主流集群配置#
主流配置基于入门级配置构建。但它提供了更强大的 GPU 和网络,从而在最大化每个机架节点数量的同时,提供每个节点的最大性能。通过添加高性能 NVIDIA Mellanox 网络,实现了节点之间更高的吞吐量,从而在执行多节点 AI 企业级工作负载时获得性能提升。
通过标准化服务器 CPU 规格,此配置还允许组织将同一基础设施用于混合工作负载。
请务必注意,规模调整计算基于每个机架 14kW 冗余 PDU 和每服务器双 1600W PSU,因为大多数企业数据中心都有这些要求。由于这些电源要求,主流配置的机架密度计算结果是每个机架的 GPU 节点少于纯 CPU 节点。此配置可能需要网络升级,具体取决于当前的基础设施;更多信息请参见网络部分。
服务器和机架配置#
下表描述了主流配置的示例。
由于升级了 GPU,此主流配置具有充足的可用资源,可以为其他工作负载以及 AI 工作负载提供额外的资源。额外的 NVMe 还可以减少 AI 工作负载的延迟,确保 GPU 有足够的数据进行处理。
企业 AI / 边缘 AI / 数据分析 |
|---|
2U NVIDIA 认证系统 |
双 Intel® Xeon® Gold 6248R 3.0G, 24核/48线程, 10.4GT/s, 35.75 M 缓存, 睿频, 超线程 (205W) DDR4-2933 |
16x 32GB RDIMM, 3200MT/s, 双列 |
2x 1.92TB SSD SATA 混合用途 6Gbps 512, 2.5英寸 热插拔 AG 驱动器, 3 DWPD, 10512 TBW |
1x 1.92TB 企业级 NVMe 读取密集型 AG 驱动器 U.2 Gen4 带载体 |
1x 16GB microSDHC/SDXC 卡 |
双路, 热插拔, 冗余电源 (1+1), 1600W |
1x NVIDIA Mellanox® ConnectX-6 Dx PCIe 25G/100G |
NVIDIA® SN3420/SN3700 机架顶部 |
1x NVIDIA A100 for PCIe |
重要提示
NVIDIA A30 和 A100 GPU 是仅计算 GPU,不适用于远程协作/ProViz 工作负载。
下表说明了主流配置的机架密度,同时提供了增加的存储、网络和 GPU 资源。此机架配置包含 15 个节点,需要约 13.6 kW 的功率。有关主流规模调整计算的更多说明,请参阅规模调整指南附录。
企业 AI / 边缘 AI / 数据分析 |
|---|

|
机架密度 15 个节点,需要约 13.6 kW 的功率。 |
网络#
为了针对多节点 AI 工作负载进行高效扩展,建议在节点之间使用高性能网络,以获得最佳的对等通信速度。提供了多种网络选项,这些选项取决于当前基础设施是否包含高性能网络功能。
如果当前基础设施基于 10G,建议升级到 100G NVIDIA Mellanox 网络基础设施,以获得最佳的多节点横向扩展性能。
如果当前基础设施支持 25G,可以选择利用 25G 版本的 NVIDIA Mellanox ConnectX-6 DX PCIe,而不是将网络基础设施升级到 100G。与 10G 基础设施相比,这可以提供更高的性能,但不如推荐的 100G 配置性能高。
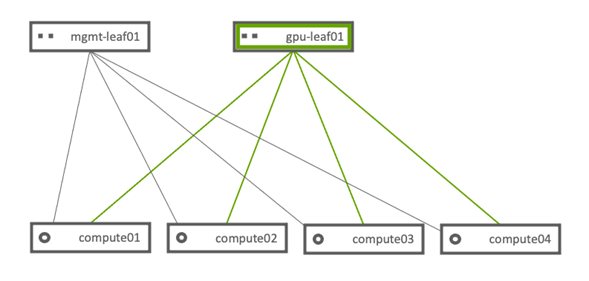
下图描述了 NVIDIA AI 企业级解决方案在 VMware vSphere 上的参考架构中所示的网络拓扑。
在此参考架构中,使用了两个网络交换机。mgmt-leaf-01 网络交换机是基础设施机架顶部交换机。gpu-leaf-01 是高性能 100G NVIDIA Mellanox 网络交换机,可在节点之间提供更高的吞吐量,从而在执行多节点企业级 AI 工作负载时获得性能提升。
注意
mgmt-leaf01 是基础设施机架顶部交换机。
gpu-leaf01 是计算型机架顶部 NVIDIA Mellanox SN3700 交换机。
存储#
主流集群配置将数据存储修改为本地数据存储,以便数据位于 GPU 本地。此配置提高了训练和推理吞吐量。节点的 NVMe 本地存储加速了对数据的访问。NVMe 驱动器以比 SSD 更高的速度连接到 PCI 总线。这消除了由存储引起的任何瓶颈,从而释放 GPU 以尽可能快地访问数据。根据数据的大小,启用 NFS 缓存可能在您的节点配置中起着至关重要的作用。
性能#
与纯 CPU 机架相比,此配置可以将性能提高高达 30 倍。通过将 A100 GPU 和高性能网络添加到现有的机架基础设施中,组织可以使用主流配置大幅提高 AI 企业级工作负载的性能吞吐量。但是,由于此配置在机架级别比纯 CPU 配置需要更多功率,因此它只能容纳 15 个 GPU 节点,而纯 CPU 节点可以容纳 20 个。
有关性能测试结果的更多信息,请参阅规模调整指南附录。