安装 DGX 软件
本节要求您已在 DGX 服务器上安装了 CentOS 或衍生操作系统。
启用存储库
- 运行以下命令以安装 DGX 软件安装包并启用 NVIDIA DGX 软件存储库。注意:通过运行这些命令,您确认您已阅读并同意遵守 DGX 软件许可协议 的约束。您还确认您理解您选择在 DGX 中安装的任何预发布软件和材料可能无法完全运行,可能包含错误或设计缺陷,并且可能具有相对于 NVIDIA 软件和材料商业版本的降低或不同的安全性、隐私性、可用性和可靠性标准,并且您自行承担使用预发布版本的风险。安装用于 Red Hat Enterprise Linux 的 NVIDIA DGX 软件包。
$ sudo yum install -y https://international.download.nvidia.com/dgx/repos/rhel-files/dgx-repo-setup-21.11-1.el7.x86_64.rpm
接下来的步骤描述了如何启用新的驱动程序分支存储库。可以通过较新的驱动程序分支存储库提供其他各种软件包的较新版本。例如,启用 rhel7-updates 将使 2.8.3 成为可用的最高 NCCL 版本,并且之后启用 rhel7-r450-cuda11-0 会将最高 NCCL 版本提升至 2.11.4。
- 启用 R450/CUDA 11.0 存储库以迁移到 R450 软件包。
DGX A100 和 DGX Station A100 需要此步骤,但对于其他 DGX 平台是可选的。
- 编辑 /etc/yum.repos.d/nvidia-dgx-7.repo 并设置 enabled=1,
[nvidia-dgx-7-r450-cuda11-0] name=NVIDIA DGX EL7 R450-CUDA11-0 baseurl=https://international.download.nvidia.com/dgx/repos/rhel7-r450-cuda11-0/ enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-dgx-cosmos-support
- 或者(如果您已安装 yum-utils 软件包),请发出以下命令。
sudo yum-config-manager --enable nvidia-dgx-7-r450-cuda11-0
- 编辑 /etc/yum.repos.d/nvidia-dgx-7.repo 并设置 enabled=1,
- (可选)启用 R470/CUDA 11.4 存储库以迁移到 R470 软件包。
如果您从 R418 存储库迁移,请先启用上一步中描述的 R450 存储库。
- 编辑 /etc/yum.repos.d/nvidia-dgx-7.repo 并设置 enabled=1,
[nvidia-dgx-7-r470-cuda11-4] name=NVIDIA DGX EL7 R470-CUDA11-4 baseurl=https://international.download.nvidia.com/dgx/repos/rhel7-r470-cuda11-4/ enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-dgx-cosmos-support
- 或者(如果您已安装 yum-utils 软件包),请发出以下命令。
sudo yum-config-manager --enable nvidia-dgx-7-r470-cuda11-4
如果构建 CUDA 11.4 示例,请安装大于或等于 5.1.0 的 GCC 版本。例如,通过安装 Red Hat Developer Toolset 9 来安装 GCC 9.1.1sudo yum install -y devtoolset-9
在本示例中,使用以下命令代替“make”命令来构建 CUDA 示例scl enable devtoolset-9 make
- 编辑 /etc/yum.repos.d/nvidia-dgx-7.repo 并设置 enabled=1,
安装必需组件
安装 DGX 工具并更新配置文件
- 安装内核开发工具。
- 安装 kernel-devel 软件包。
kernel-devel 软件包提供 NVIDIA CUDA 驱动程序所需的内核头文件。使用以下命令为系统上当前运行的内核版本安装内核头文件。
sudo yum install -y "kernel-devel-uname-r == $(uname -r)"
- 确保您已安装最新版本的 gcc,因为旧版本可能不支持构建驱动程序所需的所有功能。
sudo yum install -y gcc
- 安装 kernel-devel 软件包。
- 安装 DGX 工具和配置文件。
- 对于 DGX-1,安装 DGX-1 配置。
sudo yum group install -y 'DGX-1 Configurations'
- 对于 DGX-2,安装 DGX-2 配置。
sudo yum group install -y 'DGX-2 Configurations'
- 对于 DGX A100,安装 DGX A100 配置。
