使用 GenAI-Perf 进行基准测试#
NVIDIA GenAI-Perf 是一个客户端 LLM 专注的基准测试工具,提供关键指标,例如 TTFT、ITL、TPS、RPS 等。它支持任何符合 OpenAI API 规范的 LLM 推理服务,该规范是行业内广泛接受的事实标准。本节包含一个逐步演练,使用 GenAI-Perf 对由 NVIDIA NIM 驱动的 Llama-3 模型推理引擎进行基准测试。
步骤 1. 获取最新模型列表#
使用以下命令以 CSV 格式列出可用的 NIM。
ngc registry image list --format_type csv nvcr.io/nim/*
此命令应生成以下格式的输出
Name,Repository,Latest Tag,Image Size,Updated Date,Permission,Signed Tag?,Access Type,Associated Products
<name1>,<repository1>,<latest tag1>,<image size1>,<updated date1>,<permission1>,<signed tag?1>,<access type1>,<associated products1>
...
<nameN>,<repositoryN>,<latest tagN>,<image sizeN>,<updated dateN>,<permissionN>,<signed tag?N>,<access typeN>,<associated productsN>
当您调用 docker run 命令时,请使用 Repository 字段。使用以下命令,其中 REPO 是 Repository 字段之一,以获取模型版本的列表。
ngc registry image info --format_type ascii nvcr.io/${REPO}
此命令应生成如下所示的 Tags 部分,表明该模型有 1.0 和 1.1 版本
Tags:
latest
1.1
1.0
通常,latest 标签表示最新版本,在本例中为 1.1。您可以一起使用 Repository 和标签版本来访问特定模型。
步骤 2. 使用 NVIDIA NIM 设置兼容 OpenAI 的 LLama-3 推理服务#
NVIDIA NIM 提供了将 LLM 投入生产的最简单快捷的方法。请参阅 NIM LLM 文档以开始使用,首先查看硬件要求,并设置您的 NVIDIA NGC API 密钥。为了方便起见,以下命令已提供,用于部署 NIM 并从入门指南中执行推理
## Set Environment Variables
export NGC_API_KEY=<value>
# Choose a container name for bookkeeping
export CONTAINER_NAME=llama3-8b-instruct
# Choose a LLM NIM Image from NGC
export IMG_NAME="nvcr.io/${REPOSITORY}:${TAG}"
# Choose a path on your system to cache the downloaded models
export LOCAL_NIM_CACHE=~/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
# Start the LLM NIM
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus all \
--shm-size=16GB \
-e NGC_API_KEY \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
-p 8000:8000 \
$IMG_NAME
这些示例使用 Meta llama3-8b-instruct 模型,并将该名称用作容器的名称。这些示例引用并挂载本地目录作为缓存目录。在启动期间,NIM 容器下载所需的资源并开始在 API 端点后面提供模型服务。以下消息表示启动成功。
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
一旦启动并运行,NIM 将提供一个兼容 OpenAI 的 API,您可以查询它,如下例所示。
from openai import OpenAI
client = OpenAI(base_url="http://0.0.0.0:8000/v1", api_key="not-used")
prompt = "Once upon a time"
response = client.completions.create(
