开始上手
概述
Transformer Engine (TE) 是一个用于加速 NVIDIA GPU 上 Transformer 模型的库,在训练和推理中提供更好的性能和更低的内存利用率。它为 Hopper GPU 上的 8 位浮点 (FP8) 精度提供支持,为流行的 Transformer 架构实现了一系列高度优化的构建块,并公开了一个类似自动混合精度的 API,可以与您的 PyTorch 代码无缝使用。它还包括一个与框架无关的 C++ API,可以与其他深度学习库集成,从而为 Transformer 启用 FP8 支持。
让我们构建一个 Transformer 层!
摘要
我们使用常规 PyTorch 模块构建一个基本的 Transformer 层。这将作为我们稍后与 Transformer Engine 进行比较的基线。
让我们从使用纯 PyTorch 创建一个 GPT 编码器层开始。图 1 显示了总体结构。
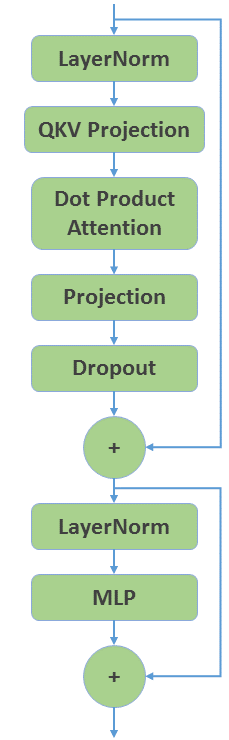
图 1:GPT 编码器层的结构。
我们按如下方式构建组件
LayerNorm:torch.nn.LayerNormQKV 投影:torch.nn.Linear(概念上是三个独立的 Q、K 和 V 的Linear层,但我们将其融合到一个更大的Linear层,其大小是原来的三倍)DotProductAttention:来自 quickstart_utils.py 的DotProductAttention投影:torch.nn.LinearDropout:torch.nn.DropoutMLP:来自 quickstart_utils.py 的BasicMLP
在本教程的过程中,我们将使用 quickstart_utils.py 中定义的一些模块和辅助函数。将它们放在一起
[1]:
import torch
import quickstart_utils as utils
class BasicTransformerLayer(torch.nn.Module):
def __init__(
self,
hidden_size: int,
ffn_hidden_size: int,
num_attention_heads: int,
layernorm_eps: int = 1e-5,
attention_dropout: float = 0.1,
hidden_dropout: float = 0.1,
):
super().__init__()
self.num_attention_heads = num_attention_heads
self.kv_channels = hidden_size // num_attention_heads
self.ln1 = torch.nn.LayerNorm(hidden_size, eps=layernorm_eps)
self.qkv_projection = torch.nn.Linear(hidden_size, 3 * hidden_size, bias=True)
self.attention = utils.DotProductAttention(
num_attention_heads=num_attention_heads,
kv_channels=self.kv_channels,
attention_dropout=attention_dropout,
)
self.projection = torch.nn.Linear(hidden_size, hidden_size, bias=True)
self.dropout = torch.nn.Dropout(hidden_dropout)
self.ln2 = torch.nn.LayerNorm(hidden_size, eps=layernorm_eps)
self.mlp = utils.BasicMLP(
hidden_size=hidden_size,
ffn_hidden_size=ffn_hidden_size,
)
def forward(
self,
x: torch.Tensor,
attention_mask: torch.Tensor
) -> torch.Tensor:
res = x
x = self.ln1(x)
# Fused QKV projection
qkv = self.qkv_projection(x)
qkv = qkv.view(qkv.size(0), qkv.size(1), self.num_attention_heads, 3 * self.kv_channels)
q, k, v = torch.split(qkv, qkv.size(3) // 3, dim=3)
x = self.attention(q, k, v, attention_mask)
x = self.projection(x)
x = self.dropout(x)
x = res + x
res = x
x = self.ln2(x)
x = self.mlp(x)
return x + res
就这样!我们现在有了一个简单的 Transformer 层。我们可以对其进行测试
[2]:
# Layer configuration
hidden_size = 4096
sequence_length = 2048
batch_size = 4
ffn_hidden_size = 16384
num_attention_heads = 32
dtype = torch.float16
# Synthetic data
x = torch.rand(sequence_length, batch_size, hidden_size).cuda().to(dtype=dtype)
dy = torch.rand(sequence_length, batch_size, hidden_size).cuda().to(dtype=dtype)
[3]:
basic_transformer = BasicTransformerLayer(
hidden_size,
ffn_hidden_size,
num_attention_heads,
)
basic_transformer.to(dtype=dtype).cuda()
[3]:
BasicTransformerLayer(
(ln1): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(qkv_projection): Linear(in_features=4096, out_features=12288, bias=True)
(attention): DotProductAttention(
(dropout): Dropout(p=0.1, inplace=False)
)
(projection): Linear(in_features=4096, out_features=4096, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(ln2): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(mlp): BasicMLP(
