初始集群设置#
本文档详细介绍了如何在 NVIDIA DGX BasePOD™ 配置上部署 NVIDIA Base Command™ Manager (BCM)。
在部署 BCM 之前,必须完成物理安装和网络交换机配置。此外,有关预期部署的信息应记录在现场勘测中。
DGX BasePOD 的部署阶段包括使用 BCM 来配置和管理 Kubernetes 集群。
将 DGX 系统配置为默认从 PXE 启动。
使用 KVM 或崩溃车连接到 DGX 系统,进入 BIOS 菜单,并将启动选项 #1 配置为 [NETWORK]。
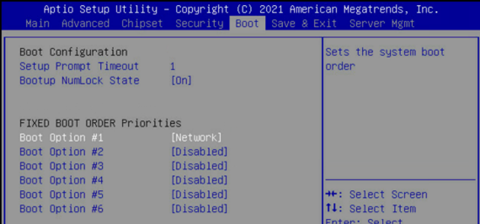
确保其他启动选项为 [Disabled],并导航到 UEFI NETWORK Drives BBS Priorities 菜单。
将启动选项 #1 和启动选项 #2 设置为对 Storage 4-2 和 Storage 5-2 使用 IPv4。
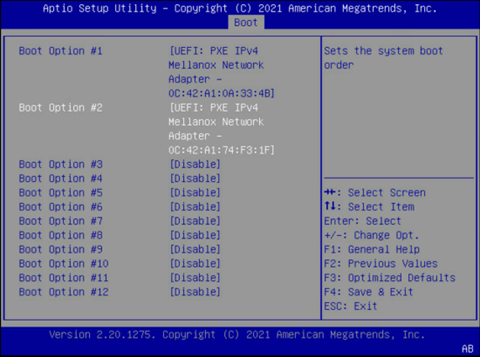
确保其他启动选项为 [Disabled]。
选择保存并退出。
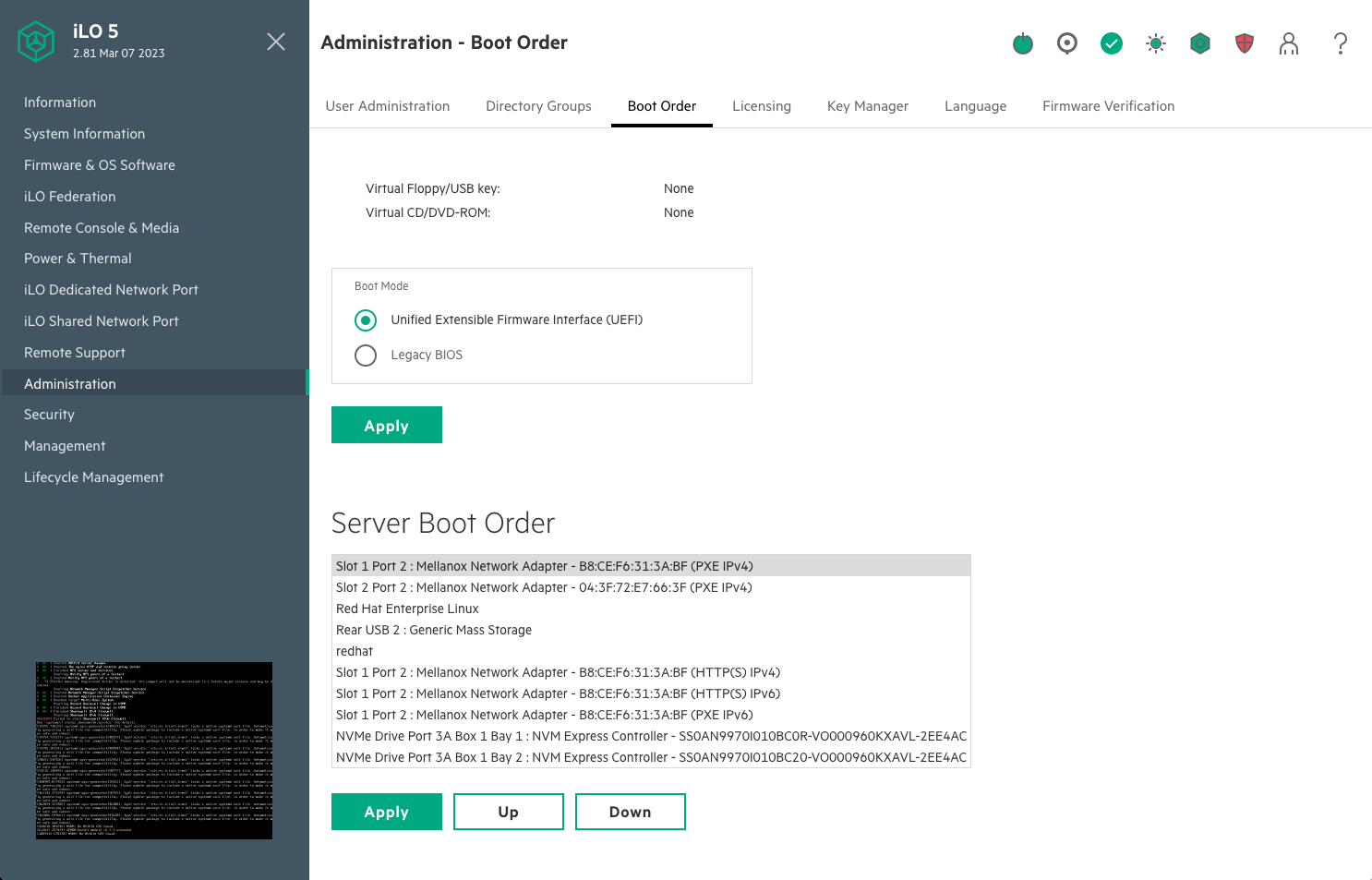
在故障转移头节点和管理节点上,确保网络启动配置为主要选项。确保连接到头节点和 CPU 节点上网络的 Mellanox 端口也设置为以太网模式。
这是一个将从网络启动的系统的示例,其中插槽 1 端口 2 和插槽 2 端口 2。
