NVIDIA Nsight Deep Learning Designer
有关工具内所有视图、控件和工作流程的信息。
概述
Nsight Deep Learning Designer 是一款软件工具,其目标是通过提供以交互方式设计和分析模型性能的工具来加速深度学习开发人员的工作流程。
使用 Nsight Deep Learning Designer,您可以通过快速启动推理运行并使用 GPU 性能计数器分析各层的行为,从而更快地迭代您的模型。
Nsight Deep Learning Designer 使用 ONNX(开放神经网络交换格式)来表示模型。性能分析使用 TensorRT 和 ONNX Runtime 作为配套的推理框架。
模型设计
理解如何在 Nsight Deep Learning Designer 中高效地设计 ONNX 模型,并利用各种功能来实现这一点至关重要。
创建新模型
Nsight Deep Learning Designer 既可以打开现有的 ONNX 模型,也可以从头开始创建一个新模型。为此,可以在文件 > 新建文件下找到一个专用向导。
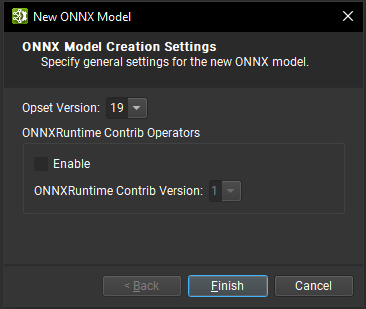
在此对话框中,可以选择新模型所需的 ONNX Opset 版本。目前支持从版本 1 到版本 19(包括版本 19)的所有 Opsets。也可以导入 ONNXRuntime Contrib Operator 集。
工作区
每个打开的 ONNX 模型都由 Nsight Deep Learning Designer 工作区中的一个文档选项卡表示。可以同时打开多个模型,并使用停靠系统进行排列。Nsight Deep Learning Designer 工作区的中心元素是画布,您可以在画布上通过拖放层节点并在它们之间创建连接来创建/编辑模型图。可以使用可停靠的工具窗口来排列工作区,以最好地适应您所需的工作流程。所有工具窗口都可以在视图 > 窗口下找到。请参阅窗口菜单下的命令以保存、应用或重置布局。
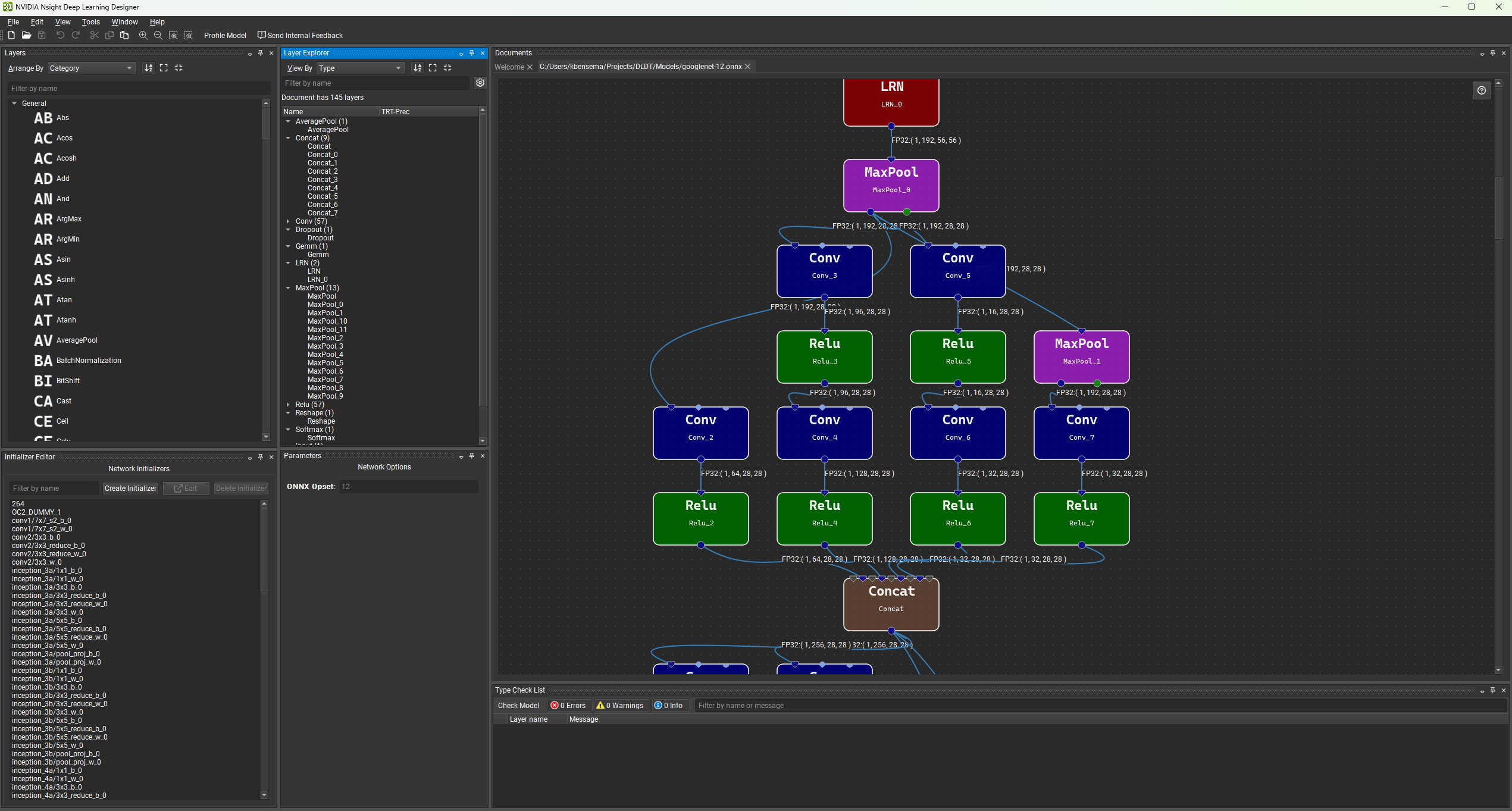
默认工作区由层调色板、参数窗口、初始化器编辑器和类型检查窗口组成。
为了更容易在画布中以视觉方式对齐节点,可以使用视图 > 显示网格菜单操作启用背景网格。画布中的节点可以通过其唯一的名称(如果 ONNX 模型中不存在,则由 Nsight Deep Learning Designer 自动生成)及其层类型来识别。
修改当前图或模型的编辑操作会将文档标记为已修改。只有在使用文件 > 保存菜单操作或 Ctrl + S 快捷键保存模型后,更改才会反映到磁盘上。可以使用编辑 > 撤消/重做菜单操作或相应的 Ctrl + Z 和 Ctrl + Y 快捷键来撤消和重做未保存的编辑操作。
布局
首次在 Nsight Deep Learning Designer 中打开模型时,布局算法会自动将节点放置在画布上。通过 Nsight Deep Learning Designer 保存的 ONNX 模型会将各个节点位置作为模型元数据保存,以便在重新打开时恢复节点位置。可以使用视图 > 排列节点菜单操作在任何模型上显式运行布局算法。
颜色
画布中的节点根据其类型进行着色。由于 ONNX 节点类型太多,无法为每种类型分配可区分的唯一颜色,因此相关的节点类型共享相同的颜色。某些类别的节点也具有不同的形状:输入和输出节点表示为菱形,而复合节点(如本地函数或包含子图的节点)则表示为方形矩形,而不是圆角矩形。
Nsight Deep Learning Designer 提供了一些替代颜色方案,这可能对色觉障碍人士有所帮助。可以在选项(工具 > 选项)对话框的网络画布首选项页面中更改颜色方案。下图显示了可用的颜色方案。
搜索栏
由于 ONNX 模型可能包含大量节点,因此 Nsight Deep Learning Designer 中存在搜索功能,以便更容易在画布中查找特定节点。可以使用画布中的 Ctrl + F 快捷键或通过编辑 > 搜索层菜单操作访问搜索栏。您可以按节点名称或类型进行搜索 — 文本框旁边的下拉列表控制搜索条件。搜索栏中的控件允许在下一个和上一个匹配项之间循环,循环时视图会聚焦于当前匹配的节点。请注意,文本搜索区分大小写。
导出画布
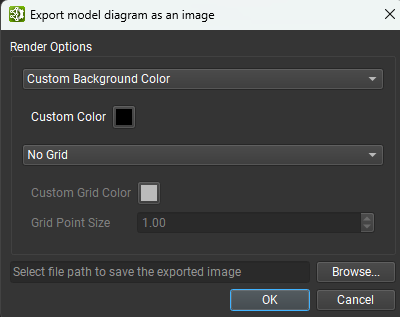
可以使用文件 > 导出 > 将画布导出为图像菜单操作将整个模型画布导出到单个图像文件。可以从下图所示的对话框中设置背景颜色、网格颜色和存在以及图像保存位置。支持的图像格式为 PNG、JPEG 和 SVG。
层
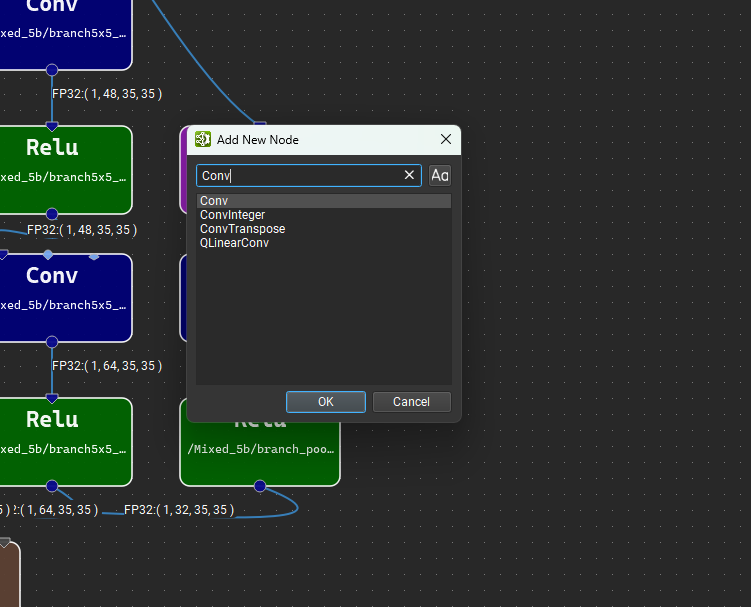
层调色板包含可以从其导入的运算符集中添加到模型的可用运算符列表。层可以按名称、集合或类别排列。层调色板也可以排序或过滤。要向画布添加新的层实例,只需从调色板中拖放即可。
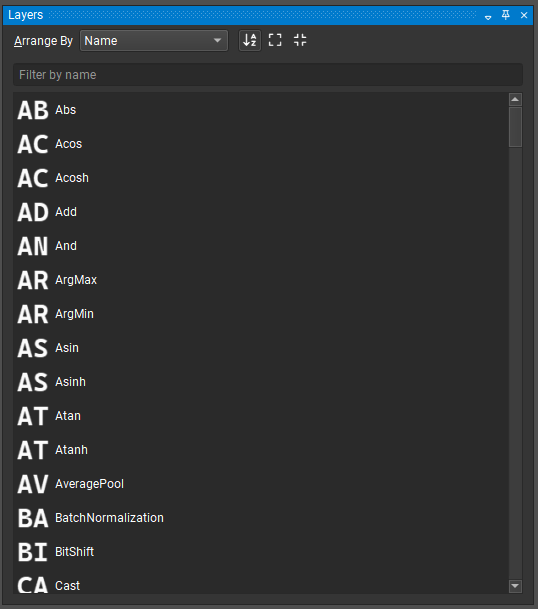
或者,将鼠标光标放置在模型画布中的任意位置,然后按“Control + Space”键打开快速节点添加对话框,如下图所示。在搜索框中键入内容将过滤可用层列表,可以使用向上和向下箭头键更改选定的层,按“Enter”键或双击列表条目会将选定的层添加到鼠标光标下的画布中。
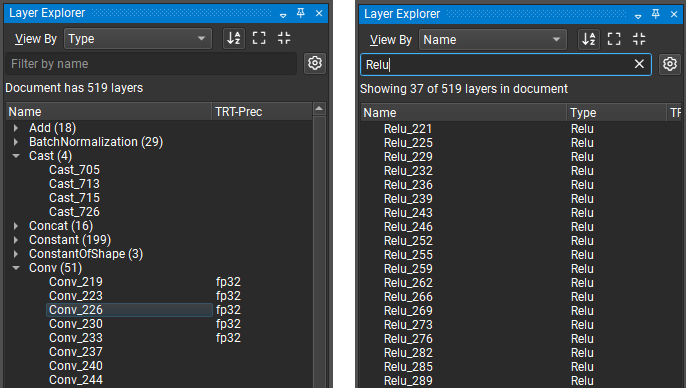
层浏览器显示模型中当前层的列表。模型层可以按层类型或名称组织,并从“按名称过滤”搜索框中按名称过滤。可以在工具栏中切换层的排序顺序,并且在按类型组织层时,可以从工具栏展开或折叠所有类型。层浏览器和画布之间的层选择是同步的。双击层浏览器中的层以跳转到画布中的层。
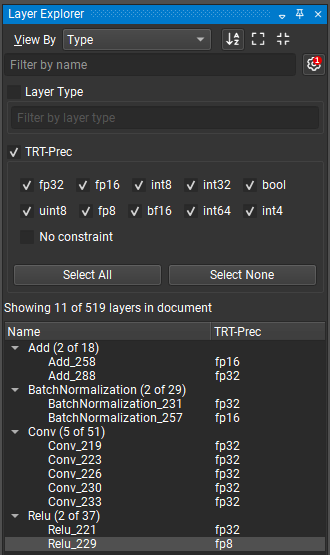
单击“按名称过滤”文本框旁边的齿轮图标可以访问层浏览器的高级过滤选项。高级过滤选项允许按层类型和分配给层的任何属性(例如 TensorRT 层精度)进行过滤。选中过滤器名称将启用它。下图显示了一个示例,该示例仅过滤那些指定了精度约束的层。在隐藏/显示高级过滤器按钮(由齿轮图标表示)上显示一个红色徽章,其中包含活动高级过滤器的数量。
默认情况下,常量节点在模型画布和层浏览器中是隐藏的。要显示常量节点,请转到视图 > 显示所有常量。要在新模型打开时不再默认隐藏常量,请转到工具 > 选项,然后在网络模型画布首选项页面下,将“隐藏常量节点”设置为否。
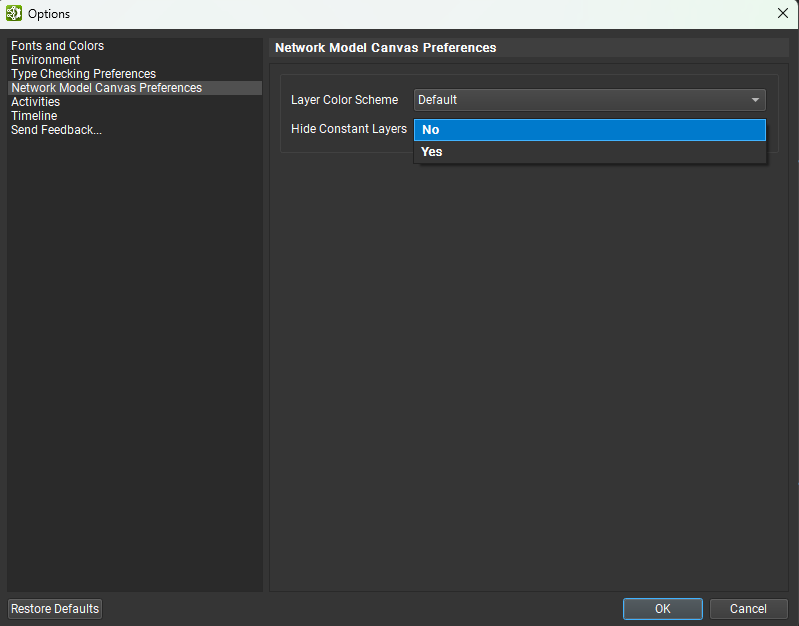
如果层将常量节点作为输入,则连接到常量节点的输入端子将以微型常量节点(圆角灰色矩形)的样式呈现。可以通过双击连接到它的端子来选择性地隐藏或显示单个常量节点。下图显示了两个具有连接到常量的输入端子的节点:一个隐藏,一个可见。
参数
参数工具窗口允许交互式修改任何节点的参数。为此,从画布中选择一个节点;然后将列出该运算符的可用参数。也可以编辑节点名称,但请注意,它在整个图中必须是唯一的。
具有未指定值的参数接收 Opset 中指定的默认值,并显示在参数编辑器的可折叠的默认值参数部分中。当参数被修改时,它会移出默认值部分。要将参数恢复为其默认值,请单击圆形箭头图标,当鼠标悬停在该字段上时,该图标在参数输入字段的右侧可见。
张量/列表值应采用以下格式:[1, 2, 3, 4],并且可以嵌套用于多维张量:[[1, 2], [3, 4]]。字符串值必须用单引号引起来:'Some text'。可以使用 \ 将单引号嵌入到字符串文字中:'It\'s alive!'。对于更高级的张量或列表编辑功能,请使用张量编辑器,方法是单击任何张量/列表类型参数最右侧的右上箭头按钮。
如果当前未选择任何层,则会显示模型信息,例如导入的 ONNX opset 版本。可以一次选择多个层以进行批量参数编辑。仅显示选定节点共有的参数。
类型检查列表
模型的迭代是设计工作流程的主要部分。为了确保快速和交互式迭代,类型检查列表报告当前模型结构引起的任何错误、警告或问题。您可以双击类型检查器中的任何消息,以在画布中聚焦相应的运算符。这有助于在设计过程中识别模型中的潜在问题。

