部署指南
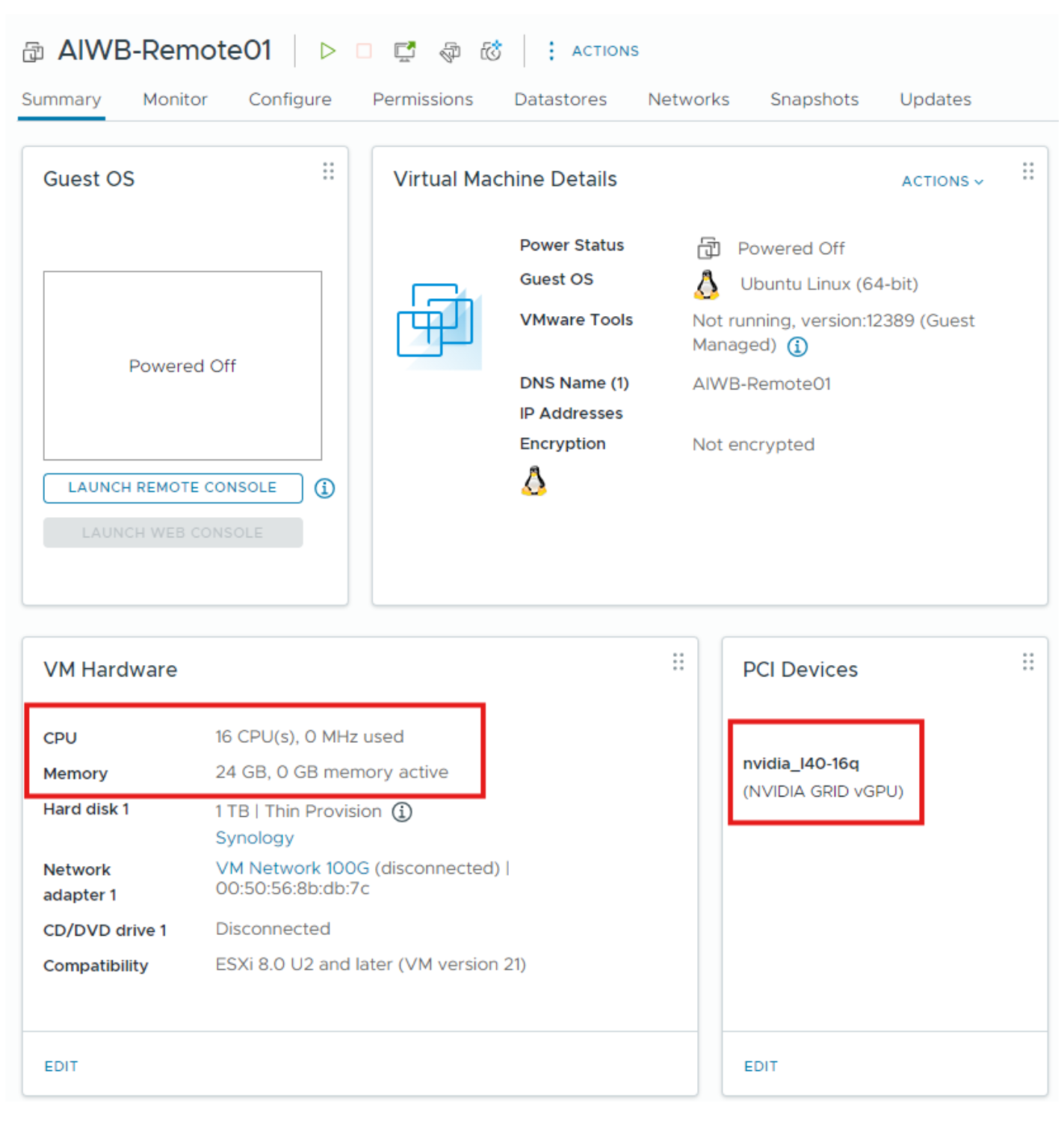
在 vCenter 中设置 Linux VM,配置如下
vCPU - 16 CPU
内存 - 24 GB
vGPU 配置文件 - 16Q
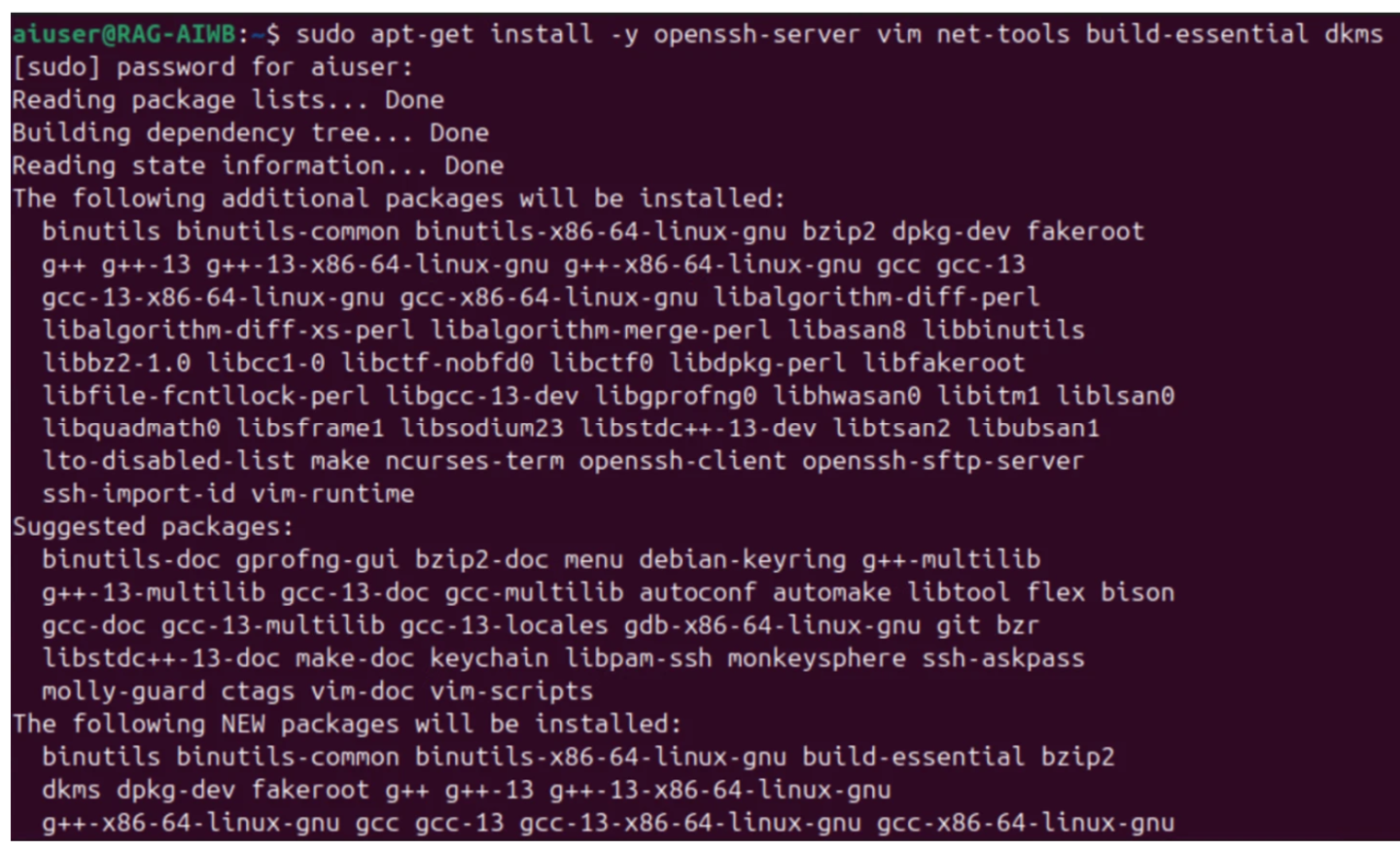
安装 Ubuntu 并设置以下必要的依赖项
open-vm-tool(安装后需要重启)
openssh-server
vim
net-tools
build-essential
dkms
fuse3
libfuse2
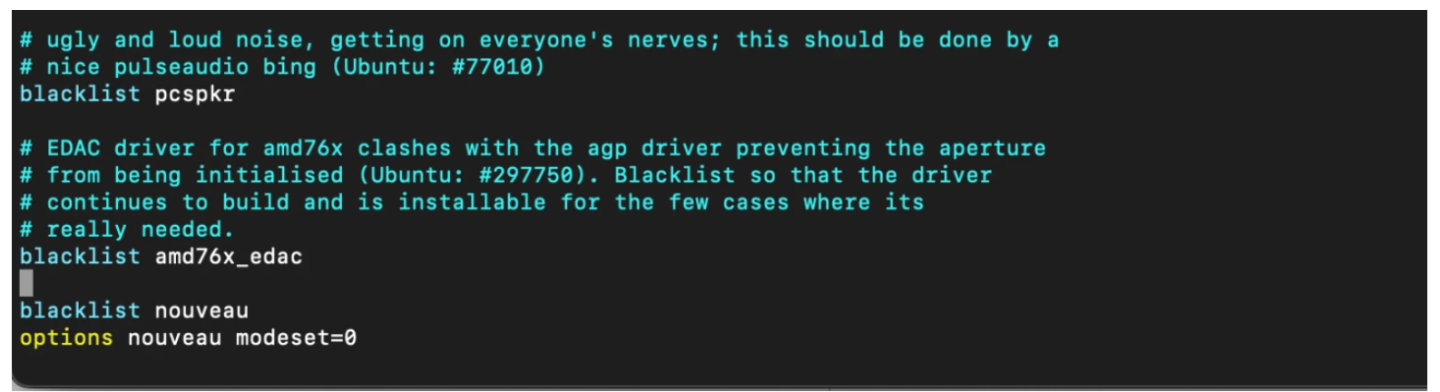
禁用 nouveau 驱动程序
$ sudo vim /etc/modprobe.d/blacklist.conf $ blacklist nouveau $ options nouveau modeset=0
更新 initramfs,然后重启。
$ sudo update-initramfs -u $ sudo reboot
安装您首选的远程协议(例如,NoMachine、Horizon、VNC)。本指南的其余部分将使用 NoMachine 作为远程协议。
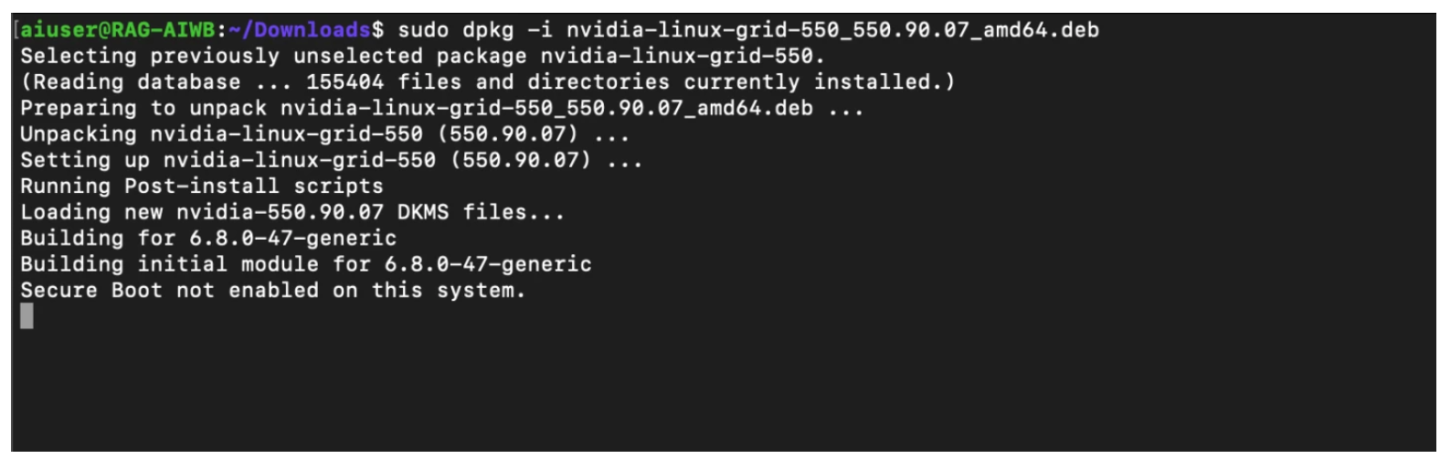
下载并安装 NVIDIA vGPU 软件。
