技术简报#
概述#
您是否对 AI 聊天机器人如何工作感到好奇?首先,生成式 AI 从在大量未标记数据上训练的基础模型开始。这些 Large language models (LLMs) 在大量的在线文本数据上进行训练,在某些情况下,还会针对特定的行业或领域专业知识进行训练。LLM 可以理解您(用户)提供的提示,然后生成新颖的、类似人类的响应。企业可以构建应用程序来利用 LLM 的这种能力;例如,用于营销的创意写作助手、用于法律团队的文档摘要以及用于软件开发的代码编写。
此参考解决方案演示了如何通过增强现有基础 LLM 以适应您的业务用例,从而在生成式 AI 中找到业务价值。这是通过检索增强生成 (RAG) 完成的,RAG 从包含公司业务数据的企业知识库中检索事实。本简报中描述了一个功能强大的基于 RAG 的 AI 聊天机器人的参考解决方案,其中包括 NVIDIA 的 Generative AI Examples Github 中为开发人员提供的代码。请特别注意您可以利用特定领域的业务数据增强 LLM 的方式,以创建对新发展具有敏捷性和响应能力的 AI 应用程序。
一些示例包括
基于 Web 的聊天机器人:许多企业已经使用 AI 聊天机器人来支持其网站上的基本客户互动。借助 RAG,公司可以构建高度特定于其业务的聊天体验。例如,关于产品规格的问题会得到及时解答。
客户服务:公司可以授权现场服务代表快速回答客户问题,并提供准确、最新的信息。
企业文档搜索:企业在整个组织中拥有丰富的知识,包括技术文档、公司政策、IT 支持文章和代码存储库。员工可以查询内部搜索引擎,以更快、更高效地检索信息。
金融服务表格数据搜索:AI 可以浏览大量的金融数据,立即找到关键的见解,从而增强决策过程。
此参考解决方案基于 NVIDIA AI RAG 聊天机器人,我们在内部使用该聊天机器人来简化员工的生活。该聊天机器人旨在帮助员工回答与公司沟通相关的问题。自从最初部署以来,我们已在公司内多个团队中使用了多个聊天机器人,以加速整个公司的生产力。
