高级学习
本节将重点介绍主要的 Nsight Graphics 工具的关键概念、高级信息以及操作方法。
简介
自从图形加速技术问世以来,NVIDIA 一直在创造世界上性能最高、功能最丰富的 GPU 方面处于领先地位。每一代 GPU 都变得更快,也因此变得更加复杂。为了创建能够充分利用现代 GPU 中存在的复杂功能的应用程序,作为程序员的您必须深入了解 GPU 的运行方式,以及一种查看 GPU 状态(与该操作相关)的方法。幸运的是,NVIDIA 图形开发者工具的使命很简单:提供一个工具生态系统,让您拥有这种超能力。
本参考指南由开发者工具团队的专家创建,旨在温和地介绍一些关键的工具功能,这些功能将帮助您调试、分析并最终优化您的应用程序。
您可以随意跳到与您最相关的部分。如果您发现任何信息不足,请通过 NsightGraphics@nvidia.com 联系我们,以便我们改进本参考。除了本指南外,我们也很乐意与个别开发者合作进行培训。最后,如果出现任何问题,请记住使用工具窗口右上角的“反馈”按钮,以便我们有机会让工具更好地为您服务。
谢谢!
Aurelio Reis
图形开发者工具 SWE 总监
NVIDIA
GPU 跟踪
它是什么?
GPU 跟踪是一个 D3D12/DXR 和 Vulkan/VKRay 图形分析器,用于识别图形应用程序中的性能限制因素。它使用一种称为定期采样的技术来收集与不同 GPU 硬件单元相关的指标和详细的时序统计信息。借助多通道指标,该工具可以使用多个通道和统计采样来收集指标。对于标准指标收集,它利用专门的 Turing 硬件,以最小的开销在单通道中捕获这些数据。
GPU 跟踪将此数据保存到报告文件中,并通过名为“TraceCompare”的功能包含“差异”功能。数据以直观的可视化形式呈现在时间轴上,该时间轴可配置且易于导航。数据以分层自上而下的方式组织,因此您可以在深入了解各个问题区域之前观察整个帧的行为。以前需要猜测和测试才能解决的问题现在可以一目了然地直观识别。
在本节中,我们将重点介绍 GPU 跟踪工具引入的关键概念,并深入解释其检索的数据。
GPU 概述
GPU 跟踪允许您观察 D3D12 和 Vulkan 图形管线所有阶段的指标。下图命名了与每个逻辑管线状态相关的 NVIDIA 硬件单元
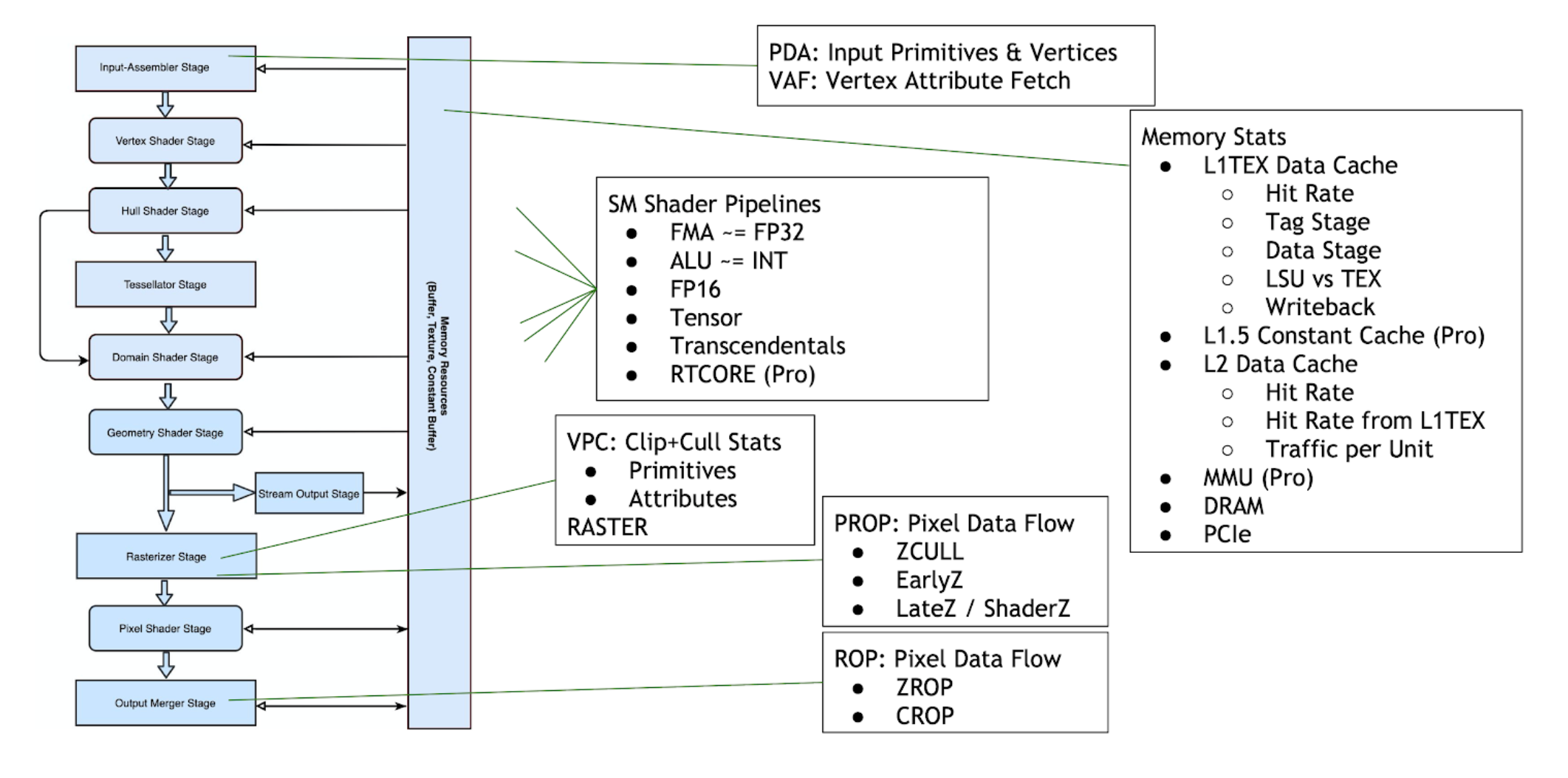
单元吞吐量
