显示配置和启动
NVIDIA® Jetson™ 板级支持包 (BSP) 支持 HDMI 和 DP 显示器的多种模式,包括 CEA 模式和来自显示器 EDID 的详细时序模式。
设置 HDMI 或 DP 屏幕分辨率
可以使用 xrandr 实用程序或 RandR 协议修改屏幕分辨率,协议位于
要更改默认的 HDMI/DP 屏幕分辨率
1. 导出 DISPLAY 变量。
export DISPLAY=:0
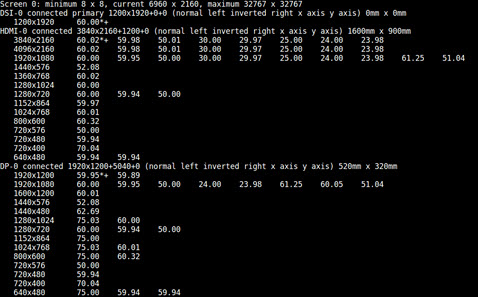
2. 获取适用的分辨率列表。
xrandr
如果已连接 HDMI 和 DP,则生成的输出将显示 HDMI 和 DP 设置的列表。
3. 将分辨率切换到所需的显示分辨率。
xrandr --output HDMI-0 --mode <res>
xrandr --output DP-0 --mode <res>
其中 <res> 是所需的分辨率,例如,640x480。
将自动选择指定模式支持的最高刷新率。
4. 选择所需的刷新率。
xrandr --output HDMI-0 --mode <res> --rate <refresh_rate>
其中 <refresh_rate> 是所需的刷新率,例如,60。
使用 xrandr 显示模式支持的所有刷新率。
镜像或扩展显示
当连接多个显示器时,您可以选择每个显示器(HDMI 或 DP)的相对位置。
要选择每个显示器的相对位置
1. 执行以下命令以在 HDMI 显示器上镜像 DP 显示器。
xrandr --output DP-0 --same-as HDMI-0
2. 执行以下命令以通过将 DP 显示器放置在 HDMI 显示器的左侧来扩展显示环境。
xrandr --output DP-0 --left-of HDMI-0
3. 执行此命令以将 DP 显示器放置在 HDMI 显示器的右侧。
xrandr --output DP-0 --right-of HDMI-0
为 HDMI 硬编码内核显示启动模式
由于已知的 fbconsole 像素时钟计算问题,Linux 内核启动日志和文本模式登录提示无法在某些显示器上显示。
受影响的显示器包括
• Acer S277HK
• Dell 24 英寸 4K 显示器
• Viewsonic VP2780
• ASUS MX27UQ
• Samsung 8500 UHD TV
• NEC MultiSync LCD2070VX
• LG Flatron W2246
• ASUS VW220TE
NVIDIA 已打包一个实用程序来更新内核 DTB 文件并解决此问题。
要更新内核 DTB 文件
1. 导航到内核目录,路径为
<top>/Linux_for_Tegra/kernel
2. 执行此命令以更新 DTB
./nv-enable-hard-coded-kernel-boot-display-mode.sh dtb/tegra194-p2888-0001-p2822-0000.dtb
3. 刷写系统。
成功启动后,fbconsole 将以指定的模式显示。默认显示模式为 720x480p@60Hz CEA。
DTB 文件位于
kernel/dtb/tegra194-p2888-0001-p2822-0000.dtb
要指定与默认模式不同的模式
1. 在您喜欢的编辑器中打开该实用程序。
2. 在 properties 数组中,更新每个模式参数的“:”(冒号)左侧的值。
3. 保存实用程序脚本并退出编辑器。
4. 使用 更新内核 DTB 文件 中的说明重新执行该实用程序。
指南
• 可以使用 Monitor/TV 上任何已知的工作模式来代替 720x480p 模式。
• 如果 nvidia,fbcon-default-mode 节点已存在,则脚本可能会打印错误消息。可以安全地忽略此消息。
• 默认情况下,HDMI 映射到两个平台上的 SOR1。如果您将其更新为 SOR0,请确保节点路径也已更新并分配给脚本中的 fbcon_node 变量。