在 Nsight Deep Learning Designer 中,模型类型检查由 Polygraphy linter 提供。
在任何影响 ONNX 模型的编辑操作之后,都会自动运行模型验证。
对于较大的 ONNX 模型,类型检查器需要更多时间,因此可以使用工具窗口左上角的取消检查按钮取消验证过程。可以通过单击检查模型按钮显式请求新的模型验证运行。
请注意,对于非常大的 ONNX 模型,自动类型检查已禁用,但仍可以执行显式检查。
编辑模型
将运算符拖放到画布中会创建该运算符类型的新实例,并自动生成名称。所有实例都必须具有唯一的名称,您可以编辑该名称;名称应为有效的 C90 标识符。运算符在画布上由矩形节点表示。此节点显示运算符的名称和类型,以及类型检查器是否报告任何问题的图标。
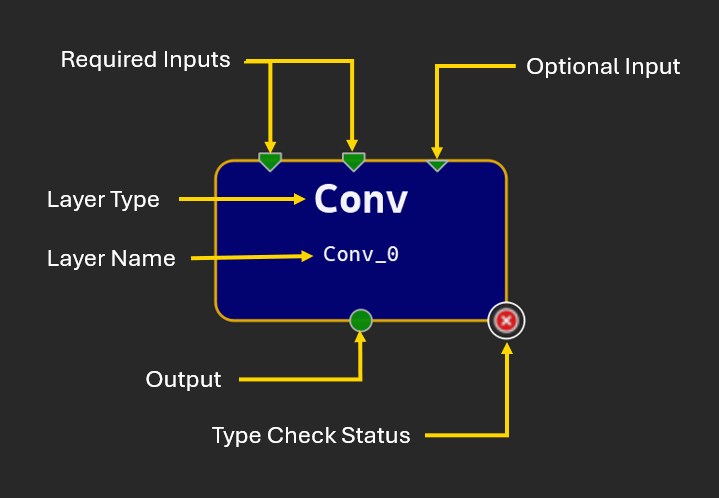
节点字形使用端子表示运算符的输入和输出。节点顶部的三角形表示输入,节点底部的圆形表示输出。大多数输入端子都需要连接才能使模型有效,但可选输入端子不是强制性的。可选输入在字形上用较小的三角形表示。多个链接可以从单个输出端子开始,但只有一个链接可以连接到给定的输入端子。未连接的端子为绿色,带有链接的端子为深蓝色,连接到初始化器的输入端子为浅蓝色。
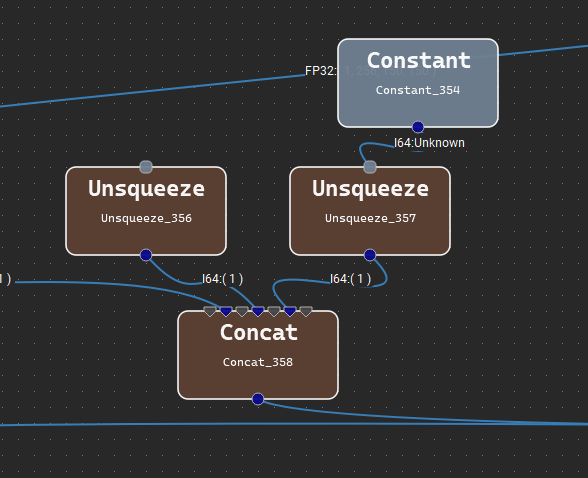
某些运算符接受给定参数的可变数量的输入张量,或为给定的输出名称生成可变数量的输出张量。Nsight Deep Learning Designer 通过特殊的“无限”端子表示这些。在与无限端子建立连接后,每个连接的端子之间将出现更多灰色端子,表示潜在的新连接点。下图显示了一个具有可变数量输出的运算符以及子图的示例。
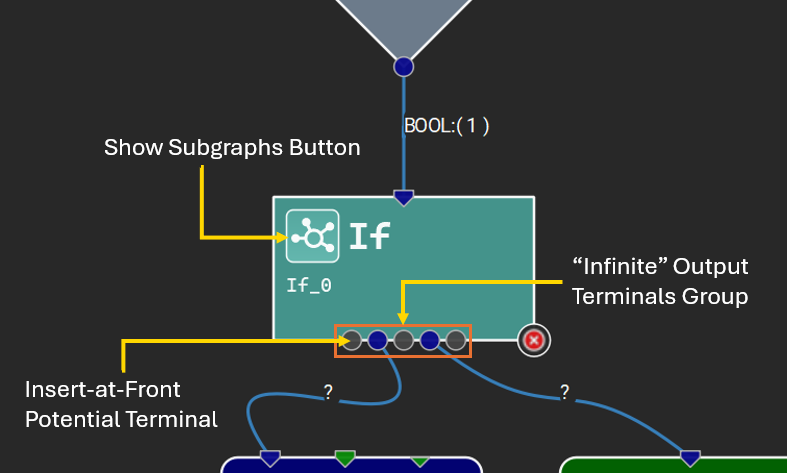
有关特定运算符的输入和参数的详细信息,请参阅编辑器文档浏览器(帮助 > 层文档)中的运算符描述。
要将节点 A 连接到节点 B,请单击并从节点 A 上的任何输入端子拖动到节点 B 上的任何输出端子(或从节点 A 上的任何输出端子拖动到节点 B 上的任何输入端子)。此操作将创建一个链接。可以通过选择运算符和链接并使用 Delete 键来删除它们。模型验证成功后,将计算中间张量大小并将其显示在相应的链接旁边。
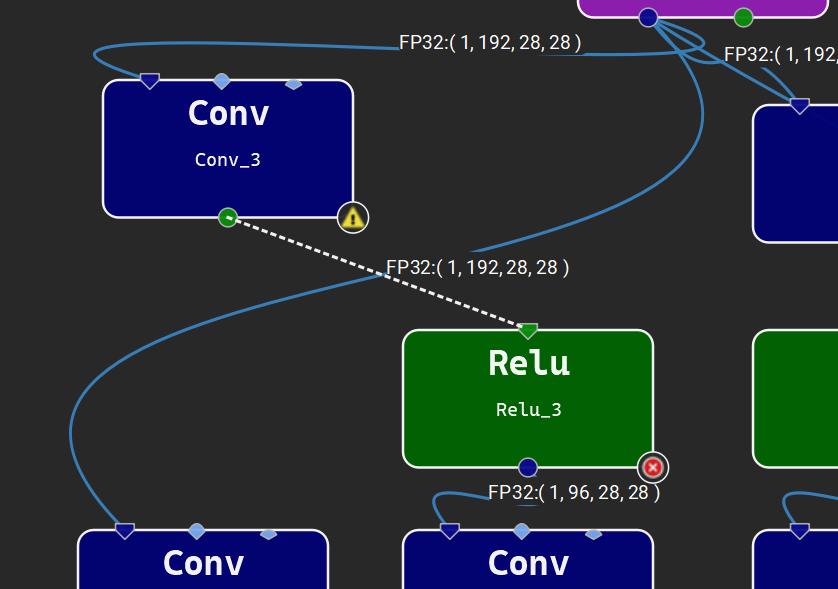
加载模型时会自动布局节点,并且可以通过单击并拖动画布上的节点来自由重新排列节点。可以使用视图 > 显示网格打开背景网格以帮助对齐层。
双击节点上未分配的输入或输出端子将自动创建输入或输出运算符,并将其链接到该端子。
初始化器
初始化器在 ONNX 中用于表示常量张量值,例如权重。它们可以直接用作输入,而无需引入额外的常量运算符。单个初始化器可以被图中的多个运算符使用。初始化器值可以直接嵌入到 ONNX 模型中,也可以从外部二进制文件引用。每个初始化器都由模型中的唯一名称标识。
在 Nsight Deep Learning Designer 中,初始化器编辑器工具窗口允许用户查看和编辑已打开的 ONNX 模型的初始化器。
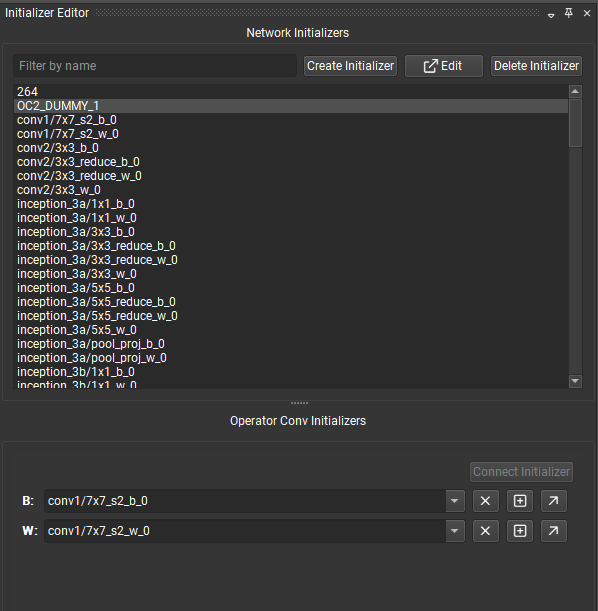
初始化器编辑器分为两个部分:上部用于查看、创建、编辑和删除模型中的任何初始化器,下部用于查看和连接当前选定节点的初始化器。如果当前未选择任何节点,则下部将被隐藏。
可以按名称过滤网络初始化器列表。选定的初始化器可以
从模型中删除,这也将断开它们与当前正在使用它的任何节点的连接。
使用张量编辑器进行编辑。
可以使用创建初始化器按钮打开的对话框从头开始创建初始化器。
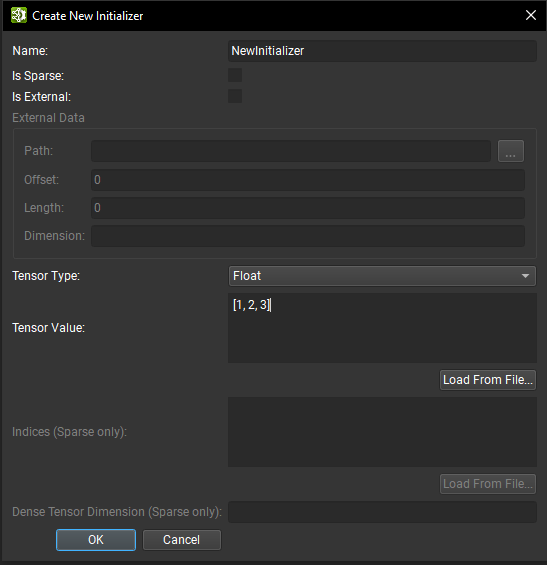
从那里,可以提供初始化器信息,例如名称、张量类型和张量值。张量值应采用以下格式:[1, 2, 3, 4],并且可以嵌套用于多维张量:[[1, 2], [3, 4]]。字符串值必须用单引号引起来:'Some text'。可以使用 \ 将单引号嵌入到字符串文字中:'It\'s alive!'。可以从 Numpy 文件加载张量值。请注意,数据类型必须与 Numpy 文件中的数据类型匹配,然后才能加载。
如果初始化器是稀疏的,则除了非默认值张量之外,还必须提供索引张量和密集张量维度。有关 ONNX 期望的格式的更多信息,请参阅 ONNX SparseTensorProto 规范。
如果初始化器标记为外部的,则必须提供磁盘上二进制文件的路径。外部文件必须位于相对于模型存储位置的位置。偏移量是存储数据开始的文件中的字节位置,长度是包含数据的字节数。外部初始化器张量数据不会直接存储在 ONNX 模型中。这可以减小模型文件的大小。
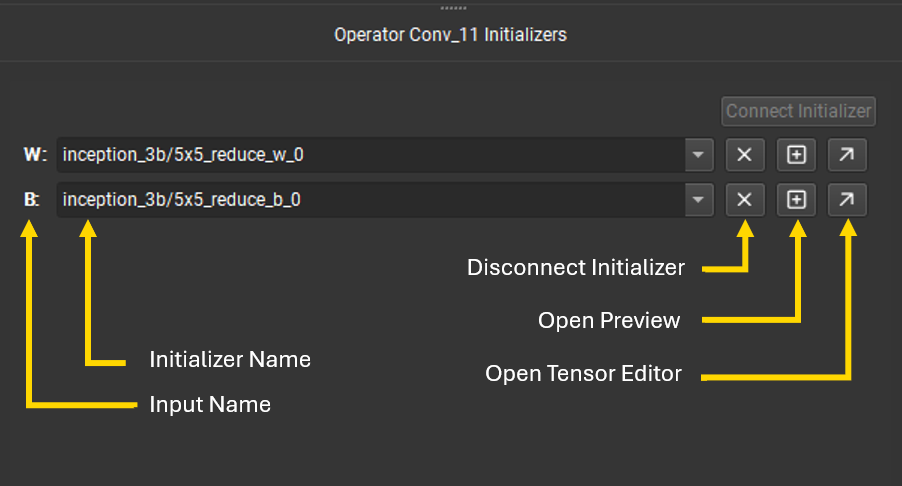
从画布中选择节点,并且如果它有一个空闲端子,则启用连接初始化器按钮以允许将模型初始化器连接到它。连接后,端子将在节点字形上变为黄色,表示它已连接到初始化器。连接链接将断开初始化器与节点输入的连接。
初始化器编辑器的底部列出了当前选定节点的所有连接到初始化器的端子。可以使用下拉菜单切换端子使用的初始化器。下拉菜单可以按名称过滤。使用叉号按钮可以断开初始化器与端子的连接。加号按钮打开张量值预览,对角箭头按钮将打开张量编辑器。
张量编辑器
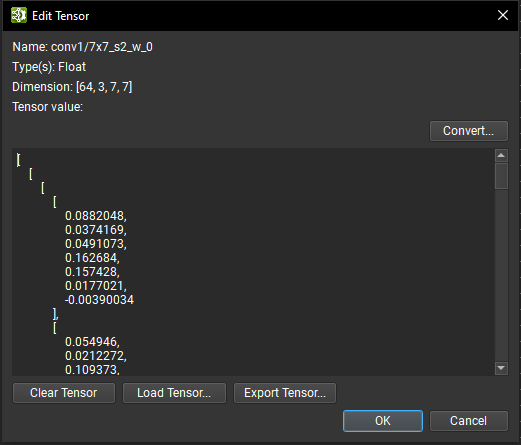
可以使用张量编辑器修改 ONNX 张量数据。可以直接编辑张量值,并且一旦验证编辑,张量维度将自动更新。如果张量具有超过一万个元素,则它不可编辑,但仍然可以使用 Numpy 文件更新张量值。当前张量数据也可以导出到 Numpy 文件以进行外部处理。
对于稀疏张量,可以修改索引和密集张量维度。对于外部张量,可以编辑路径、偏移量和长度信息。在所有情况下,只有初始化器的名称不能修改。
可以使用转换按钮将张量的数据转换为不同的数据类型;唯一的例外是外部数据和布尔或字符串类型的张量。数据类型转换对话框列出了可以将张量转换为的所有可用数据类型。请注意,根据源和目标转换数据类型,可能会发生数据精度损失和/或截断。
子图
某些 ONNX 控制流运算符(例如 Loop 和 If)将一个或多个子图作为参数。子图是 ONNX 图,它们与其包含的模型共享初始化器和导入的 opset。
子图的作用域由其父级确定,无论是运算符实例还是本地函数定义。作用域内的所有子图都必须具有唯一的名称。
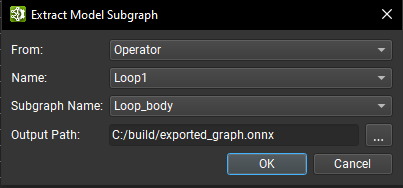
可以使用 Nsight Deep Learning Designer 中的工具 > 提取模型子图命令将子图导出到独立的 ONNX 模型中。在打开的对话框中,通过识别其父级的类型(运算符或本地函数)、其父级作用域的名称以及该作用域内的子图名称来选择子图。然后,为保存提取的子图选择输出路径。
仅列出当前文档中的运算符。要从另一个子图或本地函数内的运算符导出子图,必须从相应的子图或本地函数文档中打开工具 > 提取模型子图向导。
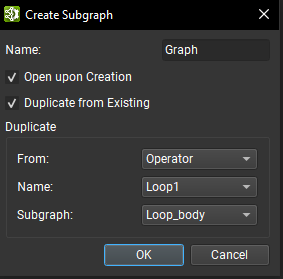
可以使用子图类型运算符参数旁边的 + 按钮从头开始创建子图。在创建对话框中,必须提供给定其作用域的唯一子图名称。可以启用一些选项,以便在创建后打开子图,以及从运算符或本地函数子图复制现有子图。
对于子图列表类型的参数,列表视图显示参数列表中包含的所有图,并且可以使用 + 按钮创建新子图并将其添加到列表中,而 - 按钮将删除选定的子图。使用右上箭头按钮,可以在 Nsight Deep Learning Designer 中的单独文档中打开当前选定的图。

可以在单独的文档选项卡中可视化子图。要打开子图,请单击运算符字形上的子图按钮,然后从菜单中选择所需的子图,或单击参数编辑器工具窗口中的子图链接。子图按钮在下图中以红色框突出显示。
打开后,可以在 Nsight Deep Learning Designer 中编辑子图,就像编辑普通 ONNX 模型一样,尽管模型初始化器在子图中没有类似物,因此无法编辑。使用主工具栏上的确认子图编辑按钮在封闭文档中保留子图中的更改。此命令更新父文档以反映对子图的更改。当父文档的子图打开进行编辑时,父文档在其他情况下是只读的。
