监控
能够监控您的系统是管理它们的第一步。NVIDIA 提供了一些非常有用的命令行工具,可以专门用于监控 GPU。
DCGM
- 主动健康监控
- 诊断
- 系统验证
- 策略
- 电源和时钟管理
- 组配置和记帐
DCGM 工具包附带用户指南,其中解释了如何使用名为 dcgmi 的命令行工具,以及 API 指南(DCGM 没有 GUI)。除了命令行工具外,DCGM 还附带用于在 Python 或 C 中编写自己的工具的头文件和库。
DCGM 不会将每个 GPU 视为单独的资源,而是允许您将它们分组,然后将策略或调优选项应用于该组。这还包括能够对该组运行诊断。
将 DCGM 与 DGX 设备结合使用有几个最佳实践。首先是命令行工具可以对 GPU 运行诊断。您可以在 DGX 上创建一个简单的 cron 作业来检查 GPU,并将结果存储到简单的平面文件或简单的数据库中。
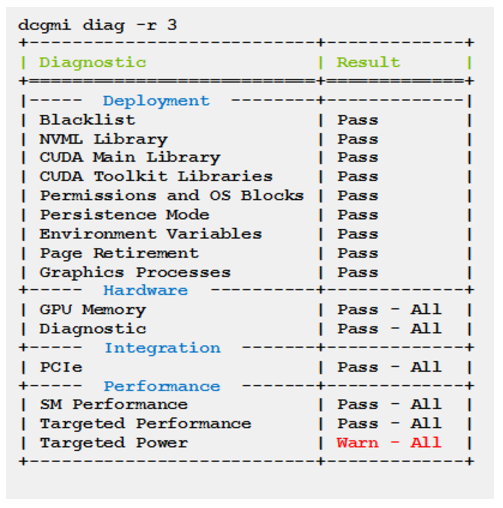
解析此输出以查找输出中的错误非常容易。如果发现错误,您可以轻松发送电子邮件或发出其他警报。
利用 DCGM 的第二个最佳实践是,如果您安装了资源管理器(换句话说,作业调度器)。在用户作业运行之前,资源管理器通常可以执行所谓的序言。也就是说,在用户作业执行之前的任何系统调用。这是一个运行快速诊断的好地方,也可以使用 DCGM 开始收集有关作业的统计信息。下面是特定作业的统计信息收集示例
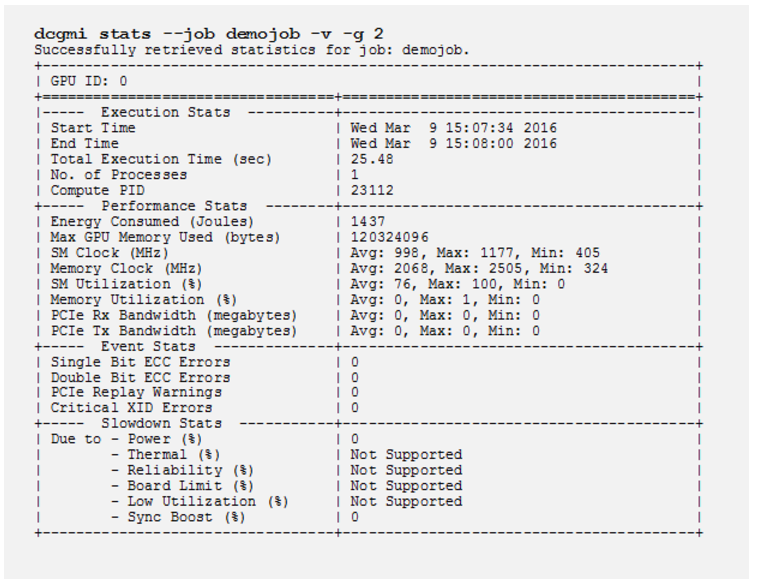
当用户作业完成时,资源管理器可以运行称为尾声的操作。系统可以在此处运行一些系统调用,以执行诸如清理环境或总结运行结果(包括来自上述命令的 GPU 统计信息)之类的操作。请查阅用户指南以了解有关 DCGM 统计信息的更多信息。
如果您创建一组运行诊断的序言和尾声脚本,您可能需要考虑将结果存储在平面文件或简单数据库中。这使您可以保留 GPU 诊断的历史记录,以便您可以查明任何问题(如果有)。
有效使用 DCGM 的第三种方法是将其与 并行 shell 工具(例如 pdsh)结合使用。使用并行 shell,您可以在集群中的所有节点或节点的特定子集上运行相同的命令。您可以使用它来运行 dcgmi,以跨多个 DGX 设备或 DGX 设备和非 GPU 启用系统的组合运行诊断。您可以轻松捕获此输出并将其存储在平面文件或数据库中。然后,您可以解析输出并根据输出创建警告或电子邮件。
拥有所有这些诊断输出也是创建有关利用率等主题的报告的绝佳信息来源。
有关 DCGM 的更多信息,请参阅 NVIDIA 数据中心 GPU 管理器简化集群管理。
使用 nvidia-smi 监控特定 DGX
如前所述,DCGM 是跨多个节点监控 GPU 的绝佳工具。有时,系统管理员可能希望实时监控特定的 DGX 系统。一种简单的方法是登录到 DGX 并结合 watch 命令运行 nvidia-smi。
例如,您可以运行命令 watch -n 1 nvidia-smi,该命令每秒运行一次 nvidia-smi 命令(-n 1 表示以 1 秒间隔运行命令)。您还可以向 watch 添加 -d 选项,以便突出显示自上次运行以来发生的更改或差异。这使您可以轻松查看发生了哪些更改。
就像 ctop 一样,您可以在 tmux 终端的窗格中使用 nvidia-smi 和 watch 来监视相对少量的 DGX 服务器。