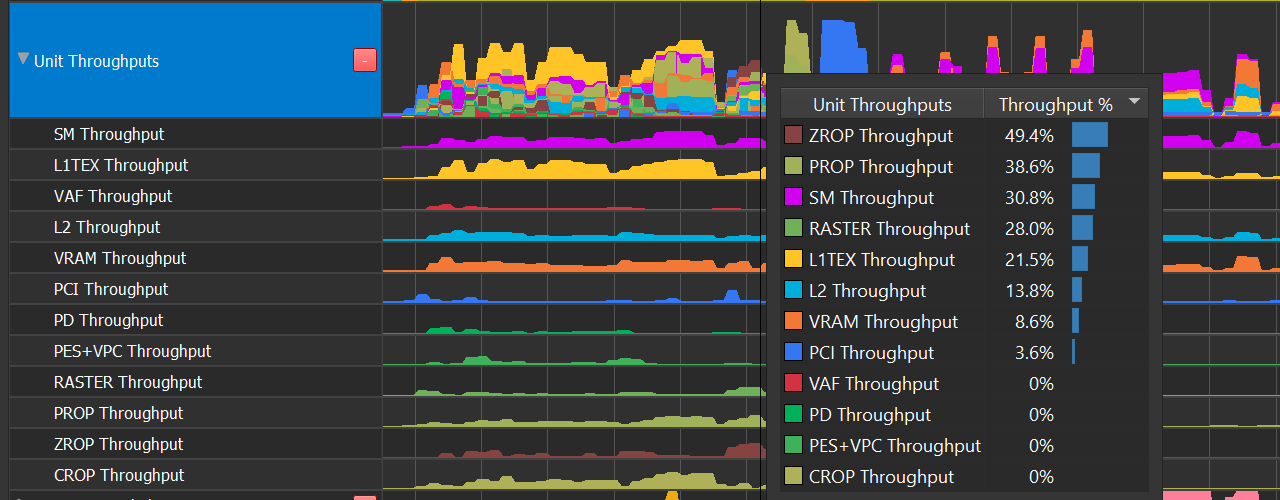
单元吞吐量行叠加了 GPU 中每个硬件单元的 %-of-max-throughput。多个单元可以在任何时刻同时接近 100%。
单元 |
管线区域 |
描述 |
|---|---|---|
SM |
着色器 |
流式多处理器执行着色器代码。 |
L1TEX |
内存 |
L1TEX 单元包含 SM 的 L1 数据缓存,以及两个并行管线:LSU 或加载/存储单元,以及 TEX 用于纹理查找和过滤。 |
L2 |
内存 |
L2 缓存为 GPU 上的所有单元提供服务,并且是连贯性的中心点。 |
VRAM |
内存 |
|
PD |
世界管线 |
图元分发器从索引缓冲区中获取索引,并将三角形发送到顶点着色器。 |
VAF |
世界管线 |
顶点属性获取单元从内存中读取属性值,并将它们发送到顶点着色器。VAF 是图元引擎的一部分。 |
PES+VPC |
世界管线 |
图元引擎协调图元和属性数据在所有世界管线着色器阶段(顶点、细分、几何)之间的流动。 PES 包含流(变换反馈)单元。 VPC 单元执行裁剪和剔除。 |
RASTER |
屏幕管线 |
光栅单元从世界管线接收图元,并输出像素(片段)和样本(覆盖掩码),供 PROP、像素着色器和 ROP 处理。 |
PROP |
屏幕管线 |
Pre-ROP 单元协调深度和颜色像素(片段)和样本的流动,以进行最终输出。PROP 强制执行像素着色、深度测试和颜色混合的 API 顺序。Early-Z 和 Late-Z 模式在 PROP 中处理。 |
ZROP |
屏幕管线 |
深度光栅操作单元执行深度测试、模板测试以及深度/模板缓冲区更新。 |
CROP |
屏幕管线 |
颜色光栅操作单元执行最终颜色混合和渲染目标更新。CROP 实现了“高级混合方程” |
SM 占用率行
SM 占用率行显示了 warp 插槽随时间的驻留情况。每个 Turing SM 都有 32 个 warp 插槽,已启动的 warp 在其中驻留,轮流发出指令。
异步计算
并发运行计算和 3D 的唯一方法是同时
将 3D 工作发送到 DIRECT 队列
将计算工作发送到 ASYNC_COMPUTE 队列
在 Ampere 上,您还可以通过在 DIRECT 和 ASYNC_COMPUTE 队列上都调度计算工作负载来调度并发计算工作负载。
您可以通过以下几种方式检测程序是否利用了异步计算