从 Bright 下载站点 下载 BCM ISO。选择 Base Command Manager 10、RHEL 9.2 并选中“Include NVIDIA CUDA Packages and MOFED packages”复选框。
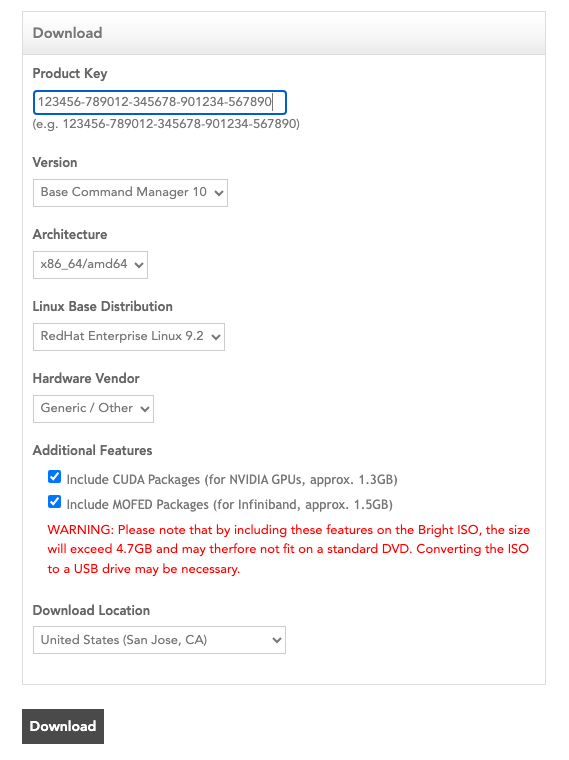
将 ISO 刻录到 DVD 或可启动 USB 设备。
它也可以作为虚拟介质挂载并使用 BMC 安装。后者的具体机制因供应商而异。
确保目标头节点的 BIOS 配置为 UEFI 模式,并且其启动顺序配置为启动包含 BCM 安装程序映像的介质。
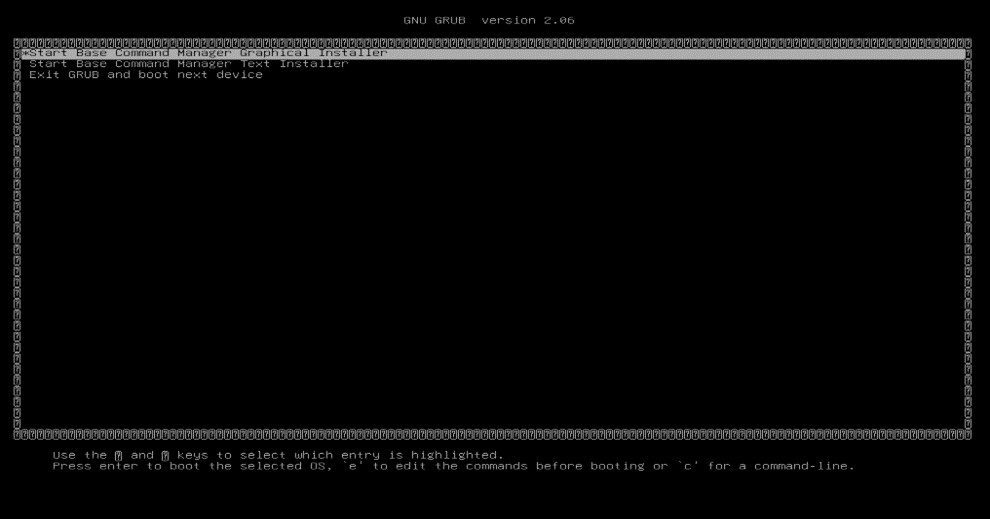
启动安装介质。
在 grub 菜单中,选择启动 Base Command Manager 图形安装程序。