来自 Meta 的开源 LLM,Llama2 被用作高级起点和低成本解决方案,企业可以利用它来生成针对其特定用例量身定制的准确且精确的响应。
生成式 AI 从在大量未标记数据上训练的基础模型开始。Large language models (LLMs) 在大量的在线文本数据上进行训练。这些 LLM 可以理解提示并生成新颖的、类似人类的响应。企业可以构建应用程序来利用 LLM 的这种能力;例如,用于营销的创意写作助手、用于法律团队的文档摘要以及用于软件开发的代码编写。
为了从 LLM 中创造真正的商业价值,这些基础模型需要根据您的企业用例进行定制。在此工作流程中,我们使用 RAG 和来自 Meta 的开源模型 Llama2 来实现此目的。增强现有的 AI 基础模型可提供高级起点和低成本解决方案,企业可以利用它来生成针对其特定用例的准确而清晰的响应。
注意
此参考示例使用 Llama2 13B 参数聊天模型,该模型需要 50 GB 的 GPU 内存,但也可以使用其他兼容的基础 LLM。
参考解决方案中包含的示例知识库数据集包含 NVIDIA 过去两年的新闻稿和公司博客文章。它会定期更新,因此,例如,当我们发布新的 GPU 产品(如 Grace Hopper)时,增强的 LLM 可以回答更新和更相关的开发内容。
当您阅读示例工作流程时,写下您可以将此参考解决方案调整为您的业务目标的方式可能会很有用。
软件组件#
这种基于 RAG 的 AI 聊天机器人提供了一个参考,可以用最少的努力构建企业 AI 解决方案,并且包含以下软件组件
提供了示例 Jupyter 笔记本以及带有 API 调用的示例聊天机器人 Web 应用程序,以便您可以交互式地测试聊天系统。
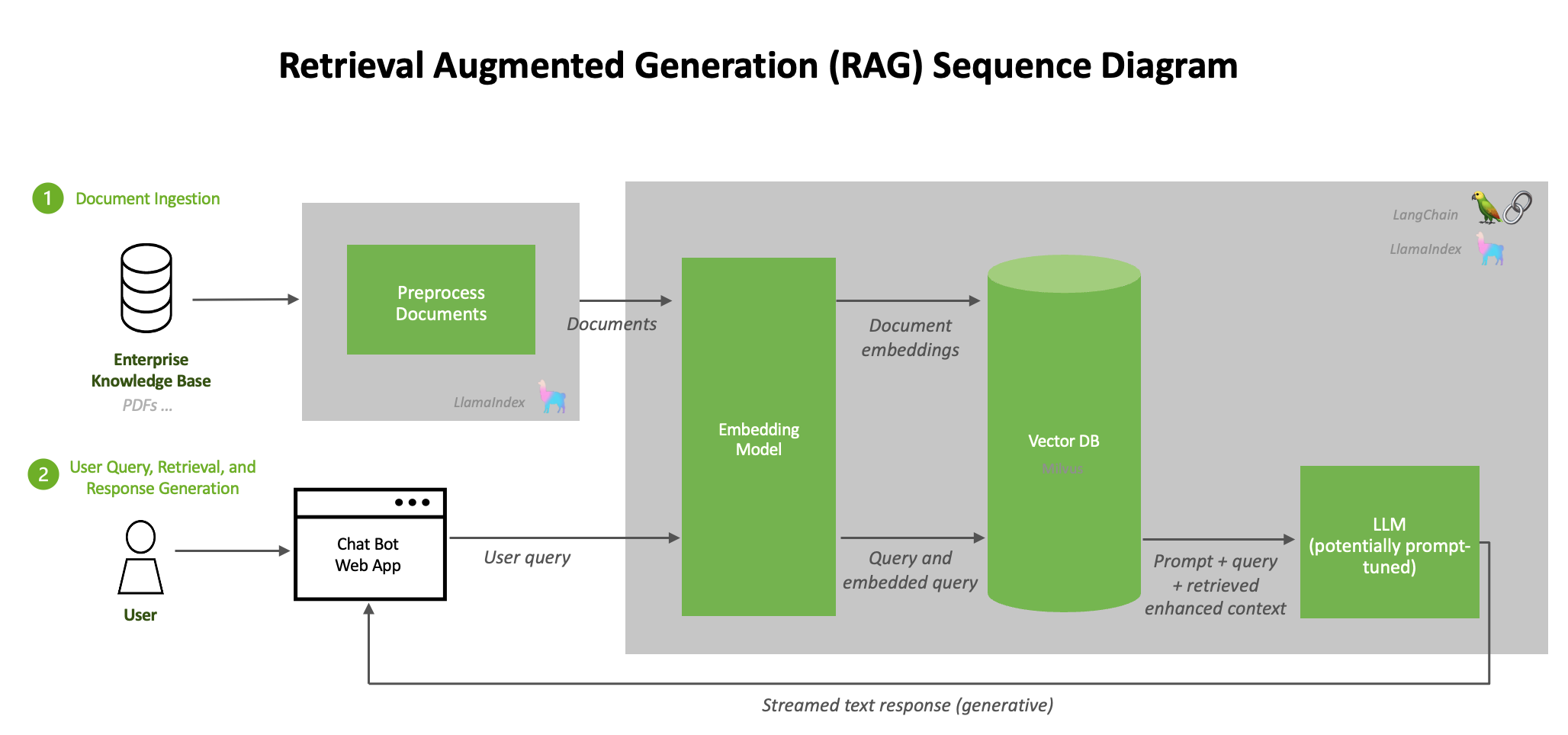