$ sudo chmod +x nvidia-linux-grid-xxx_xxx.xx.xx_amd64.deb $ sudo dpkg -i nvidia-linux-grid-xxx_xxx.xx.xx_amd64.deb
驱动程序实用程序完成安装后,重启,然后运行 nvidia-smi 命令以验证驱动程序是否已正确安装。
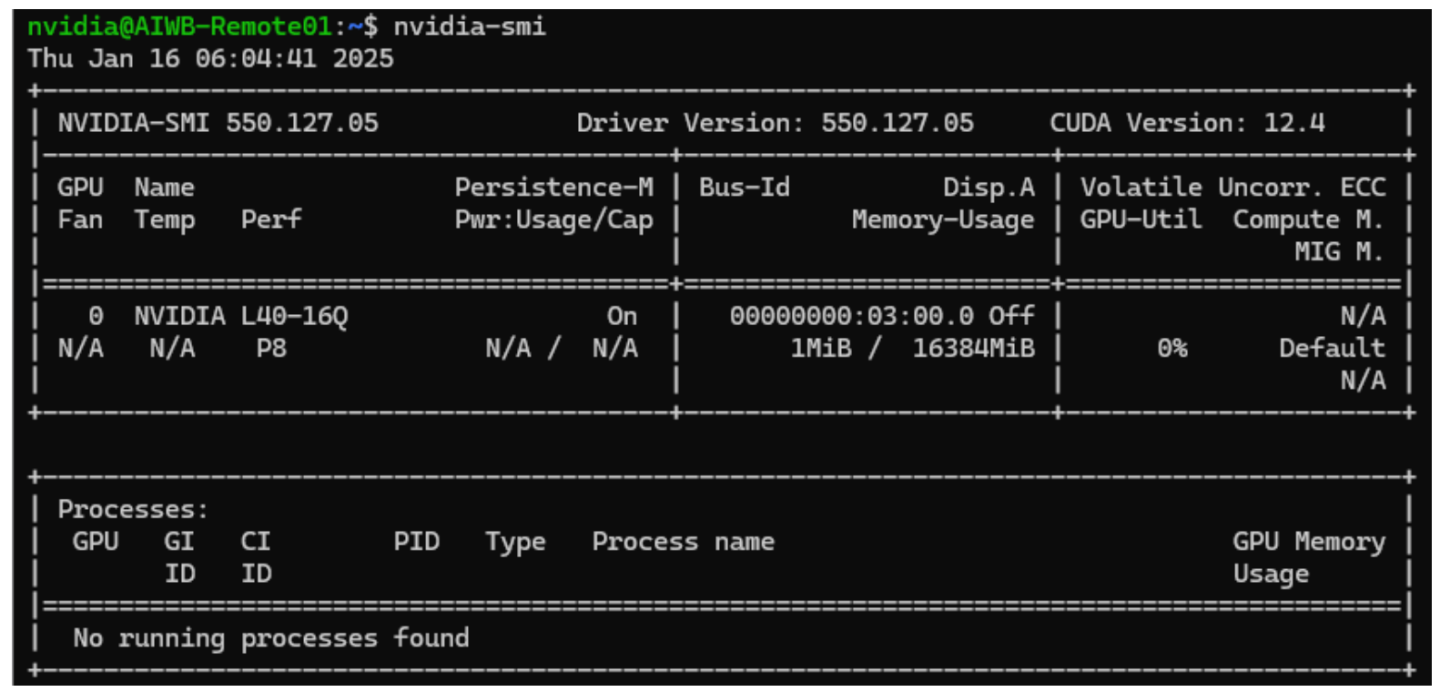
至此,VM 设置完成。接下来,在 Ubuntu VW 上安装 AI Workbench。可以从 NVIDIA 网站下载 AI Workbench。 Ubuntu 的安装指南可以在此处找到。





在本地计算机上更新 AI Workbench 后,您还必须更新任何连接的远程位置。有关详细信息,请参阅在远程计算机上更新 AI Workbench。

从 GitHub 克隆 Llamafactory 项目。在 AI Workbench 中,选择“克隆项目”,然后输入存储库 URL 以开始克隆过程。
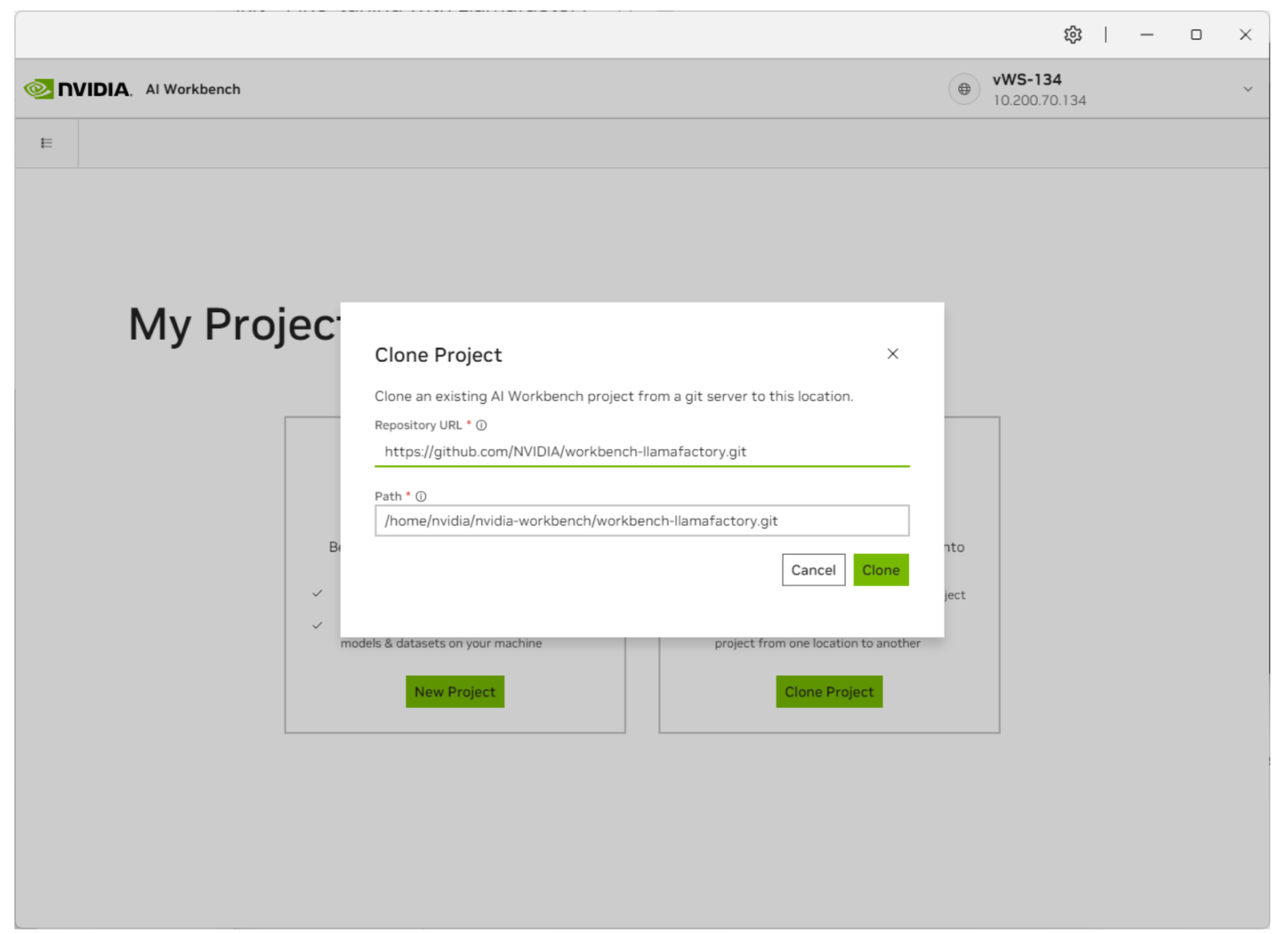
AI Workbench 将需要一些时间来拉取存储库。您可以通过单击底部状态栏查看进度。
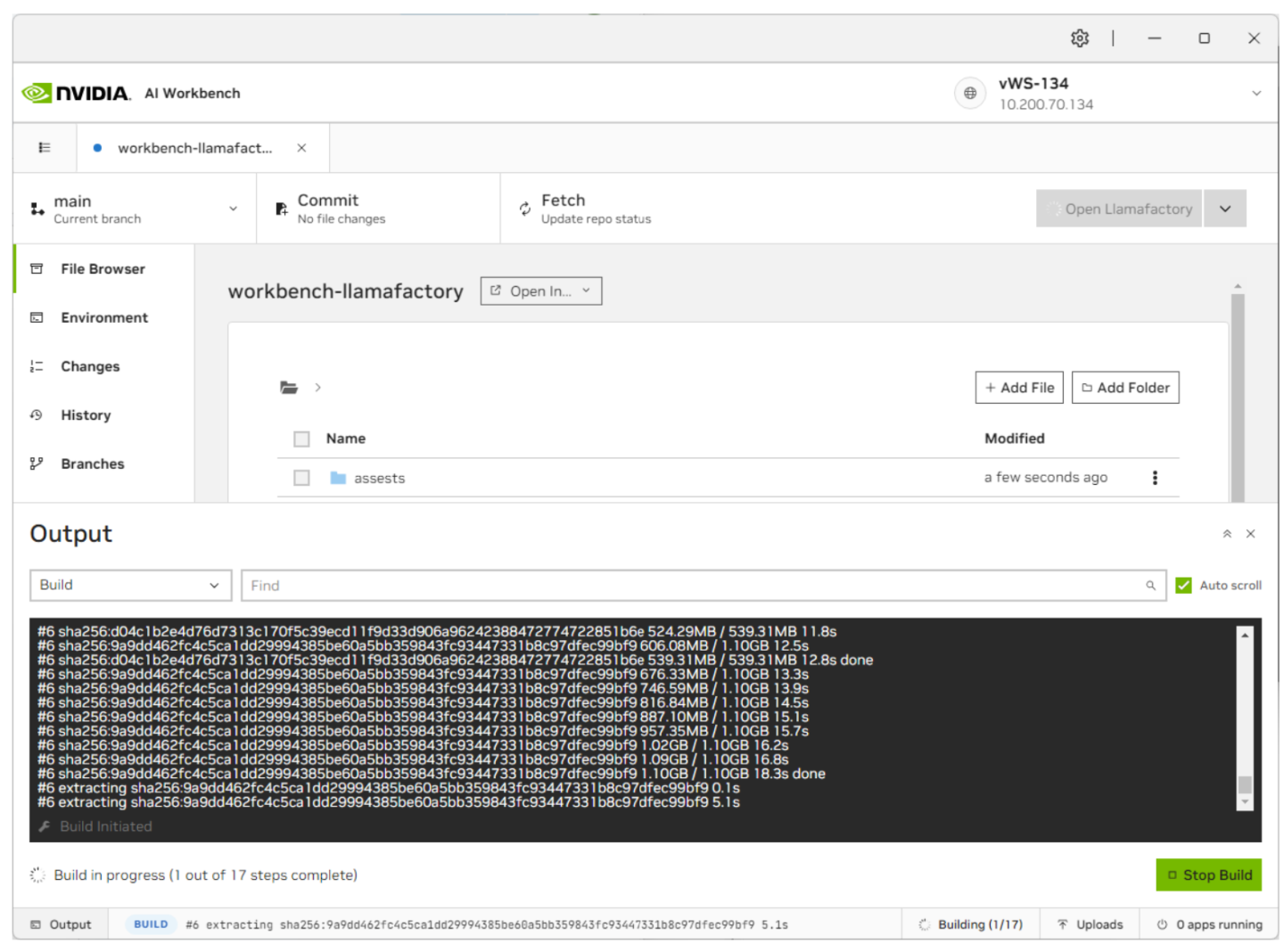
构建完成后,单击左侧的“环境”选项卡,然后向下滚动到“密钥”。本指南还将使用 Llama-3-8B,一个门控 LLM。创建一个 HuggingFace 帐户并请求访问 LLM。完成后,您必须在“环境”下创建一个名为
