DLProf Viewer 用户指南
1.1. 概述
DLProf Viewer 通过显示耗时最多的前 10 个操作、Tensor Core 操作的资格和 Tensor Core 使用率,以及交互式迭代报告,使可视化模型性能变得容易。
1.2. 1.8.0 版本的新增功能
- 这是 DLProf Viewer 的最后一个版本。
- 与 DLProf CLI v1.8.0 兼容。
1.3. 功能
- 面板化仪表板摘要视图:一个包含多个面板的摘要视图,可快速概览性能结果。
- 顶层关键指标:摘要视图显示了几个用于快速衡量性能质量的关键指标,包括平均迭代时间和 Tensor Core 利用率。
- 前 10 个 GPU Ops 节点:摘要视图中的一个表格列出了 GPU 上花费时间最多的前 10 个 Op 节点。
- 专家系统面板:此面板显示 DLProf 专家系统检测到的任何问题,以及关于如何解决问题和提高模型性能的建议。
- 迭代摘要面板:此面板以可视化方式显示迭代。用户可以快速查看模型中有多少次迭代、聚合/分析的迭代以及每次迭代中 tensor core 内核的持续时间。
- 交互式表格:详细视图中的所有表格都是完全交互式的,允许用户对显示进行排序、过滤和分页。
- 可互操作的表格:多个视图都具有向下钻取以获取更多信息的能力。在一个表格中选择一行将在下一个表格中填充与所选内容相关的性能信息。
- 客户端/服务器架构:
- 所有数据现在都在关系数据库中。
- 所有视图的加载时间都得到了改善。
- GPU 视图:显示分析期间使用的所有 GPU 的 GPU 利用率和 GPU 属性。
2.1. 使用 Python Wheel 安装
DLProf Viewer 可以从 NVIDIA PY 索引轻松安装。
安装 nvidia-pyindex。
$ pip install nvidia-pyindex
接下来使用 pip 安装 DLProf Viewer
$ pip install nvidia-dlprofviewer
2.2. 使用 NGC Docker 容器
- 确保您有权访问并已登录到 NGC。有关分步说明,请参阅NGC 入门指南。
- 安装 Docker 和 nvidia-docker。对于 DGX 用户,请参阅准备使用 NVIDIA 容器。对于 DGX 以外的用户,请参阅nvidia-docker 安装文档。
使用 docker pull 从 NGC 获取 TensorFlow 容器
$ docker pull nvcr.io/nvidia/tensorflow:xx.yy>-tf1-py3
假设模型的训练数据在 /full/path/to/training/data 中可用,您可以使用以下命令启动容器
$ docker run --rm --gpus=1 --shm-size=1g --ulimit memlock=-1 \
--ulimit stack=67108864 -it -p8000:8000 -v/full/path/to/training/data:/data \
nvcr.io/nvidia/tensorflow:<xx.yy>-tf1-py3
2.3. 生成 DLProf 数据库
DLProf 数据库直接从深度学习分析器创建。有关如何生成数据库的信息,请参阅深度学习分析器用户指南。
2.4. 启动 DLProf Viewer
DLProf Viewer 安装在所有安装了 DLProf 的容器中,这些容器位于NVIDIA GPU 云 (NGC)中。容器必须使用 -p8000:8000 选项运行,才能为 DLProf Viewer 打开端口 8000。使用任何端口,例如 8001、8002 等。
用法
Usage: dlprofviewer [-h] [--version] [-b ADDRESS] [-p PORT] database
positional arguments:
database Specify path to DLProf database.
optional arguments:
-h, --help Show this help message and exit
--version Show program's version number and exit
-b ADDRESS, --bind ADDRESS
Specify alternate bind address. Use '0.0.0.0' to serve to the entire local network. [default: localhost]
-p PORT, --port PORT Specify alternate port. [default: 8000]
DLProf Viewer 服务器直接从容器启动
$ dlprofviewer dlprof_dldb.sqlite
其中 dlprof_dldb.sqlite 是 DLProf 数据库的路径。
注意:使用此示例会将此查看器在网络上的可见性限制为仅“localhost”。有关如何增加此 DLProf 数据库在网络上的可见性的信息,请参阅绑定部分。
2.5. 绑定
如果您希望本地网络上的任何人都能在其浏览器中访问您的 dlprofviewer 服务器,请使用 -b 0.0.0.0 启动
$ dlprofviewer -b 0.0.0.0 dlprof_dldb.sqlite
服务器运行后,可以使用 URL 在浏览器中查看 DLProf 应用程序
http://<machine IP Address>:8000
2.6. 端口
您还可以使用 -p PORT 指定自定义端口,例如(端口 8001)
$ dlprofviewer -b 0.0.0.0 -p 8001 dlprof_dldb.sqlite
然后使用您的浏览器转到此 URL
http://<machine IP Address>:8000
2.7. 如何启动 DLProf Viewer
DLProf Viewer 安装在所有安装了 DLProf 的容器中,这些容器位于NVIDIA GPU 云 (NGC)中。容器必须使用 -p8000:8000 选项运行,才能为 DLProf Viewer 打开端口 8000。使用任何端口,例如 8001、8002 等。
2.8. 向后兼容性
一些旧版本的 DLProf 数据库可以用作最新 dlprofviewer 的输入:
- DLProf 数据库的初始版本是用于创建它的 DLProf 版本。
- DLProf 数据库 v1.3+ 可以用作 DLProf CLI v1.3+ 的输入
- DLProf 数据库版本仍应小于或等于 dlprofviewer 版本。
- DLProf 数据库 v1.1 和 v1.2 不能用作 dlprofviewer v1.3+ 的输入。
- 当旧版本的 DLProf 数据库用作输入时,将对其进行一些小的更改,以使其能够与最新的 dlprofviewer 正确使用。
- 向后兼容性在每个主要版本中都会“重置”。
- dlprofviewer v2.x 将不支持 DLProf 数据库 v1.y。
3.1. 术语和定义
| 术语 | 定义 |
|---|---|
| 聚合 | 给定迭代开始、迭代停止和关键节点,对指标进行汇总。 |
| Op 节点 | 图中一个节点,在该节点上对传入的 tensor 执行操作。 |
| 模型、图、网络 | <同义词> |
3.2. 窗格概述
| 窗格 | 定义 |
| 内容窗格 | 也称为 VIEWS 窗格,您可以在其中看到已分析的神经网络的所有不同部分。 |
| 详细信息窗格 | 此窗格用于显示有关在内容窗格中选择的信息的更多详细信息。假设您正在内容窗格中查看内核摘要面板,并且想要查看有关内核的更多信息。单击 
|
3.3. 导航栏
此标准导航栏是位于查看器顶部的导航标题。它包含一些按钮,就像大多数标准网站一样。它不会滚动出屏幕,因此这些按钮始终可用。