软件组件用于部署 LLM 和推理管道。下图提供了基于 RAG 的 AI 聊天机器人参考解决方案的概述
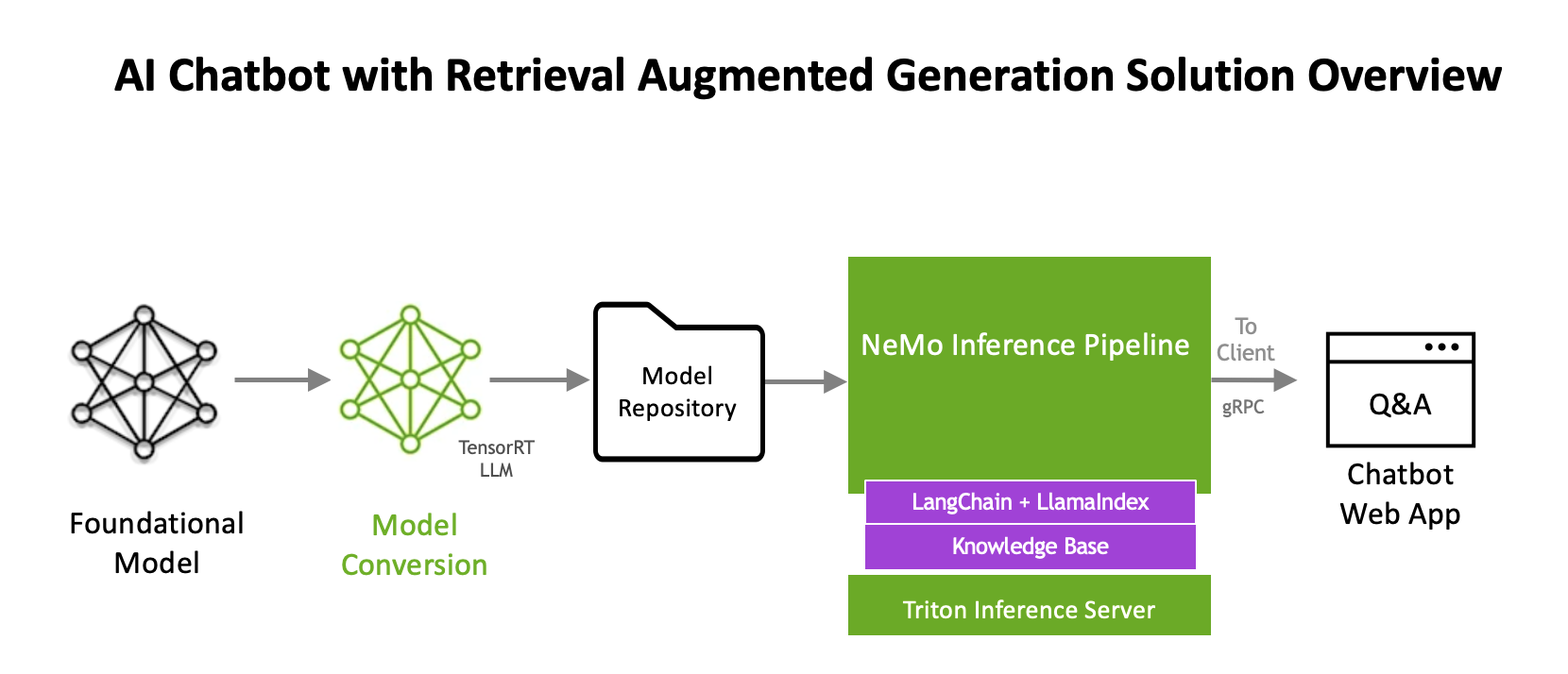
NVIDIA NeMo Framework#
开箱即用地使用基础模型可能具有挑战性,因为模型经过训练可以处理各种任务,但可能不包含特定领域/企业的知识。NVIDIA NeMo framework 帮助解决了这个问题。它是一个端到端、云原生的框架,用于在任何地方构建、定制和部署生成式 AI 模型。该框架包括训练和推理软件、护栏 和数据整理工具。它支持最先进的社区和 NVIDIA 预训练 LLM,为企业提供了一种简单、经济高效且快速的方式来采用生成式 AI。
NVIDIA TensorRT-LLM 优化#
NVIDIA NeMo 利用 TensorRT-LLM 进行模型部署,从而优化模型以实现最新的 LLM 的突破性推理加速和 GPU 效率。TensorRT-LLM 提供的效率允许更大的模型部署灵活性,从而开启了使用相同基础设施运行并发模型的潜力。如本参考解决方案中所述,我们利用了 Llama 2 13B 参数聊天模型。我们使用 TensorRT-LLM 将基础模型转换为 TensorRT 格式,以进行优化的推理。
TensorRT-LLM 还包括一种称为飞行中批处理的优化调度技术。这利用了 LLM 的整体文本生成过程可以分解为在模型上多次迭代执行的事实。通过飞行中批处理,TensorRT-LLM 运行时不会等待整个批处理完成才继续处理下一组请求,而是立即从批处理中逐出已完成的序列。然后,它开始执行新的请求,而其他请求仍在飞行中。
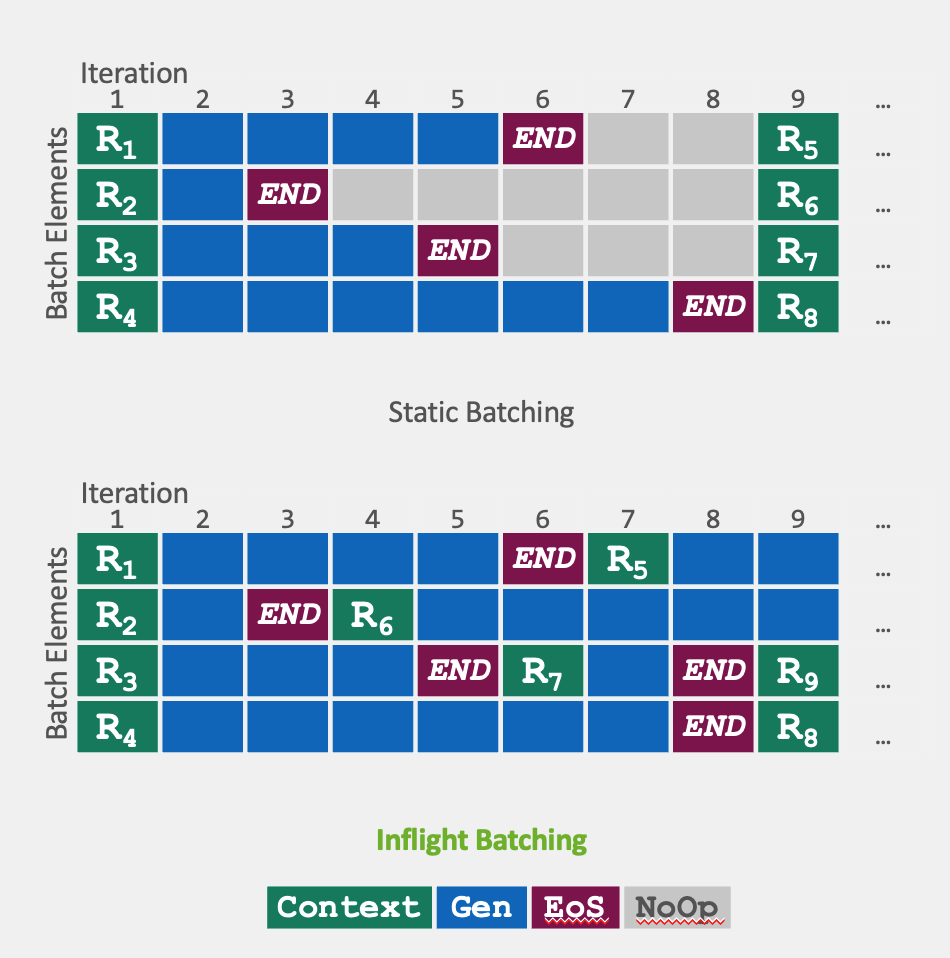
飞行中批处理和额外的内核级优化提高了 GPU 使用率并使吞吐量翻倍,这有助于降低能源成本并最大限度地减少 TCO。
NVIDIA Triton Inference Server#