HUGGING_FACE_HUB_TOKEN的新条目,并输入您的 Huggingface 访问令牌。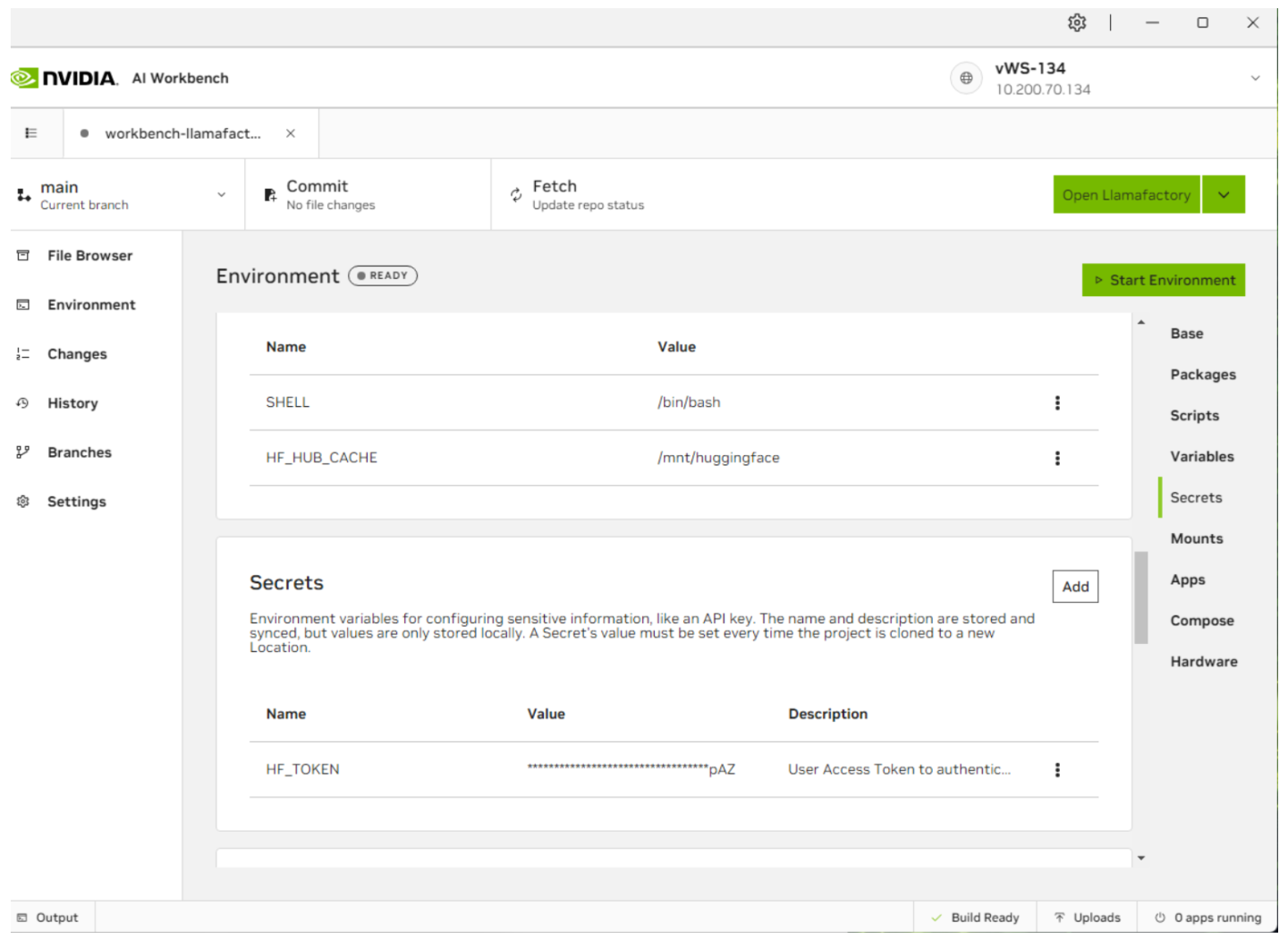
输入密钥后,单击右上角的启动环境。这将启动此模型的容器服务。
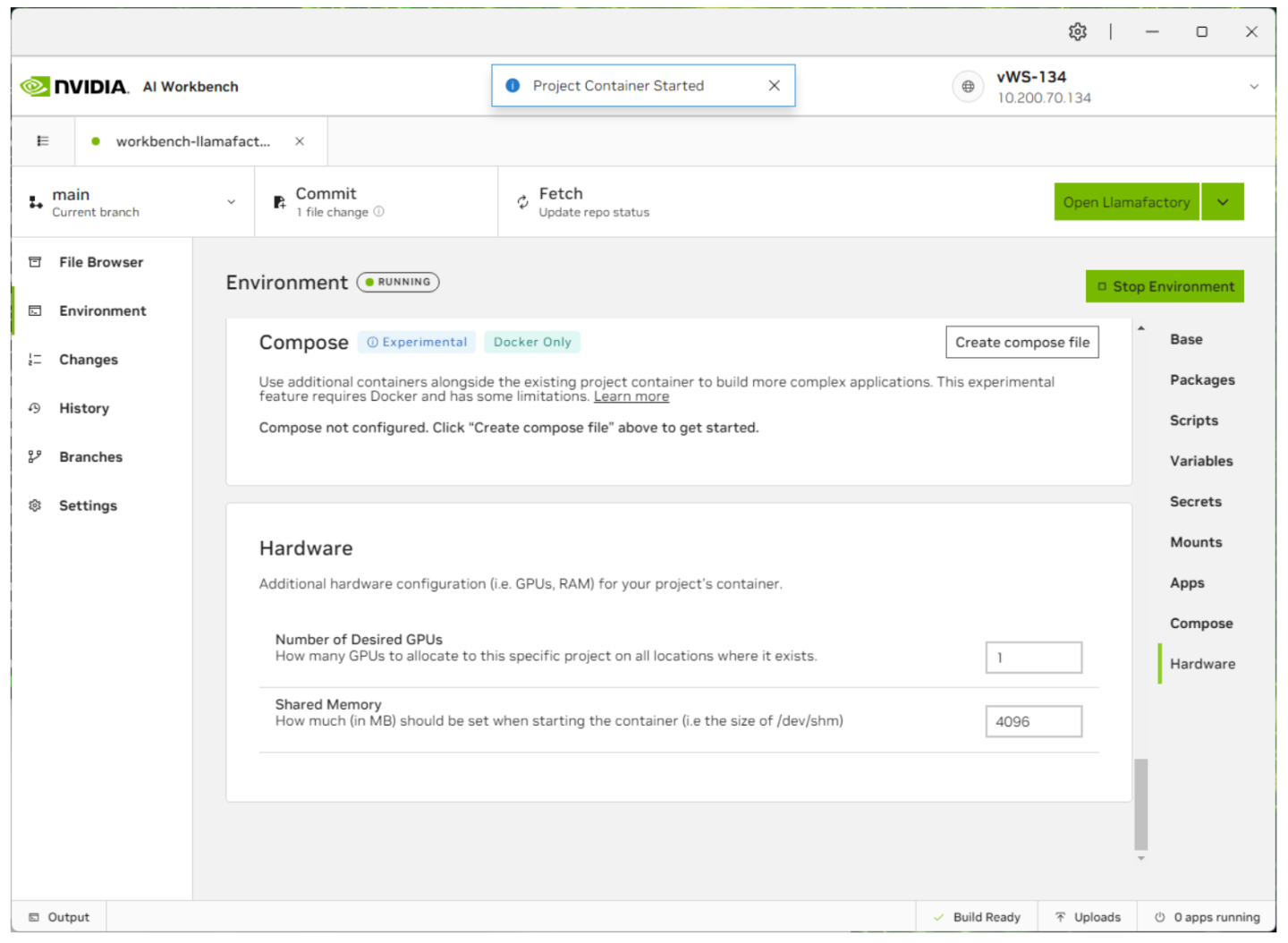
现在容器已启动,选择 jupyterlab 以配置项目或 Open Llamafactory 以启动 Llamafactory UI。您还可以通过单击右下角的状态栏来显示每个应用程序的状态。
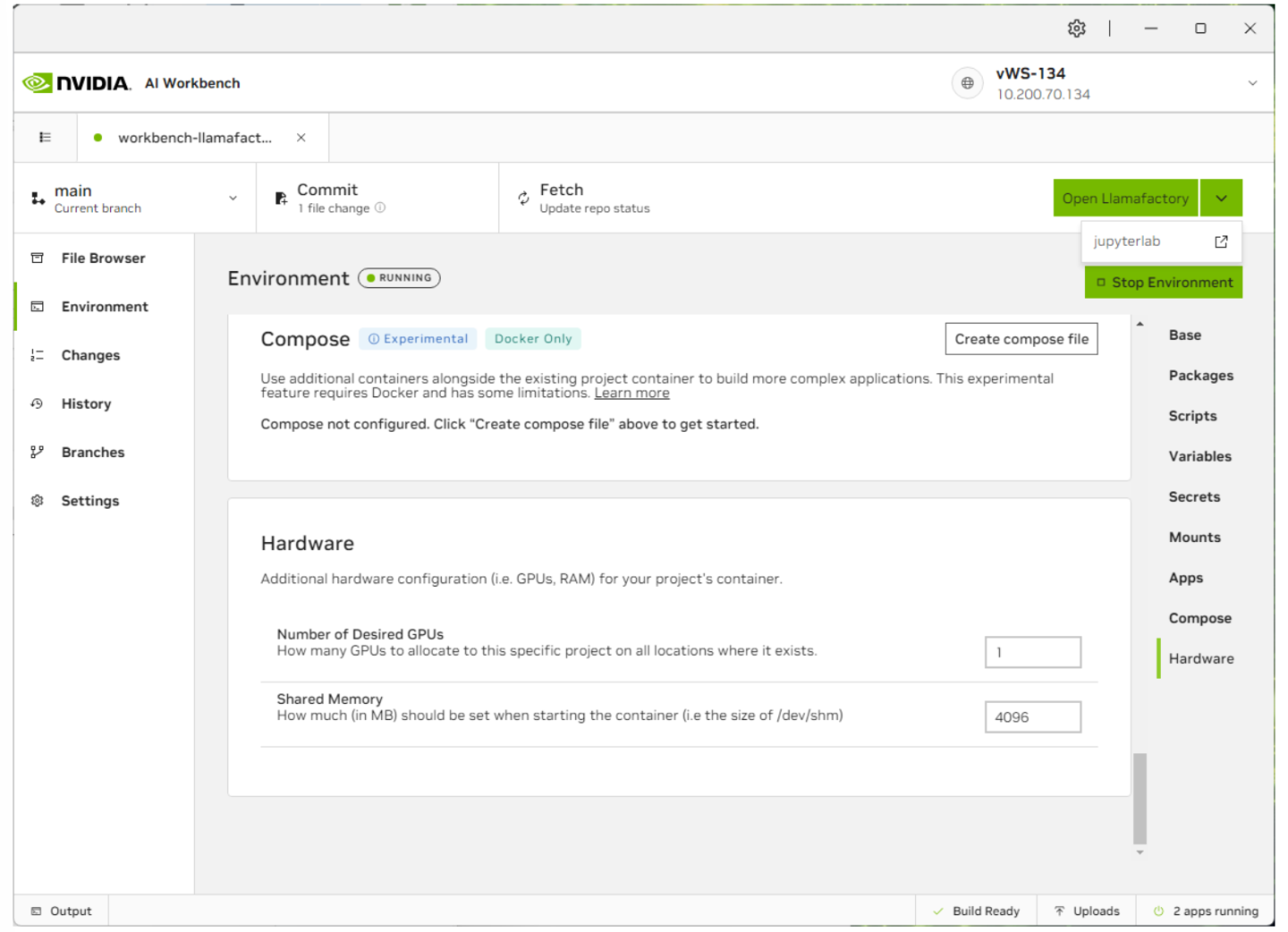





借助 AI Workbench,您可以轻松使用 Jupyter Notebook 功能来更改和自定义 Llamafactory 应用程序。在以下屏幕截图中,我们可以包含其他库工具来协助我们的自定义微调项目。
如果您已更新 postinstall.sh 文件或任何其他文件以包含新的库或工具,则需要重建项目。

参数高效微调 (PEFT) 概述
PEFT 仅调整预训练模型中参数的子集,从而优化资源使用并降低成本。诸如量化低秩自适应 (QLoRA) 等技术将 4 位量化和 LoRA 结合起来以实现高效微调。 Llamafactory 支持全精度 (None)、8 位和 4 位量化