本地函数
图组件通常在模型中重复出现。本地函数可用于表示这些重复出现的模式。这通过将模式抽象为单个节点来创建模型的更高级别表示。
本地函数在模型级别定义,并且可以像从层调色板中的任何其他运算符类型一样实例化。本地函数实例可以在画布中通过其黑色背景颜色、方形边缘和 f(x) 符号来识别。单击该符号将在 Nsight Deep Learning Designer 中的单独文档中打开函数定义。
在 Nsight Deep Learning Designer 中打开本地函数后,可以像编辑普通模型一样编辑它,除了创建或删除模型初始化器。必须使用主工具栏上的确认本地函数编辑按钮来应用对本地函数所做的更改。应用后,本地函数定义将在模型中更新。
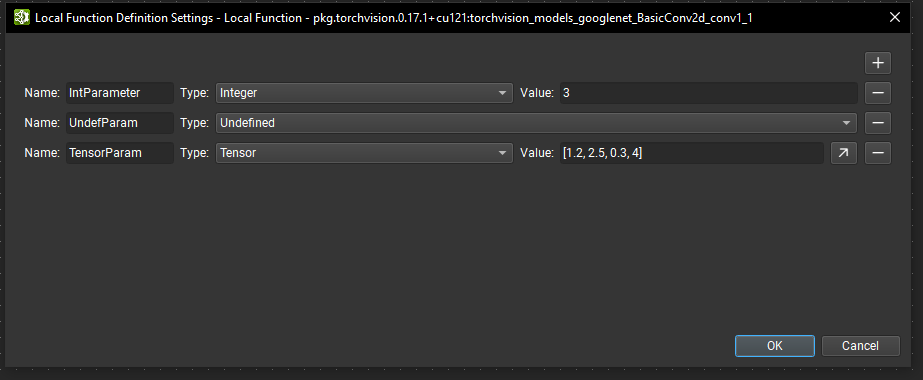
此外,本地函数可以参数化。在 Nsight Deep Learning Designer 中编辑函数时,可以使用工具 > 本地函数设置操作或在未选择任何节点时使用参数编辑器中的编辑本地函数参数按钮打开本地函数定义设置对话框。
在此对话框中,可以使用 + 按钮定义新参数。必须提供唯一的名称以及参数类型。未定义类型的参数要求函数的每个实例在传递此参数的值时提供类型信息。否则,必须为所有其他类型提供默认值。也可以通过单击相应的 - 按钮来删除参数。
作为本地函数一部分的运算符可以引用提供给封闭函数的参数,而不是提供特定的参数值。具有参数引用的运算符将使用本地函数实例提供的相应引用值。
当选择运算符时,可以使用参数编辑器顶部的设置引用参数按钮将其参数分配给引用。打开一个对话框,其中包含一个下拉列表,其中包含此运算符的可用参数,这些参数尚未使用引用。第二个下拉列表包含所有可用的可用作引用的本地函数参数。
不兼容类型的本地函数参数将灰显,并且无法选择。在对话框关闭时验证引用分配。
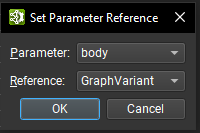
引用参数在参数编辑器中以下拉列表表示。可以使用下拉控件直接切换当前引用。可以使用 X 按钮删除引用;这会将参数恢复为其原始类型和默认值。
可以使用模型本地函数工具窗口管理本地函数。它列出了模型中当前定义的所有函数,列表可以按名称过滤。
可以使用箭头和保存按钮分别打开选定的函数或将其提取到独立的 ONNX 模型中。
+ 按钮允许您从头开始创建本地函数。您必须首先提供函数名称和域。最后,可以使用 - 按钮从模型中删除本地函数。该函数的所有实例都将转换为自定义运算符。
批量修改
在某些工作流程中,可能需要修改 ONNX 模型的很大一部分或对每个节点执行特定的修改。Nsight Deep Learning Designer 针对某些常见用例具有批量修改操作。它们可以在工具 > 全局模型修改对话框下找到。
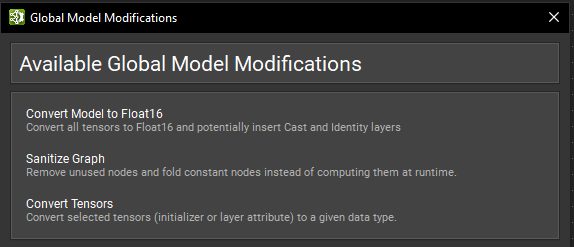
将模型转换为 FP16
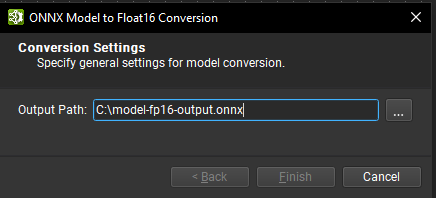
一种常见的模型优化技术是将模型权重转换为半精度格式(例如 FP16)。这可以将模型大小最多减少一半,并提高某些 GPU 的性能,但可能会牺牲一些准确性。
使用 Nsight Deep Learning Designer 的工具 > 全局模型修改对话框下的将模型转换为 Float16 批量修改操作,可以将 ONNX 模型转换为使用 Float16。为转换后的模型提供输出路径,然后单击完成。执行转换时会出现一个旋转轮。当过程完成时,将出现一个对话框,显示转换的状态,其中包含一个可展开的部分,其中包含详细日志。
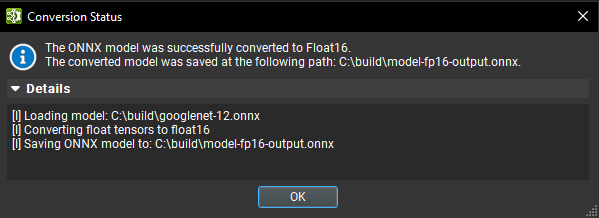
Nsight Deep Learning Designer 的 Float16 转换由 Polygraphy convert 子工具提供,该子工具在适用时将初始化器和张量转换为 Float16,并且可以插入 Cast 运算符以最大化将以 Float16 数据运行的运算符数量。
清理图
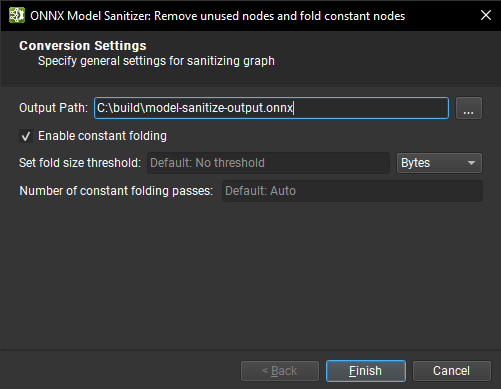
清理图批量修改操作(位于工具 > 全局模型修改对话框下)可以通过执行常量折叠和删除未使用的节点来帮助减小 ONNX 模型的大小。
要执行图清理,请在对话框中为清理后的模型提供输出路径,然后单击完成。执行清理时会出现一个旋转轮。当过程完成时,将出现一个对话框,显示状态,其中包含一个可展开的部分,其中包含详细日志。
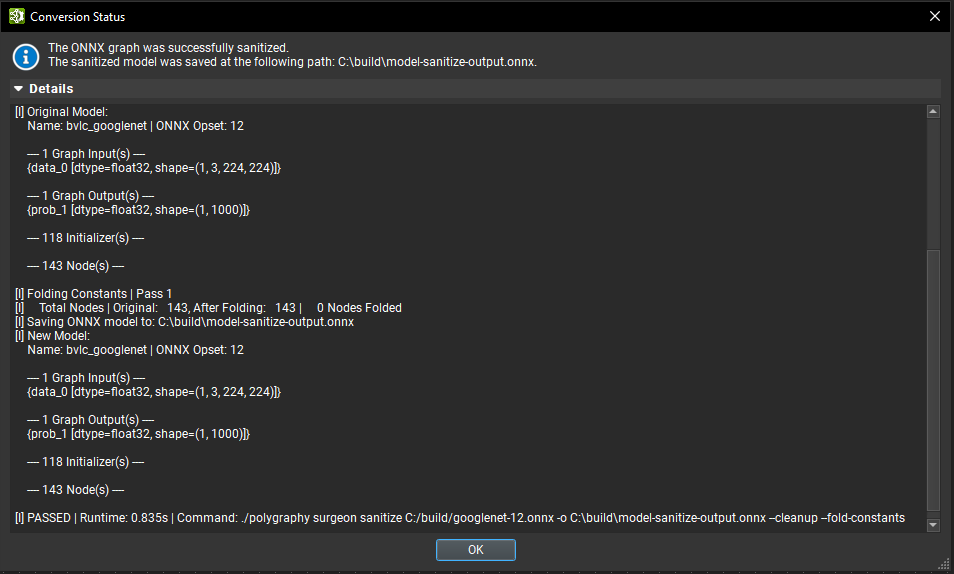
转换由 Polygraphy sanitize 子工具提供。
提供了一些选项
启用常量折叠:默认开启。如果关闭,则不会执行常量折叠。
折叠大小阈值:设置应用常量折叠的最大单张量大小阈值(以字节为单位)。生成大于此大小的张量的任何节点都不会被折叠掉。
传递次数:设置要运行的常量折叠传递次数。计算张量形状的子图可能无法在一次传递中折叠。如果留空,Polygraphy 将确定必要的传递次数。
转换张量
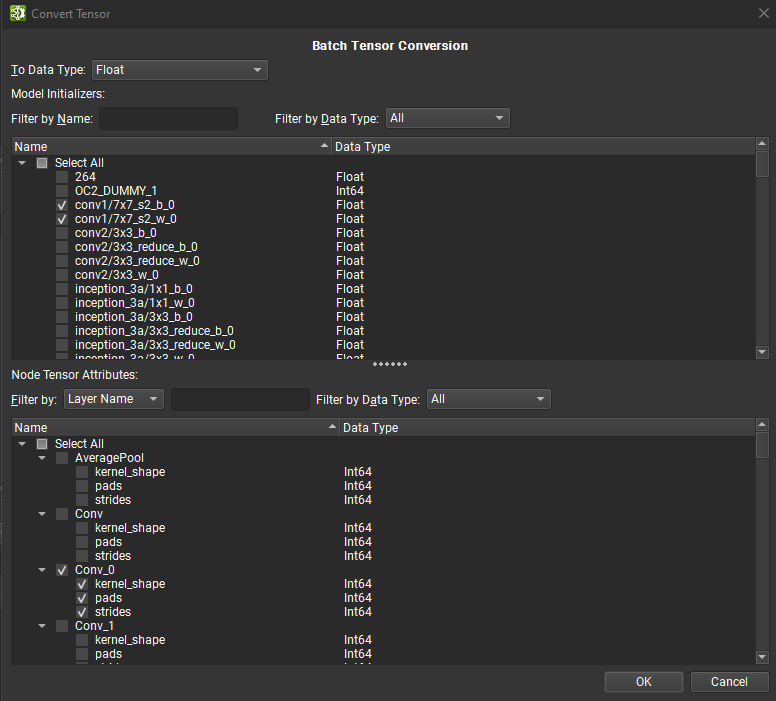
可以使用批量张量转换对话框批量转换多个张量。要访问此对话框,请打开工具 > 全局模型修改对话框,然后单击转换张量。可以在张量编辑器内转换单个张量。
批量张量转换对话框分为两个面板:顶部面板列出所有模型初始化器,而底部面板包含所有基于张量或列表的节点属性。初始化器可以按名称和数据类型进行筛选,而节点的张量或列表可以按节点或张量名称和数据类型进行筛选。
可以选择节点张量、列表和初始化器的混合项,使用对话框顶部的组合框转换为单个目标数据类型。选择所有必要的张量后,单击“确定”开始批量转换。对话框将显示转换进度以及在此过程中观察到的任何错误。
根据源数据类型和目标数据类型,可能会发生数据精度损失和/或截断。请注意,撤消批量转换会将所有先前转换的张量恢复为其原始数据类型和值。
用户工具
当用户工作流程需要超出全局模型修改系统提供的处理能力时,Nsight Deep Learning Designer 支持自定义用户工具。用户工具是一种将 ONNX 模型的自定义处理整合到 Nsight Deep Learning Designer 设计工作流程中的方法。
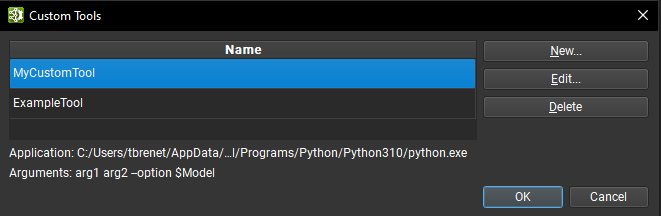
可以通过工具 > 自定义工具下的对话框管理自定义工具。该对话框包含用户定义的自定义工具列表。从列表中选择一个工具将在底部显示其应用程序路径和参数。可以使用对话框右侧的相应按钮删除或编辑选定的自定义工具。
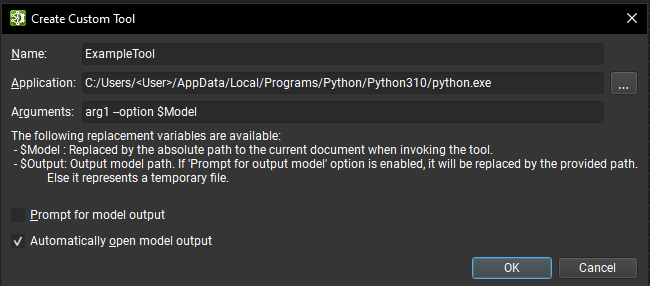
可以使用创建按钮创建新的自定义工具,这将打开一个新的对话框窗口,必须在其中提供工具信息
用于标识工具的唯一名称。
表示启动工具的可执行进程的应用程序路径。
传递给应用程序的可选参数。 有两个特殊的替换参数可用
$Model:在启动工具时,替换为当前 ONNX 文档的绝对路径。$Output:替换为工具应用于保存修改后模型的目的地文件。 提示模型输出选项会提示输入此路径。 如果禁用该选项,则这是一个临时文件的路径。
提示模型输出:如果启用,则在调用工具时,将打开一个对话框,要求输入将用于替换
$Output参数的路径。自动打开模型输出:如果启用,则当工具成功完成后,并且如果在参数列表中设置了
$Output变量,Nsight Deep Learning Designer 将自动打开输出文档。
请注意,要运行 Python 脚本,应用程序路径应指向 Python 解释器,并且提供的第一个参数应该是 Python 脚本的路径。
可以在工具 > 用户工具子菜单下找到自定义用户工具,从该菜单中选择一个工具将调用它,并给定当前聚焦的 ONNX 模型。 将打开一个对话框窗口,提供工具进程的当前状态以及标准输出和错误日志。 可以使用取消按钮取消自定义工具进程,这将导致进程被终止。 根据是否为工具设置了自动打开模型输出选项,Nsight Deep Learning Designer 将在工具成功退出时打开输出模型(如果有)。
活动平台设置