model="meta/llama3-8b-instruct",
prompt=prompt,
max_tokens=16,
stream=False
)
completion = response.choices[0].text
print(completion)
注意
在我们广泛的基准测试中,我们观察到,通过指定额外的 Docker 标志,无论是 –security-opt seccomp=unconfined(禁用 Seccomp 安全配置文件)还是 –privileged(授予容器几乎所有主机的功能,包括直接访问硬件、设备文件和某些内核功能),推理性能可以进一步提高,使用 NIM TensorRT-LLM v0.10.0 后端可提高高达 5%,使用 OSS vLLM(在 v0.4.3 上测试)或 NIM vLLM 后端(在 NIM 1.0.0 上测试)可提高高达 20%。这已在 DGX A100 和 H100 系统上得到验证,但可能广泛适用于其他 GPU 系统。禁用 Seccomp 或使用特权模式可以消除与容器化安全措施相关的一些开销,从而允许 NIM 和 vLLM 更有效地利用资源。然而,虽然存在性能优势,但由于安全漏洞的提升,应极其谨慎地使用这些标志。有关更多详细信息,请参阅 Docker 文档。
步骤 3. 设置 GenAI-Perf 并进行预热:基准测试单个用例#
一旦 NIM LLama-3 推理服务运行,您就可以设置基准测试工具。最简单的方法是使用预构建的 docker 容器。我们建议在与 NIM 相同的服务器上启动 GenAI-perf 容器,以避免网络延迟,除非您特别希望将网络延迟作为测量的一部分考虑在内。
注意
有关入门的综合指南,请查阅 GenAI-Perf 文档。
运行以下命令以使用预构建的容器。
export RELEASE="24.06" # recommend using latest releases in yy.mm format
export WORKDIR=<YOUR_GENAI_PERF_WORKING_DIRECTORY>
docker run -it --net=host --gpus=all -v $WORKDIR:/workdir nvcr.io/nvidia/tritonserver:${RELEASE}-py3-sdk
进入容器后,您可以按如下方式启动 genAI-perf 评估工具,这将对 NIM 后端运行预热负载测试。
export INPUT_SEQUENCE_LENGTH=200
export INPUT_SEQUENCE_STD=10
export OUTPUT_SEQUENCE_LENGTH=200
export CONCURRENCY=10
export MODEL=meta/llama3-8b-instruct
cd /workdir
genai-perf \
-m $MODEL \
--endpoint-type chat \
--service-kind openai \
--streaming \
-u localhost:8000 \
--synthetic-input-tokens-mean $INPUT_SEQUENCE_LENGTH \
--synthetic-input-tokens-stddev $INPUT_SEQUENCE_STD \
--concurrency $CONCURRENCY \
--output-tokens-mean $OUTPUT_SEQUENCE_LENGTH \
--extra-inputs max_tokens:$OUTPUT_SEQUENCE_LENGTH \
--extra-inputs min_tokens:$OUTPUT_SEQUENCE_LENGTH \
--extra-inputs ignore_eos:true \
--tokenizer meta-llama/Meta-Llama-3-8B-Instruct \
-- \
-v \
--max-threads=256
此示例指定了输入和输出序列长度以及要测试的并发性。它还告诉后端忽略特殊的“EOS”令牌,以便输出达到预期的长度。
注意
此测试将使用 HuggingFace 的 llama-3 分词器,这是一个受保护的 存储库。您需要申请访问权限,然后使用您的 HF 凭据登录。
pip install huggingface_hub
huggingface-cli login
注意
有关完整选项和参数集,请参阅 GenAI-perf 文档。
成功执行后,您应该在终端中看到类似于以下内容的结果
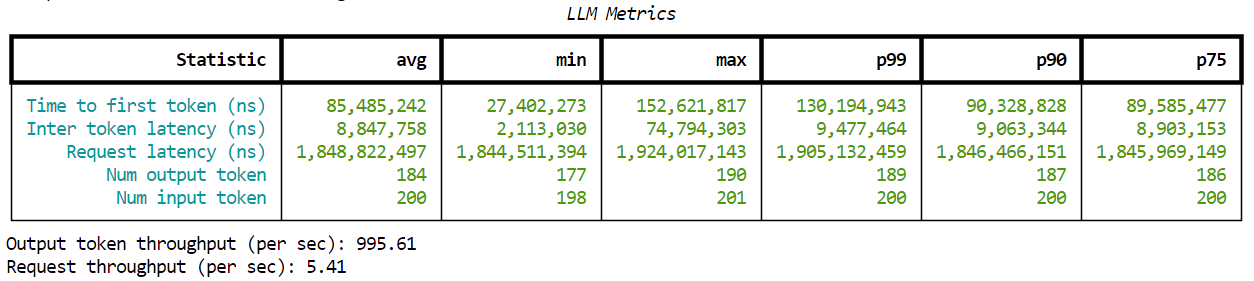
图 6. genAI-perf 的示例输出。#
步骤 4. 遍历多个用例#