注意
本文档中的一些屏幕截图可能在导航栏中有一个名为 域 的下拉菜单。此功能已从 DLProf Viewer 中删除。
| 控件 | 定义 |
| NVIDIA DLProf Viewer 按钮 | 这是品牌按钮。单击后,用户将导航到仪表板视图。 |
| 视图 | 此下拉列表提供了可用视图的列表。单击下拉列表中的名称会在主显示面板中加载该视图。可用视图包括 |
| 聚合(可选) | 当网络被重新聚合(即,聚合多次)时,会出现此可选下拉列表。 聚合是迭代开始、迭代停止和关键节点的组合。 迭代停止和迭代停止值在下拉列表中列出,如上所示。要查看相应的关键节点,请单击下拉列表并将鼠标悬停在列表中的每个聚合上。 |
| 帮助 / 深度学习分析器 | 此链接将用户导航到 DLProf 用户指南的在线版本。 |
| 帮助 / Viewer | 此链接将用户导航到本文档的在线版本 |
| 帮助 / 联系我们 | 请告诉我们!如果您有任何意见、问题或建议,请单击此链接。它将启动您的默认电子邮件软件,并且已填写了收件人地址。只需填写主题行,键入您的电子邮件消息,然后单击发送即可。 |
3.4. 内容窗格
3.4.1. 仪表板
仪表板视图在面板化视图中提供了性能结果的高级摘要。此视图用作分析结果的起点,并提供几个关键指标。

3.4.1.1. GPU 利用率面板
GPU 空闲面板以可视化方式指示聚合迭代执行期间的 GPU 利用率时间百分比。将鼠标悬停在图表中的切片上将显示数值百分比。

| 图例标签 | 定义 |
| 正在使用 GPU | 所有 GPU 的平均 GPU 利用率百分比。 |
| 空闲 GPU | 所有 GPU 的平均 GPU 空闲百分比。 |
| 控件 | 定义 |
| 图例标签 | 在图表中隐藏和显示图例条目之间切换。 |
| 更多... | 显示更多视图的下拉菜单(仅当在分析期间使用多个 GPU 时才可见)。 |
3.4.1.2. 资源使用情况细分面板

| 图例标签 | 定义 |
| 正在使用 Tensor Cores | 所有使用 tensor core 的内核的累积持续时间。 |
| 未使用 Tensor Cores | 所有未使用 tensor core 的内核的累积持续时间。 |
| 内存 | 所有内存操作的累积持续时间。 |
| 数据加载器 | 数据加载器操作的累积持续时间。 |
| I/O | I/O 操作的累积持续时间。 |
| CPU | 所有 CPU 操作的累积持续时间。 |
| 其他 | 不在任何其他类别中的所有时间。 |
| 控件 | 定义 |
| 图例标签 | 在图表中隐藏和显示图例条目之间切换。 |
3.4.1.3. 内核 GPU 总时间面板
- 将鼠标悬停在图表中的切片上将显示聚合的 GPU 时间。
- 单击图例项目将在图表中切换其可视化效果。