Nsight Deep Learning Designer 活动在目标机器上运行。 活动可以在 Linux、Windows 或 NVIDIA L4T 上本地运行,也可以在 Linux 和 NVIDIA L4T 目标机器上远程运行(从任何受支持的 Nsight Deep Learning Designer 主机)。 主机平台 指的是运行 Nsight Deep Learning Designer 的机器。 目标平台 指的是将要运行活动的机器。 对于本地运行的活动,主机和目标机器是同一台机器。
连接管理
在 Nsight Deep Learning Designer 中启动活动时,活动窗口的顶部用于选择将在哪个目标机器上执行活动。 根据平台类型,支持本地和远程目标。 默认情况下选择主机应用程序正在运行的平台。
目前,Nsight Deep Learning Designer 支持以下平台
Windows x86_64:仅本地。
Linux x86_64:本地和远程。
NVIDIA L4T arm64:本地和远程。
使用远程目标时,必须从顶部下拉列表中选择或创建连接。 要创建新连接,请选择 + 并输入远程连接详细信息。 使用本地平台时,将选择 localhost 作为默认值,并且不需要进一步的连接设置。
远程连接
支持 SSH 的远程目标可以在连接对话框中配置为目标。 要配置远程设备,请确保选择了支持 SSH 的目标平台,然后按 + 按钮。 将显示以下配置对话框。
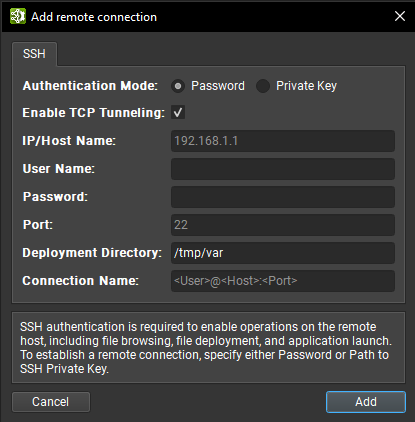
Nsight Deep Learning Designer 支持密码和私钥身份验证方法。 在此对话框中,选择身份验证方法并输入以下信息
密码
IP/主机名:目标设备的 IP 地址或主机名。
用户名:用于 SSH 连接的用户名。
密码:用于 SSH 连接的用户密码。
端口:用于 SSH 连接的端口。(默认值为 22。)
部署目录:在目标设备上用于部署支持文件的目录。 指定的用户必须对此位置具有写入权限。 支持相对路径。
连接名称:将在连接对话框中显示的远程连接的名称。 如果未设置,则默认为
<User>@<Host>:<Port>。
私钥
IP/主机名:目标设备的 IP 地址或主机名。
用户名:用于 SSH 连接的用户名。
SSH 私钥:用于向 SSH 服务器进行身份验证的私钥。
SSH 密钥密码:私钥的密码。
端口:用于 SSH 连接的端口。(默认值为 22。)
部署目录:在目标设备上用于部署支持文件的目录。 指定的用户必须对此位置具有写入权限。 支持相对路径。
连接名称:将在连接对话框中显示的远程连接的名称。 如果未设置,则默认为
<User>@<Host>:<Port>。
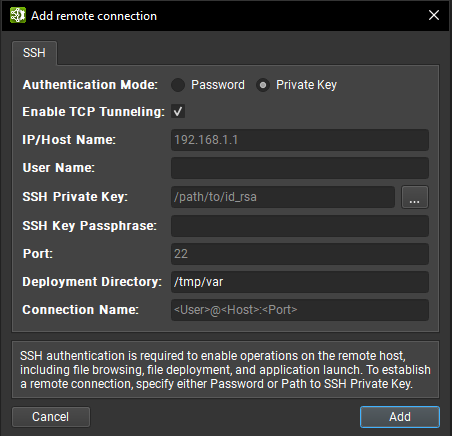
除了路径指定的密钥文件和纯密码身份验证之外,Nsight Deep Learning Designer 还支持交互式身份验证和标准密钥文件路径搜索。 输入所有信息后,单击添加按钮以使用此新连接。
远程启动活动后,如果需要,所需的二进制文件和库将复制到远程机器上的部署目录。
在 Linux 和 NVIDIA L4T 主机平台上,对于无法从运行 UI 的机器直接寻址的目标机器,Nsight Deep Learning Designer 支持通过 ProxyJump 和 ProxyCommand SSH 选项进行 SSH 远程分析。 这些选项可用于指定要连接的中间主机,或指定要运行以获取连接到目标主机上的 SSH 服务器的套接字的实际命令,并且可以添加到您的 SSH 配置文件中。
请注意,对于这两个选项,Nsight Deep Learning Designer 运行外部命令,并且不实现任何机制来使用在连接对话框中输入的凭据向中间主机进行身份验证。 这些凭据将仅用于向机器链中的最终目标进行身份验证。
使用 ProxyJump 选项时,Nsight Deep Learning Designer 使用 OpenSSH 客户端来建立与中间主机的连接。 这意味着为了使用 ProxyJump 或 ProxyCommand,主机机器上必须安装支持这些选项的 OpenSSH 版本。
在这种情况下,向中间主机进行身份验证的常用方法是使用 SSH 代理,并让它持有用于身份验证的私钥。
由于使用了 OpenSSH SSH 客户端,因此您还可以使用 SSH askpass 机制以交互方式处理这些身份验证。
有关 OpenSSH 客户端的可用选项以及可以用于身份验证的工具生态系统的更多信息,请参阅官方手册页。
部署工作流程
Nsight Deep Learning Designer 中的活动依赖于共享库来支持推理。 例如,TensorRT 分析器依赖于 TensorRT 库、CUDA 工具包和 cuDNN。 Nsight Deep Learning Designer 使用按需部署工作流程,这意味着这些依赖项不会与 Nsight Deep Learning Designer 一起安装,而是在启动活动之前部署在选定的目标上。
在开始活动之前,Nsight Deep Learning Designer 将检查目标机器上是否已存在所有必要的依赖项;对于远程目标,Nsight Deep Learning Designer 将在提供的部署文件夹内查找。 对话框显示活动的依赖项列表和验证进度。 如果某些依赖项缺失或不是最新版本,则它们在对话框中的条目将显示警告图标,并且 Nsight Deep Learning Designer 将开始在目标上部署它们。
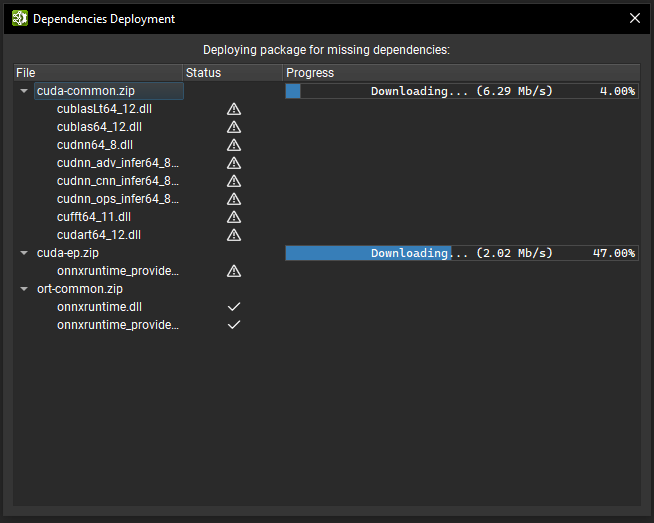
为了部署依赖项,Nsight Deep Learning Designer 在目标机器上运行一个帮助程序二进制文件(对于远程目标,通过 SSH 部署),该文件通过 HTTPS 从存储服务器下载必要的软件包。 然后,帮助程序二进制文件从软件包中提取新的库。 部署对话框显示软件包下载和提取过程的进度。 请注意,目标机器必须具有互联网访问权限,按需部署才能工作。
当 HTTPS 部署到远程目标失败时,Nsight Deep Learning Designer 会提出一种回退工作流程,该工作流程首先将依赖项部署到主机应用程序正在运行的本地机器上,然后通过 SSH 将每个依赖项传输到目标机器。 请注意,此回退工作流程预计会较慢,因为需要传输的文件通常很大(超过 200 MB)。
在目标机器上部署所有依赖项后,Nsight Deep Learning Designer 将继续启动活动。 后续启动将更快,因为只要依赖项仍然符合活动要求,Nsight Deep Learning Designer 就不会重新部署依赖项。
Nsight Deep Learning Designer 在主机上存储下载的依赖项和目标机器的帮助程序二进制文件,并在目标机器上存储定时缓存和一些其他验证缓存,存储在本地缓存目录中。 默认情况下,本地缓存目录存储在 Windows 上的 $HOME\AppData\Local 中,以及 Linux 上的 $HOME/.config 中。 可以通过设置 NV_DLD_CACHE_DIR 环境变量来更改此目录。
使用 TensorRT
Nsight Deep Learning Designer 可以将 ONNX 模型导出到 TensorRT 引擎,并可选择对其进行分析。 生成的引擎文件与其他 TensorRT 10.8 应用程序完全兼容。
注意
使用 Nsight Deep Learning Designer 创建的 TensorRT 引擎特定于创建它们的 TensorRT 版本和创建它们的 GPU。 有关详细信息,请参阅TensorRT 文档。
Nsight Deep Learning Designer 在构建 TensorRT 网络时使用定时缓存。 对于常用层,策略定时将尽可能从缓存加载。
引擎构建和分析阶段依赖于推理算法的精确计时,以进行引擎优化和性能报告。 为了获得最佳结果,请勿在与 TensorRT 活动并行运行其他 GPU 工作,因为这会歪曲结果。
导出和分析活动都可以从启动活动对话框启动,该对话框可以从欢迎页面访问。
动态形状和 TensorRT
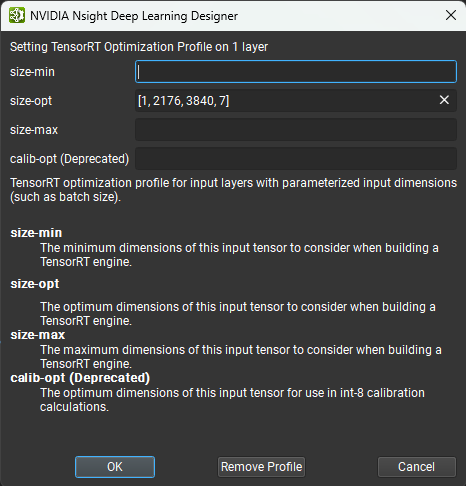
