运行 Mortgage Benchmark
使用左侧菜单链接连接到 系统控制台。
连接到 sparkrunner pod。
kubectl exec --stdin --tty sparkrunner-0 -- /bin/bash
cd 到 /home/spark/spark-scripts 并执行 系统控制台 中的
/home/spark/spark-scripts/lp-runjupyter-etl-gpu.sh或/home/spark/spark-scripts/lp-runjupyter-etl-cpu.sh。在左侧菜单中打开 桌面 链接,然后单击 VNC 连接按钮。

在 Linux 桌面中打开 Web 浏览器。

浏览到 172.16.0.10:30002。
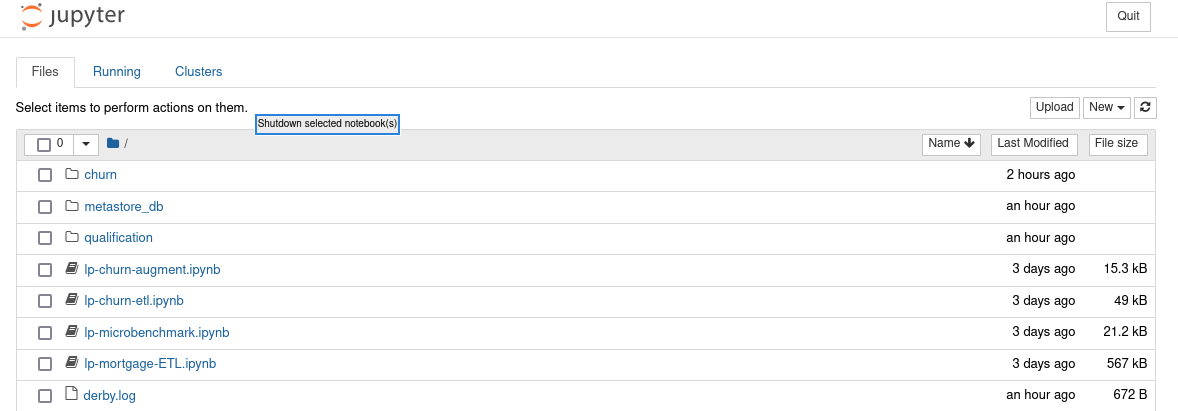
您应该看到上面的列表。
单击
lp-mortgageETL.ipynb链接,这应该会启动 Jupyter notebook。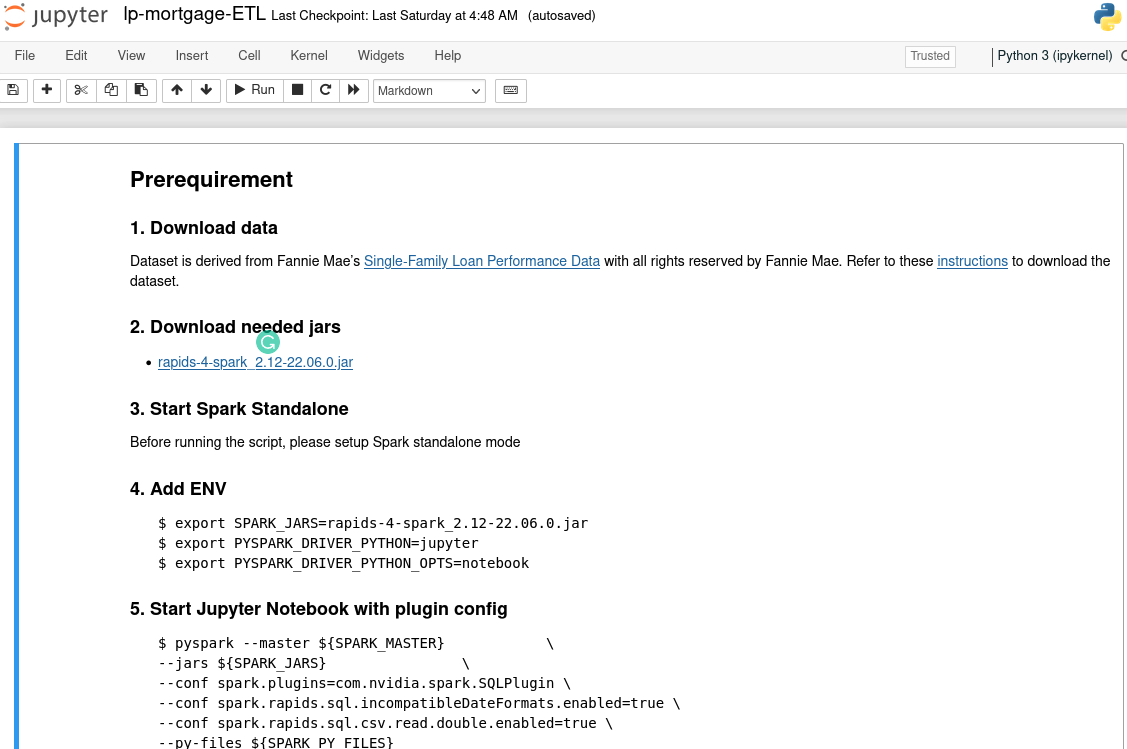 注意
注意请在运行 notebook 之前“信任”它。