“正在进行的计算”行包含“异步计算正在进行”计数器。
观察 SM 占用率行上执行的计算 warp,并根据“正在进行的计算”行的颜色确定它们是同步还是异步。

查找多个队列行;ASYNC_COMPUTE 队列将显示为 Q0 以外的其他内容。
只有从 ASYNC_COMPUTE 队列提交时,计算才会与图形同时运行。这可以消除 SM 占用率行的歧义。

Warp 无法启动原因
当绘制调用或计算调度排队的工作量超过 SM 一次性容纳的工作量时,SM 将报告“额外的 warp 无法启动”。我们可以将这些信号随时间绘制成图表,以确定限制因素。
3D 着色器
3D warp 可能因以下原因而无法启动
寄存器分配
Warp 分配
属性分配(VTG 的 ISBE 或 PS 的 TRAM)
GPU 跟踪允许您确定以下内容
像素着色器在任何原因下都无法启动的时间。
像素着色器启动受寄存器限制的时间。
Warp 占用率图表中的 warp 分配限制区域。当没有灰色区域时,表示没有空闲插槽。
通过推断,如果 SM 占用率显示大片像素 warp 区域,并且没有可见的限制因素,则表示
没有 warp 启动停顿,而是 warp 运行时间非常长 [不太可能],或者
warp 启动因属性分配而停顿。
计算着色器 计算 warp 可能因以下原因而无法启动
寄存器分配
Warp 分配
CTA 分配
共享内存分配
GPU 跟踪允许您确定以下内容
计算着色器应在“正在进行的计算”行中运行的时间。
计算着色器启动受寄存器限制的时间。
Warp 占用率图表中的 warp 分配限制区域。当没有灰色区域时,表示没有空闲插槽。
通过推断,如果 SM 占用率显示大片计算 warp 区域,并且没有可见的限制因素,则表示
没有 warp 启动停顿,而是 warp 运行时间非常长 [不太可能],或者
其他原因之一(CTA、共享内存)是原因。
进一步消除上述 4a 和 4b 之间的歧义
CTA 维度(HLSL numthreads)是否是着色器的理论占用率限制因素?具有 32 个或更少线程的线程组将被限制为半占用率。增加到每个 CTA 64 个线程将缓解此问题。
每个 CTA 的共享内存大小是否是着色器的理论占用率限制因素?(HLSL groupshared 变量) (numCTAs * shmemSizePerCTA) 是否超过每个 SM 限制 64KiB [仅计算模式] 或 32KiB [SCG 模式]?