sudo yum group install -y 'DGX A100 Configurations'
- 对于 DGX Station,安装 DGX Station 配置。
sudo yum group install -y 'DGX Station Configurations'
- 对于 DGX Station A100,安装 DGX Station A100 配置。
sudo yum group install -y 'DGX Station A100 Configurations'
配置更改仅在系统重启后生效,这将在下一步中介绍。
- 对于 DGX-1,安装 DGX-1 配置。
- 更新内核。
- 发出以下命令。
$ sudo yum update
执行此更新还会将已安装的 Red Hat Enterprise Linux 7 发行版更新到最新版本。要检查最新的 Red Hat Enterprise Linux 7 版本,请访问 https://access.redhat.com/articles/3078。 - 将服务器重启到更新后的内核。
$ sudo reboot
- 发出以下命令。
配置 /raid 分区
将 /raid 分区配置为 NFS 缓存
- 配置 RAID 阵列。
这将创建 RAID 组,将其挂载到 /raid,并在 /etc/fstab 中创建适当的条目。
- 要配置 RAID 0 阵列,请发出以下命令
sudo configure_raid_array.py -c -f
- 要配置 RAID 5 阵列,请发出以下命令
sudo configure_raid_array.py -c -5 -f
注意必须在安装 dgx-conf-cachefilesd 之前配置 RAID 阵列,这将把正确的 SELinux 标签放在 /raid 目录上。如果您需要重新创建 RAID 阵列 - 这将清除 /raid 上的任何标签 - 在已安装 dgx-conf-cachefilesd 之后,请务必在重新启动 cachefilesd 之前手动恢复标签。
sudo restorecon /raid sudo systemctl restart cachefilesd
- 要配置 RAID 0 阵列,请发出以下命令
- 安装 dgx-conf-cachefilesd 以更新 cachefilesd 配置以使用 /raid 分区。
sudo yum install -y dgx-conf-cachefilesd
将 /raid 分区配置为本地持久存储
如果您在 DGX Station 中使用数据 SSD 进行本地持久存储,请将这些 SSD 配置为 RAID 0 或 RAID 5 阵列,并挂载到 /raid。
RAID 0 提供最大的存储容量,但不提供任何冗余。如果阵列中的单个 SSD 发生故障,则阵列上存储的所有数据都将丢失。RAID 5 提供一定程度的保护,防止单个 SSD 发生故障,但存储容量低于 RAID 0。
-
要配置 RAID 0 阵列,请运行以下命令。
sudo configure_raid_array.py -c -f
-
要配置 RAID 5 阵列,请运行以下命令。
sudo configure_raid_array.py -c -f -5
这些命令将创建 RAID 组,将其挂载到 /raid,并在 /etc/fstab 中创建适当的条目。
安装和加载 NVIDIA CUDA 驱动程序
- 安装驱动程序软件包。
这将构建并安装驱动程序内核模块。安装 dkms-nvidia 软件包可能需要大约五分钟。
sudo yum install -y cuda-drivers dgx-persistence-mode
- (仅限 DGX Station A100):安装其他必需的 Station A100 软件包。
这些软件包必须在安装 cuda-drivers 软件包后安装。
sudo yum install -y nvidia-conf-xconfig nv-docker-gpus
- 重启系统以加载驱动程序并更新系统配置。
sudo reboot
- 系统重启后,验证驱动程序是否已加载并正在处理 NVIDIA 设备。
nvidia-smi
输出应显示所有可用的 GPU。
示例:来自 DGX-1 系统的输出+-----------------------------------------------------------------------+ | NVIDIA-SMI 450.51.05 Driver Version: 450.51.05 CUDA Version: 11.0 | |----------------------------+-------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |============================+===================+======================| | 0 Tesla V100-SXM2... On | ...00:06:00.0 Off | 0 | | N/A 33C P0 45W / 300W | 0MiB / 32480MiB | 0% Default | +----------------------------+-------------------+----------------------+ | 1 Tesla V100-SXM2... On | ...00:07:00.0 Off | 0 | | N/A 35C P0 44W / 300W | 0MiB / 32480MiB | 0% Default | +----------------------------+-------------------+----------------------+ : : : : +----------------------------+-------------------+----------------------+ | 7 Tesla V100-SXM2... On | ...00:8A:00.0 Off | 0 | | N/A 34C P0 44W / 300W | 0MiB / 32480MiB | 0% Default | +----------------------------+-------------------+----------------------+ +-----------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=======================================================================| | No running processes found | +-----------------------------------------------------------------------+
安装 NVIDIA 容器运行时
- 从 centos-extras 存储库安装 Docker 1.13。
sudo yum install -y docker
- 安装 NVIDIA 容器运行时组。
sudo yum groupinstall -y 'NVIDIA Container Runtime'
- (仅限 DGX Station A100):重启 nv-docker-gpus 服务。
$ sudo systemctl restart nv-docker-gpus
- 运行以下命令以验证安装。
- 如果安装了 R418 驱动程序软件包
sudo docker run --security-opt label=type:nvidia_container_t --rm nvcr.io/nvidia/cuda:10.0-base nvidia-smi
- 如果安装了 R450 驱动程序软件包
sudo docker run --security-opt label=type:nvidia_container_t --rm nvcr.io/nvidia/cuda:11.0-base nvidia-smi
输出应显示所有可用的 GPU。
示例:DGX -1 系统上的输出
+-----------------------------------------------------------------------+ | NVIDIA-SMI 450.51.05 Driver Version: 450.51.05 CUDA Version: 11.0 | |----------------------------+-------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |============================+===================+======================| | 0 Tesla V100-SXM2... On | ...00:06:00.0 Off | 0 | | N/A 33C P0 45W / 300W | 0MiB / 32480MiB | 0% Default | +----------------------------+-------------------+----------------------+ | 1 Tesla V100-SXM2... On | ...00:07:00.0 Off | 0 | | N/A 35C P0 44W / 300W | 0MiB / 32480MiB | 0% Default | +----------------------------+-------------------+----------------------+ : : : : +----------------------------+-------------------+----------------------+ | 7 Tesla V100-SXM2... On | ...00:8A:00.0 Off | 0 | | N/A 34C P0 44W / 300W | 0MiB / 32480MiB | 0% Default | +----------------------------+-------------------+----------------------+ +-----------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=======================================================================| | No running processes found | +-----------------------------------------------------------------------+