| 图例标签 | 定义 |
| 正在使用 Tensor Cores | 聚合使用 Tensor Core 的所有内核的 GPU 总时间。 |
| 内存内核 | 聚合所有与内存相关的内核的 GPU 总时间。 |
| 所有其他内核 | 聚合所有剩余内核类型的 GPU 总时间。 |
| 控件 | 定义 |
|
|
在详细信息窗格中显示内核详细信息面板。 |
| 图例标签 | 在图表中隐藏和显示图例条目之间切换。 |
| 更多... | 显示更多视图的下拉菜单。 |
3.4.1.4. Tensor Core 内核效率面板
- 将鼠标悬停在图表中的切片上将显示百分比。
- 单击图例项目将在图表中切换其可视化效果。

性能摘要面板
性能摘要面板提供了有关在特定迭代范围内聚合的性能数据的顶层关键指标。将鼠标悬停在“i”图标上时,将出现有用的工具提示文本。

| 字段 | 定义 |
| 挂钟时间 | 这是聚合范围的总运行时间,定义为 CPU 上开始迭代中第一个操作的开始时间与 CPU 或 GPU 上最终迭代中最后一个操作的结束时间之间的时间,以时间戳最大者为准。 |
| Tensor Core 内核效率 % | 此高级指标表示 Tensor Core 启用内核的利用率。Tensor Core 操作可以提供性能改进,应尽可能使用。此指标的计算公式为:[Tensor Core 内核的 GPU 总时间] / [Tensor Core 合格 Ops 的 GPU 总时间] 100% Tensor Core 利用率意味着所有合格 Ops 仅在 GPU 上运行 Tensor Core 启用内核。50% Tensor Core 利用率可能意味着所有合格 Ops 仅在一半时间内运行 Tensor Core 内核,或者仅一半的合格 Ops 仅运行 Tensor Core 内核。此指标应与 Op 摘要面板一起使用,以确定 Tensor Core 使用的质量。 越高越好。 |
| GPU 利用率 % | 所有 GPU 的平均 GPU 利用率。 越高越好。 |
| 总迭代次数 | 在网络中找到的迭代总数。 |
| 已分析迭代 | 用于聚合性能结果的迭代总数。此数字是使用“开始迭代”和“停止迭代”计算得出的。 |
| 开始迭代 | 用于生成性能结果的开始迭代编号。 |
| 停止迭代 | 用于生成性能结果的结束迭代编号。 |
| 平均迭代时间 | 平均迭代时间是总挂钟时间除以迭代次数。 |
3.4.1.6. 迭代摘要面板
此面板以可视化方式显示迭代。用户可以快速查看模型中有多少次迭代、聚合/分析的迭代以及每次迭代中 tensor core 内核的持续时间。此面板上的颜色与所有其他仪表板面板上的颜色匹配。

有关此面板的更多信息,请参阅迭代视图。
3.4.1.7. 前 10 个 GPU Ops 面板
前 10 个 GPU Ops 表格显示了在 GPU 上执行时间最长的前 10 个操作。此表格已预先排序,每行的顺序按 GPU 时间降序排列。该表格不可排序或搜索。

| 列 | 定义 |
| GPU 时间 | 显示所有 GPU 上所有内核的 GPU 总时间。 |
| Op 名称 | op 的名称。 |
| 方向 | op 的 fprop/bprop 方向。(仅在 PyTorch 运行中可见)。 |
| Op 类型 | op 的类型。 |
| 调用 | op 被调用的次数。 |
| TC 合格 | 一个真/假字段,指示 op 是否有资格使用 Tensor Core 内核。 |
| 正在使用 TC | 一个真/假字段,指示在此 op 中启动的内核之一是否正在使用 Tensor Core。 |
3.4.1.8. 系统配置面板

| 字段 | 定义 |
| 分析名称 | (可选)用于描述已分析网络的有用标签。此字段中的值对应于 DLProf 中 --profile_name 命令行参数中提供的值。 |
| GPU 计数 | 在训练期间在计算机上找到的 GPU 设备数量。 |
| GPU 名称 | 在训练期间在计算机上找到的 GPU 设备列表。 |
| CPU 型号 | 训练期间计算机上 CPU 的型号。 |
| GPU 驱动程序版本 | 用于 NVIDIA Graphics GPU 的驱动程序版本。 |
| 框架 | 用于生成分析数据的框架(例如,TensorFlow、PyTorch)。 |
| CUDA 版本 | CUDA 并行计算平台的版本。 |
| cuDNN 版本 | 训练期间使用的 CUDA 深度神经网络的版本。 |
| NSys 版本 | 训练期间使用的 Nsight Systems 的版本。 |
| DLProf 版本 | 用于生成 DLProf Viewer 中可视化的数据的深度学习分析器的版本。 |
| DLProf DB 版本 | DLProf 数据库的版本。 |
| DLProf Viewer 版本 | DLProf Viewer 的版本。 |
3.4.1.9. 专家系统面板
专家系统面板显示在已分析网络中检测到的常见问题,并提供解决问题的潜在解决方案和建议。该面板仅显示 DLProf 检测到的问题。有关 DLProf 查找的潜在问题的完整列表,请参阅深度学习分析器用户指南中的专家系统部分。
单击双绿色箭头可显示有关检测到的问题的更多信息。