无 (None):最高精度,但需要大量内存。
8 位:平衡的性能和效率。
4 位:最适合内存受限的设置,但精度略有降低。
单击 Open Llamafactory 按钮后,您将看到 Llamafactory UI。从这里我们可以开始我们的微调过程。
我们将从 Hugging Face 拉取 Meta/Llama-3-8b-instruct 模型,并使用 Codealpaca 数据集对其进行微调。此数据集用于训练 LLM(如 Llama-3-8b-instruct)生成代码,并包含数以万计的编码示例。公司还可以根据其专有代码和编码标准创建自己的数据集。这将确保当开发人员与微调模型聊天时,它将根据公司的标准生成代码。
由于我们使用 16q 配置文件,因此我们需要使用 QLoRA 和 4 位量化才能使用我们拥有的 vGPU 内存量来微调模型。虽然将量化设置为 4 位确实允许我们在 vGPU 内存较少的场景中运行微调,但这会以牺牲精度和准确性为代价。
如果您选择使用不同的 LLM、量化位或 vGPU 配置文件,您可以查看“大小调整”部分中的详细信息以了解推荐配置。
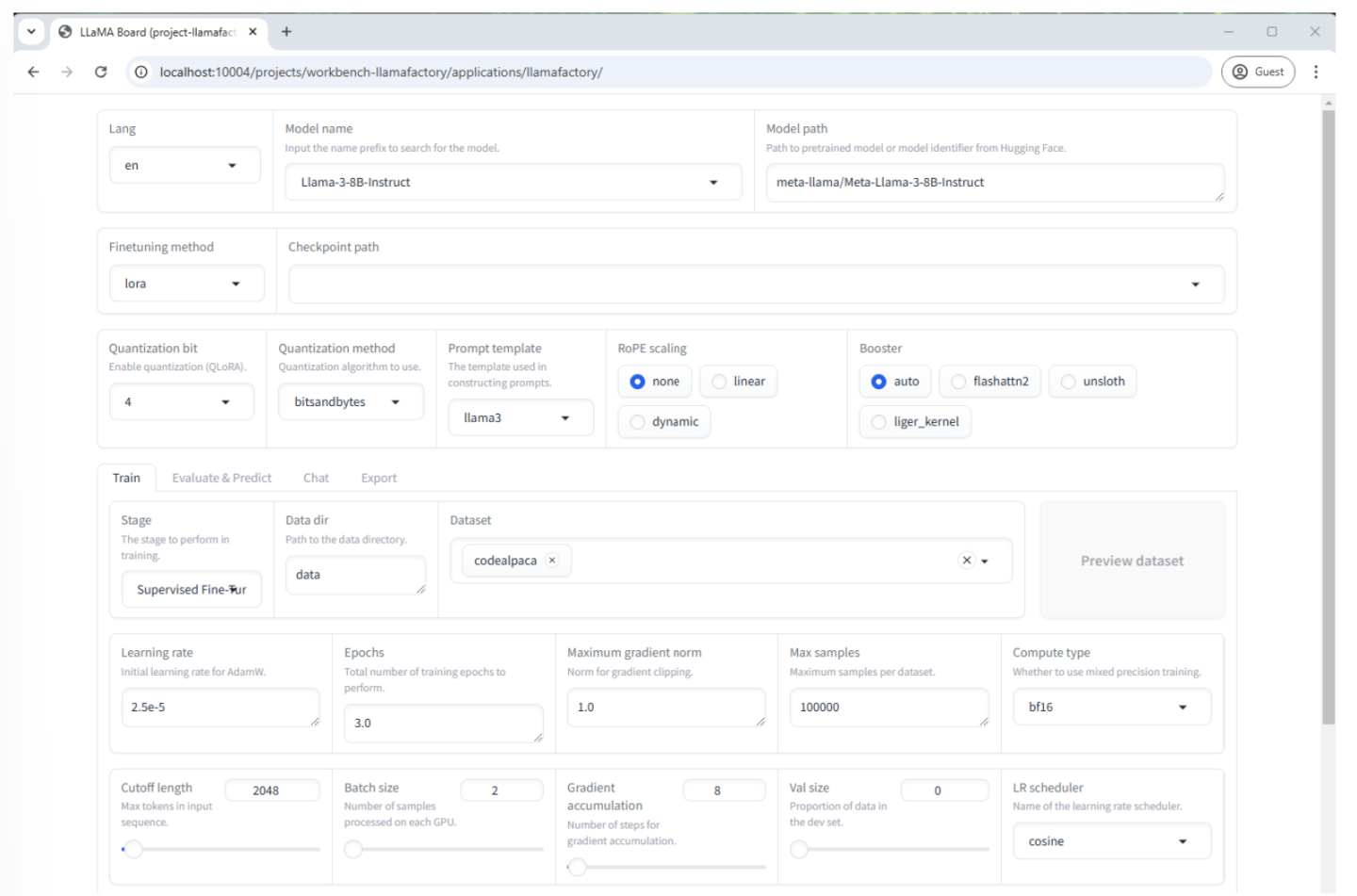
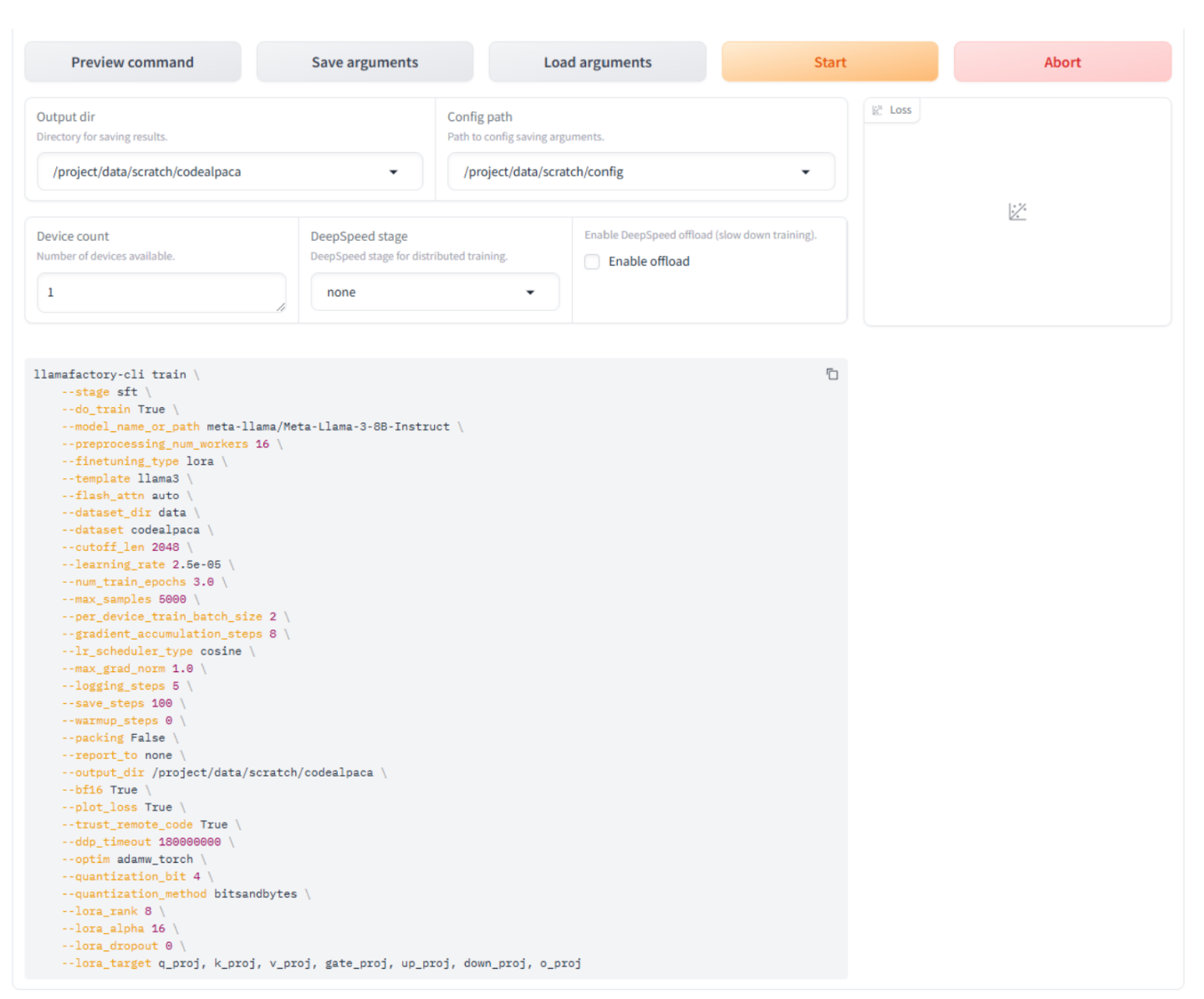
在 Llamafactory UI 中,将这些字段设置为以下值
模型名称:Llama-3-8B-Instruct(这将自动填充“模型路径”字段)