优化的 LLM 与 Triton Inference Server 一起部署,以实现高性能、经济高效和低延迟的推理。Triton Inference Server 是一种推理服务软件,可简化 AI 推理。
基于 RAG 的 AI 聊天机器人推理管道#
要开始使用推理管道,首先,我们将 LLM 连接到示例数据集:NVIDIA 新闻稿和公司博客文章。这种外部知识可以有多种形式,包括产品规格、人力资源文档或财务电子表格。通过 RAG 可以增强模型在此知识方面的能力。
注意
对于此参考解决方案,我们使用 Python 抓取了 NVIDIA 过去两年的新闻稿和公司博客文章。这些内容以一系列 PDF 的形式保存。
RAG 由两个过程组成:1. 从文档存储库、数据库或 API 中提取文档,这些文档都位于基础模型的知识之外。2. 在推理期间检索相关文档数据并生成响应。
下图描述了这些过程
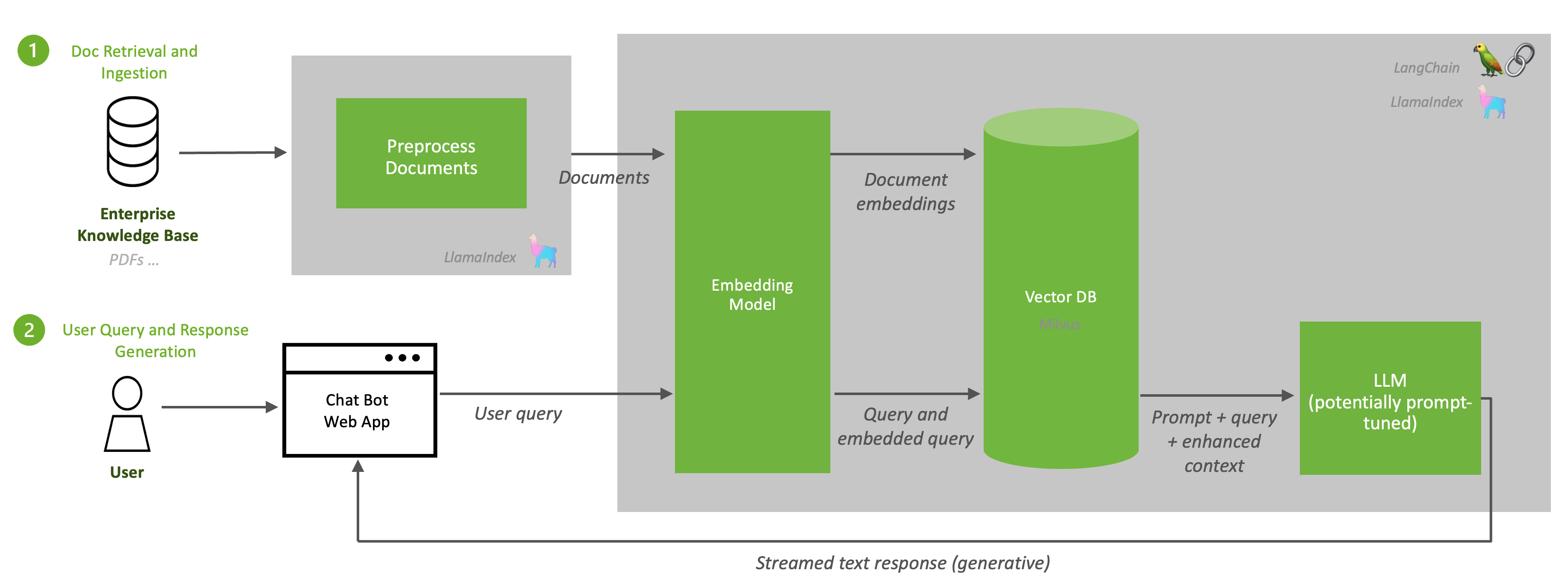
由于 RAG 从包含相关、最新信息的知识库开始,因此将新文档摄取到知识库中应该是一个重复的过程,并安排为作业。
注意
注意:文档摄取管道包装在 API 调用中;因此,此管道可以轻松地安排为重复的批处理过程。
文档摄取和检索#
来自知识库的内容被传递到嵌入模型(在本工作流程中为 e5-large-v2),该模型将内容转换为向量(称为“嵌入”)。生成嵌入是 RAG 中的关键步骤;它允许对文本信息进行密集的数值表示。然后,这些向量嵌入存储在向量数据库中,在本例中为 Milvus,它在 NVIDIA GPU 上是 RAFT 加速 的。
向量在高维度上表示数据,推理管道执行相似性搜索,以识别与其他向量数据点最相似的当前查询。下图对此进行了直观说明。
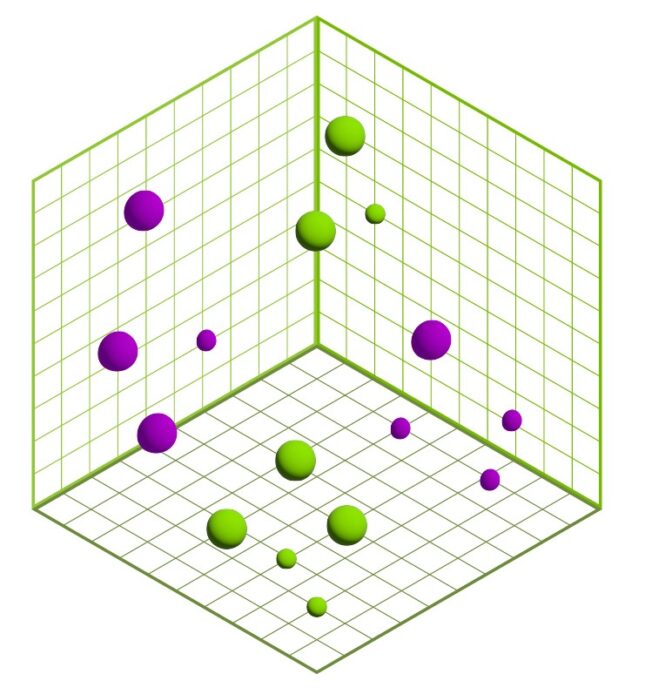
用户查询和响应生成#