当处理动态输入大小时,TensorRT 需要优化配置文件。 静态确定的输入大小不需要其他信息,但是每个动态输入大小(例如 ['batch', 3, 544, 960] 或 ['W', 'H'])都需要优化配置文件详细信息。 如果输入未以此方式完全指定,TensorRT 将失败并显示错误,例如 input_name: dynamic input is missing dimensions in profile 0。
Nsight Deep Learning Designer 提供了两种在主机 GUI 中定义优化配置文件的方法
带有单个前导通配符的动态输入(例如
['batch', 3, 544, 960]、['size']或['n', 204800, 4])可以使用称为推断批大小的预填充值自动设置。 具有多个通配符维度的输入可能无法使用推断批大小定义。可以通过TensorRT 优化配置文件属性设置各个层的优化配置文件。 右键单击画布或图层资源管理器中的输入层,然后选择设置 TensorRT 优化配置文件上下文菜单项。 这将打开一个对话框,您可以在其中定义输入的最小、最大和最佳大小。 可选的
size-min和size-max字段用于定义输入的最小和最大大小。 对于详细探索具有多个通配符的模型,建议使用此选项。 下图显示了优化配置文件编辑器。 请注意,优化配置文件只能应用于顶层图的输入,而不能应用于子图或局部函数。
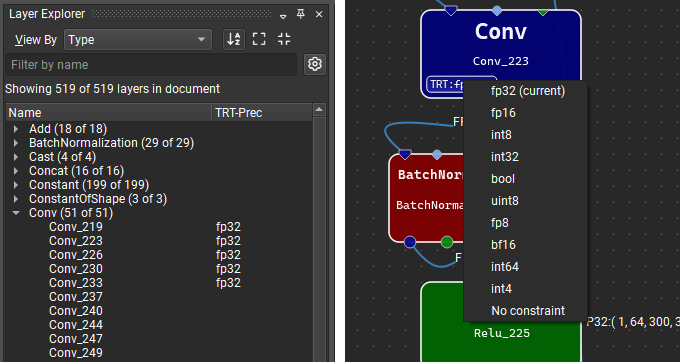
为 TensorRT 指定图层精度
使用默认设置运行时,TensorRT 将使用自动调优从启用的策略中为每个图层选择数据类型精度,以最大限度地提高性能。 但是,可以通过使用 Nsight Deep Learning Designer 中的TensorRT 图层精度属性,在每个图层的基础上强制执行精度约束。 可用的浮点精度选项为:fp32、fp16、bf16 和 fp8。 积分选项为 int64、int32、int8、int4、uint8 和 bool。 如果未为图层分配精度,TensorRT 将使用自动调优为该图层选择最佳精度。 请注意,除了指定精度约束之外,您还必须在活动设置中将类型模式设置为服从精度约束或首选精度约束。 有关更多详细信息,请参见下文。
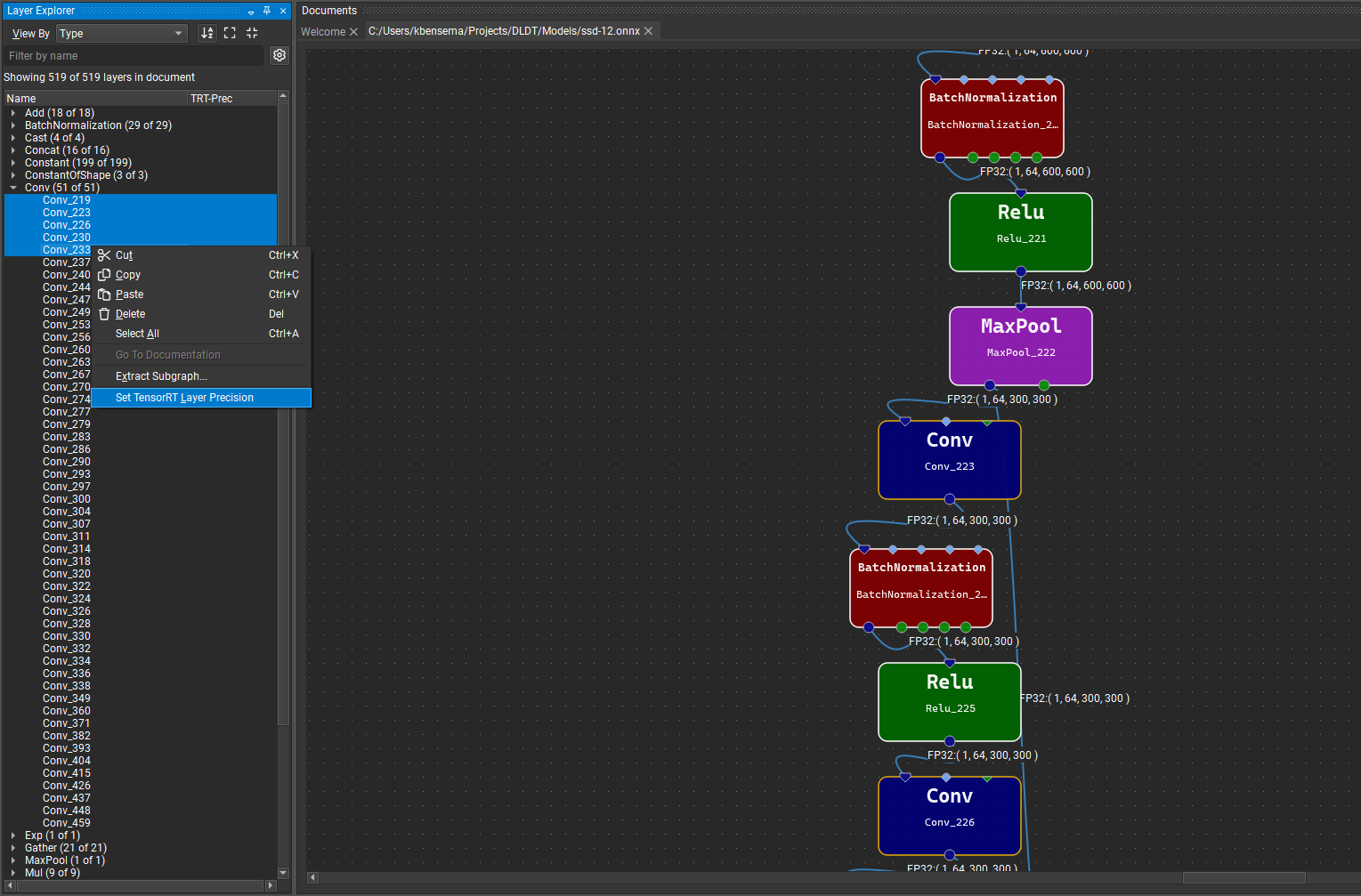
可以通过在图层资源管理器中的选定行或模型画布中的节点上单击鼠标右键,然后选择设置图层精度上下文菜单项,并在出现的对话框中选择精度选项,在 Nsight Deep Learning Designer 中设置图层精度约束。 要清除精度约束,请为选定的图层选择无约束选项。
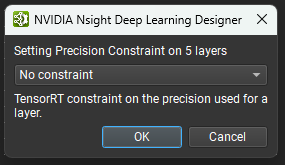
具有精度约束的图层将在图层资源管理器的 TRT-Prec 列中显示约束值,并且图层字形上将显示带有选定精度的小徽章。 单击此徽章将显示一个快速菜单,其中包含用于更改或删除约束的选项。
导出 TensorRT 引擎
要导出 TensorRT 引擎,请打开您要导出的 ONNX 模型,然后使用文件 > 导出 > TensorRT 引擎菜单项。 也可以从启动活动对话框导出 ONNX 模型,而无需事先打开它们。
选择版本
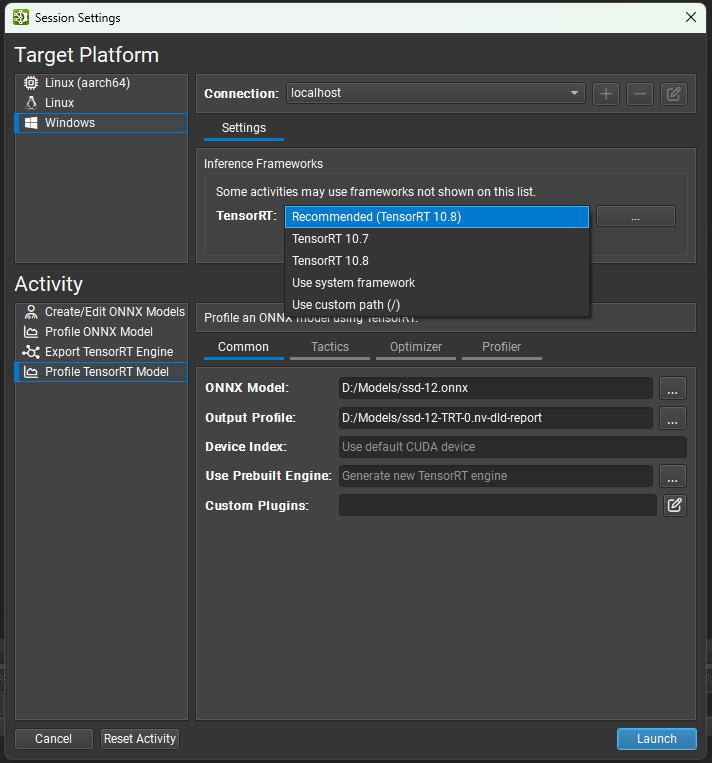
Nsight Deep Learning Designer 支持 TensorRT 10 的多个次要版本。 使用下拉选择器选择您要使用的 TensorRT 版本。 有选定的 TensorRT 版本可用于自动下载和部署(以及推荐版本)。 您也可以选择使用目标系统上系统安装的 TensorRT,或指定自定义路径。 如果您指定自定义路径,则它必须是目标机器上部署目录到 TensorRT 共享库位置的相对路径。
常用设置
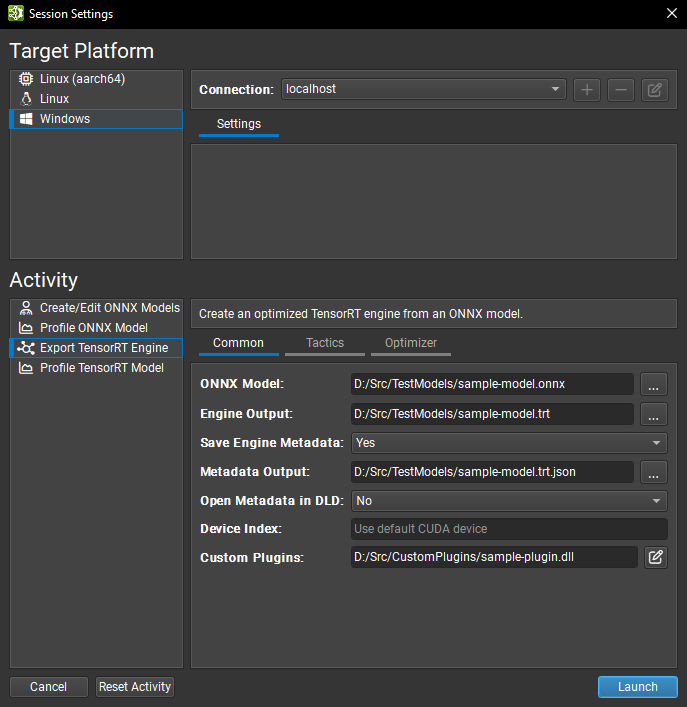
ONNX 模型参数是您要导出的模型的本地路径。 如果需要,它将被复制到目标系统。
引擎输出参数是您要保存导出的 TensorRT 引擎的本地目标位置。 如果需要,它将从目标系统复制。 该活动会根据 ONNX 模型文件名为此参数建议一个默认名称。
保存引擎元数据参数控制存储在 TensorRT 引擎中的元数据量。 当设置为是时,
DETAILED级别元数据(完整信息)将存储在引擎中。 将此选项设置为否将删除所有图层信息。元数据输出参数是可选的。 如果为此参数提供本地路径,Nsight Deep Learning Designer 将在导出后创建 TensorRT
IEngineInspector类的实例,并从目标系统复制其输出。 如果此参数留空,则不会创建元数据文件。 该活动会根据 ONNX 模型文件名为此参数建议一个默认名称。在 DLD 中打开元数据参数控制是否在导出后将元数据文件作为模型在 Nsight Deep Learning Designer 中打开以进行可视化。 仅当生成元数据文件时,此选项才可用。
设备索引选项控制在多 GPU 系统上使用哪个 CUDA 设备。 设备零表示默认 CUDA 设备,设备的排序方式与
cudaSetDevice调用中相同。 如果此设置留空,Nsight Deep Learning Designer 将使用第一个 CUDA 设备。自定义插件参数允许传递可选的自定义 TensorRT 插件的路径,以便在引擎构建期间加载。 提供的路径必须相对于选定的目标系统。 插件必须与 TensorRT 10.8 兼容。 有关自定义插件的更多详细信息,请参阅TensorRT 文档。
策略设置
本节中的大多数设置都与 TensorRT 的 BuilderFlags 枚举密切相关。
FP32 张量格式和策略始终可用于 TensorRT。 如果 TensorRT 认为选择更高精度的图层格式可以获得整体更低的运行时,或者如果不存在更低精度的实现,TensorRT 仍然可以选择更高精度的图层格式。
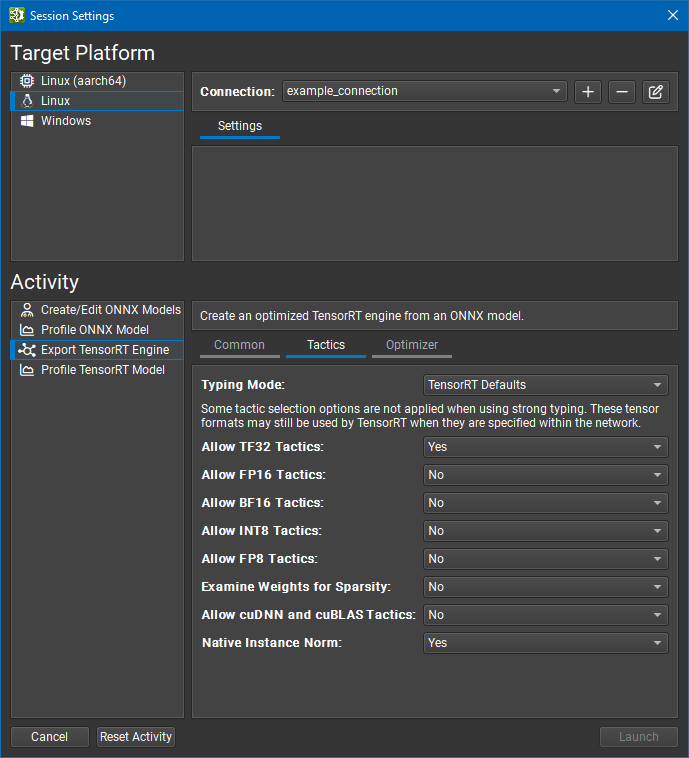
类型模式设置控制 TensorRT 的类型系统
TensorRT 默认值选项指示 TensorRT 的优化器使用自动调优来确定张量类型。 此选项生成最快的引擎,但当模型精度要求图层以高于 TensorRT 选择的精度运行时,可能会导致精度损失。 在此模式下,将忽略图层精度约束。
强类型选项指示 TensorRT 的优化器使用 ONNX 运算符类型规范中的规则来确定张量类型。 类型不会自动调优,并且可能会导致引擎比 TensorRT 选择张量类型的引擎慢,但是较小的内核替代方案集可以缩短引擎构建时间。 在此模式下,将忽略图层精度约束以及 FP16、BF16、INT8 和 FP8 策略设置。
服从精度约束选项使用 TensorRT 自动调优,其中尚未使用 Nsight Deep Learning Designer 设置图层精度约束。 如果对于特定的精度约束不存在图层实现,则引擎构建将失败。
首选精度约束选项类似于服从精度约束,但是如果无法遵守图层精度约束或导致网络速度变慢,TensorRT 将发出警告消息而不是构建引擎失败。
允许 TF32 策略设置允许 TensorRT 的优化器选择 TensorFloat-32 精度。 此格式需要 NVIDIA Ampere GPU 架构或更高版本。
允许 FP16 策略设置允许 TensorRT 的优化器选择 IEEE 754 半精度。
允许 BF16 策略设置允许 TensorRT 的优化器选择 Bfloat16 精度。 此格式需要 NVIDIA Ampere GPU 架构或更高版本。
允许 INT8 策略设置允许 TensorRT 的优化器使用量化八位整数精度。 建议使用显式量化网络,但如果网络是隐式量化的并且未提供校准缓存,Nsight Deep Learning Designer 将分配占位符动态范围(类似于
trtexec)。允许 FP8 策略设置允许 TensorRT 的优化器使用量化八位浮点精度。 此设置与 INT8 设置互斥,并且通常仅对于具有插件生成的可选 FP8 张量的网络才需要。
