简介#
NVIDIA NIM 是一组易于使用的微服务,旨在加速生成式 AI 模型在云、数据中心和工作站的部署。NIM 按模型系列和每个模型进行分类。例如,用于大型语言模型 (LLM) 的 NVIDIA NIM 将最先进的 LLM 的强大功能带入企业应用程序,提供无与伦比的自然语言处理和理解能力。
NIM 使 IT 和 DevOps 团队能够在其自身管理的环境中轻松地自托管大型语言模型 (LLM),同时仍为开发人员提供行业标准 API,使他们能够构建强大的副驾驶、聊天机器人和 AI 助手,从而改变他们的业务。借助 NVIDIA 的尖端 GPU 加速和可扩展部署,NIM 以无与伦比的性能提供了最快的推理路径。
高性能特性#
NIM 抽象化了模型推理的内部细节,例如执行引擎和运行时操作。无论使用 TRT-LLM、vLLM 还是其他,它们也是可用的性能最高的选项。NIM 提供以下高性能特性
可扩展部署,性能卓越,可以轻松无缝地从少量用户扩展到数百万用户。
先进的语言模型支持,为各种前沿 LLM 架构预生成优化的引擎。
灵活的集成,可轻松将微服务集成到现有工作流程和应用程序中。开发人员可以使用与 OpenAI API 兼容的编程模型和自定义 NVIDIA 扩展来获得额外的功能。
企业级安全性,通过使用 safetensors、持续监控和修补我们堆栈中的 CVE 以及进行内部渗透测试来强调安全性。
应用场景#
聊天机器人和虚拟助手:使机器人具备类人语言理解和响应能力。
内容生成和摘要:轻松生成高质量内容或将冗长的文章提炼成简洁的摘要。
情感分析:实时了解用户情绪,从而推动更好的业务决策。
语言翻译:通过高效准确的翻译服务打破语言障碍。
还有更多... NIM 的潜在应用非常广泛,跨越各个行业和用例。
架构#
NIM 以每个模型/模型系列为基础打包为容器镜像。每个 NIM 都是其自身的 Docker 容器,其中包含一个模型,例如 meta/llama3-8b-instruct。这些容器包含一个运行时,该运行时可以在任何具有足够 GPU 内存的 NVIDIA GPU 上运行,但某些模型/GPU 组合经过优化。NIM 会自动从 NGC 下载模型,并在本地文件系统缓存可用时加以利用。每个 NIM 都是从一个通用基础构建的,因此一旦下载了一个 NIM,下载其他 NIM 就会非常快。
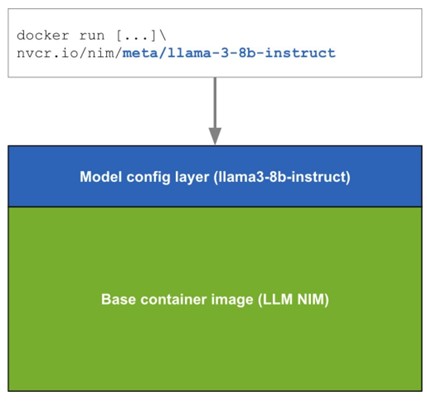
当首次部署 NIM 时,NIM 会检查本地硬件配置和模型注册表中可用的优化模型,然后自动选择适用于可用硬件的最佳模型版本。对于一部分 NVIDIA GPU(请参阅支持的模型),NIM 会下载优化的 TRT 引擎并使用 TRT-LLM 库运行推理。对于所有其他 NVIDIA GPU,NIM 会下载非优化模型并使用 vLLM 库运行它。
NIM 作为 NGC 容器镜像通过 NVIDIA NGC 目录分发。NGC 目录中的每个容器都有安全扫描报告,其中提供了该镜像的安全评级、按软件包划分的 CVE 严重程度细分以及指向 CVE 详细信息的链接。
NIM 部署生命周期#
`docker run ...`] --> B[Docker 容器下载] B --> C{模型是否在\n本地文件系统上?} C -->|否| D[从 NGC 下载模型] C -->|是| E[运行模型] D --> E E --> F[启动符合 OpenAI 规范的
Completions REST API 服务器]
NVIDIA 开发者计划#
想要了解更多关于 NIM 的信息?加入 NVIDIA 开发者计划,即可免费访问在任何基础设施(云、数据中心或个人工作站)上最多 16 个 GPU 上自托管 NVIDIA NIM 和微服务的权限。
加入免费的 NVIDIA 开发者计划后,您可以随时通过 NVIDIA API 目录 访问 NIM。为了获得企业级安全性、支持和 API 稳定性,请选择通过我们的免费 90 天 NVIDIA AI Enterprise 试用版(使用企业电子邮件地址)访问 NIM 的选项。
请参阅 NVIDIA NIM 常见问题解答 以获取更多信息。