nvimp_util: 用于计算特定显示配置 (IMP) 的内存带宽的工具
IMP 代表 “Is Mode Possible?”(模式是否可能?)。它是一种算法,您可以运行该算法来确定
1. 在给定某些带宽约束的情况下,提议的显示配置是否可能
2. 如果配置是可能的,则必须编程到硬件中以支持该配置的预期带宽值
“显示配置” 广义上是指所有活动头、窗口和光标的状态。
通常,有几个因素会影响 IMP,例如每个活动窗口的最大缩小比例因子、每个窗口的表面尺寸、特定头上的栅格时序等。IMP 会考虑所有这些因素。
nvimp_util 是一个离线实用程序,可让您通过命令行输入显示配置并在其上运行 IMP。如果 IMP 通过,则该实用程序会输出带宽值,您可以在设备树中指定这些值以支持显示配置。本主题介绍如何使用 nvimp_util 运行 IMP 以及如何相应地编程设备树。
您必须具有 sudo 权限才能运行此工具。
命令行选项
nvimp_util 的命令行选项分为两个主要类别:每头和每窗口。
必需的每头选项
选项名称 | 描述 | 值 |
--head <n> -h <n> | 指定头的物理显示 ID。所有其他每头选项都适用于此头。 | 整数 NVIDIA® Jetson AGX Xavier™ 系列: [0, 3] Jetson TX2 系列: [0, 2] |
--pclkMHz <fp> -p <fpK> | 头的像素时钟值,单位为兆赫兹。 | 浮点数 [0, MAX_FLOAT] |
--h_active <n> -a <n> | 水平活动栅格宽度,以像素为单位。 | 整数 [0, MAX_INT] |
--v_active <n> -b <n> | 垂直活动栅格高度,以行为单位。 | 整数 [0, MAX_INT] |
--h_blank <n> -A <n> | 总水平行消隐,以像素为单位。 | 整数 [0, MAX_INT] |
--v_blank <n> -B <n> | 总垂直消隐,以行为单位。 | 整数 [0, MAX_INT] |
可选的每头选项
选项名称 | 描述 | 值 |
--cursor_active <b> -C <b> | 指示头的硬件光标是否处于活动状态。 | 整数 零 (FALSE) 或非零 (TRUE)。 默认为 FALSE。 |
--output_lut_enable <b> -l <b> (小写 L) | 指示头的 OLUT(输出查找表)是否已启用。 | 整数 零 (FALSE) 或非零 (TRUE)。 默认为 FALSE。 |
--output_lut_size <n> -g <n> | 指定 OLUT 中的条目数。 仅当 output_lut_enable 为 TRUE 时才应指定。 | 整数 257 或 1025 无默认值。 |
必需的每窗口选项
注意 | 可以完全省略每窗口选项。如果存在 window 选项(可选,在下表中),则必须全部指定 “必需” 选项。 |
选项名称 | 描述 | 值 |
--sizeInX <n> -X <n> | 窗口的输入宽度,以像素为单位。 如果指定了 e,则为必需。 | 整数 [1, MAX_INT] |
--sizeInY <n> -y <n> | 如果指定了 "window",则为 NO 窗口的输入高度,以行为单位。 | 整数 [1, MAX_INT] |
--sizeOutX <n> -X <n> | 如果指定了 "window",则为 NO 窗口的输出宽度,以像素为单位。 | 整数 [1, h_active] |
--sizeOutY <n> -Y <n> | 如果指定了 "window",则为 NO 窗口的输出高度,以行为单位。 | 整数 [1, v_active] |
可选的每窗口选项
选项名称 | 描述 | 值 |