微调方法:lora
量化位: 4
提示模板:llama3
数据集:codealpaca
学习率:2.5e-5
最大样本数: 5000
以下是我们选择的选项的更多详细信息
模型名称:这是我们用于微调的预训练 LLM (Llama-3-8Bi-instruct)
微调方法 - 有三种可用的微调方法
完整 - 此方法调整 LLM 中的所有参数。虽然这将为我们带来最佳结果,但它需要最多的时间、精力和资源才能完成
冻结 - 仅调整 LLM 特定层中的参数,而其他参数则“冻结”。这在性能和效率之间提供了最佳平衡。
LoRA(低秩自适应) - 这是一种参数高效的微调技术。 LoRA 不是直接修改原始模型的权重,而是添加小的“适配器”层来注入新信息。
量化位 - 这指的是用于表示 LLM 权重的位数。 Llamafactory 提供三个选项。请注意,如果在微调方法为 LoRa 的情况下选择 8 位或 4 位,则称为 QLoRA。 QLoRA 的关键概念是减少模型的内存占用,以实现高效微调。这允许在内存较少的 GPU 上微调更大的 LLM。
无 (None) - 这表示将不使用量化,并且模型权重将保持其原始精度。对于 Llama-3-8B-instruct,这将是 16 位。
8 位 - 在节省内存和保持模型精度之间提供平衡。
4 位 - 提供最显著的内存节省,使您能够微调非常大的模型。
权衡
