开始使用#
先决条件#
CPU#
具有至少 8 个内核的 x86 处理器 (推荐使用现代处理器)
内存需求因用例而异。对于
trtllm_buildable配置文件,内存需求大约等于 GPU 使用的内存量。
GPU#
NVIDIA NIM for LLMs 应该 (但不保证) 在任何 NVIDIA GPU 上运行,只要 GPU 具有足够的内存,或者在多个具有足够聚合内存和 CUDA 计算能力 > 7.0 (bfloat16 为 8.0) 的同构 NVIDIA GPU 上运行。
您可以使用以下指南来估算所需的内存量。但是,这些指南不适用于 trtllm_buildable 配置文件
5–10 GB 用于操作系统和其他进程
16 GB 用于 Docker (在多 GPU、非 NVLink 情况下,docker 需要 16 GB 的共享内存)
# 模型参数 * 2 GB 内存
Llama 8B: ~ 15 GB
Llama 70B: ~ 131 GB
Mistral 7B Instruct v0.3: ~ 14 GB
Mixtral 8x7B Instruct v0.1: ~ 88 GB
这些建议仅为粗略指南,实际所需内存可能因硬件和 NIM 配置而异。
某些模型/GPU 组合 (包括 vGPU) 经过优化。有关更多信息,请参阅 支持的模型。
软件#
Linux 操作系统 (推荐 Ubuntu 20.04 或更高版本),该系统
具有
glibc>= 2.35 (请参阅ld -v的输出)
NVIDIA 驱动程序 560 或更高版本。但是,如果您在数据中心 GPU (例如 A100) 上运行,则可以使用 NVIDIA 驱动程序版本 470.57 或更高版本 R470、535.86 或更高版本 R535 或 550.54 或更高版本 R550。
NVIDIA Docker >= 23.0.1
NVIDIA AI Enterprise 许可证: NVIDIA NIM for LLMs 在 NVIDIA AI Enterprise 许可证下可用于自托管。 注册 NVIDIA AI Enterprise 许可证。
NVIDIA GPU(s): NVIDIA NIM for LLMs 可在任何具有足够 GPU 内存的 NVIDIA GPU 上运行,但某些模型/GPU 组合已优化。还支持启用 张量并行 的同构多 GPU 系统。有关更多信息,请参阅 支持的模型。
CUDA 驱动程序: 按照 安装指南 进行操作。我们建议
注意
安装工具包后,请按照 NVIDIA Container Toolkit 文档中的 配置 Docker 部分中的说明进行操作。
为了确保您的设置正确,请运行以下命令 (有关使用 --gpus all 的注意事项,请参阅 GPU 选择 部分)
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
此命令应产生类似于以下内容的输出,您可以在其中确认 CUDA 驱动程序版本和可用的 GPU。
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.14 Driver Version: 550.54.14 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA H100 80GB HBM3 On | 00000000:1B:00.0 Off | 0 |
| N/A 36C P0 112W / 700W | 78489MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
为 Windows 安装 WSL2#
某些可下载的 NIM 可以在具有 Windows Linux 子系统 (WSL) 的 RTX Windows 系统上使用。要启用 WSL2,请执行以下步骤。
请确保您的计算机能够运行 WSL2,如 WSL2 文档的 先决条件 部分所述。
按照 安装 WSL 命令 中列出的步骤,在您的 Windows 计算机上启用 WSL2。默认情况下,这些步骤会安装 Ubuntu Linux 发行版。有关其他安装的列表,请参阅 更改默认安装的 Linux 发行版。