--window <n> -W <n> | 指定硬件窗口的物理 ID。 适用于相应的 “head” 参数,因为窗口始终由头拥有。 如果指定了任何其他每窗口选项,则为必需。所有其他每窗口选项都适用于此窗口。 | 整数 [0, 5] 无默认值。 |
--format <str> -f <str> | 窗口表面的输入颜色格式。 | 字符串 值必须是以下之一 • FORMAT_420_PLANAR_10_12_BIT • FORMAT_420_SEMI_PLANAR_10_12_BIT • FORMAT_422_SEMI_PLANAR_10_12_BIT • FORMAT_422R_SEMI_PLANAR_10_12_BIT • FORMAT_444_PLANAR_10_12_BIT • FORMAT_444_SEMI_PLANAR_10_12_BIT • FORMAT_1BPP_PACKED • FORMAT_2BPP_PACKED • FORMAT_4BPP_PACKED • FORMAT_8BPP_PACKED • FORMAT_420_PLANAR • FORMAT_420_SEMI_PLANAR • FORMAT_422_PACKED • FORMAT_422_SEMI_PLANAR • FORMAT_422R_SEMI_PLANAR • FORMAT_444_PLANAR • FORMAT_444_SEMI_PLANAR 默认为 FORMAT_4BPP_PACKED。 |
--surface <str> -g <str> | 描述窗口表面的内存布局。 | 字符串 值必须是以下之一 • PITCH • BLOCKLINEAR 默认为 PITCH。 |
--pointOutX <n> -i <n> | 活动栅格中窗口左上角的输出 X 坐标。 | 整数 [0, (h_active‒1)] 默认为 0。 |
--pointOutY <n> -J <n> | 活动栅格中窗口左上角的输出 Y 坐标。 | 整数 [0, (v_active‒1)] 默认为 0。 |
--pointInX <n> -i <n> | 表面提取偏移的输入 X 坐标;0 表示提取整个表面。 | 整数 [0, (sizeInX‒1)] 默认为 0。 |
--pointInY <n> -j <n> | 表面提取偏移的输入 Y 坐标;0 表示提取整个表面。 | 整数 [0, (sizeInY‒1)] 默认为 0。 |
--rotation <b> -r <b> | 指定是否为此窗口启用硬件 SCAN_COLUMN 旋转。 | 整数 零 (FALSE) 或非零 (TRUE)。 默认为 FALSE。 |
--compression <b> -z <b> | 指定是否对窗口的表面应用 CDE 压缩。 | 整数 零 (false) 或非零 (true)。默认为零。 适用于: 仅限 Jetson TX2 系列 |
其他选项
选项名称 | 描述 | 值 |
--help -H | 列出可用的命令行参数以及每个参数的简短描述。 | 不适用 |
--version -V | 显示 nvimp_util 的版本号。 |
多头/多窗口输入配置
nvimp_util 允许您指定包含多个活动显示头和/或窗口的输入配置。紧跟 ‑‑head 或 ‑‑window 选项之后的所有参数都适用于该头或窗口。
例如,假设您要指定具有以下头到窗口映射的输入配置
• HEAD0: WINDOW0, WINDOW1
• HEAD1: WINDOW2, WINDOW3
• HEAD2: WINDOW4, WINDOW5
nvimp_util 命令行将如下所示,其中 “...” 表示其他选项
# nvimp_util --head 0 --window 0 ... --window 1 ... \
--head 1 --window 2 ... --window 3 ... \
--head 2 --window 4 ... --window 5 ...