当用户查询发送到推理服务器时,它会使用嵌入模型转换为嵌入。这与用于转换知识库中文档的嵌入模型相同(在本工作流程中为 e5-large-v2)。向量数据库执行相似性/语义搜索,以查找与用户意图最相似的向量,并将其作为增强的上下文提供给 LLM。
下图直观地表示了相似性/语义向量搜索。

由于 Milvus 是 RAFT 加速的,因此相似性搜索在 GPU 上进行了优化。最后,LLM 用于生成完整的答案,并将其流式传输给用户。这一切都通过 LangChain 和 LlamaIndex 轻松完成。
下图进一步说明了文档的摄取和响应的生成。
由于 LangChain 允许您为您自己的自定义 LLM 编写 LLM 包装器,因此我们为从在 Triton Inference Server 上运行的 TensorRT-LLM Llama 2 模型流式传输响应提供了一个示例包装器。此包装器使我们能够利用 LangChain 的标准接口与 LLM 进行交互,同时仍然实现 TensorRT-LLM 的巨大性能加速以及 Triton Inference Server 的可扩展和灵活的推理。
提供的示例聊天机器人 Web 应用程序允许您交互式地测试聊天系统。对聊天系统的请求包装在 API 调用中,因此可以将这些请求抽象到其他应用程序。
其他组件#
Triton Inference Server
NVIDIA Triton Inference Server 使用存储在模型存储库中的模型,该存储库在本地可用,用于服务推理请求。一旦它们在 Triton 中可用,推理请求就会从客户端应用程序发送。Python 和 C++ 库提供 API 以简化通信。客户端使用 HTTP/REST 或 gRPC 协议将 HTTP/REST 请求直接发送到 Triton。
在此工作流程中,Llama2 LLM 使用 NVIDIA TensorRT for LLMs 进行了优化,后者加速并最大限度地提高了最新 LLM 的推理性能。