精度:量化有时会导致模型精度略有下降,尤其是在较低的位值(如 4 位)下。但是,QLoRA 旨在最大限度地减少这种影响。
性能:由于减少了内存访问时间,量化模型有时可以运行得更快。
提示模板 - 这可以被认为是预先设计的表格或填空结构,用于指导 LLM 的响应。它可以帮助您向模型提供明确的指令和上下文,以获得更一致和相关的输出。将提示模板与 LLM 匹配将获得最佳结果。
数据集 - 它们提供了 LLM 从中学习的示例。我们正在使用 Codealpaca,这是一个用于帮助训练或微调 LLM 以执行代码相关任务的数据集。
学习率 - 此字段确定在学习过程的每个步骤中模型权重的调整量。较高的学习率可能使模型能够快速学习,但会以不稳定和不太准确的结果为代价。较低的学习率将花费更长的时间,但会带来更准确的结果。通常,2.5e-5 是一个安全的起点。
最大样本数 - 这是我们将从 Codealpaca 数据集中使用的最大训练样本数。通常,此数字设置较低并逐渐增加。这可以帮助加快训练时间并减少资源(如内存)的使用。它还可以帮助防止过度提升或模型过于专注于训练数据而无法很好地推广到新数据。
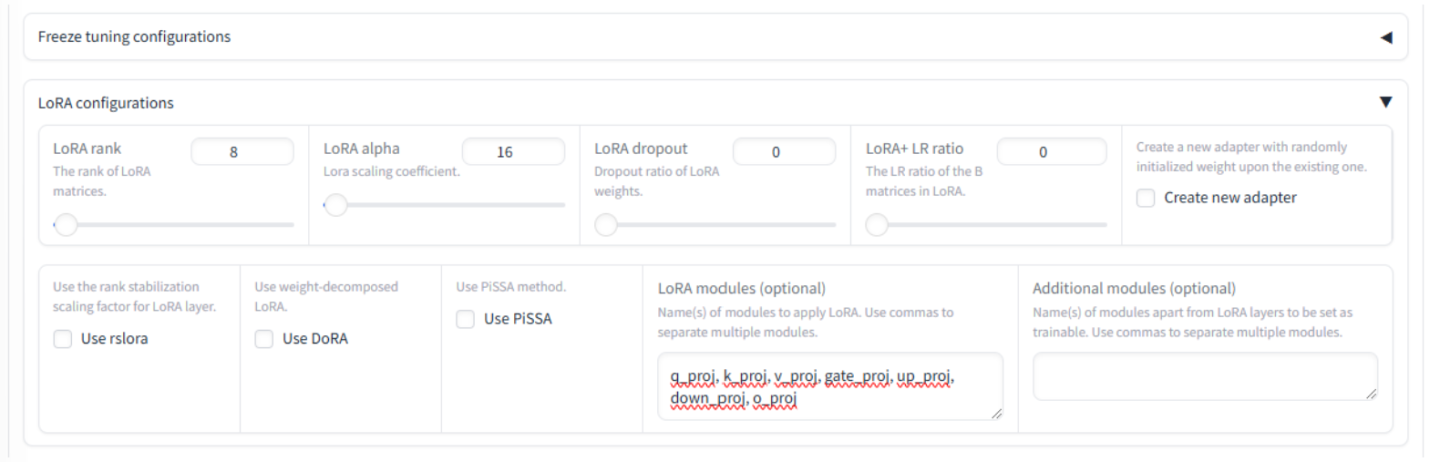
展开 LoRA 配置并将“LoRA 模块(可选)”字段更新为包含
q_proj, k_proj, v_proj, gate_proj, up_proj, down_proj, o_proj这些投影模块帮助模型专注于最重要的信息,并学习单词和概念之间复杂的关联。