| 列 | 定义 |
| 问题 | DLProf 在分析网络时检测到的场景的描述。 |
| >> | (可选)如果存在,单击双箭头将显示一个新视图,详细显示问题。 |
| 建议 | 建议或可操作的反馈,用户可以采取的切实建议来改进网络。单击建议中的超链接将在浏览器中打开一个新选项卡。 |
3.4.1.10. 指导面板
此面板为用户提供静态指导,以帮助用户了解有关 Tensor Core、混合精度训练的更多信息。该面板具有用于进一步阅读的超链接。单击指导面板内的超链接将在浏览器中打开一个新选项卡。

3.4.2. Op 类型摘要
此表格汇总了所有 op 类型的指标,并使用户能够查看所有 ops 在其类型方面的性能,例如卷积、矩阵乘法等。

| 列名 | 描述 |
|---|---|
| Op 类型 | 操作类型。 |
| Op 数量 | 具有上述 Op 类型的 op 数量。 |
| 调用次数 | 操作被调用/执行的实例数。 |
| CPU 总时间(纳秒) | 此 op 类型的所有实例的 CPU 总时间。 |
| 平均 CPU 时间(纳秒) | 此 op 类型的所有实例的平均 CPU 时间。 |
| 最小 CPU 时间(纳秒) | 在此 op 类型的所有实例中找到的最小 CPU 时间。 |
| 最大 CPU 时间(纳秒) | 在此 op 类型的所有实例中找到的最大 CPU 时间。 |
| GPU 总时间(纳秒) | 此 op 类型的所有实例的 GPU 总时间。 |
| 平均 GPU 时间(纳秒) | 此 op 类型的所有实例的平均 GPU 时间。 |
| 最小 GPU 时间(纳秒) | 在此 op 类型的所有实例中找到的最小 GPU 时间。 |
| 最大 GPU 时间(纳秒) | 在此 op 类型的所有实例中找到的最大 GPU 时间。 |
| CPU 总开销时间(纳秒) | 此 op 类型的所有实例的 CPU 总开销。 |
| 平均 CPU 开销时间(纳秒) | 此 op 类型的所有实例的平均 CPU 开销。 |
| 最小 CPU 开销时间(纳秒) | 在此 op 类型的所有实例中找到的最小 CPU 开销。 |
| 最大 CPU 开销时间(纳秒) | 在此 op 类型的所有实例中找到的最大 CPU 开销。 |
| GPU 总空闲时间(纳秒) | 此 op 类型的所有实例的 GPU 总空闲时间。 |
| 平均 GPU 空闲时间(纳秒) | 此 op 类型的所有实例的平均 GPU 空闲时间。 |
| 最小 GPU 空闲时间(纳秒) | 在此 op 类型的所有实例中找到的最小 GPU 空闲时间。 |
| 最大 GPU 空闲时间(纳秒) | 在此 op 类型的所有实例中找到的最大 GPU 空闲时间。 |
3.4.3. 组 Ops
此视图以分层视图显示所有操作。此新视图基于 DLProf CLI 提供的“组节点报告”。CLI 提供的文本报告是一个 CSV 文件,而此视图是交互式的,支持过滤、排序和分页。此信息是交互式的,它提供了一种强大的机制来快速查找消耗过多持续时间的操作和组。

上方黑色高亮框的交集描绘了级别 17 组“Conv2d::_conv_forward”中的前八个(共 32 个)操作。网络图上层级别中的值是下层级别中所有操作的总和。


| 控件 | 定义 |
| 全部展开 全部折叠 |
展开或折叠所有组。 全部展开将显示级别 1 的组和 Op。 全部折叠将显示所有组和 Op。 |
| 选择 | 定义 |
| 组 | 
|
| Op 名称和 Op ID 匹配 | (未图示:与上面的“组”相同,只是标签是“Op 名称已选择”) |
| Op 名称和 Op ID 不匹配 | 
|
3.4.4. Ops 和内核
此视图使用户能够查看、搜索、排序整个网络中的所有 op 及其相应的内核。