(linear1): Linear(in_features=4096, out_features=16384, bias=True)
(linear2): Linear(in_features=16384, out_features=4096, bias=True)
)
)
[4]:
torch.manual_seed(1234)
y = basic_transformer(x, attention_mask=None)
[5]:
utils.speedometer(
basic_transformer,
x,
dy,
forward_kwargs = { "attention_mask": None },
)
Mean time: 43.0663916015625 ms
认识 Transformer Engine
摘要
我们修改示例 Transformer 层以包含最简单的 TE 模块:Linear 和 LayerNorm。
现在我们有了一个基本的 Transformer 层,让我们使用 Transformer Engine 来加速训练。
[6]:
import transformer_engine.pytorch as te
TE 提供了一组 PyTorch 模块,可用于构建 Transformer 层。提供的最简单的模块是 Linear 和 LayerNorm 层,我们可以使用它们来代替 torch.nn.Linear 和 torch.nn.LayerNorm。让我们修改 BasicTransformerLayer
[7]:
class BasicTEMLP(torch.nn.Module):
def __init__(self,
hidden_size: int,
ffn_hidden_size: int) -> None:
super().__init__()
self.linear1 = te.Linear(hidden_size, ffn_hidden_size, bias=True)
self.linear2 = te.Linear(ffn_hidden_size, hidden_size, bias=True)
def forward(self, x):
x = self.linear1(x)
x = torch.nn.functional.gelu(x, approximate='tanh')
x = self.linear2(x)
return x
class BasicTETransformerLayer(torch.nn.Module):
def __init__(self,
hidden_size: int,
ffn_hidden_size: int,
num_attention_heads: int,
layernorm_eps: int = 1e-5,
attention_dropout: float = 0.1,
hidden_dropout: float = 0.1):
super().__init__()
self.num_attention_heads = num_attention_heads
self.kv_channels = hidden_size // num_attention_heads
self.ln1 = te.LayerNorm(hidden_size, eps=layernorm_eps)
self.qkv_projection = te.Linear(hidden_size, 3 * hidden_size, bias=True)
self.attention = utils.DotProductAttention(
num_attention_heads=num_attention_heads,
kv_channels=self.kv_channels,
attention_dropout=attention_dropout,
)
self.projection = te.Linear(hidden_size, hidden_size, bias=True)
self.dropout = torch.nn.Dropout(hidden_dropout)
self.ln2 = te.LayerNorm(hidden_size, eps=layernorm_eps)
self.mlp = BasicTEMLP(
hidden_size=hidden_size,
ffn_hidden_size=ffn_hidden_size,
)
def forward(self,
x: torch.Tensor,
attention_mask: torch.Tensor):
res = x
x = self.ln1(x)
# Fused QKV projection
qkv = self.qkv_projection(x)
qkv = qkv.view(qkv.size(0), qkv.size(1), self.num_attention_heads, 3 * self.kv_channels)
q, k, v = torch.split(qkv, qkv.size(3) // 3, dim=3)
x = self.attention(q, k, v, attention_mask)
x = self.projection(x)
x = self.dropout(x)
x = res + x
res = x
x = self.ln2(x)
x = self.mlp(x)
return x + res
[8]:
basic_te_transformer = BasicTETransformerLayer(
hidden_size,
ffn_hidden_size,
num_attention_heads,
)
basic_te_transformer.to(dtype=dtype).cuda()
utils.share_parameters_with_basic_te_model(basic_te_transformer, basic_transformer)
[9]:
torch.manual_seed(1234)
y = basic_te_transformer(x, attention_mask=None)
[10]:
utils.speedometer(
basic_te_transformer,
x,
dy,
forward_kwargs = { "attention_mask": None },
)
Mean time: 43.1413232421875 ms
融合 TE 模块
摘要
我们使用 TE 模块优化示例 Transformer 层以进行融合操作。
Linear 层足以构建任何 Transformer 模型,并且即使对于非常自定义的 Transformer,它也能够使用 Transformer Engine。但是,更多关于模型的知识可以实现额外的优化,例如内核融合,从而提高可实现的加速。
因此,Transformer Engine 提供了跨越多个层的更粗粒度的模块
LayerNormLinearLayerNormMLPTransformerLayer
