尺寸指南#
为了计算整个机架的性能提升,4 节点集群同时运行,为整个机架创建了一个线性扩展模型。每种配置的预测性能提升基于仅 CPU 的结果,并线性外推到包含五个 4 节点集群的完整 20 节点仅 CPU 机架。
重要的是要注意,由于电源要求,机架密度计算导致每个机架的 GPU 节点少于仅 CPU 节点,因为大多数企业数据中心每个机架需要一个 14kW 冗余 PDU 和每个服务器一个双 1600W PSU。下面显示的相对性能数字假设了这些硬性功率限制。 尽管如此,使用 GPU 节点代替仅 CPU 节点时,性能仍有显着提升。 可以突破这些机架功率限制的企业可能会获得更可观的性能提升。
入门级性能集群#
对于入门级集群配置,20 个物理节点可以装入机架,从而允许五个 4 节点集群。此配置使用 A30,预计其吞吐量约为 A100 的 60%。 这些假设用于计算与上述仅 CPU 机架场景相比的预期性能。 与仅 CPU 机架相比,入门级配置的预期性能提升为 20 倍。
与 vGPU 加速的 VM 相比,仅 CPU 测试分配了多 75% 的 vCPU 资源。 如果您的处理器具有更高的核心数和时钟速度,您可能会看到性能提升幅度降低。
主流性能集群#
对于主流配置,15 个物理节点可以装入机架,从而在机架中形成 3.75 个 4 节点集群。 可以使用分数 4 节点集群,因为性能改进在此规模下呈线性关系。 此配置还通过 NVIDIA Connect-x6 利用 RoCE 与 ATS,从而在 100GbE 网络上进一步提高性能。 这些假设用于计算与上述仅 CPU 机架场景相比的预期性能。 与仅 CPU 机架相比,主流配置的预期性能提升为 30 倍。
最佳性能集群#
对于最佳性能配置,11 个物理节点可以装入机架,从而在机架中形成 2.75 个 4 节点集群。 可以使用分数 4 节点集群,因为性能改进在此规模下呈线性关系。 此配置还通过 NVIDIA Connect-x6 利用 RoCE 与 ATS,从而在 100GbE 网络上进一步提高性能。 此外,每个服务器中放置了 2 个 A100 GPU,每个服务器允许 2 个 VM,使每个机架的虚拟节点数量翻倍。 这些假设用于计算与上述仅 CPU 机架场景相比的预期性能。 与仅 CPU 机架相比,最佳性能配置的预期性能提升为 44 倍。
可扩展性测试#
所有可扩展性测试均使用 ResNet-50 训练模型完成,精度为 FP16,2 个 epoch,批量大小为 512。 该模型在 4 个节点上执行,每个测试每个节点 1 个 VM。
CPU 通过 10G 网络运行 |
GPU 通过 10G 网络运行 |
GPU 通过 100G + RoCE 网络运行 |
|||
|---|---|---|---|---|---|
GPU 配置文件 |
不适用 |
GPU 配置文件 |
裸机 |
GPU 配置文件 |
裸机 |
图像/秒 (总计) |
212.87 |
图像/秒 (总计) |
6964.61 |
图像/秒 (总计) |
8484.07 |
瓦特 (总计) |
2304 |
瓦特 (总计) |
2337 |
瓦特 (总计) |
2453 |
节点数量 |
4 (每个节点 1 个 VM) |
节点数量 |
4 (每个节点 1 个 VM) |
节点数量 |
4 (每个节点 1 个 VM) |
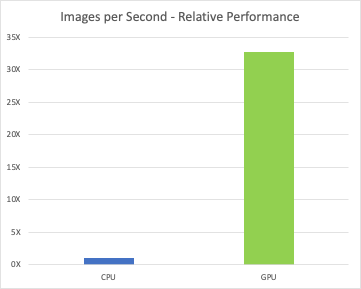
