PEFT_SOURCE 环境变量在 NIM for LLMs 中启用 PEFT。有关更多信息,请参见 环境变量。
PEFT 缓存和动态混合批次 LoRA (Multi-LoRA)#
LoRA 推理由三个级别的 PEFT (LoRA) 存储和优化的内核组成,用于混合批次 LoRA 推理。
PEFT 源。由
NIM_PEFT_SOURCE配置,这是一个目录,其中存储了特定模型的所有服务的 LoRA。必须设置此环境变量才能使 PEFT LoRA 与 NIM 一起运行。可以存储在此处的 LoRA 数量没有限制。有关目录布局以及支持的格式和模块的详细信息,请参见 LoRA 模型目录结构。NIM for LLMs 在启动时在NIM_PEFT_SOURCE中搜索 LoRA。PEFT 源动态刷新。如果您设置
NIM_PEFT_REFRESH_INTERVAL,NIM for LLMs 会每NIM_PEFT_REFRESH_INTERVAL秒检查一次LOCAL_PEFT_DIRECTORY,并添加它找到的任何新 LoRA。如果您添加一个新的 LoRA 适配器,例如new-lora到LOCAL_PEFT_DIRECTORY,则new-lora现在将在NIM_PEFT_SOURCE中。如果NIM_PEFT_REFRESH_INTERVAL设置为 10,则 NIM for LLMs 每 10 秒检查一次NIM_PEFT_SOURCE以查找新模型。在下一个刷新间隔,NIM for LLMs 检测到 “new-lora” 不在现有的 LoRA 列表中,并将其添加到可用模型列表中。如果您在NIM_PEFT_REFRESH_INTERVAL秒后检查/v1/models,您将在模型列表中看到 “new-lora”。NIM_PEFT_REFRESH_INTERVAL的默认值为 None,这意味着一旦在启动时从NIM_PEFT_SOURCE添加了 LoRA,NIM for LLMs 将不再检查NIM_PEFT_SOURCE,如果您希望将新的 LoRA 添加到LOCAL_PEFT_DIRECTORY并使其显示在可用模型列表中,则必须重新启动服务。CPU PEFT 缓存。此缓存将
NIM_PEFT_SOURCE中的 LoRA 子集保存在主机内存中。当为该 LoRA 发出请求时,LoRA 将加载到 CPU 缓存中。为了加快后续请求,LoRA 将保存在 CPU 内存中,直到缓存已满。当需要更多空间来存放不在缓存中的 LoRA 时,最近最少使用的 LoRA 将被删除。通过设置NIM_MAX_CPU_LORAS环境变量来指定 CPU PEFT 缓存中 LoRA 的最大数量。此环境变量确定可以保存在 CPU 内存中的 LoRA 的最大数量。CPU 缓存的大小也是所有活动请求中可能存在的不同 LoRA 数量的上限。如果活动 LoRA 的数量超过缓存的容量,则服务将返回 429,指示缓存已满,您应该减少活动 LoRA 的数量。GPU PEFT 缓存。此缓存通常保存 CPU PEFT 缓存中的 LoRA 子集。这是保存 LoRA 以进行推理的地方。LoRA 在计划执行时动态加载到 GPU 缓存中。与 CPU 缓存一样,只要有空间,LoRA 就会保留在 GPU 缓存中,并且首先删除最近最少使用的 LoRA。GPU 缓存的大小通过设置
NIM_MAX_GPU_LORAS环境变量来配置。GPU 缓存中可以容纳的 LoRA 数量是可以在同一批次中执行的 LoRA 数量的上限。请注意,更大的数字会导致更高的内存使用率。
CPU 和 GPU 缓存都将根据 NIM_MAX_CPU_LORAS、NIM_MAX_GPU_LORAS 和 NIM_MAX_LORA_RANK 进行预分配。NIM_MAX_LORA_RANK 设置最大支持的低秩(适配器大小)。
PEFT 缓存内存需求#
缓存 LoRA 所需的内存由您希望缓存的 LoRA 的秩和数量决定。LoRA 的大小大致为 low_rank * inner_dim * num_modules * num_layers,其中 inner_dim 是您正在适配的层的隐藏维度,num_modules 是您每层适配的模块数量(例如,q、k 和 v 张量)。请注意,inner_dim 可能因模块而异。
TensorRT-LLM 后端: 缓存预先分配了足够的内存,以便所有 LoRA 都具有 NIM_MAX_LORA_RANK。LoRA 不需要具有相同的秩,如果在推理时使用秩较低的 LoRA,则将有超过指定的 NIM_MAX_GPU_LORAS 和 NIM_MAX_CPU_LORAS 的 LoRA 适合缓存。例如,如果 GPU 缓存配置为 8 个秩为 64 的 LoRA,则 NIM for LLMs 可以运行一批 32 个秩为 16 的 LoRA。
除了权重的缓存之外,TensorRT-LLM 引擎还为 LoRA 激活预先分配了额外的内存。所需的空间与 max_batch_size * max_lora_rank 成比例缩放。NIM for LLMs 会自动估计启动时激活和 PEFT 缓存所需的内存,并为键值缓存保留剩余内存。
启动带有 PEFT 的 NIM for LLMs#
本节包括在 LLama 3.1 8B Instruct 上微调的 LoRA 的设置说明。为 LLama 3.1 8B Instruct 设置 LoRA 的工作流程是类似的。请注意,Llama3 70B 的更大的底层模型尺寸会导致其 LoRA 版本具有更大的内存需求。请参见 PEFT 缓存内存需求。
导出所有非默认环境变量,然后运行服务器。如果您使用来自 NGC 下载的四个模型,那么您将有一个基础模型和四个 LoRA 可用于推理。有关 --gpus all 的说明,请参阅 GPU 选择 部分。
export LOCAL_PEFT_DIRECTORY=~/loras
mkdir $LOCAL_PEFT_DIRECTORY
export NIM_PEFT_SOURCE=/home/nvs/loras
export NIM_PEFT_REFRESH_INTERVAL=3600 # will check NIM_PEFT_SOURCE for newly added models every hour
export CONTAINER_NAME=llama-3.1-8b-instruct
export NIM_CACHE_PATH=~/nim-cache
mkdir -p "$NIM_CACHE_PATH"
chmod -R 777 $NIM_CACHE_PATH
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus all \
--shm-size=16GB \
-e NGC_API_KEY=$NGC_API_KEY \
-e NIM_PEFT_SOURCE \