使用 LayerNormLinear 和 LayerNormMLP 构建 Transformer 层的第三次迭代
[11]:
class FusedTETransformerLayer(torch.nn.Module):
def __init__(self,
hidden_size: int,
ffn_hidden_size: int,
num_attention_heads: int,
layernorm_eps: int = 1e-5,
attention_dropout: float = 0.1,
hidden_dropout: float = 0.1):
super().__init__()
self.num_attention_heads = num_attention_heads
self.kv_channels = hidden_size // num_attention_heads
self.ln_qkv = te.LayerNormLinear(hidden_size, 3 * hidden_size, eps=layernorm_eps, bias=True)
self.attention = utils.DotProductAttention(
num_attention_heads=num_attention_heads,
kv_channels=self.kv_channels,
attention_dropout=attention_dropout,
)
self.projection = te.Linear(hidden_size, hidden_size, bias=True)
self.dropout = torch.nn.Dropout(hidden_dropout)
self.ln_mlp = te.LayerNormMLP(hidden_size, ffn_hidden_size, eps=layernorm_eps, bias=True)
def forward(self,
x: torch.Tensor,
attention_mask: torch.Tensor):
res = x
qkv = self.ln_qkv(x)
# Split qkv into query, key and value
qkv = qkv.view(qkv.size(0), qkv.size(1), self.num_attention_heads, 3 * self.kv_channels)
q, k, v = torch.split(qkv, qkv.size(3) // 3, dim=3)
x = self.attention(q, k, v, attention_mask)
x = self.projection(x)
x = self.dropout(x)
x = res + x
res = x
x = self.ln_mlp(x)
return x + res
[12]:
fused_te_transformer = FusedTETransformerLayer(hidden_size, ffn_hidden_size, num_attention_heads)
fused_te_transformer.to(dtype=dtype).cuda()
utils.share_parameters_with_fused_te_model(fused_te_transformer, basic_transformer)
[13]:
torch.manual_seed(1234)
y = fused_te_transformer(x, attention_mask=None)
[14]:
utils.speedometer(
fused_te_transformer,
x,
dy,
forward_kwargs = { "attention_mask": None },
)
Mean time: 43.1981201171875 ms
最后,TransformerLayer 模块方便创建标准的 Transformer 架构,并提供最高程度的性能优化
[15]:
te_transformer = te.TransformerLayer(hidden_size, ffn_hidden_size, num_attention_heads)
te_transformer.to(dtype=dtype).cuda()
utils.share_parameters_with_transformerlayer_te_model(te_transformer, basic_transformer)
[16]:
torch.manual_seed(1234)
y = te_transformer(x, attention_mask=None)
[17]:
utils.speedometer(
te_transformer,
x,
dy,
forward_kwargs = { "attention_mask": None },
)
Mean time: 39.99169921875 ms
启用 FP8
摘要
我们配置一个 TE 模块以在 FP8 中执行计算。
在 Transformer Engine 中启用 FP8 支持非常简单。我们只需要将模块包装在 fp8_autocast 上下文管理器中即可。请注意,fp8_autocast 应该仅用于包装前向传播,并且必须在开始反向传播之前退出。有关 FP8 配方和支持选项的详细说明,请参阅 FP8 教程。
[18]:
from transformer_engine.common.recipe import Format, DelayedScaling
te_transformer = te.TransformerLayer(hidden_size, ffn_hidden_size, num_attention_heads)
te_transformer.to(dtype=dtype).cuda()
utils.share_parameters_with_transformerlayer_te_model(te_transformer, basic_transformer)
fp8_format = Format.HYBRID
fp8_recipe = DelayedScaling(fp8_format=fp8_format, amax_history_len=16, amax_compute_algo="max")
torch.manual_seed(1234)
with te.fp8_autocast(enabled=True, fp8_recipe=fp8_recipe):
y = te_transformer(x, attention_mask=None)
[19]:
utils.speedometer(
te_transformer,
x,
dy,
forward_kwargs = { "attention_mask": None },
fp8_autocast_kwargs = { "enabled": True, "fp8_recipe": fp8_recipe },
)
Mean time: 28.61394775390625 ms