- 如果安装了 R418 驱动程序软件包
安装诊断组件
- 安装 CentOS 软件集合存储库。
sudo yum install centos-release-scl
- 启用测试存储库。
- 如果您尚未安装 yum 实用程序,请安装它们。
sudo yum -y install yum-utils
- 使用 yum-config-manager 启用测试存储库。
sudo yum-config-manager –enable centos-sclo-rh-testing
- 如果您尚未安装 yum 实用程序,请安装它们。
- 安装 Python 3.6。
sudo yum install -y rh-python36
重要提示:NVIDIA DGX 系统的诊断组件 不支持 python3 软件包。请务必仅安装 rh-python36 软件包。 - 安装 DGX 系统管理软件包组。
sudo yum groupinstall -y 'DGX System Management'
在 DGX-2 或 DGX A100 上复制 EFI 系统分区
- 您正在 NVIDIA DGX-2 或 DGX A100 上安装 CentOS,并且
- 您已按照 在 DGX-2 上安装 或 在 DGX A100 上安装 部分中的说明在 RAID 1 阵列上安装了 CentOS。
- 启动 NVSM 工具。
sudo nvsm
- 导航到 /systems/localhost/storage/volumes/md0。
nvsm-> cd /systems/localhost/storage/volumes/md0
- 启动重建过程。
nvsm(/systems/localhost/storage/volumes/md0)-> start rebuild
- 在第一个提示符处,指定第二个 M.2 磁盘。
PROMPT: In order to rebuild this volume, a spare drive is required. Please specify the spare drive to use to rebuild md0. Name of spare drive for md0 rebuild (CTRL-C to cancel): nvme1n1
这应该是您未在其上安装 ESP 的 M.2 磁盘。- 如果您按照 在 DGX-2 上安装 部分中的说明操作,则应为 'nvme1n1'
- 如果您按照 在 DGX A100 上安装 部分中的说明操作,则应为 'nvme2n1'
- 在第二个提示符处,确认您要继续。
WARNING: Once the volume rebuild process is started, the process cannot be stopped. Start RAID-1 rebuild on md0? [y/n] y
成功完成后,应显示以下消息,指示 ESP 已被复制/systems/localhost/storage/volumes/md0/rebuild started at 2019-03-07 14:40:55.844542 RAID-1 rebuild exit status: ESP_REBUILT
如果需要,RAID 1 阵列将在 ESP 复制后重建。Finished rebuilding RAID-1 on volume md0 100.0% [=========================================] Status: Done
- 在第一个提示符处,指定第二个 M.2 磁盘。
安装可选组件
- 安装 CUDA 工具包。
sudo yum install cuda
- 安装 NVIDIA Collectives Communication Library (NCCL) 运行时。
sudo yum groupinstall 'NVIDIA Collectives Communication Library Runtime'
- 安装 CUDA Deep Neural Networks (cuDNN) 库运行时。
sudo yum groupinstall 'CUDA Deep Neural Networks Library Runtime'
- 安装 NVIDIA TensorRT。
sudo yum install tensorrt
将 NVIDIA 外观应用于桌面用户界面
- 安装 DGX 桌面主题 软件包组。
sudo yum groupinstall -y 'DGX Desktop Theme'
- 启动 gnome-tweaks。
- 在打开的 外观 窗口中,在 微调 下,单击 扩展。