在启动画面上选择开始安装。
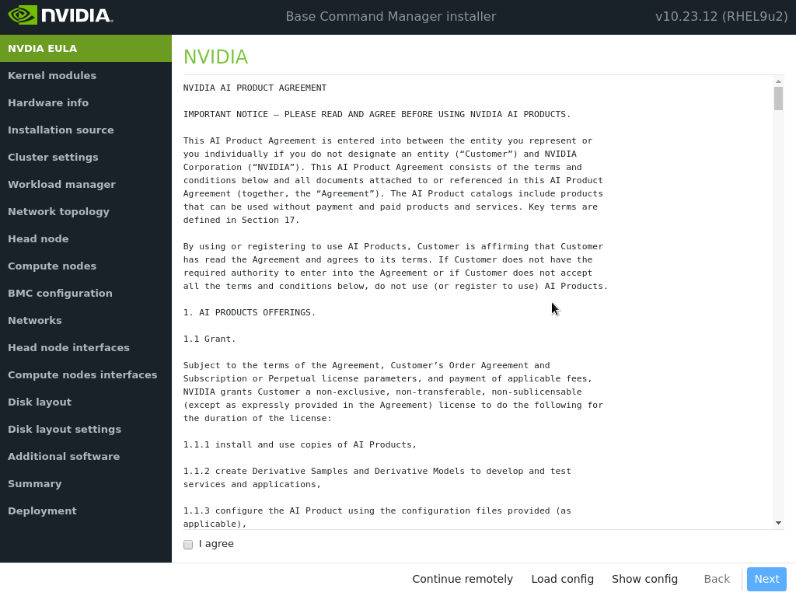
通过选中我同意,然后选择下一步,接受 NVIDIA EULA 的条款。
通过选中我同意,然后选择下一步,接受 Ubuntu Server UELA 的条款。
除非另有指示,否则选择下一步,无需修改启动时要加载的内核模块。
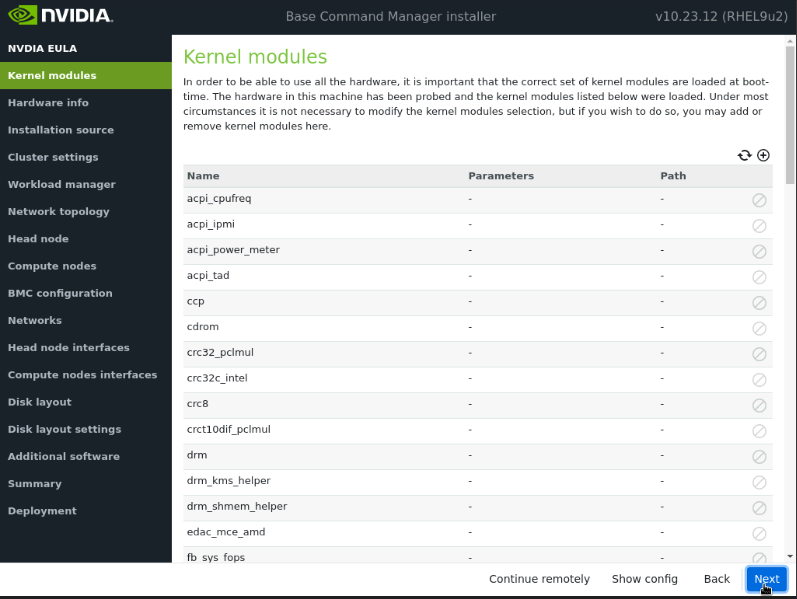
验证硬件信息是否正确,然后选择下一步。
例如,目标存储设备和已布线的主机网络接口存在(在本例中,三个 NVMe 驱动器是目标存储设备,ens1np0 和 ens2np01 是已布线的主机网络接口)。
在安装源屏幕上,选择合适的源,然后选择下一步。