-e NIM_PEFT_REFRESH_INTERVAL \
-v $NIM_CACHE_PATH:/opt/nim/.cache \
-v $LOCAL_PEFT_DIRECTORY:$NIM_PEFT_SOURCE \
-p 8000:8000 \
nvcr.io/nim/meta/llama-3.1-8b-instruct:latest
运行 Multi-LoRA 推理#
可以通过运行以下命令找到可用于推理的模型列表
curl -X GET 'http://0.0.0.0:8000/v1/models'
为了使输出更易于阅读,请将 curl 命令的结果通过管道传输到像 jq 或 python -m json.tool 这样的工具中。例如:curl -s http://0.0.0.0:8000/v1/models | jq。
输出
{
"object": "list",
"data": [
{
"id": "meta/llama3-8b-instruct",
"object": "model",
"created": 1715702314,
"owned_by": "vllm",
"root": "meta/llama3-8b-instruct",
"parent": null,
"permission": [
{
"id": "modelperm-8d8a74889cfb423c97b1002a0f0a0fa1",
"object": "model_permission",
"created": 1715702314,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
},
{
"id": "llama3-8b-instruct-lora_vnemo-math-v1",
"object": "model",
"created": 1715702314,
"owned_by": "vllm",
"root": "meta/llama3-8b-instruct",
"parent": null,
"permission": [
{
"id": "modelperm-7c9916a6ba414093a6befe6e28937a34",
"object": "model_permission",
"created": 1715702314,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
},
{
"id": "llama3-8b-instruct-lora_vhf-math-v1",
"object": "model",
"created": 1715702314,
"owned_by": "vllm",
"root": "meta/llama3-8b-instruct",
"parent": null,
"permission": [
{
"id": "modelperm-e88bf7b1b63e4a35b831e17e0b98cb67",
"object": "model_permission",
"created": 1715702314,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
},
{
"id": "llama3-8b-instruct-lora_vnemo-squad-v1",
"object": "model",
"created": 1715702314,
"owned_by": "vllm",
"root": "meta/llama3-8b-instruct",
"parent": null,
"permission": [
{
"id": "modelperm-fbfcfd4e59974a0bad146d7ddda23f45",
"object": "model_permission",
"created": 1715702314,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
},
{
"id": "llama3-8b-instruct-hf-squad-v1",
"object": "model",
"created": 1715702314,
"owned_by": "vllm",
"root": "meta/llama3-8b-instruct",
"parent": null,
"permission": [
{
"id": "modelperm-7a5509ab60f94e78b0433e7740b05934",
"object": "model_permission",
"created": 1715702314,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
}
]
}
接下来,针对基础模型或任何 LoRA 提交完成或聊天完成推理请求。您可以向 /v1/models 返回的任何和所有模型发出推理请求。首次向 LoRA 适配器发出推理请求时,可能会有加载时间,但是后续对同一 LoRA 适配器的请求将具有更低的延迟,因为权重是从缓存中流式传输的。
curl -X 'POST' \
'http://0.0.0.0:8000/v1/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "llama3-8b-instruct-lora_vhf-math-v1",
"prompt": "John buys 10 packs of magic cards. Each pack has 20 cards and 1/4 of those cards are uncommon. How many uncommon cards did he get?",
"max_tokens": 128
}'
这将产生以下输出
{
"id": "cmpl-7996e1f532804a278535a632906bae07",
"object": "text_completion",
"created": 1715664944,
"model": "llama3-8b-instruct-lora_vhf-math-v1",
"choices": [
{
"index": 0,
"text": " (total) 10*20= <<10*20=200>>200\n200*1/4=<<200*1/4=50>>50\n50 of John's cards are uncommon cards.\n#### 50",
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 35,
"total_tokens": 82,
"completion_tokens": 47
}
}