请参阅 支持的模型 以确保满足硬件和软件要求。
启动 NVIDIA NIM for LLMs#
您可以从 API 目录或 NGC 下载并运行您选择的 NIM。
选项 1:从 API 目录#
观看此 视频,其中演示了以下步骤。
生成 API 密钥#
导航到 API 目录。
选择一个模型。
选择一个 输入 选项。以下示例是提供 Docker 选项的模型。并非所有模型都提供此选项,但所有模型都包含“获取 API 密钥”链接。
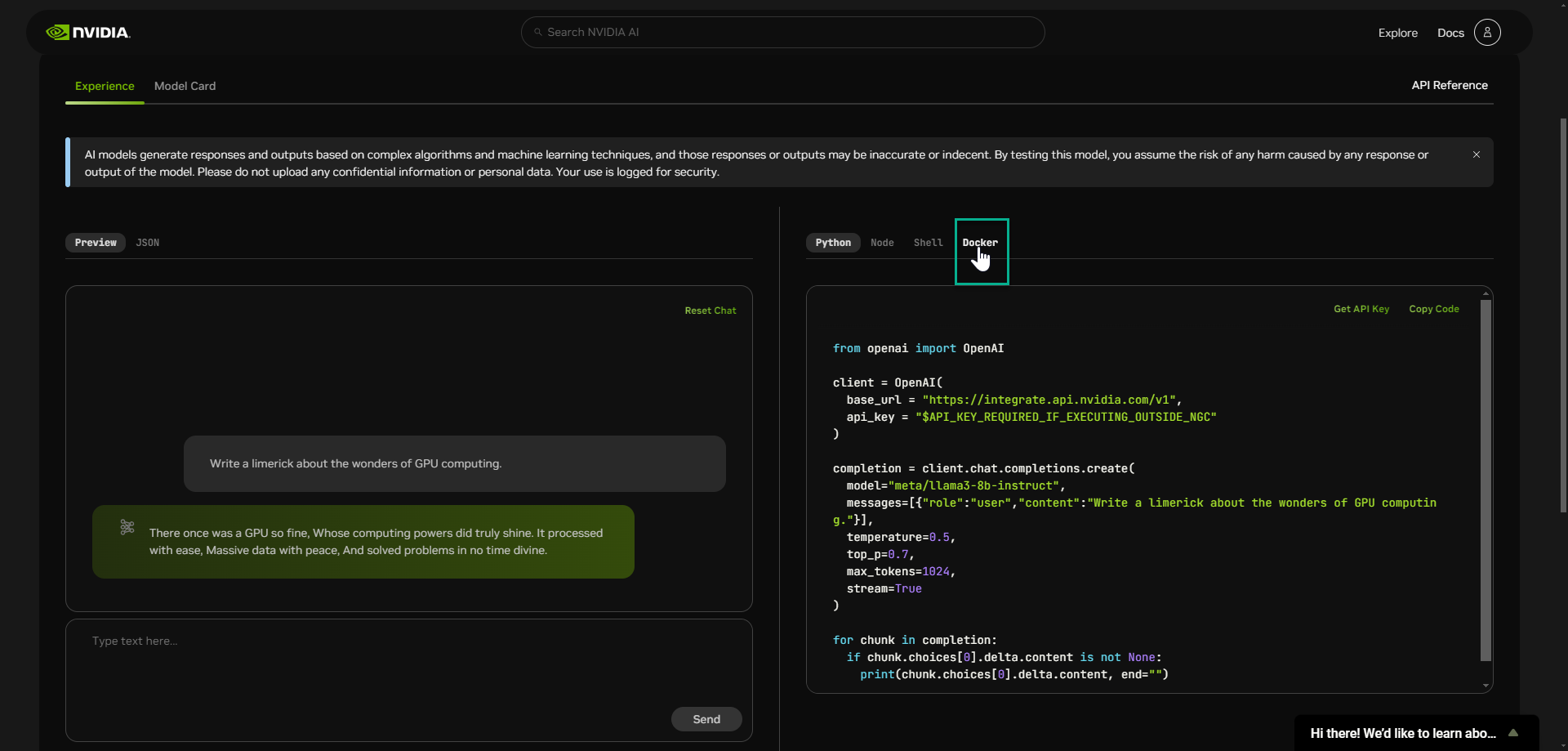
选择“获取 API 密钥”,并在出现提示时登录。
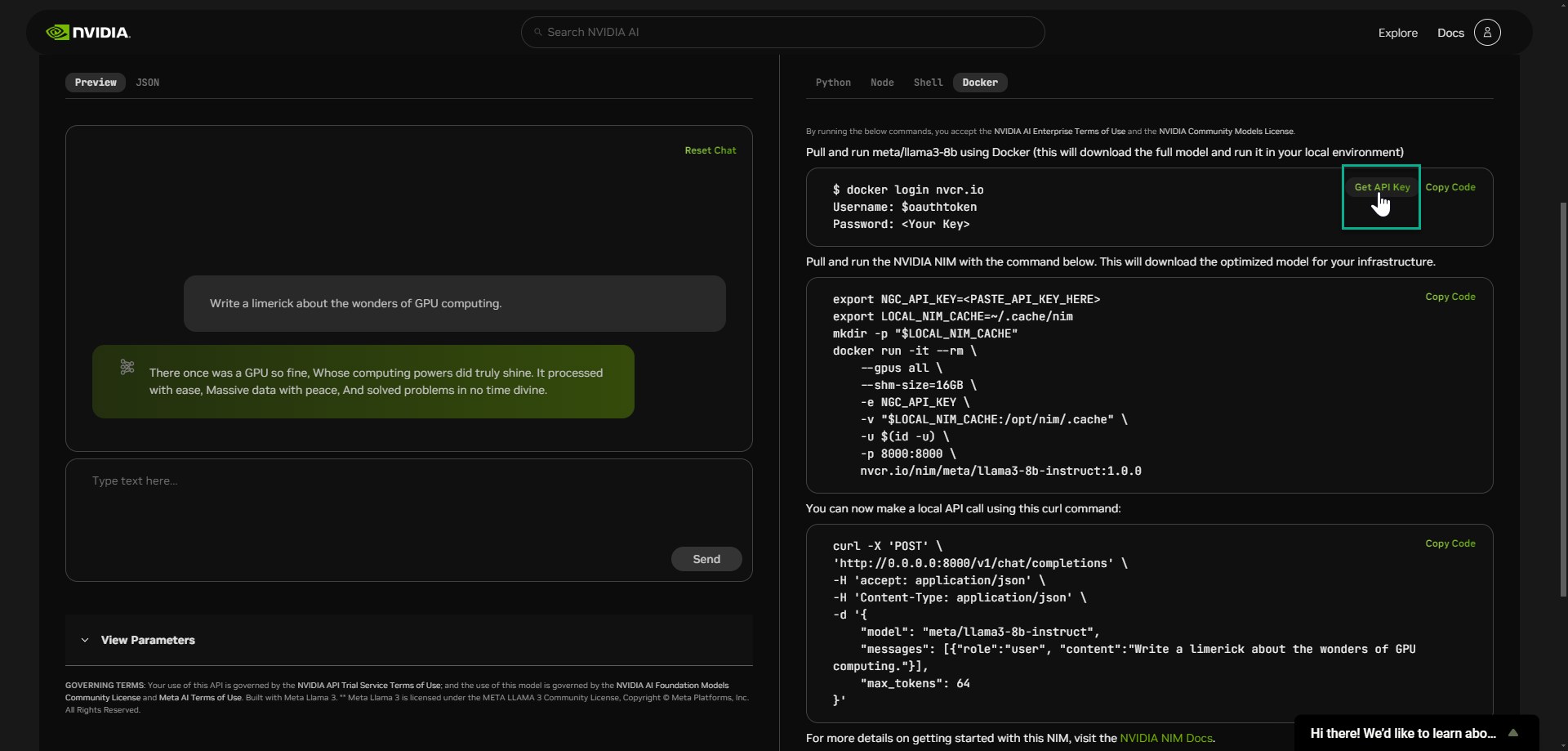
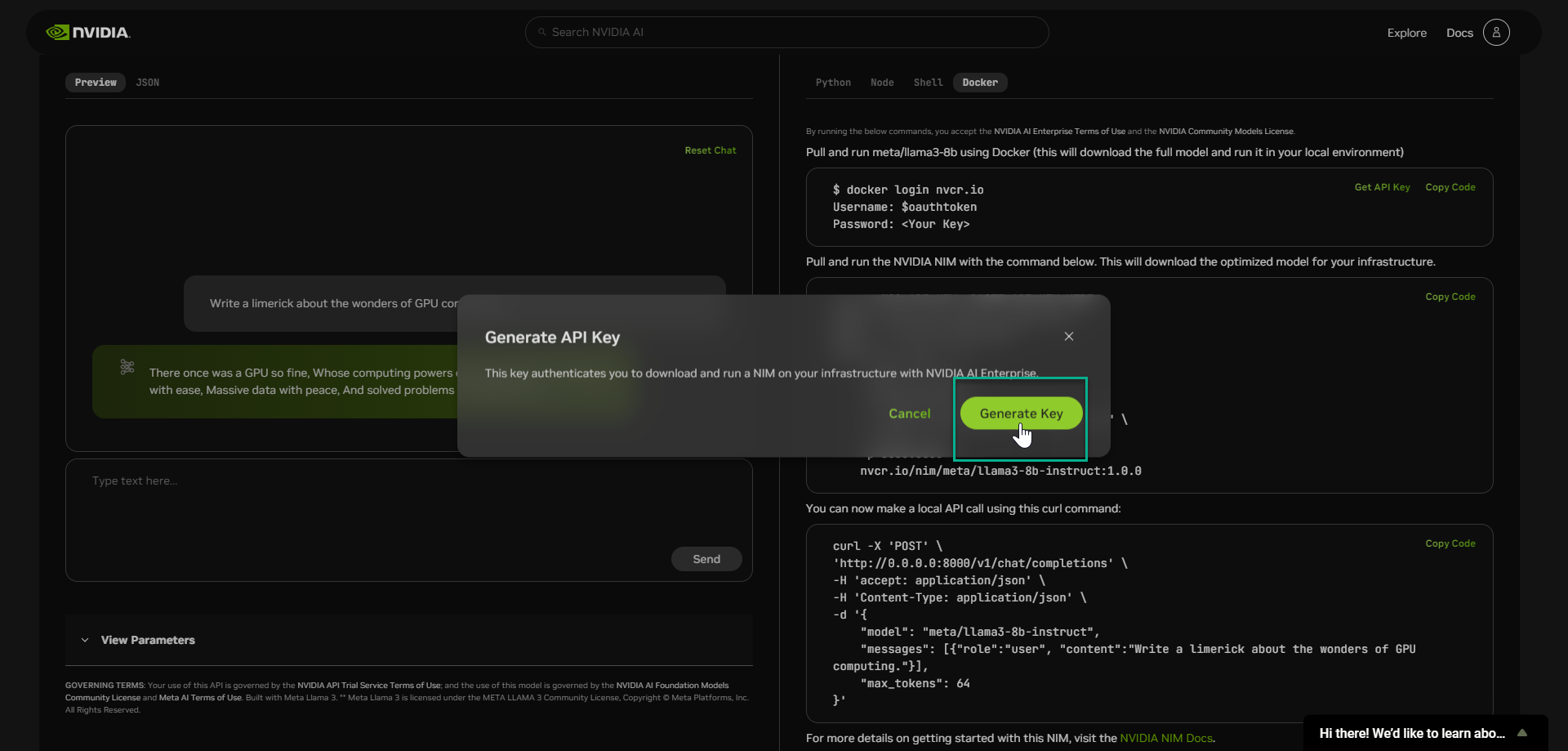
选择“生成密钥”
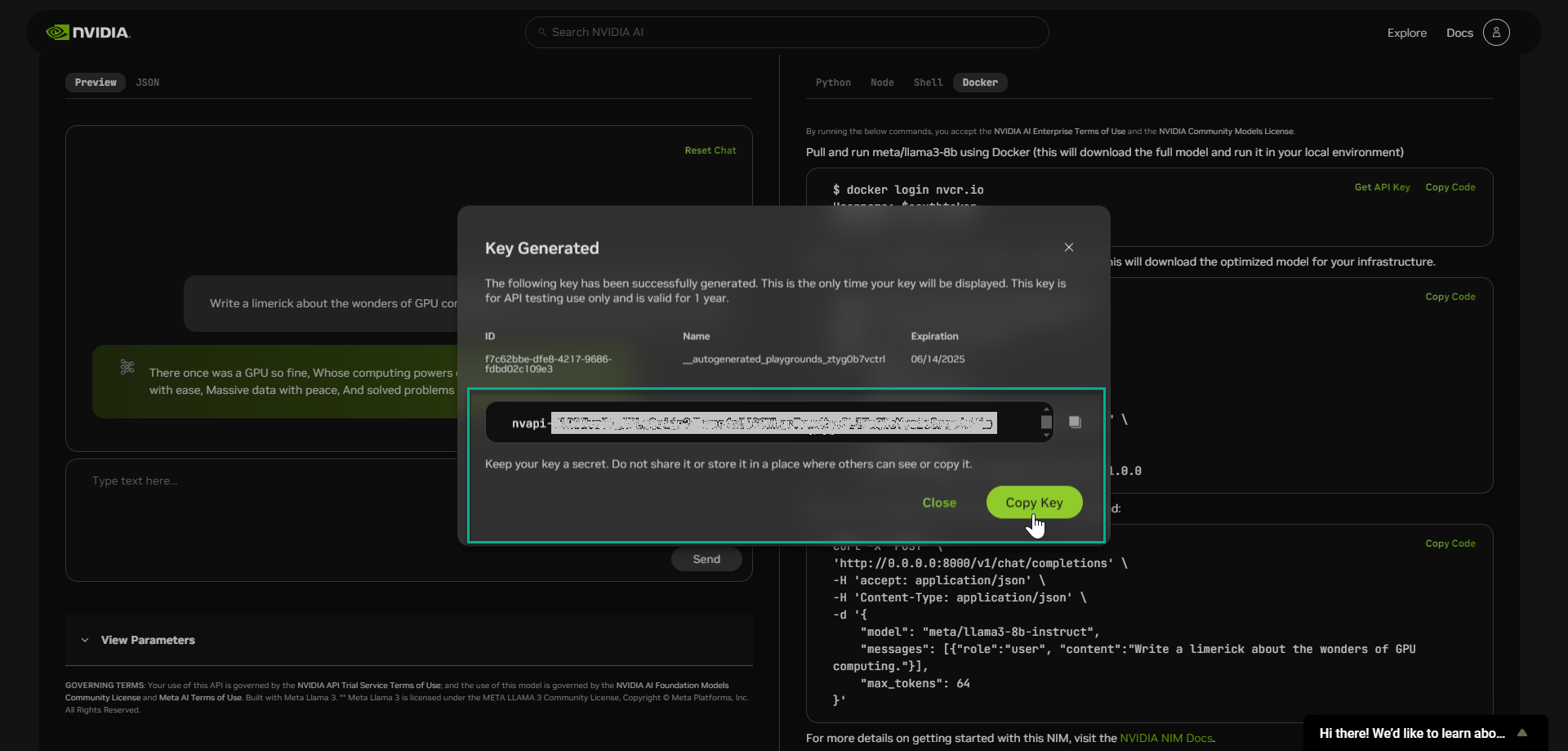
复制您的密钥并将其存储在安全的地方。请勿共享。
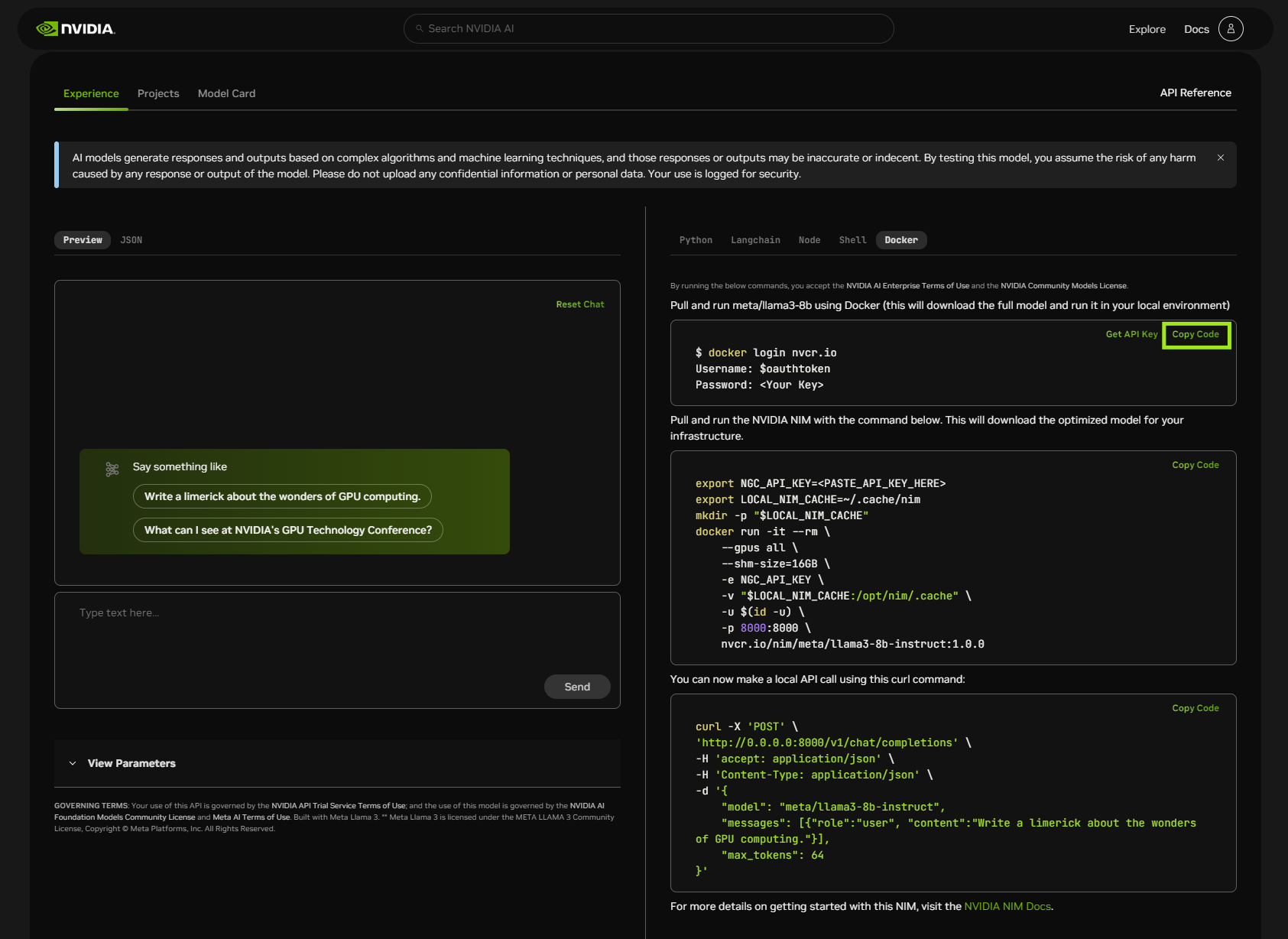
登录 Docker#
使用 docker login 命令 (如下面的屏幕截图所示) 登录 Docker。将用户名和密码的占位符替换为您自己的值。
下载并启动 NVIDIA NIM for LLMs#
使用以下命令拉取并运行使用 Docker 的 NIM。
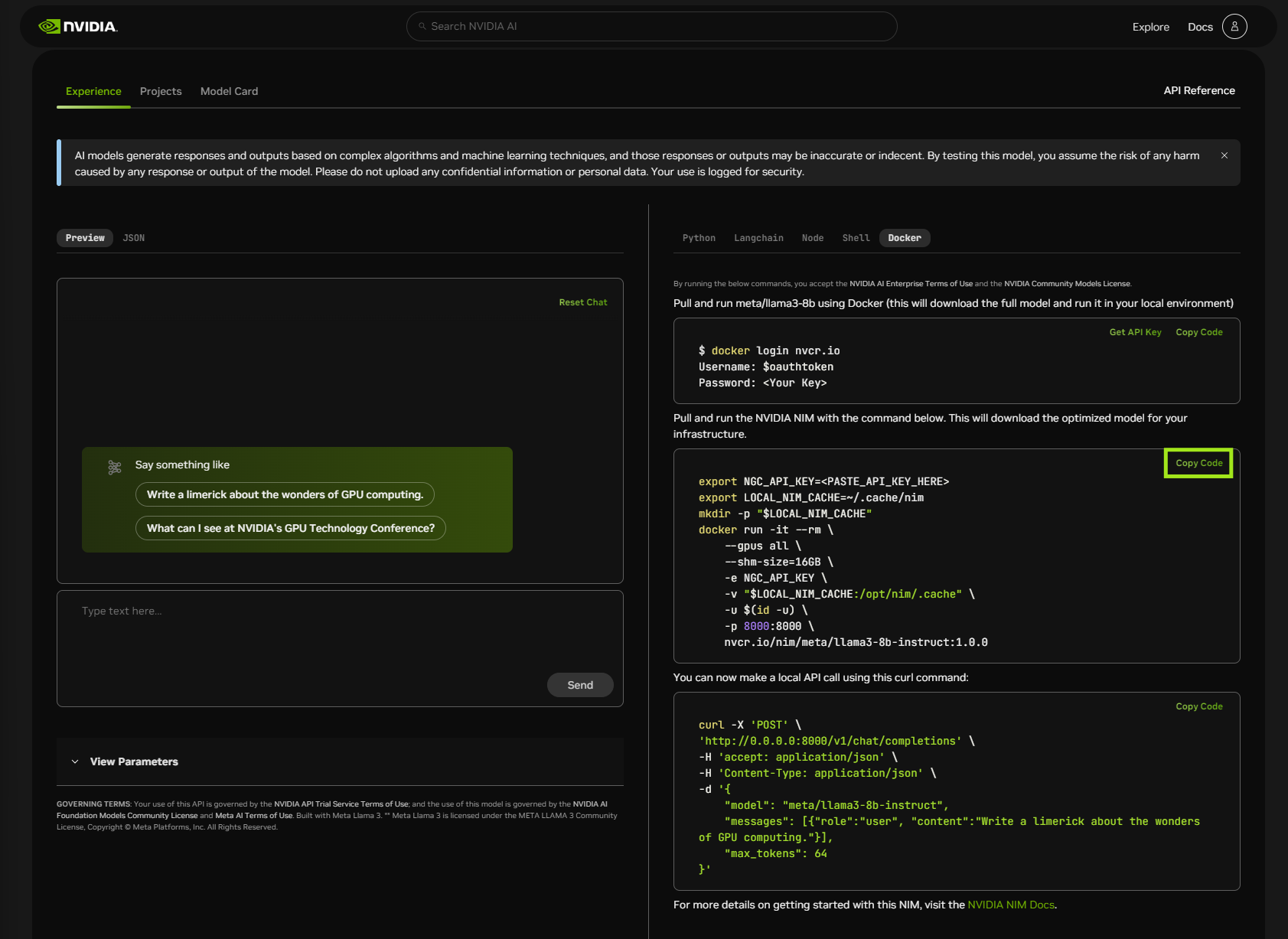
要修改 docker run 参数,请参阅 Docker 运行参数。
现在,您可以跳转到 运行推理。
选项 2:从 NGC#
生成 API 密钥#
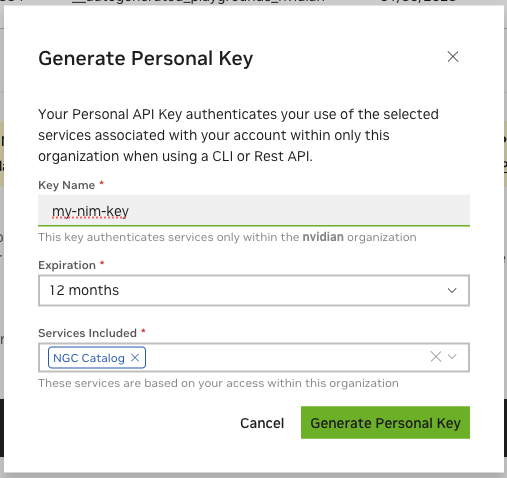
访问 NGC 资源需要 NGC API 密钥,密钥可以在此处生成:https://org.ngc.nvidia.com/setup/personal-keys。
创建 NGC API 密钥时,请确保从“包含的服务”下拉列表中至少选择“NGC Catalog”。如果要将此密钥重用于其他目的,则可以包含更多服务。
导出 API 密钥#
在下一节中,将 API 密钥的值作为 NGC_API_KEY 环境变量传递给 docker run 命令,以便在启动 NIM 时下载相应的模型和资源。
如果您不熟悉如何创建 NGC_API_KEY 环境变量,最简单的方法是在您的终端中导出它,如下例所示,其中 VALUE 是您的 API 密钥的值
export NGC_API_KEY=VALUE
运行以下命令之一以使密钥在启动时可用
# If using bash
echo "export NGC_API_KEY=VALUE" >> ~/.bashrc
# If using zsh
echo "export NGC_API_KEY=VALUE" >> ~/.zshrc
注意
其他更安全的选择包括将值保存在文件中,以便您可以使用类似于 cat $NGC_API_KEY_FILE 的命令检索,或者使用 密码管理器。
Docker 登录到 NGC#
要从 NGC 拉取 NIM 容器镜像,请首先使用以下命令通过 NVIDIA Container Registry 进行身份验证
echo "$NGC_API_KEY" | docker login nvcr.io --username '$oauthtoken' --password-stdin
使用 $oauthtoken 作为用户名,NGC_API_KEY 作为密码。$oauthtoken 用户名是一个特殊名称,指示您将使用 API 密钥而不是用户名和密码进行身份验证。
列出可用的 NIM#
本文档在许多示例中使用了 ngc CLI 工具。有关下载和配置该工具的信息,请参阅 NGC CLI 文档。
使用以下命令以 CSV 格式列出可用的 NIM。
ngc registry image list --format_type csv nvcr.io/nim/*
此命令应产生以下格式的输出