3.4.4.1. Ops 数据表
在 Ops 表格中选择一行时,将在底部表格中显示该 op 的每个内核的摘要。
| 条目 | 描述 |
|---|---|
| GPU 时间(纳秒) | 执行为 op 启动的所有 GPU 内核的累积时间。 |
| CPU 时间(纳秒) | 在 CPU 上执行所有 op 实例的累积时间。 |
| Op 名称 | op 的名称。 |
| 方向 | op 的 fprop/bprop 方向。(仅在 PyTorch 运行中可见)。 |
| Op 类型 | op 的操作。 |
| 调用 | op 被调用的次数。 |
| TC 合格 | 一个真/假字段,指示 op 是否有资格使用 Tensor Core 内核。要过滤,请输入“1”表示 true,输入“0”表示 false。 |
| 正在使用 TC | 一个真/假字段,指示在此 op 中启动的内核之一是否正在使用 Tensor Core。要过滤,请输入“1”表示 true,输入“0”表示 false。 |
| 内核调用 | 在 op 中启动的内核数。 |
| 数据类型 | 此 op 的数据类型(例如,float16、int64、int32) |
| 堆栈跟踪 | op 的堆栈跟踪。(仅在 PyTorch 运行中可见)。 如果此单元格的内容超过 100 个字符,则会显示“查看更多”超链接。单击后,将显示单元格的完整内容。当单元格展开时,超链接文本将更改为“查看更少”。单击后,单元格将折叠回前 100 个字符。 |
3.4.4.2. 内核摘要数据表
| 条目 | 描述 |
|---|---|
| 内核名称 | 内核的全名。 |
| 正在使用 TC | 一个真/假字段,指示内核是否实际正在使用 Tensor Core。要过滤,请输入“1”表示 true,输入“0”表示 false。 |
| 调用 | 调用次数 |
| GPU 时间(纳秒) | 此内核启动的次数。 |
| 每次内核启动的聚合持续时间。 | 每次内核启动的平均持续时间。 |
| 所有内核启动的最小持续时间。 | 最大值 (ns) |
| 所有内核启动的最大持续时间。 | 3.4.5. 按迭代划分的内核 |
按迭代划分的内核视图显示了每次迭代的操作及其执行时间。您可以在一个视图中比较迭代在时间和执行的内核方面的差异。
3.4.5.1. 迭代摘要数据表

要查看特定迭代的内核,请单击顶部表格中的一行。“所选迭代中的内核”表格将填充来自所选迭代的内核。
列
3.4.5.2. 所选迭代中的内核
| 列 | 描述 |
|---|---|
| Op 名称 | 启动内核的 op 的名称。 |
| 内核名称 | 内核的名称。 |
| 设备 ID | 内核的设备 ID。 |
| 内核时间戳(纳秒) | CPU 线程中此内核的 CUDA API 调用时的时间戳。有助于查看内核被调用的顺序。 |
| GPU 时间(纳秒) | 在 GPU 上执行内核所花费的时间。 |
| 用户 TC | 一个真/假字段,指示内核是否使用 Tensor Core。要过滤,请输入“1”表示 true,输入“0”表示 false。 |
| 网格 | 内核的网格大小。 |
| 块 | 内核的块大小。 |
3.4.6. 按 Op 划分的内核
按 Op 划分的内核视图是按迭代划分的内核视图的变体。它能够按迭代和 op 过滤内核列表。

3.4.6.1. 迭代摘要数据表
在迭代摘要表格中选择一个迭代将在所选迭代中的 Ops 表格中填充来自所选迭代的 ops 的所有分析数据。在所选迭代中的 Ops 表格中选择一个 op 将在所选 Op 中的内核表格中填充为所选 Op 和迭代执行的内核列表和计时数据。
3.4.6.2. 所选迭代中的 Ops 表格
所选迭代中的 Ops
| 列 | 描述 |
|---|---|
| Op 名称 | 启动内核的 op 的名称。 |
| 方向 | op 的 fprop/bprop 方向。(仅在 PyTorch 运行中可见)。 |
| Op 类型 | op 的类型。 |
| 内核总数 | 在此迭代期间调用的 GPU 内核数。 |
| TC 内核 | 在此迭代期间调用的 GPU Tensor Core 内核数。 |
| GPU 总时间(纳秒) | 在操作期间,GPU 上所有内核的累积执行时间。 |
| TC GPU 时间 (纳秒) | 在操作期间,GPU 上所有 Tensor Core 内核的累积执行时间。 |
| 数据类型 | 此操作的数据类型(例如,float16、int64、int32)。 |
| 堆栈跟踪 | 操作的堆栈跟踪。(仅在 PyTorch 运行时可见) 如果此单元格的内容超过 100 个字符,则会显示“查看更多”超链接。单击后,将显示单元格的完整内容。当单元格展开时,超链接文本将更改为“查看更少”。单击后,单元格将折叠回前 100 个字符。 |
3.4.6.3. 选定迭代/操作组合的内核表
选定迭代/操作组合中的内核
| 列 | 描述 |
|---|---|
| 内核名称 | 内核的名称。 |
| 设备 ID | 内核的设备 ID。 |
| 内核时间戳(纳秒) |
CPU 线程中此内核的 CUDA API 调用时的时间戳。有助于查看内核被调用的顺序。 |
| GPU 时间(纳秒) | 在 GPU 上执行内核所花费的时间。 |
| 使用 TC | 一个真/假字段,指示内核是否使用 Tensor Core。要过滤,请输入“1”表示 true,输入“0”表示 false。 |
| 网格 | 内核的网格大小。 |
| 块 | 内核的块大小。 |
3.4.7. 迭代视图
此视图以可视化方式显示迭代。用户可以快速查看模型中有多少次迭代、已聚合/分析的迭代以及每次迭代中张量核心内核的累积持续时间。