运行介质完整性检查是可选的。
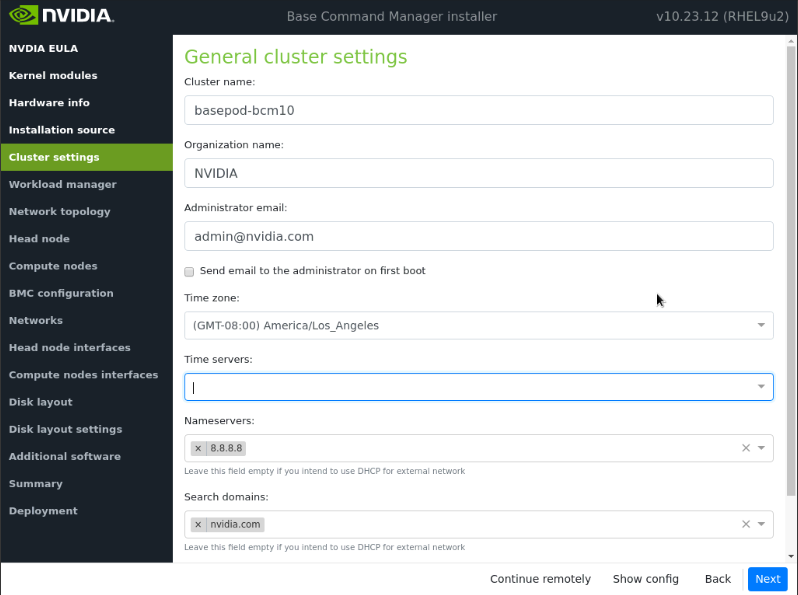
在集群设置屏幕上,输入所需信息,然后选择下一步。
在工作负载管理器屏幕上,选择“无”,然后选择下一步。

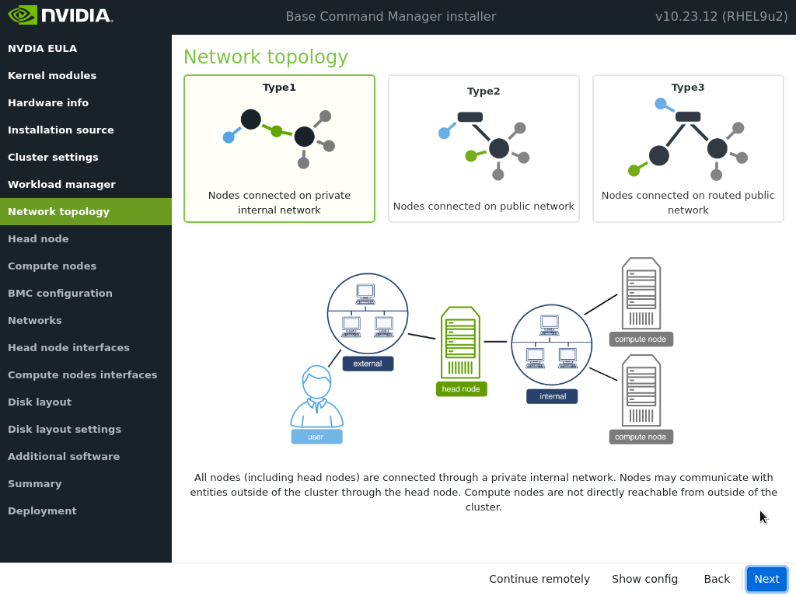
在网络拓扑屏幕上,为数据中心环境选择网络类型,然后选择下一步。
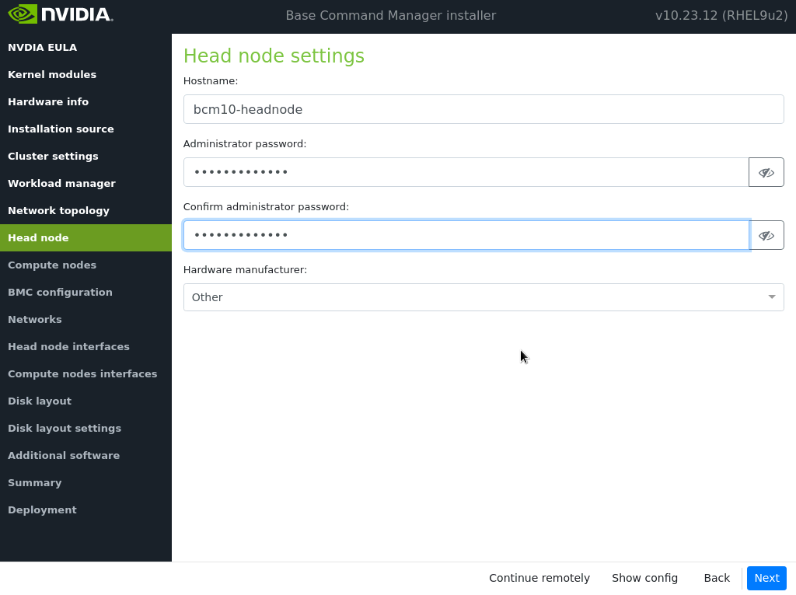
在头节点屏幕上,输入主机名、管理员密码,为硬件制造商选择“其他”,然后选择下一步。
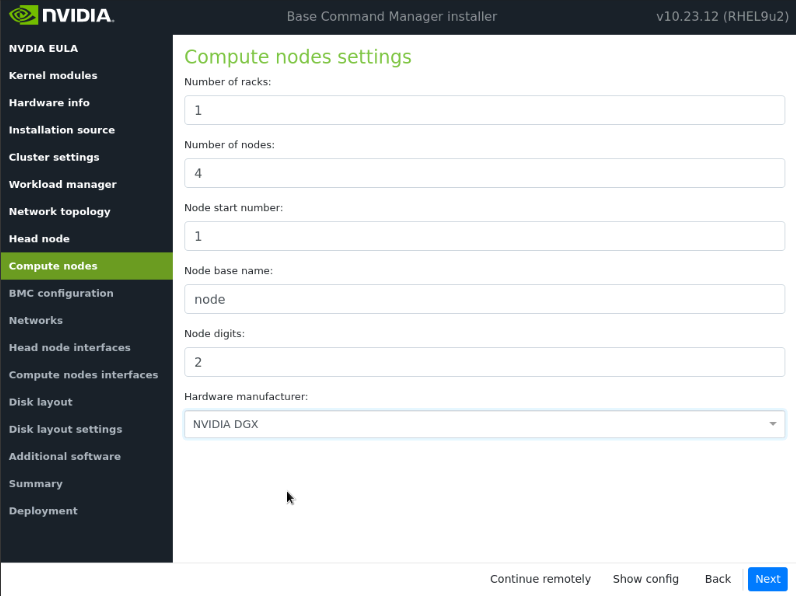
在“计算节点设置”中将节点位数调整为 2,然后选择下一步。