Name,Repository,Latest Tag,Image Size,Updated Date,Permission,Signed Tag?,Access Type,Associated Products
<name1>,<repository1>,<latest tag1>,<image size1>,<updated date1>,<permission1>,<signed tag?1>,<access type1>,<associated products1>
...
<nameN>,<repositoryN>,<latest tagN>,<image sizeN>,<updated dateN>,<permissionN>,<signed tag?N>,<access typeN>,<associated productsN>
在调用 docker run 命令时使用 Repository 字段,如下节所示。
启动 NIM#
以下命令启动 llama3-8b-instruct 模型的 Docker 容器。要为不同的 NIM 启动容器,请将 Repository 的值替换为上一个 image list 命令中的值,并将 CONTAINER_NAME 的值更改为适当的名称。
您可以通过使用以下命令获取有关模型的信息来判断您是否具有正确的 Repository 值
ngc registry image info --format_type ascii ${Repository}:latest
这应该产生如下输出
----------------------------------------------------------
Model Version Information
Id: 0.10.0+e6f46027-h100x1-fp16-balanced.24.06.15839955
Batch Size:
Memory Footprint:
Number Of Epochs:
Accuracy Reached:
GPU Model:
Access Type:
Associated Products:
Created Date: 2024-06-14T22:28:17.604Z
Description:
Status: UPLOAD_COMPLETE
Total File Count: 11
Total Size: 14.96 GB
----------------------------------------------------------
注意
要部署不适合单个节点的模型,请参阅 多节点部署
# Choose a container name for bookkeeping
export CONTAINER_NAME=Llama3-8B-Instruct
# The container name from the previous ngc registgry image list command
Repository=nim/meta/llama3-8b-instruct
# Choose a LLM NIM Image from NGC
export IMG_NAME="nvcr.io/${Repository}:latest"
# Choose a path on your system to cache the downloaded models
export LOCAL_NIM_CACHE=~/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
# Start the LLM NIM
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus all \
--shm-size=16GB \
-e NGC_API_KEY=$NGC_API_KEY \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
-p 8000:8000 \
$IMG_NAME
Docker 运行参数#
标志 |
描述 |
|---|---|
|
|