输出值
nvimp_util 输出由 IMP 计算的带宽值。必须将这些值编程到硬件中以支持提议的显示配置。
输出值可以分为三个类别:系统、每窗口和每光标。系统值适用于整个显示。每窗口值适用于特定窗口。每光标值适用于特定光标。
下表列出了输出值,并简要描述了每个值
系统输出值
值名称 | 描述 |
nvidia,total_disp_bw_with_catchup | 显示所需的总 ISO 带宽,包括补偿因子。 添加补偿因子作为裕量,以覆盖可能中断分配给显示的瞬时带宽的事件(例如,DVFS)。 |
nvidia,total_disp_bw_without_catchup | 显示所需的总 ISO 带宽,不 包括补偿因子。 |
nvidia,disp_emc_floor | 满足各种 MC 延迟允许约束所需的 EMC 底限。 |
nvidia,disp_min_hubclk | 所需的最小 hubclk 速率。hubclk 是 isohub 使用的主要接口时钟。Isohub 是从 DRAM 中提取表面、缓冲它们并将它们排入 nvdisplay 管道的硬件单元。 |
nvidia,total_win_fetch_slots | 分配给所有活动窗口的聚合提取槽数。将提取槽视为分配给窗口或光标管道以从 DRAM 中提取数据的时间槽。如下所述,每个窗口管道都分配有自己的提取槽数。 |
nvidia,total_cursor_fetch_slots | 分配给所有活动光标的聚合提取槽数。如下所述,每个单独的光标管道都分配有自己的提取槽数。 |
窗口输出值
值名称 | 描述 |
nvidia,win_fetch_meter_slots | 分配给每个活动窗口管道的提取槽数。 |
nvidia,win_dvfs_watermark_values | 指定每个活动窗口管道的 DVFS 水印值。如果当前缓冲量高于水印阈值,则显示硬件允许存储器控制器 (MC) 在必要时调度 DVFS 事件。 |
nvidia,win_pipe_meter_values | 必须在窗口预补偿侧应用的计量量。这有效地控制了像素从 isohub 流向预补偿的速度。一个无符号定点 (U8.8) 值。 |
nvidia,win_mempool_buffer_entries | 分配给窗口的 mempool 缓冲条目数。每个 mempool 条目宽 128 字节。 |
nvidia,win_thread_groups | 指定分配给窗口的线程组。每个线程组可能包含不同数量的线程。线程数控制支持哪些半平面/平面输入格式,以及硬件旋转是否可以与某些输入格式结合使用。 |
光标输出值
值名称 | 描述 |
nvidia,cursor_fetch_meter_slots | 分配给每个活动光标管道的提取槽数。 |
nvidia,cursor_dvfs_watermark_values | 指定每个活动光标管道的 DVFS 水印值。如果当前缓冲量高于水印阈值,则显示硬件允许存储器控制器 (MC) 在必要时调度 DVFS 事件。 |
nvidia,cursor_pipe_meter_values | 必须在窗口预补偿侧应用的计量量。这有效地控制了像素从 isohub 流向预补偿的速度。一个无符号定点 (U8.8) 值。 |
nvidia,cursor_mempool_buffer_entries | 分配给光标的 mempool 缓冲条目数。每个 mempool 条目宽 128 字节。 |
设备树配置
nvimp_util 将上述输出值打印到控制台。然后必须将这些值编程到设备树中。Jetson 显示驱动程序在启动时从设备树读取值,并将它们编程到硬件中。
例如,假设您运行此 nvimp_util 命令
# nvimp_util -h 0 -p 100 -a 480 -b 640 -A 128 -B 505 -l 1 -g 257 -C 1 \
-W 1 -f FORMAT_4BPP_PACKED -s BLOCKLINEAR -x 640 -y 480 -X 640 -Y 480 -i 0 -j 0 -I 0 -J 0 -r 1 -z 1 \
-h 2 -p 74.25 -a 1280 -b 720 -A 370 -B 30 -l 1 -g 257 -C 1 \
-W 5 -f FORMAT_4BPP_PACKED -s BLOCKLINEAR -x 1280 -y 720 -X 1280 -Y 720 -i 0 -j 0 -I 0 -J 0 -r 0 -z 1 \
-W 2 -f FORMAT_1BPP_PACKED -s BLOCKLINEAR -x 1280 -y 720 -X 1280 -Y 720 -i 0 -j 0 -I 0 -J 0 -r 1 -z 0
程序显示此输出
输入参数
头: 0
pclkMHz: 100
h_active: 480
v_active: 640
h_blank: 128
v_blank: 505
output_lut_enable: 1
output_lut_size: 257
cursor_active: 1
窗口: 1
color_format: FORMAT_4BPP_PACKED