SM 吞吐量
SM 吞吐量揭示了着色器代码中最常见的计算管线限制因素
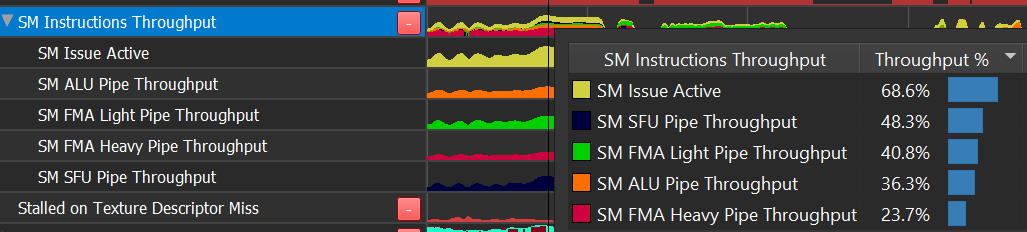
Issue Active : 指令发出受限
ALU 管线 : INT(乘法除外)、位操作、较低频率的 FP32(如比较和最小值/最大值)。
FMA 管线 : FP32 加法和乘法、整数乘法。
FP16+Tensor : FP16 指令(每个指令执行一个 vec2)以及深度学习使用的 Tensor 操作。
SFU 管线 : 超越函数(sqrt、rsqrt、sin、cos、log、exp 等)
SM 吞吐量中未涵盖的管线:IPA、LSU、TEX、CBU、ADU、RTCORE、UNIFORM。
LSU 和 TEX 永远不是 SM 中的限制因素;请参阅 L1 吞吐量。
到 TRAM 的 IPA 流量计为 LSU 的一部分
RTCORE 有其自己的吞吐量指标
UNIFORM 和 CBU 未被考虑在内,但很少成为限制因素
问题解决
如果 FP32 很高,请考虑使用 FP16 代替。
理论上,仅由于管线宽度,速度提高 2 倍是可能的。
理论上,通过完美平衡 FP32 和 FP16,速度提高 3 倍是可能的。
L1 吞吐量
GPU 跟踪公开了 L1TEX 数据缓存的简化模型,该模型仍然揭示了着色器程序中最常见的内存限制因素类型。
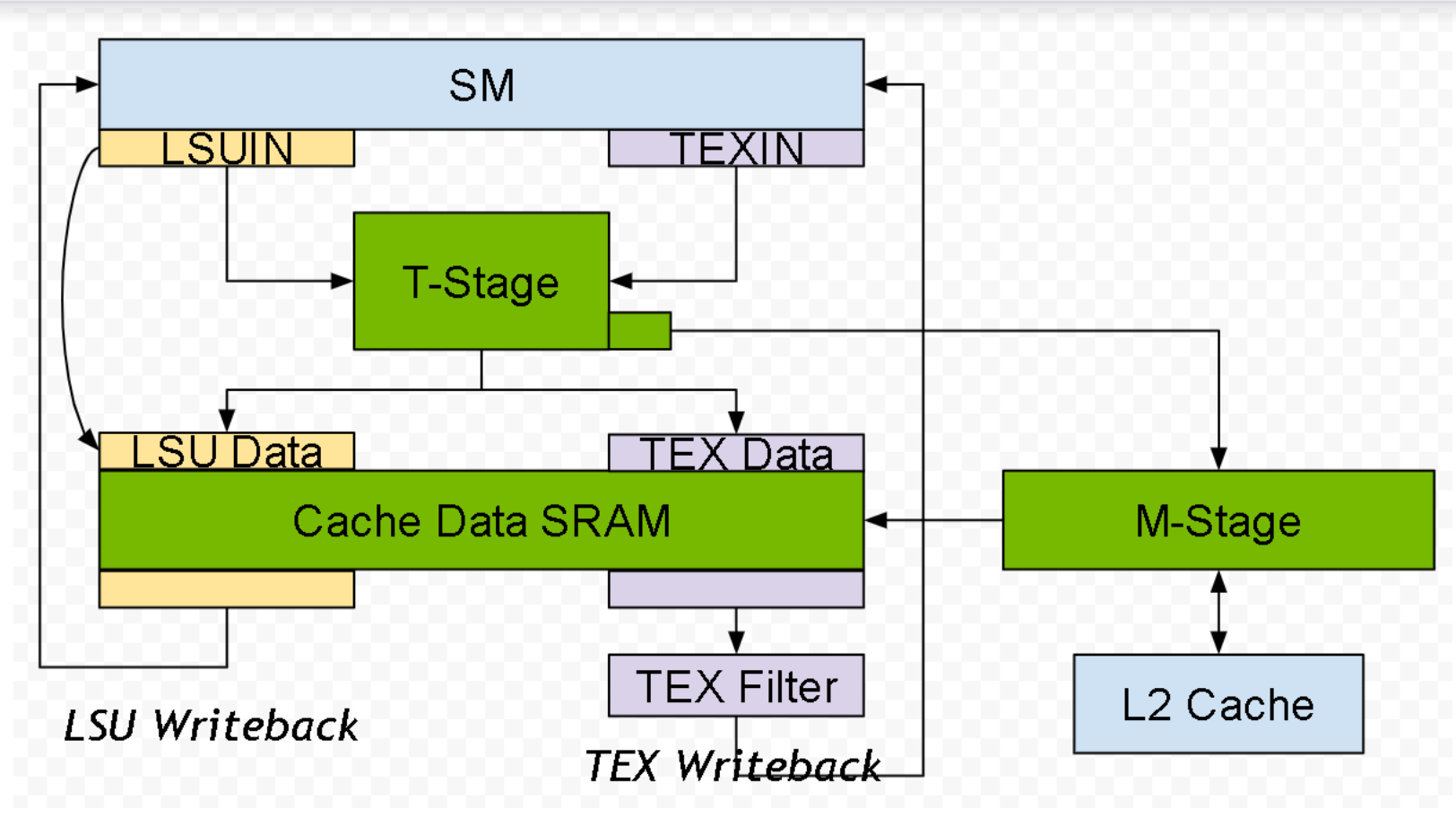
Turing 和 GA10x L1TEX 缓存共享相似的设计,能够进行并发访问
输入:每个周期同时接受一个 LSU 指令和 TEX 四元组
输入:LSUIN 每个周期从 AGU 接受 16 个线程的地址
数据:同时读取或写入 LSU 和 TEX 的数据 SRAM。
回写:同时返回 LSU 和 TEX 读取的数据
其他缓存属性
T 阶段(缓存标签)、数据阶段和 M 阶段在 LSU 和 TEX 之间共享
T 阶段地址合并器每个周期最多可以输出 4 个标签,用于发散访问。与数据阶段相比,这确保了 T 阶段几乎永远不是限制因素
每个周期,M 阶段可以同时从 L2 读取和写入 L2。M 阶段和 L2 之间有一个交叉开关 (XBAR),上图中未显示