|
在容器停止后删除容器 (请参阅 Docker –rm 容器命令) |
|
为 NIM 容器命名以进行簿记 (此处为 |
|
确保 NVIDIA 驱动程序在容器中可访问。 |
|
在容器内公开所有 NVIDIA GPU。有关挂载特定 GPU,请参阅 配置页面。 |
|
为多 GPU 通信分配主机内存。单 GPU 模型或启用 NVLink 的 GPU 不需要。 |
|
为容器提供从 NGC 下载足够模型和资源所需的令牌。请参阅 导出 API 密钥。 |
|
从您的系统 (此处为 |
|
在 NIM 容器内部使用与您的系统用户相同的用户,以避免在本地缓存目录中下载模型时出现权限不匹配。 |
|
转发 NIM 服务器在容器内发布的端口,以便从主机系统访问。 |
|
来自 NGC 的 LLM NIM 容器的名称和版本。如果在此之后未提供任何参数,则 LLM NIM 服务器会自动启动。 |
注意
有关其他配置设置的信息,请参阅 配置 NIM 主题。
注意
如果您在本地缓存目录中下载模型时遇到权限不匹配问题,请将 -u $(id -u) 选项添加到 docker run 调用中。
注意
NIM 会根据您的系统规范自动选择最合适的配置文件。有关详细信息,请参阅 自动配置文件选择
运行推理#
在启动期间,NIM 容器下载所需的资源并开始在 API 端点后面提供模型服务。以下消息指示启动成功。
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
看到此消息后,您可以执行推理请求来验证 NIM 的部署。在新终端中,运行以下命令以显示可用于推理的模型列表
curl -X GET 'http://0.0.0.0:8000/v1/models'
为了使输出更易于阅读,请将 curl 命令的结果通过管道传递到诸如 jq 或 python -m json.tool 之类的工具中。例如:curl -s http://0.0.0.0:8000/v1/models | jq。
此命令应产生类似于以下内容的输出
{
"object": "list",
"data": [
{
"id": "meta/llama3-8b-instruct",
"object": "model",
"created": 1715659875,
"owned_by": "vllm",
"root": "meta/llama3-8b-instruct",
"parent": null,
"permission": [
{
"id": "modelperm-e39aaffe7015444eba964fa7736ae653",
"object": "model_permission",
"created": 1715659875,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
}
]
}
OpenAI Completion 请求#
Completions 端点通常用于 base 模型。通过 Completions 端点,提示以纯字符串形式发送,模型会生成最有可能的文本完成,但受所选其他参数的约束。要流式传输结果,请设置 "stream": true。
要更新模型名称,例如对于 llama3-8b-instruct 模型,请使用以下命令
curl -X 'POST' \
'http://0.0.0.0:8000/v1/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta/llama3-8b-instruct",
"prompt": "Once upon a time",
"max_tokens": 64
}'
您还可以使用 OpenAI Python API 库。
from openai import OpenAI
client = OpenAI(base_url="http://0.0.0.0:8000/v1", api_key="not-used")
prompt = "Once upon a time"
response = client.completions.create(
