指标#
本节介绍了一些常见的 LLM 推理指标。请注意,不同工具之间的基准测试结果可能存在差异。下图说明了一些广泛使用的 LLM 推理指标。
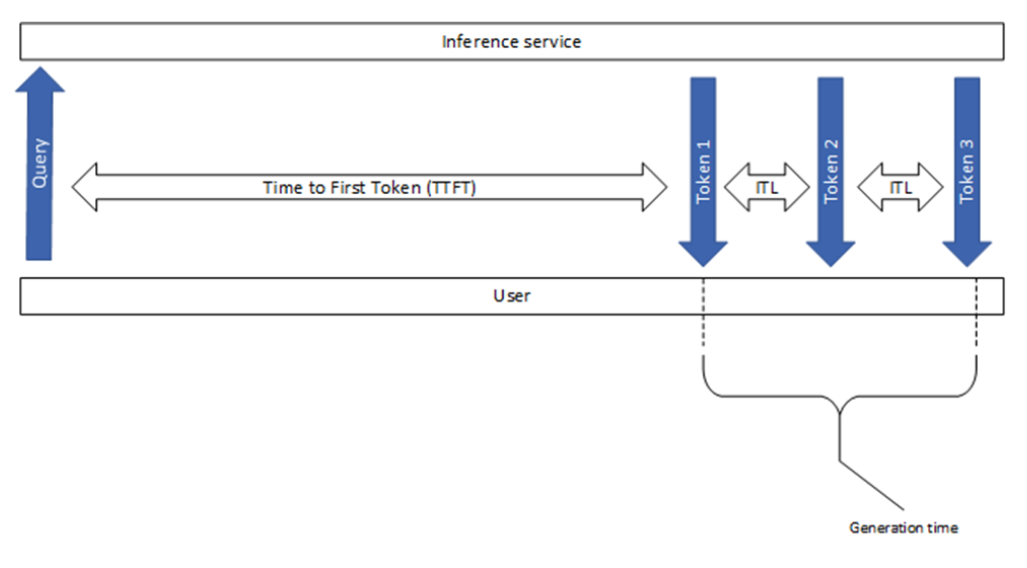
图 1. 常用 LLM 推理性能指标概述。#
首个令牌时间 (TTFT)#
此指标显示用户需要等待多久才能看到模型的输出。这是从提交查询到接收到第一个令牌(如果响应不为空)所花费的时间。

图 2:TTFT - 首个令牌时间,包括第一个输出令牌的令牌化和反令牌化步骤。#
注意
NVIDIA GenAI-Perf 和 LLMPerf 基准测试工具都忽略了没有内容或内容为空字符串(没有令牌)的初始响应。这是因为当第一个响应中没有令牌时,TTFT 测量是毫无意义的。
首个令牌时间通常包括请求排队时间、预填充时间和网络延迟。提示越长,TTFT 越大。这是因为注意力机制需要整个输入序列来计算并创建所谓的键值缓存(也称为 KV-cache),迭代生成循环可以从这一点开始。此外,生产应用程序可能同时有多个请求正在进行中,因此一个请求的预填充阶段可能与另一个请求的生成阶段重叠。
注意
传统的 Web 服务基准测试工具(如 K6)也可以通过 HTTP 请求中的计时事件提供 TTFT。
端到端请求延迟 (e2e_latency)#
此指标指示从提交查询到接收完整响应所花费的时间,包括您的排队/批处理机制和网络延迟的性能,如图 3 所示。
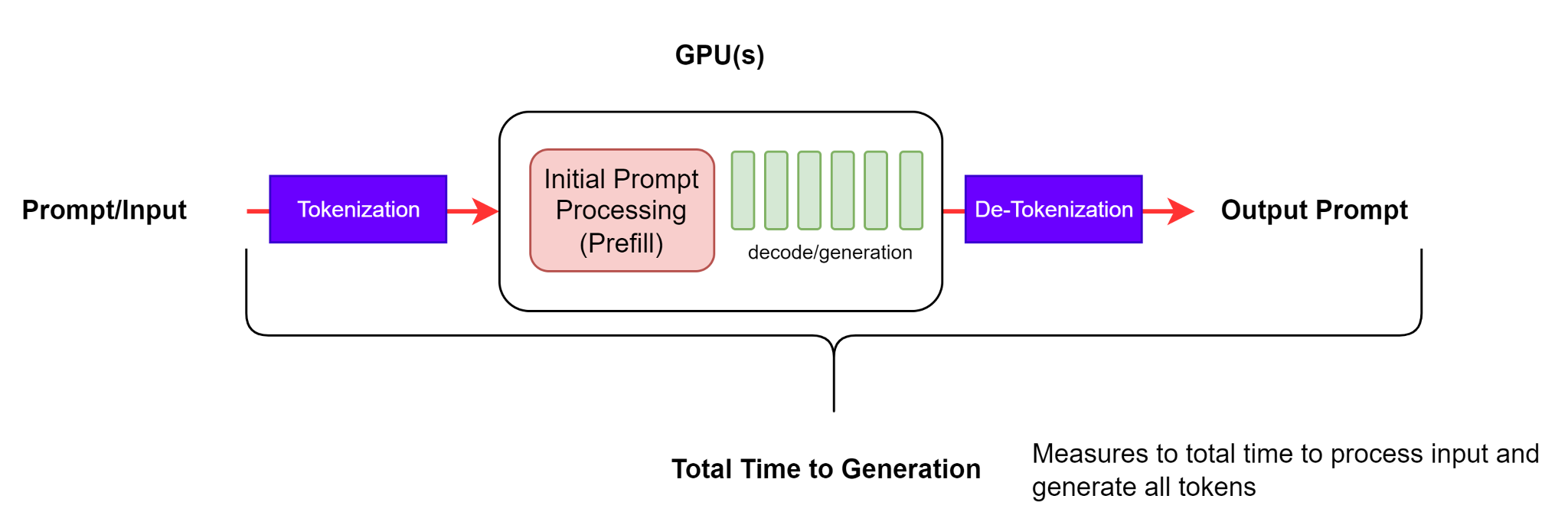
图 3. 端到端请求延迟#
注意