检查权重的稀疏性设置指示 TensorRT 的优化器检查权重,并在权重具有合适的稀疏性时使用优化的函数。
允许 cuDNN 和 cuBLAS 策略设置允许 TensorRT 使用 cuDNN 和 cuBLAS 库进行图层实现。 禁用此设置后,将仅考虑内部 TensorRT 内核。 启用此设置将导致 cuDNN 下载到目标。
原生实例规范化设置指示 TensorRT 使用其自己的实例规范化实现,而不是使用 cuDNN 的基于插件的实现。 禁用此设置将导致 cuDNN 下载到目标。
优化器设置
此页面中的设置主要控制 TensorRT IBuilderConfig 接口。
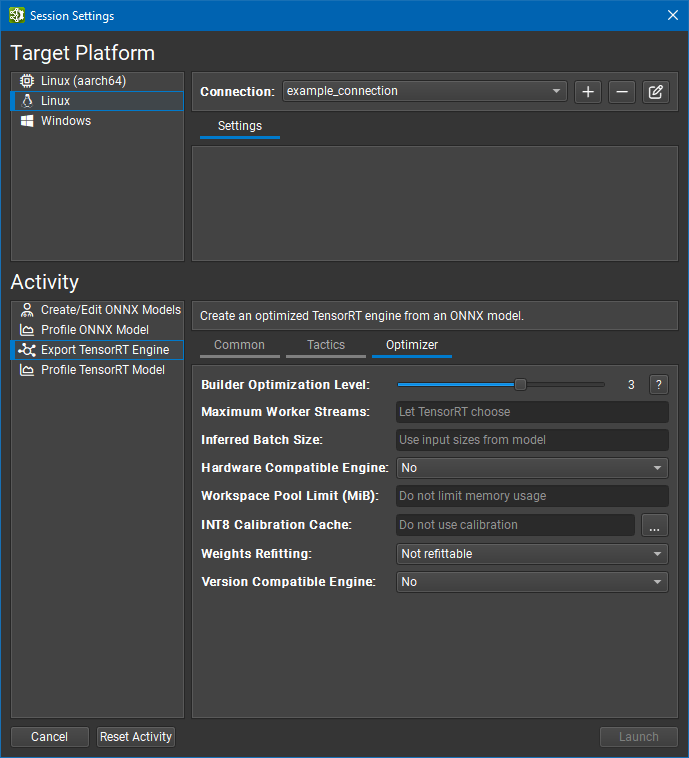
构建器优化级别选项控制引擎构建时间和推理时间之间的权衡。 更高的优化级别允许优化器花费更多时间搜索优化机会,这可能会在运行时带来更好的性能。 有关更多详细信息,请参阅 TensorRT
setBuilderOptimizationLevel函数文档。最大工作流数量选项控制多流推理。 如果模型包含可以并行运行的运算符,TensorRT 可以在辅助流上执行它们。 此设置的值定义了在构建时提供给 TensorRT 的最大流数。 如果此设置留空,TensorRT 将使用内部启发式方法来选择合适的数字。 将此值设置为零以禁用流并行性。
推断批大小选项允许为
['N', sizes...]形式的动态输入隐式指定 TensorRT 优化配置文件。 有关推断批大小功能的更多详细信息,请参阅动态形状和 TensorRT。硬件兼容引擎选项创建一个 TensorRT 引擎,该引擎可在所有支持 TensorRT 的具有 Ampere 架构或更高版本的独立 GPU 上工作。 使用此功能可能会对性能产生影响,因为它排除了针对更高版本 GPU 架构的优化。
工作区池限制 (MiB) 选项控制 TensorRT 使用的工作区内存池的大小。 该值应以 MiB 为单位指定;一个 MiB 为 220 字节。 将此值设置得太小可能会阻止 TensorRT 为图层找到有效的实现。 将此值留空(默认值)将删除限制,并允许 TensorRT 使用 GPU 上的所有可用全局内存。
INT8 校准缓存选项允许您为隐式量化的 INT8 网络指定校准缓存文件。 将此值留空(默认值)将禁用校准。 校准缓存对于显式量化网络或不使用 INT8 策略的网络既不是必需的,也不会使用。
权重重新拟合选项控制权重是否存储在生成的 TensorRT 模型中,以及它们是否可以在推理时更改。 不可重新拟合选项是 TensorRT 默认值。 它嵌入了可能无法重新拟合的权重。 可重新拟合(包含权重)选项对应于 TensorRT 的
kREFIT标志;它嵌入权重并允许重新拟合所有权重。 可重新拟合(已剥离权重)选项对应于 TensorRT 的kSTRIP_PLAN标志。 此选项仅嵌入具有性能敏感优化的那些权重;所有其他权重都被省略并且是可重新拟合的。 应用程序应在推理时将原始权重重新拟合到引擎中。版本兼容引擎选项创建一个 TensorRT 引擎,该引擎可用于更高版本的 TensorRT 进行推理。 有关详细信息,请参阅 TensorRT 文档。
可视化 TensorRT 引擎
TensorRT 引擎的图层可以在 Nsight Deep Learning Designer 中通过元数据文件可视化,该元数据文件可以选择在 TensorRT 引擎导出活动期间生成,也可以在命令行中使用 trtexec 工具生成。 如果在 Nsight Deep Learning Designer 外部生成元数据文件,则必须将 --profilingVerbosity 标志设置为 detailed。
可以使用文件 > 打开菜单项并选择元数据文件,在 Nsight Deep Learning Designer 中打开现有的 TensorRT 引擎元数据文件。 引擎将在工作区中可视化为模型。 由于这只是描述引擎的元数据文件;因此无法对参数或图层进行编辑。 请注意,Nsight Deep Learning Designer 期望使用 .trt.json 文件扩展名。
分析
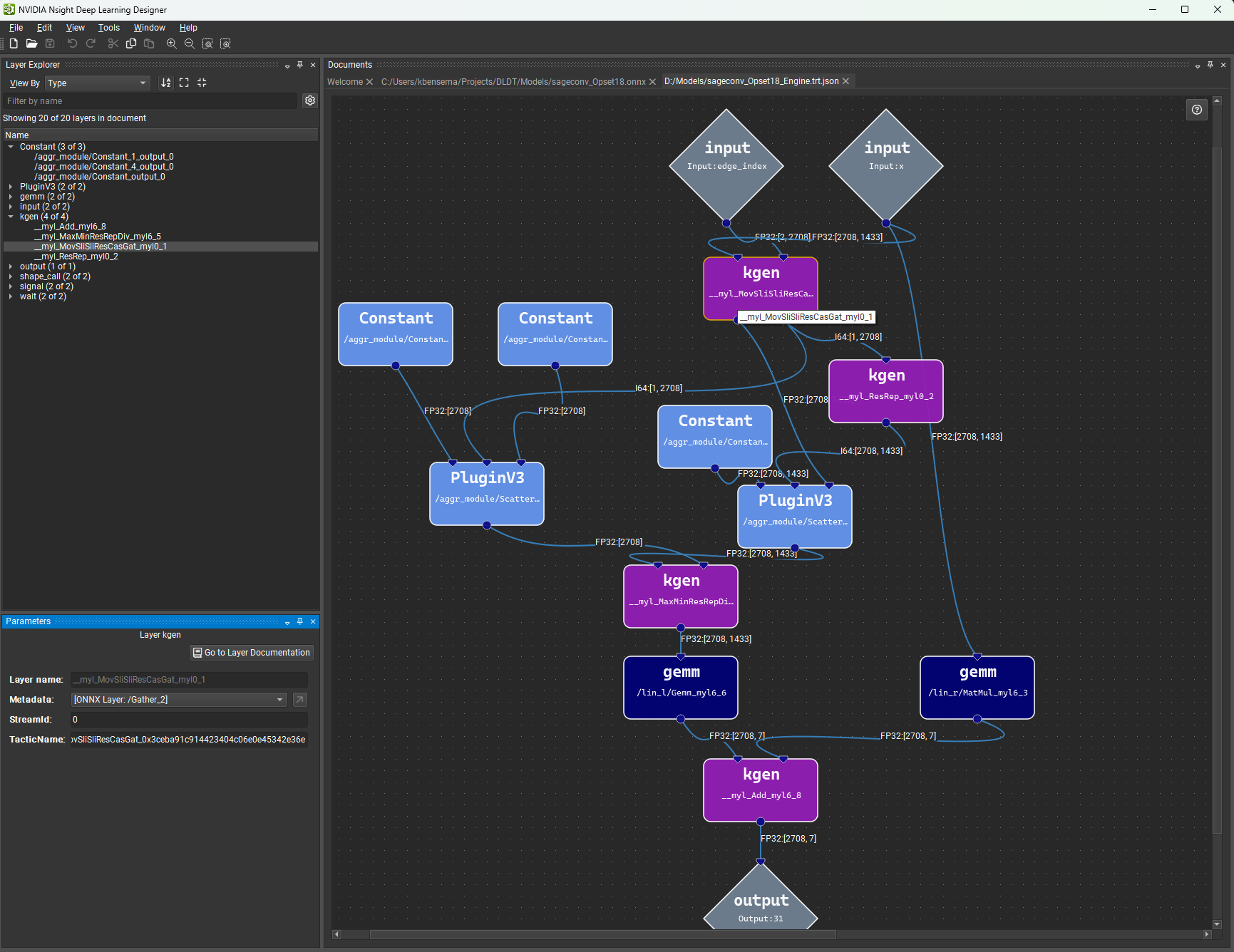
Nsight Deep Learning Designer 支持使用 TensorRT 或 ONNX Runtime 作为推理框架来分析网络。 仅当使用 TensorRT 进行分析时,GPU 性能指标才可用。
要进行分析,请打开您要分析的 ONNX 模型,然后使用分析模型工具栏按钮或工具 > 分析模型菜单项。 也可以从启动活动对话框分析 ONNX 模型,而无需事先打开它们。
注意:当以 NVIDIA L4T 平台为目标时,用户(本地或远程)需要成为 debug 组的成员才能进行分析。
使用 ONNX Runtime 进行分析
要使用 ONNX Runtime 分析模型,请打开您要分析的 ONNX 模型,然后使用工具 > 分析模型菜单项。 也可以从启动活动对话框(可通过欢迎页面访问)分析 ONNX 模型,而无需事先打开它们。
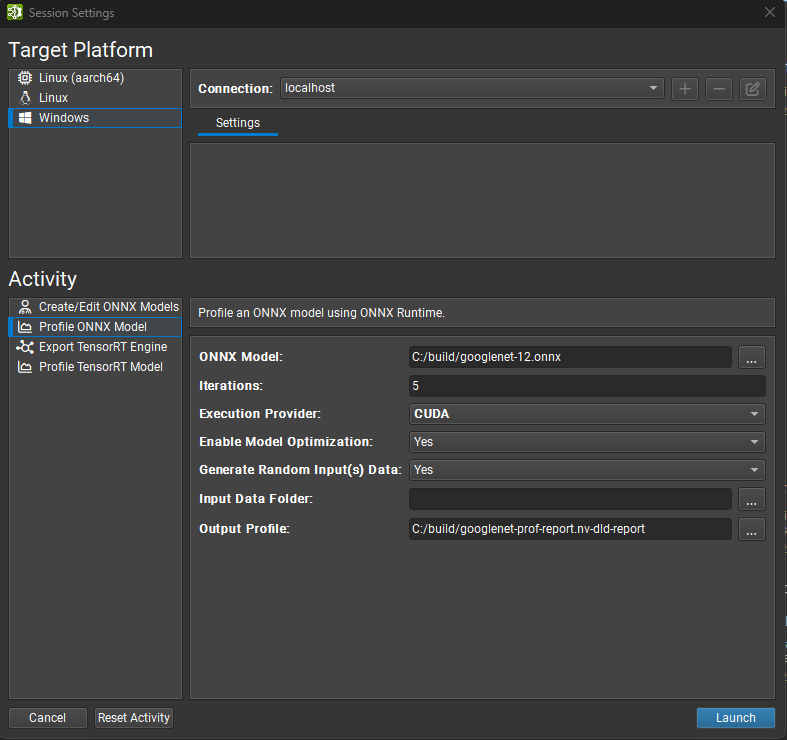
Nsight Deep Learning Designer 的 ONNX Runtime 分析器基于 ONNXRuntime 性能测试 二进制文件。 以下是 ONNX Runtime 分析的选项
ONNX 模型参数是您要分析的模型的本地路径。 模型文件将在必要时复制到目标系统。
迭代次数选项控制在收集数据时执行多少次推理迭代。 增加此值会在计算中位数推理传递时减少噪声,因为采样了更多数据点,但是相应地增加了分析模型所花费的时间。
执行提供程序选项定义 ONNX Runtime 分析器在推理期间将使用的后端。 CPU 和 CUDA 提供程序在所有目标平台上都受支持。 Windows 目标还支持 DirectML 提供程序。
启用模型优化选项控制分析器是否应首先应用图级转换来优化模型,然后再运行推理。 如果启用,分析器将应用 ONNX Runtime 中的图优化中所述的最高级别优化。
生成随机输入数据选项控制分析器是否应为模型的输入生成随机数据,而模型中没有嵌入数据或从外部文件引用数据。 自由维度被视为 1。 如果关闭,则必须提供输入数据文件夹。
输入数据文件夹选项控制分析器应在何处查找模型输入的数据。 必须关闭生成随机输入数据才能定义数据文件夹。 它应指向一个目录,该目录包含每个模型输入一个带有 ONNX TensorProto 的文件。 Protobuf 文件需要命名为其对应的模型输入,例如:
input_0.pb。 输入数据将在必要时复制到目标系统。输出配置文件参数是您要保存分析器报告的本地目标位置。 如果需要,它将从目标系统复制。 该活动会根据 ONNX 模型文件名为此参数建议一个默认名称。
使用 TensorRT 进行分析
要使用 TensorRT 分析模型,请打开您要分析的 ONNX 模型,然后使用工具 > 分析模型菜单项。 也可以从启动活动对话框(可通过欢迎页面访问)分析 ONNX 模型,而无需事先打开它们。
使用动态输入大小分析 ONNX 模型需要 TensorRT 优化配置文件。在生成随机输入数据时,Profiler 将使用输入最佳大小。
选择版本
Nsight Deep Learning Designer 支持多个 TensorRT 10 的次要版本以进行分析。使用下拉选择器选择您希望使用的 TensorRT 版本。有精选的 TensorRT 版本可用于自动下载和部署(以及推荐版本)。您也可以选择使用目标系统上系统安装的 TensorRT,或指定自定义路径。如果您指定自定义路径,则它必须是目标机器上部署目录到 TensorRT 共享库位置的相对路径。
常用设置
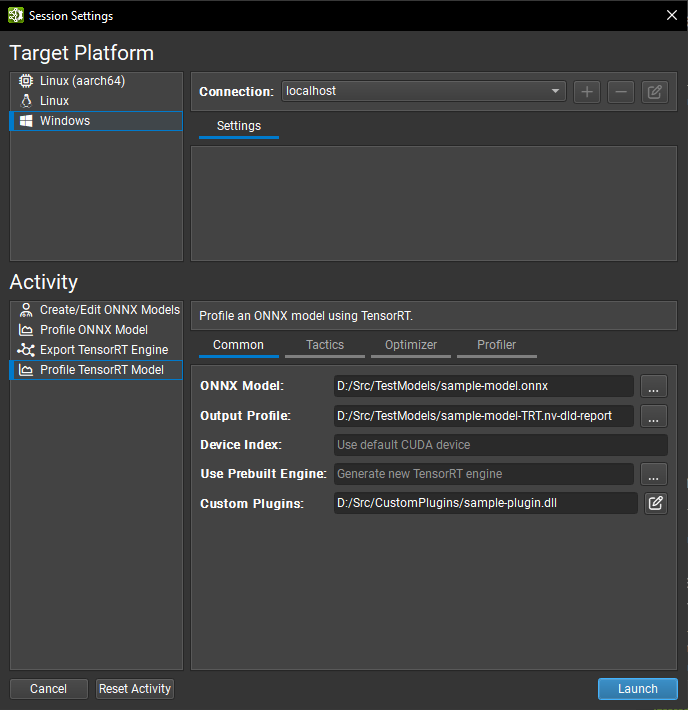
ONNX 模型参数是您希望分析的模型的本地路径。如有必要,它将被复制到目标系统。
输出配置文件参数是您要保存分析器报告的本地目标位置。 如果需要,它将从目标系统复制。 该活动会根据 ONNX 模型文件名为此参数建议一个默认名称。
设备索引选项控制在多 GPU 系统上使用哪个 CUDA 设备。设备 0 代表默认 CUDA 设备,设备按照