model="meta/llama3-8b-instruct",
prompt=prompt,
max_tokens=16,
stream=False
)
completion = response.choices[0].text
print(completion)
# Prints:
# , there was a young man named Jack who lived in a small village at the
OpenAI Chat Completion 请求#
Chat Completions 端点通常与 chat 或 instruct 调优的模型一起使用,这些模型旨在通过对话方式使用。通过 Chat Completions 端点,提示以带有角色和内容的消息形式发送,从而提供了一种自然的方式来跟踪多轮对话。要流式传输结果,请设置 "stream": true。
要更新模型名称,例如对于 llama3-8b-instruct 模型,请使用以下命令
curl -X 'POST' \
'http://0.0.0.0:8000/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta/llama3-8b-instruct",
"messages": [
{
"role":"user",
"content":"Hello! How are you?"
},
{
"role":"assistant",
"content":"Hi! I am quite well, how can I help you today?"
},
{
"role":"user",
"content":"Can you write me a song?"
}
],
"max_tokens": 32
}'
您还可以使用 OpenAI Python API 库。
from openai import OpenAI
client = OpenAI(base_url="http://0.0.0.0:8000/v1", api_key="not-used")
messages = [
{"role": "user", "content": "Hello! How are you?"},
{"role": "assistant", "content": "Hi! I am quite well, how can I help you today?"},
{"role": "user", "content": "Write a short limerick about the wonders of GPU computing."}
]
chat_response = client.chat.completions.create(
model="meta/llama3-8b-instruct",
messages=messages,
max_tokens=32,
stream=False
)
assistant_message = chat_response.choices[0].message
print(assistant_message)
这将打印
ChatCompletionMessage(content='There once was a GPU so fine,\nProcessed data in parallel so divine,\nIt crunched with great zest,\nAnd computational quest,\nUnleashing speed, a true wonder sublime!', role='assistant', function_call=None, tool_calls=None)
如果您遇到 BadRequestError,并且错误消息指示您缺少 messages 或 prompt 字段,则您可能不小心使用了错误的端点。
例如,如果您使用旨在用于 Chat Completions 的请求正文发出 Completions 请求,您将收到以下错误
{
"object": "error",