在这个简化模型中,内存和纹理请求遵循以下路径
本地/全局指令 → LSUIN → T 阶段 → LSU 数据 → LSU 回写 → SM
共享内存指令 → LSUIN → LSU 数据 → LSU 回写 → RF
包括计算共享内存和 3D 着色器属性
一些非内存操作(例如 HLSL Wave Broadcast)在此处计数
纹理/表面读取 → TEXIN → T 阶段 → TEX 数据 → 过滤器 → 回写 → SM
包括纹理获取、纹理加载、表面加载和表面原子操作
表面写入 → TEXIN… → T 阶段 → LSU 数据 → 回写 → RF
表面写入跨越到 LSU 数据路径
内存屏障 → LSUIN & TEXIN → … 流经管道的两侧
图元引擎属性写入到 (ISBE, TRAM) → LSU 数据
图元引擎属性从 ISBE 读取 → LSU 数据
本地/全局/纹理/表面 → T 阶段 [未命中!] → M 阶段 → XBAR → L2 → XBAR → M 阶段 → 缓存数据 SRAM
Turing 问题解决
Turing 报告以下活动
LSU 数据和 TEX 数据的吞吐量
LSU 数据中用于本地/全局与共享内存的单独计数器
LSU 回写和 TEX 过滤器的吞吐量
通过比较可用吞吐量的值,我们可以得出以下结论
所有值都相等:最有可能请求受限
TEX 数据 > 其他值:带宽受限;缓存行/指令 > 1
TEX 过滤器 > 其他值:昂贵的过滤(三线性/各向异性)或纹理回写由于宽采样器格式(或禁用采样器时的表面格式)而受限
LSU 数据 > 其他值:可能性是
纯带宽受限
每个指令的缓存行 > 1,导致序列化
共享内存库冲突,导致序列化
向量化共享内存访问(64 位、128 位)需要多周期访问
大量使用 SHFL (HLSL Wave Broadcast)
LSU 回写 > 其他值:受合并的宽加载(64 位或 128 位)限制
注意:这意味着有效使用 LSU 数据
LSU LG 数据或 TEX 数据接近 100%:意味着高命中率
如果扇区命中率低:可能意味着受 L2 或 VRAM 访问的延迟限制
GA10x 问题解决
GA10x 报告以下活动
LSU 数据和 TEX 数据的吞吐量