确保节点基本名称为 node。其他值将在安装后期更新。
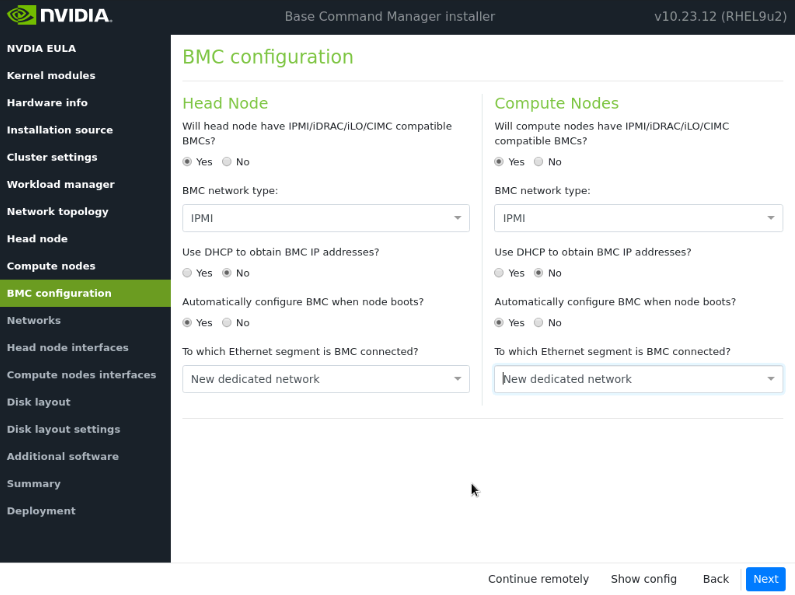
在 BMC 配置屏幕上,对于头节点和计算节点都选择是。按照下面的屏幕截图进行其余配置。然后选择下一步。
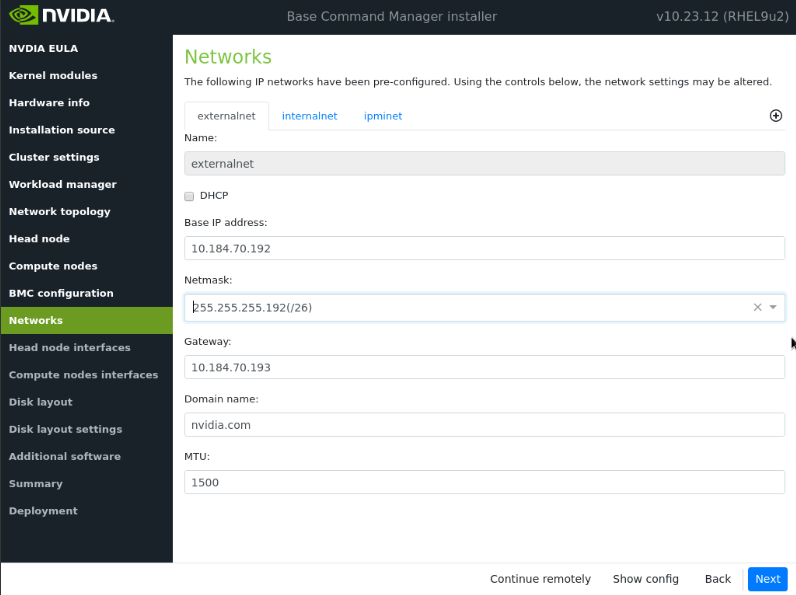
在“网络”屏幕上,输入 externalnet 的所需信息,然后选择下一步。
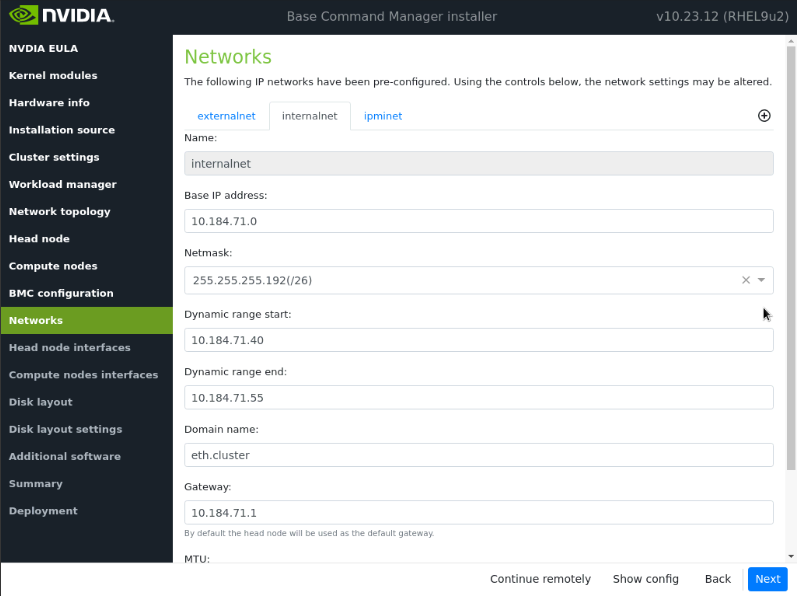
导航到 internalnet 选项卡,输入 internalnet 的所需信息,将 MTU 值保留为默认值,然后选择下一步。
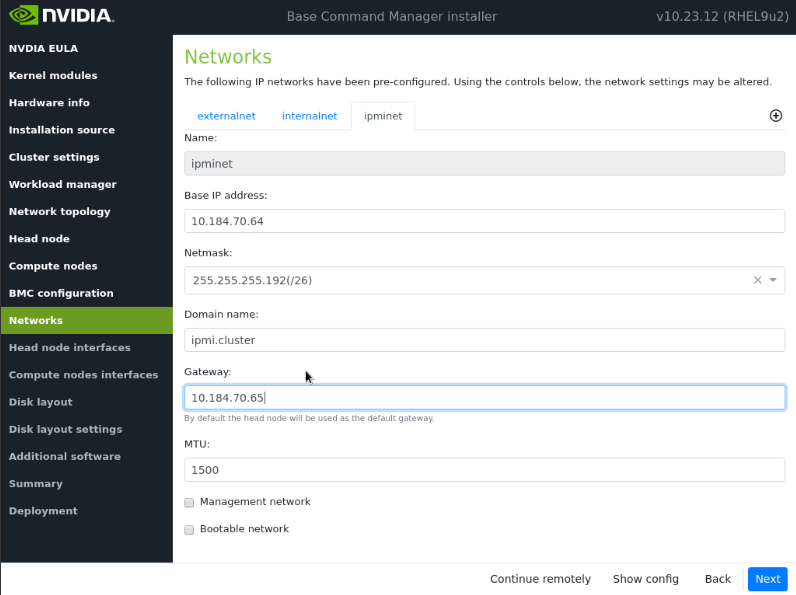