"message": "[{'type': 'missing', 'loc': ('body', 'prompt'), 'msg': 'Field required', ...",
"type": "BadRequestError",
"param": null,
"code": 400
}
相反,如果您使用旨在用于 Completions 的请求正文发出 Chat Completions 请求,您将收到以下错误
{
"object": "error",
"message": "[{'type': 'missing', 'loc': ('body', 'messages'), 'msg': 'Field required', ...",
"type": "BadRequestError",
"param": null,
"code": 400
}
验证您正在使用的端点 (例如 /v1/completions 或 /v1/chat/completions) 是否已为您的请求正确配置。
提高 TRT-LLM 性能#
TRT-LLM 是 支持的模型 中列为优化的模型配置的运行时,它具有许多您可以调整以提高性能的参数。有关详细信息,请参阅 调整 TensorRT-LLM 性能的最佳实践。
参数高效微调#
参数高效微调 (PEFT) 方法能够有效地调整大型预训练模型。目前,NIM 仅支持 LoRA PEFT。有关详细信息,请参阅 参数高效微调。
停止容器#
如果 Docker 容器是使用 --name 命令行选项启动的,则可以使用以下命令停止正在运行的容器。
docker stop $CONTAINER_NAME
如果 stop 没有响应,请使用 docker kill。如果您不打算按原样重启容器 (使用 docker start $CONTAINER_NAME),请在该命令之后执行 docker rm $CONTAINER_NAME,在这种情况下,您需要重用本节开头的 docker run ... 指令来为您的 NIM 启动新容器。
如果您在启动容器时未使用 --name,请检查 docker ps 命令的输出,以获取您使用的给定镜像的容器 ID。
Kubernetes 安装#
nim-deploy GitHub 存储库展示了 Kubernetes 安装的几个参考实现。这些示例是实验性的,可能需要修改才能在您特定的集群设置中运行。
从本地资产提供模型服务#
NIM for LLMs 提供了实用程序,可以使模型下载到本地目录,作为模型存储库或 NIM 缓存。有关详细信息,请参阅 实用程序 部分。
使用以下命令启动 NIM 容器。从那里,您可以查看并在本地下载模型。
# Choose a container name for bookkeeping
export CONTAINER_NAME=Llama-3.1-8B-instruct
# The container name from the previous ngc registgry image list command
Repository=nim/meta/llama-3.1-8b-instruct
# Choose a LLM NIM Image from NGC
export IMG_NAME="nvcr.io/${Repository}:latest"
# Choose a path on your system to cache the downloaded models
export LOCAL_NIM_CACHE=~/.cache/downloaded-nim
mkdir -p "$LOCAL_NIM_CACHE"
# Add write permissions to the NIM cache for downloading model assets
chmod -R a+w "$LOCAL_NIM_CACHE"
docker run -it --rm --name=$CONTAINER_NAME \
-e LOG_LEVEL=$LOG_LEVEL \
-e NGC_API_KEY=$NGC_API_KEY \