surface_format: BLOCKLINEAR
sizeInX: 640
sizeInY: 480
sizeOutX: 640
sizeOutY: 480
pointInX: 0
pointInY: 0
pointOutX: 0
pointOutY: 0
rotation: 1
compression: 1
头: 2
pclkMHz: 74.25
h_active: 1280
v_active: 720
h_blank: 370
v_blank: 30
output_lut_enable: 1
output_lut_size: 257
cursor_active: 1
窗口: 5
color_format: FORMAT_4BPP_PACKED
surface_format: BLOCKLINEAR
sizeInX: 1280
sizeInY: 720
sizeOutX: 1280
sizeOutY: 720
pointInX: 0
pointInY: 0
pointOutX: 0
pointOutY: 0
rotation: 0
compression: 1
窗口: 2
color_format: FORMAT_1BPP_PACKED
surface_format: BLOCKLINEAR
sizeInX: 1280
sizeInY: 720
sizeOutX: 1280
sizeOutY: 720
pointInX: 0
pointInY: 0
pointOutX: 0
pointOutY: 0
rotation: 1
compression: 0
*******输入参数解析完成*******
窗口数 = 3
窗口 1 连接到头 0
窗口 5 连接到头 2
窗口 2 连接到头 2
光标数 = 2
光标 0 连接到头 0
光标 1 连接到头 2
头数 = 2
请求的模式是可能的!
在设备树中添加以下值
/* 全局设置 */
nvidia,total_disp_bw_with_catchup = <0 1497231>;
nvidia,total_disp_bw_without_catchup = <0 1361119>;
nvidia,disp_emc_floor = <0 102000000>;
nvidia,disp_min_hubclk = <0 28073088>;
nvidia,total_win_fetch_slots = /bits/ 16 <15>;
nvidia,total_cursor_fetch_slots = /bits/ 16 <8>;
/* 窗口设置 */
nvidia,imp_win_mapping = /bits/ 8 <1 5 2 >;
nvidia,win_fetch_meter_slots = /bits/ 16 <15 8 2 >;
nvidia,win_dvfs_watermark_values = <0 28274 0 16893 0 26794 >;
nvidia,win_pipe_meter_values = <256 256 256 >;
nvidia,win_mempool_buffer_entries = <0 2399 0 1269 0 280 >;
nvidia,win_thread_groups = /bits/ 8 <-1 -1 0 >;
/* 光标设置 */
nvidia,imp_head_mapping = /bits/ 8 <0 2 >;
nvidia,cursor_fetch_meter_slots = /bits/ 16 <15 5 >;
nvidia,cursor_dvfs_watermark_values = <0 9135 0 2762 >;
nvidia,cursor_pipe_meter_values = <256 256 >;
nvidia,cursor_mempool_buffer_entries = <0 798 0 241 >;
注意 | 尽管 nvimp_util 输出显示了压缩值,但该设置未在 T194 平台上实现,并且会被忽略。 |
上面 “全局设置”、“窗口设置” 和 “光标设置” 部分中显示的值必须复制到设备树。涉及两组节点
• /host1x/disp_imp_table
此节点包含已针对某些配置计算的 IMP 设置组。
num_settings 属性指定节点中包含的 IMP 设置组的数量。
• /host1x/disp_imp_table/disp_imp_settings_<n>
这是一组节点;<n> 是一个数字,对应于每个节点在 /host1x/disp_imp_table 下出现的顺序。也就是说,<n> 对于第一个节点为 0,对于第二个节点为 1,依此类推。
每个 disp_imp_settings_<n> 节点都包含必须为特定输入配置编程的 IMP 输出设置。设备树属性名称与 nvimp_util 写入控制台的相应参数名称相同。
窗口和光标设备树属性各自指定一个值数组(每个窗口或每个光标一个值)。使用 nvidia,imp_win_mapping 和 nvidia,imp_head_mapping 属性显式指定节点适用于哪个窗口或哪些光标。