cudaSetDevice调用中的顺序排列。如果此设置留空,Nsight Deep Learning Designer 将使用第一个 CUDA 设备。使用预构建引擎选项允许您分析来自导出 TensorRT 引擎活动或其他工作流程(如
trtexec)的预先存在的 TensorRT 引擎,而不是构建新的引擎。引擎文件必须从正在分析的 ONNX 模型构建,必须具有kDETAILED分析详细程度,并且如果可能,将在推理之前自动重新拟合。当分析预构建引擎时,策略和优化器页面中的设置将被忽略。该引擎被认为是可信的,并且任何嵌入式主机代码(如 TensorRT 版本兼容性或插件嵌入选项)都将被反序列化并根据需要执行。自定义插件参数允许传递可选的自定义 TensorRT 插件的路径,以便在引擎构建期间加载。 提供的路径必须相对于选定的目标系统。 插件必须与 TensorRT 10.8 兼容。 有关自定义插件的更多详细信息,请参阅TensorRT 文档。
策略设置
本节中的大多数设置都与 TensorRT 的 BuilderFlags 枚举密切相关。
FP32 张量格式和策略始终可用于 TensorRT。 如果 TensorRT 认为选择更高精度的图层格式可以获得整体更低的运行时,或者如果不存在更低精度的实现,TensorRT 仍然可以选择更高精度的图层格式。
类型模式设置控制 TensorRT 的类型系统
TensorRT 默认值选项指示 TensorRT 的优化器使用自动调优来确定张量类型。 此选项生成最快的引擎,但当模型精度要求图层以高于 TensorRT 选择的精度运行时,可能会导致精度损失。 在此模式下,将忽略图层精度约束。
强类型选项指示 TensorRT 的优化器使用 ONNX 运算符类型规范中的规则来确定张量类型。 类型不会自动调优,并且可能会导致引擎比 TensorRT 选择张量类型的引擎慢,但是较小的内核替代方案集可以缩短引擎构建时间。 在此模式下,将忽略图层精度约束以及 FP16、BF16、INT8 和 FP8 策略设置。
服从精度约束选项使用 TensorRT 自动调优,其中尚未使用 Nsight Deep Learning Designer 设置图层精度约束。 如果对于特定的精度约束不存在图层实现,则引擎构建将失败。
首选精度约束选项类似于服从精度约束,但是如果无法遵守图层精度约束或导致网络速度变慢,TensorRT 将发出警告消息而不是构建引擎失败。
允许 TF32 策略设置允许 TensorRT 的优化器选择 TensorFloat-32 精度。 此格式需要 NVIDIA Ampere GPU 架构或更高版本。
允许 FP16 策略设置允许 TensorRT 的优化器选择 IEEE 754 半精度。
允许 BF16 策略设置允许 TensorRT 的优化器选择 Bfloat16 精度。 此格式需要 NVIDIA Ampere GPU 架构或更高版本。
允许 INT8 策略设置允许 TensorRT 的优化器使用量化八位整数精度。 建议使用显式量化网络,但如果网络是隐式量化的并且未提供校准缓存,Nsight Deep Learning Designer 将分配占位符动态范围(类似于
trtexec)。允许 FP8 策略设置允许 TensorRT 的优化器使用量化八位浮点精度。 此设置与 INT8 设置互斥,并且通常仅对于具有插件生成的可选 FP8 张量的网络才需要。
检查权重的稀疏性设置指示 TensorRT 的优化器检查权重,并在权重具有合适的稀疏性时使用优化的函数。
允许 cuDNN 和 cuBLAS 策略设置允许 TensorRT 使用 cuDNN 和 cuBLAS 库进行图层实现。 禁用此设置后,将仅考虑内部 TensorRT 内核。 启用此设置将导致 cuDNN 下载到目标。
原生实例规范化设置指示 TensorRT 使用其自己的实例规范化实现,而不是使用 cuDNN 的基于插件的实现。 禁用此设置将导致 cuDNN 下载到目标。
优化器设置
此页面中的设置主要控制 TensorRT IBuilderConfig 接口。
构建器优化级别选项控制引擎构建时间和推理时间之间的权衡。 更高的优化级别允许优化器花费更多时间搜索优化机会,这可能会在运行时带来更好的性能。 有关更多详细信息,请参阅 TensorRT
setBuilderOptimizationLevel函数文档。最大工作流数量选项控制多流推理。 如果模型包含可以并行运行的运算符,TensorRT 可以在辅助流上执行它们。 此设置的值定义了在构建时提供给 TensorRT 的最大流数。 如果此设置留空,TensorRT 将使用内部启发式方法来选择合适的数字。 将此值设置为零以禁用流并行性。
推断批大小选项允许为
['N', sizes...]形式的动态输入隐式指定 TensorRT 优化配置文件。硬件兼容引擎选项创建一个 TensorRT 引擎,该引擎可在所有支持 TensorRT 的具有 Ampere 架构或更高版本的独立 GPU 上工作。 使用此功能可能会对性能产生影响,因为它排除了针对更高版本 GPU 架构的优化。
工作区池限制 (MiB) 选项控制 TensorRT 使用的工作区内存池的大小。 该值应以 MiB 为单位指定;一个 MiB 为 220 字节。 将此值设置得太小可能会阻止 TensorRT 为图层找到有效的实现。 将此值留空(默认值)将删除限制,并允许 TensorRT 使用 GPU 上的所有可用全局内存。
INT8 校准缓存选项允许您为隐式量化的 INT8 网络指定校准缓存文件。将此值留空(默认值)将禁用校准。当网络显式量化或未启用 INT8 策略时,校准缓存既不是必需的,也不会使用。
权重重新拟合选项控制权重是否存储在生成的 TensorRT 模型中,以及它们是否可以在推理时更改。 不可重新拟合选项是 TensorRT 默认值。 它嵌入了可能无法重新拟合的权重。 可重新拟合(包含权重)选项对应于 TensorRT 的
kREFIT标志;它嵌入权重并允许重新拟合所有权重。 可重新拟合(已剥离权重)选项对应于 TensorRT 的kSTRIP_PLAN标志。 此选项仅嵌入具有性能敏感优化的那些权重;所有其他权重都被省略并且是可重新拟合的。 应用程序应在推理时将原始权重重新拟合到引擎中。版本兼容引擎选项创建一个 TensorRT 引擎,该引擎可用于与更高版本的 TensorRT 进行推理。有关详细信息,请参阅 TensorRT 文档。
Profiler 设置
此页面中的设置控制 Nsight Deep Learning Designer Profiler 的行为,而不是 TensorRT 的行为。
测量轮数选项控制在收集数据时执行多少次推理迭代。增加此值可在计算中间推理轮数时减少噪声,因为采样了更多数据点,但相应地增加了分析模型所需的时间。
采样率选项控制 GPU 性能计数器收集的频率。增加此值会为分析报告收集更多数据,但可能会导致大型模型上的收集缓冲区溢出。
锁定时钟到基本频率选项控制 GPU 时钟是否锁定到其基本值,从而在分析期间禁用时钟加速。锁定时钟提高了测量一致性,但代价是降低了推理性能。
隐藏非计算操作选项控制是否将 Profiler 开销(例如主机/设备内存副本)包含在测量循环和生成的 Profiler 报告中。
当对模型设计进行增量更改时,应将时钟锁定到基本值。各个层的计时值将反映 GPU 的一致性能状态,并且在模型的不同版本之间具有有意义的可比性。当测量真实世界配置中的端到端性能时,应解锁时钟,隐藏非计算操作,并将测量轮数值设置为较大的数字(通常两百次就足够了)。增加轮数可确保 GPU 保持活动状态足够长的时间以达到其最大时钟频率。从分析操作中省略非计算操作进一步饱和了 GPU,因为 SM 操作不会与内存副本交错进行。
从命令行分析
Nsight Deep Learning Designer 包含一个轻量级命令行 TensorRT Profiler,用于非交互式用例。命令行 Profiler 称为 ndld-prof。在从 Nsight Deep Learning Designer GUI 交互式分析后,可以将其复制到远程目标的部署目录。