--gpus all \
-v $LOCAL_NIM_CACHE:/opt/nim/.cache \
-u $(id -u) \
$IMG_NAME \
bash -i
使用 list-model-profiles 命令列出可用的配置文件。
list-model-profiles \
-e NGC_API_KEY=$NGC_API_KEY
#SYSTEM INFO
#- Free GPUs:
# - [26b3:10de] (0) NVIDIA RTX 5880 Ada Generation (RTX A6000 Ada) [current utilization: 1%]
# - [26b3:10de] (1) NVIDIA RTX 5880 Ada Generation (RTX A6000 Ada) [current utilization: 1%]
# - [1d01:10de] (2) NVIDIA GeForce GT 1030 [current utilization: 2%]
#MODEL PROFILES
#- Compatible with system and runnable:
# - 19031a45cf096b683c4d66fff2a072c0e164a24f19728a58771ebfc4c9ade44f (vllm-fp16-tp2)
# - 8835c31752fbc67ef658b20a9f78e056914fdef0660206d82f252d62fd96064d (vllm-fp16-tp1)
# - With LoRA support:
# - c5ffce8f82de1ce607df62a4b983e29347908fb9274a0b7a24537d6ff8390eb9 (vllm-fp16-tp2-lora)
# - 8d3824f766182a754159e88ad5a0bd465b1b4cf69ecf80bd6d6833753e945740 (vllm-fp16-tp1-lora)
#- Incompatible with system:
# - dcd85d5e877e954f26c4a7248cd3b98c489fbde5f1cf68b4af11d665fa55778e (tensorrt_llm-h100-fp8-tp2-latency)
# - f59d52b0715ee1ecf01e6759dea23655b93ed26b12e57126d9ec43b397ea2b87 (tensorrt_llm-l40s-fp8-tp2-latency)
# - 30b562864b5b1e3b236f7b6d6a0998efbed491e4917323d04590f715aa9897dc (tensorrt_llm-h100-fp8-tp1-throughput)
# - 09e2f8e68f78ce94bf79d15b40a21333cea5d09dbe01ede63f6c957f4fcfab7b (tensorrt_llm-l40s-fp8-tp1-throughput)
# - a93a1a6b72643f2b2ee5e80ef25904f4d3f942a87f8d32da9e617eeccfaae04c (tensorrt_llm-a100-fp16-tp2-latency)
# - e0f4a47844733eb57f9f9c3566432acb8d20482a1d06ec1c0d71ece448e21086 (tensorrt_llm-a10g-fp16-tp2-latency)
# - 879b05541189ce8f6323656b25b7dff1930faca2abe552431848e62b7e767080 (tensorrt_llm-h100-fp16-tp2-latency)
# - 24199f79a562b187c52e644489177b6a4eae0c9fdad6f7d0a8cb3677f5b1bc89 (tensorrt_llm-l40s-fp16-tp2-latency)
# - 