模型存储
NVIDIA NGC 在此工作流程中用作模型存储,但您可以自由选择不同的模型存储解决方案,如 Azure AI Studio、MLFlow 或 AWS SageMaker。
向量数据库
Milvus 是一个开源向量数据库,旨在为嵌入相似性搜索和 AI 应用程序提供支持。它通过将来自 API 调用、PDF 和其他文档的非结构化数据存储为嵌入,从而使这些数据更易于访问。当来自知识库的内容传递到嵌入模型 (e5-large-v2) 时,它会将内容转换为向量(称为“嵌入”)。这些嵌入存储在向量数据库中。此工作流程中使用的向量数据库是 Milvus。Milvus 是一个能够进行 NVIDIA GPU 加速向量搜索的开源向量数据库。
虽然此参考解决方案使用 Milvus,但也可以使用其他数据库代替。例如,其他集成 RAPIDS RAFT 以实现 GPU 加速的向量数据库包括 Chroma、FAISS 或 Lance;或者您可以使用其他按需付费数据库,如 Redis、Pinecone 和 MongoDB vCore。
注意
如果需要,请参阅 Milvus 的文档,了解如何为 Milvus 配置 Docker Compose 文件。
回顾#
让我们回顾一下关键问题,这些问题可以帮助您将此参考解决方案调整到您特定的业务用例
您的企业中可以使用哪些不同的数据源来增强 LLM?
注意
此参考解决方案使用 LangChain。可以利用其他数据连接器。
此参考解决方案中的哪些组件可以在您的企业中用于推理管道?哪些组件需要更换?
注意
一个例子是模型存储。此参考解决方案使用 NGC,但您的企业可能已在使用 MLflow 作为您的模型存储解决方案。
您是否打算在生产环境中运行基于 RAG 的 AI 聊天机器人?在 AI 上运营业务的企业依靠 NVIDIA AI Enterprise 提供的安全性、支持和稳定性来确保从试点到生产的平稳过渡。