工作流程
有时 DLProf 命令行上的原始聚合参数指定了迭代开始值、迭代停止值,甚至关键节点,这些值产生了网络配置文件的次优表示(例如,包括预热节点)。此功能允许用户更改这些值并重新聚合。这是一个示例:
- 请注意上面的“迭代视图”屏幕截图:
- 迭代 8 不包含任何工作,并且
- 迭代 9 到 15(以及其他迭代)包含过多的工作。整个查看器中的聚合值包含这些操作和内核,并可能歪曲结果。
- 您可以通过多种方式更改迭代开始和迭代停止值:键入和单击向上和向下调节器。最好的方法是将光标悬停在字段上并滚动鼠标滚轮。
- 某些平台没有神经网络的默认关键节点。有时预定义的关键节点是次优的。通过单击“选择关键节点”选择器,可以选择一个关键节点。这是一个功能齐全的面板,允许进行过滤、排序和分页以查找关键节点。请参阅名为操作和内核的视图以获取更多详细信息。注意
注意:此处的列数少于视图中的列数,但可用性相同。

- 一旦这三个字段中的任何一个发生更改,请单击“重新聚合”按钮。将显示一个确认对话框:

- 确认后,将向后端 DLProf 服务器发送消息,以使用这些值重新聚合配置文件。此重新聚合过程可能需要几分钟,因此以下面板将显示在所有面板上方:
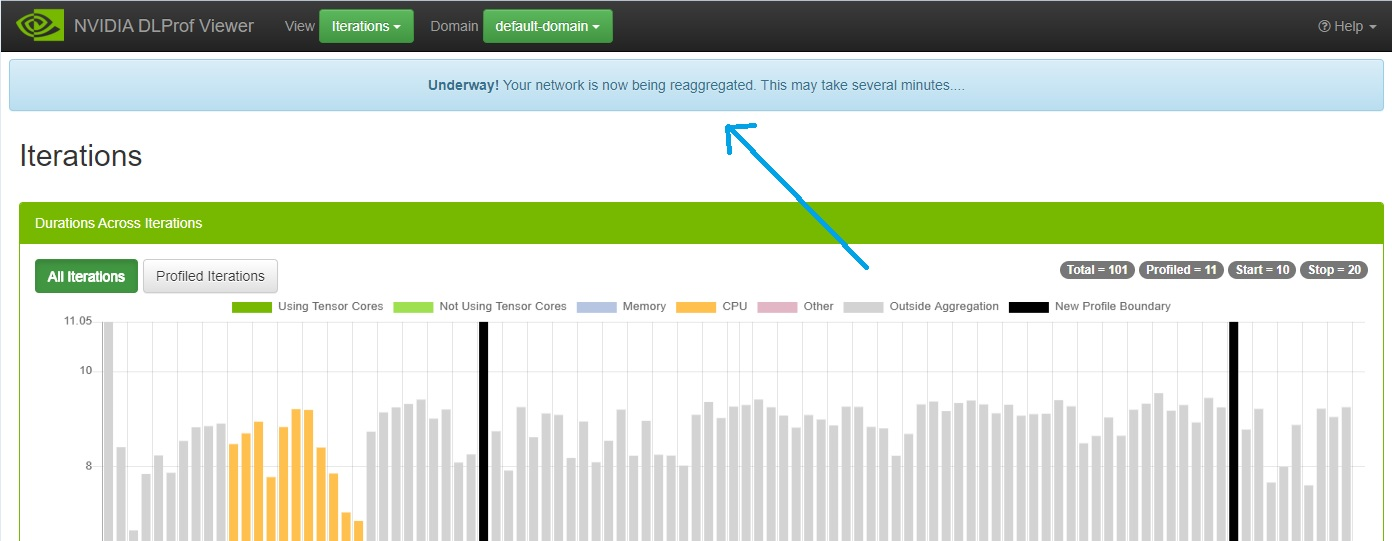
重新聚合正在进行时,查看器功能齐全。“进行中!”面板将保持在所有其他视图和面板之上,直到重新聚合完成。
注意注意:请勿单击浏览器的“后退”或“刷新”按钮。如果意外单击了其中任何一个按钮,“进行中!”面板将不再显示。重新聚合将继续进行,不受影响。
- 重新聚合完成后,将显示一个“成功!”面板,如下所示:

- 此时,单击“刷新”按钮会将所有新重新聚合的数据加载到查看器中。如果“聚合”下拉列表尚未显示,则它将显示在导航栏中:
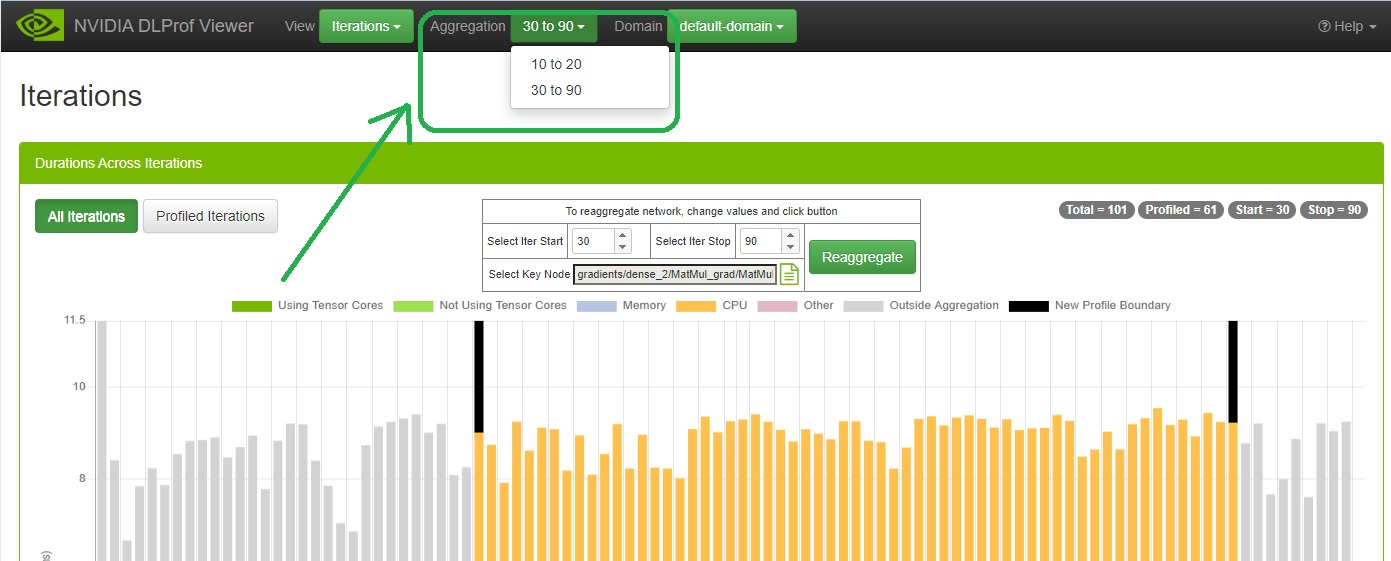





3.4.8. GPU 视图
此视图显示配置文件运行期间所有 GPU 的利用率。它分为两个不同但相关的元素:
- 条形图 - 快速可视化,您可以在其中查看配置文件期间使用的每个 GPU 的 GPU 利用率。此视图仅在配置文件中使用多个 GPU 时显示。
- 表格 - 此表格显示有关每个 GPU 设备的更多详细信息,包括其名称、计算能力和 SM 计数。

3.4.9. 详细信息窗格
3.4.9.1. 内核详细信息面板

| 字段 | 定义 |
| 所有内核 | 聚合网络中所有内核的总 GPU 时间和计数。 |
| 使用 TC 的内核 | 聚合使用 Tensor Core 的所有内核的总 GPU 时间和计数。 |
| 内存内核 | 聚合所有内存内核的总 GPU 时间和计数。 |
| 所有其他内核 | 聚合所有剩余内核类型的总 GPU 时间和计数。 |
| 控件 | 定义 |
| X | 关闭“详细信息”窗格。 |
3.5. 使用数据表
数据表在 DLProf 查看器的许多视图中使用。数据表中的功能使用户能够快速查找信息。下面是一个屏幕截图,显示了这些功能的位置,随后是一个表格,描述了每个功能的功能。

| 数据表功能 | 定义 |
| 显示标签 | 表格下方的标签(左下角)将显示表格中行数的实时计数。 |
| 搜索文本框 | 按文本搜索筛选结果。在此字段中键入将仅显示包含框中文本的行。在“搜索”框中添加或删除文本将更新“显示…”标签。 |
| 列搜索 | 在大多数列标题下方的文本框中键入将仅显示包含输入文本的行。这很强大,因为用户可以为多个列输入搜索条件,以精确定位感兴趣的行。带有“x”和“复选标记”的列是布尔字段。用户可以输入“1”以显示带有“复选标记”的行,输入“0”以仅显示带有“x”的行。 |
| 排序切换按钮 | 单击列标题将对表格进行排序。单击后,所有行都将按升序或降序排序。大多数数字列的初始排序是降序。 |
| 显示条目下拉列表 | 此下拉列表允许用户显示 10、25、50 或 100 行。更改设置将更新“显示…”标签。 |
| 分页按钮 | 上一页、下一页和页码导航。允许用户快速翻阅大型数据集。使用“显示条目”设置并更新“显示…”标签。 |
| 导出到按钮 | 允许用户轻松地将数据表中的数据导出为众所周知的格式。当在 DLProf 中使用 警告:单击这些按钮中的任何一个按钮处理大型网络时,会出现轻微延迟。 在浏览器中启用弹出窗口以导出为 PDF。 |