751382df4272eafc83f541f364d61b35aed9cce8c7b0c869269cea5a366cd08c (tensorrt_llm-a100-fp16-tp1-throughput)
# - c334b76d50783655bdf62b8138511456f7b23083553d310268d0d05f254c012b (tensorrt_llm-a10g-fp16-tp1-throughput)
# - cb52cbc73a6a71392094380f920a3548f27c5fcc9dab02a98dc1bcb3be9cf8d1 (tensorrt_llm-h100-fp16-tp1-throughput)
# - d8dd8af82e0035d7ca50b994d85a3740dbd84ddb4ed330e30c509e041ba79f80 (tensorrt_llm-l40s-fp16-tp1-throughput)
# - 9137f4d51dadb93c6b5864a19fd7c035bf0b718f3e15ae9474233ebd6468c359 (tensorrt_llm-a10g-fp16-tp2-throughput-lora)
# - cce57ae50c3af15625c1668d5ac4ccbe82f40fa2e8379cc7b842cc6c976fd334 (tensorrt_llm-a100-fp16-tp1-throughput-lora)
# - 3bdf6456ff21c19d5c7cc37010790448a4be613a1fd12916655dfab5a0dd9b8e (tensorrt_llm-h100-fp16-tp1-throughput-lora)
# - 388140213ee9615e643bda09d85082a21f51622c07bde3d0811d7c6998873a0b (tensorrt_llm-l40s-fp16-tp1-throughput-lora)
您可以使用 download-to-cache 命令将任何这些配置文件下载到 NIM 缓存。以下示例将 tensorrt_llm-l40s-fp8-tp1-throughput 配置文件下载到 NIM 缓存。
download-to-cache --profile 09e2f8e68f78ce94bf79d15b40a21333cea5d09dbe01ede63f6c957f4fcfab7b
您还可以让 download-to-cache 决定给定硬件的最优配置文件进行下载,方法是不提供要下载的配置文件,如下例所示。
download-to-cache
有关 download-to-cache 工具的更多信息,请执行以下命令
download-to-cache -h
# Downloads selected or default model profiles to NIM cache. Can be used to pre-
# cache profiles prior to deployment.
# options:
# -h, --help show this help message and exit
# --profiles [PROFILES ...], -p [PROFILES ...]
# Profile hashes to download. If none are provided, the
# optimal profile is downloaded. Multiple profiles can
# be specified separated by spaces.
# --all Set this to download all profiles to cache
# --lora Set this to download default lora profile. This
# expects --profiles and --all arguments are not
# specified.
有关在气隙系统中提供模型服务的信息,请参阅 气隙部署。