最佳性能集群配置#
最佳性能配置旨在提供每个节点的最大性能,从而最大限度地增加向上扩展和向外扩展的节点数量。通过提供每个机架最多的 GPU 数量(22 个 GPU,而 15 个 GPU),可以最佳地实现最大吞吐量。
重要的是要注意,规模调整计算基于每个机架 14kW 冗余 PDU 和每个服务器双 1600W PSU,因为大多数企业数据中心都有这些要求。由于这些电力需求,机架密度计算导致最佳性能配置的每个机架 GPU 节点数量少于每个机架仅 CPU 节点数量。
服务器和机架配置#
最佳性能配置最大限度地提高了 2U 系统内的 GPU 数量。最佳性能配置与主流配置中使用的相同服务器硬件配置和相同 CPU 保持一致,进一步增加了 RAM、存储、电源尺寸和网卡,并将 GPU 数量翻倍。由于每个服务器的 GPU 数量翻倍,因此作为四节点集群的 VM 总数为 21 个,每个服务器 2 个 VM。
企业 AI / 边缘 AI / 数据分析 |
|---|
2U NVIDIA 认证系统 |
双 Intel® Xeon® Gold 6248R 3.0G, 24C/48T, 10.4GT/s, 35.75 M 缓存, Turbo, HT (205W) DDR4-2933 |
24x 32GB RDIMM, 3200MT/s, 双列 |
2x 1.92TB SSD SATA 混合用途 6Gbps 512, 2.5 英寸热插拔 AG 驱动器, 3 DWPD, 10512 TBW |
1x 3.84TB 企业级 NVMe 读取密集型 AG 驱动器 U.2 Gen4 带载体 |
1x 16GB microSDHC/SDXC 卡 |
双路热插拔冗余电源 (1+1), 2000W |
2x NVIDIA® BlueField-2® 100G 或 NVIDIA ConnectX-6 DX 100G / 200G |
NVIDIA® SN3420/SN3700 机架顶部 |
2x NVIDIA A100 for PCIe |
重要提示
NVIDIA A30 和 A100 GPU 仅为计算型 GPU,不适用于远程协作/ProViz 工作负载。
下表说明了最佳性能配置的机架密度。机架配置将包含 11 个节点,需要约 13.7 kW 的功率。有关最佳性能规模调整计算的更多说明,请参阅规模调整指南附录。
企业 AI / 边缘 AI / 数据分析 |
|---|

|
机架密度 11 个节点,需要约 13.7 kW 的功率。 |
重要的是要注意:最佳性能配置增加了 GPU 资源量,从而提高了性能吞吐量。机架中的节点数量减少了(最佳 – 11 个,主流 – 15 个),功耗 kW 大致相同。但是,由于每个服务器的 GPU 数量翻倍,因此作为 4 节点集群的 VM 总数为 21 个 – 每个服务器 2 个 VM。
网络#
最佳性能配置提供最高性能的网络,因为这对于 AI Enterprise 工作负载的横向扩展和纵向扩展至关重要。每个机架最多 11 个节点,每个机架 22 个 GPU,将 NVIDIA Mellanox ConnectX-6 DX PCIe 升级到 100 或 200GB 和 NVIDIA SN37000 交换机将进一步最大限度地提高计算节点之间的吞吐量。
下图描述了网络拓扑。此网络拓扑使用与主流配置相同的拓扑,但引入了双非阻塞 GPU 叶交换机设计,以实现计算节点之间的最大吞吐量。
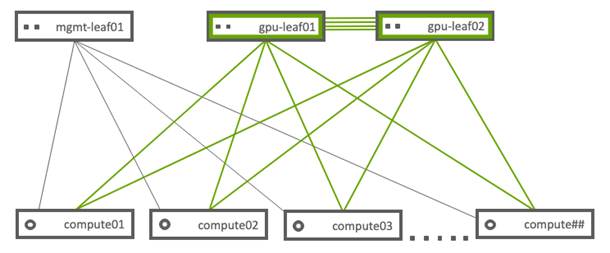
注意
mgmt-leaf01 是基础设施机架顶部交换机。
gpu-leaf01 和 gpu-leaf02 是计算型机架顶部 NVIDIA Mellanox SN3700 交换机。
存储#
最佳性能集群配置增加了 NVMe 和 NFS 缓存驱动器,超过了主流配置,以实现最大吞吐量和更大的模型尺寸。此配置包含更多 GPU 资源,允许 AI Enterprise 工作负载使用更广泛的数据。添加额外的 NVMe 驱动器可以进一步提高性能和吞吐量。
最佳性能配置还定位于为未来的存储技术做准备,例如 NVMe over Fabric (NVMeoF) 和 GPU Direct Storage (GDS)。
性能#
与仅 CPU 机架相比,此配置可以将性能提高高达 44 倍。通过在使用最佳性能配置的 NVIDIA 认证系统中最大限度地利用 A100 GPU 和 NVIDIA NIC,组织可以显着提高 AI Enterprise 工作负载的性能吞吐量。但是,由于此配置比仅 CPU 配置需要更多功率,因此在机架级别,它只能容纳 11 个 GPU 节点,而仅 CPU 节点为 20 个。
有关性能测试结果的更多信息,请参阅规模调整指南附录。