技术简报#
概述#
大型语言模型 (LLM) 和生成式 AI 为零售商提供了一个绝佳的机会,让他们能够以更自然和个性化的方式跨全渠道平台与客户互动。
此零售购物顾问 AI 工作流程展示了如何开发一个由 LLM 驱动的检索增强生成 (RAG) 应用程序,该应用程序可以摄取产品目录数据并使用一些最新的生成式 AI 功能,从而提供差异化的体验,为客户的咨询和推荐请求提供上下文准确、类人般的答案,包括产品见解、交叉销售和追加销售建议等等。这种更自然的互动、搜索和发现方式就像为每次客户互动都配备了您最好的销售助理。
在线购物体验通常会变得不必要的令人沮丧。购物顾问需要提供个性化服务,并能够回答自然语言、长尾、复杂的问题。然而,目前的工具通常只在较短的、基于关键词的查询中表现良好。这导致了客户无法找到他们想要的一切,或者在构思他们需要的产品时需要帮助的情况,从而在竞争激烈的零售环境中导致购物车放弃和糟糕的客户体验。无论是策划家庭办公室所需的所有物品,还是试图为一个 8 岁的孩子创建一个足球主题的生日派对,搜索过程通常需要多次尝试,有时甚至徒劳无功。这不仅让消费者感到沮丧,而且对于零售商来说,这也是一个错失良机,无法获取收入并推动追加销售和交叉销售收入。
此零售购物顾问 AI 工作流程为企业提供了一种从试点到业务价值的快速且先进的方法。它拥有使消费者购物体验更具对话性、精确性和准确性所需的一切。零售购物顾问参考解决方案附带了来自 NVIDIA 员工装备商店的产品数据示例数据集,该数据集代表产品目录。您可以使用此参考示例添加您自己的产品目录和相关数据,为您的业务创建一个交互式购物顾问。此工作流程中包含一个 Jupyter Lab 笔记本服务器,其中包含一个示例笔记本,该笔记本展示了解决方案的功能,因此您可以快速原型化并使用自己的数据进行实验。
软件组件#
基于 RAG 的 AI 购物顾问工作流程基于 Docker,并为构建企业级生成式 AI 解决方案提供了一个参考,只需最少的努力。它包含以下软件组件
NVIDIA NIM 微服务
大型语言模型 - Llama3 70b
NVIDIA NeMo Retriever 嵌入模型 (NV-Embed-QA-4)
LangChain
向量数据库:Milvus (GPU 优化)
您将使用一个示例 Jupyter 笔记本和 Jupyter Lab 服务直接与代码进行交互。
NVIDIA NIM#
NVIDIA 通过在 NVIDIA 堆栈中实施优化来加速 LLM 的推理。像 Llama 3 这样的开放模型经过优化并打包为 NVIDIA NIM 微服务,该微服务具有标准的应用程序编程接口,使开发人员能够快速创新。该工作流程允许您以一种方式进行设置,其中 NVIDIA API 目录或本地部署的 NIM 的使用是一个配置设置。
当使用 NVIDIA API 目录时,该工作流程利用 NVIDIA AI 基础模型,这些模型由 NVIDIA 托管,因此无需您自己的 GPU 即可开始开发推理。NVIDIA 的 API 目录允许您通过浏览器或模型 API 端点与最新的 NVIDIA AI 基础模型 进行交互。