导航到 ipminet 选项卡,输入 ipminet 的所需信息,然后选择下一步。
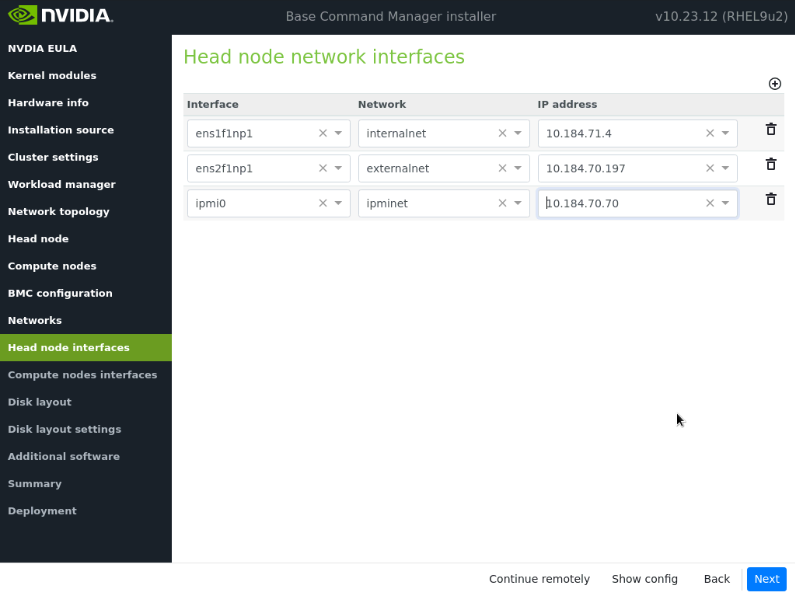
在“头节点接口”屏幕上,确保一个接口配置了头节点的目标 internalnet IP,然后选择下一步。
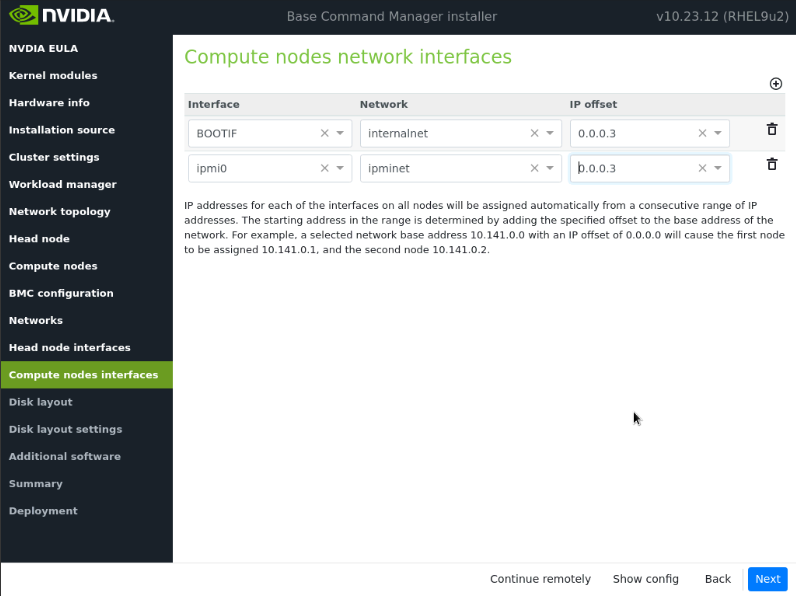
在计算节点接口屏幕上,将偏移量更改为 0.0.0.3,然后选择下一步。
这些将在安装后更新。
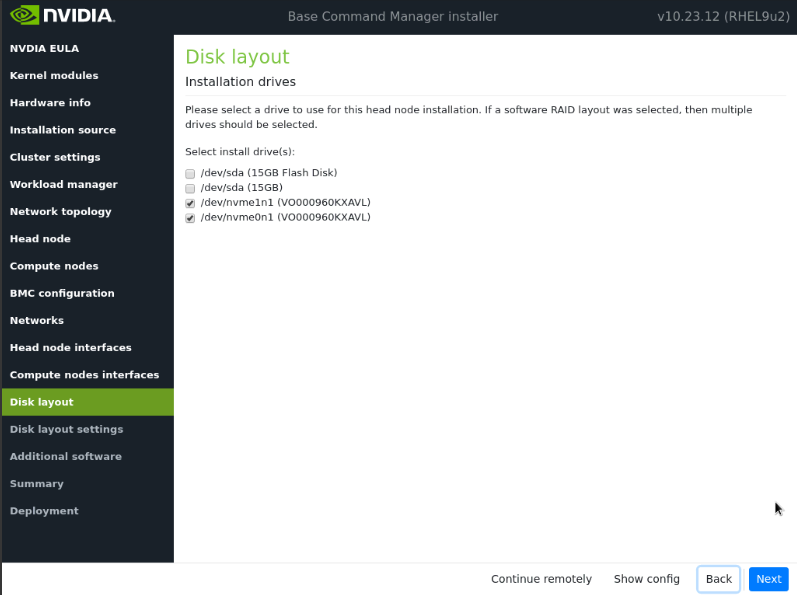
在磁盘布局屏幕上,选择目标安装位置,然后选择下一步。
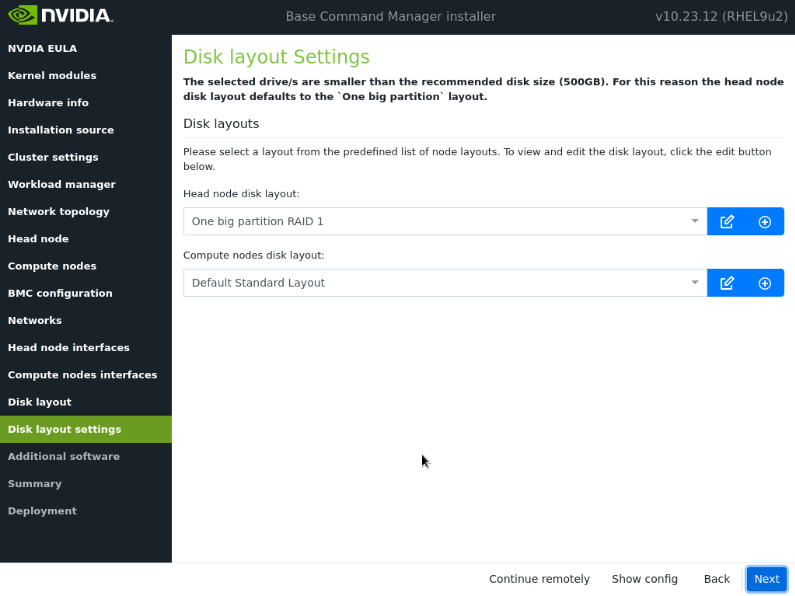