通常在基准测试中,测试将设置为遍历多个用例,例如输入/输出长度组合和负载场景,例如不同的并发值。使用以下 bash 脚本定义参数,以便 genAI-perf 执行所有组合。
注意
在进行基准测试遍历之前,建议运行预热测试。在我们的例子中,这已在之前的步骤 3 中执行。
declare -A useCases
# Populate the array with use case descriptions and their specified input/output lengths
useCases["Translation"]="200/200"
useCases["Text classification"]="200/5"
useCases["Text summary"]="1000/200"
# Function to execute genAI-perf with the input/output lengths as arguments
runBenchmark() {
local description="$1"
local lengths="${useCases[$description]}"
IFS='/' read -r inputLength outputLength <<< "$lengths"
echo "Running genAI-perf for $description with input length $inputLength and output length $outputLength"
#Runs
for concurrency in 1 2 5 10 50 100 250; do
local INPUT_SEQUENCE_LENGTH=$inputLength
local INPUT_SEQUENCE_STD=0
local OUTPUT_SEQUENCE_LENGTH=$outputLength
local CONCURRENCY=$concurrency
local MODEL=meta/llama3-8b-instruct
genai-perf \
-m $MODEL \
--endpoint-type chat \
--service-kind openai \
--streaming \
-u localhost:8000 \
--synthetic-input-tokens-mean $INPUT_SEQUENCE_LENGTH \
--synthetic-input-tokens-stddev $INPUT_SEQUENCE_STD \
--concurrency $CONCURRENCY \
--output-tokens-mean $OUTPUT_SEQUENCE_LENGTH \
--extra-inputs max_tokens:$OUTPUT_SEQUENCE_LENGTH \
--extra-inputs min_tokens:$OUTPUT_SEQUENCE_LENGTH \
--extra-inputs ignore_eos:true \
--tokenizer meta-llama/Meta-Llama-3-8B-Instruct \
--measurement-interval 10000 \
--profile-export-file ${INPUT_SEQUENCE_LENGTH}_${OUTPUT_SEQUENCE_LENGTH}.json \
-- \
-v \
--max-threads=256
done
}
# Iterate over all defined use cases and run the benchmark script for each
for description in "${!useCases[@]}"; do
runBenchmark "$description"
done
将此脚本保存在工作目录中,例如 /workdir/benchmark.sh 下。然后,您可以使用以下命令执行它。
cd /workdir
bash benchmark.sh
注意
“–measurement-interval 10000” 是用于每次测量的以毫秒为单位的时间间隔。GenAI-perf 测量在指定时间间隔内完成的请求。选择一个足够大的值,以便完成多个请求。对于更大的网络(例如 Llama-3 70B)和更高的并发性(例如 250),请选择更高的值(例如 100000,即 100 秒)。
步骤 5. 分析输出#
当测试完成时,GenAI-perf 会在您挂载的工作目录(在这些示例中为 /workdir)下的名为“artifacts”的默认目录中生成结构化输出,按模型名称、并发性和输入/输出长度组织。您的结果应类似于以下内容。
/workdir/artifacts