有关 Profiler 接受的命令行参数的完整详细信息,可以使用 --help 选项查看。使用命令行 Profiler 时,支持来自分析 TensorRT 模型活动界面的所有选项。
使用命令行 Profiler 时,无需保存完整的分析报告。Profiler 将在 stdout 上显示性能分类信息。
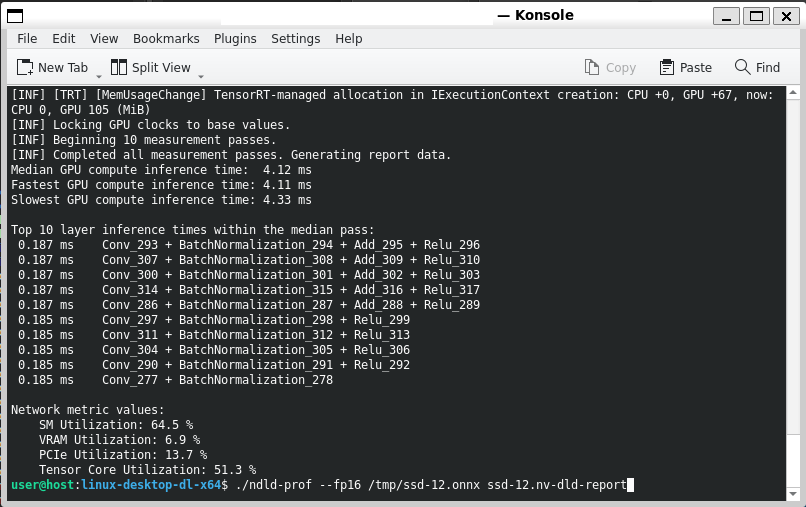
来自命令行 Profiler 的示例输出
分析报告
Nsight Deep Learning Designer 使用通用报告格式来存储来自 ONNX Runtime 和 TensorRT 的分析数据。可以使用文件 > 打开文件命令重新打开现有的分析报告。分析 TensorRT 模型和分析 ONNX 模型活动将在成功完成分析运行后自动打开新的 Profiler 报告。
分析报告描述了 ONNX 模型在选定推理框架中的执行情况,这通常指的是网络的运行时优化版本。来自 ONNX 模型的节点组可以融合到单个优化层中,并且其他节点可能会在优化过程中完全删除。
分析报告有四个主要部分。下面描述了每个部分,包括 ONNX Runtime 和 TensorRT Profiler 之间的任何差异。
网络摘要

摘要部分显示有关分析运行的高级详细信息。
网络名称:已分析的 ONNX 模型的名称。
后端:用于分析的推理框架,无论是 ONNX Runtime 还是 TensorRT。
执行提供程序(仅限 ONNX Runtime):用于分析的首选 ONNX Runtime 执行提供程序。
推理设备(仅限 TensorRT):用于推理的 GPU 的名称,由 CUDA 驱动程序返回。
中间网络推理时间:中间推理轮次所用的实际时间。
# 推理轮数:分析期间执行的推理轮数。
设备所需内存(仅限 TensorRT):编译后的 TensorRT 引擎在推理期间所需的最大设备内存,由
ICudaEngine::getDeviceMemorySize返回。
推理时间线
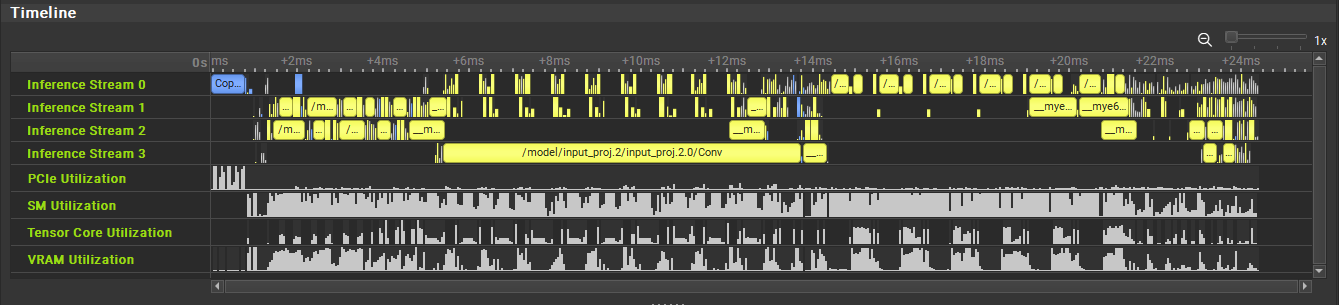
推理时间线显示中间推理轮次中各个层的执行情况。每个并发执行流(如 TensorRT 的多流推理功能中)都显示在单独的行中。可以使用滚动条滚动视图,并通过在移动鼠标滚轮的同时按住 Ctrl 键来缩放视图。可以通过单击鼠标左键并拖动来测量特定时间段。通过右键单击时间线内的任意位置访问上下文菜单,可以获得其他缩放选项。
仅限 TensorRT:时间线中包含从主机到设备 (H2D) 的输入副本和从设备到主机 (D2H) 的输出副本的开销。
可识别为“开销”的层,例如重格式化操作、内存副本和 TensorRT NoOp 层,在时间线中使用与正常计算层不同的颜色描绘。
GPU 指标(仅限 TensorRT)
Nsight Deep Learning Designer TensorRT Profiler 在推理期间收集 GPU 级别的性能指标。这些指标显示为时间线内的额外行。值已标准化以进行渲染,以便填充可用的垂直空间;将鼠标光标悬停在数据点上以查看收集的实际值。
SM 利用率:流式多处理器 (SM) 上至少有一个 warp 正在执行的时间比例。SM 的高利用率与计算密集型操作相关。
VRAM 利用率:GPU DRAM 控制器的峰值吞吐量的比例。DRAM 控制器的高利用率与 GPU 上的内存密集型操作相关。
PCIe 利用率:PCI Express 总线的峰值吞吐量的比例。PCIe 总线的高利用率与 CPU 和 GPU 之间的内存副本相关。
Tensor Core 利用率:SM 的 Tensor Core 处于活动状态的时间比例。SM Tensor Core 的高利用率表明推理框架使用降精度张量格式执行了大量工作。
网络指标和层表
“网络指标”部分提供了推理框架内各个层执行行为的详细视图。

摘要视图显示表中每列的最常见值。当离散变量(如精度或输入维度)出现多个值时,仍然可以访问完整的值列表。将鼠标光标悬停在列表上将显示一个工具提示,其中包含每个观察到的值,按频率降序排列。连续变量(如推理时间)以最小值、最大值、总值和平均值(算术平均值)的形式呈现。
当选择多个层行时,摘要视图会更改以反映所选层。如果仅选择一个层,或者清除选择,则摘要视图将返回以显示整个推理轮次。
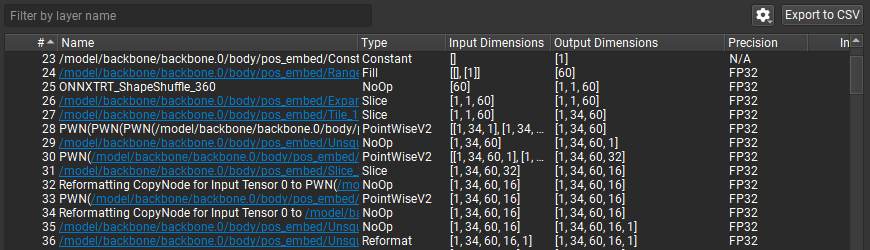
层表显示有关已执行网络的每个层的信息。可以使用导出到 CSV 按钮将此表导出为 CSV 格式。在按层名称筛选文本框中键入内容会将表筛选为仅包含作为子字符串的筛选文本的层。筛选检查不区分大小写。
设置按钮(显示为齿轮)显示一个弹出菜单,其中包含层表的选项
显示推理时间热图颜色使用颜色标度渲染推理时间列,以便执行时间较长的层以更强烈的颜色显示。提供多种配色方案。可以从“选项”对话框的环境选项卡中更改颜色标度,该对话框可以使用工具 > 选项访问。
在百分比中使用完整轮次时间控制推理时间百分比的计算方式。默认情况下(未选中状态),层推理时间百分比相对于各个层推理时间之和,从而隐藏框架开销(如输入缓冲区副本)。当选中此设置时,层推理时间百分比将改为相对于整个推理轮次的持续时间计算。
已执行网络的每个层都显示为表中的单独行。双击表中的条目会将时间线缩放到适合视图中的层。此层表包含以下信息列
#:每个层的推理顺序。对于多流推理,顺序反映层何时排队到流,而不一定反映层何时开始执行。
名称:层的名称。许多优化的层名称包含有关其原始 ONNX 节点的信息。单击层内的超链接将在 Nsight Deep Learning Designer 编辑器中打开原始 ONNX 模型,并选择相应的节点。单击选定层的放大镜按钮将弹出一个关联的 ONNX 源节点菜单:直接贡献于优化层的节点、生成优化层使用的输入张量的节点以及使用来自优化层的输出的节点。选择菜单中的任何选项都将打开源 ONNX 模型并选择节点,就像单击超链接一样。
类型:推理框架报告的层的类型。
输入维度:层输入张量的维度。
输出维度:层输出张量的维度。
执行提供程序(仅限 ONNX Runtime):用于此层的 ONNX Runtime 执行提供程序。
精度:此层的输入精度。对于具有多个输入的层,这是第一个输入张量的精度。没有直接输入张量的层(例如 Constant 层)在此处显示为
N/A。推理时间 (%):此层的推理时间,以百分比表示。有关如何计算此百分比的描述,请参阅在百分比中使用完整轮次时间。
推理时间 (ms):此层的推理时间,以毫秒为单位。
网络图
分析报告包括两个图表,按类型汇总层行为。可以通过拖动将它们与层表分开的分隔条来调整这些图表的大小。
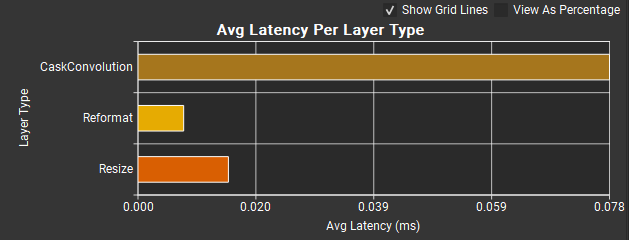
每层类型平均延迟图表显示网络中每种层类型的平均推理时间。较长的条表示较长的推理时间。水平轴刻度默认以毫秒为单位。选中按百分比查看复选框会将 X 轴重新缩放以表示层推理时间总和的百分比。前面描述的在百分比中使用完整轮次时间选项不适用于此图表。
显示网格线复选框控制是否在图表中显示网格线。
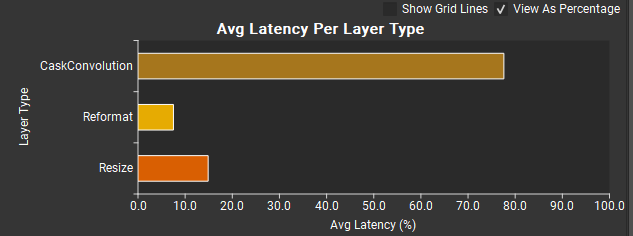
上图,但选中了按百分比查看,取消选中了显示网格线。
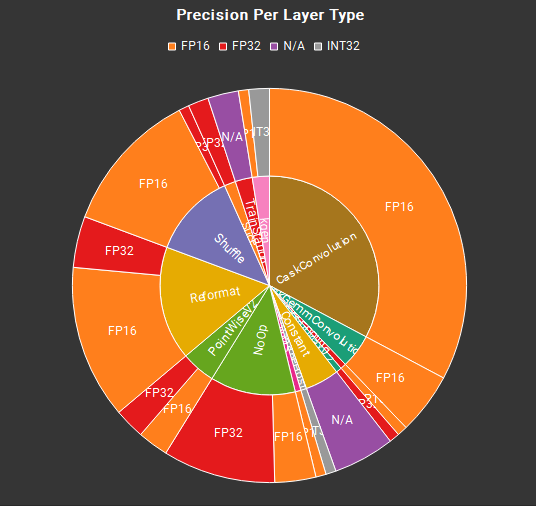
每层类型精度图表显示用于每种层类型的输入张量精度的分布。饼图的内环包含网络执行的各种层类型。每个层类型在外环中按其在层表中定义的实例精度细分。在上面的示例中,所有 CaskConvolution 层都以 FP16 精度执行,但 PointWiseV2 层以 FP16 和 FP32 精度的均等混合执行。以 FP32 执行的层代表了降低精度以提高内存占用和执行性能的机会。
具有许多运算符类型的网络可能会导致图表中出现小的单独段。将鼠标悬停在图表段上以在视觉上展开它并显示带有段的文本和值的工具提示。层类型百分比(图表的内环)相对于网络中层总数的百分比。层精度百分比(外环)相对于该类型的层数的百分比。
主菜单和工具栏
有关主菜单和工具栏的信息。
编辑模式

主工具栏
主工具栏显示主菜单中常用的操作。请参阅主菜单以获取其描述。此外,工具栏还包含以下命令
分析模型
打开最近使用的分析活动对话框。