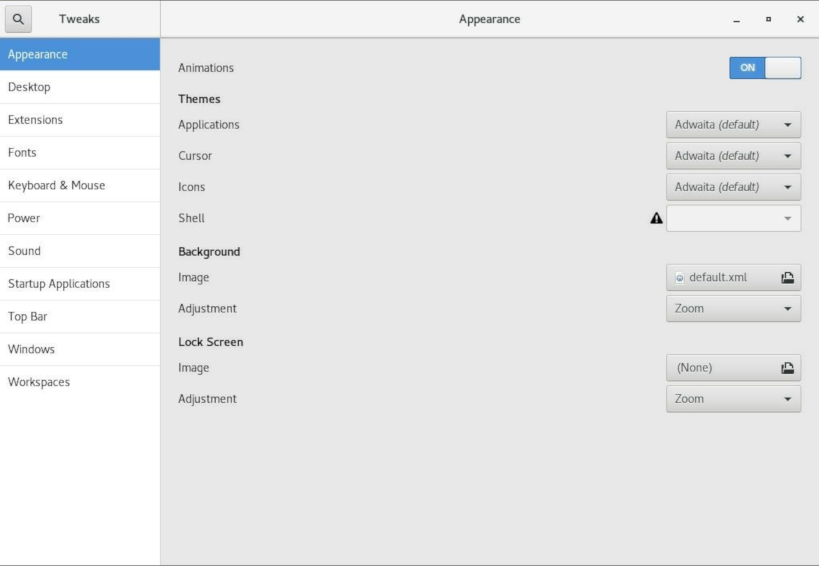
- 在打开的 扩展 窗口中,将标题栏中的 扩展 和 用户主题 设置为 开启。
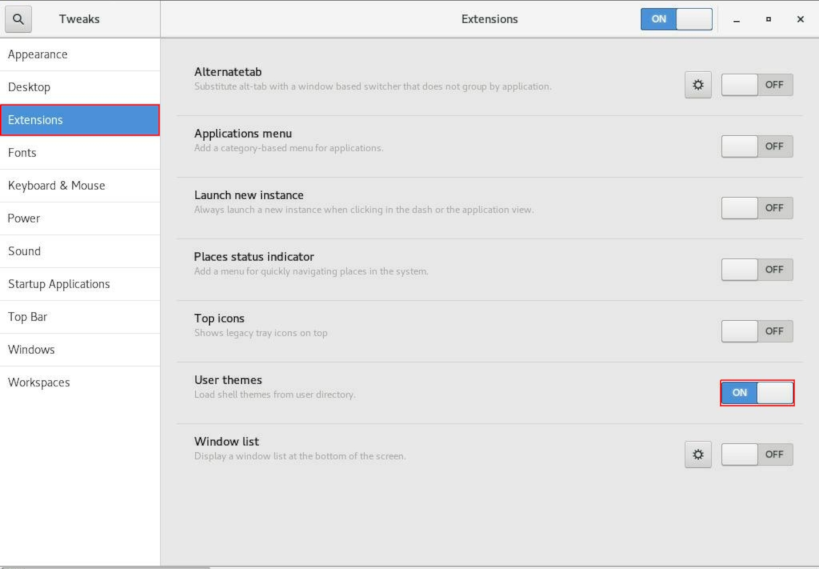
- 停止并重新启动 gnome-tweaks。
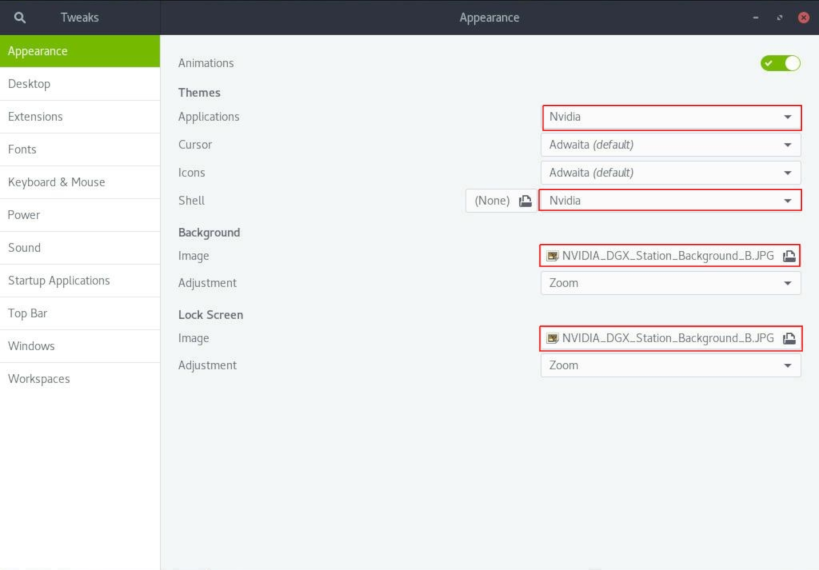
- 在打开的 外观 窗口中,将 NVIDIA 主题应用于应用程序和 shell,并使用 NVIDIA 图像作为桌面背景和锁屏界面。
- 在 主题 下,在 应用程序 和 Shell 的下拉列表中,单击 Nvidia。
- 在 背景 和 锁屏界面 下,单击 图像 文件选择器。
- 在打开的 图像 窗口中,选择 NVIDIA DGX Station 背景图像,例如 NVIDIA_DGX_Station_Background_B.JPG,然后单击 打开。
管理 CPU 缓解措施
用于 CentOS 的 DGX 软件 包括安全更新,以缓解 CPU 推测性侧信道漏洞。这些缓解措施可能会降低深度学习和机器学习工作负载的性能。
如果您的 DGX 系统安装包含其他缓解这些漏洞的措施(例如集群级别的措施),您可以禁用单个 DGX 节点的 CPU 缓解措施,从而提高性能。此功能从 用于 CentOS 的 DGX 软件软件版本 EL7-20.02 开始提供。
确定 DGX 系统的 CPU 缓解状态
如果您不知道是否启用了或禁用了 CPU 缓解措施,请发出以下命令。
$ cat /sys/devices/system/cpu/vulnerabilities/*
- 如果输出由多个以 Mitigation: 为前缀的行组成,则表示启用了 CPU 缓解措施。
示例
KVM: Mitigation: Split huge pages Mitigation: PTE Inversion; VMX: conditional cache flushes, SMT vulnerable Mitigation: Clear CPU buffers; SMT vulnerable Mitigation: PTI Mitigation: Speculative Store Bypass disabled via prctl and seccomp Mitigation: usercopy/swapgs barriers and __user pointer sanitization Mitigation: Full generic retpoline, IBPB: conditional, IBRS_FW, STIBP: conditional, RSB filling Mitigation: Clear CPU buffers; SMT vulnerable
- 如果输出由多个以 Vulnerable 为前缀的行组成,则表示禁用了 CPU 缓解措施。
示例
KVM: Vulnerable Mitigation: PTE Inversion; VMX: vulnerable Vulnerable; SMT vulnerable Vulnerable Vulnerable Vulnerable: __user pointer sanitization and usercopy barriers only; no swapgs barriers Vulnerable, IBPB: disabled, STIBP: disabled Vulnerable
禁用 CPU 缓解措施
- 应用 dgx*-no-mitigations 配置文件。
- 在 DGX-2 系统上,发出
$ sudo tuned-adm profile dgx2-no-mitigations
- 在 DGX-1 系统上,发出
$ sudo tuned-adm profile dgx-no-mitigations
- 在 DGX Station 工作站上,发出
$ sudo tuned-adm profile dgxstation-no-mitigations
- 在 DGX-2 系统上,发出
- 重启系统。
- 验证 CPU 缓解措施是否已禁用。
$ cat /sys/devices/system/cpu/vulnerabilities/*
输出应包括多个 Vulnerable 行。有关示例输出,请参阅 确定 DGX 系统的 CPU 缓解状态。
重新启用 CPU 缓解措施
- 应用 dgx*-performance 软件包。
- 在 DGX-2 系统上,发出
$ sudo tuned-adm profile dgx2-performance
- 在 DGX-1 系统上,发出
$ sudo tuned-adm profile dgx-performance
- 在 DGX Station 工作站上,发出
$ sudo tuned-adm profile dgxstation-performance
- 在 DGX-2 系统上,发出
- 重启系统。
- 验证 CPU 缓解措施是否已启用。
$ cat /sys/devices/system/cpu/vulnerabilities/*
输出应包括多个 Mitigations 行。有关示例输出,请参阅 确定 DGX 系统的 CPU 缓解状态。