第一个测试比较了仅 CPU 节点与在 10GbE 网络上具有单个 A100 的节点。
注意
相对性能,4 节点,TensorFlow ResNet-50 V1.5 训练,使用 Horovod,FP16,BS:512
服务器配置:2x Intel(R) Xeon(R) (Gold 6240R @2.4GHz), VMware vSphere 7.0u2,
CPU 结果:Ubuntu 18.04, 72 vCPU, 64 GB RAM, 板载 10GbE 网络。
GPU 结果:Ubuntu 18.04, 16 vCPU, 64 GB RAM, NVIDIA vGPU 12.0 40C 配置文件, 每个节点 1 个 NVIDIA A100, 驱动程序 460.32.04, 板载 10GbE 网络。
上图表明,与仅使用 CPU 的服务器相比,在每个服务器中使用单个 A100 GPU 可以使训练性能提高约 30 倍。 重要的是要注意,与非 GPU 加速的 VM 相比,GPU 加速的 VM 所需的 vCPU 数量减少了约 75%。
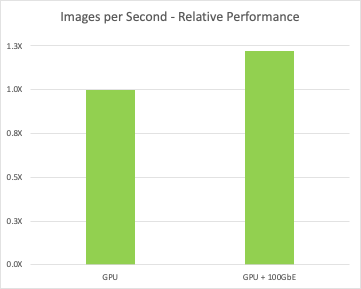
高性能 100GbE NVIDIA Mellanox 网络交换机在节点之间提供更高的吞吐量,从而在执行多节点 AI 企业级工作负载时获得性能提升。 下图说明了运行训练工作负载时多节点集群的性能提升示例。
注意
相对性能,4 节点,TensorFlow ResNet-50 V1.5 训练,使用 Horovod,FP16,BS:512
服务器配置:2x Intel(R) Xeon(R) (Gold 6240R @2.4GHz), VMware vSphere 7.0u2,
GPU 结果:Ubuntu 18.04, 16 vCPU, 64 GB RAM, NVIDIA vGPU 12.0 40C 配置文件, 每个节点 1 个 NVIDIA A100, 驱动程序 460.32.04, 板载 10GbE 网络。
GPU +100GbE 结果:Ubuntu 18.04, 16 vCPU, 64 GB RAM, NVIDIA vGPU 12.0 40C 配置文件, 每个节点 1 个 NVIDIA A100, 驱动程序 460.32.04, NVIDIA Mellanox CX-6 Dx 100G 配对 NVIDIA SN3700
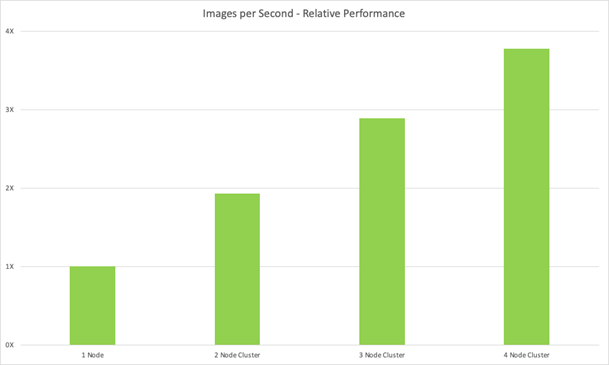
高性能网络基础设施在节点之间提供更高的吞吐量,从而在执行多节点 AI 企业级工作负载时获得性能提升。 下图说明了当深度学习训练工作负载扩展到多节点时吞吐量的增加。 随着测试的扩展,相对性能提升呈线性关系。
注意
服务器配置:Intel Xeon Gold(6240R @ 2.4GHz), Ubuntu 18.04, VMware vSphere 7.0u2, VM,配备 16 个 vCPU,64 GB RAM, NVIDIA vGPU 12.0 (40C 配置文件), 每个节点 1xNVIDIA A100, 驱动程序 460.32.04, NVIDIA Mellanox ConnectX-6 Dx, RoCE 已启用, ATS 已启用, TensorFlow Resnet-50 V1.5 训练,使用 Horovod,FP16,BS: 512