以下设备树属性对 64 位数字进行操作
• nvidia,total_disp_bw_with_catchup
• nvidia,total_disp_bw_without_catchup
• nvidia,disp_emc_floor
• nvidia,disp_min_hubclk
• nvidia,win_dvfs_watermark_values
• nvidia,win_mempool_buffer_entries
• nvidia,cursor_dvfs_watermark_values
• nvidia,cursor_mempool_buffer_entries
您可以使用两种简单的方法将值复制到设备树
• 直接编辑 SOC 级别的 IMP 设备树设置。
• Jetson AGX Xavier 系列: SOC 级别的 IMP 设备树源文件可能位于
$TOP/hardware/nvidia/soc/t19x/kernel-dts/tegra194-soc/tegra194-soc-disp-imp.dtsi
• Jetson TX2 系列: 源文件可能位于
$TOP/hardware/nvidia/soc/t18x/kernel-dts/tegra186-soc/tegra186-soc-disp-imp.dtsi
要复制您的值,请删除或注释掉现有的 disp_imp_table 节点并添加您自己的节点。
• 创建您自己的 DTSI 片段,其中包含适当的 disp_imp_table 节点。
• Jetson AGX Xavier 系列: 将您的片段插入 tegra194-soc-base.dtsi。注释掉顶部用于通用 tegra194-soc-disp-imp.dtsi 文件的 #include。
• Jetson TX2 系列: 将您的片段插入 tegra186-soc-base.dtsi。注释掉顶部用于通用 tegra186-soc-disp-imp.dtsi 文件的 #include 文件。
这是上述示例对应的设备树条目的外观
/ {
host1x {
disp_imp_table: disp_imp_table {
status = "okay";
num_settings = <1>;
disp_imp_settings_0 {
/* 全局设置 */
nvidia,total_disp_bw_with_catchup = <0 1497231>;
nvidia,total_disp_bw_without_catchup = <0 1361119>;
nvidia,disp_emc_floor = <0 102000000>;
nvidia,disp_min_hubclk = <0 28073088>;
nvidia,total_win_fetch_slots = /bits/ 16 <15>;
nvidia,total_cursor_fetch_slots = /bits/ 16 <8>;
/* 窗口设置 */
nvidia,imp_win_mapping = /bits/ 8 <1 5 2 >;
nvidia,win_fetch_meter_slots = /bits/ 16 <15 8 2 >;
nvidia,win_dvfs_watermark_values = <0 28274 0 16893 0 26794 >;
nvidia,win_pipe_meter_values = <256 256 256 >;
nvidia,win_mempool_buffer_entries = <0 2399 0 1269 0 280 >;
nvidia,win_thread_groups = /bits/ 8 <-1 -1 0 >;
/* 光标设置 */
nvidia,imp_head_mapping = /bits/ 8 <0 2 >;
nvidia,cursor_fetch_meter_slots = /bits/ 16 <15 5 >;
nvidia,cursor_dvfs_watermark_values = <0 9135 0 2762 >;
nvidia,cursor_pipe_meter_values = <256 256 >;
nvidia,cursor_mempool_buffer_entries = <0 798 0 241 >;
};
};
};
};
更新 DTS 后,重新构建它并将新的 DTB blob 刷写到设备上。
DP 上的无缝显示 (通过 USB-C)
在当前版本中,Jetson AGX Xavier 系列的 DP 未启用无缝显示(引导加载程序进行的显示初始化)。
这是因为对于 DP,引导加载程序显示默认最多轮询 1 毫秒,以尝试检测接收器是否已断言 HPD。您可能连接到 Galen 上 Type-C 端口的不同 Type-C 下游设备(电缆、适配器、集线器等)可能会在触发通过 Type-C 驱动 DP 所需的握手过程之前产生不同的延迟量。延迟是不确定的,因此添加循环来轮询 HPD 状态可能会增加启动时间。DP 上已禁用无缝显示,以避免行为不一致。