向下滚动到页面底部并更新这些字段
输出目录:
/project/data/scratch/codealpaca配置路径:
/project/data/scratch/config
单击预览命令按钮以预览 Llamafactory 将用于启动训练的命令。
现在一切都已配置完毕,我们准备好微调模型了。单击启动按钮开始该过程。





根据您的互联网连接,下载 Llama3-8b-instruct 模型 (16GB) 可能需要长达 90 分钟。您可以使用 AI Workbench 窗口底部的状态栏查看进度。

微调过程大约需要 30 到 40 分钟才能完成,具体取决于代码集、模型大小、量化、VM 大小等。UI 将显示状态和损失函数图,以提供对该过程的深入了解。

微调完成后,您将在底部的滚动日志中看到完成。

评估模型
现在微调模型已完成,我们可以使用内置的聊天功能评估模型。
单击聊天选项卡并验证或更新这些设置
量化位 仍设置为 4(确保选择与微调时选择的量化位相同)。
检查点路径:
/project/data/scratch/codealpaca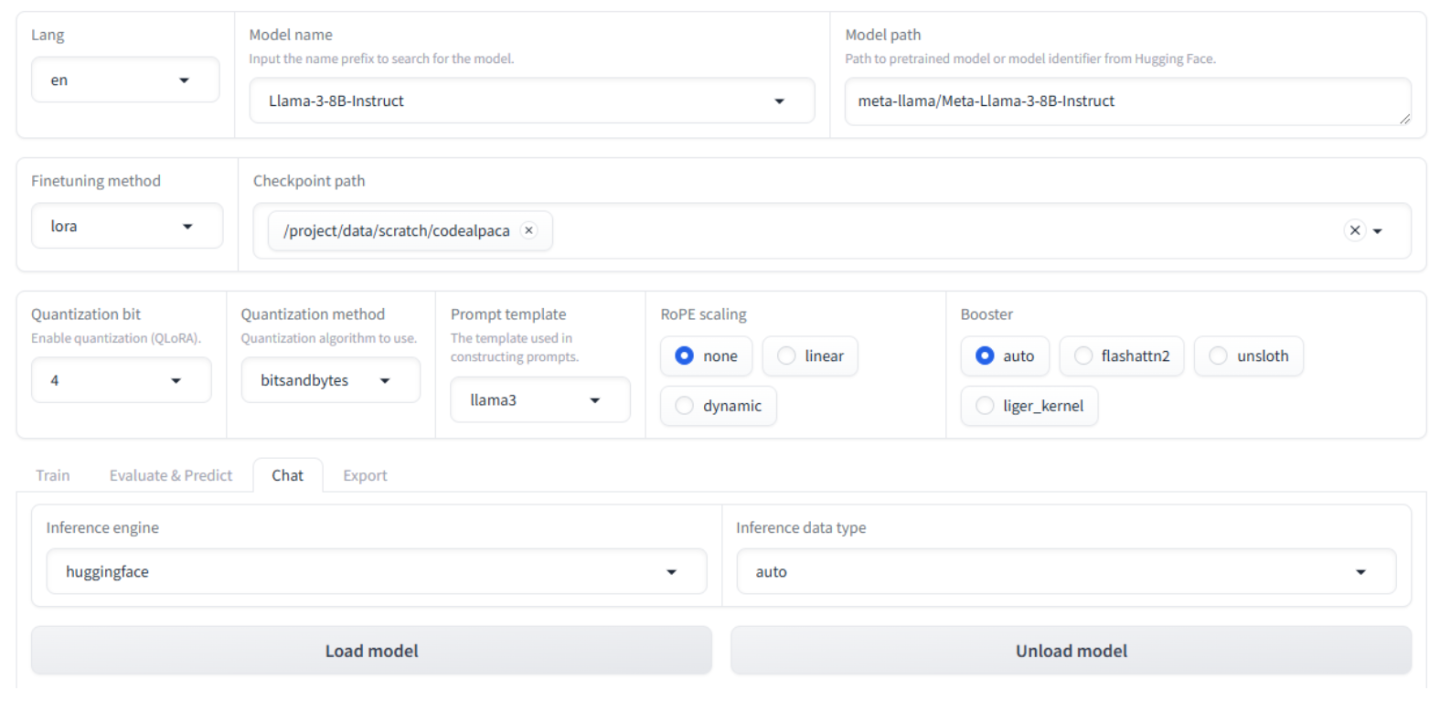
单击加载模型按钮并等待其完成。
模型加载完成后,您可以通过在输入…框中提问来与模型交互。我们用于微调模型的数据集专门用于编码和编程。您可以向模型询问有关编程语言和语法的问题,或让它为您编写程序。例如,键入以下内容并单击提交按钮