通知
本文档仅供参考,不得视为对产品的特定功能、状态或质量的保证。NVIDIA Corporation(“NVIDIA”)对本文档中包含的信息的准确性或完整性不作任何明示或暗示的陈述或保证,并且对本文档中包含的任何错误不承担任何责任。NVIDIA 对因使用此类信息而造成的后果或使用,或因使用此类信息而可能导致的侵犯第三方专利或其他权利的行为概不负责。本文档不承诺开发、发布或交付任何材料(如下定义)、代码或功能。
NVIDIA 保留随时对此文档进行更正、修改、增强、改进和任何其他更改的权利,恕不另行通知。
客户应在下订单前获取最新的相关信息,并应验证此类信息是否为最新且完整。
NVIDIA 产品根据订单确认时提供的 NVIDIA 标准销售条款和条件进行销售,除非 NVIDIA 和客户的授权代表签署的个别销售协议(“销售条款”)另有约定。NVIDIA 在此明确反对将任何客户通用条款和条件应用于购买本文档中引用的 NVIDIA 产品。本文档未直接或间接形成任何合同义务。
NVIDIA 产品并非设计、授权或保证适用于医疗、军事、航空、航天或生命支持设备,也不适用于 NVIDIA 产品的故障或失灵可能合理预期会导致人身伤害、死亡或财产或环境损害的应用。NVIDIA 对在此类设备或应用中包含和/或使用 NVIDIA 产品不承担任何责任,因此此类包含和/或使用由客户自行承担风险。
NVIDIA 不作任何陈述或保证,保证基于本文档的产品将适合任何特定用途。NVIDIA 不一定对每个产品的所有参数进行测试。客户全权负责评估和确定本文档中包含的任何信息的适用性,确保产品适合客户计划的应用,并为该应用执行必要的测试,以避免应用或产品的默认设置。客户产品设计中的缺陷可能会影响 NVIDIA 产品的质量和可靠性,并可能导致超出本文档中包含的附加或不同条件和/或要求。NVIDIA 对可能基于或归因于以下原因的任何默认设置、损坏、成本或问题不承担任何责任:(i) 以任何与本文档相悖的方式使用 NVIDIA 产品,或 (ii) 客户产品设计。
本文档未授予任何 NVIDIA 专利权、版权或其他 NVIDIA 知识产权下的任何明示或暗示的许可。NVIDIA 发布的有关第三方产品或服务的信息不构成 NVIDIA 授予使用此类产品或服务的许可,也不构成 NVIDIA 对其的保证或认可。使用此类信息可能需要获得第三方的专利或其他知识产权下的第三方许可,或获得 NVIDIA 的专利或其他知识产权下的 NVIDIA 许可。
仅在 NVIDIA 事先书面批准的情况下,才允许复制本文档中的信息,复制时不得进行更改,并应完全遵守所有适用的出口法律和法规,并附带所有相关的条件、限制和通知。
本文档和所有 NVIDIA 设计规范、参考板、文件、图纸、诊断、列表和其他文档(统称为“材料”,单独而言也称为“材料”)均按“原样”提供。NVIDIA 对这些材料不作任何明示、暗示、法定或其他形式的保证,并明确声明不承担所有关于不侵权、适销性和特定用途适用性的默示保证。在法律未禁止的范围内,在任何情况下,NVIDIA 均不对因使用本文档而引起的任何损害(包括但不限于任何直接、间接、特殊、附带、惩罚性或后果性损害,无论如何引起,也无论责任理论如何)负责,即使 NVIDIA 已被告知可能发生此类损害。尽管客户可能因任何原因遭受任何损害,但 NVIDIA 对本文所述产品的总计和累积责任应根据产品的销售条款进行限制。
HDMI
HDMI、HDMI 标志和高清多媒体接口是 HDMI Licensing LLC 的商标或注册商标。
OpenCL
OpenCL 是 Apple Inc. 的商标,已获得 Khronos Group Inc. 的许可使用。
商标
NVIDIA、NVIDIA 标志以及 cuBLAS、CUDA、cuDNN、DALI、DIGITS、DGX、DGX-1、DGX-2、DGX Station、DLProf、Jetson、Kepler、Maxwell、NCCL、Nsight Compute、Nsight Systems、NvCaffe、NVIDIA Ampere GPU Architecture、PerfWorks、Pascal、SDK Manager、Tegra、TensorRT、Triton Inference Server、Tesla、TF-TRT 和 Volta 是 NVIDIA Corporation 在美国和其他国家/地区的商标和/或注册商标。其他公司和产品名称可能是与其相关联的各自公司的商标。