在流式模式下,当部分结果返回给用户时,反令牌化步骤可以执行多次。
对于单个请求,端到端请求延迟是请求发送和最终令牌接收之间的时间差。因此
注意
Generation_time 是从接收到第一个令牌到接收到最终令牌的持续时间,如图 1 所示。此外,GenAI-Perf 移除了最后的 [done] 信号或空响应,因此它们不会包含在 e2e 延迟中。
令牌间延迟 (ITL)#
这定义为连续令牌之间的平均时间,也称为每个输出令牌的时间 (TPOT)。
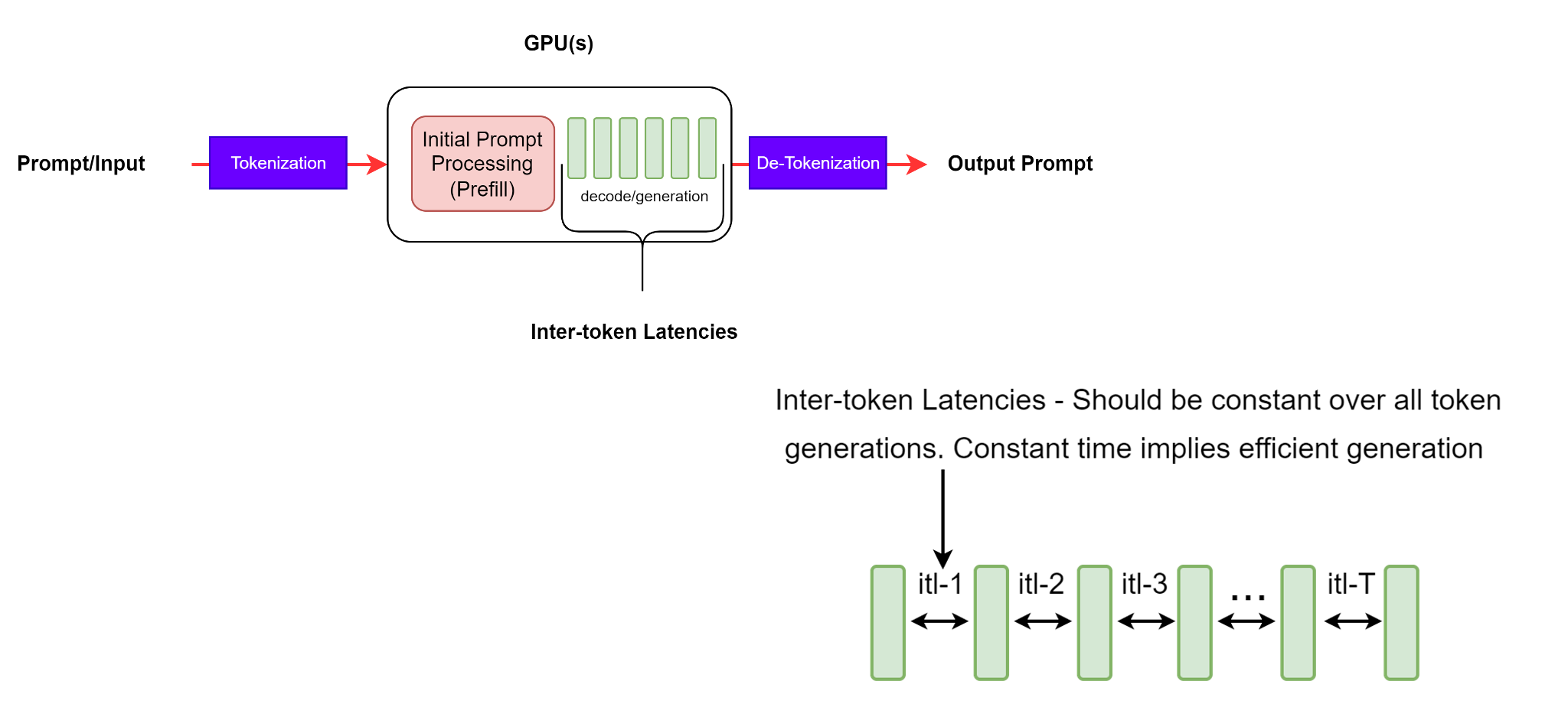
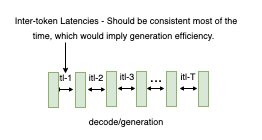
图 4:ITL - 连续令牌生成之间的延迟。#
虽然这看起来是一个简单明了的定义,但在收集指标时,不同的基准测试工具会考虑一些复杂的问题。例如,这个平均计算是否应该包括首个令牌时间 (TTFT)?NVIDIA genAI-perf 不包括,而 LLMPerf 则包括。
GenAI-Perf 将 ITL 定义如下
此指标使用的公式不包括第一个令牌(因此在分母中减去 1)。这样做是为了使 ITL 仅作为请求处理的解码部分的特征。
重要的是要注意,对于更长的输出序列,KV 缓存会增长,从而增加内存成本。注意力计算的成本也会增加:对于每个新令牌,此成本与到目前为止的输入 + 输出序列的长度成线性关系(但此计算通常不是计算密集型的)。一致的令牌间延迟表示高效的内存管理、更好的内存带宽以及高效的注意力计算。
每秒令牌数 (TPS)#