以下模型(API 端点或本地部署的 NIM)在工作流程中使用。在您开发时,您可以尝试更改模型以使用其他 NVIDIA 托管模型或提供的 NIM。
Llama3 70b - 预训练和指令调优的生成式文本模型,针对对话用例进行了优化,具有 700 亿个参数。Llama 3 是一个自回归语言模型,它在 NVIDIA GPU 上使用和优化 Transformer 架构。
NV-Embed-QA - NVIDIA NeMo Retriever QA 嵌入模型针对文本问答检索进行了优化。嵌入模型是文本检索系统的关键组件,因为它将文本信息转换为密集的向量表示。它们通常是 Transformer 编码器,处理输入文本的标记(例如,问题、段落)以输出嵌入。
有关更多信息,请参阅官方 NVIDIA NIM 文档 和 AI 聊天机器人与 RAG 技术简报。
NVIDIA LangChain 端点 API#
此参考 AI 工作流程展示了如何使用 LangChain 连接器,通过 NVIDIA 的 API 端点来交互和开发零售购物顾问。
注意
有关如何部署 NVIDIA AI 基础端点的更多信息(如果感兴趣),请参阅 LangChain 的文档。
向量数据库:Milvus#
Milvus 是一个高度灵活、可靠且速度极快的云原生 开源向量数据库。它为嵌入相似性搜索和 AI 应用程序提供支持,并致力于使每个组织都能访问向量数据库。Milvus 可以存储、索引和管理由深度神经网络和其他机器学习 (ML) 模型生成的十亿+ 嵌入向量。
推理管线#
作为推理管线的一部分,我们将 LLM 连接到示例数据集:在本例中为 NVIDIA 员工装备商店。这种外部知识可以有多种形式,包括产品目录、财务电子表格或员工文档。使用向量 RAG 可以利用这些知识来增强模型的功能。
为了生成产品推荐,嵌入模型检索最相关的产品,然后 LLM 使用它来生成响应。但是,在某些情况下,仅对用户的查询使用检索增强生成是不够的。例如,当用户要求聊天机器人将商品添加到他们的购物车时,LLM 需要知道用户的意图,然后采取正确的操作。为此,LLM 必须理解诸如意图、数量和商品名称等信息,然后调用正确的内部 API。这称为函数调用。在此工作流程中,我们将演示 LLM 如何使用 NVIDIA API 目录上的 Llama3-70B 模型在零售 API 上执行函数调用。
下图描述了这些过程
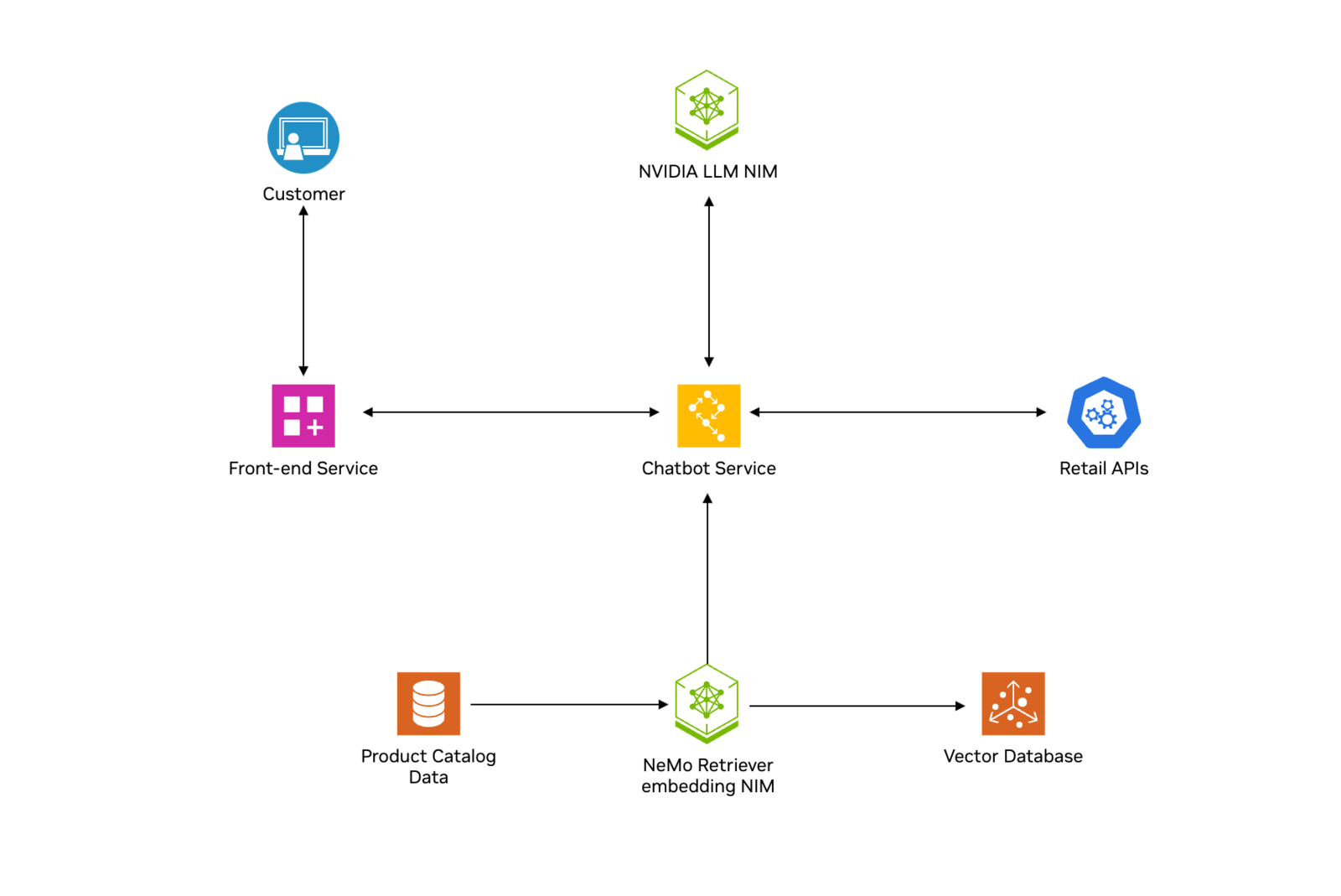
有关文档摄取和检索以及用户查询和响应生成的更多信息,请参阅 AI 聊天机器人与 RAG 技术简报,此零售购物助理工作流程基于该简报。
其他组件#
以下附加组件用作工作流程解决方案的一部分
Jupyter Lab 服务#
提供了一个示例笔记本,允许您与为购物顾问 AI 工作流程构建的代码进行交互。此笔记本公开了工作流程的功能,并且一旦您将产品目录引入工作流程,它将是迭代解决方案的好地方。