LSU 数据中用于本地/全局、表面和共享内存的单独计数器
LSU 回写、TEX 过滤器和 TEX 回写的吞吐量
L1TEX 扇区命中率 - 报告本地、全局、纹理、表面的集体命中率 - 请注意,共享内存和 3D 属性不影响命中率
通过比较可用吞吐量的值,我们可以得出以下结论
所有值都相等:最有可能请求受限
TEX 数据 > 其他值:带宽受限;缓存行/指令 > 1
TEX 过滤器 > 其他值:昂贵的过滤(三线性/各向异性)
TEX 回写 > 其他值:受限的宽采样器格式(或禁用采样器时的表面格式)
LSU 数据 > 其他值:可能性是
纯带宽受限
每个指令的缓存行 > 1,导致序列化
共享内存库冲突,导致序列化
向量化共享内存访问(64 位、128 位)需要多周期访问
大量使用 HLSL Wave Broadcast
LSU 回写 > 其他值:受合并的宽加载(64 位或 128 位)限制
注意:这意味着有效使用 LSU 数据
LSU LG 数据或 TEX 数据接近 100%:意味着高命中率;与 L1TEX 扇区命中率交叉检查
如果扇区命中率低:可能意味着受 L2 或 VRAM 访问的延迟限制
VRAM
GPU 的 VRAM 是用 DRAM 构建的。DRAM 是半双工接口,这意味着相同的线路用于读取和写入,但不能同时进行。这就是为什么 VRAM 总带宽是读取和写入之和。
VRAM 带宽行将带宽显示为堆叠图,使其易于可视化读取和写入流量之间的平衡。VRAM 流量意味着 L2 缓存未命中或 L2 回写。在任何一种情况下,高 VRAM 流量都可能是 L2 缓存使用率不佳的症状——工作集太大或访问模式欠佳。

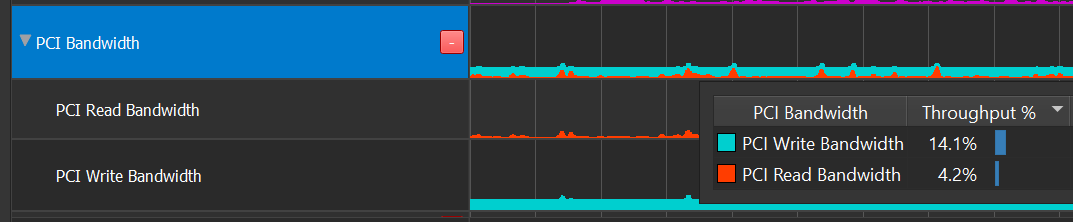
PCI 带宽
GPU 通过 PCI Express (PCIe) 连接到计算机的其余部分。PCIe 是全双工接口,这意味着单独的线路用于读取和写入,并且可以同时发生。这就是为什么 PCIe 行显示为叠加层,其中读取和写入可以独立达到 100%。
当 GR 引擎空闲时(图形或计算均未运行),通常是由于数据依赖性,其中先前的数据传输(DMA 复制)必须在绘制或计算调度可以开始之前完成。将 GPU 活动行与吞吐量行进行比较,以确认该假设。