在磁盘布局设置屏幕上,为头节点选择一个大分区,为计算节点选择默认标准布局。然后选择下一步。
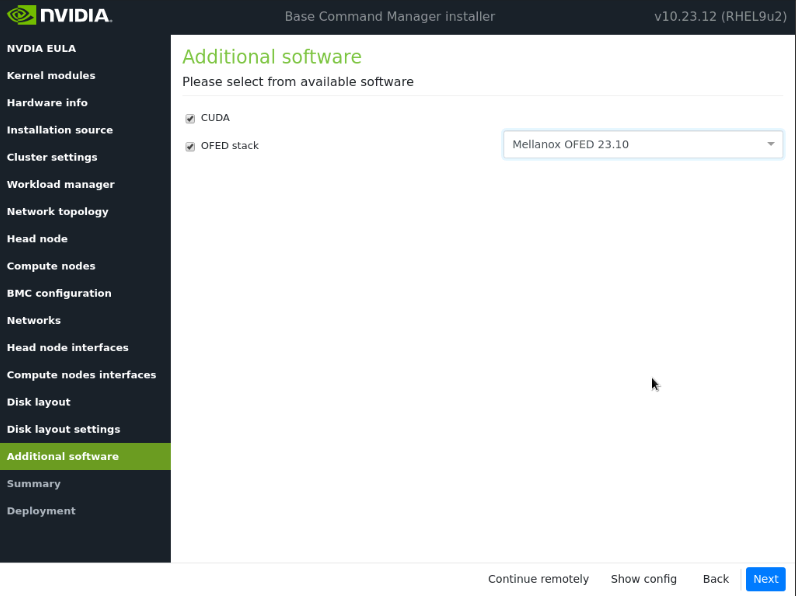
在附加软件屏幕中,选择 CUDA 和 MOFED 23.10,然后选择下一步。
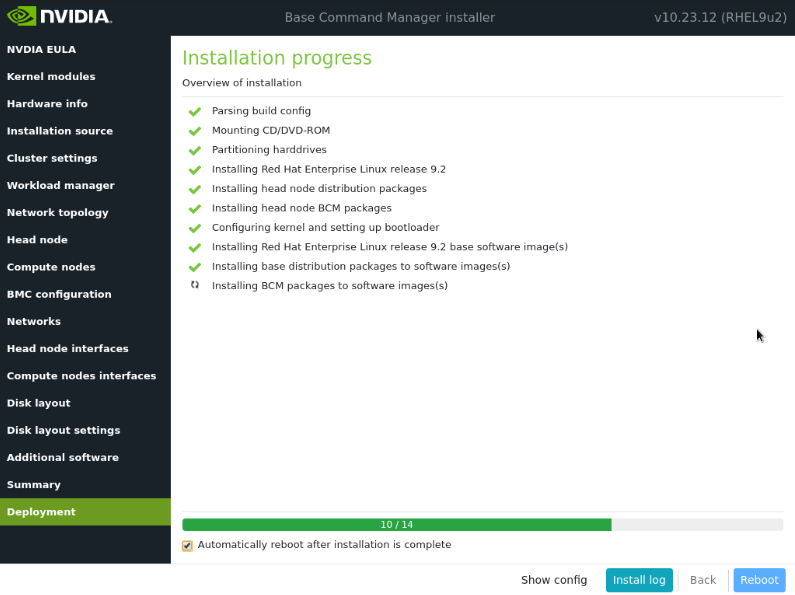
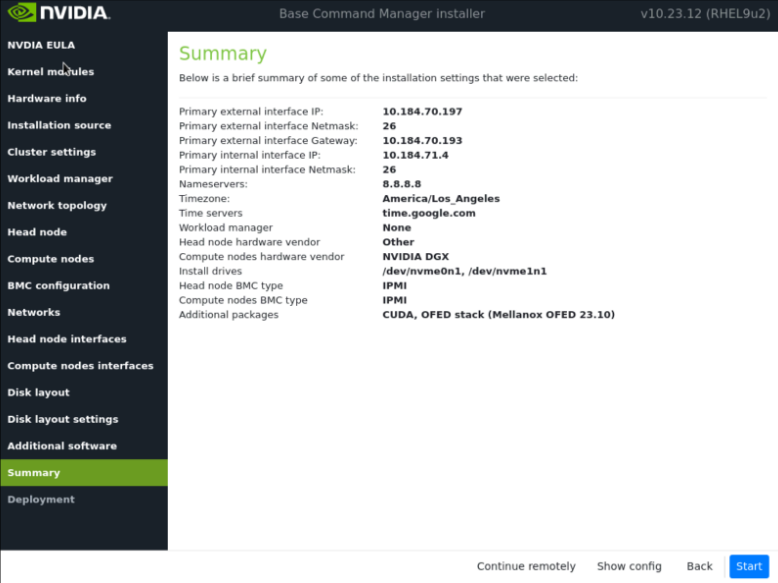
在摘要屏幕上确认信息,然后选择下一步。
摘要屏幕提供了在部署开始之前确认头节点和基本集群配置的机会。此配置将在部署完成后为 DGX BasePOD 更新/修改。如果值与预期不符,请使用“后退”按钮导航到相应的屏幕以纠正任何错误。
部署完成后,选择重启。