使用以下命令验证 Mortgage Benchmark pod 的创建。
打开另一个 系统控制台。
kubectl get pods | grep app-name
输出应类似于此。
app-name-79d837808b2d2ba5-exec-1 1/1 Running 0 31m app-name-79d837808b2d2ba5-exec-2 1/1 Running 0 31m app-name-79d837808b2d2ba5-exec-3 1/1 Running 0 31m
在前一步的控制台会话中为 Mortgage Dataset 创建两个目录。
cd `mount | awk -F ':' '/spark-rapids-claim/ {print $2}'|grep var | awk '{print $1}'` mkdir -p mortgage/input mkdir -p mortgage/output chmod 777 mortgage/output
从 LaunchPad 桌面 从 Fannie Mae 网站下载输入数据集。
转到 Single-Family Loan Performance Data 页面。
登录或注册为新用户。
选择 HP。
单击 Download Data 并选择 Single-Family Loan Performance Data。您将找到一个表格列表,其中包含基于年份和季度排序的 Acquisition and Performance 文件。单击文件进行下载。例如:2017Q1.zip
解压缩下载的文件以提取 csv 文件:例如:2017Q1.csv
将 csv 文件复制到 GPU 节点。
scp 2017Q1.csv nvidia@172.16.0.10:/data/${your-default-spark-rapids-claim-path}/mortgage/input/
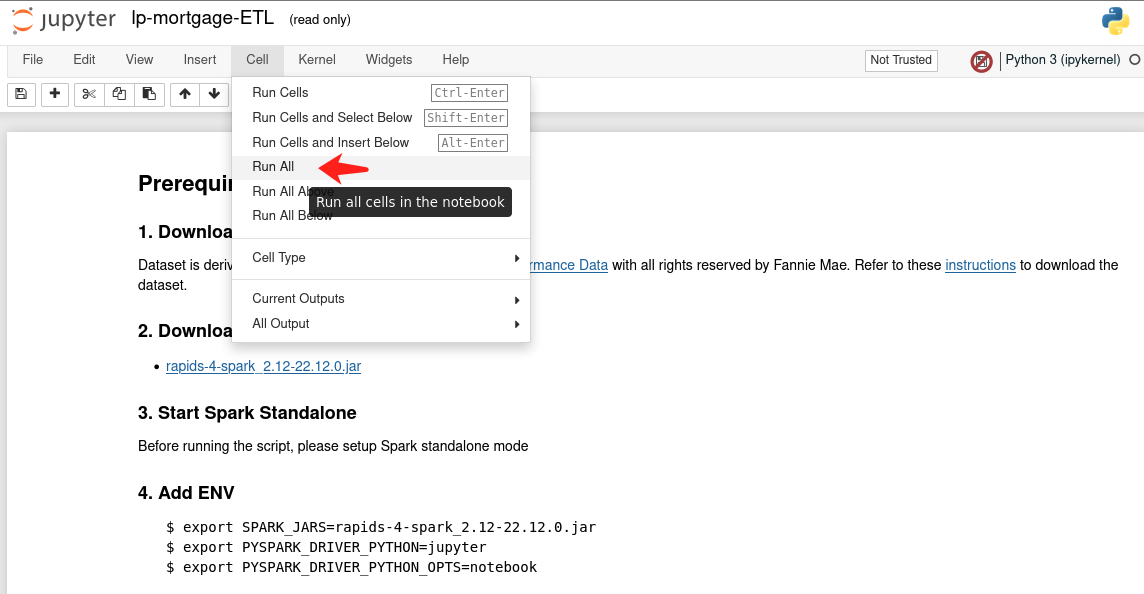
通过单击 Cell -> Run All 运行 notebook。
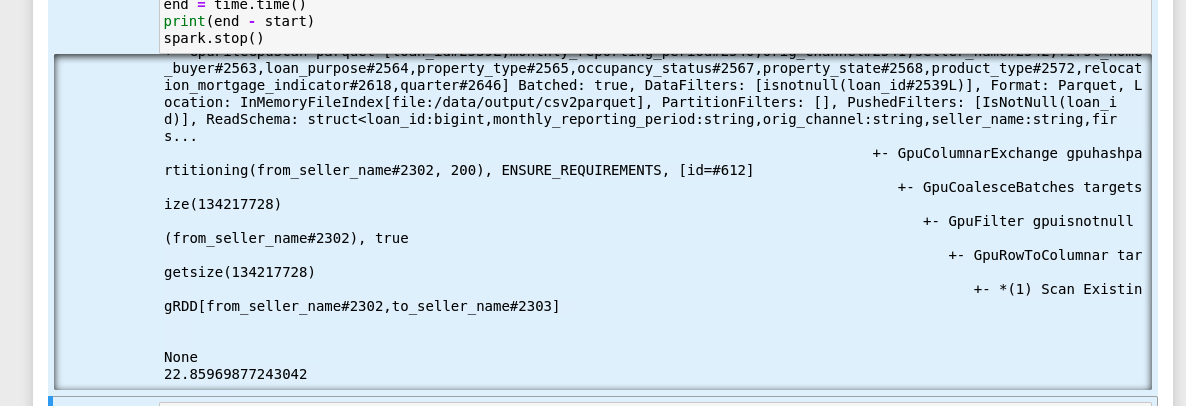
记下 benchmark 的时间,以便您可以与 CPU 运行时间进行比较。
通过在启动 notebook 的系统控制台窗口中按 ctrl-c 来停止在步骤 1 中启动的 notebook。当询问您是否要“关闭此 notebook 服务器?”时,回答 Y。
仅使用 CPU 运行相同的 Mortgage Benchmark。
执行
lp-runjupyter-etl-cpu.sh脚本。
比较两个输出之间的差异。







您必须关闭 notebook 标签页,然后关闭 notebook 才能启动另一个会话。如果未完成此操作,您将无法启动另一个 spark 会话。