系统总 TPS 表示每秒输出令牌总吞吐量,考虑了所有同时发生的请求。随着请求数量的增加,系统总 TPS 也会增加,直到达到所有可用 GPU 计算资源的饱和点,超过该点可能会降低。
给定整个基准测试的时间线,总共有 n 个请求。

图 5:基准测试运行中的事件时间线#
其中
Li : 第 i 个请求的端到端延迟
T_start : 基准测试开始时间
Tx : 第一个请求的时间戳
Ty : 最后一个请求的最后一个响应的时间戳
T_end : 基准测试结束时间
GenAI-perf 将 TPS 定义为输出令牌总数除以第一个请求和最后一个请求的最后一个响应之间的端到端延迟。
请注意,LLM-perf 将 TPS 定义为输出令牌总数除以整个基准测试持续时间。
因此,它还将以下开销纳入指标中:(1)输入提示生成;(2)请求准备和(3)存储响应。在我们的观察中,在单并发场景中,这些开销有时可能占整个基准测试持续时间的 33%。
请注意,之前的计算是以批处理方式完成的,而不是实时的运行指标。此外,GenAI-perf 使用滑动窗口技术来查找稳定的测量值。这意味着给定的测量值来自完全完成的请求的代表性子集,这意味着在计算指标时不包括“预热”和“冷却”请求。
每用户 TPS 表示从单个用户角度来看的吞吐量,定义为每个用户的请求的(输出序列长度)/(e2e_latency),随着输出序列长度的增加,它会渐近地接近 1/ITL。请注意,随着系统中并发请求数量的增加,整个系统的总 TPS 会增加,而每用户 TPS 会随着延迟变差而降低。
每秒请求数 (RPS)#
这是系统在 1 秒内可以成功完成的平均请求数。计算公式为