编写一个 Python 程序,提示用户输入温度,然后询问他们是否要将其转换为华氏温度或摄氏温度。
聊天机器人将根据我们提出的请求回复 Python 代码。
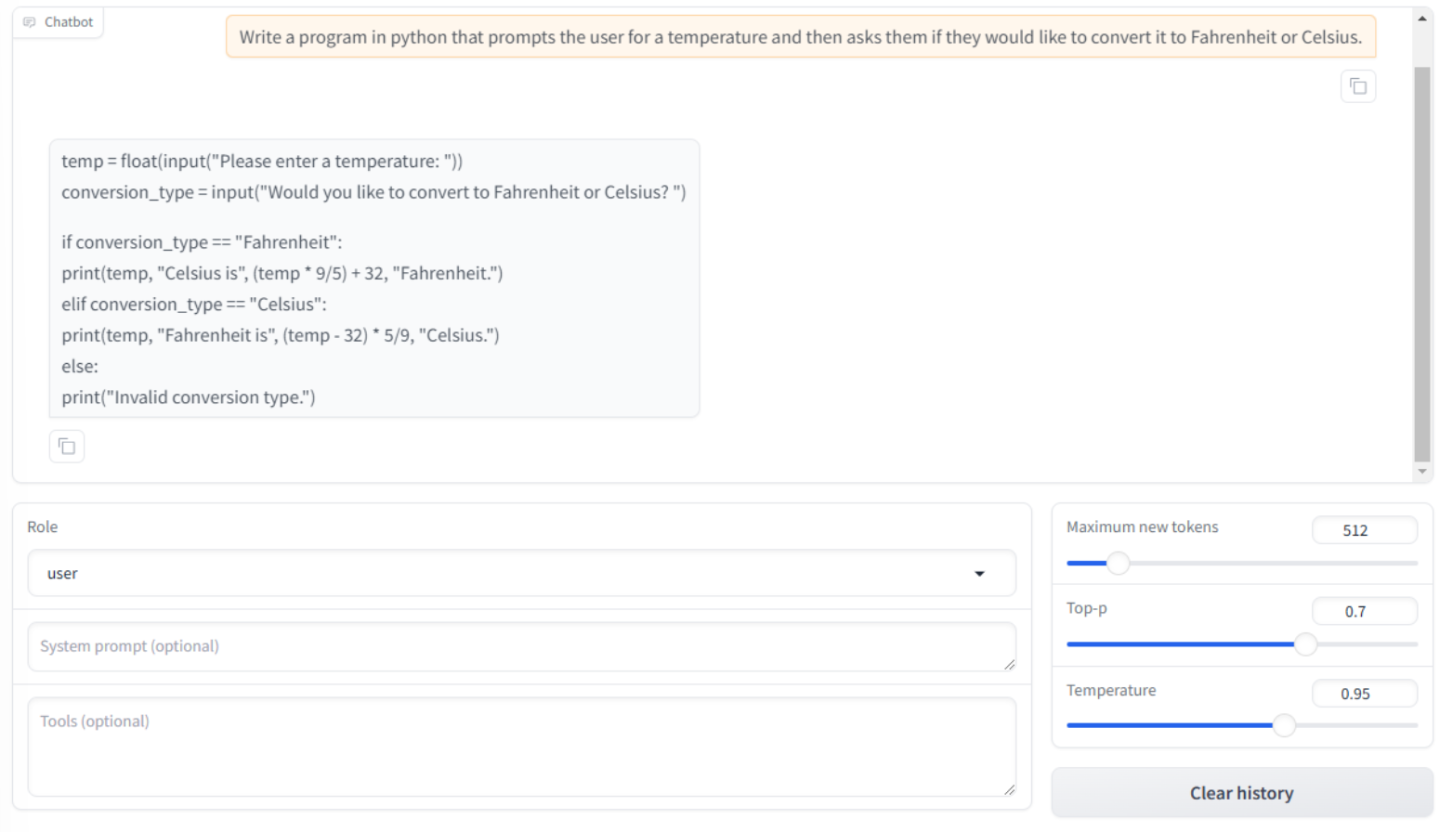
聊天机器人将根据我们提出的请求回复 Python 代码。



您将注意到聊天窗口下方有三个设置。您可以调整这些设置,直到获得所需的响应。
最大新令牌数 - 这决定了在生成响应时可以生成多少个新令牌。这将设置生成文本长度的限制。
Top-p - 这也称为 nucleus 采样,是一个参数,用于控制推理期间文本生成的多样性和创造力。使用较高的 Top-p,您将看到更具创造性和多样性的响应,但它们可能不太相关或连贯。使用较低的 Top-p,您将看到更集中和可预测的响应,但它们可能更重复。
温度 - 此设置控制将多少随机性或不可预测性引入到生成的文本中。
温度 = 0 - 模型每次都会选择最可能的单词,从而提供最可预测的输出
温度 = 1 - 使用原始概率,并在创造力和焦点之间取得平衡
温度 > 1 - 模型更有可能选择意外和有创意的单词,这可能会导致更具创造性但不太连贯的响应。
其他评估是 vLLM-OpenAI 和 GenAI Perf。合并的检查点可以通过 vLLM-OpenAI 容器部署,并使用 GenAI Perf 进行基准测试。