├── meta_llama3-8b-instruct-openai-chat-concurrency1
│ ├── 200_200.csv
│ ├── 200_200_genai_perf.csv
│ ├── 200_5.csv
│ ├── 200_5_genai_perf.csv
│ ├── all_data.gzip
│ ├── llm_inputs.json
│ ├── plots
│ └── profile_export_genai_perf.json
├── meta_llama3-8b-instruct-openai-chat-concurrency10
│ ├── 200_200.csv
│ ├── 200_200_genai_perf.csv
│ ├── 200_5.csv
│ ├── 200_5_genai_perf.csv
│ ├── all_data.gzip
│ ├── llm_inputs.json
│ ├── plots
│ └── profile_export_genai_perf.json
├── meta_llama3-8b-instruct-openai-chat-concurrency100
│ ├── 200_200.csv
…
“*genai_perf.csv” 文件包含主要的基准测试结果。使用以下 Python 代码片段将给定用例的文件解析为 Pandas 数据帧。
import pandas as pd
import io
def parse_data(file_path):
# Create a StringIO buffer
buffer = io.StringIO()
with open(file_path, 'rt') as file:
for i, line in enumerate(file):
if i not in [6,7]:
buffer.write(line)
# Make sure to reset the buffer's position to the beginning before reading
buffer.seek(0)
# Read the buffer into a pandas DataFrame
df = pd.read_csv(buffer)
return df
您还可以使用以下 bash 脚本读取给定用例的所有并发性的每秒令牌数和 TTFT 指标。
import os
root_dir = "./artifacts"
directory_prefix = "meta_llama3-8b-instruct-openai-chat-concurrency"
concurrencies = [1, 2, 5, 10, 50, 100, 250]
TPS = []
TTFT = []
for con in concurrencies:
df = parse_data(os.path.join(root_dir, directory_prefix+str(con), f"200_200_genai_perf.csv"))
TPS.append(df.iloc[5]['avg'])
TTFT.append(df.iloc[0]['avg']/1e9)
最后,我们可以使用以下代码,使用收集的数据绘制和分析延迟-吞吐量曲线。在这里,每个数据点都对应一个并发值。
import plotly.express as px
fig = px.line(x=TTFT, y=TPS, text=concurrencies)
fig.update_layout(xaxis_title="Single User: time to first token(s)", yaxis_title="Total System: tokens/s")
fig.show()
使用 genAI-perf 测量数据生成的最终图看起来像下面这样。
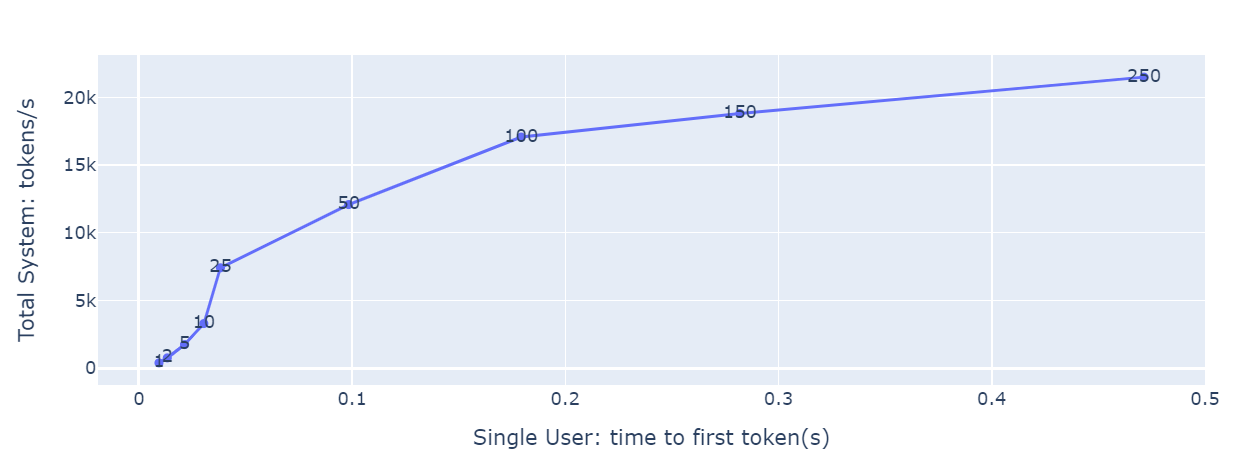
图 7:使用 GenAI-perf 生成的数据绘制的延迟-吞吐量曲线图。#
步骤 6. 解释结果#
之前的图表在 x 轴上显示 TTFT,在 y 轴上显示总系统吞吐量,每个点上显示并发性。有两种方法可以使用该图表
具有延迟预算的 LLM 应用程序所有者,其中最大 TTFT 是可接受的,使用该值作为 x,并查找匹配的 y 值和并发性。这显示了在该延迟限制和相应的并发值下可以实现的最大吞吐量。
LLM 应用程序所有者可以使用并发值在图表上找到点。匹配的 x 和 y 值显示了该并发级别的延迟和吞吐量。
该图表还显示了延迟增长迅速但吞吐量几乎没有增加的并发性。例如,在上面的图表中,并发性=100 就是这样一个值。
类似的图表可以使用 ITL、e2e_latency 或 TPS_per_user 作为 X 轴,显示总系统吞吐量和个人用户延迟之间的权衡。